Πολυνηματικές Αρχιτεκτονικές
|
|
|
- Λυσιμάχη Βιλαέτης
- 7 χρόνια πριν
- Προβολές:
Transcript
1 Πολυνηματικές Αρχιτεκτονικές 1
2 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance = IPC x Hz instr. count clock speed ( Hz) αρχιτεκτονικές βελτιστοποιήσεις ( IPC): pipelining, superscalar execution, branch prediction, out-of-order execution cache ( IPC) 2
3 Περιορισμοί Αύξησης Απόδοσης o ILP εκμεταλλεύεται παράλληλες λειτουργίες, συνήθως μη οριζόμενες από τον προγραμματιστή σε μια «ευθεία» ακολουθία εντολών (χωρίς branches) ανάμεσα σε διαδοχικές επαναλήψεις ενός loop δύσκολο το να εξάγουμε ολοένα και περισσότερο ILP από ένα και μόνο νήμα εκτέλεσης εγγενώς χαμηλός ILP σε πολλές εφαρμογές ανεκμετάλλευτες πολλές από τις μονάδες ενός superscalar επεξεργαστή συχνότητα ρολογιού: φυσικά εμπόδια στη συνεχόμενη αύξησή της μεγάλη έκλυση θερμότητας, μεγάλη κατανάλωση ισχύος, διαρροή ρεύματος πρέπει να βρούμε άλλον τρόπο πέρα από τον ILP + συχνότητα ρολογιού για να βελτιώσουμε την απόδοση 3
4 Πολυνηματισμός Σκοπός: χρήση πολλών ανεξάρτητων instruction streams από πολλαπλά νήματα εκτέλεσης ο παραλληλισμός σε επίπεδο νήματος (Thread-Level Parallelism TLP) αναπαρίσταται ρητά από τον προγραμματιστή, χρησιμοποιώντας πολλαπλά νήματα εκτέλεσης τα οποία είναι εκ κατασκευής παράλληλα πολλά φορτία εργασίας έχουν σαν χαρακτηριστικό τους τον TLP: TLP σε πολυπρογραμματιζόμενα φορτία (εκτέλεση ανεξάρτητων σειριακών εφαρμογών) TLP σε πολυνηματικές εφαρμογές (επιτάχυνση μιας εφαρμογής διαχωρίζοντάς την σε νήματα και εκτελώντας τα παράλληλα) οι πολυνηματικές αρχιτεκτονικές χρησιμοποιούν τον TLP σε τέτοια φορτία εργασίας για να βελτιώσουν τα επίπεδα χρησιμοποίησης των μονάδων του επεξεργαστή βελτίωση του throughput πολυπρογραμματιζόμενων φορτίων βελτίωση του χρόνου εκτέλεσης πολυνηματικών εφαρμογών 4
5 Παράδειγμα: κίνδυνοι δεδομένων t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11 t12 t13 t14 LW r1, 0(r2) LW r5, 12(r1) ADDI r5, r5,#12 SW r5, 12(r1) F D X M W F D X M W F D X M W F D Οι εξαρτήσεις μεταξύ των εντολών αποτελούν περιοριστικό παράγοντα για την εξαγωγή παραλληλισμού Τι μπορεί να γίνει προς αυτή τη κατεύθυνση; 5
6 Αντιμετώπιση με πολυνηματισμό Πώς μπορούμε να μειώσουμε τις εξαρτήσεις μεταξύ των εντολών σε ένα pipeline? - Ένας τρόπος είναι να επικαλύψουμε την εκτέλεση εντολών από διαφορετικά νήματα στο ίδιο pipeline Επικάλυψη εκτέλεσης 4 νημάτων, T1-T4, στο απλό 5-stage pipeline t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 T1: LW r1,0(r2) T2: ADD r7,r1,r4 T3: XORI r5,r4,#12 T4: SW r5,0(r7) T1: LW r5,12(r1) F D X M W F D X M W F D X M W F D X M W F D X M W Η προηγούμενη εντολή στο νήμα ολοκληρώνει το WB προτού η επόμενη εντολή στο ίδιο νήμα διαβάσει το register file 6
7 Απλή μορφή πολυνηματικού pipeline PC PC PC 1 PC I$ IR GPR1 GPR1 GPR1 GPR1 X Y D$ +1 2 Thread select το software «βλέπει» πολλαπλές CPUs κάθε νήμα χρειάζεται να διατηρεί τη δική του αρχιτεκτονική κατάσταση program counter general purpose registers τα νήματα μοιράζονται τις ίδιες μονάδες εκτέλεσης 2 hardware για γρήγορη εναλλαγή των threads πρέπει να είναι πολύ πιο γρήγορη από ένα software-based process switch ( 100s s κύκλων) 7
8 Πολυνηματισμός Πλεονεκτήματα Δε χρειάζεται dependency checking μεταξύ των εντολών Δε χρειάζεται branch prediction Αποφυγή bubbles πραγματοποιώντας χρήσιμη δουλειά από άλλα threads Βελτίωση system throughput, utilization, latency tolerance Μειονεκτήματα Πολυπλοκότητα hardware (PCs, register files, thread selection logic, ) Χειρότερο single thread performance (1 instruction every N cycles) Yψηλός ανταγωνισμός για πόρους (resource contention for caches & memory) 8


9 Για αρκετές εφαρμογές, οι περισσότερες μονάδες εκτέλεσης σε έναν OoO superscalar μένουν ανεκμετάλλευτες Αποτελέσματα για 8-way superscalar. [Tullsen, Eggers, and Levy, Simultaneous Multithreading: Maximizing On-chip Parallelism, ISCA 1995.] 9
10 ΟοΟ superscalar Time Issue slots Horizontal waste Vertical waste horizontal waste: εξαιτίας χαμηλού ILP vertical waste: εξαιτίας long-latency γεγονότων cache misses pipeline flushes λόγω branch mispredictions 10
11 Chip Multi-Processor Time CPU0 CPU1 τα προβλήματα εξακολουθούν να υφίστανται... 11
12 Fine-grained multithreading Time Issue slots το «κίτρινο» thread είναι stalled και παρακάμπτεται εναλλαγή μεταξύ των threads σε κάθε κύκλο, με αποτέλεσμα την επικάλυψη της εκτέλεσης των threads η CPU είναι αυτή που κάνει την εναλλαγή σε κάθε κύκλο γίνεται με round-robin τρόπο (κυκλικά), παρακάμπτοντας threads τα οποία είναι stalled σε κάποιο long-latency γεγονός αντιμετωπίζει το vertical waste, τόσο για μικρά όσο και για μεγάλα stalls, αφού όταν ένα thread είναι stalled το επόμενο μπορεί να γίνει issue μειονεκτήματα: δεν αντιμετωπίζει το horizontal waste καθυστερεί την εκτέλεση ενός thread το οποίο είναι έτοιμο να εκτελεστεί, χωρίς stalls, αφού ανάμεσα σε διαδοχικούς κύκλους αυτού του thread παρεμβάλλονται κύκλοι εκτέλεσης από όλα τα υπόλοιπα threads e.g., UltraSPARC T1 ( Niagara ), Cray MTA 12
13 Coarse-grained multithreading ( switch-on-event ) Time Issue slots εναλλαγή thread μόνο μετά από stall του thread που εκτελείται, π.χ. λόγω L2 cache miss πλεονεκτήματα: δε χρειάζεται να έχει πολύ γρήγορο μηχανισμό εναλλαγής των threads δεν καθυστερεί την εκτέλεση ενός thread, αφού οι εντολές από άλλα threads γίνονται issue μόνο όταν το thread αντιμετωπίσει κάποιο stall μειονεκτήματα: δεν αντιμετωπίζει το horizontal waste σε μικρά stalls, η εναλλαγή του stalled thread και η δρομολόγηση στο pipeline κάποιου έτοιμου thread μπορεί να έχει απώλειες στην απόδοση του πρώτου thread αν τελικά οι κύκλοι που stall-άρει είναι λιγότεροι από τους κόστος εκκίνησης του pipeline με το νέο thread εξαιτίας αυτού του start-up κόστους, το coarse-grained multithreading είναι καλύτερο για την μείωση του κόστους από μεγάλα stalls, για τα οποία το stall time >> pipeline refill time e.g. IBM AS/400 13
14 Simultaneous Multithreading (SMT) Time Issue slots γίνονται issue εντολές από πολλαπλά νήματα ταυτόχρονα αντιμετωπίζεται το horizontal waste όταν ένα νήμα stall-άρει λόγω ενός long-latency γεγονότος, τα υπόλοιπα νήματα μπορούν να δρομολογηθούν και να χρησιμοποιήσουν τις διαθέσιμες μονάδες εκτέλεσης αντιμετωπίζεται το vertical waste Μέγιστη χρησιμοποίηση των επεξεργαστικών πόρων από ανεξάρτητες λειτουργίες 14
15 Προσαρμοστικότητα του SMT στο είδος του διαθέσιμου παραλληλισμού Για περιοχές με υψηλά επίπεδα TLP, ολόκληρο το έυρος του επεξεργαστή μοιράζεται από όλα τα threads Για περιοχές με χαμηλά επίπεδα TLP, ολόκληρο το εύρος του επεξεργαστή είναι διαθέσιμο για την εκμετάλλευση του (όποιου) ILP Issue width Issue width Time Time 15
16 Αρχιτεκτονική SMT Βασικές επεκτάσεις σε σχέση με μια συμβατική superscalar αρχιτεκτονική πολλαπλοί program counters και κατάλληλος μηχανισμός μέσω του οποίου η fetch unit επιλέγει κάποιον από αυτούς σε κάθε κύκλο (π.χ. με βάση κάποια συγκεκριμένη πολιτική) thread-id σε κάθε ΒΤΒ entry για την αποφυγή πρόβλεψης branches που ανήκουν σε άλλα threads ξεχωριστή RAS για κάθε thread για την πρόβλεψη της διεύθυνσης επιστροφής μετά από κλήση υπορουτίνας σε κάθε thread ξεχωριστός ROB για κάθε thread προκειμένου το commit και η διαχείριση των mispredicted branches + των exceptions να γίνεται ανεξάρτητα για κάθε thread μεγαλύτερο register file, για να υποστηρίζει λογικούς καταχωρητές για όλα τα threads + επιπλέον καταχωρητές για register renaming ξεχωριστό renaming table για κάθε thread» εφόσον οι λογικοί καταχωρητές για όλα τα threads απεικονίζονται όλοι σε διαφορετικούς φυσικούς καταχωρητές, οι εντολές από διαφορετικά threads μπορούν να αναμιχθούν μετά το renaming χωρίς να συγχέονται οι source και target operands ανάμεσα στα threads 16
17 2-way SMT Case-study 1: SMT in Hyperthreading technology (~2002) το λειτουργικό «βλέπει» 2 CPUs εκτελεί δύο διεργασίες ταυτόχρονα» πολυπρογραμματιζόμενα φορτία» πολυνηματικές εφαρμογές o φυσικός επεξεργαστής διατηρεί την αρχιτεκτονική για 2 λογικούς επεξεργαστές επιπλέον κόστος για υποστήριξη 2 ταυτόχρονων νημάτων εκτέλεσης < 5% του αρχικού hardware 17
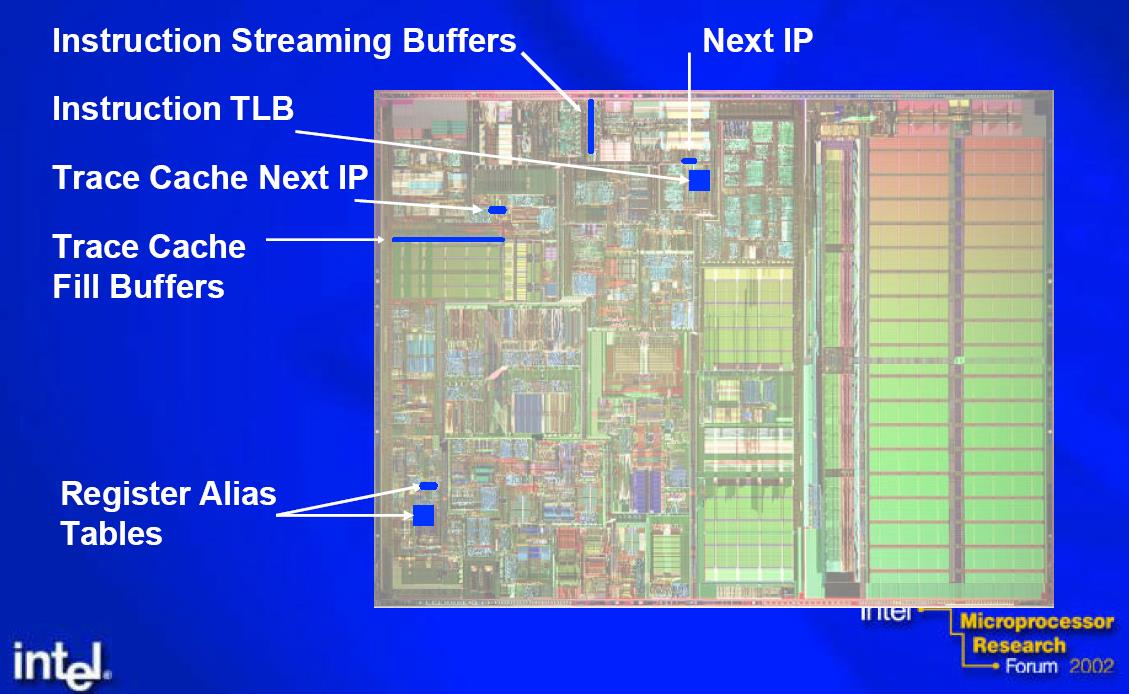
18 Τι προστέθηκε... 18
19 Επεξεργαστικοί πόροι: πολλαπλά αντίγραφα vs. διαμοιρασμός Multiprocessor Hyperthreading Architectural State Architectural State Architectural State Architectural State D-TLB D-TLB D-TLB L2 U-cache L3 U-cache L1 D-cache L2 U-cache L3 U-cache L1 D-cache L2 U-cache L3 U-cache L1 D-cache BTB, I-TLB Cache control Decode BTB Trace cache Rename / Alloc ucode ROM uop queues Schedulers Integer reg. file FP reg. file Load AGU Store AGU ALU ALU ALU FP Load FP Store FP Add FP Mul FP Div MMX,SSE Reorder / Retire BTB, I-TLB Cache control Decode BTB Trace cache Rename / Alloc ucode ROM uop queues Schedulers Integer reg. file FP reg. file Load AGU Store AGU ALU ALU ALU FP Load FP Store FP Add FP Mul FP Div MMX,SSE Reorder / Retire BTB, I-TLB Cache control Decode BTB Trace cache Rename / Alloc ucode ROM uop queues Schedulers Integer reg. file FP reg. file Load AGU Store AGU ALU ALU ALU FP Load FP Store FP Add FP Mul FP Div MMX,SSE Reorder / Retire στους πολυεπεξεργαστές τα resources βρίσκονται σε πολλαπλά αντίγραφα στο Hyper-threading τα resources διαμοιράζονται 19
20 Διαχείριση επεξεργαστικών πόρων Πόροι σε πολλαπλά αντίγραφα: αρχιτεκτονική κατάσταση: GPRs, control registers, APICs instruction pointers, renaming hardware smaller resources: ITLBs, branch target buffer, return address stack Στατικά διαχωρισμένοι πόροι: ROB, Load/Store queues, instruction queues κάθε νήμα μπορεί να χρησιμοποιήσει έως τα μισά (το πολύ) entries κάθε τέτοιου πόρου» ένα νήμα δεν μπορεί να οικειοποιηθεί το σύνολο των entries, στερώντας τη δυνατότητα από το άλλο νήμα να συνεχίσει την εκτέλεσή του» εξασφαλίζεται η απρόσκοπτη πρόοδος ενός νήματος, ανεξάρτητα από την πρόοδο του άλλου νήματος Δυναμικά διαμοιραζόμενοι πόροι (κατ απαίτηση): out-of-order execution engine, caches 20
21 Pentium 4 w/ Hyper-Threading: Front End trace cache hit Trace cache «ειδική» instruction cache που κρατάει αποκωδικοποιημένες μικρο-εντολές σε κάθε cache line αποθηκεύονται οι μικροεντολές στη σειρά με την οποία εκτελούνται (π.χ. εντολή άλματος μαζί με την ακολουθία εντολών στην προβλεφθείσα κατεύθυνση) Σε ταυτόχρονη ζήτηση από τους 2 LPs, η πρόσβαση εναλλάσσεται κύκλο-ανά-κύκλο Όταν μόνο 1 LP ζητάει πρόσβαση, μπορεί να χρησιμοποιήσει την TC στο μέγιστo δυνατό fetch bandwidth (3 μipc) I-Fetch IP IP Trace Cache Uop queue 21
22 Pentium 4 w/ Hyper-Threading: Front End trace cache miss L2 Access Queue Decode Queue Trace Cache fill Uop queue IP ITLB ITLB IP L2 Access Decode Trace Cache L2 cache η πρόσβαση γίνεται με FCFS τρόπο Decode σε ταυτόχρονη ζήτηση από τους 2 LPs, η πρόσβαση εναλλάσσεται, αλλά με πιο coarsegrained τρόπο (δηλ. όχι κύκλο-ανά-κύκλο, αλλά k κύκλους-ανά-k κύκλους) 22
23 Pentium 4 w/ Hyper-Threading: Execution engine I-Fetch Uop queue Rename Queue Schedulers Register Read Execute L1 Cache Register Write Retire IP IP general Store Buffer Re-Order Buffer ITLB Register Rename Trace Cache ITLB Allocator memory Registers L1 D-Cache Registers In-Order Out-Of-Order In-Order Allocator: εκχωρεί entries σε κάθε LP 63/126 ROB entries 24/48 Load buffer entries 12/24 Store buffer entries 128/128 Integer physical registers 128/128 FP physical registers Σε ταυτόχρονη ζήτηση από τους 2 LPs, η πρόσβαση εναλλάσσεται κύκλο-ανά-κύκλο stall-άρει έναν LP όταν επιχειρεί να χρησιμοποιήσει περισσότερα από τα μισά entries των στατικά διαχωρισμένων πόρων 23
24 Pentium 4 w/ Hyper-Threading: Execution engine I-Fetch Uop queue Rename Queue Schedulers Register Read Execute L1 Cache Register Write Retire IP IP general Store Buffer Re-Order Buffer ITLB Register Rename Trace Cache ITLB Allocator memory Registers L1 D-Cache Registers In-Order Out-Of-Order In-Order Register renaming unit επεκτείνει δυναμικά τους architectural registers απεικονίζοντάς τους σε ένα μεγαλύτερο σύνολο από physical registers ξεχωριστό register map table για κάθε LP 24
25 Pentium 4 w/ Hyper-Threading: Execution engine I-Fetch Uop queue Rename Queue Schedulers Register Read Execute L1 Cache Register Write Retire IP IP general Store Buffer Re-Order Buffer ITLB Register Rename Trace Cache ITLB Allocator memory Registers L1 D-Cache Registers In-Order Out-Of-Order In-Order Schedulers / Execution units στην πραγματικότητα δε (χρειάζεται να) ξέρουν σε ποιον LP ανήκει η εντολή που εκτελούν general+memory queues στέλνουν μικρο-εντολές στους δρομολογητές, με την πρόσβαση να εναλλάσσεται κύκλο-ανά-κύκλο ανάμεσα στους 2 LPs 6 μipc dispatch/execute bandwidth ( 3 μipc per-lp effective bandwidth, όταν και οι 2 LPs είναι ενεργοί) 25
26 Pentium 4 w/ Hyper-Threading: Retirement I-Fetch Uop queue Rename Queue Schedulers Register Read Execute L1 Cache Register Write Retire IP IP general Store Buffer Re-Order Buffer ITLB Register Rename Trace Cache ITLB Allocator memory Registers L1 D-Cache Registers In-Order Out-Of-Order In-Order H αρχιτεκτονική κατάσταση κάθε LP γίνεται commit με τη σειρά προγράμματος, εναλλάσσοντας την πρόσβαση στον ROB ανάμεσα στους 2 LPs κύκλο-ανά-κύκλο 3 μipc retirement bandwidth 26

27 Multithreaded speedup SPLASH2 Benchmarks: NAS Parallel Benchmarks: From: Tuck and Tullsen, Initial Observations of the Simultaneous Multithreading Pentium 4 Processor, PACT
28 Case-study 2 Power 5 :επέκταση του Power 4 για υποστήριξη SMT (2004) Single-threaded «προκάτοχος» του Power5 8 execution units 2 Float. Point, 2 Load/Store, 2 Fixed Point, 1 Branch, 1 Conditional Reg. unit κάθε μία μπορεί να κάνει issue 1 εντολή ανά κύκλο Execution bandwidth: 8 operations ανά κύκλο (1 fpadd + 1 fpmult) x 2FP + 1 load/store x 2 LD/ST + 1 integer x 2 FX 28
 2 fetch (PC), 2 initial")
29 Power 4 Power 5 2 commits (architected register sets) 2 fetch (PC), 2 initial decodes 29

30 SMT resource management 30
31 Αλλαγές στον Power 5 για να υποστηρίζεται το SMT Aύξηση συσχετιστικότητας της L1 instruction cache και των ITLBs Ξεχωριστές Load/Store queues για κάθε νήμα Αύξηση μεγέθους των L2 (1.92 vs MB) και L3 caches Ξεχωριστό instruction prefetch hardware και instruction buffers για κάθε νήμα Αύξηση των registers από 152 σε 240 Αύξηση του μεγέθους των issue queues Αύξηση μεγέθους κατά 24% σε σχέση με τον Power4 εξαιτίας της προσθήκης hardware για υποστήριξη SMT 31
32 Power 5 datapath στο IF στάδιο η πρόσβαση εναλλάσσεται κύκλο-ανά-κύκλο ανάμεσα στα 2 threads 2 instruction fetch address registers, 1 για κάθε νήμα μπορούν να φορτωθούν 8 instructions σε κάθε κύκλο (στάδιο IC) από την I-Cache σε έναν συγκεκριμένο κύκλο, οι εντολές που φορτώνονται προέρχονται όλες από το ίδιο thread και τοποθετούνται στο instruction buffer του thread αυτού (στάδιο D0) 32
33 Power 5 datapath στα στάδια D1-D3, ανάλογα με την προτεραιότητα κάθε thread, ο επεξεργαστής διαλέγει εντολές από έναν από τους δύο instruction buffers και σχηματίζει ένα group όλες οι εντολές σε ένα group προέρχονται από το ίδιο thread και αποκωδικοποιούνται παράλληλα κάθε group μπορεί να περιέχει το πολύ 5 εντολές 33
34 Power 5 datapath όταν όλοι οι απαιτούμενοι πόροι γίνονται διαθέσιμοι για τις εντολές ενός group, τότε το group μπορεί να γίνει dispatch (στάδιο GD) το group τοποθετείται στο Global Completion Table (ROB) τα entries στο GCT εκχωρούνται με τη σειρά προγράμματος για κάθε thread, και απελευθερώνονται (πάλι με τη σειρά προγράμματος) μόλις το group γίνει commit μετά το dispatch, κάθε εντολή του group διέρχεται μέσα από το register renaming στάδιο (MP) 120 physical GPRs, 120 physical FPRs τα 2 νήματα διαμοιράζονται δυναμικά registers 34
35 Power 5 datapath Issue, execute, write-back δε γίνεται διάκριση ανάμεσα στα 2 threads Group completion (στάδιο CP) 1 group commit ανά κύκλο για κάθε thread στη σειρά προγράμματος του κάθε thread 35
36 Δυναμική εξισορρόπηση επεξεργαστικών πόρων Πρέπει να εξασφαλιστεί η απρόσκοπτη και ομαλή ροή των threads στο pipeline, ανεξάρτητα από τις απαιτήσεις του καθενός σε επεξεργαστικούς πόρους Μηχανισμοί περιορισμού ενός πολύ απαιτητικού thread: μείωση προτεραιότητας του thread, όταν διαπιστώνεται ότι τα GCT entries που χρησιμοποιεί ξεπερνούν ένα καθορισμένο όριο όταν ένα thread έχει πολλά L2 misses, τότε οι μεταγενέστερες εξαρτώμενες εντολές του μπορούν να γεμίσουν τις issue queues, εμποδίζοντας να γίνουν dispatch εντολές από το άλλο thread» παρακολούθηση της Load Miss Queue ενός thread έτσι ώστε όταν τα misses του υπερβαίνουν κάποιο όριο, η αποκωδικοποίηση εντολών του να σταματάει μέχρι να αποσυμφορηθούν οι issue queues συμφόρηση στις issue queues μπορεί να συμβεί και όταν ένα thread εκτελεί μια εντολή που απαιτεί πολύ χρόνο» flushing των εντολών του thread που περιμένουν να γίνουν dispatch και προσωρινή διακοπή της αποκωδικοποίησης εντολών του μέχρι να αποσυμφορηθούν οι issue queues 36
37 Ρυθμιζόμενη προτεραιότητα threads επιτρέπει στο software να καθορίσει πότε ένα thread θα πρέπει να έχει μεγαλύτερο ή μικρότερο μερίδιο επεξεργαστικών πόρων πιθανές αιτίες για διαφορετικές προτεραιότητες: ένα thread εκτελεί ένα spin-loop περιμένοντας να πάρει κάποιο lock δεν κάνει χρήσιμη δουλειά όσο spin-άρει ένα thread δεν έχει δουλειά να εκτελέσει και περιμένει να του ανατεθεί δουλειά σε ένα idle loop μία εφαρμογή πρέπει να τρέχει πιο γρήγορα σε σχέση με μία άλλη (π.χ. real-time application vs. background application) 8 software-controlled επίπεδα προτεραιότητας για κάθε thread o επεξεργαστής παρατηρεί τη διαφορά των επιπέδων προτεραιότητας των threads, και δίνει στο thread με τη μεγαλύτερη προτεραιότητα περισσότερους διαδοχικούς κύκλους για αποκωδικοποίηση εντολών του 37

38 Επίδραση προτεραιότητας στην απόδοση κάθε thread Όταν τα threads έχουν ίδιες προτεραιτότητες, εκτελούνται πιο αργά απ ό,τι αν κάθε thread είχε διαθέσιμα όλα τα resources του επεξεργαστή (single-thread mode) 38
» χαμηλός ILP (υψηλά miss rates, πολλά unpredictable branches, συχνές load-load εξαρτήσεις)» το memory access time κυριαρχεί στο συνολικό χρόνο εκτέλεσης ο ILP επεξεργαστής μειώνει μόνο το")
39 Case-study 3: UltraSPARC T1 ( Niagara ) (2005) Συμπεριφορά επεξεργαστών βελτιστοποιημένων για TLP και ILP σε server workloads: server workloads:» υψηλός TLP (μεγάλος αριθμός παράλληλων client requests)» χαμηλός ILP (υψηλά miss rates, πολλά unpredictable branches, συχνές load-load εξαρτήσεις)» το memory access time κυριαρχεί στο συνολικό χρόνο εκτέλεσης ο ILP επεξεργαστής μειώνει μόνο το computation time το memory access time κυριαρχεί σε ακόμα μεγαλύτερο ποσοστό στον TLP επεξεργαστή, το memory access ενός thread επικαλύπτεται από computations από άλλα threads η απόδοση αυξάνεται για μια memory-bound multithreaded εφαρμογή 39
40 UltraSPARC T1 in-order, single-issue επικεντρώνεται πλήρως στην εκμετάλλευση του TLP 4-8 cores, 4 threads ανά core max 32 threads fine-grained multithreading L1D + L1I μοιραζόμενες από τα 4 threads L2 cache + FPU μοιραζόμενη από όλα τα threads ξεχωριστό register set + instruction buffers + store buffers για κάθε thread 40
41 UltraSPARC T1 pipeline όπως το κλασικό 5-stage pipeline + thread select stage Fetch stage: o thread select mux επιλέγει ποιος από τους 4 PCs θα πρέπει να προσπελάσει την ICache και το ITLB Thread select stage: αποφασίζει σε κάθε κύκλο ποιος από τους 4 instruction buffers θα τροφοδοτήσει με εντολές τα επόμενα στάδια αν το thread-select στάδιο επιλέξει ένα νήμα από το οποίο θα στείλει εντολές, το fetch στάδιο θα επιλέξει το ίδιο thread για να προσπελάσει την ICache 41
42 UltraSPARC T1 pipeline πολιτική επιλογής thread: εναλλαγή μεταξύ διαθέσιμων threads σε κάθε κύκλο προτεραιότητα στο least recently used thread (round-robin) λόγοι μη διαθεσιμότητας (και μη επιλογής) ενός thread long-latency εντολές (π.χ. branches, mult/div) οδηγούν στη μη-επιλογή του αντίστοιχου thread για όσους κύκλους διαρκούν stalls λόγω cache misses stalls λόγω structural hazards για μια non-pipelined δομή που χρησιμοποιείται ήδη από κάποιο άλλο thread (π.χ. divider) 42

43 UltraSPARC T1 pipeline 43
44 UltraSPARC T1 performance fine-grained multithreading μεταξύ 4 threads ιδανικό perthread CPI = 4 ιδανικό per-core CPI = 1 effective CPI = per-core CPI / #cores effective throughput: μεταξύ 56% και 71% του ιδανικού 44

45 Προφίλ εκτέλεσης ενός μέσου thread 45

46 Λόγοι για τη μη διαθεσιμότητα ενός thread pipeline delay: long-latency εντολές όπως branches, loads, fp, int mult/div 46
47 «Crash-test» multicore επεξεργαστών (~2005) βασικές διαφορές: εκμετάλλευση ILP vs. TLP (Power5 Opteron, Pentium D T1) floating point performance (Power5 Opteron, Pentium D T1) memory bandwidth (T1 Power5 Opteron Pentium D)» επηρεάζει την απόδοση εφαρμογών με μεγάλο miss rate 47
48 «Crash-test» multicore επεξεργαστών 48
49 «Crash-test» multicore επεξεργαστών (~2010) AMD Opteron 8439 IBM Power 7 Intel Xenon 7560 Sun T2 Transistors (M) Power (W) Max cores/chip Mutlithreading No SMT SMT Fine-grained Threads/ core Instr. issue/clock 3 from 1 thread 6 from 1 thread 4 from 1 thread 2 from 2 threads Clock rate (GHz) Outermost cache L3, 6MB, shared L3, 32MB, shared or private/core L3, 24MB shared L2, 4MB, shared Inclusion No Yes Yes Yes Coherence protocol MOESI Extended MESI MESIF MOESI Coherence implementation Extended coherence support Snooping L3 Directory L3 Directory L2 Directory Up to 8 processor chips (NUMA) Up to 32 processor chips (UMA) Up to 8 processor cores Up to 2/4 chips (directly/external ASICs) 49








50 Today: Many Cores on Chip Simpler and lower power than a single large core Large scale parallelism on chip AMD Barcelona 4 cores Intel Core i7 8 cores IBM Cell BE 8+1 cores IBM POWER7 8 cores Sun Niagara II 8 cores Nvidia Fermi 448 cores Intel SCC 48 cores, networked Tilera TILE Gx 100 cores, networked 50
51 Chips Today ( ) Intel Nehalem (~2010) slides by Krste Asanovic (Berkeley, CS152 - link) HotChips 2012 (HC24 ) Intel s 3 rd generation processors Ivy Bridge (link) AMD s Jaguar next generation low power x86 core (link) Knight s Corner - Intel s MIC (link) Power 7+ (link) HotChips 2013 (HC25 ) Power 8 (link) Intel s 4 th generation processors Haswell (link) HotChips 2014 (HC26 ) AMD s Kaveri APU (link) AMD s Opteron A1100 (link) Next generation SPARC Processor Cache Hierarchy (link) Intel C2000 Atom Microserver (link) NVIDIA s Denver Processor (link) MIT Scorpio (link) Powering the IoT (link) 51
Πολυνηματικές Αρχιτεκτονικές
 Πολυνηματικές Αρχιτεκτονικές Όρια του ILP Θεωρούμε ένα ιδανικό επεξεργαστή Register Renaming : Άπειροι καταχωρητές Branch Prediction : Όλες οι διακλαδώσεις προβλέπονται σωστά Memory Analysis : Οι διευθύνσεις
Πολυνηματικές Αρχιτεκτονικές Όρια του ILP Θεωρούμε ένα ιδανικό επεξεργαστή Register Renaming : Άπειροι καταχωρητές Branch Prediction : Όλες οι διακλαδώσεις προβλέπονται σωστά Memory Analysis : Οι διευθύνσεις
Πολυνηματικές Αρχιτεκτονικές
 Πολυνηματικές Αρχιτεκτονικές 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance
Πολυνηματικές Αρχιτεκτονικές 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance
Πολυνηματικές Αρχιτεκτονικές
 Πολυνηματικές Αρχιτεκτονικές 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance
Πολυνηματικές Αρχιτεκτονικές 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance
Εισαγωγή. SMT 6 IPC, δυναμικά διαμοιραζόμενο. Superscalar 6 IPC. CMP 4x2 IPC
 Πολυνηματικές Αρχιτεκτονικές Εισαγωγή Η ενσωμάτωση πολλαπλών ροών εκτέλεσης αποτελεί πλέον μονόδρομο στην τεχνολογία των επεξεργαστών Ελάχιστη ανταπόδοση από την εκμετάλλευση περισσότερου παραλληλισμού
Πολυνηματικές Αρχιτεκτονικές Εισαγωγή Η ενσωμάτωση πολλαπλών ροών εκτέλεσης αποτελεί πλέον μονόδρομο στην τεχνολογία των επεξεργαστών Ελάχιστη ανταπόδοση από την εκμετάλλευση περισσότερου παραλληλισμού
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I
 ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
Thread Level Parallelism & Data Level Parallelism
 Thread Level Parallelism & Data Level Parallelism 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI)
Thread Level Parallelism & Data Level Parallelism 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI)
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
Υπερβαθµωτή Οργάνωση Υπολογιστών
 Υπερβαθµωτή Οργάνωση Υπολογιστών Από τις βαθµωτές στις υπερβαθµωτές αρχιτεκτονικές αγωγού Τα όρια του Παραλληλισµού σε επίπεδο εντολών (Instruction Level Parallelism - ILP) Weiss and Smith [1984] Sohi
Υπερβαθµωτή Οργάνωση Υπολογιστών Από τις βαθµωτές στις υπερβαθµωτές αρχιτεκτονικές αγωγού Τα όρια του Παραλληλισµού σε επίπεδο εντολών (Instruction Level Parallelism - ILP) Weiss and Smith [1984] Sohi
Παραλληλισμός σε επίπεδο εντολών
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Κεντρική Μονάδα Επεξεργασίας. Επανάληψη: Απόδοση ΚΜΕ. ΚΜΕ ενός κύκλου (single-cycle) Παραλληλισμός σε επίπεδο εντολών. Υπολογιστικό σύστημα
 Παραλληλισμός σε επίπεδο εντολών. Υπολογιστικό σύστημα") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
ΠΛΕ- 027 Μικροεπεξεργαστές 8ο μάθημα: Παραλληλία επιπέδου εντολής
 ΠΛΕ- 027 Μικροεπεξεργαστές 8ο μάθημα: Παραλληλία επιπέδου εντολής Αρης Ευθυμίου Ταχύτερη εκτέλεση Με τις τεχνικές που είδαμε στα προηγούμενα μαθήματα μπορούμε να εκτελέσουμε (με επικάλυψη) περίπου 1 εντολή
ΠΛΕ- 027 Μικροεπεξεργαστές 8ο μάθημα: Παραλληλία επιπέδου εντολής Αρης Ευθυμίου Ταχύτερη εκτέλεση Με τις τεχνικές που είδαμε στα προηγούμενα μαθήματα μπορούμε να εκτελέσουμε (με επικάλυψη) περίπου 1 εντολή
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών
 Οργάνωση Υπολογιστών") Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
Περιορισμοί των βαθμωτών αρχιτεκτονικών
 Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άδεια χρήσης άλλου τύπου, αυτή πρέπει να αναφέρεται ρητώς. Περιορισμοί
Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άδεια χρήσης άλλου τύπου, αυτή πρέπει να αναφέρεται ρητώς. Περιορισμοί
Υ- 07 Παράλληλα Συστήματα Αρχιτεκτονική σύγχρονων πυρήνων επεξεργαστών
 Υ- 07 Παράλληλα Συστήματα Αρχιτεκτονική σύγχρονων πυρήνων επεξεργαστών Αρης Ευθυμίου Διαδικαστικά Ιστοσελίδα μαθήματος: h:p://www.cs.uoi.gr/~plmy07/ Διαφάνειες μαθημάτων, κτλ 2 Γρήγορη εκτέλεση σειριακού
Υ- 07 Παράλληλα Συστήματα Αρχιτεκτονική σύγχρονων πυρήνων επεξεργαστών Αρης Ευθυμίου Διαδικαστικά Ιστοσελίδα μαθήματος: h:p://www.cs.uoi.gr/~plmy07/ Διαφάνειες μαθημάτων, κτλ 2 Γρήγορη εκτέλεση σειριακού
(Branch Prediction Mechanisms)
") Μέθοδοι Πρόβλεψης Διακλαδώσεων (Branch Prediction Mechanisms) 1 Εντολές Διακλάδωσης Περίπου 20% των εντολών είναι εντολές διακλάδωσης Πολλά στάδια μεταξύ υπολογισμού του επόμενου PC και εκτέλεσης του branch
Μέθοδοι Πρόβλεψης Διακλαδώσεων (Branch Prediction Mechanisms) 1 Εντολές Διακλάδωσης Περίπου 20% των εντολών είναι εντολές διακλάδωσης Πολλά στάδια μεταξύ υπολογισμού του επόμενου PC και εκτέλεσης του branch
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 6ο μάθημα: χρονοπρογραμματισμός, αλγόριθμος Tomasulo, εικασία Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου InstrucDon- Level
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 6ο μάθημα: χρονοπρογραμματισμός, αλγόριθμος Tomasulo, εικασία Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου InstrucDon- Level
Δυναμική Δρομολόγηση Εντολών (Dynamic Scheduling)
") Δυναμική Δρομολόγηση Εντολών (Dynamic Scheduling) Απόδοση pipeline Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: μέτρο της μέγιστης απόδοσης
Δυναμική Δρομολόγηση Εντολών (Dynamic Scheduling) Απόδοση pipeline Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: μέτρο της μέγιστης απόδοσης
Διάλεξη 12 Καθυστερήσεις (Stalls) Εκκενώσεις Εντολών (Flushing)
 Εκκενώσεις Εντολών (Flushing)") ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 2 Καθυστερήσεις (Stalls) Εκκενώσεις Εντολών (Flushing) Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Καθυστερήσεις και Εκκενώσεις Εντολών
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 2 Καθυστερήσεις (Stalls) Εκκενώσεις Εντολών (Flushing) Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Καθυστερήσεις και Εκκενώσεις Εντολών
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπερβαθμωτοι επεξεργαστές
 Υ- 01 Αρχιτεκτονική Υπολογιστών Υπερβαθμωτοι επεξεργαστές Αρης Ευθυμίου Το σημερινό μάθημα Υπερβαθμωτοί επεξεργαστές (superscalar) Εκτέλεση σε σειρά Εκτέλεση εκτός σειράς Alpha 21164 Scoreboard Μετονομασία
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπερβαθμωτοι επεξεργαστές Αρης Ευθυμίου Το σημερινό μάθημα Υπερβαθμωτοί επεξεργαστές (superscalar) Εκτέλεση σε σειρά Εκτέλεση εκτός σειράς Alpha 21164 Scoreboard Μετονομασία
Chapter 6 Αύξηση της απόδοσης με διοχέτευση (pipeline)
") Chapter 6 Αύξηση της απόδοσης με διοχέτευση (pipeline) Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση: Καθ. Εφαρμογών Νικόλαος Πετράκης, Τμήματος Ηλεκτρονικών Μηχανικών
Chapter 6 Αύξηση της απόδοσης με διοχέτευση (pipeline) Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση: Καθ. Εφαρμογών Νικόλαος Πετράκης, Τμήματος Ηλεκτρονικών Μηχανικών
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
Υ- 01 Αρχιτεκτονική Υπολογιστών Front- end: Προσκόμιση, αποκωδικοποίηση, μετονομασία καταχωρητών
 Υ- 01 Αρχιτεκτονική Υπολογιστών Front- end: Προσκόμιση, αποκωδικοποίηση, μετονομασία καταχωρητών Αρης Ευθυμίου Το σημερινό μάθημα Προσκόμιση (fetch) πολλαπλές εντολές ανά κύκλο Μετονομασία καταχωρητών
Υ- 01 Αρχιτεκτονική Υπολογιστών Front- end: Προσκόμιση, αποκωδικοποίηση, μετονομασία καταχωρητών Αρης Ευθυμίου Το σημερινό μάθημα Προσκόμιση (fetch) πολλαπλές εντολές ανά κύκλο Μετονομασία καταχωρητών
Εντολές Διακλάδωσης. #bubbles ~= pipeline depth X loop length. Next fetch started. Fetch. I-cache. Fetch Buffer. Decode. Issue Buffer.
 Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άδεια χρήσης άλλου τύπου, αυτή πρέπει να αναφέρεται ρητώς. Εντολές
Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άδεια χρήσης άλλου τύπου, αυτή πρέπει να αναφέρεται ρητώς. Εντολές
Ενσωµατωµένα Υπολογιστικά Συστήµατα (Embedded Computer Systems)
") Ενσωµατωµένα Υπολογιστικά Συστήµατα (Embedded Computer Systems) Μαθηµα 2 ηµήτρης Λιούπης 1 Intel SA-1110 µc StrongARM core. System-on-Chip. Εξέλιξη των SA-110 και SA-1100. 2 ARM cores ARM: IP (intellectual
Ενσωµατωµένα Υπολογιστικά Συστήµατα (Embedded Computer Systems) Μαθηµα 2 ηµήτρης Λιούπης 1 Intel SA-1110 µc StrongARM core. System-on-Chip. Εξέλιξη των SA-110 και SA-1100. 2 ARM cores ARM: IP (intellectual
Υποθετική Εκτέλεση Εντολών
 Υποθετική Εκτέλεση Εντολών ( Speculation (Hardware-Based Τεχνικές βελτίωσης του CPI register renaming δυναμική εκτέλεση Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + υπερβαθμωτή
Υποθετική Εκτέλεση Εντολών ( Speculation (Hardware-Based Τεχνικές βελτίωσης του CPI register renaming δυναμική εκτέλεση Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + υπερβαθμωτή
Συστήματα σε Ολοκληρωμένα Κυκλώματα
 Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
30 min κάθε «φάση» Pipeline: Ένα παράδειγµα από.τη καθηµερινή ζωή. 1. Πλυντήριο. 2. Στεγνωτήριο. 3. ίπλωµα. 4. αποθήκευση. προσέγγιση για 4.
 Pipeline: Ένα παράδειγµα από.τη καθηµερινή ζωή Time 6 PM 7 8 9 10 11 12 1 2 AM 1. Πλυντήριο 2. Στεγνωτήριο 3. ίπλωµα 4. αποθήκευση Task order A B C D Σειριακή προσέγγιση για 4 φορτία =8h 30 min κάθε «φάση»
Pipeline: Ένα παράδειγµα από.τη καθηµερινή ζωή Time 6 PM 7 8 9 10 11 12 1 2 AM 1. Πλυντήριο 2. Στεγνωτήριο 3. ίπλωµα 4. αποθήκευση Task order A B C D Σειριακή προσέγγιση για 4 φορτία =8h 30 min κάθε «φάση»
Πολσνηματικές Αρτιτεκτονικές
 Πολσνηματικές Αρτιτεκτονικές Ο Νόκνο ηεο απόδνζεο ησλ κηθξνεπεμεξγαζηώλ 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance
Πολσνηματικές Αρτιτεκτονικές Ο Νόκνο ηεο απόδνζεο ησλ κηθξνεπεμεξγαζηώλ 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI) (cycle time) Performance
Κεντρική Μονάδα Επεξεργασίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών
 Οργάνωση Υπολογιστών") Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών. Διάλεξη 13. Διακλαδώσεις. Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 13 Διακλαδώσεις Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Η μέχρι τώρα μικρο-αρχιτεκτονική (Eντολές Διακλάδωσης) Η μικρο-αρχιτεκτονική
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 13 Διακλαδώσεις Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Η μέχρι τώρα μικρο-αρχιτεκτονική (Eντολές Διακλάδωσης) Η μικρο-αρχιτεκτονική
Multi Cycle Datapath. Αρχιτεκτονική Υπολογιστών. 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: Νεκ. Κοζύρης
 Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Multi Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Multi Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Τέτοιες λειτουργίες γίνονται διαμέσου του
 Για κάθε εντολή υπάρχουν δυο βήματα που πρέπει να γίνουν: Προσκόμιση της εντολής (fetch) από τη θέση που δείχνει ο PC Ανάγνωση των περιεχομένων ενός ή δύο καταχωρητών Τέτοιες λειτουργίες γίνονται διαμέσου
Για κάθε εντολή υπάρχουν δυο βήματα που πρέπει να γίνουν: Προσκόμιση της εντολής (fetch) από τη θέση που δείχνει ο PC Ανάγνωση των περιεχομένων ενός ή δύο καταχωρητών Τέτοιες λειτουργίες γίνονται διαμέσου
Κάθε functional unit χρησιμοποιείται μια φορά σε κάθε κύκλο: ανάγκη για πολλαπλό hardware = κόστος υλοποίησης!
 Single-cyle υλοποίηση: Διάρκεια κύκλου ίση με τη μεγαλύτερη εντολή-worst case delay (εδώ η lw) = χαμηλή απόδοση! Αντιβαίνει με αρχή: Κάνε την πιο απλή περίπτωση γρήγορη (ίσως και εις βάρος των πιο «σύνθετων»
Single-cyle υλοποίηση: Διάρκεια κύκλου ίση με τη μεγαλύτερη εντολή-worst case delay (εδώ η lw) = χαμηλή απόδοση! Αντιβαίνει με αρχή: Κάνε την πιο απλή περίπτωση γρήγορη (ίσως και εις βάρος των πιο «σύνθετων»
ΗΥ425 Αρχιτεκτονική Υπολογιστών. Προχωρημένες Τεχνικές Pipelining. Ιάκωβος Μαυροειδής
 ΗΥ425 Αρχιτεκτονική Υπολογιστών Προχωρημένες Τεχνικές Pipelining. Ιάκωβος Μαυροειδής WB Data Imm Επεξεργαστής DLX Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory Access Write Back
ΗΥ425 Αρχιτεκτονική Υπολογιστών Προχωρημένες Τεχνικές Pipelining. Ιάκωβος Μαυροειδής WB Data Imm Επεξεργαστής DLX Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory Access Write Back
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control)
 και η μονάδα ελέγχου (control)") O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
Μηχανοτρονική. Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο,
 Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Instruction-Level Parallelism and its Dynamic Exploitation. Μάθηµα 3ο Computer Architecture-A Quantitative Approach
 Instruction-Level Parallelism and its Dynamic Exploitation Μάθηµα 3ο Computer Architecture-A Quantitative Approach Instruction-Level Parallelism (ILP) Επικάλυψη εντολών στοχεύοντας στην παράλληλη εκτέλεσή
Instruction-Level Parallelism and its Dynamic Exploitation Μάθηµα 3ο Computer Architecture-A Quantitative Approach Instruction-Level Parallelism (ILP) Επικάλυψη εντολών στοχεύοντας στην παράλληλη εκτέλεσή
Μέθοδοι Πρόβλεψης Διακλαδώσεων (Branch Prediction Mechanisms)
") Μέθοδοι Πρόβλεψης Διακλαδώσεων (Branch Prediction Mechanisms) 1 Εντολές Διακλάδωσης Περίπου 20% των εντολών είναι εντολές διακλάδωσης Πολλά στάδια μεταξύ υπολογισμού του επόμενου PC και εκτέλεσης του branch
Μέθοδοι Πρόβλεψης Διακλαδώσεων (Branch Prediction Mechanisms) 1 Εντολές Διακλάδωσης Περίπου 20% των εντολών είναι εντολές διακλάδωσης Πολλά στάδια μεταξύ υπολογισμού του επόμενου PC και εκτέλεσης του branch
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control)
 και η μονάδα ελέγχου (control)") O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
Εισαγωγή. Σύνοψη βασικών εννοιών, 5-stage pipeline, επεκτάσεις για λειτουργίες πολλαπλών κύκλων
 Εισαγωγή Σύνοψη βασικών εννοιών, 5-stage pipeline, επεκτάσεις για λειτουργίες πολλαπλών κύκλων 1 Παράγοντες που επηρεάζουν την επίδοση της CPU CPU time = Seconds = Instructions Cycles Seconds --------------
Εισαγωγή Σύνοψη βασικών εννοιών, 5-stage pipeline, επεκτάσεις για λειτουργίες πολλαπλών κύκλων 1 Παράγοντες που επηρεάζουν την επίδοση της CPU CPU time = Seconds = Instructions Cycles Seconds --------------
ΠΛΕ- 027 Μικροεπεξεργαστές 6ο μάθημα: Αρχιτεκτονική πυρήνα: υλοποίηση με διοχέτευση
 ΠΛΕ- 027 Μικροεπεξεργαστές 6ο μάθημα: Αρχιτεκτονική πυρήνα: υλοποίηση με διοχέτευση Αρης Ευθυμίου Απόδοση απλής υλοποίησης Υλοποίηση ενός κύκλου είναι πολύ αργή κάθε κύκλος είναι τόσο μεγάλος όσο χρειάζεται
ΠΛΕ- 027 Μικροεπεξεργαστές 6ο μάθημα: Αρχιτεκτονική πυρήνα: υλοποίηση με διοχέτευση Αρης Ευθυμίου Απόδοση απλής υλοποίησης Υλοποίηση ενός κύκλου είναι πολύ αργή κάθε κύκλος είναι τόσο μεγάλος όσο χρειάζεται
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Dynamic Instruction Scheduling: Scoreboard CS425 - Vassilis Papaefstathiou 1 DLX Processor Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory
CS425 Computer Systems Architecture Fall 2017 Dynamic Instruction Scheduling: Scoreboard CS425 - Vassilis Papaefstathiou 1 DLX Processor Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory
και η µονάδα ελέγχου (control) O επεξεργαστής: Η δίοδος δεδοµένων (datapath) Εντολές διακλάδωσης (branch beq, bne) I Type Σχεδίαση datapath
 O επεξεργαστής: Η δίοδος δεδοµένων (datapath) Εντολές διακλάδωσης (branch beq, bne) I Type Σχεδίαση datapath") O επεξεργαστής: Η δίοδος δεδοµένων (path) και η µονάδα ελέγχου (control) Σχεδίαση path 4 κατηγορίες εντολών: Αριθµητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη µνήµη (lw, sw) I
O επεξεργαστής: Η δίοδος δεδοµένων (path) και η µονάδα ελέγχου (control) Σχεδίαση path 4 κατηγορίες εντολών: Αριθµητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη µνήµη (lw, sw) I
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Υπερβαθµωτή Οργάνωση Υπολογιστών
 Υπερβαθµωτή Οργάνωση Υπολογιστών Από τις βαθµωτές στις υπερβαθµωτές αρχιτεκτονικές αγωγού Ανάγνωση εντολής (Instruction Fetch) Σε µία αρχιτεκτονική πλάτους s, πρέπει διαβάζονται s εντολές σε κάθε κύκλο
Υπερβαθµωτή Οργάνωση Υπολογιστών Από τις βαθµωτές στις υπερβαθµωτές αρχιτεκτονικές αγωγού Ανάγνωση εντολής (Instruction Fetch) Σε µία αρχιτεκτονική πλάτους s, πρέπει διαβάζονται s εντολές σε κάθε κύκλο
Πολυπύρηνοι επεξεργαστές Multicore processors
 Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Διάλεξη 12 Καθυστερήσεις (Stalls)
") ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 12 Καθυστερήσεις (Stalls) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ 1 Καθυστερήσεις και Εκκενώσεις Εντολών Οι κίνδυνοι δεδομένων (data
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 12 Καθυστερήσεις (Stalls) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ 1 Καθυστερήσεις και Εκκενώσεις Εντολών Οι κίνδυνοι δεδομένων (data
Αρχιτεκτονική Υπολογιστών
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Οργάνωση επεξεργαστή Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε
ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Οργάνωση επεξεργαστή Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε
Pipeline: Ένα παράδειγμα από.τη καθημερινή ζωή. 30 min κάθε «φάση»
 Pipeline: Ένα παράδειγμα από.τη καθημερινή ζωή 1. Πλυντήριο 2. Στεγνωτήριο 3. Δίπλωμα 4. αποθήκευση Σειριακή προσέγγιση για 4 φορτία = 8h 30 min κάθε «φάση» Pipelined προσέγγιση για 4 φορτία = 3.5h Το
Pipeline: Ένα παράδειγμα από.τη καθημερινή ζωή 1. Πλυντήριο 2. Στεγνωτήριο 3. Δίπλωμα 4. αποθήκευση Σειριακή προσέγγιση για 4 φορτία = 8h 30 min κάθε «φάση» Pipelined προσέγγιση για 4 φορτία = 3.5h Το
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
Υ- 01 Αρχιτεκτονική Υπολογιστών Πολυεπεξεργαστές, 2ο μέρος
 Υ- 01 Αρχιτεκτονική Υπολογιστών Πολυεπεξεργαστές, 2ο μέρος Αρης Ευθυμίου Το σημερινό μάθημα! Cache coherence directory protocols! Memory consistency! MulG- threading 2 Cache coherence & scalability! Τα
Υ- 01 Αρχιτεκτονική Υπολογιστών Πολυεπεξεργαστές, 2ο μέρος Αρης Ευθυμίου Το σημερινό μάθημα! Cache coherence directory protocols! Memory consistency! MulG- threading 2 Cache coherence & scalability! Τα
1. Οργάνωση της CPU 2. Εκτέλεση εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο επίπεδο των επεξεργαστών
 ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΟΡΓΑΝΩΣΗ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ι Γ. Τσιατούχας 2 ο Κεφάλαιο ιάρθρωση 1. Οργάνωση της 2. εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο
ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΟΡΓΑΝΩΣΗ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ι Γ. Τσιατούχας 2 ο Κεφάλαιο ιάρθρωση 1. Οργάνωση της 2. εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπόβαθρο: Διοχέτευση
 Υ- 01 Αρχιτεκτονική Υπολογιστών Υπόβαθρο: Διοχέτευση Αρης Ευθυμίου Το σημερινό μάθημα Υπόβαθρο: Διοχέτευση (Pipelining) Βασική οργάνωση Δομικοί κίνδυνοι Κίνδυνοι δεδομένων (hazards): RAW, WAR, WAW Stall
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπόβαθρο: Διοχέτευση Αρης Ευθυμίου Το σημερινό μάθημα Υπόβαθρο: Διοχέτευση (Pipelining) Βασική οργάνωση Δομικοί κίνδυνοι Κίνδυνοι δεδομένων (hazards): RAW, WAR, WAW Stall
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Απόδοση ΚΜΕ. (Μέτρηση και τεχνικές βελτίωσης απόδοσης)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Επανάληψη Σύστημα Διασωλήνωσης (Pipelining) Κεφάλαιο 4 - Σύστημα ιασωλήνωσης
 Κεφάλαιο 4 - Σύστημα ιασωλήνωσης") Επανάληψη Σύστημα Διασωλήνωσης (Pipelining) 1 ιασωλήνωση 2 Pipelining Παραλληλισμός + Pipelining 3 Χρόνος Εκτέλεσης = I x CPI x Cycle Time Με ή χωρις pipeline το Ι είναι το ίδιο όπως και τo CPI = 1. Το
Επανάληψη Σύστημα Διασωλήνωσης (Pipelining) 1 ιασωλήνωση 2 Pipelining Παραλληλισμός + Pipelining 3 Χρόνος Εκτέλεσης = I x CPI x Cycle Time Με ή χωρις pipeline το Ι είναι το ίδιο όπως και τo CPI = 1. Το
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
Παράλληλα Συστήματα. Γιώργος Δημητρίου. Ενότητα 3 η : Παράλληλη Επεξεργασία. Πανεπιστήμιο Θεσσαλίας - Τμήμα Πληροφορικής
 Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 3: Διασωλήνωση, Clusters, Στοιχεία Παράλληλου Προγραμματισμού Δρ. Μηνάς Δασυγένης mdasyg@ieee.org
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 3: Διασωλήνωση, Clusters, Στοιχεία Παράλληλου Προγραμματισμού Δρ. Μηνάς Δασυγένης mdasyg@ieee.org
i Όλες οι σύγχρονες ΚΜΕ είναι πολυπλοκότερες!
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Η υπολογιστική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Η υπολογιστική
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 7ο μάθημα: Κρυφές μνήμες (cache) - εισαγωγή Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Σύστημα μνήμης! Η μνήμη είναι σημαντικό
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 7ο μάθημα: Κρυφές μνήμες (cache) - εισαγωγή Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Σύστημα μνήμης! Η μνήμη είναι σημαντικό
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 3: Διασωλήνωση, Clusters, Στοιχεία Παράλληλου Προγραμματισμού Δρ. Μηνάς Δασυγένης mdasyg@ieee.org
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 3: Διασωλήνωση, Clusters, Στοιχεία Παράλληλου Προγραμματισμού Δρ. Μηνάς Δασυγένης mdasyg@ieee.org
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΠΛ221: Οργάνωση Υπολογιστών και Συμβολικός Προγραμματισμός Κεφ. 4: O επεξεργαστής Σύστημα Διασωλήνωσης (Pipelining)
") ΕΠΛ221: Οργάνωση Υπολογιστών και Συμβολικός Προγραμματισμός Κεφ. 4: O επεξεργαστής Σύστημα Διασωλήνωσης (Pipelining) 1 ιασωλήνωση 2 Διασωλήνωση και Παραλληλισμός (Parallelism) Διασωλήνωση (Pipelining):
ΕΠΛ221: Οργάνωση Υπολογιστών και Συμβολικός Προγραμματισμός Κεφ. 4: O επεξεργαστής Σύστημα Διασωλήνωσης (Pipelining) 1 ιασωλήνωση 2 Διασωλήνωση και Παραλληλισμός (Parallelism) Διασωλήνωση (Pipelining):
Θέµατα Φεβρουαρίου
 Θέµατα Φεβρουαρίου 2-2 cslab@ntua 2- Θέµα ο (3%): Έστω η παρακάτω ακολουθία εντολών που χρησιµοποιείται για την αντιγραφ από µια θέση µνµης σε µια άλλη (memory-to-memory copy): lw $2, ($) sw $2, 2($) i)
Θέµατα Φεβρουαρίου 2-2 cslab@ntua 2- Θέµα ο (3%): Έστω η παρακάτω ακολουθία εντολών που χρησιµοποιείται για την αντιγραφ από µια θέση µνµης σε µια άλλη (memory-to-memory copy): lw $2, ($) sw $2, 2($) i)
1.1 ΑΣΚΗΣΗ ΛΥΣΗ 2.1 ΑΣΚΗΣΗ ΛΥΣΗ 3.1 ΑΣΚΗΣΗ
 1.1 ΑΣΚΗΣΗ i) Έστω ότι οι εντολές κινητής υποδιαστολής ευθύνονται για το 25% του χρόνου εκτέλεσης ενός προγράµµατος σε ένα µηχάνηµα. Προτείνεται να βελτιωθεί το υλικό που σχετίζεται µε αριθµούς κινητής
1.1 ΑΣΚΗΣΗ i) Έστω ότι οι εντολές κινητής υποδιαστολής ευθύνονται για το 25% του χρόνου εκτέλεσης ενός προγράµµατος σε ένα µηχάνηµα. Προτείνεται να βελτιωθεί το υλικό που σχετίζεται µε αριθµούς κινητής
Single Cycle Datapath. Αρχιτεκτονική Υπολογιστών. 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: Νεκ. Κοζύρης
 Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Single Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Single Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων
 ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων Εισαγωγή στην Αρχιτεκτονική Υπολογιστών Γλώσσα Μηχανής Εκτέλεση προγράμματος Αριθμητικές και λογικές εντολές Παράδειγμα: μια απλή Γλώσσα Μηχανής Επικοινωνία με άλλες συσκευές
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων Εισαγωγή στην Αρχιτεκτονική Υπολογιστών Γλώσσα Μηχανής Εκτέλεση προγράμματος Αριθμητικές και λογικές εντολές Παράδειγμα: μια απλή Γλώσσα Μηχανής Επικοινωνία με άλλες συσκευές
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 Πολυπύρηνοι επεξεργαστές, μέρος 2 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Cache coherence & scalability! Τα πρωτόκολλα
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 Πολυπύρηνοι επεξεργαστές, μέρος 2 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Cache coherence & scalability! Τα πρωτόκολλα
ΠΛΕ- 027 Μικροεπεξεργαστές 7ο μάθημα: Αρχιτεκτονική πυρήνα: Πρόβλεψη διακλάδωσης, Εξαιρέσεις
 ΠΛΕ- 027 Μικροεπεξεργαστές 7ο μάθημα: Αρχιτεκτονική πυρήνα: Πρόβλεψη διακλάδωσης, Εξαιρέσεις Αρης Ευθυμίου Κόστος διακλαδώσεων Οι διακλαδώσεις έχουν σχετικά μεγάλο κόστος χρόνου Τουλάχιστον ένας κύκλος
ΠΛΕ- 027 Μικροεπεξεργαστές 7ο μάθημα: Αρχιτεκτονική πυρήνα: Πρόβλεψη διακλάδωσης, Εξαιρέσεις Αρης Ευθυμίου Κόστος διακλαδώσεων Οι διακλαδώσεις έχουν σχετικά μεγάλο κόστος χρόνου Τουλάχιστον ένας κύκλος
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 6: Διασωλήνωση Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 6: Διασωλήνωση Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Σύγχρονοι υπολογιστές Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Σύγχρονοι υπολογιστές Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Κρυφές Μνήμες. (οργάνωση, λειτουργία και απόδοση)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232)
") ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Δευτέρα, 3 Νοεμβρίου 25 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΛΕΠΤΑ Για πλήρη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Δευτέρα, 3 Νοεμβρίου 25 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΛΕΠΤΑ Για πλήρη
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων
 ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων 2.1 Αρχιτεκτονική Υπολογιστών 2.2 Γλώσσα Μηχανής 2.3 Εκτέλεση προγράμματος 2.4 Αριθμητικές και λογικές εντολές 2.5 Επικοινωνία με άλλες συσκευές 2.6 Άλλες αρχιτεκτονικές
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων 2.1 Αρχιτεκτονική Υπολογιστών 2.2 Γλώσσα Μηχανής 2.3 Εκτέλεση προγράμματος 2.4 Αριθμητικές και λογικές εντολές 2.5 Επικοινωνία με άλλες συσκευές 2.6 Άλλες αρχιτεκτονικές
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΤΕΛΙΚΟ ΔΙΑΓΩΝΙΣΜΑ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Τετάρτη, 21 Δεκεμβρίου 2016 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΩΡΕΣ Για πλήρη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΤΕΛΙΚΟ ΔΙΑΓΩΝΙΣΜΑ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Τετάρτη, 21 Δεκεμβρίου 2016 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΩΡΕΣ Για πλήρη
i Throughput: Ο ρυθμός ολοκλήρωσης έργου σε συγκεκριμένο χρόνο
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική
 ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική") Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Υ07. Διδάσκων: ΠΑΡΑΛΛΗΛΑ ΣΥΣΤΗΜΑΤΑ. Β. Δημακόπουλος.
 Υ07 ΠΑΡΑΛΛΗΛΑ ΣΥΣΤΗΜΑΤΑ Διδάσκων: Β. Δημακόπουλος dimako@cse.uoi.gr Υ07 Παράλληλα Συστήματα 2015-16 23/2/2016 Εισαγωγή στα Παράλληλα Συστήματα (Οργάνωση-Προγραμματισμός) Οργάνωση του μαθήματος Διδάσκων:
Υ07 ΠΑΡΑΛΛΗΛΑ ΣΥΣΤΗΜΑΤΑ Διδάσκων: Β. Δημακόπουλος dimako@cse.uoi.gr Υ07 Παράλληλα Συστήματα 2015-16 23/2/2016 Εισαγωγή στα Παράλληλα Συστήματα (Οργάνωση-Προγραμματισμός) Οργάνωση του μαθήματος Διδάσκων:
5/3/2012. Εισαγωγή στα Παράλληλα Συστήµατα (Οργάνωση-Προγραµµατισµός) Β. Δημακόπουλος Α. Ευθυμίου
 Β. Δημακόπουλος Α. Ευθυμίου") 5/3/2012 Εισαγωγή στα Παράλληλα Συστήµατα (Οργάνωση-Προγραµµατισµός) Β. Δημακόπουλος Α. Ευθυμίου Τι περιλαμβάνει το σημερινό μάθημα; Εισαγωγή στα παράλληλα συστήματα Τι είναι; Πώς φτάσαμε ως εδώ; Τι σημαίνει
5/3/2012 Εισαγωγή στα Παράλληλα Συστήµατα (Οργάνωση-Προγραµµατισµός) Β. Δημακόπουλος Α. Ευθυμίου Τι περιλαμβάνει το σημερινό μάθημα; Εισαγωγή στα παράλληλα συστήματα Τι είναι; Πώς φτάσαμε ως εδώ; Τι σημαίνει
Α. Δίνονται οι. (i) στη. πρέπει να. πιο. (ii) $a0. $s0 θα πρέπει να. αποθήκευση. αυξάνει τον. f: sub sll add sub jr. h: addi sw sw.
 στη. πρέπει να. πιο. (ii) $a0. $s0 θα πρέπει να. αποθήκευση. αυξάνει τον. f: sub sll add sub jr. h: addi sw sw.") ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΡ ΙΟ ΥΠΟΛΟΟ ΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua. gr ΑΡΧΙΤΕΚΤΟΝΙΚΗ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΡ ΙΟ ΥΠΟΛΟΟ ΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua. gr ΑΡΧΙΤΕΚΤΟΝΙΚΗ
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 11-12 : Δομή και Λειτουργία της CPU Ευάγγελος Καρβούνης Παρασκευή, 22/01/2016 2 Οργάνωση της CPU Η CPU πρέπει:
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 11-12 : Δομή και Λειτουργία της CPU Ευάγγελος Καρβούνης Παρασκευή, 22/01/2016 2 Οργάνωση της CPU Η CPU πρέπει:
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ ΝΗΜΑΤΑ
 ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Διάλεξη 3 ΝΗΜΑΤΑ Οι διαφάνειες έχουν καθαρά επικουρικό χαρακτήρα στην παρουσίαση των διαλέξεων του μαθήματος. Δεν αντικαθιστούν σε καμία περίπτωση την παρακάτω βιβλιογραφία που αποτελεί
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Διάλεξη 3 ΝΗΜΑΤΑ Οι διαφάνειες έχουν καθαρά επικουρικό χαρακτήρα στην παρουσίαση των διαλέξεων του μαθήματος. Δεν αντικαθιστούν σε καμία περίπτωση την παρακάτω βιβλιογραφία που αποτελεί
Κεφάλαιο 4. Ο επεξεργαστής. Οργάνωση και Σχεδίαση Υπολογιστών Η ιασύνδεση Υλικού και Λογισµικού, 4 η έκδοση
 Οργάνωση και Σχεδίαση Υπολογιστών Η ιασύνδεση Υλικού και Λογισµικού, 4 η έκδοση Κεφάλαιο 4 Ο επεξεργαστής ιαφάνειες διδασκαλίας του πρωτότυπου βιβλίου µεταφρασµένες στα ελληνικά και εµπλουτισµένες (µετάφραση,
Οργάνωση και Σχεδίαση Υπολογιστών Η ιασύνδεση Υλικού και Λογισµικού, 4 η έκδοση Κεφάλαιο 4 Ο επεξεργαστής ιαφάνειες διδασκαλίας του πρωτότυπου βιβλίου µεταφρασµένες στα ελληνικά και εµπλουτισµένες (µετάφραση,
ΑΡΧΙΤΕΚΤΟΝΙΚΗ HARDWARE ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ
 ΨΗΦΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΚΕΦΑΛΑΙΟ 7ο ΑΡΧΙΤΕΚΤΟΝΙΚΗ HARDWARE ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Γενικό διάγραμμα υπολογιστικού συστήματος Γενικό διάγραμμα υπολογιστικού συστήματος - Κεντρική Μονάδα Επεξεργασίας ονομάζουμε
ΨΗΦΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΚΕΦΑΛΑΙΟ 7ο ΑΡΧΙΤΕΚΤΟΝΙΚΗ HARDWARE ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Γενικό διάγραμμα υπολογιστικού συστήματος Γενικό διάγραμμα υπολογιστικού συστήματος - Κεντρική Μονάδα Επεξεργασίας ονομάζουμε
http://www.cslab.ece.ntua.gr/diplom/
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ KΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr/ ιπλωµατική
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ KΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr/ ιπλωµατική
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 11ο μάθημα: πολυπύρηνοι επεξεργαστές, μέρος 1 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Παράλληλη επεξεργασία Στο προηγούμενο
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 11ο μάθημα: πολυπύρηνοι επεξεργαστές, μέρος 1 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Παράλληλη επεξεργασία Στο προηγούμενο
ΗΥ425 Αρχιτεκτονική Υπολογιστών. Static Scheduling. Ιάκωβος Μαυροειδής
 ΗΥ425 Αρχιτεκτονική Υπολογιστών Static Scheduling Ιάκωβος Μαυροειδής Τεχνικές ελάττωσης stalls. CPI = Ideal CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls Θα μελετήσουμε
ΗΥ425 Αρχιτεκτονική Υπολογιστών Static Scheduling Ιάκωβος Μαυροειδής Τεχνικές ελάττωσης stalls. CPI = Ideal CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls Θα μελετήσουμε
ΔΙΑΛΕΞΗ 16: ΠΑΡΑΛΛΗΛΙΣΜΟΣ ΣΤΗΝ ΕΚΤΕΛΕΣΗ ΕΝΤΟΛΩΝ
 ΗΜΥ 312 -- ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΗΛΕΚΤΡΟΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΔΙΑΛΕΞΗ 16: ΠΑΡΑΛΛΗΛΙΣΜΟΣ ΣΤΗΝ ΕΚΤΕΛΕΣΗ ΕΝΤΟΛΩΝ Διδάσκουσα: ΜΑΡΙΑ Κ. ΜΙΧΑΗΛ Επίκουρη Καθηγήτρια, ΗΜΜΥ (mmichael@ucy.ac.cy) [Προσαρμογή από Computer Architecture:
ΗΜΥ 312 -- ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΗΛΕΚΤΡΟΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΔΙΑΛΕΞΗ 16: ΠΑΡΑΛΛΗΛΙΣΜΟΣ ΣΤΗΝ ΕΚΤΕΛΕΣΗ ΕΝΤΟΛΩΝ Διδάσκουσα: ΜΑΡΙΑ Κ. ΜΙΧΑΗΛ Επίκουρη Καθηγήτρια, ΗΜΜΥ (mmichael@ucy.ac.cy) [Προσαρμογή από Computer Architecture:
2η ΑΣΚΗΣΗ ΣΤΗΝ ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ Ακ. έτος , 5ο Εξάμηνο Σχολή ΗΜ&ΜΥ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ Α Σ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ Ι Κ Ω Ν Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ Α Σ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ Ι Κ Ω Ν Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.
Προχωρηµένα Θέµατα Αρχιτεκτονικής
 Προχωρηµένα Θέµατα Αρχιτεκτονικής Μάθηµα 2 ο : Instruction Set Principles and Examples Μάθηµα 2 ο Προχωρηµένα Θέµατα Αρχιτεκτονικής 1 Σχεδιασµός Συνόλου Εντολών Θέµατα που θα συζητηθούν ιαφορετικές επιλογές
Προχωρηµένα Θέµατα Αρχιτεκτονικής Μάθηµα 2 ο : Instruction Set Principles and Examples Μάθηµα 2 ο Προχωρηµένα Θέµατα Αρχιτεκτονικής 1 Σχεδιασµός Συνόλου Εντολών Θέµατα που θα συζητηθούν ιαφορετικές επιλογές
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 6: Διασωλήνωση Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 6: Διασωλήνωση Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών Τομέας Πληροφορικής και Τεχνολογίας Υπολογιστών
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών Τομέας Πληροφορικής και Τεχνολογίας Υπολογιστών Τεχνικές για την Βελτιστοποίηση και Αποδοτική Απεικόνιση Παράλληλων Κωδίκων
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών Τομέας Πληροφορικής και Τεχνολογίας Υπολογιστών Τεχνικές για την Βελτιστοποίηση και Αποδοτική Απεικόνιση Παράλληλων Κωδίκων
Υ- 01 Αρχιτεκτονική Υπολογιστών Πρόβλεψη διακλάδωσης
 Υ- 01 Αρχιτεκτονική Υπολογιστών Πρόβλεψη διακλάδωσης Αρης Ευθυμίου Το σημερινό μάθημα Πρόβλεψη διακλάδωσης (branch predicfon) ποιο είναι το πρόβλημα και τι προκαλεί πρόβλεψη κατεύθυνσης πρόβλεψη στόχου
Υ- 01 Αρχιτεκτονική Υπολογιστών Πρόβλεψη διακλάδωσης Αρης Ευθυμίου Το σημερινό μάθημα Πρόβλεψη διακλάδωσης (branch predicfon) ποιο είναι το πρόβλημα και τι προκαλεί πρόβλεψη κατεύθυνσης πρόβλεψη στόχου