«Μέθοδοι Πολυμεταβλητής Στατιστικής Ανάλυσης με εφαρμογές στην Ασφάλεια Πληροφοριακών Συστημάτων»
|
|
|
- Ἑλένη Αλεξανδρίδης
- 8 χρόνια πριν
- Προβολές:
Transcript

1 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΤΕΥΘΥΝΣΗ ΠΛΗΡΟΦΟΡΙΑΚΩΝ ΣΥΣΤΗΜΑΤΩΝ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΓΕΡΟΦΩΤΗ ΜΑΡΙΑ (Α.Μ. 47) «Μέθοδοι Πολυμεταβλητής Στατιστικής Ανάλυσης με εφαρμογές στην Ασφάλεια Πληροφοριακών Συστημάτων» Επιβλέπων καθηγητής Ελευθέριος Αγγελής Επιτροπή Ελευθέριος Αγγελής Αθηνά Βακάλη Ιωάννης Σταμέλος Θεσσαλονίκη, Ιούνιος 007
2 ΠΙΝΑΚΑΣ ΠΕΡΙΕΧΟΜΕΝΩΝ ΠΙΝΑΚΑΣ ΠΕΡΙΕΧΟΜΕΝΩΝ... Περίληψη... 6 Κεφάλαιο Εισαγωγή στην Ασφάλεια Συστημάτων & την Ανίχνευση Εισβολών Η ασφάλεια στην Κοινωνία της Πληροφορίας Ασφάλεια Ιδιότητες της ασφάλειας Εισβολή και Εισβολέας Κατηγορίες Εισβολέων Ανίχνευση Εισβολών και Συστήματα Ανίχνευσης Εισβολών Ανάγκη ανάπτυξης IDS Τύποι Συστημάτων Ανίχνευσης Εισβολών Χαρακτηριστικά ενός IDS Κατηγορίες Απειλών Ενδείξεις Προσπάθειας Εισβολής Κατηγορίες Τεχνικών Ανίχνευσης Εισβολών Anomaly detection Misuse detection Σύγκριση των μεθόδων των κατηγοριών Προσεγγίσεις για anomaly detection Προσεγγίσεις για misuse detection Μοντέλα Ασφάλειας...3 Κεφάλαιο Παρουσίαση Προϊόντων IDS Shadow (US Navy Naval Surface Warfare Center) RealSecure (Internet Security Systems) Network Flight Recorder (Network Flight Recorder, Inc.) CyberCorp Monitor (Network Associates) POLYCENTER (Compaq) NetRanger (Cisco Systems, Inc) Intruder Alert (Axent Technologies) Άλλα εμπορικά IDS...39 Κεφάλαιο Μέθοδοι Πολυμεταβλητής Στατιστικής Ανάλυσης στην Ανίχνευση Εισβολών Στατιστικό Υπόβαθρο...4
3 3.1.1 Μέση τιμή, Τυπική απόκλιση και Διακύμανση Στατιστικά στοιχεία του δείγματος Έλεγχος Υποθέσεων Έλεγχος Kolmogorov-Smirnov Κινητοί Μέσοι Simple Moving Average Weighted Moving Average Exponentially Weighted Moving Average Διαγράμματα Ελέγχου EWMA Τεχνικές Statistical Process Control Univariate Statistical Process Control (USPC) Multivariate Statistical Process Control (MSPC) SPC τεχνικές στην Ανίχνευση Εισβολών USPC στην ανίχνευση εισβολών Τεχνικές EWMA Εφαρμογή της μεθόδου MSPC στην ανίχνευση εισβολών Ευκλείδεια απόσταση Μετρική Minkowski Συντελεστής του Czekanowski Μετρική Ομοιότητας βασισμένη στον έλεγχο Kolmogorov- Smirnov Απόσταση Canberra Στατιστικός έλεγχος X Υπολογισμός X Εφαρμογή της μεθόδου Σύγκριση Στατιστικών Ελέγχων T και X Μετρική της Canberra Υπολογισμός απόστασης Canberra Εφαρμογή της μεθόδου Σύγκριση μεθόδων με τις αποστάσεις Canberra και X Έγκαιρη ανίχνευση επιθέσεων DoS με διάφορες μετρικές απόστασης Ανίχνευση Εισβολών με την Ανάλυση Κυρίων Συνιστωσών (PCA) Εισαγωγή PCA Principal Component Analysis Εφαρμογή της μεθόδου Εντοπισμός Ακραίων Τιμών (Outlier Detection) Principal Component Classifier PCC Εφαρμογή της μεθόδου Πλεονεκτήματα της PCC Ανάλυση Παραγόντων στην Ανίχνευση Εισβολών (Factor Analysis) Εισαγωγή Ανάλυση Παραγόντων (Factor Analysis FA) Αριθμός Παραγόντων και Εκτίμηση των Παραγόντων Εκτίμηση με τη μέθοδο Κυρίων Συνιστωσών
4 3.7.5 Εκτίμηση με τη μέθοδο μεγίστης πιθανοφάνειας Άλλες μέθοδοι Εκτίμησης Περιστροφή των παραγόντων Υπολογισμός των σκορ των παραγόντων Εφαρμογή της μεθόδου Ανάλυση Διακρίσεων στην Ανίχνευση Εισβολών Εισαγωγή Ανάλυση Διακρίσεων για δύο πληθυσμούς Εφαρμογή της μεθόδου Λογαριθμική Παλινδρόμηση στην Ανίχνευση Εισβολών Εισαγωγή Γραμμική Παλινδρόμηση (Linear Regression) Λογαριθμική παλινδρόμηση (Logistic Regression) Το υπόδειγμα της λογαριθμικής παλινδρόμησης Δυαδική Λογαριθμική Παλινδρόμηση (Binary Logistic Regression) Πολυωνυμική Λογαριθμική Παλινδρόμηση (Multinomial Logistic Regression) Εφαρμογή της μεθόδου Κεφάλαιο Πειραματική Ανάλυση Μέθοδοι Ανάλυσης Σύνολο Δεδομένων Σύνολο Χαρακτηριστικών Μεθοδολογία Παραγοντική Ανάλυση (Factor Analysis) Παραγοντική Ανάλυση Μοντέλο Ι Παραγοντική Ανάλυση Μοντέλο ΙΙ Ανάλυση Διακρίσεων (Discriminant Analysis) Ανάλυση Διακρίσεων Μοντέλο ΙΙΙ Ανάλυση Διακρίσεων Μοντέλο ΙV Ανάλυση Διακρίσεων Μοντέλο V Λογαριθμική Παλινδρόμηση (Logistic Regression) Λογαριθμική Παλινδρόμηση Μοντέλο VΙ Λογαριθμική Παλινδρόμηση Μοντέλο VΙ Κεφάλαιο Συμπεράσματα και Μελλοντικές Κατευθύνσεις Σύνοψη Ανασκόπηση των στατιστικών μεθόδων Συμπεράσματα της πειραματικής ανάλυσης Γενικά Συμπεράσματα Μελλοντικές Προκλήσεις
5 ΒΙΒΛΙΟΓΡΑΦΙΑ Παράρτημα A Παράρτημα Β
6 Περίληψη Η σημερινή εποχή χαρακτηρίζεται από την ιδιαίτερα μεγάλη ανάπτυξη και τη γενικευμένη χρήση της τεχνολογίας της πληροφορικής και των επικοινωνιών. Οι υπολογιστές χρησιμοποιούνται σήμερα σε όλες σχεδόν τις ανθρώπινες δραστηριότητες και σε κάθε είδους εργασίες. Οι δυνατότητες και οι ευκαιρίες είναι αναντίρρητα απεριόριστες. Παράλληλα όμως αυξάνονται οι κίνδυνοι και τα κρούσματα από ηθελημένες ή τυχαίες καταστροφές, αλλοιώσεις ή μη εξουσιοδοτημένη χρήση των δεδομένων και γενικότερα των υπολογιστικών πόρων. [1] Με την εμφάνιση και τη μεγάλη εξάπλωση του Διαδικτύου και του Ηλεκτρονικού Εμπορίου (E-Commerce) σε κάθε γωνιά της γης, τα υπολογιστικά συστήματα εκτίθενται σε εκατοντάδες εισβολές (intrusions) διαφόρων ειδών, προερχόμενες από τον Παγκόσμιο Ιστό (World Wide Web) σε καθημερινή πλέον βάση. [] Αυτή τη στιγμή υπάρχουν ποικίλες απειλές και ευπάθειες στην ασφάλεια των πληροφοριακών συστημάτων και δικτύων απέναντι σε αυτές τις εισβολές. Παράλληλα με την παγκόσμια διάδοση του Διαδικτύου και την δραματικά αυξανόμενη χρήση και διαθεσιμότητα ασύρματων υπηρεσιών, ο αριθμός και ο αντίκτυπος των επιθέσεων αυτών αυξάνεται ολοένα και περισσότερο και η εξασφάλιση ασφαλών δικτύων προβάλει στον ορίζοντα ως μια δυνητικά επιτακτική ανάγκη. Η παρούσα μελέτη 1 τοποθετείται σε ένα συγκεκριμένο πεδίο θεωριών και μεθοδολογιών που αφορούν στις στατιστικές προσεγγίσεις ανίχνευσης εισβολών. Στο σύνολο της η μελέτη αποτελείται από πέντε κεφάλαια. Κάθε κεφάλαιο αναφέρεται σε συγκεκριμένο θέμα, το οποίο και αναλύεται διεξοδικά. Ακολουθεί μια συνοπτική παρουσίαση των κεφαλαίων. Στο πρώτο κεφάλαιο περιέχεται η περιγραφή, η οριοθέτηση και η σημασία επίλυσης του προβλήματος. Συγκεκριμένα, θεμελιώνονται οι βασικές έννοιες που σχετίζονται με την ασφάλεια ενός Πληροφοριακού Συστήματος και την Ανίχνευση Εισβολών. Με βασικό κριτήριο την ασφάλεια ενός Π.Σ. και τις επιμέρους ιδιότητές της, παραθέτονται οι δυνητικές απειλές που αντιμετωπίζουν τα ΠΣ, αναδεικνύεται ο ρόλος και η σημασία της ανίχνευσης επιθέσεων και προσεγγίζονται οι δύο μεγάλες κατηγορίες τεχνικών ανίχνευσης της anomaly και misuse detection. 1 Η εικόνα του συνοδευτικού cd αυτής της μελέτης είναι βασισμένη στο λογότυπο της ερευνητικής ομάδας AAIDG (Autonomous Agents for Intrusion Detection Group) του CERIAS του Πανεπιστημίου του Rurdue. Περισσότερες πληροφορίες μπορείτε να βρείτε στο σύνδεσμο 6
7 Το δεύτερο κεφάλαιο διαπραγματεύεται μια σύντομη παρουσίαση ορισμένων εμπορικών συστημάτων ανίχνευσης εισβολών που κυκλοφορούν στην αγορά και των κυριότερων χαρακτηριστικών τους. Το τρίτο κεφάλαιο συνιστά μια σύνοψη βιβλιογραφικής έρευνας σχετικής με τις στατιστικές μεθόδους ανίχνευσης εισβολών, και κατά κύριο λόγο με πολυμεταβλητές τεχνικές. Αν και ορισμένες από αυτές βασίζονται σε πολύ γνωστές στατιστικές μεθόδους (Ανάλυση Κυρίων Συνιστωσών, Ανάλυση Παραγόντων, Ανάλυση Διακρίσεων κλπ), προηγείται της εφαρμογής η θεωρητική προσέγγιση της ε- κάστοτε μεθόδου αναλυτικά. Παράλληλα, εξηγούνται τεχνικές εντοπισμού επιθέσεων μέσω της ανομοιότητας μεταξύ παρατηρήσεων και προφίλ φυσιολογικών συμπεριφορών, η οποία ποσοτικοποιείται με τη χρήση διαφόρων μετρικών απόστασης ( X, T, Canberra κλπ), οι οποίες συνοδεύονται και από συγκριτικές με- λέτες. Να σημειωθεί πως για την αποφυγή παρερμηνειών σε επίπεδο ορολογίας, όπου κρίθηκε απαραίτητο, αναφέρεται μαζί με την εκτιμώμενη μετάφραση και ο πρωτότυπος όρος (σε αγγλική γλώσσα). Το τέταρτο κεφάλαιο είναι και το σημαντικότερο, μιας και σ αυτό επιχειρείται η πραγμάτωση του σκοπού της συγκεκριμένης μελέτης. Ειδικότερα, εφαρμόζονται ορισμένες μέθοδοι πολυμεταβλητής ανάλυσης σε ένα συγκεκριμένο σύνολο δεδομένων, το οποίο περιέχει χαρακτηριστικά που σχετίζονται με τον εντοπισμό επιθέσεων σε ένα σύστημα. Τα μοντέλα που μελετώνται αναπτύσσονται με το στατιστικό πακέτο SPSS Τέλος, στο πέμπτο κεφάλαιο αυτής της μελέτης παρατίθεται η συνολική συμπερασματολογία και σκιαγραφούνται οι προοπτικές για περαιτέρω έρευνα. 7
8 Κεφάλαιο 1 Εισαγωγή στην Ασφάλεια Συστημάτων & την Ανίχνευση Εισβολών 8
9 1.1 Η ασφάλεια στην Κοινωνία της Πληροφορίας Το πρόβλημα της ασφάλειας των δεδομένων είναι ιδιαίτερα σημαντικό στα σύγχρονα πληροφοριακά συστήματα και δίκτυα [76]. Πρόσφατα επιτεύγματα στον τομέα της κρυπτογράφησης (κβαντική κρυπτογραφία), τις μεθόδους ανταλλαγής δημοσίου κλειδιού, την πιστοποίηση ταυτότητας με χρήση ψηφιακών υπογραφών και την εξασφάλιση ασφαλών συνδέσεων (SSL) έχουν θέσει τα θεμέλια για την ασφάλεια του Ιστού και των επικοινωνιών, την άνθιση του Ηλεκτρονικού Εμπορίου και των διαδικτυακών συναλλαγών. Ωστόσο, η ασφάλεια ενός δικτύου / πληροφοριακού συστήματος έχει να κάνει με κάτι παραπάνω από την απλή κρυπτογράφηση δεδομένων. Είναι επιτακτικό να εξοπλίσουμε τα υπολογιστικά συστήματα και δίκτυα με καλά σχεδιασμένες, πλήρεις και ολοκληρωμένες πολιτικές και συσκευές καταπολέμησης τέτοιων κακόβουλων επιθέσεων. Είναι σημαντικό οι μηχανισμοί ασφάλειας ενός υπολογιστικού συστήματος, δικτύου ή πληροφοριακού συστήματος να σχεδιαστούν με τέτοιο τρόπο ώστε να εμποδίζουν μη εξουσιοδοτημένη προσπέλαση σε πόρους και δεδομένα. Εντούτοις, η πλήρης παρεμπόδιση παραβιάσεων ασφάλειας εμφανίζεται ουτοπική και ανέφικτη. Μπορούμε ωστόσο να προσπαθήσουμε να ανιχνεύσουμε αυτές τις προσπάθειες παραβίασης έτσι ώστε να ληφθούν ενέργειες για αντιμετώπιση των ζημιών που προκλήθηκαν. Αυτός ο τομέας έρευνας καλείται Ανίχνευση Εισβολών Ασφάλεια Η ασφάλεια είναι μια ευρεία έννοια που καλύπτει διαφορετικές πλευρές, οι οποίες κυμαίνονται από κοινωνικά ζητήματα, αισθήματα και εμπιστοσύνη σε τεχνικές λύσεις και πολιτικές. Συνολικά η ασφάλεια σχετίζεται με περιουσιακά στοιχεία (assets) και προστασίες. Τα περιουσιακά στοιχεία είναι πολύτιμα για την επιχείρηση / οργανισμό και μπορεί να αφορούν στη φήμη, στο προσωπικό, στην ιδιοκτησία και στις πληροφορίες. Οι μέθοδοι που χρησιμοποιούνται για την προστασία αυτών των περιουσιακών στοιχείων διακρίνονται σε δύο κατηγορίες: τις υποχρεωτικές και τις κατ επιλογήν. Η ασφάλεια και η διαχείριση των περιουσιακών στοιχείων ανήκουν στις υποχρεωτικές αφού πρέπει να καλύπτονται από όλους ανεξαιρέτως. Οι κατ επιλογήν μέθοδοι διακρίνονται σε τέσσερις κατηγορίες: φυσική ασφάλεια, ασφάλεια προσωπικού, ασφάλεια πληροφοριών και λειτουργική ασφάλεια. Η ασφάλεια πληροφοριών μπορεί να επιτευχθεί είτε με παθητικά είτε με ενεργητικά μέτρα. Η κρυπτογραφία είναι ένα παράδειγμα παθητικού μέτρου ενώ η ανίχνευση εισβολών ανήκει στα ενεργητικά μέτρα. Η ανίχνευση εισβολών είναι ένα μόνο δομικό στοιχείο για την εξασφάλιση της ασφάλειας των πληροφοριών και δεν αποτελεί, ούτε υπήρξε ποτέ η πρόθεση να αποτελέσει, η καλύτερη και μόνη λύση. Η ασφάλεια πληροφοριών αναφέρεται σε μέτρα ασφάλειας που υλοποιούν και εξασφαλίζουν υπηρεσίες ασφάλειας σε υπολογιστικά και δικτυακά συστήματα επικοινωνίας. Πιο συγκεκριμένα η ασφάλεια ενός συστήματος σχετίζεται με [76]: 9
10 Πρόληψη (prevention): τη λήψη δηλαδή μέτρων για να προληφθούν φθορές των συστατικών ενός δικτύου. Ανίχνευση (detection): τη λήψη μέτρων για τον εντοπισμό του πότε, πως και από ποιον προκλήθηκε φθορά σε ένα συστατικό του δικτύου. Αντίδραση (reaction): τη λήψη μέτρων για την αποκατάσταση ή ανάκτηση των συστατικών ενός δικτύου. Στο χώρο της ασφάλειας, έκθεση σε κίνδυνο ονομάζεται μια μορφή πιθανής α- πώλειας ή ζημιάς σε ένα υπολογιστικό σύστημα. Παραδείγματα εκθέσεων σε κίνδυνο είναι η μη εξουσιοδοτημένη αποκάλυψη ή τροποποίηση δεδομένων ή η άρνηση θεμιτής προσπέλασης υπολογιστικών πόρων. Ευπάθεια καλείται μια αδυναμία, ένα γνωστό ή υποπτευόμενο τρωτό σημείο ελάττωμα στο υλικό, το λογισμικό ή μια λειτουργία του συστήματος, το οποίο αν αξιοποιηθεί κατάλληλα, μπορεί να εκθέσει το σύστημα σε διείσδυση από αναρμόδιους ή τις πληροφορίες σε τυχαία αποκάλυψη, προκαλώντας απώλειες ή ζημιές. Όταν κάποιος εκμεταλλεύεται μια ευπάθεια βάσει συγκεκριμένου σχεδίου, τότε διαπράττει μια επίθεση στο σύστημα Ιδιότητες της ασφάλειας Παραθέτοντας τα λόγια των Garfinkel & Spafford [3], «Ένας υπολογιστής είναι ασφαλής εάν συμπεριφέρεται κατά τον τρόπο που περιμένει κάποιος να συμπεριφερθεί». Από μια πιο αυστηρή οπτική γωνία, ως θεμελιώδεις ιδιότητες ασφάλειας ενός συστήματος θεωρούνται η ακεραιότητα, η εμπιστευτικότητα και η διαθεσιμότητα, οι οποίες ορίζονται ως εξής [77] : Ακεραιότητα (Integrity): Αναφέρεται στην ιδιότητα των δεδομένων να μην έχουν τροποποιηθεί, καταστραφεί ή χαθεί με μη εξουσιοδοτημένο ή τυχαίο τρόπο. Δηλαδή η μη-εξουσιοδοτημένη τροποποίηση της πληροφορίας και των προγραμμάτων θα πρέπει να αποτρέπεται, ενώ κάθε αλλαγή του περιεχομένου των δεδομένων να είναι αποτέλεσμα εξουσιοδοτημένης και ε- λεγχόμενης ενέργειας. Εμπιστευτικότητα (Confidentiality): Αναφέρεται στην πρόληψη της προσπέλασης του συστήματος από αναρμόδιους χρήστες οντότητες διεργασίες. Δηλαδή, η ιδιότητα των δεδομένων να καθίστανται αναγνώσιμα μόνο από εξουσιοδοτημένα λογικά υποκείμενα, όπως φυσικές οντότητες και διεργασίες λογισμικού. Διαθεσιμότητα (Availability): Αναφέρεται στην ιδιότητα του να είναι διαθέσιμες και προσπελάσιμες και χωρίς αδικαιολόγητη καθυστέρηση οι υ- πηρεσίες ενός υπολογιστικού συστήματος (ή το ίδιο το σύστημα) όταν τις χρειάζεται μια εξουσιοδοτημένη οντότητα του συστήματος. Αυτό σημαίνει ότι οι εξουσιοδοτημένοι χρήστες δεν αντιμετωπίζουν πρόβλημα προσωρι- 10
11 νής ή μόνιμης άρνησης εξυπηρέτησης (denial of service) και διάθεσης της πληροφορίας όταν επιθυμούν να προσπελάσουν τους πόρους ενός συστήματος. Στη βιβλιογραφία ωστόσο υποστηρίζεται πως οι παραπάνω τρεις ιδιότητες δεν επαρκούν προκειμένου να οριστεί πλήρως η ασφάλεια των πληροφοριών. Πρόσθετες ιδιότητες που αναφέρονται από τον Parker [4] είναι η αυθεντικότητα (Authenticity), δηλαδή η πιστοποίηση της προέλευσης και του ιδιοκτήτη της πληροφορίας, η ιδιότητα της χρησιμότητας (Utility), δηλαδή ότι τα δεδομένα του συστήματος πρέπει να είναι χρήσιμα για ένα συγκεκριμένο σκοπό και η ιδιότητα της κατοχής (Possession), που αναφέρεται στην ικανότητα των χρηστών του συστήματος να μπορούν να ελέγξουν το σύστημα, αφού αν ο έλεγχος χαθεί, επηρεάζονται όλοι οι χρήστες που έχουν εξουσιοδότηση να εργάζονται σε αυτό. Άλλες ιδιότητες που συναντώνται είναι η ιδιότητα της εγκυρότητας (Validity) [78], δηλαδή ότι η πληροφορία αντιπροσωπεύει την πραγματικότητα και είναι επίκαιρη, ενώ σε άλλες πηγές [5] αναφέρονται η μοναδικότητα (Uniqueness), δηλαδή η αδυναμία αντιγραφής και αναπαραγωγής της πληροφορίας χωρίς εξουσιοδότηση και η μη αποποίηση (Non Repudiation) δηλαδή η αδυναμία άρνησης των ενεργειών που έχουν εκτελεστεί για την τροποποίηση, την αποστολή ή τη λήψη μίας πληροφορίας. Η ύπαρξη διαφορετικών απόψεων για τις ιδιότητες της ασφάλειας δεν θα πρέπει να θεωρηθεί παράδοξο, καθώς στον τομέα της πληροφορικής η ασφάλεια μπορεί να επιδεχτεί ποικίλες ερμηνείες, ανάλογα με την οπτική του ερευνητή και το πληροφοριακό σύστημα στο οποίο αναφέρεται. Συνεπώς, σε κάθε ειδική περίπτωση που μελετάμε θα πρέπει να ορίζουμε με σαφήνεια τις συγκεκριμένες ιδιότητες της πληροφορίας που καλούμαστε να προστατέψουμε. Παρά τη σαφήνεια και την απλότητα των ορισμών που δίδονται για τις τρεις βασικές ιδιότητες, στην πράξη δεν είναι πάντοτε εύκολο να προσδιοριστεί πότε μία από αυτές έχει παραβιαστεί. Για παράδειγμα, η άρνηση διάθεσης της πληροφορίας (παραβίαση της διαθεσιμότητας) μπορεί να εκτιμηθεί με άλλο τρόπο σε διαφορετικές περιπτώσεις, αφού ο χρόνος αναμονής που θεωρείται ανεκτός διαφέρει από εφαρμογή σε εφαρμογή. Έτσι, μία καθυστέρηση ενός λεπτού στην παροχή μίας κρίσιμης ιατρικής πληροφορίας μπορεί να θεωρηθεί ως έλλειψη διαθεσιμότητας, ενώ ο ίδιος χρόνος στην αναζήτηση της καρτέλας ενός πελάτη μιας τράπεζας να θεωρηθεί αποδεκτός και αναμενόμενος [79]. Εύκολα συμπεραίνεται πως είναι σημαντικό να δοθεί τεράστια έμφαση στις ιδιότητες ασφάλειας που πρέπει να ικανοποιεί ένα σύστημα ανίχνευσης εισβολών από το διαχειριστή κατά τη φάση σχεδιασμού του εν λόγω συστήματος. 1. Εισβολή και Εισβολέας Ο Anderson [6], εισάγοντας το 1980 την έννοια της ανίχνευσης εισβολών, όρισε την προσπάθεια εισβολής ή μια απειλή ως «τη δυνατή πιθανότητα μιας σκόπιμης μη εξουσιοδοτημένης προσπάθειας να προσπελάσει και να χειριστεί πληροφορίες ή να καταστήσει ένα σύστημα αναξιόπιστο ή μη χρησιμοποιήσιμο». 11
12 Οι Heady et al [7] ορίζουν την εισβολή ως «ένα οποιοδήποτε σύνολο ενεργειών που προσπαθεί να διακινδυνέψει την ακεραιότητα, την εμπιστευτικότητα ή τη διαθεσιμότητα ενός πληροφοριακού συστήματος». Η αναγνώριση ενός τέτοιου συνόλου κακόβουλων ενεργειών καλείται Ανίχνευση Εισβολών. [8] Ο Kumar ορίζει την εισβολή ως «μια παραβίαση της πολιτικής ασφάλειας ενός συστήματος», ενώ σε άλλη πηγή [9] η εισβολή αναφέρεται ως «η μη εξουσιοδοτημένη προσπέλαση σε, και / ή δραστηριότητες σε ένα πληροφοριακό σύστημα». Με τον όρο εισβολέα (intruder) [77] χαρακτηρίζεται κάποιος ο οποίος προσπαθεί να διαρρήξει ηλεκτρονικά ή να προκαλέσει ανεπιθύμητες λειτουργίες σε ένα πληροφοριακό σύστημα, όπως το να υποκλέψει απόρρητες πληροφορίες, να δημιουργήσει χάος σε ένα δίκτυο ή να αναστείλει τις δραστηριότητες των κανονικών χρηστών του, προκαλώντας κατ επέκταση τεράστιες απώλειες σε αξιοπιστία και χρήμα. 1.3 Κατηγορίες Εισβολέων Ο Anderson διέκρινε επίσης τους εισβολείς σε κατηγορίες [6]. Στους Εξωτερικούς (External) Εισβολείς, οι οποίοι δεν έχουν καμία εξουσιοδοτημένη πρόσβαση στο σύστημα στο οποίο επιτίθενται, και τους Εσωτερικούς (Internal) Εισβολείς, οι οποίοι έχουν ως ένα συγκεκριμένο βαθμό εξουσιοδοτημένη πρόσβαση στο σύστημα. Οι εσωτερικοί διακρίνονται παραπέρα σε άλλες υποκατηγορίες. Στους «Υποκριτές» ή «Μεταμφιεσμένους» (Masqueraders), οι οποίοι είναι εξωτερικοί εισβολείς που με κάποιο τρόπο κατόρθωσαν να αποκτήσουν πρόσβαση στο σύστημα και τώρα ενεργούν ως εξουσιοδοτημένες οντότητες. Τους Νόμιμους (Legitimate) Εισβολείς, οι οποίοι έχουν πρόσβαση τόσο στο σύστημα όσο και στα δεδομένα αλλά καταχρώνται αυτό το προνόμιο (misfeasors). Τους Κρυφούς Εισβολείς (Clandestine) οι οποίοι έχουν ή αποκτούν εποπτικό (root) έλεγχο του συστήματος και ως τέτοιοι μπορούν να λειτουργήσουν κάτω από το επίπεδο της επίβλεψης (auditing) ή να εκμεταλλευτούν τα προνόμια για να διαφύγουν της ε- πίβλεψης σταματώντας, αλλάζοντας ή διαγράφοντας τις εγγραφές ελέγχου (audit records). Οι ορολογίες που χρησιμοποιούνται σήμερα για τους εισβολείς είναι Hackers, Crackers, Sniffers κτλ ανάλογα με τη σκοπιμότητα του καθενός. Κατά συνέπεια, τα Συστήματα Ανίχνευσης Εισβολών (Intrusion Detection Systems IDS) πραγματικού χρόνου ή όχι είναι τα εργαλεία εκείνα τα οποία επιτρέπουν τον εντοπισμό των εισβολέων. Οι εξωτερικοί Hackers χρησιμοποιούν μια διαδικασία 4 βημάτων για την διεκπεραίωση εισβολών [10]: προκαταρκτική μελέτη (reconnaissance) ή «αναγνώριση εδάφους», εκμετάλλευση (exploitation), εκτέλεση (execution) και καθάρισμα (clean-up). 1
, η οποία καθορίζει ποιες θύρες ενός υπολογιστή είναι «ανοιχτές» όπως επίσης")
13 Σχήμα 1.1 Στάδια Επιθέσεων των Hackers Η προκαταρκτική μελέτη σχετίζεται με μια μέθοδο που καλείται σάρωση θυρών (port scanning), η οποία καθορίζει ποιες θύρες ενός υπολογιστή είναι «ανοιχτές» όπως επίσης και τι είδους προγράμματα ή υπηρεσίες τρέχουν σε ένα συγκεκριμένο σύστημα, στέλνοντας μια ακολουθία πακέτων στο σύστημα-στόχο και παρακολουθώντας τις αποκρίσεις του. Αναπόφευκτα, τα προγράμματα έχουν αδυναμίες, τις οποίες μπορούν να εκμεταλλευτούν οι επίδοξοι εισβολείς. Από τη στιγμή που θα ανακαλυφθεί μια αδυναμία ενός συστήματος, ο εισβολέας εκμεταλλεύεται αυτό το ελάττωμα για να διεισδύσει στο σύστημα, συνήθως υποκρινόμενος κάποιον νόμιμο χρήστη. Έπειτα, ο εισβολέας εκτελεί την επίθεση, η οποία μπορεί να είναι από αναπαραγωγή ενός σκουληκιού μέχρι και κλοπή πολύτιμων πληροφοριών. Τέλος, συνήθως οι hackers καλύπτουν τα ίχνη τους, ειδικά μάλιστα όταν το ενδεχόμενο να παρακολουθούνται από εξειδικευμένο λογισμικό είναι πολύ πιθανό [10]. 1.4 Ανίχνευση Εισβολών και Συστήματα Ανίχνευσης Εισβολών Όπως αναφέρθηκε προηγουμένως, η αναγνώριση ενός συνόλου ενεργειών που στοχεύουν στο να διακινδυνέψουν την ακεραιότητα, την εμπιστευτικότητα ή τη διαθεσιμότητα κάποιων υπολογιστικών πόρων, προκαλώντας άρνηση εξυπηρέτησης, τοποθετώντας ιούς ή αξιοποιώντας ευπάθειες λογισμικού, καλείται Ανίχνευση Εισβολών. Ένα σύστημα που προορίζεται για να εντοπίζει τέτοιες κακόβουλες ενέργειες ονομάζεται Σύστημα Ανίχνευσης Εισβολών. Τα ενεργά IDS προσπαθούν να μπλοκάρουν τις επιθέσεις, αποκρίνονται με αντίμετρα ή τουλάχιστον προειδοποιούν τους διαχειριστές, κατά την εξέλιξη της επίθεσης. Τα παθητικά IDS απλώς καταγράφουν την εισβολή ή δημιουργούν ίχνη παρακολούθησης, τα οποία γίνονται εμφανή αφού επιτύχει η επίθεση. Τα Συστήματα Ανίχνευσης Εισβολών συνήθως αναπτύσσονται παράλληλα με άλλους προληπτικούς μηχανισμούς ασφάλειας, όπως αντιπυρικές ζώνες (firewalls), έλεγχο προσπέλασης (access control) και πιστοποίηση (authentication), ως δεύτερη γραμμή άμυνας που προστατεύει τα πληροφοριακά συστήματα [76]. Ακόμη και στην περίπτωση που οι μηχανισμοί αυτοί επαρ- 13
14 κούν για την προστασία ενός συστήματος, εξακολουθεί να είναι επιθυμητό να γνωρίζουμε τι επιθέσεις έχουν συνέβη ή συμβαίνουν, ώστε να κατανοήσουμε πλήρως τις ενδεχόμενες απειλές και τα ρίσκα και να είμαστε κατά συνέπεια καλύτερα προετοιμασμένοι για μελλοντικές επιθέσεις. Παρά τη σπουδαιότητά τους, τα IDS δεν μπορούν να παράσχουν επαρκή προστασία. Ως ένα ακραίο παράδειγμα, εάν ένας εισβολέας σβήσει όλα τα δεδομένα ενός πληροφοριακού συστήματος, ο εντοπισμός των επιθέσεων δεν μπορεί να μειώσει το κόστος της ζημιάς. Είναι επιτακτικό τέτοια συστήματα να χρησιμοποιούνται σε συνδυασμό με άλλους μηχανισμούς ασφαλείας για πληρέστερη και αποτελεσματικότερη προστασία. Στο σχήμα 1. φαίνεται ένα απλό δίκτυο, το οποίο προστατεύεται από ένα σύστημα ανίχνευσης εισβολών [11]. Υπάρχουν δύο επιλογές για την πλήρη προστασία του συστήματος, είτε να εμποδίζονται οι απειλές και οι ευπάθειες που προέρχονται από ελαττώματα στο λειτουργικό σύστημα και τις εφαρμογές, είτε να ανιχνεύονται και να λαμβάνονται μέτρα και ενέργειες ώστε να αποτρέπονται μελλοντικά και φυσικά να διορθώνεται η ζημιά που έγινε. Η σχεδίαση ενός πλήρως ασφαλούς συστήματος είναι αν όχι πρακτικά αδύνατη, πάρα πολύ δύσκολη. Οι κρυπτογραφικές μέθοδοι μπορούν να υπονομευθούν εάν καταφέρει ο επίδοξος εισβολέας / επιτιθέμενος να υποκλέψει τα συνθηματικά και τα κλειδιά. Όσο α- σφαλές και να είναι ένα σύστημα, είναι πάντα ευπαθές και τρωτό σε εσωτερικούς εισβολείς που κάνουν κατάχρηση των δικαιωμάτων τους. Σχήμα 1. Δίκτυο που προστατεύεται από ένα IDS Ένα IDS μπορεί να είναι συνδυασμός υλικού και λογισμικού [1]. Η πλειοψηφία των IDS προσπαθούν να πραγματοποιούν τις εργασίες τους σε πραγματικό χρόνο. Ωστόσο υπάρχουν IDS που δε λειτουργούν σε πραγματικό χρόνο, είτε εξαιτίας της φύσης της ανάλυσης την οποία πραγματοποιούν είτε επειδή προορίζονται να κάνουν ανάλυση του τι συνέβη στο παρελθόν σε ένα σύστημα (forensic analysis). Ένα IDS συνήθως δεν λαμβάνει προληπτικά μέτρα όταν ανιχνεύεται μια επίθεση. Είναι περισσότερο αντιδραστικό (reactive) στοιχείο παρά προληπτικό (proactive). Ουσιαστικά αναλαμβάνει το ρόλο του πληροφοριοδότη (informant) παρά του αστυνόμου. Βέβαια υπάρχουν IDS που προσπαθούν να α- ντιδράσουν κάθε φορά που εντοπίζουν μια μη εξουσιοδοτημένη ενέργεια. Αυτές 14
15 οι αντιδράσεις συνήθως αφορούν στον περιορισμό της ζημιάς που επήλθε, για παράδειγμα τερματίζοντας μια σύνδεση δικτύου. Ο πιο συνηθισμένος τρόπος εντοπισμού εισβολών είναι με χρήση των δεδομένων ελέγχου (audit data), τα οποία παράγονται από το λειτουργικό σύστημα. Ένα ίχνος ελέγχου (audit trail) είναι μια εγγραφή από δραστηριότητες σε ένα σύστημα, οι οποίες καταγράφονται με χρονολογική σειρά. Βέβαια το απίστευτα μεγάλο μέγεθος αυτών των δεδομένων (της τάξης των 100 MByte ανά μέρα) καθιστούν τη χειροκίνητη ανάλυσή τους πρακτικά αδύνατη. Τα IDS αυτοματοποιούν τη διαδικασία αυτή ανάλυσης των δεδομένων. Τα ίχνη ελέγχου είναι ιδιαίτερα χρήσιμα γιατί μπορούν να χρησιμοποιηθούν για να αποδείξουν την ενοχή των επιτιθέμενων και συχνά αποτελούν το μόνο τρόπο εντοπισμού μη εξουσιοδοτημένης αλλά υπονομευτικής δραστηριότητας χρηστών. Πολλές φορές, αφού μια επίθεση έχει πραγματοποιηθεί, είναι σημαντικό να γίνεται ανάλυση των δεδομένων ελέγχου ώστε να καθοριστεί το ύψος της ζημιάς, να διευκολυνθεί η διαδικασία εντοπισμού των εισβολέων και να ληφθούν μέτρα πρόληψης τέτοιων επιθέσεων στο μέλλον. Επομένως, είναι προφανές πως ένα IDS μπορεί να χρησιμοποιηθεί στην ανάλυση τέτοιων δεδομένων με σκοπό την απόκτηση τέτοιας γνώσης. Αυτό καθιστά τα IDS πολύτιμα ως εργαλεία ανάλυσης τόσο πραγματικού χρόνου όσο και ανασκόπησης. 1.5 Ανάγκη ανάπτυξης IDS Η ανάγκη για ανάπτυξη συστημάτων ανίχνευσης εισβολών πραγματικού χρόνου (real-time) κινητοποιείται από τους εξής παράγοντες [1] [13]: 1. Η πλειοψηφία των υπαρχόντων συστημάτων έχουν ελαττώματα ασφαλείας που τα καθιστούν επιρρεπή σε εισβολές, διεισδύσεις και άλλες μορφές κατάχρησης. Ο εντοπισμός και η διόρθωση όλων αυτών των ελαττωμάτων δεν είναι εφικτή για τεχνικούς και οικονομικούς λόγους. Ο Miller [14] δίνει μια επιτακτική αναφορά σε ελαττώματα πολύ γνωστών προγραμμάτων και λειτουργικών συστημάτων από την οποία προκύπτει πως η ανάπτυξη λογισμικού χωρίς ελαττώματα αποτελεί ουτοπία και πως κανείς δεν φαίνεται να θέλει να προσπαθήσει να αναπτύξει τέτοιο λογισμικό.. Υπάρχοντα συστήματα με γνωστά ελαττώματα δεν αντικαθίστανται εύκολα από συστήματα που πιθανόν να είναι περισσότερο ασφαλή είτε γιατί τα πρώτα έχουν περισσότερα «ελκυστικά» χαρακτηριστικά τα οποία απουσιάζουν από τα δεύτερα, είτε γιατί δεν είναι εύκολο να αντικατασταθούν για οικονομικούς λόγους. 3. Η ανάπτυξη συστημάτων που είναι απόλυτα ασφαλή είναι εξαιρετικά δύσκολη, εάν όχι πρακτικά αδύνατη. 15
16 4. Οι κρυπτογραφικές μέθοδοι έχουν και αυτές τα δικά τους προβλήματα. Οι κωδικοί μπορούν να ανακαλυφθούν, οι χρήστες μπορεί να χάσουν τα συνθηματικά τους και ολόκληρα κρυπτοσυστήματα μπορούν να ανατραπούν. 5. Ακόμα και τα πιο ασφαλή συστήματα είναι ευαίσθητα σε καταχρήσεις εκ των έσω από ανθρώπους που καταχρώνται τα δικαιώματά τους. 6. Έχει φανεί πως η σχέση ανάμεσα στο επίπεδο του ελέγχου προσπέλασης και της αποδοτικότητα του χρήστη είναι αντίστροφη, που σημαίνει πως όσο πιο αυστηροί είναι οι μηχανισμοί ασφάλειας, τόσο πιο χαμηλή είναι η αποδοτικότητα του χρήστη. 7. Οι χρήστες διαλέγουν αδύναμους, εύκολα παραβιάσιμους κωδικούς επειδή τα ισχυρά συνθηματικά που αποτελούνται από μεγάλου μήκους τυχαίες ακολουθίες αλφαριθμητικών χαρακτήρων και σημείων στίξης είναι δύσκολο να τα ενθυμούνται [15]. Επίσης, δε δείχνουν ιδιαίτερο ενδιαφέρον και καχυποψία ως προς το περιεχόμενο που κατεβάζουν από το Διαδίκτυο και εκτελούν στους υπολογιστές τους, ούτε είναι συνεπείς ως προς την ενημέρωση των επιπέδων ασφαλείας των προγραμμάτων τους. 1.6 Τύποι Συστημάτων Ανίχνευσης Εισβολών Μπορούμε να κατηγοριοποιήσουμε τα υπάρχοντα IDS σε τρεις τύπους, τα Hostbased IDS, τα Network-based IDS και τα Router-based IDS [16]. 1. Τα Host-based συστήματα καταγράφουν / παρακολουθούν τη συμπεριφορά τόσο των χρηστών-μελών όσο και των παρείσακτων ενός δικτύου υπολογιστών βάσει των δραστηριοτήτων τους σε ξεχωριστούς υπολογιστές υπηρεσίας (hosts) του δικτύου. Συνήθως στοχεύουν στον εντοπισμό επιθέσεων σε έναν μόνο host.. Τα Network-based συστήματα παρακολουθούν την κίνηση των δεδομένων που στέλνονται και λαμβάνονται μεταξύ διαφορετικών hosts, παίρνοντας το βάρος από τους hosts οι οποίοι ασχολούνται με την παροχή κανονικών υπηρεσιών. 3. Τα Router-based συστήματα, που εγκαθίστανται στους δρομολογητές, προσπαθούν να εμποδίσουν τον εισβολέα ακόμα και να διεισδύσει στο δίκτυο. Το κύριο πλεονέκτημα των Host-based συστημάτων έναντι των άλλων τύπων είναι ότι μπορούν να ανιχνεύσουν και εσωτερικές και εξωτερικές εισβολές, ειδικά εκείνες που έχουν ως στόχο συγκεκριμένους hosts. Τα Network-based συστήματα, τα οποία είναι γνωστά και ως «Packet Sniffers» εγκαθίστανται σε ελάχιστους συγκεκριμένους στρατηγικούς υπολογιστές του δικτύου έτσι ώστε να ελέγχουν όλα τα πακέτα δεδομένων που στέλνονται μεταξύ των hosts, ωστόσο πιθανόν να 16
17 μην είναι αποτελεσματικά στον εντοπισμό εσωτερικών επιθέσεων. Το ίδιο πρόβλημα συναντάται και στα Router-based συστήματα. 1.7 Χαρακτηριστικά ενός IDS Όπως είναι ευνόητο οι απαιτούμενες ιδιότητες που πρέπει να έχει ένα IDS ώστε να θεωρηθεί αποτελεσματικό δεν είναι σταθερές για όλα τα υπολογιστικά συστήματα, αλλά εξαρτώνται κυρίως από τη δυναμικότητα που υπάρχει τόσο στο σύστημα όσο και στο περιβάλλον του. Αναλυτικότερα, το επίπεδο ασφάλειας που απαιτείται για να προστατευθεί ένα υπολογιστικό σύστημα εξαρτάται από δύο παράγοντες: τη φύση των διαχειριζόμενων δεδομένων του συστήματος και το συγκεκριμένο χωρο-χρονικό πλαίσιο. Τα διαχειριζόμενα δεδομένα μπορεί να χαρακτηριστούν κάτω από συγκεκριμένες συνθήκες ως άξια προστασίας ή όχι. Τα δεδομένα που χρήζουν προστασίας από δυνητικές απειλές αποκαλούνται ευπαθή. Επίσης, η απαίτηση για ασφάλεια ορισμένων δεδομένων υπάρχει περίπτωση να μην ισχύει για όλα τα κοινωνικά περιβάλλοντα. Η ίδια κατηγορία δεδομένων είναι πολύ πιθανό να χρήζει προστασίας σε ένα συγκεκριμένο περιβάλλον ενώ σε ένα άλλο να μην εκλαμβάνεται ως ευπαθές δεδομένο. Το σίγουρο πάντως είναι πως μερικά σημαντικά χαρακτηριστικά που θα πρέπει να κατέχει ένα σύστημα ανίχνευσης εισβολών είναι τα ακόλουθα [1]: Να είναι ανεκτικό σε σφάλματα και να τρέχει συνεχώς με την ελάχιστη ανθρώπινη επίβλεψη. Το σύστημα πρέπει να είναι ικανό να αποκατασταθεί έπειτα από κατάρρευση, είτε αυτή είναι τυχαία είτε προκλήθηκε σκόπιμα από κακόβουλες δραστηριότητες. Να κατέχει την ικανότητα να αντιστέκεται σε προσπάθειες ανατροπής έτσι ώστε ο επιτιθέμενος να μην μπορεί να αχρηστεύσει ή να τροποποιήσει το σύστημα εύκολα. Επιπλέον θα πρέπει να μπορεί να εντοπίζει οποιαδήποτε αλλαγή του επιβάλλεται από τον «εχθρό». Να επιβαρύνει το σύστημα όσο το δυνατόν λιγότερο. Να είναι προσαρμόσιμο σε αλλαγές του συστήματος και της συμπεριφοράς των χρηστών σε βάθος χρόνου. Να είναι εύκολο στην ανάπτυξη. Αυτό μπορεί να επιτευχθεί μέσω φορητότητας σε διαφορετικές αρχιτεκτονικές και λειτουργικά συστήματα, απλών μηχανισμών εγκατάστασης και ευκολίας χρήσης από το χειριστή. Να είναι αρκετά γενικό ώστε να εντοπίζει διαφορετικούς τύπους επιθέσεων. Επιπλέον, να μην αναγνωρίζει εσφαλμένα οποιαδήποτε νόμιμη δραστηριότητα ως επίθεση (false positives), αλλά ταυτόχρονα να μην απο- 17
18 τυγχάνει να αναγνωρίσει οποιαδήποτε πραγματική απειλή (false negatives). 1.8 Κατηγορίες Απειλών Μια σύνοψη των κυριότερων κατηγοριών απειλών παρουσιάζονται στη συνέχεια [79]. Παρακολούθηση γραμμών επικοινωνίας (tapping): Παρακολουθώντας τις επικοινωνιακές γραμμές μπορεί κανείς να αποκτήσει μη εξουσιοδοτημένη πρόσβαση σε μεταδιδόμενα δεδομένα, με πιθανό αποτέλεσμα να παραβιαστεί η ιδιωτικότητά τους. Ανάλυση κυκλοφορίας (traffic analysis): Για δεδομένες διευθύνσεις πηγής και προορισμού η παρακολούθηση των μεταδιδόμενων δεδομένων μπορεί να οδηγήσει σε ανάπτυξη ενός προτύπου (pattern) κυκλοφορίας. Η στατιστική και μόνο ανάλυση της επικοινωνίας, χωρίς απαραίτητα να γίνεται ανάγνωση των ίδιων των δεδομένων, μπορεί να οδηγήσει σε χρήσιμα συμπεράσματα για κάποιον τρίτο. Αποτυχία ή καταστροφή υλικού (hardware failure): Σημαντική απειλή στη διαθεσιμότητα ενός υπολογιστικού συστήματος αποτελεί η ενδεχόμενη καταστροφή του χρησιμοποιούμενου υλικού, είτε από κακόβουλη ενέργεια, είτε από αστοχία υλικού είτε από φυσική αιτία. Πλαστογράφηση διευθύνσεων δικτύου (spoofing): Καταργείται η ιδιότητα της μονοσήμαντης αντιστοίχισης των διευθύνσεων δικτύου σε μία συγκεκριμένη θέση, με αποτέλεσμα τα διακινούμενα δεδομένα να χάνουν την ιδιότητα της αυθεντικότητας της προέλευσης. Υποκλοπή συνθηματικών (password stealing): Ένα συνθηματικό μπορεί να διαρρεύσει σε έναν δυνητικό εισβολέα είτε από αμέλεια του χρήστη του συστήματος είτε μετά από παρακολούθηση των διακινούμενων πακέτων (sniffing) είτε με τη χρήση της μεθόδου ωμής δοκιμής (brute force attack). Αξιοποίηση καταπακτών (trapdoors exploiting): Οι καταπακτές είναι γνωστές ή άγνωστες αδυναμίες των υπηρεσιών του συστήματος που επιτρέπουν την υπέρβαση των μηχανισμών ασφάλειας για την προσπέλαση στους πόρους του συστήματος. Η ύπαρξη των αδυναμιών αυτών γίνεται γνωστή στους εισβολείς έπειτα από δοκιμαστική ανίχνευση που πραγματοποιούν σε όλες τις θύρες επικοινωνίας του συστήματος (port-scanning). Μη εξουσιοδοτημένη τροποποίηση (unauthorised modification) : Η κακόβουλη τροποποίηση των δεδομένων ενός συστήματος έπεται της παρακολούθησης των γραμμών επικοινωνίας ή της παρείσφρησης στο σύστημα έπειτα από υποκλοπή συνθηματικού ή αξιοποίηση καταπακτών. 18
19 Άρνηση παροχής υπηρεσίας (Denial of Service) : Σε αυτή την περίπτωση ο εισβολέας επιχειρεί να επηρεάσει αρνητικά τη διαθεσιμότητα μίας υπηρεσίας, αφού έχει παρεισφρήσει στο σύστημα που την παρέχει. Το ίδιο μπορεί να συμβεί όταν ο εισβολέας κατορθώσει να εγκαταστήσει λογισμικό που καταναλώνει ανεξέλεγκτα όλους τους διαθέσιμους πόρους του συστήματος ή του δικτύου, με αποτέλεσμα οι υπόλοιπες υπηρεσίες να παραμείνουν ουσιαστικά ανενεργές. Κατανεμημένη επίθεση άρνησης παροχής υπηρεσίας (Distributed Denial of Service): Η λογική είναι η ίδια με την άρνηση παροχής υπηρεσίας, με τη διαφορά ότι ο εισβολέας έχει εγκαταστήσει το κακόβουλο λογισμικό σε δεκάδες συστήματα αφού έχει παρεισφρήσει σε αυτά και τα χρησιμοποιεί ως μεσάζοντες (agents). Τα συστήματα αυτά με τη σειρά τους επιτίθενται συντονισμένα προς τον τελικό στόχο με δραματικές συνέπειες στους πόρους του συστήματος αυτού, αλλά και στο δίκτυο που οδηγεί προς αυτό. Κατάχρηση πόρων (misuse of resources): Μία μη εξουσιοδοτημένη ο- ντότητα είναι πιθανό να υποκλέψει πόρους ενός συστήματος, όπως κύκλους του επεξεργαστή, εύρος ζώνης δικτύου, χωρητικότητα δίσκων, είτε για να εξυπηρετηθούν διεργασίες του εισβολέα είτε για να προκληθεί άρνηση παροχής υπηρεσίας. Διάψευση εκτέλεσης ενέργειας (repudiation of action): Μία οντότητα μπορεί να αρνηθεί ότι δημιούργησε και απέστειλε ένα μήνυμα ή ότι τροποποίησε κάποια δεδομένα, εφόσον δεν υπάρχουν επαρκή αποδεικτικά στοιχεία. Ομοίως ο παραλήπτης του μηνύματος μπορεί να διαψεύσει την παραλαβή του και την ανάγνωση του περιεχομένου του. Εσωτερικοί κίνδυνοι (internal threats): Είναι πιθανό μέλη του απασχολούμενου προσωπικού σε μία επιχείρηση να υποκλέψουν χρήσιμες πληροφορίες για παράνομη χρήση. Παράλληλα η έλλειψη ασφάλειας στην φυσική πρόσβαση στο υλικό του συστήματος δημιουργεί επιπλέον κινδύνους. Πλαστοπροσωπία (masquerade): Στο επίπεδο εφαρμογής είναι πιθανό η προέλευση ενός μηνύματος να φαίνεται διαφορετική από την πραγματική. Λογισμικό ιών (viral software): Πρόκειται για κακόβουλο λογισμικό που εκτελείται ή φορτώνεται δυναμικά στο σύστημα και προκαλεί ποικίλα σημαντικά προβλήματα. Συνήθως βρίσκεται ενσωματωμένο σε εκτελέσιμο κώδικα ή αυτόνομο σε μορφή δέσμης εντολών (script). Φροντίζει να προσκολλάται σε άλλα εκτελέσιμα αρχεία ή να διαδίδεται μέσω δικτυακών εφαρμογών, έτσι ώστε να επηρεάζει όσο το δυνατόν περισσότερα συστήματα. Καταχρηστικά μηνύματα (spamming): Αφορά κυρίως τις υπηρεσίες μηνυμάτων όπως τα νέα και η ηλεκτρονική αλληλογραφία. Πρόκειται για μηνύματα διαφημιστικού και πολλές φορές προσβλητικού περιεχομένου που α- ποστέλλονται μαζικά σε μεγάλο αριθμό χρηστών, χωρίς να υπάρχει υπαρ- 19
20 κτή διεύθυνση αποστολέα και από εξυπηρετητές που έχουν εκτεθεί στους εισβολείς, έτσι ώστε να μην είναι ανιχνεύσιμη η προέλευσή τους ούτε σε ε- πίπεδο εφαρμογής ούτε σε επίπεδο δικτύου. 1.9 Ενδείξεις Προσπάθειας Εισβολής Η ανίχνευση εισβολών βασίζεται στην υπόθεση ότι οι αδιάκριτες δραστηριότητες είναι σημαντικά διαφορετικές από εκείνες των φυσιολογικών χρηστών, άρα και εύκολα ανιχνεύσιμες [1]. Επομένως παραβιάσεις ασφάλειας θα μπορούσαν να ανιχνευτούν από ασυνήθιστα μοτίβα της χρήσης του συστήματος. Μερικά τέτοια παραδείγματα ασυνήθιστων μοτίβων αφορούν [1]: Προσπάθειες για διάρρηξη (Attempted break-in): Κάποιος που προσπαθεί να διεισδύσει σε ένα σύστημα μπορεί να παράγει έναν ασυνήθιστα υψηλό ρυθμό λανθασμένων συνθηματικών εισόδου σε έναν απλό λογαριασμό ή στο σύστημα ως σύνολο. Μεταμφιέσεις ή επιτυχή διείσδυση (Masquerading or successful breakin): Κάποιος που μπαίνει σε ένα σύστημα μέσω μη εξουσιοδοτημένου λογαριασμού και συνθηματικού μπορεί να έχει διαφορετική ώρα εισόδου, τοποθεσία ή τύπο σύνδεσης από τα αντίστοιχα του νόμιμου χρήστη. Επίσης, η συμπεριφορά του εισβολέα μπορεί να διαφέρει σημαντικά από εκείνη του νόμιμου χρήστη του λογαριασμού. Πολλές τέτοιες παραβιάσεις έχουν ανακαλυφθεί από υπεύθυνους ασφάλειας ή άλλους χρήστες του συστήματος οι οποίοι παρατήρησαν ότι ο υποτιθέμενος χρήστης συμπεριφερόταν παράξενα. Διείσδυση από νόμιμο χρήστη (Penetration by legitimate user): Ένας χρήστης ο οποίος προσπαθεί να παραβιάσει τους μηχανισμούς ασφάλειας ενός λειτουργικού συστήματος πιθανόν να εκτελέσει διαφορετικά προγράμματα ή να ενεργοποιήσει περισσότερες παραβιάσεις ασφάλειας μέσω προσπαθειών να αποκτήσει πρόσβαση σε μη εξουσιοδοτημένα αρχεία ή προγράμματα. Εάν η προσπάθειά του επιτύχει, θα αποκτήσει πρόσβαση σε αρχεία και εντολές, τις οποίες κανονικά δεν του επιτρέπεται να προσπελάσει. Διαρροή από νόμιμο χρήστη (Leakage by legitimate user): Ένας χρήστης που προσπαθεί να διαρρεύσει / διακινήσει απόρρητα έγγραφα πιθανόν να εισέρχεται στο σύστημα σε ασυνήθιστες ώρες ή να δρομολογεί δεδομένα σε απομακρυσμένους εκτυπωτές που δε χρησιμοποιούνται κανονικά. Δούρειοι Ίπποι (Trojan Horses): Η συμπεριφορά ενός δούρειου ίππου που εμφυτεύεται σε ή αντικαθιστά ένα πρόγραμμα μπορεί να διαφέρει από το κανονικό πρόγραμμα από άποψη χρόνων του επεξεργαστή ή δραστηριότητας I/O. Ιός (Virus): Ένας ιός σε ένα σύστημα υπάρχει περίπτωση να προκαλέσει μια αύξηση στη συχνότητα επανεγγραφής των εκτελέσιμων αρχείων, απο- 0
21 θήκευσής τους ή εκτέλεσης ενός συγκεκριμένου προγράμματος καθώς ο ιός εξαπλώνεται. Άρνηση υπηρεσίας (Denial-of-Service): Ένας εισβολέας ικανός να μονοπωλεί ένα συγκεκριμένο πόρο του συστήματος πιθανόν να έχει ασυνήθιστα υψηλή δραστηριότητα ως προς αυτόν τον πόρο, ενώ η δραστηριότητα των άλλων χρηστών να είναι ασυνήθιστα χαμηλή. Ωστόσο, οι παραπάνω μορφές αποκλίνουσας χρήσης μπορούν να σχετίζονται και με ενέργειες που δεν σχετίζονται με παραβιάσεις της ασφάλειας ενός συστήματος. Θα μπορούσαν να είναι ένδειξη της διάθεσης ενός χρήστη να αλλάζει εργασίες, να αποκτά νέες δεξιότητες ή να κάνει τυπικά σφάλματα, ή ακόμη και ένδειξη ενημέρωσης προγραμμάτων. Κύριος στόχος είναι ο σαφής καθορισμός των δραστηριοτήτων και των μετρικών που θα παράσχουν το καλύτερο αποτέλεσμα ως προς τον εντοπισμό των κακόβουλων ενεργειών Κατηγορίες Τεχνικών Ανίχνευσης Εισβολών Γενικά, οι υπάρχουσες τεχνικές ανίχνευσης εισβολών εμπίπτουν σε κατηγορίες [1]. Την ανίχνευση ανωμαλιών (anomaly detection) και την ανίχνευση κατάχρησης (misuse detection ή signature detection) Anomaly detection Οι τεχνικές αυτής της κατηγορίας υποθέτουν πως όλες οι κακόβουλες δραστηριότητες είναι απαραίτητα ανώμαλες. Αυτό σημαίνει πως αν μπορούσαμε να συνθέσουμε ένα προφίλ κανονικής συμπεριφοράς για ένα σύστημα ένα norm profile, θα μπορούσαμε θεωρητικά να χαρακτηρίζουμε όλες τις καταστάσεις του συστήματος, οι οποίες απέχουν / διαφέρουν σε στατιστικά σημαντικές ποσότητες από το καθιερωμένο προφίλ, ως προσπάθειες εισβολής [13]. Για την αναπαράσταση του φυσιολογικού προφίλ χρησιμοποιούνται συμβολοσειρές, Formal logic, τεχνητά νευρωνικά δίκτυα και ιστογράμματα συχνοτήτων. Ωστόσο, αν θεωρήσουμε πως το σύνολο των κακοηθών δραστηριοτήτων μόνο τέμνει το σύνολο των ανώμαλων δραστηριοτήτων αντί να ταυτίζεται με αυτό, υπάρχει ενδιαφέροντα ενδεχόμενα. Πρώτον, μη κανονικές δραστηριότητες που δεν είναι κακοήθεις να χαρακτηρίζονται ως κακοήθεις (false positives), και δεύτερον, κακοήθεις δραστηριότητες που δεν είναι ανώμαλες δεν χαρακτηρίζονται ως κακοήθεις (false negatives). Τα κύρια σημεία στην ανίχνευση ανωμαλιών επομένως είναι η επιλογή κατάλληλων τιμών ορίων (threshold), έτσι ώστε κανένα από τα παραπάνω προβλήματα να μην μεγεθύνεται παράλογα και η επιλογή των χαρακτηριστικών που θα καταγράφονται [13]. Ταυτόχρονα, τα συστήματα ανίχνευσης ανωμαλιών είναι υπολογιστικά ακριβά εξαιτίας του κόστους και του φόρτου καταγραφής, και πιθανόν και ενημέρωσης, αρκετών μετρικών του προφίλ του συστήματος. 1
![Σχήμα 1.3 Σύστημα Ανίχνευσης Ανωμαλιών [13] Μπορούν να διακριθούν σε στατικές και δυναμικές [1].](/docs-images/59/43898540/images/22-0.png "Μια στατική τέτοια μέθοδος ανίχνευσης βασίζεται στην υπόθεση ότι υπάρχει ένα μέρος του συστήματος που παρακολουθείται, το οποίο δεν αλλάζει.")
22 Σχήμα 1.3 Σύστημα Ανίχνευσης Ανωμαλιών [13] Μπορούν να διακριθούν σε στατικές και δυναμικές [1]. Μια στατική τέτοια μέθοδος ανίχνευσης βασίζεται στην υπόθεση ότι υπάρχει ένα μέρος του συστήματος που παρακολουθείται, το οποίο δεν αλλάζει. Συνήθως οι στατικοί ανιχνευτές α- πευθύνονται μόνο στο κομμάτι του λογισμικού ενός συστήματος και υποθέτουν ότι δεν υπάρχει λόγος να ελέγχεται το υλικό. Το στατικό τμήμα ενός συστήματος είναι ο κώδικας για το σύστημα και η αμετάβλητη ποσότητα των δεδομένων από τα οποία εξαρτάται η σωστή λειτουργία του συστήματος. Εάν οποιαδήποτε στιγμή το στατικό μέρος του συστήματος παρεκκλίνει από την αρχική του μορφή, τότε ή έχει συμβεί κάποιο λάθος ή κάποιος εισβολέας το έχει παραποιήσει. Μπορούμε να πούμε ότι οι στατικοί ανιχνευτές αυτής της κατηγορίας εστιάζουν στον έλεγχο της ακεραιότητας. Οι δυναμικοί ανιχνευτές συνήθως λειτουργούν με βάση τις εγγραφές ελέγχου (audit records) ή την καταγεγραμμένη κυκλοφορία δεδομένων ενός δικτύου. Οι εγγραφές ελέγχου των λειτουργικών συστημάτων δεν καταγράφουν όλα τα συμβάντα (events), αλλά εκείνα μόνο που παρουσιάζουν ενδιαφέρον. Κατά συνέπεια καταγράφεται η συμπεριφορά εκείνη η οποία προκαλεί το συμβάν το οποίο υπάρχει στην εγγραφή ελέγχου. Τα συμβάντα αυτά είναι πιθανό να συμβαίνουν με μια αλληλουχία. Σε κατανεμημένα συστήματα, μερική διάταξη των συμβάντων επαρκεί για την ανίχνευση. Σε άλλες περιπτώσεις, η σειρά δεν αναπαρίσταται άμεσα, αλλά διατηρούνται μόνο αθροιστικές πληροφορίες, όπως η αθροιστική χρήση του επεξεργαστή κατά τη διάρκεια ενός χρονικού διαστήματος. Σε αυτήν την περίπτωση, καθορίζονται thresholds για να διαχωριστεί η ονομαστική κατανάλωση πόρων από την ανώμαλη κατανάλωση πόρων Misuse detection Στη βιβλιογραφία οι προσεγγίσεις αυτής της κατηγορίας αναφέρονται και ως τεχνικές αναγνώρισης υπογραφών (signature-recognition techniques). Βασίζονται στη γνώση των ευπαθειών του συστήματος και των προτύπων γνωστών ε- πιθέσεων. Η λογική πίσω από τις τεχνικές ανίχνευσης κατάχρησης έγκειται στο
![γεγονός ότι υπάρχουν τρόποι αναπαράστασης των επιθέσεων με τη μορφή ενός προτύπου ή μιας υπογραφής έτσι ώστε να εντοπίζονται ακόμη και παραλλαγές της ίδιας επίθεσης [13].](/docs-images/59/43898540/images/23-0.png "Οι μέθοδοι αυτές ασχολούνται με τον εντοπισμό των εισβολέων που προσπαθούν να διεισδύσουν σε ένα σύστημα εκμεταλλευόμενοι κάποιο γνωστό ευάλωτο σημείο του συστήματος.")
23 γεγονός ότι υπάρχουν τρόποι αναπαράστασης των επιθέσεων με τη μορφή ενός προτύπου ή μιας υπογραφής έτσι ώστε να εντοπίζονται ακόμη και παραλλαγές της ίδιας επίθεσης [13]. Οι μέθοδοι αυτές ασχολούνται με τον εντοπισμό των εισβολέων που προσπαθούν να διεισδύσουν σε ένα σύστημα εκμεταλλευόμενοι κάποιο γνωστό ευάλωτο σημείο του συστήματος. Ιδανικά, ο διαχειριστής του συστήματος θα έπρεπε να γνωρίζει όλες τις πιθανές «ευαισθησίες» και να τις εξαλείψει. Ο όρος Σενάριο Εισβολής χρησιμοποιείται για να περιγράψει ένα γνωστό είδος εισβολής [1]. Πρόκειται για μια ακολουθία συμβάντων που θα κατέληγε σε εισβολή χωρίς καμία εξωτερική αποτρεπτική παρέμβαση. Ένα IDS επανειλημμένα συγκρίνει την πρόσφατη δραστηριότητα με γνωστά σενάρια εισβολών προκειμένου να εξασφαλίσει ότι ένας ή περισσότεροι επιτιθέμενοι δεν προσπαθούν να εκμεταλλευτούν γνωστές ευπάθειες. Σε περίπτωση εντοπισμού κάποιας αντιστοιχίας (match), σημαίνει συναγερμός. Για να είναι εφικτό αυτό, είναι απαραίτητο κάθε σενάριο προηγουμένως να έχει περιγραφεί ή μοντελοποιηθεί. Σχήμα 1.4 Σύστημα Ανίχνευσης Κατάχρησης [13] Η διαφορά ανάμεσα στις τεχνικές αυτής της κατηγορίας έγκειται στον τρόπο με τον οποίο περιγράφουν ή μοντελοποιούν εκείνη τη συμπεριφορά που είναι ενδεικτική μιας επίθεσης [1]. Τα πρώτα συστήματα αυτής της κατηγορίας χρησιμοποιούσαν κανόνες για να περιγράψουν συμβάντα ενδεικτικά κακόβουλων ενεργειών. Ένας μεγάλος αριθμός τέτοιων κανόνων συχνά είναι δύσκολο να ερμηνευτεί αποτελεσματικά και έγκαιρα. Σήμερα χρησιμοποιούνται διαγράμματα μετάβασης καταστάσεων, έγχρωμα δίκτυα Petri, κανόνες απόφασης και δομές συμπλεγμάτων (clusters) για την αναπαράσταση των «υπογραφών» των εισβολών. Το κύριο ζήτημα στα συστήματα ανίχνευσης κατάχρησης είναι το πώς θα αναπτυχθεί μια υπογραφή που να καλύπτει όλες τις πιθανές παραλλαγές για την κατάλληλη επίθεση και πώς θα αναπτυχθούν υπογραφές επιθέσεων για τις οποίες δεν θα υπάρχει αντιστοιχία με μη κακόβουλη δραστηριότητα [13]. 3
24 Όπως αναφέρθηκε προηγουμένως, δύο μεγάλης σημασίας λάθη μπορούν να προκύψουν από ένα IDS, τα οποία λέγονται λάθη εσφαλμένα θετικών αποφάσεων (false positives) και λάθη εσφαλμένα αρνητικών αποφάσεων (false negatives). Ένα false negative λάθος προκύπτει όταν κακόβουλη συμπεριφορά αναγνωρίζεται από το σύστημα ανίχνευσης εισβολών ως συμπεριφορά φυσιολογικών χρηστών, ενώ ένα false positive λάθος προκύπτει όταν συμπεριφορά νόμιμων χρηστών αναγνωρίζεται από το σύστημα ως κακόβουλη συμπεριφορά Σύγκριση των μεθόδων των κατηγοριών Αυτό που πρέπει να σημειωθεί είναι πως τα συστήματα ανίχνευσης ανωμαλιών προσπαθούν να εντοπίσουν το συμπλήρωμα της κακής συμπεριφοράς, ενώ τα συστήματα ανίχνευσης κατάχρησης προσπαθούν να αναγνωρίσουν την κακή συμπεριφορά [1]. Το κύριο μειονέκτημα των προσεγγίσεων της misuse detection είναι ότι μπορούν να ανιχνεύουν μόνο τις επιθέσεις τις οποίες έχουν εκπαιδευτεί να ανιχνεύουν. Νέες ή άγνωστες επιθέσεις ή ακόμα και παραλλαγές γνωστών επιθέσεων δε θα εντοπίζονται. Σε μια εποχή που ελαττώματα ασφάλειας στο λογισμικό ανακαλύπτονται και αξιοποιούνται από αναρμόδιους χρήστες καθημερινά, η αντίδραση που προσφέρουν οι μέθοδοι της misuse detection δεν είναι ικανή να αποτρέψει κακόβουλες ενέργειες. Το κύριο πλεονέκτημα των προσεγγίσεων της anomaly detection είναι η ικανότητα να εντοπίζει καινούριες ή άγνωστες επιθέσεις, παραλλαγές γνωστών επιθέσεων, ακόμα και αποκλίσεις από την κανονική χρήση των προγραμμάτων ανεξάρτητα από το αν η πηγή είναι ένας εξουσιοδοτημένος εσωτερικός χρήστης ή ένας μη εξουσιοδοτημένος εξωτερικός χρήστης. Ωστόσο, το μειονέκτημα των μεθόδων αυτών είναι ότι πολύ γνωστές επιθέσεις πιθανόν να μην ανιχνεύονται, ειδικά αν ταιριάζουν με το καθιερωμένο προφίλ του χρήστη. Από τη στιγμή που θα ανιχνευτεί, συχνά είναι δύσκολο να χαρακτηριστεί η φύση της επίθεσης. Ένα άλλο μειονέκτημα αρκετών τεχνικών της anomaly detection είναι ότι ένας κακόβουλος χρήστης, που γνωρίζει ότι παρακολουθείται με σκοπό τη δημιουργία του προφίλ του, μπορεί σταδιακά σε μεγάλο βάθος χρόνου να αλλάξει τη συμπεριφορά του προκειμένου να εκπαιδεύσει το σύστημα ανίχνευσης να αναγνωρίζει την κακόβουλη συμπεριφορά ως φυσιολογική. Τέλος, σημαντική αδυναμία τους είναι το υψηλό ποσοστό εσφαλμένων συναγερμών (false alarm rate). Αυτό οφείλεται στο γεγονός ότι συμπεριφορές που δεν έχουν παρατηρηθεί παλαιότερα, αν και νόμιμες και φυσιολογικές, μπορούν να αναγνωριστούν ως ανωμαλίες. Τα πλεονεκτήματα και τα μειονεκτήματα των προαναφερθέντων προσεγγίσεων συνοψίζονται στον παρακάτω πίνακα. 4

25 Anomaly Detection Misuse Detection Πλεονεκτήματα Καινούριες επιθέσεις μπορούν να ανιχνευτούν. Χαμηλότερος ρυθμός false positive. Μειονεκτήματα Υψηλότερος ρυθμός false positive. Καινούριες επιθέσεις δεν μπορούν να ανιχνευτούν. Η βάση δεδομένων των επιθέσεων πρέπει να ενημερώνεται σε τακτική βάση. Για κάθε τεχνική υπάρχουν διαφορετικές προσεγγίσεις. Ο διαχειριστής ασφάλειας του δικτύου έχει να αντιμετωπίσει το πρόβλημα της επιλογής ενός κατάλληλου IDS για το συγκεκριμένο υπολογιστικό σύστημα. Η επιλογή αυτή περιπλέκεται από τη διαθεσιμότητα πολλών διαφορετικών προσεγγίσεων. Προκειμένου τα υπολογιστικά συστήματα και δίκτυα, κυβερνητικά ή επιχειρησιακά, να καταστούν στο μέγιστο βαθμό ασφαλή και ανθεκτικά ενάντια στο τεράστιο φάσμα απειλών και ευπαθειών, πρέπει οι δύο παραπάνω μεθοδολογίες να συνδυάζονται και να υλοποιούνται παράλληλα με μηχανισμούς πρόληψης επιθέσεων DoS (Σχήμα 1.5) [17]. Σχήμα 1.5 Καμία τεχνική ή μεθοδολογία από μόνη της δεν μπορεί να εγγυηθεί πλήρη προστασία από πιθανές μελλοντικές επιθέσεις 5
26 Προσεγγίσεις για anomaly detection 1. Στατιστικές (Statistical) Αυτές οι προσεγγίσεις καθορίζουν τη φυσιολογική ή αναμενόμενη συμπεριφορά συλλέγοντας δεδομένα τα οποία σχετίζονται με τη συμπεριφορά των νόμιμων χρηστών κατά τη διάρκεια μιας συγκεκριμένης περιόδου χρόνου. Στη συνέχεια εφαρμόζονται στατιστικοί έλεγχοι στην παρατηρούμενη συμπεριφορά προκειμένου για τον καθορισμό της ως νομιμότητάς της. Ειδικότερα, στις στατιστικές προσεγγίσεις προφίλ συμπεριφοράς των υποκειμένων αρχικά παράγονται καθώς το σύστημα συνεχίζει να λειτουργεί κανονικά και ο ανιχνευτής ανωμαλιών συνεχώς συγκρίνει τη variance του τρέχοντος προφίλ με εκείνο το προφίλ αναφοράς (Baseline) [13]. Το κύριο πλεονέκτημα των στατιστικών συστημάτων είναι ότι προσαρμοστικά μελετούν τις συμπεριφορές των χρηστών και είναι επομένως πιθανόν πιο ευαίσθητα από ανθρώπους ειδικούς. Ω- στόσο υφίστανται κάποια προβλήματα με αυτές τις μεθόδους. Ένα πρόβλημα είναι ότι οι εισβολείς μπορούν συστηματικά να τα εκπαιδεύσουν ώστε τελικά τα κακόβουλα γεγονότα να εκλαμβάνονται ως φυσιολογικά. Ένα δεύτερο πρόβλημα είναι ότι μπορούν να παραχθούν είτε false positives ή false negatives, ανάλογα με το πόσο χαμηλή ή πόσο υψηλή είναι η τιμή κατώφλι. Τέλος, ένα τρίτο πρόβλημα είναι ότι υπάρχει το ενδεχόμενο οι σχέσεις μεταξύ των γεγονότων να προσπεραστούν εξαιτίας της αδυναμίας των στατιστικών μέτρων να λάβουν υπόψη τη σειρά διάταξη των γεγονότων. Ένα ανοικτό πρόβλημα με τις στατιστικές μεθόδους συγκεκριμένα, και με τις μεθόδους που χρησιμοποιούνται για ανίχνευση ανωμαλιών γενικότερα, είναι η επιλογή των μετρικών που πρέπει να παρακολουθούνται / καταγράφονται [13]. Το υποσύνολο όλων των πιθανών μετρικών που προβλέπει τις κακόβουλες δραστηριότητες με ακρίβεια είναι άγνωστο. Στατικές μέθοδοι καθορισμού αυτών των μετρικών είναι μερικές φορές παραπλανητικές εξαιτίας των μοναδικών χαρακτηριστικών και ιδιαιτεροτήτων ενός συγκεκριμένου συστήματος. Επομένως, είναι προφανές πως είναι απαραίτητος ο συνδυασμός στατικού και δυναμικού καθορισμού ενός τέτοιου συνόλου μετρικών. Μερικά προβλήματα που σχετίζονται με αυτές τις τεχνικές έχουν αντιμετωπιστεί με άλλες μεθόδους, συμπεριλαμβανομένου και της μεθόδου που σχετίζεται με Predictive Pattern Generation, η οποία κατά την ανάλυση των δεδομένων λαμβάνει υπόψη και παρελθοντικά γεγονότα.. Αναμενόμενη Παραγωγή Προτύπων (Predictive pattern generation) Αυτή η μέθοδος ανίχνευσης εισβολών προσπαθεί να προβλέψει μελλοντικά γεγονότα βασισμένη σε γεγονότα που έχουν ήδη προηγηθεί [19]. Κανόνες που παράγονται από το IDS καθορίζουν την πιθανότητα να συμβεί ένα συγκεκριμένο συμβάν. Ένας κανόνας αποτελείται από κομμάτια, το αριστερό καθορίζοντας ταυτόχρονα συμβάντα, και το δεξιό παρέχοντας την πιθανότητα ενός συγκεκρι- 6
27 μένου συμβάντος που έπεται των συμβάντων που ορίστηκαν στο αριστερό τμήμα του κανόνα. Επομένως θα μπορούσαμε να έχουμε έναν κανόνα Ε1 Ε (Ε3 = 75%, Ε4 = 15%, Ε5 = 5%) Αυτό θα σήμαινε ότι δεδομένου ότι τα γεγονότα Ε1 και Ε έχουν συμβεί, με το γεγονός Ε1 να προηγείται του γεγονότος Ε, υπάρχει μια 75% πιθανότητα να ακολουθήσει το γεγονός Ε3, μια 15% πιθανότητα να ακολουθήσει το γεγονός Ε4 και μια 5% πιθανότητα να ακολουθήσει το γεγονός Ε5 [13] [18]. Το πρόβλημα με αυτήν την προσέγγιση έγκειται στο γεγονός ότι ορισμένα σενάρια εισβολών τα οποία δεν περιγράφονται από τους κανόνες δε θα εντοπιστούν ως κακόβουλα. Επομένως, αν υπάρχει μια ακολουθία γεγονότων Α Β Γ η οποία είναι κακοήθης αλλά δεν υπάρχει στη βάση των κανόνων, τότε θα κατηγοριοποιηθεί ως μη αναγνωρίσιμη και επομένως μη ανιχνεύσιμη. Αυτό το πρόβλημα μπορεί μερικώς να λυθεί καταδεικνύοντας ως εισβολές οποιαδήποτε άγνωστα γεγονότα (αυξάνοντας κατά συνέπεια την πιθανότητα για περισσότερα false positives) ή καταδεικνύοντάς τα ως μη ενοχλητικά (αυξάνοντας κατά συνέπεια την πιθανότητα για περισσότερα false negatives). Τυπικά, ωστόσο, ένα γεγονός κατηγοριοποιείται ως παρεισφρητικό εάν υπάρχει αντιστοιχία στο αριστερό μέρος ενός κανόνα, αλλά το δεξί αποκλίνει στατιστικά σημαντικά από την πρόβλεψη. Αυτή η προσέγγιση έχει μερικά πλεονεκτήματα [13]. Καταρχάς, διαδοχικά πρότυπα βασισμένα σε κανόνες μπορούν να εντοπίσουν αποκλίνουσες / ύποπτες δραστηριότητες, οι οποίες ήταν δύσκολο να εντοπιστούν με παραδοσιακές μεθόδους. Κατά δεύτερο λόγο, συστήματα βασισμένα σε αυτό το μοντέλο είναι ευπροσάρμοστα σε μεγάλο βαθμό σε αλλαγές. Αυτό συμβαίνει επειδή πρότυπα χαμηλής ποιότητας συνεχώς εξαλείφονται, αφήνοντας εν τέλει μόνο πρότυπα υψηλής ποιότητας. Τρίτον, είναι ευκολότερο να ανιχνευθούν χρήστες που προσπαθούν να εκπαιδεύσουν το σύστημα κατά την περίοδο μάθησης. Τέλος, κακοήθεις δραστηριότητες μπορούν να ανιχνευτούν και να αναφερθούν εντός δευτερολέπτων από τη στιγμή λήψης των γεγονότων ελέγχου (audit events). 3. Νευρωνικά Δίκτυα (Neural networks) Αυτά τα συστήματα μαθαίνουν να προβλέπουν την επόμενη εντολή ή ενέργεια βασισμένα σε μια ακολουθία από προηγούμενες εντολές ή ενέργειες ενός συγκεκριμένου χρήστη. Η κατασκευή ενός IDS με νευρωνικά δίκτυα αποτελείται από 3 φάσεις [5]: 1. Η συλλογή των συνόλου δεδομένων εκπαίδευσης (training set) χρησιμοποιώντας τα αρχεία ελέγχου (audit logs) για κάθε χρήστη για μια δεδομένη χρονική περίοδο. Κατ αυτόν τον τρόπο σχηματίζεται ένα διάνυσμα για κάθε μέρα και για κάθε χρήστη, το οποίο δείχνει πόσο συχνά ο χρήστης εκτέλεσε κάθε εντολή - ενέργεια. 7
28 . Η εκπαίδευση του νευρωνικού δικτύου ώστε να αναγνωρίζει το χρήστη βάσει των διανυσμάτων κατανομής των εντολών (command distribution vectors). 3. Αναγνώριση του χρήστη βάσει του προαναφερθέντος διανύσματος. Εάν το δίκτυο αποφαίνεται ότι δεν πρόκειται για τον πραγματικό χρήστη, σημαίνει συναγερμός. Μερικά πλεονεκτήματα της χρήσης νευρωνικών δικτύων είναι ότι αντιμετωπίζουν ικανοποιητικά δεδομένα που περιέχουν θόρυβο, η επιτυχία τους δε εξαρτάται από οποιαδήποτε στατιστική υπόθεση σχετικά με τη φύση των υπό εξέταση δεδομένων και είναι ευκολότερη η τροποποίησή τους για νέες κοινότητες χρηστών [13]. Εντούτοις παρουσιάζουν και κάποιες αδυναμίες. Καταρχάς, ένα μικρό παράθυρο θα καταλήξει σε false positives ενώ ένα μεγάλο παράθυρο θα καταλήξει σε άσχετα δεδομένα καθώς επίσης και σε αύξηση των false negatives. Επιπλέον, η τοπολογία δικτύου καθορίζεται μόνον μετά από σημαντικό αριθμό δοκιμών και λαθών (trial and error) και τέλος ένας εισβολέας μπορεί να εκπαιδεύσει το δίκτυο κατά τη φάση της μάθησης. 4. Αντιστοίχιση Ακολουθιών και Μάθηση (Sequence matching and learning) Οι Lane & Brodley [0] εισήγαγαν μια εφαρμογή μηχανικής μάθησης για την ανίχνευση ανωμαλιών. Αυτή η προσέγγιση χρησιμοποιεί την υπόθεση ότι ένας χρήστης ανταποκρίνεται με έναν προβλέψιμο τρόπο σε παρόμοιες καταστάσεις, ο οποίος οδηγεί σε επαναλαμβανόμενες ακολουθίες ενεργειών. Για να δημιουργηθεί το προφίλ ενός χρήστη, η προσέγγισή τους μαθαίνει χαρακτηριστικές ακολουθίες ενεργειών που παράγονται από τους χρήστες. Οι διαφορές στις χαρακτηριστικές ακολουθίες χρησιμοποιούνται για να ξεχωρίσουν ένα έγκυρο χρήστη από έναν εισβολέα που μεταμφιέζεται ως εκείνον Προσεγγίσεις για misuse detection 1. Έμπειρα Συστήματα βασισμένα σε Κανόνες (Ruled-Based Expert systems) Τα Έμπειρα Συστήματα μοντελοποιούνται με τέτοιο τρόπο ώστε να διαχωρίσουν τη φάση αντιστοίχισης κανόνων από τη φάση ενεργειών [13]. Η αντιστοίχιση γίνεται σύμφωνα με τα γεγονότα των ιχνών ελέγχου (audit trail events). Το σύστημα NIDES [1] που αναπτύχθηκε από το SRI είναι μια ενδιαφέρουσα περίπτωση προσέγγισης βασισμένης σε έμπειρα συστήματα. Το NIDES ακολουθεί μια υβριδική τεχνική ανίχνευσης εισβολών η οποία αποτελείται από ένα συστατικό ανίχνευσης κατάχρησης καθώς επίσης και από ένα συστατικό ανίχνευσης ανωμαλιών. Ο ανιχνευτής ανωμαλιών είναι βασισμένος σε μια στατιστική προσέγγιση και κατηγοριοποιεί τα γεγονότα ως παρεισφρητικά ενοχλητικά εάν αποκλίνουν σημαντικά από την αναμενόμενη συμπεριφορά. Προκειμένου να το επιτύχει αυτό, δημιουργεί προφίλ χρηστών βασιζόμενο σε περισσότερα από 30 κριτήρια, συμπεριλαμβανομένης της χρήσης CPU και I/O, των εντολών που χρησιμοποιήθη- 8
29 καν, της δραστηριότητας τοπικού δικτύου, των λαθών του συστήματος κλπ. Αυτά τα προφίλ ενημερώνονται κατά περιοδικά διαστήματα. Το συστατικό ανίχνευσης κατάχρησης του έμπειρου συστήματος κωδικοποιεί γνωστά σενάρια εισβολών και μοτίβα επιθέσεων. Η βάση δεδομένων των κανόνων μπορεί να τροποποιηθεί για διαφορετικά συστήματα [13]. Ένα πλεονέκτημα της προσέγγισης του NIDES είναι ότι διαθέτει ένα στατιστικό συστατικό καθώς και ένα συστατικό έμπειρου συστήματος. Αυτό αυξάνει την πιθανότητα ένα σύστημα να εντοπίσει εισβολές που διαφεύγουν ενός άλλου. Παρόλα ταύτα, υπάρχουν και κάποια μειονεκτήματα. Για παράδειγμα, το έμπειρο σύστημα πρέπει να συνταχθεί από κάποιον επαγγελματία στην ασφάλεια, επομένως το σύστημα είναι τόσο ισχυρό όσο ο ειδικός που το προγραμματίζει []. Αυτό σημαίνει ότι υπάρχει μεγάλη πιθανότητα τα έμπειρα συστήματα να αποτύχουν να εντοπίσουν τις εισβολές. Για ακριβώς αυτόν το λόγο το NIDES έχει συστατικά και ανίχνευσης ανωμαλιών και ανίχνευσης κατάχρησης. Αυτά τα συστατικά είναι χαλαρά συνδεδεμένα μεταξύ τους με την έννοια ότι στο μεγαλύτερο κομμάτι λειτουργούν ανεξάρτητα το ένα από το άλλο. Το NIDES τρέχει σε διαφορετικό μηχάνημα από αυτά που παρακολουθούνται, το οποίο θα μπορούσε να επιφέρει μεγάλο κόστος. Παράλληλα, προσθήκες και διαγραφές κανόνων από τη βάση πρέπει να λαμβάνουν υπόψη τις εσωτερικές εξαρτήσεις μεταξύ διαφορετικών κανόνων εντός της βάσης. Και δεν υπάρχει αναγνώριση της διαδοχικής διάταξης των δεδομένων διότι οι διάφορες συνθήκες που φτιάχνουν έναν κανόνα δεν αναγνωρίζονται ως διατεταγμένες.. Ανάλυση Μετάβασης Καταστάσεων (State transition analysis) Το υπό παρακολούθηση υπολογιστικό σύστημα μπορεί να αναπαρασταθεί ως ένα διάγραμμα μετάβασης καταστάσεων, το οποίο είναι μια γραφική αναπαράσταση (Σχήμα 4) των ενεργειών που πραγματοποιούνται από έναν εισβολέα για να πετύχει υπονόμευση του συστήματος [13]. Στην Ανάλυση Μετάβασης Καταστάσεων, μια εισβολή λαμβάνεται ως μια ακολουθία ενεργειών που πραγματοποιούνται από έναν εισβολέα, η οποία οδηγεί από κάποια αρχική κατάσταση του υπολογιστικού συστήματος σε μια τελική μη ασφαλή κατάσταση βάσει προτύπων γνωστών επιθέσεων. Η μετάβαση από τη μία κατάσταση στην άλλη προκύπτει ως αποτέλεσμα της ισχύος μιας λογικής συνθήκης (δηλ. να είναι αληθής η συνθήκη). Τα διαγράμματα ανάλυσης μετάβασης καταστάσεων αναγνωρίζουν τις απαιτήσεις και τον κίνδυνο μιας διείσδυσης. Επίσης απαριθμούν τις ενέργειεςκλειδιά που πρέπει να συμβούν για την επιτυχή ολοκλήρωση μιας εισβολής. Τα προβλήματα που παρουσιάζονται εδώ είναι τα εξής [13]. Αρχικά, τα πρότυπα των επιθέσεων μπορούν να καθορίσουν μόνο μια ακολουθία γεγονότων και όχι πιο περίπλοκες μορφές. Επίσης, δεν μπορούν να ανιχνεύσουν επιθέσεις άρνησης εξυπηρέτησης, αποτυχημένων εισόδων, αποκλίσεις από φυσιολογική συμπεριφορά κλπ, διότι αυτές οι ενέργειες δεν μπορούν να αναπαρασταθούν με διαγράμματα μετάβασης καταστάσεων. 9
 Η παρακολούθηση πλήκτρων είναι μια πολύ απλή διαδικασία που χρησιμοποιείται για να δούμε ή να καταγράψουμε τόσο την ακολουθία πλήκτρων που εισάγει ένας")
30 Σχήμα 1.6 State transition Analysis 3. Παρακολούθηση Πλήκτρων (Keystroke monitoring) Η παρακολούθηση πλήκτρων είναι μια πολύ απλή διαδικασία που χρησιμοποιείται για να δούμε ή να καταγράψουμε τόσο την ακολουθία πλήκτρων που εισάγει ένας χρήστης όσο και την απόκριση του υπολογιστή κατά τη διάρκεια μιας διαδραστικής συνεδρίας [13]. Ωστόσο, τέτοια συστήματα παρουσιάζουν ελαττώματα. Η μέθοδος δεν αναλύει την εκτέλεση ενός προγράμματος αλλά μόνο το πάτημα των πλήκτρων. Αυτό σημαίνει πως ένα κακόβουλο πρόγραμμα δεν μπορεί να εντοπιστεί για τις κακοήθεις ενέργειες που εκτελεί. Ταυτόχρονα, τα λειτουργικά συστήματα δεν προσφέρουν ιδιαίτερη υποστήριξη για παρακολούθηση των πλήκτρων που πατιούνται. 4. Βασισμένες σε μοντέλα (Model-based) Τέτοιες προσεγγίσεις ανίχνευσης δηλώνουν ότι ορισμένα σενάρια συμπεραίνονται από ορισμένες άλλες παρατηρούμενες δραστηριότητες. Εάν οι δραστηριότητες αυτές καταγράφονται, είναι πιθανό να εντοπιστούν προσπάθειες εισβολής ελέγχοντας δραστηριότητες που συνεπάγονται ένα συγκεκριμένο σενάριο εισβολής. Ένα τέτοιο σχέδιο αποτελείται από 3 σημαντικά μέρη [3]: εκείνον που προσδοκά (anticipator), εκείνον που σχεδιάζει (planner) και εκείνον που διερμηνεύει (interpreter). Ο anticipator χρησιμοποιεί ενεργά μοντέλα και τα μοντέλα του σεναρίου για να προσπαθήσει να προβλέψει το επόμενο βήμα που αναμένεται να συμβεί στο σενάριο. Ένα μοντέλο σεναρίου είναι μια βάση γνώσεων με προδιαγραφές σεναρίων εισβολών. Ο planner στη συνέχεια μεταφράζει την υπόθεση σε μια μορφή που δείχνει τη συμπεριφορά όπως θα συνέβαινε στο ίχνος ελέγχου. Χρησιμοποιεί την προβλεπόμενη πληροφορία για να σχεδιάσει τι να ψάξει στη συνέχεια. Ο interpreter έπειτα ψάχνει για αυτά τα δεδομένα στο ίχνος ελέγχου. Το σύστημα προχωράει μ αυτόν τον τρόπο, συγκεντρώνοντας περισσότερες αποδείξεις μιας προσπάθειας εισβολής μέχρι να ξεπεραστεί μια τιμή κατώφλι. Σε αυτό το σημείο, σημαίνει συναγερμό. Επειδή ο planner και ο interpreter γνωρίζουν τι ψάχνουν σε κάθε βήμα, οι μεγάλες ποσότητες θορύβου που εντοπίζονται στα δεδομένα ελέγχου μπορούν να φιλτραριστούν, οδηγώντας σε βελτιώσεις απόδοσης. Επιπλέον, το σύστημα μπορεί να προβλέψει την επόμενη κίνηση του εχθρού βάσει του μοντέλου εισβολής. Αυτές οι προβλέψεις μπορούν να χρησιμοποιηθούν για να βεβαιώσουν μια υπόθεση εισβολής, να ληφθούν προληπτικά μέτρα ή να καθορίσουν τι είδους δεδομένα πρέπει να αναζητηθούν στη συνέχεια. 30
31 Ωστόσο, υπάρχουν κάποια κρίσιμα θέματα που σχετίζονται με αυτό το σύστημα [13]. Πρώτον, τα πρότυπα για σενάρια εισβολών πρέπει να αναγνωρίζονται εύκολα. Δεύτερον, τα πρότυπα πρέπει πάντα να συμβαίνουν στη συμπεριφορά που ελέγχεται. Και τέλος, τα πρότυπα πρέπει να ξεχωρίζουν. Δεν πρέπει να συσχετίζονται με καμία άλλη φυσιολογική συμπεριφορά. 5. Αντιστοίχιση Προτύπων (Pattern matching) Η βάση αυτού του μοντέλου είναι η κωδικοποίηση υπογραφών γνωστών εισβολών ως πρότυπα, τα οποία αναζητούνται στα δεδομένα ελέγχου (audit data) [8]. Το μοντέλο αυτό επιχειρεί να ταιριάξει εισερχόμενα συμβάντα με πρότυπα που αναπαριστούν σενάρια εισβολών. Αυτό το μοντέλο βασίζεται στην έννοια του συμβάντος, το οποίο αποτελείται από καταγραμμένες αλλαγές στην κατάσταση του συστήματος ή ενός μέρους του. Μπορεί να αναπαριστά μία μόνο ενέργεια στο σύστημα ενός συγκεκριμένου χρήστη ή μια ενέργεια του συστήματος, ή ακόμα και μια σειρά ενεργειών που καταλήγουν σε μία μόνο παρατηρούμενη εγγραφή. Στα πλεονεκτήματα της προσέγγισης αυτής συγκαταλέγονται η δυνατότητα χρησιμοποίησης πολλαπλών γεγονότων ροής, τα οποία μπορούν να υποστούν επεξεργασία ανεξάρτητα και να συνδυαστούν έπειτα προκειμένου να καταδείξουν κακοήθη δραστηριότητα, η μεταφερσιμότητα, οι άψογες ικανότητες σε περιβάλλοντα real-time και η ικανότητα να εντοπίσει επιθέσεις που τα διαγράμματα μετάβασης καταστάσεων δεν μπορούν. Ένα πρόβλημα με αυτό το μοντέλο είναι ότι μπορεί να εντοπίσει μόνο επιθέσεις βασισμένες σε γνωστές ευπάθειες [13]. Επιπλέον, η αντιστοίχιση προτύπων δεν είναι πολύ χρήσιμη στο να αναπαραστήσει κακώς ορισμένα πρότυπα και δεν είναι εύκολη εργασία να μεταφραστούν γνωστά σενάρια επιθέσεων σε πρότυπα που μπορούν να χρησιμοποιηθούν από αυτό το μοντέλο. Επίσης δεν μπορεί να εντοπίσει επιθέσεις spoofing στις οποίες ένα μηχάνημα προσποιείται ότι είναι κάποιο άλλο χρησιμοποιώντας την IP διεύθυνσή του. 6. Αυτόνομοι Πράκτορες (Autonomous Agents) Αντί για ένα μόνο μεγάλο IDS να υπερασπίζεται το σύστημα, μπορεί να χρησιμοποιηθεί μια προσέγγιση όπου μερικές ανεξάρτητες μικρές διεργασίες λειτουργούν καθώς συνεργάζονται στη συντήρηση του συστήματος [4]. Τα πλεονεκτήματα αυτής της προσέγγισης είναι η απόδοση, η ανεκτικότητα σε λάθη, η επεκτασιμότητα και η κλιμάκωση. Στα μειονεκτήματα συγκαταλέγονται το κόστος τόσων πολλών διεργασιών, μεγάλοι χρόνοι εκπαίδευσης και το γεγονός ότι αν το σύστημα ανατραπεί, αποτελεί πλέον ρήξη της ασφάλειας. Μια ενδιαφέρουσα προοπτική που ανοίγεται είναι αυτή της ενεργής άμυνας, η οποία μπορεί να αποκρίνεται στις εισβολές αντί της παθητικής αναφοράς τους (για παράδειγμα ο τερματισμός ύποπτων συνδέσεων). 31
32 1.11 Μοντέλα Ασφάλειας Τα τελευταία χρόνια έχουν καθοριστεί δύο κύρια μοντέλα ασφάλειας, το IDES και το CIDF μοντέλο [1] [5] [77]. Το IDES μοντέλο αποτελεί τη βάση για πολλές IDS εφαρμογές και προϊόντα [1]. Έχει προταθεί από την Denning (1987) και είναι ανεξάρτητο από οποιοδήποτε σύστημα, περιβάλλον εφαρμογής, ευπάθειες συστημάτων ή τύπο εισβολών, παρέχοντας κατ επέκταση ένα γενικό πλαίσιο (framework) για την ανάπτυξη ενός «γενικού σκοπού» έμπειρου συστήματος ανίχνευσης εισβολών. Μάλιστα το μοντέλο αυτό εμφανίζεται με ελάχιστες τροποποιήσεις σε πολλά εμπορικά συστήματα που έχουν αναπτυχθεί. Το μοντέλο της Denning περιλαμβάνει 5 συστατικά: 1. Υποκείμενα και Αντικείμενα (Subjects and Objects). Υποκείμενα είναι οι ενεργοί υποκινητές των δραστηριοτήτων που καταγράφονται σε ένα σύστημα συνήθως οι χρήστες, ενώ τα αντικείμενα είναι οι πόροι πάνω στους οποίους τα υποκείμενα πραγματοποιούν τις ενέργειες ή λειτουργίες τους αρχεία, κατάλογοι, εντολές, συσκευές κλπ.. Εγγραφές Ελέγχου (Audit Records). Παράγονται από το σύστημα ως απάντηση σε ενέργειες που πραγματοποιούνται ή επιχειρούνται από τα υποκείμενα πάνω στα αντικείμενα είσοδος χρήστη, εκτέλεση εντολών, πρόσβαση σε αρχεία κλπ. Προκειμένου ένα IDS σύστημα να έχει πρακτική εφαρμογή, οι διάφοροι τύποι πληροφοριών και οι θέσεις τους στις εγγραφές ελέγχου πρέπει να είναι γνωστές εκ των προτέρων προκειμένου οι πληροφορίες να υποστούν σωστή επεξεργασία από το μηχανισμό ανίχνευσης εισβολών. 3. Προφίλ (Profiles). Είναι δομές που χαρακτηρίζουν τη συμπεριφορά των υποκειμένων σε σχέση με τα αντικείμενα βάσει στατιστικών μετρικών και μοντέλων παρατηρούμενης δραστηριότητας. Χρησιμοποιούνται για να χαρακτηρίσουν αναμενόμενη φυσιολογική συμπεριφορά στο υπολογιστικό σύστημα. Κλασσικοί τύποι πληροφοριών σε αυτά τα προφίλ είναι η δραστηριότητα εισόδου (login activity) και η πρόσβαση σε αρχεία (file access). 4. Εγγραφές Ανωμαλιών (Anomaly Records). Πρόκειται για ειδοποιήσεις (alarms) που δημιουργούνται οποτεδήποτε κάποια συμπεριφορά η οποία παρατηρείται δεν ταιριάζει με τα προφίλ. 5. Κανόνες Δραστηριοτήτων (Activity Rules). Πρόκειται για ενέργειες που συμβαίνουν όταν κάποια συνθήκη ικανοποιείται, οι οποίες ενημερώνουν τα προφίλ, ανιχνεύουν μη φυσιολογική συμπεριφορά, συσχετίζουν ανωμαλίες με ενδεχόμενες εισβολές και παράγουν αναφορές. 3
33 Αυτό το μοντέλο προνοεί για την ανάπτυξη στατιστικών πληροφοριών της φυσιολογικής συμπεριφοράς, έτσι ώστε η παράξενη ή παράνομη συμπεριφορά να μπορεί να αναγνωριστεί και να αναφερθεί. Το CIDF μοντέλο καθορίζει ένα σύνολο συστατικών που περιγράφει ένα σύστημα ανίχνευσης εισβολών, τα οποία αναλύονται παρακάτω [5] [77]. Ένα σύνολο αρχών που περιγράφει ικανοποιητικά τα Συστήματα Ανίχνευσης Εισβολών είναι το «Κοινό Πλαίσιο Ανίχνευσης Εισβολών» - Common Intrusion Detection Framework (CIDF). Το CIDF αναπτύχθηκε από μια ομάδα εργασίας ο αρχικός σχηματισμός της οποίας προέκυψε από την συνεργασία ανάμεσα στην DARPA (Defence Advanced Research Projects Agency), η οποία χρηματοδοτούσε σχετικά προγράμματα, και τους οργανισμούς / ινστιτούτα που ανταποκρίθηκαν σε αυτά τα προγράμματα. Το CIDF μοντέλο καθορίζει ένα σύνολο συστατικών που περιγράφει ένα σύστημα ανίχνευσης εισβολών, τα οποία αναλύονται παρακάτω. 1. Οι Γεννήτριες Γεγονότων (Event Generators ή E-boxes) λαμβάνουν πληροφορίες από πηγές γεγονότων μέσα από το υπολογιστικό σύστημα. Τα γεγονότα αυτά μπορούν να προέρχονται από στοιχεία του δικτύου, από εφαρμογές ή οποιοδήποτε άλλο αντικείμενο που µας ενδιαφέρει. Ο σκοπός είναι να παρέχουν πληροφορίες για γεγονότα / συμβάντα στο υπόλοιπο σύστημα.. Οι Αναλυτές Γεγονότων (Event Analyzers ή A-boxes) λαμβάνουν πληροφορίες από τις γεννήτριες και επιχειρούν να αναλύσουν τα δεδομένα, αναζητώντας ασφαλώς πιθανές εισβολές. Για το σκοπό αυτό μπορούν να χρησιμοποιηθούν πολλαπλοί μηχανισμοί όπως η στατιστική ανάλυση και η αναγνώριση προτύπων αναζητώντας ακολουθίες γεγονότων. 3. Η αποθήκευση γεγονότων και πληροφοριών γίνεται µε τις Βάσεις Δεδομένων Γεγονότων (Event Databases ή D-boxes). Τόσο τα γεγονότα χαμηλού επιπέδου (raw events) όσο και τα υψηλού επιπέδου (που έχουν μεταφραστεί από τους αναλυτές) είναι θεμιτό να αποθηκεύονται σε μόνιμη βάση, ώστε να είναι διαθέσιμα αργότερα. 4. Οι Μονάδες Απόκρισης (Event Response Units ή R-boxes) λαμβάνουν τις πληροφορίες αυτές που σχετίζονται µε την ασφάλεια του συστήματος και εκκινούν τον αντίστοιχο μηχανισμό απόκρισης για να ματαιώσουν ή να αποτρέψουν κάποια ηλεκτρονική επίθεση. Πιθανές αποκρίσεις είναι ο τερματισμός συγκεκριμένων λειτουργιών (killing processes), ο επαναπροσδιορισμός των συνδέσεων και η αλλαγή των δικαιωμάτων πρόσβασης στα αρχεία του συστήματος. 33
34 Κεφάλαιο Παρουσίαση Προϊόντων IDS 34
35 Η έρευνα για την ανάπτυξη συστημάτων ανίχνευσης εισβολών είναι πρόσφατη [6] [77]. Τα τελευταία 0 χρόνια μάλιστα παρουσιάστηκαν αρκετά βιώσιμα συστήματα, μερικά από τα οποία υπήρξαν προσοδοφόρα εμπορικά εγχειρήματα. Σε αυτήν την ενότητα ακολουθεί μια περίληψη κάποιων συστημάτων ανίχνευσης εισβολών που κυκλοφορούν στην αγορά..1 Shadow (US Navy Naval Surface Warfare Center) Το Shadow (Secondary Heuristics for Defensive Online Warfare) είναι ένα δωρεάν network-based σύστημα ανίχνευσης κατάχρησης που τρέχει σε Unix [6] [77]. Πραγματοποιεί ανάλυση TCP/IP κυκλοφορίας και αποτελείται από συστατικά: έναν αισθητήρα και ένα σταθμό ανάλυσης. Ο αισθητήρας «κάθεται» στο υπό α- νάλυση δίκτυο και καταγράφει όλη την κυκλοφορία. Τα ακατέργαστα αρχεία δεδομένων από τον αισθητήρα στέλλονται μέσω ασφαλούς καναλιού στο σταθμό ανάλυσης για αναγνώριση προτύπων. Το Shadow απαιτεί εκτεταμένη χειροκίνητη ανάλυση και απόκριση σε γεγονότα. Σε αντίθεση με άλλα εμπορικά συστήματα, που αυτοματοποιούν τουλάχιστον ένα μέρος της ανάλυσης, αυτές οι εργασίες αφήνονται στα χέρια ειδικών ασφάλειας και απαιτούν πολλή εμπειρία και επιδεξιότητα.. RealSecure (Internet Security Systems) Το RealSecure είναι ένα εμπορικό, ολοκληρωμένο host- και network-based σύστημα ανίχνευσης κατάχρησης που τρέχει σε Windows και μερικές πλατφόρμες Unix [6]. Ο ανιχνευτής RealSecure λειτουργεί με δικτυακή και τερματική λογική και έχει σύστημα απόκρισης που λειτουργεί σε πραγματικό χρόνο (real time response). Χρησιμοποιεί προκαθορισμένα σχήματα επιθέσεων ή εσφαλμένων χρήσεων, για να ανιχνεύσει ενέργειες που παραβιάζουν τη δεδηλωμένη πολιτική ασφάλεια της επιχείρησης. Η αρχιτεκτονική του RealSecure αποτελείτε από τρεις βασικές λειτουργικές μονάδες: Μηχανή του RealSecure (RealSecure Engines) Εντολοδόχους του RealSecure (RealSecure Agents) Γενικός διαχειριστής (RealSecure Manager) Οι εντολοδόχοι (agents) είναι οι ομόλογοι της μηχανής του RealSecure βασιζόμενοι όμως σε τερματική λογική (δηλ. τρέχουν σε αυτόνομα τερματικά στοιχεία του δικτύου). Οι εντολοδόχοι αναλύουν τα αρχεία ημερολογίου των τερματικών με παρόμοιο τρόπο με αυτόν που χρησιμοποιεί η μηχανή του RealSecure για την ανάλυση των πακέτων του δικτύου. Εφόσον έχει ανιχνευτεί επίθεση ο εντολοδόχος έχει την δυνατότητα να τερματίσει διεργασίες του συστήματος ή να απενεργοποιήσει λογαριασμούς χρηστών. Οι εντολοδόχοι του RealSecure έχουν ακόμα την δυνατότητα να αναδιαμορφώσουν τόσο την μηχανή όσο και τους firewalls, 35
36 έτσι ώστε να εμποδίσουν / μπλοκάρουν πιθανές μελλοντικές επιθέσεις / εισβολές από συγκεκριμένες πηγές. Ο γενικός διαχειριστής του RealSecure είναι μια κονσόλα διαχείρισης που δίνει την δυνατότητα συνολικής παρακολούθησης με γραφικό περιβάλλον όλου του συστήματος καθώς και της μηχανής και των εντολοδόχων που προαναφέρθηκαν. Η κονσόλα υποστηρίζει τρεις βασικές υπηρεσίες: 1. Κεντρική παρουσίαση συναγερμών σε πραγματικό χρόνο. Κεντρική διαχείριση δεδομένων 3. Κεντρική ρύθμιση (configuration) της μηχανής του RealSecure.3 Network Flight Recorder (Network Flight Recorder, Inc.) Το Network Flight Recorder (NFS) δεν μπορεί να χαρακτηριστεί ως ένα αμιγές σύστημα ανίχνευσης ηλεκτρονικών εισβολών, παρότι έχει αρκετά χαρακτηριστικά ενός IDS [77]. Όπως καταδεικνύει και το όνομα του προϊόντος το Network Flight Recorder σχεδιάστηκε με πρωταρχικό στόχο την επίτευξη μιας μεταμοντέρνας ανάλυσης των γεγονότων που συμβαίνουν σε ένα δίκτυο, όπως για παράδειγμα όταν ένας administrator θέλει να διαπιστώσει τι πραγματικά έγινε στο δίκτυο κατά την εισβολή ή κάποια άλλη ανωμαλία του συστήματος. Το Network Flight Recorder παρέχει δυνατότητες καταγραφής και φιλτραρίσματος της κίνησης στο δίκτυο με σκοπό την καταχώρηση σε αρχεία ή την στατιστική ανάλυση και μπορεί να ρυθμιστεί έτσι ώστε να πυροδοτεί (trigger) συναγερμό σε συγκεκριμένα γεγονότα. Σύμφωνα με την ομάδα που το ανάπτυξε, το Network Flight Recorder σχεδιάστηκε για να συμπληρώνει ένα σύστημα ανίχνευσης ηλεκτρονικών εισβολών..4 CyberCorp Monitor (Network Associates) Η Network Associates παρέχει μια σειρά από προϊόντα ανίχνευσης ηλεκτρονικών εισβολών υπό την ονομασία CyberCorp. Τα CyberCorp Network και CyberCorp Server είναι τμήματα του συνόλου προγραμμάτων της Network Associates με την ονομασία Net Tools Secure. To CyberCorp Network (CCN) παρέχει ανίχνευση ηλεκτρονικών εισβολών σε πραγματικό χρόνο αξιοποιώντας πληροφορίες από το τοπικό δίκτυο. Το CyberCorp Server (CCS) εστιάζει στην προστασία των servers και των άλλων τερματικών μέσα στο δικτυακό περιβάλλον. Είναι ένας συμβιβασμός μεταξύ network-based και host-based συστημάτων ανίχνευσης κατάχρησης. Υπάρχει στον υπολογιστή υπηρεσίας αλλά εκτός από την εξέταση των log files στον host, είναι ικανό να πραγματοποιεί packet sniffing, το οποίο ωστόσο περιορίζεται στα πακέτα που ταξιδεύουν από και προς τον υπο- 36
37 λογιστή στον οποίο βρίσκεται. Αυτό έχει ως αποτέλεσμα να είναι δυσκολότερη η εφαρμογή του απ ό,τι σε συστήματα όπως το RealSecure, αφού θα πρέπει να εγκατασταθεί σε κάθε υπολογιστή προκειμένου να δημιουργήσει μια πλήρη εικόνα της δραστηριότητας του δικτύου. Το CyberCorp έχει δυο βασικές λειτουργικές μονάδες: Τους αισθητήρες CyberCorp (sensors) Το διακομιστή διαχείρισης CyberCorp (management server) Τα αντικείμενα στα οποία το CyberCorp ανιχνεύει επιθέσεις συμπεριλαμβάνουν: Unix & Windows/Windows NT τερματικά Δικτυακές Υπηρεσίες (network Services) Web Servers & browsers Διάφορες εφαρμογές Σωρούς πρωτοκόλλων (Protocol stacks).5 POLYCENTER (Compaq) Το POLYCENTER είναι ανιχνευτής ηλεκτρονικών εισβολών που λειτουργεί βασισμένο σε τερματική λογική που σημαίνει ότι είναι εγκατεστημένο στα τερματικά που είναι κατανεμημένα μέσα στo δίκτυο [77]. Εντοπίζει εισβολές και προσπάθειες εισβολής εξετάζοντας τα αρχεία ελέγχου στα επιμέρους τερματικά. Το POLYCENTER μπορεί να ρυθμιστεί έτσι ώστε να ανιχνεύει πολλαπλές κατηγορίες εισβολών όπως: Προσπάθειες εκτέλεσης προγραμμάτων χωρίς εξουσιοδότηση Ύποπτες μεταφορές αρχείων μέσα στο δίκτυο Ύποπτες ενέργειες προς κάποιο τερματικό, χρήστη ή αρχείο Δραστηριότητες εκτός του κανονικού ωραρίου εργασίας Η ανάλυση των δεδομένων ελέγχου χρησιμοποιεί διαδικασίες τεχνητής νοημοσύνης (AI). Οι πληροφορίες που υπάρχουν σε σχέση με τα γνωστά σενάρια επίθεσης χρησιμοποιούνται από το POLYCENTER, για να εντοπιστούν ύποπτες δραστηριότητες που θα μπορούσαν να υποδείξουν επίθεση προς κάποιο τερματικό στοιχείο του δικτύου. Ένα μοντέλο «περιπτώσεων» (case model) χρησιμοποιείται για να αναθέσει σε συγκεκριμένους εικονικούς εντολοδόχους του συστήματος ανίχνευσης (agents) την παρακολούθηση ύποπτων συμπεριφορών. Ο εικονικός 37
38 εντολοδόχος παρακολουθεί τον ύποπτο και τα αποδεικτικά στοιχεία (log files) της υπόθεσης. Με την ανάλυση των γεγονότων ασφάλειας (security events) ανά υπόθεση / περίπτωση, το POLYCENTER είναι σε θέση να διακρίνει τις πραγματικές απειλές από τις απλές λανθασμένες συμπεριφορές..6 NetRanger (Cisco Systems, Inc) Το NetRanger είναι ένα πραγματικού χρόνου σύστημα ανίχνευσης ηλεκτρονικών εισβολών σχεδιασμένο έτσι ώστε να εντοπίζει επιθέσεις μέσα στην δικτυακή υ- ποδομή των επιχειρήσεων [6] [77]. Είναι αμιγώς σύστημα με δικτυακή λογική και αναλύει διεξοδικά τα πακέτα που κυκλοφορούν στο δίκτυο. Το μοντέλο ανίχνευσης «εσφαλμένης χρήσης» χρησιμοποιείται στον εντοπισμό παραβιάσεων της πολιτικής ασφάλειας της επιχείρησης. Ακόμα το NetRanger έχει δυνατότητες απόκρισης σε πραγματικό χρόνο με ενέργειες όπως ο τερματισμός συγκεκριμένων συνδέσεων και το μπλοκάρισμα αναμενόμενων προσπαθειών εισβολής. Το NetRanger αποτελείται από τρεις βασικές λειτουργικές μονάδες: Αισθητήρες (Sensors) Οδηγό (Director) Διαδικασίες Post Office.7 Intruder Alert (Axent Technologies) Το Intruder Alert είναι ένα πραγματικού χρόνου, βασισμένο σε κανόνες σύστημα ανίχνευσης ηλεκτρονικών εισβολών [77]. Παρακολουθεί τα ακολουθιακά δεδομένα ελέγχου των τερματικών μέσα σε ένα κατανεμημένο περιβάλλον. Η ανίχνευση των προσπαθειών εισβολών βασίζεται σε κανόνες ή απρόβλεπτα λάθη του συστήματος (exceptions). Η μηχανή που βασίζεται σε κανόνες αναζητά συγκεκριμένες και προκαθορισμένες ακολουθίες δεδομένων. Οι ακολουθίες αυτές ονομάζονται «χνάρια» (footprints) και αναγνωρίζουν μονοσήμαντα ανώμαλες συμπεριφορές / πλάνα μέσα στα ακολουθιακά δεδομένα ελέγχου των τερματικών (audit trails). Το Intruder Alert αποτελείτε από τρεις βασικές λειτουργικές μονάδες: Interface κονσόλας (interface concole) Γενικός διαχειριστής (Manager) Εντολοδόχοι (Agent) 38
39 .8 Άλλα εμπορικά IDS Στην ενότητα αυτή γίνεται μια απλή αναφορά κάποιων επιπλέον γνωστών συστημάτων ανίχνευσης ηλεκτρονικής εισβολής. Συγκεκριμένα αναφέρουμε τα εξής: Kane Security Monitor (Security Dynamics) CMDS (Science Application International Corporation) SecureNet Pro (MimeStar, Inc.) Session Wall-3 (AbirNet) Entrax (Centrax Corporation) INTOUCH INSA (Touch Technologies, Inc.) NIDES (SRI International) ID-Trak (Internet Tools, Inc.) SecureCom Suite (ODS Networks) 39
40 Κεφάλαιο 3 Μέθοδοι Πολυμεταβλητής Στατιστικής Ανάλυσης στην Ανίχνευση Εισβολών 40
41 Στη βιβλιογραφία υπάρχει μια πλειάδα εργασιών και ερευνών που ασχολούνται με ανίχνευση εισβολών με ποικίλες μεθόδους, όπως για παράδειγμα με μεθόδους clustering, νευρωνικών δικτύων, στατιστικές μεθόδους, εξόρυξης δεδομένων (data mining), μηχανικής μάθησης (machine learning) κλπ. Η ακόλουθη ενότητα αφορά σε εκείνες τις ερευνητικές εργασίες οι οποίες εστιάζουν στη χρήση στατιστικών προσεγγίσεων για την ανίχνευση ανωμαλιών. Πριν προχωρήσουμε στην ανάλυση ορισμένων στατιστικών μεθόδων που έχουν προταθεί, επιγραμματικά μπορούμε να αναφέρουμε κάποιες από τις προσπάθειες που έχουν γίνει προς αυτήν την κατεύθυνση. Οι Ye et al [7] [8] προτείνουν πιθανοκρατικές τεχνικές (probabilistic) ανίχνευσης εισβολών, συμπεριλαμβανομένων του ελέγχου T του Hotelling, του πολυμεταβλητού ελέγχου X και των αλυσίδων Markov. Αυτοί οι έλεγχοι εφαρμόζονται σε δεδομένα ελέγχου για να ερευνηθούν οι ιδιότητες της συχνότητας και της διάταξής τους. Οι Taylor et al [9] [30] παρουσιάζουν μια μέθοδο για εντοπισμό εισβολών σε δίκτυα που απευθύνεται στο πρόβλημα της παρακολούθησης και καταγραφής κίνησης δικτύων υψηλών ταχυτήτων και των χρονικών περιορισμών των διαχειριστών για το χειρισμό της ασφάλειας του δικτύου. Χρησιμοποιούν πολυμεταβλητές στατιστικές τεχνικές, κυρίως Ανάλυση Συστάδων (Cluster Analysis) και Ανάλυση Κυρίων Συνιστωσών (Principal Component Analysis PCA) για να ε- ντοπίσουν ομάδες στα παρατηρούμενα δεδομένα. Οι Staniford-Chen et al [31] απευθύνονται στο πρόβλημα εντοπισμού εισβολέων που κρύβουν την ταυτότητά τους «περνώντας» μέσω μιας αλυσίδας πολλαπλών μηχανημάτων. Χρησιμοποιούν την PCA για να συμπεράνουν την καλύτερη επιλογή αποτύπωσης παραμέτρων από τα δεδομένα. Εισάγουν τα αποτυπώματα, τα οποία αποτελούν σύντομες περιλήψεις του περιεχομένου μιας σύνδεσης. Στη συνέχεια ακολουθεί μια σύντομη αναφορά βασικών στατιστικών εννοιών και έπειτα η παρουσίαση των βασικότερων τεχνικών και προσεγγίσεων που έχουν προταθεί στη βιβλιογραφία για τον εντοπισμό ανωμαλιών κάνοντας χρήση στατιστικών μεθόδων. 41
42 3.1 Στατιστικό Υπόβαθρο Μέση τιμή, Τυπική απόκλιση και Διακύμανση Οι βασικότερες παράμετροι που χρησιμοποιούνται για την περιγραφή της κατανομής μιας τυχαίας μεταβλητής X είναι η αναμενόμενη τιμή της ή αλλιώς ο μέσος της, η διακύμανση και η θετική τετραγωνική ρίζα της διακύμανσης, η οποία καλείται τυπική απόκλιση [74]. μ = Ε[ Χ ] Var [ ] ( X ) = σ = Ε ( Χ μ) σ = Var ( X ) = όπου μ είναι η αναμενόμενη τιμή ή μέσος, σ η διακύμανση και σ η τυπική α- πόκλιση. Ο μέσος μπορεί να θεωρηθεί ως το μέτρο του κέντρου καθώς δείχνει το κέντρο πυκνότητας της κατανομής. Η διακύμανση αποτελεί την πιο ευρέως χρησιμοποιούμενη μετρική για να εκφράσει πόσο κοντά στο μέσο είναι συγκεντρωμένη η κατανομή. Αυτές είναι οι θεωρητικές παράμετροι της τυχαίας μεταβλητής και είναι σπάνια γνωστές στην πράξη. Συνήθως έχουμε έναν πληθυσμό, μια μεγάλη ομάδα αντικειμένων για την οποία θα θέλαμε να προσεγγίσουμε αυτές τις παραμέτρους από ένα σχετικά μικρό δείγμα που λαμβάνεται από τον εν λόγω πληθυσμό Στατιστικά στοιχεία του δείγματος Δεδομένου ενός τυχαίου δείγματος μεγέθους n του πληθυσμού, είναι δυνατόν να εκτιμήσουμε τις παραπάνω παραμέτρους με το δειγματικό μέσο X, τη δειγματική διακύμανση S και τη δειγματική τυπική απόκλιση S [74]. σ 1 X = n S = S = i = 1 n ( Xi X ) i = 1 S n X i n 1 4
43 Αν το σύνολο δεδομένων περιέχει μια παρατήρηση της X για κάθε μέλος του πληθυσμού, δεν είναι δείγμα. Τότε, ο μέσος μ του πληθυσμού δεν εκτιμάται α- πλώς, αλλά είναι στην ουσία ο αριθμητικός μέσος των παρατηρήσεων μ = x = 1 n x n i = 1 i και η διακύμανση σ του πληθυσμού δίνεται από σ n i = 1 ( x ) i x =. n Έλεγχος Υποθέσεων Κατά τον έλεγχο υποθέσεων υπάρχει μια βασική υπόθεση για την τιμή της παραμέτρου, η οποία δηλώνεται στην μηδενική υπόθεση H 0 και κάτι που πρέπει να ανιχνευτεί, μια υπόθεση που προτείνεται από τον ερευνητή και καλείται εναλλακτική υπόθεση H 1. Η μηδενική υπόθεση σχετίζεται με τη μηδενική τιμή θ 0, η ο- ποία θα μπορούσε να είναι η πραγματική τιμή της θ. Η απόφαση για την αποδοχή της εναλλακτικής υπόθεσης ή όχι χρησιμοποιεί ένα στατιστικό τεστ. Η κατανομή πιθανοτήτων του πρέπει να είναι γνωστή στην περίπτωση που η μηδενική υπόθεση είναι αληθής, δηλαδή θ = θ0. Τότε οι κρίσιμες τιμές για το στατιστικό έλεγχο που προκαλούν την απόρριψη της μηδενικής υπόθεσης καθορίζονται σύμφωνα με το επίπεδο σημαντικότητας α του ελέγχου. Το α είναι η πιθανότητα να παρατηρηθεί μια κρίσιμη τιμή ακόμα και αν ισχύει θ = θ0. Η εσφαλμένη απόρριψη και αποδοχή της H 0 καλούνται αντίστοιχα σφάλμα Τύπου Ι και σφάλμα Τύπου ΙΙ Έλεγχος Kolmogorov-Smirnov Ο έλεγχος K-S χρησιμοποιείται προκειμένου να αποφανθούμε εάν ένα δείγμα προέρχεται από ένα πληθυσμό με μια συγκεκριμένη κατανομή και βασίζεται στην συνάρτηση εμπειρικής κατανομής (ECDF). Ο έλεγχος K-S καθορίζεται ως εξής: H 0 : τα δεδομένα ακολουθούν μια συγκεκριμένη κατανομή H a : τα δεδομένα δεν ακολουθούν τη συγκεκριμένη κατανομή Το στατιστικό K-S είναι i 1 i D = max F Yi, F Y 1 i N N N ( ) ( ) i 43
44 όπου F είναι η θεωρητική αθροιστική συνάρτηση κατανομής, της κατανομής η οποία ελέγχεται, η οποία πρέπει να είναι συνεχής και πλήρως καθορισμένη (δηλαδή οι παράμετροι θέσης, κλίμακας και σχήματος δεν μπορούν να εκτιμούνται από τα δεδομένα) N το πλήθος των σημείων και Y i τα διατεταγμένα σημεία. Ένα ελκυστικό χαρακτηριστικό του συγκεκριμένου ελέγχου είναι πως η κατανομή του K-S ελέγχου δεν εξαρτάται από την αθροιστική συνάρτηση κατανομής που ελέγχεται. Ένα ακόμη πλεονέκτημα είναι πως πρόκειται για έναν ακριβή έλεγχο. Ωστόσο, ο έλεγχος K-S έχει κάποιους σημαντικούς περιορισμούς: 1. Εφαρμόζεται μόνο σε συνεχείς κατανομές. Τείνει να είναι περισσότερο ευαίσθητος κοντά στο κέντρο της κατανομής απ ό,τι στα άκρα 3. Ίσως ο πιο σημαντικός περιορισμός είναι πως η κατανομή πρέπει να είναι πλήρως καθορισμένη. Δηλαδή, εάν οι παράμετροι θέσης, κλίμακας και σχήματος εκτιμούνται από τα δεδομένα, η κρίσιμη περιοχή του ελέγχου K- S δεν είναι πλέον έγκυρη. Εξαιτίας των δύο τελευταίων περιορισμών, πολλοί προτιμούν τον έλεγχο Anderson-Darling, ο οποίος ωστόσο είναι διαθέσιμος για λίγες συγκεκριμένες κατανομές. Ο έλεγχος A-D χρησιμοποιείται προκειμένου να ελέγξει εάν ένα δείγμα δεδομένων προέρχεται από μια συγκεκριμένη κατανομή. Είναι παραλλαγή του K-S ελέγχου και δίνει περισσότερο βάρος στις άκρες της κατανομής απ ό,τι ο K-S έ- λεγχος. Ο K-S έλεγχος είναι ανεξάρτητος κατανομής υπό την έννοια ότι οι κρίσιμες τιμές δεν εξαρτώνται από τη συγκεκριμένη κατανομή η οποία ελέγχεται. 3. Κινητοί Μέσοι Ο μέσος, η τυπική απόκλιση και η διακύμανση είναι κάπως περιορισμένα στατιστικά μέτρα για μεγάλα σύνολα δεδομένων. Το κύριο πρόβλημα προκύπτει από την ανάγκη να αποθηκευτούν όλα τα παρελθοντικά δεδομένα. Ένα άλλο ζήτημα είναι πως τα μέτρα αυτά δεν είναι πλέον ευαίσθητα σε αλλαγές όταν η ποσότητα των δεδομένων αυξάνεται. Για την αντιμετώπιση αυτών των θεμάτων, έχουν προταθεί διαφορετικοί τύποι κινητών μέσων [74]. Οι πιο βασικοί κινητοί μέσοι απαιτούν την αποθήκευση των N πιο πρόσφατων μονάδων δεδομένων, οπότε και οι πιο παλιές τιμές μπορούν να αγνοηθούν. Αυτά τα δεδομένα έπειτα μπορούν να χρησιμοποιηθούν για τους υπολογισμούς του μέσου και της τυπικής απόκλισης. 44
45 Οι κινητοί μέσοι χρησιμοποιούνται ευρέως για να εξομαλύνουν (smooth) τις βραχυπρόθεσμες διακυμάνσεις στα δεδομένα και για να εντοπίσουν τη μακροπρόθεσμη κατεύθυνση της κατανομής των χρονικά εξαρτημένων γεγονότων. Για παράδειγμα η παρακολούθηση του χρηματιστηρίου και ο στατιστικός έλεγχος διαδικασιών είναι πεδία που κάνουν εκτεταμένη χρήση αυτών των τεχνικών. Εδώ παρουσιάζονται τρεις κοινοί κινητοί μέσοι, που ονομάζονται Απλός Κινητός Μέσος (Simple Moving Average SMA), Σταθμισμένος Κινητός Μέσος (Weighted Moving Average WMA) και Εκθετικά Σταθμισμένος Κινητός Μέσος (Exponentially Weighted Moving Average EWMA) Simple Moving Average Λέγεται επίσης και Standard Moving Average. Το μοντέλο αυτό χρησιμοποιεί ένα παράθυρο των n πιο πρόσφατων δειγμάτων για τον υπολογισμό του μέσου αθροίζοντάς τα και διαιρώντας με τον αριθμό των δειγμάτων που χρησιμοποιήθηκαν. MA ( n ) = 1 n x n i = 1 όπου n το μέγεθος του παραθύρου. Το μοντέλο του κινητού μέσου μπορεί να εξομαλύνει τυχαίες μεταβολές στα δεδομένα τόσο καλύτερα, όσο μεγαλύτερο είναι το μέγεθος παραθύρου και επομένως να δείξει τη μακροπρόθεσμη κατεύθυνση στην οποία κινούνται οι τιμές των δεδομένων. Ωστόσο, όσο πιο μεγάλο είναι το παράθυρο, τόσο περισσότερο η τάση που δίνεται από το μοντέλο υστερεί της πραγματικής τάσης. 3.. Weighted Moving Average Σε ορισμένες περιπτώσεις, τα πιο πρόσφατα δεδομένα έχουν μεγαλύτερη σημασία από τα πιο παλιά. Ο WMA δίνει λύση σε αυτό το ζήτημα. Το μοντέλο δίνει ένα διαφορετικό βάρος σε κάθε δείγμα δεδομένων πολλαπλασιάζοντας την τιμή των δεδομένων με το αντίστοιχο βάρος προτού προσθέσει όλες τις τιμές. WMA ( n ) = wix n i = 1 i i με βάρη w > 0 i τέτοια ώστε n i = 1 w i = 1. Εναλλακτικά, εάν το άθροισμα των βαρών είναι διάφορο του 1, το άθροισμα των τιμών πρέπει να διαιρεθεί με το άθροισμα των βαρών, δηλαδή 45
46 WMA ( n ) = n wix 1 n i 1 w = i i = 1 Αναθέτοντας μικρότερα βάρη στα παλιότερα δείγματα από ό,τι στα καινούρια είναι πιθανό να δοθεί περισσότερη σχετικότητα στα πιο πρόσφατα δεδομένα. Εάν όλα τα βάρη έχουν την ίδια τιμή, ο WMA ουσιαστικά είναι ο SMA. Υπάρχουν διαφορετικά συστήματα απόδοσης βαρών, ένα από τα οποία έχει αποδειχθεί ιδιαίτερα χρήσιμο είναι το γεωμετρικό σύστημα γνωστό και ως εκθετική απόδοση βαρών Exponentially Weighted Moving Average Ο EWMA έχει τις ρίζες του στο Στατιστικό Έλεγχο Διαδικασιών (Statistical Process Control SPC), όπου έχουν χρησιμοποιηθεί διαφορετικά διαγράμματα ελέγχου για να παράσχουν πληροφορία σχετική με τη λειτουργία μιας διαδικασίας. Το μοντέλο αρχικά προτάθηκε από τον Roberts το 1959 (Control Chart Tests Based On Geometric Moving Averages, Technometrics) όπου το στατιστικό μέτρο καθορίζεται από τον αναδρομικό τύπο i z i = ( 1 λ ) zi 1 + λx i για 0 < λ 1. Για λ = 1 το στατιστικό μέτρο παρακολουθεί μόνο την τρέχουσα τιμή, ενώ τα παρελθοντικά δεδομένα δεν έχουν καμία σημασία. Επίσης z0 = μ0, όπου μ 0 η εκτίμηση του μέσου της διαδικασίας. Η προηγούμενη EWMA τιμή πολλαπλασιάζεται με τον παράγοντα ( 1 λ ), ο οποίος καλείται παράγοντας εξομάλυνσης (smoothing factor). Από τον αναδρομικό τύπο που αναφέρθηκε παραπάνω, η σχέση ανάμεσα σε δύο προηγούμενους κινητούς μέσους δεν είναι απαραίτητα ξεκάθαρη. Το σύστημα απόδοσης βαρών είναι πιο εμφανές αν γράψουμε 1 z = λx + λ( 1 λ) x + λ( 1 λ) x + K i i i 1 i i i 1 i K+ λ ( 1 λ) x + λ( 1 λ) x + ( 1 λ) μ 1 όπου i 0. Τώρα γίνεται πιο εύκολα αντιληπτό το σύστημα εκθετικής απόδοσης βαρών όπου τα τρέχοντα δεδομένα λαμβάνουν βάρος λ και τα δεδομένα της χρονικής στιγμής i j λαμβάνουν βάρος λ (1 λ) j. Εάν το ενδιαφέρον είναι στην μακροπρόθεσμη τάση στα δεδομένα, θα έπρεπε να χρησιμοποιούνται μικρότερες τιμές για το λ. Εάν τα ιστορικά δεδομένα παίζουν μικρό ρόλο και η βραχυπρόθεσμη τάση παρουσιάζει το μεγαλύτερο ενδιαφέρον, θα έπρεπε να ανατίθενται μεγάλες τιμές στο λ. 0 46
47 Ο EWMA είναι βασικά ένας WMA με άπειρο μέγεθος παραθύρου και συγκεκριμένο σύνολο βαρών που εκλαμβάνονται ως εκθετικά συγκεκριμένου παράγοντα. Επομένως το EWMA μοντέλο θα μπορούσε να προσεγγιστεί με τον WMA ( n ) με n i βάρη wi = λ( 1 λ), όταν το n είναι αρκετά μεγάλο. Αυτό γίνεται περισσότερο εμφανές χρησιμοποιώντας τον τύπο z i = i n = 1 i n ( 1 λ ) x ( i n) + 1 i n = 1 ( 1 λ ) n 1 Περισσότερο διαισθητική σχέση ανάμεσα στο λ και την εξασθένηση της σημαντικότητας των παρελθοντικών δεδομένων δίνεται μέσω της πρόχειρης προσέγγισης με τον SMA(n) όπου η σχέση μεταξύ λ και n είναι λ = n + 1. Παρά το γεγονός πως το μοντέλο EWMA χρησιμοποιεί όλα τα παρελθοντικά δεδομένα, ελαχιστοποιεί τις απαιτήσεις για αποθήκευση δεδομένων συγχρόνως. Χάρη στον αναδρομικό τύπο, είναι αρκετό να γνωρίζει μόνο την προηγούμενη τιμή για το στατιστικό EWMA, τον παράγοντα εξομάλυνσης και την τρέχουσα τιμή του παρακολουθούμενου στατιστικού μέτρου. Ο SMA και ο WMA απαιτούν να αποθηκεύονται οι τιμές για ολόκληρο το παράθυρο προκειμένου να πραγματοποιηθούν οι υπολογισμού. Γενικά η κατεύθυνση είναι πιο ομαλή όταν χρησιμοποιούνται περισσότερα δεδομένα για τους υπολογισμούς των μέσων, ωστόσο αυξάνεται ο χρόνος καθυστέρησης. 3.3 Διαγράμματα Ελέγχου EWMA Αν και ο EWMA χρησιμοποιείται σήμερα ευρέως σε οικονομικές εφαρμογές, α- ναπτύχθηκε αρχικά για χρήση σε διαγράμματα ελέγχου. Στο στατιστικό έλεγχο διαδικασιών, μια διαδικασία παραγωγής λαμβάνεται ως μετρήσιμη οντότητα με μια κατανομή. Η συνολική ποιότητα του προϊόντος που παράγεται από τη διαδικασία θεωρείται εξαρτημένο από τις μεταβολές του μέσου της διαδικασίας, η ο- ποία πρέπει να διατηρηθεί στο ίδιο επίπεδο και οι μεταβολές όσο το δυνατόν πιο μικρές. Η βασική προσέγγιση είναι πως αλλαγή στην κατανομή της διαδικασίας μπορεί να συμβεί μόνο εξαιτίας της εμφάνισης προβλήματος στη διαδικασία. Τότε λέμε πως όταν αλλάζει η κατανομή, η διαδικασία είναι εκτός ελέγχου ή ασταθής (out of control unstable). Η αλλαγή στην κατανομή μπορεί να εμφανιστεί ως μεταβολή του μέσου, της διακύμανσης ή άλλων χαρακτηριστικών. Ένα διάγραμμα ελέγχου είναι μια συχνά χρησιμοποιούμενη τεχνική για την παρακολούθηση των κατανομών των διαδικασιών. Συνήθως όταν αναλύεται η κατάσταση μιας διαδικασίας, δύο είδη πληροφοριών χρησιμοποιούνται: η θέση της κατανομής και το πλάτος της κατανομής. Έπειτα αναπτύσσονται δύο διαγράμματα. Το διάγραμμα που ακολουθεί τους μέ- 47
48 σους του δείγματος δίνει πληροφορίες για τη θέση της κατανομής και τις κινήσεις της και μπορεί να ανιχνεύσει για παράδειγμα την εμφάνιση συστηματικού σφάλματος στην διαδικασία. Το διάγραμμα που ακολουθεί την τυπική απόκλιση περιγράφει την τρέχουσα μεταβολή της διαδικασίας που είναι η φυσική μεταβολή που υπάρχει σε κάθε διαδικασία και ελέγχει το πλάτος της κατανομής της διαδικασίας. Η βασική υπόθεση είναι πως οποιαδήποτε στιγμή η διαδικασία έχει ένα μέσο μ = μ0 + δ, όπου το μ 0 είναι ο ονομαστικός μέσος της διαδικασίας και το δ αντιπροσωπεύει την απόκλιση από την ονομαστική τιμή, η οποία είναι ίση με 0 όταν δεν υπάρχει κανένα πρόβλημα. Επομένως, η διαδικασία του διαγράμματος ελέγχου μπορεί να ληφθεί ως μια σειρά αποφάσεων για το αν η διαδικασία λειτουργεί όπως θα έπρεπε ή όχι. Το διάγραμμα ελέγχου παρέχει μια οπτική περίληψη των δεδομένων που συλλέγονται για συνεχή έλεγχο της κατάστασης της διαδικασίας. Η βασική γραμμή του διαγράμματος αντιπροσωπεύει το επίπεδο στο οποίο η διαδικασία λειτουργεί ό- ταν δεν υπάρχει κανένα πρόβλημα. Τα όρια ελέγχου έπειτα τοποθετούνται πάνω και κάτω από την κεντρική γραμμή. Μέτρηση που πέφτει εκτός των ορίων εκλαμβάνεται ως ένδειξη προβλήματος. Αυτά τα όρια ονομάζονται Ανώτατο Όριο Ελέγχου (Upper Control Limit UCL) και Κατώτατο Όριο Ελέγχου (Lower Control Limit LCL). Στο στατιστικό έλεγχο διαδικασιών τα όρια ελέγχου ουσιαστικά καθορίζονται χρησιμοποιώντας εκτιμήσεις τριών τυπικών αποκλίσεων και από τις δύο πλευρές του μέσου. Εάν το παρακολουθούμενο μέγεθος είναι κανονικά κατανεμημένο, αυτό σημαίνει πως το 99,73% των τιμών θα βρίσκεται εντός των ο- ρίων. 3.4 Τεχνικές Statistical Process Control Οι τεχνικές για το στατιστικό έλεγχο διαδικασιών (Statistical Process Control SPC) τυπικά χρησιμοποιούνται για την παρακολούθηση και τον έλεγχο της ποιότητας των βιομηχανικών και παραγωγικών διαδικασιών [3]. Μπορούμε να τις διαχωρίσουμε σε κατηγορίες: τις μονομεταβλητές τεχνικές Univariate Statistical Process Control (USPC) και τις πολυμεταβλητές Multivariate Statistical Process Control (MSPC). Έχουν την ικανότητα να ανιχνεύουν αλλαγές στο μέσο της διαδικασίας (mean shifts), στη διακύμανση της διαδικασίας (variance changes), στις σχέσεις μεταξύ πολλαπλών μεταβλητών (counterrelationships) κλπ. Σχεδιάζονται για να χειρίζονται διαφορετικά σενάρια αλλά δουλεύουν μαζί στον έλεγχο διαδικασίας. Σύμφωνα με τους Alt & Smith [33], ένας στατιστικός έλεγχος διαδικασίας αποτελείται από φάσεις. 48
49 Φάση 1 η : Εκτίμηση των παραμέτρων της διαδικασίας Στάδιο 1 ο : Αναδρομικός (Retrospective) έλεγχος της συμπεριφοράς των υπο-ομάδων. Στάδιο ο : Μελλοντικός (Prospective) έλεγχος μελλοντικών υπο-ομάδων Φάση η : Χρήση των αποτελεσμάτων της 1 ης φάσης ως παραμέτρους της διαδικασίας. Η μέθοδος αυτή μπορεί να εφαρμοστεί στο χώρο της ανίχνευσης εισβολών. Στο 1 ο στάδιο, παρελθοντικές παρατηρήσεις υπόκεινται σε ανάλυση, φυσιολογικές συμπεριφορές εξάγονται και εσωτερικές παράμετροι (in-control parameters) της διαδικασίας εκτιμούνται. Στο ο στάδιο, χρησιμοποιούνται διαγράμματα ελέγχου για τον εντοπισμό μη φυσιολογικών γεγονότων χρησιμοποιώντας τις ήδη ε- κτιμημένες στατιστικές παραμέτρους. Εάν οποιοδήποτε αντικρουόμενο ή ανώμαλο φαινόμενο βρεθεί σε αυτό το στάδιο, οι παράμετροι οι οποίες εκτιμήθηκαν στην 1 η φάση, επανελέγχονται και επανεκτιμούνται. Μόνο οι αποδεκτές παράμετροι θα χρησιμοποιηθούν στη η Φάση για να ελεγχθεί η διαδικασία σε πραγματικό περιβάλλον Univariate Statistical Process Control (USPC) Όταν αναλύουμε τα γεγονότα ενός υπολογιστικού συστήματος και δικτύου χρησιμοποιώντας USPC τεχνικές, δίνεται σήμα στη η Φάση για μια παρατήρηση εάν δε συμμορφώνεται με το πρότυπο προφίλ, το οποίο δημιουργείται χρησιμοποιώντας προηγούμενα δεδομένα κατά την 1 η Φάση [34]. Αυτό το σήμα μπορεί να οφείλεται σε μετατόπιση του μέσου (mean shift) της διαδικασίας ή / και σε μετατόπιση στη διασπορά (variance shift) της διαδικασίας. Αφού μόνο μία μεταβλητή μελετάται κάθε φορά, η σχέση της με τις άλλες μεταβλητές μπορεί να αγνοηθεί και συνεπώς να χάσουμε κάποια σημαντική πληροφορία Multivariate Statistical Process Control (MSPC) Όταν αναλύουμε τα γεγονότα ενός υπολογιστικού συστήματος και δικτύου χρησιμοποιώντας MSPC τεχνικές, δίνεται σήμα για μια παρατήρηση εάν οποιαδήποτε από τις k μεταβλητές της διαδικασίας ξεφύγει εκτός των ορίων της διασποράς της διαδικασίας η οποία προέκυψε από τα προηγούμενα δεδομένα στην 1 η Φάση [34]. Επίσης, μπορεί να δοθεί σήμα για ένα γεγονός όταν αλλάξουν οι σχέσεις ανάμεσα στις μεταβλητές. Αυτή η αλλαγή μπορεί ωστόσο να αντικρούει τη σχέση που δημιουργήθηκε στην 1 η Φάση. Οπότε μια MSPC τεχνική παρέχει περισσότερες πληροφορίες απ ό,τι μια USPC. Παρόλο που η MSPC μέθοδος μπορεί να εντοπίσει τη στατιστική μετατόπιση κάθε μεταβλητής ξεχωριστά και οποιαδήποτε αλλαγή στις σχέσεις των μεταβλητών, δεν μπορεί απευθείας να καταδείξει ποια από αυτές τις μετατοπίσεις προκαλεί το σήμα και ποιο σύνολο μεταβλητών ευθύνεται γι αυτό. Η μέθοδος δεν μπορεί να 49
50 δώσει περαιτέρω εξήγηση στην ακόλουθη, αρκετά συνηθισμένη, κατάσταση όταν καμία από τις μεταβλητές δε δείχνει κάποια απόκλιση αλλά οι μεταβλητές έχουν αλλάξει τη θέση τους χωρίς να επηρεαστεί η συνολική στατιστική τιμή. Αν και οι τεχνικές αυτές έχουν τα ελαττώματά τους, μερικές φορές οι πληροφορίες που παρέχουν επαρκούν για ανάλυση, ειδικά όταν αυτό που ενδιαφέρει είναι η συνολική στατιστική τιμή. 3.5 SPC τεχνικές στην Ανίχνευση Εισβολών Η ανίχνευση εισβολών είναι η διαδικασία της αναγνώρισης κακόβουλης πρόθεσης να διακινδυνευτεί η ασφάλεια ενός υπολογιστικού συστήματος και δικτύου. Τεχνικές βασισμένες σε στατιστικές μεθόδους μπορούν να χρησιμοποιηθούν για να σχηματίσουν με ποσοτικές μετρικές ένα στατιστικό προφίλ της μακροπρόθεσμης (long-term) κανονικής συμπεριφοράς του χρήστη και να εντοπίσουν σημαντικές αποκλίσεις της βραχυπρόθεσμης (short-term) συμπεριφοράς του από το μακροπρόθεσμο στατιστικό προφίλ. Κάθε φορά που μη φυσιολογική συμπεριφορά εντοπίζεται, σημαίνει σήμα ειδοποίησης. Διάφορες στατιστικές μέθοδοι [35] έχουν αναπτυχθεί για την παρακολούθηση του μέσου (mean) και της διακύμανσης (variance) μιας διαδικασίας από τη στιγμή που το Walter Shewhart εισήγαγε την τεχνική του διαγράμματος ελέγχου (control-chart) το 194. Παραδοσιακές SPC μέθοδοι υποθέτουν πως τα δεδομένα είναι στατιστικά ανεξάρτητα και στατικά. Αλλά στα σενάρια ανίχνευσης εισβολών, τα δεδομένα συνήθως αποτελούνται από μη γραμμικά χρονικά συσχετισμένα γεγονότα. Σε αυτήν την περίπτωση, οι παραδοσιακές SPC μέθοδοι δεν είναι αποτελεσματικές και κατάλληλες USPC στην ανίχνευση εισβολών Τα διαγράμματα ελέγχου Shewhart, CUSUM (Cumulative Control Charts) και EWMA (Exponentially Weighted Moving Average Control Charts) αποτελούν μονομεταβλητές SPC τεχνικές που χρησιμοποιούνται συνήθως για εντοπισμό μεταβολών του μέσου. Τα EWMV διαγράμματα (Exponentially Weighted Moving Variance Control Charts) είναι σχεδιασμένα να εντοπίζουν μεταβολές στη διακύμανση, αλλά είναι αρκετά ευαίσθητα σε μεταβολές του μέσου επίσης. Τα EWMA διαγράμματα είναι ανθεκτικά στην s-κανονικότητα των δεδομένων. Στη βιβλιογραφία, οι Ye et al [36] παρουσιάζουν την εργασία που πραγματοποίησαν εφαρμόζοντας ένα είδος SPC τεχνικών, τις EWMA, στην ανίχνευση εισβολών για την παρακολούθηση και τον εντοπισμό επιθέσεων που εκδηλώνονται μέσα από μη κανονικές αλλαγές στην πυκνότητα (intensity) των γεγονότων σε ένα πληροφοριακό σύστημα. Προτού προχωρήσουμε στην παρουσίαση της μεθόδου που υλοποιήθηκε βάσει των EWMA, ας δούμε πως μπορεί να πραγματοποιηθεί ο εντοπισμός εισβολών μέσα από ανώμαλες αλλαγές στην πυκνότητα των γεγονότων. 50
51 Συγκεκριμένα, πολλές εισβολές εκδηλώνονται μέσα από την s-σημαντική αυξανόμενη ή μειούμενη πυκνότητα των γεγονότων που συμβαίνουν σε ένα σύστημα. Για παράδειγμα, σε κλασσικές επιθέσεις άρνησης εξυπηρέτησης (DoS attacks), ένας τεράστιος αριθμός αιτημάτων για εξυπηρέτηση μπορεί να σταλεί σε έναν διακομιστή ενός συστήματος σε υπερβολικά μικρό χρονικό διάστημα προκειμένου να εξαντλήσει τα υπολογιστικά αποθέματα του διακομιστή και κατά συνέπεια να προκαλέσει την άρνησή του να ικανοποιήσει τα αιτήματα των χρηστών. Τέτοιες DoS επιθέσεις αυξάνουν την πυκνότητα γεγονότων σε ένα διακομιστή. Σε πολλές επιθέσεις σκουληκιών ή ιών μέσω διακομιστών των , ο αριθμός των που λαμβάνονται σε πολύ μικρό χρονικό διάστημα επίσης αυξάνει απότομα κατά τη διάρκεια διεξαγωγής των επιθέσεων. Αναρμόδιοι χρήστες που έχουν αποκτήσει προνόμια σούπερ-χρηστών μπορούν να απενεργοποιήσουν πολλούς πόρους ενός πληροφοριακού συστήματος, οδηγώντας σε μειωμένη πυκνότητα γεγονότων. Από τα προηγούμενα είναι εμφανές πως η έγκαιρη ανίχνευση των s- σημαντικών αλλαγών στην πυκνότητα των γεγονότων μπορεί να συνδράμει ουσιαστικά στην αντιμετώπιση αυτών των επιθέσεων προκειμένου να προστατέψουν τα πληροφοριακά συστήματα και να εξασφαλίζουν την αξιοπιστία και την ποιότητα των υπηρεσιών που παρέχουν. Η πυκνότητα των γεγονότων είναι ο αριθμός των γεγονότων ανά μονάδα χρόνου. Μπορεί να θεωρηθεί ως μια συνεχής μεταβλητή που μετρά τις δραστηριότητες σε ένα σύστημα. Υπάρχουσα έρευνα στην παρακολούθηση μιας ξεχωριστής συνεχούς μεταβλητής για εντοπισμό εισβολών βασίζεται στην τεχνική ανίχνευσης α- νωμαλιών που αναπτύχθηκε για το NIDES [37]. Ωστόσο, η τεχνική που προτείνεται στο συγκεκριμένο σύστημα δεν είναι ανθεκτική στην s-κανονικότητα των δεδομένων. Σε αντίθεση, η μέθοδος που προτείνεται από τους Ye et al [36] χρησιμοποιεί τεχνικές EWMA, οι οποίες είναι ανθεκτικές στην s-κανονικότητα των δεδομένων, παρακολουθώντας και εντοπίζοντας s-σημαντικές αλλαγές στην πυκνότητα των γεγονότων Τεχνικές EWMA Αν και τα γεγονότα σε ένα πληροφοριακό σύστημα είναι συνήθως αυτοσυσχετιζόμενα μιας και οι χρήστες συνήθως διεκπεραιώνουν μια σειρά σχετικών μεταξύ τους εντολών για την ολοκλήρωση μιας συγκεκριμένης εργασίας στην έρευνα τους οι Ye et al [36] εφαρμόζουν, ελέγχουν και συγκρίνουν τεχνικές, μία για αυτοσυσχετιζόμενα δεδομένα και μία για μη συσχετιζόμενα δεδομένα, και για διαφορετικές τιμές των παραμέτρων τους. 1. Αν τα δεδομένα περιέχουν μια ακολουθία μη συσχετιζόμενων παρατηρήσεων x () i της διαδικασίας, τότε το EWMA διάγραμμα σχεδιάζει τις τιμές z() i, οι οποίες υπολογίζονται ως εξής [3]: με λ (0,1]. z() i = λ x ( i) + ( 1 λ ) z( i 1) 51
52 Ο μέσος μ z και η διακύμανση σ z της z( i ) είναι μz = μx και λ σz = σ x λ, ό- σ μπορούν να εκτιμηθούν από τα δεδομένα εκπαί- που οι ποσότητες μ x και x δευσης πριν τον έλεγχο [3]. Τα κάτω και άνω όρια (LCL και UCL αντίστοιχα) για το διάγραμμα ελέγχου είναι LCLz = μz L σ z και UCL z = μ z + L σ z αντίστοιχα. Για επίπεδο s-σημαντικότητας ίσο με 5%, η τιμή του L είναι L = 1,96. Αν η τιμή z( i ) πέφτει εκτός των ορίων UCL και LCL, αυτό σημαίνει πως εντοπίστηκε κακόβουλη δραστηριότητα και παράγεται ένα σήμα ειδοποίησης.. Αν τα δεδομένα περιέχουν μια ακολουθία αυτοσυσχετιζόμενων παρατηρήσεων x () i, τότε ο στατιστικός EWMA μπορεί να χρησιμοποιηθεί για να παράσχει ένα μοντέλο πρόβλεψης ενός-βήματος-μπροστά (1-step-ahead) αυτοσυσχετιζόμενων δεδομένων όταν ο μέσος της διαδικασίας δεν μεταβάλλεται πολύ γρήγορα [38]. Η 1-step-ahead πρόβλεψη για την x ( i ) είναι η z( i 1). Το σφάλμα e() i είναι e() i = x () i z( i 1). Η τιμή του λ μπορεί να οριστεί από την ελαχιστοποίηση του αθροίσματος των τετραγώνων των σφαλμάτων της 1-step-ahead πρόβλεψης στα δεδομένα εκπαίδευσης [38]. Τα σφάλματα e() i είναι s-ανεξάρτητα κατανεμημένα με μέσο 0 και e() i. Τα όρια τυπική απόκλιση LCL και UCL είναι LCL σ e. Το διάγραμμα EWMA σχεδιάζει τα σφάλματα e = L σe και UCL e = L σ e. Το διάγραμμα EWMA των e( i ) είναι ισοδύναμο με το διάγραμμα EWMA των x( i ) με LCL () i = z ( i 1) L σ ( i 1) και UCL ( i ) = z ( i 1) + L σ ( i 1). x e Η τιμή του L είναι L = 1,96 για επίπεδο σημαντικότητας 5%. Η τυπική απόκλιση σ μπορεί να εκτιμηθεί υπολογίζοντας μια εξομαλυσμένη διακύμανση e σ e= α e() i + ( 1 α) σe ( i 1) με α (0,1] Εφαρμογή της μεθόδου Οι Ye et al [36] εφάρμοσαν αυτήν τη μέθοδο χρησιμοποιώντας δεδομένα ελέγχου (audit data) από έναν Unix-based υπολογιστή υπηρεσίας (Sun SPARC 10 Workstation with Solaris). Το λειτουργικό σύστημα Solaris παρέχει το BSM πρότυπο ασφαλείας, το οποίο μπορεί να παρακολουθεί τις δραστηριότητες σε έναν υπολογιστή υπηρεσίας και να καταγράφει γεγονότα σχετικά με την ασφάλεια. Στο BSM ορίζονται 84 τύποι γεγονότων. Μια BSM εγγραφή ελέγχου για κάθε γεγονός περικλείει μια ποικιλία πληροφοριών, συμπεριλαμβανομένου του χρόνου που παρατηρήθηκε το γεγονός, του τύπου του γεγονότος, του αναγνωριστικού ID του χρήστη, του αναγνωριστικού ID της ομάδας στην οποία ανήκει ο χρήστης, το αντικείμενο του συστήματος που προσπελάστηκε κλπ. Η συγκεκριμένη έρευνα ασχολείται με την πυκνότητα των γεγονότων, επομένως η μόνη πληροφορία που x e 5
53 εξάγεται και χρησιμοποιείται για την ανίχνευση επιθέσεων είναι ο χρόνος-στιγμή που συνέβη το γεγονός. Η συλλογή των δεδομένων ελέγχου, για κανονικά γεγονότα τα οποία προέκυψαν από προσομοίωση δραστηριοτήτων που παρατηρούνται σε πραγματικά συστήματα σε συνθήκες φυσιολογικής λειτουργίας, προέρχεται από το MIT Lincoln Laboratory (LL). Η πυκνότητα των γεγονότων υπολογίζεται μετρώντας τον αριθμό των γεγονότων ανά δευτερόλεπτο, k ( i ). Χρησιμοποιείται η τεχνική εξομάλυνσης (smoothing) για τις παρατηρήσεις της πυκνότητας των γεγονότων προκειμένου να μειωθεί η επίδραση των outliers ή των ακραίων τιμών των παρατηρήσεων. Η εξομαλυσμένη τιμή της πυκνότητας βάσει της σχέσης x () i = n k ( i) + ( 1 n) x ( i 1) ανανεώνεται κάθε δευτερόλεπτο. Επειδή όμως τα γεγονότα συμβαίνουν σε διάστημα μικρότερο του ενός δευτερολέπτου, το χρονικό κενό που υφίσταται ανάμεσα στη δειγματοληψία γεγονότων διαδοχικών δευτερολέπτων αρκεί για να προκληθεί ζημιά από κακοήθεις ενέργειες (όπως εκείνων που προκαλούν DoS, όπου ο αριθμός των γεγονότων ανά δευτερόλεπτο που παράγονται μπορεί να είναι ε- κατοντάδες ή ακόμα και χιλιάδες εντός δευτερολέπτου). Κατά συνέπεια, η εξομαλυσμένη τιμή των παρατηρήσεων πρέπει να ανανεώνεται για κάθε γεγονός σύμφωνα με τον τύπο ( j ) = 1+ ( 1 ) ( j j 1) ( j 1) x t n n t t x t Βέβαια, το αποτέλεσμα για την τιμή της πυκνότητας παραμένει ίδιο με εκείνο της προηγούμενης σχέσης στο τέλος του κάθε δευτερολέπτου. Στα πειράματα που πραγματοποιήθηκαν δοκιμάστηκαν οι μέθοδοι για αυτοσυσχετιζόμενα και μη συσχετιζόμενα δεδομένα για διάφορες τιμές των παραμέτρων τους λ, n, L και α. Και για τις μεθόδους υλοποιήθηκαν δύο φάσεις, εκπαίδευσης και ελέγχου, και υπολογίστηκαν τα ποσοστά εσφαλμένων συναγερμών και ανίχνευσης εισβολών. Από τα αποτελέσματα των πειραμάτων προκύπτει πως και οι δύο μέθοδοι αποδίδουν καλά για εντοπισμό εισβολών που εκδηλώνονται μέσω s-σημαντικών μεταβολών στην πυκνότητα γεγονότων που συμβαίνουν σε ένα σύστημα. Το πλεονέκτημα της τεχνικής EWMA για μη συσχετιζόμενα δεδομένα είναι ότι μπορεί να εντοπίσει όχι μόνο απότομες μεταβολές στην πυκνότητα των γεγονότων αλλά επίσης και μικρές μεταβολές του μέσου [3] μέσω της σταδιακά αυξανόμενης ή 53
54 μειούμενης πυκνότητας, σε αντίθεση με την τεχνική EWMA για αυτοσυσχετιζόμενα δεδομένα. Ωστόσο, αν χρησιμοποιηθεί η μέθοδος για μη συσχετιζόμενα, η αρχική τιμή της εξομαλυσμένης πυκνότητας πρέπει να αρχικοποιείται κάθε φορά που ανιχνεύεται κάποια εισβολή για να αποφευχθεί το φαινόμενο του «carry-over effect». Στην περίπτωση της μεθόδου για αυτοσυσχετιζόμενα δεδομένα, αυτό δεν είναι απαραίτητο αφού η μέθοδος αυτόματα προσαρμόζει τα όρια LCL και UCL. Συνολικά, η σταθερά εξομάλυνσης για τον υπολογισμό της εξομαλυσμένης πυκνότητας γεγονότων δεν πρέπει να είναι πολύ μικρή, προκειμένου να συλλαμβάνει τη βραχυπρόθεσμη τάση της πυκνότητας στο πρόσφατο παρελθόν. Οι τιμές των λ και α έτσι ώστε τα όρια LCL και UCL να αντανακλούν τη μακροπρόθεσμη τάση της πυκνότητας θα πρέπει να είναι πολύ μικρότερες (της τάξης του 0,0001) της σταθεράς εξομάλυνσης (της τάξης του 0,-0,3). Για αυτές τις τιμές παρατηρείται ποσοστό ανίχνευσης πρόωρων εισβολών ίσο με 50% και ποσοστό εσφαλμένων συναγερμών ίσο με 0%. Οι Ye et al κρίνουν το αποτέλεσμα αυτό ικανοποιητικό υποστηρίζοντας πως ο έγκαιρος εντοπισμός κακόβουλων ενεργειών θα πρέπει να ενεργοποιεί μηχανισμούς και ενέργειες προκειμένου να αποφευχθούν αργότερα κακόβουλα γεγονότα. Κατ αυτούς, η έγκαιρη ανίχνευση πρώιμων κακοπροαίρετων δραστηριοτήτων είναι πολύ πιο σημαντική από ένα ποσοστό ανίχνευσης 100% όλων των κακόβουλων γεγονότων. Τέλος, για επίπεδο s- σημαντικότητας ίσο με 5%, η τιμή L = 1,96 έχει ικανοποιητικά αποτελέσματα MSPC στην ανίχνευση εισβολών Η βασική έννοια πάνω στην οποία στηρίζονται οι πολυμεταβλητές στατιστικές μέθοδοι είναι αυτή της ανομοιότητας, η οποία μετράται με κάποια μετρική απόστασης. Μερικές από τις πιο διαδεδομένες και ευρέως χρησιμοποιούμενες τεχνικές MSPC που μπορούν να χρησιμοποιηθούν στο χώρο της ανίχνευσης εισβολών είναι τα πολυμεταβλητά αθροιστικά διαγράμματα ελέγχου (Multivariate Cumulative Control Charts MCUSUM Charts) [39], ο πολυμεταβλητός εκθετικά σταθμισμένος κινητός μέσος (Multivariate Exponentially Weighted Moving Average EWMA) [40] [41], ο έλεγχος καλής προσαρμογής X [4] και ο έλεγχος T του Hotelling [43]. Θεωρητικά, αυτές οι πολυμεταβλητές τεχνικές μπορούν να εφαρμοστούν στην ανίχνευση εισβολών για παρακολούθηση και εντοπισμό ανωμαλιών μιας διαδικασίας σε ένα πληροφοριακό σύστημα. Πρακτικά, η υπολογιστικά έντονη διαδικασία αυτών των τεχνικών δεν μπορεί να ικανοποιήσει τις απαιτήσεις της ανίχνευσης εισβολών για τους εξής λόγους [44]. Πρώτον, η ανίχνευση εισβολών καλείται να χειριστεί τεράστιους όγκους πολυδιάστατων δεδομένων εξαιτίας του μεγάλου αριθμού (εκατοντάδες ή χιλιάδες) μετρικών συμπεριφοράς και της υψηλής συχνότητας εμφάνισης των γεγονότων. Κατά δεύτερον, η ανίχνευση εισβολών απαιτεί μια ελάχιστη καθυστέρηση επεξεργασίας κάθε γεγονότος σε ένα σύστημα προκειμένου να εξασφαλίσει μια έγκαιρη ένδειξη και προειδοποίηση των εισβο- 54
55 λών. Κατ επέκταση, υπάρχει επιτακτική ανάγκη για μια πολυμεταβλητή τεχνική ανίχνευσης εισβολών με χαμηλό υπολογιστικό κόστος. Όπως αναφέρθηκε προηγουμένως, ο στόχος των στατιστικών μεθόδων ανίχνευσης ανωμαλιών είναι τα εισερχόμενα γεγονότα να κατηγοριοποιούνται ως κανονικά ή κακόβουλα υπολογίζοντας τιμές ειδοποίησης επίθεσης (Intrusion Warning values IW values) χρησιμοποιώντας αποδοτικές μετρικές απόστασης [34]. Η τιμή της μετρικής απόστασης χρησιμοποιείται για να προσδιοριστεί η ομοιότητα ή η ανομοιότητα της τρέχουσας παρατήρησης από το ήδη διαμορφωμένο κανονικό προφίλ. Η τιμή IW προσδιορίζει πόσο απέχει η παρατηρούμενη δραστηριότητα από το κανονικό προφίλ σε μια κλίμακα από 0 έως 1. Μια IW τιμή ίση με 1 σημαίνει πως η παρατηρούμενη δραστηριότητα ανήκει σε μια ακολουθία γεγονότων επίθεσης, ενώ μια τιμή ίση με 0 αποτελεί ένδειξη κανονικής δραστηριότητας. Οι τιμές μεταξύ 0 και 1 μαρτυρούν το βαθμό αδιακρισίας ενός γεγονότος, δηλαδή όσο πιο υψηλή η τιμή, τόσο πιο κακόηθες το γεγονός. Επομένως, αυτή η κανονικοποιημένη τιμή IW δίνει περισσότερες πληροφορίες απ ό,τι η μετρική απόστασης μόνη της. Στη βιβλιογραφία υπάρχουν μελέτες στις οποίες ερευνάται η απόδοση διαφόρων τεχνικών βασισμένων σε ποικίλες μετρικές απόστασης, με ή χωρίς χρήση των τιμών IW. Στη συνέχεια ακολουθεί μια παρουσίαση των μετρικών απόστασης ομοιότητας που μπορούν να χρησιμοποιηθούν στην ανίχνευση εισβολών και μια συζήτηση των αποτελεσμάτων ορισμένων μόνο από τις μελέτες που έχουν πραγματοποιηθεί Ευκλείδεια απόσταση Η Ευκλείδεια απόσταση [45] ανάμεσα σε 1 παρατήρηση διανύσματος των μέσων του δείγματος ορίζεται ως k διαστάσεων και του (, ) = ( i i) = ( )'( ) d x x k x x x x x x. Η στατιστική απόσταση ανάμεσα στα ίδια διανύσματα είναι i = 1 d( x, x ) = ( x x )' A( x x ) 1 όπου A = S και S ο πίνακας διασπορών-συνδιασπορών του δείγματος. Επειδή το κάθε διάνυσμα συμμετέχει ισόβαθμα στον υπολογισμό της Ευκλείδειας απόστασης, η απόσταση αυτή δεν είναι επιθυμητή σε πολλές εφαρμογές Μετρική Minkowski Άλλη μετρική απόστασης είναι η μετρική Minkowski [45] 55
56 k d ( x, x ) = x i x i = 1 Για m = 1, η απόσταση d ( x, x ) είναι η απόσταση Manhattan (city-block) μεταξύ σημείων k διαστάσεων. Για i m 1 m m =, η απόσταση (, ) d x x είναι η Ευκλείδεια απόσταση που αναφέρθηκε προηγουμένως. Γενικά, ποικίλες τιμές του m το βάρος μεγαλύτερων και μικρότερων διαφορών Συντελεστής του Czekanowski αλλάζουν Αποτελεί άλλη μια δημοφιλή μετρική απόστασης η οποία ορίζεται για μη αρνητικές μεταβλητές μόνο ως εξής [46]: d ( x x ) i = 1 k ( x i x i) min,, = 1 k ( x i + x i) i = Μετρική Ομοιότητας βασισμένη στον έλεγχο Kolmogorov-Smirnov Στο HIDE σύστημα (Hierarchical Intrusion Detection System) των Manikopoulos & Papavassiliou [], το οποίο χρησιμοποιεί νευρωνικά δίκτυα για την κατηγοριοποίηση των παρατηρούμενων μοτίβων και την αναγνώρισή τους ως εισβολές ή όχι, τα προφίλ των χρηστών αναπαρίστανται από συναρτήσεις πυκνότητας πιθανότητας. Οι μετρικές ομοιότητας που χρησιμοποιούν βασίζονται στον έλεγχο Kolmogorov-Smirnov. Χρησιμοποιώντας τον K-S έλεγχο, τα μοντέλα αναφοράς και οι παρατηρούμενες δραστηριότητες του συστήματος αναπαρίστανται από αθροιστικές συναρτήσεις πυκνότητας (cumulative density functions CDFs). Ο έλεγχος K-S βρίσκει τη μεγαλύτερη διαφορά ανάμεσα στις παρατηρούμενες και τις αναμενόμενες αθροιστικές συχνότητες, η οποία καλείται στατιστικό D (Dstatistic). Το D-statistic είναι η μέγιστη απόσταση ανάμεσα στις καμπύλες των συναρτήσεων της εμπειρικής (παρατηρούμενης) και της αναμενόμενης κατανομής. Αυτό συγκρίνεται με το κρίσιμο στατιστικό D για αυτό το μέγεθος δείγματος. Εάν το υπολογισμένο D είναι μεγαλύτερο από το κρίσιμο, τότε η μηδενική υπόθεση ότι η εμπειρική κατανομή είναι της αναμενόμενης μορφής απορρίπτεται. Αυτό που καθιστά τον έλεγχο K-S ισχυρό είναι το γεγονός πως είναι μηπαραμετρικός και ανεξάρτητος κατανομής και επομένως απαλλαγμένος από την άμεση ή έμμεση υπόθεση της κανονικότητας της κατανομής. Υπάρχουν διάφορες παραλλαγές του ελέγχου K-S που μελετήθηκαν από τους Manikopoulos & Papavassiliou. Ανάμεσα σε αυτές είναι το στατιστικό Anderson-Darlin που υπολογίζει μια σταθμισμένη K-S μετρική και το στατιστικό του Kuiper. Η μετρική ομοιότητας που χρησιμοποίησαν είναι η ακόλουθη: 56
57 k Q = f n p p + p p i = 1 i = 1 k ( ) i' i max ( i' i ) όπου f ( n ) η συνάρτηση που λαμβάνει υπόψη το συνολικό αριθμό εμφανίσεων στο εκάστοτε χρονικό «παράθυρο», p i η αναμενόμενη πιθανότητα της εμφάνισης του γεγονότος E i pi ' η πραγματική πιθανότητα της εμφάνισης του γεγονότος E i n k ο συνολικός αριθμός εμφανίσεων και ο αριθμός των γεγονότων Απόσταση Canberra Η απόσταση Canberra [46] ορίζεται επίσης για μη αρνητικές μεταβλητές μόνο και δίνεται από τη σχέση d ( x, x ) = k x x i i i = 1 ( x i + x i) Ο αριθμητής στην εξίσωση της μετρικής Canberra υποδηλώνει τη διαφορά και ο παρονομαστής στην ουσία κανονικοποιεί αυτή τη διαφορά. Από τις μετρικές απόστασης που αναφέρθηκαν, η αδυναμία της Ευκλείδειας α- πόστασης και της μετρικής Minkowski είναι πως δεν κλιμακώνουν κάθε διάσταση κατά τον υπολογισμό της απόστασης. Μάλιστα σε πειράματα των Ye & Emran [44] αποδεικνύεται η χαμηλή απόδοση της Ευκλείδειας απόστασης στην ανίχνευση εισβολών και επομένως, η ακαταλληλότητά της να επιλεγεί ως μετρική ομοιότητας Στατιστικός Έλεγχος Hotelling T βασισμένος στην απόσταση Mahalanobis Έστω i = ( i1, i, K, ip X X X X ) μια παρατήρηση p χαρακτηριστικών μιας διαδικασίας τη χρονική στιγμή i [7] [44]. Εάν υποθέσουμε πως όταν η διαδικασία λειτουργεί φυσιολογικά (in control), ο πληθυσμός του X ακολουθεί πολυμεταβλητή κανονική κατανομή με μέσο μ και πίνακα συνδιακυμάνσεων Σ. Χρησιμοποιώντας ένα δείγμα δεδομένων μεγέθους n, ο μέσος του δείγματος X και ο πίνακας διασπορών-συνδιασπορών S συνήθως χρησιμοποιούνται για τον υπολογισμό των μ και Σ, όπου 57
58 1 = ( 1,, K p ) και S = ( Xi X )( Xi X )' X X X X 1 n n 1 i = 1 Ο στατιστικός έλεγχος Hotelling T για μια παρατήρηση X i χρησιμοποιεί την στατιστική απόσταση Mahalanobis [47]: ( i )' ( i ) T = X X S 1 X X i Μια μεγάλη τιμή για το T υποδεικνύει μια μεγάλη απόκλιση της παρατήρησης X από τον φυσιολογικό πληθυσμό. Μπορούμε να χρησιμοποιήσουμε μια μετασχηματισμένη τιμή του στατιστικού F κατανομή με p και ( n p) n( n p) τη σταθερά p( n+ 1)( n 1) T, την n( n p) ( + 1)( n 1) p n T, η οποία ακολουθεί βαθμούς ελευθερίας, πολλαπλασιάζοντας το T με. Εάν η μετασχηματισμένη τιμή του στατιστικού T είναι μεγαλύτερη από την αντίστοιχη τιμή F του πίνακα για ένα δεδομένο επίπεδο σημαντικότητας α, τότε η μηδενική υπόθεση ότι η διαδικασία είναι κανονική (in control) απορρίπτεται και η διαδικασία σηματοδοτείται ως μη κανονική (out of control). Εάν η X i δεν ακολουθεί πολυμεταβλητή κανονική μεταβλητή, η μετασχηματισμέ- νη τιμή του στατιστικού ελέγχου T πιθανόν να μην ακολουθεί F κατανομή. Συνεπώς, δεν μπορεί να χρησιμοποιηθεί η τιμή F του πίνακα ως τιμή κατώφλι προκειμένου να αποφασίσει εάν μια μετασχηματισμένη τιμή T είναι αρκετά μεγάλη για να σηματοδοτηθεί κακόβουλη συμπεριφορά. Στην ανίχνευση εισβολών, πολλαπλά μέτρα δραστηριοτήτων σε ένα πληροφοριακό σύστημα αναπαρίστανται από πολλαπλές τυχαίες μεταβλητές. Τυπικά, δεν είμαστε σε θέση να γνωρίζουμε εκ των προτέρων τι κατανομή ακολουθεί η κάθε μεταβλητή και επομένως δεν μπορούμε να υποθέσουμε αυθαίρετα ότι ακολουθεί κανονική κατανομή. Ωστόσο, εάν οι μεταβλητές είναι ανεξάρτητες και ο αριθμός τους μεγάλος (μεγα- λύτερος του 30), το T ακολουθεί κατά προσέγγιση κανονική κατανομή σύμφωνα με το Κεντρικό Οριακό Θεώρημα, ανεξάρτητα από την κατανομή που η καθεμιά από τις μεταβλητές ακολουθεί [8]. Χρησιμοποιώντας ένα δείγμα τιμών T, ο μέ- σος και η τυπική απόκλιση του T πληθυσμού μπορεί να εκτιμηθεί με το δειγματικό μέσο T και τη δειγματική τυπική απόκλιση S T. Τα όρια κανονικής λειτουργίας για την ανίχνευση εισβολών ορίζονται T 3 S, T + 3S T T. Αφού ενδιαφερόμαστε για τον εντοπισμό μεγάλων τιμών T, ορίζουμε μόνο το άνω όριο. Επο- 58
59 μένως, αν η υπολογισμένη τιμή T T + 3S T, σηματοδοτείται κακόβουλη συμπεριφορά. για μια παρατήρηση είναι μεγαλύτερη από Ο υπολογισμός του T απαιτεί τον πίνακα διασπορών-συνδιασπορών και τον αντίστροφό του. Ακόμη και τα σύγχρονα υπολογιστικά συστήματα συναντούν δυσκολία στην αποθήκευση τεράστιων πινάκων διασπορών-συνδιασπορών για εκατοντάδες ή χιλιάδες μεταβλητές στη μνήμη. Επιπλέον, είναι πιθανόν να υπάρχουν εκατοντάδες ή χιλιάδες γεγονότα που συμβαίνουν σε ένα υπολογιστικό σύστημα κατά τη διάρκεια μιας μικρής χρονικής περιόδου. Ο υπολογισμός του στατιστικού T για όλα τα γεγονότα που συμβαίνουν με υψηλή συχνότητα έχει ως αποτέλεσμα αβάσταχτο υπολογιστικό χρόνο και η καθυστέρηση κατά τον υπολογισμό του πίνακα διασπορών-συνδιασπορών και του αντιστρόφου του για κάθε γεγονός καθίσταται μη αποδεκτή. Ο έλεγχος T δεν είναι κλιμακωτός σε μεγάλες ποσότητες δεδομένων ελέγχου που παράγονται από ένα υπολογιστικό σύστημα σε πραγματικό χρόνο Στατιστικός έλεγχος X Για τους λόγους που αναφέρθηκαν προηγουμένως, κρίνεται αναγκαία η χρήση μιας πολυμεταβλητής τεχνικής ανίχνευσης εισβολών με χαμηλό υπολογιστικό κόστος. Αφού το T αποτελεί ένα μέτρο της στατιστικής απόστασης μιας παρατήρησης από τον εκτιμημένο μέσο μιας πολυμεταβλητής κανονικής κατανομής, μπορούμε να χρησιμοποιήσουμε μια μετρική απόστασης βασισμένη στην μετρική X [34] [7] [8] ως εξής: X ( παρατηρούμενη αναμενόμενη ) ( O E ) = = αναμενόμενη i i E i ή αλλιώς X n = i = 1 ( X E ) i E i i όπου X i είναι η παρατηρούμενη τιμή της i οστής μεταβλητής, E i η αναμενόμενη τιμή της i οστής μεταβλητής και n ο αριθμός των μεταβλητών. Το X έχει μικρή τιμή αν μια παρατήρηση των μεταβλητών απέχει ελάχιστα από την προσδοκώμενη. Χρησιμοποιώντας τους μέσους X1, X, K Xn ως εκτίμηση των προσδοκώμενων τιμών, το X ορίζεται ως X ( ) ( X ) i X i n =. E i = 1 i Υπολογισμός X Α. Τεχνική του EWMA 59
60 Μπορούμε να χρησιμοποιήσουμε την τεχνική του εκθετικά σταθμισμένου κινητού μέσου (EWMA) για την εξομάλυνση των παρατηρούμενων τιμών των μεταβλητών που παρακολουθούνται. Όταν επιλεγεί μια κατάλληλη σταθερά εξομάλυνσης λ, το μέτρο της παρατήρησης αντανακλά τα χαρακτηριστικά των μεταβλητών του «πιο πρόσφατου παρελθόντος». Η βελτιωμένη παρατήρηση υπολογίζεται με βάση τον τύπο O = λ θ + ( 1 λ) O όπου O,0 = 0 για i = 1,..., k. in, i in, 1 Η πιο πρόσφατη παρατήρηση n, την τρέχουσα χρονική στιγμή i, λαμβάνει ένα βάρος λ, η παρατήρηση τη χρονική στιγμή i 1 λαμβάνει ένα βάρος λ ( λ 1) και η παρατήρηση τη χρονική στιγμή i k λαμβάνει ένα βάρος λ( λ 1) k. Επομένως, το Oin, αντιπροσωπεύει έναν εκθετικά μειούμενο μετρητής του γεγονότος i, ο οποίος μετρά την παρουσία του γεγονότος i στο πρόσφατο παρελθόν. Στον παραπάνω τύπο το Oin, είναι η εξομαλυσμένη τιμή της παρατήρησης, το θ είναι έ- νας δείκτης της παρατήρησης, εάν ο τύπος γεγονότος i είναι παρών στην τρέχουσα παρατήρηση το θ έχει την τιμή 1, διαφορετικά την τιμή 0, το O in, 1 είναι η προηγούμενη εξομαλυσμένη παρατήρηση και το λ είναι η σταθερά εξομάλυνσης (0 < λ < 1) η οποία καθορίζει το ρυθμό εξασθένησης (decay rate). Συνήθως η τιμή της σταθεράς τίθεται ίση με 0,3. i Σχήμα 3.1 Η σταθερά εξομάλυνσης λ Στο σχήμα 7 φαίνεται η επίδραση εξασθένησης της σταθεράς εξομάλυνσης για τιμή λ = 0,3. Με την προσέγγιση του «πιο πρόσφατου παρελθόντος», προσθέτουμε το χαρακτηριστικό του χρόνου στην τιμή της παρατήρησης. Η τιμή της παρατήρησης όχι μόνο δείχνει την τρέχουσα κατανομή πιθανοτήτων του διανύσματος της κατηγορίας, αλλά αντανακλά την κατανομή πιθανοτήτων της πρόσφατης περιόδου. Β. Η μέθοδος του X 60
61 Χρησιμοποιήσαμε τον X για τον υπολογισμό της αναμενόμενης τιμής των μεταβλητών που παρακολουθούνται. Αντανακλά ένα μακράς περιόδου χαρακτηριστικό των μεταβλητών που παρατηρούμε. Λαμβάνοντας υπόψη ότι τα γεγονότα σε έναν υπολογιστή υπηρεσίας στην πραγματικότητα δεν φτάνουν όλα μαζί αλλά διαδοχικά, για τον υπολογισμό του X χρησιμοποιείται ο ακόλουθος αυξητικός τύπος έπειτα από κάθε γεγονός [34]: X ( in, ) (, 1 n O i j) in, 1 in, j = 0 ( n ) X ( ) + O( ) = = n Σύμφωνα με το Κεντρικό Οριακό Θεώρημα (Central Limit Theorem), όταν ο α- ριθμός των μεταβλητών είναι αρκετά μεγάλος (μεγαλύτερος από 30), το X ως το άθροισμα των τετραγώνων των διαφορών των παρατηρούμενων και των προσδοκώμενων τιμών αυτών των μεταβλητών ακολουθεί περίπου κανονική κατανομή [46]. Επομένως, το διάστημα μ Zα / σ, μ+ Zα/σ περιέχει (1 α ) τοις εκατό των πιθανών τιμών X του πληθυσμού, όπου μ και σ ο μέσος και η διακύμανση του X πληθυσμού, α το επίπεδο σημαντικότητας και η τιμή του πίνακα της τυπικής κανονικής κατανομής. Ο μέσος και η τυπική απόκλιση του X πληθυσμού μπορούν να εκτιμηθούν από το δειγματικό μέσο X και τη δειγματική τυπική απόκλιση. Τα όρια κανονικής λειτουργίας για την ανίχνευση S X εισβολών ορίζονται X 3 S, X + 3S. Αφού ενδιαφερόμαστε για τον εντοπισμό μεγάλων τιμών X (δηλαδή μεγάλων διαφορών μεταξύ παρατηρούμενων X X και αναμενόμενων τιμών), ορίζουμε μόνο το άνω όριο. Επομένως, αν η υπολογισμένη τιμή n Z α / X για μια παρατήρηση είναι μεγαλύτερη από X + 3S X, σηματοδοτείται κακόβουλη συμπεριφορά Εφαρμογή της μεθόδου Προτού δούμε τα αποτελέσματα της εφαρμογής της μεθόδου με βάση τους ελέγχους X και T, ας δώσουμε τους ορισμούς του ποσοστού εσφαλμένων συνα- γερμών (false alarm rate) και του ποσοστού ανίχνευσης εισβολών (attackdetection rate). Number of Signals in Normal Events False Alarm rate = Number of Normal Events Attack Number of Signals in Attack Events det ection rate = Number of Attack Events 61
62 Στη βιβλιογραφία το ποσοστό ανίχνευσης εισβολών συναντάται και με τον όρο Hit rate. Το ποσοστό εσφαλμένων συναγερμών αφορά στα κανονικά γεγονότα που εσφαλμένα χαρακτηρίζονται ως απειλές και το ποσοστό ανίχνευσης εισβολών αφορά στις εισβολές που επιτυχώς ανιχνεύονται ως απειλές. Για ένα δεδομένο στατιστικό έλεγχο, διαφορετικά κατώφλια-τιμές σήμανσης συναγερμού οδηγούν σε διαφορετικά ζεύγη ποσοστού ανίχνευσης και ποσοστού εσφαλμένων συναγερμών, τα οποία σύμφωνα με τη Θεωρία Ανίχνευσης Σημάτων περιγράφουν την απόδοση του στατιστικού ελέγχου. Οι καμπύλες ROC (Receiver Operating Characteristic) αποτελούν την πλέον κοινή προσέγγιση για την εκτίμηση των συστημάτων ανίχνευσης. Οι καμπύλες ROC δείχνουν πως το ποσοστό ανίχνευσης εισβολών αλλάζει καθώς μεταβάλλονται οι τιμές-κατώφλια σήμανσης συναγερμού προκειμένου να παραχθούν λιγότεροι ή περισσότεροι εσφαλμένοι συναγερμοί και να εξισορροπείται η ακρίβεια ανίχνευσης έναντι του φόρτου εργασίας του αναλυτή. Η μέτρηση του ποσοστού ανίχνευσης μόνο υποδεικνύει μόνο τους τύπους επιθέσεων που μπορεί να εντοπίσει ένα IDS και όχι τον ανθρώπινο φόρτο εργασίας που απαιτείται για την ανάλυση των εσφαλμένων συναγερμών που παράγονται από την κανονική κυκλοφορία δεδομένων. Επομένως, μια καμπύλη ROC δείχνει τη συμμεταβολή των δύο αυτών ποσοστών, σχεδιάζοντας ζεύγη τους ως σημεία στο μοναδιαίο τετράγωνο [0,1] x [0,1] για διαφορετικές τιμές κατωφλιών. Όσο πιο κοντά είναι η καμπύλη ROC στην άνω αριστερή γωνία (η οποία αντιστοιχεί σε 100% ποσοστό ανίχνευσης εισβολών και 0% ποσοστό εσφαλμένων συναγερμών), τόσο καλύτερη είναι η απόδοση ενός στατιστικού ελέγχου. Χαμηλό ποσοστό εσφαλμένων συναγερμών μαζί με υψηλό ποσοστό ανίχνευσης επιθέσεων συνεπάγονται αξιοπιστία στο αποτέλεσμα του αποτελέσματος ανίχνευσης και ελαχιστοποίηση του ανθρώπινου φόρτου για επιβεβαίωση οποιασδήποτε επίθεσης. Οι Ye et al [7] [8] εφάρμοσαν αυτήν τη μέθοδο χρησιμοποιώντας δεδομένα ε- λέγχου (audit data) από έναν Unix-based υπολογιστή υπηρεσίας (Sun SPARC 10 Workstation with Solaris). Το λειτουργικό σύστημα Solaris παρέχει το BSM πρότυπο ασφαλείας, το οποίο μπορεί να παρακολουθεί τις δραστηριότητες σε έναν υπολογιστή υπηρεσίας και να καταγράφει γεγονότα σχετικά με την ασφάλεια. Συγκεκριμένα, το BSM καταγράφει την εκτέλεση κλήσεων του συστήματος από όλες τις διεργασίες που εκκινούνται από τους χρήστες. Στο BSM ορίζονται 84 τύποι γεγονότων. Θεώρησαν επομένως ότι το σύστημα έχει 84 κατηγορίες. Στη ροή γεγονότων (event stream), ο τύπος του τρέχοντος γεγονότος έχει μία παρατήρηση 1 και οι υπόλοιποι τύποι γεγονότων έχουν παρατηρήσεις 0. Στην εφαρμογή που πραγματοποίησαν, δημιούργησαν ένα μακροπρόθεσμο κανονικό προφίλ χρησιμοποιώντας ιστορικά δεδομένα στην 1 η φάση και στη η φάση συνέκριναν τις δραστηριότητες του πρόσφατου παρελθόντος με το μακροπρόθεσμο κανονικό προφίλ. Εάν για κάποιο γεγονός, παρατηρούνταν σημαντική απόκλιση σε αυτό το στάδιο, το γεγονός αυτό εκλαμβανόταν ως μη κακόβουλο. Στόχος τους ήταν να ελέγξουν αν η κατανομή των τύπων γεγονότων ακολουθεί 6
63 το προφίλ που προέκυψε από την εκπαίδευση με κανονικά γεγονότα. Υπάρχουν 4 πιθανοί συνδυασμοί αποφάσεων, όπως φαίνεται στον ακόλουθο πίνακα. Απόφαση δείγματος H 0 : Το γεγονός είναι επίθεση H 1 : Το γεγονός δεν είναι επίθεση Απόρριψη της (Αποδοχή H ) H 1 0 Κανονικό Γεγονός Εσφαλμένος Συναγερμός Απόρριψη της (Αποδοχή H ) H 0 1 Εσφαλμένος Συναγερμός Κακόβουλο Γεγονός Χρησιμοποιώντας τους στατιστικούς ελέγχους T και X, μπόρεσαν να αναλύσουν τη σχέση ανάμεσα σε αυτούς τους 84 τύπους γεγονότων. Κανονικές και κακόβουλες δραστηριότητες προσομοιώθηκαν για την παραγωγή των δεδομένων ελέγχου που χρησιμοποιήθηκαν στις φάσεις εκπαίδευσης και ε- λέγχου. Οι φυσιολογικές δραστηριότητες προσομοιώνονται από το MIT Lincoln Laboratory (LL) σύμφωνα με κανονικές δραστηριότητες ενός πραγματικού υπολογιστικού και δικτυακού συστήματος. Επίσης, ένας αριθμός επιθέσεων προσομοιώνονται στο εργαστήριο σε έναν υπολογιστή με Solaris.5, συμπεριλαμβανομένων εικασιών συνθηματικών, χρήση συμβολικών συνδέσεων για να αποκτηθούν root προνόμια, προσπάθειες να επιτευχθεί μη εξουσιοδοτημένη απομακρυσμένη πρόσβαση κλπ Σύγκριση Στατιστικών Ελέγχων T και Και οι δύο έλεγχοι μετρούν την απόσταση μιας παρατήρησης από το πολυμετα- βλητό διάνυσμα μέσου ενός πληθυσμού [7] [8]. Ο έλεγχος T χρησιμοποιεί τη στατιστική απόσταση που βασίζεται στον πίνακα διασπορών-συνδιασπορών, σε X X αντίθεση με τον έλεγχο ο οποίος χρησιμοποιεί την απόσταση. Γενικά, ανωμαλίες που αφορούν σε πολλές μεταβλητές μπορούν να προκληθούν από μεταβολές στους μέσους αυτών των μεταβλητών (mean shifts), μεταβολές (departures) στις σχέσεις μεταβλητών (counterrelationships) ή συνδυασμούς μεταβολών των μέσων και των σχέσεων. Σε αντίθεση με τον έλεγχο, ο έλεγχος δεν λαμβάνει υπόψη τη συσχετισμένη δομή των p T X μεταβλητών. Μόνο ο μέσος του κανονικού προφίλ του χρήστη. Επομένως, ο έλεγχος X X εκτιμάται για τη διαμόρφωση T εντοπίζει και μετα- 63
64 βολές των μέσων και των σχέσεων, ενώ ο έλεγχος εντοπίζει μόνο τη μεταβολή στο μέσο μιας ή περισσοτέρων από τις p μεταβλητές. Ο έλεγχος X εμφανίζει καλή απόδοση στην ανίχνευση εισβολών. Ειδικότερα, βάσει ερευνών των Ye et al [7] [8], κατά τον έλεγχο μικρού συνόλου δεδομένων ελέγχου, από τις καμπύλες ROC και των ελέγχων προκύπτει πως ο έλεγχος X έχει καλύτερη απόδοση από τον έλεγχο T (ως προς και τα ποσοστά) όταν επιχειρείται ανίχνευση εισβολών σε επίπεδο γεγονότων. Κατά τον έλεγχο μεγάλου συνόλου δεδομένων ελέγχου, από τις καμπύλες ROC και των ελέγχων προκύπτει πως κανένας από τους ελέγχους X και T δεν έχει ικανοποιητικά αποτελέσματα σε επίπεδο γεγονότων. Από τις δοκιμές που πραγματοποίησαν οι Ye et al, ο έλεγχος X είχε ποσοστό ανίχνευσης 90% αλλά με ποσοστό εσφαλμένων συναγερμών 40%, ενώ η απόδοση του ελέγχου T δεν ήταν καθόλου ικανοποιητική, αφού σήμανε συναγερμός σε πολλά κανονικά γεγονότα και πολλά κακόβουλα γεγονότα πέρασαν απαρατήρητα ως κανονικά. Σε μεγάλα σύνολα δεδομένων, τα οποία περιέχουν ένα μεγάλο αριθμό γεγονότων, αν η ROC ανάλυση πραγματοποιηθεί όχι βάσει ξεχωριστών γεγονότων αλλά βάσει sessions, τα αποτελέσματα είναι διαφορετικά. Πιο συγκεκριμένα, τα γεγονότα ομαδοποιούνται κατά περίοδο, μετράται ο αριθμός των γεγονότων της κάθε περιόδου στα οποία σημαίνει συναγερμός και υπολογίζεται έπειτα η αναλογία του αριθμού των σημάτων ως προς τον αριθμό των γεγονότων εντός της περιόδου. Η αναλογία αυτή καλείται Session Signal Ratio (SSR). Εάν κατά τη συγκεκριμένη περίοδο παρουσιάζεται επίθεση, η τιμή του SSR είναι υψηλή, σε α- ντίθεση με κάποια περίοδο κατά την οποία παρατηρούνται κανονικές δραστηριότητες όπου η τιμή αυτή είναι χαμηλή. Μια καμπύλη ROC βασισμένη στο Session Signal Ratio δείχνει πόσο καλά ξεχωρίζουν οι περίοδοι με προσπάθειες εισβολής από τις περιόδους με φυσιολογικές δραστηριότητες. Βάσει των δοκιμών που πραγματοποιήθηκαν σε επίπεδο sessions, από τις καμπύλες ROC και των δύο ελέγχων προκύπτει πως και οι δύο αποδίδουν αρκετά καλά. Με ποσοστό εσφαλμένων συναγερμών 0%, ο έλεγχος T υπερτερεί του X με ποσοστό ανίχνευσης 95% έναντι 60%, αλλά με ποσοστό εσφαλμένων συ- X T ναγερμών 5%, ο έχει καλύτερη απόδοση από τον. Βάσει των παραπάνω αποτελεσμάτων των Ye et al, παρατηρούμε πως η απόδοση του ελέγχου X είναι είτε καλύτερη είτε συγκρίσιμη με αυτή του ελέγχου T τόσο για μικρά όσο και για μεγάλα σύνολα δεδομένων. Και οι δύο έλεγχοι ανιχνεύουν μεταβολές των μέσων. Ο έλεγχος T διαφέρει από τον X μόνο στην επιπλέον ικανότητά του να εντοπίζει counterrelationships. Λαμβάνοντας υπόψη την ομοιότητα και τη διαφορά των δύο ελέγχων, η καλύτερη ή συγκρίσιμη απόδοση του ελέγχου X υποδεικνύει ενδεχόμενα. Πρώτον, οι εισβολές γίνονται εμφανείς κυρίως μέσα από μεταβολές των μέσων της κατανομής εμφάνισης των τύπων των γεγονότων. Επομένως, η ικανότητα του X στην ανίχνευση μεταβο- X 64
65 λών των μέσων επαρκεί για την ανίχνευση εισβολών. Δεύτερον, η επιπλέον ικανότητα του T να εντοπίζει counterrelationships μπορεί να εντοπίσει κάποιους φυσιολογικούς θορύβους που οδηγούν σε counterrelationships, οι οποίες αυξάνουν τη διακύμανση των τιμών του ελέγχου T για γεγονότα κανονικών δραστη- ριοτήτων, και επομένως η διαχωριστική γραμμή μεταξύ κανονικών και κακόβουλων ενεργειών να είναι λιγότερο distinctive. Επίσης, ο έλεγχος για εισβολές σε επίπεδο sessions είναι αναμενόμενο να είναι περισσότερο αξιόπιστος από τον έλεγχο σε επίπεδο γεγονότων. Αυτό συμβαίνει γιατί ορισμένα από τα γεγονότα τα οποία χρησιμοποιούνται σε προσπάθειες εισβολής τυχαίνει να είναι κανονικά (για παράδειγμα εντολές που εμφανίζουν τα αρχεία ενός συστήματος ls) με αποτέλεσμα να μην θεωρούνται κακοήθη, αλλά σε συνδυασμό με άλλα να υποδηλώνουν κακόβουλη πρόθεση. Τέλος, χωρίς την ανάγκη υπολογισμού του πίνακα διασπορών-συνδιασπορών, η υπολογιστική πολυπλοκότητα του ελέγχου X είναι πολύ μικρότερη από εκείνη του ελέγχου T. Κατ επέκταση, ο στατιστικός έ- λεγχος X, όντας μια περισσότερο κλιμακωτή τεχνική πολυμεταβλητής ανάλυσης η οποία ανιχνεύει μεταβολές μέσων, κρίνεται επαρκής για την ανίχνευση εισβολών Μετρική της Canberra Όπως σημειώνεται και παραπάνω, η απόσταση Canberra [45] [46] ορίζεται για μη αρνητικές μεταβλητές μόνο και δίνεται από τη σχέση d ( x, x ) = k x x i i i = 1 ( x i + x i) Στην ανίχνευση επιθέσεων, στόχος είναι να υπολογιστεί πόσο απέχει η τιμή της τρέχουσας παρατήρησης από την τιμή του κανονικού προφίλ που έχει δημιουργηθεί από τα ιστορικά δεδομένα, επομένως η μετρική Canberra τροποποιείται ως εξής [45]: C = k π αρατηρο ύ μενη αναμεν ό μενη ( παρατηρούμενη + αναμενόμενη ) i = Υπολογισμός απόστασης Canberra Όπως αναφέρθηκε και στην περίπτωση του ελέγχου X, για τον υπολογισμό των παρατηρούμενων τιμών χρησιμοποιείται η τεχνική του EWMA ώστε οι παρατηρούμενες τιμές να αντανακλούν τα χαρακτηριστικά του «πιο πρόσφατου παρελθόντος» των μεταβλητών. Κατ αυτόν τον τρόπο, η βελτιωμένη παρατήρηση υ- πολογίζεται με βάση τον τύπο Oin, = λ θi+ ( 1 λ) Oin, 1 όπου O i,0 = 0 για i = 1,..., k, O είναι η εξομαλυσμένη τιμή της παρατήρησης, θ είναι ένας δείκτης in,. 65
66 της παρατήρησης(εάν ο τύπος γεγονότος i είναι παρών στην τρέχουσα παρατήρηση το θ έχει την τιμή 1, διαφορετικά την τιμή 0), O in, 1 είναι η προηγούμενη ε- ξομαλυσμένη παρατήρηση και λ είναι η σταθερά εξομάλυνσης (0 < λ < 1) [45]. Συνήθως η τιμή της σταθεράς τίθεται ίση με 0,3. Όμοια, για τον υπολογισμό της αναμενόμενης τιμής των μεταβλητών που παρακολουθούνται χρησιμοποιείται ο X, σύμφωνα με τον αυξητικό τύπο X ( in, ) (, 1 n O i j) in, 1 in, j = 0 ( n ) X ( ) + O( ) = = n Συνδυάζοντας τα παραπάνω, ο τύπος για τη μετρική της Canberra μορφοποιείται ως εξής [45]: n C n = O X k ( in, ) i i = 1 ( O( in, ) + X i ) Μια καλή ιδιότητα αυτής της μετρικής είναι πως για αριθμό μεταβλητών μεγαλύτερο από 30, η C n ακολουθεί κατά προσέγγιση κανονική κατανομή, ανεξάρτητα από την κατανομή που ακολουθεί καθεμιά από τις μεταβλητές ξεχωριστά [46]. Μπορεί επομένως να χρησιμοποιηθεί το 3 S(σίγμα) όριο για τη σηματοδότηση της εκάστοτε παρατήρησης ως κακόβουλης ή όχι. Το άνω όριο υπολογίζεται χρησιμοποιώντας το μέσο και τη διακύμανση της και ορίζεται να είναι C n Upper Limit ( UL) = C + 3S C Στα σενάρια ανίχνευσης εισβολών, υπολογίζουμε την ποσότητα Βάρος Εισβολής Intrusion Weight (IW ), μια κανονικοποιημένη τιμή, για να καθορίσουμε εάν μια παρατήρηση είναι κανονική ή εκτός ελέγχου. Η τιμή IW υπολογίζεται με βάση Cn τον τύπο IW ( Cn ) = min 1, UL. Εάν κατά τη διάρκεια της φάσης ελέγχου, η τιμή C n υπερβαίνει αυτό το άνω όριο, τότε η τιμή του IW τίθεται ίση με 1 και παράγεται ένα σήμα ειδοποίησης, διαφορετικά η τιμή του IW είναι μικρότερη του 1 και η παρατήρηση θεωρείται κανονική. Ωστόσο, δεν μπορούμε να εγγυηθούμε με ασφάλεια ότι τα «κανονικά» γεγονότα που δεν υπερβαίνουν την τιμή του άνω ορίου είναι κανονικά στην πραγματικότητα Εφαρμογή της μεθόδου Όπως και στις μελέτες που αφορούσαν τις μετρικές ομοιότητας T και X, οι Ye et al [45] [48] εφάρμοσαν τη βασισμένη στην απόσταση Canberra μέθοδο χρησι-. 66
67 μοποιώντας δεδομένα ελέγχου (audit data) από έναν Unix-based υπολογιστή υπηρεσίας (Sun SPARC 10 Workstation with Solaris). Το λειτουργικό σύστημα Solaris της Sun Microsystems Inc. παρέχει το BSM πρότυπο ασφαλείας, το ο- ποίο μπορεί να παρακολουθεί τις δραστηριότητες σε έναν υπολογιστή υπηρεσίας και να καταγράφει γεγονότα σχετικά με την ασφάλεια. Όπως προαναφέρθηκε, στο BSM ορίζονται 84 τύποι γεγονότων. Στη ροή γεγονότων (event stream), ο τύπος του τρέχοντος γεγονότος έχει μία παρατήρηση 1 και οι υπόλοιποι τύποι γεγονότων έχουν παρατηρήσεις 0. Μια μεγάλη ποσότητα των δεδομένων που χρησιμοποιήθηκαν προέρχονται από το MIT Lincoln Laboratory (LL), το οποίο με χορηγία του DARPA (Defense Advanced Research Projects Agency) δημιούργησε δεδομένα ελέγχου κανονικών και κακόβουλων δραστηριοτήτων για την αξιολόγηση συγκεκριμένων IDS που αναπτύχθηκαν σε προγράμματα του DARPA. Κακοήθεις και φυσιολογικές δραστηριότητες προσομοιώνονται ταυτόχρονα σε ένα πραγματικό υπολογιστικό και δικτυακό σύστημα σε μια βάση της Πολεμικής Αεροπορίας των Ηνωμένων Πολιτειών Σύγκριση μεθόδων με τις αποστάσεις Canberra και X Η έρευνα αφορά στα αποτελέσματα των πολυμεταβλητών SPC τεχνικών βασισμένων στις μετρικές της X απόστασης και της απόστασης Canberra. Η εκτί- μηση της απόδοσης της ανίχνευσης επιθέσεων γίνεται με τις καμπύλες ROC. Σε μικρά σύνολα δεδομένων, από τις καμπύλες ROC βάσει γεγονότων προκύπτει πως σε συνθήκες ιδανικές με μηδενικό ή πολύ χαμηλά επίπεδα θορύβου, η απόσταση Canberra επιτυγχάνει καλύτερη απόδοση από την X [48]. Εντούτοις, σε συνθήκες μέτριου ή υψηλού επιπέδου θορύβου, η X απόσταση επιτυγχάνει υψηλότερη απόδοση από την απόσταση Canberra. Επομένως, όσο το επίπεδο θορύβου αυξάνεται, η απόδοση της Canberra πέφτει σημαντικά. Σε μεγάλα σύνολα δεδομένων, τα οποία περιέχουν ένα μεγάλο αριθμό γεγονότων, η ROC ανάλυση πραγματοποιείται όχι βάσει ξεχωριστών γεγονότων αλλά βάσει περιόδων και της τιμής του Session Signal Ratio (SSR). Εάν κατά τη συγκεκριμένη περίοδο παρουσιάζεται επίθεση, η τιμή του SSR είναι υψηλή, σε α- ντίθεση με κάποια περίοδο κατά την οποία παρατηρούνται κανονικές δραστηριότητες όπου η τιμή αυτή είναι χαμηλή. Από την καμπύλη ROC φαίνεται πως η μετρική της X απόστασης αποδίδει καλύτερα από τη μετρική της απόστασης Canberra στο διαχωρισμό των περιόδων με προσπάθειες εισβολής από τις περιόδους με φυσιολογικές δραστηριότητες, βάσει της τιμής του Session Signal Ratio. Συνοψίζοντας, το συμπέρασμα που προκύπτει είναι πως η MSPC τεχνική βασισμένη στη X απόσταση επιδεικνύει καλύτερη απόδοση κάτω από συνθήκες διαφορετικών επιπέδων θορύβου απ ό,τι η MSPC τεχνική βασισμένη στην από- 67
68 σταση Canberra [48]. Η μετρική της X απόστασης είναι πολύ πιο ανθεκτική στο θόρυβο των δεδομένων από την μετρική της απόστασης Canberra. Επίσης, το υπολογιστικό κόστος στη βασισμένη στη X απόσταση τεχνική είναι μικρό, με αποτέλεσμα η τεχνική να μπορεί να κλιμακωθεί σε μεγάλους όγκους δεδομένων ελέγχου για ανίχνευση εισβολών σε πραγματικό χρόνο Έγκαιρη ανίχνευση επιθέσεων DoS με διάφορες μετρικές απόστασης Οι Li & Manikopoulos [49] υλοποιούν μια μέθοδο εντοπισμού επιθέσεων DoS χρησιμοποιώντας διάφορες μετρικές απόστασης για τον υπολογισμό της ομοιότητας ανάμεσα σε μια παρατηρούμενη συνάρτηση πυκνότητας πιθανότητας και μια συνάρτηση αναφοράς για συγκεκριμένες παραμέτρους της κυκλοφορίας ενός δικτύου. Βάσει της τιμής της ομοιότητας που υπολογίζεται για κάθε μετρική απόστασης, ένα νευρωνικό δίκτυο διακρίνει τις φυσιολογικές δραστηριότητες από τις επιθέσεις. Οι μετρικές απόστασης που ελέγχθηκαν είναι οι εξής: ένας έλεγχος χ (CST), ένας έλεγχος Kolmogorov-Smirnov (KST), μια στατιστική μετρική τύπου Kupier (KKS), ένας συνδυασμένος έλεγχος περιοχής και KS (AKS) και μια α- πλούστερη μηδαμινή απόκλιση από το στατιστικό μέσο (FDM). Συγκεκριμένα η μονάδα του στατιστικού ανιχνευτή ανωμαλιών μετατρέπει τις τιμές των παραμέτρων της κίνησης ενός δικτύου, οι οποίες συλλέγονται κατά τη διάρκεια κάθε «παραθύρου» παρατηρήσεων, σε μια συνάρτηση πυκνότητας πιθανότητας (Probability Density Function PDF) για κάθε παράμετρο. Η τρέχουσα συνάρτηση PDF συγκρίνεται με τη συνάρτηση αναφοράς για τη συγκεκριμένη παράμετρο και για το συγκεκριμένο χρονικό διάστημα παράθυρο παρατηρήσεων. Η σύγκριση αυτή υλοποιείται με χρήση μιας μετρικής απόστασης από εκείνες που αναφέρθηκαν παραπάνω. Μ αυτόν τον τρόπο παράγεται ένα σκορ ομοιότητας με τιμές που κυμαίνονται στο διάστημα [ 1,1] [49]. Όλα τα σκορ χρησιμοποιούνται για την κατασκευή ενός διανύσματος κατάστασης ανωμαλιών (Anomaly Status Vector ASV) για κάθε χρονική περίοδο. Το μοτίβο των τιμών αυτού του διανύσματος αντιπροσωπεύει την κατάσταση ομαλότητας ή/και ανωμαλιών του δικτύου εκείνη τη χρονική περίοδο. Το ASV διάνυσμα τροφοδοτείται ως είσοδος στο νευρωνικό ταξινομητή ο οποίος αποφαίνεται για το αν υφίσταται επίθεση ή όχι. Η ομοιότητα των δύο συναρτήσεων γίνεται με χρήση των ακόλουθων μετρικών απόστασης: 1. Έλεγχος τύπου χ (CST) Αν με s() i και r () i αναπαρίστανται οι τιμές του κομματιού (bin) i των τμημάτων των ιστογραμμάτων της παρατηρούμενης συνάρτησης PDF και της συνάρτησης αναφοράς αντίστοιχα, και με N και N αναπαρίσταται ο αριθμός δειγμάτων των δύο συναρτήσεων αντίστοιχα, τότε η απόσταση χ και μια σχετιζόμενη τιμή V της μετρικής ομοιότητας δίνονται από τις σχέσεις [49] S R 68
69 χ = i s() i N S + r () i N r () i N R R V ( χ ) tan 0,01 = π 1 Η τιμή V εφαρμόζεται ως είσοδος στο νευρωνικό δίκτυο.. KS Έλεγχος (KST) Η απόσταση της μετρικής ομοιότητας δίνεται από [49] D = max S( i) R ( i) i όπου S() i και R ( i ) αναπαριστούν τις τιμές του κομματιού (bin) i του ιστογράμματος της παρατηρούμενης συνάρτησης PDF και της συνάρτησης αναφοράς αντίστοιχα. Ο έλεγχος Kolmogorov-Smirnov γενικά έχει το πλεονέκτημα ότι είναι ανεξάρτητος κατανομής. 3. Στατιστική μετρική Kupier τύπου KS (KKS) Το στατιστικό Kupier είναι το άθροισμα των μέγιστων αποκλίσεων που χωρίζουν την κατανομή S( x ) από την κατανομή R ( x ), ως προς τις θετικές αλλά και τις αρνητικές κατευθύνσεις [49]. [ ( ) ( )] max [ ( ) ( )] D = max S i R i + R i S i 4. Συνδυασμένος έλεγχος Περιοχής-KS (AKS) i Η απόσταση της μετρικής ομοιότητας δίνεται από [49] D = max s( i) r ( i) + Σ s( i) r ( i ) i Ο πρώτος όρος είναι ο έλεγχος KS ενώ ο δεύτερος αντιπροσωπεύει μια διαφορά περιοχής ανάμεσα στις δύο συναρτήσεις PDF (παρατηρούμενη και α- ναφοράς) για κάθε παράμετρο. 5. Μηδαμινή απόκλιση από το στατιστικό μέσο (Fractional Deviation from the Mean - FDM) Έστω A S ο μέσος όρος των μετρήσεων μιας παρακολουθούμενης παραμέτρου σε ένα δεδομένο χρονικό παράθυρο παρατηρήσεων και A R ο μέσος i i 69
70 όρος των μετρήσεων του μοντέλου αναφοράς για αυτήν την παράμετρο, τότε η απόσταση μηδαμινής απόκλισης από το στατιστικό μέσο δίνεται από [49] ( S R ) / R D = A A A Να σημειωθεί ως από τις παραπάνω μετρικές απόστασης η μόνη που δεν απαιτεί μια συνάρτηση πυκνότητας πιθανότητας για τον υπολογισμό της είναι η FDM (ο υπολογισμός της μπορεί να γίνει από scalar τιμές). Οι Li & Manikopoulos [49] μελέτησαν την αποδοτικότητα αυτών των μετρικών ε- ξετάζοντας 9 διαφορετικά σενάρια πυκνότητας κίνησης δεδομένων (traffic intensity). Από τα αποτελέσματα των δοκιμών, η μετρική KST βρέθηκε να αποδίδει ελαφρώς καλύτερα από τις υπόλοιπες ενώ η FDM φάνηκε να αποδίδει ιδιαίτερα καλά σε χαμηλές πυκνότητες κίνησης δεδομένων σχετικών με επιθέσεις. Σε υψηλά ποσοστά επιθέσεων, όλες οι μετρικές εκτός της FDM, αποδίδουν ικανοποιητικά. Η μέθοδος αυτή υλοποιήθηκε στο σύστημα MAID. Βάσει της έρευνας των Li & Manikopoulos βρέθηκε πως βοηθά στην έγκαιρη ανίχνευση επιθέσεων DoS, όταν ακόμα η επίθεση είναι στα αρχικά της στάδια, γεγονός που επιτρέπει τη λήψη α- ντίμετρων πριν συμβεί η ζημιά. 3.6 Ανίχνευση Εισβολών με την Ανάλυση Κυρίων Συνιστωσών (PCA) Η PCA είναι μια πολυμεταβλητή στατιστική μέθοδος, η οποία έχει ως βασικό στόχο την προβολή ενός πολυδιάστατου συνόλου ποσοτικών δεδομένων σε έναν υποχώρο λιγότερων διαστάσεων. Η μέθοδος των κυρίων συνιστωσών έχει σκοπό να δημιουργήσει γραμμικούς συνδυασμούς των αρχικών μεταβλητών έτσι ώστε οι γραμμικοί αυτοί συνδυασμοί να είναι ασυσχέτιστοι μεταξύ τους αλλά να περιέχουν όσο γίνεται μεγαλύτερο μέρος της διακύμανσης των αρχικών μεταβλητών [81]. Στη σχετική με την ανίχνευση εισβολών βιβλιογραφία, αρκετοί έχουν χρησιμοποιήσει την PCA κυρίως για τη μείωση των διαστάσεων των συλλεγόμενων δεδομένων ή για τον εντοπισμό ομάδων στα παρατηρούμενα δεδομένα [9] [30] [31]. Η μείωση των διαστάσεων διευκολύνει την καλύτερη απεικόνιση ο- πτικοποίηση και ανάλυση των δεδομένων Εισαγωγή Η Ανάλυση Κυρίων Συνιστωσών είναι μια στατιστική μέθοδος η οποία μετασχηματίζει γραμμικά ένα σύνολο δεδομένων σε ένα σύνολο νέων μη συσχετιζόμενων μεταβλητών [80] [81] [8]. Από τις νέες μεταβλητές, που ονομάζονται Κύριες Συνιστώσες, μόνο ένα μέρος αυτών θα χρησιμοποιηθεί για την εξαγωγή συμπεράσματος. Η μελέτη δύο ή τριών μη συσχετιζόμενων μεταβλητών είναι ευκολότερη από τη μελέτη του συνόλου των αρχικών μεταβλητών. 70
71 Η μέθοδος αρχικά περιγράφηκε το 1901 από τον Karl Pearson και αναπτύχθηκε περισσότερο το 1933 από τον Hotelling. Η Ανάλυση Κυρίων Συνιστωσών καλείται επίσης και διακριτός μετασχηματισμός Karhunen-Loève (KLT, από τους Kari Karhunen και Michel Loève) ή μετασχηματισμός Hotelling (προς τιμή του Harold Hotelling).Στην PCA ανήκει ο τίτλος του βέλτιστου γραμμικού μετασχηματισμού για τη διατήρηση του χώρου με τη μέγιστη διασπορά. Ωστόσο, η πρακτική χρήση της μεθόδου PCA ακολούθησε μετά την ευρεία διάδοση των Η/Υ, επειδή οι μαθηματικές πράξεις ήταν πολύ δύσκολο να πραγματοποιηθούν με το χέρι για περισσότερες από τέσσερις μεταβλητές. Η PCA αποτελεί μια καλά εδραιωμένη τεχνική για μείωση των διαστάσεων και πολυμεταβλητή ανάλυση. Κάποιοι από τους τομείς στους οποίους βρίσκει εφαρμογή είναι η συμπίεση δεδομένων, η επεξεργασία εικόνας, η αναγνώριση προτύπων, η απεικόνιση και η πρόβλεψη χρονικών σειρών. Οι λόγοι για τους οποίους η PCA είναι δημοφιλής είναι οι εξής [50]: Αποτελεί το βέλτιστο γραμμικό σχέδιο για τη συμπίεση ενός συνόλου διανυσμάτων πολλών διαστάσεων σε ένα σύνολο διανυσμάτων λιγότερων διαστάσεων και στη συνέχεια την ανακατασκευή του. Οι παράμετροι του μοντέλου μπορούν να εκτιμηθούν απευθείας από τα δεδομένα, για παράδειγμα διαγωνιοποιώντας τη διακύμανση του δείγματος. Η συμπίεση και η αποσυμπίεση αποτελούν εύκολα υλοποιήσιμες λειτουργίες δεδομένων των παραμέτρων του μοντέλου, αφού απαιτούν μονάχα πολλαπλασιασμό πινάκων. Οι πολυμεταβλητοί χώροι τις περισσότερες φορές είναι δύσκολο να απεικονιστούν, καθιστώντας κατά συνέπεια επιτακτική τη μείωση των διαστάσεων. Η μείωση αυτή ουσιαστικά επιτυγχάνεται μέσω της σύνοψης πολυμεταβλητών χαρακτηριστικών με δύο ή τρεις νέες μεταβλητές, οι οποίες μπορούν να αναπαρασταθούν γραφικά με κόστος βέβαια να χαθεί κάποιο (όσο το δυνατόν πιο μικρό) ποσοστό της συνολικής μεταβλητότητας. Αυτό ουσιαστικά αντιστοιχεί με απώλεια πληροφορίας. Σε μερικές εφαρμογές αυτό είναι ζωτικής σημασίας. Για παράδειγμα σε μια τεράστια βάση δεδομένων αντί να αποθηκεύουμε όλες τις μεταβλητές μπορούμε να αποθηκεύουμε μόνο κάποιον αριθμό κυρίων συνιστωσών. Σίγουρα χάνουμε κάποιο μέρος της πληροφορίας αλλά το κέρδος σε χώρο αλλά και ταχύτητα επεξεργασίας μπορεί να είναι τεράστιο. Από την άλλη πλευρά πολλές φορές συμβαίνει να έχουμε λίγες παρατηρήσεις αλλά πολλές μεταβλητές. Τέτοια προβλήματα για παράδειγμα εμφανίζονται στην αρχαιομετρία ένα πεδίο εφαρμογής στατιστικών μεθόδων στην αρχαιολογία, όπου τα αντικείμενα που θέλει κάποιος να μελετήσει είναι συνήθως λίγα (π.χ. αμφορείς της κλασσικής περιόδου) αλλά τα στοιχεία και οι μεταβλητές που έχει είναι πάρα πολλά. Η μείωση των διαστάσεων του προβλήματος φαντάζει η μόνη λύση για να προχωρήσει κανείς σε στατιστική επεξεργασία. 71
72 Ένα άλλο μεγάλο πλεονέκτημα (το οποίο από την άλλη ίσως είναι και μειονέκτημα για πολλούς) είναι πως με τη μέθοδο των κυριών συνιστωσών μπορούμε να εξετάσουμε τις συσχετίσεις ανάμεσα στις μεταβλητές και να διαπιστώσουμε πόσο οι μεταβλητές μοιάζουν ή όχι. Επίσης η μέθοδος μας επιτρέπει να αναγνωρίσουμε ποιες από τις αρχικές μεταβλητές έχουν μεγάλη επίδραση στις κύριες συνιστώσες. Αυτό είναι πολύ χρήσιμο σε κάποιες επιστήμες καθώς μας επιτρέπουν να ποσοτικοποιήσουμε μη μετρήσιμες ποσότητες, όπως η αγάπη, η ευφυΐα, η ικανότητα ενός μπασκετμπολίστα, η εμπορευσιμότητα ενός προϊόντος και άλλες αφηρημένες έννοιες. Το γεγονός βέβαια πως τέτοιες ερμηνείες εμπεριέχουν σε μεγάλο βαθμό υποκειμενικά κριτήρια έχει οδηγήσει πολλούς στο να κατηγορούν τη μέθοδο και να μην την εμπιστεύονται Η PCA συνοψίζει τη διακύμανση ενός συσχετιζόμενου πολυμεταβλητού συνόλου σε ένα σύνολο μη συσχετιζόμενων συνιστωσών, καθεμία από τις οποίες είναι έ- νας ξεχωριστός γραμμικός συνδυασμός των αρχικών μεταβλητών και παραμένει μετασχηματισμένη ως προς μηδενικό μέσο όρο (mean corrected). Οι εξαγόμενες μη συσχετιζόμενες συνιστώσες ονομάζονται Κύριες Συνιστώσες και εκτιμώνται από τα ιδιοδιανύσματα του πίνακα διακυμάνσεων ή συσχετίσεων των αρχικών μεταβλητών. Για κάθε σύστημα συντεταγμένων, το νέφος των σημείων χαρακτηρίζεται από συγκεκριμένη διακύμανση (variance) σε κάθε κατεύθυνση. Η διακύμανση αυτή δηλώνει τη διασπορά γύρω από τη μέση τιμή σε αυτή την κατεύθυνση. Υπό τη συνθήκη ότι το σύστημα συντεταγμένων είναι ορθογώνιο, η συνολική διακύμανση είναι σταθερή. Η PCA επιλέγει το σύστημα συντεταγμένων τοποθετώντας τον πρώτο άξονα στην κατεύθυνση μέγιστης διακύμανσης και επιλέγοντας κάθε επόμενο άξονα κάθετα στον προηγούμενό του μεγιστοποιώντας κάθε φορά τη διακύμανση. Η διαδικασία συνεχίζεται έως ότου όλοι οι νέοι άξονες καθοριστούν και οι νέες μεταβλητές εκφράζουν το μέγιστο της κάθε φορά υπολοίπουσας διακύμανσης, με την προϋπόθεση πάντα οι νέες μεταβλητές να μη συσχετίζονται. Η διακύμανση ανά άξονα (συνιστώσα) εκφράζεται ως ποσοστό % επί του (σταθερού) συνόλου. Η ολική διακύμανση δεν αλλάζει, κάτι που είναι αναμενόμενο α- φού παραμένει αμετάβλητη η διευθέτηση των σημείων στο χώρο. Η p νέα μεταβλητή εξηγεί τη μέγιστη διακύμανση που δεν εξηγείται από τις προηγούμενες p 1 μεταβλητές. Από τις συνιστώσες που προκύπτουν επιλέγονται εκείνες (συνήθως δύο ή τρεις) που θεωρούνται πιο σημαντικές και που εξηγούν το μεγαλύτερο μέρος της ολικής διακύμανσης χωρίς σημαντική απώλεια πληροφορίας. Για ένα σύνολο n δεδομένων σε χώρο p διαστάσεων, η PCA αναζητά m άξονες, ορθογώνιους μεταξύ τους, τέτοιους ώστε οι προβολές των σημείων πάνω τους να έχουν τη μέγιστη διασπορά. Αυτή είναι και η βάση της μεθόδου PCA. Η εξαγωγή των κυρίων συνιστωσών μπορεί να γίνει χρησιμοποιώντας είτε το αρχικό πολυμεταβλητό σύνολο δεδομένων είτε χρησιμοποιώντας τον πίνακα διακυμάνσεων ή συσχετίσεων, εάν το αρχικό σύνολο δεδομένων δεν είναι διαθέσιμο. Συνήθως χρησιμοποιείται ο πίνακας συσχετίσεων όταν οι κλίμακες με τις οποίες 7
73 μετρούνται οι μεταβλητές διαφέρουν και κατά συνέπεια διαφέρουν και οι διακυμάνσεις τους. Ακόμη και αν οι κλίμακες μέτρησης είναι ίδιες, υπάρχει περίπτωση οι διακυμάνσεις των μεταβλητών πάλι να διαφέρουν. Για να αποφευχθεί μια μεταβλητή να έχει υπερβολική επιρροή στη δημιουργία των κυρίων συνιστωσών, συνηθίζεται ο μετασχηματισμός του συνόλου των μεταβλητών έτσι ώστε να έχουν μηδενικό μέσο όρο και διακύμανση ίση με τη μονάδα [5]. Ο μετασχηματισμός αυτός καλείται τυποποίηση (standardization). Από την άλλη πλευρά πάντως, η γενικευμένη χρήση του πίνακα συσχετίσεων δεν ενδείκνυται καθώς η διαφορά στις διακυμάνσεις ενδέχεται να περιέχει πληροφορία πολύτιμη για το θέμα που εξετάζεται. Ίσως δηλαδή κάποιες μεταβλητές να πρέπει να θεωρηθούν πως έχουν μεγαλύτερο βάρος εξαιτίας της και επομένως θέτοντας όλες τις μεταβλητές να έχουν το ίδιο βάρος χάνεται χρήσιμη πληροφορία. Κατά συνέπεια στην πράξη δεν είναι ξεκάθαρο ποιος από τους δύο πίνακες πρέπει να χρησιμοποιείται. Μια καλή στρατηγική είναι να αποφεύγεται ο πίνακας διακύμανσης όταν υπάρχουν κάποιες μεταβλητές με πολύ μεγαλύτερη διακύμανση από ότι οι υπόλοιπες. Αν οι διακυμάνσεις διαφέρουν μεν αλλά είναι συγκρίσιμες (π.χ. αναφέρονται σε ίδιες μονάδες) τότε καλό είναι αυτή την πληροφορία να χρησιμοποιείται. Εναλλακτικά θα μπορούσε κανείς να μετασχηματίσει τα δεδομένα του ώστε να κάνει τις διακυμάνσεις συγκρίσιμες PCA Principal Component Analysis Έστω ένας n p πίνακας δεδομένων n παρατηρήσεων σε καθεμιά από τις p μεταβλητές [46] [80]. Εάν ( X1, X, K, X p ) και ο ( λ1, e1),( λ, e),,( λp, ep) S p p πίνακας διακυμάνσεων των του πίνακα S, τότε η i οστή κύρια συνιστώσα είναι όπου i = 1,, K, p, X1, X, K, X p K τα p ζεύγη ιδιοτιμών / ιδιοδιανυσμάτων ( ) 1( 1 1) ( ) K ( ) y = e x x = e x x + e x x + + e x x λ λ K λ 0, 1 p ' i i i i ip p p e = ( e, e, K, e ) το i οστό ιδιοδιάνυσμα, ' i i1 i ip x' = ( x1, x, K, x p ) ένα οποιοδήποτε διάνυσμα παρατήρηση των μεταβλητών X, X, K, X και 1 p x' = ( x 1, x, K, x p ) X, X, K, X. 1 p τα διάνυσμα μέσων του δείγματος των μεταβλητών 73
74 Η i οστή κύρια συνιστώσα έχει διασπορά λ i και η διακύμανση οποιουδήποτε ζεύγους κυρίων συνιστωσών είναι μηδενική. Επιπλέον, αν s ii είναι η δειγματική διακύμανση της μεταβλητής X i, τότε η συνολική δειγματική διακύμανση όλων των μεταβλητών X, X, K, X είναι 1 p p s ii i = 1 = λ1 + λ + K + λp που είναι η συνολική δειγματική διακύμανση όλων των κυρίων συνιστωσών. Αυτό σημαίνει πως όλη η διακύμανση των αρχικών δεδομένων εξηγείται από τις κύριες συνιστώσες. 1 p ( 1 1) ( ) ( p p) Η μέθοδος PCA μπορεί να εφαρμοστεί και σε ένα p p πίνακα συσχετίσεων R των μεταβλητών X, X, K, X με τρόπο όμοιο με αυτόν του πίνακα διακυμάνσεων. Εάν λ, e, λ, e, K, λ, e τα p ζεύγη ιδιοτιμών / ιδιοδιανυσμάτων του πίνακα R, τότε η i οστή κύρια συνιστώσα είναι y = e z = e z + e z + K+ e i ' i i1 1 i ip z p όπου ( 1,, p ) ' z z z z = K το διάνυσμα των τυποποιημένων παρατηρήσεων που ορίζονται ως εξής: z k ( x k x k ) = με k = 1,, K, p. s kk Οι κύριες συνιστώσες του πίνακα συσχετίσεων R έχουν τις ίδιες ιδιότητες όπως προηγουμένως. Δηλαδή, η i οστή κύρια συνιστώσα έχει δειγματική διακύμανση λ i, η δειγματική διακύμανση οποιουδήποτε ζεύγους κυρίων συνιστωσών είναι μηδενική και η συνολική διακύμανση όλων των κυρίων συνιστωσών είναι λ1 + λ + K+ λp = p, που αποτελεί τη συνολική δειγματική διακύμανση όλων των τυποποιημένων μεταβλητών z, Kz Εφαρμογή της μεθόδου z 1, p Οι Labib και Vemuri [50] [51] χρησιμοποίησαν την PCA για ανίχνευση επιθέσεων DoS και Probe. Σε μια DoS επίθεση (Denial-of-Service), ο επιτιθέμενος καθιστά κάποιον πόρο πολύ απασχολημένο ώστε να αδυνατεί να χειριστεί τα αιτήματα των νόμιμων χρηστών. Προτού όμως εξαπολύσει την επίθεση σε μια συγκεκριμένη ιστοσελίδα, ουσιαστικά εξετάζει το δίκτυο ή τον υπολογιστή υπηρεσίας του θύματος προς αναζήτηση ανοιχτών θυρών. Αυτό γίνεται με μια διαδικασία σαρώματος (sweeping) όλων των υπολογιστών υπηρεσίας ενός δικτύου ή ενός 74
75 μόνο υπολογιστή ερευνώντας τις ανοιχτές θύρες. Αυτού του είδους η επίθεση ονομάζεται Probe επίθεση. Οι τύποι επιθέσεων που μελετά η συγκεκριμένη έρευνα είναι οι επιθέσεις Smurf, Portsweep, Neptune και IPsweep [50] [51]. Τα δεδομένα που χρησιμοποιήθηκαν προέρχονται από τα σύνολα δεδομένων του DARPA 1998 για ανίχνευση εισβολών. Συγκεκριμένα, δημιουργήθηκαν 7 σύνολα δεδομένων, καθένα από τα οποία περιείχε 300 διανύσματα χαρακτηριστικών με 1 συστατικά το καθένα. Η ανάλυση έγινε με το στατιστικό εργαλείο S- Plus. Κάθε διάνυσμα έχει την παρακάτω μορφή SIPx SPort DIPx DPort Prot Plen όπου = [ 1 4]. Τέσσερα τέ- SIPx ένα κομμάτι της IP διεύθυνσης της πηγής με x τοια κομμάτια συνθέτουν ολόκληρη την IP διεύθυνση SPort αριθμός θύρας της πηγής DIPx ένα κομμάτι της IP διεύθυνσης του προορισμού με x = [ 1 4]. DPort αριθμός θύρας του προορισμού Prot τύπος πρωτοκόλλου (TCP, UDP, ICMP) Plen Μήκος του πακέτου σε bytes Οι IP διευθύνσεις είναι χωρισμένες στις διευθύνσεις των δικτύων και υπολογιστών υπηρεσίας τους, προκειμένου να είναι εφικτή η ανάλυση όλων των τύπων διευθύνσεων των δικτύων. Τα φορτία των κυρίων συνιστωσών παρέχουν μια περίληψη της επιρροής των αρχικών μεταβλητών επί των κυρίων συνιστωσών και αποτελούν επομένως μια καλή βάση για ερμηνεία των δεδομένων. Βάσει των αποτελεσμάτων της έρευνας των Labib και Vemuri [50], είναι δυνατόν να χρησιμοποιηθούν τα φορτία των δύο πρώτων κυρίων συνιστωσών προκειμένου για την αναγνώριση μιας επίθεσης. Για φυσιολογική κυκλοφορία δεδομένων, οι τιμές των φορτίων εμφανίζονται παρόμοιες, ενώ κατά τη διάρκεια επιθέσεων οι τιμές αυτές διαφέρουν σημαντικά για τις πρώτες κύριες συνιστώσες. Μια τιμή-κατώφλι μπορεί να χρησιμοποιηθεί για το διαχωρισμό αυτό. Επιπλέον, οι τιμές των τυπικών αποκλίσεων για τις πρώτες κύριες συνιστώσες θα μπορούσαν να συνηγορήσουν υπέρ του χαρακτηρισμού μιας ενέργειας ως επίθεσης. Ειδικότερα, όποτε αυτές οι τιμές διαφέρουν σημαντικά, αυτό θα μπορούσε να είναι μια ακόμη ένδειξη ενδεχόμενης επίθεσης. Ένα πιθανό κριτήριο C βασισμένο στις τιμές των φορτίων για τον προσδιορισμό μιας επίθεσης αναπαρίσταται με την ακόλουθη σχέση [50]: 75
76 (( 1 ) 100 ) C = abs l l p ν όπου l 1,l οι τιμές των φορτίων των δύο πρώτων κυρίων συνιστωσών και p v η αθροιστική ποσότητα της διακύμανσης για τις δύο κύριες συνιστώσες. Για τιμή του κριτηρίου C = 1 επιτυγχάνεται 100% ποσοστό ανίχνευσης εισβολών. Επίσης, με τη χρήση διαγραμμάτων Bi-plot είναι εφικτή η οπτική ερμηνεία των τιμών των φορτίων των κυρίων συνιστωσών. Ένα διάγραμμα Bi-plot επιτρέπει την αναπαράσταση τόσο των αρχικών μεταβλητών όσο και των μετασχηματισμένων παρατηρήσεων στους άξονες των κυρίων συνιστωσών. Οι αρχικές μεταβλητές αναπαρίστανται με βέλη, τα οποία δείχνουν γραφικά το ποσοστό της αρχικής διακύμανσης που εξηγείται από τις δύο πρώτες συνιστώσες. Η διεύθυνση των βελών δείχνει τα σχετικά φορτία στις δύο πρώτες κύριες συνιστώσες. Μια άλλη μέθοδος που χρησιμοποιεί έναν ταξινομητή κυρίων συνιστωσών (Principal Component Classifier PCC) προτείνεται από τους Shyu et al [5]. Υποθέτοντας πως οι ανωμαλίες μπορούν να εκληφθούν ως ακραίες τιμές (outliers), ένα μοντέλο πρόβλεψης για ανίχνευση εισβολών κατασκευάζεται από τις πρωτεύουσες περισσότερο σημαντικές (major) κύριες συνιστώσες και τις δευτερεύουσες λιγότερο σημαντικές (minor) κύριες συνιστώσες κανονικών στιγμιότυπων. Μια μετρική της διαφοράς μιας ανωμαλίας από ένα κανονικό στιγμιότυπο είναι η απόσταση στο χώρο των κυρίων συνιστωσών. Όντας μια μέθοδος ανίχνευσης ακραίων τιμών, ο ταξινομητής κυρίων συνιστωσών μπορεί να βρει ε- φαρμογή και σε άλλους τομείς πέραν του εντοπισμού εισβολών (fault detection, sensor detection, statistical process control, distributed sensor network κλπ) Εντοπισμός Ακραίων Τιμών (Outlier Detection) Τα περισσότερα σύνολα δεδομένων περιλαμβάνουν μία ή περισσότερες ασυνήθιστες παρατηρήσεις που δεν ανήκουν στο πρότυπο μεταβλητότητας των υπολοίπων [5]. Όταν μια παρατήρηση είναι διαφορετική από την πλειοψηφία των δεδομένων ή είναι αρκετά απίθανο να ακολουθεί το υποτιθέμενο μοντέλο πιθανοτήτων των δεδομένων, τότε θεωρείται ως τιμή προς εξαίρεση (outlier). Σε δεδομένα με ένα μόνο χαρακτηριστικό, ασυνήθιστες παρατηρήσεις είναι εκείνες που είναι είτε πολύ μεγάλες είτε πολύ μικρές σε σχέση με τις άλλες. Εάν υποτεθεί πως ακολουθούν την κανονική κατανομή, οποιαδήποτε παρατήρηση της οποίας η τυποποιημένη τιμή είναι μεγάλη κατά απόλυτη τιμή (λόγου χάρη μεγαλύτερη από 3 ή 4), συχνά αναγνωρίζεται ως ακραία τιμή. Στην περίπτωση πολλών χαρακτηριστικών όμως, όπως συμβαίνει στην ανίχνευση εισβολών, μπορεί να υφίστανται ακραίες τιμές που δεν εμφανίζονται ως τέτοιες όταν κάθε διάσταση λαμβάνεται υπόψη ξεχωριστά και κατά συνέπεια να μην εντοπιστούν χρησιμοποιώντας ένα μονομεταβλητό κριτήριο. Υπάρχει επομένως η ανάγκη να αντιμετωπίζονται όλα τα χαρακτηριστικά ως ενιαίο σύνολο χρησιμοποιώντας μια πολυμεταβλητή προσέγγιση. Η διαδικασία που χρησιμοποιείται συνήθως είναι ο υπολογισμός της απόστασης κάθε παρατήρησης από το κέντρο των δεδομένων χρησιμοποιώντας την μετρική 76
77 της απόστασης Mahalanobis. Εάν η κατανομή των μεταβλητών X1, X, K, Xn είναι πολυμεταβλητή κανονική, τότε για μια μελλοντική παρατήρηση X της ίδιας κατανομής, ο στατιστικός έλεγχος T βασισμένος στην απόσταση Mahalanobis ( i )' ( i ) T = X X S 1 X X ( n 1) p κατανέμεται ως Fpn, p, όπου Fpn, p μια τυχαία μεταβλητή που ακολουθεί F n p κατανομή με p και ( n p) βαθμούς ελευθερίας. Μια μεγάλη τιμή για το T υποδεικνύει μια μεγάλη απόκλιση της παρατήρησης ( n p) X i από το κέντρο του πληθυσμού και το στατιστικό F-test T μπορεί να χρησιμοποιηθεί για τον εντοπισμό των ακραίων p( n+ 1)( n 1) τιμών. Αντί για την απόσταση Mahalanobis, μπορεί να χρησιμοποιηθεί οποιαδήποτε άλλη μετρική απόστασης, όπως η Ευκλείδεια ή η Canberra [5]. Οποιαδήποτε παρατήρηση έχει απόσταση μεγαλύτερη από μια τιμή-κατώφλι θεωρείται ακραία τιμή. Το κατώφλι συνήθως καθορίζεται από την εμπειρική κατανομή της απόστασης. Η PCA χρησιμοποιείται αρκετά για εντοπισμό πολυμεταβλητών ακραίων τιμών. ' Έστω οι κύριες συνιστώσες y1, y, K, y p μιας παρατήρησης x με yi = ei ( x x ) για i = 1,, K, p. Το άθροισμα των τιμών (scores) των τυποποιημένων κυρίων συνιστωσών p yi y y 1 y p = + + K λ λ λ λ i = 1 i 1 p ισούται με την απόσταση Mahalanobis της παρατήρησης δείγματος, όπως αυτή ορίστηκε παραπάνω [53]. x από το μέσο του Οι πρώτες λίγες κύριες συνιστώσες έχουν μεγάλες διακυμάνσεις και εξηγούν το μεγαλύτερο αθροιστικό ποσοστό της συνολικής διακύμανσης του δείγματος [5]. Αυτές οι περισσότερο σημαντικές συνιστώσες τείνουν να είναι στενά συνδεδεμένες με χαρακτηριστικά που έχουν σχετικά μεγάλες διακυμάνσεις και συνδιακυμάνσεις, συνεπώς οι παρατηρήσεις που είναι ακραίες τιμές ως προς τις πιο σημαντικές κύριες συνιστώσες συνήθως ανταποκρίνονται σε ακραίες τιμές ως προς μία ή περισσότερες από τις αρχικές μεταβλητές. Από την άλλη μεριά, οι λιγότερο σημαντικές κύριες συνιστώσες αναπαριστούν γραμμικές συναρτήσεις των αρχικών μεταβλητών με ελάχιστη διακύμανση. Αυτές οι συνιστώσες είναι ευαίσθητες στις παρατηρήσεις που είναι δεν συμφωνούν με την δομή συσχέτισης των δεδο- 77
78 μένων αλλά δεν είναι ακραίες τιμές ως προς τις αρχικές μεταβλητές. Επομένως μεγάλες τιμές των παρατηρήσεων στις λιγότερο σημαντικές συνιστώσες αντιπροσωπεύουν πολυμεταβλητές ακραίες τιμές που δεν είναι ανιχνεύσιμες χρησιμοποιώντας το κριτήριο βάσει των μεγάλων τιμών των αρχικών μεταβλητών Principal Component Classifier PCC Στο προτεινόμενο σχήμα, ο ταξινομητής κυρίων συνιστωσών αποτελείται από δύο συναρτήσεις τιμών (scores) των κυρίων συνιστωσών, μία από τις περισσότερο σημαντικές συνιστώσες p y i i = p r + 1 λi και μία από τις λιγότερο σημαντικές συνιστώσες q y i i = 1 λi [5]. Η πρώτη συνάρτηση, η οποία χρησιμοποιείται και συχνότερα στη βιβλιογραφία, χρησιμοποιείται για τον εντοπισμό ακραίων παρατηρήσεων με μεγάλες τιμές σε ορισμένα από τα αρχικά χαρακτηριστικά. Η δεύτερη συνάρτηση προτείνεται σε συνδυασμό με την πρώτη για να βοηθήσει τον εντοπισμό των παρατηρήσεων που δε συμμορφώνονται με την κανονική δομή συσχέτισης. Όταν οι λιγότερο σημαντικές συνιστώσες εξηγούν το μεγαλύτερο ποσοστό διακύμανσης μιας παρατήρησης, αυτό αποτελεί ένδειξη πως η παρατήρηση είναι ακραία τιμή σε σχέση με τη δομή συσχέτισης. Ένα πλεονέκτημα της συγκεκριμένης προσέγγισης είναι πως διατηρείται η πληροφορία που αφορά στη φύση των ακραίων τιμών ως προς το αν είναι όντως ακραίες τιμές ή δεν έχουν την ίδια δομή συσχέτισης με τα κανονικά στιγμιότυπα. Ο αριθμός q των κυρίων συνιστωσών καθορίζεται από το ποσοστό διακύμανσης των δεδομένων εκπαίδευσης που εξηγούνται από αυτές τις συνιστώσες [5]. Βάσει πειραμάτων, προτείνεται η χρήση των q κυρίων συνιστωσών που μπορούν να εξηγήσουν περίπου το 50% της συνολικής διακύμανσης των τυποποιημένων χαρακτηριστικών. Όταν τα αρχικά χαρακτηριστικά είναι ασυσχέτιστα, κάθε κύρια συνιστώσα του πίνακα συσχετίσεων έχει ιδιοτιμή ίση με τη μονάδα. Επομένως, οι r λιγότερο σημαντικές συνιστώσες που χρησιμοποιούνται στον PCC είναι εκείνες οι συνιστώσες των οποίων η διακύμανση ή η ιδιοτιμή είναι μικρότερη από 0,0, τιμή που θα μπορούσε να υποδηλώσει κάποιες σχέσεις ανάμεσα στα χαρακτηριστικά. Η κατηγοριοποίηση βάσει του PCC γίνεται ως εξής: Υπολογισμός των τιμών (scores) των κυρίων συνιστωσών της παρατήρησης της οποίας η κλάση πρέπει να καθοριστεί και x Κατηγοριοποίηση της x q y i ως επίθεση εάν > c λ i = 1 i 1 y p i ή > c i = p r + 1 λi Κατηγοριοποίηση της x q y ως κανονικό στιγμιότυπο εάν i c λ i = 1 i 1 p y i και c i = p r + 1 λi 78
79 όπου c,c 1 τιμές-κατώφλια για ακραίες τιμές τέτοιες ώστε ο ταξινομητής να παράγει ένα συγκεκριμένο ποσοστό εσφαλμένων συναγερμών. Με την υπόθεση πως τα δεδομένα ακολουθούν την πολυμεταβλητή κανονική κατανομή, το ποσοστό εσφαλμένων συναγερμών αυτού του ταξινομητή είναι α = α + α α α όπου 1 1 q y i α1 = P > c1 η x είναι κανονικό στιγμιότυπο και i = 1 λi p y i α = P > c η x είναι κανονικό στιγμιότυπο. i= p r+ 1 λi Κάτω από άλλες συνθήκες, ένα άνω και κάτω όριο για το ποσοστό εσφαλμένων συναγερμών α παρέχονται από τις ανισότητες Cauchy-Schwartz και Bonferroni [54] α + α α α α α + α Οι τιμές των a1,a επιλέγονται ώστε να αντανακλούν τη σχετική σημαντικότητα όλων των τύπων ακραίων τιμών που επιθυμούμε να ανιχνεύσουμε [5]. Αφού η υπόθεση της κανονικότητας είναι πολύ πιθανό να παραβιάζεται και θεωρώντας πως a = a, τα κατώφλια καθορίζονται βάσει των εμπειρικών κατανομών των q y i i = 1 λi 1 p y i i = p r + 1 λi και στα δεδομένα εκπαίδευσης. Δηλαδή τα c,c 1 είναι το 0,9899 quantile της εμπειρικής κατανομής των q y i i = 1 λi p y i i = p r + 1 λi και αντίστοιχα. Στην περίπτωση που η υπόθεση της κανονικότητας ισχύει, πως το μέγεθος του δείγματος είναι αρκετά μεγάλο και πως όλες οι ιδιοτιμές είναι διακριτές και θετικές, προκύπτει πως το q y i i = 1 λi με q p ακολουθεί κατανομή X με q βαθμούς ε- λευθερίας και με επίπεδο σημαντικότητας ίσο με α %, το κριτήριο εντοπισμού των ακραίων τιμών είναι: Η παρατήρηση q yi x είναι ακραία τιμή εάν > X q ( α ). λ i = 1 i Εφαρμογή της μεθόδου Στη μέθοδο των Shyu et al χρησιμοποιήθηκε το KDD CUP 1999 σύνολο δεδομένων, το οποίο περιλαμβάνει τα δεδομένα που χρησιμοποιήθηκαν στο «Third International Knowledge Discovery and Data Mining Tools Competition». Λεπτομέρειες για τα δεδομένα και τα χαρακτηριστικά τους βρίσκονται στα [55] [56] [57]. 79
80 Η απόδοση της προσέγγισης PCC μελετάται σε σύγκριση με την προσέγγιση LOF (Density-based Local Outliers) [58] και με άλλες δύο μεθόδους εντοπισμού εισβολών βασισμένες σε μετρικές απόστασης, την Ευκλείδεια απόσταση και την απόσταση Canberra. Η βασισμένη στην Ευκλείδεια απόσταση τεχνική ουσιαστικά είναι η μέθοδος των k κοντινότερων γειτόνων. Εδώ η σύγκριση γίνεται για k = 1 και k = 5. Το αποτέλεσμα της κατηγοριοποίησης συνήθως παρουσιάζεται σε έναν πίνακα ο οποίος καλείται Πίνακας Σύγχυσης (Confusion Matrix) και φαίνεται παρακάτω. Η ακρίβεια του ταξινομητή μετράται με το ποσοστό λανθασμένης κατηγοριοποίησης ή εναλλακτικά με το ποσοστό της σωστής κατηγοριοποίησης. Προβλεπόμενη Παρατήρηση Επίθεση Κανονικό Στιγμιότυπο Πραγματική παρατήρηση Επίθεση Κανονικό Στιγμιότυπο True Positive - TP (Ορθώς ανιχνεύτηκαν) False Positive - FP (Εσφαλμένος συναγερμός) False Negative - FN True Negative - TN Δύο ακόμη μετρικές απόδοσης παρουσιάζουν ενδιαφέρον. Πρόκειται για το precision και το recall, οι οποίες ορίζονται ως [59]: TP Pr ecision = TP + FP Re call TP = TP + FN Ακόμη ένα πολύτιμο εργαλείο για την αξιολόγηση μιας τεχνικής ανίχνευσης ανωμαλιών, όπως έχει προαναφερθεί, είναι και οι καμπύλες ROC. Από τα αποτελέσματα των πειραμάτων προκύπτει πως όσο το ποσοστό της διακύμανσης που εξηγείται από τις κύριες συνιστώσες μεγαλώνει (που σημαίνει πως επιλέγεται μεγαλύτερος αριθμός κυρίων συνιστωσών), το ποσοστό ανίχνευσης αυξάνει, εκτός από το ποσοστό εσφαλμένων συναγερμών της τάξης του 1-%. Παράλληλα, φαίνεται πως η επιλογή των κυρίων συνιστωσών που εξηγούν περίπου το 50% της συνολικής διακύμανσης είναι η βέλτιστη για την επίτευξη χαμη- 80
81 λού ποσοστού εσφαλμένων συναγερμών αλλά αποδεικνύεται επαρκής και για το υψηλό ποσοστό εσφαλμένων συναγερμών. Ο αριθμός των περισσότερο σημαντικών κυρίων συνιστωσών επιλέγεται να είναι q = 5. Σε γενικές γραμμές, η απόσταση Canberra παρουσιάζει πολύ χαμηλή απόδοση. Το αποτέλεσμα αυτό συμφωνεί και με τα αποτελέσματα των Emran and Ye [45], οι οποίοι επίσης συμφωνούν πως δεν αποδίδει σε ικανοποιητικό και αποδεκτό επίπεδο. Η PCC μέθοδος έχει ποσοστό ανίχνευσης ίσο με 99% με πάρα πολύ μικρή τυπική απόκλιση σε όλα τα επίπεδα εσφαλμένων συναγερμών και ξεπερνά τις υπόλοιπες μεθόδους (κοντινότερου γείτονα, προσέγγιση LOF και αναγνώριση outliers με χρήση της απόστασης Canberra) βάσει των καμπυλών ROC. Για ποσοστό εσφαλμένων συναγερμών ίσο με 1%, η PCC έχει τις μεγαλύτερες τιμές σε recall και precision (για παράδειγμα επιτυγχάνει 98.94% σε recall και 97.89% σε precision, ενώ διατηρεί το ποσοστό εσφαλμένων συναγερμών στο 0.9%. Συνολικά, η μόνη συγκρίσιμη και ανταγωνίσιμη τεχνική είναι αυτή των LOF, αλλά μόνο όταν το ποσοστό εσφαλμένων συναγερμών είναι 4% ή υψηλότερο. Από την ανάλυση των αποτελεσμάτων ανίχνευσης προκύπτει πως ένας μεγάλος αριθμός επιθέσεων μπορούν να ανιχνευθούν χρησιμοποιώντας και τις περισσότερο σημαντικές και τις λιγότερο σημαντικές κύριες συνιστώσες, κάποιες μπορούν να εντοπιστούν χρησιμοποιώντας είτε τις πρώτες είτε τις δεύτερες και ορισμένες περνούν εντελώς απαρατήρητες αφού δεν είναι ποιοτικά διαφορετικές από τα κανονικά στιγμιότυπα Πλεονεκτήματα της PCC Το σχήμα εντοπισμού ανωμαλιών αυτής της προσέγγισης βασίζεται στις κύριες συνιστώσες και τον εντοπισμό ακραίων τιμών (outlier detection). Η βασική ιδέα της συγκεκριμένης μεθόδου έγκειται στο ότι οι επιθέσεις εμφανίζονται ως ακραίες τιμές σε σύγκριση με τα κανονικά δεδομένα. Η μέθοδος αυτή έχει ορισμένα πλεονεκτήματα. Καταρχάς, δεν κάνει καμιά υπόθεση σχετικά με τις κατανομές. Πολλές στατιστικές μέθοδοι υποθέτουν πως τα δεδομένα ακολουθούν κανονική κατανομή ή καταφεύγουν στη χρήση του Κεντρικού Οριακού Θεωρήματος (όπως είδαμε και σε προηγούμενες παραγράφους) απαιτώντας ο αριθμός των χαρακτηριστικών να είναι μεγαλύτερος από 30. Κατά δεύτερο λόγο, είναι αναμενόμενο τα δεδομένα αυτού του τύπου να είναι πολυδιάστατα [5]. Επομένως, στην προκειμένη περίπτωση εφαρμόζεται η Ανάλυση Κυρίων Συνιστωσών για τη μείωση του αριθμού των διαστάσεων και τη σύνθεση ενός ταξινομητή, ο οποίος είναι μια α- πλή συνάρτηση των κυρίων συνιστωσών. Με την PCA επιτυγχάνεται η μείωση των διαστάσεων χωρίς να θυσιάζονται πολύτιμες πληροφορίες. Ένα ακόμη όφελος της προτεινόμενης μεθοδολογίας είναι πως οι στατιστικές ποσότητες που χρησιμοποιεί μπορούν να υπολογιστούν σε λιγότερο χρόνο κατά το στάδιο της ανίχνευσης, γεγονός που καθιστά τη συγκεκριμένη μέθοδο κατάλληλη για ανίχνευση εισβολών σε πραγματικό χρόνο. 81
82 3.7 Ανάλυση Παραγόντων στην Ανίχνευση Εισβολών (Factor Analysis) Για τη μείωση των διαστάσεων των πολυμεταβλητών δεδομένων μπορεί να χρησιμοποιηθεί και η ανάλυση παραγόντων. Η εργασία των Wu & Zhang [60] πραγματεύεται μια τεχνική ανίχνευσης εισβολών, η οποία χρησιμοποιεί την ανάλυση παραγόντων για να αποκαλύψει τη λανθάνουσα δομή ενός συνόλου μεταβλητών και να μειώσει το χώρο των διαστάσεων, και την απόσταση Mahalanobis για να καθορίσει την «ομοιότητα» ενός συνόλου τιμών ενός αγνώστου δείγματος με ένα σύνολο τιμών μιας συλλογής γνωστών δειγμάτων και κατ επέκταση να προσδιορίσει αν το διάνυσμα τιμών του δείγματος είναι ακραία τιμή (επομένως και επίθεση) στο μοντέλο που παράγεται από την ανάλυση παραγόντων Εισαγωγή Η παραγοντική ανάλυση είναι μια στατιστική μέθοδος που αποτελεί μια γενίκευση της μεθόδου των κυρίων συνιστωσών και έχει σκοπό να βρει την ύπαρξη παραγόντων κοινών ανάμεσα σε μια ομάδα μεταβλητών [80] [81]. Βασίζεται στη μελέτη των συσχετίσεων ανάμεσα σε μεγάλο αριθμό αλληλοσυσχετισμένων ποσοτικών μεταβλητών. Μειώνει το χώρο των αρχικών μεταβλητών υπολογίζοντας ένα μικρότερο αριθμό νέων μεταβλητών που ονομάζονται παράγοντες (factors). Η μείωση αυτή επιτυγχάνεται με την ομαδοποίηση των μεταβλητών σε παράγοντες ώστε οι μεταβλητές μέσα στον κάθε παράγοντα να είναι πολύ συσχετισμένες ενώ μεταβλητές σε διαφορετικούς παράγοντες να είναι λιγότερο συσχετισμένες. Η ιστορία της γενικής μεθόδου FA έχει τις ρίζες της στις αρχές του 0 ου αιώνα και συγκεκριμένα στις προσπάθειες των Pearson και Spearman να ορίσουν και να μετρήσουν τη νοημοσύνη. Μάλιστα, η ανάλυση παραγόντων βασίζεται ως ένα σημείο σε συμπεράσματα ερευνών που έγιναν στα επιστημονικά πεδία της Ψυχομετρίας και της Βιομετρίας. Έτσι, εκφράζοντας αυτούς τους παράγοντες (οι οποίοι δεν είναι μια υπαρκτή ποσότητα αλλά την «κατασκευάζουμε» για τις ανάγκες μας) μπορούμε να χρησιμοποιήσουμε την ανάλυση παραγόντων για τους ακόλουθους σκοπούς [80]: 1. Να μειώσουμε τις διαστάσεις του προβλήματος. Αντί να δουλεύουμε με τις αρχικές μεταβλητές να δουλέψουμε με λιγότερες αφού οι παράγοντες είναι κατασκευασμένοι κατά τέτοιο τρόπο ώστε να διατηρούν όσο γίνεται την πληροφορία που υπήρχε στις αρχικές μεταβλητές. Ειδικότερα η FA χρησιμοποιείται στη διαδικασία που είναι γνωστή ως κατασκευή μοντέλων με δομικές εξισώσεις (Structural Equation Modeling SEM).. Να δημιουργήσουμε νέες μεταβλητές, τους παράγοντες, τις οποίες μπορούμε με έναν υποκειμενικό τρόπο να αναγνωρίσουμε ως κάποιες μη μετρήσιμες μεταβλητές όπως π.χ. η ευφυΐα στην ψυχολογία ή η ελκυστικότητα ενός προϊόντος στο Μάρκετινγκ. 8
83 3. Να εξηγήσουμε τις συσχετίσεις που υπάρχουν στα δεδομένα, για τις οποίες έχουμε υποθέσει ότι οφείλονται αποκλειστικά στην ύπαρξη κάποιων κοινών παραγόντων που δημιούργησαν τα δεδομένα. Αυτό που πρέπει να έχει κανείς υπόψη του είναι πως η παραγοντική ανάλυση προσπαθεί περισσότερο να ερμηνεύσει τη δομή παρά τη μεταβλητότητα. Γενικά θα μπορούσαμε να διακρίνουμε δύο είδη της ανάλυσης παραγόντων ανάλογα με τους σκοπούς της [80]: 1. Διερευνητική ανάλυση παραγόντων (Exploratory factor analysis EFA): Αναφέρεται στην αναζήτηση της συγκαλυμμένης δομής ενός μεγάλου συνόλου μεταβλητών. Η αρχική υπόθεση είναι ότι η καθεμιά από τις αρχικές μεταβλητές μπορεί να σχετίζεται με οποιονδήποτε παράγοντα, οπότε ο σκοπός της ανάλυσης είναι να αποκαλυφθούν αυτές οι σχέσεις και επομένως η λανθάνουσα δομή των δεδομένων.. Επιβεβαιωτική ανάλυση παραγόντων (Confirmatory factor analysis CFA): Στην περίπτωση αυτή υπάρχει συγκεκριμένη αρχική υπόθεση σχετικά με τις σχέσεις των παραγόντων και των μεταβλητών του δείγματος, οπότε ο ερευνητής προσπαθεί με την FA να επιβεβαιώσει το αναμενόμενο αποτέλεσμα από μια θεμελιωμένη θεωρία. Οι διαφορές της με την Ανάλυση σε Κύριες Συνιστώσες είναι οι εξής [81]: Στην παραγοντική ανάλυση υπάρχει ένα δομημένο μοντέλο και κάποιες υποθέσεις. Από αυτή την άποψη είναι μια στατιστική τεχνική, κάτι που δεν ισχύει με την ανάλυση σε κύριες συνιστώσες η οποία είναι καθαρά ένας μαθηματικός μετασχηματισμός. Στην ανάλυση σε κύριες συνιστώσες το ενδιαφέρον στηρίζεται στο να εξηγηθεί η διακύμανση ενώ με την παραγοντική ανάλυση εξηγούμε την συνδιακύμανση των μεταβλητών. Το μοντέλο της ανάλυσης παραγόντων προσπαθεί να εκφράσει τις μεταβλητές ως γραμμικό συνδυασμό των παραγόντων ενώ στην ανάλυση σε κύριες συνιστώσες νοιαζόμαστε περισσότερο να εκφράσουμε τις κύριες συνιστώσες ως γραμμικό συνδυασμό των αρχικών μεταβλητών. Οι παράγοντες που προκύπτουν έχουν την ίδια διακύμανση. Αυτό αποτελεί βασική διαφορά από την ανάλυση σε κύριες συνιστώσες όπου θέλουμε οι κύριες συνιστώσες να είναι σε φθίνουσα τάξη διακύμανσης. Συνεπώς οι παράγοντες που προκύπτουν δεν είναι απαραίτητα σε κάποια σειρά (αν και αυτό εξαρτάται και από τη μέθοδο εκτίμησης). Η παραγοντική ανάλυση έχει δεχτεί πολλές κριτικές από πολλούς επιστήμονες. Τα κυριότερα προβλήματα που συνδυάζονται με την παραγοντική ανάλυση είναι ότι [81]: 83
84 Στηρίζεται σε ένα πλήθος υποθέσεων οι οποίες δεν είναι απαραίτητα ρεαλιστικές για πραγματικά προβλήματα και συνήθως ο ερευνητής δεν μπορεί να τις ελέγξει εύκολα. Οι παράγοντες οι οποίοι προκύπτουν μπορούν να δεχτούν διαφορετικές ερμηνείες οι οποίες μπορεί και να έρχονται σε αντιπαράθεση. Μπορούμε από τα ίδια δεδομένα να καταλήξουμε σε εντελώς διαφορετικές ερμηνείες κάτι που επιστημονικά δεν είναι αποδεκτό. Ο αριθμός των παραγόντων που χρειάζεται να εξάγουμε ώστε τα αποτελέσματα να είναι χρήσιμα, δεν είναι προφανής κι εξαρτάται και από τη μέθοδο εκτίμησης που θα χρησιμοποιηθεί. Αυτό επιτρέπει στον επιστήμονα να δουλεύει σε μια μεροληπτική βάση έτσι ώστε να εμφανίζει τα αποτελέσματα όπως τον συμφέρουν. Να σημειωθεί επίσης πως η ερμηνεία των παραγόντων μπορεί να εξαρτάται και από τον αριθμό τους, δηλαδή προσθέτοντας παράγοντες αυτοί να παύουν να έχουν την ίδια ερμηνεία (αν και αυτό είναι μια ένδειξη ακαταλληλότητας του μοντέλου). Για μερικές μεθόδους εκτίμησης υπάρχει περιορισμός στον αριθμό των παραγόντων που μπορούν να εκτιμηθούν. Παρόλα αυτά η παραγοντική ανάλυση αποτελεί πολύτιμο εργαλείο σε πολλές ε- πιστήμες και κυρίως στην Ψυχομετρία και την έρευνα αγοράς. Ο βασικός λόγος είναι πως αποτελεί μεθοδολογία για την ποσοτικοποίηση μη παρατηρήσιμων ποσοτήτων οι οποίες εμφανίζονται συχνά σε αυτές τις επιστήμες Ανάλυση Παραγόντων (Factor Analysis FA) Έστω X το παρατηρούμενο τυχαίο διάνυσμα m μεταβλητών X1, X, K, Xm με μέσο μ και πίνακα συνδιασπορών Σ [80]. Το μοντέλο παραγόντων ορίζει ως προϋπόθεση το X να είναι γραμμικά εξαρτημένο από ορισμένες μη παρατηρούμενες τυχαίες μεταβλητές F, F, K F, οι οποίες καλούνται κοινοί παράγοντες και 1, p m επιπλέον πηγές διασποράς e1, e, K, em που καλούνται σφάλματα (ή μοναδικοί παράγοντες specific factors). Το μοντέλο της ανάλυσης παραγόντων είναι αυτό που εκφράζει κάθε μεταβλητή X i ως γραμμικό συνδυασμό των παραγόντων F, F, K,F και είναι το ακόλουθο [46]: 1 p X μ = l F + l F + L+ l F + ε p p 1 X μ = l F + l F + L+ l F + ε M 1 1 p p X μ = l F + l F + L+ l F + ε m m m1 1 m mp p m ή με τη μορφή πινάκων 84
85 X μ = LF + e όπου X είναι το διάνυσμα των αρχικών m μεταβλητών, μ είναι το διάνυσμα των μέσων, L είναι ο πίνακας των φορτίων όπου το l (loading) του j οστού παράγοντα F στη μεταβλητή X, j ij είναι η επιβάρυνση φορτίο i F είναι ο πίνακας με τους παράγοντες (σκορ των παραγόντων) και ε είναι το σφάλμα ή μοναδικός παράγοντας. Το σφάλμα ε i είναι ο μοναδικός παράγοντας της i οστής μεταβλητής και είναι το μέρος της μεταβλητής το οποίο δεν μπορεί να εξηγηθεί από τους παράγοντες. Οι m αποκλίσεις X1 μ1, X μ, L, Xm μm εκφράζονται σε όρους m+ p τυχαίων μεταβλητών F1, F, K, Fp, e1, e, K, e m που δεν είναι παρατηρήσιμες. Υποθέτουμε πως τα σφάλματα e1, e, K,em έχουν μέση τιμή 0 και είναι ασυσχέτιστα μεταξύ τους αλλά και με τις μεταβλητές F, F, K,F. Επίσης, χωρίς περιορισμό της γενικότητας 1 p 1 p μπορούμε να θεωρήσουμε ότι οι μεταβλητές F, F, K,F έχουν μέση τιμή 0, τυπική απόκλιση 1 και είναι ασυσχέτιστες μεταξύ τους. Συνοπτικά οι υποθέσεις που προαναφέρονται είναι: E( F) = 0 Cov ( F ) = I E( e) = 0 Cov ( e ) = Ψ Cov ( e, F ) = 0 όπου ο πίνακας διασπορών-συνδιασπορών των σφαλμάτων είναι Cov e ψ 1 0 L 0 0 ψ L 0 = = = M M L M 0 0 L ψ m ( ) Ψ diag ( ψ1, K, ψm ) Οι παραπάνω υποθέσεις και το μοντέλο με τη μορφή πινάκων αποτελούν το ορθογώνιο μοντέλο παραγόντων. 85
86 Η υπόθεση Cov ( F )= I σημαίνει ότι οι παράγοντες είναι ορθογώνιοι μεταξύ τους. Για αυτό το λόγο ονομάζουμε το μοντέλο ως ορθογώνιο. Αυτό δεν είναι καθόλου ρεαλιστικό σε πραγματικές εφαρμογές. Αν επιτρέψουμε κάποια μορφή συσχέτισης τότε μπορούμε να ορίσουμε ένα γενικότερο μοντέλο παραγοντικής ανάλυσης το οποίο δεν είναι ορθογώνιο. Προκύπτει επίσης πως οι διακυμάνσεις των παραγόντων είναι ίσες με τη μονάδα, άρα όλοι οι παράγοντες έχουν την ίδια διακύμανση. Από τις παραπάνω υποθέσεις μπορεί να δειχθεί ότι Σ = Cov ( X ) = Cov ( LF + ε) = LCov ( F ) L' + Cov ( ε) = LL ' + Ψ καθώς από τις υποθέσεις του μοντέλου η συνδιακύμανση μεταξύ F και ε είναι μηδέν. Συνεπώς βλέπουμε πως ο πίνακας διακύμανσης μπορεί να διασπαστεί σε δυο μέρη, το πρώτο είναι το κομμάτι που ερμηνεύουν οι κοινοί παράγοντες και ονομάζεται εταιρικότητα ή συμμετοχικότητα (communality) και το δεύτερο το κομμάτι που οφείλεται στους μοναδικούς παράγοντες, και άρα το μοντέλο δεν μπορεί να ερμηνεύσει και ονομάζεται ιδιαιτερότητα ή ειδική μεταβλητότητα (specificity). Στην παραγοντική ανάλυση σκοπός είναι να εκτιμήσουμε τους πίνακες L και Ψ, να αναπαραστήσουμε δηλαδή τον πίνακα διακύμανσης του πληθυσμού. Για να το επιτύχουμε αυτό έχουν αναπτυχθεί διάφορες μέθοδοι εκτίμησης οι οποίες θα αναλυθούν αργότερα. Το πρόβλημα με το μοντέλο FA που κατασκευάζεται είναι ότι αποτελείται κυρίως από θεωρητικές οντότητες, οι οποίες πρέπει να εκτιμηθούν βάσει του δείγματος. Συγκεκριμένα, πρέπει να εκτιμηθούν [80]: 1. Ο αριθμός p των παραγόντων: Προφανώς ενδιαφέρει ο μικρότερος αριθμός p ώστε να έχουμε μια επαρκή προσαρμογή στα δεδομένα.. Τα φορτία των παραγόντων l : Αφού οι παράγοντες δεν είναι δυνατόν να i, j μετρηθούν, τα φορτία είναι τα μέσα για να δώσουμε υπόσταση στον κάθε παράγοντα. Αναγνωρίζοντας τους παράγοντες με μεγάλα φορτία για κάθε μεταβλητή είναι πιθανό να μπορέσουμε να αποδώσουμε ερμηνεία στους παράγοντες. 3. Οι διασπορές των σφαλμάτων ψ,, 1 K ψ p : Οι ποσότητες αυτές καθορίζουν πόση από τη μεταβλητότητα της κάθε μεταβλητής δεν μπορεί να αποδοθεί στους παράγοντες και κατά συνέπεια πόσο αξιόπιστα μπορεί να παρασταθεί κάθε μεταβλητή με το μοντέλο FA. 4. Τα σκορ των παραγόντων Fj' ( fi1,, fi ) = K p : Παρέχουν μια βαθμολογία των ατόμων του δείγματος ως προς τους παράγοντες που έχουν αναγνωριστεί. 86
87 3.7.3 Αριθμός Παραγόντων και Εκτίμηση των Παραγόντων Ένα από τα βασικά ερωτήματα στην Παραγοντική Ανάλυση είναι ο καθορισμός του αριθμού των παραγόντων που θα χρησιμοποιήσουμε [81]. Ο αριθμός αυτός δεν είναι γνωστός και υπάρχουν διάφορες μέθοδοι για να εκτιμηθεί. Πολλά στατιστικά πακέτα επιτρέπουν στον ερευνητή να καθορίσει εκ των προτέρων τον α- ριθμό αυτό αλλά γενικά αυτό γίνεται κυρίως για λόγους ευκολίας. Για να βρεθεί ο αριθμός λοιπόν των παραγόντων ο ερευνητής μπορεί να χρησιμοποιήσει τις τιμές των ιδιοτιμών του πίνακα διακύμανσης συνδιακύμανσης, τιμές που εξηγούν κάποιο ποσοστό της διακύμανσης ή το scree plot (το γράφημα των ιδιοτιμών ως προς τον αύξοντα αριθμό τους). Σημαντικό είναι πως ο αριθμός των παραγόντων χρειάζεται να καθοριστεί πριν γίνει η εκτίμηση τους. Επομένως κάποιος θα μπορούσε να δουλέψει με διαδοχικά αυξανόμενο αριθμό παραγόντων και να κρατήσει το μοντέλο με βάση κάποιο κριτήριο καλής προσαρμοστικότητας. Να σημειωθεί επίσης πως: Η ερμηνεία των παραγόντων μπορεί να εξαρτάται και από τον αριθμό τους, δηλαδή προσθέτοντας παράγοντες αυτοί να παύουν να έχουν την ί- δια ερμηνεία (αν και αυτό είναι μια ένδειξη ακαταλληλότητας του μοντέλου). Για μερικές μεθόδους εκτίμησης υπάρχει περιορισμός στον αριθμό των παραγόντων που μπορούν να εκτιμηθούν. Οι δύο βασικές μέθοδοι εκτίμησης που χρησιμοποιούνται στην πράξη είναι η μέθοδος των κυρίων συνιστωσών και η μέθοδος μεγίστης πιθανοφάνειας [81]. Συγκριτικά έχουμε: Όταν εκτιμούμε το μοντέλο με τη μέθοδο των κυρίων συνιστωσών, προσθέτοντας παράγοντες δεν αλλάζουν τα φορτία των παραγόντων που είχαμε πάρει πριν. Αυτό δεν ισχύει με τη μέθοδο μεγίστης πιθανοφάνειας όπου προσθέτοντας παράγοντες αλλάζουν τα φορτία των προηγούμενων παραγόντων και άρα η ερμηνεία τους. Με τη μέθοδο μεγίστης πιθανοφάνειας μπορούμε να κάνουμε ελέγχους καλής προσαρμογής του μοντέλου βασισμένοι στον κλασσικό έλεγχο λόγου πιθανοφανειών. Η μέθοδος των κυρίων συνιστωσών εξαρτάται από τις μονάδες μέτρησης κι έτσι αν αλλάξουν μπορεί να αλλάξει ριζικά η λύση που έχουμε πάρει. Αυτό δεν ισχύει με τη μέθοδο μεγίστης πιθανοφάνειας που είναι ανεξάρτητη των μονάδων μέτρησης. Έτσι ενώ στη μέθοδο κυρίων συνιστωσών πρέπει να γίνει επιλογή ανάμεσα στον πίνακα διακύμανσης και τον πίνακα συσχέτισης στη μέθοδο μεγίστης πιθανοφάνειας δεν υφίσταται τέτοιο πρόβλημα. 87
88 Η μέθοδος των κυρίων συνιστωσών δεν βάζει περιορισμούς στον αριθμό των παραγόντων που μπορούμε να εκτιμήσουμε. Όταν η μέθοδος μεγίστης πιθανοφάνειας δεν δουλεύει αυτό είναι μια ένδειξη ότι υπάρχει πρόβλημα με το μοντέλο. Αντίθετα η μέθοδος κυρίων συνιστωσών επειδή είναι στην ουσία ένας μαθηματικός μετασχηματισμός των δεδομένων δουλεύει πάντα χωρίς όμως να δίνει κάποια ένδειξη αν καλώς δουλεύει ή όχι. Με τη μέθοδο μεγίστης πιθανοφάνειας τα σκορ των παραγόντων δεν μπορούν να υπολογιστούν ακριβώς όπως συμβαίνει με τη μέθοδο κυρίων συνιστωσών Εκτίμηση με τη μέθοδο Κυρίων Συνιστωσών Η εκτίμηση με τη μέθοδο των κυρίων συνιστωσών βασίζεται στη φασματική ανάλυση του πίνακα διακύμανσης (συσχέτισης) [81]. Όταν λέμε πως θέλουμε να ε- κτιμήσουμε τις παραμέτρους του παραγοντικού μοντέλου εννοούμε πως θέλουμε να εκτιμήσουμε τα στοιχεία του πίνακα φορτίων L και τα στοιχεία της διαγωνίου του πίνακα Ψ. Το πλήθος των στοιχειών του πίνακα L έχει να κάνει με το πλήθος των παραγόντων που έχουμε υποθέσει πως υπάρχουν. Επομένως σκοπός μας είναι να βρούμε πίνακες $L, Ψ για τους όποιους ο πίνακας LL $$ ' + Ψ να είναι όσο γίνεται πιο κοντά στον πίνακα δειγματικής διακύμανσης (συσχέτισης). Βάσει της φασματικής ανάλυσης ενός πίνακα διακύμανσης μπορούμε να τον γράψουμε στη μορφή Σ = ΑΑ', όπου Α = ΠΛ 1 όπου Λ ο διαγώνιος πίνακας που περιέχει στη διαγώνιο τις ιδιοτιμές και Π ο πίνακας με στήλες τα ιδιοδιανύσματα του πίνακα Σ. Επομένως μπορούμε να αναπαραστήσουμε πλήρως τον πίνακα Σ. Στην πράξη δουλεύουμε με το δειγματικό πίνακα διακύμανσης S. Αν το πλήθος των παραγόντων είναι ίδιο με το πλήθος των αρχικών μεταβλητών, επιτυγχάνουμε την πλήρη αναπαράσταση του δειγματικού πίνακα διακύμανσης (συσχέτισης) και επομένως οι εκτιμήσεις των ιδιαιτεροτήτων ψ i είναι 0, δηλαδή οι παράγοντες εξηγούν όλη τη διακύμανση. Αν ο αριθμός των παραγόντων είναι μικρότερος από τον αριθμό των αρχικών μεταβλητών, τότε ο πίνακας LL' $$ δεν μπορεί να αναπαραστήσει πλήρως τον αρχικό πίνακα διακύμανσης. Έτσι σε αυτή την περίπτωση μπορούμε να εκτιμήσουμε και τις ιδιαιτερότητες ως Ψ m i = si Li j j = 1 όπου L είναι το ij στοιχείο του πίνακα LL $$ ', δηλαδή το φορτίο του j παράγοντα ij στην i μεταβλητή, με j = 1,, K, p και i = 1,, K,m. Ο δεύτερος όρος στο δεξί μέλος της ισότητας είναι η συμμετοχικότητα της μεταβλητής. 88
89 Μια εναλλακτική παρουσίαση της εκτίμησης των ιδιαιτεροτήτων είναι πως αυτές εκτιμούνται ως τα διαγώνια στοιχεία του πίνακα S LL $$ ' (προσοχή, μόνο τα διαγώνια). Επομένως μετά την εκτίμηση του μοντέλου, αν έχουμε χρησιμοποιήσει λιγότερους παράγοντες από το πλήθος των μεταβλητών μας, θα υπάρχουν κατάλοιπα ανάμεσα στον πραγματικό πίνακα διακύμανσης από όπου ξεκινήσαμε και τον εκτιμηθέντα από το μοντέλο. Μερικές χρήσιμες παρατηρήσεις σχετικά με τη μέθοδο κυρίων συνιστωσών είναι οι εξής [81]: 1. Αν χρησιμοποιήσουμε πολλούς παράγοντες μπορούμε να αναπαραστήσουμε πλήρως τον αρχικό πίνακα. Σε αυτήν όμως την περίπτωση δεν έ- χουμε κερδίσει κάτι σημαντικό αφού χρησιμοποιήσαμε πολλούς παράγοντες και στην ουσία απλά μετασχηματίσαμε τα δεδομένα μας. Δεν υπάρχει περιορισμός ως προς τον αριθμό των παραγόντων που μπορώ να εκτιμήσω με τη μέθοδο κυρίων συνιστωσών. 3. Είναι διαφορετικό πράγμα να χρησιμοποιώ την μέθοδο ανάλυσης σε κύριες συνιστώσες και το να χρησιμοποιώ τη μέθοδο κυρίων συνιστωσών για να εκτιμήσω το παραγοντικό μοντέλο. Μπορεί τα ονόματα να είναι ό- μοια αλλά υπάρχουν σημαντικές διαφορές. Η μια είναι αυτοτελής μέθοδος ανάλυσης και η άλλη απλά ένα εργαλείο εκτίμησης του παραγοντικού μοντέλου Εκτίμηση με τη μέθοδο μεγίστης πιθανοφάνειας Για να χρησιμοποιήσουμε τη μέθοδο μεγίστης πιθανοφάνειας χρειάζεται να κάνουμε κάποιες υποθέσεις σχετικά με τον πληθυσμό από όπου προήλθαν τα δεδομένα μας [81]. Συγκεκριμένα υποθέτουμε πως τα σφάλματα (μοναδικοί όροι) ακολουθούν πολυμεταβλητή κανονική κατανομή με διάνυσμα μέσων το μηδενικό διάνυσμα και πίνακα διακύμανσης το διαγώνιο πίνακα Ψ. Επομένως το διάνυσμα των τυχαίων μεταβλητών X δοθέντος του διανύσματος των παραγόντων F ακολουθεί την πολυδιάστατη κανονική κατανομή και άρα αν υποθέσουμε πως και οι παράγοντες προέρχονται από πολυδιάστατη κανονική κατανομή, προκύπτει πως Χ Ν ( LF, LL' + Ψ ). m Δηλαδή οι παραπανίσιες υποθέσεις είχαν να κάνουν με την κανονικότητα των σφαλμάτων και των παραγόντων. Άρα τώρα έχουμε ένα παραμετρικό μοντέλο και τα δεδομένα προέρχονται από πολυμεταβλητή κανονική κατανομή. Αυτό α- φενός σημαίνει πως έχουμε να ελέγξουμε μια υπόθεση η οποία μάλιστα δεν είναι εύκολο να ελεγχθεί (πολυμεταβλητή κανονικότητα) αλλά αφετέρου μπορούμε να κάνουμε στατιστική συμπερασματολογία. Επίσης η υπόθεση της κανονικότητας ισοδυναμεί με το ότι οι μεταβλητές μας είναι συνεχείς. 89
90 Αν λοιπόν έχουμε ένα δείγμα από πολυμεταβλητή κανονική κατανομή μπορεί να δειχτεί ότι η πιθανοφάνεια είναι συνάρτηση του πίνακα διακύμανσης Σ του πληθυσμού n 1 l ( X, Σ) = mln( π) + ln Σ + tr ( Σ S) όπου n είναι το μέγεθος του δείγματος, m ο αριθμός των μεταβλητών και S ο δειγματικός πίνακας διακυμάνσεων. Από την παραπάνω πιθανοφάνεια έχουμε εξαφανίσει το διάνυσμα των μέσων μ αφού αυτό δεν επηρεάζει το μοντέλο μας (ή ισοδύναμα έχουμε κεντροποιήσει όλες τις μεταβλητές να έχουν μέση τιμή 0). Για να εκτιμήσουμε το μοντέλο με τη μέθοδο μεγίστης πιθανοφάνειας πρέπει να μεγιστοποιήσουμε τη συνάρτηση ( ) n 1 l ( X, L, Ψ ) = mln( π) + ln ( LL' + Ψ ) + tr ( LL' + Ψ ) S ως προς L και Ψ. Αν το μοντέλο έχει p παράγοντες τότε ο πίνακας L έχει m p στοιχεία ενώ ο πίνακας Ψ επειδή είναι διαγώνιος έχει m στοιχεία. Συνολικά έ- χουμε ( m+ 1) p παραμέτρους ενώ ο πίνακας Σ από όπου ξεκινάμε έχει m ( 1 m + ) διαφορετικά στοιχεία (θυμηθείτε πως είναι συμμετρικός). Για να έχει λύση λοιπόν θα πρέπει να βάλουμε περιορισμό στο p, τον αριθμό των παραγόντων που μπορούμε να εκτιμήσουμε. Επομένως με τη μέθοδο μέγιστης πιθανοφάνειας υπάρχει περιορισμός στον αριθμό των παραγόντων (κάτι που δεν υπήρχε στη μέθοδο κυρίων συνιστωσών). Μπορεί κανείς να δει πως ο μέγιστος αριθμός p των παραγόντων που μπορούμε να εκτιμήσουμε είναι m όπου [ α ] είναι το ακέραιο μέρος του α. Ο πίνακας που ακολουθεί δείχνει το μέγιστο αριθμό παραγόντων που μπορούμε να εκτιμήσουμε με τη μέθοδο μεγίστης πιθανοφάνειας για κάθε πλήθος μεταβλητών m. m Μέγιστο p Επίσης για να μπορούμε να ταυτοποιήσουμε χρειαζόμαστε έναν ακόμα περιορισμό. Αυτός που συνήθως χρησιμοποιείται (και που χρησιμοποιούν τα περισσότερα στατιστικά πακέτα) είναι πως ο πίνακας LΨ ' 1 L είναι διαγώνιος και τα στοιχεία του είναι σε φθίνουσα σειρά. Δεν έχει σημασία με ποιον πίνακα (διακύμανσης ή συσχετίσεων) θα δουλέψουμε αφού η λύση είναι αδιάφορη των μονάδων μέτρησης. Ένα από τα πλεονεκτήματα της μεθόδου μεγίστης πιθανοφάνειας είναι 90
91 πως μας επιτρέπει να κάνουμε έλεγχο καλής προσαρμογής του ορθογώνιου μοντέλου που προσαρμόσαμε Άλλες μέθοδοι Εκτίμησης Εκτός από τις δύο μεθόδους εκτίμησης που αναφέρθηκαν προηγουμένως υπάρχουν αρκετές άλλες μέθοδοι εκτίμησης στη βιβλιογραφία [81]. Η παραγοντική α- νάλυση, αν και θεωρητικά ήταν γνωστή πολλά χρόνια, δεν ήταν εύκολο να χρησιμοποιηθεί λόγω της πολυπλοκότητας των υπολογισμών για την εκτίμηση των παραμέτρων. Έτσι διάφορες τεχνικές αναπτύχθηκαν με βασικό σκοπό να απλοποιηθεί η διαδικασία εκτίμησης. Μερικές από τις μεθόδους αυτές είναι Μέθοδος ελαχίστων τετραγώνων: Η μέθοδος αυτή προσπαθεί να ελαχιστοποιήσει το άθροισμα των τετραγωνικών διαφορών των πραγματικών συνδιακυμάνσεων με αυτές που το μοντέλο εκτιμά. Το πρόβλημα επομένως ανάγεται σε πρόβλημα ελαχίστων τετραγώνων το οποίο από αρκετά χρόνια πριν ήταν σχετικά ευκολότερο να αντιμετωπιστεί. Στην πράξη η μέθοδος μπορεί να δώσει εκτιμήσεις σε προβλήματα που η μέθοδος μέγιστης πιθανοφάνειας αποτυγχάνει. Τα αποτελέσματα όμως αλλάζουν αν αλλάξει η κλίμακα. Όσο προσθέτουμε παράγοντες αλλάζει και η εκτίμηση των φορτίων τους. Γενικευμένη μέθοδος ελαχίστων τετραγώνων. Η μέθοδος είναι παραλλαγή της προηγούμενης. Στη γραμμική παλινδρόμηση είναι γνωστό πως οι απλοί εκτιμητές ελαχίστων τετραγώνων δεν είναι συνεπείς όταν η διακύμανση δεν είναι σταθερή. Κάτι αντίστοιχο έχουμε και εδώ όπου η διακύμανση των τυχαίων όρων δεν είναι η ίδια για όλες τις μεταβλητές. Επομένως αυτή η μέθοδο χρησιμοποιεί ως βάρη τις αντίστροφες τιμές των μοναδικών διακυμάνσεων. Ισχύουν όλα τα πλεονεκτήματα και τα μειονεκτήματα που αναφέραμε για την απλή μέθοδο των ελαχίστων τετραγώνων. Μέθοδος των κυρίων αξόνων (Principal Axis Model): Η μέθοδος είναι παραλλαγή της μεθόδου των κυρίων συνιστωσών. Αντικαθιστά τις μονάδες στη διαγώνιο του πίνακα συσχέτισης με εκτιμήσεις της συμμετοχικότητας. Στην πραγματικότητα δίνει σε κάθε μεταβλητή διαφορετικό βάρος καθώς τα διαγώνια στοιχεία δεν είναι πια μονάδες. Η μέθοδος λειτουργεί επαναληπτικά και ξεκινά με αρχικές εκτιμήσεις για την συμμετοχικότητα κάθε μεταβλητής τον συντελεστή προσδιορισμού από τη γραμμική παλινδρόμηση που έχει τη μεταβλητή αυτή ως εξαρτημένη και τις υπόλοιπες ως ανεξάρτητες. Χρησιμοποιώντας τη λογική της μεθόδου των κυρίων συνιστωσών (υπολογίζοντας ιδιοτιμές και ιδιοδιανύσματα και εκτιμώντας την συμμετοχικότητα όπως είπαμε) αντικαθιστά τις αρχικές τιμές της συμμετοχικότητας και επαναλαμβάνει τη διαδικασία (βρίσκοντας πάλι τα ιδιοδιανύσματα κλπ) μέχρι να σταματήσουν να υπάρχουν αλλαγές ανάμεσα σε δύο επαναλήψεις. Στην περίπτωση που οι αρχικές συμμετοχικότητες είναι ίσες με 1 τα αποτελέσματα θα ταυτιστούν με αυτά της μεθόδου κυρίων συνιστωσών. Image Factoring: Παρόμοια λογική χρησιμοποιεί και η μέθοδος αυτή η οποία επιτρέπει οι μοναδικοί παράγοντες να είναι συσχετισμένοι (και άρα ο πίνακας Ψ 91
92 να μην είναι διαγώνιος). Στη βιβλιογραφία είναι γνωστό πως και οι δύο δίνουν μη συνεπή αποτελέσματα και για αυτό δεν χρησιμοποιούνται συχνά στην πράξη Περιστροφή των παραγόντων Στην εφαρμογή της ανάλυσης παραγόντων συνήθως οι παράγοντες που προκύπτουν δεν είναι εφικτό να ερμηνευτούν άμεσα. Αυτό συμβαίνει επειδή κάποιες μεταβλητές τείνουν να «φορτώνονται» σε πολλούς παράγοντες. Η περιστροφή των παραγόντων επιχειρεί να κάνει τους παράγοντες πιο ερμηνεύσιμους. Με την περιστροφή δεν αλλάζουν κάποια από τα χαρακτηριστικά του μοντέλου όπως η καλή του προσαρμοστικότητα και το ποσό της διακύμανσης-συνδιακύμανσης που ερμηνεύει το μοντέλο παρά μόνο οι τιμές των φορτίων. Υπάρχουν λοιπόν τεχνικές κάτω από την κοινή ονομασία περιστροφή των παραγόντων (factor rotation) οι οποίες εφαρμόζουν έναν ορθογώνιο μετασχηματισμό του πίνακα των φορτίων με σκοπό την ευκολότερη ερμηνεία των παραγόντων [80]. Η περιστροφή επηρεάζει τα φορτία και τις χαρακτηριστικές ρίζες (eigenvalues), δηλαδή τα ποσοστά διασποράς που εξηγεί ο κάθε άξονας. Εντούτοις, το άθροισμα των χαρακτηριστικών ριζών παραμένει το ίδιο. Στα στατιστικά πακέτα υπάρχουν διάφορες μέθοδοι περιστροφής που αντιστοιχούν σε διαφορετικά στατιστικά κριτήρια. Οι βασικές μέθοδοι περιστροφής είναι: Varimax (μεγιστοποίηση της διακύμανσης μεταξύ των παραγόντων): Προσπαθεί να ελαχιστοποιήσει τον αριθμό των μεταβλητών που έχουν μεγάλες επιβαρύνσεις για κάθε παράγοντα. Quartimax (μεγιστοποίηση της διακύμανσης μεταξύ των μεταβλητών): Προσπαθεί να ελαχιστοποιήσει τον αριθμό των παραγόντων που εξηγούν μια μεταβλητή. Equimax: Συνδυασμός των varimax και quartimax. Oblique: Μη ορθογώνια περιστροφή, οι άξονες που προκύπτουν δεν είναι πια ορθογώνιοι (και άρα οι παράγοντες δεν είναι ανεξάρτητοι). Η ερμηνεία των αποτελεσμάτων είναι πιο δύσκολη. Στην πράξη τον χρησιμοποιούμε όταν δεν θέλουμε οι παράγοντες που προκύπτουν να είναι ασυσχέτιστοι. Σε αυτήν την κατηγορία περιστροφής, ανήκουν οι μέθοδοι Direct Oblimin και Promax Υπολογισμός των σκορ των παραγόντων Όπως είπαμε προηγουμένως ένας από του σκοπούς της παραγοντικής ανάλυσης είναι να μειώσει τον αριθμό των μεταβλητών. Για να επιτευχθεί αυτό μπορούμε να δημιουργήσουμε καινούριες μεταβλητές, τους παράγοντες, ως γραμμικούς συνδυασμούς των αρχικών μεταβλητών.όταν το μοντέλο έχει εκτιμηθεί με τη μέθοδο κυριών συνιστωσών οι παράγοντες είναι ακριβείς, δηλαδή μπορούν να υπολογιστούν χωρίς σφάλμα. Αντίθετα για μοντέλα εκτιμημένα με τη μέθοδο με- 9
93 γίστης πιθανοφάνειας προσεγγιστικές μέθοδοι χρησιμοποιούνται. Να σημειωθεί ότι εξ ορισμού οι νέες μεταβλητές θα έχουν μέση τιμή 0 και θα είναι ασυσχέτιστες, δεδομένου πως το μοντέλο είναι ορθογώνιο. Με τη χρήση του μοντέλου που μελετήθηκε παραπάνω, μπορούμε να δημιουργήσουμε καινούριες μεταβλητές για περαιτέρω χρήση, όπως π.χ. για διακριτική ανάλυση, να δούμε πως κάποιοι υ- ποπληθυσμοί διαφέρουν κλπ. Έχοντας λοιπόν εκτιμήσει ένα παραγοντικό μοντέλο και έστω L και Ψ οι εκτιμήσεις μας για τις παραμέτρους αυτού, (πριν η μετά την περιστροφή) τότε μπορούμε να βρούμε τα factor scores δηλαδή τις τιμές των καινούριων μεταβλητών για κάθε μεταβλητή. Οι μέθοδοι που προσφέρονται είναι πολλές. Αυτές που τα περισσότερα στατιστικά πακέτα και ανάμεσα τους το SPSS προσφέρουν είναι οι εξής [81]: 1. Regression method: Η μέθοδος αυτή βασίζεται στη μέθοδο ελαχίστων τετραγώνων ανάμεσα στις πραγματικές τιμές και αυτές που το παραγοντικό μοντέλο προβλέπει.. Bartlett method. Σε σχέση με την παραπάνω μέθοδο ο Bartlett πρότεινε αντί να χρησιμοποιήσει κανείς την απλή μέθοδο ελαχίστων τετραγώνων να χρησιμοποιήσει γενικευμένα ελάχιστα τετράγωνα καθώς η διακύμανση δεν είναι η ίδια για όλες τις παρατηρήσεις. 3. Μέθοδος του Anderson. Συνοψίζοντας, ο παρακάτω πίνακας μας δίνει τους συντελεστές των σκορ των παραγόντων για τις διάφορες μεθόδους εκτίμησης. Μέθοδος Συντελεστές των σκορ των παραγόντων 1. Regression ( LL ' ) 1 L'. Bartlett ( ' Ψ ) 1 L L L' Ψ Anderson ( )( ) L' Ψ L Ι + L' Ψ L L' Ψ Και οι τρεις μέθοδοι δίνουν παράγοντες με μέση τιμή μηδέν (άλλωστε αυτή ήταν και η αρχική υπόθεση). Η μέθοδος του Anderson οδηγεί πάντα σε ασυσχέτιστους παράγοντες ακόμα και αν εξαιτίας μη ορθογώνιας περιστροφής οι παράγοντες θα έπρεπε να είναι συσχετισμένοι. Η μέθοδος της παλινδρόμησης μπορεί να οδηγή- 93
94 σει σε πίνακα διακύμανσης των παραγόντων ο οποίος δεν είναι ο μοναδιαίος, δηλαδή τα διαγώνια στοιχεία να μην είναι 1 και να υπάρχουν συσχετίσεις Εφαρμογή της μεθόδου Οι Wu & Zhang [60] προτείνουν ένα σχέδιο ανίχνευσης ανωμαλιών βασισμένο στην ανάλυση παραγόντων και την απόσταση Mahalanobis, η οποία έχει αναφερθεί σε προηγούμενη ενότητα. Η ανάλυση παραγόντων χρησιμοποιείται για την αποκάλυψη της λανθάνουσας δομής ενός συνόλου μεταβλητών. Μειώνει το χώρο των διαστάσεων από ένα μεγάλο αριθμό μεταβλητών σε ένα μικρότερο α- ριθμό παραγόντων. Η απόσταση Mahalanobis χρησιμοποιείται για τον καθορισμό της ομοιότητας ενός συνόλου τιμών ενός άγνωστου δείγματος με ένα σύνολο τιμών μιας συλλογής γνωστών δειγμάτων. Σε συνδυασμό με την ανάλυση παραγόντων, η απόσταση Mahalanobis εκτείνεται για να εξετάσει εάν ένα δεδομένο διάνυσμα είναι μια ακραία τιμή σε ένα μοντέλο βασισμένο στους παράγοντες που προέκυψαν από την παραγοντική ανάλυση. Η απόσταση Mahalanobis είναι η απόσταση ενός διανύσματος από το κεντροειδές (centroid) το πολυμεταβλητό αντίστοιχο του μέσου στον πολυδιάστατο χώρο, που καθορίζεται από τις συσχετιζόμενες ανεξάρτητες μεταβλητές [60]. Εάν οι ανεξάρτητες μεταβλητές είναι ασυσχέτιστες, είναι το ίδιο με την Ευκλείδεια α- πόσταση. Αυτή η μετρική παρέχει μια ένδειξη του εάν μια παρατήρηση αποτελεί ακραία τιμή ή όχι ως προς τις τιμές των ανεξάρτητων μεταβλητών. Θεωρητικά, δείγματα με απόσταση Mahalanobis μεγαλύτερη ή ίση του 3 έχουν μια πιθανότητα της τάξης του 0,01 ή και λιγότερο και μπορούν να κατηγοριοποιηθούν ως α- κραίες τιμές, ενώ δείγματα με απόσταση μικρότερη του 3 κατηγοριοποιούνται ως μέλη της ομάδας. Βέβαια, ο καθορισμός της οριακής τιμής κατώφλι εξαρτάται από την εφαρμογή και τον τύπο των δειγμάτων. Η απόσταση Mahalanobis αναγνωρίζει παρατηρήσεις που βρίσκονται μακριά από το κέντρο του νέφους των δεδομένων, δίνοντας λιγότερο βάρος σε μεταβλητές με μεγάλες διακυμάνσεις ή σε ομάδες υψηλά συσχετισμένων μεταβλητών. Αυτή η απόσταση προτιμάται συχνά έναντι της Ευκλείδειας, η οποία αγνοεί τη δομή διακύμανσης και επομένως αντιμετωπίζει όλες τις μεταβλητές όμοια. Σημεία δεδομένων που βρίσκονται μακριά από το νέφος των δεδομένων (O 1 ) έχουν μεγαλύτερες αποστάσεις Mahalanobis απ ό,τι σημεία που βρίσκονται εντός του νέφους (O ) (Σχήμα 3.). Τα δεδομένα που χρησιμοποιήθηκαν προέρχονται από τα σύνολα δεδομένων του DARPA 1998 και 1999 για ανίχνευση εισβολών και αφορούν εγγραφές TCP/IP συνδέσεων. Στις εγγραφές αυτές εφαρμόστηκαν κανόνες συσχέτισης. Ο λόγος για τον οποίο χρησιμοποιήθηκαν κανόνες συσχέτισης αντί για τις ακατέργαστες εγγραφές συνδέσεων είναι ότι τα πρότυπα συμπεριφοράς στα σύνολα δεδομένων αντιπροσωπεύονται καλύτερα από το σύνολο των κανόνων συσχέτισης γιατί η εμφάνιση μιας ξεχωριστής σύνδεσης είναι συχνά συμπτωματική και δεν δίνει πληροφορίες για την ιδιότητα άλλων συνδέσεων, ενώ ένας κανόνας συ- 94
95 σχέτισης συνήθως περιγράφει μια κοινή ιδιότητα που τη μοιράζονται ένα σύνολο συνδέσεων. Χρησιμοποιήθηκαν τρεις αλγόριθμοι του πεδίου της εξόρυξης δεδομένων και ειδικότερα η επιλογή χαρακτηριστικών, κανόνες συσχέτισης απλού ε- πιπέδου και κανόνες συσχέτισης πολλαπλών επιπέδων. Το σύνολο κανόνων που προέκυψε από τον κάθε αλγόριθμο εξόρυξης δεδομένων μεταφράστηκε σε ένα σύνολο διανυσμάτων, το οποίο αναπαρίσταται από έναν πίνακα. Σχήμα 3. Απόσταση Mahalanobis και Ευκλείδεια Απόσταση Από τα πειράματα των Wu & Zhang προέκυψαν τα εξής συμπεράσματα. Χρησιμοποιώντας έναν αλγόριθμο εξαγωγής κανόνων συσχέτισης πολλαπλών επιπέδων (multilevel) και επιλογή χαρακτηριστικών, η μέθοδος έδωσε ποσοστό ανίχνευσης ίσο με 100%, χαμηλό ποσοστό εσφαλμένων συναγερμών (από 0,5% έως 1,%) και ποσοστό των επιθέσεων που διέφυγαν ίσο με 0%. Εντούτοις, στην περίπτωση του αλγορίθμου εξόρυξης απλού επιπέδου τα αποτελέσματα δεν είναι ικανοποιητικά. Συνολικά, προκύπτει πως ο συνδυασμός της παραγοντικής ανάλυσης με την απόσταση Mahalanobis είναι αποτελεσματικός στην ανίχνευση δικτυακών εισβολών με ανεκτά ποσοστά εσφαλμένης ανίχνευσης. 3.8 Ανάλυση Διακρίσεων στην Ανίχνευση Εισβολών Η μέθοδος που προτάθηκε από τους Asaka et al [61] [6] είναι βασισμένη στον αριθμό των κλήσεων του συστήματος (συγκεκριμένα μόνον έντεκα από ένα σύνολο εξήντα επτά κλήσεων) κατά τη διάρκεια της δραστηριότητας ενός χρήστη δικτύου σε έναν υπολογιστή υπηρεσίας. Η μέθοδος επιχειρεί να διαχωρίσει τις εισβολές από τις φυσιολογικές δραστηριότητες χρησιμοποιώντας την ανάλυση διακρίσεων (Discriminant Analysis), η οποία αποτελεί ένα είδος πολυμεταβλητής ανάλυσης. Χρησιμοποιώντας μάλιστα την απόσταση Mahalanobis, μπορεί να διακρίνει αν ένα άγνωστο δείγμα είναι εισβολή ή όχι. 95
96 3.8.1 Εισαγωγή Με τον όρο διάκριση εννοούμε στη στατιστική τις πολυμεταβλητές μεθόδους διαχωρισμού συνόλων αντικειμένων και διανομής νέων παρατηρήσεων σε ομάδες που έχουν προηγουμένως οριστεί. Η ανάλυση διακρίσεων είναι από τη φύση της μια διερευνητική μεθοδολογία [80] [81]. Ως διαδικασία διαχωρισμού χρησιμοποιείται συχνά για να ερευνά διαφορές που ήδη έχουν παρατηρηθεί αλλά οι αιτίες τους δεν είναι πλήρως κατανοητές. Ως διαδικασία κατάταξης δεν είναι και τόσο διερευνητική, με την έννοια ότι έχει προηγηθεί ο καθορισμός καλά ορισμένων κανόνων που χρησιμοποιούνται στην κατάταξη των νέων αντικειμένων στις ομάδες τους. Η ανάλυση διακρίσεων έχει μεγάλη εφαρμογή στην Ιατρική όπου μας ενδιαφέρει να εντοπίσουμε πιθανούς ασθενείς με βάση τα συμπτώματα τους, στη χρηματοοικονομική επιστήμη όπου οι τράπεζες ενδιαφέρονται να εντοπίσουν «καλούς» και «κακούς» πελάτες πριν τη χορήγηση δανείου ή πιστωτικής κάρτας (credit scoring). Άλλη σημαντική εφαρμογή προέρχεται από το χώρο του marketing όπου ζητείται ο διαχωρισμός επιτυχημένων και αποτυχημένων αγορών ή διαφημιστικών εκστρατειών. Στην πρώτη περίπτωση μια εταιρεία αποφασίζει αν θα μπει σε μια αγορά ή όχι, ενώ στη δεύτερη περίπτωση ποια διαφημιστική εκστρατεία ταιριάζει καλύτερα στην κάθε περίπτωση. Μια τελευταία εφαρμογή της ανάλυση διακρίσεων προέρχεται από το χώρο της ασφάλισης όπου μια εταιρεία πρέπει να αποφασίσει αν θα ασφαλίσει ή όχι ένα κίνδυνο (insurance risk management) [81]. Στη γενικότερη περίπτωση, σκοπός της ανάλυσης διακρίσεων είναι να «διαχωρίσει» ή να κατανείμει κάθε νέα παρατήρηση σε k γνωστούς πληθυσμούς ομάδες. Προφανώς αναζητείται ένας διαχωριστικός κανόνας που μπορεί να καταχωρίσει σωστά όσο τον δυνατόν περισσότερες παρατηρήσεις. Να σημειωθεί πως ενώ η ανάλυση διακρίσεων μοιάζει με την ανάλυση κατά συστάδες (Cluster Analysis) έχει σημαντικές διαφορές. Η πρώτη και πιο σημαντική είναι ότι στην ανάλυση διακρίσεων οι ομάδες είναι γνωστές ενώ στην ανάλυση κατά συστάδες δεν είναι. Για το λόγο αυτό ο στόχος είναι διαφορετικός. Στην α- νάλυση διακρίσεων κύριο μέλημα μας είναι η κατασκευή ενός κανόνα που θα μας βοηθήσει να λάβουμε αποφάσεις στο μέλλον ενώ στην ανάλυση κατά συστάδες ο κύριος στόχος μας είναι να δημιουργήσουμε ομοειδείς ομάδες με κύριο στόχο την κατανόηση των ήδη υπαρχόντων στοιχείων και τη μείωση της διασποράς σε επιμέρους ομάδες. Στην προκειμένη περίπτωση, η ανάλυση διακρίσεων χρησιμοποιείται ως μια πολυμεταβλητή μέθοδος ανάλυσης, ο στόχος της οποίας είναι να διαχωρίσει δύο ομάδες πληθυσμούς που επικαλύπτονται. Η ανάλυση προσπαθεί να ελαχιστοποιήσει την πιθανότητα εσφαλμένης κατάταξης. Εάν οι δύο ομάδες διαχωρίζονται με μια ευθεία γραμμή, η γραμμή (δηλαδή η συνάρτηση) καλείται γραμμική διαχωριστική συνάρτηση (linear discriminant function) και μπορούμε να ταξινομήσουμε ένα δείγμα αντικαθιστώντας την τιμή του δείγματος στη διαχωριστική 96
97 συνάρτηση. Εάν οι δύο ομάδες διαχωρίζονται με μια εκθετική καμπύλη (quadratic curve), μπορούμε να ταξινομήσουμε ένα δείγμα χρησιμοποιώντας την α- πόσταση Mahalanobis [63] Ανάλυση Διακρίσεων για δύο πληθυσμούς Συμβολίζουμε τους δύο πληθυσμούς με π 1 και π, ενώ ο διαχωρισμός γίνεται με βάση p χαρακτηριστικά μεταβλητές [80]. Οι τιμές των μεταβλητών διαφέρουν σε κάποιο βαθμό στις δύο ομάδες (ή ισοδύναμα οι μεταβλητές μπορούν να χρησιμοποιηθούν για το διαχωρισμό των ομάδων). Οι δύο πληθυσμοί μπορούν να περιγραφούν από κατανομές με πολυμεταβλητές συναρτήσεις πυκνότητας πιθανότητας f1 ( x ) και f ( x ). Οι συναρτήσεις διάκρισης και οι κανόνες κατάταξης εξάγονται από την ανάλυση που γίνεται σε ένα δείγμα αντικειμένων που περιλαμβάνει μετρήσεις από τις p μεταβλητές. Υποθέτουμε πως υπάρχει διαθέσιμος ένας πίνακας δεδομένων X με n αντικείμενα και p μεταβλητές. Επίσης υπάρχει μια πρόσθετη μεταβλητή διάκρισης με δύο τιμές η οποία δείχνει σε ποια από τις δύο ομάδες ανήκει το κάθε αντικείμενο. Είναι προφανές πως οι κανόνες κατάταξης που προκύπτουν από οποιαδήποτε στατιστική ανάλυση υπόκεινται σε κάποιο σφάλμα. Αυτό κυρίως συμβαίνει γιατί υπάρχει επικάλυψη των πληθυσμών. Επομένως το πρόβλημα έγκειται στην κατασκευή ενός κανόνα κατάταξης (που να ορίζει δύο περιοχές, έστω R 1 και R ), ώστε να ελαχιστοποιείται η πιθανότητα να συμβούν τέτοια σφάλματα. Μια «καλή» διαδικασία κατάταξης των αντικειμένων συνεπάγεται όσο το δυνατόν λιγότερες εσφαλμένες κατατάξεις. Υπάρχουν δύο ακόμη θέματα που πρέπει να λαμβάνονται υπόψη σε μια τέτοια διαδικασία [80]. 1. Υπάρχει περίπτωση ο ένας πληθυσμός να έχει μεγαλύτερη πιθανότητα εμφάνισης από τον άλλο, επειδή είναι σχετικά πολύ μεγαλύτερος. Αυτές οι «εκ των προτέρων» (prior) πιθανότητες πρέπει να συνυπολογίζονται στον κανόνα κατάταξης.. Το κόστος της εσφαλμένης κατάταξης δεν είναι πάντοτε το ίδιο για τους δύο πληθυσμούς. Είναι δυνατό η κατάταξη ενός αντικειμένου από τον πληθυσμό π 1 στον π να αντιπροσωπεύει πολύ πιο σοβαρό σφάλμα από την κατάταξη ενός αντικειμένου από τον π στον π 1 (ή αντίστροφα). Επομένως, η διαδικασία πρέπει να υπολογίζει και το κόστος της εσφαλμένης κατάταξης, όποτε αυτό είναι δυνατό. Αν λοιπόν οι συναρτήσεις πυκνότητας πιθανότητας για τα διανύσματα των δύο πληθυσμών είναι f1 ( x ) και f ( x ) και Ω ο δειγματοχώρος, δηλαδή το σύνολο όλων των πιθανών διανυσμάτων x με παρατηρήσεις από τις μεταβλητές, τότε ορίζεται: 97
98 R 1 : το σύνολο των διανυσμάτων x τα οποία κατατάσσονται στον πληθυσμό π 1 R = Ω R 1: σύνολο των διανυσμάτων x τα οποία κατατάσσονται στον πληθυσμό π. Ισχύει: R 1 R = Ω R R = 1 Επίσης, αν συμβολίσουμε με P ( /1) την πιθανότητα να κατατάξουμε ένα αντικείμενο εσφαλμένα στον πληθυσμό π ενώ στην πραγματικότητα προέρχεται από τον πληθυσμό π 1 και με P ( 1/) την πιθανότητα να κατατάξουμε ένα αντικείμενο εσφαλμένα στον πληθυσμό π 1 ενώ στην πραγματικότητα προέρχεται από τον πληθυσμό π, ισχύει: ( /1 ) = ( / π1) = R ( ) 1 ( 1/ ) = ( / π ) = ( ) P P x R x f x P P x R x f x 1 R 1 Αν επίσης συμβολίσουμε αντίστοιχα τα κόστη των εσφαλμένων κατατάξεων με c ( /1) και c ( 1/), και τις εκ των προτέρων πιθανότητες με p1 και p, τότε μπορούμε να εκφράσουμε το μέσο κόστος λάθους κατάταξης (Expected Cost of Misclassification) ως εξής: ECM = c ( /1) P ( /1) p + c ( 1/) P ( 1/) p Είναι επομένως λογικό να αναζητούμε έναν κανόνα κατάταξης ο οποίος θα ελαχιστοποιεί το ECM. Αποδεικνύεται θεωρητικά ότι οι περιοχές R 1 και R που ελαχιστοποιούν το ECM ορίζονται ως οι τιμές του διανύσματος x οι οποίες ικανοποιούν τις ανισότητες: dx dx 1 R 1 : f ( x ) c( 1/) p f ( x ) c( /1) p 1 1 και R : f ( x ) c( 1/) p < f ( x ) c( /1) p 1 1 Από τις παραπάνω σχέσεις προκύπτει ότι για να εφαρμόσουμε τον κανόνα του ελαχίστου ECM, απαιτείται να γνωρίζουμε για κάθε νέα παρατήρηση x 0 το λόγο των συναρτήσεων πυκνότητας, το λόγο από τα κόστη και το λόγο των εκ των προτέρων πιθανοτήτων. Στην περίπτωση που αγνοούμε το κόστος, το κριτήριο ονομάζεται συνολική πιθανότητα λάθους κατάταξης (Total Probability of Misclassification) και ορίζεται: 98
99 TPM = P ( /1) p + P ( 1/) p 1 Η ελαχιστοποίηση του κριτηρίου αυτού οδηγεί στον ορισμό των περιοχών: R 1 : f1 ( x ) p f ( x ) p και R : < f ( x ) p f ( x ) p Το πρόβλημα με τους παραπάνω κανόνες είναι η γνώση των κατανομών f1 ( x ) και f ( x ). Η συνήθης υπόθεση που κάνουμε είναι πως οι δύο πληθυσμοί ακολουθούν πολυμεταβλητές κανονικές κατανομές, ότι δηλαδή οι συναρτήσεις πυκνότητας πιθανότητας των π 1 και π είναι όπου i =1, fi ( x ) = p e 1 ( π) Σ 1 i 1 1 ( x μ )' Σ ( x μ ) i i i μ i το διάνυσμα των μέσων τιμών του πληθυσμού π i και Σ i ο πίνακας διασπορών-συνδιασπορών των μεταβλητών του πληθυσμού π i. Βέβαια, ακόμα και κάτω από την υπόθεση της κανονικής κατανομής, οι παράμετροι των πληθυσμών μ i και Σ i πρέπει να εκτιμηθούν από το δείγμα που διαθέτουμε και συγκεκριμένα από: x i n 1 = i x n i j = 1 1 j 1 1 n και Si = ( x ij x i)( x ij x i) ' n i i j = 1 για i =1,. Αν τώρα δίνεται ένα διάνυσμα x 0, τότε ο κανόνας κατάταξής του σε έναν από τους δύο πληθυσμούς εξαρτάται από την υπόθεση που θα κάνουμε σχετικά με την ισότητα των δύο πινάκων διασπορών-συνδιασπορών των πληθυσμών. Συγκεκριμένα διακρίνουμε δύο περιπτώσεις [80]: Περίπτωση 1 η : Σ1 = Σ = Σ Στην περίπτωση αυτή οι δειγματικοί πίνακες S1 και S συνδυάζονται για τον υπολογισμό ενός αμερόληπτου εκτιμητή του άγνωστου πίνακα Σ. Αυτός προκύπτει από τη σχέση: 1 S n S n ( 1) ( 1) = pooled 1 1 n1 + n + S 99
100 Ο κανόνας κατάταξης σύμφωνα με το κριτήριο της ελαχιστοποίησης του είναι: ECM «Το x κατατάσσεται στην ομάδα π αν c( 1/ ) p ' ' ln ( x 1 x ) Spooled x0 ( x 1 x ) Spooled ( x 1 x ) c( / 1) p1 διαφορετικά κατατάσσεται στην ομάδα π». Περίπτωση η : Σ1 Σ Στην περίπτωση αυτή ο κανόνας κατάταξης διαμορφώνεται ως εξής: «Το x κατατάσσεται στην ομάδα π αν ' c( 1/ ) p x 0 S1 S x 0 + x S1 x S x 0 k ln c( /1) p1 ' ' ( ) ( 1 ) διαφορετικά κατατάσσεται στην ομάδα π». Η ισότητα των πινάκων Σ1 και Σ ελέγχεται με τους κατάλληλους στατιστικούς ελέγχους που βασίζονται στους δειγματικούς πίνακες S1 και S. Η αξιολόγηση της διαδικασίας κατάταξης γίνεται χρησιμοποιώντας ένα απλό στον υπολογισμό και την ερμηνεία μέτρο, το οποίο καλείται φαινομενικός βαθμός σφάλματος (apparent error rate APER). Ο APER ορίζεται ως το ποσοστό των παρατηρήσεων που κατατάσσονται εσφαλμένα από τη συνάρτηση κατάταξης που χρησιμοποιήθηκε. Υπολογίζεται εύκολα από τον πίνακα σύγχυσης και δεν απαιτεί γνώση των κατανομών αλλά ούτε και των συναρτήσεων πυκνότητας πιθανότητας. Έτσι αν ο πίνακας σύγχυσης είναι ο ακόλουθος Προβλεπόμενη Ομάδα π 1 π Πραγματική Ομάδα π 1 π n 1C n 1M n M n C 100
101 ο φαινομενικός βαθμός σφάλματος ορίζεται ως: APER n = + n n 1M 1M όπου n + n = n 1C 1M nc + nm = n n + n = n 1 Παρόλο που το APER είναι τόσο βολικό μέτρο αξιολόγησης, έχει το μειονέκτημα ότι υποεκτιμά το πραγματικό βαθμό σφάλματος, ο οποίος εξαρτάται από τις συναρτήσεις πυκνότητας πιθανότητας. Εναλλακτικά, μπορεί να χρησιμοποιηθεί η λύση του χωρισμού του δείγματος σε δείγμα εκπαίδευσης και δείγμα αξιολόγησης (η οποία όμως απαιτεί μεγάλα δείγματα) ή της επαναληπτικής διαδικασίας κατακράτησης ενός αντικειμένου έξω από το σύνολο του Lachenbruch (Holdout procedure ή Jackknifing ή Cross Validation) [65]. Να σημειωθεί σε αυτό το σημείο πως η επαναληπτική διαδικασία Cross Validation κατασκευάζει μια συνάρτηση κατάταξης από όλα σχεδόν τα δείγματα και περιλαμβάνει τα εξής βήματα [80]: 1. Από το σύνολο των δεδομένων παραλείπεται ένα αντικείμενο κάθε φορά. Κατασκευάζεται η συνάρτηση κατάταξης από τα υπόλοιπα 3. Το αντικείμενο που παραλείφθηκε κατατάσσεται με βάση τη συνάρτηση 4. Το ποσοστό των αντικειμένων που κατατάχτηκαν σε λάθος ομάδα χρησιμοποιείται ως εκτίμηση της μέσης τιμής του πραγματικού βαθμού σφάλματος Εφαρμογή της μεθόδου Οι Asaka et al [61] [6] στην εργασία τους διαχωρίζουν τις εισβολές από τις κανονικές δραστηριότητες υπολογίζοντας τους πίνακες διασπορών-συνδιασπορών των δύο ομάδων. Στην περίπτωση που οι δύο πίνακες είναι ίσοι μεταξύ τους, ο διαχωρισμός στις ομάδες γίνεται με χρήση μιας γραμμικής διαχωριστικής συνάρτησης. Στην περίπτωση που οι πίνακες είναι διαφορετικοί, τα δείγματα διαχωρίζονται βάσει της απόστασης Mahalanobis. Χρησιμοποιούν ένα εργαλείο (audit tool) που ανέπτυξαν οι ίδιοι, το οποίο τρέχει σε Redhat Linux και καταγράφει τις κλήσεις συστήματος. Η συλλογή των δεδομένων του δείγματος έγινε με τη χρήση του συγκεκριμένου εργαλείου. Μάλιστα ο διαχωρισμός στις δύο ομάδες γίνεται λαμβάνοντας ως ερμηνευτικές μεταβλητές μόνο έντεκα συγκεκριμένες κλήσεις του συστήματος από εξήντα επτά συνολικά που εμφανίστηκαν στα δείγματα δε
102 δομένων. Η έρευνα αφορά σε απομακρυσμένες επιθέσεις και φυσιολογικές δραστηριότητες σε περιβάλλον Redhat Linux 5.. Να σημειωθεί πως αν ενδιαφέρει απλώς ο διαχωρισμός των εισβολών και των κανονικών δραστηριοτήτων σε δύο ομάδες, τότε δεν είναι αναγκαία η υπόθεση της κανονικότητας των δύο ομάδων. Ωστόσο, αν υπάρχει ανάγκη για κατάταξη νέων και άγνωστων δραστηριοτήτων (αγνώστου δείγματος δηλαδή) σε μία από τις δύο ομάδες, τότε πρέπει πρώτα να ελεγχθεί εάν οι δύο ομάδες είναι κανονικά κατανεμημένες. Ο πληθυσμός των κλήσεων του συστήματος δεν ακολουθεί πολυμεταβλητή κανονική κατανομή, επομένως τα δείγματα θα μετασχηματιστούν ώστε να προσεγγίζουν την κανονική κατανομή με βάση την Ανάλυση Κυρίων Συνιστωσών. Κατ επέκταση, η Ανάλυση Διακρίσεων θα γίνει χρησιμοποιώντας ως ερμηνευτικές μεταβλητές τις κύριες συνιστώσες. Υπενθυμίζεται σε αυτό το σημείο πως η Ανάλυση Κυρίων Συνιστωσών δίνει τη δυνατότητα να αναπαραχθεί η συνολική μεταβλητότητα της ομάδας των κλήσεων συστήματος από τις νέες συνιστώσες, κατά τέτοιο τρόπο ώστε να ο αριθμός των συνιστωσών να είναι μικρότερος από τον αριθμό των κλήσεων (δηλαδή των αρχικών μεταβλητών). Εάν τα σκορ των κυρίων συνιστωσών ακολουθούν κανονική κατανομή, είναι εφικτή η κατάταξη ενός νέου δείγματος σε μία από τις δύο ομάδες (εισβολή ή φυσιολογική δραστηριότητα). Μια κύρια συνιστώσα αντιστοιχεί σε ένα ιδιοδιάνυσμα του πίνακα διακυμάνσεων ή συσχετίσεων. Στην εργασία των Asaka et al, από την ανάλυση κυρίων συνιστωσών επελέγησαν τρεις κύριες συνιστώσες, εκείνες των οποίων οι ιδιοτιμές έχουν τιμή μεγαλύτερη της μονάδας, και το αθροιστικό ποσοστό της συνολικής διασποράς που ε- ξηγούν ξεπερνά το 80% (84,78%). Επειδή τα δείγματα που προέκυψαν από την ανάλυση κυρίων συνιστωσών δεν είναι κανονικά κατανεμημένα, χρησιμοποιούνται οι μετασχηματισμοί που προτάθηκαν από τους Box & Cox για την κανονικοποίηση των μεταβλητών [64]. Ειδικότερα: Component1: x Component: x Component1: x 0,6 ( x + ) 1 a 0,6 1,6 ( x + 3) 1 a 1,6,4 ( x + 3) 1 a,4 Ο έλεγχος για το αν τα δείγματα ακολουθούν κανονική κατανομή γίνεται με τη μέθοδο των διαγραμμάτων Q-Q (Q-Q plots) [46]. Η ορθότητα ενός τέτοιου διαγράμματος μετράται με τον υπολογισμό του συντελεστή συσχέτισης των σημείων του διαγράμματος. Για μέγεθος δείγματος n 10, η υπόθεση της κανονικότητας απορρίπτεται με επίπεδο σημαντικότητας 1% εάν το πέσει κάτω του 0,88. Για μέγεθος δείγματος n 36, η υπόθεση της κανονικότητας απορρίπτεται με επίπεδο σημαντικότητας 1% εάν το r Q πέσει κάτω του 0,958. Στην προκειμένη r Q r Q 10
103 περίπτωση, κάθε συντελεστής συσχέτισης των κυρίων συνιστωσών είναι πάνω από 0,958 για την ομάδα των φυσιολογικών δραστηριοτήτων και για την ομάδα των εισβολών είναι πάνω από 0,88. Επομένως, η υπόθεση της κανονικότητας δεν απορρίπτεται. Για την ισότητα των πινάκων διασπορών-συνδιασπορών χρησιμοποιείται ο έλεγχος M του Box (Box s M-test). Μια κρίσιμη περιοχή για τον έλεγχο της υπόθεσης δίνεται από τη σχέση όπου και ( p( p ) ) /, χ χ α + n1+ n p 3p 1 S χ0 = 1 + log 1 1 n n ( ) ( 1) ( ) n n n + n p + S S p ο αριθμός των ερμηνευτικών μεταβλητών, α το επίπεδο σημαντικότητας, n 1 και n ο αριθμός δειγμάτων της κάθε ομάδας αντίστοιχα, S () i ο sum-of-square sum-of-product πίνακας της ομάδας i, S ο σταθμισμένος μέσος των και S με S ( 1) ( ) S = ( 1 1) + ( 1) ( n + n ) n S n S ( 1) ( ) 1 Στην προκειμένη περίπτωση επειδή ( ) χ 6, 0,1 = 16,81 χ 0 = 40,345 και ( ) προκύ- πτει πως χ0 > χ 6, 0,1, επομένως οι πίνακες διασπορών-συνδιασπορών των δύο ομάδων είναι διαφορετικοί και η ανάλυση διακρίσεων θα γίνει με βάση την απόσταση Mahalanobis. Η απόσταση Mahalanobis D ανάμεσα στο σημείο X και μια ομάδα που έχει κατανομή N μ, Σ ορίζεται ως όπου μ ο μέσος της ομάδας και ( ) ( μ )' Σ ( μ) 1 D = X X 1 Σ ο αντίστροφος πίνακας του πίνακα διακυμάνσεων της ομάδας. 103
104 Στα 4 δείγματα συνολικά, από τα οποία 6 είναι εισβολές και 36 φυσιολογικές δραστηριότητες, εφαρμόζοντας ανάλυση διακρίσεων μόνο δείγματα κατηγοριοποιούνται εσφαλμένα ως εισβολές. Επομένως, ο φαινομενικός βαθμός σφάλματος είναι πολύ χαμηλός ( /4= 4,46 (%)). Για την αξιολόγηση της κατάταξης νέων και άγνωστων δειγμάτων σε μία από τις δύο ομάδες εφαρμόζεται η μέθοδος της Cross Validation στα δείγματα που χρησιμοποιήθηκαν και προηγουμένως. Η διαδικασία της αξιολόγησης υλοποιείται ως εξής: Αρχικά τα 41 δείγματα διαχωρίζονται στις δύο ομάδες με την ανάλυση διακρίσεων και το εναπομένον δείγμα εκλαμβάνεται ως άγνωστο. Χρησιμοποιώντας την απόσταση Mahalanobis, κατατάσσεται σε μία από τις δύο ομάδες. Από τα αποτελέσματα της Cross Validation για όλα τα δείγματα ο φαινομενικός βαθμός σφάλματος υπολογίζεται σε 4 / 4 = 9,5 (% ) ( φυσιολογικές δραστηριότητες κατατάχτηκαν στις εισβολές και εισβολές κατατάχτηκαν στις φυσιολογικές δραστηριότητες). Η χρήση της μεθόδου των Asaka et al επιτρέπει τη μείωση του υπολογιστικού φόρτου και του κόστους της επίβλεψης και της ανάλυσης. Ουσιαστικά αναλύει τις κλήσεις συστήματος με τη βοήθεια της ανάλυσης διακρίσεων και είναι σε θέση να εντοπίζει εισβολές χρησιμοποιώντας συγκεκριμένες μόνο κλήσεις. Επιπλέον, η μέθοδος μπορεί να εντοπίσει ακόμη και άγνωστα μοτίβα απομακρυσμένων εισβολών. 3.9 Λογαριθμική Παλινδρόμηση στην Ανίχνευση Εισβολών Εισαγωγή Η ανάλυση παλινδρόμησης (regression analysis) περιγράφει τη μεταβλητότητα μιας τυχαίας μεταβλητής Y χρησιμοποιώντας την πληροφορία που έχουμε για μια ή περισσότερες μεταβλητές X1, X, K, Xr [83]. Το πρόβλημα της παλινδρόμησης είναι η εύρεση ενός μοντέλου που περιγράφει την εξάρτηση της τυχαίας μεταβλητής Y, που ονομάζεται εξαρτημένη μεταβλητή (dependent or response variable), από μια μεταβλητή X που ονομάζεται ανεξάρτητη μεταβλητή (independent or explanatory variable or predictor) ή κι από περισσότερες από μια μεταβλητές. Πρόκειται για μια στατιστική μεθοδολογία πρόβλεψης των τιμών μιας ή περισσότερων εξαρτημένων μεταβλητών από ένα σύνολο ανεξάρτητων μεταβλητών. Χρησιμοποιείται και για την ερμηνεία της επίδρασης των ανεξάρτητων μεταβλητών πάνω στις εξαρτημένες. Συνοπτικά μπορούμε να πούμε ότι το αντικείμενο της RA είναι η κατασκευή μοντέλων με τη μορφή εξισώσεων που έχουν διπλό ρόλο: 1. Τον καθορισμό της φύσης της εξάρτησης ανάμεσα στις εξαρτημένες και τις ανεξάρτητες μεταβλητές. Την πρόβλεψη των τιμών των εξαρτημένων μεταβλητών όταν δίνονται οι τιμές των ανεξάρτητων 104
105 Η πιο συνηθισμένη περίπτωση είναι η γραμμική παλινδρόμηση όπου υπάρχει μια μόνο εξαρτημένη μεταβλητή και πολλές ανεξάρτητες Γραμμική Παλινδρόμηση (Linear Regression) Οι συντελεστές συσχέτισης προσδιορίζουν το βαθμό (ή αλλιώς την ένταση) της σχέσης που υπάρχει μεταξύ δύο ποσοτικών μεταβλητών υπό την προϋπόθεση ότι η σχέση αυτή είναι γραμμική [83]. Αν η γραμμική σχέση των δύο μεταβλητών οριστεί με όρους εξάρτησης της μίας από την άλλη, δηλαδή αν η μεταβολή των τιμών της μίας μεταβλητής θεωρηθεί ότι προκύπτει με γραμμικό τρόπο από τη μεταβολή των τιμών της άλλης, τότε η ανάλυση της σχέσης των δύο μεταβλητών πραγματοποιείται με τη βοήθεια ενός υποδείγματος απλής γραμμικής παλινδρόμησης. Το υπόδειγμα αυτό είναι η απλούστερη περίπτωση ενός γενικότερου υ- ποδείγματος που χρησιμοποιείται στη στατιστική συμπερασματολογία, σύμφωνα με το οποίο η μεταβολή των τιμών μιας ποσοτικής μεταβλητής ερμηνεύεται γραμμικά από τη μεταβολή των τιμών ενός συνόλου k άλλων ποσοτικών μεταβλητών. Ας υποθέσουμε ότι έχουμε r ανεξάρτητες μεταβλητές X1, X, K, Xr, οι οποίες σχετίζονται με κάποια εξαρτημένη μεταβλητή Y. Το κλασικό γραμμικό μοντέλο εκφράζει τη μεταβλητή Y ως σύνθεση μιας μέσης τιμής η οποία εξαρτάται από τις X1, X, K, Xr και ένα τυχαίο σφάλμα ε, το οποίο αντιπροσωπεύει το σφάλμα της μέτρησης και τις επιδράσεις άλλων μεταβλητών που όμως δεν συμμετέχουν στο μοντέλο. Οι τιμές των ανεξάρτητων μεταβλητών οι οποίες είτε καταγράφονται είτε καθορίζονται από τον ερευνητή θεωρούνται σταθερές. Το σφάλμα θεωρείται τυχαία μεταβλητή της οποίας η συμπεριφορά χαρακτηρίζεται από ένα σύνολο υποθέσεων σχετικά με την κατανομή του. Αυτό βέβαια σημαίνει ότι και η εξαρτημένη είναι τυχαία μεταβλητή που ακολουθεί κάποια κατανομή. Συγκεκριμένα, το μοντέλο της γραμμικής παλινδρόμησης έχει τη μορφή Y = β + βχ + βχ + L+ βχ + ε r r Ο όρος «γραμμική» σημαίνει ότι η μέση τιμή EY = β0 + β1x 1 + L+ βrx r είναι μια γραμμική συνάρτηση με άγνωστες παραμέτρους β0, β1, K. βr. Οι συντελεστές του υποδείγματος της γραμμικής παλινδρόμησης εκτιμούνται με τη μέθοδο των ελαχίστων τετραγώνων Λογαριθμική παλινδρόμηση (Logistic Regression) Η τεχνική της γραμμικής παλινδρόμησης εκτιμά την πληθυσμιακή εξίσωση της παλινδρόμησης, y = β + β x + β x + L + β x + ε r r με τη βοήθεια ενός δειγματικού υποδείγματος της μορφής 105
106 y= b + bx + bx + L+ bx + e r r Η χρήση του προηγούμενου υποδείγματος προϋποθέτει ότι η εξαρτημένη μεταβλητή Y είναι ποσοτική και ότι η κατανομή της είναι κανονική. Επιπλέον, απαιτεί οι διακυμάνσεις των υποπληθυσμών της Y που ορίζονται για κάθε σύνολο τιμών x 1, x, K, x r των ανεξάρτητων μεταβλητών να είναι ίσες. Χρησιμοποιώντας τη δειγματική εξίσωση της παλινδρόμησης είναι δυνατόν να εκτιμηθεί (ή να προβλεφθεί) η μέση τιμή της Y για ένα συγκεκριμένο σύνολο τιμών των ανεξάρτητων μεταβλητών X, X, K X. 1, r Σε περίπτωση που η εξαρτημένη μεταβλητή είναι δίτιμη δηλαδή μια μεταβλητή που στη γενική μορφή της υποδηλώνει την πραγματοποίηση ή όχι ενός γεγονότος το υπόδειγμα της γραμμικής παλινδρόμησης δεν είναι κατάλληλο για την εκτίμηση των τιμών της εξαρτημένης μεταβλητής από τις τιμές των ανεξάρτητων. Σε μια τέτοια περίπτωση, χρησιμοποιώντας την τιμή 1 για το ενδεχόμενο της επιτυχίας (την πραγματοποίηση δηλαδή του γεγονότος) και την τιμή 0 για το ενδεχόμενο της αποτυχίας, ο υπολογισμός της μέσης τιμής της εξαρτημένης δίτιμης μεταβλητής, ουσιαστικά ορίζει την αναλογία p των επιτυχιών στο σύνολο των δυνατών τιμών της. Όπως εκτιμάται η μέση τιμή της συνεχούς μεταβλητής Y για ένα συγκεκριμένο σύνολο τιμών των ανεξάρτητων μεταβλητών με τη βοήθεια του υποδείγματος της γραμμικής παλινδρόμησης, έτσι μπορεί να εκτιμηθεί (με τη χρήση κατάλληλου υποδείγματος) και η πιθανότητα p της επιτυχίας μιας δίτιμης μεταβλητής (η μέση τιμή της δηλαδή) για ένα σύνολο τιμών μίας ή περισσότερων ανεξάρτητων μεταβλητών. Η τεχνική που χρησιμοποιείται σε αυτές τις περιπτώσεις ονομάζεται λογαριθμική παλινδρόμηση Το υπόδειγμα της λογαριθμικής παλινδρόμησης Αν επιχειρήσουμε να εκφράσουμε την πιθανότητα της επιτυχίας p μιας δίτιμης μεταβλητής Y με τη βοήθεια ενός απλού γραμμικού υποδείγματος [83] p = b + b x 0 1, όπου x οι τιμές μιας ανεξάρτητης μεταβλητής X, το κύριο πρόβλημα που θα συναντήσουμε είναι ότι αν και οι τιμές της p θεωρητικά δεν μπορούν να βρίσκονται εκτός του διαστήματος [ 0,1 ], οι τιμές της ποσότητας b0 + b1x μπορούν να διακυμαίνονται σε όλο το εύρος των πραγματικών αριθμών. Ένα βήμα προς τη διευθέτηση του προβλήματος θα ήταν να αντικαταστήσουμε στο υπόδειγμα την πιθανότητα p του γεγονότος της επιτυχίας με τη σχετική πιθανότητα της επιτυχίας. Δηλαδή με το λόγο της πιθανότητας της επιτυχίας προς την πιθανότητα του p γεγονότος της αποτυχίας. 1 p 106
107 Ο συγκεκριμένος λόγος αν και θεωρητικά μπορεί να διακυμαίνεται μέχρι το +, δεν μπορεί να παίρνει τιμές μικρότερες του 0. Οι τιμές του δηλαδή είναι θετικές ή ίσες με το μηδέν. Άρα και στην περίπτωση αυτή ένα γραμμικό υπόδειγμα της μορφής p b0 b1x 1 p = + δεν είναι επαρκές για την εκτίμηση της p. Ένας επιπλέον μετασχηματισμός της σχετικής πιθανότητας επιλύει το πρόβλημα. p p Αν αντί του λόγου χρησιμοποιηθεί ο φυσικός του λογάριθμος ln, τότε οι τιμές του μετασχηματισμένου λόγου οι οποίες διακυμαίνονται πλέον στο 1 p 1 p διάστημα (, + ) μπορούν να εκτιμηθούν με τη βοήθεια ενός γραμμικού υποδείγματος της μορφής p ln = b0 + b1x 1 p. p Η συνάρτηση ln η οποία συνδέει (linking function) την πιθανότητα της επιτυχίας p με την ανεξάρτητη μεταβλητή X ονομάζεται logit της p και συμβολίζεται 1 p με logit( p ). Η εκτίμηση της πιθανότητας της επιτυχίας p της δίτιμης μεταβλητής Y είναι 1 p =, όπου z = b. Η διαγραμματική απεικόνιση της συνάρτησης z 1 + e 0 + b1x 1 f ( z) =, η οποία εκτιμά την p είναι σιγμοειδής, ενώ οι τιμές της κυμαίνονται z 1 + e στο διάστημα [ 0,1 ] εφόσον οι τιμές της z μεταβάλλονται στο διάστημα (, + ). Η συναρτησιακή έκφρασή της είναι επομένως κατάλληλη να χρησιμοποιηθεί ως υπόδειγμα για την εκτίμηση μιας πιθανότητας. Από τη διαγραμματική απεικόνισή της προκύπτει ότι η σχέση της ανεξάρτητης μεταβλητής X και της πιθανότητας πραγματοποίησης του γεγονότος είναι μη γραμμική. Το γραμμικό υπόδειγμα που χρησιμοποιήθηκε για την εκτίμηση του λογάριθμου της σχετικής πιθανότητας της επιτυχίας της δίτιμης μεταβλητής Y διευρύνεται και στην περίπτωση των περισσοτέρων της μίας ανεξάρτητων μεταβλητών. Η χρήση πάντων της μεθόδου των ελαχίστων τετραγώνων, μέσω της οποίας ε- κτιμούνται οι συντελεστές του υποδείγματος της γραμμικής παλινδρόμησης, δεν μπορεί να χρησιμοποιηθεί και για την εκτίμηση των συντελεστών του λογαριθμι- 107
108 κού υποδείγματος. Για το υπόδειγμα της λογαριθμικής παλινδρόμησης χρησιμοποιείται η μέθοδος των εκτιμήσεων μέγιστης πιθανοφάνειας (maximum likelihood estimations). Για την αξιολόγηση της προσαρμογής του λογαριθμικού υποδείγματος χρησιμοποιείται το μέτρο καλής προσαρμογής R των Cox και Snell. Το πρόβλημα με το συγκεκριμένο συντελεστή προσδιορισμού είναι ότι ποτέ δεν καταλήγει να πάρει μέγιστη τιμή το 1. Ο Nagelkerke το 1991 πρότεινε μια τροποποίηση του συντελεστή των Cox και Snell, προκειμένου να παρακαμφθεί το συγκεκριμένο πρόβλημα. Ο συντελεστής που πρότεινε ο Nagelkerke είναι ο R = ( 0,1), όπου R R [ L ] n R max = 1 0, n το μέγεθος του δείγματος και L 0 η μέγιστη τιμή πιθανοφάνειας του logit ( p ) = b Δυαδική Λογαριθμική Παλινδρόμηση (Binary Logistic Regression) Η δυαδική λογαριθμική παλινδρόμηση είναι περισσότερο χρήσιμη στην περίπτωση που επιθυμούμε να μοντελοποιήσουμε την πιθανότητα ενός γεγονότος για μια κατηγορική εξαρτημένη μεταβλητή με δύο πιθανές τιμές Πολυωνυμική Λογαριθμική Παλινδρόμηση (Multinomial Logistic Regression) Ένα πολυωνυμικό μοντέλο λογαριθμικής παλινδρόμησης χρησιμοποιείται για δεδομένα στα οποία η εξαρτημένη μεταβλητή είναι μη διατεταγμένη ή πολύτιμη (polytomous), και οι ανεξάρτητες μεταβλητές είναι συνεχείς ή κατηγορικές [66]. Αυτός ο τύπος μοντέλου μετράται επομένως σε ονομαστική (nominal) κλίμακα και προτάθηκε από το McFadden [67]. Σε αντίθεση με το δυαδικό λογαριθμικό μοντέλο, στο οποίο μια εξαρτημένη μεταβλητή μπορεί να πάρει μόνο τιμές (π.χ. παρουσία απουσία ενός χαρακτηριστικού), η εξαρτημένη μεταβλητή σε ένα πολυωνυμικό μοντέλο λογαριθμικής παλινδρόμησης μπορεί να πάρει τιμή από περισσότερες από δύο επιλογές, οι οποίες κωδικοποιούνται κατηγορικά, και μία από αυτές τις κατηγορίες εκλαμβάνεται ως κατηγορία αναφοράς. Έστω yi είναι η εξαρτημένη μεταβλητή με k πιθανές κατηγορίες για κάθε περίπτωση i και η πιθανότητα να ανήκει στην κατηγορία s συμβολίζεται με ( s ) (0) π i = Pr ( yi = s), με π i η επιλεγμένη κατηγορία αναφοράς [83]. Τότε για ένα α- πλό μοντέλο με μία ανεξάρτητη μεταβλητή x i, ένα πολυωνυμικό λογαριθμικό μοντέλο παλινδρόμησης με logit link μπορεί να αναπαρασταθεί ως εξής: ( s ) π i log β ( 0 ) = + π i ( s) ( s) 0 β1 x i, με s = 1, K, k max 108
109 Σε αυτό το μοντέλο, η ίδια ανεξάρτητη μεταβλητή εμφανίζεται σε καθεμία από τις κατηγορίες και ένα ξεχωριστό s ( s ) Η παράμετρος β 1 αντιπροσωπεύει την αθροιστική επίδραση της αύξησης κατά μία μονάδα στην ανεξάρτητη μεταβλητή x στις λογαριθμο-πιθανότητες επιτυχίας (log-odds) δηλαδή να ανήκει στην κατηγορία s, παρά στην κατηγορία αναφοράς. Πιθανόν να έχει περισσότερο νόημα να ερμηνεύεται η ποσότητα exp β ( s ) 1, που αποτελεί την πολλαπλασιαστική επίδραση της αύξησης κατά μία μονάδα στη μεταβλητή x στις λογαριθμο-πιθανότητες να ανήκει στην κατηγορία s, παρά στην κατηγορία αναφοράς. Ένας άλλος εναλλακτικός τρόπος να ερμηνευτεί η ε- πίδραση μιας ανεξάρτητης μεταβλητής x είναι να χρησιμοποιηθούν εκτιμώμενες ( ) i s (predicted) πιθανότητες π για διαφορετικές τιμές της x π ( s ) i ( s) ( s) exp ( β0 + β1 x i ) k ( j) ( j) ( β0 β1 x i ) j = 1 = 1+ exp + Τότε, η πιθανότητα να ανήκει στην κατηγορία αναφοράς μπορεί να υπολογιστεί με αφαίρεση: π k ( 0 ) ( k ) i = 1 πi j = Εφαρμογή της μεθόδου Ο Wang [66] εφάρμοσε τη μοντελοποίηση πολυωνυμικής λογαριθμικής παλινδρόμησης για την πρόβλεψη πολλαπλών τύπων επιθέσεων στο σύνολο δεδομένων KDD Cup Χρησιμοποίησε επίσης bootstrap προσομοίωση για να προσαρμόσει 3000 τέτοια μοντέλα (πολυωνυμικής λογαριθμικής παλινδρόμησης) με τους πιο συχνούς τύπους επιθέσεων (probe, DoS, UR και RL ) ως μη διατεταγμένη ανεξάρτητη μεταβλητή. Αυτή η μελέτη χρησιμοποιεί το «0» ως κατηγορία αναφοράς ενώ οι υπόλοιπες 4 κατηγορίες για την εξαρτημένη μεταβλητή είναι «1» για επιθέσεις Probe, για επιθέσεις DoS, «3» για επιθέσεις UR και «4» για επιθέσεις RL. Με την έρευνά του αναγνώρισε 13 παράγοντες κινδύνου που σχετίζονται στατιστικώς σημαντικά με αυτές τις επιθέσεις. Οι παράγοντες αυτοί στη συνέχεια χρη- Probe: Ο επιτιθέμενος προσπαθεί να αποκτήσει πληροφορίες για τον υπολογιστή στόχο. DoS (Denial of Service): Ο επιτιθέμενος προσπαθεί να εμποδίσει τους νόμιμους χρήστες να χρησιμοποιήσουν μια υπηρεσία ή έναν πόρο. UR (User to Root): Ο επιτιθέμενος έχει τοπική πρόσβαση στον υπολογιστή του θύματος και προσπαθεί να αποκτήσει προνόμια υπερχρήστη διαχειριστή. RL (Remote to Loca): Ο επιτιθέμενος δεν έχει λογαριασμό για τον υπολογιστή του θύματος, επομένως προσπαθεί να αποκτήσει πρόσβαση σε αυτό. 109
110 σιμοποιούνται για την κατασκευή ενός τελικού μοντέλου πολυωνυμικής λογαριθμικής παλινδρόμησης. Το τελικό αυτό μοντέλο παρουσίασε στο διάγραμμα ROC περιοχή κάτω από την καμπύλη ίση με 0,99 για την ανίχνευση μη φυσιολογικών γεγονότων. Μάλιστα συγκρίνοντας τα αποτελέσματα της έρευνάς του με έναν rule-based αλγόριθμο δέντρων απόφασης (που ήταν και ο νικητής του διαγωνισμού KDD Cup 1999) [68], τα αποτελέσματα κατάταξης του μοντέλου που κατασκεύασε ήταν παρόμοια ή ακόμα και καλύτερα % vs. 99.5% στον εντοπισμό φυσιολογικών γεγονότων 85.6% vs. 83.3% επιθέσεων Probe 97.% vs. 97.1% επιθέσεων DoS, 5.9% vs. 13.% επιθέσεων UR 11.% vs. 8.4% επιθέσεων RL 18.9% vs. 35.7% συνολικό ποσοστό λανθασμένης κατάταξης. 110
111 Κεφάλαιο 4 Πειραματική Ανάλυση 111
112 4.1 Μέθοδοι Ανάλυσης Το τέταρτο κεφάλαιο είναι και το σημαντικότερο, μιας και σ αυτό επιχειρείται η εφαρμογή ορισμένων από τις πολυμεταβλητές μεθόδους που αναφέρθηκαν προηγουμένως. Συγκεκριμένα η προτεινόμενη εφαρμογή βασίζεται στις μεθόδους της παραγοντικής ανάλυσης, της ανάλυσης διακρίσεων και της λογαριθμικής παλινδρόμησης Σύνολο Δεδομένων Ορισμένες από τις προτεινόμενες μεθοδολογίες εφαρμόστηκαν σε ένα αρχικό σύνολο Ν (335) περιπτώσεων ενός αρχικού συνόλου δεδομένων 41 χαρακτηριστικών. Το σύνολο δεδομένων attacks.sav δημιουργήθηκε από τυχαία επιλογή 335 περιπτώσεων (cases) από ένα αρχικό σύνολο δεδομένων το οποίο περιείχε περισσότερες από περιπτώσεις. Πρόκειται για το σύνολο δεδομένων KDD Cup 1999 Data, το οποίο χρησιμοποιήθηκε στον Τρίτο Διεθνή Διαγωνισμό Ανακάλυψης Γνώσης και Εργαλείων Εξόρυξης Δεδομένων (Third International Knowledge Discovery and Data Mining Tools Competition), ο οποίος πραγματοποιήθηκε σε συνδυασμό με το Πέμπτο Διεθνές Συνέδριο του KDD-99, το οποίο αφορούσε σε Ανακάλυψη Γνώσης και Εξόρυξη Δεδομένων (KDD-99 The Fifth International Conference on Knowledge Discovery and Data Mining). Σκοπός του διαγωνισμού ήταν η κατασκευή ενός ανιχνευτή εισβολών δικτύων, ενός μοντέλου πρόβλεψης ικανού να διακρίνει τις «κακές» συνδέσεις, οι οποίες καλούνται επιθέσεις ή εισβολές, από τις καλές κανονικές συνδέσεις. Μια σύνδεση είναι μια ακολουθία πακέτων TCP που εκκινεί και τερματίζει σε καλά καθορισμένες χρονικές στιγμές, μεταξύ των οποίων δεδομένα ρέουν προς και από μια IP διεύθυνση πηγή σε μια IP διεύθυνση στόχο μέσω ενός καλά καθορισμένου πρωτοκόλλου. Κάθε σύνδεση χαρακτηρίζεται είτε ως κανονική, είτε ως επίθεση, με ακριβώς έναν συγκεκριμένο τύπο επίθεσης. Το σύνολο των δεδομένων που χρησιμοποιήθηκαν για το συγκεκριμένο διαγωνισμό είναι μια έκδοση ενός συνόλου που δημιουργήθηκε από τα MIT Lincoln Labs, το οποίο περιλαμβάνει μια ευρεία ποικιλία εισβολών που προσομοιώθηκαν σε ένα στρατιωτικό περιβάλλον δικτύων. Περισσότερες πληροφορίες για το σύνολο δεδομένων μπορείτε να βρείτε στα [55] [56] [57] Σύνολο Χαρακτηριστικών Από τα 41 χαρακτηριστικά του αρχικού συνόλου δεδομένων επελέγησαν να χρησιμοποιηθούν μόνον 15 από αυτά ποιοτικά και ποσοτικά στη συγκεκριμένη εφαρμογή, καθώς οι τιμές των υπολοίπων χαρακτηριστικών για τις 335 περιπτώσεις που επιλέχθηκαν τυχαία ήταν μηδενικές. Τα χαρακτηριστικά αυτά συνοψίζονται στον πίνακα
113 Όνομα Χαρακτηριστικού duration protocol_type service src_bytes dst_bytes hot num_failed_logins logged_in num_compromised num_root num_file_creations num_shells num_access_files count srv_count Σύντομη Περιγραφή Αριθμός δευτερολέπτων της σύνδεσης [length (number of seconds) of the connection] Τύπος πρωτοκόλλου, π.χ. tcp, udp, κλπ. [type of the protocol, e.g. tcp, udp, etc.] Υπηρεσία δικτύου του προορισμού, π.χ. http, telnet, ftp κλπ. [network service on the destination, e.g., http, telnet, etc.] Αριθμός bytes δεδομένων από την πηγή στον προορισμό [number of data bytes from source to destination] Αριθμός bytes δεδομένων από τον προορισμό στην πηγή [number of data bytes from destination to source] Αριθμός «καυτών» ενδείξεων [number of hot indicators] Αριθμός αποτυχημένων προσπαθειών εισόδου [number of failed login attempts] 1 για επιτυχή είσοδο, διαφορετικά 0 [1 if successfully logged in; 0 otherwise] Αριθμός «επικίνδυνων» συνθηκών [number of compromised conditions] Αριθμός προσπελάσεων ως υπερχρήστης [number of root accesses] Αριθμός λειτουργιών δημιουργίας αρχείων [number of file creation operations] Αριθμός εντολών κελύφους [number of shell prompts] Αριθμός λειτουργιών σε αρχεία ελέγχου πρόσβασης [number of operations on access control files] Αριθμός συνδέσεων στον ίδιο υπολογιστή υπηρεσίας με την τρέχουσα σύνδεση τα τελευταία δύο δευτερόλεπτα [number of connections to the same host as the current connection in the past two seconds] Αριθμός συνδέσεων στην ίδια υπηρεσία με την τρέχουσα σύνδεση τα τελευταία δύο δευτερόλεπτα [number of connections to the same service as the current connection in the past two seconds] Πίνακας 4.1 Τύπος συνεχής διακριτή διακριτή συνεχής συνεχής συνεχής συνεχής διακριτή συνεχής συνεχής συνεχής συνεχής συνεχής συνεχής συνεχής 113
114 Την πλήρη λίστα με όλα τα χαρακτηριστικά και την περιγραφή τους μπορείτε να βρείτε στο Παράρτημα Α. Ο πίνακας αυτός προέκυψε από το [57]. Επίσης στο αρχείο attack.sav υπάρχει ακόμα μία μεταβλητή, η attack, η οποία παίρνει διακριτές τιμές και συγκεκριμένα αλφαριθμητικές τιμές και αφορά στο χαρακτηρισμό της σύνδεσης ως επίθεση ή ως κανονική. Να σημειωθεί σε αυτό το σημείο πως τα ποιοτικά ονομαστικά (nominal) χαρακτηριστικά protocol_type και service του αρχικού συνόλου δεδομένων έχουν α- ντικατασταθεί από τα nominal χαρακτηριστικά protocol_type_1 και service_1. Το ίδιο ισχύει για τη μεταβλητή attack ή οποία έχει αντικατασταθεί από το χαρακτηριστικό group, με δύο μόνο τιμές 1 αν πρόκειται για κανονική σύνδεση και σε περίπτωση επίθεσης. Οι αντικαταστάσεις που αφορούν στα χαρακτηριστικά protocol_type και service σε αντίστοιχες μεταβλητές έχουν γίνει ως εξής: protocol_type protocol_type_1 service service_1 tcp 1 udp icm 3 http 1 private x11 3 auth 4 ecr_i 5 domain_u 6 eco_i 7 smtp 8 telnet 9 ftp_data 10 finger 11 ftp 1 pop_3 13 sunrpc 14 other 15 imap 16 Στο σύνολο δεδομένων attack.sav η μεταβλητή group με τιμές 1 και (1 για κανονική σύνδεση, για επίθεση) χρησιμοποιείται για να αντικαταστήσει τις τιμές normal και όνομα_επίθεσης, όπου το όνομα_επίθεσης προέρχεται από μια λίστα συγκεκριμένων επιθέσεων (π.χ. neptune, guess_passwd, processtable, buffer_overflow, satan κλπ). 4. Μεθοδολογία Στα 15 χαρακτηριστικά (εκτός του group) που προαναφέρθηκαν εφαρμόστηκαν ορισμένες μέθοδοι πολυμεταβλητής ανάλυσης. Ειδικότερα, η εφαρμογή αυτή βασίζεται στις μεθόδους της παραγοντικής ανάλυσης, της ανάλυσης διακρίσεων και της λογαριθμικής παλινδρόμησης, οι οποίες διενεργούνται μέσω του στατιστικού πακέτου SPSS Μάλιστα, οι τεχνικές αυτές εφαρμόστηκαν σε διάφορα μοντέλα με βάση τον αριθμό και τον τύπο των μεταβλητών τους. 114
115 4.3 Παραγοντική Ανάλυση (Factor Analysis) Παραγοντική Ανάλυση Μοντέλο Ι Αρχικά επιλέγονται όλα τα χαρακτηριστικά πλην των εξής παρακάτω ονομαστικών: protocol_type_1, service_1 και logged_in, τα οποία είναι ποιοτικά. Στα 1 εναπομείναντα ποσοτικά χαρακτηριστικά εφαρμόζεται η Ανάλυση Παραγόντων με τη μέθοδο των Κυρίων Συνιστωσών, ώστε να μειωθεί ο χώρος των διαστάσεων. Οι παράγοντες που προκύπτουν με περιστροφή, σε συνδυασμό με τις ποιοτικές μεταβλητές, υπόκεινται σε Ανάλυση Διακρίσεων (σε διαφορετικό μοντέλο) ώστε οι 335 περιπτώσεις να ομαδοποιηθούν σε ξεχωριστές ομάδες group 1 (=κανονική) και group (=επίθεση). Από την Ανάλυση Διακρίσεων ενδιαφέρουν τα αποτελέσματα της κατηγοριοποίησης και συγκεκριμένα η σωστή ή εσφαλμένη κατάταξη καθεμίας από τις 335 περιπτώσεις στις κατηγορίες. Το σύνολο δεδομένων που θα εξεταστεί αποτελείται από 335 συνδέσεις TCP, οι οποίες χαρακτηρίζονται από μία μεταβλητή attack (ή group), που εκφράζει την κατηγορία στην οποία ανήκει μια σύνδεση, και από 15 μεταβλητές που σχετίζονται με καθεμιά από αυτές. Η περιγραφή των μεταβλητών δίνεται στον πίνακα 4.1. Επειδή ο σκοπός των μετρήσεων σε αυτές τις περιπτώσεις είναι η αξιοποίηση των δεδομένων για την κατασκευή ενός μοντέλου πρόβλεψης για τη μεταβλητή group, θα αναφερόμαστε σε αυτή ως εξαρτημένη μεταβλητή και στις υπόλοιπες ως ανεξάρτητες μεταβλητές. Στα δεδομένα αυτά θα εφαρμόσουμε Παραγοντική Ανάλυση και συγκεκριμένα στις 1 ποσοτικές μεταβλητές, με σκοπό τη μείωση των διαστάσεων και την προβολή των συνδέσεων σε έναν υποχώρο που ορίζουν οι κύριες συνιστώσες. Αρχικά παίρνουμε κάποια περιγραφικά στατιστικά μέτρα για τις ανεξάρτητες μεταβλητές, τα οποία φαίνονται στον πίνακα 4.. Οι πίνακες 4.3, 4.4 και 4.5 είναι οι πίνακες συχνοτήτων των ποιοτικών μεταβλητών protocol_type_1, service_1 και logged_in. Από τον πίνακα 4. παρατηρούμε πως οι ανεξάρτητες μεταβλητές διαφέρουν αρκετά στις μονάδες μέτρησής τους και στις διασπορές τους. Η παρατήρηση αυτή μας οδηγεί στο συμπέρασμα ότι είναι προτιμότερο να εφαρμόσουμε την Παραγοντική Ανάλυση σε τυποποιημένες μεταβλητές ή αλλιώς να εργαστούμε με τον πίνακα συσχετίσεων (και όχι με τον πίνακα διασπορώνσυνδιασπορών). Οι συντελεστές συσχέτισης ανάμεσα στις ανεξάρτητες μεταβλητές δίνονται στον πίνακα 4.6. Όπως προκύπτει από το συγκεκριμένο πίνακα, υ- πάρχουν κάποιες μεταβλητές οι οποίες είναι συσχετισμένες μεταξύ τους και σε μεγάλο βαθμό μάλιστα. Η ύπαρξη συσχετίσεων είναι εμφανής και στον πίνακα 4.7 με τις συσχετίσεις του Pearson, όπου σημειώνονται με αστερίσκους οι σημαντικές συσχετίσεις μαζί με το επίπεδο σημαντικότητάς τους. Όσο πιο κοντά στη μονάδα είναι ο συντελεστής, τόσο μεγαλύτερη είναι η συσχέτιση ανάμεσα στις μεταβλητές. Ο συντελεστής του Pearson παίρνει τιμές στο διάστημα [ 1,1], όπου τιμές κοντά στο 1 δηλώνουν ισχυρή θετική συσχέτιση (όσο αυξάνει η μια μετα- 115
, τιμές κοντά στο -1 δηλώνουν ισχυρή αρνητική συσχέτιση και τιμές κοντά στο 0 δηλώνουν γραμμική ανεξαρτησία")

116 βλητή. αυξάνει κι άλλη), τιμές κοντά στο -1 δηλώνουν ισχυρή αρνητική συσχέτιση και τιμές κοντά στο 0 δηλώνουν γραμμική ανεξαρτησία των μεταβλητών. Σχετικά με τον αριθμό των παραγόντων που θα εξαχθούν από τα δεδομένα, α- ποφασίζουμε να θεωρήσουμε σημαντικούς όσους παράγοντες αντιστοιχούν σε χαρακτηριστικές ρίζες (και επομένως διασπορές) μεγαλύτερες της μονάδας. Επίσης στα Σχήματα 4.1 και 4. φαίνονται τα ιστογράμματα των ποιοτικών μεταβλητών protocol_type_1 και service_1 αντίστοιχα. Σχήμα 4.1 Σχήμα
117 Descriptive Statistics N Minimum Maximum Mean Std. Deviation Duration 335,0 7686,0 475, ,7874 Protocol_type_ ,45,650 Service_ ,6 4,088 Src_bytes 335, , , ,8888 Dst_bytes 335, , , ,07894 Hot 335 0,10,44 Num_failed_logins ,01,077 Logged_in ,33,471 Num_compromised ,05,468 Num_root ,03,349 Num_file_creations ,01,5 Num_shells ,00,055 Num_access_files ,00,055 Count 335 1,0 511,0 40, ,0700 Srv_count 335 1,0 511,0 6, ,4890 Valid N (listwise) 335 Πίνακας 4. Protocol_type_1 Frequency Percent Valid Percent Cumulative Percent Valid ,3 63,3 63,3 94 8,1 8,1 91, ,7 8,7 100,0 Total ,0 100,0 Πίνακας 4.3 Service_1 Frequency Percent Valid Percent Cumulative Percent Valid ,9 6,9 6, ,3 31,3 58, 3,6,6 58,8 4 1,3,3 59, ,5 4,5 63, ,6 3,6 67, , 4, 71,3 8 9,7,7 74, ,9 11,9 86, ,8 4,8 90, ,8 1,8 9,5 1 9,7,7 95, ,8 1,8 97,0 14,6,6 97, ,8 1,8 99,4 16,6,6 100,0 Total ,0 100,0 Πίνακας 4.4 Logged_in Frequency Percent Valid Percent Cumulative Percent Valid ,9 66,9 66, ,1 33,1 100,0 Total ,0 100,0 Πίνακας 4.5 Correlation Matrix(a,b) Duration Src_ bytes Dst_b ytes Hot Num_faile d_logins Num_com promised Num_ root Num_file_ creations Num_ shells Num_acc ess_files Count Srv_count Correlation Duration 1,000 -,019 -,063 -,035 -,01,06,018,041 -,013 -,013 -,089 -,066 Src_bytes -,019 1,000,144,065 -,010,03 -,008 -,006 -,007 -,007 -,04 -,030 Dst_bytes -,063,144 1,000,17 -,03,339,18,73,009,009 -,100 -,063 Hot -,035,065,17 1,000 -,018,494,34,55,111,111 -,077 -,057 Num_failed_logins -,01 -,010 -,03 -,018 1,000 -,009 -,006 -,005 -,004 -,004 -,06 -,019 Num_compromised,06,03,339,494 -,009 1,000,578,903 -,006 -,006 -,038 -,08 Num_root,018 -,008,18,34 -,006,578 1,000,794,780,780 -,06 -,019 Num_file_creations,041 -,006,73,55 -,005,903,794 1,000,40,40 -,0 -,016 Num_shells -,013 -,007,009,111 -,004 -,006,780,40 1,000 1,000 -,018 -,014 Num_access_files -,013 -,007,009,111 -,004 -,006,780,40 1,000 1,000 -,018 -,014 Count -,089 -,04 -,100 -,077 -,06 -,038 -,06 -,0 -,018 -,018 1,000,845 Srv_count -,066 -,030 -,063 -,057 -,019 -,08 -,019 -,016 -,014 -,014,845 1,000 a Determinant =,000 b This matrix is not positive definite. Πίνακας
118 Duration Src_bytes Dst_bytes Hot Correlations Num_faile d_logins Num_comp romised Num_r oot Num_file_cr eations Num_sh ells Num_acc ess_files Count Srv_count Duration Pearson Correlation 1 -,019 -,063 -,035 -,01,06,018,041 -,013 -,013 -,089 -,066 Sig. (-tailed),75,48,53,708,641,739,454,813,813,105,9 N Src_bytes Pearson Correlation -,019 1,144(**),065 -,010,03 -,008 -,006 -,007 -,007 -,04 -,030 Sig. (-tailed),75,008,35,853,554,879,911,898,898,446,584 N Dst_bytes Pearson Correlation -,063,144(**) 1,17(**) -,03,339(**),18(**),73(**),009,009 -,100 -,063 Sig. (-tailed),48,008,000,677,000,001,000,873,873,068,51 N Hot Pearson Correlation -,035,065,17(**) 1 -,018,494(**),34(**),55(**),111(*),111(*) -,077 -,057 Sig. (-tailed),53,35,000,738,000,000,000,04,04,159,30 Num_failed _logins Num_comp romised N Pearson Correlation -,01 -,010 -,03 -, ,009 -,006 -,005 -,004 -,004 -,06 -,019 Sig. (-tailed),708,853,677,738,871,913,95,938,938,636,76 N Pearson Correlation,06,03,339(**),494(**) -,009 1,578(**),903(**) -,006 -,006 -,038 -,08 Sig. (-tailed),641,554,000,000,871,000,000,909,909,49,615 N Num_root Pearson Correlation,018 -,008,18(**),34(**) -,006,578(**) 1,794(**),780(**),780(**) -,06 -,019 Sig. (-tailed),739,879,001,000,913,000,000,000,000,638,77 Num_file_cr eations N Pearson Correlation,041 -,006,73(**),55(**) -,005,903(**),794(**) 1,40(**),40(**) -,0 -,016 Sig. (-tailed),454,911,000,000,95,000,000,000,000,685,764 N Num_shells Pearson Correlation -,013 -,007,009,111(*) -,004 -,006,780(**),40(**) 1 1,000(**) -,018 -,014 Sig. (-tailed),813,898,873,04,938,909,000,000,000,738,804 Num_acces s_files N Pearson Correlation -,013 -,007,009,111(*) -,004 -,006,780(**),40(**) 1,000(**) 1 -,018 -,014 Sig. (-tailed),813,898,873,04,938,909,000,000,000,738,804 N Count Pearson Correlation -,089 -,04 -,100 -,077 -,06 -,038 -,06 -,0 -,018 -,018 1,845(**) Sig. (-tailed),105,446,068,159,636,49,638,685,738,738,000 N Srv_count Pearson Correlation -,066 -,030 -,063 -,057 -,019 -,08 -,019 -,016 -,014 -,014,845(**) 1 Sig. (-tailed),9,584,51,30,76,615,77,764,804,804,000 N ** Correlation is significant at the 0.01 level (-tailed). Πίνακας * Correlation is significant at the 0.05 level (-tailed).
119 Στη συνέχεια μπορούμε να προχωρήσουμε στην εφαρμογή της Παραγοντικής Ανάλυσης με τη μέθοδο των κυρίων συνιστωσών. Στον πίνακα 4.8 φαίνονται οι συντελεστές συμμετοχικότητας (communalities) των μεταβλητών. Αυτοί εκφράζουν το ποσοστό της διασποράς της κάθε μεταβλητής που εξηγείται από όλους μαζί τους παράγοντες και δείχνουν την αξιοπιστία της μεταβλητής. Όταν κάποια μεταβλητή έχει μικρό συντελεστή συμμετοχικότητας, αυτό σημαίνει πως το FA μοντέλο δεν είναι αρκετά καλό για τη συγκεκριμένη μεταβλητή και κατ επέκταση ίσως αυτή να πρέπει να αφαιρεθεί από το μοντέλο. Στην προκειμένη περίπτωση οι τιμές των συντελεστών στην πλειοψηφία τους είναι μεγάλοι, εκτός από τις 4 πρώτες μεταβλητές που έχουν χαμηλό συντελεστή συμμετοχικότητας (μικρότερο του 0,55), και ειδικότερα την dst_bytes και την hot. Πιθανόν να είναι προτιμότερο να αφαιρεθούν οι συγκεκριμένες μεταβλητές από το μοντέλο. Αυτό το ενδεχόμενο θα εξεταστεί στη συνέχεια. Communalities Initial Extraction Duration 1,000,55 Src_bytes 1,000,541 Dst_bytes 1,000,46 Hot 1,000,365 Num_failed_logins 1,000,797 Num_compromised 1,000,960 Num_root 1,000,978 Num_file_creations 1,000,895 Num_shells 1,000,990 Num_access_files 1,000,990 Count 1,000,916 Srv_count 1,000,907 Extraction Method: Principal Component Analysis. Πίνακας 4.8 Στον πίνακα 4.9 δίνεται το ποσοστό διασποράς που εξηγείται αρχικά από όλους τους παράγοντες και στη συνέχεια από τους πιο σημαντικούς. Συγκεκριμένα, στο πρώτο τμήμα του πίνακα (Initial Eigenvalues) παρουσιάζονται στατιστικά στοιχεία για όλους τους παράγοντες, ενώ στο δεύτερο τμήμα (Extraction Sums of Squared Loadings) εμφανίζονται τα ίδια στατιστικά για τους παράγοντες με χαρακτηριστικές ρίζες μεγαλύτερες της μονάδας. Σε περίπτωση περιστροφής (για καλύτερη ερμηνεία των παραγόντων), τα δύο αυτά τμήματα του πίνακα γενικά διαφέρουν. Από τον πίνακα φαίνεται πως από τους 1 παράγοντες, μόνον οι 5 έχουν χαρακτηριστική ρίζα μεγαλύτερη της μονάδας και επομένως είναι αυτοί που θεωρούνται σημαντικοί για την προσέγγιση του μοντέλου. Η στήλη Total δείχνει τη συνολική διασπορά που εξηγείται από κάθε παράγοντα. Η στήλη % of Variance δείχνει το ποσοστό της συνολικής διασποράς που αντιστοιχεί σε κάθε παράγοντα. Στη στήλη Cumulative % φαίνεται το αθροιστικό ποσοστό της διασποράς που εξηγείται από τους παράγοντες. Από τα αποτελέσματα του πίνακα προκύπτει 119
120 πως το ποσοστό της συνολικής διασποράς που εξηγείται από τους 5 παράγοντες είναι 77,715%. Γενικά μπορούμε να πούμε πως το ποσοστό αυτό θεωρείται ως ένα βαθμό ικανοποιητικό και επομένως μπορούμε να θεωρήσουμε ως καλή προσέγγιση του αρχικού μοντέλου την προβολή σε έναν υποχώρο 5 διαστάσεων που ορίζεται από τους 5 πρώτους παράγοντες (αν και υφίσταται σημαντική απώλεια πληροφορίας ίση με 3% περίπου). Component Total Variance Explained Initial Eigenvalues Extraction Sums of Squared Loadings Total % of Variance Cumulative % Total % of Variance Cumulative % 1 3,384 8,197 8,197 3,384 8,197 8,197 1,993 16,605 44,80 1,993 16,605 44,80 3 1,84 15,198 59,999 1,84 15,198 59, ,11 9,69 69,69 1,11 9,69 69,69 5 1,014 8,447 77,715 1,014 8,447 77,715 6,953 7,938 85,653 7,799 6,661 9,314 8,741 6,17 98,486 9,153 1,78 99,764 10,08,36 100, ,64E-016 3,03E , ,58E-016-4,65E ,000 Extraction Method: Principal Component Analysis. Πίνακας 4.9 Component Total Variance Explained Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings Total % of Variance Cumulative % Total % of Variance Cumulative % Total % of Variance Cumulative % 1 3,384 8,197 8,197 3,384 8,197 8,197,671,56,56 1,993 16,605 44,80 1,993 16,605 44,80,634 1,947 44,03 3 1,84 15,198 59,999 1,84 15,198 59,999 1,870 15,58 59, ,11 9,69 69,69 1,11 9,69 69,69 1,136 9,464 69,48 5 1,014 8,447 77,715 1,014 8,447 77,715 1,016 8,467 77,715 6,953 7,938 85,653 7,799 6,661 9,314 8,741 6,17 98,486 9,153 1,78 99,764 10,08,36 100, ,64E-016 3,03E , ,58E-016-4,65E ,000 Extraction Method: Principal Component Analysis. Πίνακας 4.10 Στον πίνακα 4.10 δίνεται το ποσοστό διασποράς που εξηγείται αρχικά από όλους τους παράγοντες και στη συνέχεια από τους πιο σημαντικούς πριν και μετά την περιστροφή, η οποία έγινε χρησιμοποιώντας τη μέθοδο Varimax (μέγιστος αριθμός επαναλήψεων ίσος με 5) προκειμένου για τη διευκόλυνση της ερμηνείας των αποτελεσμάτων. Παρατηρούμε πως μετά την περιστροφή το ποσοστό της 10

121 συνολικής διασποράς που εξηγείται από τους 5 παράγοντες δεν αλλάζει, αλλά αλλάζει το ποσοστό που εξηγεί ο κάθε παράγοντας, έτσι ώστε να μειώνονται οι μεταξύ τους διαφορές. Να σημειωθεί σε αυτό το σημείο ότι δοκιμάστηκε και περιστροφή με βάση τη μέθοδο Equamax, κατά την οποία το ποσοστό της συνολικής διασποράς που εξηγείται από τους 5 παράγοντες είναι ομοίως ίσο με 77,715%. Σχήμα 4.3 Στο σχήμα 4.3 δίνεται η γραφική παράσταση των χαρακτηριστικών ριζών διασπορών ως προς τη σειρά διάταξής τους στον πίνακα 4.10 Η γραφική αυτή παράσταση (Scree Plot) χρησιμοποιείται για την αναγνώριση των πιο σημαντικών παραγόντων από τις μεγάλες χαρακτηριστικές ρίζες (>1) που έχουν εμφανείς διαφορές από τις μικρότερες. Στην προκειμένη περίπτωση είναι εμφανής ο αριθμός των παραγόντων που πρέπει να χρησιμοποιηθούν. Ωστόσο, υπάρχει περίπτωση το scree plot να μην είναι σε θέση να δώσει ιδιαίτερα χρήσιμες πληροφορίες. Αυτό μπορεί να συμβεί στην περίπτωση που κάποιοι από τους παράγοντες συνωστίζονται πολύ μεταξύ τους, με αποτέλεσμα κάποιος να θεωρήσει ως σημαντικούς μόνον τους πρώτους πιο εμφανείς (εκείνους που βρίσκονται στην «steep slope» - απότομη κλίση του διαγράμματος) αγνοώντας τους υπόλοιπους λιγότερο προφανείς, οι οποίοι προκύπτουν ως σημαντικοί με βάση το κριτήριο των χαρακτηριστικών τιμών μεγαλύτερων του 1. 11
122 Με εφαρμογή της Παραγοντικής Ανάλυσης όχι με το κριτήριο οι χαρακτηριστικές τιμές να είναι μεγαλύτερες του 1 αλλά από τις 1 ποσοτικές μεταβλητές να προκύψουν τελικά μόνο 3 νέοι παράγοντες, τότε το ποσοστό της συνολικής διασποράς που θα εξηγούνταν από τους παράγοντες αυτούς δε θα ξεπερνούσε το 60% (59,999%), ποσοστό απαράδεκτο. Το ίδιο συμβαίνει και στην περίπτωση που το κριτήριο είναι ο αριθμός των παραγόντων να είναι ίσος με 4 (ποσοστό συνολικής διασποράς 69,69%). Στους δύο επόμενους πίνακες 4.11 και 4.1 φαίνονται τα φορτία των παραγόντων πριν και μετά την περιστροφή, τα οποία δείχνουν τον τρόπο με τον οποίο συσχετίζονται οι παράγοντες με τις μεταβλητές, δηλαδή ποιος παράγοντας συνεισφέρει περισσότερο στην ερμηνεία της κάθε μεταβλητής. Η κάθε μεταβλητή εκφράζεται γραμμικά ως προς τους παράγοντες με τα φορτία. Για παράδειγμα εδώ φαίνεται πως οι μεταβλητές που «φορτώνονται» στον πρώτο παράγοντα είναι οι Num_root και Num_file_creations, ενώ για το δεύτερο παράγοντα αυτές είναι οι Num_shells και Num_access_files. Ωστόσο τόσο για αυτούς τους παράγοντες, όσο και για τους υπόλοιπους τα πράγματα δεν είναι εντελώς ξεκάθαρα και υπάρχει κάποια ασάφεια. Παρατηρούμε επίσης πως ορισμένες μεταβλητές δεν εξηγούνται από κανέναν παράγοντα, οπότε το κλίμα ασάφειας είναι γενικότερο. Component Matrix(a) Component Duration,01 -,074 -,13 -,579 -,408 Src_bytes,033 -,145 -,013,684 -,5 Dst_bytes,314 -,41,136,408 -,037 Hot,4 -,361,148,185,010 Num_failed_logins -,014 -,00 -,051 -,059,889 Num_compromised,67 -,573,39 -,155,03 Num_root,971,164 -,008 -,08,008 Num_file_creations,806 -,39,89 -,7,030 Num_shells,7,601 -,310,103 -,018 Num_access_files,7,601 -,310,103 -,018 Count -,097,493,814,016 -,01 Srv_count -,083,478,819,08 -,09 Extraction Method: Principal Component Analysis. a 5 components extracted. Πίνακας 4.11 Μετά την περιστροφή ο προηγούμενος πίνακας μετασχηματίζεται στον πίνακα 4.1. Όπως προκύπτει, τα πράγματα φαίνεται να ξεκαθαρίζουν περισσότερο, ε- ξακολουθεί όμως να υπάρχει κάποια ασάφεια ως προς τη χρησιμότητα της μεταβλητής Duration. Επίσης, ενώ προηγουμένως η μεταβλητή Hot δε «φορτωνόταν» σε κάποιον παράγοντα, μετά την περιστροφή βλέπουμε πως ο δεύτερος παράγοντας μπορεί να συνεισφέρει για την ερμηνεία της συγκεκριμένης μεταβλητής. 1
123 Rotated Component Matrix(a) Component Duration -,040,056 -,167 -,5 -,469 Src_bytes,000,007 -,05,717 -,157 Dst_bytes -,047,465 -,09,485 -,011 Hot,044,541 -,070,56,013 Num_failed_logins -,017,015 -,066 -,147,878 Num_compromised -,017,979,006 -,030 -,010 Num_root,788,593,009 -,077 -,009 Num_file_creations,57,899,06 -,138 -,014 Num_shells,994,01 -,013,00,001 Num_access_files,994,01 -,013,00,001 Count -,010 -,039,956 -,08 -,001 Srv_count -,010 -,00,95 -,013 -,009 Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. a Rotation converged in 5 iterations. Πίνακας 4.1 Ο πίνακας 4.13 είναι ο πίνακας που χρησιμοποιήθηκε για την περιστροφή, δηλαδή αυτός με τον οποίο πολλαπλασιάστηκε ο αρχικός πίνακας των φορτιών προκειμένου να προκύψει ο τελικός πίνακας των φορτιών μετά την περιστροφή. Component Transformation Matrix Component ,710,700 -,064,031 -,013,66 -,58,494 -,154, ,309,391,866,041,001 4,087 -,16,041,98, ,019,040 -,0 -,098,994 Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. Πίνακας 4.13 Αναφορικά με τα σκορ των παραγόντων, αυτά υπολογίστηκαν με τη μέθοδο Anderson-Rubin, ώστε να μην είναι συσχετισμένα ακόμα και μετά την περιστροφή. Ο πίνακας 4.14 δίνει τους συντελεστές που χρησιμοποιούνται για τον υπολογισμό των σκορ από τις αρχικές μεταβλητές. Έτσι για παράδειγμα προκύπτει για τον πρώτο παράγοντα: Factor_1 = 0,036*Duration + 0,01*Src_bytes *Count 0.003*Srv_count Factor_ = 0.045* Duration 0.040*Src_bytes *Count *Srv_count.. Factor_5 = 0,456*Duration 0.159*Src_bytes *Count 0.017*Srv_count 13
124 Με τον παραπάνω υπολογισμό των σκορ, δημιουργούνται 5 νέες μεταβλητές οι παράγοντες οπότε είναι σκόπιμο να τις μελετήσουμε με κάποια γενικά περιγραφικά μέτρα, τα οποία φαίνονται στον πίνακα Component Score Coefficient Matrix Component Duration -,036,045 -,094 -,469 -,456 Src_bytes,01 -,040 -,013,637 -,159 Dst_bytes -,057,170 -,030,40 -,005 Hot -,036,04 -,01,197,00 Num_failed_logins -,016,09 -,046 -,139,867 Num_compromised -,118,410,05 -,081,006 Num_root,50,161,015 -,077 -,001 Num_file_creations -,001,35,031 -,164,000 Num_shells,401 -,105 -,007,046 -,00 Num_access_files,401 -,105 -,007,046 -,00 Count -,00,008,51 -,004 -,010 Srv_count -,003,015,510,008 -,017 Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. Component Scores. Πίνακας 4.14 Από τον πίνακα 4.15 παρατηρούμε ότι όλες οι νέες μεταβλητές παράγοντες είναι τυποποιημένες με μέση τιμή 0 και διασπορά 1. A-R factor score 1 for analysis 1 A-R factor score for analysis 1 A-R factor score 3 for analysis 1 A-R factor score 4 for analysis 1 A-R factor score 5 for analysis 1 Valid N (listwise) 335 Descriptive Statistics N Range Minimum Maximum Mean Std. Deviation Variance , , ,14719, , , , , ,80736, , , , ,857 4,53588, , , , , ,40558, , , , , ,31150, , ,000 Πίνακας 4.15 Οι συσχετίσεις ανάμεσα στα σκορ δίνονται στον πίνακα Όπως ήταν αναμενόμενο, τα σκορ είναι ασυσχέτιστα μεταξύ τους. 14

125 A-R factor score 1 for analysis 1 A-R factor score for analysis 1 A-R factor score 3 for analysis 1 A-R factor score 1 for analysis 1 Correlations A-R factor score for analysis 1 A-R factor score 3 for analysis 1 A-R factor score 4 for analysis 1 A-R factor score 5 for analysis 1 Pearson Correlation 1,000,000,000,000 Sig. (-tailed) 1,000 1,000 1,000 1,000 N Pearson Correlation,000 1,000,000,000 Sig. (-tailed) 1,000 1,000 1,000 1,000 N Pearson Correlation,000,000 1,000,000 Sig. (-tailed) 1,000 1,000 1,000 1,000 N A-R factor score 4 for analysis 1 A-R factor score 5 for analysis 1 Pearson Correlation,000,000,000 1,000 Sig. (-tailed) 1,000 1,000 1,000 1,000 N Pearson Correlation,000,000,000,000 1 Sig. (-tailed) 1,000 1,000 1,000 1,000 N Πίνακας 4.16 Στο σχήμα 4.4 βλέπουμε μια γραφική παράσταση των φορτίων των μεταβλητών στον τρισδιάστατο χώρο που ορίζεται από τους τρεις πρώτους παράγοντες μετά την περιστροφή. Παρατηρούμε πως τα σύνολα των μεταβλητών που διακρίναμε στον πίνακα 4.14 φαίνονται εδώ καθαρά να συγκεντρώνονται κατά μήκος των 3 αξόνων. Σχήμα
126 Reproduced Correlations Reproduced Correlation Duration Src_bytes Dst_bytes Hot Num_faile d_logins Num_comp romised Num_root Num_file_cr eations Num_shells Num_acces s_files Count Srv_count Duration,55(b) -,91 -,04 -,099 -,33,075,045,115 -,047 -,047 -,146 -,149 Src_bytes -,91,541(b),357,189 -,39 -,013 -,050 -,09,015,015 -,070 -,058 Dst_bytes -,04,357,46(b),380 -,067,441,01,337 -,06 -,06 -,119 -,103 Hot -,099,189,380,365(b) -,015,51,335,461,061,061 -,095 -,081 Num_failed _logins -,33 -,39 -,067 -,015,797(b),010 -,00,015 -,018 -,018 -,061 -,069 Num_comp romised,075 -,013,441,51,010,960(b),569,880,003,003 -,031 -,014 Num_root,045 -,050,01,335 -,00,569,978(b),746,794,794 -,01 -,010 Num_file_cr eations,115 -,09,337,461,015,880,746,895(b),71,71 -,009,006 Num_shells -,047,015 -,06,061 -,018,003,794,71,990(b),990 -,04 -,0 Num_acces s_files -,047,015 -,06,061 -,018,003,794,71,990,990(b) -,04 -,0 Count -,146 -,070 -,119 -,095 -,061 -,031 -,01 -,009 -,04 -,04,916(b),911 Srv_count -,149 -,058 -,103 -,081 -,069 -,014 -,010,006 -,0 -,0,911,907(b) Residual(a) Duration,7,141,064,30 -,050 -,06 -,074,034,034,058,083 Src_bytes,7 -,13 -,14,9,046,04,086 -,0 -,0,08,08 Dst_bytes,141 -,13 -,163,044 -,10 -,019 -,064,035,035,00,040 Hot,064 -,14 -,163 -,004 -,07 -,101 -,06,050,050,018,05 Num_failed _logins,30,9,044 -,004 -,018 -,004 -,00,013,013,035,050 Num_comp romised -,050,046 -,10 -,07 -,018,009,0 -,009 -,009 -,006 -,014 Num_root -,06,04 -,019 -,101 -,004,009,048 -,014 -,014 -,005 -,009 Num_file_cr eations -,074,086 -,064 -,06 -,00,0,048 -,031 -,031 -,013 -,0 Num_shells,034 -,0,035,050,013 -,009 -,014 -,031,010,005,009 Num_acces s_files,034 -,0,035,050,013 -,009 -,014 -,031,010,005,009 Count,058,08,00,018,035 -,006 -,005 -,013,005,005 -,066 Srv_count,083,08,040,05,050 -,014 -,009 -,0,009,009 -,066 Extraction Method: Principal Component Analysis. a Residuals are computed between observed and reproduced correlations. There are 19 (8,0%) nonredundant residuals with absolute values greater than b Reproduced communalities Πίνακας
. Στον πίνακα 4.17 γίνεται μια τέτοια σύγκριση.")
127 Ένα καλό μέτρο αξιολόγησης του γραμμικού μοντέλου με τους παράγοντες που προσαρμόστηκε στα δεδομένα μας είναι ο εκτιμώμενος από το μοντέλο πίνακας συσχετίσεων ανάμεσα στις αρχικές μεταβλητές. Αν το μοντέλο είναι τέλειο, αυτός ο πίνακας θα πρέπει να συμπίπτει με τον πραγματικό πίνακα συσχετίσεων του δείγματος (γεγονός που δε συμβαίνει εδώ). Στον πίνακα 4.17 γίνεται μια τέτοια σύγκριση. Συγκεκριμένα στο πάνω μέρος του πίνακα, δίνονται στα μη-διαγώνια στοιχεία οι εκτιμώμενες από το μοντέλο συσχετίσεις και στα διαγώνια στοιχεία οι συντελεστές συμμετοχικότητας, ενώ στο κάτω μέρος δίνονται τα υπόλοιπα (residuals), δηλαδή οι διαφορές που προκύπτουν αν αφαιρέσουμε τις εκτιμώμενες τιμές από τις πραγματικές. Στο σχήμα 4.5 δίνονται τα box plots για τα 5 σκορ που υπολογίστηκαν, των ο- ποίων η χρησιμότητα είναι μεγάλη στην ανίχνευση ακραίων τιμών, ενώ στη συνέχεια ακολουθεί το σχήμα 4.6 με τα διαγράμματα διασποράς ανάμεσα στα σκορ. Τα διαγράμματα αυτά είναι επίσης χρήσιμα για την αναζήτηση ακραίων τιμών αλλά και ομάδων στα δεδομένα. Στο σχήμα 4.7 δίνεται το διάγραμμα διασποράς για τους παράγοντες 1, και 3 σε τρισδιάστατο χώρο. Σχήμα
128 Σχήμα 4.6 Σχήμα
129 4.3. Παραγοντική Ανάλυση Μοντέλο ΙΙ Όπως αναφέρθηκε προηγουμένως, στον πίνακα με τους συντελεστές συμμετοχικοτήτων υπήρχαν κάποιες μεταβλητές που είχαν χαμηλή τιμή και πιθανόν θα ή- ταν σκόπιμο να αφαιρεθούν από το μοντέλο. Κατ επέκταση, επιλέγουμε να απομακρύνουμε τις μεταβλητές με τιμή του συντελεστή συμμετοχικότητας μικρότερη του 0,50 και εφαρμόζουμε Παραγοντική Ανάλυση από την αρχή ξανά. Οι μεταβλητές που απομακρύνουμε είναι οι Hot και Dst_bytes. Στη συνέχεια ακολουθούν τα αποτελέσματα της νέας ανάλυσης παραγόντων. Descriptive Statistics N Minimum Maximum Mean Std. Deviation Variance Duration 335,0 7686,0 475, , ,119 Src_bytes 335, , , , ,46 Num_failed_logins ,01,077,006 Num_compromised ,05,468,19 Num_root ,03,349,1 Num_file_creations ,01,5,051 Num_shells ,00,055,003 Num_access_files ,00,055,003 Count 335 1,0 511,0 40, , ,386 Srv_count 335 1,0 511,0 6, , ,06 Valid N (listwise) 335 Πίνακας 4.18 Duration Src_by tes Correlation Matrix(a,b) Num_failed Num_comp Num_root _logins romised Num_file_ creations Num_s hells Num_acc ess_files Count Srv_count Correlation Duration 1,000 -,019 -,01,06,018,041 -,013 -,013 -,089 -,066 Src_bytes -,019 1,000 -,010,03 -,008 -,006 -,007 -,007 -,04 -,030 Num_failed_l ogins -,01 -,010 1,000 -,009 -,006 -,005 -,004 -,004 -,06 -,019 Num_compr omised,06,03 -,009 1,000,578,903 -,006 -,006 -,038 -,08 Num_root,018 -,008 -,006,578 1,000,794,780,780 -,06 -,019 Num_file_cre ations,041 -,006 -,005,903,794 1,000,40,40 -,0 -,016 Num_shells -,013 -,007 -,004 -,006,780,40 1,000 1,000 -,018 -,014 Num_access _files -,013 -,007 -,004 -,006,780,40 1,000 1,000 -,018 -,014 Count -,089 -,04 -,06 -,038 -,06 -,0 -,018 -,018 1,000,845 Srv_count -,066 -,030 -,019 -,08 -,019 -,016 -,014 -,014,845 1,000 a Determinant =,000 b This matrix is not positive definite. Πίνακας 4.19 Οι μεγάλες διαφορές στις μέσες τιμές και τις τυπικές αποκλίσεις δικαιολογεί τη χρήση του πίνακα συσχετίσεων (πίνακας 4.19) και όχι του πίνακα διασπορώνσυνδιασπορών. Όπως προκύπτει, υπάρχουν κάποια ζεύγη μεταβλητών οι οποίες είναι συσχετισμένες μεταξύ τους (αυτές είναι με έντονη μπλε γραμματοσειρά). 19
130 Υπάρχει δηλαδή μια δομή συσχετίσεων η οποία χρειάζεται περαιτέρω διερεύνηση. Από τον πίνακα 4.0 των συντελεστών συμμετοχικοτήτων προκύπτει ότι το μοντέλο FA είναι καλό για όλες τις μεταβλητές που έχουμε συμπεριλάβει στην ανάλυση (οι συντελεστές έχουν όλοι υψηλές τιμές, με μια μικρή επιφύλαξη για τη μεταβλητή Duration). Communalities Initial Extraction Duration 1,000,56 Src_bytes 1,000,750 Num_failed_logins 1,000,794 Num_compromised 1,000,961 Num_root 1,000,995 Num_file_creations 1,000,975 Num_shells 1,000,997 Num_access_files 1,000,997 Count 1,000,917 Srv_count 1,000,91 Extraction Method: Principal Component Analysis. Πίνακας 4.0 Βάσει του πίνακα 4.1 οι 10 πλέον αρχικές μεταβλητές μπορούν να αντικατασταθούν από 5 και αυτή τη φορά παράγοντες οι οποίοι αρχικά χωρίς περιστροφή ε- ξηγούν το 88,46% της συνολικής διασποράς, διαφορά αρκετά σημαντική με το προηγούμενο μοντέλο που περιείχε και τις δύο επιπλέον μεταβλητές. Component Initial Eigenvalues Total Variance Explained Extraction Sums of Squared Loadings Total % of Variance Cumulative % Total % of Variance Cumulative % 1 3,0 3,00 3,00 3,0 3,00 3,00 1,865 18,65 50,67 1,865 18,65 50,67 3 1,76 17,6 67,934 1,76 17,6 67, ,01 10,1 78,146 1,01 10,1 78, ,010 10,099 88,46 1,010 10,099 88,46 6,949 9,493 97,739 7,154 1,545 99,83 8,07, , ,00E-016 4,00E , ,85E-016-1,85E ,000 Extraction Method: Principal Component Analysis. Πίνακας

131 Component Εφαρμόζοντας Παραγοντική Ανάλυση με περιστροφή Varimax προκύπτουν 5 παράγοντες οι οποίοι πάλι εξηγούν το 88,46% της συνολικής διασποράς (πίνακας 4.). Το ποσοστό αυτό είναι αρκετά ικανοποιητικό συγκριτικά και με το προηγούμενο μοντέλο αφού η απώλεια πληροφορίας που παρατηρείται δεν ξεπερνά το 1%. Total Total Variance Explained Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings % of Variance Cumulative % Total % of Variance Cumulative % Total % of Variance Cumulative % 1 3,0 3,00 3,00 3,0 3,00 3,00,60 6,198 6,198 1,865 18,65 50,67 1,865 18,65 50,67,310 3,098 49,96 3 1,76 17,6 67,934 1,76 17,6 67,934 1,86 18,6 67, ,01 10,1 78,146 1,01 10,1 78,146 1,018 10,178 78, ,010 10,099 88,46 1,010 10,099 88,46 1,015 10,149 88,46 6,949 9,493 97,739 7,154 1,545 99,83 8,07, , ,00E-016 4,00E , ,85E-016-1,85E ,000 Extraction Method: Principal Component Analysis. Πίνακας 4. Παρακάτω φαίνεται το αντίστοιχο scree plot (σχήμα 3.8) όπου και αυτήν τη φορά οι αποφάσεις για τους σημαντικότερους παράγοντες είναι ξεκάθαρες. Σχήμα
132 Στον πίνακα 4.3 φαίνονται τα φορτία των παραγόντων μετά την περιστροφή, τα οποία όπως έχει προαναφερθεί δείχνουν τον τρόπο με τον οποίο συσχετίζονται οι παράγοντες με τις μεταβλητές, δηλαδή ποιος παράγοντας συνεισφέρει περισσότερο στην ερμηνεία της κάθε μεταβλητής. Rotated Component Matrix(a) Component Duration -,03,05 -,150 -,551 -,443 Src_bytes -,01,08 -,085,840 -,190 Num_failed_logins -,014,010 -,059 -,089,884 Num_compromised -,05,978 -,00,01 -,006 Num_root,761,645 -,008 -,014 -,003 Num_file_creations,1,964 -,004 -,03 -,004 Num_shells,998,038 -,009,001 -,001 Num_access_files,998,038 -,009,001 -,001 Count -,011 -,016,957,001 -,005 Srv_count -,008 -,007,955 -,003 -,01 Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. a Rotation converged in 5 iterations. Πίνακας 4.3 Ο πίνακας 4.4 είναι ο πίνακας που χρησιμοποιήθηκε για την περιστροφή, δηλαδή αυτός με τον οποίο πολλαπλασιάστηκε ο αρχικός πίνακας των φορτιών προκειμένου να προκύψει ο τελικός πίνακας των φορτιών μετά την περιστροφή. Component Transformation Matrix Component ,777,68 -,049 -,009 -,009,166 -,18,977,016,0 3 -,608,767,05 -,00 -,09 4 -,006,06 -,0,813, ,013,019 -,004 -,581,813 Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. Πίνακας 4.4 Ο πίνακας 4.5 δίνει τους συντελεστές που χρησιμοποιούνται για τον υπολογισμό των σκορ από τις αρχικές μεταβλητές. Έτσι για παράδειγμα προκύπτει για τον πρώτο παράγοντα: Factor_1 = 0,00*Duration 0,009*Src_bytes *Count *Srv_count Factor_ = 0.017* Duration *Src_bytes *Count *Srv_count.. Factor_5 = 0,43*Duration 0.190*Src_bytes *Count 0.019*Srv_count 13
133 Component Score Coefficient Matrix Component Duration -,00,017 -,073 -,538 -,43 Src_bytes -,009,017 -,050,87 -,190 Num_failed_logins -,011,018 -,037 -,09,873 Num_compromised -,148,470,00,06,008 Num_root,34,07,007 -,008,003 Num_file_creations -,036,49,01 -,017,009 Num_shells,411 -,111 -,001,005 -,005 Num_access_files,411 -,111 -,001,005 -,005 Count,001,007,515 -,006 -,01 Srv_count,001,010,513 -,009 -,019 Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization. Component Scores. Πίνακας 4.5 Το factor loading plot (σχήμα 4.9), που έπεται του Component Score Coefficient Matrix (πίνακας 4.5), αποτελεί μια οπτική αναπαράσταση του περιστρεμμένου πίνακα παραγόντων. Σχήμα
134 Ως προς το δεύτερο μοντέλο έχουμε να κάνουμε τις εξής ακόλουθες παρατηρήσεις. Αν και έδωσε σαφώς καλύτερα αποτελέσματα από το αρχικό μοντέλο που περιείχε και τις 1 μεταβλητές, εντούτοις απέκλεισε 1 σημαντική παράμετρο: τη μεταβλητή Hot, η οποία αφορά στον αριθμό «θερμών» ενδείξεων για απειλητικές συμπεριφορές. Σαφώς, τα αποτελέσματα μιας τέτοιας έρευνας σχετικά με την α- νίχνευση εισβολών διαφοροποιούνται και εξαρτώνται σε μεγάλο βαθμό και από άλλους παράγοντες, οι οποίοι έχουν να κάνουν εκτός των άλλων και με τη συμπεριφορά των νόμιμων χρηστών και τους ποικίλους διαφορετικούς τύπους επιθέσεων. Επομένως, πιθανόν να είναι επιτακτική και η ενσωμάτωση και άλλων μεταβλητών (ίσως και περισσότερο σημαντικών) σε ένα τέτοιο μοντέλο ώστε να εξασφαλίζονται περισσότερο ακριβή, ικανοποιητικά και ρεαλιστικά αποτελέσματα. 4.4 Ανάλυση Διακρίσεων (Discriminant Analysis) Στους παράγοντες που προέκυψαν από το πρώτο προηγούμενο μοντέλο της α- νάλυσης παραγόντων θα εφαρμόσουμε στη συνέχεια την Ανάλυση Διακρίσεων. Επιθυμούμε να κατατάξουμε τις συνδέσεις σε δύο κατηγορίες, αυτές που είναι φυσιολογικές και αυτές που πιθανόν να εκφράζουν μια απειλητική συμπεριφορά. Οι κατηγορίες αυτές αντιστοιχούν στις τιμές 1 και αντίστοιχα της μεταβλητής group (η οποία προέκυψε από τη μεταβλητή attack). Σκοπός είναι ο διαχωρισμός των δύο αυτών ομάδων με βάση τους παραχθέντες παράγοντες του μοντέλου Ι. Η μεταβλητή διάκρισης θα είναι η group η οποία παίρνει τιμή 1 αν η σύνδεση είναι κανονική και την τιμή αν η σύνδεση αφορά σε κάποιον τύπο επίθεσης Ανάλυση Διακρίσεων Μοντέλο ΙΙΙ Αρχικά παίρνουμε κάποια στατιστικά μέτρα για τις δύο ομάδες στο πρώτο μοντέλο παραγόντων που προέκυψε από τις 1 αρχικές ποσοτικές μεταβλητές. Τα μέτρα αυτά φαίνονται στον πίνακα 4.6. Στο σχήμα 4.10 παρατηρούμε τα διαγράμματα διασποράς των 5 παραγόντων με τα σημεία που αντιστοιχούν στις διαφορετικές ομάδες χρωματισμένα διαφορετικά. Όπως είναι προφανές η διάκριση των δύο ομάδων δεν είναι εμφανής και υπάρχει επικάλυψη των ομάδων σε μεγάλο βαθμό. Αυτό φαίνεται άλλωστε και από τις μέσες τιμές των παραγόντων στον πίνακα 4.6. Μια σημαντική παρατήρηση που προκύπτει από τον ίδιο πίνακα είναι πως οι τυπικές αποκλίσεις των παραγόντων στην ομάδα attack δε διαφέρουν σημαντικά, σε αντίθεση με την ο- μάδα normal όπου υπάρχουν σημαντικές διαφορές. Όπως έχει αναφερθεί, στην Ανάλυση Διακρίσεων γίνεται η υπόθεση πως οι αντίστοιχοι πίνακες των πληθυσμών είναι ίσοι μεταξύ τους, υπόθεση που ελέγχεται στα πλαίσια του πίνακα 4.7. Οι τιμές log-determinants εκφράζουν τον όγκο του ελλειψοειδούς που περικλείει τα δεδομένα, μετρούν τη μεταβλητότητα των ομάδων και είναι ενδείξεις για πιθανή διαφορά των πινάκων συνδιασποράς ανάμεσα στις ομάδες. Μεγάλες διαφορές στις τιμές αυτές αποτελούν ένδειξη ότι οι ομάδες έχουν διαφορετικούς πίνακες συνδιασπορών. Συγκεκριμένα, παρατηρούμε ότι 134
135 υπάρχει μια μεγάλη διαφορά 56 μονάδων ανάμεσα στις δυο ομάδες ενώ το κοινό τμήμα διαφέρει 54 μονάδες από την πρώτη και από τη δεύτερη. Θεωρούμε ότι οι τιμές αυτές είναι αρκετά μεγάλες, οπότε και συμπεραίνουμε ότι οι δυο ομάδες είναι μεταβλητές και έχουν διαφορετικούς πίνακες διασπορών-συνδιασπορών. Ο στατιστικός έλεγχος Box s M ελέγχει την υπόθεση της ισότητας των συνδιασπορών μεταξύ των ομάδων. Ο έλεγχος αυτός έχει σημαντικότητα 0,000 οπότε συμπεραίνουμε πως οι πίνακες διασπορών συνδιασπορών διαφέρουν. Group Statistics Valid N (listwise) group Mean Std. Deviation Unweighted Weighted factor score 1 -, , ,000 normal attack Total factor score -, , ,000 factor score 3 -,764, ,000 factor score 4,130179, ,000 factor score 5,073584, ,000 factor score 1, , ,000 factor score, , ,000 factor score 3, , ,000 factor score 4 -, , ,000 factor score 5 -, , ,000 factor score 1, , ,000 factor score, , ,000 factor score 3, , ,000 factor score 4, , ,000 factor score 5, , ,000 Πίνακας 4.6 Log Determinants Log Determinant group Rank normal 5-54,30 attack 5,346 Pooled within-groups 5 -,043 The ranks and natural logarithms of determinants printed are those of the group covariance matrices. Test Results Box's M 6738,690 F Approx. 441,65 df1 15 df 35569,439 Sig.,000 Tests null hypothesis of equal population covariance matrices. Πίνακας

136 Σχήμα 4.10 Οι έλεγχοι της ισότητας των μέσων των ομάδων μετρούν την ικανότητα κάθε ανεξάρτητου παράγοντα πριν δημιουργηθεί το μοντέλο διάκρισης. Κάθε έλεγχος δείχνει τα αποτελέσματα ενός μονόδρομου ANOVA για την ανεξάρτητη μεταβλητή χρησιμοποιώντας τη μεταβλητή ομαδοποίησης ως παράγοντα. Εάν η τιμή σημαντικότητας είναι μεγαλύτερη από 0,10, η μεταβλητή πιθανόν να μη συνεισφέρει στο μοντέλο. Στην προκειμένη περίπτωση (πίνακας 4.8), τα αποτελέσματα των ελέγχων δεν είναι καθόλου καλά, αφού μόνο ένας παράγοντας στο μοντέλο διάκρισης είναι σημαντικός, ο παράγοντας 3 (γεγονός που υποστηρίζεται και παρακάτω με επιπλέον ελέγχους). Tests of Equality of Group Means Wilks' Lambda F df1 df Sig. factor score 1,999, ,49 factor score,994 1, ,174 factor score 3,965 11, ,001 factor score 4,989 3, ,05 factor score 5,996 1, ,7 Πίνακας
137 Ο πίνακας 4.9 παρουσιάζει κάποια μέτρα για τη συνάρτηση διάκρισης που χρησιμοποιείται στη διαδικασία της ανάλυσης διάκρισης. Αρχικά, το στατιστικό μέτρο Eigenvalue μετρά τη διασπορά των κέντρων των ομάδων και χρησιμοποιείται για περισσότερες ομάδες. Σε περίπτωση δύο ομάδων το στατιστικό μέτρο Canonical Correlation έχει σημασία. Εκφράζει τη συσχέτιση ανάμεσα στη νέα μεταβλητή που προκύπτει από τη συνάρτηση διάκρισης και στη μεταβλητή που περιέχει τις ομάδες. Στην προκειμένη περίπτωση, η τιμή είναι 0,38, όχι αρκετά κοντά στη μονάδα, οπότε και η συσχέτιση δεν είναι μεγάλη. Eigenvalues Function Eigenvalue % of Variance Cumulative % Canonical Correlation 1,060(a) 100,0 100,0,38 a First 1 canonical discriminant functions were used in the analysis. Πίνακας 4.9 Ο πίνακας 4.30 παρουσιάζει το στατιστικό μέτρο Wilks Lambda, το οποίο εκφράζει το ποσοστό της συνολικής διασποράς των τιμών της συνάρτησης που δεν ε- ξηγείται από τις διαφορές ανάμεσα στις ομάδες. Παρατηρούμε από τον πίνακα ότι η τιμή αυτή είναι ίση με που σημαίνει ότι το 94,3% της διασποράς δεν εξηγείται από τις διαφορές των ομάδων. Το μέτρο αυτό ελέγχει τη μηδενική υπόθεση ότι οι μέσες τιμές όλων των παραγόντων δε διαφέρουν ανάμεσα στις ομάδες. Ο έλεγχος της τιμής του γίνεται με ένα μετασχηματισμό του που ακολουθεί κατανομή chi-square και εδώ δίνει σημαντικότητα 0,00, πράγμα που σημαίνει πως δεν υπάρχει σημαντική διαφορά ανάμεσα στα κέντρα των συστάδων. Γενικά μικρές τιμές του μέτρου Wilks Lambda δείχνουν καλύτερη ικανότητα διάκρισης. Wilks' Lambda Wilks' Test of Function(s) Lambda Chi-square df Sig. 1,943 19,43 5,00 Πίνακας 4.30 Στον πίνακα 4.31 δίνονται σε κάθε στήλη οι συντελεστές της συνάρτησης κατάταξης για κάθε ομάδα ξεχωριστά. Classification Function Coefficients group normal attack factor score 1 -,049,03 factor score -,096,064 factor score 3 -,41,160 factor score 4,138 -,09 factor score 5,078 -,05 (Constant) -,738 -,713 Fisher's linear discriminant functions Πίνακας
138 Από τις δύο στήλες αυτές και από τις τιμές των παραγόντων προκύπτουν οι τιμές των συναρτήσεων μέσω των σχέσεων: Για την ομάδα Normal: y = 0,049*F1 0,096*F 0,41*F3 + 0,138*F4 + 0,078*F5 0,738 Για την ομάδα Attack: y = 0,03*F1 + 0,064*F + 0,160*F3 0,09*F4 0,05*F5 0,713 Η κατάταξη των ατόμων γίνεται σύμφωνα με τον εξής κανόνα: Ένα άτομο κατατάσσεται στην ομάδα στην οποία η τιμή της συνάρτησής της είναι μεγαλύτερη. Εναλλακτικά, από τις δύο παραπάνω εξισώσεις μπορούμε να υπολογίσουμε τη γραμμική συνάρτηση διάκρισης (Fisher s linear discriminant function) ως εξής: y = ( 0,049 0,03)*F1 + ( 0,096 0,064)*F + ( 0,41 0,160)*F3 + (0, ,09)*F4 + (0, ,05)*F5 + ( 0, ,713) Οι τιμές της συνάρτησης συγκρίνονται με το 0: Αν για κάποιο άτομο ισχύει y > 0, τότε κατατάσσεται στην 1η ομάδα ενώ αν y < 0, κατατάσσεται στη η. To SPSS υπολογίζει μια κανονικοποιημένη μεταβλητή (canonical variable) διάκρισης της οποίας οι συντελεστές δίνονται στο αριστερό πλαίσιο του πίνακα 4.3. Canonical Discriminant Function Coefficients Function 1 factor score 1,163 factor score,3 factor score 3,805 factor score 4 -,460 factor score 5 -,60 (Constant),000 Unstandardized coefficients Standardized Canonical Discriminant Function Coefficients Function 1 factor score 1,163 factor score,3 factor score 3,79 factor score 4 -,458 factor score 5 -,60 Πίνακας 4.3 Από αυτή προκύπτει η εξίσωση Score = 0,163*F1 + 0,3*F + 0,805*F3 0,460*F4 0,60*F5 138
139 η οποία έχει αντίστοιχη χρήση με την προηγούμενη. Στο δεξιό πλαίσιο του πίνακα 4.3 φαίνονται οι συντελεστές των παραγόντων μετά από τυποποίηση. Αυτό γίνεται για να μπορέσουμε να συγκρίνουμε ποια από τις δύο μεταβλητές έχει μεγαλύτερη επίδραση στο διαχωρισμό των ομάδων, κάτι που δεν μπορεί να γίνει με τις προηγούμενες εξισώσεις. Στο συγκεκριμένο παράδειγμα βλέπουμε ότι οι παράγοντες 3 και 4 έχουν μεγαλύτερο συντελεστή (σε απόλυτη τιμή) και επομένως φαίνεται να προσφέρουν περισσότερο στη διάκριση, και περισσότερο ο παράγοντας 3 (στο ίδιο συμπέρασμα θα καταλήξουμε και από επόμενο έλεγχο). Στον πίνακα 4.33 δίνονται οι συσχετίσεις των πέντε αρχικών παραγόντων με τη νέα μεταβλητή διάκρισης. Είναι ακόμα ένας τρόπος για να εξετάσουμε ποιος από τους παράγοντες είναι πιο χρήσιμος στη διάκριση των ομάδων. Εδώ και πάλι βλέπουμε ότι οι δύο πρώτοι παράγοντες (παράγοντες 3 και 4) έχουν μεγαλύτερη (απόλυτα) συσχέτιση. Structure Matrix Function 1 factor score 3,774 factor score 4 -,437 factor score,305 factor score 5 -,46 factor score 1,154 Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function. Πίνακας 4.33 Στον πίνακα 4.34 δίνονται οι μέσες τιμές της μεταβλητής διάκρισης για τις δύο ομάδες. Βλέπουμε και εδώ ότι οι τιμές της μεταβλητής συγκεντρώνονται γύρω από αρνητική τιμή στην πρώτη ομάδα ενώ γύρω από θετική τιμή στη δεύτερη ομάδα. Functions at Group Centroids Function group 1 normal -,99 attack,199 Unstandardized canonical discriminant functions evaluated at group means Πίνακας


140 Σχήμα 4.11 Classification Results(b,c) group Predicted Group Membership normal attack Total Original Count normal Στο σχήμα 4.11 δίνονται οι κατανομές της μεταβλητής διάκρισης στις δύο ομάδες με τη βοήθεια ιστογραμμάτων. Παρατηρούμε τη διαφορά στις δύο αυτές κατανομές. Crossvalidated(a) attack % normal 99,3,7 100,0 attack 67, 3,8 100,0 Count normal attack % normal 99,3,7 100,0 attack 68, 31,8 100,0 a Cross validation is done only for those cases in the analysis. In cross validation, each case is classified by the functions derived from all cases other than that case. b 59,4% of original grouped cases correctly classified. c 58,8% of cross-validated grouped cases correctly classified. Πίνακας 4.35 Ενδιαφέρον παρουσιάζει ο πίνακας 4.35, στον οποίο δίνονται τα αποτελέσματα της κατάταξης όλων των περιπτώσεων του δείγματος με βάση τη συνάρτηση διάκρισης που κατασκευάστηκε από την Ανάλυση Διακρίσεων. Δίνονται δύο διαφορετικά αποτελέσματα, το ένα είναι από τη συνάρτηση που προκύπτει από όλα τα δεδομένα και δοκιμάζεται επάνω τους με συνολικό ποσοστό σωστής κατάταξης 59,4% ενώ το δεύτερο αφορά Στη διαδικασία αποκλεισμού cross-validation, 140

141 κατά την οποία το SPSS κάθε φορά αφήνει εκτός των δεδομένων μία περίπτωση, κατασκευάζει μοντέλο διάκρισης με τις υπόλοιπες και την κατατάσσει. Το συνολικό ποσοστό των σωστών κατατάξεων σ αυτή την περίπτωση είναι 58,8% και είναι απαλλαγμένο από τη μεροληψία που έχει το προηγούμενο ποσοστό. Ενδιαφέρον παρουσιάζει και ολόκληρος ο πίνακας αυτός ο οποίος μας λέει για παράδειγμα ότι από τις συνδέσεις που στην πραγματικότητα είναι επιθέσεις, το 68,% κατατάσσεται εσφαλμένα στις κανονικές και επομένως μη ύποπτες συμπεριφορές, απόδοση επιεικώς απαράδεκτη. Τέλος, ακολουθεί το σχήμα 4.1, στο οποίο δίνονται τα διαγράμματα διασποράς των πέντε παραγόντων όπου τα σημεία έχουν χρωματιστεί όχι ανάλογα με την πραγματική τους ομάδα, αλλά ανάλογα με την ομάδα στην οποία κατατάχτηκαν (είτε σωστά είτε εσφαλμένα) από τη συνάρτηση διάκρισης. Σχήμα 4.1 Αφού στην ανάλυση που πραγματοποιήσαμε ο έλεγχος Box s M βρέθηκε σημαντικός (sig = 0,000), αξίζει να κάνουμε μια δεύτερη ανάλυση για να διαπιστώσουμε εάν η χρήση πίνακα συνδιασπορών ξεχωριστών ομάδων αλλάζει την κατηγοριοποίηση. 141
142 Οι διαφορές που παρατηρούνται αφορούν στις τιμές των log determinants και του ελέγχου Box s M, όπως φαίνεται και από τον πίνακα Log Determinants group Rank Log Determinant normal 1 -,976 attack 1,489 (identity matrix) 1,000 The ranks and natural logarithms of determinants printed are those of the group covariance matrices of the canonical discriminant functions. Test Results Box's M 97,955 F Approx. 97,308 df1 1 df 98176,698 Sig.,000 Tests null hypothesis of equal population covariance matrices of canonical discriminant function Πίνακας 4.36 Τέλος (πίνακας 4.37), ως προς τα αποτελέσματα της κατηγοριοποίησης παρατηρούμε πως το συνολικό ποσοστό ορθής κατάταξης είναι 58,%, μικρότερο μάλιστα από ό,τι στην προηγούμενη περίπτωση (59,4%). Επίσης, ας παρατηρήσουμε ότι και σε αυτήν την περίπτωση από τις συνδέσεις που στην πραγματικότητα είναι επιθέσεις, το 66,% κατατάσσεται εσφαλμένα στις κανονικές και επομένως μη ύποπτες συμπεριφορές, απόδοση κατά % καλύτερη σε σχέση με πριν (68,%), εντούτοις απαράδεκτη. Classification Results(a) group Predicted Group Membership normal attack Total normal Count attack Original normal 94,8 5, 100,0 % attack 66, 33,8 100,0 a 58,% of original grouped cases correctly classified. Πίνακας Ανάλυση Διακρίσεων Μοντέλο ΙV Εφαρμόζουμε ακριβώς την Ανάλυση Διακρίσεων για μοντέλο Ι που προέκυψε από την Ανάλυση Παραγόντων των 1 αρχικών ποσοτικών μεταβλητών αλλά λαμβάνοντας υπόψη και τις ποιοτικές μεταβλητές protocol_type_1, service_1 και logged_in. Στο σχήμα 4.13 παρατηρούμε τα διαγράμματα διασποράς των 8 μεταβλητών (5 παραγόντων και 3 μεταβλητών) με τα σημεία που αντιστοιχούν στις διαφορετικές ομάδες χρωματισμένα διαφορετικά. Όπως είναι προφανές η διάκριση των δύο ομάδων δεν είναι εμφανής και υπάρχει επικάλυψη των ομάδων σε μεγάλο βαθμό. Αυτό φαίνεται άλλωστε και από τις μέσες τιμές των παραγόντων στον πίνακα 14

143 4.38. Μια σημαντική παρατήρηση που προκύπτει από τον ίδιο πίνακα είναι πως οι τυπικές αποκλίσεις των παραγόντων στην ομάδα attack δε διαφέρουν στην πλειοψηφία τους σημαντικά, σε αντίθεση με την ομάδα normal όπου υπάρχουν μεγάλες διαφορές. Σχήμα 4.13 Στους πίνακες 4.39 και 4.40 βλέπουμε διάφορες πληροφορίες για τους πίνακες διασπορών-συνδιασπορών για κάθε ομάδα ξεχωριστά, για ολόκληρο το δείγμα και για τον κοινό (pooled) που υπολογίζεται για τις ανάγκες των κανόνων κατάταξης. 143
144 Group Statistics group Mean Std. Deviation normal attack Total Valid N (listwise) Unweighted Weighted Protocol_type_1 1,308955, ,000 Service_1,574669, ,000 Logged_in,649537, ,000 factor score 1 -, , ,000 factor score -, , ,000 factor score 3 -,764, ,000 factor score 4,130179, ,000 factor score 5,073584, ,000 Protocol_type_1 1,54886, ,000 Service_1 5, , ,000 Logged_in, , ,000 factor score 1, , ,000 factor score, , ,000 factor score 3, , ,000 factor score 4 -, , ,000 factor score 5 -, , ,000 Protocol_type_1 1, , ,000 Service_1 4, , ,000 Logged_in, , ,000 factor score 1, , ,000 factor score, , ,000 factor score 3, , ,000 factor score 4, , ,000 factor score 5, , ,000 Πίνακας 4.38 Pooled Within-Groups Matrices(a) Protocol_type_1 Service_1 Logge d_in factor score 1 factor score factor score 3 factor score 4 factor score 5 Covariance Protocol_type_1,41 -,506 -,13 -,013 -,084,67 -,034,09 Service_1 -,506 13,94 -,1,11 -,071 -,19 -,77,034 Logged_in -,13 -,1,155,030,17 -,09,097,007 factor score 1 -,013,11,030 1,00 -,003 -,007,004,00 factor score -,084 -,071,17 -,003,997 -,014,008,004 factor score 3,67 -,19 -,09 -,007 -,014,968,00,011 factor score 4 -,034 -,77,097,004,008,00,99 -,006 factor score 5,09,034,007,00,004,011 -,006,999 Correlation Protocol_type_1 1,000 -,11 -,486 -,00 -,13,4 -,053,045 Service_1 -,11 1,000 -,083,056 -,019 -,05 -,08,009 Logged_in -,486 -,083 1,000,076,33 -,074,47,017 factor score 1 -,00,056,076 1,000 -,003 -,007,004,00 factor score -,13 -,019,33 -,003 1,000 -,014,008,005 factor score 3,4 -,05 -,074 -,007 -,014 1,000,00,011 factor score 4 -,053 -,08,47,004,008,00 1,000 -,006 factor score 5,045,009,017,00,005,011 -,006 1,000 a The covariance matrix has 333 degrees of freedom. Πίνακας
145 group Protocol_type _1 Covariance Matrices(a) Logg ed_in factor score 1 factor score factor score 3 factor score 4 factor score 5 normal Protocol_type_1,35,0 -,10,010 -,031 -,005 -,073,00 Service_1,0 7,690 -,474,050 -,148 -,031 -,337,003 Logged_in -,10 -,474,9 -,011,034,006,080 -,00 factor score 1,010,050 -,011,006 -,018,003 -,043,001 factor score -,031 -,148,034 -,018,054 -,009,18 -,00 factor score 3 -,005 -,031,006,003 -,009,005 -,01,000 Service_1 factor score 4 -,073 -,337,080 -,043,18 -,01,304 -,004 factor score 5,00,003 -,00,001 -,00,000 -,004 6,51E- 005 attack Protocol_type_1,59 -,990 -,065 -,08 -,10,448 -,008,048 Service_1 -,990 18,100,111,318 -,00 -,99-1,061,054 Logged_in -,065,111,106,057,189 -,05,108,01 factor score 1 -,08,318,057 1,664,007 -,014,035,003 factor score -,10 -,00,189,007 1,65 -,017 -,07,009 factor score 3,448 -,99 -,05 -,014 -,017 1,609,047,019 factor score 4 -,008-1,061,108,035 -,07,047 1,449 -,008 factor score 5,048,054,01,003,009,019 -,008 1,664 Total Protocol_type_1,4 -,33 -,151 -,008 -,076,86 -,045,03 Service_1 -,33 16,708 -,558,74,054,10 -,948 -,067 Logged_in -,151 -,558,,00,107 -,077,14,0 factor score 1 -,008,74,00 1,000 -,11E- -,06E- -3,70E- -1,3E factor score -,076,054,107 -,11E-,19E- 1,3E- -,47E- 1, factor score 3,86,10 -,077 -,06E-,19E-,10E- -,5E- 1, factor score 4 -,045 -,948,14-3,70E- 1,3E-,10E- -1,3E- 1, factor score 5,03 -,067,0-1,3E- -,47E- -,5E- -1,3E ,000 a The total covariance matrix has 334 degrees of freedom. Πίνακας 4.40 Ως προς τον πίνακα 4.41, μεγάλες διαφορές στις τιμές των log determinants α- ποτελούν ένδειξη όπως είπαμε ότι οι ομάδες έχουν διαφορετικούς πίνακες συνδιασπορών. Ειδικότερα εδώ παρατηρούμε ότι υπάρχει μια μεγάλη διαφορά 58 μονάδων ανάμεσα στις δυο ομάδες ενώ το κοινό τμήμα διαφέρει 56 μονάδες από την πρώτη και από τη δεύτερη. Θεωρούμε ότι οι τιμές αυτές είναι αρκετά μεγάλες, οπότε και συμπεραίνουμε ότι οι δυο ομάδες είναι μεταβλητές και έχουν διαφορετικούς πίνακες διασπορών-συνδιασπορών. Ο στατιστικός έλεγχος Box s M ελέγχει την υπόθεση της ισότητας των συνδιασπορών μεταξύ των ομάδων. Ο έ- λεγχος αυτός έχει σημαντικότητα 0,000 οπότε συμπεραίνουμε πως οι πίνακες διασπορών συνδιασπορών διαφέρουν. 145
146 Log Determinants Log Determinant group Rank normal 8-57,96 attack 8 1,44 Pooled within-groups 8 -,99 The ranks and natural logarithms of determinants printed are those of the group covariance matrices. Test Results Box's M 7093,863 F Approx. 191,783 df1 36 df 75437,84 9 Sig.,000 Tests null hypothesis of equal population covariance matrices. Πίνακας 4.41 Οι έλεγχοι της ισότητας των μέσων των ομάδων μετρούν την ικανότητα κάθε ανεξάρτητου παράγοντα πριν δημιουργηθεί το μοντέλο διάκρισης. Εάν η τιμή σημαντικότητας είναι μεγαλύτερη από 0,10, η μεταβλητή πιθανόν να μη συνεισφέρει στο μοντέλο. Στην προκειμένη περίπτωση (πίνακας 4.4), τα αποτελέσματα των ελέγχων δίνουν 4 μεταβλητές ως σημαντικές στο μοντέλο διάκρισης, ο παράγοντας 3 και οι ποιοτικές μεταβλητές protocol_type_1, service_1 και logged_in. Η διαπίστωση αυτή ενισχύεται και παρακάτω με επιπλέον ελέγχους. Tests of Equality of Group Means Wilks' Lambda F df1 df Sig. Protocol_type_1,97 9, ,00 Service_1,83 67, ,000 Logged_in, , ,000 factor score 1,999, ,49 factor score,994 1, ,174 factor score 3,965 11, ,001 factor score 4,989 3, ,05 factor score 5,996 1, ,7 Πίνακας 4.4 Ο πίνακας 4.43 παρουσιάζει κάποια μέτρα για τη συνάρτηση διάκρισης που χρησιμοποιείται στη διαδικασία της ανάλυσης διάκρισης. Στην περίπτωση των δύο ομάδων το στατιστικό μέτρο Canonical Correlation εκφράζει τη συσχέτιση ανάμεσα στη νέα μεταβλητή που προκύπτει από τη συνάρτηση διάκρισης και στη μεταβλητή που περιέχει τις ομάδες. Στην προκειμένη περίπτωση, η τιμή είναι 0,660, κοντά στη μονάδα, οπότε και η συσχέτιση είναι μεγάλη. 146
147 Eigenvalues Function Eigenvalue % of Variance Cumulative % Canonical Correlation 1,770(a) 100,0 100,0,660 a First 1 canonical discriminant functions were used in the analysis. Πίνακας 4.43 Ο πίνακας 4.44 παρουσιάζει το στατιστικό μέτρο Wilks Lambda, το οποίο εκφράζει το ποσοστό της συνολικής διασποράς των τιμών της συνάρτησης που δεν ε- ξηγείται από τις διαφορές ανάμεσα στις ομάδες. Παρατηρούμε από τον πίνακα ότι η τιμή αυτή είναι ίση με που σημαίνει ότι το 56,5% της διασποράς δεν εξηγείται από τις διαφορές των ομάδων. Το μέτρο αυτό ελέγχει τη μηδενική υπόθεση ότι οι μέσες τιμές όλων των παραγόντων δε διαφέρουν ανάμεσα στις ομάδες και δίνει σημαντικότητα < 0,005, πράγμα που σημαίνει πως υπάρχει σημαντική διαφορά ανάμεσα στα κέντρα των ομάδων. Γενικά μικρές τιμές του μέτρου Wilks Lambda δείχνουν καλύτερη ικανότητα διάκρισης. Test of Function(s) Wilks' Lambda Wilks' Lambda Chi-square df Sig. 1, ,817 8,000 Πίνακας 4.44 Classification Function Coefficients group normal attack Protocol_type_1 8,743 8,045 Service_1,567,774 Logged_in 1,143 7,64 factor score 1 -,43 -,70 factor score -,887 -,198 factor score 3 -,177-1,681 factor score 4 -,64,079 factor score 5 -,55 -,341 (Constant) -11,410-9,537 Fisher's linear discriminant functions Πίνακας 4.45 Στον πίνακα 4.45 δίνονται σε κάθε στήλη οι συντελεστές της συνάρτησης κατάταξης για κάθε ομάδα ξεχωριστά. Από τις δύο στήλες αυτές και από τις τιμές των παραγόντων προκύπτουν οι τιμές των συναρτήσεων μέσω των σχέσεων: 147
148 Για την ομάδα Normal: y = 8,743*protocol_type_1 + 0,567*service_1 + 7,64*logged_in 0,43*F1 0,887*F,177*F3 0,64*F4 0,55*F5 11,410 Για την ομάδα Attack: y = 8,045*protocol_type_1 + 0,774*service_1 + 1,143*logged_in 0,70*F1 0,198*F 1,681*F3 + 0,079*F4 0,341*F5 9,537 Η κατάταξη των ατόμων γίνεται σύμφωνα με τον εξής κανόνα: Ένα άτομο κατατάσσεται στην ομάδα στην οποία η τιμή της συνάρτησής της είναι μεγαλύτερη. Εναλλακτικά, από τις δύο παραπάνω εξισώσεις μπορούμε να υπολογίσουμε τη γραμμική συνάρτηση διάκρισης (Fisher s linear discriminant function) ως εξής: y = (8,743 8,045)*protocol_type_1 + (0,567 0,774)*service_1 +( 7,64 1,143)*logged_in + ( 0,43 + 0,70)*F1 + ( 0, ,198)*F+ (, ,681)*F3 + ( 0,64 0,079)*F4+ ( 0,55 + 0,341)*F5 + ( 11, ,537) Οι τιμές της συνάρτησης συγκρίνονται με το 0: Αν για κάποιο άτομο ισχύει y > 0, τότε κατατάσσεται στην 1η ομάδα ενώ αν y < 0, κατατάσσεται στη η. To SPSS υπολογίζει μια κανονικοποιημένη μεταβλητή (canonical variable) διάκρισης της οποίας οι συντελεστές δίνονται στο αριστερό πλαίσιο του πίνακα Από αυτή προκύπτει η εξίσωση Score = 0,391*protocol_type_1 + 0,116*service_1,531*logged_in + 0,091*F1 + 0,386*F + 0,78*F3 + 0,19*F4 0,048*F5 + 0,0871 η οποία έχει αντίστοιχη χρήση με την προηγούμενη. Στο δεξιό πλαίσιο του πίνακα 4.46 φαίνονται οι συντελεστές των παραγόντων μετά από τυποποίηση. Αυτό γίνεται για να μπορέσουμε να συγκρίνουμε ποια από τις δύο μεταβλητές έχει μεγαλύτερη επίδραση στον διαχωρισμό των ομάδων, κάτι που δεν μπορεί να γίνει με τις προηγούμενες εξισώσεις. Στο συγκεκριμένο παράδειγμα βλέπουμε ότι οι μεταβλητές logged_in, service_1 και ο παράγοντας 3 έχουν μεγαλύτερο συντελεστή (σε απόλυτη τιμή) και επομένως φαίνεται να προσφέρουν περισσότερο στη διάκριση. Στον πίνακα 4.47 παρατηρούμε πως από τις μεταβλητές τις πιο χρήσιμες στη διάκριση των ομάδων κυριότερη είναι η logged_in, ενώ ο παράγοντας που βρέθηκε προηγουμένως σημαντικός έδωσε τη θέση του στον παράγοντα
149 Canonical Discriminant Function Coefficients Function 1 Protocol_type_1 -,391 Service_1,116 Logged_in -,531 factor score 1,091 factor score,386 factor score 3,78 factor score 4,19 factor score 5 -,048 (Constant),871 Unstandardized coefficients Standardized Canonical Discriminant Function Coefficients Function Protocol_type_1 -,51 Service_1,433 Logged_in -,997 factor score 1,091 factor score,385 factor score 3,73 factor score 4,191 factor score 5 -,048 1 Πίνακας 4.46 Structure Matrix Function Logged_in -,753 Service_1,51 factor score 3,16 Protocol_type_1,193 factor score 4 -,1 factor score,085 factor score 5 -,069 factor score 1,043 1 Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function. Πίνακας 4.47 Στον πίνακα 4.48 δίνονται οι μέσες τιμές της μεταβλητής διάκρισης για τις δύο ομάδες. Βλέπουμε και εδώ ότι οι τιμές της μεταβλητής συγκεντρώνονται γύρω από αρνητική τιμή στην πρώτη ομάδα ενώ γύρω από θετική τιμή στη δεύτερη ομάδα. Functions at Group Centroids Function group 1 normal -1,071 attack,714 Unstandardized canonical discriminant functions evaluated at group means Πίνακας 4.48 Το ενδιαφέρον μας εστιάζεται στον πίνακα 4.49, ο οποίος δίνει τα αποτελέσματα της κατάταξης όλων των περιπτώσεων του δείγματος με βάση τη συνάρτηση διάκρισης που κατασκευάστηκε από την Ανάλυση Διακρίσεων. Δίνονται δύο διαφορετικά αποτελέσμα- 149
150 τα, το ένα είναι από τη συνάρτηση που προκύπτει από όλα τα δεδομένα και δοκιμάζεται επάνω τους με συνολικό ποσοστό σωστής κατάταξης 79,4% ενώ στο δεύτερο, που α- φορά τη διαδικασία αποκλεισμού cross-validation, το συνολικό ποσοστό των σωστών κατατάξεων είναι 79,1% και είναι απαλλαγμένο από τη μεροληψία που έχει το προηγούμενο ποσοστό. Το σημαντικό σε αυτήν την περίπτωση είναι πως από τον πίνακα προκύπτει ότι από τις συνδέσεις που στην πραγματικότητα είναι επιθέσεις, μόνο το 11,4% κατατάσσεται εσφαλμένα στις κανονικές συμπεριφορές (σε σχέση με το 6,8% της προηγούμενης ανάλυσης), απόδοση ικανοποιητική. Classification Results(b,c) group Predicted Group Membership Total normal attack Original Count normal attack % normal 64,9 35,1 100,0 attack 10,9 89,1 100,0 Cross-validated(a) Count normal attack % normal 64,9 35,1 100,0 attack 11,4 88,6 100,0 a Cross validation is done only for those cases in the analysis. In cross validation, each case is classified by the functions derived from all cases other than that case. b 79,4% of original grouped cases correctly classified. c 79,1% of cross-validated grouped cases correctly classified. Πίνακας 4.49 Στο σχήμα 4.14 δίνονται οι κατανομές της μεταβλητής διάκρισης στις δύο ομάδες με τη βοήθεια ιστογραμμάτων. Παρατηρούμε τη διαφορά στις δύο αυτές κατανομές. Τέλος, ακολουθεί το σχήμα 4.15, στο οποίο δίνονται τα διαγράμματα διασποράς των οχτώ μεταβλητών όπου τα σημεία έχουν χρωματιστεί όχι ανάλογα με την πραγματική τους ομάδα, αλλά ανάλογα με την ομάδα στην οποία κατατάχτηκαν (είτε σωστά είτε ε- σφαλμένα) από τη συνάρτηση διάκρισης. 150

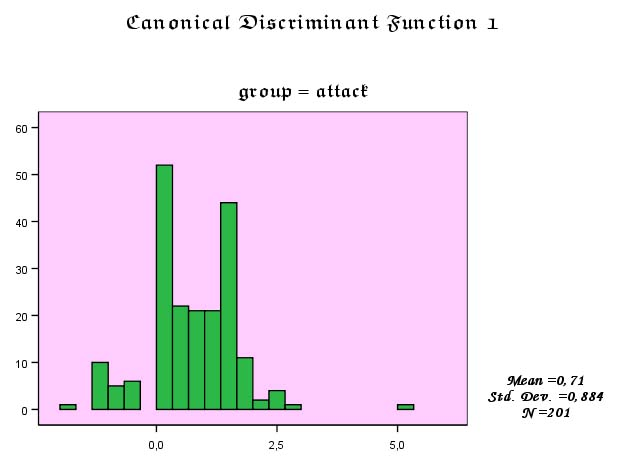
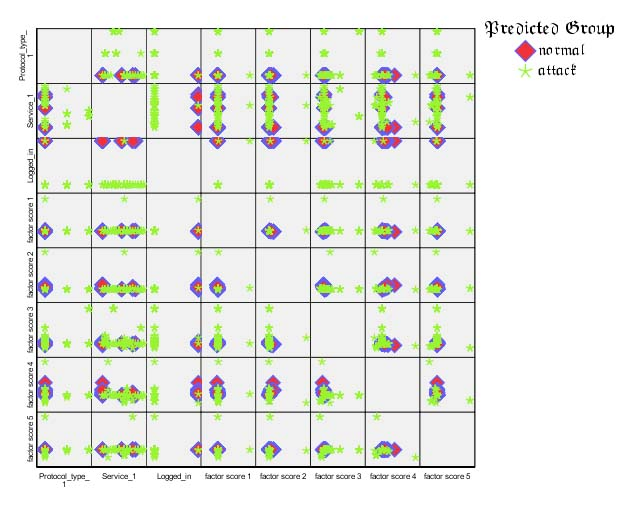
151 Σχήμα 4.14 Σχήμα
152 4.4.3 Ανάλυση Διακρίσεων Μοντέλο V Στο συγκεκριμένο μοντέλο θα ληφθούν ορισμένες από τις αρχικές μεταβλητές (ποσοτικές και ποιοτικές μαζί) για τη διάκριση της ομάδας στην οποία ανήκει καθεμιά από τις 335 περιπτώσεις. Εφαρμόζοντας αρχικά Ανάλυση Διακρίσεων χρησιμοποιώντας και τις 15 μεταβλητές προκύπτουν οι εξής πίνακες ( ). Log Determinants group Rank Log Determinant normal 8.(a) attack 13 54,033 Pooled within-groups 13 5,697 The ranks and natural logarithms of determinants printed are those of the group covariance matrices. a Singular Πίνακας 4.50 Test Results(a) Tests null hypothesis of equal population covariance matrices. a No test can be performed with fewer than two nonsingular group covariance matrices. Πίνακας 4.51 Variables Failing Tolerance Test(a) Within-Groups Minimum Variance Tolerance Tolerance Num_shells,003,000,000 Num_access_files,003,000,000 All variables passing the tolerance criteria are entered simultaneously. a Minimum tolerance level is,001. Πίνακας 4. Απομακρύνοντας αρχικά τις μεταβλητές Num_shells και Num_access_files δημιουργείται ξανά πρόβλημα στον υπολογισμό των log determinants της κατηγορίας normal και επομένως στον υπολογισμό του ελέγχου Box s M βάσει του οποίου προσδιορίζεται η ισότητα ή όχι των πινάκων διασπορών συνδιασπορών. Το πρόβλημα ξεπερνιέται α- πομακρύνοντας ταυτόχρονα και τις μεταβλητές Hot, Num_failed_logins, Num_compromised, Num_root, Num_file_creations. Εφαρμόζουμε Ανάλυση Διακρίσεων στις εναπομένουσες 8 μεταβλητές. 15

153 Στο σχήμα 4.16 παρατηρούμε τα διαγράμματα διασποράς των 8 μεταβλητών με τα σημεία που αντιστοιχούν στις διαφορετικές ομάδες χρωματισμένα διαφορετικά. Όπως και στις προηγούμενες περιπτώσεις, η διάκριση των δύο ομάδων δεν είναι εμφανής και υ- πάρχει επικάλυψη των ομάδων σε μεγάλο βαθμό. Αυτό προκύπτει άλλωστε και από τις μέσες τιμές των μεταβλητών στον πίνακα 4.53, που έχουν μεγάλες διαφορές. Επίσης στον ίδιο πίνακα φαίνεται πως οι τυπικές αποκλίσεις των παραγόντων στις ομάδες attack και normal διαφέρουν σημαντικά. Σχήμα
154 Group Statistics group Mean Std. Deviation normal attack Total Valid N (listwise) Unweighted Weighted Duration,1716 1, ,000 Protocol_type_1 1,309, ,000 Service_1,5746, ,000 Src_bytes 417, , ,000 Dst_bytes 3116, , ,000 Logged_in,6493, ,000 Count 5,1418 5, ,000 Srv_count 6,8881 7, ,000 Duration 791, , ,000 Protocol_type_1 1,543, ,000 Service_1 5,9900 4, ,000 Src_bytes 16699, , ,000 5 Dst_bytes 840, , ,000 Logged_in,1194, ,000 Count 63,49 146, ,000 Srv_count 39, , ,000 Duration 475, , ,000 Protocol_type_1 1,4537, ,000 Service_1 4,639 4, ,000 Src_bytes 10186, , ,000 5 Dst_bytes 1750, , ,000 Logged_in,3313, ,000 Count 40, , ,000 Srv_count 6, , ,000 Πίνακας 4.53 Στους πίνακες 4.54 και 4.55 βλέπουμε διάφορες πληροφορίες για τους πίνακες διασπορών-συνδιασπορών για κάθε ομάδα ξεχωριστά, για ολόκληρο το δείγμα και για τον κοινό (pooled) που υπολογίζεται για τις ανάγκες των κανόνων κατάταξης. 154
155 Covariance Matrices(a) group Duration Protocol_type_1 Service_1 Src_bytes Dst_bytes Logged_in Count Srv_count Total Duration ,119-07, , , ,79-146, , ,371 Protocol_type_1-07,890,4 -,33-455, ,474 -,151 5,159 31,587 Service_1 146,953 -,33 16, , ,866 -,558 49,799 1,769 Src_bytes , , , , , , , ,884 Dst_bytes ,79-764, , , , , , ,55 Logged_in -146,79 -,151 -, , ,530, -11,438-6,133 Count ,563 5,159 49, , ,994-11, , ,731 Srv_count ,371 31,587 1, , ,55-6, , ,06 a The total covariance matrix has 334 degrees of freedom. Πίνακας 4.54 Pooled Within-Groups Matrices(a) Duration Protocol_type _1 Service_1 Src_bytes Dst_bytes Logged_i n Count Srv_count Covariance Duration ,816-50, , , ,438-45, , ,475 Protocol_type_1-50,86,41 -, , ,101 -,13,10 9,965 Service_1 1500,65 -,506 13,94-38, ,101 -,1 1,889-4,710 Src_bytes , ,917-38, , , , , ,50 Dst_bytes -1807, , , , , , , ,10 Logged_in -45,906 -,13 -,1 636,39 748,457,155-4,016 -,043 Count -9806,004,10 1, , ,594-4, , ,954 Srv_count ,475 9,965-4, , ,10 -, , ,911 Correlation Duration 1,000 -,3,9 -,043 -,00 -,066 -,149 -,103 Protocol_type_1 -,3 1,000 -,11 -,110 -,190 -,486,303,465 Service_1,9 -,11 1,000 -,011 -,16 -,083,004 -,066 Src_bytes -,043 -,110 -,011 1,000,170,01 -,070 -,047 Dst_bytes -,00 -,190 -,16,170 1,000,358 -,05 -,03 Logged_in -,066 -,486 -,083,01,358 1,000 -,090 -,05 Count -,149,303,004 -,070 -,05 -,090 1,000,843 Srv_count -,103,465 -,066 -,047 -,03 -,05,843 1,000 a The covariance matrix has 333 degrees of freedom. Πίνακας 4.55 Ως προς τον πίνακα 4.56, μεγάλες διαφορές στις τιμές των log determinants αποτελούν ένδειξη πως οι ομάδες έχουν διαφορετικούς πίνακες συνδιασπορών. Ειδικότερα εδώ παρατηρούμε ότι υπάρχει μια μεγάλη διαφορά 36 μονάδων ανάμεσα στις δυο ομάδες ενώ το κοινό τμήμα διαφέρει 35 μονάδες από την πρώτη και 1 από τη δεύτερη. Θεωρούμε ότι οι τιμές αυτές είναι αρκετά μεγάλες, οπότε και συμπεραίνουμε ότι οι δυο ομάδες είναι μεταβλητές και έχουν διαφορετικούς πίνακες διασπορών-συνδιασπορών. Ο στατιστικός έλεγχος Box s M ελέγχει την υπόθεση της ισότητας των συνδιασπορών με- 155
156 ταξύ των ομάδων. Ο έλεγχος αυτός έχει σημαντικότητα 0,000 οπότε συμπεραίνουμε πως οι πίνακες διασπορών συνδιασπορών διαφέρουν. group Log Determinants Rank Log Determinant normal 8 35,87 attack 8 71,619 Pooled within-groups 8 70,780 The ranks and natural logarithms of determinants printed are those of the group covariance matrices. Test Results Box's M 4480,891 F Approx. 11,141 df1 36 df 75437,84 9 Sig.,000 Tests null hypothesis of equal population covariance matrices. Πίνακας 4.56 Οι έλεγχοι της ισότητας των μέσων των ομάδων μετρούν την ικανότητα κάθε ανεξάρτητου παράγοντα πριν δημιουργηθεί το μοντέλο διάκρισης. Εάν η τιμή σημαντικότητας είναι μεγαλύτερη από 0,10, η μεταβλητή πιθανόν να μη συνεισφέρει στο μοντέλο. Στην προκειμένη περίπτωση (πίνακας 4.57), τα αποτελέσματα των ελέγχων δίνουν 7 μεταβλητές ως σημαντικές στο μοντέλο διάκρισης και μία που πιθανόν δε συνεισφέρει στο μοντέλο, την Src_bytes. Η διαπίστωση αυτή ενισχύεται παρακάτω με επιπλέον ελέγχους. Tests of Equality of Group Means Wilks' Lambda F df1 df Sig. Duration,953 16, ,000 Protocol_type_1,97 9, ,00 Service_1,83 67, ,000 Src_bytes,989 3, ,059 Dst_bytes,957 14, ,000 Logged_in, , ,000 Count,940 1, ,000 Srv_count,976 8, ,004 Πίνακας 4.57 Στον πίνακα 4.58 παρουσιάζεται το στατιστικό μέτρο Canonical Correlation, το οποίο εκφράζει τη συσχέτιση ανάμεσα στη νέα μεταβλητή που προκύπτει από τη συνάρτηση διάκρισης και στη μεταβλητή που περιέχει τις ομάδες. Στην προκειμένη περίπτωση, η τιμή είναι 0,636, κοντά στη μονάδα, οπότε και η συσχέτιση είναι μεγάλη. 156
157 Eigenvalues Function Eigenvalue % of Variance Cumulative % Canonical Correlation 1,678(a) 100,0 100,0,636 a First 1 canonical discriminant functions were used in the analysis. Πίνακας 4.58 Στον πίνακα 4.59 φαίνεται το στατιστικό μέτρο Wilks Lambda, το οποίο εκφράζει το ποσοστό της συνολικής διασποράς των τιμών της συνάρτησης που δεν εξηγείται από τις διαφορές ανάμεσα στις ομάδες. Παρατηρούμε από τον πίνακα ότι η τιμή αυτή είναι ίση με που σημαίνει ότι το 59,6% της διασποράς δεν εξηγείται από τις διαφορές των ομάδων. Το μέτρο αυτό ελέγχει τη μηδενική υπόθεση ότι οι μέσες τιμές όλων των παραγόντων δε διαφέρουν ανάμεσα στις ομάδες και δίνει σημαντικότητα < 0,005, πράγμα που σημαίνει πως υπάρχει σημαντική διαφορά ανάμεσα στα κέντρα των ομάδων. Wilks' Lambda Test of Function(s) Wilks' Lambda Chi-square df Sig. 1, ,389 8,000 Πίνακας 4.59 Classification Function Coefficients group normal attack Duration,001,001 Protocol_type_1 10,604 10,19 Service_1,54,717 Src_bytes 8,40E-006 1,16E-005 Dst_bytes 5,15E-005 7,60E-005 Logged_in 1,949 9,403 Count,05,09 Srv_count -,049 -,048 (Constant) -1,55-11,745 Fisher's linear discriminant functions Πίνακας 4.60 Στον πίνακα 4.60 δίνονται σε κάθε στήλη οι συντελεστές της συνάρτησης κατάταξης για κάθε ομάδα ξεχωριστά. Από τις δύο στήλες αυτές και από τις τιμές των παραγόντων προκύπτουν οι τιμές των συναρτήσεων μέσω των σχέσεων: 157
158 Για την ομάδα Normal: y = 0,001*duration + 10,604*protocol_type_1 + 0,54*service_1 + 8,40E-006*Src_bytes + 5,15E-005*Dst_bytes + 1,949*logged_in + 0,05*count 0,049*Srv_count 1,55 Για την ομάδα Attack: y = 0,001*duration + 10,19*protocol_type_1 + 0,717*service_1 + 1,16E-005*Src_bytes + 7,60E-005*Dst_bytes + 9,403*logged_in + 0,09*count 0,048*Srv_count 11,745 Η κατάταξη των ατόμων γίνεται σύμφωνα με τον εξής κανόνα: Ένα άτομο κατατάσσεται στην ομάδα στην οποία η τιμή της συνάρτησής της είναι μεγαλύτερη. Εναλλακτικά, από τις δύο παραπάνω εξισώσεις μπορούμε να υπολογίσουμε τη γραμμική συνάρτηση διάκρισης (Fisher s linear discriminant function) ως εξής: y = (0,001 0,001*)duration + (10,604 10,19)*protocol_type_1 + (0,54 0,717)*service_1 + ( 8,40E-006 1,16E-005)*Src_bytes + (5,15E-005 7,60E- 005)*Dst_bytes + (1,949 9,403)* logged_in + (0,05 0,09)*count + ( 0, ,048)*Srv_count + ( 11, ,537) Οι τιμές της συνάρτησης συγκρίνονται με το 0: Αν για κάποιο άτομο ισχύει y > 0, τότε κατατάσσεται στην 1η ομάδα ενώ αν y < 0, κατατάσσεται στη η. To SPSS υπολογίζει μια κανονικοποιημένη μεταβλητή (canonical variable) διάκρισης της οποίας οι συντελεστές δίνονται στο αριστερό πλαίσιο του πίνακα Από αυτή προκύπτει η εξίσωση Score = 0,000*duration 0,9*protocol_type_1 + 0,115*service_1 + 0,000*Src_bytes + 0,000*Dst_bytes,116*logged_in + 0,003*count + 0,000*Srv_count + 0,314 η οποία έχει αντίστοιχη χρήση με την προηγούμενη. Μάλιστα παρατηρούμε πως στον υπολογισμό του Score οι μεταβλητές duration, Src_bytes, Dst_bytes και Srv_count δε συμμετέχουν καθόλου. Στο δεξιό πλαίσιο του πίνακα 4.61 φαίνονται οι συντελεστές των παραγόντων μετά από τυποποίηση. Αυτό γίνεται για να μπορέσουμε να συγκρίνουμε ποια από τις δύο μεταβλητές έχει μεγαλύτερη επίδραση στον διαχωρισμό των ομάδων, κάτι που δεν μπορεί να γίνει με τις προηγούμενες εξισώσεις. Στο συγκεκριμένο παράδειγμα βλέπουμε ότι οι μεταβλητές logged_in και service_1 έχουν μεγαλύτερο συντελε- 158
159 στή (κατ απόλυτη τιμή) και επομένως φαίνεται να προσφέρουν περισσότερο στη διάκριση. Αυτό φαίνεται και στον ακόλουθο πίνακα 4.6, όπου οι δύο πρώτες μεταβλητές είναι αυτές είναι πιο χρήσιμες στη διάκριση των ομάδων, με κυριότερη τη μεταβλητή logged_in. Canonical Discriminant Function Coefficients Function 1 Duration,000 Protocol_type_1 -,9 Service_1,115 Src_bytes,000 Dst_bytes,000 Logged_in -,116 Count,003 Srv_count,000 (Constant),314 Unstandardized coefficients Standardized Canonical Discriminant Function Coefficients Function Duration,136 Protocol_type_1 -,147 Service_1,49 Src_bytes,146 Dst_bytes,078 Logged_in -,833 Count,85 Srv_count,08 1 Πίνακας 4.61 Structure Matrix Function Logged_in -,803 Service_1,546 Count,306 Duration,69 Dst_bytes -,56 Protocol_type_1,06 Srv_count,191 Src_bytes,16 Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function. Πίνακας 4.6 Στον πίνακα 4.63 δίνονται οι μέσες τιμές της μεταβλητής διάκρισης για τις δύο ομάδες. Βλέπουμε και εδώ ότι οι τιμές της μεταβλητής συγκεντρώνονται γύρω από αρνητική τιμή στην ομάδα normal ενώ γύρω από θετική τιμή στην ομάδα attack. Functions at Group Centroids Function group 1 normal -1,006 attack,671 Unstandardized canonical discriminant functions evaluated at group means Πίνακας
160 Ο σημαντικότερος πίνακας είναι ο πίνακας 4.64 στον οποίο φαίνονται τα αποτελέσματα της κατάταξης όλων των περιπτώσεων του δείγματος με βάση τη συνάρτηση διάκρισης που κατασκευάστηκε από την Ανάλυση Διακρίσεων. Δίνονται δύο ίδια αποτελέσματα, το ένα είναι από τη συνάρτηση που προκύπτει από όλα τα δεδομένα και δοκιμάζεται επάνω τους με συνολικό ποσοστό σωστής κατάταξης 78,8% και στο δεύτερο, που αφορά τη διαδικασία αποκλεισμού cross-validation, το συνολικό ποσοστό των σωστών κατατάξεων παραμένει 78,8% (αν και είναι απαλλαγμένο από τη μεροληψία που έχει το προηγούμενο ποσοστό). Το σημαντικό σε αυτήν την περίπτωση είναι πως από τον πίνακα προκύπτει ότι από τις συνδέσεις που στην πραγματικότητα είναι επιθέσεις, μόνο το 11,9% κατατάσσεται εσφαλμένα στις κανονικές συμπεριφορές (σε σχέση με το 6,8% της πρώτης ανάλυσης). Η απόδοση της διάκρισης κρίνεται ικανοποιητική και είναι σχεδόν ίδια με εκείνη του αμέσως προηγούμενου μοντέλου (79,4%), που περιείχε τους παράγοντες και τις ποιοτικές μεταβλητές. Total normal attack Original Count normal attack Classification Results(b,c) Predicted Group Membership group Crossvalidated(a) % normal 64,9 35,1 100,0 Count attack 11,9 88,1 100,0 normal attack % normal 64,9 35,1 100,0 attack 11,9 88,1 100,0 a Cross validation is done only for those cases in the analysis. In cross validation, each case is classified by the functions derived from all cases other than that case. b 78,8% of original grouped cases correctly classified. c 78,8% of cross-validated grouped cases correctly classified. Πίνακας 4.64 Στο σχήμα 4.17 δίνονται οι κατανομές της μεταβλητής διάκρισης στις δύο ομάδες με τη βοήθεια ιστογραμμάτων. Παρατηρούμε ότι υπάρχει διαφορά στις δύο αυτές κατανομές. 160


 από τη")
161 Σχήμα 4.17 Τέλος, ακολουθεί το σχήμα 4.18, στο οποίο δίνονται τα διαγράμματα διασποράς των οχτώ μεταβλητών όπου τα σημεία έχουν χρωματιστεί όχι ανάλογα με την πραγματική τους ομάδα, αλλά ανάλογα με την ομάδα στην οποία κατατάχτηκαν (είτε σωστά είτε ε- σφαλμένα) από τη συνάρτηση διάκρισης. Σχήμα
162 4.5 Λογαριθμική Παλινδρόμηση (Logistic Regression) Λογαριθμική Παλινδρόμηση Μοντέλο VΙ Θεωρούμε πως η τιμή της εξαρτημένης μεταβλητής είναι η απάντηση στην ερώτηση: «Είναι η συγκεκριμένη σύνδεση ενδεικτική κακόβουλης συμπεριφοράς επίθεσης;». Η δημιουργία του μοντέλου λογαριθμικής παλινδρόμησης βασίζεται αρχικά σε ένα απλό υπόδειγμα που περιλαμβάνει μόνο το σταθερό όρο και στη συνέχεια εισάγονται μία μία οι ανεξάρτητες μεταβλητές με τη μέθοδο Forward (LR). Εφαρμόζουμε κατ επέκταση τη λογαριθμική παλινδρόμηση με τη συγκεκριμένη μέθοδο. Case Processing Summary Unweighted Cases(a) N Percent Selected Cases Included in Analysis ,0 Missing Cases 0,0 Total ,0 Unselected Cases 0,0 Total ,0 a If weight is in effect, see classification table for the total number of cases. Πίνακας 4.65 Στον πίνακα 4.65 δίνεται ο αριθμός των έγκυρων παρατηρήσεων της ανάλυσης, καθώς και ο αριθμός των παρατηρήσεων με missing values. Στην προκειμένη περίπτωση, τέτοιες παρατηρήσεις δεν υφίστανται (με missing values). Στον επόμενο πίνακα 4.66 δίνεται η εσωτερική κωδικοποίηση των κατηγοριών της εξαρτημένης μεταβλητής κατά την ανάλυση. Ο μικρότερος κωδικός της εξαρτημένης μεταβλητής επανακωδικοποιείται ε- σωτερικά με την τιμή 0 ενώ ο μεγαλύτερος με την τιμή 1 (με την τιμή που δηλώνει την πραγματοποίηση του γεγονότος). Εδώ, η πραγματοποίηση του γεγονότος (δηλαδή η απάντηση ΝΑΙ στην ερώτηση) είναι κωδικοποιημένη στο αρχείο των δεδομένων με την τιμή, επομένως επανακωδικοποιείται με την τιμή 1. Αντίστοιχα η μη πραγματοποίηση του γεγονότος (η απάντηση ΟΧΙ στην ερώτηση) επανακωδικοποιείται με την τιμή 0. Dependent Variable Encoding Original Value Internal Value normal 0 attack 1 Πίνακας 4.66 Αφού οι μεταβλητές service_1, protocol_type_1 και logged_in είναι κατηγορικές, πρέπει να επανακωδικοποιηθούν κατάλληλα για να εισαχθούν στο υπόδειγμα (πίνακας 4.67). Το σχήμα κωδικοποίησης που θα χρησιμοποιήσουμε είναι το indicator (default επιλογή) και ως κατηγορία αναφοράς επιλέγουμε first. Με την κωδικοποίηση αυτή, ως κατηγορία αναφοράς των κατηγορικών μεταβλητών χρησιμοποιείται η κατηγορία με το μικρότερο αριθμό. Οι τρεις πίνακες υπό τον τίτλο «Block 0: Beginning Block» (συγκεντρωτικός πίνακας 4.68) δεν έχουν ιδιαίτερο ενδιαφέρον διότι αφορούν το αρχικό υπόδειγμα της ανάλυσης, το οποίο αποτελείται μόνο από το σταθερό όρο χωρίς άλλη ανεξάρτητη μεταβλητή στην εξίσωση της παλινδρόμησης. 16
163 Frequency Categorical Variables Codings Parameter coding (1) () (3) (4) (5) (6) (7) (8) (9) (10) (11) (1) (13) (14) (15) Service_1 http 90 1,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 private 105,000 1,000,000,000,000,000,000,000,000,000,000,000,000,000,000 X11,000,000 1,000,000,000,000,000,000,000,000,000,000,000,000,000 auth 1,000,000,000 1,000,000,000,000,000,000,000,000,000,000,000,000 ecr_i 15,000,000,000,000 1,000,000,000,000,000,000,000,000,000,000,000 domain_u 1,000,000,000,000,000 1,000,000,000,000,000,000,000,000,000,000 eco_i 14,000,000,000,000,000,000 1,000,000,000,000,000,000,000,000,000 smtp 9,000,000,000,000,000,000,000 1,000,000,000,000,000,000,000,000 telnet 40,000,000,000,000,000,000,000,000 1,000,000,000,000,000,000,000 ftp_data 16,000,000,000,000,000,000,000,000,000 1,000,000,000,000,000,000 finger 6,000,000,000,000,000,000,000,000,000,000 1,000,000,000,000,000 ftp 9,000,000,000,000,000,000,000,000,000,000,000 1,000,000,000,000 pop_3 6,000,000,000,000,000,000,000,000,000,000,000,000 1,000,000,000 sunrpc,000,000,000,000,000,000,000,000,000,000,000,000,000 1,000,000 other 6,000,000,000,000,000,000,000,000,000,000,000,000,000,000 1,000 imap,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 Protocol_type_1 tcp 1 1,000,000 udp 94,000 1,000 icm 9,000,000 Logged_in 0 4 1, ,000 Πίνακας 4.67 Block 0: Beginning Block Classification Table(a,b) Predicted group Percentage Correct Observed normal attack Step 0 group normal 0 134,0 attack ,0 Overall Percentage 60,0 a Constant is included in the model. b The cut value is,500 Variables in the Equation B S.E. Wald df Sig. Exp(B) Step 0 Constant,405,11 13,18 1,000 1,
164 Variables not in the Equation(a) Score df Sig. Step 0 Variables Duration 15,703 1,000 Protocol_type_1 17,675,000 Protocol_type_1(1),775 1,096 Protocol_type_1(),71 1,399 Service_1 179,976 15,000 Service_1(1) 106,413 1,000 Service_1() 9,768 1,00 Service_1(3) 1,341 1,47 Service_1(4) 1,504 1,0 Service_1(5) 7,70 1,007 Service_1(6) 18,669 1,000 Service_1(7) 9,740 1,00 Service_1(8) 13,873 1,000 Service_1(9) 30,8 1,000 Service_1(10) 3,161 1,075 Service_1(11) 4,073 1,044 Service_1(1) 3,16 1,073 Service_1(13) 4,073 1,044 Service_1(14) 1,341 1,47 Service_1(15) 1,386 1,39 Src_bytes 3,573 1,059 Dst_bytes 14,53 1,000 Hot 1,498 1,000 Num_failed_logins 1,341 1,47 Logged_in(1) 101,878 1,000 Num_compromised,958 1,085 Num_root 1,35 1,50 Num_file_creations,985 1,31 Num_shells,669 1,414 Num_access_files,669 1,414 Count 19,986 1,000 Srv_count 8,076 1,004 a Residual Chi-Squares are not computed because of redundancies. Πίνακας 4.68 Για το συγκεκριμένο υπόδειγμα, δίνεται ο πίνακας ταξινόμησης (Classification Table), η τιμή του σταθερού όρου και οι αντίστοιχοι έλεγχοι επ αυτού (Variables in the Equation), καθώς και η αξιολόγηση των μεταβλητών που δεν έχουν εισέλθει ακόμη στο υπόδειγμα (Variables not in the Equation). Δηλαδή η σημαντικότητα καθεμιάς από τις ανεξάρτητες μεταβλητές αν έμπαινε μόνη της στο υ- πόδειγμα μαζί με το σταθερό όρο. Το κριτήριο με βάση το οποίο γίνεται ο έλεγχος (Score) δίνει με αδρό τρόπο τη βαρύτητα κάθε ανεξάρτητης μεταβλητής στην πρόγνωση των τιμών της εξαρτημένης μεταβλητής. Σε κάθε βήμα, η μεταβλητή με τη μεγαλύτερη τιμή Score, της οποίας το Sig είναι μικρότερο από μια συγκεκριμένη τιμή προστίθεται στο μοντέλο. Από μια πρώτη ματιά στις τιμές του Score αλλά και των αντίστοιχων πιθανοτήτων (Sig), προκύπτει ότι μεγαλύτερη βαρύτη- 164
165 τα στην πρόγνωση της εξαρτημένης μεταβλητής έχουν οι μεταβλητές που είναι υπογραμμισμένες με γαλάζιο χρώμα με επίπεδα σημαντικότητας <0,0005 και υψηλές τιμές Score, χωρίς αυτό βέβαια να είναι απολύτως βέβαιο. Οι μεταβλητές που μένουν εκτός της ανάλυσης στο τελευταίο βήμα έχουν όλες υψηλά επίπεδα σημαντικότητας, οπότε δεν προστίθενται άλλες στο μοντέλο. Στη συνέχεια, οι επόμενοι πίνακες αφορούν τη μορφή του τελικού υποδείγματος, καθώς και την αξιολόγησή του. Εφόσον χρησιμοποιήθηκε ως μέθοδος κατά την ανάλυση η Forward Stepwise, οι μεταβλητές εισάγονται μία μία με τη σειρά. Step 1 Step Step 3 Step 4 Step 5 Step 6(a) Omnibus Tests of Model Coefficients Chi-square df Sig. Step 18,354 15,000 Block 18,354 15,000 Model 18,354 15,000 Step 48,744 1,000 Block 67,098 16,000 Model 67,098 16,000 Step 15,43 1,000 Block 8,51 17,000 Model 8,51 17,000 Step 4,768 1,000 Block 307,89 18,000 Model 307,89 18,000 Step 5,78 1,017 Block 313,017 19,000 Model 313,017 19,000 Step, ,000 Block 313,017 18,000 Model 313,017 18,000 Πίνακας 4.69 Η αξιολόγηση της προσαρμογής του υποδείγματος στα δειγματικά δεδομένα γίνεται με το λόγο των μέγιστων τιμών της συνάρτησης πιθανοφάνειας για το πλήρες υπόδειγμα και για το υπόδειγμα που περιλαμβάνει μόνο το σταθερό όρο. Η τιμή του λόγου είναι 313,017 (Model Chi-Square) ενώ η πιθανότητα να προκύψει μια τιμή τόσο μεγάλη είναι Sig<0,0005 (πίνακας 4.69). Επομένως μπορούμε να θεωρήσουμε πως οι ανεξάρτητες μεταβλητές συνδυαζόμενες μεταξύ τους με τη μορφή του λογαριθμικού υποδείγματος συμβάλλουν σημαντικά στην πρόγνωση των τιμών της εξαρτημένης μεταβλητής. Το στατιστικό μέτρο Hosmer-Lemeshow που φαίνεται στον πίνακα 4.70 αποτελεί ένδειξη κακής προσαρμογής αν το επίπεδο σημαντικότητας είναι μικρότερο από 0,05. Εδώ, το μοντέλο είναι καλό και προσαρμόζεται επαρκώς στα δεδομένα, αφού sig = 0,903 > 0,
166 Hosmer and Lemeshow Test Step Chi-square df Sig. 1, ,000, ,000 3, , ,460 7, ,454 8, ,454 8,903 Πίνακας 4.70 Step 1 Step Step 3 Step 4 Step 5 Contingency Table for Hosmer and Lemeshow Test group = normal group = attack Observed Expected Observed Expected Total 1,000 0, , , , , , , , , , , ,000 0, , , , , , , , , , , , , ,000 0, , , , , , , , , , , , , ,903 0, ,641 1, , , , , ,13 3 5, , , , , , , , , ,903 0, ,641 1, , , , ,


167 Step ,13 3 5, , , , , , , , , , , ,903 0, ,641 1, , , , , ,13 3 5, , , , , , , , , , ,000 6 Πίνακας 4.71 Αυτός ο στατιστικός έλεγχος είναι ο πιο αξιόπιστος για προσαρμογή μοντέλου στην δυαδική λογαριθμική παλινδρόμηση, επειδή συγκεντρώνει τις παρατηρήσεις σε ομάδες «παρόμοιων» περιπτώσεων. Ο έλεγχος γίνεται έπειτα βάσει αυτών των ομάδων. Η μεταβολή στην απόκλιση μπορεί να υπολογιστεί με τετραγωνισμό των studentized καταλοίπων. Στο σχήμα 4.19 φαίνεται η γραφική παράσταση των καταλοίπων. Η μεταβολή στο διάγραμμα αποκλίσεων μας βοηθά να αναγνωρίσουμε περιπτώσεις που δεν ταιριάζουν στο μοντέλο. Μεγάλες μεταβολές στην απόκλιση αποτελούν ένδειξη κακής προσαρμογής. Σχήμα 4.19 Σχήμα
168 Το σχήμα του διαγράμματος των αποστάσεων Cook (σχήμα 4.0) γενικά ακολουθεί τη μορφή του προηγούμενου σχήματος, με κάποιες μικρές εξαιρέσεις, οι οποίες αφορούν σε σημεία υψηλής επιρροής. Καλό είναι να εντοπίζεται ποιες περιπτώσεις αντιστοιχούν σε αυτά τα σημεία (εάν υπάρχουν) για περαιτέρω ανάλυση. Οι μεταβλητές που επιλέγονται με τη μέθοδο forward stepwise όλες πρέπει να έχουν σημαντικές μεταβολές στη λογαριθμο-πιθανοφάνεια. Η αλλαγή στη λογαριθμο-πιθανοφάνεια γενικά είναι περισσότερη αξιόπιστη από το στατιστικό μέτρο Wald. Εάν υπάρχει διαφορά ανάμεσα στα δύο μέτρα για τη χρησιμότητα μιας μεταβλητής στο μοντέλο, καλό είναι να εμπιστευόμαστε την αλλαγή στη λογαριθμοπιθανοφάνεια. Στους πίνακες 4.7 και 4.73 φαίνονται τα δύο αυτά στατιστικά μέτρα. Επίσης στον πίνακα 4.73 φαίνονται και ποιες είναι τελικά οι μεταβλητές που συμπεριλήφθησαν στο μοντέλο που παράχθηκε. Ο πίνακας 4.73 είναι σημαντικός γιατί μας δίνει τους συντελεστές του τελικού υ- ποδείγματος μαζί με τους αντίστοιχους επαγωγικούς ελέγχους και τα διαστήματα εμπιστοσύνης αυτών. Σε αυτόν φαίνονται τα στοιχεία που αφορούν μόνο στο τελευταίο βήμα. Ολόκληρος ο πίνακας δίνεται στο Παράρτημα Β. Στον πίνακα 4.73 ο λόγος των συντελεστών (Β) προς το τυπικό του σφάλμα, υψωμένος στο τετράγωνο ισούται με το στατιστικό μέτρο Wald. Εάν το επίπεδο σημαντικότητας του στατιστικού Wald είναι χαμηλό ή αλλιώς όσο πιο υψηλή είναι η τιμή του μέτρου τότε η παράμετρος είναι χρήσιμη στο μοντέλο. Με βάση το συγκεκριμένο κριτήριο, σημαντική επίδραση στον χαρακτηρισμό μιας σύνδεσης ως επίθεσης έ- χουν οι μεταβλητές service_1 και count. Οι προβλέψεις γίνονται με βάση τις μεταβλητές και τους συντελεστές του τελευταίου βήματος. Η στήλη Exp(B) δίνει τους λόγους των σχετικών πιθανοτήτων επιτυχίας. Model if Term Removed Variable Model Log Likelihood Change in - Log Likelihood df Sig. of the Change Step 1 Service_1-5,459 18,354 15,000 Step Service_1-19,716 55,61 15,000 Num_compromised -116,8 48,744 1,000 Step 3 Step 4 Step 5 Service_1-153,71 139,08 15,000 Logged_in -91,910 15,43 1,000 Num_compromised -11,004 55,611 1,000 Service_1-144,61 144,893 15,000 Logged_in -79,446 15,63 1,000 Num_compromised -101,59 58,890 1,000 Count -84,198 4,768 1,000 Service_1-16,97 115,953 15,000 Hot -71,814 5,78 1,017 Logged_in -78,1 18,541 1,000 Num_compromised -68,950, ,000 Count -81,37 4,754 1,
169 Step 6 Service_1-16,97 115,953 15,000 Hot -101,59 64,618 1,000 Logged_in -78,1 18,541 1,000 Count -81,37 4,754 1,000 Step 6(e) Πίνακας 4.7 Variables in the Equation B S.E. Wald df Sig. Exp(B) Service_1 1, ,000 95,0% C.I.for EXP(B) Lower Upper Service_1(1) 9, ,136, , ,967,000. Service_1() -0, ,690,000 1,999,000,000. Service_1(3), ,948, ,000 1,051,000. Service_1(4) -4, ,116,000 1,999,000,000. Service_1(5) -3,47 841,416,000 1,999,000,000. Service_1(6) -4, ,566,000 1,999,000,000. Service_1(7), ,000, ,000 1,051,000. Service_1(8) -7,96 333,564, ,000,001,000. Service_1(9) 3, ,084, ,000 6,038,000. Service_1(10) -19, ,690,000 1,999,000,000. Service_1(11) -1, ,57, ,000,65,000. Service_1(1) -3, ,480, ,000,035,000. Service_1(13) 34, ,375,000 1, ,000,000. Service_1(14), ,948, ,000 1,051,000. Service_1(15) -1, ,690,000 1,999,000,000. Hot 7, ,43,000 1, ,338,000. Logged_in(1) 35, ,439,000 1, ,000,000. Count,050,036 1,87 1,171 1,051,979 1,18 Constant -13, ,136, ,000,000 a Variable(s) entered on step 1: Service_1. b Variable(s) entered on step : Num_compromised. c Variable(s) entered on step 3: Logged_in. d Variable(s) entered on step 4: Count. e Variable(s) entered on step 5: Hot. Πίνακας 4.73 Μπορούμε να χρησιμοποιήσουμε τις τιμές των SEs του πίνακα 4.73 για να ελέγξουμε αν υπάρχει πολυσυγγραμμικότητα. Αν κάποια τιμή είναι πολύ μεγάλη, αυτό σημαίνει πως υπάρχει πολυσυγγραμικότητα και το μοντέλο δεν είναι στατιστικά σταθερό. Για να διευθετηθεί το πρόβλημα που εντοπίζεται, θα μπορούσαμε να εξαλείψουμε την «προβληματική» μεταβλητή (που έχει τη μεγαλύτερη τιμή SE) και να συνεχίσουμε να αφαιρούμε μεταβλητές σταδιακά μέχρις ότου το εύρος των SE να περιοριστεί στις τιμές 0,001 5,0. Δεν υπάρχει σταθερό κριτήριο ως προς το πόσο μικρές πρέπει να είναι οι τιμές SE αλλά είναι θέμα κρίσης του κάθε ερευνητή. 169
170 Στον επόμενο πίνακα 4.74 δίνεται η τιμή της συνάρτησης λογαριθμοπιθανοφάνειας (137,901) για το τελικό υπόδειγμα μαζί με το συντελεστή προσδιορισμού των Cox και Snell (0,607) και το συντελεστή προσδιορισμού του Nagelkerke (0,81). Ο συντελεστής R των Cox και Snell βασίζεται στη σύγκριση της πιθανοφάνειας του τρέχοντος μοντέλου με το «μηδενικό» μοντέλο (εκείνο που δεν έχει καθόλου ανεξάρτητες μεταβλητές). Μεγαλύτερες τιμές του συντελεστή αποτελούν ένδειξη ότι η περισσότερη από τη μεταβλητότητα εξηγείται από το μοντέλο, ξεκινώντας από 0 έως 1. Η μέγιστη τιμή του συντελεστή R των Cox και Snell είναι στην πραγματικότητα λίγο μικρότερη του 1. Ο συντελεστής R του Nagelkerke αποτελεί διόρθωση του συντελεστή των Cox και Snell, έτσι ώστε η μέγιστη τιμή του να είναι 1. Σύμφωνα με το συντελεστή του Nagelkerke περίπου το 8% της μεταβλητότητας της εξαρτημένης μεταβλητής ερμηνεύεται από τις α- νεξάρτητες μεταβλητές του υποδείγματος. Model Summary Step - Log likelihood Cox & Snell R Square Nagelkerke R Square 1 3,564(a),479, ,80(a),549, ,396(a),570, ,69(a),600, ,901(a),607, ,901(a),607,81 a Estimation terminated at iteration number 0 because maximum iterations has been reached. Final solution cannot be found. Πίνακας 4.74 Ο πίνακας 4.75 είναι ο πίνακας ταξινόμησης του τελικού υποδείγματος. Σε έναν τέτοιο πίνακα θα πρέπει οι παρατηρούμενες και οι εκτιμώμενες τιμές να συμφωνούν όσο το δυνατόν περισσότερο. Στην προκειμένη περίπτωση, η συμφωνία αυτή προσεγγίζει το 90% περίπου (89,6%) του συνόλου των παρατηρήσεων. Τα διαγώνια κελιά του πίνακα περιέχουν τις παρατηρήσεις που συμφωνούν ως προς τις δύο ταξινομήσεις (την παρατηρούμενη και την εκτιμώμενη από το υπόδειγμα), ενώ τα εκτός διαγωνίου κελιά περιέχουν τις παρατηρήσεις με ασυμφωνία. Για παράδειγμα από τον πίνακα προκύπτει πως από τις 01 περιπτώσεις συνδέσεων με επίθεση, οι 199 ορθά κατηγοριοποιούνται ως επιθέσεις, ενώ μόνο από αυτές χαρακτηρίζονται ως κανονικές, απόδοση ιδιαίτερα ικανοποιητική. 170
171 Classification Table(a) Observed group Predicted Percentage Correct normal attack Step 1 group normal ,9 attack ,5 Overall Percentage 85,7 Step group normal ,9 attack ,5 Overall Percentage 88,7 Step 3 group normal ,9 attack ,5 Overall Percentage 89,3 Step 4 group normal ,6 attack ,0 Overall Percentage 89,3 Step 5 group normal ,4 attack ,0 Overall Percentage 89,6 Step 6 group normal ,4 attack ,0 Overall Percentage 89,6 a The cut value is,500 Πίνακας 4.75 Από τον πίνακα ταξινόμησης 4.75 μπορούμε να υπολογίσουμε και μέτρα χρησιμότητας του υποδείγματος ταξινόμησης. Το πρώτο ονομάζεται ευαισθησία (sensitivity) και είναι η πιθανότητα μια «θετική» περίπτωση να κατηγοριοποιηθεί σωστά, και σχεδιάζεται στον άξονα y μιας καμπύλης ROC. Ουσιαστικά είναι το ποσοστό των γεγονότων που προβλέφθηκαν ορθώς. Η ποσότητα (1 sensitivity) είναι το ποσοστό των εσφαλμένα αρνητικών αποφάσεων (false negative rate). Το άλλο μέτρο είναι η specificity και είναι η πιθανότητα μια «αρνητική» περίπτωση να κατηγοριοποιηθεί σωστά. Η ποσότητα (1- specificity) είναι το ποσοστό των εσφαλμένα θετικών αποφάσεων (false positive rate). Σύμφωνα με τον πίνακα, οι τιμές των δύο αυτών μέτρων είναι: 199 sensitivity = = 0, specificity = = 0, Η περιοχή κάτω από την καμπύλη ROC (σχήμα 4.1), η οποία κυμαίνεται από 0 έως 1, μπορεί επίσης να χρησιμοποιηθεί για την αξιολόγηση του μοντέλου διάκρισης [69]. Μια τιμή ίση με 0,5 σημαίνει πως το μοντέλο είναι άχρηστο για διά- 171

172 κριση (ισοδύναμο με τη ρίψη ενός νομίσματος) και τιμές κοντά στο 1 σημαίνουν πως υψηλότερες πιθανότητες θα ανατεθούν σε περιπτώσεις που έχουν την τιμή ενδιαφέροντος, σε σύγκριση με περιπτώσεις που δεν έχουν την τιμή. Η περιοχή κάτω από την καμπύλη ROC είναι 0,953, που σημαίνει πως σχεδόν στο 95% όλων των πιθανών ζευγών των περιπτώσεων στα οποία η μία περίπτωση είναι επίθεση και η άλλη κανονική, αυτό το μοντέλο θα αναθέσει μεγαλύτερη πιθανότητα στην περίπτωση που είναι επίθεση. Ο βέλτιστος λόγος sensitivity δίνεται από specificity το σημείο που βρίσκεται πιο κοντά στην άνω αριστερή γωνία του διαγράμματος. Σχήμα 4.1 Στο σχήμα 4. φαίνεται το ιστόγραμμα των εκτιμώμενων πιθανοτήτων ή αλλιώς το διάγραμμα ταξινόμησης των παρατηρήσεων (classification plot). Ο οριζόντιος άξονας του διαγράμματος ταξινόμησης αντιστοιχεί στις εκτιμώμενες από το υπόδειγμα πιθανότητες. Επάνω στον άξονα τοποθετούνται οι παρατηρήσεις της ανάλυσης υπό μορφή ιστογράμματος. Οι παρατηρήσεις οι οποίες έχουν εκτιμώμενη πιθανότητα πραγματοποίησης του γεγονότος μεγαλύτερη του 0,5 τοποθετούνται στο δεξιό μέρος του άξονα, ενώ οι παρατηρήσεις με πιθανότητα μικρότερη του 0,5 στο αριστερό. Επίσης η κάθε παρατήρηση ορίζεται από το αρχικό γράμμα της κατηγορίας που αντιστοιχεί στην πραγματοποίηση ή μη του γεγονότος. Σε μια ιδανική περίπτωση θα έπρεπε οι δύο ομάδες (n και a) να είναι όσο το δυνατόν πιο απομακρυσμένες στα δυο άκρα του άξονα, γεγονός που θα υποδήλωνε μικρές διαφοροποιήσεις των εκτιμώμενων τιμών από τις πραγματικές. 17
173 Σχήμα Λογαριθμική Παλινδρόμηση Μοντέλο VΙ Η δημιουργία αυτού του μοντέλου λογαριθμικής παλινδρόμησης βασίζεται αρχικά σε ένα απλό υπόδειγμα που περιλαμβάνει μόνο το σταθερό όρο και στη συνέχεια εισάγονται όλες μαζί οι ανεξάρτητες μεταβλητές με τη μέθοδο Enter, που είναι και η default επιλογή. Η εσωτερική κωδικοποίηση των κατηγοριών της εξαρτημένης μεταβλητής κατά την ανάλυση παραμένει ίδια με εκείνη που έγινε στο προηγούμενο μοντέλο. Δηλαδή, ο μικρότερος κωδικός της εξαρτημένης μεταβλητής επανακωδικοποιείται εσωτερικά με την τιμή 0 ενώ ο μεγαλύτερος με την τιμή 1. Στην προκειμένη περίπτωση, η πραγματοποίηση του γεγονότος (δηλαδή η απάντηση ΝΑΙ στην ερώτηση) είναι κωδικοποιημένη στο αρχείο των δεδομένων με την τιμή, επομένως 173
174 επανακωδικοποιείται με την τιμή 1. Αντίστοιχα η μη πραγματοποίηση του γεγονότος (η απάντηση ΟΧΙ στην ερώτηση) επανακωδικοποιείται με την τιμή 0. Το σχήμα κωδικοποίησης που θα χρησιμοποιήσουμε για τις κατηγορικές μεταβλητές είναι ξανά το indicator (default επιλογή) και ως κατηγορία αναφοράς επιλέγουμε first. Με την κωδικοποίηση αυτή, ως κατηγορία αναφοράς των κατηγορικών μεταβλητών χρησιμοποιείται όπως προαναφέρθηκε η κατηγορία με το μικρότερο αριθμό. Παρακάτω ακολουθούν και σχολιάζονται τα αποτελέσματα της ανάλυσης. Η τιμή του λόγου των μέγιστων τιμών της συνάρτησης πιθανοφάνειας για το πλήρες υπόδειγμα και για το υπόδειγμα που περιλαμβάνει μόνο το σταθερό όρο, η οποία χρησιμοποιείται για την αξιολόγηση της προσαρμογής του υποδείγματος, είναι 330,683 (πίνακας 4.76) ενώ η πιθανότητα να προκύψει μια τιμή τόσο μεγάλη είναι Sig<0,0005. Επομένως μπορούμε να θεωρήσουμε πως οι ανεξάρτητες μεταβλητές συνδυαζόμενες μεταξύ τους με τη μορφή του λογαριθμικού υποδείγματος συμβάλλουν σημαντικά στην πρόγνωση των τιμών της εξαρτημένης μεταβλητής. Step 1 Omnibus Tests of Model Coefficients Chi-square df Sig. Step 330,683 7,000 Block 330,683 7,000 Model 330,683 7,000 Πίνακας 4.76 Το στατιστικό μέτρο Hosmer-Lemeshow που φαίνεται στον πίνακα 4.77 αποτελεί ένδειξη κακής προσαρμογής αν το επίπεδο σημαντικότητας είναι μικρότερο από 0,05. Εδώ, το μοντέλο είναι καλό και προσαρμόζεται επαρκώς στα δεδομένα, αφού sig = 0,703 > 0,05. Hosmer and Lemeshow Test Step Chi-square df Sig. 1 5,499 8,703 Πίνακας 4.77 Στον πίνακα 4.78 δίνεται η τιμή της συνάρτησης λογαριθμο-πιθανοφάνειας (10,34) για το τελικό υπόδειγμα μαζί με το συντελεστή προσδιορισμού των Cox και Snell (0,67) και το συντελεστή προσδιορισμού του Nagelkerke (0,848). Σύμφωνα με το συντελεστή του Nagelkerke περίπου το 85% της μεταβλητότητας της εξαρτημένης μεταβλητής ερμηνεύεται από τις ανεξάρτητες μεταβλητές του υποδείγματος. 174
175 Model Summary - Log likelihood Cox & Snell Nagelkerke R Step R Square Square 1 10,34(a),67,848 a Estimation terminated at iteration number 0 because maximum iterations has been reached. Final solution cannot be found. Πίνακας 4.78 Ο πίνακας 4.79 είναι ο πίνακας ταξινόμησης του τελικού υποδείγματος. Στην προκειμένη περίπτωση, η συμφωνία αυτή ανάμεσα σε παρατηρούμενες και εκτιμώμενες τιμές προσεγγίζει το 90% περίπου (90,4%) του συνόλου των παρατηρήσεων. Όπως φαίνεται από τον πίνακα από τις 01 περιπτώσεις συνδέσεων με επίθεση, όλες κατηγοριοποιούνται ορθώς ως επιθέσεις, απόδοση 100%. Observed Classification Table(a) Predicted group normal attack Percentage Correct Step 1 group normal ,1 attack ,0 Overall Percentage 90,4 a The cut value is,500 Πίνακας 4.79 Παράλληλα σύμφωνα με τον παραπάνω πίνακα, οι τιμές των μέτρων sensitivity και specificity είναι: 01 sensitivity = = 100, specificity = = 0, Στο σχήμα 4.3 φαίνεται το ιστόγραμμα των εκτιμώμενων πιθανοτήτων ή αλλιώς το διάγραμμα ταξινόμησης των παρατηρήσεων (classification plot). Στο σχήμα 4.4 φαίνεται η καμπύλη ROC. Η περιοχή κάτω από την καμπύλη είναι 0,959, οπότε στο 96% όλων των πιθανών ζευγών των περιπτώσεων στα οποία η μία περίπτωση είναι επίθεση και η άλλη κανονική, αυτό το μοντέλο θα αναθέσει μεγαλύτερη πιθανότητα στην περίπτωση που είναι επίθεση. Τέλος ακολουθεί ο πίνακας 4.80 ο οποίος δίνει τους συντελεστές του τελικού υ- ποδείγματος μαζί με τους αντίστοιχους επαγωγικούς ελέγχους και τα διαστήματα εμπιστοσύνης αυτών. Βάσει του πίνακα προκύπτει πως μοναδική ανεξάρτητη μεταβλητή με σημαντική επίδραση στις τιμές της εξαρτημένης μεταβλητής είναι η Src_bytes. Οι υπόλοιπες μεταβλητές του υποδείγματος δεν έχουν σημαντική επίδραση στις τιμές της εξαρτημένης μεταβλητής. 175

176 Σχήμα 4.3 Σχήμα
Ασφάλεια Υπολογιστικών Συστηµάτων
 Ασφάλεια ενός Π.Σ.: Η ικανότητα ενός οργανισµού να προστατεύει τις πληροφορίες/πόρους του από τυχόν αλλοιώσεις, καταστροφές και µη εξουσιοδοτηµένη χρήση Η ικανότητά του να παρέχει ορθές και αξιόπιστες
Ασφάλεια ενός Π.Σ.: Η ικανότητα ενός οργανισµού να προστατεύει τις πληροφορίες/πόρους του από τυχόν αλλοιώσεις, καταστροφές και µη εξουσιοδοτηµένη χρήση Η ικανότητά του να παρέχει ορθές και αξιόπιστες
ΠΡΟΣΤΑΣΙΑ ΠΡΟΣΩΠΙΚΩΝ ΔΕΔΟΜΕΝΩΝ ΣΤΙΣ ΤΕΧΝΟΛΟΓΙΕΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΕΠΙΚΟΙΝΩΝΙΩΝ ΚΑΘΩΣ ΚΑΙ ΣΤΟ ΔΙΑΔΙΚΤΥΟ
 ΠΡΟΣΤΑΣΙΑ ΠΡΟΣΩΠΙΚΩΝ ΔΕΔΟΜΕΝΩΝ ΣΤΙΣ ΤΕΧΝΟΛΟΓΙΕΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΕΠΙΚΟΙΝΩΝΙΩΝ ΚΑΘΩΣ ΚΑΙ ΣΤΟ ΔΙΑΔΙΚΤΥΟ ΔΙΑΔΙΚΤΥΟ Το διαδίκτυο προσφέρει: Μετατροπή των δεδομένων σε ψηφιακή - ηλεκτρονική μορφή. Πρόσβαση
ΠΡΟΣΤΑΣΙΑ ΠΡΟΣΩΠΙΚΩΝ ΔΕΔΟΜΕΝΩΝ ΣΤΙΣ ΤΕΧΝΟΛΟΓΙΕΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΕΠΙΚΟΙΝΩΝΙΩΝ ΚΑΘΩΣ ΚΑΙ ΣΤΟ ΔΙΑΔΙΚΤΥΟ ΔΙΑΔΙΚΤΥΟ Το διαδίκτυο προσφέρει: Μετατροπή των δεδομένων σε ψηφιακή - ηλεκτρονική μορφή. Πρόσβαση
Ασφάλεια Στο Ηλεκτρονικό Εμπόριο. Λάζος Αλέξανδρος Α.Μ. 3530
 Ασφάλεια Στο Ηλεκτρονικό Εμπόριο Λάζος Αλέξανδρος Α.Μ. 3530 Ηλεκτρονικό Εμπόριο Χρησιμοποιείται για να περιγράψει την χρήση τηλεπικοινωνιακών μέσων (κυρίως δικτύων) για κάθε είδους εμπορικές συναλλαγές
Ασφάλεια Στο Ηλεκτρονικό Εμπόριο Λάζος Αλέξανδρος Α.Μ. 3530 Ηλεκτρονικό Εμπόριο Χρησιμοποιείται για να περιγράψει την χρήση τηλεπικοινωνιακών μέσων (κυρίως δικτύων) για κάθε είδους εμπορικές συναλλαγές
Ασφάλεια Πληροφοριακών Συστημάτων
 Ανοικτά Ακαδημαϊκά Μαθήματα στο ΤΕΙ Ιονίων Νήσων Ασφάλεια Πληροφοριακών Συστημάτων Ενότητα 11: Δικτυακές απειλές - συστήματα προστασίας Θεματική Ενότητα: Εισαγωγή στον Προγραμματισμό Το περιεχόμενο του
Ανοικτά Ακαδημαϊκά Μαθήματα στο ΤΕΙ Ιονίων Νήσων Ασφάλεια Πληροφοριακών Συστημάτων Ενότητα 11: Δικτυακές απειλές - συστήματα προστασίας Θεματική Ενότητα: Εισαγωγή στον Προγραμματισμό Το περιεχόμενο του
GDPR και Τεχνικά Μέτρα Ασφάλειας Πληροφοριακών Συστημάτων
 GDPR και Τεχνικά Μέτρα Ασφάλειας Πληροφοριακών Συστημάτων Εισηγητής Νικόλαος Δούλος IT & Business Development Consultant n.doulos@altiusconsultants.gr Mobile : 6936 733 950 tel : 210 60 46 340 www.altiusconsultants.gr
GDPR και Τεχνικά Μέτρα Ασφάλειας Πληροφοριακών Συστημάτων Εισηγητής Νικόλαος Δούλος IT & Business Development Consultant n.doulos@altiusconsultants.gr Mobile : 6936 733 950 tel : 210 60 46 340 www.altiusconsultants.gr
Ηλεκτρονικό εμπόριο. HE 6 Ασφάλεια
 Ηλεκτρονικό εμπόριο HE 6 Ασφάλεια Ηλεκτρονικό εμπόριο και ασφάλεια Δισταγμός χρηστών στην χρήση του ηλεκτρονικού εμπορίου Αναζήτηση ασφαλούς περιβάλλοντος ηλεκτρονικού εμπορίου Ζητούμενο είναι η ασφάλεια
Ηλεκτρονικό εμπόριο HE 6 Ασφάλεια Ηλεκτρονικό εμπόριο και ασφάλεια Δισταγμός χρηστών στην χρήση του ηλεκτρονικού εμπορίου Αναζήτηση ασφαλούς περιβάλλοντος ηλεκτρονικού εμπορίου Ζητούμενο είναι η ασφάλεια
Security & Privacy. Overview
 Security & Privacy Καλλονιά Χρήστος Overview Βασικές Έννοιες ενός Πληροφοριακού Συστήματος Ασφάλεια Πληροφοριακών Συστημάτων Βασικές Ιδιότητες Ασφάλειας Ασφάλεια vs Ιδιωτικότητα Βασικές Αρχές Ιδιωτικότητας
Security & Privacy Καλλονιά Χρήστος Overview Βασικές Έννοιες ενός Πληροφοριακού Συστήματος Ασφάλεια Πληροφοριακών Συστημάτων Βασικές Ιδιότητες Ασφάλειας Ασφάλεια vs Ιδιωτικότητα Βασικές Αρχές Ιδιωτικότητας
Ηλεκτρονικό Εμπόριο. Ενότητα 9: Ασφάλεια Ηλεκτρονικού Εμπορίου Σαπρίκης Ευάγγελος Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά)
") Ηλεκτρονικό Εμπόριο Ενότητα 9: Ασφάλεια Ηλεκτρονικού Εμπορίου Σαπρίκης Ευάγγελος Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons.
Ηλεκτρονικό Εμπόριο Ενότητα 9: Ασφάλεια Ηλεκτρονικού Εμπορίου Σαπρίκης Ευάγγελος Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons.
Ασφάλεια Υπολογιστικών Συστημάτων
 Ασφάλεια Υπολογιστικών Συστημάτων Ενότητα 1: Εισαγωγή Νικολάου Σπύρος Τμήμα Μηχανικών Πληροφορικής ΤΕ Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Ασφάλεια Υπολογιστικών Συστημάτων Ενότητα 1: Εισαγωγή Νικολάου Σπύρος Τμήμα Μηχανικών Πληροφορικής ΤΕ Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
ΕΠΑΝΑΛΗΠΤΙΚΟ ΤΕΣΤ ΣΤΗΝ ΕΝΟΤΗΤΑ
 ΕΠΑ.Λ. Άμφισσας Σχολικό Έτος : 2011-2012 Τάξη : Γ Τομέας : Πληροφορικής Μάθημα : ΔΙΚΤΥΑ ΥΠΟΛΟΓΙΣΤΩΝ ΙΙ Διδάσκων : Χρήστος Ρέτσας Η-τάξη : tiny.cc/retsas-diktya2 ΕΠΑΝΑΛΗΠΤΙΚΟ ΤΕΣΤ ΣΤΗΝ ΕΝΟΤΗΤΑ 8.3.1-8.3.3
ΕΠΑ.Λ. Άμφισσας Σχολικό Έτος : 2011-2012 Τάξη : Γ Τομέας : Πληροφορικής Μάθημα : ΔΙΚΤΥΑ ΥΠΟΛΟΓΙΣΤΩΝ ΙΙ Διδάσκων : Χρήστος Ρέτσας Η-τάξη : tiny.cc/retsas-diktya2 ΕΠΑΝΑΛΗΠΤΙΚΟ ΤΕΣΤ ΣΤΗΝ ΕΝΟΤΗΤΑ 8.3.1-8.3.3
ΤΕΧΝΟΛΟΓΙΕΣ & ΑΣΦΑΛΕΙΑ ΠΛΗΡΟΦΟΡΙΩΝ ΙΩΑΝΝΗ Δ. ΙΓΓΛΕΖΑΚΗ
 ΤΕΧΝΟΛΟΓΙΕΣ & ΑΣΦΑΛΕΙΑ ΠΛΗΡΟΦΟΡΙΩΝ ΙΩΑΝΝΗ Δ. ΙΓΓΛΕΖΑΚΗ Εισαγωγή Το πρόβλημα της διαχείρισης της ασφάλειας πληροφοριών αποτελεί ένα ιδιαίτερα σημαντικό ζήτημα για τα σύγχρονα πληροφοριακά συστήματα, καθώς
ΤΕΧΝΟΛΟΓΙΕΣ & ΑΣΦΑΛΕΙΑ ΠΛΗΡΟΦΟΡΙΩΝ ΙΩΑΝΝΗ Δ. ΙΓΓΛΕΖΑΚΗ Εισαγωγή Το πρόβλημα της διαχείρισης της ασφάλειας πληροφοριών αποτελεί ένα ιδιαίτερα σημαντικό ζήτημα για τα σύγχρονα πληροφοριακά συστήματα, καθώς
Εισβολείς. Προτεινόµενες ιστοσελίδες. Τεχνικές εισβολής Προστασία µε συνθηµατικό Στρατηγικές επιλογής συνθηµατικών Εντοπισµός εισβολών
 Giannis F. Marias 1 Εισβολείς Τεχνικές εισβολής Προστασία µε συνθηµατικό Στρατηγικές επιλογής συνθηµατικών Εντοπισµός εισβολών Προτεινόµενες ιστοσελίδες Giannis F. Marias 2 Τρεις κατηγορίες εισβολέων:
Giannis F. Marias 1 Εισβολείς Τεχνικές εισβολής Προστασία µε συνθηµατικό Στρατηγικές επιλογής συνθηµατικών Εντοπισµός εισβολών Προτεινόµενες ιστοσελίδες Giannis F. Marias 2 Τρεις κατηγορίες εισβολέων:
ΤΕΧΝΙΚΕΣ ΕΠΙΘΕΣΗΣ (1/8)
") ΑΣΦΑΛΕΙΑ WEB CLIENT ΤΕΧΝΙΚΕΣ ΕΠΙΘΕΣΗΣ (1/8) Επίθεση άρνησης υπηρεσίας (Denial of Service-DoS). Αποστολή πολλών αιτήσεων στο µηχάνηµα-στόχο ώστε τα resources που του αποµένουν (σε αυτόν ή και στο δίκτυο).
ΑΣΦΑΛΕΙΑ WEB CLIENT ΤΕΧΝΙΚΕΣ ΕΠΙΘΕΣΗΣ (1/8) Επίθεση άρνησης υπηρεσίας (Denial of Service-DoS). Αποστολή πολλών αιτήσεων στο µηχάνηµα-στόχο ώστε τα resources που του αποµένουν (σε αυτόν ή και στο δίκτυο).
ΕΚΤΕΛΕΣΤΙΚΟΣ ΚΑΝΟΝΙΣΜΟΣ (ΕΕ) /... ΤΗΣ ΕΠΙΤΡΟΠΗΣ. της
 /... ΤΗΣ ΕΠΙΤΡΟΠΗΣ. της") ΕΥΡΩΠΑΪΚΗ ΕΠΙΤΡΟΠΗ Βρυξέλλες, 30.1.2018 C(2018) 471 final ΕΚΤΕΛΕΣΤΙΚΟΣ ΚΑΝΟΝΙΣΜΟΣ (ΕΕ) /... ΤΗΣ ΕΠΙΤΡΟΠΗΣ της 30.1.2018 που θεσπίζει κανόνες για την εφαρμογή της οδηγίας (ΕΕ) 2016/1148 του Ευρωπαϊκού Κοινοβουλίου
ΕΥΡΩΠΑΪΚΗ ΕΠΙΤΡΟΠΗ Βρυξέλλες, 30.1.2018 C(2018) 471 final ΕΚΤΕΛΕΣΤΙΚΟΣ ΚΑΝΟΝΙΣΜΟΣ (ΕΕ) /... ΤΗΣ ΕΠΙΤΡΟΠΗΣ της 30.1.2018 που θεσπίζει κανόνες για την εφαρμογή της οδηγίας (ΕΕ) 2016/1148 του Ευρωπαϊκού Κοινοβουλίου
ΤΕΧΝΟΛΟΓΙΑ ΔΙΚΤΥΩΝ ΕΠΙΚΟΙΝΩΝΙΩΝ
 Σε δίκτυο υπολογιστών εμπιστευτική πληροφορία μπορεί να υπάρχει αποθηκευμένη σε μέσα αποθήκευσης (σκληροί δίσκοι, μνήμες κ.λ.π.), ή να κυκλοφορεί μέσου του δικτύου με τη μορφή πακέτων. Η ύπαρξη πληροφοριών
Σε δίκτυο υπολογιστών εμπιστευτική πληροφορία μπορεί να υπάρχει αποθηκευμένη σε μέσα αποθήκευσης (σκληροί δίσκοι, μνήμες κ.λ.π.), ή να κυκλοφορεί μέσου του δικτύου με τη μορφή πακέτων. Η ύπαρξη πληροφοριών
Χρήστος Ξενάκης Τμήμα Ψηφιακών Συστημάτων Πανεπιστήμιο Πειραιώς
 Συστήματα Ανίχνευσης Εισβολών Χρήστος Ξενάκης Τμήμα Ψηφιακών Συστημάτων Πανεπιστήμιο Πειραιώς Στόχοι του Κεφαλαίου Παρουσιάζονται και αναλύονται οι τεχνικές και μηχανισμοί για την προστασία των συστημάτων.
Συστήματα Ανίχνευσης Εισβολών Χρήστος Ξενάκης Τμήμα Ψηφιακών Συστημάτων Πανεπιστήμιο Πειραιώς Στόχοι του Κεφαλαίου Παρουσιάζονται και αναλύονται οι τεχνικές και μηχανισμοί για την προστασία των συστημάτων.
Παρουσίαση Μεταπτυχιακής Εργασίας
 Πανεπιστήμιο Πειραιώς Τμήμα Πληροφορικής Πρόγραμμα Μεταπτυχιακών Σπουδών «Προηγμένα Σύστήματα Πληροφορικής» Παρουσίαση Μεταπτυχιακής Εργασίας «Ανασκόπηση και περιγραφή των μεθοδολογιών, προτύπων και εργαλείων
Πανεπιστήμιο Πειραιώς Τμήμα Πληροφορικής Πρόγραμμα Μεταπτυχιακών Σπουδών «Προηγμένα Σύστήματα Πληροφορικής» Παρουσίαση Μεταπτυχιακής Εργασίας «Ανασκόπηση και περιγραφή των μεθοδολογιών, προτύπων και εργαλείων
Ασφάλεια Υπολογιστικών Συστηµάτων
 Βασικοί τύποι επιθέσεων στο Internet Βασισµένες σε κωδικό πρόσβασης (password-based attacks): προσπάθεια παραβίασης του κωδικού πρόσβασης Υποκλοπή πακέτων µετάδοσης (packet sniffing attacks): παρακολούθηση
Βασικοί τύποι επιθέσεων στο Internet Βασισµένες σε κωδικό πρόσβασης (password-based attacks): προσπάθεια παραβίασης του κωδικού πρόσβασης Υποκλοπή πακέτων µετάδοσης (packet sniffing attacks): παρακολούθηση
ΠΡΟΣΤΑΣΙΑ ΛΟΓΙΣΜΙΚΟΥ- ΙΟΙ ΚΕΦΑΛΑΙΟ 7
 ΠΡΟΣΤΑΣΙΑ ΛΟΓΙΣΜΙΚΟΥ- ΙΟΙ ΚΕΦΑΛΑΙΟ 7 Ερωτήσεις Τι είναι η πειρατεία λογισμικού Παραδείγματα πειρατείας Τι είναι το πιστοποιητικό αυθεντικότητας; Αναφέρετε κατηγορίες λογισμικού που διατίθεται στο διαδίκτυο
ΠΡΟΣΤΑΣΙΑ ΛΟΓΙΣΜΙΚΟΥ- ΙΟΙ ΚΕΦΑΛΑΙΟ 7 Ερωτήσεις Τι είναι η πειρατεία λογισμικού Παραδείγματα πειρατείας Τι είναι το πιστοποιητικό αυθεντικότητας; Αναφέρετε κατηγορίες λογισμικού που διατίθεται στο διαδίκτυο
Πρακτικά όλα τα προβλήματα ασφαλείας οφείλονται σε λάθη στον κώδικα
 1 2 3 Το λογισμικό αποτελεί το τσιμέντο της σύγχρονης κοινωνίας. Τα πάντα γύρω μας ελέγχονται από εφαρμογές, συνεπώς ο κώδικας από τον οποίο αποτελούνται είναι ένα κρίσιμο στοιχείο για την ίδια μας τη
1 2 3 Το λογισμικό αποτελεί το τσιμέντο της σύγχρονης κοινωνίας. Τα πάντα γύρω μας ελέγχονται από εφαρμογές, συνεπώς ο κώδικας από τον οποίο αποτελούνται είναι ένα κρίσιμο στοιχείο για την ίδια μας τη
ΕΝΙΑΙΟ ΠΛΑΙΣΙΟ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΠΟΥΔΩΝ
 ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΕΝΙΑΙΟ ΠΛΑΙΣΙΟ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΠΟΥΔΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΙΣΧΥΕΙ ΚΑΤΑ ΤΟ ΜΕΡΟΣ ΠΟΥ ΑΦΟΡΑ ΤΟ ΛΥΚΕΙΟ ΓΙΑ ΤΗΝ ΥΠΟΧΡΕΩΤΙΚΗ ΕΚΠΑΙΔΕΥΣΗ ΙΣΧΥΟΥΝ ΤΟ ΔΕΠΠΣ
ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΕΝΙΑΙΟ ΠΛΑΙΣΙΟ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΠΟΥΔΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΙΣΧΥΕΙ ΚΑΤΑ ΤΟ ΜΕΡΟΣ ΠΟΥ ΑΦΟΡΑ ΤΟ ΛΥΚΕΙΟ ΓΙΑ ΤΗΝ ΥΠΟΧΡΕΩΤΙΚΗ ΕΚΠΑΙΔΕΥΣΗ ΙΣΧΥΟΥΝ ΤΟ ΔΕΠΠΣ
ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΩΝ Διαχείριση Ασφαλείας (Ι) Απειλές Ασφαλείας Συμμετρική & Μη-Συμμετρική Κρυπτογραφία
 Απειλές Ασφαλείας Συμμετρική & Μη-Συμμετρική Κρυπτογραφία") ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΩΝ Διαχείριση (Ι) Απειλές Συμμετρική & Μη-Συμμετρική Κρυπτογραφία Β. Μάγκλαρης maglaris@netmode.ntua.gr www.netmode.ntua.gr 13/11/2017 ΘΕΜΑΤΙΚΕΣ ΠΕΡΙΟΧΕΣ ΑΣΦΑΛΕΙΑΣ Είδη Απειλών και Επιθέσεων
ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΩΝ Διαχείριση (Ι) Απειλές Συμμετρική & Μη-Συμμετρική Κρυπτογραφία Β. Μάγκλαρης maglaris@netmode.ntua.gr www.netmode.ntua.gr 13/11/2017 ΘΕΜΑΤΙΚΕΣ ΠΕΡΙΟΧΕΣ ΑΣΦΑΛΕΙΑΣ Είδη Απειλών και Επιθέσεων
Κεφάλαιο 16 Ασφάλεια και Προστασία στο Διαδίκτυο. Εφαρμογές Πληροφορικής Κεφ. 16 Καραμαούνας Πολύκαρπος
 Κεφάλαιο 16 Ασφάλεια και Προστασία στο Διαδίκτυο Εφαρμογές Πληροφορικής Κεφ. 16 Καραμαούνας Πολύκαρπος 16.1 Ασφάλεια υπολογιστικού συστήματος Κακόβουλο λογισμικό: το λογισμικό το οποίο εκ προθέσεως διαθέτει
Κεφάλαιο 16 Ασφάλεια και Προστασία στο Διαδίκτυο Εφαρμογές Πληροφορικής Κεφ. 16 Καραμαούνας Πολύκαρπος 16.1 Ασφάλεια υπολογιστικού συστήματος Κακόβουλο λογισμικό: το λογισμικό το οποίο εκ προθέσεως διαθέτει
ΜΑΘΗΤΕΣ:ΑΝΤΩΝΙΟΥ ΕΥΑΓΓΕΛΙΑ,ΔΑΡΑΜΑΡΑ ΑΓΓΕΛΙΚΗ,ΖΑΡΚΑΔΟΥΛΑ ΔΕΣΠΟΙΝΑ,ΚΑΠΟΥΛΑΣ ΑΠΟΣΤΟΛΟΣ,ΚΟΛΟΒΟΣ ΠΑΝΑΓΙΩΤΗΣ ΚΑΘΗΓΗΤΡΙΑ:ΧΑΛΙΜΟΥΡΔΑ ΑΓΓΕΛΙΚΗ ΕΡΕΥΝΗΤΙΚΗ
 ΜΑΘΗΤΕΣ:ΑΝΤΩΝΙΟΥ ΕΥΑΓΓΕΛΙΑ,ΔΑΡΑΜΑΡΑ ΑΓΓΕΛΙΚΗ,ΖΑΡΚΑΔΟΥΛΑ ΔΕΣΠΟΙΝΑ,ΚΑΠΟΥΛΑΣ ΑΠΟΣΤΟΛΟΣ,ΚΟΛΟΒΟΣ ΠΑΝΑΓΙΩΤΗΣ ΚΑΘΗΓΗΤΡΙΑ:ΧΑΛΙΜΟΥΡΔΑ ΑΓΓΕΛΙΚΗ ΕΡΕΥΝΗΤΙΚΗ ΕΡΓΑΣΙΑ ΜΑΙΟΣ 2015 ΗΛΕΚΤΡΟΝΙΚΟ ΕΓΚΛΗΜΑ Μορφές ηλεκτρονικού
ΜΑΘΗΤΕΣ:ΑΝΤΩΝΙΟΥ ΕΥΑΓΓΕΛΙΑ,ΔΑΡΑΜΑΡΑ ΑΓΓΕΛΙΚΗ,ΖΑΡΚΑΔΟΥΛΑ ΔΕΣΠΟΙΝΑ,ΚΑΠΟΥΛΑΣ ΑΠΟΣΤΟΛΟΣ,ΚΟΛΟΒΟΣ ΠΑΝΑΓΙΩΤΗΣ ΚΑΘΗΓΗΤΡΙΑ:ΧΑΛΙΜΟΥΡΔΑ ΑΓΓΕΛΙΚΗ ΕΡΕΥΝΗΤΙΚΗ ΕΡΓΑΣΙΑ ΜΑΙΟΣ 2015 ΗΛΕΚΤΡΟΝΙΚΟ ΕΓΚΛΗΜΑ Μορφές ηλεκτρονικού
ΔΗΜΟΣΙΑ ΠΟΛΙΤΙΚΗ. για την προστασία Φυσικών Προσώπων έναντι της επεξεργασίας προσωπικών δεδομένων τους
 ΔΗΜΟΣΙΑ ΠΟΛΙΤΙΚΗ για την προστασία Φυσικών Προσώπων έναντι της επεξεργασίας προσωπικών δεδομένων τους Εισαγωγή Ο κανονισμός 679/2016 της Ε.Ε. θεσπίζει κανόνες που αφορούν την προστασία των φυσικών προσώπων
ΔΗΜΟΣΙΑ ΠΟΛΙΤΙΚΗ για την προστασία Φυσικών Προσώπων έναντι της επεξεργασίας προσωπικών δεδομένων τους Εισαγωγή Ο κανονισμός 679/2016 της Ε.Ε. θεσπίζει κανόνες που αφορούν την προστασία των φυσικών προσώπων
Αντιµετώπιση εισβολών σε δίκτυα υπολογιστών Η πλατφόρµα HELENA. Βαλεοντής Ευτύχιος Μηχανικός Η/Υ, MSc Τοµέας Ασφάλειας / ΕΑΙΤΥ
 Αντιµετώπιση εισβολών σε δίκτυα υπολογιστών Η πλατφόρµα HELENA Βαλεοντής Ευτύχιος Μηχανικός Η/Υ, MSc Τοµέας Ασφάλειας / ΕΑΙΤΥ Ο «εισβολέας» Network Intrusion 1/2 An intrusion, also known as a system compromise,
Αντιµετώπιση εισβολών σε δίκτυα υπολογιστών Η πλατφόρµα HELENA Βαλεοντής Ευτύχιος Μηχανικός Η/Υ, MSc Τοµέας Ασφάλειας / ΕΑΙΤΥ Ο «εισβολέας» Network Intrusion 1/2 An intrusion, also known as a system compromise,
Σκοπιµότητα των firewalls
 Σκοπιµότητα των firewalls Παρέχουν προστασία των εσωτερικών δικτύων από απειλές όπως: Μη εξουσιοδοτηµένη προσπέλαση των δικτυακών πόρων: όταν επίδοξοι εισβολείς προσπαθούν να εισχωρήσουν στο δίκτυο και
Σκοπιµότητα των firewalls Παρέχουν προστασία των εσωτερικών δικτύων από απειλές όπως: Μη εξουσιοδοτηµένη προσπέλαση των δικτυακών πόρων: όταν επίδοξοι εισβολείς προσπαθούν να εισχωρήσουν στο δίκτυο και
ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΩΝ Διαχείριση Ασφαλείας (ΙΙ) Πρωτόκολλα & Αρχιτεκτονικές Firewalls Anomaly & Intrusion Detection Systems (IDS)
 Πρωτόκολλα & Αρχιτεκτονικές Firewalls Anomaly & Intrusion Detection Systems (IDS)") ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΩΝ Διαχείριση Ασφαλείας (ΙΙ) Πρωτόκολλα & Αρχιτεκτονικές email Firewalls Anomaly & Intrusion Detection Systems (IDS) Β. Μάγκλαρης maglaris@netmode.ntua.gr www.netmode.ntua.gr 30/11/2015
ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΩΝ Διαχείριση Ασφαλείας (ΙΙ) Πρωτόκολλα & Αρχιτεκτονικές email Firewalls Anomaly & Intrusion Detection Systems (IDS) Β. Μάγκλαρης maglaris@netmode.ntua.gr www.netmode.ntua.gr 30/11/2015
Διαχείριση Ασφάλειας και Εμπιστοσύνης σε Πολιτισμικά Περιβάλλοντα
 Διαχείριση Ασφάλειας και Εμπιστοσύνης σε Πολιτισμικά Περιβάλλοντα Ενότητα 11: ΑΣΦΑΛΕΙΑ ΛΕΙΤΟΥΡΓΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ, ΑΝΤΙΜΕΤΩΠΙΣΗ ΕΙΣΒΟΛΗΣ Δημήτριος Κουκόπουλος Σχολή Οργάνωσης και Διοίκησης Επιχειρήσεων Τμήμα
Διαχείριση Ασφάλειας και Εμπιστοσύνης σε Πολιτισμικά Περιβάλλοντα Ενότητα 11: ΑΣΦΑΛΕΙΑ ΛΕΙΤΟΥΡΓΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ, ΑΝΤΙΜΕΤΩΠΙΣΗ ΕΙΣΒΟΛΗΣ Δημήτριος Κουκόπουλος Σχολή Οργάνωσης και Διοίκησης Επιχειρήσεων Τμήμα
Ηλεκτρονικό εμπόριο. HE 7 Τεχνολογίες ασφάλειας
 Ηλεκτρονικό εμπόριο HE 7 Τεχνολογίες ασφάλειας Πρόκληση ανάπτυξης ασφαλών συστημάτων Η υποδομή του διαδικτύου παρουσίαζε έλλειψη υπηρεσιών ασφάλειας καθώς η οικογένεια πρωτοκόλλων TCP/IP στην οποία στηρίζεται
Ηλεκτρονικό εμπόριο HE 7 Τεχνολογίες ασφάλειας Πρόκληση ανάπτυξης ασφαλών συστημάτων Η υποδομή του διαδικτύου παρουσίαζε έλλειψη υπηρεσιών ασφάλειας καθώς η οικογένεια πρωτοκόλλων TCP/IP στην οποία στηρίζεται
Κακόβουλο Λογισμικό Ηλιάδης Ιωάννης
 Κακόβουλο Λογισμικό Ηλιάδης Ιωάννης Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων Πανεπιστήμιο Αιγαίου jiliad@aegean.gr Αθήνα, Ιούλιος 2004 Η έννοια του Κακόβουλου Λογισμικού Το Λογισμικό
Κακόβουλο Λογισμικό Ηλιάδης Ιωάννης Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων Πανεπιστήμιο Αιγαίου jiliad@aegean.gr Αθήνα, Ιούλιος 2004 Η έννοια του Κακόβουλου Λογισμικού Το Λογισμικό
ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ
 ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ Μάθημα 10: Ανάπτυξη ΠΣ Μαρίνος Θεμιστοκλέους Email: mthemist@unipi.gr Ανδρούτσου 150 Γραφείο 206 Τηλ. 210 414 2723 Ώρες Γραφείου: Δευτέρα 11-12 πμ Ενδεικτικά Περιεχόμενα Εργασίας
ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ Μάθημα 10: Ανάπτυξη ΠΣ Μαρίνος Θεμιστοκλέους Email: mthemist@unipi.gr Ανδρούτσου 150 Γραφείο 206 Τηλ. 210 414 2723 Ώρες Γραφείου: Δευτέρα 11-12 πμ Ενδεικτικά Περιεχόμενα Εργασίας
κρυπτογραϕία Ψηφιακή ασφάλεια και ιδιωτικότητα Γεώργιος Σπαθούλας Msc Πληροφορική και υπολογιστική βιοιατρική Πανεπιστήμιο Θεσσαλίας
 κρυπτογραϕία Ψηφιακή ασφάλεια και ιδιωτικότητα Γεώργιος Σπαθούλας Msc Πληροφορική και υπολογιστική βιοιατρική Πανεπιστήμιο Θεσσαλίας ιδιότητες ασϕάλειας ιδιότητες ασϕάλειας αγαθών Εμπιστευτικότητα (Confidentiality)
κρυπτογραϕία Ψηφιακή ασφάλεια και ιδιωτικότητα Γεώργιος Σπαθούλας Msc Πληροφορική και υπολογιστική βιοιατρική Πανεπιστήμιο Θεσσαλίας ιδιότητες ασϕάλειας ιδιότητες ασϕάλειας αγαθών Εμπιστευτικότητα (Confidentiality)
ΕΙΔΗ ΕΡΕΥΝΑΣ I: ΠΕΙΡΑΜΑΤΙΚΗ ΕΡΕΥΝΑ & ΠΕΙΡΑΜΑΤΙΚΟΙ ΣΧΕΔΙΑΣΜΟΙ
 ΤΕΧΝΙΚΕΣ ΕΡΕΥΝΑΣ (# 252) Ε ΕΞΑΜΗΝΟ 9 η ΕΙΣΗΓΗΣΗ ΣΗΜΕΙΩΣΕΙΣ ΕΙΔΗ ΕΡΕΥΝΑΣ I: ΠΕΙΡΑΜΑΤΙΚΗ ΕΡΕΥΝΑ & ΠΕΙΡΑΜΑΤΙΚΟΙ ΣΧΕΔΙΑΣΜΟΙ ΛΙΓΗ ΘΕΩΡΙΑ Στην προηγούμενη διάλεξη μάθαμε ότι υπάρχουν διάφορες μορφές έρευνας
ΤΕΧΝΙΚΕΣ ΕΡΕΥΝΑΣ (# 252) Ε ΕΞΑΜΗΝΟ 9 η ΕΙΣΗΓΗΣΗ ΣΗΜΕΙΩΣΕΙΣ ΕΙΔΗ ΕΡΕΥΝΑΣ I: ΠΕΙΡΑΜΑΤΙΚΗ ΕΡΕΥΝΑ & ΠΕΙΡΑΜΑΤΙΚΟΙ ΣΧΕΔΙΑΣΜΟΙ ΛΙΓΗ ΘΕΩΡΙΑ Στην προηγούμενη διάλεξη μάθαμε ότι υπάρχουν διάφορες μορφές έρευνας
8.3 Ασφάλεια ικτύων. Ερωτήσεις
 8.3 Ασφάλεια ικτύων Ερωτήσεις 1. Με τι ασχολείται η ασφάλεια των συστηµάτων; 2. Τι είναι αυτό που προστατεύεται στην ασφάλεια των συστηµάτων και για ποιο λόγο γίνεται αυτό; 3. Ποια η διαφορά ανάµεσα στους
8.3 Ασφάλεια ικτύων Ερωτήσεις 1. Με τι ασχολείται η ασφάλεια των συστηµάτων; 2. Τι είναι αυτό που προστατεύεται στην ασφάλεια των συστηµάτων και για ποιο λόγο γίνεται αυτό; 3. Ποια η διαφορά ανάµεσα στους
ΑΣΦΑΛΕΙΑ ΔΕΔΟΜΕΝΩΝ ΣΤΗΝ ΚΟΙΝΩΝΙΑ ΤΗΣ ΠΛΗΡΟΦΟΡΙΑΣ (Κακόβουλο Λογισμικό)
") ΑΣΦΑΛΕΙΑ ΔΕΔΟΜΕΝΩΝ ΣΤΗΝ ΚΟΙΝΩΝΙΑ ΤΗΣ ΠΛΗΡΟΦΟΡΙΑΣ (Κακόβουλο Λογισμικό) Καλλονιάτης Χρήστος Επίκουρος Καθηγητής Τμήμα Πολιτισμικής Τεχνολογίας και Επικοινωνίας, Πανεπιστήμιο Αιγαίου http://www.ct.aegean.gr/people/kalloniatis
ΑΣΦΑΛΕΙΑ ΔΕΔΟΜΕΝΩΝ ΣΤΗΝ ΚΟΙΝΩΝΙΑ ΤΗΣ ΠΛΗΡΟΦΟΡΙΑΣ (Κακόβουλο Λογισμικό) Καλλονιάτης Χρήστος Επίκουρος Καθηγητής Τμήμα Πολιτισμικής Τεχνολογίας και Επικοινωνίας, Πανεπιστήμιο Αιγαίου http://www.ct.aegean.gr/people/kalloniatis
ΑΡΧΗ ΔΙΑΣΦΑΛΙΣΗΣ ΤΟΥ ΑΠΟΡΡΗΤΟΥ ΤΩΝ ΕΠΙΚΟΙΝΩΝΙΩΝ ΣΧΕΔΙΟ
 ΣΧΕΔΙΟ «Κοινή Πράξη της Αρχής Προστασίας Δεδομένων Προσωπικού Χαρακτήρα (Α.Π.Δ.Π.Χ.) και της Αρχής Διασφάλισης του Απορρήτου των Επικοινωνιών (Α.Δ.Α.Ε.) ως προς τις υποχρεώσεις των παρόχων για την προστασία
ΣΧΕΔΙΟ «Κοινή Πράξη της Αρχής Προστασίας Δεδομένων Προσωπικού Χαρακτήρα (Α.Π.Δ.Π.Χ.) και της Αρχής Διασφάλισης του Απορρήτου των Επικοινωνιών (Α.Δ.Α.Ε.) ως προς τις υποχρεώσεις των παρόχων για την προστασία
ΚΕΦΑΛΑΙΟ 4. Τεχνική Ανίχνευσης του. Πτυχιακή Εργασία Σελίδα 95
 ΚΕΦΑΛΑΙΟ 4 Τεχνική Ανίχνευσης του ICMP Echo Spoofing Πτυχιακή Εργασία Σελίδα 95 Περιεχόμενα ΕΙΣΑΓΩΓΗ 98 ΜΕΡΟΣ Α: Έλεγχος του Icmp Echo Reply Πακέτου 103 A.1. Ανίχνευση του spoofed Icmp Echo Request Πακέτου.
ΚΕΦΑΛΑΙΟ 4 Τεχνική Ανίχνευσης του ICMP Echo Spoofing Πτυχιακή Εργασία Σελίδα 95 Περιεχόμενα ΕΙΣΑΓΩΓΗ 98 ΜΕΡΟΣ Α: Έλεγχος του Icmp Echo Reply Πακέτου 103 A.1. Ανίχνευση του spoofed Icmp Echo Request Πακέτου.
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων
 Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων Διαβάθμιση Εγγράφου: Κωδικός Εγγράφου: GDPR-DOC-17 Έκδοση: 1η Ημερομηνία: 23 May 2018 Συγγραφέας: Ομάδα Υλοποίησης της Συμμόρφωσης
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων Διαβάθμιση Εγγράφου: Κωδικός Εγγράφου: GDPR-DOC-17 Έκδοση: 1η Ημερομηνία: 23 May 2018 Συγγραφέας: Ομάδα Υλοποίησης της Συμμόρφωσης
Πως μπορούν τα μέρη του υλικού ενός υπολογιστή να επικοινωνούν και να συνεργάζονται μεταξύ τους; Επειδή ακολουθούν συγκεκριμένες οδηγίες (εντολές).
.") Κεφάλαιο 5 Πως μπορούν τα μέρη του υλικού ενός υπολογιστή να επικοινωνούν και να συνεργάζονται μεταξύ τους; Επειδή ακολουθούν συγκεκριμένες οδηγίες (εντολές). Το σύνολο αυτών των εντολών το ονομάζουμε
Κεφάλαιο 5 Πως μπορούν τα μέρη του υλικού ενός υπολογιστή να επικοινωνούν και να συνεργάζονται μεταξύ τους; Επειδή ακολουθούν συγκεκριμένες οδηγίες (εντολές). Το σύνολο αυτών των εντολών το ονομάζουμε
Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών. Aσφάλεια
 Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών Aσφάλεια ΣΤΟΧΟΙ ΚΕΦΑΛΑΙΟΥ Ορισµός τριών στόχων ασφάλειας - Εµπιστευτικότητα, ακεραιότητα και διαθεσιµότητα Επιθέσεις Υπηρεσίες και Τεχνικές
Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών Aσφάλεια ΣΤΟΧΟΙ ΚΕΦΑΛΑΙΟΥ Ορισµός τριών στόχων ασφάλειας - Εµπιστευτικότητα, ακεραιότητα και διαθεσιµότητα Επιθέσεις Υπηρεσίες και Τεχνικές
Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών. Aσφάλεια
 Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών Aσφάλεια Περιεχόμενα Πλευρές Ασφάλειας Ιδιωτικό Απόρρητο Μέθοδος Μυστικού Κλειδιού (Συμμετρική Κρυπτογράφηση) Μέθοδος Δημόσιου Κλειδιού (Ασύμμετρη
Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών Aσφάλεια Περιεχόμενα Πλευρές Ασφάλειας Ιδιωτικό Απόρρητο Μέθοδος Μυστικού Κλειδιού (Συμμετρική Κρυπτογράφηση) Μέθοδος Δημόσιου Κλειδιού (Ασύμμετρη
SNMP ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΟΥ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ
 Κεφάλαιο 4 SNMP ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΟΥ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ 1 4.1 ΕΙΣΑΓΩΓΗ...3 4.2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ...3 4.2.1 Η ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΤΗΣ ΔΙΑΧΕΙΡΙΣΗΣ ΔΙΚΤΥΟΥ...3 4.2.1.1 ΣΤΑΘΜΟΣ ΔΙΑΧΕΙΡΙΣΗΣ ΔΙΚΤΥΟΥ...4 4.2.1.2 ΔΙΑΧΕΙΡΙΖΟΜΕΝΟΙ
Κεφάλαιο 4 SNMP ΔΙΑΧΕΙΡΙΣΗ ΔΙΚΤΥΟΥ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ 1 4.1 ΕΙΣΑΓΩΓΗ...3 4.2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ...3 4.2.1 Η ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΤΗΣ ΔΙΑΧΕΙΡΙΣΗΣ ΔΙΚΤΥΟΥ...3 4.2.1.1 ΣΤΑΘΜΟΣ ΔΙΑΧΕΙΡΙΣΗΣ ΔΙΚΤΥΟΥ...4 4.2.1.2 ΔΙΑΧΕΙΡΙΖΟΜΕΝΟΙ
Εισαγωγή στην πληροφορική
 Εισαγωγή στην πληροφορική Ενότητα 5: Δικτύωση και Διαδίκτυο II Πασχαλίδης Δημοσθένης Τμήμα Ιερατικών Σπουδών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Εισαγωγή στην πληροφορική Ενότητα 5: Δικτύωση και Διαδίκτυο II Πασχαλίδης Δημοσθένης Τμήμα Ιερατικών Σπουδών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Πολιτική Προστασίας Ιδιωτικότητας και Προσωπικών Δεδομένων στον Δήμο Καλαμαριάς. 2 Πολιτική Προστασίας Ιδιωτικότητας και Προσωπικών Δεδομένων
 Πολιτική Προστασίας Ιδιωτικότητας και Προσωπικών Δεδομένων στον Δήμο Καλαμαριάς 1 Εισαγωγή Στις καθημερινές του δραστηριότητες, ο Δήμος Καλαμαριάς χρησιμοποιεί μία πληθώρα δεδομένων, τα οποία αφορούν σε
Πολιτική Προστασίας Ιδιωτικότητας και Προσωπικών Δεδομένων στον Δήμο Καλαμαριάς 1 Εισαγωγή Στις καθημερινές του δραστηριότητες, ο Δήμος Καλαμαριάς χρησιμοποιεί μία πληθώρα δεδομένων, τα οποία αφορούν σε
ΚΡΥΠΤΟΓΡΑΦΙΑ ΚΑΙ ΑΣΦΑΛΕΙΑ ΥΠΟΛΟΓΙΣΤΩΝ. Δ Εξάμηνο
 ΚΡΥΠΤΟΓΡΑΦΙΑ ΚΑΙ ΑΣΦΑΛΕΙΑ ΥΠΟΛΟΓΙΣΤΩΝ Δ Εξάμηνο Εισαγωγή- Βασικές Έννοιες Διδάσκων : Δρ. Παρασκευάς Κίτσος Επίκουρος Καθηγητής e-mail: pkitsos@teimes.gr, pkitsos@ieee.org Αντίρριο 2015 1 ΤΙ ΕΙΝΑΙ Η ΚΡΥΠΤΟΛΟΓΙΑ?
ΚΡΥΠΤΟΓΡΑΦΙΑ ΚΑΙ ΑΣΦΑΛΕΙΑ ΥΠΟΛΟΓΙΣΤΩΝ Δ Εξάμηνο Εισαγωγή- Βασικές Έννοιες Διδάσκων : Δρ. Παρασκευάς Κίτσος Επίκουρος Καθηγητής e-mail: pkitsos@teimes.gr, pkitsos@ieee.org Αντίρριο 2015 1 ΤΙ ΕΙΝΑΙ Η ΚΡΥΠΤΟΛΟΓΙΑ?
Στόχος της ψυχολογικής έρευνας:
 Στόχος της ψυχολογικής έρευνας: Συστηματική περιγραφή και κατανόηση των ψυχολογικών φαινομένων. Η ψυχολογική έρευνα χρησιμοποιεί μεθόδους συστηματικής διερεύνησης για τη συλλογή, την ανάλυση και την ερμηνεία
Στόχος της ψυχολογικής έρευνας: Συστηματική περιγραφή και κατανόηση των ψυχολογικών φαινομένων. Η ψυχολογική έρευνα χρησιμοποιεί μεθόδους συστηματικής διερεύνησης για τη συλλογή, την ανάλυση και την ερμηνεία
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων
 Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων 1 Εισαγωγή Στις καθημερινές επιχειρηματικές λειτουργίες, η FHL Η.ΚΥΡΙΑΚΙΔΗΣ Α.Β.Ε.Ε. χρησιμοποιεί μία πληθώρα δεδομένων που αφορούν
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων 1 Εισαγωγή Στις καθημερινές επιχειρηματικές λειτουργίες, η FHL Η.ΚΥΡΙΑΚΙΔΗΣ Α.Β.Ε.Ε. χρησιμοποιεί μία πληθώρα δεδομένων που αφορούν
ΑΣΦΑΛΕΙΕΣ ΣΤΑ ΔΙΚΤΥΑ
 ΑΝΩΤΑΤΟ ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΑΡΤΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΑΣΦΑΛΕΙΕΣ ΣΤΑ ΔΙΚΤΥΑ ΤΜΗΜΑ: ΤΗΛΕΠΛΗΡΟΦΟΡΙΚΗΣ Σ.Δ.Ο ΣΠΟΥΔΑΣΤΕΣ ΚΥΡΙΤΣΗΣ ΧΑΡΙΛΑΟΣ ΣΑΒΒΑΛΑΚΗΣ ΝΙΚΟΛΑΟΣ ΣΤΟΧΟΙ ΤΗΣ ΑΣΦΑΛΕΙΑΣ: ΜΥΣΤΙΚΟΤΗΤΑ ΑΚΕΡΑΙΟΤΗΤΑ
ΑΝΩΤΑΤΟ ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΑΡΤΑΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΑΣΦΑΛΕΙΕΣ ΣΤΑ ΔΙΚΤΥΑ ΤΜΗΜΑ: ΤΗΛΕΠΛΗΡΟΦΟΡΙΚΗΣ Σ.Δ.Ο ΣΠΟΥΔΑΣΤΕΣ ΚΥΡΙΤΣΗΣ ΧΑΡΙΛΑΟΣ ΣΑΒΒΑΛΑΚΗΣ ΝΙΚΟΛΑΟΣ ΣΤΟΧΟΙ ΤΗΣ ΑΣΦΑΛΕΙΑΣ: ΜΥΣΤΙΚΟΤΗΤΑ ΑΚΕΡΑΙΟΤΗΤΑ
Ημερομηνία: 2 Μαρτίου Ευρωπαϊκό Δίκτυο Διαχειριστών Συστημάτων Μεταφοράς Ηλεκτρικής Ενέργειας
 Ευρωπαϊκό Δίκτυο Διαχειριστών Συστημάτων Μεταφοράς Ηλεκτρικής Ενέργειας Πρόταση όλων των ΔΣΜ της Ηπειρωτικής Ευρώπης (CE) και της Σκανδιναβίας για τις παραδοχές και τη μεθοδολογία ανάλυσης κόστους/οφέλους
Ευρωπαϊκό Δίκτυο Διαχειριστών Συστημάτων Μεταφοράς Ηλεκτρικής Ενέργειας Πρόταση όλων των ΔΣΜ της Ηπειρωτικής Ευρώπης (CE) και της Σκανδιναβίας για τις παραδοχές και τη μεθοδολογία ανάλυσης κόστους/οφέλους
Ασφάλεια Υπολογιστικών Συστημάτων
 Ασφάλεια Υπολογιστικών Συστημάτων Ενότητα 7: Εισβολείς Νικολάου Σπύρος Τμήμα Μηχανικών Πληροφορικής ΤΕ Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Ασφάλεια Υπολογιστικών Συστημάτων Ενότητα 7: Εισβολείς Νικολάου Σπύρος Τμήμα Μηχανικών Πληροφορικής ΤΕ Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Ασφαλίστε τις εμπιστευτικές πληροφορίες σας.
 Ασφαλίστε τις εμπιστευτικές πληροφορίες σας. Οι υπολογιστές σας προφυλάσσονται πλέον χάρη στην εξελιγμένη τεχνολογία με τείχη προστασίας, προγράμματα έναντι ιών, ακόμα και με την κρυπτογράφηση δεδομένων.
Ασφαλίστε τις εμπιστευτικές πληροφορίες σας. Οι υπολογιστές σας προφυλάσσονται πλέον χάρη στην εξελιγμένη τεχνολογία με τείχη προστασίας, προγράμματα έναντι ιών, ακόμα και με την κρυπτογράφηση δεδομένων.
Ενότητα 12 (κεφάλαιο 28) Αρχιτεκτονικές Εφαρμογών
 Αρχιτεκτονικές Εφαρμογών") ΕΠΛ362: Τεχνολογία Λογισμικού ΙΙ (μετάφραση στα ελληνικά των διαφανειών του βιβλίου Software Engineering, 9/E, Ian Sommerville, 2011) Ενότητα 12 (κεφάλαιο 28) Αρχιτεκτονικές Εφαρμογών Οι διαφάνειες αυτές
ΕΠΛ362: Τεχνολογία Λογισμικού ΙΙ (μετάφραση στα ελληνικά των διαφανειών του βιβλίου Software Engineering, 9/E, Ian Sommerville, 2011) Ενότητα 12 (κεφάλαιο 28) Αρχιτεκτονικές Εφαρμογών Οι διαφάνειες αυτές
Τεχνολογίες & Εφαρμογές Πληροφορικής Ενότητα 10: Ασφάλεια στο Διαδίκτυο
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΙΚΑ ΜΑΘΗΜΑΤΑ Τεχνολογίες & Εφαρμογές Πληροφορικής Ενότητα 10: Ασφάλεια στο Διαδίκτυο Ανδρέας Βέγλης, Αναπληρωτής Καθηγητής Άδειες Χρήσης Το παρόν εκπαιδευτικό
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΙΚΑ ΜΑΘΗΜΑΤΑ Τεχνολογίες & Εφαρμογές Πληροφορικής Ενότητα 10: Ασφάλεια στο Διαδίκτυο Ανδρέας Βέγλης, Αναπληρωτής Καθηγητής Άδειες Χρήσης Το παρόν εκπαιδευτικό
Ασφάλεια Δικτύων. Τι (δεν) είναι Ασφάλεια Δικτύων. Γιάννης Ηλιάδης Υπεύθυνος Ασφάλειας Δικτύου ΤΕΙΡΕΣΙΑΣ Α.Ε. 24/11/07
 είναι Ασφάλεια Δικτύων. Γιάννης Ηλιάδης Υπεύθυνος Ασφάλειας Δικτύου ΤΕΙΡΕΣΙΑΣ Α.Ε. 24/11/07") Ασφάλεια Δικτύων Τι (δεν) είναι Ασφάλεια Δικτύων Γιάννης Ηλιάδης Υπεύθυνος Ασφάλειας Δικτύου ΤΕΙΡΕΣΙΑΣ Α.Ε. 24/11/07 Περίμετρος Δικτύου Αποτελεί κρίσιμο ζήτημα η περιφρούρηση της περιμέτρου δικτύου Έλεγχος
Ασφάλεια Δικτύων Τι (δεν) είναι Ασφάλεια Δικτύων Γιάννης Ηλιάδης Υπεύθυνος Ασφάλειας Δικτύου ΤΕΙΡΕΣΙΑΣ Α.Ε. 24/11/07 Περίμετρος Δικτύου Αποτελεί κρίσιμο ζήτημα η περιφρούρηση της περιμέτρου δικτύου Έλεγχος
Περίληψη Λαμπρόπουλος
 Περίληψη Λαμπρόπουλος 1. Αντικείμενο και Περιγραφή της Διατριβής H διδακτορική διατριβή με τίτλο «Σχεδιασμός και υλοποίηση συστήματος διαχείρισης και ενοποίησης διαφορετικών ταυτοτήτων χρηστών σε δίκτυα
Περίληψη Λαμπρόπουλος 1. Αντικείμενο και Περιγραφή της Διατριβής H διδακτορική διατριβή με τίτλο «Σχεδιασμός και υλοποίηση συστήματος διαχείρισης και ενοποίησης διαφορετικών ταυτοτήτων χρηστών σε δίκτυα
Παραβίαση της ασφάλειας των προσωπικών δεδομένων
 Παραβίαση της ασφάλειας των προσωπικών δεδομένων Ενέργειες των επιχειρήσεων πριν από την επιβολή κυρώσεων Δήμητρα Γαμπά ΜΔΕ, ΚΔΕΟΔ Δύο είναι οι βασικές εκφάνσεις μίας πολιτικής ασφάλειας των προσωπικών
Παραβίαση της ασφάλειας των προσωπικών δεδομένων Ενέργειες των επιχειρήσεων πριν από την επιβολή κυρώσεων Δήμητρα Γαμπά ΜΔΕ, ΚΔΕΟΔ Δύο είναι οι βασικές εκφάνσεις μίας πολιτικής ασφάλειας των προσωπικών
ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΠΡΟΣΩΠΙΚΩΝ ΔΕΔΟΜΕΝΩΝ
 ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΠΡΟΣΩΠΙΚΩΝ ΔΕΔΟΜΕΝΩΝ Η διαχείριση και προστασία των προσωπικών δεδομένων του επισκέπτη/χρήστη της ιστοσελίδας της ADVITY IKE, που στο εξής θα αναφέρεται ως ADVITY, υπόκειται στους όρους
ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΠΡΟΣΩΠΙΚΩΝ ΔΕΔΟΜΕΝΩΝ Η διαχείριση και προστασία των προσωπικών δεδομένων του επισκέπτη/χρήστη της ιστοσελίδας της ADVITY IKE, που στο εξής θα αναφέρεται ως ADVITY, υπόκειται στους όρους
Ασφάλεια Υπολογιστικών Συστηµάτων
 Βασικές έννοιες Γεγονός (event) σε ένα υπολογιστικό σύστηµα ή δίκτυο: οτιδήποτε µπορεί να συµβεί σε αυτό, π.χ. η είσοδος ενός χρήστη, η εκτέλεση ενός προγράµµατος, κλπ. ιαδικασίες παρακολούθησης δραστηριότητας
Βασικές έννοιες Γεγονός (event) σε ένα υπολογιστικό σύστηµα ή δίκτυο: οτιδήποτε µπορεί να συµβεί σε αυτό, π.χ. η είσοδος ενός χρήστη, η εκτέλεση ενός προγράµµατος, κλπ. ιαδικασίες παρακολούθησης δραστηριότητας
Κεφάλαιο 4: Λογισμικό Συστήματος
 Κεφάλαιο 4: Λογισμικό Συστήματος Ερωτήσεις 1. Να αναφέρετε συνοπτικά τις κατηγορίες στις οποίες διακρίνεται το λογισμικό συστήματος. Σε ποια ευρύτερη κατηγορία εντάσσεται αυτό; Το λογισμικό συστήματος
Κεφάλαιο 4: Λογισμικό Συστήματος Ερωτήσεις 1. Να αναφέρετε συνοπτικά τις κατηγορίες στις οποίες διακρίνεται το λογισμικό συστήματος. Σε ποια ευρύτερη κατηγορία εντάσσεται αυτό; Το λογισμικό συστήματος
Πολιτική Ιδιωτικότητας και Προστασίας Δεδομένων Προσωπικού Χαρακτήρα
 Πολιτική Ιδιωτικότητας και Προστασίας Δεδομένων Προσωπικού Χαρακτήρα Νοέμβριος 2018 Περιεχόμενα 1 ΕΙΣΑΓΩΓΗ... 2 2 ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΤΗΣ ΙΔΙΩΤΙΚΟΤΗΤΑΣ ΚΑΙ ΤΩΝ ΔΕΔΟΜΕΝΩΝ ΠΡΟΣΩΠΙΚΟΥ ΧΑΡΑΚΤΗΡΑ... 3 2.1 Ο
Πολιτική Ιδιωτικότητας και Προστασίας Δεδομένων Προσωπικού Χαρακτήρα Νοέμβριος 2018 Περιεχόμενα 1 ΕΙΣΑΓΩΓΗ... 2 2 ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΤΗΣ ΙΔΙΩΤΙΚΟΤΗΤΑΣ ΚΑΙ ΤΩΝ ΔΕΔΟΜΕΝΩΝ ΠΡΟΣΩΠΙΚΟΥ ΧΑΡΑΚΤΗΡΑ... 3 2.1 Ο
γ. Αυθεντικότητα (authentication) δ. Εγκυρότητα (validity) Μονάδες 5
 δ. Εγκυρότητα (validity) Μονάδες 5") ΠΑΝΕΛΛΑΔΙΚΕΣ ΕΞΕΤΑΣΕΙΣ ΗΜΕΡΗΣΙΩΝ ΕΠΑΛ (ΟΜΑΔΑ Α ) ΚΑΙ ΜΑΘΗΜΑΤΩΝ ΕΙΔΙΚΟΤΗΤΑΣ ΗΜΕΡΗΣΙΩΝ ΕΠΑΛ (ΟΜΑΔΑ Α ΚΑΙ Β ) ΠΑΡΑΣΚΕΥΗ 13 ΙΟΥΝΙΟΥ 2014 ΕΞΕΤΑΖΟΜΕΝΟ ΜΑΘΗΜΑ: ΔΙΚΤΥΑ ΥΠΟΛΟΓΙΣΤΩΝ ΙΙ ΘΕΜΑ Α Α1. Να χαρακτηρίσετε
ΠΑΝΕΛΛΑΔΙΚΕΣ ΕΞΕΤΑΣΕΙΣ ΗΜΕΡΗΣΙΩΝ ΕΠΑΛ (ΟΜΑΔΑ Α ) ΚΑΙ ΜΑΘΗΜΑΤΩΝ ΕΙΔΙΚΟΤΗΤΑΣ ΗΜΕΡΗΣΙΩΝ ΕΠΑΛ (ΟΜΑΔΑ Α ΚΑΙ Β ) ΠΑΡΑΣΚΕΥΗ 13 ΙΟΥΝΙΟΥ 2014 ΕΞΕΤΑΖΟΜΕΝΟ ΜΑΘΗΜΑ: ΔΙΚΤΥΑ ΥΠΟΛΟΓΙΣΤΩΝ ΙΙ ΘΕΜΑ Α Α1. Να χαρακτηρίσετε
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων
 Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων Περιεχόμενα 1 ΕΙΣΑΓΩΓΗ... 2 2 ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΤΗΣ ΙΔΙΩΤΙΚΟΤΗΤΑΣ ΚΑΙ ΤΩΝ ΔΕΔΟΜΕΝΩΝ ΠΡΟΣΩΠΙΚΟΥ ΧΑΡΑΚΤΗΡΑ... 3 2.1 Ο ΓΕΝΙΚΟΣ ΚΑΝΟΝΙΣΜΟΣ
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων Περιεχόμενα 1 ΕΙΣΑΓΩΓΗ... 2 2 ΠΟΛΙΤΙΚΗ ΠΡΟΣΤΑΣΙΑΣ ΤΗΣ ΙΔΙΩΤΙΚΟΤΗΤΑΣ ΚΑΙ ΤΩΝ ΔΕΔΟΜΕΝΩΝ ΠΡΟΣΩΠΙΚΟΥ ΧΑΡΑΚΤΗΡΑ... 3 2.1 Ο ΓΕΝΙΚΟΣ ΚΑΝΟΝΙΣΜΟΣ
Κεφάλαιο 1. Επισκόπηση
 Κεφάλαιο 1 Επισκόπηση Η ασφάλεια υπολογιστών ορίζεται στο Εγχειρίδιο ασφάλειας υπολογιστών (Computer Security Handbook) του NIST ως εξής: Η τριάδα CIA Βασικές έννοιες της ασφάλειας Εμπιστευτικότητα Η διατήρηση
Κεφάλαιο 1 Επισκόπηση Η ασφάλεια υπολογιστών ορίζεται στο Εγχειρίδιο ασφάλειας υπολογιστών (Computer Security Handbook) του NIST ως εξής: Η τριάδα CIA Βασικές έννοιες της ασφάλειας Εμπιστευτικότητα Η διατήρηση
Τείχος Προστασίας Εφαρμογών Διαδικτύου
 Τείχος Προστασίας Εφαρμογών Διαδικτύου Web Application Firewalls Ιωάννης Στάης {istais@census-labs.com} Γιατί είναι σημαντική η προστασία των εφαρμογών ιστού; Πάνω από 70% όλων των επιθέσεων συμβαίνουν
Τείχος Προστασίας Εφαρμογών Διαδικτύου Web Application Firewalls Ιωάννης Στάης {istais@census-labs.com} Γιατί είναι σημαντική η προστασία των εφαρμογών ιστού; Πάνω από 70% όλων των επιθέσεων συμβαίνουν
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ
 ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ Κ. Δεμέστιχας Εργαστήριο Πληροφορικής Γεωπονικό Πανεπιστήμιο Αθηνών Επικοινωνία μέσω e-mail: cdemest@aua.gr, cdemest@cn.ntua.gr Διαφάνειες: Καθ. Νικόλαος Λορέντζος 1 11. ΠΛΗΡΟΦΟΡΙΑΚΑ
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ Κ. Δεμέστιχας Εργαστήριο Πληροφορικής Γεωπονικό Πανεπιστήμιο Αθηνών Επικοινωνία μέσω e-mail: cdemest@aua.gr, cdemest@cn.ntua.gr Διαφάνειες: Καθ. Νικόλαος Λορέντζος 1 11. ΠΛΗΡΟΦΟΡΙΑΚΑ
Διαδικτυακό Περιβάλλον Διαχείρισης Ασκήσεων Προγραμματισμού
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ Διπλωματική Εργασία με θέμα: Διαδικτυακό Περιβάλλον Διαχείρισης Ασκήσεων Προγραμματισμού Καραγιάννης Ιωάννης Α.Μ.
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ Διπλωματική Εργασία με θέμα: Διαδικτυακό Περιβάλλον Διαχείρισης Ασκήσεων Προγραμματισμού Καραγιάννης Ιωάννης Α.Μ.
Δεδομένα υπό πολιορκία
 Δεδομένα υπό πολιορκία Πραγματικά περιστατικά απώλειας & διαρροής δεδομένων και πώς μπορείτε να προστατέψετε την προσωπική και την εταιρική σας ψηφιακή περιουσία Παναγιώτης Πιέρρος Managing Director της
Δεδομένα υπό πολιορκία Πραγματικά περιστατικά απώλειας & διαρροής δεδομένων και πώς μπορείτε να προστατέψετε την προσωπική και την εταιρική σας ψηφιακή περιουσία Παναγιώτης Πιέρρος Managing Director της
Εισαγωγή στην επιστήμη της Πληροφορικής και των. Aσφάλεια
 Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών Aσφάλεια Περιεχόμενα Πλευρές Ασφάλειας Ιδιωτικό Απόρρητο Μέθοδος Μυστικού Κλειδιού (Συμμετρική Κρυπτογράφηση) Μέθοδος Δημόσιου Κλειδιού (Ασύμμετρη
Εισαγωγή στην επιστήμη της Πληροφορικής και των Τηλεπικοινωνιών Aσφάλεια Περιεχόμενα Πλευρές Ασφάλειας Ιδιωτικό Απόρρητο Μέθοδος Μυστικού Κλειδιού (Συμμετρική Κρυπτογράφηση) Μέθοδος Δημόσιου Κλειδιού (Ασύμμετρη
Ενότητα 1: Εισαγωγή. ΤΕΙ Στερεάς Ελλάδας. Τμήμα Φυσικοθεραπείας. Προπτυχιακό Πρόγραμμα. Μάθημα: Βιοστατιστική-Οικονομία της υγείας Εξάμηνο: Ε (5 ο )
") ΤΕΙ Στερεάς Ελλάδας Τμήμα Φυσικοθεραπείας Προπτυχιακό Πρόγραμμα Μάθημα: Βιοστατιστική-Οικονομία της υγείας Εξάμηνο: Ε (5 ο ) Ενότητα 1: Εισαγωγή Δρ. Χρήστος Γενιτσαρόπουλος Λαμία, 2017 1.1. Σκοπός και
ΤΕΙ Στερεάς Ελλάδας Τμήμα Φυσικοθεραπείας Προπτυχιακό Πρόγραμμα Μάθημα: Βιοστατιστική-Οικονομία της υγείας Εξάμηνο: Ε (5 ο ) Ενότητα 1: Εισαγωγή Δρ. Χρήστος Γενιτσαρόπουλος Λαμία, 2017 1.1. Σκοπός και
Τεχνικές Εκτίμησης Υπολογιστικών Συστημάτων Ενότητα 7: Η επιλογή των πιθανοτικών κατανομών εισόδου
 Τεχνικές Εκτίμησης Υπολογιστικών Συστημάτων Ενότητα 7: Η επιλογή των πιθανοτικών κατανομών εισόδου Γαροφαλάκης Ιωάννης Πολυτεχνική Σχολή Τμήμα Μηχ/κών Η/Υ & Πληροφορικής Περιεχόμενα ενότητας Εισαγωγή Συλλογή
Τεχνικές Εκτίμησης Υπολογιστικών Συστημάτων Ενότητα 7: Η επιλογή των πιθανοτικών κατανομών εισόδου Γαροφαλάκης Ιωάννης Πολυτεχνική Σχολή Τμήμα Μηχ/κών Η/Υ & Πληροφορικής Περιεχόμενα ενότητας Εισαγωγή Συλλογή
ΟΡΟΙ & ΠΡΟΥΠΟΘΕΣΕΙΣ Α. ΓΕΝΙΚΟΙ ΟΡΟΙ
 ΟΡΟΙ & ΠΡΟΥΠΟΘΕΣΕΙΣ Α. ΓΕΝΙΚΟΙ ΟΡΟΙ 1. Εισαγωγή : Ο παρών διαδικτυακός τόπος αποτελεί την ηλεκτρονική ιστοσελίδα της ανώνυμης εταιρίας με την επωνυμία ΠΕΤΡΟΓΚΑΖ ΑΝΩΝΥΜΗ ΕΛΛΗΝΙΚΗ ΕΤΑΙΡΕΙΑ ΥΓΡΑΕΡΙΩΝ, ΒΙΟΜΗΧΑΝΙΚΩΝ
ΟΡΟΙ & ΠΡΟΥΠΟΘΕΣΕΙΣ Α. ΓΕΝΙΚΟΙ ΟΡΟΙ 1. Εισαγωγή : Ο παρών διαδικτυακός τόπος αποτελεί την ηλεκτρονική ιστοσελίδα της ανώνυμης εταιρίας με την επωνυμία ΠΕΤΡΟΓΚΑΖ ΑΝΩΝΥΜΗ ΕΛΛΗΝΙΚΗ ΕΤΑΙΡΕΙΑ ΥΓΡΑΕΡΙΩΝ, ΒΙΟΜΗΧΑΝΙΚΩΝ
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ
 ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
DDoS (Denial of Service Attacks)
") Το Πρόβλημα των Επιθέσεων DoS/DDoS DDoS (Denial of Service Attacks) Γεώργιος Κουτέπας, Γεώργιος Αδαμόπουλος Τράπεζα Πληροφοριών του ΤΕΕ Ημερίδα: Ηλεκτρονικές Επικοινωνίες Πόσο Ασφαλείς είναι; Τεχνικό Επιμελητήριο
Το Πρόβλημα των Επιθέσεων DoS/DDoS DDoS (Denial of Service Attacks) Γεώργιος Κουτέπας, Γεώργιος Αδαμόπουλος Τράπεζα Πληροφοριών του ΤΕΕ Ημερίδα: Ηλεκτρονικές Επικοινωνίες Πόσο Ασφαλείς είναι; Τεχνικό Επιμελητήριο
(Εννοιολογική θεμελίωση)
") ΑΥΑΛΕΙΑ ΔΕΔΟΜΕΝΩΝ ΣΗΝ ΚΟΙΝΩΝΙΑ ΣΗ ΠΛΗΡΟΥΟΡΙΑ (Εννοιολογική θεμελίωση) Καλλονιάτης Χρήστος Λέκτορας Τμήμα Πολιτισμικής Τεχνολογίας και Επικοινωνίας, Πανεπιστήμιο Αιγαίου http://www.aegean.gr/culturaltec/kalloniatis
ΑΥΑΛΕΙΑ ΔΕΔΟΜΕΝΩΝ ΣΗΝ ΚΟΙΝΩΝΙΑ ΣΗ ΠΛΗΡΟΥΟΡΙΑ (Εννοιολογική θεμελίωση) Καλλονιάτης Χρήστος Λέκτορας Τμήμα Πολιτισμικής Τεχνολογίας και Επικοινωνίας, Πανεπιστήμιο Αιγαίου http://www.aegean.gr/culturaltec/kalloniatis
ISMS κατά ISO Δεκέμβριος 2016
 ISMS κατά ISO 27001 Δεκέμβριος 2016 E-mail: info@motive.com.gr, Web: www.motive.com.gr ISO 27001:2013 Το ISO 27001:2013 είναι ένα διεθνώς αναγνωρισμένο πρότυπο το οποίο προσδιορίζει τις προδιαγραφές για
ISMS κατά ISO 27001 Δεκέμβριος 2016 E-mail: info@motive.com.gr, Web: www.motive.com.gr ISO 27001:2013 Το ISO 27001:2013 είναι ένα διεθνώς αναγνωρισμένο πρότυπο το οποίο προσδιορίζει τις προδιαγραφές για
Αρχιτεκτονική Ασφάλειας
 Αρχιτεκτονική Ασφάλειας Τμήμα Μηχανικών Πληροφορικής ΤΕΙ Κρήτης Αρχιτεκτονική Ασφάλειας 1 Ασφάλεια Πληροφοριών Η ασφάλεια ενός οποιουδήποτε συστήματος ασχολείται με την προστασία αντικειμένων που έχουν
Αρχιτεκτονική Ασφάλειας Τμήμα Μηχανικών Πληροφορικής ΤΕΙ Κρήτης Αρχιτεκτονική Ασφάλειας 1 Ασφάλεια Πληροφοριών Η ασφάλεια ενός οποιουδήποτε συστήματος ασχολείται με την προστασία αντικειμένων που έχουν
Περιεχόμενα. Πρόλογος... 15
 Περιεχόμενα Πρόλογος... 15 Κεφάλαιο 1 ΘΕΩΡΗΤΙΚΑ ΚΑΙ ΦΙΛΟΣΟΦΙΚΑ ΟΝΤΟΛΟΓΙΚΑ ΚΑΙ ΕΠΙΣΤΗΜΟΛΟΓΙΚΑ ΖΗΤΗΜΑΤΑ ΤΗΣ ΜΕΘΟΔΟΛΟΓΙΑΣ ΕΡΕΥΝΑΣ ΤΟΥ ΠΡΑΓΜΑΤΙΚΟΥ ΚΟΣΜΟΥ... 17 Το θεμελιώδες πρόβλημα των κοινωνικών επιστημών...
Περιεχόμενα Πρόλογος... 15 Κεφάλαιο 1 ΘΕΩΡΗΤΙΚΑ ΚΑΙ ΦΙΛΟΣΟΦΙΚΑ ΟΝΤΟΛΟΓΙΚΑ ΚΑΙ ΕΠΙΣΤΗΜΟΛΟΓΙΚΑ ΖΗΤΗΜΑΤΑ ΤΗΣ ΜΕΘΟΔΟΛΟΓΙΑΣ ΕΡΕΥΝΑΣ ΤΟΥ ΠΡΑΓΜΑΤΙΚΟΥ ΚΟΣΜΟΥ... 17 Το θεμελιώδες πρόβλημα των κοινωνικών επιστημών...
Αρχές Δικτύων Επικοινωνιών. Επικοινωνίες Δεδομένων Μάθημα 4 ο
 Αρχές Δικτύων Επικοινωνιών Επικοινωνίες Δεδομένων Μάθημα 4 ο Τα επικοινωνιακά δίκτυα και οι ανάγκες που εξυπηρετούν Για την επικοινωνία δύο συσκευών απαιτείται να υπάρχει μεταξύ τους σύνδεση από σημείο
Αρχές Δικτύων Επικοινωνιών Επικοινωνίες Δεδομένων Μάθημα 4 ο Τα επικοινωνιακά δίκτυα και οι ανάγκες που εξυπηρετούν Για την επικοινωνία δύο συσκευών απαιτείται να υπάρχει μεταξύ τους σύνδεση από σημείο
Ανάλυση Απαιτήσεων Απαιτήσεις Λογισµικού
 ΧΑΡΟΚΟΠΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΜΑΤΙΚΗΣ Ανάλυση Απαιτήσεων Απαιτήσεις Λογισµικού Μάρα Νικολαϊδου Δραστηριότητες Διαδικασιών Παραγωγής Λογισµικού Καθορισµός απαιτήσεων και εξαγωγή προδιαγραφών
ΧΑΡΟΚΟΠΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΜΑΤΙΚΗΣ Ανάλυση Απαιτήσεων Απαιτήσεις Λογισµικού Μάρα Νικολαϊδου Δραστηριότητες Διαδικασιών Παραγωγής Λογισµικού Καθορισµός απαιτήσεων και εξαγωγή προδιαγραφών
Εργαστήριο Ασφάλεια Πληροφοριακών Συστημάτων. PGP (Pretty Good Privacy)
") Εργαστήριο Ασφάλεια Πληροφοριακών Συστημάτων PGP (Pretty Good Privacy) Εισαγωγή Το λογισμικό Pretty Good Privacy (PGP), το οποίο σχεδιάστηκε από τον Phill Zimmerman, είναι ένα λογισμικό κρυπτογράφησης
Εργαστήριο Ασφάλεια Πληροφοριακών Συστημάτων PGP (Pretty Good Privacy) Εισαγωγή Το λογισμικό Pretty Good Privacy (PGP), το οποίο σχεδιάστηκε από τον Phill Zimmerman, είναι ένα λογισμικό κρυπτογράφησης
Πολιτική Απορρήτου (07/2016)
") ΕΛΛΗΝΙΚΟ ΚΕΙΜΕΝΟ Πολιτική Απορρήτου (07/2016) Η CELLebrate είναι μια ιδιωτική εταιρεία με βάση το Ισραήλ, με κέντρο επιχειρηματικής δραστηριότητας στη διεύθυνση Box Office 211, Kiryat Chayim, Haifa. Η
ΕΛΛΗΝΙΚΟ ΚΕΙΜΕΝΟ Πολιτική Απορρήτου (07/2016) Η CELLebrate είναι μια ιδιωτική εταιρεία με βάση το Ισραήλ, με κέντρο επιχειρηματικής δραστηριότητας στη διεύθυνση Box Office 211, Kiryat Chayim, Haifa. Η
ΚΡΥΠΤΟΓΡΑΦΙΑ ΚΑΙ ΑΣΦΑΛΕΙΑ ΥΠΟΛΟΓΙΣΤΩΝ. Δ Εξάμηνο
 ΚΡΥΠΤΟΓΡΑΦΙΑ ΚΑΙ ΑΣΦΑΛΕΙΑ ΥΠΟΛΟΓΙΣΤΩΝ Δ Εξάμηνο Εισαγωγή- Βασικές Έννοιες Διδάσκων : Δρ. Παρασκευάς Κίτσος diceslab.cied.teiwest.gr Επίκουρος Καθηγητής Εργαστήριο Σχεδίασης Ψηφιακών Ολοκληρωμένων Κυκλωμάτων
ΚΡΥΠΤΟΓΡΑΦΙΑ ΚΑΙ ΑΣΦΑΛΕΙΑ ΥΠΟΛΟΓΙΣΤΩΝ Δ Εξάμηνο Εισαγωγή- Βασικές Έννοιες Διδάσκων : Δρ. Παρασκευάς Κίτσος diceslab.cied.teiwest.gr Επίκουρος Καθηγητής Εργαστήριο Σχεδίασης Ψηφιακών Ολοκληρωμένων Κυκλωμάτων
«ΣΥΓΧΡΟΝΑ ΕΡΓΑΛΕΙΑ, ΤΕΧΝΙΚΕΣ ΚΑΙ ΜΕΘΟΔΟΛΟΓΙΕΣ ΓΙΑ ΤΟ ΧΑΡΑΚΤΗΡΙΣΜΟ ΚΥΒΕΡΝΟΕΠΙΘΕΣΕΩΝ ΚΑΙ ΚΑΚΟΒΟΥΛΟΥ Λ ΟΓΙΣΜΙΚΟΥ»
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Π.Μ.Σ ΤΜΗΜΑΤΟΣ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ «ΣΥΓΧΡΟΝΑ ΕΡΓΑΛΕΙΑ, ΤΕΧΝΙΚΕΣ ΚΑΙ ΜΕΘΟΔΟΛΟΓΙΕΣ ΓΙΑ ΤΟ ΧΑΡΑΚΤΗΡΙΣΜΟ ΚΥΒΕΡΝΟΕΠΙΘΕΣΕΩΝ ΚΑΙ ΚΑΚΟΒΟΥΛΟΥ Λ ΟΓΙΣΜΙΚΟΥ» Δ Ι Π Λ Ω Μ Α Τ Ι Κ Η Ε Ρ
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Π.Μ.Σ ΤΜΗΜΑΤΟΣ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ «ΣΥΓΧΡΟΝΑ ΕΡΓΑΛΕΙΑ, ΤΕΧΝΙΚΕΣ ΚΑΙ ΜΕΘΟΔΟΛΟΓΙΕΣ ΓΙΑ ΤΟ ΧΑΡΑΚΤΗΡΙΣΜΟ ΚΥΒΕΡΝΟΕΠΙΘΕΣΕΩΝ ΚΑΙ ΚΑΚΟΒΟΥΛΟΥ Λ ΟΓΙΣΜΙΚΟΥ» Δ Ι Π Λ Ω Μ Α Τ Ι Κ Η Ε Ρ
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων
 Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων Διαβάθμιση Εγγράφου: Κωδικός Εγγράφου: GDPR-DOC-17 Έκδοση: 1η Ημερομηνία: 7 Μαΐου 2018 Συγγραφέας: Ομάδα Υλοποίησης Συμμόρφωσης
Πολιτική για την Ιδιωτικότητα και την Προστασία των Προσωπικών Δεδομένων Διαβάθμιση Εγγράφου: Κωδικός Εγγράφου: GDPR-DOC-17 Έκδοση: 1η Ημερομηνία: 7 Μαΐου 2018 Συγγραφέας: Ομάδα Υλοποίησης Συμμόρφωσης
Ασφάλεια Πληροφοριακών Συστημάτων
 Ανοικτά Ακαδημαϊκά Μαθήματα στο ΤΕΙ Ιονίων Νήσων Ασφάλεια Πληροφοριακών Συστημάτων Ενότητα 8: Επιθέσεις Το περιεχόμενο του μαθήματος διατίθεται με άδεια Creative Commons εκτός και αν αναφέρεται διαφορετικά
Ανοικτά Ακαδημαϊκά Μαθήματα στο ΤΕΙ Ιονίων Νήσων Ασφάλεια Πληροφοριακών Συστημάτων Ενότητα 8: Επιθέσεις Το περιεχόμενο του μαθήματος διατίθεται με άδεια Creative Commons εκτός και αν αναφέρεται διαφορετικά
8.3.4 Τεχνικές Ασφάλειας Συμμετρική Κρυπτογράφηση Ασυμμετρική Κρυπτογράφηση Ψηφιακές Υπογραφές
 Κεφάλαιο 8 8.3.4 Τεχνικές Ασφάλειας Συμμετρική Κρυπτογράφηση Ασυμμετρική Κρυπτογράφηση Ψηφιακές Υπογραφές Σελ. 320-325 Γεώργιος Γιαννόπουλος ΠΕ19, ggiannop (at) sch.gr http://diktya-epal-g.ggia.info/ Creative
Κεφάλαιο 8 8.3.4 Τεχνικές Ασφάλειας Συμμετρική Κρυπτογράφηση Ασυμμετρική Κρυπτογράφηση Ψηφιακές Υπογραφές Σελ. 320-325 Γεώργιος Γιαννόπουλος ΠΕ19, ggiannop (at) sch.gr http://diktya-epal-g.ggia.info/ Creative
1. Τι είναι ακεραιότητα δεδομένων, με ποιους μηχανισμούς επιτυγχάνετε κ πότε θα χρησιμοποιούσατε τον καθένα εξ αυτών;
 1. Τι είναι ακεραιότητα δεδομένων, με ποιους μηχανισμούς επιτυγχάνετε κ πότε θα χρησιμοποιούσατε τον καθένα εξ αυτών; Η ακεραιότητα δεδομένων(data integrity) Είναι η ιδιότητα που μας εξασφαλίζει ότι δεδομένα
1. Τι είναι ακεραιότητα δεδομένων, με ποιους μηχανισμούς επιτυγχάνετε κ πότε θα χρησιμοποιούσατε τον καθένα εξ αυτών; Η ακεραιότητα δεδομένων(data integrity) Είναι η ιδιότητα που μας εξασφαλίζει ότι δεδομένα
ΚΕΦΑΛΑΙΟ 12: Επίλυση Προβλημάτων Δικτύων Εισαγωγή
 ΚΕΦΑΛΑΙΟ 12: Επίλυση Προβλημάτων Δικτύων 12.1. Εισαγωγή Τα προβλήματα δικτύων είναι μια πολύ συνηθισμένη κατάσταση για τους περισσότερους χρήστες υπολογιστών. Στην ενότητα αυτή θα προσπαθήσουμε να καλύψουμε
ΚΕΦΑΛΑΙΟ 12: Επίλυση Προβλημάτων Δικτύων 12.1. Εισαγωγή Τα προβλήματα δικτύων είναι μια πολύ συνηθισμένη κατάσταση για τους περισσότερους χρήστες υπολογιστών. Στην ενότητα αυτή θα προσπαθήσουμε να καλύψουμε
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Εξαγωγή γεωγραφικής πληροφορίας από δεδομένα παρεχόμενα από χρήστες του
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Εξαγωγή γεωγραφικής πληροφορίας από δεδομένα παρεχόμενα από χρήστες του
ΕΠΙΚΟΙΝΩΝΙΕΣ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΕΣ INTERNET
 ΕΠΙΚΟΙΝΩΝΙΕΣ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΕΣ INTERNET Κεφάλαιο 4: Τεχνικές Μετάδοσης ΜΕΤΑΓΩΓΗ Τεχνική µεταγωγής ονομάζεται ο τρόπος µε τον οποίο αποκαθίσταται η επικοινωνία ανάµεσα σε δύο κόµβους με σκοπό την
ΕΠΙΚΟΙΝΩΝΙΕΣ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΕΣ INTERNET Κεφάλαιο 4: Τεχνικές Μετάδοσης ΜΕΤΑΓΩΓΗ Τεχνική µεταγωγής ονομάζεται ο τρόπος µε τον οποίο αποκαθίσταται η επικοινωνία ανάµεσα σε δύο κόµβους με σκοπό την
Κεφάλαιο 1.6: Συσκευές αποθήκευσης
 Κεφάλαιο 1.6: Συσκευές αποθήκευσης 1.6.1 Συσκευές αποθήκευσης Μνήμη τυχαίας προσπέλασης - RAM Η μνήμη RAM (Random Access Memory Μνήμη Τυχαίας Προσπέλασης), κρατεί όλη την πληροφορία (δεδομένα και εντολές)
Κεφάλαιο 1.6: Συσκευές αποθήκευσης 1.6.1 Συσκευές αποθήκευσης Μνήμη τυχαίας προσπέλασης - RAM Η μνήμη RAM (Random Access Memory Μνήμη Τυχαίας Προσπέλασης), κρατεί όλη την πληροφορία (δεδομένα και εντολές)
Κώστας Βούλγαρης Financial Lines & Casualty Manager. CyberEdge
 Κώστας Βούλγαρης Financial Lines & Casualty Manager CyberEdge Δήλωση αποποίησης ευθύνης & πνευματικής ιδιοκτησίας Η Παρουσίαση αυτή ετοιμάστηκε από την AIG και προορίζεται αποκλειστικά για σκοπούς ενημέρωσης
Κώστας Βούλγαρης Financial Lines & Casualty Manager CyberEdge Δήλωση αποποίησης ευθύνης & πνευματικής ιδιοκτησίας Η Παρουσίαση αυτή ετοιμάστηκε από την AIG και προορίζεται αποκλειστικά για σκοπούς ενημέρωσης
ΣΥΜΒΟΥΛΙΟ ΤΗΣ ΕΥΡΩΠΑΪΚΗΣ ΕΝΩΣΗΣ. Βρυξέλλες, 25 Μαρτίου 2011 (31.03) (OR. en) 8068/11 PROCIV 32 JAI 182 ENV 223 FORETS 26 AGRI 237 RECH 69
 (OR. en) 8068/11 PROCIV 32 JAI 182 ENV 223 FORETS 26 AGRI 237 RECH 69") ΣΥΜΒΟΥΛΙΟ ΤΗΣ ΕΥΡΩΠΑΪΚΗΣ ΕΝΩΣΗΣ Βρυξέλλες, 25 Μαρτίου 2011 (31.03) (OR. en) 8068/11 PROCIV 32 JAI 182 ENV 223 FORETS 26 AGRI 237 RECH 69 ΣΗΜΕΙΩΜΑ ΣΗΜΕΙΟΥ «I/A» της: Γενικής Γραμματείας προς: την ΕΜΑ/ το
ΣΥΜΒΟΥΛΙΟ ΤΗΣ ΕΥΡΩΠΑΪΚΗΣ ΕΝΩΣΗΣ Βρυξέλλες, 25 Μαρτίου 2011 (31.03) (OR. en) 8068/11 PROCIV 32 JAI 182 ENV 223 FORETS 26 AGRI 237 RECH 69 ΣΗΜΕΙΩΜΑ ΣΗΜΕΙΟΥ «I/A» της: Γενικής Γραμματείας προς: την ΕΜΑ/ το
CyberEdge από την AIG
 Προστασία από τις συνέπειες των ηλεκτρονικών και διαδικτυακών κινδύνων Business Solutions CyberEdge από την AIG ηλεκτρονικοί και Οι ηλεκτρονικοί και διαδικτυακοί κίνδυνοι αποτελούν καθημερινή πραγματικότητα
Προστασία από τις συνέπειες των ηλεκτρονικών και διαδικτυακών κινδύνων Business Solutions CyberEdge από την AIG ηλεκτρονικοί και Οι ηλεκτρονικοί και διαδικτυακοί κίνδυνοι αποτελούν καθημερινή πραγματικότητα
ΚΙΝΔΥΝΟΙ ΣΤΟ ΔΙΑΔΙΚΤΥΟ
 ΚΙΝΔΥΝΟΙ ΣΤΟ ΔΙΑΔΙΚΤΥΟ TROJAN Στην πληροφορική, ο δούρειος ίππος (trojan horse ή απλά trojan) είναι ένα κακόβουλο πρόγραμμα που ξεγελάει τον χρήστη και τον κάνει να πιστεύει ότι εκτελεί κάποια χρήσιμη
ΚΙΝΔΥΝΟΙ ΣΤΟ ΔΙΑΔΙΚΤΥΟ TROJAN Στην πληροφορική, ο δούρειος ίππος (trojan horse ή απλά trojan) είναι ένα κακόβουλο πρόγραμμα που ξεγελάει τον χρήστη και τον κάνει να πιστεύει ότι εκτελεί κάποια χρήσιμη
7.9 ροµολόγηση. Ερωτήσεις
 7.9 ροµολόγηση Ερωτήσεις 1. Να δώσετε τον ορισµό της δροµολόγησης; 2. Από τι εξαρτάται η χρονική στιγµή στην οποία λαµβάνονται οι αποφάσεις δροµολόγησης; Να αναφέρετε ποια είναι αυτή στην περίπτωση των
7.9 ροµολόγηση Ερωτήσεις 1. Να δώσετε τον ορισµό της δροµολόγησης; 2. Από τι εξαρτάται η χρονική στιγµή στην οποία λαµβάνονται οι αποφάσεις δροµολόγησης; Να αναφέρετε ποια είναι αυτή στην περίπτωση των
Αντιμετώπιση ανεπιθύμητης αλληλογραφίας (spam)
") Vodafone Business E-mail Αντιμετώπιση ανεπιθύμητης αλληλογραφίας (spam) Οδηγός χρήσης Καλώς ορίσατε Ο παρών οδηγός θα σας βοηθήσει να ρυθμίσετε τα κατάλληλα μέτρα για την αντιμετώπιση της ανεπιθύμητης
Vodafone Business E-mail Αντιμετώπιση ανεπιθύμητης αλληλογραφίας (spam) Οδηγός χρήσης Καλώς ορίσατε Ο παρών οδηγός θα σας βοηθήσει να ρυθμίσετε τα κατάλληλα μέτρα για την αντιμετώπιση της ανεπιθύμητης
Σύντομη παρουσίαση των εργαλείων/εντολών telnet, ping, traceroute nslookup και nmap, zenmap
 Σύντομη παρουσίαση των εργαλείων/εντολών telnet, ping, traceroute nslookup και nmap, zenmap Version 2.00 Επιμέλεια Σημειώσεων: Δημήτρης Κόγιας Πατρικάκης Χαράλαμπος Πίνακας περιεχομένων TELNET... 2 PING...
Σύντομη παρουσίαση των εργαλείων/εντολών telnet, ping, traceroute nslookup και nmap, zenmap Version 2.00 Επιμέλεια Σημειώσεων: Δημήτρης Κόγιας Πατρικάκης Χαράλαμπος Πίνακας περιεχομένων TELNET... 2 PING...