Vector Αρχιτεκτονικές, SIMD Extensions & GPUs
|
|
|
- Γαλήνη Κωνσταντίνου
- 6 χρόνια πριν
- Προβολές:
Transcript
1 Vector Αρχιτεκτονικές, SIMD Extensions & GPUs 1
2 Πηγές/Βιβλιογραφία Computer Architecture: A Quantitative Approach, J. L. Hennessy, D. A. Patterson, Morgan Kaufmann Publishers, INC. 6 th Edition, 2017 Krste Asanovic, Vectors & GPUs, CS 152 Computer Architecture and Engineering, EECS Berkeley, Onur Mutlu, SIMD Processors & GPUs, Computer Architecture ETH Zurich, 2017 (slides)
3 Προσεγγίσεις Αύξησης Απόδοσης Παραλληλισμός σε επίπεδο εντολής (Instruction Level Parallelism ILP) Εξαρτάται από τις πραγματικές εξαρτήσεις δεδομένων που υφίστανται ανάμεσα στις εντολές. Παραλληλισμός σε επίπεδο νήματος (Thread-Level Parallelism TLP) Αναπαρίσταται ρητά από τον προγραμματιστή, χρησιμοποιώντας πολλαπλά νήματα εκτέλεσης τα οποία είναι εκ κατασκευής παράλληλα. Παραλληλισμός σε επίπεδο δεδομένων (Data-Level Parallelism DLP) Αναπαρίσταται ρητά από τον προγραμματιστή ή δημιουργείται αυτόματα από τον μεταγλωττιστή. Οι ίδιες εντολές επεξεργάζονται πολλαπλά δεδομένα ταυτόχρονα 3
4 Ταξινόμηση Παράλληλων Αρχιτεκτονικών Single Instruction stream, Single Data stream (SISD) Uniprocessor. Single Instruction stream, Multiple Data streams (SIMD) Πολλαπλοί επεξεργαστές, ίδιες εντολές, διαφορετικά δεδομένα (data-level parallelism). Multiple Instruction streams, Single Data stream (MISD) Μέχρι σήμερα δεν έχει εμφανιστεί στην αγορά κάποιο τέτοιο σύστημα (είναι κυρίως για fault tolerance, π.χ. υπολογιστές που ελέγχουν πτήση αεροσκαφών). Multiple Instruction streams, Multiple Data streams (MIMD) O κάθε επεξεργαστής εκτελεί τις δικές του εντολές και επεξεργάζεται τα δικά του δεδομένα. Πολλαπλά παράλληλα νήματα (thread-level parallelism). [Mike Flynn, Very high-speed computing systems. Proc. of IEEE 54, 1966] 4
5 Παραλληλισμός σε επίπεδο Δεδομένων Προκύπτει από το γεγονός ότι οι ίδιες εντολές επεξεργάζονται πολλαπλά διαφορετικά δεδομένα ταυτόχρονα. Πολλαπλές «επεξεργαστικές» μονάδες Παραδείγματα εφαρμογών με σημαντικό παραλληλισμό δεδομένων: Επιστημονικές εφαρμογές (πράξεις με πίνακες) Επεξεργασία εικόνας και ήχου Αλγόριθμοι μηχανικής μάθησης 5
6 Παραλληλισμός σε επίπεδο Δεδομένων Γιατί Single Instruction Multiple Data (SIMD) αρχιτεκτονική? Mια εντολή πολλαπλά δεδομένα Καλύτερο energyefficiency Όταν υπάρχει DLP εξαρτάται από την εφαρμογή, τον αλγόριθμο, προγραμματιστή, τον μεταγλωττιστή Mobile devices Ο προγραμματιστής συνεχίζει να σκέφτεται (περίπου) ακολουθιακά 6
7 DLP Αρχιτεκτονικές 1. Vector 2. SIMD Extensions 3. GPUs 7
8 Vector Architecture Πρόκεται για αρχιτεκτονική που υποστηρίζει στο υλικό την εκτέλεση διανυσμάτων ή αλλιώς vectors Ένας vector (διάνυσμα) είναι ένας μονοδιάστατος πίνακας αριθμών Εμφανίζονται σε πολλές εφαρμογές for (i=0; i<n; i++) C[i] = A[i] + B[i]; Ιστορικά Εμφανίστηκαν στην δεκαετία του 1970 Κυριάρχησαν στον χώρο του supercomputing ( ) Σημαντικά πλεονεκτήματα για συγκεκριμένες εφαρμογές επανέρχονται δυναμικά 8
9 Vector Architecture Γενική Ιδέα 1. Φέρνει από την μνήμη ένα σύνολο δεδομένων και τα αποθηκεύει σε μεγάλα register files Vector registers 2. Εκτελεί μία πράξη στο σύνολο όλων αυτών των δεδομένων 3. Γράφει τα αποτελέσματα πίσω στην μνήμη Οι καταχωρητές ελέγχονται από τον compiler και χρησιμοποιούντια για να: Κρύψουν τον χρόνο πρόσβασης στην μνήμη Εκμεταλλευτούν το memory bandwidth Vector Instructions & Architecture Support 9
10 Vector Architecture Functionality Μια εντολή vector πραγματοποιεί μία πράξη σε κάθε στοιχείο του vector σε διαδοχικούς κύκλους Pipelined functional units Κάθε στάδιο του pipeline επεξεργάζεται ένα διαφορετικό στοιχείο Οι vector εντολές επιτρέπουν την υλοποίηση pipelines με περισσότερα στάδια (deep pipelines) Δεν υπάρχουν εξαρτήσεις μέσα στους vectors Δεν υπάρχει έλεγχος ροής μέσα στους vectors H γνώση των strides σχετικά με τις προσβάσεις στην μνήμη επιτρέπει αποτελεσματικό prefetching 10
11 Vector Architecture Functionality for (i=0; i<n; i++) C[i] = A[i] * B[i]; V 1 V 2 V 3 } Six stage multiply pipeline V1 * V2 V3 11

12 Vector Architecture Cray-1 (1978) Scalar Unit Load/Store Architecture Vector Extensions Vector Registers Vector Instructions Highly pipelined functional units Interleaved memory system Memory banks No data caches No virtual memory 12
13 Vector Architecture Πλεονεκτήματα Δεν υπάρχουν εξαρτήσεις μέσα στους vectors H pipeline τεχνική δουλεύει πολύ καλά Επιτρέπει την ύπαρξη deep pipelines Κάθε εντολή αντιπροσωπεύει πολλή δουλειά Απλούστερη λογική για instruction fetch και ανάγκη για λιγότερο memory bandwidth λόγω instructions Οι προσβάσεις στην μνήμη γίνονται με regular patterns Λιγότερα branch instructions 13
14 Vector Architecture Μειονεκτήματα Δουλεύει καλά μόνο όταν υπάρχει διαθέσιμος παραλληλισμός δεδομένων στην εφαρμογή Μπορεί να δημιουργηθεί πρόβλημα λόγω memory bandwidth όταν: Ο λόγος των εντολών υπολογισμού προς τις εντολές μνήμης δεν καλύπτει το κόστος της ανάγνωσης/εγγραφής των vectors από την μνήμη Τα δεδομένα δεν είναι κατάλληλα αποθηκευμένα στην μνήμη (memory banks) 14
15 Vector Architecture VMIPS RV64V (RISC-V base instructions + vector extensions) Αρχιτεκτονική βασισμένη στον Cray-1 Vector data registers 32 registers, 64-bits wide each element 16 read ports & 8 write ports Vector functional units Fully pipelined Data and control hazard detection Vector load/store unit Fully pipelined One word per clock cycle after initial latency Scalar registers 31 general purpose registers + 32 floating point registers 15
16 Vector data registers Vector Architecture Registers Vector control registers VLEN, VMASK, VSTR VLEN (Vector Length Register) Δηλώνει το μέγεθος του vector Η μέγιστη τιμή του καθορίζεται από την αρχιτεκτονική MVL Maximum Vector Length VMASK (Vector Mask Register) Δηλώνει τα στοιχεία του vector στα οποία εφαρμόζονται οι vector instructions VSTR (Vector Stride Register) Δηλώνει την απόσταση των στοιχείων στην μνήμη για την δημιουργία ενός vector 16
17 DAXPY Παράδειγμα Scalar Code double a, X[N], Y[N]; for (i=0; i<32; i++) { Y[i] = a*x[i] + Y[i]; } fld f0,a # Load scalar a addi x28,x5,#256 # Last address to load Loop: fld f1,0(x5) # load X[i] fmul.d f1,f1,f0 # a * X[i] fld f2,0(x6) # load Y[i] fadd.d f2,f2,f1 # a * X[i] + Y[i] fsd f2,0(x6) # store into Y[i] addi x5,x5,#8 # Increment index to X addi x6,x6,#8 # Increment index to Y bne x28,x5,loop # check if done 17
18 DAXPY Παράδειγμα Vector Code double a, X[N], Y[N]; for (i=0; i<32; i++) { Y[i] = a*x[i] + Y[i]; } vsetdcfg 4*FP64 # Enable 4 DP FP vregs fld f0,a # Load scalar a vld v0,x5 # Load vector X vmul v1,v0,f0 # Vector-scalar mult vld v2,x6 # Load vector Y vadd v3,v1,v2 # Vector-vector add vst v3,x6 # Store the sum vdisable # Disable vector regs 8 instructions for RV64V (vector code) vs. 258 instructions for RV64G (scalar code) 18
19 Vector Execution Time Η επίδοση εξαρτάται από τρεις παράγοντες: Μέγεθος των vectors Δομικοί κίνδυνοι (structural hazards) Εξαρτήσεις δεδομένων (data dependencies) Lanes Πολλαπλά παράλληλα pipelines που παράγουν δύο ή περισσότερα αποτελέσματα σε κάθε κύκλο Convoy Vector instructions που θα μπορούσαν να εκτελεστούν ταυτόχρονα Χωρίς δομικούς κινδύνους 19
20 Vector Chaining & Chimes Ακολουθίες από read-after-write εξαρτήσεις δεδομένων τοποθετούνται στο ίδιο convoy και εκτελούνται μέσω της τεχνικής του chaining LV v1 MULV v3,v1,v2 ADDV v5, v3, v4 V 1 V 2 V 3 V 4 V 5 Load Unit Memory Chain Mult. Chain Add 20
21 Chaining Vector Chaining & Chimes Μια vector εντολή ξεκινάει να εκτελείται καθώς στοιχεία του vector source operand γίνονται διαθέσιμα Chime Μονάδα χρόνου για την εκτέλεση ενός convoy m convoys εκτελούνται σε m chimes για vector length n Χρειάζεται (m x n) κύκλους για vector length n 21
22 Vector Chaining & Chimes Παράδειγμα vld v0,x5 # Load vector X vmul v1,v0,f0 # Vector-scalar multiply vld v2,x6 # Load vector Y vadd v3,v1,v2 # Vector-vector add vst v3,x6 # Store the sum Convoys: 1 st chime: vld vmul 2 nd chime: vld vadd 3 rd chime: vst 3 chimes, 2 FP ops per result, cycles per FLOP = 1.5 For 32 element vectors, requires 32 x 3 = 96 clock cycles 22
23 Vector Architecture Challenges Start up time Καθυστέρηση μέχρι να γεμίσει το pipeline Execute more than vector elements per cycle? Multiple lanes execution Vector length!= Maximum Vector Length (MVL)? Vector Length Register + Strip mining If statements + vector operations? Vector Mask Register + Predication Memory system? Memory banks Multiple dimensional matrices? Vector Stride Register Sparse matrices? Scatter/gather operations Programming a vector computer? 23
24 Multiple Lanes Execution VADD A,B C Execution using one pipelined functional unit Execution using four pipelined functional units A[6] B[6] A[24] B[24] A[25] B[25] A[26] B[26] A[27] B[27] A[5] B[5] A[20] B[20] A[21] B[21] A[22] B[22] A[23] B[23] A[4] B[4] A[16] B[16] A[17] B[17] A[18] B[18] A[19] B[19] A[3] B[3] A[12] B[12] A[13] B[13] A[14] B[14] A[15] B[15] C[2] C[8] C[9] C[10] C[11] C[1] C[4] C[5] C[6] C[7] C[0] C[0] C[1] C[2] C[3] 24
25 Multiple Lanes Execution Το στοιχείο n του vector register A είναι hardwired στο στοιχείο n του vector register Β multiple HW lanes Functional Unit Vector Registers Elements 0, 4, 8, Elements 1, 5, 9, Elements 2, 6, 10, Elements 3, 7, 11, Lane Memory Subsystem 25
26 Vector Instruction Parallelism Can overlap execution of multiple vector instructions example machine has 32 elements per vector register and 8 lanes time load load Load Unit Multiply Unit Add Unit mul add mul add Instruction issue Complete 24 operations/cycle while issuing 1 short instruction/cycle 26
27 Vector Length Register Strip-Mining Technique vsetdcfg 2 DP FP # Enable 2 64b Fl.Pt. regs fld f0,a # Load scalar a loop: setvl t0,a0 # vl = t0 = min(mvl,n) vld v0,x5 # Load vector X for (i=0; i<n; i++) { slli t1,t0,3 # t1 = vl * 8 (in bytes) Y[i] = a*x[i] + Y[i]; add x5,x5,t1 # Increment pointer to X by vl*8 } vmul v0,v0,f0 # Vector-scalar mult vld v1,x6 # Load vector Y vadd v1,v0,v1 # Vector-vector add sub a0,a0,t0 # n -= vl (t0) vst v1,x6 # Store the sum into Y add x6,x6,t1 # Increment pointer to Y by vl*8 bnez a0,loop # Repeat if n!= 0 vdisable # Disable vector regs} 27
28 Vector Mask Registers Disable elements through predication for (i = 0; i < 64; i=i+1) { if (X[i]!= 0) X[i] = X[i] Y[i]; } vsetdcfg 2*FP64 # Enable 2 64b FP vector regs vsetpcfgi 1 # Enable 1 predicate register vld v0,x5 # Load vector X into v0 vld v1,x6 # Load vector Y into v1 fmv.d.x f0,x0 # Put (FP) zero into f0 vpne p0,v0,f0 # Set p0(i) to 1 if v0(i)!=f0 vsub v0,v0,v1 # Subtract under vector mask vst v0,x5 # Store the result in X vdisable # Disable vector registers vpdisable # Disable predicate registers 28
29 Memory Banks Το σύστημα μνήμης πρέπει να υποστηρίζει υψηλό bandwidth για vector loads & stores Προσέγγιση: Διαμοιρασμός των προσβάσεων μνήμης σε πολλαπλά banks H μνήμη χωρίζεται σε banks τα οποία προσπελαύνονται ανεξάρτητα Control bank addresses independently Load or store non sequential words Support multiple vector processors sharing the same memory Μπορεί να εξυπηρετήσει Ν παράλληλες προσπελάσεις αν όλες πηγαίνουν σε διαφορετικά banks 29
30 Memory Banks Bank 0 Bank 1 Bank 2 Bank 15 MDR MAR MDR MAR MDR MAR MDR MAR Data bus Address bus CPU 30
31 Memory Banks Vector Registers Base Stride Address Generator A B C D E F Memory Banks 31
32 Παράδειγμα: Stride Accesses for (i = 0; i < 100; i=i+1) for (j = 0; j < 100; j=j+1) { A[i][j] = 0.0; for (k = 0; k < 100; k=k+1) A[i][j] = A[i][j] + B[i][k] * D[k][j]; } Vector Stride Register Stride: απόσταση μεταξύ δύο στοιχείων για τον σχηματισμό vector Ίσως προκύψουν bank conflicts 32
33 Παράδειγμα: for (i = 0; i < n; i=i+1) A[K[i]] = A[K[i]] + C[M[i]]; Scatter-Gather Index vector instructions vsetdcfg 4*FP64 # 4 64b FP vector registers vld v0, x7 # Load K[] vldx v1, x5, v0 # Load A[K[]] vld v2, x28 # Load M[] vldx v3, x6, v2 # Load C[M[]] vadd v1, v1, v3 # Add them vstx v1, x5, v0 # Store A[K[]] vdisable # Disable vector registers 33
34 Programming a Vector computer Ο compiler μπορεί να δώσει feedback στον προγραμματιστή Για να εφαρμόσει vector optimizations Ο πρoγραμματιστής μπορεί να δώσει hints στον compiler Ποια κομμάτια κώδικα να γίνουν vectorized 34
35 DLP Αρχιτεκτονικές 1. Vector 2. SIMD Extensions 3. GPUs 35
36 SIMD Extensions Πολλές εφαρμογές πολυμέσων επεξεργάζονται δεδομένα που έχουν μέγεθος μικρότερο από το μέγεθος λέξης (π.χ. 32 bits) για το οποίο ο επεξεργαστής είναι βελτιστοποιημένος Παραδείγματα: Τα pixels γραφικών αναπαριστώνται συνήθως με 8 bits για κάθε κύριο χρώμα + 8 bits για transparency Τα δείγματα ήχου αναπαριστώνται συνήθως με 8 ή 16 bits SIMD Extensions Διαμοιρασμός των functional units για την ταυτόχρονη επεξεργασία στοιχείων μικρών vectors Παράδειγμα: partitioned adder 36
37 SIMD Extensions vs. Vectors SIMD extensions operate on small vectors Πολύ μικρότερα register files Λιγότερη ανάγκη για υψηλό memory bandwidth Περιορισμοί των SIMD Extensions: Ο αριθμός των data operands αντικατοπτρίζεται στο op-code Το instruction set γίνεται περισσότερο περίπλοκο Δεν υπάρχει Vector Length Register Δεν υποστηρίζονται περίπλοκοι τρόποι διευθυνσιοδότησης (strided, scatter/gather) Δεν υπάρχει Vector Mask Register 37
38 Intel MMX (1996) SIMD Extensions Υλοποιήσεις Eight 8-bit integer ops or four 16-bit integer ops Peleg and Weiser, MMX Technology Extension to the Intel Architecture, IEEE Micro, 1996 Streaming SIMD Extensions (SSE) (1999) Eight 16-bit integer ops Four 32-bit integer/fp ops or two 64-bit integer/fp ops Advanced Vector Extensions (2010) Four 64-bit integer/fp ops AVX-512 (2017) Eight 64-bit integer/fp ops Operands must be consecutive and aligned memory locations 38
39 SIMD Extensions Παράδειγμα for (i=0; i<n; i++) { Y[i] = a*x[i] + Y[i]; } fld f0,a # Load scalar a splat.4d f0,f0 # Make 4 copies of a addi x28,x5,#256 # Last addr. to load Loop: fld.4d f1,0(x5) # Load X[i]... X[i+3] fmul.4d f1,f1,f0 # a x X[i]... a x X[i+3] fld.4d f2,0(x6) # Load Y[i]... Y[i+3] fadd.4d f2,f2,f1 # a x X[i]+Y[i] # a x X[i+3]+Y[i+3] fsd.4d f2,0(x6) # Store Y[i]... Y[i+3] addi x5,x5,#32 # Increment index to X addi x6,x6,#32 # Increment index to Y bne x28,x5,loop # Check if done 39
40 DLP Αρχιτεκτονικές 1. Vector 2. SIMD Extensions 3. GPUs 40
41 Graphical Processing Units Επιταχυντές για την επεξεργασία γραφικών Υψηλός παραλληλισμός σε εφαρμογές γραφικών GP-GPUs General-Purpose computation on Graphics Processing Units Χρησιμοποιούνται ευρέως για την επιτάχυνση data και compute intensive εφαρμογών Εφαρμογές ιδανικές για GPGPUs Υψηλός παραλληλισμός Υψηλό arithmetic intensity Μεγάλα data sets 41
42 Graphical Processing Units Ετερογενές μοντέλο εκτέλεσης H CPU είναι ο Host H GPU είναι το device Επικοινωνία μέσω PCIe bus Μοντέλο προγραμματισμού C-like γλώσσα προγραμματισμού για GPU Βασίζεται στην έννοια των threads Single Instruction, Multiple threads (SIMT) Multi-threaded προγραμματιστικό μοντέλο Διαφορετικό από SIMD που χρησιμοποιεί data parallel προγραμματιστικό μοντέλο Συνδυάζει SIMD και Multithreading 42
43 GPUs & Flynn s Taxonomy Οι GPUs αποτελούνται από πολλαπλούς επεξεργαστές Κάθε ένας επεξεργαστής αποτελείται από ένα multithreaded SIMD pipeline To pipeline εκτέλεσης των εντολών λειτουργεί σαν ένα SIMD pipeline Όμως, ο προγραμματισμός γίνεται με την έννοια των threads Όχι με την έννοια των SIMD εντολών Κάθε thread εκτελεί την ίδια εντολή αλλά επεξεργάζεται διαφορετικά δεδομένα Κάθε thread έχει το δική του κατάσταση και μπορεί να εκτελεστεί ανεξάρτητα 43
44 SIMD Extensions GPUs & Flynn s Taxonomy (2) To SIMD υλικό αξιοποιείται μέσα από: GPUs data parallel προγραμματιστικό μοντέλο Ο προγραμματιστής (ή ο μεταγλωττιστής) χρησιμοποιεί τις SIMD εντολές για να εκτελέσει την ίδια εντολή σε πολλά δεδομένα Το οποίο εκτελείται μέσα από ένα SIMD μοντέλο εκτέλεσης To SIMD υλικό αξιοποιείται μέσα από: Multithreaded προγραμματιστικό μοντέλο Ο προγραμματιστής (ή ο μεταγλωττιστής) παράγει σειριακό κώδικα και δημιουργεί νήματα για να εκτελέσει τον ίδιο κώδικα σε πολλά δεδομένα Το οποίο εκτελείται μέσα από ένα SIMD μοντέλο εκτέλεσης 44
45 SIMD vs. SIMT Μοντέλο Εκτέλεσης Υλικού Μοντέλο Εκτέλεσης Υλικού Καθορίζει πως εκτελείται ένας κώδικας στο υλικό SIMD Single Instruction Multiple Data Μία ροή από διαδοχικές SIMD εντολές Κάθε SIMD εντολή καθορίζει πολλά δεδομένα προς επεξεργασία SIMT Single Instruction Multiple Threads Πολλές ροές από scalar εντολές (μία για κάθε νήμα εκτέλεσης) Πολλά νήματα ομαδοποιούνται δυναμικά από το hardware για να εκτελέσουν την ίδια ροή σε διαφορετικά δεδομένα 45
46 Πλεονεκτήματα SIMT Μοντέλου Εκτέλεσης To υλικό μεταχειρίζεται κάθε thread σαν ανεξάρτητη οντότητα Μπορεί να εκτελέσει κάθε thread ανεξάρτητα Κερδίζοντας τα οφέλη του ΜIMD μοντέλου εκτέλεσης Το υλικό μπορεί να σχηματίσει δυναμικά groups από threads Που εκτελούν την ίδια εντολή Κερδίζοντας τα οφέλη του SIMD μοντέλου εκτέλεσης 46
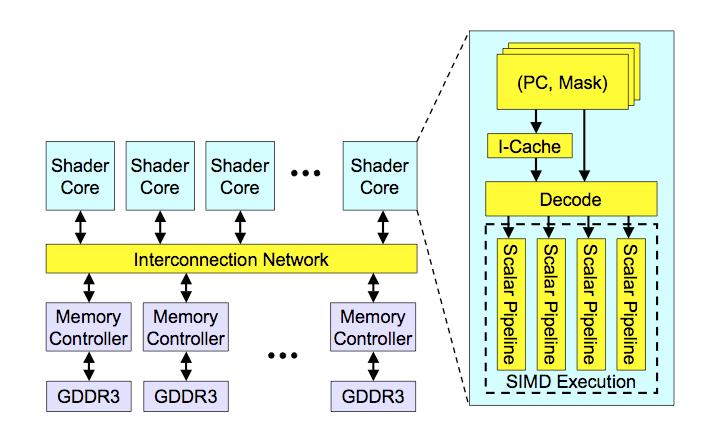
47 GPU Αρχιτεκτονική 47
48 Threads and Blocks Ένα thread συνδέεται με την επεξεργασία ενός υποσυνόλου του data set (data elements) Τα threads οργανώνονται σε blocks Τα blocks οργανώνονται σε ένα grid To υλικό (hardware) της GPU διαχειρίζεται τα νήματα Όχι οι εφαρμογές ή το λειτουργικό σύστημα Multithreading SIMD execution 48
49 Παράδειγμα CPU code for (i = 0; i < 8192; ++i) { A[i] = B[i] * C[i]; } CUDA code // there are 8192 threads global void KernelFunction( ) { int tid = blockdim.x * blockidx.x + threadidx.x; int varb = B[tid]; int varc = C[tid]; A[tid] = varb + varc; } 49
50 Παράδειγμα Threads and Blocks Code that works over all elements is the grid Thread blocks break this down into manageable sizes 512 threads per block (defined by the programmer) Groups of 32 threads combined into a SIMD thread or warp Grid size = 16 thread blocks 8192 elements / 512 threads per block Block is analogous to a strip-mined vector loop with vector length of 32 A thread block is assigned to a multithreaded SIMD processor by the thread block scheduler Current-generation GPUs have tens of multithreaded SIMD processors 50
51 Παράδειγμα Threads and Blocks 51
52 Παράδειγμα GPU αρχιτεκτονική Groups of 32 threads combined into a SIMD thread or warp Mapped to 16 (or 32) physical lanes Up to 32 warps are scheduled on a single SIMD processor Each warp has its own PC Each thread in a warp has its own register set (depends on the architecture & limits the number of warps per SIMD processor) Thread scheduler uses scoreboard to dispatch warps By definition, no data dependencies between warps Dispatch warps into pipeline, hide memory latency Thread block scheduler schedules blocks to SIMD processors Within each SIMD processor: Wide and shallow pipelined functional units compared to vector processors 52
53 Παράδειγμα GPU αρχιτεκτονική 53
 A single thread block can contain multiple warps, all mapped to single SIMD processor Can have multiple thread blocks executing on one SIMD")
54 Warps are multithreaded on the SIMD core Warp == SIMD thread One warp is a single thread in the hardware Multiple warps are interleaved in execution on a single SIMD processor to hide latencies (memory and functional unit) A single thread block can contain multiple warps, all mapped to single SIMD processor Can have multiple thread blocks executing on one SIMD processor 54
55 NVIDIA Instruction Set Architecture ISA is an abstraction of the hardware instruction set Parallel Thread Execution (PTX) opcode.type d,a,b,c; Χρησιμοποιεί virtual registers Η μετάφραση σε κώδικα μηχανής πραγματοποιείται από το software Παράδειγμα: shl.s32 R8, blockidx, 9 ; Thread Block ID * Block size (512 or 29) add.s32 R8, R8, threadidx ; R8 = i = my CUDA thread ID ld.global.f64 RD0, [X+R8] ; RD0 = X[i] ld.global.f64 RD2, [Y+R8] ; RD2 = Y[i] mul.f64 R0D, RD0, RD4 ; Product in RD0 = RD0 * RD4 (scalar a) add.f64 R0D, RD0, RD2 ; Sum in RD0 = RD0 + RD2 (Y[i]) st.global.f64 [Y+R8], RD0 ; Y[i] = sum (X[i]*a + Y[i]) 55
56 Conditional Branching Like vector architectures, GPU branch hardware uses internal masks Also uses Branch synchronization stack Entries consist of masks for each SIMD lane I.e. which threads commit their results (all threads execute) Instruction markers to manage when a branch diverges into multiple execution paths Push on divergent branch and when paths converge Act as barriers Pops stack Per-thread-lane 1-bit predicate register, specified by programmer 56
57 Shallow memory hierarchy GPU Memory Structures Multithreading hides memory latency Each SIMD Lane has private section of off-chip DRAM Private memory ( local memory in NVIDIA s terminology) Contains stack frame, spilling registers, and private variables Each multithreaded SIMD processor also has local memory local memory ( shared memory in NVIDIA s terminology) Scratchpad memory managed explicitly by the programmer Shared by SIMD lanes / threads within a block Memory shared by SIMD processors is GPU Memory GPU memory ( global memory in NVIDIA s terminology) Host can read and write GPU memory 57
58 NVIDIA s Pascal Architecture Innovations Each SIMD processor has: Two SIMD thread (warp) schedulers, two instruction dispatch units Two sets of: 16 SIMD lanes (SIMD width=32, chime=2 cycles) 16 load-store units, 8 special function units Two threads of SIMD instructions (warps) are scheduled every two clock cycles simultaneously Fast single-, double-, and half-precision High Bandwidth Memory 2 (HBM2) at 732 GB/s NVLink between multiple GPUs (20 GB/s in each direction) Unified virtual memory and paging support 58

59 NVIDIA s Pascal SIMD Processor 59
60 GPUs vs. Vector Architectures Ομοιότητες με vector αρχιτεκτονικές Δουλεύει επίσης καλά για data-level parallel προβλήματα Scatter-gather transfers Mask registers Large register files Διαφορές με vector αρχιτεκτονικές Δεν υπάρχει scalar επεξεργαστής Χρησιμοποιεί multithreading για να κρύψει την καθυστέρηση στην πρόσβαση της μνήμης Έχει πολλαπλά functional units, σε αντίθεση με τα λίγα deeply pipelined functional units που έχουν οι vector αρχιτεκτονικές 60
61 GPUs vs. Vector Architectures Vector Architecture GPU Architecture 61
62 SIMD Extensions vs. GPUs Οι GPUs έχουν περισσότερα SIMD lanes Οι GPUs υποστηρίζουν στο υλικό περισσότερα threads Και οι δύο έχουν 2:1 αναλογία μεταξύ double- and singleprecision performance Και οι δύο έχουν 64-bit διευθύνσεις, αλλά οι GPUs έχουν μικρότερη μνήμη Τα SIMD extensions δεν υποστηρίζουν scatter-gather εντολές 62
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I
 ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
Thread Level Parallelism & Data Level Parallelism
 Thread Level Parallelism & Data Level Parallelism 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI)
Thread Level Parallelism & Data Level Parallelism 1 Ο Νόμος της απόδοσης των μικροεπεξεργαστών 1 Time Instructions Cycles Time = = x x Performance Program Program Instruction Cycle (instr. count) (CPI)
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών
 Οργάνωση Υπολογιστών") Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
Περιορισμοί των βαθμωτών αρχιτεκτονικών
 Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άδεια χρήσης άλλου τύπου, αυτή πρέπει να αναφέρεται ρητώς. Περιορισμοί
Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άδεια χρήσης άλλου τύπου, αυτή πρέπει να αναφέρεται ρητώς. Περιορισμοί
Προχωρηµένα Θέµατα Αρχιτεκτονικής
 Προχωρηµένα Θέµατα Αρχιτεκτονικής Μάθηµα 2 ο : Instruction Set Principles and Examples Μάθηµα 2 ο Προχωρηµένα Θέµατα Αρχιτεκτονικής 1 Σχεδιασµός Συνόλου Εντολών Θέµατα που θα συζητηθούν ιαφορετικές επιλογές
Προχωρηµένα Θέµατα Αρχιτεκτονικής Μάθηµα 2 ο : Instruction Set Principles and Examples Μάθηµα 2 ο Προχωρηµένα Θέµατα Αρχιτεκτονικής 1 Σχεδιασµός Συνόλου Εντολών Θέµατα που θα συζητηθούν ιαφορετικές επιλογές
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control)
 και η μονάδα ελέγχου (control)") O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
Παράλληλα Συστήματα. Γιώργος Δημητρίου. Ενότητα 3 η : Παράλληλη Επεξεργασία. Πανεπιστήμιο Θεσσαλίας - Τμήμα Πληροφορικής
 Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Παραλληλισμός σε επίπεδο εντολών
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
ΗΥ425 Αρχιτεκτονική Υπολογιστών. Static Scheduling. Ιάκωβος Μαυροειδής
 ΗΥ425 Αρχιτεκτονική Υπολογιστών Static Scheduling Ιάκωβος Μαυροειδής Τεχνικές ελάττωσης stalls. CPI = Ideal CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls Θα μελετήσουμε
ΗΥ425 Αρχιτεκτονική Υπολογιστών Static Scheduling Ιάκωβος Μαυροειδής Τεχνικές ελάττωσης stalls. CPI = Ideal CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control stalls Θα μελετήσουμε
και η µονάδα ελέγχου (control) O επεξεργαστής: Η δίοδος δεδοµένων (datapath) Εντολές διακλάδωσης (branch beq, bne) I Type Σχεδίαση datapath
 O επεξεργαστής: Η δίοδος δεδοµένων (datapath) Εντολές διακλάδωσης (branch beq, bne) I Type Σχεδίαση datapath") O επεξεργαστής: Η δίοδος δεδοµένων (path) και η µονάδα ελέγχου (control) Σχεδίαση path 4 κατηγορίες εντολών: Αριθµητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη µνήµη (lw, sw) I
O επεξεργαστής: Η δίοδος δεδοµένων (path) και η µονάδα ελέγχου (control) Σχεδίαση path 4 κατηγορίες εντολών: Αριθµητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη µνήµη (lw, sw) I
Συστήματα σε Ολοκληρωμένα Κυκλώματα
 Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
Μηχανοτρονική. Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο,
 Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Τέτοιες λειτουργίες γίνονται διαμέσου του
 Για κάθε εντολή υπάρχουν δυο βήματα που πρέπει να γίνουν: Προσκόμιση της εντολής (fetch) από τη θέση που δείχνει ο PC Ανάγνωση των περιεχομένων ενός ή δύο καταχωρητών Τέτοιες λειτουργίες γίνονται διαμέσου
Για κάθε εντολή υπάρχουν δυο βήματα που πρέπει να γίνουν: Προσκόμιση της εντολής (fetch) από τη θέση που δείχνει ο PC Ανάγνωση των περιεχομένων ενός ή δύο καταχωρητών Τέτοιες λειτουργίες γίνονται διαμέσου
Instruction Execution Times
 1 C Execution Times InThisAppendix... Introduction DL330 Execution Times DL330P Execution Times DL340 Execution Times C-2 Execution Times Introduction Data Registers This appendix contains several tables
1 C Execution Times InThisAppendix... Introduction DL330 Execution Times DL330P Execution Times DL340 Execution Times C-2 Execution Times Introduction Data Registers This appendix contains several tables
Τελική Εξέταση, Απαντήσεις/Λύσεις
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών (ΗΜΜΥ) HMΜY 212 Οργάνωση Η/Υ και Μικροεπεξεργαστές Εαρινό Εξάμηνο, 2007 Τελική Εξέταση, Απαντήσεις/Λύσεις Άσκηση 1: Assembly για
ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών (ΗΜΜΥ) HMΜY 212 Οργάνωση Η/Υ και Μικροεπεξεργαστές Εαρινό Εξάμηνο, 2007 Τελική Εξέταση, Απαντήσεις/Λύσεις Άσκηση 1: Assembly για
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών
 Οργάνωση Υπολογιστών") Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
Υπερβαθμωτή (superscalar) Οργάνωση Υπολογιστών 1 Περιορισμοί των βαθμωτών αρχιτεκτονικών Μέγιστο throughput: 1 εντολή/κύκλο ρολογιού (IPC 1) Υποχρεωτική ροή όλων των (διαφορετικών) τύπων εντολών μέσα από
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control)
 και η μονάδα ελέγχου (control)") O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
O επεξεργαστής: Η δίοδος δεδομένων (datapath) και η μονάδα ελέγχου (control) 4 κατηγορίες εντολών: Σχεδίαση datapath Αριθμητικές-λογικές εντολές (add, sub, slt κλπ) R Type Εντολές αναφοράς στη μνήμη (lw,
ΗΥ425 Αρχιτεκτονική Υπολογιστών. Static Scheduling. Βασίλης Παπαευσταθίου Ιάκωβος Μαυροειδής
 ΗΥ425 Αρχιτεκτονική Υπολογιστών Static Scheduling Βασίλης Παπαευσταθίου Ιάκωβος Μαυροειδής Τεχνικές ελάττωσης stalls. CPI = Ideal CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control
ΗΥ425 Αρχιτεκτονική Υπολογιστών Static Scheduling Βασίλης Παπαευσταθίου Ιάκωβος Μαυροειδής Τεχνικές ελάττωσης stalls. CPI = Ideal CPI + Structural stalls + RAW stalls + WAR stalls + WAW stalls + Control
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
Αρχιτεκτονικές Συνόλου Εντολών
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Αρχιτεκτονικές Συνόλου Εντολών (Instruction Set Architectures - ISA) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ο
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Αρχιτεκτονικές Συνόλου Εντολών (Instruction Set Architectures - ISA) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ο
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2017 1 Εισαγωγικά 2 Compute Unified Device
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2017 1 Εισαγωγικά 2 Compute Unified Device
Δυναμική Δρομολόγηση Εντολών (Dynamic Scheduling)
") Δυναμική Δρομολόγηση Εντολών (Dynamic Scheduling) Απόδοση pipeline Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: μέτρο της μέγιστης απόδοσης
Δυναμική Δρομολόγηση Εντολών (Dynamic Scheduling) Απόδοση pipeline Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: μέτρο της μέγιστης απόδοσης
FX10 SIMD SIMD. [3] Dekker [4] IEEE754. a.lo. (SpMV Sparse matrix and vector product) IEEE754 IEEE754 [5] Double-Double Knuth FMA FMA FX10 FMA SIMD
![FX10 SIMD SIMD. [3] Dekker [4] IEEE754. a.lo. (SpMV Sparse matrix and vector product) IEEE754 IEEE754 [5] Double-Double Knuth FMA FMA FX10 FMA SIMD](/thumbs/80/81651565.jpg "FX10 SIMD SIMD. [3] Dekker [4] IEEE754. a.lo. (SpMV Sparse matrix and vector product) IEEE754 IEEE754 [5] Double-Double Knuth FMA FMA FX10 FMA SIMD") FX,a),b),c) Bailey Double-Double [] FMA FMA [6] FX FMA SIMD Single Instruction Multiple Data 5 4.5. [] Bailey SIMD SIMD 8bit FMA (SpMV Sparse matrix and vector product) FX. DD Bailey Double-Double a) em49@ns.kogakuin.ac.jp
FX,a),b),c) Bailey Double-Double [] FMA FMA [6] FX FMA SIMD Single Instruction Multiple Data 5 4.5. [] Bailey SIMD SIMD 8bit FMA (SpMV Sparse matrix and vector product) FX. DD Bailey Double-Double a) em49@ns.kogakuin.ac.jp
Κεντρική Μονάδα Επεξεργασίας. Επανάληψη: Απόδοση ΚΜΕ. ΚΜΕ ενός κύκλου (single-cycle) Παραλληλισμός σε επίπεδο εντολών. Υπολογιστικό σύστημα
 Παραλληλισμός σε επίπεδο εντολών. Υπολογιστικό σύστημα") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2015 Περιεχόμενα 2 01 / 2014 Προγραμματισμός
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2015 Περιεχόμενα 2 01 / 2014 Προγραμματισμός
Ενσωµατωµένα Υπολογιστικά Συστήµατα (Embedded Computer Systems)
") Ενσωµατωµένα Υπολογιστικά Συστήµατα (Embedded Computer Systems) Μαθηµα 2 ηµήτρης Λιούπης 1 Intel SA-1110 µc StrongARM core. System-on-Chip. Εξέλιξη των SA-110 και SA-1100. 2 ARM cores ARM: IP (intellectual
Ενσωµατωµένα Υπολογιστικά Συστήµατα (Embedded Computer Systems) Μαθηµα 2 ηµήτρης Λιούπης 1 Intel SA-1110 µc StrongARM core. System-on-Chip. Εξέλιξη των SA-110 και SA-1100. 2 ARM cores ARM: IP (intellectual
Single Cycle Datapath. Αρχιτεκτονική Υπολογιστών. 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: Νεκ. Κοζύρης
 Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Single Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Single Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Υπερβαθµωτή Οργάνωση Υπολογιστών
 Υπερβαθµωτή Οργάνωση Υπολογιστών Από τις βαθµωτές στις υπερβαθµωτές αρχιτεκτονικές αγωγού Τα όρια του Παραλληλισµού σε επίπεδο εντολών (Instruction Level Parallelism - ILP) Weiss and Smith [1984] Sohi
Υπερβαθµωτή Οργάνωση Υπολογιστών Από τις βαθµωτές στις υπερβαθµωτές αρχιτεκτονικές αγωγού Τα όρια του Παραλληλισµού σε επίπεδο εντολών (Instruction Level Parallelism - ILP) Weiss and Smith [1984] Sohi
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Dynamic Instruction Scheduling: Scoreboard CS425 - Vassilis Papaefstathiou 1 DLX Processor Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory
CS425 Computer Systems Architecture Fall 2017 Dynamic Instruction Scheduling: Scoreboard CS425 - Vassilis Papaefstathiou 1 DLX Processor Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory
EM 361: Παράλληλοι Υπολογισμοί
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #2: Αρχιτεκτονική Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #2: Αρχιτεκτονική Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική
 ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική") Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Multi Cycle Datapath. Αρχιτεκτονική Υπολογιστών. 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: Νεκ. Κοζύρης
 Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Multi Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Multi Cycle Datapath http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Προγραμματισμός GPUs μέσω του περιβάλλοντος CUDA
 Προγραμματισμός GPUs μέσω του περιβάλλοντος CUDA Κωνσταντινίδης Ηλίας Υποψήφιος Διδάκτωρ Τμήμα Πληροφορικής & Τηλεπικοινωνιών Εθνικό και Καποδιστριακό Πανεπιστήμιο Αθηνών Νόμος Moore density doubles/18m
Προγραμματισμός GPUs μέσω του περιβάλλοντος CUDA Κωνσταντινίδης Ηλίας Υποψήφιος Διδάκτωρ Τμήμα Πληροφορικής & Τηλεπικοινωνιών Εθνικό και Καποδιστριακό Πανεπιστήμιο Αθηνών Νόμος Moore density doubles/18m
ΗΥ425 Αρχιτεκτονική Υπολογιστών. Προχωρημένες Τεχνικές Pipelining. Ιάκωβος Μαυροειδής
 ΗΥ425 Αρχιτεκτονική Υπολογιστών Προχωρημένες Τεχνικές Pipelining. Ιάκωβος Μαυροειδής WB Data Imm Επεξεργαστής DLX Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory Access Write Back
ΗΥ425 Αρχιτεκτονική Υπολογιστών Προχωρημένες Τεχνικές Pipelining. Ιάκωβος Μαυροειδής WB Data Imm Επεξεργαστής DLX Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Memory Access Write Back
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Φεβρουάριος 2014 Περιεχόμενα 1 Εισαγωγή 2 Επεξεργαστές
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Φεβρουάριος 2014 Περιεχόμενα 1 Εισαγωγή 2 Επεξεργαστές
Πολυπύρηνοι επεξεργαστές Multicore processors
 Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Αρχιτεκτονική Υπολογιστών
 Γιώργος Δημητρίου Ενότητα 11 η : Εισαγωγή σε Παράλληλες Αρχιτεκτονικές Παράλληλη Επεξεργασία Επίπεδο Παραλληλισμού Από εντολές έως ανεξάρτητες διεργασίες Οργανώσεις Παράλληλων Αρχιτεκτονικών Συμμετρικοί,
Γιώργος Δημητρίου Ενότητα 11 η : Εισαγωγή σε Παράλληλες Αρχιτεκτονικές Παράλληλη Επεξεργασία Επίπεδο Παραλληλισμού Από εντολές έως ανεξάρτητες διεργασίες Οργανώσεις Παράλληλων Αρχιτεκτονικών Συμμετρικοί,
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Pipeline: Ένα παράδειγμα από.τη καθημερινή ζωή. 30 min κάθε «φάση»
 Pipeline: Ένα παράδειγμα από.τη καθημερινή ζωή 1. Πλυντήριο 2. Στεγνωτήριο 3. Δίπλωμα 4. αποθήκευση Σειριακή προσέγγιση για 4 φορτία = 8h 30 min κάθε «φάση» Pipelined προσέγγιση για 4 φορτία = 3.5h Το
Pipeline: Ένα παράδειγμα από.τη καθημερινή ζωή 1. Πλυντήριο 2. Στεγνωτήριο 3. Δίπλωμα 4. αποθήκευση Σειριακή προσέγγιση για 4 φορτία = 8h 30 min κάθε «φάση» Pipelined προσέγγιση για 4 φορτία = 3.5h Το
Θέµατα Φεβρουαρίου
 Θέµατα Φεβρουαρίου 2-2 cslab@ntua 2- Θέµα ο (3%): Έστω η παρακάτω ακολουθία εντολών που χρησιµοποιείται για την αντιγραφ από µια θέση µνµης σε µια άλλη (memory-to-memory copy): lw $2, ($) sw $2, 2($) i)
Θέµατα Φεβρουαρίου 2-2 cslab@ntua 2- Θέµα ο (3%): Έστω η παρακάτω ακολουθία εντολών που χρησιµοποιείται για την αντιγραφ από µια θέση µνµης σε µια άλλη (memory-to-memory copy): lw $2, ($) sw $2, 2($) i)
Αρχιτεκτονική Επεξεργαστών Ψ.Ε.Σ
 ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων Αρχιτεκτονική Επεξεργαστών Ψ.Ε.Σ Βιβλιογραφία Ενότητας Kehtarnavaz [2005]: Chapter 3 Kuo [2005]: Chapters 1 & 4-5 Lapsley [2002]: Chapter 4 Hayes [2000]: Κεφάλαιo 8
ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων Αρχιτεκτονική Επεξεργαστών Ψ.Ε.Σ Βιβλιογραφία Ενότητας Kehtarnavaz [2005]: Chapter 3 Kuo [2005]: Chapters 1 & 4-5 Lapsley [2002]: Chapter 4 Hayes [2000]: Κεφάλαιo 8
GPGPU. Grover. On Large Scale Simulation of Grover s Algorithm by Using GPGPU
 GPGPU Grover 1, 2 1 3 4 Grover Grover OpenMP GPGPU Grover qubit OpenMP GPGPU, 1.47 qubit On Large Scale Simulation of Grover s Algorithm by Using GPGPU Hiroshi Shibata, 1, 2 Tomoya Suzuki, 1 Seiya Okubo
GPGPU Grover 1, 2 1 3 4 Grover Grover OpenMP GPGPU Grover qubit OpenMP GPGPU, 1.47 qubit On Large Scale Simulation of Grover s Algorithm by Using GPGPU Hiroshi Shibata, 1, 2 Tomoya Suzuki, 1 Seiya Okubo
Chapter 6 Αύξηση της απόδοσης με διοχέτευση (pipeline)
") Chapter 6 Αύξηση της απόδοσης με διοχέτευση (pipeline) Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση: Καθ. Εφαρμογών Νικόλαος Πετράκης, Τμήματος Ηλεκτρονικών Μηχανικών
Chapter 6 Αύξηση της απόδοσης με διοχέτευση (pipeline) Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση: Καθ. Εφαρμογών Νικόλαος Πετράκης, Τμήματος Ηλεκτρονικών Μηχανικών
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 9 : Ομάδες Εντολών: Ιδιότητες και Λειτουργίες Ευάγγελος Καρβούνης Παρασκευή, 15/01/2016 Τι είναι ομάδα εντολών;
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 9 : Ομάδες Εντολών: Ιδιότητες και Λειτουργίες Ευάγγελος Καρβούνης Παρασκευή, 15/01/2016 Τι είναι ομάδα εντολών;
Παράλληλος Προγραμματισμός με OpenCL
 Παράλληλος Προγραμματισμός με OpenCL Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2017 1 Γενικά για OpenCL 2 Platform Model 3 Execution Model
Παράλληλος Προγραμματισμός με OpenCL Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2017 1 Γενικά για OpenCL 2 Platform Model 3 Execution Model
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232)
") ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Δευτέρα, 3 Νοεμβρίου 25 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΛΕΠΤΑ Για πλήρη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Δευτέρα, 3 Νοεμβρίου 25 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΛΕΠΤΑ Για πλήρη
1. Οργάνωση της CPU 2. Εκτέλεση εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο επίπεδο των επεξεργαστών
 ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΟΡΓΑΝΩΣΗ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ι Γ. Τσιατούχας 2 ο Κεφάλαιο ιάρθρωση 1. Οργάνωση της 2. εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο
ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΟΡΓΑΝΩΣΗ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ι Γ. Τσιατούχας 2 ο Κεφάλαιο ιάρθρωση 1. Οργάνωση της 2. εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο
Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών
 Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2010 Περιεχόμενα...1 Σύντομη Ιστορική Αναδρομή...2
Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2010 Περιεχόμενα...1 Σύντομη Ιστορική Αναδρομή...2
Κεντρική Μονάδα Επεξεργασίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 6ο μάθημα: χρονοπρογραμματισμός, αλγόριθμος Tomasulo, εικασία Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου InstrucDon- Level
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 6ο μάθημα: χρονοπρογραμματισμός, αλγόριθμος Tomasulo, εικασία Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου InstrucDon- Level
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
CMOS Technology for Computer Architects
 CMOS Technology for Computer Architects Iakovos Mavroidis Giorgos Passas Manolis Katevenis Lecture 13: On chip SRAM Technology FORTH ICS / EURECCA & UoC GREECE ABC A A E F A BCDAECF A AB C DE ABCDAECF
CMOS Technology for Computer Architects Iakovos Mavroidis Giorgos Passas Manolis Katevenis Lecture 13: On chip SRAM Technology FORTH ICS / EURECCA & UoC GREECE ABC A A E F A BCDAECF A AB C DE ABCDAECF
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Κρυφές Μνήμες. (οργάνωση, λειτουργία και απόδοση)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Αρχιτεκτονική Υπολογιστών
 Γιώργος Δημητρίου Ενότητα 7 η : Στατική Δρομολόγηση Εντολών (Επεξεργαστές VLIW) Εκμετάλλευση ILP Περιορισμοί στη δυναμική δρομολόγηση εντολών: Μέγεθος παραθύρου εντολών Αριθμός φυσικών καταχωρητών Αποτυχία
Γιώργος Δημητρίου Ενότητα 7 η : Στατική Δρομολόγηση Εντολών (Επεξεργαστές VLIW) Εκμετάλλευση ILP Περιορισμοί στη δυναμική δρομολόγηση εντολών: Μέγεθος παραθύρου εντολών Αριθμός φυσικών καταχωρητών Αποτυχία
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών. Διάλεξη 13. Διακλαδώσεις. Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 13 Διακλαδώσεις Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Η μέχρι τώρα μικρο-αρχιτεκτονική (Eντολές Διακλάδωσης) Η μικρο-αρχιτεκτονική
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 13 Διακλαδώσεις Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Η μέχρι τώρα μικρο-αρχιτεκτονική (Eντολές Διακλάδωσης) Η μικρο-αρχιτεκτονική
; Τι περιέχεται στη συσκευασία ενός μικροεπεξεργαστή σήμερα;
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Αρχιτεκτονικές Συνόλου Εντολών (Instruction Set Architectures - ISA) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Τι
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Αρχιτεκτονικές Συνόλου Εντολών (Instruction Set Architectures - ISA) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Τι
Υλοποίηση Mικροεπεξεργαστή MIPS -16
 Υλοποίηση Mικροεπεξεργαστή MIPS -16 Διάδρομος Δεδομένων και Μονάδα Ελέγχου 1 Περίληψη Μνήμη RAM Εκτέλεση εντολών με πολλαπλούς κύκλους Σχεδιασμός Διαδρόμου Δεδομένων (Data Path) Καταχωρητής Εντολών (Instruction
Υλοποίηση Mικροεπεξεργαστή MIPS -16 Διάδρομος Δεδομένων και Μονάδα Ελέγχου 1 Περίληψη Μνήμη RAM Εκτέλεση εντολών με πολλαπλούς κύκλους Σχεδιασμός Διαδρόμου Δεδομένων (Data Path) Καταχωρητής Εντολών (Instruction
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Απόδοση ΚΜΕ. (Μέτρηση και τεχνικές βελτίωσης απόδοσης)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Κεντρική Μονάδα Επεξεργασίας (ΚΜΕ) Τμήματα ΚΜΕ (CPU) Ένα τυπικό υπολογιστικό σύστημα σήμερα. Οργάνωση Υπολογιστών (Ι)
 Τμήματα ΚΜΕ (CPU) Ένα τυπικό υπολογιστικό σύστημα σήμερα. Οργάνωση Υπολογιστών (Ι)") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2015-16 Οργάνωση Υπολογιστών (Ι) (η κεντρική μονάδα επεξεργασίας) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2015-16 Οργάνωση Υπολογιστών (Ι) (η κεντρική μονάδα επεξεργασίας) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα
Οργάνωση Υπολογιστών (Ι)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2014-15 Οργάνωση Υπολογιστών (Ι) (η κεντρική μονάδα επεξεργασίας) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2014-15 Οργάνωση Υπολογιστών (Ι) (η κεντρική μονάδα επεξεργασίας) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπερβαθμωτοι επεξεργαστές
 Υ- 01 Αρχιτεκτονική Υπολογιστών Υπερβαθμωτοι επεξεργαστές Αρης Ευθυμίου Το σημερινό μάθημα Υπερβαθμωτοί επεξεργαστές (superscalar) Εκτέλεση σε σειρά Εκτέλεση εκτός σειράς Alpha 21164 Scoreboard Μετονομασία
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπερβαθμωτοι επεξεργαστές Αρης Ευθυμίου Το σημερινό μάθημα Υπερβαθμωτοί επεξεργαστές (superscalar) Εκτέλεση σε σειρά Εκτέλεση εκτός σειράς Alpha 21164 Scoreboard Μετονομασία
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
30 min κάθε «φάση» Pipeline: Ένα παράδειγµα από.τη καθηµερινή ζωή. 1. Πλυντήριο. 2. Στεγνωτήριο. 3. ίπλωµα. 4. αποθήκευση. προσέγγιση για 4.
 Pipeline: Ένα παράδειγµα από.τη καθηµερινή ζωή Time 6 PM 7 8 9 10 11 12 1 2 AM 1. Πλυντήριο 2. Στεγνωτήριο 3. ίπλωµα 4. αποθήκευση Task order A B C D Σειριακή προσέγγιση για 4 φορτία =8h 30 min κάθε «φάση»
Pipeline: Ένα παράδειγµα από.τη καθηµερινή ζωή Time 6 PM 7 8 9 10 11 12 1 2 AM 1. Πλυντήριο 2. Στεγνωτήριο 3. ίπλωµα 4. αποθήκευση Task order A B C D Σειριακή προσέγγιση για 4 φορτία =8h 30 min κάθε «φάση»
Είδη των Cache Misses: 3C s
 Είδη των Cache Misses: 3C s 1 Compulsory: Συμβαίνουν κατά την πρώτη πρόσβαση σε ένα block. Το block πρέπει να κληθεί από χαμηλότερα επίπεδα μνήμης και να τοποθετηθεί στην cache (αποκαλούνται και cold start
Είδη των Cache Misses: 3C s 1 Compulsory: Συμβαίνουν κατά την πρώτη πρόσβαση σε ένα block. Το block πρέπει να κληθεί από χαμηλότερα επίπεδα μνήμης και να τοποθετηθεί στην cache (αποκαλούνται και cold start
ΕΙΣΑΓΩΓΗ στους Η/Υ. Δρ. Β Σγαρδώνη. Τμήμα Τεχνολογίας Αεροσκαφών ΤΕΙ ΣΤΕΡΕΑΣ ΕΛΛΑΔΑΣ. Χειμερινό Εξάμηνο 2013-14
 ΕΙΣΑΓΩΓΗ στους Η/Υ Τμήμα Τεχνολογίας Αεροσκαφών ΤΕΙ ΣΤΕΡΕΑΣ ΕΛΛΑΔΑΣ Δρ. Β Σγαρδώνη Χειμερινό Εξάμηνο 2013-14 Εισαγωγικές Έννοιες Τι είναι ένας ηλεκτρονικός υπολογιστής ; Ιστορία των Η/Υ Αρχιτεκτονική των
ΕΙΣΑΓΩΓΗ στους Η/Υ Τμήμα Τεχνολογίας Αεροσκαφών ΤΕΙ ΣΤΕΡΕΑΣ ΕΛΛΑΔΑΣ Δρ. Β Σγαρδώνη Χειμερινό Εξάμηνο 2013-14 Εισαγωγικές Έννοιες Τι είναι ένας ηλεκτρονικός υπολογιστής ; Ιστορία των Η/Υ Αρχιτεκτονική των
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2016 1 Εισαγωγικά 2 Compute Unified Device
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2016 1 Εισαγωγικά 2 Compute Unified Device
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών. Intel x86 ISA. Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών ΗΥ
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Intel x86 ISA Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών ΗΥ RISC vs. CISC Η assembly των επεξεργαστών ARM, SPARC (Sun), και Power (IBM) είναι όμοιες
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Intel x86 ISA Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών ΗΥ RISC vs. CISC Η assembly των επεξεργαστών ARM, SPARC (Sun), και Power (IBM) είναι όμοιες
i Throughput: Ο ρυθμός ολοκλήρωσης έργου σε συγκεκριμένο χρόνο
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
Κάθε functional unit χρησιμοποιείται μια φορά σε κάθε κύκλο: ανάγκη για πολλαπλό hardware = κόστος υλοποίησης!
 Single-cyle υλοποίηση: Διάρκεια κύκλου ίση με τη μεγαλύτερη εντολή-worst case delay (εδώ η lw) = χαμηλή απόδοση! Αντιβαίνει με αρχή: Κάνε την πιο απλή περίπτωση γρήγορη (ίσως και εις βάρος των πιο «σύνθετων»
Single-cyle υλοποίηση: Διάρκεια κύκλου ίση με τη μεγαλύτερη εντολή-worst case delay (εδώ η lw) = χαμηλή απόδοση! Αντιβαίνει με αρχή: Κάνε την πιο απλή περίπτωση γρήγορη (ίσως και εις βάρος των πιο «σύνθετων»
add $t0,$zero, $zero I_LOOP: beq $t0,$s3, END add $t1, $zero,$zero J_LOOP: sub $t2, $s3, $t0 add $t2, $t2, $s1 int i, j, tmp; int *arr, n;
 Άσκηση 1 η Μέρος Α Ζητούμενο: Δίνεται το παρακάτω πρόγραμμα σε C καθώς και μια μετάφραση του σε assembly MIPS. Συμπληρώστε τα κενά. Σας υπενθυμίζουμε ότι ο καταχωρητής $0 (ή $zero) είναι πάντα μηδέν. int
Άσκηση 1 η Μέρος Α Ζητούμενο: Δίνεται το παρακάτω πρόγραμμα σε C καθώς και μια μετάφραση του σε assembly MIPS. Συμπληρώστε τα κενά. Σας υπενθυμίζουμε ότι ο καταχωρητής $0 (ή $zero) είναι πάντα μηδέν. int
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων
 ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων 2.1 Αρχιτεκτονική Υπολογιστών 2.2 Γλώσσα Μηχανής 2.3 Εκτέλεση προγράμματος 2.4 Αριθμητικές και λογικές εντολές 2.5 Επικοινωνία με άλλες συσκευές 2.6 Άλλες αρχιτεκτονικές
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων 2.1 Αρχιτεκτονική Υπολογιστών 2.2 Γλώσσα Μηχανής 2.3 Εκτέλεση προγράμματος 2.4 Αριθμητικές και λογικές εντολές 2.5 Επικοινωνία με άλλες συσκευές 2.6 Άλλες αρχιτεκτονικές
ΠΛΕ- 027 Μικροεπεξεργαστές 8ο μάθημα: Παραλληλία επιπέδου εντολής
 ΠΛΕ- 027 Μικροεπεξεργαστές 8ο μάθημα: Παραλληλία επιπέδου εντολής Αρης Ευθυμίου Ταχύτερη εκτέλεση Με τις τεχνικές που είδαμε στα προηγούμενα μαθήματα μπορούμε να εκτελέσουμε (με επικάλυψη) περίπου 1 εντολή
ΠΛΕ- 027 Μικροεπεξεργαστές 8ο μάθημα: Παραλληλία επιπέδου εντολής Αρης Ευθυμίου Ταχύτερη εκτέλεση Με τις τεχνικές που είδαμε στα προηγούμενα μαθήματα μπορούμε να εκτελέσουμε (με επικάλυψη) περίπου 1 εντολή
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχανικών - Μηχανικών Υπολογιστών. Αρχιτεκτονική Υπολογιστών Νεκτάριος Κοζύρης. Cache Optimizations
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχανικών - Μηχανικών Υπολογιστών Αρχιτεκτονική Υπολογιστών Νεκτάριος Κοζύρης Cache Optimizations Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχανικών - Μηχανικών Υπολογιστών Αρχιτεκτονική Υπολογιστών Νεκτάριος Κοζύρης Cache Optimizations Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
; Γιατί είναι ταχύτερη η λήψη και αποκωδικοποίηση των εντολών σταθερού μήκους;
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Δομή Εντολών και Παραδείγματα) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Δομή Εντολών και Παραδείγματα) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 5ο μάθημα:αρχές, ιδιότητες αρχιτεκτονικού συνόλου εντολών (ISA) Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Εσωτερική αποθήκευση
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 5ο μάθημα:αρχές, ιδιότητες αρχιτεκτονικού συνόλου εντολών (ISA) Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Εσωτερική αποθήκευση
Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy. Chapter 5. Ο επεξεργαστής: διαδρομή δεδομένων και μονάδα ελέγχου
 Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy Chapter 5 Ο επεξεργαστής: διαδρομή δεδομένων και μονάδα ελέγχου Ενδέκατη (11 η ) δίωρη διάλεξη. Διαφάνειες διδασκαλίας από το
Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy Chapter 5 Ο επεξεργαστής: διαδρομή δεδομένων και μονάδα ελέγχου Ενδέκατη (11 η ) δίωρη διάλεξη. Διαφάνειες διδασκαλίας από το
Διάλεξη 12 Καθυστερήσεις (Stalls) Εκκενώσεις Εντολών (Flushing)
 Εκκενώσεις Εντολών (Flushing)") ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 2 Καθυστερήσεις (Stalls) Εκκενώσεις Εντολών (Flushing) Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Καθυστερήσεις και Εκκενώσεις Εντολών
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 2 Καθυστερήσεις (Stalls) Εκκενώσεις Εντολών (Flushing) Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Καθυστερήσεις και Εκκενώσεις Εντολών
Επεξεργαστής Υλοποίηση ενός κύκλου μηχανής
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 9 Επεξεργαστής Υλοποίηση ενός κύκλου μηχανής Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων 1 Ti είναι Αρχιτεκτονική και τι Μικροαρχιτεκτονική
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 9 Επεξεργαστής Υλοποίηση ενός κύκλου μηχανής Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων 1 Ti είναι Αρχιτεκτονική και τι Μικροαρχιτεκτονική
ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟ ΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ. ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥ ΩΝ (3 η Κατεύθυνση)
") ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟ ΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥ ΩΝ (3 η Κατεύθυνση) ΠΡΟΗΓΜΕΝΗ ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ιδάσκων : Καθηγητής Κ. Χαλάτσης
ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟ ΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥ ΩΝ (3 η Κατεύθυνση) ΠΡΟΗΓΜΕΝΗ ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ιδάσκων : Καθηγητής Κ. Χαλάτσης
Chapter 2. Εντολές : Η γλώσσα του υπολογιστή. (συνέχεια) Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L.
 Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L.") Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy Chapter 2 Εντολές : Η γλώσσα του υπολογιστή (συνέχεια) Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση:
Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy Chapter 2 Εντολές : Η γλώσσα του υπολογιστή (συνέχεια) Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση:
Instruction-Level Parallelism and its Dynamic Exploitation. Μάθηµα 3ο Computer Architecture-A Quantitative Approach
 Instruction-Level Parallelism and its Dynamic Exploitation Μάθηµα 3ο Computer Architecture-A Quantitative Approach Instruction-Level Parallelism (ILP) Επικάλυψη εντολών στοχεύοντας στην παράλληλη εκτέλεσή
Instruction-Level Parallelism and its Dynamic Exploitation Μάθηµα 3ο Computer Architecture-A Quantitative Approach Instruction-Level Parallelism (ILP) Επικάλυψη εντολών στοχεύοντας στην παράλληλη εκτέλεσή
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών. Διάλεξη 2 Οργάνωση μνήμης Καταχωρητές του MIPS Εντολές του MIPS 1
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 2 Οργάνωση μνήμης Καταχωρητές του MIPS Εντολές του MIPS 1 Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων 1 Σύνολο Εντολών Το ρεπερτόριο
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 2 Οργάνωση μνήμης Καταχωρητές του MIPS Εντολές του MIPS 1 Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων 1 Σύνολο Εντολών Το ρεπερτόριο
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων
 ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων Εισαγωγή στην Αρχιτεκτονική Υπολογιστών Γλώσσα Μηχανής Εκτέλεση προγράμματος Αριθμητικές και λογικές εντολές Παράδειγμα: μια απλή Γλώσσα Μηχανής Επικοινωνία με άλλες συσκευές
ΚΕΦΑΛΑΙΟ 2: Χειρισμός Δεδομένων Εισαγωγή στην Αρχιτεκτονική Υπολογιστών Γλώσσα Μηχανής Εκτέλεση προγράμματος Αριθμητικές και λογικές εντολές Παράδειγμα: μια απλή Γλώσσα Μηχανής Επικοινωνία με άλλες συσκευές
Επιτεύγµατα των Λ.Σ.
 Επιτεύγµατα των Λ.Σ. ιεργασίες ιαχείριση Μνήµης Ασφάλεια και προστασία δεδοµένων Χρονοπρογραµµατισµός & ιαχείρηση Πόρων οµή Συστήµατος ιεργασίες Ένα πρόγραµµα σε εκτέλεση Ένα στιγµιότυπο ενός προγράµµατος
Επιτεύγµατα των Λ.Σ. ιεργασίες ιαχείριση Μνήµης Ασφάλεια και προστασία δεδοµένων Χρονοπρογραµµατισµός & ιαχείρηση Πόρων οµή Συστήµατος ιεργασίες Ένα πρόγραµµα σε εκτέλεση Ένα στιγµιότυπο ενός προγράµµατος
Ιεραρχία Μνήμης. Ιεραρχία μνήμης και τοπικότητα. Σκοπός της Ιεραρχίας Μνήμης. Κρυφές Μνήμες
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Για βελτίωση της απόδοσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Για βελτίωση της απόδοσης
Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2017-18 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Αρχιτεκτονική x86-64) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2017-18 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Αρχιτεκτονική x86-64) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
LANGUAGE OF THE MACHINE. TEI Κρήτης, Τμ. ΕΠΠ, Αρχιτεκτονική Υπολογιστών. Οργάνωση Υπολογιστή. Τυπική οργάνωση υπολογιστή
 INSTRUCTIONS LANGUAGE OF THE MACHINE Οργάνωση Υπολογιστή Τυπική οργάνωση υπολογιστή 1 Εκτέλεση προγραμμάτων σε υπολογιστή INSTRUCTION SET Οι λέξεις στη γλώσσα μηχανής ονομάζονται εντολές (instructions)
INSTRUCTIONS LANGUAGE OF THE MACHINE Οργάνωση Υπολογιστή Τυπική οργάνωση υπολογιστή 1 Εκτέλεση προγραμμάτων σε υπολογιστή INSTRUCTION SET Οι λέξεις στη γλώσσα μηχανής ονομάζονται εντολές (instructions)
Διάλεξη 15 Απόδοση της Ιεραρχίας Μνήμης Βελτιστοποίηση της απόδοσης
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 5 Απόδοση της Ιεραρχίας Μνήμης Βελτιστοποίηση της απόδοσης Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Πόσο μεγάλη είναι μια μνήμη cache;
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 5 Απόδοση της Ιεραρχίας Μνήμης Βελτιστοποίηση της απόδοσης Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Πόσο μεγάλη είναι μια μνήμη cache;
Αρχιτεκτονική x86(-64) 32-bit και 64-bit λειτουργία. Αρχιτεκτονική x86(-64) Αρχιτεκτονική επεξεργαστών x86(-64) Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ)
 32-bit και 64-bit λειτουργία. Αρχιτεκτονική x86(-64) Αρχιτεκτονική επεξεργαστών x86(-64) Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ)") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2017-18 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Αρχιτεκτονική x86-64) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2017-18 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Αρχιτεκτονική x86-64) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Instruction-Level Parallelism and its Dynamic Exploitation. Κεφάλαια 4o Computer Architecture-A Quantitative Approach 3 rd Edition
 Instruction-Level Parallelism and its Dynamic Exploitation Κεφάλαια 4o Computer Architecture-A Quantitative Approach 3 rd Edition Basic Pipeline Για την αποφυγή ενός pipeline stall πρέπει µια εξαρτώµενη
Instruction-Level Parallelism and its Dynamic Exploitation Κεφάλαια 4o Computer Architecture-A Quantitative Approach 3 rd Edition Basic Pipeline Για την αποφυγή ενός pipeline stall πρέπει µια εξαρτώµενη
Προχωρηµένα Θέµατα Αρχιτεκτονικής
 Προχωρηµένα Θέµατα Αρχιτεκτονικής Memory Hierarchy Design. Λιούπης Ιεραρχία Μνήµης Τα προγράµµατα απαιτούν όλο και περισσότερη και πιο γρήγορη µνήµη Γρήγορη και µεγάλη µνήµη -> ακριβή Αυτό οδηγεί σε ιεραρχία
Προχωρηµένα Θέµατα Αρχιτεκτονικής Memory Hierarchy Design. Λιούπης Ιεραρχία Μνήµης Τα προγράµµατα απαιτούν όλο και περισσότερη και πιο γρήγορη µνήµη Γρήγορη και µεγάλη µνήµη -> ακριβή Αυτό οδηγεί σε ιεραρχία
ΕΘΝΙKΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ. Ονοματεπώνυμο: ΑΜ:
 ΕΘΝΙKΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ονοματεπώνυμο: ΑΜ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ (τμήμα Μ - Ω) Κανονική εξεταστική Φεβρουαρίου
ΕΘΝΙKΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ονοματεπώνυμο: ΑΜ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ (τμήμα Μ - Ω) Κανονική εξεταστική Φεβρουαρίου