Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Ηλεκτρονικών Υπολογιστών Τηλεπικοινωνιών & Δικτύων
|
|
|
- Ὀρφεύς Κουρμούλης
- 7 χρόνια πριν
- Προβολές:
Transcript
1 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Ηλεκτρονικών Υπολογιστών Τηλεπικοινωνιών & Δικτύων Διπλωματική Εργασία «Μεταφορά και Βελτιστοποίηση Εφαρμογής Υπολογιστικής Βιολογίας (RAxML) σε Many-Core Σύστημα» Porting and Optimization of a Computational Biology Application (RAxML) on a Many-Core System Παπαχαρισίου Κωνσταντίνος Επιβλέποντες Καθηγητές: Αντωνόπουλος Χρήστος Επίκουρος Καθηγητής Μπέλλας Νικόλαος Αναπληρωτής Καθηγητής Βόλος, Σεπτέμβριος 2012
2 1
3 Περίληψη Η παρούσα εργασία είχε ως αφορμή την εκμετάλλευση της τεράστιας υπολογιστικής ισχύος που μας δίνεται με την αξιοποίηση της νέας γενιάς καρτών γραφικών για την επιτάχυνση της εκτέλεσης εφαρμογών γενικού σκοπού και τη βελτιστοποίηση της απόδοσής τους. Στόχος της διπλωματικής είναι η περιγραφή της διαδικασίας που ακολουθήσαμε για τη μεταφορά της εκτέλεσης μιας υπολογιστικά απαιτητικής εφαρμογής βιοπληροφορικής (RAxML) σε ένα πολυ-πυρηνικό σύστημα (GPU). Συγκεκριμένα γίνεται περιγραφή των προγραμματιστικών τεχνικών που χρησιμοποιήθηκαν για την μεταφορά της, τη βελτιστοποίησή της καθώς και την επίλυση των προβλημάτων που προέκυψαν. Αρχικά γίνεται μία αναφορά στην εφαρμογή RAxML επικεντρώνοντας στο παράλληλο κομμάτι, της εκτέλεσης της φυλογενετικής συνάρτησης πιθανοφάνειας. Έπειτα, ανάλυση της τεχνικής προγραμματισμού μαζικά παράλληλων επεξεργαστών και συγκεκριμένα το μοντέλο CUDA και περιγραφή της αρχιτεκτονικής Fermi της κάρτας GTX480 στην οποία θα γίνει η ανάπτυξη του κώδικα. Στο κύριο μέρος της εργασίας, σε κάθε βήμα περιγράφονται οι στόχοι και τα προβλήματα που εμφανίστηκαν για την επίτευξή τους. Έπειτα, η τεχνική επίλυσης των προβλημάτων καθώς και η επίδραση στο χρόνο εκτέλεσης της εφαρμογής και τέλος οι περιορισμοί που επιφέρει η κάθε λύση. Τέλος γίνεται η αξιολόγηση της απόδοσης με βάση τη μορφή της εφαρμογής. 2
4 Ευχαριστίες Με το πέρας της διπλωματικής θα ήθελα να ευχαριστήσω τον καθηγητή μου κ. Αντωνόπουλο Χρήστο για την έμπνευση ενασχόλησης με τα συστήματα υψηλών επιδόσεων, την πρόταση του θέματος καθώς και την καθοδήγησή του κατά την υλοποίηση. Επίσης ένα μεγάλο ευχαριστώ στην οικογένεια και του φίλους μου για την στήριξή τους καθ όλη τη διάρκεια των σπουδών μου. Τέλος θα ήθελα να επισημάνω την κύρια συμβολή στην επίλυση των προβλημάτων που προέκυψαν, της κοινότητας των προγραμματιστών λογισμικού που έχει αναπτυχθεί στο διαδίκτυο. 3
5 Περιεχόμενα Περίληψη... 2 Εισαγωγή... 6 Φυλογενετική ανάλυση... 7 Γενικά... 7 Το πρόγραμμα RAxML... 8 Η φυλογενετική συνάρτηση πιθανοφάνειας... 9 General Purpose computing on Graphics Processor Units (GPGPU) Γενικά Το μοντέλο προγραμματισμού CUDA (Compute Unified Device Architecture) - H Αρχιτεκτονική Fermi Διαδικασία Μεταφοράς RAxML σε GPGPU Profiling Γενική λεπτομερής παραλληλοποίηση εφαρμογής Αρχική στρατηγική υβριδικής εκτέλεσης σε CPU/GPU Διαχείριση μεταφοράς δεδομένων από και προς τη GPU Οργάνωση μνήμης για μεταφορά δεδομένων με μία κλήση Aligned memory error Αποτελέσματα στο χρόνο εκτέλεσης Μείωση πολλαπλών κλήσεων του device Master worker scheme on GPU Υλοποίηση GPU global barrier Μεταφορά φυλογενετικού δέντρου (διπλά διασυνδεμένη λίστα) Διαχείριση αναδρομικών κλήσεων Συμπεράσματα - Αποτελέσματα στο χρόνο εκτέλεσης Τεχνικές μη δυνατές για εκμετάλλευση λόγω της δομής του αλγορίθμου Βιβλιογραφία
6 5
7 Εισαγωγή Στη βιοπληροφορική (Bioinformatics) η ανακατασκευή του εξελικτικού δέντρου από μια μοριακή ακολουθία δεδομένων είναι σχετικά παλιό πρόβλημα, δεδομένου ότι σχεδόν τρεις δεκαετίες πριν (1981) ο Joe Felsenstein δημοσίευσε την εργασία του [3] σχετικά με τον υπολογισμό του βαθμού πιθανοφάνειας. Ωστόσο σημαντικές εξελίξεις στις τεχνικές μοριακών ακολουθιών με την εισαγωγή για παράδειγμα του, the 454 sequencers [4], έφεραν στην επιφάνεια μια πρωτοφανή πληθώρα δεδομένων. Επιπλέον, τα τελευταία χρόνια παρατηρείται η ανάδειξη των πολυπύρηνων (multi-cores) αρχιτεκτονικών όπως οι GPUs ή ο IBM Cell που έφεραν νέες προκλήσεις στην φυλογενετική ανάλυση και ειδικά όσον αφορά την οργάνωση της εκτέλεσης της φυλογενετικής συνάρτησης πιθανοφάνειας (Phylogenetic Likelihood Function - PLF). Στην πραγματικότητα, η κοινότητα της βιοπληροφορικής βρίσκεται σε διαρκή αγώνα να ανταπεξέλθει στην ολοένα και μεγαλύτερη συσσώρευση δεδομένων αναπτύσσοντας ολοένα και πιο δυνατά εργαλεία για την επεξεργασία και διαχείριση των δεδομένων. Ενδεικτικά είναι συνηθισμένο για ένα πρόγραμμα στον πραγματικό κόσμο που εκτελεί ανάλυση μέγιστης πιθανοφάνειας (Maximum Likelihood - ML) να απαιτεί περισσότερα από 50GB μνήμη και η εκτέλεσή του να παίρνει πάνω από 2 εκατομμύρια ώρες στη CPU. Επομένως η μελέτη της συμπεριφοράς του αλγορίθμου σε μία αρχιτεκτονική πολλαπλών πυρήνων όπως οι νέας γενιάς GPU παρουσιάζει ενδιαφέρον. 6
 που αναπαριστά έναν οργανισμό μπορεί να αποτελείται από ένα μίγμα DNA, πρωτεϊνών, ή/και μορφολογικών χαρακτήρων.")
8 Φυλογενετική ανάλυση Γενικά Σκοπός της φυλογενετικής ανάλυσης (Phylogenetic inference) είναι η ανακατασκευή της εξελικτικής ιστορίας ενός πλήθους n οργανισμών από τις αντίστοιχες μοριακές τους ακολουθίες. Μια μοριακή ακολουθία (taxa) που αναπαριστά έναν οργανισμό μπορεί να αποτελείται από ένα μίγμα DNA, πρωτεϊνών, ή/και μορφολογικών χαρακτήρων. Τα δεδομένα εισόδου για μια φυλογενετική ανάλυση αποτελούνται από μια πολλαπλή «καλά» ευθυγραμμισμένη ακολουθία taxa των n οργανισμών ίδιου μεγέθους m. Ένα παράδειγμα μιας τέτοιας ακολουθίας τεσσάρων οργανισμών φαίνεται παρακάτω. Ένα φυλογενετικό δέντρο συνήθως αναπαρίσταται ως ένα δυαδικό δέντρο χωρίς ρίζα. Το σύνολο των n οργανισμών (taxa) που εξετάζονται τοποθετούνται στα φύλλα του δέντρου και οι εσωτερικοί κόμβοι αναπαριστούν τους εξαφανισμένους κοινούς προγόνους. Οι αριθμοί σε κάθε διακλάδωση φανερώνουν την εκτίμηση για τον χρονικό προσδιορισμό της μετάλλαξης/εξέλιξης. 7
![Είναι σημαντικό να τονίσουμε ότι το πρόβλημα της εύρεσης του βέλτιστου δέντρου είναι NP-hard. Ο αριθμός των εναλλακτικών διακριτών δέντρων χωρίς ρίζα για n οργανισμούς είναι [9].](/docs-images/67/56645767/images/9-0.jpg "Ενώ υπάρχει αρκετή βιβλιογραφία πάνω στους ευριστικούς αλγορίθμους αναζήτησης που χρησιμοποιούνται για το πρόβλημα της βελτιστοποίησης του βαθμού πιθανοφάνειας, όλοι βασίζονται στην επαναληπτική")
9 Είναι σημαντικό να τονίσουμε ότι το πρόβλημα της εύρεσης του βέλτιστου δέντρου είναι NP-hard. Ο αριθμός των εναλλακτικών διακριτών δέντρων χωρίς ρίζα για n οργανισμούς είναι [9]. Ενώ υπάρχει αρκετή βιβλιογραφία πάνω στους ευριστικούς αλγορίθμους αναζήτησης που χρησιμοποιούνται για το πρόβλημα της βελτιστοποίησης του βαθμού πιθανοφάνειας, όλοι βασίζονται στην επαναληπτική εκτέλεση της συνάρτησης πιθανοφάνειας για την εξερεύνηση του δέντρου, που αντιπροσωπεύει και το κύριο σημείο συμφόρησης της μνήμης και εντατικών υπολογισμών. Τα φυλογενετικά δέντρα έχουν αρκετές σημαντικές εφαρμογές στην έρευνα της ιατρικής και της βιολογίας, με κυρίαρχα προγράμματα φυλογένειας μέγιστης πιθανοφάνειας (Maximum Likelihood - ML) να είναι τα PAML, PHYML, PAUP, GARLI, RAxML, IQPNNI, MrBayes, PhyloBayes, BEAST [1]. Το πρόγραμμα RAxML Το πρόγραμμα RAxML (Randomized Accelerated Maximum Likelihood) χρησιμοποιείται για την εκτέλεση μεγάλης κλίμακας φυλογενετικών αναλύσεων με τη μέθοδο μέγιστης πιθανοφάνειας. Αρχικά δημιουργεί ένα φειδωλό δέντρο (parsimony tree) χρησιμοποιώντας το πρόγραμμα dnapars του πακέτου PHILIP και ξεκινάει μια ακολουθία αναδιατάξεων στα υποδέντρα. Σε κάθε αναδιάταξη υπολογίζει το βαθμό πιθανοφάνειας (Likelihood Score) εκτελώντας την φυλογενετική συνάρτηση (Phylogenetic Function) για κάθε τοπολογία. Αν ο βαθμός είναι μεγαλύτερος τότε χρησιμοποιείται το δέντρο για τη συνέχιση των αναδιατάξεων. Μετά από κάθε βήμα αναδιάταξης πραγματοποιείται η διαδικασία βελτιστοποίησης των μηκών των κλαδιών (branch length optimization) και επαναλαμβάνεται ο υπολογισμός του βαθμού πιθανοφάνειας, μέχρι να καλυφθούν ορισμένα κριτήρια σύγκλησης οπότε και σταματάει η διαδικασία. Παρακάτω φαίνεται ένα απλοποιημένο διάγραμμα ροής της εφαρμογής: 8

10 Η φυλογενετική συνάρτηση πιθανοφάνειας Ας δούμε πιο αναλυτικά τον τρόπο λειτουργίας της φυλογενετικής συνάρτησης πιθανοφάνειας η οποία είναι και ο πυρήνας της εφαρμογής. Όπως έχουμε πει είσοδός μας είναι οι n ακολουθίες οργανισμών μήκους m. Υποθέτουμε ότι έχουμε μια δοσμένη τοπολογία δέντρου από τη οποία θα υπολογίσουμε το βαθμό πιθανοφάνειας. Οι περισσότεροι υπολογισμοί επιδρούν, εκτός από τις άλλες παραμέτρους που θα αναλύσουμε παρακάτω, κυρίως στους πίνακες πιθανοτήτων. Κάθε εγγραφή του πίνακα πιθανοτήτων στα φύλλα και στους εσωτερικούς κόμβους του δέντρου μας, περιέχει στη θέση =1..m τις τέσσερεις πιθανότητες P(A), P(C), P(G), P(T). Αυτές εκφράζουν την πιθανότητα να παρατηρηθεί ένα νουκλεοτίδιο A, C, G, T σε μια συγκεκριμένη στήλη c της ακολουθίας εισόδου. Οι πίνακες αρχικοποιούνται κατάλληλα στα φύλα θέτοντας την τιμή 1.0 στην αντίστοιχη θέση του νουκλεοτιδίου. Για παράδειγμα στην παρατήρηση του νουκλεοτιδίου Α ο πίνακας θα είναι L=[1.0, 0.0, 0.0, 0.0]. Η μορφή των πινάκων αυτών φαίνεται στην παρακάτω εικόνα: Έπειτα έχοντας τον πατρικό κόμβο k και τους δύο κόμβων-παιδιά του i και j, τους πίνακες πιθανοτήτων,, τα αντίστοιχα μήκη διακλάδωσης, και τους πίνακες πιθανοτήτων μετάβασης, ο υπολογισμός της πιθανότητας να παρατηρηθεί μια A στη θέση c του διανύσματος στον πατρικό κόμβο k γίνεται ως εξής: 9
11 Ο πίνακας πιθανοτήτων μετάβασης P(b) για ένα δοσμένο μήκος διακλάδωσης b υπολογίζεται ως, όπου Q ο (4x4) πίνακας υποκατάστασης που περιέχει τις πιθανότητες μετάβασης μεταξύ των νουκλεοτιδίων. Μόλις υπολογιστούν οι πίνακες πιθανοτήτων μετάβασης των δύο παιδιών της ρίζας i, j ο βαθμός πιθανοφάνειας για κάθε στήλη c=1 m προκύπτει ως ακολούθως (δεδομένου και του μήκους διακλάδωσης μεταξύ των κόμβων I,j): Ο τελικός βαθμός πιθανοφάνειας του δέντρου υπολογίζεται προσθέτοντας το λογάριθμο του κάθε στοιχείου του προηγούμενου διανύσματος: Μια σημαντική ιδιότητα, που μας ενδιαφέρει άμεσα στην παράλληλη εκτέλεση της συνάρτησης είναι η υπόθεση ότι οι οργανισμοί εξελίσσονται ανεξάρτητα, δηλαδή κάθε εγγραφή c του πίνακα πιθανοτήτων μπορεί να υπολογιστεί ανεξάρτητα. Επομένως για μια πλήρη διαπέραση του δέντρου χρειάζεται μόνο μια πράξη ελαχιστοποίησης (reduction) του αποτελέσματος άρα ένα σημείο συγχρονισμού. Επίσης όσον αφορά τη μνήμη που χρειαζόμαστε για την εκτέλεση της εφαρμογής εκτός από τις δομές αποθήκευσης που περιγράψαμε έως τώρα, μπορεί να χρειαστούμε και επιπλέον μνήμη ανάλογα με το μοντέλο που χρησιμοποιούμε για την ανάλυση. Εμείς θα χρησιμοποιήσουμε το Γ μοντέλο (GAMMA model) στο οποίο οι πράξεις είναι ελάχιστα πιο περίπλοκες καθώς για τον υπολογισμό των πινάκων πιθανοτήτων μετάβασης λαμβάνονται υπόψη και τέσσερεις διακριτές συντελεστές r0, r1, r2,r3 έτσι ώστε. Αυτό σημαίνει ότι τετραπλασιάζονται οι πράξεις και η κατανάλωση μνήμης. Το πρόγραμμα RAxML ενσωματώνει και χρησιμοποιεί πολύ περισσότερες παραμέτρους όπως επιβάλλεται και από το αντίστοιχο βιολογικό μοντέλο, περαιτέρω ανάλυση των οποίων δεν έχει νόημα για τους σκοπούς της παρούσας εργασίας. Μία αναλυτική περιγραφή γίνεται στο [1]. 10
, οι οποίες ήταν διευθετήσιμες (configurable) αλλά όχι προγραμματίσιμες (programmable).")
12 General Purpose computing on Graphics Processor Units (GPGPU) Γενικά Από την αρχή της δεκαετίας του 1980 μέχρι το τέλος της δεκαετίας του 1990, το κορυφαίο σε απόδοση υλικό γραφικών χρησιμοποιούσε διοχετεύσεις σταθερών συναρτήσεων (fixedfunctions pipelines), οι οποίες ήταν διευθετήσιμες (configurable) αλλά όχι προγραμματίσιμες (programmable). Τότε, απέκτησαν δημοτικότητα διάφορες σημαντικές βιβλιοθήκες διασύνδεσης προγραμματισμού εφαρμογών γραφικών (API Application Programming Interface) όπως είναι το DirectX (Microsoft) και το OpenGL (open source). Εικόνα 1 fixed functions pipelines Την περίοδο οι επιστήμονες άρχισαν να χρησιμοποιούν τις κάρτες γραφικών για την επιτάχυνση της εκτέλεσης εφαρμογών από διάφορους τομείς καθώς τότε δόθηκε μια γενική δυνατότητα προγραμματισμού σε διάφορα στάδια που μέχρι πριν ήταν σταθερών συναρτήσεων (π.χ. η GPU GeForce 3 το 2001 στο στάδιο VS/T&L). Αυτή ήταν και η απαρχή της χρήσης του όρου GPGPU (General - Purpose computation on GPU) στον προγραμματισμό εφαρμογών. Οποιαδήποτε επιτάχυνση στο χρόνο εκτέλεσης ερχόταν με τη χρήση του API για τον προγραμματισμό της κάρτας, πράγμα το οποίο περιόριζε την πλήρη εκμετάλλευση των δυνατοτήτων της και το εύρος των προγραμματιστών που μπορούσαν να τις αξιοποιήσουν. Για να προσπελάσει ένας προγραμματιστής υπολογιστικούς πόρους έπρεπε να εκφράσει το πρόβλημά του σε εγγενείς λειτουργίες γραφικών έτσι ώστε ο υπολογισμός να μπορεί να ξεκινήσει μέσω κλήσεων API του OpenGL ή DirectX. To 2006 με την ανάπτυξη της αρχιτεκτονικής Tesla, η nvidia συνειδητοποίησε ότι η πιθανή χρησιμότητά της θα ήταν πολύ μεγαλύτερη αν οι προγραμματιστές μπορούσαν να θεωρήσουν την GPU ως έναν επεξεργαστή δηλώνοντας ρητά τις πτυχές της εργασία τους που περιέχουν παραλληλία δεδομένων. Ταυτόχρονα με την διάθεση μοντέλων 11
, έφεραν τη δυνατότητα ανάπτυξης εφαρμογών σε ένα τεράστιο εύρος προγραμματιστών.")
13 προγραμματισμού όπως τα CUDA (nvidia) και OpenCL (open source) ουσιαστικά οι κάρτες γραφικών έγιναν πλήρως προγραμματίσιμες και καθώς επίσης τα μοντέλα είναι επέκταση γνωστών γλωσσών προγραμματισμού (C/C++, FORTRAN), έφεραν τη δυνατότητα ανάπτυξης εφαρμογών σε ένα τεράστιο εύρος προγραμματιστών. To GPU computing έφερε επιταχύνσεις στην εκτέλεση εφαρμογών γενικού σκοπού μεταφέροντας τα υπολογιστικά χρονοβόρα κομμάτια τους στην GPU ενώ η υπόλοιπη εφαρμογή εκτελείτε στην CPU. Έτσι ο συνδυασμός CPU+GPU είναι αρκετά δυνατός διότι η CPU αποτελείται από λίγους πυρήνες βελτιστοποιημένους για σειριακή εκτέλεση ενώ η GPU από χιλιάδες μικρότερους πιο αποτελεσματικούς πυρήνες σχεδιασμένους για παράλληλη απόδοση. Τα σειριακά κομμάτια του κώδικα εκτελούνται στη CPU ενώ τα παράλληλα στη GPU. Εικόνα 2 hybrid programming 12

 εγγενή παραλληλισμό της εκάστοτε εφαρμογής. Παρακάτω περιγράφουμε εν συντομία το μοντέλο.")
14 Το μοντέλο προγραμματισμού CUDA (Compute Unified Device Architecture) - H Αρχιτεκτονική Fermi Για τους προγραμματιστές CUDA και OpenCL, οι μονάδες επεξεργασίας γραφικών (GPU) είναι μαζικά παράλληλοι επεξεργαστές αριθμητικών υπολογισμών που προγραμματίζονται σε C/C++ με επεκτάσεις της. Ο προγραμματισμός αυτών των επεξεργαστών δεν απαιτεί την κατανόηση των αλγορίθμων ή της ορολογίας γραφικών. Σύμφωνα με την κατηγοριοποίηση του Flynn στις παράλληλες αρχιτεκτονικές το μοντέλο CUDA ανήκει στην SIMD(Single Instruction Multiple Data) όπου η ίδια εντολή σε πολλαπλές μονάδες εκτέλεσης επιδρά σε διαφορετικά δεδομένα εκμεταλλευόμενη έτσι τον (πιθανό) εγγενή παραλληλισμό της εκάστοτε εφαρμογής. Παρακάτω περιγράφουμε εν συντομία το μοντέλο. Ένα πρόγραμμα σε CUDA καλεί το παράλληλο τμήμα κώδικα, τους πυρήνες. Ένας πυρήνας περιέχει ένα πλήθος ανεξάρτητων νημάτων για εκτέλεση οργανωμένων από τον προγραμματιστή σε μπλοκ νημάτων (thread blocks) και πλέγματα (grids). Επομένως η μονάδα εκτέλεσης γραφικών (GPU) δημιουργεί ένα πλέγμα από μπλοκ νημάτων κάθε ένα νήμα από τα οποία εκτελεί ένα στιγμιότυπο του πυρήνα και έχει (μπορεί να εξάγει) το δικό του μοναδικό ID, καταχωρητές (registers), ιδιωτική μνήμη. Σε επίπεδο εκτέλεσης μπλοκ το μοντέλο CUDA προσφέρει κοινή μνήμη ανάμεσα στα νήματα του ίδιου μπλοκ (shared memory), συγχρονισμό νημάτων με φράγματα (barrier), ενώ κάθε μπλοκ έχει μοναδικό ID. Τέλος σε επίπεδο πλέγματος τα μπλοκ εκτελούν ανεξάρτητα μεταξύ τους τον ίδιο πυρήνα και επικοινωνούν μέσω την καθολικής μνήμης (global memory) έχοντας ως μοναδικό καθολικό σημείο συγχρονισμού την περάτωση της εκτέλεσης του πυρήνα. 13
15 Επομένως, σύμφωνα με τα παραπάνω καταλαβαίνουμε ότι στην αρχιτεκτονική Fermi και συγκεκριμένα στην κάρτα που θα δουλέψουμε GTX480 έχουμε μονάδες εκτέλεσης με διάφορα επίπεδα μνήμης τα οποία είναι κοινά σε διαφορετικές ιεραρχίες πλέγματος/μπλοκ/νήματος. Επίσης διαφορετική είναι και η ταχύτητα προσπέλασης του κάθε επιπέδου μνήμης για την ανάγνωση/εγγραφή δεδομένων. Οι μονάδες εκτέλεσης είναι οργανωμένες σε Streaming Multiprocessors. H GTX480 διαθέτει 15 SM με 32 cores/sm. Άρα συνολικά μπορεί να εκτελεί ταυτόχρονα 15*32=480 νήματα. Η αρχιτεκτονική όμως επιτρέπει τη δημιουργία πολύ περισσότερων νημάτων. Συγκεκριμένα τα χαρακτηριστικά της συσκευής μας είναι: Total amount of global memory: bytes Number of multiprocessors: 15 Number of cores: 480 Total amount of constant memory: bytes Total amount of shared memory per block: bytes Total number of registers available per block: Warp size: 32 Maximum number of threads per block: 1024 Maximum sizes of each dimension of a block: 1024 x 1024 x 64 Maximum sizes of each dimension of a grid: x x 1 Πιο αναλυτικά, η δρομολόγηση της εκτέλεσης γίνεται σε επίπεδο warp. Τα νήματα κάθε μπλοκ οργανώνονται σε ομάδες των 32 και ανατίθενται σε κάθε SM για εκτέλεση. Το υλικό μπορεί αυτόματα να διαχειριστεί την απόκλιση (divergence) που πιθανόν να υπάρξει στην εκτέλεση του warp. Επίσης κάθε SM έχει 2 warp schedulers, 2 dispatch units, μονάδες ειδικών συναρτήσεων (SFU), μονάδες φόρτωσης/αποθήκευσης, καθώς και 64KB παραμετροποιήσιμη cache/shared memory. 14

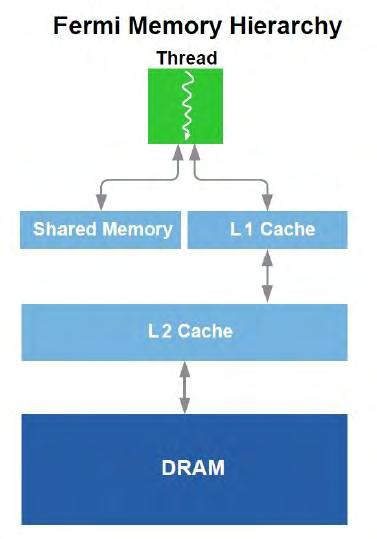
16 Το γεγονός του πλήθους νημάτων που η αρχιτεκτονική μας επιτρέπει να δημιουργήσουμε, σε συνδυασμό με την εναλλαγή τους χωρίς κόστος, επιδρά θετικά στο χρόνο εκτέλεσης καθώς μπορεί να επικαλυφθεί η καθυστέρηση πρόσβασης στη μνήμη με την εκτέλεση νημάτων που είναι έτοιμα. Επομένως ο παραλληλισμός των εφαρμογών για μία τέτοια αρχιτεκτονική επιβάλει τη λεπτομερή διαμέριση του προβλήματος έτσι ώστε να δημιουργηθεί ένας ικανός αριθμός νημάτων για την εκμετάλλευσή της. Σε επίπεδο μνήμης η αρχιτεκτονική Fermi περιέχει τις shared memory, L1 cache, L2 cache, DRAM. Η shared memory, διαχειρίσιμη από τον προγραμματιστή, είναι γρήγορη μνήμη μεγέθους 48 ή 16ΚΒ (ανάλογα το μέγεθος της L1 cache) η οποία είναι κοινή σε όλα τα νήματα του μπλοκ. Η Global memory DRAM είναι κοινή σε όλα τα νήματα έχει αρκετό μέγεθος για την αποθήκευση των δεδομένων (1,5GB) αλλά η προσπέλασή της είναι πιο αργή (100x σε σχέση με την shared). Η DRAM χρησιμοποιείται για την αποθήκευση των δεδομένων που μεταφέρονται από τον host και των αποτελεσμάτων μετά την επεξεργασία τους. Ενδιάμεσα για την επιτάχυνση των προσπελάσεων από την Global memory υπάρχει η L1 και η L2 cache. Η L1 cache είναι non-coherent δηλαδή μία αλλαγή από κάποιο νήμα στην Global memory, μεταβλητής που υπάρχει στην L1 cache δεν ενημερώνει την υπάρχουσα τιμή στην cache. Tο μέγεθός της μπορούμε να το αυξομειώσουμε κατά το compile time σε σχέση με τη shared memory (16/48KB). Τέλος η L2 cache είναι μεγαλύτερη (768 KB), κοινή σε όλα τα μπλοκ και είναι coherent. 15
17 16
18 Διαδικασία Μεταφοράς RAxML σε GPGPU Profiling Το profiling της εφαρμογής έγινε με το πρόγραμμα vtune της Intel. Όπως κάθε άλλο πρόγραμμα που χρησιμοποιείται σε φυλογενετικές αναλύσεις έτσι και στο RAxML το μεγαλύτερο ποσοστό του συνολικού χρόνου εκτέλεσης καταναλώνεται στον υπολογισμό του βαθμού πιθανοφάνειας μιας δοσμένης τοπολογίας δέντρου. Συγκεκριμένα το profiling έδειξε ότι το 98% του χρόνου καταναλώνεται σε τρεις συναρτήσεις εκ των οποίων: το 80% στη newview(), η οποία υπολογίζει τους πίνακες πιθανοφάνειας που περιγράψαμε στην αρχή, 15% στη makenewz() η οποία βελτιστοποιεί το μήκος των κλαδιών χρησιμοποιώντας τη μέθοδο Newton Raphson και το 3% στην evaluate() όπου υπολογίζεται ο τελικός βαθμός πιθανοφάνειας. Θεωρητικά, σύμφωνα με το νόμο του Amdahl το μέγιστο speedup που μπορούμε να πετύχουμε μεταφέροντας τη newview() στην GTX480 είναι: Γενική λεπτομερής παραλληλοποίηση εφαρμογής Στην παρούσα stable έκδοση του RAxML έχει υλοποιηθεί με pthreads ένα σχήμα από master-worker threads. Το μόνο νήμα ουσιαστικά που χρειάζεται να «καταλάβει» την τοπολογία του δέντρου είναι το master. Τα worker threads χρησιμοποιούνται για να διεκπεραιώσουν τους εντατικούς υπολογισμούς κινητής υποδιαστολής, δεσμεύουν τη δικιά τους περιοχή μνήμης για την επεξεργασία των δεδομένων και επιδρούν μόνο στο δικό τους κομμάτι από τους πίνακες πιθανοτήτων L. Οι workers κάνουν τη διαπέραση του δέντρου άρα και την εκτέλεση των πράξεων κάθε φορά, σύμφωνα με τα δεδομένα που είναι αποθηκευμένα στη δομή που περιέχει τις πληροφορίες διάτρεξης (traversal descriptor). Συγκεκριμένα κάθε φορά πρέπει να ξέρουν τον αριθμό των κόμβων που θα προσπελάσουν (count), το είδος του κόμβου(tipcase), τους κόμβους πατέρα-παιδιά(pnumber, rnumber, qnumber), και το αντίστοιχο μήκος διακλάδωσης μεταξύ τους (qz, rz). 17
19 Τελικά όπως φαίνεται και στην επόμενη εικόνα κάθε worker thread μπορεί να εκτελέσει τους υπολογισμούς ανεξάρτητα από τους υπόλοιπους σεβόμενο την σειρά διαπέρασης των κόμβων που έχει αποφασίσει το master thread. Άρα καταλήγουμε στο ότι μοναδικό σημείο συγχρονισμού μεταξύ τους είναι η εικονική ρίζα του δέντρου για τον υπολογισμό του βαθμού πιθανοφάνειας. 18
20 Αρχική στρατηγική υβριδικής εκτέλεσης σε CPU/GPU Ο γενικός αλγόριθμος εκτέλεσης της εφαρμογής είναι: 1. Υπολογισμός της τοπολογίας του δέντρου 2. Εξαγωγή της σειράς διάτρεξης των κόμβων 3. Βελτιστοποίηση μήκους διακλαδώσεων 4. Εκτέλεση των υπολογισμών (ML function) και αποθήκευση του βαθμού πιθανοφάνειας 5. Έλεγχος του αποτελέσματος και επιστροφή στο βήμα 2 ή συνέχεια Στο βήμα 4 είναι η εκτέλεση της συνάρτησης υπολογισμού βαθμού πιθανοφάνειας και περιλαμβάνει το κομμάτι που καταναλώνει το 80% του χρόνου εκτέλεσης όπως περιγράψαμε πριν. Επίσης όπως έχουμε πει μπορεί να εκτελεστεί παράλληλα άρα είναι το αρχικό υποψήφιο κομμάτι κώδικα για μεταφορά της εκτέλεσης στη GPU και την επιτάχυνσή του. Επομένως ο αλγόριθμος γίνεται: 1. Υπολογισμός της τοπολογίας του δέντρου 2. Εξαγωγή της σειράς διάτρεξης των κόμβων 3. Βελτιστοποίηση μήκους διακλαδώσεων 4. Μεταφορά δεδομένων προς τη GPU 5. Εκτέλεση των υπολογισμών στη GPU 6. Επιστροφή αποτελέσματος στη RAM (διάνυσμα με το αποτέλεσμα κάθε GPU νήματος) 7. Reduction με πρόσθεση του αποτελέσματος 8. Έλεγχος του αποτελέσματος και επιστροφή στο βήμα 2 ή συνέχεια Τα βήματα 1, 2, 3, 7, 8 εκτελούνται στη CPU ενώ το βήμα 3 - όπου περιλαμβάνονται και οι συναρτήσεις που καταναλώνουν τον περισσότερο χρόνο εκτέλεσης εκτελείται ταυτόχρονα από τα νήματα τηςgpu. Με τη μεταφορά της εκτέλεσης των workers στην GPU έχουμε καταφέρει η ίδια δουλειά να σπάσει σε περισσότερα κομμάτια σε σχέση με την CPU διότι έχουμε περισσότερους πυρήνες(μονάδες εκτέλεσης) στη διάθεσή μας με αποτέλεσμα κάθε νήμα εκτέλεσης να έχει λιγότερους υπολογισμούς. Η εκτέλεση του κύριου νήματος, με τον υπολογισμό της τοπολογίας και την αρχικοποίηση/βελτιστοποίηση των μεταβλητών σε κάθε φάση και την 19
21 ενορχήστρωση της εκτέλεσης παραμένει στη CPU. 20
22 Διαχείριση μεταφοράς δεδομένων από και προς τη GPU Καθώς ο χώρος δεδομένων δεν είναι κοινός μεταξύ των μονάδων εκτέλεσης πρέπει κάθε αλλαγή σε μία μονάδα να κρατά ενήμερη την άλλη. Ο μόνος τρόπος για να γίνει αυτό είναι μέσω της μεταφοράς των αλλαγών από τη CPU στη GPU και αντίστροφα. Συγκεκριμένα στην παρούσα φάση του αλγορίθμου πριν την εκτέλεση της συνάρτησης πιθανοφάνειας πρέπει να μεταφέρονται εκτός από τον traversal descriptor για κάθε κόμβο του δέντρου και όλες οι παράμετροι που περιγράψαμε μέχρι τώρα οι οποίες υπολογίζονται στην CPU. Οργάνωση μνήμης για μεταφορά δεδομένων με μία κλήση Πολλαπλές μικρές αποστολές δεδομένων προς την GPU έχουν αρνητικά αποτελέσματα ως προς τον χρόνο εκτέλεσης διότι, πρώτον δεν εκμεταλλευόμαστε πλήρως το bandwidth (μπορούσαμε να στείλουμε περισσότερα δεδομένα στον ίδιο χρόνο) και δεύτερον αναπόφευκτα με κάθε κλήση μεταφοράς δεδομένων cudaμemcpy() προσθέτουμε overhead της κλήσης/εναλλαγής στο περιβάλλον της GPU. Επομένως υλοποιήσαμε έναν memory manager ο οποίος οργανώνει τη δέσμευση συνεχόμενου χώρου μνήμης στη RAM έτσι ώστε η αποστολή των δεδομένων στη GPU να γίνεται με μία κλήση της cudaμemcpy(). Όπως φαίνεται και στο επόμενο σχήμα: Εικόνα 3 Πριν την υλοποίηση memory manager (3 μεταφορές) 21


23 Εικόνα 4 Μετά την υλοποίηση του memory manager (1 μεταφορά) Aligned memory error Στη μεταφορά την δεδομένων με τον memory manager είχαμε μεταβλητές διαφόρων τύπων, μεταξύ των οποίων και τύπου char για την αποθήκευση των οποίων χρειαζόμαστε 1byte. Επομένως μετά τη δέσμευση χώρου για έναν αριθμό chars υπάρχει περίπτωση η επόμενη διαθέσιμη διεύθυνση για την αποθήκευση του επόμενου τύπου δεδομένων (π.χ. double) να μην είναι πολλαπλάσια του 8 και κατά την προσπέλαση των δεδομένων να έχουμε misaligned address error. Το πρόβλημα μπορεί να λυθεί με μια mask operation στα τελευταία 4 bits του δείκτη που χρησιμοποιείται για να δείχνει τη θέση του επόμενου προς αποθήκευση στοιχείου. Για παράδειγμα, αν η μεταβλητή memptr έχει την misaligned διεύθυνση μνήμης 0xFFAB μετά τη mask operation void *ptr = ((char *)memptr+16) & ~ 0x0F; η μεταβλητή ptr θα έχει τη διεύθυνση 0xFFB0 που είναι aligned. 22
24 Αποτελέσματα στο χρόνο εκτέλεσης Sec (normalized) CPU serial Total execution times GPU data Transfers ML function Ενώ έχουμε πετύχει ένα speedup 3x στο χρόνο εκτέλεσης της φυλογενετικής συνάρτησης ο συνολικός χρόνος της εφαρμογής είναι πιο αργός καθώς κάθε φορά πριν την εκτέλεση του kernel στην GPU έχουμε 2 μεταφορές δεδομένων από και προς τη GPU η καθυστέρηση των οποίων όχι μόνο εξαλείφει το speedup αλλά προσθέτει και overhead. Άρα ο επόμενος στόχος είναι η ελαχιστοποίηση των δεδομένων που μεταφέρονται. 23

25 Μείωση πολλαπλών κλήσεων του device Master worker scheme on GPU Για να μειώσουμε τις πολλαπλές κλήσεις των kernel από τον host και επομένως τις μεταφορές δεδομένων πρέπει να μεταφέρουμε μέρος του κώδικα που εκτελεί το νήμα της CPU στη GPU. Αυτό συνεπάγεται συγχρονισμό των νημάτων στην GPU τα οποία μέχρι τώρα εκτελούνταν ανεξάρτητα. Το κομμάτι του master που θα μεταφέρουμε αρχικά διατρέχει το δέντρο με αναδρομικές κλήσεις συναρτήσεων και εξάγει τις πληροφορίες διαπέρασής του. Μόλις τα δεδομένα είναι έτοιμα ειδοποιεί τα worker threads για να υπολογίσουν το βαθμό πιθανοφάνειας. Έπειτα ελέγχει το βαθμό σε σχέση με ένα κριτήριο σύγκλησης και αποφασίζει αν εκτελεστεί ξανά η συνάρτηση πιθανοφάνειας από τους workers ή αν τους ειδοποιήσει να τερματίσουν την εκτέλεσή τους επιστρέφοντας τη ροή στη CPU. Δηλαδή έχει την ευθύνη της ενορχήστρωσης/συγχρονισμού της όλης διαδικασίας. Η λογική της εκτέλεσης στη GPU φαίνεται στο επόμενο διάγραμμα. Παρακάτω φαίνεται ένα σχήμα υλοποίησης όπου το master thread εκτελεί βελτιστοποίηση των μηκών των διακλαδώσεων και καλεί τους workers για τον υπολογισμό του βαθμού πιθανοφάνειας: 24
26 /* * MASTER CODE */ _device void toplevelmakenewz() { do{ /*...computations...*/ execkernel = NEWZCORE; //set which kernel to execute if (tr_executemodel){ globalbarrier(); globalbarrier(); //start workers //end workers //reduction results dlnldlz[0] = 0.0; d2lnldlz2[0] = 0.0; for(i=0; i<alignlength; i++) { dlnldlz[0] += d_dlnldlz[i]; d2lnldlz2[0] += d_d2lnldlz2[i]; /*...computations...*/ while (!loopconverged); //broadcast to workers that kernel finished chklast = 1; globalbarrier(); endgpuexecution = TRUE; globalbarrier(); b.blockfinish = 0; /* * WORKERS CODE */ device void parallelexecution() { while(!endgpuexecution) { globalbarrier(); if (chklast) globalbarrier(); //check if device is done. Return to host if (!endgpuexecution) { //choose kernel switch (execkernel) { case NEWZCORE: { parallelnewzcore(); break; case NEWVIEW: { parallelnewview(); break; case EVALUATE: { parallelevaluate(); break; default: assert(0); globalbarrier(); //calculations done! for all device threads 25
27 Υλοποίηση GPU global barrier Στο προγραμματιστικό μοντέλο CUDA, ο μόνος τρόπος συγχρονισμού όλων των νημάτων που τρέχουν στη συσκευή είναι με τον τερματισμό του πυρήνα εκτέλεσης. Δεν παρέχεται κάποια λειτουργία φράγματος(barrier) που να εγγυάται τη συνεπή εκτέλεση όλων των νημάτων. Υλοποιήσαμε μια λειτουργία καθολικού φράγματος (global barrier), όπου τα νήματα που φτάνουν πρώτα στο φράγμα περιμένουν με ενεργή αναμονή μέχρι την άφιξη και του τελευταίου νήματος. Όπως φαίνεται παρακάτω στον κώδικα στον global barrier χρησιμοποιούνται οι: syncthreads(): φράγμα που εγγυάται τον συγχρονισμό των νημάτων σε επίπεδο block attomicadd(): εγγυάται την συνεπή αύξηση της τιμής ενός μετρητή που πειράζουν περισσότερα από ένα νήματα ταυτόχρονα. /* global barrier * GTX 480 max dims: 120x128 (blocks, threads/block) */ device void globalbarrier() { int nofblocks = griddim.x*griddim.y*griddim.z; if (threadidx.x == 0){ int mysense =!(b.sense); int old = atomicadd((int *)&b.blockfinish, 1); if (old == nofblocks-1){ b.blockfinish = 0; b.sense =!(b.sense); else { while (mysense!= b.sense); syncthreads(); Εδώ αξίζει να σημειώσουμε ότι για τη λειτουργία του master thread χρησιμοποιούμε ένα ολόκληρο thread block. Συγκεκριμένα αν κάθε block έχει π.χ. 32 threads, στο block που δημιουργήθηκε για να τρέξει το master thread τερματίζουμε την εκτέλεση των 31 threads και το αυτό που μένει, εκτελεί τον κώδικα του master. Αυτό το κάνουμε λόγο της συνάρτησης syncthreads() που υπάρχει στον global barrier η οποία έχει τον περιορισμό (σύμφωνα με το μοντέλο CUDA) όλα τα νήματα μέσα σε ένα block πρέπει να πέφτουν στην ίδια syncthreads() (ακολουθώντας το ίδιο μονοπάτι). Ένα παράδειγμα λανθασμένης εκτέλεσης φαίνεται παρακάτω: 26
28 /* σε ένα warp με 32 threads * αν ο πίνακας count[] είναι αρχικοποιημένος στο 0 * τελικά οι θέσεις του count[] έχουν τιμή 0 */ global void syncwrongex(int *count) { if (threadidx.x>15) { syncthreads(); count[threadidx.x] = count[threadidx.x%16]; else { count[threadidx.x] = threadidx.x; syncthreads(); Η ενεργή αναμονή γίνεται σε μία μεταβλητή στην global memory για να είναι ορατές οι αλλαγές από όλα τα νήματα. Επίσης η συσκευή μας GTX480 ενσωματώνει για αύξηση της απόδοσης δύο επίπεδα μνήμης cache L1, L2. Η L2 cache είναι συνεπής (coherent) πράγμα που σημαίνει ότι αν αλλάξει η τιμή μιας μεταβλητής στην global memory η τιμή της στην cache μαρκάρεται ως άκυρη, με αποτέλεσμα η επόμενη προσπέλαση της μεταβλητής να γίνει από την global memory, διαβάζοντας τη σωστή τιμή και φέρνοντάς την ταυτόχρονα στην cache για μελλοντικές προσπελάσεις. Η L1 cache δεν είναι συνεπής επομένως πρέπει να την απενεργοποιήσουμε στο compile-time για να είναι σωστή η λειτουργία του global barrier. Η απενεργοποίηση της L1 cache ρίχνει την απόδοση για όλη την εφαρμογή. Μία λύση στη χρήση της είναι η απενεργοποίησή της μόνο για την μεταβλητή που διαβάζουμε από τη global memory και θέλουμε να είναι συνεπείς. Αυτό μπορούμε να το πετύχουμε ενσωματώνοντας κώδικα assembly για τις προσπελάσεις μνήμης που γίνονται στη συγκεκριμένη μεταβλητή. Ένα παράδειγμα φαίνεται παρακάτω: device inline int ld_gbl_cg(const int *addr) { int return_value; asm("ld.global.cg.s32 %0, [%1];" : "=r"(return_value) : "l"(addr)); return return_value; Ένας ακόμη περιορισμός στη χρήση του global barrier λόγω hardware, έγκειται στον μέγιστο αριθμό block/thread που μπορούμε να δημιουργήσουμε. Το μοντέλο προγραμματισμού δεν μας εγγυάται παραχώρηση μονάδων εκτέλεσης σε όλα τα blocks/warps που έχουν δημιουργηθεί παρά μόνο όταν κάποια τελειώσουν την εκτέλεσή τους και ελευθερωθούν πόροι (λογικό αφού το μοντέλο έχει δημιουργηθεί με την υπόθεση ανεξαρτησίας μεταξύ των νημάτων). Άρα πρέπει κάθε φορά να δημιουργούμε τόσα νήματα όσα μπορούν να γίνουν mapping στο hardware με την προϋπόθεση ότι θα τους δοθεί κάποια στιγμή η σειρά εκτέλεσης. Έτσι αποκλείουμε τη περίπτωση του deadlock. 27
/120(blocks/SM) = 128(thread/block).")
29 Σύμφωνα με τα παραπάνω, η αρχιτεκτονική Fermi, μπορεί να κάνει scheduling 8 blocks σε κάθε streaming multiprocessor. Επομένως στην GTX480, 15(SM)*8(blocks) = 120 blocks max. Επίσης κάθε multiprocessor μπορεί να έχει μέχρι και 1024 threads άρα 1024(threads)/120(blocks/SM) = 128(thread/block). Άρα οι μέγιστες διαστάσεις είναι 120*128 = threads τα οποία είναι αρκετά για την εκτέλεση της φυλογενετικής ανάλυσης. 28

30 Μεταφορά φυλογενετικού δέντρου (διπλά διασυνδεμένη λίστα) Το δέντρο εκτέλεσης είναι υλοποιημένο με μία διπλά διασυνδεμένη λίστα κάθε στοιχείο της οποίας έχει της πληροφορίες κάθε κόμβου. Το πλήθος των στοιχείων της λίστας και οι διευθύνσεις τους είναι γνωστά πριν την μεταφορά. Στόχος είναι χωρίς καμία αλλαγή στον κώδικα να μπορεί να γίνει προσπέλαση της λίστας από το master thread στη GPU. Επομένως ο αλγόριθμος υλοποίησης είναι ο εξής: 1. Αποθήκευση των διευθύνσεων της λίστας στον πίνακα listaddr[] 2. Δέσμευση χώρου στο device και αποθήκευση των διευθύνσεων στον host στον πίνακα listaddr2d[] 3. Δέσμευση χώρου bufflist[] στον host για αποθήκευση της λίστας που θα στείλουμε στο device. 4. Για κάθε στοιχείο της λίστας ελέγχουμε τη θέση των δεικτών διασύνδεσης στον πίνακα listaddr() και βάζουμε στο αντίστοιχο στοιχείο λίστας του bufflist[] το στοιχείο της ίδιας θέσης του list2addr[] 5. Μεταφέρουμε το bufflist[] στο χώρο που έχει δεσμευτεί στο device. Στην επόμενη εικόνα φαίνεται ο αλγόριθμος, όπου initlist είναι η αρχική λίστρα (δέντρο) στη RAM, bufflist ένας buffer στη RAM όπου προετοιμάζουμε τη λίστα που θα στείλουμε στη GPU και devicelist η τελική λίστα που έχει η GPU. Βλέπουμε ότι η λογική διασύνδεση των δεδομένων στη GPU είναι ίδια με τη RAM. 29
. To default stack size για κάθε thread είναι στο 1KB.")
31 Διαχείριση αναδρομικών κλήσεων Επί το πλείστον οι κάρτες γραφικών δεν υποστηρίζουν αναδρομή. Ο κύριος λόγος είναι ότι δεν μπορεί το κάθε thread να διατηρεί τη δική του stack. Στην GTX480 όμως η αναδρομή υποστηρίζεται εφόσον γίνει compile για sm_20 (compute capability). To default stack size για κάθε thread είναι στο 1KB. Στον αλγόριθμό μας, η συνάρτηση που εκτελεί την αναδρομή απαιτεί 16 bytes στο stack για την αποθήκευση των τοπικών μεταβλητών και το μέγιστο μέγεθος του stack για ένα πλήρη μονοπάτι εκτέλεσης (χωρίς αναδρομή) είναι 5360 bytes. Επομένως, αν αυξήσουμε το μέγιστο μέγεθος του stack για κάθε thread σε bytes θα έχουμε = bytes διαθέσιμα για αναδρομικές κλήσεις και 11024/16 = 689 μέγιστες συνεχόμενες κλήσεις. Ο αλγόριθμος διατρέχει αναδρομικά, δυαδικά δέντρα χωρίς ρίζα. Το μέγιστο μήκος ενός τέτοιο δέντρου (άρα και το μέγιστο μήκος αναδρομής) για Ν οργανισμούς-φύλλα είναι Ν-1, το οποίο σημαίνει ότι δεν έχουμε υπερχείλιση (stack overflow) όσο τρέχουμε τον αλγόριθμο για N<690 οργανισμούς. Εικόνα 5 - Μέγιστο μήκος αναδρομής 5 σε δέντρο με 6 οργανισμούς 30
, τα μήκη διακλαδώσεων (branch lengths) και")
32 Συμπεράσματα - Αποτελέσματα στο χρόνο εκτέλεσης Όπως φαίνεται στο παρακάτω διάγραμμα με τη μεταφορά σχεδόν ολόκληρης της εφαρμογής στη GPU: 1. Το σχήμα master/worker δουλεύει σωστά στην κάρτα. Με το master thread συγκεκριμένα να: κατευθύνει την εκτέλεση, διατρέχει το δέντρο και υπολογίζει με αναδρομή τις πληροφορίες διαπέρασης (traversal Info), τα μήκη διακλαδώσεων (branch lengths) και εκτελεί την αναδιάταξή του (rearrange tree). 2. Οι μεταφορές δεδομένων έχουν μειωθεί στο 0,18% του συνολικού χρόνου καθώς τα μόνα δεδομένα που πρέπει να μεταφέρουμε είναι το αρχικό και τα ενδιάμεσα βέλτιστα δέντρα για να αποθηκευτούν σε αρχεία. 3. Ο συνολικός χρόνος παραμένει χειρότερος από τη σειριακή εκτέλεση πιθανώς λόγο του πυρήνα εκτέλεσης των workers ο οποίος χρειάζεται περεταίρω βελτιστοποίηση. Τελική μορφή αλγορίθμου υβριδικής εκτέλεσης σε CPU-GPU: 31

33 Αποτελέσματα: Αντίθετα με αυτό που περιμέναμε ο χρόνος εκτέλεσης στο σχήμα master-worker δεν βελτιώθηκε σε σχέση με πριν. Αυτό μπορεί να οφείλεται: 1. Αργή εκτέλεση του παράλληλου τμήματος που εκτελούν οι workers σε σχέση με την πρώτη έκδοση του kernel καθώς για την υλοποίηση του σχήματος άλλαξε ο κώδικας εκτέλεσης. Συγκεκριμένα οι περισσότερες από τις πράξεις των threads γίνονται με δομένα και αποτελέσματα στην global memory γεγονός που είναι υποψήφιο να επιφέρει μεγάλη καθυστέρηση. Εδώ μπορεί να υπάρξει βελτίωση με χρήση της shared memory ανά block και με αλλαγή των δομών αποθήκευσης για αποδοτικότερη μεταφορά δεδομένων. 2. Ένας ακόμα πιθανός παράγοντας είναι το μονοπάτι εκτέλεσης του master thread στη GPU να είναι βαρύ για μια μονάδα εκτέλεσης της κάρτας (CUDA core) και σε συνδυασμό με τη δρομολόγηση εκτέλεσης στα warp που είναι διαθέσιμα, να περνά αρκετός χρόνος περιμένοντας τους workers στο global barrier. 32

34 Τεχνικές μη δυνατές για εκμετάλλευση λόγω της δομής του αλγορίθμου Streams: Ένα CUDA stream αντιπροσωπεύει μία σειρά ενεργειών που εκτελείτε ακολουθιακά. Πολλαπλά streams μπορούν να εκτελεστούν ταυτόχρονα. Η χρήση των CUDA streams επιτρέπει την ταυτόχρονη μεταφορά δεδομένων από και προς την GPU με την εκτέλεση του πυρήνα της εφαρμογής. Έτσι υπάρχει επικάλυψη των εναργειών με αποτέλεσμα τη μείωση του χρόνου εκτέλεσης. Ένα παράδειγμα με streams όπου επιτυγχάνεται περίπου 2x speedup σπάζοντας τις μεταφορές και την εκτέλεση του πυρήνα σε 3 κομμάτια ανεξάρτητα μεταξύ τους, φαίνεται παρακάτω: Στη RAxML η εξάρτηση δεδομένων μεταξύ των εκτελέσεων της φυλογενετικής συνάρτησης δεν επιτρέπει τη χρήση τους, καθώς κάθε φορά πρέπει να ελέγχεται ο βαθμός πιθανοφάνειας της δοσμένης τοπολογίας πριν την απόφαση εκτέλεσης του επόμενου βήματος. Concurrent kernel execution: Εκτέλεση περισσότερων του ενός kernel ταυτόχρονα. Η συσκευή μας έχει τη δυνατότητα να εκτελεί ταυτόχρονα περισσότερους του ενός kernels. Ομοίως εξαιτίας της εξάρτησης δεδομένων δεν μπορούμε να χρησιμοποιήσουμε αυτό το χαρακτηριστικό. 33
35 Βιβλιογραφία [1] Orchestrating the Phylogenetic Likelihood Function on Emerging Parallel Architectures. Stamatakis, Alexandros. [2] Programming Massively Parallel Processors (David B. Kirk, Wen-mei W. Hwu) [3] J. Felsenstein. Evolutionary trees from DNA sequences: a maximum likelihood approach. J. Mol. Evol., 17: , [4] J. Shendure and H. Ji. Next-generation DNA sequencing. nature biotechnology, 26(10): , [5] F. Pratas, P. Trancoso, A. Stamatakis, L. Sousa: "Fine-grain parallelism using Multi-core, Cell/BE, and GPU systems: Accelerating the Phylogenetic Likelihood Function". Proceedings of ICPP 2009, accepted for publication, Vienna, Austria, September PDF [6] J. Zhang, A. Stamatakis: "The Multi-Processor Scheduling Problem in Phylogenetics", accepted for publication at 11th IEEE HICOMB workshop (in conjunction with IPDPS 2012). PDF [7] W. Pfeiffer, A. Stamatakis: "Hybrid MPI/Pthreads Parallelization of the RAxML Phylogenetics Code". Accepted for publication at HICOMB workshop, held in conjunction with IPDPS 2010, Atlanta, Georgia, April PDF [8] Shucai Xiao and Wu-chun Feng, Department of Computer Science Virginia Tech Inter- Block GPU Communication via Fast Barrier Synchronization [9] AWF Edwards, LL Cavalli-Sforza, VH Heywood, and J. McNeill. Phenetic and Phylogenetic classification. Systematics Association Publication, 6:67 76, [10] Filip Blagojevic, Dimitrios S. Nikolopoulos, Alexandros Stamatakis, Christos D. Antonopoulos. "RAxML-Cell: Parallel Phylogenetic Tree Inference on the Cell Broadband Engine". Proceedings of the 21st IEEE International Parallel & Distributed Processing Symposium (IPDPS-07), Long Beach, CA, USA, March IEEE Computer Society Press, ISBN [11] RAxML Groups [12] Nvidia Forums [13] Exelixis Lab [14] Wikipedia [15] Developer tools/manuals/guides CUDA C Programming Guide, cuda-memcheck,cuda-gdb, Compute Visual Profiler User Guide [16] Professional Programming Discussion 34
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική
 ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική") Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC
 Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC Πλεονεκτήματα MPSoC Είναι ευκολότερο να σχεδιαστούν πολλαπλοί πυρήνες επεξεργαστών από τον σχεδιασμό ενός ισχυρότερου και πολύ πιο σύνθετου μονού επεξεργαστή.
Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC Πλεονεκτήματα MPSoC Είναι ευκολότερο να σχεδιαστούν πολλαπλοί πυρήνες επεξεργαστών από τον σχεδιασμό ενός ισχυρότερου και πολύ πιο σύνθετου μονού επεξεργαστή.
Προγραμματισμός Συστημάτων Υψηλών Επιδόσεων (ΗΥ421) Εργασία Εξαμήνου
 Εργασία Εξαμήνου") Προγραμματισμός Συστημάτων Υψηλών Επιδόσεων (ΗΥ421) Εργασία Εξαμήνου ΟΜΑΔΑ: Ιωαννίδης Σταύρος ΑΕΜ: 755 Ντελής Γιώργος ΑΕΜ: 726 Επιλογή της Εργασίας Για την εργασία μας επιλέξαμε την βελτιστοποίηση της
Προγραμματισμός Συστημάτων Υψηλών Επιδόσεων (ΗΥ421) Εργασία Εξαμήνου ΟΜΑΔΑ: Ιωαννίδης Σταύρος ΑΕΜ: 755 Ντελής Γιώργος ΑΕΜ: 726 Επιλογή της Εργασίας Για την εργασία μας επιλέξαμε την βελτιστοποίηση της
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2015 Περιεχόμενα 2 01 / 2014 Προγραμματισμός
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2015 Περιεχόμενα 2 01 / 2014 Προγραμματισμός
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
GPU. CUDA GPU GeForce GTX 580 GPU 2.67GHz Intel Core 2 Duo CPU E7300 CUDA. Parallelizing the Number Partitioning Problem for GPUs
 GPU 1 1 NP number partitioning problem Pedroso CUDA GPU GeForce GTX 580 GPU 2.67GHz Intel Core 2 Duo CPU E7300 CUDA C Pedroso Python 323 Python C 12.2 Parallelizing the Number Partitioning Problem for
GPU 1 1 NP number partitioning problem Pedroso CUDA GPU GeForce GTX 580 GPU 2.67GHz Intel Core 2 Duo CPU E7300 CUDA C Pedroso Python 323 Python C 12.2 Parallelizing the Number Partitioning Problem for
Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών
 Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2010 Περιεχόμενα...1 Σύντομη Ιστορική Αναδρομή...2
Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2010 Περιεχόμενα...1 Σύντομη Ιστορική Αναδρομή...2
Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1
 Προγραμματισμός II 1") Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1 lalis@inf.uth.gr Ο κώδικας δεν εκτελείται «μόνος του» Ο εκτελέσιμος κώδικας αποθηκεύεται σε ένα αρχείο Το αρχείο είναι μια «παθητική» οντότητα
Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1 lalis@inf.uth.gr Ο κώδικας δεν εκτελείται «μόνος του» Ο εκτελέσιμος κώδικας αποθηκεύεται σε ένα αρχείο Το αρχείο είναι μια «παθητική» οντότητα
Προγραμματισμός Συστημάτων Υψηλών Επιδόσεων (ΗΥ421) 3η Εργαστηριακή Άσκηση
 3η Εργαστηριακή Άσκηση") Προγραμματισμός Συστημάτων Υψηλών Επιδόσεων (ΗΥ421) 3η Εργαστηριακή Άσκηση ΟΝΟΜΑ: Ιωαννίδης Σταύρος ΑΕΜ: 755 Αποτελέσματα devicequery Profiling με το Vtune Το profiling έδειξε πως οι πιο αργές συναρτήσεις
Προγραμματισμός Συστημάτων Υψηλών Επιδόσεων (ΗΥ421) 3η Εργαστηριακή Άσκηση ΟΝΟΜΑ: Ιωαννίδης Σταύρος ΑΕΜ: 755 Αποτελέσματα devicequery Profiling με το Vtune Το profiling έδειξε πως οι πιο αργές συναρτήσεις
Παράλληλα Συστήματα. Γιώργος Δημητρίου. Ενότητα 3 η : Παράλληλη Επεξεργασία. Πανεπιστήμιο Θεσσαλίας - Τμήμα Πληροφορικής
 Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Παράλληλος Προγραμματισμός με OpenCL
 Παράλληλος Προγραμματισμός με OpenCL Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2017 1 Γενικά για OpenCL 2 Platform Model 3 Execution Model
Παράλληλος Προγραμματισμός με OpenCL Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Δεκέμβριος 2017 1 Γενικά για OpenCL 2 Platform Model 3 Execution Model
Παράλληλη Επεξεργασία
 Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στα Πολυεπεξεργαστικά Συστήματα Διερασίες και Νήματα σε Πολυεπεξεργαστικά Συστήματα Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed
Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στα Πολυεπεξεργαστικά Συστήματα Διερασίες και Νήματα σε Πολυεπεξεργαστικά Συστήματα Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed
Παράλληλη Επεξεργασία
 Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στο OpenMP Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed Systems Group Τι είναι το OpenMP Πρότυπο Επέκταση στη C/C++ και τη Fortran
Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στο OpenMP Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed Systems Group Τι είναι το OpenMP Πρότυπο Επέκταση στη C/C++ και τη Fortran
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
Τμήμα Λογιστικής. Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές. Μάθημα 8. 1 Στέργιος Παλαμάς
 ΤΕΙ Ηπείρου Παράρτημα Πρέβεζας Τμήμα Λογιστικής Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές Μάθημα 8 Κεντρική Μονάδα Επεξεργασίας και Μνήμη 1 Αρχιτεκτονική του Ηλεκτρονικού Υπολογιστή Μονάδες Εισόδου Κεντρική
ΤΕΙ Ηπείρου Παράρτημα Πρέβεζας Τμήμα Λογιστικής Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές Μάθημα 8 Κεντρική Μονάδα Επεξεργασίας και Μνήμη 1 Αρχιτεκτονική του Ηλεκτρονικού Υπολογιστή Μονάδες Εισόδου Κεντρική
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Φεβρουάριος 2014 Περιεχόμενα 1 Εισαγωγή 2 Επεξεργαστές
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Φεβρουάριος 2014 Περιεχόμενα 1 Εισαγωγή 2 Επεξεργαστές
ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων. Βιβλιογραφία Ενότητας
 ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων Βελτιστοποίηση κώδικα σε επεξεργαστές ΨΕΣ Τµήµα Επιστήµη και Τεχνολογίας Τηλεπικοινωνιών Πανεπιστήµιο Πελοποννήσου Βιβλιογραφία Ενότητας Kehtarnavaz [2005]: Chapter
ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων Βελτιστοποίηση κώδικα σε επεξεργαστές ΨΕΣ Τµήµα Επιστήµη και Τεχνολογίας Τηλεπικοινωνιών Πανεπιστήµιο Πελοποννήσου Βιβλιογραφία Ενότητας Kehtarnavaz [2005]: Chapter
ΠΡΟΗΓΜΕΝΟΙ ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ PROJECT 2: MEMORY MANAGEMENT
 ΠΡΟΗΓΜΕΝΟΙ ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ PROJECT 2: MEMORY MANAGEMENT ΘΕΩΡΙΑ Στο project αυτό έχουμε υλοποιήσει τις βασικές συναρτήσεις της stdlib της C malloc και free Η συνάρτηση malloc είναι η void *malloc(int
ΠΡΟΗΓΜΕΝΟΙ ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ PROJECT 2: MEMORY MANAGEMENT ΘΕΩΡΙΑ Στο project αυτό έχουμε υλοποιήσει τις βασικές συναρτήσεις της stdlib της C malloc και free Η συνάρτηση malloc είναι η void *malloc(int
Μηχανοτρονική. Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο,
 Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Προγραμματισμός GPUs μέσω του περιβάλλοντος CUDA
 Προγραμματισμός GPUs μέσω του περιβάλλοντος CUDA Κωνσταντινίδης Ηλίας Υποψήφιος Διδάκτωρ Τμήμα Πληροφορικής & Τηλεπικοινωνιών Εθνικό και Καποδιστριακό Πανεπιστήμιο Αθηνών Νόμος Moore density doubles/18m
Προγραμματισμός GPUs μέσω του περιβάλλοντος CUDA Κωνσταντινίδης Ηλίας Υποψήφιος Διδάκτωρ Τμήμα Πληροφορικής & Τηλεπικοινωνιών Εθνικό και Καποδιστριακό Πανεπιστήμιο Αθηνών Νόμος Moore density doubles/18m
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2016 1 Εισαγωγικά 2 Compute Unified Device
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2016 1 Εισαγωγικά 2 Compute Unified Device
Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών
 Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Αρχιτεκτονική Υπολογιστών Άσκηση 6: Ασκήσεις Εξαμήνου Μέρος Β Νοέμβριος 2016 Στην άσκηση αυτή θα μελετήσουμε την εκτέλεση ενός
Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Αρχιτεκτονική Υπολογιστών Άσκηση 6: Ασκήσεις Εξαμήνου Μέρος Β Νοέμβριος 2016 Στην άσκηση αυτή θα μελετήσουμε την εκτέλεση ενός
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων
 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Προσομοίωση μεγάλης κλίμακας γραμμικών κυκλωμάτων σε παράλληλες πλατφόρμες Ειδικό Θέμα Ιωαννίδης Κ. Σταύρος Αριθμός Ειδικού Μητρώου:
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Προσομοίωση μεγάλης κλίμακας γραμμικών κυκλωμάτων σε παράλληλες πλατφόρμες Ειδικό Θέμα Ιωαννίδης Κ. Σταύρος Αριθμός Ειδικού Μητρώου:
Διαφορές single-processor αρχιτεκτονικών και SoCs
 13.1 Τα συστήματα και η επικοινωνία μεταξύ τους γίνονται όλο και περισσότερο πολύπλοκα. Δεν μπορούν να περιγραφούνε επαρκώς στο επίπεδο RTL καθώς αυτή η διαδικασία γίνεται πλέον αρκετά χρονοβόρα. Για αυτό
13.1 Τα συστήματα και η επικοινωνία μεταξύ τους γίνονται όλο και περισσότερο πολύπλοκα. Δεν μπορούν να περιγραφούνε επαρκώς στο επίπεδο RTL καθώς αυτή η διαδικασία γίνεται πλέον αρκετά χρονοβόρα. Για αυτό
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 11-12 : Δομή και Λειτουργία της CPU Ευάγγελος Καρβούνης Παρασκευή, 22/01/2016 2 Οργάνωση της CPU Η CPU πρέπει:
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 11-12 : Δομή και Λειτουργία της CPU Ευάγγελος Καρβούνης Παρασκευή, 22/01/2016 2 Οργάνωση της CPU Η CPU πρέπει:
All Pairs Shortest Path
 All Pairs Shortest Path χρησιμοποιώντας Κυπριώτη Αικατερίνη 6960 Μόσχογλου Στυλιανός 6978 20 Ιανουαρίου 2012 Περιεχόμενα 1 Πρόλογος 3 2 Ο σειριακός APSP 3 3 Η παραλληλοποίηση με 5 3.1 Το προγραμματιστικό
All Pairs Shortest Path χρησιμοποιώντας Κυπριώτη Αικατερίνη 6960 Μόσχογλου Στυλιανός 6978 20 Ιανουαρίου 2012 Περιεχόμενα 1 Πρόλογος 3 2 Ο σειριακός APSP 3 3 Η παραλληλοποίηση με 5 3.1 Το προγραμματιστικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Κρυφές Μνήμες. (οργάνωση, λειτουργία και απόδοση)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί
 Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 3: Θεωρία Παράλληλου Προγραμματισμού
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 3: Θεωρία Παράλληλου Προγραμματισμού
Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1
 Προγραμματισμός II 1") Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1 lalis@inf.uth.gr Πρόγραμμα και εκτέλεση προγράμματος Ο εκτελέσιμος κώδικας αποθηκεύεται σε ένα αρχείο Το αρχείο είναι μια «παθητική» οντότητα
Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1 lalis@inf.uth.gr Πρόγραμμα και εκτέλεση προγράμματος Ο εκτελέσιμος κώδικας αποθηκεύεται σε ένα αρχείο Το αρχείο είναι μια «παθητική» οντότητα
Προσομοιώσεις Monte Carlo σε GPU
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΕΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΚΑΙ ΦΥΣΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΟΜΕΑΣ ΦΥΣΙΚΗΣ Προσομοιώσεις Monte Carlo σε GPU Δημήτρης Καρκούλης Επιβλέπων: Κ. Αναγνωστόπουλος 15/07/2010 Πρακτική στο
ΕΘΝΙΚΟ ΜΕΤΣΟΒΕΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΚΑΙ ΦΥΣΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΟΜΕΑΣ ΦΥΣΙΚΗΣ Προσομοιώσεις Monte Carlo σε GPU Δημήτρης Καρκούλης Επιβλέπων: Κ. Αναγνωστόπουλος 15/07/2010 Πρακτική στο
ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟΔΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ
 ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟΔΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ "ΤΕΧΝΟΛΟΓΙΑ ΣΥΣΤΗΜΑΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ" ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΥΛΟΠΟΙΗΣΗ
ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟΔΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ "ΤΕΧΝΟΛΟΓΙΑ ΣΥΣΤΗΜΑΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ" ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΥΛΟΠΟΙΗΣΗ
ΣΥΣΤΗΜΑΤΑ ΠΑΡΑΛΛΗΛΗΣ ΕΠΕΞΕΡΓΑΣΙΑΣ 9o εξάμηνο ΗΜΜΥ, ακαδημαϊκό έτος
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΞΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr ΣΥΣΤΗΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΞΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr ΣΥΣΤΗΜΑΤΑ
Δομημένος Προγραμματισμός (ΤΛ1006)
") Τεχνολογικό Εκπαιδευτικό Ίδρυμα Κρήτης Σχολή Εφαρμοσμένων Επιστημών Τμήμα Ηλεκτρονικών Μηχανικών Τομέας Αυτοματισμού και Πληροφορικής Δομημένος Προγραμματισμός (ΤΛ1006) Δρ. Μηχ. Νικόλαος Πετράκης, Καθηγητής
Τεχνολογικό Εκπαιδευτικό Ίδρυμα Κρήτης Σχολή Εφαρμοσμένων Επιστημών Τμήμα Ηλεκτρονικών Μηχανικών Τομέας Αυτοματισμού και Πληροφορικής Δομημένος Προγραμματισμός (ΤΛ1006) Δρ. Μηχ. Νικόλαος Πετράκης, Καθηγητής
Προγραμματισμός Ι. Δυναμική Διαχείριση Μνήμης. Δημήτρης Μιχαήλ. Ακ. Έτος 2011-2012. Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο
 Προγραμματισμός Ι Δυναμική Διαχείριση Μνήμης Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ακ. Έτος 2011-2012 Ανάγκη για Δυναμική Μνήμη Στατική Μνήμη Μέχρι τώρα χρησιμοποιούσαμε
Προγραμματισμός Ι Δυναμική Διαχείριση Μνήμης Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ακ. Έτος 2011-2012 Ανάγκη για Δυναμική Μνήμη Στατική Μνήμη Μέχρι τώρα χρησιμοποιούσαμε
FORTRAN και Αντικειμενοστραφής Προγραμματισμός
 FORTRAN και Αντικειμενοστραφής Προγραμματισμός Παραδόσεις Μαθήματος 2016 Δρ Γ Παπαλάμπρου Επίκουρος Καθηγητής ΕΜΠ georgepapalambrou@lmentuagr Εργαστήριο Ναυτικής Μηχανολογίας (Κτίριο Λ) Σχολή Ναυπηγών
FORTRAN και Αντικειμενοστραφής Προγραμματισμός Παραδόσεις Μαθήματος 2016 Δρ Γ Παπαλάμπρου Επίκουρος Καθηγητής ΕΜΠ georgepapalambrou@lmentuagr Εργαστήριο Ναυτικής Μηχανολογίας (Κτίριο Λ) Σχολή Ναυπηγών
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών
 Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2017 1 Εισαγωγικά 2 Compute Unified Device
Παράλληλος Προγραμματισμός σε Επεξεργαστές Γραφικών Συστήματα Παράλληλης Επεξεργασίας 9ο εξάμηνο, ΣΗΜΜΥ Εργαστήριο Υπολογιστικών Συστημάτων (CSLab) Νοέμβριος 2017 1 Εισαγωγικά 2 Compute Unified Device
i Throughput: Ο ρυθμός ολοκλήρωσης έργου σε συγκεκριμένο χρόνο
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
ΘΕΜΑ PROJECT COMPILER FLAGS ΤΡΑΧΑΝΗΣ ΔΗΜΗΤΡΗΣ 6108 ΤΡΑΧΑΝΗΣ ΓΕΩΡΓΙΟΣ 5789
 ΘΕΜΑ PROJECT COMPILER FLAGS ΤΡΑΧΑΝΗΣ ΔΗΜΗΤΡΗΣ 6108 ΤΡΑΧΑΝΗΣ ΓΕΩΡΓΙΟΣ 5789 Γενικά Οι compilers προσφέρουν μία σειρά από τεχνικές βελτιστοποίησης Στόχοι: Αύξηση ταχύτητας εκτέλεσης Μείωση μεγέθους Εφικτές
ΘΕΜΑ PROJECT COMPILER FLAGS ΤΡΑΧΑΝΗΣ ΔΗΜΗΤΡΗΣ 6108 ΤΡΑΧΑΝΗΣ ΓΕΩΡΓΙΟΣ 5789 Γενικά Οι compilers προσφέρουν μία σειρά από τεχνικές βελτιστοποίησης Στόχοι: Αύξηση ταχύτητας εκτέλεσης Μείωση μεγέθους Εφικτές
Αρχιτεκτονική Επεξεργαστών Ψ.Ε.Σ
 ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων Αρχιτεκτονική Επεξεργαστών Ψ.Ε.Σ Βιβλιογραφία Ενότητας Kehtarnavaz [2005]: Chapter 3 Kuo [2005]: Chapters 1 & 4-5 Lapsley [2002]: Chapter 4 Hayes [2000]: Κεφάλαιo 8
ΕΣ 08 Επεξεργαστές Ψηφιακών Σηµάτων Αρχιτεκτονική Επεξεργαστών Ψ.Ε.Σ Βιβλιογραφία Ενότητας Kehtarnavaz [2005]: Chapter 3 Kuo [2005]: Chapters 1 & 4-5 Lapsley [2002]: Chapter 4 Hayes [2000]: Κεφάλαιo 8
Προγραμματισμός Ι (HY120)
") Προγραμματισμός Ι (HY20) # μνήμη & μεταβλητές πρόγραμμα & εκτέλεση Ψηφιακά δεδομένα, μνήμη, μεταβλητές 2 Δυαδικός κόσμος Οι υπολογιστές είναι δυαδικές μηχανές Όλη η πληροφορία (δεδομένα και κώδικας) κωδικοποιείται
Προγραμματισμός Ι (HY20) # μνήμη & μεταβλητές πρόγραμμα & εκτέλεση Ψηφιακά δεδομένα, μνήμη, μεταβλητές 2 Δυαδικός κόσμος Οι υπολογιστές είναι δυαδικές μηχανές Όλη η πληροφορία (δεδομένα και κώδικας) κωδικοποιείται
Παράλληλα Συστήματα. Γιώργος Δημητρίου. Ενότητα 4 η : Παράλληλος Προγραμματισμός. Πανεπιστήμιο Θεσσαλίας - Τμήμα Πληροφορικής
 Γιώργος Δημητρίου Ενότητα 4 η : Παράλληλος Προγραμματισμός Παράλληλος Προγραμματισμός Ο παράλληλος προγραμματισμός με βάση την αφαιρετικότητα: Ελάχιστη έως καμία γνώση της αρχιτεκτονικής Επεκτάσεις παράλληλου
Γιώργος Δημητρίου Ενότητα 4 η : Παράλληλος Προγραμματισμός Παράλληλος Προγραμματισμός Ο παράλληλος προγραμματισμός με βάση την αφαιρετικότητα: Ελάχιστη έως καμία γνώση της αρχιτεκτονικής Επεκτάσεις παράλληλου
Προγραμματισμός συστημάτων UNIX/POSIX. Θέμα επιλεγμένο από τους φοιτητές: Προγραμματιστικές τεχνικές που στοχεύουν σε επιδόσεις
 Προγραμματισμός συστημάτων UNIX/POSIX Θέμα επιλεγμένο από τους φοιτητές: Προγραμματιστικές τεχνικές που στοχεύουν σε επιδόσεις Βελτιστοποιήσεις με στόχο τις επιδόσεις Σε αρκετές περιπτώσεις δεν αρκεί να
Προγραμματισμός συστημάτων UNIX/POSIX Θέμα επιλεγμένο από τους φοιτητές: Προγραμματιστικές τεχνικές που στοχεύουν σε επιδόσεις Βελτιστοποιήσεις με στόχο τις επιδόσεις Σε αρκετές περιπτώσεις δεν αρκεί να
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Απόδοση ΚΜΕ. (Μέτρηση και τεχνικές βελτίωσης απόδοσης)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
; Γιατί είναι ταχύτερη η λήψη και αποκωδικοποίηση των εντολών σταθερού μήκους;
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Δομή Εντολών και Παραδείγματα) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Δομή Εντολών και Παραδείγματα) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Προγραμματισμός Η/Υ (ΤΛ2007 )
") Τμήμα Ηλεκτρονικών Μηχανικών Τ.Ε.Ι. Κρήτης Προγραμματισμός Η/Υ (ΤΛ2007 ) Δρ. Μηχ. Νικόλαος Πετράκης (npet@chania.teicrete.gr) Ιστοσελίδα Μαθήματος: https://eclass.chania.teicrete.gr/ Εξάμηνο: Εαρινό 2015-16
Τμήμα Ηλεκτρονικών Μηχανικών Τ.Ε.Ι. Κρήτης Προγραμματισμός Η/Υ (ΤΛ2007 ) Δρ. Μηχ. Νικόλαος Πετράκης (npet@chania.teicrete.gr) Ιστοσελίδα Μαθήματος: https://eclass.chania.teicrete.gr/ Εξάμηνο: Εαρινό 2015-16
Ιεραρχία Μνήμης. Ιεραρχία μνήμης και τοπικότητα. Σκοπός της Ιεραρχίας Μνήμης. Κρυφές Μνήμες
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Για βελτίωση της απόδοσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Για βελτίωση της απόδοσης
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Συστήματα Παράλληλης
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Συστήματα Παράλληλης
Υπάρχουν δύο τύποι μνήμης, η μνήμη τυχαίας προσπέλασης (Random Access Memory RAM) και η μνήμη ανάγνωσης-μόνο (Read-Only Memory ROM).
 και η μνήμη ανάγνωσης-μόνο (Read-Only Memory ROM).") Μνήμες Ένα από τα βασικά πλεονεκτήματα των ψηφιακών συστημάτων σε σχέση με τα αναλογικά, είναι η ευκολία αποθήκευσης μεγάλων ποσοτήτων πληροφοριών, είτε προσωρινά είτε μόνιμα Οι πληροφορίες αποθηκεύονται
Μνήμες Ένα από τα βασικά πλεονεκτήματα των ψηφιακών συστημάτων σε σχέση με τα αναλογικά, είναι η ευκολία αποθήκευσης μεγάλων ποσοτήτων πληροφοριών, είτε προσωρινά είτε μόνιμα Οι πληροφορίες αποθηκεύονται
CUDA Compute Unified Device Architecture
 CUDA Compute Unified Device Architecture Καλέρης Κωνσταντίνος Πεµπτοετής φοιτητής του τµήµατος Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Η/Υ του Πανεπιστηµίου Πατρών ee5972@upnet.gr Καλλέργης Γεώργιος Πεµπτοετής
CUDA Compute Unified Device Architecture Καλέρης Κωνσταντίνος Πεµπτοετής φοιτητής του τµήµατος Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Η/Υ του Πανεπιστηµίου Πατρών ee5972@upnet.gr Καλλέργης Γεώργιος Πεµπτοετής
Πανεπιστήμιο Πειραιώς Τμήμα Πληροφορικής Πρόγραμμα Μεταπτυχιακών Σπουδών «Πληροφορική»
 Πανεπιστήμιο Πειραιώς Τμήμα Πληροφορικής Πρόγραμμα Μεταπτυχιακών Σπουδών «Πληροφορική» Μεταπτυχιακή Διατριβή Τίτλος Διατριβής Ονοματεπώνυμο Φοιτητή Πατρώνυμο Αριθμός Μητρώου Επιβλέπων Επιτάχυνση του αλγορίθμου
Πανεπιστήμιο Πειραιώς Τμήμα Πληροφορικής Πρόγραμμα Μεταπτυχιακών Σπουδών «Πληροφορική» Μεταπτυχιακή Διατριβή Τίτλος Διατριβής Ονοματεπώνυμο Φοιτητή Πατρώνυμο Αριθμός Μητρώου Επιβλέπων Επιτάχυνση του αλγορίθμου
EM 361: Παράλληλοι Υπολογισμοί
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #2: Αρχιτεκτονική Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #2: Αρχιτεκτονική Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
ΑΣΚΗΣΗ 6: ΔΕΙΚΤΕΣ. Σκοπός της Άσκησης. 1. Εισαγωγικά στοιχεία για τους Δείκτες
 Σκοπός της Άσκησης ΑΣΚΗΣΗ 6: ΔΕΙΚΤΕΣ Ο σκοπός αυτής της εργαστηριακής άσκησης είναι η εξοικείωση με τη χρήση των δεικτών (pointers). Οι δείκτες δίνουν την δυνατότητα σε προγράμματα να προσομοιώνουν τη
Σκοπός της Άσκησης ΑΣΚΗΣΗ 6: ΔΕΙΚΤΕΣ Ο σκοπός αυτής της εργαστηριακής άσκησης είναι η εξοικείωση με τη χρήση των δεικτών (pointers). Οι δείκτες δίνουν την δυνατότητα σε προγράμματα να προσομοιώνουν τη
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί
 Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 4: Παράλληλοι Αλγόριθμοι Ταξινόμηση
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 4: Παράλληλοι Αλγόριθμοι Ταξινόμηση
Τμήμα Οικιακής Οικονομίας και Οικολογίας. Οργάνωση Υπολογιστών
 Οργάνωση Υπολογιστών Υπολογιστικό Σύστημα Λειτουργικό Σύστημα Αποτελεί τη διασύνδεση μεταξύ του υλικού ενός υπολογιστή και του χρήστη (προγραμμάτων ή ανθρώπων). Είναι ένα πρόγραμμα (ή ένα σύνολο προγραμμάτων)
Οργάνωση Υπολογιστών Υπολογιστικό Σύστημα Λειτουργικό Σύστημα Αποτελεί τη διασύνδεση μεταξύ του υλικού ενός υπολογιστή και του χρήστη (προγραμμάτων ή ανθρώπων). Είναι ένα πρόγραμμα (ή ένα σύνολο προγραμμάτων)
Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών
 Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών ακ. έτος 2006-2007 Νεκτάριος Κοζύρης Νίκος Αναστόπουλος {nkoziris,anastop}@cslab.ece.ntua.gr Άσκηση 1: pipelining Εξετάζουμε την εκτέλεση του παρακάτω
Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών ακ. έτος 2006-2007 Νεκτάριος Κοζύρης Νίκος Αναστόπουλος {nkoziris,anastop}@cslab.ece.ntua.gr Άσκηση 1: pipelining Εξετάζουμε την εκτέλεση του παρακάτω
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ. Άσκηση 5: Παράλληλος προγραμματισμός σε επεξεργαστές γραφικών
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Συστήματα Παράλληλης
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Συστήματα Παράλληλης
ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ
 ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ (Τμήματα Υπολογιστή) ΕΚΠΑΙΔΕΥΤΗΣ:ΠΟΖΟΥΚΙΔΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣ ΤΜΗΜΑΤΑ ΗΛΕΚΤΡΟΝΙΚΟΥ ΥΠΟΛΟΓΙΣΤΗ Κάθε ηλεκτρονικός υπολογιστής αποτελείται
ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ (Τμήματα Υπολογιστή) ΕΚΠΑΙΔΕΥΤΗΣ:ΠΟΖΟΥΚΙΔΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣ ΤΜΗΜΑΤΑ ΗΛΕΚΤΡΟΝΙΚΟΥ ΥΠΟΛΟΓΙΣΤΗ Κάθε ηλεκτρονικός υπολογιστής αποτελείται
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΑΝΑΛΥΣΗ ΑΛΓΟΡΙΘΜΩΝ
 ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΑΝΑΛΥΣΗ ΑΛΓΟΡΙΘΜΩΝ Ενότητα 3: Ασυμπτωτικός συμβολισμός Μαρία Σατρατζέμη Τμήμα Εφαρμοσμένης Πληροφορικής Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons.
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΑΝΑΛΥΣΗ ΑΛΓΟΡΙΘΜΩΝ Ενότητα 3: Ασυμπτωτικός συμβολισμός Μαρία Σατρατζέμη Τμήμα Εφαρμοσμένης Πληροφορικής Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons.
Λειτουργικά Συστήματα 7ο εξάμηνο, Ακαδημαϊκή περίοδος
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ KΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr Λειτουργικά
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ KΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr Λειτουργικά
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Διάλεξη 2η: Αλγόριθμοι και Προγράμματα
 Διάλεξη 2η: Αλγόριθμοι και Προγράμματα Τμήμα Επιστήμης Υπολογιστών, Πανεπιστήμιο Κρήτης Εισαγωγή στην Επιστήμη Υπολογιστών Βασίζεται σε διαφάνειες του Κ Παναγιωτάκη Πρατικάκης (CSD) Αλγόριθμοι και Προγράμματα
Διάλεξη 2η: Αλγόριθμοι και Προγράμματα Τμήμα Επιστήμης Υπολογιστών, Πανεπιστήμιο Κρήτης Εισαγωγή στην Επιστήμη Υπολογιστών Βασίζεται σε διαφάνειες του Κ Παναγιωτάκη Πρατικάκης (CSD) Αλγόριθμοι και Προγράμματα
Είναι το «μυαλό» του υπολογιστή μας. Αυτός κάνει όλους τους υπολογισμούς και τις πράξεις. Έχει δική του ενσωματωμένη μνήμη, τη λεγόμενη κρυφή
 1 Είναι το «μυαλό» του υπολογιστή μας. Αυτός κάνει όλους τους υπολογισμούς και τις πράξεις. Έχει δική του ενσωματωμένη μνήμη, τη λεγόμενη κρυφή μνήμη(cache). Η cache είναι πολύ σημαντική, πολύ γρήγορη,
1 Είναι το «μυαλό» του υπολογιστή μας. Αυτός κάνει όλους τους υπολογισμούς και τις πράξεις. Έχει δική του ενσωματωμένη μνήμη, τη λεγόμενη κρυφή μνήμη(cache). Η cache είναι πολύ σημαντική, πολύ γρήγορη,
HY-486 Αρχές Κατανεμημένου Υπολογισμού Εαρινό Εξάμηνο
 HY-486 Αρχές Κατανεμημένου Υπολογισμού Εαρινό Εξάμηνο 2017-2018 Πρώτη Προγραμματιστική Εργασία Προθεσμία παράδοσης: Δευτέρα 30/4 στις 23:59. 1. Γενική Περιγραφή Στην πρώτη προγραμματιστική εργασία καλείστε
HY-486 Αρχές Κατανεμημένου Υπολογισμού Εαρινό Εξάμηνο 2017-2018 Πρώτη Προγραμματιστική Εργασία Προθεσμία παράδοσης: Δευτέρα 30/4 στις 23:59. 1. Γενική Περιγραφή Στην πρώτη προγραμματιστική εργασία καλείστε
Πρόγραμμα όρασης. Στη συνέχεια θα περιγράψουμε πώς δουλεύει το ρομπότ.
 Πρόγραμμα όρασης Υλοποιείτε ένα πρόγραμμα όρασης για ένα ρομπότ. Κάθε φορά που η κάμερα του ρομπότ βγάζει μία φωτογραφία, αυτή αποθηκεύεται στη μνήμη του ρομπότ ως μία ασπρόμαυρη εικόνα. Κάθε εικόνα είναι
Πρόγραμμα όρασης Υλοποιείτε ένα πρόγραμμα όρασης για ένα ρομπότ. Κάθε φορά που η κάμερα του ρομπότ βγάζει μία φωτογραφία, αυτή αποθηκεύεται στη μνήμη του ρομπότ ως μία ασπρόμαυρη εικόνα. Κάθε εικόνα είναι
Οι εντολές ελέγχου της ροής ενός προγράμματος.
 Κεφάλαιο ΙΙI: Οι εντολές ελέγχου της ροής ενός προγράμματος 31 Εντολές ελέγχου της ροής Στο παρόν κεφάλαιο ασχολούμαστε με την σύνταξη των εντολών της C οι οποίες εισάγουν λογική και ελέγχουν την ροή εκτέλεσης
Κεφάλαιο ΙΙI: Οι εντολές ελέγχου της ροής ενός προγράμματος 31 Εντολές ελέγχου της ροής Στο παρόν κεφάλαιο ασχολούμαστε με την σύνταξη των εντολών της C οι οποίες εισάγουν λογική και ελέγχουν την ροή εκτέλεσης
Μία μέθοδος προσομοίωσης ψηφιακών κυκλωμάτων Εξελικτικής Υπολογιστικής
 Μία μέθοδος προσομοίωσης ψηφιακών κυκλωμάτων Εξελικτικής Υπολογιστικής Βασισμένο σε μια εργασία των Καζαρλή, Καλόμοιρου, Μαστοροκώστα, Μπαλουκτσή, Καλαϊτζή, Βαλαή, Πετρίδη Εισαγωγή Η Εξελικτική Υπολογιστική
Μία μέθοδος προσομοίωσης ψηφιακών κυκλωμάτων Εξελικτικής Υπολογιστικής Βασισμένο σε μια εργασία των Καζαρλή, Καλόμοιρου, Μαστοροκώστα, Μπαλουκτσή, Καλαϊτζή, Βαλαή, Πετρίδη Εισαγωγή Η Εξελικτική Υπολογιστική
ILP (integer linear programming) βασιζόμενη εξαρτώμενη από τους πόρους μεταγλώττιση
 βασιζόμενη εξαρτώμενη από τους πόρους μεταγλώττιση") ILP (integer linear programming) βασιζόμενη εξαρτώμενη από τους πόρους μεταγλώττιση Γιατί χρησιμοποιείται μοντελοποίηση των περιορισμών με ακεραίους? Υπάρχουν ήδη εργαλεία για τον υπολογισμό και την χρήση
ILP (integer linear programming) βασιζόμενη εξαρτώμενη από τους πόρους μεταγλώττιση Γιατί χρησιμοποιείται μοντελοποίηση των περιορισμών με ακεραίους? Υπάρχουν ήδη εργαλεία για τον υπολογισμό και την χρήση
Κεντρική Μονάδα Επεξεργασίας. Επανάληψη: Απόδοση ΚΜΕ. ΚΜΕ ενός κύκλου (single-cycle) Παραλληλισμός σε επίπεδο εντολών. Υπολογιστικό σύστημα
 Παραλληλισμός σε επίπεδο εντολών. Υπολογιστικό σύστημα") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Παραλληλισμός σε επίπεδο εντολών
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Οργάνωση επεξεργαστή (1 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική
 ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική") Οργάνωση επεξεργαστή (1 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Κώδικας μηχανής (E) Ο επεξεργαστής μπορεί να εκτελέσει το αρχιτεκτονικό σύνολο εντολών (instruction set architecture) Οι
Οργάνωση επεξεργαστή (1 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Κώδικας μηχανής (E) Ο επεξεργαστής μπορεί να εκτελέσει το αρχιτεκτονικό σύνολο εντολών (instruction set architecture) Οι
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I
 ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
Κεντρική Μονάδα Επεξεργασίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
add $t0,$zero, $zero I_LOOP: beq $t0,$s3, END add $t1, $zero,$zero J_LOOP: sub $t2, $s3, $t0 add $t2, $t2, $s1 int i, j, tmp; int *arr, n;
 Άσκηση 1 η Μέρος Α Ζητούμενο: Δίνεται το παρακάτω πρόγραμμα σε C καθώς και μια μετάφραση του σε assembly MIPS. Συμπληρώστε τα κενά. Σας υπενθυμίζουμε ότι ο καταχωρητής $0 (ή $zero) είναι πάντα μηδέν. int
Άσκηση 1 η Μέρος Α Ζητούμενο: Δίνεται το παρακάτω πρόγραμμα σε C καθώς και μια μετάφραση του σε assembly MIPS. Συμπληρώστε τα κενά. Σας υπενθυμίζουμε ότι ο καταχωρητής $0 (ή $zero) είναι πάντα μηδέν. int
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων
 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Οργάνωση Η/Υ Ενότητα 1η: Εισαγωγή στην Οργάνωση Η/Υ Άσκηση 1: Αναλύστε τη διαδοχική εκτέλεση των παρακάτω εντολών MIPS με βάση τις
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Οργάνωση Η/Υ Ενότητα 1η: Εισαγωγή στην Οργάνωση Η/Υ Άσκηση 1: Αναλύστε τη διαδοχική εκτέλεση των παρακάτω εντολών MIPS με βάση τις
Το ολοκληρωμένο κύκλωμα μιας ΚΜΕ. «Φέτα» ημιαγωγών (wafer) από τη διαδικασία παραγωγής ΚΜΕ
 από τη διαδικασία παραγωγής ΚΜΕ") Το ολοκληρωμένο κύκλωμα μιας ΚΜΕ Η Κεντρική Μονάδα Επεξεργασίας (Central Processing Unit -CPU) ή απλούστερα επεξεργαστής αποτελεί το μέρος του υλικού που εκτελεί τις εντολές ενός προγράμματος υπολογιστή
Το ολοκληρωμένο κύκλωμα μιας ΚΜΕ Η Κεντρική Μονάδα Επεξεργασίας (Central Processing Unit -CPU) ή απλούστερα επεξεργαστής αποτελεί το μέρος του υλικού που εκτελεί τις εντολές ενός προγράμματος υπολογιστή
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
Σκοπός. Εργαστήριο 6 Εντολές Επανάληψης
 Εργαστήριο 6 Εντολές Επανάληψης Η δομή Επιλογής στη PASCAL H δομή Επανάληψης στη PASCAL. Ρεύμα Εισόδου / Εξόδου.. Ρεύμα Εισόδου / Εξόδου. To πρόγραμμα γραφικών gnuplot. Γραφικά στη PASCAL. Σκοπός 6.1 ΕΠΙΔΙΩΞΗ
Εργαστήριο 6 Εντολές Επανάληψης Η δομή Επιλογής στη PASCAL H δομή Επανάληψης στη PASCAL. Ρεύμα Εισόδου / Εξόδου.. Ρεύμα Εισόδου / Εξόδου. To πρόγραμμα γραφικών gnuplot. Γραφικά στη PASCAL. Σκοπός 6.1 ΕΠΙΔΙΩΞΗ
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Εισαγωγικά & Βασικές Έννοιες
 Εισαγωγικά & Βασικές Έννοιες ΙΙΙ 1 lalis@inf.uth.gr Γιατί πολλές διεργασίες/νήματα; Επίπεδο εφαρμογής Καλύτερη δόμηση κώδικα Αποφυγή μπλοκαρίσματος / περιοδικών ελέγχων Φυσική έκφραση παραλληλισμού Επίπεδο
Εισαγωγικά & Βασικές Έννοιες ΙΙΙ 1 lalis@inf.uth.gr Γιατί πολλές διεργασίες/νήματα; Επίπεδο εφαρμογής Καλύτερη δόμηση κώδικα Αποφυγή μπλοκαρίσματος / περιοδικών ελέγχων Φυσική έκφραση παραλληλισμού Επίπεδο
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 7: Αποκωδικοποίηση Εντολής x86 Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 7: Αποκωδικοποίηση Εντολής x86 Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών
Παράλληλη Επεξεργασία Κεφάλαιο 7 ο Αρχιτεκτονική Συστημάτων Κατανεμημένης Μνήμης
 Παράλληλη Επεξεργασία Κεφάλαιο 7 ο Αρχιτεκτονική Συστημάτων Κατανεμημένης Μνήμης Κωνσταντίνος Μαργαρίτης Καθηγητής Τμήμα Εφαρμοσμένης Πληροφορικής Πανεπιστήμιο Μακεδονίας kmarg@uom.gr http://eos.uom.gr/~kmarg
Παράλληλη Επεξεργασία Κεφάλαιο 7 ο Αρχιτεκτονική Συστημάτων Κατανεμημένης Μνήμης Κωνσταντίνος Μαργαρίτης Καθηγητής Τμήμα Εφαρμοσμένης Πληροφορικής Πανεπιστήμιο Μακεδονίας kmarg@uom.gr http://eos.uom.gr/~kmarg
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ Σχολή Μηχανολόγων Μηχανικών Εργαστήριο Θερμικών Στροβιλομηχανών
 2009 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ Σχολή Μηχανολόγων Μηχανικών Εργαστήριο Θερμικών Στροβιλομηχανών [ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ ΣΕ ΚΑΡΤΕΣ ΓΡΑΦΙΚΩΝ ΚΑΙ ΕΦΑΡΜΟΓΗ ΣΤΗΝ ΑΕΡΟΔΥΝΑΜΙΚΗ ΒΕΛΤΙΣΤΟΠΟΙΗΣΗ] Διπλωματική Εργασία του
2009 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ Σχολή Μηχανολόγων Μηχανικών Εργαστήριο Θερμικών Στροβιλομηχανών [ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ ΣΕ ΚΑΡΤΕΣ ΓΡΑΦΙΚΩΝ ΚΑΙ ΕΦΑΡΜΟΓΗ ΣΤΗΝ ΑΕΡΟΔΥΝΑΜΙΚΗ ΒΕΛΤΙΣΤΟΠΟΙΗΣΗ] Διπλωματική Εργασία του
GPGPU. Grover. On Large Scale Simulation of Grover s Algorithm by Using GPGPU
 GPGPU Grover 1, 2 1 3 4 Grover Grover OpenMP GPGPU Grover qubit OpenMP GPGPU, 1.47 qubit On Large Scale Simulation of Grover s Algorithm by Using GPGPU Hiroshi Shibata, 1, 2 Tomoya Suzuki, 1 Seiya Okubo
GPGPU Grover 1, 2 1 3 4 Grover Grover OpenMP GPGPU Grover qubit OpenMP GPGPU, 1.47 qubit On Large Scale Simulation of Grover s Algorithm by Using GPGPU Hiroshi Shibata, 1, 2 Tomoya Suzuki, 1 Seiya Okubo
Παράλληλος προγραμματισμός: παράλληλες λ υπολογιστικές πλατφόρμες και ανάλυση προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: παράλληλες λ υπολογιστικές πλατφόρμες και ανάλυση προγραμμάτων
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: παράλληλες λ υπολογιστικές πλατφόρμες και ανάλυση προγραμμάτων
i Όλες οι σύγχρονες ΚΜΕ είναι πολυπλοκότερες!
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Η υπολογιστική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Η υπολογιστική
Εισαγωγή στην Επεξεργασία Ερωτήσεων. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας Τα βασικά βήματα στην επεξεργασία
Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας Τα βασικά βήματα στην επεξεργασία
Άρα, Τ ser = (A 0 +B 0 +B 0 +A 0 ) επίπεδο 0 + (A 1 +B 1 +A 1 ) επίπεδο 1 + +(B 5 ) επίπεδο 5 = 25[χρονικές µονάδες]
![Άρα, Τ ser = (A 0 +B 0 +B 0 +A 0 ) επίπεδο 0 + (A 1 +B 1 +A 1 ) επίπεδο 1 + +(B 5 ) επίπεδο 5 = 25[χρονικές µονάδες]](/thumbs/27/10818274.jpg "Άρα, Τ ser = (A 0 +B 0 +B 0 +A 0 ) επίπεδο 0 + (A 1 +B 1 +A 1 ) επίπεδο 1 + +(B 5 ) επίπεδο 5 = 25[χρονικές µονάδες]") Α. Στο παρακάτω διάγραµµα εµφανίζεται η εκτέλεση ενός παράλληλου αλγόριθµου που λύνει το ίδιο πρόβληµα µε έναν ακολουθιακό αλγόριθµο χωρίς πλεονασµό. Τα Α i και B i αντιστοιχούν σε ακολουθιακά υποέργα
Α. Στο παρακάτω διάγραµµα εµφανίζεται η εκτέλεση ενός παράλληλου αλγόριθµου που λύνει το ίδιο πρόβληµα µε έναν ακολουθιακό αλγόριθµο χωρίς πλεονασµό. Τα Α i και B i αντιστοιχούν σε ακολουθιακά υποέργα
Υ- 07 Παράλληλα Συστήματα Συνέπεια και συνοχή μνήμης
 Υ- 07 Παράλληλα Συστήματα Συνέπεια και συνοχή μνήμης Αρης Ευθυμίου Λειτουργία μνήμης Η μνήμη είναι ένας πίνακας αποθήκευσης Οταν διαβάζουμε μια θέση, περιμένουμε να πάρουμε την τελευταία τιμή που έχει
Υ- 07 Παράλληλα Συστήματα Συνέπεια και συνοχή μνήμης Αρης Ευθυμίου Λειτουργία μνήμης Η μνήμη είναι ένας πίνακας αποθήκευσης Οταν διαβάζουμε μια θέση, περιμένουμε να πάρουμε την τελευταία τιμή που έχει
Θέματα Μεταγλωττιστών
 Γιώργος Δημητρίου Ενότητα 10 η : Βελτιστοποιήσεις Τοπικότητας και Παραλληλισμού: Εξαρτήσεις και Μετασχηματισμοί Βρόχων Επεξεργασία Πινάκων Παραλληλισμός επιπέδου βρόχου Λόγω παραλληλισμού δεδομένων Επιτυγχάνεται
Γιώργος Δημητρίου Ενότητα 10 η : Βελτιστοποιήσεις Τοπικότητας και Παραλληλισμού: Εξαρτήσεις και Μετασχηματισμοί Βρόχων Επεξεργασία Πινάκων Παραλληλισμός επιπέδου βρόχου Λόγω παραλληλισμού δεδομένων Επιτυγχάνεται
Εισαγωγή στα Συστήματα Ψηφιακής Επεξεργασίας Σήματος
 ΕΣ 08 Επεξεργαστές Ψηφιακών Σημάτων Εισαγωγή στα Συστήματα Ψηφιακής Επεξεργασίας Σήματος Κλήμης Νταλιάνης Λέκτορας Π.Δ.407/80 Τμήμα Επιστήμη και Τεχνολογίας Τηλεπικοινωνιών Πανεπιστήμιο Πελοποννήσου Αρχιτεκτονική
ΕΣ 08 Επεξεργαστές Ψηφιακών Σημάτων Εισαγωγή στα Συστήματα Ψηφιακής Επεξεργασίας Σήματος Κλήμης Νταλιάνης Λέκτορας Π.Δ.407/80 Τμήμα Επιστήμη και Τεχνολογίας Τηλεπικοινωνιών Πανεπιστήμιο Πελοποννήσου Αρχιτεκτονική
Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Δομή Εντολών και Παραδείγματα) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Αρχιτεκτονικές Συνόλου Εντολών (ΙΙ) (Δομή Εντολών και Παραδείγματα) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Αρχιτεκτονική
Διδάσκων: Κωνσταντίνος Κώστα Διαφάνειες: Δημήτρης Ζεϊναλιπούρ
 Διάλεξη 9: Στοίβες:Υλοποίηση & Εφαρμογές Στην ενότητα αυτή θα μελετηθεί η χρήση στοιβών στις εξής εφαρμογές: Υλοποίηση Στοιβών με Δυναμική Δέσμευση Μνήμης Εφαρμογή Στοιβών 1: Αναδρομικές συναρτήσεις Εφαρμογή
Διάλεξη 9: Στοίβες:Υλοποίηση & Εφαρμογές Στην ενότητα αυτή θα μελετηθεί η χρήση στοιβών στις εξής εφαρμογές: Υλοποίηση Στοιβών με Δυναμική Δέσμευση Μνήμης Εφαρμογή Στοιβών 1: Αναδρομικές συναρτήσεις Εφαρμογή
Εισαγωγή στον Προγραμματισμό
 Εισαγωγή στον Προγραμματισμό Πίνακες Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ακ. Έτος 2012-2013 Πίνακες Πολλές φορές θέλουμε να κρατήσουμε στην μνήμη πολλά αντικείμενα
Εισαγωγή στον Προγραμματισμό Πίνακες Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ακ. Έτος 2012-2013 Πίνακες Πολλές φορές θέλουμε να κρατήσουμε στην μνήμη πολλά αντικείμενα
HY-486 Αρχές Κατανεμημένου Υπολογισμού
 HY-486 Αρχές Κατανεμημένου Υπολογισμού Εαρινό Εξάμηνο 2016-2017 Πρώτη Προγραμματιστική Εργασία Προθεσμία παράδοσης: Τρίτη 2/5 στις 23:59. 1. Γενική Περιγραφή Στην πρώτη προγραμματιστική εργασία καλείστε
HY-486 Αρχές Κατανεμημένου Υπολογισμού Εαρινό Εξάμηνο 2016-2017 Πρώτη Προγραμματιστική Εργασία Προθεσμία παράδοσης: Τρίτη 2/5 στις 23:59. 1. Γενική Περιγραφή Στην πρώτη προγραμματιστική εργασία καλείστε
Συστήματα σε Ολοκληρωμένα Κυκλώματα
 Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
QuakeTM: Parallelizing a Complex Sequential Application Using Transactional Memory (Gajinov et al., 2009)
") Quake I QuakeTM: Parallelizing a Complex Sequential Application Using Transactional Memory (Gajinov et al., 2009) Είναι όντως χρήσιμη η transactional memory σε μεγάλες εφαρμογές; Παράλληλη υλοποίηση μιας
Quake I QuakeTM: Parallelizing a Complex Sequential Application Using Transactional Memory (Gajinov et al., 2009) Είναι όντως χρήσιμη η transactional memory σε μεγάλες εφαρμογές; Παράλληλη υλοποίηση μιας
Εισαγωγή εκτελέσιμου κώδικα σε διεργασίες
 0x375 - Thessaloniki Tech Talks Sessions Event 0x2 19 Μαρτίου 2010 Περιεχόμενα 1 Εισαγωγή 2 Η κλήση συστήματος ptrace 3 Νήματα 4 Το πρόγραμμα εισαγωγής κώδικα prez 5 Επίλογος Γιατί; Πολλές φορές θέλουμε
0x375 - Thessaloniki Tech Talks Sessions Event 0x2 19 Μαρτίου 2010 Περιεχόμενα 1 Εισαγωγή 2 Η κλήση συστήματος ptrace 3 Νήματα 4 Το πρόγραμμα εισαγωγής κώδικα prez 5 Επίλογος Γιατί; Πολλές φορές θέλουμε
Παράλληλος προγραμματισμός περιστροφικών αλγορίθμων εξωτερικών σημείων τύπου simplex ΠΛΟΣΚΑΣ ΝΙΚΟΛΑΟΣ
 Παράλληλος προγραμματισμός περιστροφικών αλγορίθμων εξωτερικών σημείων τύπου simplex ΠΛΟΣΚΑΣ ΝΙΚΟΛΑΟΣ Διπλωματική Εργασία Μεταπτυχιακού Προγράμματος στην Εφαρμοσμένη Πληροφορική Κατεύθυνση: Συστήματα Υπολογιστών
Παράλληλος προγραμματισμός περιστροφικών αλγορίθμων εξωτερικών σημείων τύπου simplex ΠΛΟΣΚΑΣ ΝΙΚΟΛΑΟΣ Διπλωματική Εργασία Μεταπτυχιακού Προγράμματος στην Εφαρμοσμένη Πληροφορική Κατεύθυνση: Συστήματα Υπολογιστών