Αναγνώριση και αποσαφήνιση ονοματικών οντοτήτων
|
|
|
- Αφροδίσια Μακρής
- 8 χρόνια πριν
- Προβολές:
Transcript
1 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Τομέας Ηλεκτρονικής και Υπολογιστών Εργαστήριο Επεξεργασίας Πληροφορίας και Υπολογισμών (ΕΠΥ) Αναγνώριση και αποσαφήνιση ονοματικών οντοτήτων Διπλωματική Εργασία Αθανασίου Σαλαμάνη Α.Ε.Μ υπό την επίβλεψη του Καθηγητή κ. Περικλή Α. Μήτκα Θεσσαλονίκη, 2012

2 2 Στην οικογένειά μου

3 3 Ευχαριστι ες Η παρούσα διπλωματική εργασία εκπονήθηκε στην ομάδα Ευφυών Συστημάτων και Τεχνολογίας Λογισμικού (Intelligent Systems and Software Engineering Laboratory - ISSEL), η οποία ανήκει στο εργαστήριο Επεξεργασίας Πληροφορίας και Υπολογισμών (ΕΠΥ) του Τμήματος Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης. Πριν την αναλυτική παρουσίαση της έρευνας που έγινε για την περάτωση αυτής της εργασίας αισθάνομαι την υποχρέωση να ευχαριστήσω τους ανθρώπους που συνέβαλαν στην ολοκλήρωσή της. Αρχικά, θα ήθελα να ευχαριστήσω τον επιβλέποντα της διπλωματικής μου εργασίας, Καθηγητή κ. Περικλή Α. Μήτκα, για την εμπιστοσύνη και το ενδιαφέρον που μου έδειξε όσον αφορά την ανάθεση του συγκεκριμένου θέματος. Θα ήθελα, επίσης, να εκφράσω την βαθιά μου εκτίμηση προς το πρόσωπό του για το ακαδημαϊκό του έργο συνολικά και τις αξίες που μου ενέπνευσε κατά την διάρκεια των σπουδών μου. Επιπλέον, ευχαριστώ θερμά τον Υποψήφιο Διδάκτορα κ. Κωνσταντίνο Ν. Βαβλιάκη για την αγαστή συνεργασία και την πολύτιμη βοήθειά του καθ όλη την διάρκεια εκπόνησης της διπλωματικής μου εργασίας. Τέλος, θα ήθελα να ευχαριστήσω από τα βάθη της καρδιάς μου όλους τους ανθρώπους από το οικογενειακό και φιλικό μου περιβάλλον για την στήριξη και την βοήθεια που μου προσέφεραν όλα τα χρόνια στων σπουδών μου. Τους γονείς μου Γιάννη και Κατερίνα για την κατανόηση και την εμπιστοσύνη τους σε όλες τις επιλογές μου. Τον αδερφό μου Κωσταντίνο για την κατανόηση και την υπομονή του κατά την διάρκεια συγγραφής της παρούσας εργασίας. Τους φίλους μου Γιάννη Γκιώση, Γιάννη Χρυσίδη, Νικηφορίδη Αλέξανδρο και Νίκο Γιόντη για τις αμέτρητες στιγμές χαράς και γέλιου. Τους συναδέλφους Γιάννη Γούτα, Σωτήρη Μπέη, Εμμανουήλ Μαστοράκη για τα όμορφα φοιτητικά χρόνια. Στοιχεία Συγγραφέα: Ο Σαλαμάνης Αθανάσιος είναι προπτυχιακός φοιτητής του Τμήματος Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης. Διεύθυνση: Σοφοκλέους 24, 54640, Θεσσαλονίκη Ηλ. Διεύθυνση: thanasis43@windowslive.com

4 4 Συ νοψη Καθώς το Διαδίκτυο διογκώνεται χρόνο με το χρόνο αυξάνεται και το πλήθος των γραπτών κειμένων που διακινούνται σε αυτό. Τα κείμενα αυτά, που ποικίλουν σε θεματολογία, μέγεθος και σημασία, αποτελούνται από λέξεις, ονόματα, προτάσεις και φράσεις, αλλά ο κόσμος στον οποίο τα κείμενα αυτά αναφέρονται αποτελείται διακριτά αντικείμενα και γεγονότα. Έτσι από τα κείμενα αυτά, τα στοιχεία που σε μεγαλύτερο βαθμό ενδιαφέρουν τους τελικούς χρήστες είναι τα κύρια ονόματα γιατί αυτά αντιστοιχούν σε οντότητες του πραγματικού κόσμου. Η αναγνώριση ενός κύριου ονόματος (named entity recognition NER), δηλαδή ο εντοπισμός του σε ένα κείμενο και η κατανόηση ότι αυτό το όνομα είναι πρόσωπο, οργανισμός ή τοποθεσία, και η αποσαφήνισή του (named entity disambiguation - NED) δηλαδή η αντιστοίχιση του στο αντικείμενο του πραγματικού κόσμου στο οποίο αναφέρεται, αποτελούν δύο κρίσιμες εργασίες που οδηγούν στην ανάκτηση της περισσότερο χρήσιμης πληροφορίας από τα κείμενα. Οι περισσότερες τεχνικές αποσαφήνισης ονοματικών οντοτήτων που έχουν προταθεί στηρίζονται στη χρήση γνώσης του πραγματικού κόσμου που είναι αποθηκευμένη σε μεγάλες βάσεις όπως πχ η Wikipedia, η DBpedia κλπ. Αυτή η στρατηγική εκτός από τα αδιαμφισβήτητα πλεονεκτήματα της (πχ υψηλή ακρίβεια) παρουσιάζει και αρκετά μειονεκτήματα όπως για παράδειγμα η έλλειψη ευελιξίας των συστημάτων. Τα τελευταία χρόνια έχει διατυπωθεί από κάποιους ερευνητές η άποψη ότι η εξερεύνηση των συντακτικών και σημασιολογικών σχέσεων ανάμεσα τόσο στις αναφορές ονομάτων μέσα από τα κείμενα στα οποία εντοπίζονται, όσο και στις ίδιες τις οντότητες του πραγματικού κόσμου μέσα από το Διαδίκτυο μπορεί να οδηγήσει στην δημιουργία κοινωνικών δικτύων αναφορών και οντοτήτων που θα διευκολύνουν το έργο της αποσαφήνισης. Η ιδέα αυτή δεν απαιτεί την ύπαρξη εξωτερικής από το σύστημα πληροφορίας. Στην παραπάνω κατεύθυνση κινείται και το σκεπτικό της παρούσας διπλωματικής εργασίας. Στόχος είναι η εξερεύνηση και ανακάλυψη συσχετίσεων ανάμεσα στις προς αποσαφήνιση αναφορές ονομάτων που έχουν αναγνωριστεί σε ένα σύνολο κειμένων. Το πρώτο βήμα ήταν η αναζήτηση κάποιο είδους ιεραρχίας ανάμεσα στις αναφορές, διαδικασία που οδήγησε στον εντοπισμό σχέσεων τύπου «πατέρας παιδί» ανάμεσά τους. Έπειτα κρίθηκε λογική η εξέταση του τι συμβαίνει όταν οι αναφορές εμφανίζονται μαζί (συναναφέρονται) σε αρκετά κείμενα. Αυτό οδήγησε στην ιδέα δημιουργίας ομάδων αναφορών τα μέλη των οποίων θα αναφέρονται είτε στην ίδια ακριβώς οντότητα του πραγματικού κόσμου είτε σε οντότητες που έχουν μεγάλη σχέση μεταξύ τους. Τέλος κρίθηκε αναγκαία η σύγκριση ανάμεσα στις αναφορές με βάση το πληροφοριακό περιεχόμενο των κειμένων στα οποία εντοπίζονται. Για το σκοπό αυτό κατασκευάστηκαν τα λεξικά αναφορών και με βάση αυτά υπολογίστηκαν στατιστικοί συντελεστές συσχέτισης. Το σύστημα ελέγχθηκε πάνω σε δύο βασικά σύνολα κειμένων από διαφορετικές πηγές και βγήκαν συμπεράσματα ως προς το πώς χαρακτηριστικά των συνόλων των κειμένων (όπως το πλήθος των

5 5 κειμένων που περιέχουν, ή η σημασιολογική συνάφεια των κειμένων κλπ) επηρεάζουν το εντοπισμό σχέσεων ανάμεσα στις αναφορές και κατ επέκταση το έργο της αποσαφήνισης. Λέξεις-Κλειδιά: Αναγνώριση Ονοματικών Οντοτήτων, Αποσαφήνιση Ονοματικών Οντοτήτων, Κύριο Όνομα, Αναφορά, Οντότητα.

6 6 Diploma Thesis Named entity recognition and disambiguation Abstract While World Wide Web swells year by year, the multitude of the written texts which are being moved in it is also being increased. These texts, which vary in topics, size and importance, consist of words, names, sentences and phrases but the world that these texts describe consists of discrete objects and events. Therefore, the elements of these texts for which the final users are mostly interested about are the proper names. Recognition of a proper name, namely the localization of it in text and the understanding that this name is person, organization or location, and its disambiguation namely its pairing to the object of the real world in which it refers to, are two critical tasks which lead to the retrieval of the most valuable information from the texts. The majority of the proper name disambiguation techniques that have been proposed are based on the use of world knowledge that is stored in huge knowledge bases such as Wikipedia. Although this strategy is very effective, it also has some disadvantages such as lack of flexibility. Lately an idea that does not depend on external knowledge has been formulated by some researchers. This says that the exploration of syntactic and semantic relationships among references of proper name in the texts that are being identified or among entities of the real world inside the Wed, can lead to the creation of social networks of references or entities which will facilitate the disambiguation task. Therefore, this paper presents a system for the exploration and discovery of correlations among the references of proper names that have been recognized and are going to be disambiguated. The first step was the search of some kind of hierarchy between the references, which led to the localization of father child type relationship. Afterwards, the examination of what happens when the proper names appear together (corefer) in the same texts was thought to be crucial. This decision gave birth to the idea of creating teams of references, which member will refer to either the exact same entities of the real world or to entities with strong relationship. Finally, it was decided that the references of proper names had to be compared based on the context of the texts in which they have been recognized. For this cause dictionaries were constructed and by comparing statistical correlation coefficients were calculated. In the end, the system was checked in two basic corpora from different sources and significant conclusions, about how corpus characteristics (such as corpus size or texts relevance) affect on the disambiguation task, emerged.

7 7 Keywords: Named Entity Recognition, Named Entity Disambiguation, Proper Name, Reference, Entity Athanasios Salamanis Department of Electrical and Computer Engineering, Aristotle University of Thessaloniki Thessaloniki, March 2013

8 8 Συντομογραφι ες-abbreviations NLP NER NED MUC WSD BOW CoNLL tf idf tf-idf GUI Natural Language Processing Named Entity Recognition Named Entity Disambiguation Message Understanding Conferences Word Sense Disambiguation Bag Of Words Computational Natural Language Learning term frequency inverse document frequency term frequency inverse document frequency Graphical User Interface

9 9 Λεξικο ο ρων Term Dictionary reference entity precision recall document corpus word subentity coreference network graph similarity coefficient entity page redirect page disambiguation page hyperlink surface form function words lexical words team file cosine similarity αναφορά οντότητα ακρίβεια ανάκληση κείμενο σύνολο κειμένων λέξη υποοντότητα συναναφορά δίκτυο γράφος συντελεστής ομοιότητας σελίδα οντότητας σελίδα ανακατεύθυνσης σελίδα αποσαφήνισης υπερσύνδεσμος αναφορά ονόματος λειτουργικές λέξεις λεξιλογικές λέξεις αρχείο ομάδας ομοιότητα συνημιτόνου

10 10 Περιεχο μενα 1. Εισαγωγή Ορισμός του προβλήματος Σημασία διαδικασιών αναγνώρισης και αποσαφήνισης Σκοπός της διπλωματικής Συνοπτική περιγραφή μεθοδολογίας Οργάνωση Κεφαλαίων Βιβλιογραφική Έρευνα Εισαγωγή WοrdNet Wikipedia Μέθοδοι αναγνώρισης και αποσαφήνισης Μέθοδος Bunescu και Pasca Μέθοδος Cucerzan Άλλες σημαντικές μέθοδοι Αρχιτεκτονική συστήματος Εισαγωγή Μονάδα ανάγνωσης xml αρχείου και μετατροπής του σε μορφή εύκολα διαχειρίσιμη από το σύστημα XML Λειτουργία μονάδας Μονάδα καθαρισμού εισόδου Καθαρισμός HTML tags Καθαρισμός Stop Words Μονάδα αναγνώρισης οντοτήτων Μονάδα εξαγωγής πληροφορίας από τα κείμενα Μονάδα κατασκευής γράφου αναφορών Κοινωνικά δίκτυα (social networks) Κοινωνικό δίκτυο αναφορών οντοτήτων... 40

11 Μονάδα εξερεύνησης συσχετίσεων αναφορών Σχέση τύπου «πατέρας - παιδί» Ομαδοποιήσεις Μονάδα κατασκευής λεξικών αναφορών Tf idf Λεξικά αναφορών Μονάδα υπολογισμού συντελεστών συσχέτισης ανάμεσα στις αναφορές με βάση τα λεξικά τους Εργαλεία και Τεχνολογίες που χρησιμοποιήθηκαν στην ανάπτυξη των μεθόδων Java JUNG (Java Universal Network/Graph Framework) Eclipse Ανασκόπηση κεφαλαίου Συνδυαστικά αποτελέσματα και συγκρίσεις Εισαγωγή Βασικά στοιχεία πειραμάτων Μέτρα αξιολόγησης Αποτελέσματα των μεθόδων που αναπτύχθηκαν Αποτελέσματα μεθόδου χωρίς την χρήση λεξικών αναφορών Αποτελέσματα μεθόδου με την χρήση λεξικών αναφορών Χρόνοι συστήματος Σύνοψη κεφαλαίου Συμπεράσματα Μελλοντική Έρευνα Σύνοψη Συμπεράσματα Προτάσεις για μελλοντική έρευνα Βιβλιογραφία... 98

12 12 Λι στα Σχημα των Σχήμα 1: Μπλοκ διάγραμμα συστήματος Σχήμα 2: Στιγμιότυπο ενός τυπικού XML αρχείου Σχήμα 3: Γράφος απεικόνισης των προσώπων που αναφέρονται στην Βίβλο και των σχέσεων ανάμεσά τους Σχήμα 4: Στιγμιότυπο γράφου αναφορών για το σύνολο αναφορών first100references από το corpus των κειμένων της Wikipedia Σχήμα 5: Στιγμιότυπο γράφου αναφορών για το σύνολο αναφορών ChosenReferences από το corpus των κειμένων της Wikipedia Σχήμα 6: Στιγμιότυπο γράφου αναφορών για το σύνολο αναφορών DifferentEntityReferencesNews από το corpus των κειμένων της ειδησεογραφίας Σχήμα 7: Στιγμιότυπο δένδρου απεικόνισης της σχέσης τύπου «πατέρας παιδί» Σχήμα 8: Στιγμιότυπο δένδρου απεικόνισης της σχέσης τύπου «πατέρας - παιδί»" Σχήμα 9: Στιγμιότυπο δένδρου απεικόνισης της σχέσης τύπου «πατέρας παιδί» Σχήμα 10: Γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 11: Γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 12: Γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση με το όριο ποσοστού κοινών γειτόνων για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 13: Γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση με το όριο ποσοστού κοινών γειτόνων για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 14: Γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση και με τα δύο όρια ομαδοποίησης για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 15: Γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση και με τα δύο όρια ομαδοποίησης για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 16: Γράφημα παρουσίασης της επίδοσης της μεθόδου χωρίς την χρήση λεξικών αναφορών για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 17: Γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας

13 13 Σχήμα 18: Γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 19: Γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση με το όριο ποσοστού κοινών γειτόνων για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 20: Γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση με το όριο ποσοστού κοινών γειτόνων για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 21: Γράφημα παρουσίασης της επίδοσης της μεθόδου χωρίς την χρήση λεξικών αναφορών για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 22: Συνδυαστικό γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για τα σύνολα αναφορών ChosenReferences και first100references από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 23: Συνδυαστικό γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για τα σύνολα αναφορών ChosenReferences και first100references από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 24: Γράφημα παρουσίασης της επίδοσης της μεθόδου χωρίς την χρήση λεξικών αναφορών για το σύνολο αναφορών ChosenReferences από τα κείμενα τηςwikipedia στο σενάριο λειτουργίας Σχήμα 25: Γράφημα παρουσίασης της επίδοσης της μεθόδου χωρίς την χρήση λεξικών αναφορών για το σύνολο αναφορών first100references από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 26:Γράφημα μεταβολής του ποσοστού σωστών ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας 1 με χρήση λεξικών αναφορών Σχήμα 27: Γράφημα μεταβολής των λάθος ομαδοποιήσεων σε συνάρτηση με το όριο βάρους ακμής για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας 1 με χρήση λεξικών αναφορών Σχήμα 28: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις σωστές ομαδοποιήσεις για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 29: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις λάθος ομαδοποιήσεις για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 30: Γράφημα παρουσίασης της επίδοσης της μεθόδου με την χρήση λεξικών αναφορών για το σύνολο αναφορών DifferentEntityReferencesNews στο σενάριο λειτουργίας Σχήμα 31: Επίδοση της μεθόδου με και χωρίς τα λεξικά αναφορών για το σύνολο αναφορών DifferentEntityReferencesNews στο σενάριο λειτουργίας

14 14 Σχήμα 32: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις σωστές ομαδοποιήσεις για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 33: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις λάθος ομαδοποιήσεις για το σύνολο αναφορών DifferentEntityReferencesNews από τα κείμενα της ειδησεογραφίας στο σενάριο λειτουργίας Σχήμα 34: Επίδοση της μεθόδου με και χωρίς τα λεξικά αναφορών για το σύνολο αναφορών DifferentEntityReferencesNews στο σενάριο λειτουργίας Σχήμα 35: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις σωστές ομαδοποιήσεις για το σύνολο αναφορών ChosenReferences από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 36: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις λάθος ομαδοποιήσεις για το σύνολο αναφορών ChosenReferences από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 37: Επίδοση της μεθόδου με και χωρίς τα λεξικά αναφορών για το σύνολο αναφορών ChosenReferences στο σενάριο λειτουργίας Σχήμα 38: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις σωστές ομαδοποιήσεις για το σύνολο αναφορών ChosenReferences από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 39: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις λάθος ομαδοποιήσεις για το σύνολο αναφορών ChosenReferences από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 40: Επίδοση της μεθόδου με και χωρίς τα λεξικά αναφορών για το σύνολο αναφορών ChosenReferences στο σενάριο λειτουργίας Σχήμα 41: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις σωστές ομαδοποιήσεις για το σύνολο αναφορών first100references από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 42: Γράφημα παρουσίασης της επίδρασης των λεξικών αναφορών στις λάθος ομαδοποιήσεις για το σύνολο αναφορών first100references από τα κείμενα της Wikipedia στο σενάριο λειτουργίας Σχήμα 43: Επίδοση της μεθόδου με και χωρίς τα λεξικά αναφορών για το σύνολο αναφορών first100references στο σενάριο λειτουργίας Σχήμα 44: Μεταβολή χρόνου επεξεργασίας σε σχέση με το όριο βάρους ακμής Σχήμα 45: Μεταβολή χρόνου επεξεργασίας σε σχέση με το όριο ποσοστού κοινών γειτόνων Σχήμα 46: Μεταβολή χρόνου επεξεργασίας σε σχέση με τον αριθμό κύριων ονομάτων (χωρίς λεξικά αναφορών) Σχήμα 47: Μεταβολή χρόνου επεξεργασίας σε σχέση με τον αριθμό κύριων ονομάτων (με λεξικά αναφορών)... 92

15 15 Λι στα Πινα κων Πίνακας 1: Αντιστοίχιση html tags με πραγματικούς χαρακτήρες Πίνακας 2: Λίστα stop words Πίνακας 3: Στατιστικά στοιχεία κειμένων αξιολόγησης Πίνακας 4: Ορισμός των όρων true positive, false positive, true negative και false negative Πίνακας 5: Παραδείγματα λάθος ομαδοποιήσεων για το σενάριο λειτουργίας

16 16 1. Εισαγωγή 1.1. Ορισμός του προβλήματος Η αναγνώριση ονοματικών οντοτήτων (named entity recognition-ner) και η αποσαφήνιση ονοματικών οντοτήτων (named entity disambiguation-ned) σε σύνολα εγγράφων που προέρχονται από διάφορες πηγές αποτελούν δύο βασικές δραστηριότητες του γενικότερου πεδίου που ονομάζεται επεξεργασία φυσικής γλώσσας (natural language processing - NLP). Η διαδικασία της αναγνώρισης οντοτήτων έγκειται στην αναζήτηση και τον εντοπισμό αναφορών οντοτήτων σε κείμενα (γνωστών και ως surface forms) και την απόδοση σε αυτές μίας ετικέτας που χαρακτηρίζει τον τύπο της οντότητας. Οι διάφοροι τύποι ονοματικών οντοτήτων, όπως έχουν οριστεί από τα Διεθνή Συνέδρια Αξιολόγησης Τεχνολογίας Εξαγωγής Πληροφορίας, είναι τα κύρια ονόματα που ορίζουν πρόσωπα, οργανισμούς και τοποθεσίες (ετικέτα ENAMEX), οι χρονικές εκφράσεις (ετικέτα TIMEX) και οι αριθμητικές και χρηματικές εκφράσεις καθώς και τα ποσοστά (ετικέτα NUMEX). Ακόλουθη της διαδικασίας αναγνώρισης οντοτήτων είναι αυτή της αποσαφήνισης οντοτήτων στην οποία και εστιάζει η παρούσα διπλωματική εργασία. Ως αποσαφήνιση οντοτήτων ορίζεται η διαδικασία αντιστοίχισης μίας λέξης σε μία οντότητα που έχει υπόσταση στον πραγματικό κόσμο π.χ. η λέξη Παρίσι αναφέρεται στην πρωτεύουσα της Γαλλίας που είναι μια οντότητα του πραγματικού κόσμου. Η μεγάλη δυσκολία της αποσαφήνισης οντοτήτων προέρχεται από το γεγονός ότι μία λέξη μπορεί έχει πολλές διαφορετικές έννοιες άρα μπορεί να αναφέρεται σε πολλές διαφορετικές οντότητες και ταυτόχρονα για μία οντότητα μπορεί να υπάρχουν πολλές διαφορετικές λέξεις που την χαρακτηρίζουν και χρησιμοποιούνται για την αναφορά σε αυτή. Για παράδειγμα η αγγλική λέξη Washington μπορεί να αναφέρεται στην πρωτεύουσα των ΗΠΑ αλλά μπορεί να αναφέρεται και στον πρώτο πρόεδρο των ΗΠΑ τον George Washington. Αντίστροφα η οντότητα της Ελλάδας σαν χώρα μπορεί να αναφέρεται με τους όρους Ελλάδα, Ελλάς, Ελληνική Δημοκρατία κ.α. Η δουλειά των συστημάτων αποσαφήνισης οντοτήτων είναι να επιλέξουν μία οντότητα,από το σύνολο των διαφορετικών οντοτήτων στις οποίες μπορεί να αναφέρεται μία υπό εξέταση λέξη, και να την αποδώσουν στην λέξη αυτή με βάση το πληροφοριακό περιεχόμενο του κειμένου στο οποίο έχει εντοπιστεί η υπό εξέταση λέξη Σημασία διαδικασιών αναγνώρισης και αποσαφήνισης Το έργο της αποσαφήνισης οντοτήτων γίνεται ολοένα και πιο σημαντικό λόγω της ραγδαίας αύξησης των πληροφοριών που μεταδίδονται κυρίως μέσω του Ιστού. Στα διάφορα κείμενα που κυκλοφορούν στο Διαδίκτυο παρατηρείται το φαινόμενο της πολυσημίας πολλών αναφορών ονομάτων. Για παράδειγμα στην αγγλική έκδοση της διαδικτυακής εγκυκλοπαίδειας Wikipedia o όρος America αναφέρεται σε 79 διαφορετικές οντότητες του πραγματικού κόσμου ξεκινώντας από την ήπειρο Αμερική και την χώρα Ηνωμένες Πολιτείες Αμερικής και φτάνοντας μέχρι τηλεοπτικές σειρές και τίτλους τραγουδιών. Στην πρόταση That date is now celebrated annually as America s Independence Day ο όρος America αναφέρεται στις ΗΠΑ ενώ στην πρόταση America is a largely political work, with much of the poem consisting.. ο όρος America αναφέρεται στο

17 17 ποίημα America του αμερικανού ποιητή Allen Ginsberg. Γίνεται λοιπόν κατανοητό το μέγεθος της πολυσημίας των διαφόρων όρων που εμφανίζονται στα κείμενα καθώς και η ανάγκη ύπαρξης συστημάτων που θα μπορούν να επιλέξουν και να αποδώσουν την σωστή έννοια σε μία λέξη. Ένα άλλο πεδίο στο οποίο εμφανίζεται η ανάγκη της επίλυσης της ασάφειας λέξεων είναι η αναζήτηση πληροφοριών στον Ιστό. Παρόλο που τα τελευταία χρόνια έχουν γίνει σαφείς βελτιώσεις στους αλγορίθμους που λειτουργούν πίσω από τις μηχανές αναζήτησης, τα αποτελέσματα δεν είναι ακόμα όσο ακριβή και στοχευόμενα θα ήθελαν οι χρήστες να είναι. Για παράδειγμα έστω ένας χρήστης που θέλει να πάρει πληροφορίες για ένα επικείμενο ταξίδι του στο Παρίσι και κάνει αναζήτηση στην μηχανή Google με τον όρο Paris. Μέσα στα πρώτα 10 αποτελέσματα που παίρνει βρίσκονται σελίδες ταξιδιωτικών γραφείων που παρέχουν πληροφορίες για το Παρίσι, η αντίστοιχη σελίδα της Wikipedia αλλά και η σελίδα της Wikipedia που αναφέρεται στον Πάρη τον πρίγκιπα της αρχαίας Τροίας καθώς και το επίσημο site της Paris Hilton. Προφανώς ο χρήστης του παραδείγματος δεν θα είχε στο νου του την Paris Hilton όταν έκανε αναζήτηση για το Παρίσι. Συστήματα λοιπόν αποσαφήνισης υψηλής ακρίβειας που θα λειτουργούν πίσω από τις μηχανές αναζήτησης θα μπορούν να αντιληφθούν ότι ο χρήστης ενδιαφέρεται να πάρει πληροφορίες για το Παρίσι και θα δίνουν ακριβή αποτελέσματα που θα ικανοποιούν τις ανάγκες του. Τέλος αξίζει να αναφερθεί και η διαδικασία αποσαφήνισης εννοιών λέξεων (word sense disambiguation WSD) που είναι παρόμοια με αυτή της αποσαφήνισης ονοματικών οντοτήτων. Το πρόβλημα που αντιμετωπίζεται και σε αυτήν είναι το ίδιο. Από το σύνολο των διαφορετικών εννοιών που έχει μία λέξη πρέπει να της αποδοθεί η σωστή έννοια με βάση την πρόταση/παράγραφο/κείμενο στην οποία βρίσκεται. Για παράδειγμα η αγγλική λέξη bank μπορεί να έχει την έννοια τράπεζα αλλά μπορεί να έχει και την έννοια της όχθης ποταμού. Σε ένα άρθρο λοιπόν που προέρχεται από μία οικονομική εφημερίδα όταν εμφανιστεί ο όρος bank το πιθανότερο θα είναι να αναφέρεται στην έννοια της τράπεζας και όχι σε αυτή της όχθης του ποταμού. Ένα τέτοιο συμπέρασμα θα πρέπει να δίνεται ως έξοδος από ένα σύστημα αποσαφήνισης λέξεων. Η διαφορά των WSD συστημάτων με τα συστήματα αποσαφήνισης οντοτήτων είναι ότι τα πρώτα δεν ασχολούνται με την αποσαφήνιση κυρίων ονομάτων. Για την αξιολόγηση συστημάτων WSD πραγματοποιούνται συχνά συνέδρια αξιολόγησης (Senseval-1,2,3 Semeval 2007, Semeval 2010) στα οποία ελέγχονται και βαθμολογούνται τα χαρακτηριστικά επίδοσης αυτών των συστημάτων όπως είναι ακρίβεια (precision), η ανάκληση (recall), η ταχύτητα επεξεργασίας κτλ. Οι αποσαφηνίσεις των διαφόρων λέξεων βρίσκονται καταχωρημένες σε γνωσιακές βάσεις ελεύθερης πρόσβασης όπως είναι το Wordnet Σκοπός της διπλωματικής Σκοπός της παρούσας διπλωματικής εργασίας είναι η ανάπτυξη και η αξιολόγηση μιας μεθόδου εξερεύνησης, ανακάλυψης και εκμετάλλευσης των συσχετίσεων ανάμεσα στις αναφορές κυρίων ονομάτων που θα προέρχονται από μεγάλα corpus κειμένων. Η μέθοδος εστιάζει κυρίως στον εντοπισμό σχέσεων ανάμεσα στις αναφορές που θα βελτιώνουν την απόδοση της διαδικασίας αποσαφήνισης χωρίς την ανάγκη ύπαρξης εξωτερικής πληροφορίας. Συνδυάζονται υπάρχουσες

18 18 ιδέες και τεχνικές που εντοπίστηκαν κατά την βιβλιογραφική έρευνα με νέες οι οποίες δεν είχαν δοκιμαστεί και αξιολογηθεί μέχρι σήμερα Συνοπτική περιγραφή μεθοδολογίας Τα περισσότερα από τα συστήματα αναγνώρισης και αποσαφήνισης οντοτήτων που έχουν αναπτυχθεί μέχρι σήμερα χρησιμοποιούν εξωτερική πληροφορία (δηλαδή κάποια εξωτερική βάση γνώσης) για να βελτιώσουν την απόδοση της διαδικασίας αποσαφήνισης. Αυτή η στρατηγική παρουσιάζει ορισμένα μειονεκτήματα όπως πχ η μείωση της ευελιξίας του συστήματος (το σύστημα μπορεί να λειτουργήσει μόνο για την δεδομένη γνωσιακή βάση). Στην παρούσα εργασίας γίνεται προσπάθεια να αξιοποιηθούν χαρακτηριστικά των αναφορών ονομάτων για την βελτίωση τη διαδικασίας αποσαφήνισης. Συγκεκριμένα αρχικά το σύστημα δέχεται σαν είσοδο ένα σύνολο από κείμενα και αφού το επεξεργαστεί κατάλληλα για το φέρει σε μορφή εύκολα διαχειρίσιμη, το τροφοδοτεί στην μονάδα αναγνώρισης οντοτήτων. Εκεί η χρησιμοποιείται η εφαρμογή αναγνώρισης οντοτήτων του πανεπιστημίου Stanford (Stanford NER [18]). Προκύπτουν οι διαφορετικές αναφορές οντοτήτων με βάση τις οποίες κατασκευάζεται το κοινωνικό δίκτυο αναφορών. Από το παραπάνω δίκτυο στη συνέχεια πραγματοποιούνται δύο από τις πιο βασικές λειτουργίες του συστήματος: Η αναγνώριση της σχέσης τύπου «πατέρας παιδί» ανάμεσα στις αναφορές Η δημιουργία των ομάδων αναφορών Στη συνέχεια υπάρχει η μονάδα κατασκευής των λεξικών των αναφορών (με υπολογισμό της tf-idf [23] τιμής κάθε λέξης κάθε λεξικού) και η ακόλουθη μονάδα υπολογισμού των συντελεστών συσχέτισης με βάση τα λεξικά. Το συγκεκριμένο κομμάτι χρησιμοποιείται για την βελτίωση της διαδικασίας δημιουργίας των ομάδων. Στο παρακάτω σχήμα (Σχήμα 1) φαίνεται το μπλοκ διάγραμμα του υπό ανάπτυξη συστήματος.
.")
19 19 Σχήμα 1: Μπλοκ διάγραμμα συστήματος
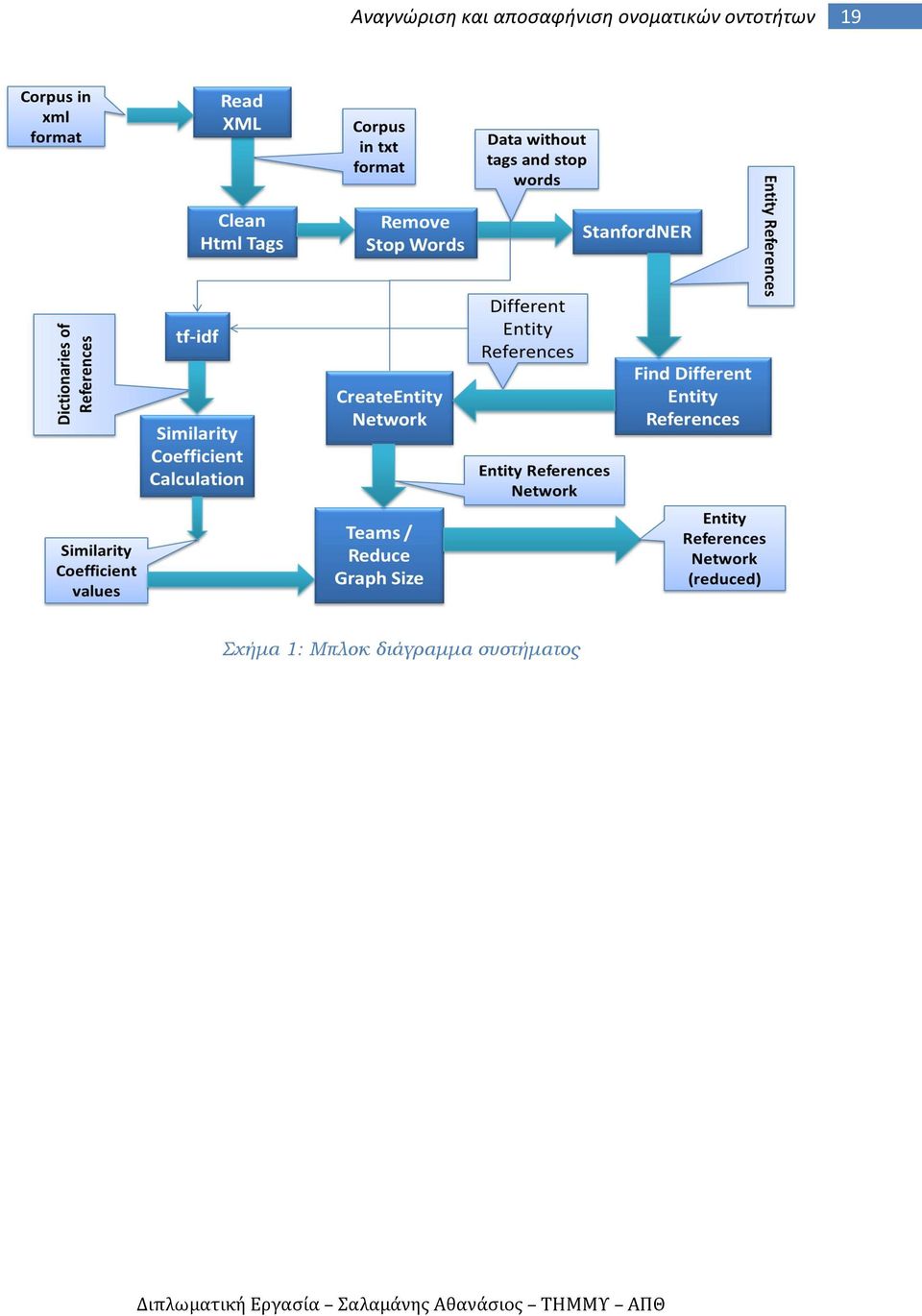
20 Οργάνωση Κεφαλαίων Κεφάλαιο 2 - Βιβλιογραφική Έρευνα: Στο κεφάλαιο αυτό γίνεται εκτενής παρουσίαση των διαφόρων μεθόδων που έχουν αναπτυχθεί στον τομέα της αναγνώρισης και αποσαφήνισης οντοτήτων και δίνεται ιδιαίτερη έμφαση στα πλεονεκτήματα και τα μειονεκτήματα της κάθε μεθόδου. Κεφάλαιο 3 Αρχιτεκτονική Συστήματος: Εδώ γίνεται λεπτομερής παρουσίαση της λειτουργίας της κάθε υπομονάδας του υπό ανάπτυξη συστήματος. Πιο συγκεκριμένα αναλύονται οι μονάδες: Ανάγνωσης xml αρχείου και μετατροπής του σε μορφή εύκολα διαχειρίσιμη από το σύστημα (3.2) «Καθαρισμού» εισόδου (3.3) Αναγνώρισης αναφορών οντοτήτων (3.4) Εξαγωγής πληροφορίας από τα κείμενα (3.5) Κατασκευής γράφου αναφορών (3.6) Εξερεύνησης συσχετίσεων αναφορών (3.7) Κατασκευής λεξικών αναφορών (3.8) Υπολογισμού συντελεστών συσχέτισης ανάμεσα στις αναφορές με βάση τα λεξικά τους (3.9) Κεφάλαιο 4 Συνδυαστικά αποτελέσματα και Συγκρίσεις: Εδώ παρουσιάζονται τα αποτελέσματα από τα πειράματα ελέγχου απόδοσης στα οποία υποβλήθηκε το σύστημα. Κεφάλαιο 5 Συμπεράσματα και Μελλοντική Έρευνα: Στο κεφάλαιο αυτό συνοψίζονται τα συμπεράσματα της παρούσας μελέτης και παρατίθενται σκέψεις και ιδέες για μελλοντική έρευνα.

21 21 2. Βιβλιογραφική Έρευνα 2.1. Εισαγωγή Την τελευταία δεκαετία έχει σημειωθεί σημαντική πρόοδος στον τομέα της αναγνώρισης και αποσαφήνισης ονοματικών οντοτήτων τόσο από θεωρητικής και ακαδημαϊκής πλευράς, όσο και από πλευράς ανάπτυξης πραγματικών (ενδεχομένως εμπορεύσιμων) συστημάτων. Έχουν προταθεί διάφορες στρατηγικές αποσαφήνισης που στοχεύουν στην βελτίωση διαφορετικών χαρακτηριστικών των συστημάτων όπως είναι η απόδοση, η ταχύτητα επεξεργασίας, το μέγεθος υπολογιστικών πόρων που απαιτούνται κλπ. Στο κεφάλαιο αυτό παρουσιάζονται αναλυτικά οι πιο σημαντικές από αυτές τόσο από άποψη απόδοσης των συστημάτων όσο και από άποψη καινοτομίας των μεθόδων. Πριν από την αναλυτική παρουσίαση των μεθόδων αυτών γίνεται μία συνοπτική αναφορά στις γνωσιακές βάσεις (knowledge bases) που παίζουν ιδιαίτερα σημαντικό ρόλο τόσο στην ανάπτυξη όσο και στην λειτουργία πολλών συστημάτων αποσαφήνισης WοrdNet Το WordNet [3] αποτελεί μία λεξικολογική βάση δεδομένων για την αγγλική γλώσσα που δημιουργήθηκε από το Εργαστήριο Γνωσιακής Επιστήμης τους πανεπιστημίου του Πρίνστον [4]. Κύρια λειτουργία του είναι η ομαδοποίηση αγγλικών λέξεων σε σύνολα συνωνύμων τα οποία ονομάζονται synsets, η διατύπωση σύντομων γενικών ορισμών και η καταγραφή των διαφόρων σημασιολογικών σχέσεων ανάμεσα στα σύνολα αυτά. Ο σκοπός του είναι διπλός: αφενός να δημιουργήσει ένα λεξικό το οποίο θα είναι πιο διαισθητικά χρησιμοποιήσιμο από τα υπόλοιπα, και αφετέρου να υποστηρίξει εφαρμογές αυτόματης ανάλυσης κειμένου και τεχνητής νοημοσύνης. Το WordNet μπορεί να ερμηνευτεί και να χρησιμοποιηθεί σαν μία λεξικολογική οντολογία στην επιστήμη υπολογιστών. Ωστόσο, μια τέτοια οντολογία θα πρέπει πρώτα να διορθωθεί προτού χρησιμοποιηθεί σε εφαρμογές αφού περιέχει εκατοντάδες βασικές σημασιολογικές ασυνέπειες όπως για παράδειγμα η ύπαρξη κοινών ειδικεύσεων για αποκλειστικές κατηγορίες. Ακόμα η μετατροπή του WordNet σε λεξικολογική οντολογία κατάλληλη για αντιπροσώπευση γνώσης περιλαμβάνει δύσκολες εργασίες όπως η συσχέτιση διαισθητικών μοναδικών χαρακτηριστικών με μία κατηγορία (στο WordNet τα synsets αντιστοιχίζονται σε κατηγορίες που αντιπροσωπεύουν το νόημά τους). Αν και τέτοιου είδους διορθώσεις έχουν πραγματοποιηθεί και καταγραφεί στα πλαίσια της μετατροπής του WordNet 1.7 στην συνεταιριστικά αναβαθμίσιμη γνωσιακή βάση WebKB-2 [5], πολλά από τα συστήματα που χρησιμοποιούν το WordNet ισχυρίζονται ότι πραγματοποιούν δικές τους διαδικασίες διόρθωσης ενώ στην πραγματικότητα χρησιμοποιούν τις παραπάνω. Το WordNet είναι το πιο συχνά χρησιμοποιούμενο υπολογιστικό λεξικό της αγγλικής γλώσσας που χρησιμοποιείται στην διαδικασία της αποσαφήνισης έννοιας λέξης (word sense disambiguation WSD [3]). Η διαδικασία αυτή είναι όμοια με την αποσαφήνιση κυρίων ονομάτων και στοχεύει στην
22 22 αντιστοίχιση της πιο κοινής έννοιας που μπορεί να έχει μία λέξη με την λέξη αυτή, η οποία έχει προηγουμένως εντοπιστεί σε ένα κείμενο. Ωστόσο έχει διατυπωθεί η άποψη ότι το WordNet κωδικοποιεί νοηματικές διακρίσεις που είναι υπερβολικά αναλυτικές ακόμα και για τον άνθρωπο. Αυτό το γεγονός εμποδίζει τα συστήματα αποσαφήνισης έννοιας λέξης να πετύχουν υψηλή απόδοση. Το πρόβλημα αυτό αντιμετωπίζεται με την χρήση μεθόδων ομαδοποίησης παρόμοιων εννοιών μίας λέξης Wikipedia Πολλές από τις εργασίες που έχουν ήδη αναπτυχθεί στηρίζονται στην παγκόσμια διαδικτυακή βάση γνώσης Wikipedia. Η Wikipedia είναι ένα συλλογικό εγκυκλοπαιδικό εγχείρημα που έχει συσταθεί στο Διαδίκτυο, παγκόσμιο, πολύγλωσσο που λειτουργεί με την αρχή του wiki και έχει ως στόχο να παρέχει ελεύθερα επαναχρησιμοποιήσιμο περιεχόμενο, με αντικειμενικά και επαληθεύσιμα στοιχεία, που ο καθένας μπορεί να τροποποιήσει και να βελτιώσει. Τα χαρακτηριστικά της Wikipedia που χρησιμοποιούνται τόσο κατά την διαδικασία της αναγνώρισης όσο και κατά την διαδικασία της αποσαφήνισης είναι: Σελίδα οντότητας (Entity page): Η κύρια σελίδα της Wikipedia που αναφέρεται σε ένα συγκεκριμένο θέμα. Σελίδα ανακατεύθυνσης (Redirect page): Για κάθε ένα από τα διαφορετικά ονόματα με τα οποία μπορεί να αναφέρεται μία οντότητα υπάρχει και μία τέτοια σελίδα στην Wikipedia με τίτλο το όνομα αυτό (με κάτω παύλες αντί για κενά) που περιέχει στο σώμα της έναν σύνδεσμο προς το entity page της οντότητας αυτής. Για παράδειγμα η οντότητα United States μπορεί να αναφέρεται και με το όνομα USA οπότε υπάρχει στην Wikipedia μία redirect page με τίτλο USA η οποία περιέχει ένα σύνδεσμο προς το άρθρο με τίτλο United_States. Σελίδα αποσαφήνισης (Disambiguation page): Ένα ασαφές όνομα μπορεί να αναφέρεται σε πολλές διαφορετικές οντότητες στην Wikipedia. Για κάθε τέτοια λέξη λοιπόν υπάρχει μία τέτοια σελίδα η οποία έχει ως τίτλο αυτή την λέξη ακολουθούμενη από την λέξη Disambiguation μέσα σε παρενθέσεις και περιέχει μία λίστα με συνδέσμους προς τις entity pages το οντοτήτων στις οποίες μπορεί να αναφέρεται. Κατηγορίες (Categories): Κάθε άρθρο στην Wikipedia πρέπει να ανήκει σε μία τουλάχιστον κατηγορία. Οι κατηγορίες βοηθούν τον χρήστη να βρίσκει παραπάνω πληροφορίες για ένα θέμα το οποίο μελετάει βλέποντας την κατηγορία στην οποία ανήκει ένα άρθρο που έχει ήδη διαβάσει. Οι κατηγορίες της Wikipedia αυξάνoυν σε μεγάλο βαθμό την απόδοση των συστημάτων αποσαφήνισης. Υπερσύνδεσμοι (Hyperlinks): Μέσα στο σώμα κάθε άρθρου της Wikipedia υπάρχουν αναφορές σε άλλες οντότητες οι οποίες αποτελούν και συνδέσμους προς τα entity pages των οντοτήτων αυτών.
23 Μέθοδοι αναγνώρισης και αποσαφήνισης Μέθοδος Bunescu και Pasca Οι Bunescu και Pasca (2006) [6] πρότειναν ένα σύστημα αναγνώρισης και αποσαφήνισης οντοτήτων που βασίζεται στην γνωσιακή βάση Wikipedia. Με βάση τη δομή της Wikipedia οι δύο συγγραφείς ορίζουν τα παρακάτω στοιχεία για να γίνει απλούστερη η κατανόηση της μεθόδου τους : e: ονοματική οντότητα E: το σύνολο όλων των ονοματικών οντοτήτων που θα αναγνωριστούν e.title: ο τίτλος του άρθρου της Wikipedia που αντιστοιχεί στην οντότητα e e.t: το κείμενο (πληροφοριακό περιεχόμενο) του άρθρου της Wikipedia που αντιστοιχεί στην οντότητα e e.r: το σύνολο όλων των ονομάτων που ανακατευθύνουν προς την οντότητα e e.d: το σύνολο όλων των ονομάτων των οποίων οι σελίδες αποσαφήνισής τους περιέχουν σύνδεσμο προς την οντότητα e e.c: το σύνολο των κατηγοριών της Wikipedia στις οποίες ανήκει το άρθρο της οντότητας e q: Ένα ερώτημα (query). Δηλαδή μία λέξη που θέλουμε να αποσαφηνιστεί q.τ: το κείμενο (πληροφοριακό περιεχόμενο) στο οποίο βρίσκεται η λέξη q q.e: το σύνολο όλων των διαφορετικών οντοτήτων στις οποίες μπορεί να αναφέρεται η λέξη q q.e k : μία υποψήφια οντότητα στην οποία μπορεί να αναφέρεται η λέξη q q.e: η πραγματική οντότητα στην οποία αναφέρεται η λέξη q Το πρώτο κομμάτι του συστήματος υλοποιεί έναν ευριστικό αλγόριθμο για την αναγνώριση οντοτήτων. Ο αλγόριθμος αυτός βασίζεται στην υπόθεση ότι οι τίτλοι όλων των άρθρων της Wikipedia αποτελούν πιθανές οντότητες. Συνοπτικά τα βήματα του αλγορίθμου είναι τα εξής: Βήμα 1 Αν ο τίτλος αποτελείται από πολλές λέξεις τότε ελέγχεται αν όλες οι λέξεις ξεκινούν με κεφαλαίο γράμμα (εξαιρούνται λέξεις όπως προθέσεις, σύνδεσμοι κλπ.). Αν ισχύει το παραπάνω τότε έχουμε μία ονοματική οντότητα. Βήμα 2 Αν ο τίτλος αποτελείται από μία λέξη ελέγχεται αν η λέξη αυτή περιέχει τουλάχιστον 2 κεφαλαία γράμματα. Αν ναι τότε έχουμε μία ονοματική οντότητα. Διαφορετικά προχωράμε στο Βήμα 3. Βήμα 3 Μετριέται πόσες φορές εμφανίζεται ο τίτλος του άρθρου μέσα στο κείμενο του άρθρου σε θέσεις που δεν είναι αρχή πρότασης. Αν στο 75% αυτών των περιπτώσεων ο τίτλος ξεκινά με κεφαλαίο γράμμα τότε έχουμε μία ονοματική οντότητα.
24 24 Μετά την αναγνώριση των οντοτήτων ακολουθεί η κατασκευή ενός λεξικού που βασίζεται στις οντότητες που έχουν αναγνωριστεί και σε διάφορα χαρακτηριστικά τις Wikipedia όπως είναι τα redirect pages και τα disambiguation pages. Για κάθε οντότητα e που έχει αναγνωριστεί, ο τίτλος του κύριου άρθρου που της αντιστοιχεί, το σύνολο όλων των redirect names (e.r) και to σύνολο όλων των disambiguation names (e.d) που τις αντιστοιχούν προστίθενται στο λεξικό. Με αυτό τον τρόπο κατασκευάζεται ένα λεξικό D όπου για κάθε καταχώρηση του d υπάρχει ένα σύνολο οντοτήτων d.e της Wikipedia που της αντιστοιχούν. Αφού κατασκευαστεί και το λεξικό ακολουθεί το κύριο μέρος του συστήματος που είναι το σύστημα αποσαφήνισης οντοτήτων. Αυτό έχει δύο υλοποιήσεις. Η πρώτη στηρίζεται στην συσχέτιση ανάμεσα στο πληροφοριακό περιεχόμενο του κειμένου στο οποίο εμφανίζεται η υπό εξέταση λέξη και αυτό των υποψήφιων ονοματικών οντοτήτων στις οποίες η λέξη αυτή μπορεί να αναφέρεται (ως πληροφοριακό περιεχόμενο μια ονοματικής οντότητας ορίζεται το κύριο άρθρο της Wikipedia που της αντιστοιχεί). Η δεύτερη είναι ουσιαστικά επέκταση της πρώτης αφού εκτός από την συσχέτιση ανάμεσα στα πληροφοριακά περιεχόμενα της υπό εξέταση λέξης και των υποψήφιων ονοματικών οντοτήτων, χρησιμοποιεί και την συσχέτιση ανάμεσα στο πληροφοριακό περιεχόμενο της υπό εξέταση λέξης και των κατηγοριών (category tags) στην Wikipedia των άρθρων των υποψήφιων ονοματικών οντοτήτων. Και στις δύο υλοποιήσεις τόσο το πληροφοριακό περιεχόμενο της υπό εξέτασης λέξης όσο και αυτό των υποψήφιων ονοματικών οντοτήτων παριστάνονται διανυσματικά. Η διαδικασία κατασκευής των διανυσματικών αυτών αναπαραστάσεων είναι η εξής: Φτιάχνεται το λεξιλόγιο (vocabulary) V της Wikipedia που περιέχει όλες τις διαφορετικές λέξεις που αναφέρονται σε όλα τα άρθρα της. Για κάθε λέξη (word - w) του λεξιλογίου υπάρχει ένας αριθμός df(w) οποίος δηλώνει πόσες φορές έχει εμφανιστεί συνολικά η λέξη w σε όλα τα κείμενα της Wikipedia. Έτσι αν έχουμε μία λέξη q που θέλουμε να αποσαφηνιστεί και το κείμενο q.t μέσα στο οποίο βρίσκεται η λέξη αυτή (δηλαδή το πληροφοριακό της περιεχόμενο) φτιάχνουμε ένα διάνυσμα μεγέθους V στο οποίο για κάθε λέξη που υπάρχει και στο V και στο q.t αντιστοιχεί ένας αριθμός N dw = f(w) ln df(w) (Εξ. 1) όπου f(w) είναι ο αριθμός εμφανίσεων της λέξης w στο q.t και N ο αριθμός όλων των άρθρων της Wikipedia. Για τις λέξεις του V που δεν ανήκουν στο q.t στις αντίστοιχες θέσεις μπαίνει μηδέν. Αντίστοιχα κατασκευάζεται το διάνυσμα που αντιστοιχεί στο πληροφοριακό περιεχόμενο μιας υποψήφιας οντότητας e k.
25 25 Στην πρώτη υλοποίηση τα 2 διανύσματα που προκύπτουν κάθε φορά συγκρίνονται μεταξύ τους μέσω του υπολογισμού του συνημίτονου της μεταξύ τους γωνίας (cosine similarity) που αποτελεί και την συνάρτηση σκοραρίσματος score(q, ek) = cos(q, ek) = q. T q. T ek. T ek. T (Εξ. 2) Όποια από τις υποψήφιες οντότητες δώσει το μεγαλύτερο σκορ είναι και αυτή που τελικά αντιστοιχίζεται από το σύστημα στην υπό εξέταση λέξη. Στην δεύτερη υλοποίηση (taxonomy kernel) η διαδικασία είναι ίδια απλά η συνάρτηση σκοραρίσματος μετασχηματίζεται και γίνεται φ cos(q, ek) = cos (q. T, ek. T) score(q, ek) = Φ(q, ek) = 1 if w q. T and c ek. C, φw, c(q, ek) = 0 otherwise. (Εξ. 3) όπου w διάνυσμα που περιγράφει την συσχέτιση των λέξεων του q.t με τις κατηγορίες του e k και οι τιμές του μπορούν να υπολογιστούν από το training dataset. Η νέα αυτή συνάρτηση σκοραρίσματος εμπεριέχει και την συσχέτιση ανάμεσα στο περιεχόμενο της λέξης και τις κατηγορίες των υποψήφιων οντοτήτων (φ w,c (q,e k )). Στην δεύτερη αυτή υλοποίηση χρησιμοποιείται ως βάση ο ταξινομητής μεγίστου περιθωρίου τύπου SVM (Support Vector Machine) για τη βελτιστοποίηση της συσχέτισης ανάμεσα στις λέξεις του πληροφοριακού περιεχομένου της υπό εξέτασης λέξης και των κατηγοριών των υποψήφιων οντοτήτων. Το σύστημα των Bunescu και Pasca παρουσιάζει υψηλή απόδοση (για την πρώτη υλοποίηση precision από 55.4% μέχρι 82.3% και για την δεύτερη υλοποίηση από 68% μέχρι 84.8% ) η οποία βελτιώνεται αρκετά με την δεύτερη υλοποίηση. Πρέπει ακόμη να αναφερθεί ότι προτείνεται και ένας τρόπος αντιμετώπισης της περίπτωσης στην οποία η οντότητα στην οποία αναφέρεται η υπό εξέταση λέξη δεν έχει καταχώρηση στην Wikipedia (out-of-wikipedia entity). Αυτό γίνεται μέσω της ύπαρξης μίας επιπλέον θεωρητικής οντότητας με μηδενικές τιμές χαρακτηριστικών και ενός ορίου τ. Αυτό που γίνεται είναι ότι υπολογίζονται και πάλι τα σκορ για όλες τις υποψήφιες οντότητες και το μέγιστο σκορ συγκρίνεται με το όριο τ. Αν το μέγιστο σκορ είναι μεγαλύτερο από το όριο τότε η αποσαφήνιση της λέξης είναι η οντότητα που έδωσε το σκορ αυτό. Διαφορετικά ως αποσαφήνιση της λέξης αυτής δίνεται η θεωρητική out-of-wikipedia οντότητα (δηλαδή στην περίπτωση αυτή η λέξη αναφέρεται σε μία οντότητα που δεν έχει καταχώρηση στην Wikipedia).
26 Μέθοδος Cucerzan Παρόμοια στρατηγική με αυτή των Bunescu και Pasca ακολουθεί και ο Cucerzan (2007) [7] για την ανάπτυξη του δικού του συστήματος. Πυρήνας της στρατηγικής του αποτελεί η προσπάθεια για μέγιστη συμφωνία ανάμεσα στο πληροφορικό περιεχόμενο της υπό εξέταση λέξης και των πληροφοριακών περιεχομένων των υποψήφιων οντοτήτων καθώς και η συμφωνία ανάμεσα στο πρώτο και τις κατηγορίες των υποψήφιων οντοτήτων στην Wikipedia. Για να το πετύχει αυτό ακολουθεί μία συστηματική διαδικασία εξαγωγής πληροφορίας από την Wikipedia την οποία στη συνέχεια χρησιμοποιεί κατά την διαδικασία αποσαφήνισης. Πιο συγκεκριμένα σε κάθε οντότητα τις Wikipedia που έχει αναγνωριστεί αντιστοιχίζονται το σύνολο των γνωστών ονομάτων (surface forms) με τα οποία μπορεί η οντότητα αυτή να αναφέρεται, τα στοιχεία πληροφοριακού περιεχομένου και οι κατηγορίες της. Για τα surface forms χρησιμοποιούνται τα χαρακτηριστικά της Wikipedia όπως είναι οι redirect pages και οι disambiguation pages. Για μία ονοματική οντότητα το σύνολο των ονομάτων που της αντιστοιχίζεται σχηματίζεται από 1) το όνομα του κύριου άρθρου της Wikipedia που την αφορά, 2) τα ονόματα όλων των redirect pages και disambiguation pages που τις αντιστοιχούν και 3) όλα τα υπόλοιπα ονόματα που χρησιμοποιούνται για αναφορά στην οντότητα αυτή, δεν ανήκουν στις παραπάνω περιπτώσεις και εμφανίζονται σε 2 τουλάχιστον άλλα άρθρα της Wikipedia Για παράδειγμα η Wikipedia περιέχει μία σελίδα με το όνομα Texas (TV series) που περιέχει πληροφορίες για μία σαπουνόπερα που προβαλλόταν από το τηλεοπτικό δίκτυο NBC από το 1980 μέχρι το Επίσης υπάρχει άλλη μία σελίδα με το όνομα Another World in Texas που περιέχει μία ανακατεύθυνση (σύνδεσμο) προς το άρθρο με τίτλο Texas (TV series). Από αυτά τα 2 άρθρα εξάγεται η οντότητα Texas (TV series) και τα surface forms της Texas (TV series), Texas και Another World in Texas. Με τον τρόπο αυτό εξάγονται περισσότερες από 1.4 εκατομμύρια οντότητες με μέσο όρο 2.4 ονόματα ανά οντότητα. Όσον αφορά τα πληροφοριακά στοιχεία της κάθε οντότητας, η διαδικασία εξαγωγής τους έχεις ως εξής: Υπάρχουν 3 πηγές πληροφοριακών στοιχείων για μία οντότητα. Η πρώτη είναι το όνομα του κυρίου άρθρου της Wikipedia που αφορά την οντότητα αυτή χωρίς τα διάφορα σημεία στίξης (πχ παρενθέσεις, παύλες κλπ.). Η δεύτερη είναι όλες οι οντότητες που αναφέρονται στην πρώτη παράγραφο του κύριου άρθρου της εξεταζόμενης οντότητας. Τέλος η τρίτη πηγή είναι όλες οι οντότητες που βρίσκονται στο υπόλοιπο σώμα του άρθρου της εξεταζόμενης οντότητας (δηλαδή εκτός της πρώτης παραγράφου) και για τις οποίες η αντίστοιχη σελίδα τους στην Wikipedia περιέχει σύνδεσμο που δείχνει πίσω στο άρθρο της εξεταζόμενης οντότητας. Για παράδειγμα για την οντότητα Texas (TV series) που αναφέρθηκε παραπάνω ορισμένα από τα στοιχεία περιεχομένου που της αντιστοιχίζονται είναι το Texas TV series (τίτλος του άρθρου χωρίς σημεία στίξης), οι οντότητες NBC, John William Corrington κ.α. που αναφέρονται στην πρώτη παράγραφο του άρθρου της, όπως επίσης και η οντότητα Pam Long η οποία βρίσκεται στο σώμα του άρθρου
27 27 (εκτός της πρώτης παραγράφου) και έχει σελίδα με σύνδεσμο προς το άρθρο της Texas (TV series). Με αυτόν τον τρόπο εξήχθησαν περίπου 38 εκατομμύρια ζεύγη της μορφής (οντότητα, πληροφοριακό στοιχείο). Τέλος για την αναγνώριση και την ανάθεση των κατηγοριών που αντιστοιχούν σε μία οντότητα ο Cucerzan χρησιμοποιεί τόσο τα list pages της Wikipedia όσο και τις κατηγορίες που φτιάχνονται και αντιστοιχίζονται στα άρθρα από τους χρήστες που γράφουν για την Wikipedia. Για παράδειγμα οι Wikipedia περιέχει μία σελίδα με τίτλο List of counties in Indiana που είναι μία λίστα με τις σελίδες που αντιστοιχούν σε όλες τις κομητείες της πολιτείας Ιντιάνα των ΗΠΑ. Από αυτήν την σελίδα μπορεί να εξαχθεί η κατηγορία LIST_counties_in_Indiana και να αποδοθεί στην οντότητα Adams County (που είναι κομητεία της Ιντιάνα). Με τον τρόπο αυτό και μετά από ένα φιλτράρισμα των αποτελεσμάτων προκύπτει ένα σύνολο 2.65 εκατομμυρίων ζευγαριών της μορφής (οντότητα, κατηγορία). Αφού τελειώσει η διαδικασία εξαγωγής πληροφορίας από την Wikipedia ακολουθεί η διαδικασία ανάλυσης του εγγράφου στο οποίο βρίσκονται οι προς αποσαφήνιση λέξεις. Τα βήματα της διαδικασίας αυτής είναι συνοπτικά τα παρακάτω: «Σπάσιμο» του εγγράφου σε προτάσεις, αναγνώριση της αρχής της κάθε πρότασης και εξέταση του αν η πρώτη λέξη κάθε πρότασης αποτελεί ονοματική οντότητα ή είναι με κεφαλαία γράμματα εξαιτίας ορθογραφικών συμβάσεων. Αναγνώριση ονοματικών οντοτήτων με χρήση κανόνων γραμματικής, στατιστικών από τον Ιστό και από παρόμοιες εργασίες καθώς και με χρήση των surface forms που έχουν αναγνωριστεί κατά την διαδικασία εξαγωγής πληροφορίας που περιγράφεται παραπάνω. Αποσαφήνιση των αναγνωρισθέντων ονοματικών οντοτήτων με την χρήση των παραπάνω πληροφοριών που εξάγονται από την Wikipedia και το κείμενο μέσα στο οποίο βρίσκονται τα προς αποσαφήνιση ονόματα με βάση ταξινομητή τύπου SVM. Με βάση τις παραπάνω πληροφορίες δημιουργούνται οι διανυσματικές αναπαραστάσεις τόσο των υποψήφιων ονοματικών οντοτήτων όσο και του κειμένου και στην συνέχεια προσπαθεί να επιτευχθεί η βέλτιστη αντιστοίχιση ονομάτων-οντοτήτων η οποία να μεγιστοποιεί έναν μαθηματικό όρο που περιγράφει στην ουσία την συμφωνία ανάμεσα στα πληροφοριακά περιεχόμενα των υπό εξέταση λέξεων και τα πληροφοριακά περιεχόμενα και τις κατηγορίες των υποψηφίων ονοματικών οντοτήτων. Μετά την ολοκλήρωση της διαδικασίας αποσαφήνισης το σύστημα δημιουργεί για κάθε έναν από τους όρους που έχουν αποσαφηνιστεί ένα σύνδεσμο προς το κύριο άρθρο της Wikipedia που της αντιστοιχεί. Το σύστημα του Cucerzan αξιολογείται πάνω σε ένα σύνολο άρθρων της Wikipedia (έκδοση 2 Απριλίου 2006) όσο και σε ένα σύνολο 100 άρθρων που προέρχονται από την ειδησεογραφία και αφορούν ένα μεγάλο εύρος θεμάτων. Όσον αφορά το σύνολο των άρθρων της Wikipedia, μετά από ένα φιλτράρισμα κάποιων ονομάτων που εμφανίζονται σε αυτά (πχ απορρίπτονται ονόματα που έχουν αποσαφήνιση που δεν έχει καταχώρηση στην Wikipedia) το σύστημα παρουσιάζει
28 28 ακρίβεια 88% ενώ στα άρθρα από την ειδησεογραφία το σύστημα παρουσίασε ακρίβεια 91.4% (και εδώ προηγήθηκε μια διαδικασία απόρριψης ονομάτων που δεν έχουν καταχώρηση στην Wikipedia non recallable surface forms). Πρέπει τέλος να σημειωθεί ότι το σύστημα του Cucerzan δεν λαμβάνει καμία μέριμνα για τον χειρισμό των περιπτώσεων στις οποίες το υπό εξέταση όνομα έχει αποσαφήνιση που δεν έχει καταχώρηση στην Wikipedia Άλλες σημαντικές μέθοδοι Όπως αναφέρθηκε παραπάνω, σημαντικές εργασίες που έχουν παρουσιαστεί όπως αυτή των Bunescu και Pasca [6], και αυτή του Cucerzan [7] βασίζονται σε χαρακτηριστικά της Wikipedia (όπως οι redirect pages και οι disambiguation pages) για την επίλυση της σημασιολογικής ασάφειας. Αυτή η επιλογή οδήγησε μεν σε συστήματα με αρκετά υψηλές αποδόσεις τα οποία όμως δεν μπορούν να λειτουργήσουν σε άλλες βάσεις γνώσεων εκτός της Wikipedia. Κάτι τέτοιο δεν συμβαίνει στο σύστημα που παρουσίασαν στην μελέτη τους οι Dredze, McNamee, Rao, Gerder και Finin (2010) [8] από το πανεπιστήμιο του Μέρυλαντ. Στην προσέγγισή τους το σύστημα που αναπτύσσεται πραγματοποιεί αποσαφήνιση ονομάτων που εμφανίζονται σε διάφορα έγγραφα ανεξάρτητα από την βάση γνώσεων που χρησιμοποιείται. Αυτό επιτυγχάνεται με την χρήση ενός μεγάλου πλήθους χαρακτηριστικών (200 βασικά και μέσω των συνδυασμών τους παράγονται συνολικά) τόσο των υπό εξέταση ονομάτων και των εγγράφων μέσα στα οποία αυτά βρίσκονται, όσο και των υποψήφιων αποσαφηνίσεών τους (υπάρχει μία διαδικασία κατασκευής ενός συνόλου υποψήφιων οντοτήτων για κάθε υπό εξέταση όνομα η οποία λειτουργεί για οποιαδήποτε βάση γνώσης). Τέτοια χαρακτηριστικά είναι πχ το document similarity δηλαδή η ομοιότητα ανάμεσα στο πληροφοριακό περιεχόμενο του ονόματος και αυτό της ονοματικής οντότητας που υπάρχει στη γνωσιακή βάση, το entity type δηλαδή αν μία ονοματική οντότητα είναι τύπου person, organization κλπ, το Popularity δηλαδή η δημοτικότητα της υποψήφιας οντότητας για την οποία χρησιμοποιείται το PageRank εργαλείο της Google που δείχνει σε ποια θέση κατατάσσεται το άρθρο της Wikipedia που αναφέρεται στην συγκεκριμένη οντότητα όταν γίνεται μία αναζήτηση αυτής στο Google, το string similarity δηλαδή η ομοιότητα ανάμεσα στο όνομα και πχ τον τίτλο του άρθρο που περιγράφει την οντότητα αυτή για τον υπολογισμό του οποίου υπάρχουν διάφορα μέτρα (Dice score, Hamming distance) και πολλά ακόμη. Ένα ακόμα σημαντικό χαρακτηριστικό του συστήματος αυτού είναι ότι αντιμετωπίζει πιο ολοκληρωμένα και προσεκτικά τις περιπτώσεις των εκτός γνωσιακών βάσεων αποσαφηνίσεων. Πιο συγκεκριμένα χρησιμοποιούνται επιπλέον μανθάνοντα χαρακτηριστικά για την αναγνώριση του εάν ένα όνομα αναφέρεται σε μία οντότητα εκτός της βάσης, όπως είναι το εάν το υπό εξέταση όνομα έχει κάποιο ακριβές ή κοντινό ταίριασμα με το όνομα κάποιας από τις υποψήφιες οντότητες, αν το πρώτο αποτέλεσμα της Google στην αναζήτηση του ονόματος είναι εκτός της λίστας των υποψήφιων οντοτήτων κ.α.
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. WordNet
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ WordNet Σημασιολογικά Δίκτυα Ένα δίκτυο που αναπαριστά συσχετίσεις μεταξύ εννοιών. Οι κορυφές παριστάνουν έννοιες και οι ακμές σημασιολογικές
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ WordNet Σημασιολογικά Δίκτυα Ένα δίκτυο που αναπαριστά συσχετίσεις μεταξύ εννοιών. Οι κορυφές παριστάνουν έννοιες και οι ακμές σημασιολογικές
ΘΕΜΑ 1 Τεχνικές Εξαγωγής Συµφράσεων από εδοµένα Κειµένου και Πειραµατική Αξιολόγηση
 ΘΕΜΑ 1 Τεχνικές Εξαγωγής Συµφράσεων από εδοµένα Κειµένου και Πειραµατική Αξιολόγηση Οι συµφράσεις είναι ακολουθίες όρων οι οποίοι συνεµφανίζονται σε κείµενο µε µεγαλύτερη συχνότητα από εκείνη της εµφάνισης
ΘΕΜΑ 1 Τεχνικές Εξαγωγής Συµφράσεων από εδοµένα Κειµένου και Πειραµατική Αξιολόγηση Οι συµφράσεις είναι ακολουθίες όρων οι οποίοι συνεµφανίζονται σε κείµενο µε µεγαλύτερη συχνότητα από εκείνη της εµφάνισης
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Τεχνικές NLP Σχεδιαστικά Θέματα
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Τεχνικές NLP Σχεδιαστικά Θέματα Natural Language Processing Επεξεργασία δεδομένων σε φυσική γλώσσα Κατανόηση φυσικής γλώσσας από τη μηχανή
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Τεχνικές NLP Σχεδιαστικά Θέματα Natural Language Processing Επεξεργασία δεδομένων σε φυσική γλώσσα Κατανόηση φυσικής γλώσσας από τη μηχανή
ΠΕΡΙΛΗΨΗ. Είναι γνωστό άτι καθημερινά διακινούνται δεκάδες μηνύματα (E~mail) μέσω του διαδικτύου
 μέσω του διαδικτύου") GREEKLISH: ΜΙΑ ΝΕΑ ΔΙΑΛΕΚΤΟΣ ΤΟΥ ΔΙΑΔΙΚΤΥΟΥ; Α.Καράκος, Λ.Κωτούλας ΠΕΡΙΛΗΨΗ Είναι γνωστό άτι καθημερινά διακινούνται δεκάδες μηνύματα (E~mail) μέσω του διαδικτύου {INTERNEη από την μια άκρη του κόσμου
GREEKLISH: ΜΙΑ ΝΕΑ ΔΙΑΛΕΚΤΟΣ ΤΟΥ ΔΙΑΔΙΚΤΥΟΥ; Α.Καράκος, Λ.Κωτούλας ΠΕΡΙΛΗΨΗ Είναι γνωστό άτι καθημερινά διακινούνται δεκάδες μηνύματα (E~mail) μέσω του διαδικτύου {INTERNEη από την μια άκρη του κόσμου
ΑΝΑΠΤΥΞΗ ΛΟΓΙΣΜΙΚΟΥ ΓΙΑ ΤΗ ΔΙΕΝΕΡΓΕΙΑ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΜΕΛΕΤΩΝ
 ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΑΝΑΠΤΥΞΗ ΛΟΓΙΣΜΙΚΟΥ ΓΙΑ ΤΗ ΔΙΕΝΕΡΓΕΙΑ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΜΕΛΕΤΩΝ ΠΛΟΣΚΑΣ ΝΙΚΟΛΑΟΣ Α.Μ. 123/04 ΕΠΙΒΛΕΠΩΝ: ΣΑΜΑΡΑΣ ΝΙΚΟΛΑΟΣ ΘΕΣΣΑΛΟΝΙΚΗ, ΙΟΥΝΙΟΣ 2007 Περιεχόμενα
ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΑΝΑΠΤΥΞΗ ΛΟΓΙΣΜΙΚΟΥ ΓΙΑ ΤΗ ΔΙΕΝΕΡΓΕΙΑ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΜΕΛΕΤΩΝ ΠΛΟΣΚΑΣ ΝΙΚΟΛΑΟΣ Α.Μ. 123/04 ΕΠΙΒΛΕΠΩΝ: ΣΑΜΑΡΑΣ ΝΙΚΟΛΑΟΣ ΘΕΣΣΑΛΟΝΙΚΗ, ΙΟΥΝΙΟΣ 2007 Περιεχόμενα
ΑΣΚΗΣΗ. Δημιουργία Ευρετηρίων Συλλογής Κειμένων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ. του Γεράσιμου Τουλιάτου ΑΜ: 697
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΣΤΑ ΠΛΑΙΣΙΑ ΤΟΥ ΜΕΤΑΠΤΥΧΙΑΚΟΥ ΔΙΠΛΩΜΑΤΟΣ ΕΙΔΙΚΕΥΣΗΣ ΕΠΙΣΤΗΜΗ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ του Γεράσιμου Τουλιάτου
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΣΤΑ ΠΛΑΙΣΙΑ ΤΟΥ ΜΕΤΑΠΤΥΧΙΑΚΟΥ ΔΙΠΛΩΜΑΤΟΣ ΕΙΔΙΚΕΥΣΗΣ ΕΠΙΣΤΗΜΗ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ του Γεράσιμου Τουλιάτου
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #02 Ιστορική αναδρομή Σχετικές επιστημονικές περιοχές 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #02 Ιστορική αναδρομή Σχετικές επιστημονικές περιοχές 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ανάκτηση Πληροφορίας
 Ανάκτηση Πληροφορίας Το μοντέλο Boolean Το μοντέλο Vector Ταξινόμηση Μοντέλων IR Ανάκτηση Περιήγηση Κλασικά Μοντέλα Boolean Vector Probabilistic Δομικά Μοντέλα Non-Overlapping Lists Proximal Nodes Browsing
Ανάκτηση Πληροφορίας Το μοντέλο Boolean Το μοντέλο Vector Ταξινόμηση Μοντέλων IR Ανάκτηση Περιήγηση Κλασικά Μοντέλα Boolean Vector Probabilistic Δομικά Μοντέλα Non-Overlapping Lists Proximal Nodes Browsing
þÿ¼ ½ ±Â : ÁÌ» Â Ä Å ÃÄ ²µ þÿä Å ÃÇ»¹º Í Á³ Å
 Neapolis University HEPHAESTUS Repository School of Economic Sciences and Business http://hephaestus.nup.ac.cy Master Degree Thesis 2015 þÿ ½»Åà Äɽ µ½½ ¹Î½ Ä Â þÿ±¾¹»ì³ à  º±¹ Ä Â þÿ±à ĵ»µÃ¼±Ä¹ºÌÄ Ä±Â
Neapolis University HEPHAESTUS Repository School of Economic Sciences and Business http://hephaestus.nup.ac.cy Master Degree Thesis 2015 þÿ ½»Åà Äɽ µ½½ ¹Î½ Ä Â þÿ±¾¹»ì³ à  º±¹ Ä Â þÿ±à ĵ»µÃ¼±Ä¹ºÌÄ Ä±Â
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ Επιβλέπων Καθηγητής: Δρ. Νίκος Μίτλεττον Η ΣΧΕΣΗ ΤΟΥ ΜΗΤΡΙΚΟΥ ΘΗΛΑΣΜΟΥ ΜΕ ΤΗΝ ΕΜΦΑΝΙΣΗ ΣΑΚΧΑΡΩΔΗ ΔΙΑΒΗΤΗ ΤΥΠΟΥ 2 ΣΤΗΝ ΠΑΙΔΙΚΗ ΗΛΙΚΙΑ Ονοματεπώνυμο: Ιωσηφίνα
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ Επιβλέπων Καθηγητής: Δρ. Νίκος Μίτλεττον Η ΣΧΕΣΗ ΤΟΥ ΜΗΤΡΙΚΟΥ ΘΗΛΑΣΜΟΥ ΜΕ ΤΗΝ ΕΜΦΑΝΙΣΗ ΣΑΚΧΑΡΩΔΗ ΔΙΑΒΗΤΗ ΤΥΠΟΥ 2 ΣΤΗΝ ΠΑΙΔΙΚΗ ΗΛΙΚΙΑ Ονοματεπώνυμο: Ιωσηφίνα
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ. Μάθημα 1 ο : Εισαγωγή στην γλωσσική τεχνολογία. Γεώργιος Πετάσης. Ακαδημαϊκό Έτος: 2012 2013
 ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 1 ο : Εισαγωγή στην γλωσσική τεχνολογία Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Τι είναι η γλωσσική τεχνολογία;
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 1 ο : Εισαγωγή στην γλωσσική τεχνολογία Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Τι είναι η γλωσσική τεχνολογία;
 Πτυχιακή Εργασία ηµιουργία Εκπαιδευτικού Παιχνιδιού σε Tablets Καλλιγάς ηµήτρης Παναγιώτης Α.Μ.: 1195 Επιβλέπων καθηγητής: ρ. Συρµακέσης Σπύρος ΑΝΤΙΡΡΙΟ 2015 Ευχαριστίες Σ αυτό το σηµείο θα ήθελα να
Πτυχιακή Εργασία ηµιουργία Εκπαιδευτικού Παιχνιδιού σε Tablets Καλλιγάς ηµήτρης Παναγιώτης Α.Μ.: 1195 Επιβλέπων καθηγητής: ρ. Συρµακέσης Σπύρος ΑΝΤΙΡΡΙΟ 2015 Ευχαριστίες Σ αυτό το σηµείο θα ήθελα να
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ. Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων. Γεώργιος Πετάσης. Ακαδημαϊκό Έτος:
 ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος
Τίμος Κουλουμπής. Τμήμα Μηχανικών Πληροφοριακών & Επικοινωνιακών Συστημάτων, Πανεπιστήμιο Αιγαίου
 Τίμος Κουλουμπής Τμήμα Μηχανικών Πληροφοριακών & Επικοινωνιακών Συστημάτων, Πανεπιστήμιο Αιγαίου Αντικείμενο Εργασίας Εισαγωγή στην Αυτόματη Κατηγοριοποίηση Κειμένου Μεθοδολογίες Συγκριτική Αποτίμηση Συμπεράσματα
Τίμος Κουλουμπής Τμήμα Μηχανικών Πληροφοριακών & Επικοινωνιακών Συστημάτων, Πανεπιστήμιο Αιγαίου Αντικείμενο Εργασίας Εισαγωγή στην Αυτόματη Κατηγοριοποίηση Κειμένου Μεθοδολογίες Συγκριτική Αποτίμηση Συμπεράσματα
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Information Extraction
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Information Extraction Information Extraction Μορφή της πληροφορίας Δομημένα δεδομένα Relational Databases (SQL) XML markup Μη-δομημένα δεδομένα
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Information Extraction Information Extraction Μορφή της πληροφορίας Δομημένα δεδομένα Relational Databases (SQL) XML markup Μη-δομημένα δεδομένα
Ανάκτηση πολυμεσικού περιεχομένου
 Ανάκτηση πολυμεσικού περιεχομένου Ανίχνευση / αναγνώριση προσώπων Ανίχνευση / ανάγνωση κειμένου Ανίχνευση αντικειμένων Οπτικές λέξεις Δεικτοδότηση Σχέσεις ομοιότητας Κατηγοριοποίηση ειδών μουσικής Διάκριση
Ανάκτηση πολυμεσικού περιεχομένου Ανίχνευση / αναγνώριση προσώπων Ανίχνευση / ανάγνωση κειμένου Ανίχνευση αντικειμένων Οπτικές λέξεις Δεικτοδότηση Σχέσεις ομοιότητας Κατηγοριοποίηση ειδών μουσικής Διάκριση
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ. Πτυχιακή εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΠΡΟΣΔΙΟΡΙΣΜΟΣ ΔΕΙΚΤΩΝ ΚΑΤΑΝΑΛΩΣΗΣ ΕΝΕΡΓΕΙΑΣ ΣΤΑ ΑΝΤΛΙΟΣΤΑΣΙΑ ΤΟΥ ΤΜΗΜΑΤΟΣ ΑΝΑΠΤΥΞΕΩΣ ΥΔΑΤΩΝ Γεωργίου
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΠΡΟΣΔΙΟΡΙΣΜΟΣ ΔΕΙΚΤΩΝ ΚΑΤΑΝΑΛΩΣΗΣ ΕΝΕΡΓΕΙΑΣ ΣΤΑ ΑΝΤΛΙΟΣΤΑΣΙΑ ΤΟΥ ΤΜΗΜΑΤΟΣ ΑΝΑΠΤΥΞΕΩΣ ΥΔΑΤΩΝ Γεωργίου
ΑΣΚΗΣΗ. Συγκομιδή και δεικτοδότηση ιστοσελίδων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2010-2011 ΑΣΚΗΣΗ Συγκομιδή και δεικτοδότηση ιστοσελίδων Σκοπός της άσκησης είναι η υλοποίηση ενός ολοκληρωμένου συστήματος συγκομιδής και δεικτοδότησης ιστοσελίδων.
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2010-2011 ΑΣΚΗΣΗ Συγκομιδή και δεικτοδότηση ιστοσελίδων Σκοπός της άσκησης είναι η υλοποίηση ενός ολοκληρωμένου συστήματος συγκομιδής και δεικτοδότησης ιστοσελίδων.
1 Συστήματα Αυτοματισμού Βιβλιοθηκών
 1 Συστήματα Αυτοματισμού Βιβλιοθηκών Τα Συστήματα Αυτοματισμού Βιβλιοθηκών χρησιμοποιούνται για τη διαχείριση καταχωρήσεων βιβλιοθηκών. Τα περιεχόμενα των βιβλιοθηκών αυτών είναι έντυπα έγγραφα, όπως βιβλία
1 Συστήματα Αυτοματισμού Βιβλιοθηκών Τα Συστήματα Αυτοματισμού Βιβλιοθηκών χρησιμοποιούνται για τη διαχείριση καταχωρήσεων βιβλιοθηκών. Τα περιεχόμενα των βιβλιοθηκών αυτών είναι έντυπα έγγραφα, όπως βιβλία
ΟΡΓΑΝΙΣΜΟΣ ΒΙΟΜΗΧΑΝΙΚΗΣ ΙΔΙΟΚΤΗΣΙΑΣ
 ΟΡΓΑΝΙΣΜΟΣ ΒΙΟΜΗΧΑΝΙΚΗΣ ΙΔΙΟΚΤΗΣΙΑΣ Ο Οργανισμός Βιομηχανικής Ιδιοκτησίας (Ο.Β.Ι.) ιδρύθηκε το 1987 (Ν.1733/1987), είναι νομικό πρόσωπο ιδιωτικού δικαίου, οικονομικά ανεξάρτητο και διοικητικά αυτοτελές.
ΟΡΓΑΝΙΣΜΟΣ ΒΙΟΜΗΧΑΝΙΚΗΣ ΙΔΙΟΚΤΗΣΙΑΣ Ο Οργανισμός Βιομηχανικής Ιδιοκτησίας (Ο.Β.Ι.) ιδρύθηκε το 1987 (Ν.1733/1987), είναι νομικό πρόσωπο ιδιωτικού δικαίου, οικονομικά ανεξάρτητο και διοικητικά αυτοτελές.
Εργαστήριο Σημασιολογικού Ιστού
 Εργαστήριο Σημασιολογικού Ιστού Ενότητα 1: Σημασιολογία και Μεταδεδομένα Μ.Στεφανιδάκης 5-2-2016. Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί στα πλαίσια του εκπαιδευτικού έργου του διδάσκοντα.
Εργαστήριο Σημασιολογικού Ιστού Ενότητα 1: Σημασιολογία και Μεταδεδομένα Μ.Στεφανιδάκης 5-2-2016. Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί στα πλαίσια του εκπαιδευτικού έργου του διδάσκοντα.
Τεχνικές Εξόρυξης Δεδομένων
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Διατμηματικό Μεταπτυχιακό Πρόγραμμα στα Πληροφοριακά Συστήματα ( MIS ) Τεχνικές Εξόρυξης Δεδομένων για την βελτίωση της απόδοσης σε Κατανεμημένα Συστήματα Ζάχος Δημήτριος Επιβλέποντες:
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Διατμηματικό Μεταπτυχιακό Πρόγραμμα στα Πληροφοριακά Συστήματα ( MIS ) Τεχνικές Εξόρυξης Δεδομένων για την βελτίωση της απόδοσης σε Κατανεμημένα Συστήματα Ζάχος Δημήτριος Επιβλέποντες:
Η θέση ύπνου του βρέφους και η σχέση της με το Σύνδρομο του αιφνίδιου βρεφικού θανάτου. ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Η θέση ύπνου του βρέφους και η σχέση της με το Σύνδρομο του αιφνίδιου βρεφικού θανάτου. Χρυσάνθη Στυλιανού Λεμεσός 2014 ΤΕΧΝΟΛΟΓΙΚΟ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Η θέση ύπνου του βρέφους και η σχέση της με το Σύνδρομο του αιφνίδιου βρεφικού θανάτου. Χρυσάνθη Στυλιανού Λεμεσός 2014 ΤΕΧΝΟΛΟΓΙΚΟ
Εργαστήριο Σημασιολογικού Ιστού
 Εργαστήριο Σημασιολογικού Ιστού Ενότητα 1: Σημασιολογία και Μεταδεδομένα Μ.Στεφανιδάκης 10-2-2017 Η αρχή: Το όραμα του Σημασιολογικού Ιστού Tim Berners-Lee, James Hendler and Ora Lassila, The Semantic
Εργαστήριο Σημασιολογικού Ιστού Ενότητα 1: Σημασιολογία και Μεταδεδομένα Μ.Στεφανιδάκης 10-2-2017 Η αρχή: Το όραμα του Σημασιολογικού Ιστού Tim Berners-Lee, James Hendler and Ora Lassila, The Semantic
Η ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΗΣΗΣ ΣΤΟ ΣΥΓΧΡΟΝΟ ΠΕΡΙΒΑΛΛΟΝ
 Η ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΗΣΗΣ ΣΤΟ ΣΥΓΧΡΟΝΟ ΠΕΡΙΒΑΛΛΟΝ Ιόνιο Πανεπιστήµιο Τµήµα Αρχειονοµίας-Βιβλιοθηκονοµίας Μεταπτυχιακό Πρόγραµµα Σπουδών2007-2008 ιδάσκουσα: Κατερίνα Τοράκη (Οι διαλέξεις περιλαµβάνουν
Η ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΗΣΗΣ ΣΤΟ ΣΥΓΧΡΟΝΟ ΠΕΡΙΒΑΛΛΟΝ Ιόνιο Πανεπιστήµιο Τµήµα Αρχειονοµίας-Βιβλιοθηκονοµίας Μεταπτυχιακό Πρόγραµµα Σπουδών2007-2008 ιδάσκουσα: Κατερίνα Τοράκη (Οι διαλέξεις περιλαµβάνουν
Ανάκτηση Πληροφορίας. Διδάσκων: Φοίβος Μυλωνάς. Διάλεξη #01
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #01 Διαδικαστικά μαθήματος Εισαγωγικές έννοιες & Ορισμοί Συστήματα ανάκτησης πληροφορίας 1
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #01 Διαδικαστικά μαθήματος Εισαγωγικές έννοιες & Ορισμοί Συστήματα ανάκτησης πληροφορίας 1
Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές
 Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές των Τμημάτων Χημείας και Επιστήμης &Τεχνολογίας Υλικών Ηράκλειο Ακαδημαϊκό Έτος 2016-7 Πρόσβαση στην επιστημονική πληροφορία Σημείο εκκίνησης http://www.lib.uoc.gr
Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές των Τμημάτων Χημείας και Επιστήμης &Τεχνολογίας Υλικών Ηράκλειο Ακαδημαϊκό Έτος 2016-7 Πρόσβαση στην επιστημονική πληροφορία Σημείο εκκίνησης http://www.lib.uoc.gr
ΤΟ ΜΟΝΤΕΛΟ Οι Υποθέσεις Η Απλή Περίπτωση για λi = μi 25 = Η Γενική Περίπτωση για λi μi..35
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΜΑΘΗΜΑΤΙΚΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΤΟΜΕΑΣ ΣΤΑΤΙΣΤΙΚΗΣ ΚΑΙ ΕΠΙΧΕΙΡΗΣΙΑΚΗΣ ΕΡΕΥΝΑΣ ΑΝΑΛΥΣΗ ΤΩΝ ΣΥΣΧΕΤΙΣΕΩΝ ΧΡΕΟΚΟΠΙΑΣ ΚΑΙ ΤΩΝ
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΜΑΘΗΜΑΤΙΚΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΤΟΜΕΑΣ ΣΤΑΤΙΣΤΙΚΗΣ ΚΑΙ ΕΠΙΧΕΙΡΗΣΙΑΚΗΣ ΕΡΕΥΝΑΣ ΑΝΑΛΥΣΗ ΤΩΝ ΣΥΣΧΕΤΙΣΕΩΝ ΧΡΕΟΚΟΠΙΑΣ ΚΑΙ ΤΩΝ
Συλλογιστική εξαγωγής συμπερασμάτων από συγκεκριμένες υποθέσεις δοθείσα μεθοδολογία διαδικασία της σκέψης, πρέπει να «συλλογιστεί» υπόθεση/παραγωγή
 REASON ING Η Συλλογιστική, είναι η πράξη εξαγωγής συμπερασμάτων από συγκεκριμένες υποθέσεις χρησιμοποιώντας μία δοθείσα μεθοδολογία. Στην ουσία είναι η ίδια η διαδικασία της σκέψης, μία λογική διαμάχη,
REASON ING Η Συλλογιστική, είναι η πράξη εξαγωγής συμπερασμάτων από συγκεκριμένες υποθέσεις χρησιμοποιώντας μία δοθείσα μεθοδολογία. Στην ουσία είναι η ίδια η διαδικασία της σκέψης, μία λογική διαμάχη,
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΠΑΡΟΥΣΙΑΣΗ ΔΙΠΛΩΜΑΤΙΚΗΣ ΕΡΓΑΣΙΑΣ ΔΟΥΒΛΕΤΗΣ ΧΑΡΑΛΑΜΠΟΣ ΕΠΙΒΛΕΠΟΝΤΕΣ ΚΑΘΗΓΗΤΕΣ Μαργαρίτης Κωνσταντίνος Βακάλη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΠΑΡΟΥΣΙΑΣΗ ΔΙΠΛΩΜΑΤΙΚΗΣ ΕΡΓΑΣΙΑΣ ΔΟΥΒΛΕΤΗΣ ΧΑΡΑΛΑΜΠΟΣ ΕΠΙΒΛΕΠΟΝΤΕΣ ΚΑΘΗΓΗΤΕΣ Μαργαρίτης Κωνσταντίνος Βακάλη
Σχολή Μηχανικής και Τεχνολογίας. Πτυχιακή εργασία
 Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία Ευφυής επεξεργασία και ανάλυση δεδομένων μεγάλου όγκου: Συλλογή και επεξεργασία δεδομένων μεγάλης συχνότητας και εύρους σε πραγματικό χρόνο για τον εντοπισμό
Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία Ευφυής επεξεργασία και ανάλυση δεδομένων μεγάλου όγκου: Συλλογή και επεξεργασία δεδομένων μεγάλης συχνότητας και εύρους σε πραγματικό χρόνο για τον εντοπισμό
ΑΛΛΗΛΕΠΙ ΡΑΣΗ ΜΟΡΦΩΝ ΛΥΓΙΣΜΟΥ ΣΤΙΣ ΜΕΤΑΛΛΙΚΕΣ ΚΑΤΑΣΚΕΥΕΣ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΤΜΗΜΑ ΠΟΛΙΤΙΚΩΝ ΜΗΧΑΝΙΚΩΝ Τοµέας οµοστατικής Εργαστήριο Μεταλλικών Κατασκευών ΑΛΛΗΛΕΠΙ ΡΑΣΗ ΜΟΡΦΩΝ ΛΥΓΙΣΜΟΥ ΣΤΙΣ ΜΕΤΑΛΛΙΚΕΣ ΚΑΤΑΣΚΕΥΕΣ ιπλωµατική Εργασία Ιωάννη Σ. Προµπονά
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΤΜΗΜΑ ΠΟΛΙΤΙΚΩΝ ΜΗΧΑΝΙΚΩΝ Τοµέας οµοστατικής Εργαστήριο Μεταλλικών Κατασκευών ΑΛΛΗΛΕΠΙ ΡΑΣΗ ΜΟΡΦΩΝ ΛΥΓΙΣΜΟΥ ΣΤΙΣ ΜΕΤΑΛΛΙΚΕΣ ΚΑΤΑΣΚΕΥΕΣ ιπλωµατική Εργασία Ιωάννη Σ. Προµπονά
Δημιουργία Ευρετηρίων Συλλογής Κειμένων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 - Project Σεπτεμβρίου Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος Εξέταση: Προφορική, στο τέλος της εξεταστικής. Θα βγει ανακοίνωση στο forum. Ομάδες
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 - Project Σεπτεμβρίου Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος Εξέταση: Προφορική, στο τέλος της εξεταστικής. Θα βγει ανακοίνωση στο forum. Ομάδες
Πληροφοριακά Συστήματα
 Πληροφοριακά Συστήματα Ανακτώντας Πληροφορία και Γνώση στον Παγκόσμιο Ιστό Γιάννης Τζίτζικας Επίκουρος Καθηγητής Τμήματος Επιστήμης Υπολογιστών και Συνεργαζόμενος Ερευνητής του ΙΤΕ-ΙΠ 3 Απριλίου 2015 Διάρθρωση
Πληροφοριακά Συστήματα Ανακτώντας Πληροφορία και Γνώση στον Παγκόσμιο Ιστό Γιάννης Τζίτζικας Επίκουρος Καθηγητής Τμήματος Επιστήμης Υπολογιστών και Συνεργαζόμενος Ερευνητής του ΙΤΕ-ΙΠ 3 Απριλίου 2015 Διάρθρωση
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΚΗΣ ΕΠΙΣΤΗΜΗΣ ΑΜΕΣΕΣ ΞΕΝΕΣ ΕΠΕΝΔΥΣΕΙΣ ΣΕ ΕΥΡΩΠΑΙΚΕΣ ΧΩΡΕΣ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΚΗΣ ΕΠΙΣΤΗΜΗΣ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΟΙΚΟΝΟΜΙΚΗ ΚΑΙ ΕΠΙΧΕΙΡΗΣΙΑΚΗ ΣΤΡΑΤΗΓΙΚΗ ΑΜΕΣΕΣ ΞΕΝΕΣ ΕΠΕΝΔΥΣΕΙΣ ΣΕ ΕΥΡΩΠΑΙΚΕΣ ΧΩΡΕΣ Αθανάσιος Νταραβάνογλου Διπλωματική
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΚΗΣ ΕΠΙΣΤΗΜΗΣ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΟΙΚΟΝΟΜΙΚΗ ΚΑΙ ΕΠΙΧΕΙΡΗΣΙΑΚΗ ΣΤΡΑΤΗΓΙΚΗ ΑΜΕΣΕΣ ΞΕΝΕΣ ΕΠΕΝΔΥΣΕΙΣ ΣΕ ΕΥΡΩΠΑΙΚΕΣ ΧΩΡΕΣ Αθανάσιος Νταραβάνογλου Διπλωματική
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ. Πτυχιακή εργασία ΟΛΙΣΘΗΡΟΤΗΤΑ ΚΑΙ ΜΑΚΡΟΥΦΗ ΤΩΝ ΟΔΟΔΤΡΩΜΑΤΩΝ ΚΥΚΛΟΦΟΡΙΑΣ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ Πτυχιακή εργασία ΟΛΙΣΘΗΡΟΤΗΤΑ ΚΑΙ ΜΑΚΡΟΥΦΗ ΤΩΝ ΟΔΟΔΤΡΩΜΑΤΩΝ ΚΥΚΛΟΦΟΡΙΑΣ Χριστοδούλου Αντρέας Λεμεσός 2014 2 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ Πτυχιακή εργασία ΟΛΙΣΘΗΡΟΤΗΤΑ ΚΑΙ ΜΑΚΡΟΥΦΗ ΤΩΝ ΟΔΟΔΤΡΩΜΑΤΩΝ ΚΥΚΛΟΦΟΡΙΑΣ Χριστοδούλου Αντρέας Λεμεσός 2014 2 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #04 Εισαγωγή στα Μοντέλα Ανάκτησης Πληροφορίας Boolean Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #04 Εισαγωγή στα Μοντέλα Ανάκτησης Πληροφορίας Boolean Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
ΓΕΩΠΟΝΙΚΗ ΣΧΟΛΗ ΑΠΘ Εργαστήριο Πληροφορικής στη Γεωργία ΠΛΗΡΟΦΟΡΙΚΗ Ι
 ΓΕΩΠΟΝΙΚΗ ΣΧΟΛΗ ΑΠΘ Εργαστήριο Πληροφορικής στη Γεωργία ΠΛΗΡΟΦΟΡΙΚΗ Ι Συστήματα Υποστήριξης Αποφάσεων Τα Συστήματα Υποστήριξης Αποφάσεων (Σ.Υ.Α. - Decision Support Systems, D.S.S.) ορίζονται ως συστήματα
ΓΕΩΠΟΝΙΚΗ ΣΧΟΛΗ ΑΠΘ Εργαστήριο Πληροφορικής στη Γεωργία ΠΛΗΡΟΦΟΡΙΚΗ Ι Συστήματα Υποστήριξης Αποφάσεων Τα Συστήματα Υποστήριξης Αποφάσεων (Σ.Υ.Α. - Decision Support Systems, D.S.S.) ορίζονται ως συστήματα
Keywords: Tutorials, pedagogic principles, print and digital distance learning materials, e-comet Laboratory of Hellenic Open University
 Οδηγοί Εκπαιδευτικών Προδιαγραφών Έντυπου και Ψηφιακού Υλικού: Μία αναπτυξιακή δράση του Εργαστηρίου Εκπαδευτικού Υλικού και Εκπαιδευτικής Μεθοδολογίας (ΕΕΥΕΜ) του ΕΑΠ Tutorials about pedagogic principles
Οδηγοί Εκπαιδευτικών Προδιαγραφών Έντυπου και Ψηφιακού Υλικού: Μία αναπτυξιακή δράση του Εργαστηρίου Εκπαδευτικού Υλικού και Εκπαιδευτικής Μεθοδολογίας (ΕΕΥΕΜ) του ΕΑΠ Tutorials about pedagogic principles
Γλωσσικη τεχνολογια. Προεπεξεργασία Κειμένου
 Γλωσσικη τεχνολογια Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε το πληροφοριακό περιεχόμενο Ποσοτικοποιήσουμε
Γλωσσικη τεχνολογια Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε το πληροφοριακό περιεχόμενο Ποσοτικοποιήσουμε
Ανάκτηση Πληροφορίας (Information Retrieval IR)
") Ανάκτηση Πληροφορίας (Information Retrieval IR) Πανεπιστήµιο Θεσσαλίας Πολυτεχνική Σχολή Τµήµα Μηχ. Η/Υ, Τηλ/νιών & ικτύων Ακαδηµαϊκό Έτος 2005-2006 ιδακτικό βοήθηµα 1 Καλύπτει το 60% του αντικειµένου
Ανάκτηση Πληροφορίας (Information Retrieval IR) Πανεπιστήµιο Θεσσαλίας Πολυτεχνική Σχολή Τµήµα Μηχ. Η/Υ, Τηλ/νιών & ικτύων Ακαδηµαϊκό Έτος 2005-2006 ιδακτικό βοήθηµα 1 Καλύπτει το 60% του αντικειµένου
CHAPTER 25 SOLVING EQUATIONS BY ITERATIVE METHODS
 CHAPTER 5 SOLVING EQUATIONS BY ITERATIVE METHODS EXERCISE 104 Page 8 1. Find the positive root of the equation x + 3x 5 = 0, correct to 3 significant figures, using the method of bisection. Let f(x) =
CHAPTER 5 SOLVING EQUATIONS BY ITERATIVE METHODS EXERCISE 104 Page 8 1. Find the positive root of the equation x + 3x 5 = 0, correct to 3 significant figures, using the method of bisection. Let f(x) =
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ. Πτυχιακή Εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή Εργασία Η ΕΠΑΓΓΕΛΜΑΤΙΚΗ ΕΞΟΥΘΕΝΩΣΗ ΠΟΥ ΒΙΩΝΕΙ ΤΟ ΝΟΣΗΛΕΥΤΙΚΟ ΠΡΟΣΩΠΙΚΟ ΣΤΙΣ ΜΟΝΑΔΕΣ ΕΝΑΤΙΚΗΣ ΘΕΡΑΠΕΙΑΣ Άντρη Αγαθαγγέλου Λεμεσός 2012 i ΤΕΧΝΟΛΟΓΙΚΟ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή Εργασία Η ΕΠΑΓΓΕΛΜΑΤΙΚΗ ΕΞΟΥΘΕΝΩΣΗ ΠΟΥ ΒΙΩΝΕΙ ΤΟ ΝΟΣΗΛΕΥΤΙΚΟ ΠΡΟΣΩΠΙΚΟ ΣΤΙΣ ΜΟΝΑΔΕΣ ΕΝΑΤΙΚΗΣ ΘΕΡΑΠΕΙΑΣ Άντρη Αγαθαγγέλου Λεμεσός 2012 i ΤΕΧΝΟΛΟΓΙΚΟ
O7: Πρόγραμμα Κατάρτισης Εκπαιδευτικών O7-A1: Αναπτύσσοντας εργαλεία για το Πρόγραμμα Κατάρτισης Εκπαιδευτικών
 O7: Πρόγραμμα Κατάρτισης Εκπαιδευτικών O7-A1: Αναπτύσσοντας εργαλεία για το Πρόγραμμα Κατάρτισης Εκπαιδευτικών Prepared by University Paderborn 30/11/2015 Project name: Project acronym: Project number:
O7: Πρόγραμμα Κατάρτισης Εκπαιδευτικών O7-A1: Αναπτύσσοντας εργαλεία για το Πρόγραμμα Κατάρτισης Εκπαιδευτικών Prepared by University Paderborn 30/11/2015 Project name: Project acronym: Project number:
Κτίρια nζεβ και προσομοίωση με την χρήση του energy+
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ Πτυχιακή εργασία Κτίρια nζεβ και προσομοίωση με την χρήση του energy+ Μυροφόρα Ιωάννου Λεμεσός, Μάιος 2017 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ Πτυχιακή εργασία Κτίρια nζεβ και προσομοίωση με την χρήση του energy+ Μυροφόρα Ιωάννου Λεμεσός, Μάιος 2017 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΗΣ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Εξαγωγή γεωγραφικής πληροφορίας από δεδομένα παρεχόμενα από χρήστες του
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Εξαγωγή γεωγραφικής πληροφορίας από δεδομένα παρεχόμενα από χρήστες του
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ
 ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ. Πτυχιακή εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή εργασία ΤΟ ΚΑΠΜΝΙΣΜΑ ΩΣ ΠΑΡΑΓΟΝΤΑΣ ΥΨΗΛΟΥ ΚΙΝΔΥΝΟΥ ΓΙΑ ΠΡΟΚΛΗΣΗ ΥΠΟΓΟΝΙΜΟΤΗΤΑΣ ΣΤΟΥΣ ΑΝΔΡΕΣ Κατσαρής Γιάγκος Λεμεσός 2014 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή εργασία ΤΟ ΚΑΠΜΝΙΣΜΑ ΩΣ ΠΑΡΑΓΟΝΤΑΣ ΥΨΗΛΟΥ ΚΙΝΔΥΝΟΥ ΓΙΑ ΠΡΟΚΛΗΣΗ ΥΠΟΓΟΝΙΜΟΤΗΤΑΣ ΣΤΟΥΣ ΑΝΔΡΕΣ Κατσαρής Γιάγκος Λεμεσός 2014 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ
ΜΗΤΡΙΚΟΣ ΘΗΛΑΣΜΟΣ ΚΑΙ ΓΝΩΣΤΙΚΗ ΑΝΑΠΤΥΞΗ ΜΕΧΡΙ ΚΑΙ 10 ΧΡΟΝΩΝ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ ΜΗΤΡΙΚΟΣ ΘΗΛΑΣΜΟΣ ΚΑΙ ΓΝΩΣΤΙΚΗ ΑΝΑΠΤΥΞΗ ΜΕΧΡΙ ΚΑΙ 10 ΧΡΟΝΩΝ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Ονοματεπώνυμο Κεντούλλα Πέτρου Αριθμός Φοιτητικής Ταυτότητας 2008761539 Κύπρος
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ ΜΗΤΡΙΚΟΣ ΘΗΛΑΣΜΟΣ ΚΑΙ ΓΝΩΣΤΙΚΗ ΑΝΑΠΤΥΞΗ ΜΕΧΡΙ ΚΑΙ 10 ΧΡΟΝΩΝ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Ονοματεπώνυμο Κεντούλλα Πέτρου Αριθμός Φοιτητικής Ταυτότητας 2008761539 Κύπρος
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Opinion Mining
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Opinion Mining Opinion Mining Συνώνυμο: Sentiment Analysis Ορισμός: Ανάλυση κειμένων που αναφέρονται σε μια οντότητα/αντικείμενο Εντοπισμός
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Opinion Mining Opinion Mining Συνώνυμο: Sentiment Analysis Ορισμός: Ανάλυση κειμένων που αναφέρονται σε μια οντότητα/αντικείμενο Εντοπισμός
ΣΧΕΔΙΑΣΜΟΣ ΚΑΙ ΕΝΙΣΧΥΣΗ ΤΩΝ ΚΟΜΒΩΝ ΟΠΛΙΣΜΕΝΟΥ ΣΚΥΡΟΔΕΜΑΤΟΣ ΜΕ ΒΑΣΗ ΤΟΥΣ ΕΥΡΩΚΩΔΙΚΕΣ
 Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία ΣΧΕΔΙΑΣΜΟΣ ΚΑΙ ΕΝΙΣΧΥΣΗ ΤΩΝ ΚΟΜΒΩΝ ΟΠΛΙΣΜΕΝΟΥ ΣΚΥΡΟΔΕΜΑΤΟΣ ΜΕ ΒΑΣΗ ΤΟΥΣ ΕΥΡΩΚΩΔΙΚΕΣ Σωτήρης Παύλου Λεμεσός, Μάιος 2018 i ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία ΣΧΕΔΙΑΣΜΟΣ ΚΑΙ ΕΝΙΣΧΥΣΗ ΤΩΝ ΚΟΜΒΩΝ ΟΠΛΙΣΜΕΝΟΥ ΣΚΥΡΟΔΕΜΑΤΟΣ ΜΕ ΒΑΣΗ ΤΟΥΣ ΕΥΡΩΚΩΔΙΚΕΣ Σωτήρης Παύλου Λεμεσός, Μάιος 2018 i ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
ΚΥΠΡΙΑΚΗ ΕΤΑΙΡΕΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ CYPRUS COMPUTER SOCIETY ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 6/5/2006
 Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Ολοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα είναι μικρότεροι το 1000 εκτός αν ορίζεται διαφορετικά στη διατύπωση του προβλήματος. Διάρκεια: 3,5 ώρες Καλή
Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Ολοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα είναι μικρότεροι το 1000 εκτός αν ορίζεται διαφορετικά στη διατύπωση του προβλήματος. Διάρκεια: 3,5 ώρες Καλή
Αλγοριθμική & Δομές Δεδομένων- Γλώσσα Προγραμματισμού Ι (PASCAL)
") Αλγοριθμική & Δομές Δεδομένων- Γλώσσα Προγραμματισμού Ι (PASCAL) Pascal- Εισαγωγή Η έννοια του προγράμματος Η επίλυση ενός προβλήματος με τον υπολογιστή περιλαμβάνει, όπως έχει ήδη αναφερθεί, τρία εξίσου
Αλγοριθμική & Δομές Δεδομένων- Γλώσσα Προγραμματισμού Ι (PASCAL) Pascal- Εισαγωγή Η έννοια του προγράμματος Η επίλυση ενός προβλήματος με τον υπολογιστή περιλαμβάνει, όπως έχει ήδη αναφερθεί, τρία εξίσου
Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές
 Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές του Τμήματος Βιολογίας Ηράκλειο Ακαδημαϊκό Έτος 2016-7 Πρόσβαση στην επιστημονική πληροφορία Σημείο εκκίνησης http://www.lib.uoc.gr επιστημονικές πηγές
Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές του Τμήματος Βιολογίας Ηράκλειο Ακαδημαϊκό Έτος 2016-7 Πρόσβαση στην επιστημονική πληροφορία Σημείο εκκίνησης http://www.lib.uoc.gr επιστημονικές πηγές
ΟΙΚΟΝΟΜΟΤΕΧΝΙΚΗ ΑΝΑΛΥΣΗ ΕΝΟΣ ΕΝΕΡΓΕΙΑΚΑ ΑΥΤΟΝΟΜΟΥ ΝΗΣΙΟΥ ΜΕ Α.Π.Ε
 Τμήμα Ηλεκτρονικών Μηχανικών Τ.Ε. ΟΙΚΟΝΟΜΟΤΕΧΝΙΚΗ ΑΝΑΛΥΣΗ ΕΝΟΣ ΕΝΕΡΓΕΙΑΚΑ ΑΥΤΟΝΟΜΟΥ ΝΗΣΙΟΥ ΜΕ Α.Π.Ε Πτυχιακή Εργασία Φοιτητής: Γεμενής Κωνσταντίνος ΑΜ: 30931 Επιβλέπων Καθηγητής Κοκκόσης Απόστολος Λέκτορας
Τμήμα Ηλεκτρονικών Μηχανικών Τ.Ε. ΟΙΚΟΝΟΜΟΤΕΧΝΙΚΗ ΑΝΑΛΥΣΗ ΕΝΟΣ ΕΝΕΡΓΕΙΑΚΑ ΑΥΤΟΝΟΜΟΥ ΝΗΣΙΟΥ ΜΕ Α.Π.Ε Πτυχιακή Εργασία Φοιτητής: Γεμενής Κωνσταντίνος ΑΜ: 30931 Επιβλέπων Καθηγητής Κοκκόσης Απόστολος Λέκτορας
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ. Πτυχιακή διατριβή
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή διατριβή Η ΣΥΓΚΕΝΤΡΩΣΗ ΤΩΝ ΒΑΡΕΩΝ ΜΕΤΑΛΛΩΝ ΣΤΟ ΕΔΑΦΟΣ ΚΑΙ ΜΕΘΟΔΟΙ ΠΡΟΣΔΙΟΡΙΣΜΟΥ ΤΟΥΣ Μιχαήλ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή διατριβή Η ΣΥΓΚΕΝΤΡΩΣΗ ΤΩΝ ΒΑΡΕΩΝ ΜΕΤΑΛΛΩΝ ΣΤΟ ΕΔΑΦΟΣ ΚΑΙ ΜΕΘΟΔΟΙ ΠΡΟΣΔΙΟΡΙΣΜΟΥ ΤΟΥΣ Μιχαήλ
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΕΙΣΑΓΩΓΗ ΣΤΟΝ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟ
 ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΕΠΙΜΕΛΕΙΑ: ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΘΕΩΡΙΑ 6 ΟΥ ΚΕΦΑΛΑΙΟΥ ΕΙΣΑΓΩΓΗ ΣΤΟΝ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟ 6.1 Τι ονοµάζουµε πρόγραµµα υπολογιστή; Ένα πρόγραµµα
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΕΠΙΜΕΛΕΙΑ: ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΘΕΩΡΙΑ 6 ΟΥ ΚΕΦΑΛΑΙΟΥ ΕΙΣΑΓΩΓΗ ΣΤΟΝ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟ 6.1 Τι ονοµάζουµε πρόγραµµα υπολογιστή; Ένα πρόγραµµα
Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων
 Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων Εισηγητής: ρ Ηλίας Ζαφειρόπουλος Εισαγωγή Ιατρικά δεδοµένα: Συλλογή Οργάνωση Αξιοποίηση Data Mining ιαχείριση εδοµένων Εκπαίδευση
Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων Εισηγητής: ρ Ηλίας Ζαφειρόπουλος Εισαγωγή Ιατρικά δεδοµένα: Συλλογή Οργάνωση Αξιοποίηση Data Mining ιαχείριση εδοµένων Εκπαίδευση
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Data Mining - Classification
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Data Mining - Classification Data Mining Ανακάλυψη προτύπων σε μεγάλο όγκο δεδομένων. Σαν πεδίο περιλαμβάνει κλάσεις εργασιών: Anomaly Detection:
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Data Mining - Classification Data Mining Ανακάλυψη προτύπων σε μεγάλο όγκο δεδομένων. Σαν πεδίο περιλαμβάνει κλάσεις εργασιών: Anomaly Detection:
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ. Πτυχιακή Εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή Εργασία Ο ΜΗΤΡΙΚΟΣ ΘΗΛΑΣΜΟΣ ΚΑΙ Η ΣΧΕΣΗ ΤΟΥ ΜΕ ΤΟ ΚΑΡΚΙΝΟ ΤΟΥ ΜΑΣΤΟΥΣ ΣΤΙΣ ΓΥΝΑΙΚΕΣ ΠΟΥ ΕΙΝΑΙ ΦΟΡΕΙΣ ΤΟΥ ΟΓΚΟΓΟΝΙΔΙΟΥ BRCA1 ΚΑΙ BRCA2. Βασούλλα
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή Εργασία Ο ΜΗΤΡΙΚΟΣ ΘΗΛΑΣΜΟΣ ΚΑΙ Η ΣΧΕΣΗ ΤΟΥ ΜΕ ΤΟ ΚΑΡΚΙΝΟ ΤΟΥ ΜΑΣΤΟΥΣ ΣΤΙΣ ΓΥΝΑΙΚΕΣ ΠΟΥ ΕΙΝΑΙ ΦΟΡΕΙΣ ΤΟΥ ΟΓΚΟΓΟΝΙΔΙΟΥ BRCA1 ΚΑΙ BRCA2. Βασούλλα
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Προεπεξεργασία Κειμένου
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή Εργασία Χαμηλά επίπεδα βιταμίνης D σχετιζόμενα με το βρογχικό άσθμα στα παιδιά και στους έφηβους Κουρομπίνα Αλεξάνδρα Λεμεσός [2014] i ΤΕΧΝΟΛΟΓΙΚΟ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ Πτυχιακή Εργασία Χαμηλά επίπεδα βιταμίνης D σχετιζόμενα με το βρογχικό άσθμα στα παιδιά και στους έφηβους Κουρομπίνα Αλεξάνδρα Λεμεσός [2014] i ΤΕΧΝΟΛΟΓΙΚΟ
Ακαδημαϊκό Έτος , Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS
 Ακαδημαϊκό Έτος 2016-2017, Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS A. Εισαγωγή στις βάσεις δεδομένων - Γνωριμία με την ACCESS B. Δημιουργία Πινάκων 1. Εξήγηση των
Ακαδημαϊκό Έτος 2016-2017, Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS A. Εισαγωγή στις βάσεις δεδομένων - Γνωριμία με την ACCESS B. Δημιουργία Πινάκων 1. Εξήγηση των
Εννοιολογική Διεύρυνση Ερωτημάτων με τη Χρήση Θησαυρού: μια εμπειρική μελέτη
 19ο Πανελλήνιο Συνέδριο Ακαδημαϊκών Βιβλιοθηκών, 3-5 Νοεμβρίου 2010, Αθήνα Εννοιολογική Διεύρυνση Ερωτημάτων με τη Χρήση Θησαυρού: μια εμπειρική μελέτη Άννα Μάστορα (1) Μαρία Μονόπωλη (2) Σαράντος Καπιδάκης
19ο Πανελλήνιο Συνέδριο Ακαδημαϊκών Βιβλιοθηκών, 3-5 Νοεμβρίου 2010, Αθήνα Εννοιολογική Διεύρυνση Ερωτημάτων με τη Χρήση Θησαυρού: μια εμπειρική μελέτη Άννα Μάστορα (1) Μαρία Μονόπωλη (2) Σαράντος Καπιδάκης
Π Τ Υ Χ Ι Α Κ Η Ε Ρ Γ Α Σ Ι Α
 ΑΝΩΤΑΤΟ ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΠΕΙΡΑΙΑ ΤΜΗΜΑ ΗΛΕΚΤΡΟΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ ΤΟΜΕΑΣ ΑΡΧΙΤΕΚΤΟΝΙΚΗΣ Η/Υ, ΠΛΗΡΟΦΟΡΙΚΗΣ & ΔΙΚΤΥΩΝ Εργ. Τεχνολογίας Λογισμικού & Υπηρεσιών S 2 E Lab Π Τ Υ Χ Ι
ΑΝΩΤΑΤΟ ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΠΕΙΡΑΙΑ ΤΜΗΜΑ ΗΛΕΚΤΡΟΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ ΤΟΜΕΑΣ ΑΡΧΙΤΕΚΤΟΝΙΚΗΣ Η/Υ, ΠΛΗΡΟΦΟΡΙΚΗΣ & ΔΙΚΤΥΩΝ Εργ. Τεχνολογίας Λογισμικού & Υπηρεσιών S 2 E Lab Π Τ Υ Χ Ι
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ. Πτυχιακή εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΜΑΘΗΜΑΤΙΚΟΙ ΑΛΓΟΡΙΘΜΟΙ ΓΙΑ ΑΝΑΛΥΣΗ ΠΙΣΤΟΠΟΙΗΤΙΚΩΝ ΕΝΕΡΓΕΙΑΚΗΣ ΑΠΟΔΟΣΗΣ ΚΤΙΡΙΩΝ Εβελίνα Θεμιστοκλέους
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΜΑΘΗΜΑΤΙΚΟΙ ΑΛΓΟΡΙΘΜΟΙ ΓΙΑ ΑΝΑΛΥΣΗ ΠΙΣΤΟΠΟΙΗΤΙΚΩΝ ΕΝΕΡΓΕΙΑΚΗΣ ΑΠΟΔΟΣΗΣ ΚΤΙΡΙΩΝ Εβελίνα Θεμιστοκλέους
Εργαστήριο Προγραμματισμού και τεχνολογίας Ευφυών συστημάτων (intelligence)
") Εργαστήριο Προγραμματισμού και τεχνολογίας Ευφυών συστημάτων (intelligence) http://www.intelligence.tuc.gr Τμήμα Ηλεκτρονικών Μηχανικών και Μηχανικών Υπολογιστών Το εργαστήριο Ένα από τα 3 εργαστήρια του
Εργαστήριο Προγραμματισμού και τεχνολογίας Ευφυών συστημάτων (intelligence) http://www.intelligence.tuc.gr Τμήμα Ηλεκτρονικών Μηχανικών και Μηχανικών Υπολογιστών Το εργαστήριο Ένα από τα 3 εργαστήρια του
[Type text] ΓΕΝΙΚΕΣ ΟΔΗΓΙΕΣ ΓΙΑ ΤΗΝ ΕΚΠΟΝΗΣΗ, ΣΥΝΤΑΞΗ, ΣΥΓΓΡΑΦΗ ΚΑΙ ΥΠΟΒΟΛΗ ΤΗΣ ΔΙΔΑΚΤΟΡΙΚΗΣ ΔΙΑΤΡΙΒΗΣ
![[Type text] ΓΕΝΙΚΕΣ ΟΔΗΓΙΕΣ ΓΙΑ ΤΗΝ ΕΚΠΟΝΗΣΗ, ΣΥΝΤΑΞΗ, ΣΥΓΓΡΑΦΗ ΚΑΙ ΥΠΟΒΟΛΗ ΤΗΣ ΔΙΔΑΚΤΟΡΙΚΗΣ ΔΙΑΤΡΙΒΗΣ](/thumbs/62/47821475.jpg "[Type text] ΓΕΝΙΚΕΣ ΟΔΗΓΙΕΣ ΓΙΑ ΤΗΝ ΕΚΠΟΝΗΣΗ, ΣΥΝΤΑΞΗ, ΣΥΓΓΡΑΦΗ ΚΑΙ ΥΠΟΒΟΛΗ ΤΗΣ ΔΙΔΑΚΤΟΡΙΚΗΣ ΔΙΑΤΡΙΒΗΣ") ΓΕΝΙΚΕΣ ΟΔΗΓΙΕΣ ΓΙΑ ΤΗΝ ΕΚΠΟΝΗΣΗ, ΣΥΝΤΑΞΗ, ΣΥΓΓΡΑΦΗ ΚΑΙ ΥΠΟΒΟΛΗ ΤΗΣ ΔΙΔΑΚΤΟΡΙΚΗΣ ΔΙΑΤΡΙΒΗΣ 1. Σημασία και Βασικές Προϋποθέσεις Διατριβής Μία διδακτορική διατριβή πρέπει να ικανοποιεί τις ακόλουθες βασικές
ΓΕΝΙΚΕΣ ΟΔΗΓΙΕΣ ΓΙΑ ΤΗΝ ΕΚΠΟΝΗΣΗ, ΣΥΝΤΑΞΗ, ΣΥΓΓΡΑΦΗ ΚΑΙ ΥΠΟΒΟΛΗ ΤΗΣ ΔΙΔΑΚΤΟΡΙΚΗΣ ΔΙΑΤΡΙΒΗΣ 1. Σημασία και Βασικές Προϋποθέσεις Διατριβής Μία διδακτορική διατριβή πρέπει να ικανοποιεί τις ακόλουθες βασικές
Ευφυείς Τεχνικές για Εφαρμογές Αποθετηρίων
 Ευφυείς Τεχνικές για Εφαρμογές Αποθετηρίων Α.-Γ. Σταφυλοπάτης Ερευνητικό Πανεπιστημιακό Ινστιτούτο Συστημάτων Επικοινωνιών και Υπολογιστών Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών Εθνικό
Ευφυείς Τεχνικές για Εφαρμογές Αποθετηρίων Α.-Γ. Σταφυλοπάτης Ερευνητικό Πανεπιστημιακό Ινστιτούτο Συστημάτων Επικοινωνιών και Υπολογιστών Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών Εθνικό
«Μηχανή Αναζήτησης Αρχείων» Ημερομηνία Παράδοσης: 30/04/2015, 09:00 π.μ.
 ΕΡΓΑΣΙΑ 4 «Μηχανή Αναζήτησης Αρχείων» Ημερομηνία Παράδοσης: 30/04/2015, 09:00 π.μ. Στόχος Στόχος της Εργασίας 4 είναι να η εξοικείωση με την αντικειμενοστρέφεια (object oriented programming). Πιο συγκεκριμένα,
ΕΡΓΑΣΙΑ 4 «Μηχανή Αναζήτησης Αρχείων» Ημερομηνία Παράδοσης: 30/04/2015, 09:00 π.μ. Στόχος Στόχος της Εργασίας 4 είναι να η εξοικείωση με την αντικειμενοστρέφεια (object oriented programming). Πιο συγκεκριμένα,
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ ΕΞΑΓΩΓΗ ΠΛΗΡΟΦΟΡΙΑΣ INFORMATION EXTRACTION
 ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ ΕΞΑΓΩΓΗ ΠΛΗΡΟΦΟΡΙΑΣ INFORMATION EXTRACTION Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί στα πλαίσια του εκπαιδευτικού έργου του διδάσκοντα. Το έργο «Ανοικτά Ακαδημαϊκά
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ ΕΞΑΓΩΓΗ ΠΛΗΡΟΦΟΡΙΑΣ INFORMATION EXTRACTION Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί στα πλαίσια του εκπαιδευτικού έργου του διδάσκοντα. Το έργο «Ανοικτά Ακαδημαϊκά
Οι στάσεις και γνώσεις των νοσηλευτών για την δωρεά οργάνων ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Οι στάσεις και γνώσεις των νοσηλευτών για την δωρεά οργάνων Αντρέας Κωνσταντίνου Λευκωσία 2012 1 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΥΓΕΙΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Οι στάσεις και γνώσεις των νοσηλευτών για την δωρεά οργάνων Αντρέας Κωνσταντίνου Λευκωσία 2012 1 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
Δομές Δεδομένων. Ενότητα 1 - Εισαγωγή. Χρήστος Γκουμόπουλος. Πανεπιστήμιο Αιγαίου Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων
 Δομές Δεδομένων Ενότητα 1 - Εισαγωγή Χρήστος Γκουμόπουλος Πανεπιστήμιο Αιγαίου Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων Αντικείμενο μαθήματος Δομές Δεδομένων (ΔΔ): Στην επιστήμη υπολογιστών
Δομές Δεδομένων Ενότητα 1 - Εισαγωγή Χρήστος Γκουμόπουλος Πανεπιστήμιο Αιγαίου Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων Αντικείμενο μαθήματος Δομές Δεδομένων (ΔΔ): Στην επιστήμη υπολογιστών
Υπηρεσίες ιστού και ιδιωτικότητα: Μια προσέγγιση βασισμένη στη δημιουργία προφίλ χρήστη για προσαρμοστικούς ιστότοπους
 Υπηρεσίες ιστού και ιδιωτικότητα: Μια προσέγγιση βασισμένη στη δημιουργία προφίλ χρήστη για προσαρμοστικούς ιστότοπους Η Μεταπτυχιακή Διατριβή παρουσιάστηκε ενώπιον του Διδακτικού Προσωπικού του Πανεπιστημίου
Υπηρεσίες ιστού και ιδιωτικότητα: Μια προσέγγιση βασισμένη στη δημιουργία προφίλ χρήστη για προσαρμοστικούς ιστότοπους Η Μεταπτυχιακή Διατριβή παρουσιάστηκε ενώπιον του Διδακτικού Προσωπικού του Πανεπιστημίου
ΣΤΙΓΜΙΑΙΑ ΚΑΤΑΣΚΕΥΗ ΣΤΕΡΕΟΥ ΜΕΙΓΜΑΤΟΣ ΥΛΙΚΟΥ ΜΕΣΑ ΑΠΟ ΕΛΕΓΧΟΜΕΝΗ ΦΥΣΙΚΗ ΔΙΑΔΙΚΑΣΙΑ
 Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία ΣΤΙΓΜΙΑΙΑ ΚΑΤΑΣΚΕΥΗ ΣΤΕΡΕΟΥ ΜΕΙΓΜΑΤΟΣ ΥΛΙΚΟΥ ΜΕΣΑ ΑΠΟ ΕΛΕΓΧΟΜΕΝΗ ΦΥΣΙΚΗ ΔΙΑΔΙΚΑΣΙΑ Χριστόδουλος Χριστοδούλου Λεμεσός, Μάϊος 2017 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ
Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία ΣΤΙΓΜΙΑΙΑ ΚΑΤΑΣΚΕΥΗ ΣΤΕΡΕΟΥ ΜΕΙΓΜΑΤΟΣ ΥΛΙΚΟΥ ΜΕΣΑ ΑΠΟ ΕΛΕΓΧΟΜΕΝΗ ΦΥΣΙΚΗ ΔΙΑΔΙΚΑΣΙΑ Χριστόδουλος Χριστοδούλου Λεμεσός, Μάϊος 2017 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ
Διακριτικές Συναρτήσεις
 Διακριτικές Συναρτήσεις Δρ. Δηµήτριος Τσέλιος Επίκουρος Καθηγητής ΤΕΙ Θεσσαλίας Τµήµα Διοίκησης Επιχειρήσεων Θερµικός χάρτης των XYZ ξενοδοχείων σε σχέση µε τη γεωγραφική περιοχή τους P. Adamopoulos New
Διακριτικές Συναρτήσεις Δρ. Δηµήτριος Τσέλιος Επίκουρος Καθηγητής ΤΕΙ Θεσσαλίας Τµήµα Διοίκησης Επιχειρήσεων Θερµικός χάρτης των XYZ ξενοδοχείων σε σχέση µε τη γεωγραφική περιοχή τους P. Adamopoulos New
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ. Πτυχιακή εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΑΝΑΛΥΣΗ ΚΟΣΤΟΥΣ-ΟΦΕΛΟΥΣ ΓΙΑ ΤΗ ΔΙΕΙΣΔΥΣΗ ΤΩΝ ΑΝΑΝΕΩΣΙΜΩΝ ΠΗΓΩΝ ΕΝΕΡΓΕΙΑΣ ΣΤΗΝ ΚΥΠΡΟ ΜΕΧΡΙ ΤΟ 2030
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΔΙΑΧΕΙΡΙΣΗΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΑΝΑΛΥΣΗ ΚΟΣΤΟΥΣ-ΟΦΕΛΟΥΣ ΓΙΑ ΤΗ ΔΙΕΙΣΔΥΣΗ ΤΩΝ ΑΝΑΝΕΩΣΙΜΩΝ ΠΗΓΩΝ ΕΝΕΡΓΕΙΑΣ ΣΤΗΝ ΚΥΠΡΟ ΜΕΧΡΙ ΤΟ 2030
Τεχνολογία Ψυχαγωγικού Λογισμικού και Εικονικοί Κόσμοι Ενότητα 8η - Εικονικοί Κόσμοι και Πολιτιστικό Περιεχόμενο
 Τεχνολογία Ψυχαγωγικού Λογισμικού και Εικονικοί Κόσμοι Ενότητα 8η - Εικονικοί Κόσμοι και Πολιτιστικό Περιεχόμενο Ιόνιο Πανεπιστήμιο, Τμήμα Πληροφορικής, 2015 Κωνσταντίνος Οικονόμου, Επίκουρος Καθηγητής
Τεχνολογία Ψυχαγωγικού Λογισμικού και Εικονικοί Κόσμοι Ενότητα 8η - Εικονικοί Κόσμοι και Πολιτιστικό Περιεχόμενο Ιόνιο Πανεπιστήμιο, Τμήμα Πληροφορικής, 2015 Κωνσταντίνος Οικονόμου, Επίκουρος Καθηγητής
Μηχανισμοί πρόβλεψης προσήμων σε προσημασμένα μοντέλα κοινωνικών δικτύων ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΕΠΙΚΟΙΝΩΝΙΩΝ, ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΣΥΣΤΗΜΑΤΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ Μηχανισμοί πρόβλεψης προσήμων σε προσημασμένα μοντέλα κοινωνικών
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΕΠΙΚΟΙΝΩΝΙΩΝ, ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΣΥΣΤΗΜΑΤΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ Μηχανισμοί πρόβλεψης προσήμων σε προσημασμένα μοντέλα κοινωνικών
Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές
 Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές του Τμήματος Φυσικής Ηράκλειο Ακαδημαϊκό Έτος 2016-7 Πρόσβαση στην επιστημονική πληροφορία Σημείο εκκίνησης http://www.lib.uoc.gr επιστημονικές πηγές
Σεμινάριο Βιβλιογραφίας στους προπτυχιακούς φοιτητές του Τμήματος Φυσικής Ηράκλειο Ακαδημαϊκό Έτος 2016-7 Πρόσβαση στην επιστημονική πληροφορία Σημείο εκκίνησης http://www.lib.uoc.gr επιστημονικές πηγές
ΚΕΦΑΛΑΙΟ 5. Κύκλος Ζωής Εφαρμογών ΕΝΟΤΗΤΑ 2. Εφαρμογές Πληροφορικής. Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών
 44 Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών Διδακτικοί στόχοι Σκοπός του κεφαλαίου είναι οι μαθητές να κατανοήσουν τα βήματα που ακολουθούνται κατά την ανάπτυξη μιας εφαρμογής.
44 Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών Διδακτικοί στόχοι Σκοπός του κεφαλαίου είναι οι μαθητές να κατανοήσουν τα βήματα που ακολουθούνται κατά την ανάπτυξη μιας εφαρμογής.
Ανάκτηση Δεδομένων (Information Retrieval)
") Ανάκτηση Δεδομένων (Information Retrieval) Παύλος Εφραιμίδης Βάσεις Δεδομένων Ανάκτηση Δεδομένων 1 Information Retrieval (1) Βάσεις Δεδομένων: Περιέχουν δομημένη πληροφορία: Πίνακες Ανάκτηση Πληροφορίας
Ανάκτηση Δεδομένων (Information Retrieval) Παύλος Εφραιμίδης Βάσεις Δεδομένων Ανάκτηση Δεδομένων 1 Information Retrieval (1) Βάσεις Δεδομένων: Περιέχουν δομημένη πληροφορία: Πίνακες Ανάκτηση Πληροφορίας
Αυτόματο Σύστημα Εύρεσης και Κατηγοριοποίησης Ευκαιριών Εργασίας Μηχανικών (ΕΥΡΗΚΑ)
") Αυτόματο Σύστημα Εύρεσης και Κατηγοριοποίησης Ευκαιριών Εργασίας Μηχανικών (ΕΥΡΗΚΑ) Λάζαρος Πολυμενάκος, καθηγητής ΑΙΤ Ηρακλής Καπρίτσας, telia.co.gr Βασίλης Κατσάρης, telia.co.gr Σύνοψη Το σύστημα ΕΥΡΗΚΑ
Αυτόματο Σύστημα Εύρεσης και Κατηγοριοποίησης Ευκαιριών Εργασίας Μηχανικών (ΕΥΡΗΚΑ) Λάζαρος Πολυμενάκος, καθηγητής ΑΙΤ Ηρακλής Καπρίτσας, telia.co.gr Βασίλης Κατσάρης, telia.co.gr Σύνοψη Το σύστημα ΕΥΡΗΚΑ
Ψηφιακή ανάπτυξη. Course Unit #1 : Κατανοώντας τις βασικές σύγχρονες ψηφιακές αρχές Thematic Unit #1 : Τεχνολογίες Web και CMS
 Ψηφιακή ανάπτυξη Course Unit #1 : Κατανοώντας τις βασικές σύγχρονες ψηφιακές αρχές Thematic Unit #1 : Τεχνολογίες Web και CMS Learning Objective : Βασικά συστατικά του Web Fabio Calefato Department of
Ψηφιακή ανάπτυξη Course Unit #1 : Κατανοώντας τις βασικές σύγχρονες ψηφιακές αρχές Thematic Unit #1 : Τεχνολογίες Web και CMS Learning Objective : Βασικά συστατικά του Web Fabio Calefato Department of
Ανάκτηση Πληροφορίας (Information Retrieval IR) ιδακτικό βοήθηµα 2. Πανεπιστήµιο Θεσσαλίας Πολυτεχνική Σχολή Τµήµα Μηχ. Η/Υ, Τηλ/νιών & ικτύων
 ιδακτικό βοήθηµα 2. Πανεπιστήµιο Θεσσαλίας Πολυτεχνική Σχολή Τµήµα Μηχ. Η/Υ, Τηλ/νιών & ικτύων") Ανάκτηση Πληροφορίας (Information Retrieval IR) Πανεπιστήµιο Θεσσαλίας Πολυτεχνική Σχολή Τµήµα Μηχ. Η/Υ, Τηλ/νιών & ικτύων Ακαδηµαϊκό Έτος 2005-2006 ιδακτικό βοήθηµα 1 Καλύπτει το 60% του 510 σελίδες 1η
Ανάκτηση Πληροφορίας (Information Retrieval IR) Πανεπιστήµιο Θεσσαλίας Πολυτεχνική Σχολή Τµήµα Μηχ. Η/Υ, Τηλ/νιών & ικτύων Ακαδηµαϊκό Έτος 2005-2006 ιδακτικό βοήθηµα 1 Καλύπτει το 60% του 510 σελίδες 1η
Εισαγωγή στην Αριθμητική Ανάλυση
 Εισαγωγή στην Αριθμητική Ανάλυση Εισαγωγή στη MATLAB ΔΙΔΑΣΚΩΝ: ΓΕΩΡΓΙΟΣ ΑΚΡΙΒΗΣ ΒΟΗΘΟΙ: ΔΗΜΗΤΡΙΑΔΗΣ ΣΩΚΡΑΤΗΣ, ΣΚΟΡΔΑ ΕΛΕΝΗ E-MAIL: SDIMITRIADIS@CS.UOI.GR, ESKORDA@CS.UOI.GR Τι είναι Matlab Είναι ένα περιβάλλον
Εισαγωγή στην Αριθμητική Ανάλυση Εισαγωγή στη MATLAB ΔΙΔΑΣΚΩΝ: ΓΕΩΡΓΙΟΣ ΑΚΡΙΒΗΣ ΒΟΗΘΟΙ: ΔΗΜΗΤΡΙΑΔΗΣ ΣΩΚΡΑΤΗΣ, ΣΚΟΡΔΑ ΕΛΕΝΗ E-MAIL: SDIMITRIADIS@CS.UOI.GR, ESKORDA@CS.UOI.GR Τι είναι Matlab Είναι ένα περιβάλλον
Μεταπτυχιακή Διατριβή
 Μεταπτυχιακή Διατριβή ΣΧΗΜΑΤΙΣΜΟΣ ΚΑΙ ΕΝΤΟΠΙΣΜΟΣ ΒΙΟΦΙΛΜ ΣΤΙΣ ΜΕΜΒΡΑΝΕΣ ΑΝΤΙΣΤΡΟΦΗΣ ΩΣΜΩΣΗΣ ΣΤΗΝ ΑΦΑΛΑΤΩΣΗ ΛΕΜΕΣΟΥ ΚΥΠΡΟΣ ΜΙΧΑΗΛ Λεμεσός, Μάιος 2017 1 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ
Μεταπτυχιακή Διατριβή ΣΧΗΜΑΤΙΣΜΟΣ ΚΑΙ ΕΝΤΟΠΙΣΜΟΣ ΒΙΟΦΙΛΜ ΣΤΙΣ ΜΕΜΒΡΑΝΕΣ ΑΝΤΙΣΤΡΟΦΗΣ ΩΣΜΩΣΗΣ ΣΤΗΝ ΑΦΑΛΑΤΩΣΗ ΛΕΜΕΣΟΥ ΚΥΠΡΟΣ ΜΙΧΑΗΛ Λεμεσός, Μάιος 2017 1 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ
ΔΙΕΡΕΥΝΗΣΗ ΤΩΝ ΑΙΤΙΩΝ ΚΑΘΥΣΤΕΡΗΣΗΣ ΣΤΑ ΚΑΤΑΣΚΕΥΑΣΤΙΚΑ ΕΡΓΑ ΣΕ ΔΙΕΘΝΕΣ ΕΠΙΠΕΔΟ ΚΑΙ ΣΤΗΝ ΚΥΠΡΟ
 Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία ΔΙΕΡΕΥΝΗΣΗ ΤΩΝ ΑΙΤΙΩΝ ΚΑΘΥΣΤΕΡΗΣΗΣ ΣΤΑ ΚΑΤΑΣΚΕΥΑΣΤΙΚΑ ΕΡΓΑ ΣΕ ΔΙΕΘΝΕΣ ΕΠΙΠΕΔΟ ΚΑΙ ΣΤΗΝ ΚΥΠΡΟ Ιωάννα Λύρα Λεμεσός, Μάϊος 2018 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
Σχολή Μηχανικής και Τεχνολογίας Πτυχιακή εργασία ΔΙΕΡΕΥΝΗΣΗ ΤΩΝ ΑΙΤΙΩΝ ΚΑΘΥΣΤΕΡΗΣΗΣ ΣΤΑ ΚΑΤΑΣΚΕΥΑΣΤΙΚΑ ΕΡΓΑ ΣΕ ΔΙΕΘΝΕΣ ΕΠΙΠΕΔΟ ΚΑΙ ΣΤΗΝ ΚΥΠΡΟ Ιωάννα Λύρα Λεμεσός, Μάϊος 2018 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Εισαγωγικό Φροντιστήριο
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Εισαγωγικό Φροντιστήριο Project του μαθήματος Εργασία 2 ατόμων Προφορική εξέταση για: Project (80%) Θεωρία (20%) Στο φροντιστήριο: Ζητήματα
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Εισαγωγικό Φροντιστήριο Project του μαθήματος Εργασία 2 ατόμων Προφορική εξέταση για: Project (80%) Θεωρία (20%) Στο φροντιστήριο: Ζητήματα
Ανάκτηση Πληροφορίας
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 4: Μοντελοποίηση: Διανυσματικό μοντέλο Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 4: Μοντελοποίηση: Διανυσματικό μοντέλο Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Ανάπτυξη διαδικτυακής διαδραστικής εκπαιδευτικής εφαρμογής σε λειτουργικό σύστημα Android
 Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα Τμήμα Ηλεκτρονικών Μηχανικών Τ.Ε. Ανάπτυξη διαδικτυακής διαδραστικής εκπαιδευτικής εφαρμογής σε λειτουργικό σύστημα Android Πτυχιακή Εργασία Φοιτητής:
Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα Τμήμα Ηλεκτρονικών Μηχανικών Τ.Ε. Ανάπτυξη διαδικτυακής διαδραστικής εκπαιδευτικής εφαρμογής σε λειτουργικό σύστημα Android Πτυχιακή Εργασία Φοιτητής:
Οι διαθέσιμες μέθοδοι σε γενικές γραμμές είναι:
 Χωρική Ανάλυση Ο σκοπός χρήσης των ΣΓΠ δεν είναι μόνο η δημιουργία μίας Β.Δ. για ψηφιακές αναπαραστάσεις των φαινομένων του χώρου, αλλά κυρίως, η βοήθειά του προς την κατεύθυνση της υπόδειξης τρόπων διαχείρισής
Χωρική Ανάλυση Ο σκοπός χρήσης των ΣΓΠ δεν είναι μόνο η δημιουργία μίας Β.Δ. για ψηφιακές αναπαραστάσεις των φαινομένων του χώρου, αλλά κυρίως, η βοήθειά του προς την κατεύθυνση της υπόδειξης τρόπων διαχείρισής
Δικτυακοί τόποι. Η σχεδίαση ενός δικτυακού τόπου. Δρ. Ματθαίος Α. Πατρινόπουλος
 Δικτυακοί τόποι Η σχεδίαση ενός δικτυακού τόπου Δρ. Ματθαίος Α. Πατρινόπουλος Πώς χρησιμοποιούμε το διαδίκτυο; ΔΙΑΦΑΝΕΙΕΣ ΤΟΥ ΜΑΘΗΜΑΤΟΣ ΣΧΕΔΙΑΣΜΟΣ ΚΑΙ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΔΙΑΔΙΚΤΥΟΥ. 2 Από το www.smartinsights.
Δικτυακοί τόποι Η σχεδίαση ενός δικτυακού τόπου Δρ. Ματθαίος Α. Πατρινόπουλος Πώς χρησιμοποιούμε το διαδίκτυο; ΔΙΑΦΑΝΕΙΕΣ ΤΟΥ ΜΑΘΗΜΑΤΟΣ ΣΧΕΔΙΑΣΜΟΣ ΚΑΙ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΔΙΑΔΙΚΤΥΟΥ. 2 Από το www.smartinsights.
ΠΙΛΟΤΙΚΗ ΕΦΑΡΜΟΓΗ ΑΥΤΟΝΟΜΩΝ ΣΥΣΤΗΜΑΤΩΝ ΠΛΟΗΓΗΣΗΣ ΓΙΑ ΤΗΝ ΠΑΡΑΓΩΓΗ ΥΨΗΛΗΣ ΑΝΑΛΥΣΗΣ ΟΡΘΟΦΩΤΟΓΡΑΦΙΩΝ ΓΕΩΡΓΙΚΩΝ ΕΚΤΑΣΕΩΝ
 Σχολή Μηχανικής & Τεχνολογίας Τμήμα Πολιτικών & Μηχανικών Γεωπληροφορικής Μεταπτυχιακή διατριβή ΠΙΛΟΤΙΚΗ ΕΦΑΡΜΟΓΗ ΑΥΤΟΝΟΜΩΝ ΣΥΣΤΗΜΑΤΩΝ ΠΛΟΗΓΗΣΗΣ ΓΙΑ ΤΗΝ ΠΑΡΑΓΩΓΗ ΥΨΗΛΗΣ ΑΝΑΛΥΣΗΣ ΟΡΘΟΦΩΤΟΓΡΑΦΙΩΝ ΓΕΩΡΓΙΚΩΝ
Σχολή Μηχανικής & Τεχνολογίας Τμήμα Πολιτικών & Μηχανικών Γεωπληροφορικής Μεταπτυχιακή διατριβή ΠΙΛΟΤΙΚΗ ΕΦΑΡΜΟΓΗ ΑΥΤΟΝΟΜΩΝ ΣΥΣΤΗΜΑΤΩΝ ΠΛΟΗΓΗΣΗΣ ΓΙΑ ΤΗΝ ΠΑΡΑΓΩΓΗ ΥΨΗΛΗΣ ΑΝΑΛΥΣΗΣ ΟΡΘΟΦΩΤΟΓΡΑΦΙΩΝ ΓΕΩΡΓΙΚΩΝ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ & ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ. Πτυχιακή εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ & ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΜΕΤΑΤΡΟΠΗ ΑΝΘΡΑΚΑ (ΚΑΡΒΟΥΝΟ) ΣΕ ΕΝΕΡΓΟ ΑΝΘΡΑΚΑ ΜΕΣΩ ΧΗΜΙΚΗΣ ΚΑΙ ΘΕΡΜΙΚΗΣ ΕΠΕΞΕΡΓΑΣΙΑΣ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΤΕΧΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ & ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία ΜΕΤΑΤΡΟΠΗ ΑΝΘΡΑΚΑ (ΚΑΡΒΟΥΝΟ) ΣΕ ΕΝΕΡΓΟ ΑΝΘΡΑΚΑ ΜΕΣΩ ΧΗΜΙΚΗΣ ΚΑΙ ΘΕΡΜΙΚΗΣ ΕΠΕΞΕΡΓΑΣΙΑΣ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΠΟΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ. Πτυχιακή εργασία
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΠΟΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία Η ΕΦΑΡΜΟΓΗ ΤΟΥ ΣΥΣΤΗΜΑΤΟΣ HACCP ΣΕ ΜΙΚΡΕΣ ΒΙΟΤΕΧΝΙΕΣ ΓΑΛΑΚΤΟΣ ΣΤΗΝ ΕΠΑΡΧΙΑ ΛΕΜΕΣΟΥ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΓΕΩΠΟΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΚΑΙ ΕΠΙΣΤΗΜΗΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΠΕΡΙΒΑΛΛΟΝΤΟΣ Πτυχιακή εργασία Η ΕΦΑΡΜΟΓΗ ΤΟΥ ΣΥΣΤΗΜΑΤΟΣ HACCP ΣΕ ΜΙΚΡΕΣ ΒΙΟΤΕΧΝΙΕΣ ΓΑΛΑΚΤΟΣ ΣΤΗΝ ΕΠΑΡΧΙΑ ΛΕΜΕΣΟΥ
Πληροφορική 2. Τεχνητή νοημοσύνη
 Πληροφορική 2 Τεχνητή νοημοσύνη 1 2 Τι είναι τεχνητή νοημοσύνη; Τεχνητή νοημοσύνη (AI=Artificial Intelligence) είναι η μελέτη προγραμματισμένων συστημάτων τα οποία μπορούν να προσομοιώνουν μέχρι κάποιο
Πληροφορική 2 Τεχνητή νοημοσύνη 1 2 Τι είναι τεχνητή νοημοσύνη; Τεχνητή νοημοσύνη (AI=Artificial Intelligence) είναι η μελέτη προγραμματισμένων συστημάτων τα οποία μπορούν να προσομοιώνουν μέχρι κάποιο
Πρόταση θέµατος πτυχιακής εργασίας
 Σχεδιασµό και υλοποίηση παιχνιδιού για τη συλλογή δεδοµένων µε σκοπό την προστασία της ιδιωτικότητας Τα παιχνίδια µε σκοπό (games with a purpose) είναι µια νέα ιδέα που εκµεταλλεύεται την ανθρώπινη αντίληψη
Σχεδιασµό και υλοποίηση παιχνιδιού για τη συλλογή δεδοµένων µε σκοπό την προστασία της ιδιωτικότητας Τα παιχνίδια µε σκοπό (games with a purpose) είναι µια νέα ιδέα που εκµεταλλεύεται την ανθρώπινη αντίληψη
Διαχείριση Έργων Πληροφορικής Εργαστήριο
 Διαχείριση Έργων Πληροφορικής Εργαστήριο «Εισαγωγή στο MS Project- Διάγραμμα Gantt» Μ.Τσικνάκης, Ρ.Χατζάκη Ε. Μανιαδή, Ά. Μαριδάκη 1. Εισαγωγή στο Microsoft Project To λογισμικό διαχείρισης έργων MS Project
Διαχείριση Έργων Πληροφορικής Εργαστήριο «Εισαγωγή στο MS Project- Διάγραμμα Gantt» Μ.Τσικνάκης, Ρ.Χατζάκη Ε. Μανιαδή, Ά. Μαριδάκη 1. Εισαγωγή στο Microsoft Project To λογισμικό διαχείρισης έργων MS Project