Διπλωματική Εργασία της φοιτήτριας του Τμήματος Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών της Πολυτεχνικής Σχολής του Πανεπιστημίου Πατρών
|
|
|
- Φόβος Λειβαδάς
- 8 χρόνια πριν
- Προβολές:
Transcript
1 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ: ΗΛΕΚΤΡΟΝΙΚΗΣ & ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΗΛΕΚΤΡΟΝΙΚΩΝ ΕΦΑΡΜΟΓΩΝ Διπλωματική Εργασία της φοιτήτριας του Τμήματος Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών της Πολυτεχνικής Σχολής του Πανεπιστημίου Πατρών Γώγουλου Ευαγγελίας του Δημητρίου Αριθμός Μητρώου: 5308 Θέμα «Μελέτη αλγορίθμων διαχείρισης κοινόχρηστης κοινής μνήμης σε συστήματα πολυπύρηνων επεξεργαστών αποτελούμενα από ετερογενείς επεξεργαστές» Επιβλέπων Σ. Κουμπιάς Αριθμός Διπλωματικής Εργασίας: Πάτρα, Οκτώβριος
2 2
3 ΠΙΣΤΟΠΟΙΗΣΗ Πιστοποιείται ότι η Διπλωματική Εργασία με θέμα «Μελέτη αλγορίθμων διαχείρισης κοινόχρηστης κοινής μνήμης σε συστήματα πολυπύρηνων επεξεργαστών αποτελούμενα από ετερογενείς επεξεργαστές» Της φοιτήτριας του Τμήματος Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Γώγουλου Ευαγγελίας του Δημητρίου Αριθμός Μητρώου: 5308 Παρουσιάστηκε δημόσια και εξετάστηκε στο Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών στις.../../ Ο Επιβλέπων Ο Διευθυντής του Τομέα Σ. Κουμπιάς Ε. Χούσος Καθηγητής Καθηγητής 3
4 4
5 Αριθμός Διπλωματικής Εργασίας: Θέμα: «Μελέτη αλγορίθμων διαχείρισης κοινόχρηστης κοινής μνήμης σε συστήματα πολυπύρηνων επεξεργαστών αποτελούμενα από ετερογενείς επεξεργαστές» Φοιτήτρια: Ευαγγελία Γώγουλου Επιβλέπων: Σ. Κουμπιάς Περίληψη Η κρυφή μνήμη συντελεί καθοριστικό ρόλο στην απόδοση των επεξεργαστών, για αυτό το λόγο συγκεντρώνει μεγάλο ερευνητικό ενδιαφέρον. Η καθιέρωση των συστημάτων πολυπύρηνων επεξεργαστών σε πληθώρα εφαρμογών καθιστά τις τεχνικές που χρησιμοποιούνται για τη διαχείριση της κοινόχρηστης κοινής μνήμης πολύ σημαντικές. Σκοπός της παρούσας διπλωματικής εργασίας είναι η μελέτη αλγορίθμων διαχείρισης κοινόχρηστης κοινής μνήμης σε συστήματα πολυπύρηνων επεξεργαστών αποτελούμενα από ετερογενείς επεξεργαστές. Συγκεκριμένα στο επίκεντρο είναι οι αλγόριθμοι αντικατάστασης της κρυφής μνήμης και ο τρόπος που γίνεται η δυναμική κατάτμηση της κατά την εκτέλεση. Υπό μελέτη επίσης τίθεται και η επίγνωση του παραλληλισμού επιπέδου μνήμης και το πως επηρεάζει την απόδοση των αλγορίθμων αντικατάστασης. Η αποτίμηση των αλγορίθμων έγινε με χρήση του SMT SimpleScalar που έχει τη δυνατότητα να εξομοιώνει CMPs με τις κατάλληλες τροποποιήσεις. 5
6 6
7 Subject: Study of cache management algorithms for CMPs composed of out-of-order processors Student: Evangellia Gogoulou Supervisor: S. Koubias Summary Cache memory has a determining value for measuring the performance of microprocessors and it is in the spotlight of research interest. Multiprocessors are widely used for a vast variety of applications and the study of the techniques for cache management is really important. The purpose of this diploma thesis is the study of cache managing algorithms for distributed shared memory for CMPs composed of out-oforder processors. We focus at replacement algorithms and dynamic cache partitioning. Taking also under consideration the memory level parallelism and how it affects the performance of replacement policies. For the measurement of the performance of these algorithms SMT SimpleScalar is used, because it has the potential to simulate CMPs when properly configured. 7
8 8
9 Ευχαριστίες Θα ήθελα να ευχαριστήσω όλους όσους συνέβαλαν στην ολοκλήρωση αυτής της διπλωματικής εργασίας και βοήθησαν να ξεπεραστούν όλα τα προβλήματα που αντιμετώπισα. Τον επιβλέποντα Σταύρο Κουμπιά και τον συνεπιβλέποντα Οδυσσέα Κουφοπαύλου για τη συμβολή του στην περάτωση της εργασίας. Τον Στέφανο Καξίρα, νυν καθηγητή του Πανεπιστημίου της Uppsala, για τη γνωριμία με τον κόσμο της αρχιτεκτονικής των πολυπύρηνων επεξεργαστών. Τον καθηγητή Δημήτριο Σερπάνο για τις συμβουλές του στην αρχιτεκτονική υπολογιστών. Τον Βαλάντη Δάτσιο πρώην μεταπτυχιακό φοιτητή και ερευνητή του ΙΝ.ΒΙ.Σ. για την καθοδήγηση του στα αρχικά στάδια εκπόνησης της εργασίας. Τέλος θα ήθελα να ευχαριστήσω την οικογένεια μου που με στήριξε καθ όλη τη διάρκεια των σπουδών μου, και όλους τους υπόλοιπους που με ανέχτηκαν τόσο καιρό. 9
10 10
11 Περιεχόμενα Ευχαριστίες 9 Κεφάλαιο 1: Εισαγωγή & διάρθρωση διπλωματικής εργασίας 13 Κεφάλαιο 2: Στοιχεία Αρχιτεκτονικής Θεωρητικό Υπόβαθρο : Μνήμη Cache & Ιεραρχία Μνήμης : Αρχές Λειτουργίας & Βασικές Έννοιες : Λειτουργία & Οργάνωση : Η μετάβαση από το ILP στο MLP ILP MLP 24 Κεφάλαιο 3: Αλγόριθμοι διαχείρισης κρυφής μνήμης : Γενικές αρχές αλγορίθμων αντικατάστασης : Παραδοσιακοί αλγόριθμοι : Ο βέλτιστος αλγόριθμος του Belady : Ο αλγόριθμος LRU : Ο αλγόριθμος FIFO : Ο τυχαίος (random) αλγόριθμος : Άλλοι αλγόριθμοι : Πρόσφατη έρευνα και νέοι αλγόριθμοι για Δυναμικό Cache Partitioning : Stack Distance Histogram (SDH) : Minimizing Total Misses : MLP Aware Dynamic Cache Partitioning : Γενική Αρχή του Αλγόριθμου : MLP Aware Stack Distance Histogram : Διαδικασία λήψης του Stack Distance Histogram : Συναρμολόγηση των παραπάνω : Χρήσιμα συμπεράσματα 41 11
12 Κεφάλαιο 4: Υπόθεση Εργασίας & εργαλεία : SimpleScalar : SMT Simplescalar : Τροποποιήσεις στον SMT SimpleScalar Παραμετροποίηση 48 Κεφάλαιο 5: Μετρήσεις Αποτελέσματα Συμπεράσματα : Επιλογή χαρακτηριστικών Συστήματος : Πειραματική Υλοποίηση : Υλοποίηση αλγορίθμου δυναμικής κατάτμησης μνήμης με βάση τον αριθμό των misses (missi_resize) : Υλοποίηση αλγορίθμου δυναμικής κατάτμησης μνήμης με βάση το mlp_cost των misses (mlp_resize) : Μετρήσεις και σύγκριση των τριών περιπτώσεων διαχείρησης : Γραφήματα για το IPC : Γραφήματα για τον αριθμό των misses της ul2 cache και το miss rate : Γραφήματα για την ταχύτητα της εξομοίωσης : Υπολογισμός του συνολικού mlp_cost : Σύγκριση της απόδοσης των τεχνικών : Συμπεράσματα & προτάσεις για βελτίωση 71 Βιβλιογραφία 73 12
13 Κεφάλαιο 1: Εισαγωγή Στο πεδίο της αρχιτεκτονικής υπολογιστών, με στόχο τη βελτιστοποίηση της απόδοσης των μικροεπεξεργαστών, έχουν συντελεστεί συνταρακτικά βήματα τα τελευταία χρόνια. Το υποσύστημα μνήμης παίζει καθοριστικό ρόλο στην απόδοση των πολυπύρηνων επεξεργαστών και το ενδιαφέρον επικεντρώνεται στην κρυφή μνήμη. Ο παραλληλισμός επιπέδου εντολών εισήγαγε την έννοια του παραλληλισμού. Πρώτα δείγματα αποτέλεσαν οι υπερβαθμωτοί επεξεργαστές (superscalar) και οι επεξεργαστές εκτός σειράς ή ετερογενείς (out-of-order). Ταυτόχρονα με την αύξηση της υπολογιστικής ισχύος αλλά και την καθιέρωση των πολυεπεξεργαστών, η εκμετάλλευση του παραλληλισμού επιπέδου εντολών έφτασε στα όρια της μετατοπίζοντας το σχεδιαστικό ενδιαφέρον στον παραλληλισμό επιπέδου μνήμης. Ο παραλληλισμός επιπέδου μνήμης είναι άρρηκτα συνδεδεμένος με τον αριθμό αστοχιών. Επιπλέον στα συστήματα πολυπύρηνων επεξεργαστών στο κομμάτι του υποσυστήματος μνήμης, σχετικά με τις κρυφές μνήμες, έχει επικρατήσει το μοντέλο ο κάθε επεξεργαστής - πυρήνας να έχει ιδιωτική κρυφή μνήμη πρώτου επιπέδου, ξεχωριστή για τις εντολές και για τα δεδομένα, και διαμοιραζόμενη κρυφή μνήμη δευτέρου επιπέδου. Συμπερασματικά, οι αλγόριθμοι που διαχειρίζονται την κοινόχρηστη κοινή μνήμη και ο τρόπος που γίνεται ο διαμοιρασμός των πόρων του συστήματος έχουν καθοριστική σημασία για την απόδοση. Ο τρόπος που γίνεται η κατάτμηση της κρυφής μνήμης δυναμικά, κατά την εκτέλεση των προγραμμάτων έχει τη δυνατότητα να βελτιώσει την απόδοση των πολιτικών αντικατάστασης και κατ' επέκταση την απόδοση του συστήματος. Σκοπός της παρούσας διπλωματικής εργασίας είναι η μελέτη αλγορίθμων διαχείρισης κοινόχρηστης κοινής μνήμης σε συστήματα πολυπύρηνων επεξεργαστών αποτελούμενα από ετερογενείς επεξεργαστές. Συγκεκριμένα στο επίκεντρο είναι οι αλγόριθμοι αντικατάστασης της κρυφής μνήμης και ο τρόπος με τον οποίο γίνεται η δυναμική κατάτμηση της αξιοποιώντας τον παραλληλισμό επιπέδου μνήμης Η οργάνωση της διπλωματικής εργασίας έχεις ως ακολούθως. Στο κεφάλαιο 2 εισαγωγικά, περιγράφονται βασικές έννοιες της αρχιτεκτονικής υπολογιστών, της ιεραρχίας μνήμης και των κρυφών μνημών στα σύγχρονα υπολογιστικά συστήματα. Παράλληλα εξηγούνται οι λόγοι που μετατοπίστηκε το σχεδιαστικό ενδιαφέρον από τον παραλληλισμό επιπέδου εντολής στον 13
14 παραλληλισμό επιπέδου μνήμης. Το κεφάλαιο 3 περιγράφει της βασικές αρχές των αλγορίθμων αντικατάστασης και σκιαγραφεί παραδοσιακούς αλγορίθμους. Στη συνέχεια, συνοπτικά παρουσιάζεται η εργασία που οδήγησε στη δυναμική κατάτμηση της κρυφής μνήμης με βάση τον αριθμό των αστοχιών αλλά και με επίγνωση του παραλληλισμού επιπέδου μνήμης. Στο κεφάλαιο 4, παρουσιάζεται το εργαλείο SimpleScalar, και το SMT SimpleScalar καθώς και οι απαραίτητες τροποποιήσεις στον κώδικα για την εξομοίωση των συστημάτων υπό μελέτη με βάση τους αλγορίθμους που παρουσιάζονται. Τέλος στο κεφάλαιο 5 υλοποιούνται οι παραπάνω αλγόριθμοι, παρουσιάζονται τα αποτελέσματα και εξάγονται συμπεράσματα σχετικά με την επίδραση στην απόδοση. 14
15 Κεφάλαιο 2: Στοιχεία Αρχιτεκτονικής Θεωρητικό Υπόβαθρο 2.1 Μνήμη Cache & Ιεραρχία Μνήμης Κρυφή Μνήμη είναι το όνομα που δίνεται στο πρώτο επίπεδο της Ιεραρχίας Μνήμης που συναντάται από την στιγμή που η διεύθυνση αφήνει την CPU. Είναι μια πολύ γρήγορη μνήμη (συνήθως SRAM) που βρίσκεται πολύ κοντά στη CPU, συνήθως μάλιστα στο ίδιο chip. Ο κυρίαρχος λόγος ύπαρξης της είναι να κρατάει αντίγραφα δεδομένων από την κύρια μνήμη,έτσι ώστε να είναι σημαντικά μικρότερος ο χρόνος προσπέλασης τους από τον επεξεργαστή. Στην Ιεραρχία Μνήμης των σύγχρονων προσωπικών υπολογιστών, υπάρχουν διάφορα επίπεδα μνήμης, μια απεικόνισης της απλής εκδοχής τους φαίνεται στην Εικόνα 2.1. Η κύρια μνήμη (main memory), που είναι η μια μεγάλη και αργή και ο δίαυλος επικοινωνίας (FSB/ Front Side Bus) δημιουργούν το θέμα της καθυστέρησης (latency) κατά την επικοινωνία και μεταφορά δεδομένων με τον επεξεργαστή. Η σπουδαιότητα αλλά και η αιτία που το ερευνητικό ενδιαφέρον στο πεδίο της Αρχιτεκτονικής Επεξεργαστών είναι στοχοπροσηλωμένο στην κρυφή μνήμη, είναι ότι είναι μικρότερη σε μέγεθος και ταχύτερη. Έτσι, αντιμετωπίζουμε το ζήτημα της καθυστέρησης. Εικόνα 2.1: Οργάνωση Μνήμης σε έναν Προσωπικό Υπολογιστή Στην Ιεραρχία Μνήμης (Εικόνα 2.2), ο γενικός κανόνας είναι όσο πιο κοντά στον Επεξεργαστή είναι τοποθετημένη μία μνήμη, τόσο μικρότερη και ταχύτερη να είναι. Κατά την απαίτηση ενός δεδομένου από τον επεξεργαστή, η αναζήτηση γίνεται πρώτα στην L1 Cache. Αν το δεδομένο δεν βρεθεί, η αναζήτηση συνεχίζεται στην L2 και ούτω καθεξής. Αν δεν βρίσκεται στην cache, τότε ο επεξεργαστής συνεχίζει την αναζήτηση πιο χαμηλά στην ιεραρχία, δηλαδή στην αργή κύρια μνήμη. 15
16 Κυρίαρχο θέμα στη λειτουργία της μνήμης cache, είναι η προσπάθεια να προβλέψει ποια δεδομένα θα χρειαστεί ο επεξεργαστής και να τα έχει διαθέσιμα, ώστε να μειωθεί ή ακόμη και να απαλειφθεί η καθυστέρηση. Τα δεδομένα αυτά, όσο και ποια θα από αυτά θα αντικατασταθούν (στην περίπτωση που η cache γεμίσει) επιλέγονται με αλγόριθμους αντικατάστασης (replacements algorithms), ώστε οι προσπελάσεις στην μνήμη να είναι ταχύτερες, αποδοτικότερες ή να έχουν χαμηλότερη κατανάλωση ενέργειας. Επιλέγουμε κάθε φορά ποιο από τα παραπάνω είναι κρισιμότερο στο σχεδιασμό μας, καθώς όσο αυξάνει η απόδοση ή η ταχύτητα, η κατανάλωση αυξάνει. Εικόνα 2.2: Ιεραρχία Μνήμης Λόγω της πολυπλοκότερης σχεδίασης των υπολογιστικών συστημάτων, έχουν υιοθετηθεί πολλαπλά επίπεδα μνημών cache (multilevel caches). Σήμερα, όπως φαίνεται και στην Εικόνα 2.3, έχουμε τις L1, L2 και L3 (L: Level) όπου η L1 είναι η πλησιέστερη στον επεξεργαστή και στην πλειοψηφία των περιπτώσεων αποτελείται από 2 ξεχωριστές μνήμες για τα δεδομένα και τις εντολές. 16
17 Εικόνα 2.3: Οργάνωση Multilevel cache Επιπλέον, με την εξέλιξη στους επεξεργαστές και την επικράτηση πολλαπλών πυρήνων (cores), καθώς και πολλαπλών νημάτων (threads) σε κάθε πυρήνα, η πολυεπίπεδη οργάνωση των μνημών cache είναι ευνοϊκότερη προσέγγιση. Η L1 cache γίνεται κοινόχρηστη μεταξύ των threads, σε κάθε πυρήνα. Και εφόσον ο κάθε πυρήνας έχει τη δική του ιδιωτική L1 cache, οι L2 και L3 caches είναι κοινόχρηστες. Με τις κοινόχρηστες μνήμες cache, έχουμε κοινή διάθεση δεδομένων σε πυρήνες και διεργασίες. Επίσης χρησιμοποιούνται για το πέρασμα μηνυμάτων και τον συγχρονισμό μεταξύ των εκτελούμενων διεργασιών, αλλά και στις υπόλοιπες ενδοδιεργασιακές επικοινωνίες (IPCs). Στους σύγχρονους οικιακούς υπολογιστές, πλέον η διάταξη των πολυεπίπεδων cache, είναι με L1 (i-cache και d-cache), L2 ανά πυρήνα, και κοινή την L3 cache, όπως φαίνεται και στην Εικόνα 4. Εικόνα 2.4: Διάταξη των πολυεπίπεδων cache σε 4-core, (Intel i7) 17
18 Τα οφέλη από τη χρήση των πολυεπίπεδων μνημών cache, είναι αρκετά, ενδεικτικά αναφέρουμε κάποια από αυτά: Βελτιστοποιείται η συνοχή της μνήμης (cache coherence). Συνεκτικό είναι ένα σύστημα μνήμης το οποίο κατά την ανάγνωση ενός αντικειμένου δεδομένων επιστρέφει την πιο πρόσφατα εγγεγραμμένη τιμή αυτού του αντικειμένου δεδομένων. Γενικά το θέμα της cache coherence απασχολεί τους σχεδιαστές καθώς δημιουργούνται προβλήματα στην ενδοεπικοινωνία αν η μνήμη cache και η κύρια μνήμη έχουν διαφορετική εικόνα για το περιεχόμενο της μνήμης. Όταν κάποιος πυρήνας είναι ανενεργός, τότε ο άλλος έχει στη διάθεση του ολόκληρη τη μνήμη cache. Οπότε μειώνεται η υποχρησιμοποίηση της cache. 2.2 Αρχές Λειτουργίας και Βασικές Έννοιες Η λειτουργία της cache βασίζεται στην τοπικότητα της αναφοράς (locality of reference). Αυτή συνοψίζεται στο εξής, ότι τείνει να χρησιμοποιείται μόνο ένα μικρό τμήμα του χώρου διευθύνσεων της μνήμης, σε οποιαδήποτε στιγμή εκτέλεσης ενός προγράμματος. Αυτό το μικρό τμήμα διευθύνσεων καθώς και τα περιεχόμενα του, είτε αυτά είναι οι εκτελούμενες από το πρόγραμμα εντολές είτε τα απαιτούμενα δεδομένα για τους υπολογισμούς του, θέλουμε να είναι κατά το δοκούν κοντά στον επεξεργαστή. Υπάρχουν οι εξής έννοιες που σχετίζονται με την τοπικότητα: Χρονική Τοπικότητα (Temporal Locality): Μια διεύθυνση μνήμης, στην οποία έγινε πρόσβαση, είναι πολύ πιθανό να ξαναχρησιμοποιηθεί στο μέλλον. Χωρική Τοπικότητα (Spatial Locality): Αν έχουμε πρόσβαση σε μία διεύθυνση μνήμης, τότε είναι πολύ πιθανό να χρησιμοποιηθούν και οι γειτονικές της στο άμεσο μέλλον. Διαδοχικότητα (Sequential Locality): Είναι πολύ πιθανό η αμέσως επόμενη πρόσβαση στη μνήμη να γίνει σε διαδοχική διεύθυνση από τη θέση μνήμης που χρησιμοποιείται στην τρέχουσα πρόσβαση. Παραθέτουμε τους ορισμούς κάποιων βασικών όρων, που θα χρησιμοποιηθούν στο κείμενο της παρούσας διπλωματικής εργασίας. Word: Η ελάχιστη μονάδα δεδομένων. Η κυρια μνήμη αποτελείται από 2 n words, και σε κάθε word αντιστοιχεί μια διεύθυνση των n bits. Block: Η βασική μονάδα δεδομένων που μπορεί να βρίσκεται αποθηκευμένη στη μνήμη. Κάθε block περιέχει K words. Ενώ η κύρια μνήμη αποτελείται από M = 2 n / K blocks. Access: Η προσπέλαση του επεξεργαστή σε μνήμη, προς αναζήτηση ενός 18
19 block δεδομένων. Ανάλογα με τη μνήμη που συντελείται η πρόσβαση έχουμε cache access ή main memory access Hit (Ευστοχία): Μετά την πρόσβαση στη μνήμη, η αναζήτηση του block ήταν επιτυχής. Hit Ratio (Ποσοστό Ευστοχίας) : (= #Hits / #Accesses) Το ποσοστό των προσβάσεων μνήμης που βρέθηκαν επιτυχώς. Hit Time (Χρόνος Ευστοχίας) : Ο χρόνος εύρεσης του block στην cache, και μεταφοράς του στον επεξεργαστή. Miss (Αστοχία) : Η αποτυχία εύρεσης του block που αναζητήθηκε, στην συγκεκριμένη μνήμη. Τα misses κατατάσσονται σε 3 διαφορετικά είδη : i. Cold (Compulsory) Miss (Αναγκαστική Αστοχία) : Όταν ένα block αναζητηθεί για πρώτη φορά στην cache, αυτό αναγκαστικά δεν θα υπάρχει και έτσι γίνεται miss. ii. Capacity Miss (Αστοχία Χωρητικότητας) : Προκαλούνται εξαιτίας του μεγέθους της cache. Αν η cache δεν είναι αρκετά μεγάλη για να χωράνε όλα τα blocks που χρειάζονται κατά την εκτέλεση του Προγράμματος, τότε κάποια blocks υποχρεωτικά θα αντικατασταθούν, αλλά στο μέλλον ίσως χρειαστεί να επανέλθουν στην cache. iii.conflict Miss (Αστοχία Σύγκρουσης) : Προκαλούνται εξαιτίας της λογικής για αντιστοίχιση των θέσεων μνήμης της cache με τις θέσεις μνήμης της main memory. Αν περισσότερα του ενός block αντιστοιχούν στην ίδια θέση μνήμης της cache, τότε η ζήτηση του ενός προκαλεί την αντικατάσταση του άλλου. Miss Ratio (Ποσοστό Αστοχίας) : (= 1 - Hit Ratio) ή (= #Misses / #Accesses) Το ποσοστό των προσβάσεων μνήμης που δεν βρέθηκαν στην cache. Miss Penalty (Ποινή Αστοχίας) : Ο χρόνος που απαιτείται για αναζήτηση του block στην cache, για την διαπίστωση του miss, την αναζήτηση του block σε κατώτερο επίπεδο μνήμης, την μεταφορά του στην cache, και τελικά, την μεταφορά του ζητούμενου δεδομένου στον επεξεργαστή. Memory Latency (Καθυστέρηση Μνήμης) : Η καθυστέρηση που υπεισέρχεται όταν πρέπει ο Επεξεργαστής να αναζητήσει ένα block μνήμης, είτε στην cache ή στην κύρια μνήμη. Memory Latency = Hit Time + P(Miss)* Miss Penalty 19
20 2.3 Λειτουργία & Οργάνωση Η μνήμη cache έχει να αντιμετωπίσει τέσσερα βασικά θέματα: Τοποθέτηση: Που μπορεί να τοποθετηθεί ένα μπλοκ δεδομένων Αναγνώριση: Όταν ένα μπλοκ δεδομένων βρίσκεται στην cache, με ποιο μηχανισμό αναγνωρίζεται Αντικατάσταση: Αφού συμβεί ένα cache miss, ποιά επιλογή μπλοκ προς αντικατάσταση είναι η βέλτιστη Εγγραφή: Με ποιο μηχανισμό εγγράφονται δεδομένα στην cache Α. Τοποθέτηση και Αναγνώριση Κατά την τοποθέτηση ενός μπλοκ στην cache, ο προσδιορισμός της τοποθεσίας του καθορίζεται από δύο παράγοντες, τη λογική αντικατάστασης (replacement policy) και το memory mapping. Με τη λογική αντικατάστασης αποφασίζουμε ποιο μπλοκ δεδομένων μας είναι λιγότερο χρήσιμο και άρα πιθανότερο να αντικατασταθεί από ένα νέο μπλοκ. Το memory mapping αντιστοιχίζει κάθε μπλοκ δεδομένων με μια cache line μέσω της συσχετιστικότητας (associativity). Με βάση τη συσχετιστικότητα γίνεται ο εξής διαχωρισμός: Direct Mapping(Άμεση Αντιστοίχηση): Κάθε μπλοκ αντιστοιχεί σε μία ακριβώς cache line, δηλαδή το μπλοκ έχει τη δυνατότητα να εμφανιστεί μόνο σε μία θέση στη κρυφή μνήμη. Η αντιστοίχηση, συνήθως, ορίζεται ως το ακέραιο υπόλοιπο της διαίρεσης : (διεύθυνση μπλοκ) MOD (συνολικός αριθμός των μπλοκ στην cache).μια cache αυτής της κατηγορίας είναι αρκετά απλή και οικονομική στην κατασκευή της όμως έχει την χειρότερη επίδοση. Fully Associative Mapping(Πλήρως Συσχετιστική Αντιστοίχηση): Κάθε μπλοκ αντιστοιχεί σε οποιαδήποτε cache line, δηλαδή μπορεί να τοποθετηθεί οπουδήποτε στην κρυφή μνήμη. Μια cache αυτής της κατηγορίας έχει πολύ υψηλό hit ratio και ξεπερνά όλα τα προβλήματα της προηγούμενης κατηγορίας. Όμως έχει σημαντικά προβλήματα απόδοσης. Set Associative (Συνολοσυσχετιστική Αντιστοίχηση): όταν κάθε μπλοκ μπορεί να τοποθετηθεί σε περιορισμένο αριθμό θέσεων της κρυφής μνήμης. Ο περιορισμένος αυτός αριθμός συνιστά ένα σύνολο. Το μπλοκ αρχικά αντιστοιχίζεται σε ένα σύνολο και μπορεί έπειτα να τοποθετηθεί οπουδήποτε μέσα σε αυτό. Συνήθως, το σύνολο προκύπτει ως το ακέραιο υπόλοιπο της διαίρεσης : (διεύθυνση μπλοκ) MOD (συνολικός αριθμός 20
21 συνόλων στην cache). Η cache διαιρείται σε ένα σύνολο από direct mapped περιοχές, που ονομάζονται sets, και κάθε set αποτελείται από cache lines. Αν έχουμε V sets και K cache lines, η cache ονομάζεται K-way set associative. Μια cache αυτής της κατηγορίας είναι επί της ουσίας η χρυσή τομή ανάμεσα στις δύο προηγούμενες, καθώς έχει τα θετικά στοιχεία τους. Διατηρεί δηλαδή τον εύκολο έλεγχο της direct mapped, έχοντας μεγαλύτερο hit ratio από αυτή, και την ευελιξία της fully associative, ενώ είναι ταχύτερη από αυτή. Β. Αντικατάσταση Όπως με συντομία αναφέραμε στο προηγούμενο εδάφιο (Τοποθέτηση και Αναγνώριση), όταν ένα νέο block εισέρχεται στην cache, εξαιτίας ενός miss, τότε πιθανότατα κάποια γραμμή της cache θα πρέπει να αντικατασταθεί. Σε μια direct mapped cache δεν έχουμε επιλογή για το που θα τοποθετηθεί το νέο block, αφού υπάρχει ακριβής αντιστοιχία, επομένως οι αλγόριθμοι αντικατάστασης δεν έχουν κάποια χρηστικότητα. Ωστόσο στις fully associative και set associative caches υπάρχει επιλογή θέσης, στις πλήρως συσχετιστικές ο αλγόριθμος επιλέγει μεταξύ όλων των στοιχείων της μνήμης και στις συνολοσυσχετιτιστικες ο αλγόριθμος επιλέγει σε ποιό από τα μπλοκ του συνόλου (δηλαδή το δρόμο ή way) θα τοποθετήσει το νέο στοιχείο. Την απόφαση αναλαμβάνει ο cache controller, βάσει των λογικών αντικατάστασης (replacement policies), ή όπως αλλιώς ονομάζονται, αλγόριθμοι αντικατάστασης (replacement algorithms). Στο επόμενο κεφάλαιο θα εξηγήσουμε τους βασικούς και ευρύτερα διαδεδομένους παραδοσιακούς αλγόριθμους αντικατάστασης και θα συγκρίνουμε δυο πιο σύγχρονες θεωρήσεις αλγορίθμων. Γ. Εγγραφή Μια Πρόσβαση στην cache (cache access), οδηγεί σε μια ανάγνωση (read) ή μια εγγραφή (write). H πλειοψηφία των προσβάσεων στην cache είναι αναγνώσεις. Το ζητούμενο block διαβάζεται ταυτόχρονα με την ανάγνωση και σύγκριση του tag με την διεύθυνση. Αν τελικά επρόκειτο για miss, η τιμή που διαβάστηκε αγνοείται, δεν υπήρξε όφελος, αλλά δεν ούτε και ζημιά από άποψη χρόνου. Αναφέρουμε τις Πολιτικές Ανάγνωσης (Read Policies), οι οποίες είναι: Read Through (Με Διανάγνωση) : Διαβάζεται μια word απευθείας από την main memory στον επεξεργαστή. No-Read Through (Χωρίς Διανάγνωση) : Διαβάζεται ένα block από την main memory στην cache, και στην συνέχεια το ζητούμενο δεδομένο από την cache στον επεξεργαστή. 21
22 Παρά την εύκολη βελτιστοποίηση της διαδικασίας των αναγνώσεων, οι εγγραφές παρουσιάζουν περισσότερη δυσκολία. Πριν μια cache line αντικατασταθεί πρέπει να γνωρίζει ο controller αν η γραμμή έχει τροποποιηθεί. Το block της main memory και η cache line αποτελούν αρχικά ακριβή αντίγραφα. Αν η γραμμή δεν έχει τροποποιηθεί δεν είναι απαραίτητο να ενημερώσουμε την main memory για καμία αλλαγή. Αντίθετα αν έχει υπάρξει τροποποίηση πρέπει να ενημερώσουμε την main memory με μια εγγραφή. Υποθέτοντας ένα cache hit, υπάρχουν δύο κύριες Πολιτικές Εγγραφής (Write Policies): Write Through (Διεγγραφή) : Τα δεδομένα εγγράφονται άμεσα και αυτόματα και στην cache line και στο block της main memory. Η πολιτική αυτή είναι εύκολη στην υλοποίηση και διατηρεί πάντα ενημερωμένη την main memory. Ωστόσο είναι πιο αργή και απαιτεί μια πρόσβαση στην main memory για κάθε εγγραφή. Write Back (Ετεροχρονισμένη Εγγραφή) : Τα δεδομένα εγγράφονται μόνο στην cache line. Η τροποποιημένη αυτή γραμμή εγγράφεται στο αντίστοιχο της block στην main memory μόνο πριν αντικατασταθεί από μια νέα γραμμή. Η πολιτική αυτή είναι ταχύτατη και απαιτεί τις ελάχιστες προσβάσεις προς την main memory, όμως είναι δυσκολότερο να υλοποιηθεί και αφήνει την main memory χωρίς ενημέρωση. Υποθέτοντας ένα Cache Miss, υπάρχουν πάλι δύο Πολιτικές Εγγραφής : Write Allocate (Κατανομής Εγγραφής) : Το block που προκάλεσε το miss, εισέρχεται στην cache. Στην συνέχεια ενεργοποιείται μια από τις δύο πολιτικές εγγραφής υποθέτοντας ένα cache hit. Write No-Allocate (Κατανομή Μη-Εγγραφής) : Το Block που προκάλεσε το Miss, εγγράφεται απευθείας στην Main Memory, χωρίς να εισαχθεί ενδιάμεσα στην Cache. Συνήθως μια Write Through Cache συνδυάζεται με Write No- Allocate Πολιτική και μια Write Back Cache συνδυάζεται με Write Allocate Πολιτική. 2.4 Η μετάβαση από το ILP στο MLP ILP (Instruction Level Parallelism/ Παραλληλισμός Επιπέδου Εντολών) Μέχρι πρόσφατα, εκτός από την μονιμοποίηση της χρήσης της μνήμης cache, ο ILP, ήταν η κυριότερη μέθοδος για τη βελτίωση της απόδοσης. Ως ILP 22
23 ορίζουμε τη μέτρηση του πλήθους των λειτουργιών που μπορούν να εκτελεστούν παράλληλα. Ένας από τους στόχους στη σχεδίαση των επεξεργαστών ήταν η αναγνώριση και εκμετάλλευση του ILP. Ενώ οι εντολές ενός προγράμματος εκτελούνται σειριακά, με τον ILP έγινε δυνατή η επικάλυψη ή η αναδιάταξη της σειράς εκτέλεσης. Κάποιοι από τους πιο διαδεδομένους τρόπους εκμετάλλευσης του ILP αναφέρονται στη συνέχεια: 1. Instruction Pipelining (Ομοχειρία Εντολών): Η εκτέλεση μιας εντολής στον επεξεργαστή διασπάται σε έναν αριθμό από ανεξάρτητα βήματα, με ενδιάμεση αποθήκευση. Έτσι ο επεξεργαστής εξυπηρετεί τις εντολές με τον ρυθμό του πιο αργού βήματος, ο οποίος είναι αρκετά πιο γρήγορος και αποδοτικός από την περίπτωση που προσπαθούσαμε να εξυπηρετήσουμε όλες τις εντολές ταυτόχρονα και παράλληλα. Τα βασικά βήματα, συγχρονισμένα από το ρολόι του Επεξεργαστή, είναι τα εξής: Instruction Fetch, Instruction Decode, Execute, Memory Access και Write Back. 2. Superscalar Επεξεργαστές: Είναι οι επεξεργαστές που δέχονται περισσότερες από μια εντολές προς εκτέλεση σε κάθε κύκλο ρολογιού, υλοποιώντας μια μορφή Παραλληλισμού. Ένας Superscalar επεξεργαστής υλοποιείται με περισσότερες από μια δομικές μονάδες (Functional Units) και είναι Pipelined. Κάθε μια από τις δομικές μονάδες περιέχει την δική της ALU (Arithmetic and Logical Unit Αριθμητική και Λογική Μονάδα) και ολισθητές, πολλαπλασιαστές κλπ. Οι εντολές έρχονται σειριακά στον Επεξεργαστή και αφού ελεγχθούν για τυχόν εξαρτήσεις των δεδομένων που τις αφορούν (Data Dependencies), ανατίθενται στις διαθέσιμες Δομικές Μονάδες. 3. Out-of-Order Επεξεργαστές: Ένας OoO ή ετερογενής επεξεργαστής είναι επεξεργαστής υψηλής απόδοσης που αξιοποιεί τους κύκλους εντολών (Instructions Cycles) που μένουν αχρησιμοποίητοι από την λογική των In-Order επεξεργαστών. Ενώ στον κώδικα του προγράμματος που εκτελείται, οι εντολές διαδέχονται οι μία την άλλη (Program Order), ο ΟοΟ Επεξεργαστής τις διαχειρίζεται με σειρά δεδομένων (Data Order). Δηλαδή με την σειρά που τα δεδομένα είναι διαθέσιμα στους Registers. Στον χρόνο αναμονής για τα δεδομένα που χρειάζεται μια εντολή, εκτελούνται επόμενες εντολές, που έχουν όλα τα απαραίτητα δεδομένα τους διαθέσιμα. Τέλος τα αποτελέσματα αναδιατάσσονται στην αρχική τους σειρά και οι εντολές αποσύρονται (Commit) από το Παράθυρο Εντολών με In-Order σειρά. Ωστόσο οι σύγχρονες εφαρμογές τείνουν να έχουν μεγάλες απαιτήσεις σε δεδομένα που ξεπερνούν τα μεγέθη των Μνημών Cache και συνεπώς χρειάζονται πολλαπλές προσβάσεις στην Κύρια Μνήμη. Τα δεδομένα αυτά 23
24 μάλιστα δεν διακρίνονται από κάποια ομαλότητα, συνήθως έχουν ακανόνιστα μοτίβα επανάληψης και εξαρτήσεις μεταξύ τους. Από τις λύσεις - βελτιστοποιήσεις που επικράτησαν για αυτό το θέμα, ξεχωρίζουν: 1. Ο Thread-Level Parallelism (TLP - Παραλληλισμός σε Επίπεδο Νήματος), που διακρίνεται σε: Multi-Threading: Ο χρόνος του επεξεργαστή μοιράζεται μεταξύ των Threads με πολύπλεξη χρόνου και κοινή χρήση όλων των πόρων του. Υλοποιείται σε οποιοδήποτε επεξεργαστή. Simultaneous Multi-Threading (SMT): Πρόκειται για υλοποίηση υλικού (Hardware) σε Superscalar επεξεργαστές και επιτρέπει την ταυτόχρονη εκτέλεση περισσότερων του ενός νημάτων. 2. Οι on-chip Multiprocessors (CMPs Συστήματα πολλαπλών επεξεργαστών ενός ολοκληρωμένου). Πρόκειται για τους πλέον διαδεδομένους πολυπύρηνους επεξεργαστές, που διαθέτουν από 2 πυρήνες και πάνω, με διάφορες επιλογές στη διάταξη τους. Οι πυρήνες είναι λιγότερο πολύπλοκοι και πραγματοποιούν πραγματική παράλληλη εκτέλεση νημάτων. Ξεπερνούν τις δυσκολίες αύξησης της απόδοσης που αντιμετώπιζαν οι τεχνικές με βάση τον ILP, έχουν σημαντικά λιγότερη κατανάλωση, ειδικά σε σύγκριση με τους πολύπλοκους Out-of-Order Επεξεργαστές και είναι απλούστεροι στην χρήση. Ο συνδυασμός με κάποια μορφή παραλληλισμού επιπέδου νήματος δεν αποκλείεται MLP (Memory Level Parallelism/Παραλληλισμός Επιπέδου Μνήμης) Από την σύντομη ανάλυση που προηγήθηκε, βλέπουμε πως εξαιτίας του συνεχώς αυξανόμενου όγκου των δεδομένων των σύγχρονων εφαρμογών, αλλά και λόγω των σύγχρονων τεχνικών και υλοποιήσεων για αύξηση της απόδοσης των Υπολογιστικών Συστημάτων, εισάγεται ένα νέο είδος παραλληλισμού, ο Παραλληλισμός Επιπέδου Μνήμης ή Memory Level Parallelism (MLP). Πληθώρα σύγχρονων τάσεων της αρχιτεκτονικής επεξεργαστών δείχνουν ότι αν εκμεταλλευτούμε τον MLP αποδοτικά, η απόδοση και συμπεριφορά των Υπολογιστικών Συστημάτων αυξάνεται ικανοποιητικά. Παράλληλα αναπτύσσονται νέες σύγχρονες τεχνικές εκμετάλλευσης του MLP που προσανατολίζονται στην επικάλυψη των Cache Misses. Η απαρχή για την αξιοποίηση του MLP εισήχθη πρώτη φορά από τον Andrew Glew [3] και αφορούσε τη μείωση του κόστους του ανεπαρκούς 24
25 παραλληλισμού στο επίπεδο της μνήμης. Ο παραλληλισμός επιπέδου μνήμης αφορά τη δυνατότητα των επεξεργαστών εκτός σειράς να εκτελούν παράλληλα προσπελάσεις στην κύρια μνήμη. Ουσιαστικά αφορά, τη δημιουργία και εξυπηρέτηση πολλαπλών εκκρεμών αστοχιών κρυφής μνήμης. Αυτό έχει ως αποτέλεσμα να υπάρχουν επικαλυπτόμενα χρονικά διαστήματα στα οποία φορτώνονται τα δεδομένα από τη μνήμη. Κατ' αυτόν τον τρόπο το κόστος μιας προσπέλασης της κύριας μνήμης διαμοιράζεται ανάμεσα στις παράλληλες προσπελάσεις που εκτελούνται και έτσι σε σχέση με το κόστος μιας μεμονωμένης προσπέλασης, της αποδίδεται ένα μέρος του. Το γεγονός αυτό τοποθετεί τα θεμέλια για αρχή που αποτέλεσε βάση για περαιτέρω έρευνα, ότι όλα τα misses δεν είναι ισοδύναμα. Μια αστοχία που εξυπηρετείται μεμονωμένα έχει μεγαλύτερο κόστος από μια παράλληλη αστοχία. Συμπερασματικά, ο παραλληλισμός επιπέδου μνήμης για τους πολυπύρηνους επεξεργαστές είναι μια παράμετρος κρίσιμη για το σχεδιασμό. Αυτός είναι και ο λόγος που υπάρχει αρκετό ερευνητικό ενδιαφέρον είτε στην κατανόηση του, είτε στην αξιοποίηση του προς όφελος της απόδοσης. Στο επόμενο κεφάλαιο, στο οποίο θα γίνει μια συνοπτική αναφορά στους παραδοσιακούς αλγόριθμους αντικατάστασης, οι οποίοι δεν αξιοποιούν τα παραπάνω, θα γίνει εμφανής η μειωμένη απόδοση τους σε σχέση με έναν αλγόριθμο με επίγνωση του παραλληλισμού επιπέδου μνήμης (MLP-Aware) ιδιαίτερα για την περίπτωση των CMPs. 25
26 26
27 Κεφάλαιο 3: Αλγόριθμοι διαχείρισης κρυφής μνήμης 3.1 Γενικές Αρχές Αλγορίθμων αντικατάστασης Όπως προαναφέρθηκε, οι αλγόριθμοι αντικατάστασης είναι η διαδικασία που εφαρμόζεται όταν παρατηρηθεί αστοχία στην κρυφή μνήμη κατά την αίτηση στοιχείου (μπλοκ, δηλαδή ομάδας δεδομένων) και η διεύθυνση αναφοράς ( η διεύθυνση που αντιστοιχεί στο συγκεκριμένο μπλοκ) είναι κατειλημμένη. Σε κρυφές μνήμες με μικρό βαθμό συσχετιστικότητας, τα στοιχεία έχουν καθορισμένες θέσεις μέσα στη μνήμη, με βάση τη διεύθυνση τους στην κύρια μνήμη, και οι αλγόριθμοι αντικατάστασης καλούνται να επιλέξουν ανάμεσα σε ελάχιστα στοιχεία ή καθόλου. Σε αυτές τις περιπτώσεις ανήκει η L1 cache, για την οποία ο LRU αλγόριθμος είναι αρκετός. Αντιθέτως, όταν μιλάμε για μεγάλο βαθμό συσχετιστικότητας (κάτι το οποίο είναι πραγματικότητα σήμερα για τις L2 κρυφές μνήμες) τότε τα στοιχεία που δύνανται να αντικατασταθούν για την εισαγωγή του νέου, είναι τα περισσότερα ή όλα (πλήρως συσχετιστική μνήμη) της cache. Έτσι, οι αλγόριθμοι που εμπίπτουν στην κατηγορία αυτή, παρουσιάζουν μεγάλο ενδιαφέρον. Για την πλήρη κατανόηση της λειτουργίας τους, πρέπει να γίνει ξεκάθαρη η βασική αρχή της τοπικότητας (locality) που χαρακτηρίζει την προσπέλαση της μνήμης των υπολογιστικών συστημάτων. Τα προγράμματα κατά την εκτέλεση τους τείνουν να υπακούν σε αυτήν την αρχή. Η τοπικότητα είναι χρονική και χωρική. Στην χρονική δεδομένα που προσπελάστηκαν πρόσφατα είναι πιθανόν να προσπελαστούν εκ νέου στο μέλλον, ενώ στην χωρική αν μια θέση μνήμης προσπελαστεί είναι πιθανόν να προσπελαστούν και οι γειτονικές της. Την βασική αυτή αρχή εκμεταλλεύεται η κρυφή μνήμη, προσπαθώντας να αποθηκεύσει δεδομένα τα οποία χρησιμοποιούνται συχνά από τον επεξεργαστή, επιτυγχάνοντας έτσι χαμηλό ποσοστό αστοχίας εντός της και κατ επέκταση μείωση της επικοινωνίας με την κύρια μνήμη, που λόγω του χάσματος απόδοσης κοστίζει. Οι Αλγόριθμοι αντικατάστασης έχουν ως στόχο την βέλτιστη επιλογή στοιχείου της κρυφής μνήμης που πρόκειται να αντικατασταθεί. Για την επίτευξη του, προσπαθούν να προσδιορίσουν την τοπικότητα των στοιχείων της cache και να κρατήσουν τα στοιχεία εκείνα που παρουσιάζουν τη μέγιστη, και να αντικαταστήσουν εκείνα που παρουσιάζουν την ελάχιστη. Το στοιχείο 27
28 εκείνο που εγκαταλείπει την κρυφή μνήμη από την αντικατάσταση, ονομάζεται θύμα ή υποψήφιος αντικατάστασης (victim of/candidate for replacement). 3.2 Παραδοσιακοί Αλγόριθμοι Οι πρώτοι αλγόριθμοι που εμφανίστηκαν κατά την υλοποίηση των πρώτων κρυφών μνημών ήταν αυτοί που πραγμάτωναν μια απλή συλλογιστική, μεθοδολογία και τεχνική στην αντικατάσταση. Τα κριτήρια που χρησιμοποιούσαν για την αυτήν βασίστηκαν σε χαρακτηριστικά όπως η σειρά άφιξης, ο χρόνος παραμονής, η συχνότητα προσπέλασης. Οι αλγόριθμοι αυτοί μπορούν πλέον να χαρακτηριστούν παραδοσιακοί ή ακόμα και κλασσικοί. Οι περισσότεροι από αυτούς δεν έχουν πλέον πρακτική σημασία, αφού θεωρούνται παρωχημένοι και ασύμφοροι, έχουν όμως διδακτική σημασία Ο βέλτιστος αλγόριθμος του Belady Ενώ άλλοι αλγόριθμοι αντικατάστασης είχαν ήδη εισαχθεί στην τεχνολογία των υπολογιστών, το 1966 ο Laszlo Belady έκανε ίσως το σημαντικότερο βήμα, οριοθετώντας ένα σταθερό μέτρο σύγκρισης όλων των αλγορίθμων. Ο Belady διαπίστωσε ότι στόχος όλων των αλγορίθμων είναι η προσέγγιση του ελάχιστου αριθμού αντικαταστάσεων μνήμης, δηλαδή των ελάχιστων αστοχιών. Προς την κατεύθυνση αυτή αναρωτήθηκε ποιος είναι ο βέλτιστος αλγόριθμος ο οποίος θα δίνει τον ελάχιστο αυτό αριθμό. Τότε, διατύπωσε την ιδέα ότι ένας τέτοιος αλγόριθμος χρειάζεται γνώση όχι του παρόντος και του παρελθόντος μόνο, αλλά και του μέλλοντος. Αυτό σημαίνει την ακριβή ακολουθία αιτήσεων των στοιχείων της μνήμης. Κάτι τέτοιο σε πραγματικό υπολογιστικό σύστημα, είναι ευκόλως κατανοητό ότι είναι αδύνατο να πραγματοποιηθεί. Θεωρητικά, όμως, θα μπορούσε να υπάρξει ένας τέτοιος μηχανισμός με γνώση του μέλλοντος. Σε αυτόν ο Belady έδειξε ότι η πολιτική που δίνει τον ελάχιστο αριθμό αντικαταστάσεων είναι εκείνη,κατά την οποία αντικαθίσταται κάθε φορά το στοιχείο εκείνο που πρόκειται να χρησιμοποιηθεί μεταγενέστερα στο μέλλον Ο αλγόριθμος LRU Ένας αλγόριθμος που αποτελεί ακόμη και σήμερα μια από τις πιο 28
29 συμφέρουσες λύσεις στο πεδίο αυτό είναι ο αλγόριθμος αντικατάστασης LRU (least recently used). Εδώ, αντικαθίσταται κάθε φορά το στοιχείο που έχει μείνει περισσότερο καιρό αχρησιμοποίητο, το στοιχείο δηλαδή που έχει προσπελαστεί λιγότερο πρόσφατα από τα άλλα. Αν και υπολείπεται του βέλτιστου, αυτός ο αλγόριθμος είναι μέχρι σήμερα η καλύτερη προσέγγιση του, από τους παραδοσιακούς αλγόριθμους. Το γεγονός αυτό τεκμηριώνεται από δύο βασικές παρατηρήσεις : 1) Ότι έχει να χρησιμοποιηθεί αρκετό καιρό, είναι πιθανό να μη χρησιμοποιηθεί πάλι στο μέλλον. 2) Ότι χρησιμοποιήθηκε πρόσφατα, είναι πολύ πιθανό να ξαναζητηθεί σύντομα στο μέλλον. Και οι δύο αρχές είναι ουσιαστικά διαφορετικές εκφάνσεις της χρονικής τοπικότητας. Οι ιδιότητες αυτές του LRU τον έκαναν ευρέως διαδεδομένο, και μέχρι την έλευση των σύγχρονων πολύπλοκων μηχανισμών αντικατάστασης, αποτελούσε αδιαφιλονίκητη πολιτική στην αντικατάσταση των κρυφών μνημών, προσεγγίζοντας το βέλτιστο αλγόριθμο (βασιζόμενος όχι στο μέλλον, αλλά στο παρελθόν) στο βαθμό που είναι δυνατόν σε ένα πραγματικό υπολογιστικό σύστημα. Η υλοποίηση του αλγορίθμου LRU έγινε εφικτή με δύο κυρίως τρόπους: 1) Με τη χρήση μετρητών. Στην απλούστερη περίπτωση προσθέτουμε ένα πεδίο χρόνου σε κάθε εγγραφή της κρυφής μνήμης. Αυτό σημειώνεται όταν το στοιχείο χρησιμοποιείται από τον επεξεργαστή. Ένα λογικό ρολόι ή μετρητής της ΚΜΕ αυξάνεται με κάθε αναφορά στη μνήμη. Όταν γίνεται χρήση ενός στοιχείου, μεταφέρεται το περιεχόμενο του στο πεδίο χρόνου χρήσης της εγγραφής της cache. Για να αντικατασταθεί το στοιχείο με τη μικρότερη εγγραφή χρόνου, γίνεται μία αναζήτηση σε κάθε αστοχία σε όλα τα στοιχεία στο πεδίο αυτό. 2)Με στοίβα. Αυτή η προσέγγιση χρησιμοποιείται ως επί το πλείστον. Η στοίβα έχει το μέγεθος της κρυφής μνήμης. Σε κάθε χρήση στοιχείου αυτό τοποθετείται στην κορυφή της στοίβας. Η πιο πρόσφατα χρησιμοποιημένη αναφορά βρίσκεται έτσι πάντα στην κορυφή. Όταν ζητηθεί ένα στοιχείο που είναι ήδη στη στοίβα, πρέπει να αφαιρεθεί από την παλιά του θέση πριν τοποθετηθεί στην κορυφή. Κατά την αντικατάσταση, αντικαθίσταται το στοιχείο που βρίσκεται στην ουρά της στοίβας Ο αλγόριθμος FIFO Από τους πρώτους που χρησιμοποιήθηκαν και ένας αλγόριθμος πολύ απλός στη συλλογιστική και διάσημος στο χώρο των υπολογιστών, είναι ο αλγόριθμος FIFO (First in, First out). Ο αλγόριθμος αυτός αντικαθιστά κάθε 29
30 φορά, το στοιχειό εκείνο που πρώτο εισήχθη στην κρυφή μνήμη σε σχέση με τα υπάρχοντα. Συσχετίζει δηλαδή κάθε μπλοκ με τη χρονική στιγμή της τελευταίας μεταφοράς του στην cache, και όχι της τελευταίας χρήσης του όπως ο LRU. Η αλήθεια είναι ότι γενικά αυτός ο αλγόριθμος δεν αποδίδει καλά στις κρυφές μνήμες. Αν και κατά την αρχικοποίηση ενός προγράμματος, ένα στοιχείο μπορεί να έρθει στην cache και μετά να μην ξαναχρειαστεί έπειτα (Ο FIFO θα αντιμετωπίσει επιτυχώς μια τέτοια περίπτωση), στοιχεία που μεταφερθήκανε νωρίς αλλά χρησιμοποιούνται συνέχεια, ο αλγόριθμος τα εξώνει από τη μνήμη, αδυνατώντας να διαχειριστεί τέτοιες περιπτώσεις Ο τυχαίος (random) αλγόριθμος Στην περίπτωση του random (τυχαίου) αλγορίθμου η αντικατάσταση δεν βασίζεται σε κανένα ντετερμινιστικό κριτήριο. Το στοιχείο επιλέγεται τυχαία, είτε μέσω μαθηματικής κατανομής ή με τη χρήση ψευδοτυχαίων αριθμών. Αυτό που παίζει πλέον ρόλο, είναι το μοντέλο που επιλέγεται για να περιγράψει το σύστημα της αποθήκευσης των στοιχείων στη μνήμη και για να εξαχθούν στατιστικά όπως το ποσοστό ευστοχίας (πχ το μοντέλο Markov έχει χρησιμοποιηθεί ). Για το υλικό, ένας τυχαίος αλγόριθμος έχει το πλεονέκτημα της απλότητας. Καθώς όμως το σύστημα μας δεν βασίζεται σε τυχαιότητα, αλλά σε καθορισμένα πρότυπα (patterns) που υπάρχουν στα προγράμματα, αποτυγχάνει στην διαχείριση της κρυφής μνήμης Άλλοι αλγόριθμοι Άλλοι παραδοσιακοί αλγόριθμοι που χρησιμοποιήθηκαν στην αντικατάσταση των κρυφών μνημών, αλλά δεν έδωσαν τόσο ικανοποιητικά αποτελέσματα όσο ο LRU, είναι οι ακόλουθοι: - MRU (Most recently used) : Σε αντίθεση με τον LRU, εδώ αντικαθίσταται το στοιχείο που έχει χρησιμοποιηθεί τελευταίο από τον επεξεργαστή. Ο MRU βασίστηκε στην αντίληψη ότι στους βρόγχους επανάληψης, αν προσπελαύνονται διαφορετικά στοιχεία, τότε θα ζητηθεί κάθε φορά το στοιχείο εκείνο που προσπελάστηκε στον αρχαιότερο χρόνο από τα άλλα στο παρελθόν. Το στοιχείο που έχει προσπελαστεί πιο πρόσφατα θα είναι το τελευταίο που θα ζητηθεί από τα στοιχεία του βρόγχου. Αυτό είναι αληθές, αλλά μόνο σε βρόγχους με αυτά τα χαρακτηριστικά. - LIFO (Last in first out) : Στην αντίθετη λογική με αυτή του FIFO, αντικαθίσταται κάθε φορά το στοιχείο που τελευταίο μεταφέρθηκε στην 30
31 κρυφή μνήμη. Χρησιμοποιήθηκε ελάχιστα και εξαρχής δεν απέδωσε καλά, γιατί μια τέτοια λογική είναι αντίθετη με την όλη φύση των προγραμμάτων, αφού όταν ένα στοιχείο μπαίνει στην μνήμη αναμένεται, για κάποιο χρονικό διάστημα τουλάχιστον, να επαναχρησιμοποιηθεί. - LFU (Least Frequently Used) : Σε αυτή την προσέγγιση αντικατάστασης, παίζει ρόλο το πλήθος των φορών που έχει χρησιμοποιηθεί το στοιχείο, η συχνότητα χρήσης του δηλαδή. Αντικαθίσταται το στοιχείο που έχει χρησιμοποιηθεί τις λιγότερες φορές, ανεξαρτήτως με το πότε προσπελάστηκε τελευταία φορά. Ο αλγόριθμος αυτός αν και εντοπίζει σωστά ενεργά στοιχεία, δηλαδή στοιχεία που χρησιμοποιούνται συχνά, αδυνατεί να συλλάβει τις αλλαγές στην πορεία του χρόνου, αφού δεν τον λαμβάνει υπόψιν του (Πχ αν ένα στοιχείο έχει χρησιμοποιηθεί πολύ κατά την αρχική φάση ενός προγράμματος και έπειτα δεν πρόκειται να χρειαστεί καθόλου, θα παραμείνει, οδηγώντας στην αντίθετη εξέλιξη από αυτή που επιτάσσει ο βέλτιστος (OPT).) Κατά καιρούς έχουν κάνει την εμφάνιση τους και άλλοι αλγόριθμοι, χωρίς σημαντικά αποτελέσματα, μερικούς από τους οποίους αναφέρουμε επιγραμματικά : MFU (Most Frequently Used - αντικατάσταση του στοιχείου που έχει χρησιμοποιηθεί περισσότερο), Pseudo - LRU, Segmented - LRU και άλλες παραλλαγές του LRU. 3.3 Πρόσφατη έρευνα και νέοι αλγόριθμοι για Δυναμικό Cache Partitioning Η δυναμική κατάτμηση (DCP) των διαμοιραζόμενων μνημών cache προτείνετε για τη βελτίωση της απόδοσης των πολιτικών αντικατάστασης σε πολυνηματικές εφαρμογές. Οι ήδη υπάρχοντες DCP αλγόριθμοι επεξεργάζονται των αριθμό των αστοχιών που προκαλούνται σε κάθε νήμα (thread) και διαχειρίζονται κάθε αστοχία ισότιμα. Όμως έχει αποδειχθεί ότι οι αστοχίες της μνήμης cache έχουν διαφορετικό αποτέλεσμα ανάλογα με την κατανομή τους. Τα συγκεντρωμένα misses μπορούν να μοιράζονται την ποινή αστοχίας γιατί εξυπηρετούνται παράλληλα, ενώ τα μεμονωμένα έχουν μεγαλύτερο αντίκτυπο στην απόδοση καθώς η καθυστέρηση μνήμης δεν μοιράζεται με τα υπόλοιπα misses. Μελετάμε ένα DCP αλγόριθμο με επίγνωση του παραλληλισμού επιπέδου μνήμης (MLP-Aware) που διαχειρίζεται τις αστοχίες διαφορετικά μεταξύ τους και ανάλογα με την επιρροή στην απόδοση Stack Distance Histogram (SDH) Εισαγωγή της ιδέας για χρήση της απόστασης στοίβας με σκοπό να μελετηθεί η συμπεριφορά της ιεραρχίας αποθήκευσης. Οι συνήθεις πολιτικές 31
 γραμμή, ενώ η τελευταία είναι η LRU.")
32 αντικατάστασης, όπως για παράδειγμα η LRU, έχουν το stack property. Κάθε set στην cache μπορεί να απεικονιστεί σαν LRU stack, στην οποία οι γραμμές ταξινομούνται με βάση το τελευταίο access cycle. Με αυτόν τον τρόπο, η πρώτη γραμμή στην LRU στοίβα είναι η MRU (Most Recently Used) γραμμή, ενώ η τελευταία είναι η LRU. Η θέση που κατέχει η γραμμή στην στοίβα όταν γίνεται ξανά προσπέλαση, ορίζεται ως η απόσταση στοίβας της προσπέλασης (stack distance). Πίνακας 1: Stack distance Histogram Στον Πίνακα 3.1(α) βλέπουμε σαν παράδειγμα μία ροή προσπελάσεων στο ίδιο set, μαζί με τις αντίστοιχες αποστάσεις στοίβας. Για μια K-way set associative cache με πολιτική αντικατάστασης LRU, χρειαζόμαστε Κ+1 counters για την υλοποίηση των SDHs, που αναπαρίστανται ως C 1, C 2,.., C K, C >K. Για κάθε προσπέλαση της cache, ένας από τους counters αυξάνει. Αν γίνεται προσπέλαση σε μία γραμμή στην i th θέση στην LRU στοίβα, ο C i αυξάνει. Αν συμβαίνει αστοχία, τότε η γραμμή δεν βρίσκεται στην LRU στοίβα, και έτσι αυξάνουμε τον miss counter C >K. Ένα SDH μπορεί να εξάγεται κατά την εκτέλεση είτε όταν εξομοιώνουμε ένα thread μόνο του στο σύστημα, είτε με την πρόσθεση hardware counters που απεικονίζουν αυτή την πληροφορία. Ένα χαρακτηριστικό αυτών των ιστογραμμάτων είναι πως ο αριθμός των αστοχιών για μία μικρότερη cache με τον ίδιο αριθμό από sets, μπορεί εύκολα να υπολογιστεί. Για παράδειγμα, για μία K' -way set associative cache, όπου Κ' <Κ, ο νέος αριθμός των αστοχιών μπορεί να υπολογιστεί από τον τύπο misses = C >K + K i=k ' +1 Ci. Στον Πίνακα 1(β) φαίνεται ένα SDH για ένα set με 4 ways. Στην περίπτωση αυτή συμβαίνουν 5 cache misses. Όμως, αν ελαττώσουμε τον αριθμό των ways σε 2, με σταθερό τον αριθμό των sets, θα προκύψουν 20 αστοχίες. 32
33 3.3.2 Minimizing Total Misses Με χρήση των SDH από N applications, μπορούμε να συμπεράνουμε το L2 cache partition που ελαχιστοποιεί τον συνολικό αριθμό των αστοχιών. Αυτός ο αριθμός αντιστοιχεί στο άθροισμα του αριθμού των αστοχιών για κάθε thread με τη δοθείσα παραμετροποίηση. Το βέλτιστο partition στην τελευταία περίοδο του χρόνου είναι κατάλληλος υποψήφιος για να γίνει το μελλοντικό βέλτιστο partition. Τα partitions, καθορίζονται περιοδικά μετά από ένα σταθερό αριθμό κύκλων. Σε αυτό το σενάριο, καθορίζονται με way granularity. Αυτός ο μηχανισμός χρησιμοποιείται με σκοπό να ελαχιστοποιήσει τον συνολικό αριθμό των αστοχιών και να μεγιστοποιήσει το throughput. Μια πρώτη προσέγγιση πρότεινε στατική κατάτμηση της μνήμης cache με βάση τις πληροφορίες προφίλ. Στην συνέχεια, μια δυναμική υλοποίηση, πρότεινε τον υπολογισμό των SDHs με χρήση πληροφοριών εντός της μνήμης cache. Τελικά, προέκυψε η πρόταση για υπολογισμό των SDHs με δειγματοληψία, η μέθοδος MinMisses. 3.4 MLP Aware Dynamic Cache Partitioning Στο [4] οι Miquel Moreto,Francisco J.Cazorla, Alex Ramirez, and Mateo Valero προτείνουν έναν αλγόριθμο με επίγνωση παραλληλισμού επιπέδου μνήμης που κάνει δυναμική κατάτμηση μνήμης. Τον παρουσιάζουμε παρακάτω και αποτελεί τη βάση της συγκεκριμένης διπλωματικής εργασίας Γενική Αρχή του Αλγόριθμου Ο αλγόριθμος 3.1 παρουσιάζει τα απαραίτητα βήματα για τη δυναμική επιλογή cache partition ανάλογα με το MLP για κάθε L2 access. Αλγόριθμος 3.1 Βήμα 1: Θέτω ένα αρχικό άρτιο partition για κάθε core Βήμα 2: τρέχω τα threads και συλλογή δεδομένων για MLP-Aware SDHs Βήμα 3: Θέτω νέο partition Βήμα 4: Ενημέρωση των SDHs Βήμα 5: πήγαινε στο βήμα 2 Στο Βήμα 1 της εκτέλεσης καθώς δεν έχουμε πρότερη γνώση των εφαρμογών, διανέμουμε εξίσου τα ways στους πυρήνες. Έτσι κάθε πυρήνας δέχεται έναν αριθμό δρόμων (ways) ίσο με το αποτέλεσμα associativity/ 33
34 number of cores της διαμοιραζόμενης cache. Στο Βήμα 2, ξεκινάει η περίοδος κατά την οποία μετράμε το ολικό MLP cost για κάθε εφαρμογή. Ορίζουμε σαν MLP-Aware SDH, το ιστόγραμμα του κάθε thead που περιέχει το ολικό MLP cost για κάθε πιθανό partition. Για μια Κ- way set associative cache, χρειαζόμαστε ακριβώς Κ καταχωρητές για να αποθηκευτούν τα ιστογράμματα. Στο Βήμα 3, στο τέλος κάθε interval, MLP-Aware SDHs αναλύονται, και επιλέγουμε νέο partition για το επόμενο interval. Υποθέτουμε ότι τα εκτελούμενα threads θα έχουν παρόμοιο μοτίβο από προσπελάσεις στην L2 στην επόμενη μετρήσιμη περίοδο. Έτσι, το βέλτιστο partition κατά την τελευταία περίοδο επιλέγεται για την επόμενη. Με την αξιολόγηση όλως των πιθανών cache partitions, προκύπτει το βέλτιστο. Αυτή η αξιολόγηση γίνεται ταυτόχρονα με το υλικό, που θέτει το partition για κάθε διεργασία για την επόμενη περίοδο. Η παραμονή σε προηγούμενες τιμές partition δεν επιδρά στην ορθότητα των αποτελεσμάτων και δεν επηρεάζει την απόδοση, καθώς η επιλογή νέου partition γίνεται σε διάστημα χιλιάδων κύκλων. Εφόσον τα χαρακτηριστικά των εφαρμογών αλλάζουν δυναμικά, οι αλλαγές αυτές ανακλώνται στα MLP-Aware SDHs. Όμως επιπλέον, χρειάζεται να διατηρούμε κάποιο ιστορικό των προηγούμενων MLP-Aware SDHs για να κάνουμε νέες επιλογές. Έτσι, για κάθε νέο partition που επιλέγουμε, πολλαπλασιάζουμε όλες τις τιμές των MLP-Aware SDHs με το ρ, ρ [0,1]. Μεγάλες τιμές του ρ, έχουν μεγαλύτερο χρόνο αντίδρασης σε αλλαγές φάσης. Αντίθετα, μικρές τιμές του ρ, έχουν γρήγορη προσαρμογή αλλά τείνει να ξεχνά τη συμπεριφορά της εφαρμογής. Επιλέγουμε ρ=0.5, και επιπλέον το χρησιμοποιούμε σα μετατοπιστή για ενημέρωση των ιστογραμμάτων. Στη συνέχεια, ξεκινάει μια νέα περίοδος μέτρησης MLP-Aware SDHs. Η βασική ιδέα του συγκεκριμένου αλγόριθμου είναι η μέθοδος για τη διαμόρφωση των MLP-Aware SDHs MLP Aware Stack Distance Histogram Με τη μέθοδο MinMisses υποθέτουμε ότι όλες οι L2 προσπελάσεις έχουν την ίδια σημασία για την απόδοση. Όμως, έχει αποδειχθεί πως οι αστοχίες της cache επηρεάζουν διαφορετικά την απόδοση των εφαρμογών, ακόμη και στην ίδια εφαρμογή. Ένα μεμονωμένο L2 data miss έχει ποινή αστοχίας που μπορεί να προσεγγιστεί από τη μέση καθυστέρηση μνήμης. Στην περίπτωση που συμβαίνει ξέσπασμα από L2 data misses που χωράνε στον ROB, η ποινή αστοχίας μοιράζεται ανάμεσα στα misses καθώς αυτά μπορούν να εξυπηρετούνται παράλληλα. Στην περίπτωση που έχουμε L2 instruction misses, εξυπηρετούνται σειριακά καθώς η φόρτωση εντολών σταματάει. Έτσι, τα L2 instruction misses έχουν σταθερή ποινή αστοχίας και MLP. 34
35 Η επιθυμία μας είναι να καθορίσουμε ένα κόστος για κάθε πρόσβαση στην L2 cache ανάλογα με την επίδραση στην απόδοση. Μια παρόμοια ιδέα ήταν η χρήση μιας τροποποιημένης LRU πολιτικής αντικατάστασης για ένα πυρήνα και single-threaded αρχιτεκτονικές. Στην παρούσα υλοποίηση χρησιμοποιούμε CMP, όπου η διαμοιραζόμενη L2 cache έχει ένα καθορισμένο αριθμό από ways για κάθε πυρήνα. Στο τέλος κάθε περιόδου, αποφασίζουμε αν θα συνεχίσουμε με το ίδιο partition, ή την αλλαγή του. Στο ενδεχόμενο της τροποποίησης του, ένας πυρήνας i που είχε w i ways πλέον θα έχει w i '. Αν w i < w i ' το thread λαμβάνει περισσότερα ways, όποτε κάποια από τα misses της προηγούμενης παραμετροποίησης θα γίνουν hits. Αντίστοιχα αν w i > w i ', το thread λαμβάνει λιγότερα ways, όποτε κάποια από τα hits της προηγούμενης παραμετροποίησης θα γίνουν misses. Θέλουμε να έχουμε μια εκτίμηση της απόδοσης όταν τα misses γίνονται hits και αντίστροφα, αυτό το αντίκτυπο στην απόδοση το ονομάζουμε MLP_cost. MLP_cost of L2 miss Για τον υπολογισμό του MLP_cost από ένα L2 miss με stack distance d i, θεωρούμε μια κατάσταση παρόμοια με αυτήν που παρουσιάζεται στην Εικόνα 3.1. Αν εξαναγκάσουμε μια παραμετροποίηση της L2 που αναθέτει ακριβώς w' i = d i ways, στο thread i με w i < w i ', κάποια από τα L2 misses του thread θα μετατραπούν σε hits, ενώ κάποια άλλα θα παραμείνουν misses, ανάλογα με την stack distance. Για να ανιχνεύσουμε αυτή την απόσταση καθώς και το MLP_cost για κάθε L2 miss, τροποποιούμε το L2 Miss Status Holding Registers(MSHR). Η δομή αυτή είναι παρόμοια με ένα L2 miss buffer και χρησιμοποιείται για την αποθήκευση της πληροφορίας σχετικά με κάθε πρόσβαση στην L2 cache που αστοχεί. Ο τροποποιημένος L2 MSHR έχει ένα επιπλέον πεδίο το οποίο περιέχει το MLP_cost από ένα miss, όπως παρουσιάζεται στην Εικόνα 3.2(b). Είναι επίσης απαραίτητο να αποθηκεύεται και η απόσταση στοίβας για κάθε πρόσβαση στο MSHR. Στην εικόνα 3.2(a) φαίνεται ο MSHR στην ιεραρχία μνήμης. 35
36 Εικόνα 3.1 MLP_cost ενός L2 miss Εικόνα 3.2 Miss Status Holding Register Όταν γίνεται πρόσβαση στην L2 cache και αναγνωρίζεται ένα L2 miss, αναθέτουμε μια MSHR entry στο miss και αναμένουμε τα δεδομένα που θα έρθουν από την Κύρια Μνήμη. Όταν γίνεται η ανάθεση της entry το πεδίο MLP_cost αρχικοποιείται σε μηδέν. Αποθηκεύουμε την απόσταση στοίβας της πρόσβασης μαζί με το αναγνωριστικό του αρχικού (ιδιοκτήτη) πυρήνα. Σε κάθε κύκλο λαμβάνουμε Ν, τον αριθμό των προσβάσεων στην L2 με απόσταση στοίβας μεγαλύτερη ή ίση από d i. Έχουμε ένα μετρητή υλικού που ανιχνεύει αυτό τον αριθμό για κάθε πιθανή τιμή του d i, που σημαίνει ένα σύνολο μετρητών ίσο με την associativity. Αν έχουμε Ν L2 misses που εξυπηρετούνται παράλληλα, η ποινή αστοχίας μοιράζεται. Με αυτό τον τρόπο, αναθέτουμε ένα ισότιμο μερίδιο 1/Ν σε κάθε miss. Η τιμή του MLP_cost ενημερώνεται μέχρι να φθάσουν τα δεδομένα από την Κύρια Μνήμη και να γεμίσουν την L2. Έκεινη τη στιγμή μπορούμε να ελευθερώσουμε την MSHR entry. Ο αριθμός των adders που χρειάζονται για την ενημέρωση του MLP_cost όλων των εγγραφών είναι ίσος με τον αριθμό των εγγραφών του MSHR. Αυτός 36
37 ο αριθμός μπορεί να μειωθεί, μοιράζοντας κάποιους adders μεταξύ έγκυρων MSHR εγγραφών με τρόπο round robin. Έτσι, αν μια εγγραφή του MSHR ενημερώνει το MLP_cost κάθε 4 κύκλους, πρέπει να προσθέσει 4/Ν. Έδω υποθέτουμε ότι ο MSHR περιέχει μόνο 4 adders για την ενημέρωση των τιμών MLP_cost, που έχει αμελητέα επίδραση στο τελικό MLP_cost. MLP_cost of L2 hits. Στη συνέχεια, θέλουμε να υπολογίσουμε το MLP_cost ενός L2 hit με απόσταση στοίβας d i όταν μετατρέπεται σε miss. Αν επιβάλουμε L2 διαμόρφωση που αναθέτει ακριβώς w' i = d i ways,στο thread i με w i > w i ', κάποια από τα L2 hits του thread θα μετατραπούν σε misses, ενώ όλα τα L2 misses θα παραμείνουν misses (Εικόνα 3.3). Τα hits που θα μετατραπούν σε misses, είναι αυτά με απόσταση στοίβας μεγαλύτερη ή ίση από d i. Μετράμε το συνολικό αριθμό των προσβάσεων με απόσταση στοίβας μεγαλύτερη ή ίση από d i ( συμπεριλαμβανομένων και των L2 hits και των misses) για να υπολογίσουμε το μήκος του συμπλέγματος των L2 misses σε αυτή τη διαμόρφωση. Εικόνα 3.3 Estimated MLP_cost when a hit becomes a miss Η στιγμή που αποφασίζουμε να ελευθερώσουμε το πεδίο που χρησιμοποιείται από ένα L2 hit είναι πιο σύνθετη από την περίπτωση του MSHR. Σε μια ισορροπημένη αρχιτεκτονική, τα L2 data misses μπορούν να εξυπηρετηθούν παράλληλα αν χωράνε στο ROB. Αντίστοιχα, υποθέτουμε ότι τα L2 data misses μπορούν να εξυπηρετηθούν παράλληλα αν είναι σε απόσταση από τον ROB, μικρότερη από το μέγεθος του ROB. Έτσι, ελευθερώνουμε την εγγραφή αν ο αριθμός των εντολών που έχουν δεσμευθεί μετά την πρόσβαση έχει φτάσει το μέγεθος του ROB ή αν ο αριθμός των κύκλων μετά το hit έφτασε τη μέση καθυστέρηση στην κύρια μνήμη. Η πρώτη συνθήκη είναι ξεκάθαρη, καθώς όλα τα L2 misses μπορούν να 37
38 επικαλύπτονται μόνο αν είναι σε απόσταση από τον ROB, μικρότερη από το μέγεθος του ROB. Όταν η εγγραφή ελευθερώνεται, πρέπει να προσθέσουμε τον αριθμό των εκκρεμών κύκλων διαιρούμενων από τον αριθμό των misses με απόσταση στοίβας μεγαλύτερη ή ίση από d i. Η δεύτερη συνθήκη είναι επίσης απαραίτητη καθώς είναι πιθανό να μην επιχειρηθεί κάποια πρόσβαση στην L2 cache για κάποιο χρονικό διάστημα. Για να εξάγουμε τη μέση καθυστέρηση μνήμης, προσθέτουμε υλικό που μετράει και υπολογίζει τον αριθμό κύκλων για τους οποίους μια εγγραφή είναι στο MSHR. Χρησιμοποιούμε νέο υλικό για το MLP_cost των L2 hits. Ορίζεται σαν Hit Status Holding Register (HSHR) καθώς είναι παρόμοιο του MSHR. Όμως, ο HSHR χρειάζεται ένα αναγνωριστικό της ROB καταχώρησης της πρόσβασης, τη διεύθυνση που γίνεται η πρόσβαση για το L2 hit, την τιμή της απόστασης στοίβας, και ένα πεδίο με το αντίστοιχο MLP_cost όπως παρουσιάζεται στην Εικόνα 4(β). Στην εικόνα 4(α) φαίνεται ο HSHR στην ιεραρχία μνήμης. Εικόνα 3.4 Hit Status Holding Register Όταν γίνεται πρόσβαση στην L2 cache και καθορίζεται ένα L2 hit, θέτουμε μία εγγραφή HSHR στο L2 hit. Αρχικοποιούμε τα πεδία της εγγραφής όπως και στον MSHR. Έχουμε μία απόσταση στοίβας d i και θέλουμε να ενημερώνεται το πεδίο MLP_cost σε κάθε κύκλο. Με αυτό το στόχο, χρειάζεται να γνωρίζουμε τον αριθμό των ενεργών εγγραφών με απόσταση στοίβας μεγαλύτερη ή ίση από d i στον HSHR, που ανιχνεύεται με ένα μετρητή υλικού για κάθε πυρήνα. Επίσης χρειαζόμαστε έναν αναγνωριστή ROB εγγραφών για κάθε πρόσβαση στην L2. Σε κάθε κύκλο, εξάγεται το Ν, ο αριθμός των L2 προσβάσεων με απόσταση στοίβας μεγαλύτερη ή ίση από d i, όπως και στον MSHR. Έχουμε ένα μετρητή που ανιχνεύει αυτόν τον αριθμό για κάθε πιθανή τιμή του d i, που σημαίνει μετρητές όσοι και ο αριθμός της συσχετιστικότητας. Για να αποφύγουμε συγκρούσεις διανυσμάτων, χρειαζόμαστε τόσες 38
39 εγγραφές στον HSHR όσες και οι πιθανές προσπελάσεις στην L2 κατά τη διάρκεια της εκτέλεσης. Αυτός ο αριθμός είναι ίσος με το μέγεθος του L1 MSHR. Κβαντοποίηση του MLP_cost Λόγω του ότι οι τιμές του MLP_cost κυμαίνονται μεταξύ του μηδενός και της καθυστέρησης της μνήμης, έχουμε σημαντικό κόστος σε υλικό. Έτσι, κβαντοποιούμε το MLP_cost με μια ακέραια τιμή μεταξύ 0 και 7. Για καθυστέρηση 300 κύκλων, φαίνεται στον Πίνακα 2 πως ποσοτικοποιούμε το MLP_cost. Χωρίζουμε το διάστημα [0,300] σε 7 διαστήματα ίσου μήκους. Πίνακας 2: Κβαντοποίηση του MLP_cost Τελικά, όταν πρέπει να ενημερωθούν τα αντίστοιχα MLP-aware SDHs, προσθέτουμε την ποσοστικοποιημένη τιμή του MLP_cost. Με αυτό τον τρόπο, τα μεμονωμένα L2 misses θα έχουν ένα βάρος 7, ενώ 2 επικαλυπτόμενα L2 misses θα έχουν βάρος 3 στο MLP-aware SDH. Αντίθετα, η μέθοδος MinMisses πάντα προσθέτει 1 στα ιστογράμματα Διαδικασία λήψης του Stack Distance Histogram Τυπικά, οι L2 caches έχουν 2 ξεχωριστά μέρη για να αποθηκεύουν δεδομένα και ετικέτες διευθύνσεων για να γνωρίζουν αν η πρόσβαση είναι ευστοχία. Ο μηχανισμός πρόβλεψης που προτείνουμε χρειάζεται να ανιχνεύει κάθε πρόσβαση στην L2 και να αποθηκεύει ένα ξεχωριστό αντίγραφο των πληροφοριών των ετικετών L2 σε ένα Auxiliary Tag Directory (ATD), μαζί με τους LRU μετρητές. Χρειαζόμαστε ένα ATD για κάθε πυρήνα που κρατάει αρχείο για τις προσπελάσεις στην L2 για κάθε πιθανή διαμόρφωση της cache. Ανεξάρτητα από τον αριθμό των ways που έχει κάθε πυρήνας, αποθηκεύουμε τις ετικέτες και τους LRU μετρητές από τις τελευταίες Κ προσπελάσεις στο thread, όπου Κ: η συσχετιστικότητα. Όπως εξηγήθηκε στο κομμάτι 2, μια πρόσβαση με απόσταση στοίβας d i αντιστοιχεί σε ένα cache miss σε κάθε διαμόρφωση η οποία αναθέτει λιγότερα από d i ways στο thread. Έτσι, με το ATD μπορούμε να καθορίσουμε αν μια πρόσβαση στην L2 είναι αστοχία ή ευστοχία για κάθε πιθανές διαμορφώσεις της cache. 39
40 3.4.4 Συναρμολόγηση των παραπάνω Στην εικόνα 3.5 φαίνεται ένα προσχέδιο της υλικής υλοποίησης της πρότασης μας. Όταν έχουμε μία πρόσβαση στην L2, το ATD καθορίζει τη δική του απόσταση στοίβας d i. Ανάλογα με το αν είναι ευστοχία ή αστοχία, είτε ο MHSR είτε ο HSHR υπολογίζει το MLP_cost της πρόσβασης. Με τη διαδικασία της ποσοτικοποίησης λαμβάνουμε το τελικό MLP_cost. Αυτός ο αριθμός καθορίζει πως επιδρά στην απόδοση το ενδεχόμενο η εφαρμογή να έχει ακριβώς w' i = d i ways. Αν w' i > w i, υπολογίζουμε το όφελος στην απόδοσης από τη μετατροπή του L2 miss σε hit. Στην περίπτωση που w' i < w i, υπολογίζουμε την υποβάθμιση της απόδοσης από τη μετατροπή του L2 hit σε miss. Τελικά, χρησιμοποιώντας την απόσταση στοίβας, το MLP_cost και το αναγνωριστικό πυρήνα, ενημερώνουμε το αντίστοιχο MLP-aware SDH. Εικόνα 3.5 Σχηματικό υλοποίησης υλικού Χρησιμοποιούνται 2 διαφορετικούς αλγόριθμους για κατάτμηση. Ο πρώτος είναι ο MLP_DCP (MLP-aware Dynamic Cache Partitionig), καθορίζει το βέλτιστο partition ανάλογα με το MLP-cost σε κάθε way. Ορίζουμε το συνολικό MLP_cost για ένα thread i που έχει w i ways σαν TMLP(i, w i ) = MLP-SDH i, >K + K j=wi MLP SDH i, j. Ορίζουμε το συνολικό MLP_cost όλων των προσβάσεων του 40
41 thread i με απόσταση στοίβας j σαν MLP-SDH i,j. Με αυτό τον τρόπο, πρέπει να ελαχιστοποιήθεί το άθροισμα του συνολικού MLP_cost για όλους τους πυρήνες: N i=1 TMLP(i, w i ), όπου i=1 N w i = Associativity. Στον δεύτερο αλγόριθμο ανατίθεται ένα βάρος σε κάθε ολικό MLP_cost χρησιμοποιώντας το IPC μιας εφαρμογής σε ένα πυρήνα i, IPC i. Σε αυτή την περίπτωση, δίνουμε προτεραιότητα στα threads με υψηλότερο IPC. Αυτό το σημείο μας δίνει καλύτερα αποτελέσματα στο throughput με το τίμημα να είναι λιγότερο δίκαιος. Το IPC i μετράται κατά την εκτέλεση με ένα μετρητή ανά πυρήνα. Ο αλγόριθμος αυτός ονομάζεται MLPIPC_DCP, στον οποίο ελαχιστοποιούμε την παρακάτω έκφραση: N i=1 IPC i TMLP(i, w i ), όπου i=1 N w i = Associativity. 3.5 Χρήσιμα συμπεράσματα Σε αυτό το κεφάλαιο της διπλωματικής εργασίας, ξεκινάμε τη σύντομη αναδρομή στους παραδοσιακούς αλγορίθμους αντικατάστασης και ανάδειξη της σημασίας που έχουν μαζί με την αναγνώριση της συμπεριφοράς της μνήμης cache σε miss event. Στη συνέχεια παρουσιάζονται πιο σύγχρονοι αλγόριθμοι, οι οποίοι προσδοκούν να αξιοποιήσουν καλύτερα τις δυνατότητες που υπάρχουν στα συστήματα πολυπύρηνων επεξεργαστών, στα οποία κομβικό ζήτημα για την απόδοση είναι η διαμοιραζόμενη κοινή μνήμη (l2). Ένα ζήτημα που αφορά της μνήμες δευτέρου επιπέδου στους CMPs είναι το πως μοιράζονται οι πόροι ανάμεσα στους πυρήνες. Ένας τρόπος για βελτίωση της απόδοσης είναι η δυναμική κατάτμηση μνήμης για την αποδοτικότερη εξυπηρέτηση των αστοχιών. Εξετάζουμε δύο περιπτώσεις, οι οποίες αποτελούν τη βάση της πειραματικής υλοποίησης του κεφαλαίου 5. Η πρώτη επιχειρεί δυναμική κατάτμηση μνήμης με κριτήριο τον αριθμό των αστοχιών, αντιμετωπίζοντας ισότιμα κάθε αστοχία. Η δεύτερη επιδιώκει να αξιοποιήσει τον παραλληλισμό επιπέδου μνήμης, και πραγματοποιεί τη δυναμική κατάτμηση αποδίδοντας μία τιμή (mlp_cost) στα l2 misses. Με αυτό τον τρόπο διαχωρίζει τις αστοχίες σε μεμονωμένες και παράλληλες, θεωρώντας πως οι μεμονωμένες κοστίζουν περισσότερο. Χρησιμοποιώντας το mlp_cost στη συνέχεια επιχειρεί δυναμική κατάτμηση μνήμης, επιβεβαιώνοντας τη σημασία του παραλληλισμού επιπέδου μνήμης στους CMPs. Σε αυτές τις προτάσεις στηριχτήκαμε για την πειραματική υλοποίηση της εργασίας, και όπως θα δείξουμε στο κεφάλαιο 5, οι μετρήσεις μας συμφωνούν με τις σύγχρονες τάσεις που αναδεικνύουν τη σημασία του MLP. 41
42 42
43 Κεφάλαιο 4: Υπόθεση Εργασίας & Εργαλεία 4.1 SimpleScalar Ο Simplescalar [5][6] είναι μια ενοποιημένη ομάδα, πλήρως παραμετροποιήσιμων εξομοιωτών, για την λεπτομερή λειτουργία της Αρχιτεκτονικής των Υπολογιστών. Περιλαμβάνει επίσης Compilers (Μεταγλωττιστές), Assemblers (Συμβολομεταφραστές), Linkers (Συνδέτες) και Βιβλιοθήκες. Δημοσιεύτηκε για πρώτη φορά το 1996 από τον τότε Διδακτορικό Todd Austin, είναι υλοποιημένο σε γλώσσα προγραμματισμού C και αποτελεί Πρόγραμμα Ανοιχτού Κώδικα (Open-Source) με ελεύθερα δικαιώματα χρήσης προς όλους. Με χρήση του Simplescalar, μπορούμε να παρατηρήσουμε στην πράξη την συμπεριφορά του ακριβούς συστήματος που μας ενδιαφέρει, ώστε να έχουμε ένα μέτρο σύγκρισης για την θεωρία που μελετάμε και τις προτάσεις υποθέσεις στις οποίες καταφεύγουμε κατά την διάρκεια της έρευνάς μας. Το Simplescalar μπορεί να μοντελοποιήσει ένα εικονικό Υπολογιστικό Σύστημα Superscalar Επεξεργαστών και μας δίνει την δυνατότητα να διερευνήσουμε σε βάθος τις διάφορες κατηγορίες Ενδο-διεργασιακών Επικοινωνιών (Interprocess Communications ή IPC). Λόγω της πολυπλοκότητας των σύγχρονων Επεξεργαστών, η αξιολόγηση των επιδόσεων τους θα ήταν πολύ δύσκολη χωρίς την βοήθεια του Simplescalar. Το Simplescalar παρέχει την δυνατότητα να δούμε το πλήρες ιστορικό της Εξομοίωσης της εκτέλεσης του Προγράμματος και τα στατιστικά που επιθυμούμε για κάθε εντολή που εκτελέστηκε κατά την διάρκεια της Εξομοίωσης, με την εξαγωγή των Traces (Ίχνη). Αυτά χρησιμοποιούμε για να κάνουμε τους υπολογισμούς μας και να προχωρήσουμε στις απαραίτητες συγκρίσεις. O εξομοιωτής SimpleScalar χρησιμοποιείται ως βάση για την ανάπτυξη εξομοιωτών για αρχιτεκτονικές execution-driven. Περιέχει αρκετές συναρτήσεις C, που αποκωδικοποιούν SS binaries, εξομοιώνουν την cache και τους branch predictors, μαζί με άλλες Ι/Ο και διαχείρισης πόρων συναρτήσεις. Στον εξομοιωτή SimpleScalar Tool Set ένας από τους βασικούς εξομοιωτές είναι ο sim-outorder, που εξομοιώνει superscalar αρχιτεκτονικές με branch prediction, register renaming, & εκτέλεση out-of-order. Ο εξομοιωτής χρησιμοποιεί την RUU(Register Update Unit) για να αποθηκεύει τις εντολές και να ελέγχει τις εξαρτήσεις και τη μετονομασία. Κρατάει τις εντολές μέχρι το commit (δέσμευση). Στην εικόνα 4.2 φαίνονται τα 6 στάδια της αρχιτεκτονικής: fetch, decode, issue, execution, write-back & commit και στην 4.1 πως υλοποιείται το pipeline μέσα στην sim_main(). 43
44 Εικόνα 4.1: Η sim_main() Εικόνα 4.2: Γενική εικόνα της αρχιτεκτονικής του sim-outorder 1. Fetch Stage: σε αυτό το στάδιο, φορτώνονται οι εντολές από την i- cache, αποθηκεύονται στην i-queue και προβλέπονται οι διακλαδώσεις. Οι εικονικές διευθύνσεις των εντολών και των δεδομένων μετατρέπονται σε φυσικές από τον i-tlb και τον d-tlb αντίστοιχα. Οι αστοχίες στην i-cache ή στον i-tlb μπλοκάρουν το στάδιο της φόρτωσης για έναν αριθμό κύκλων. Ο αριθμός των χρήσιμων εντολών που φορτώνονται εξαρτάται από το fetch width, i- queue διαθεσιμότητα και ακρίβεια στο branch prediction. 2. Decode Stage: οι εντολές που αποκωδικοποιούνται από την i-queue, μετονομάζονται και αποθηκεύονται στην ruu-q. Οι εντολές load/store χωρίζονται σε 2 μέρη: μια εντολή πρόσθεσης που υπολογίζει την effective memory address που αποθηκεύται στην ruu-q και την load/store εντολή που αποθηκεύται στη load/store queue(ls-q). Αμφότερες οι ls-q & ruu-q είναι σταθμοί δέσμευσης (reservation stations), διατεταγμένες όπως ο reorder 44
45 buffer. Περιέχουν πληροφορίες αποκωδικοποίησης, τελεστές, busy bits και ετικέτες για τον έλεγχο των εξαρτήσεων. Ο αριθμός των αποκωδικοποιημένων εντολών ανά κύκλο εξαρτάται και από το πλάτος του decode αλλά και από την διαθεσιμότητα των εντολών στην i-queue και στους σταθμούς δέσμευσης (στη RUU) 3. Issue Stage: σε αυτό το στάδιο επαληθεύονται ποιες από τις εντολές στην ruu-q και στην ls-q είναι έτοιμες για εκτέλεση (πχ να είναι διαθέσιμοι οι τελεστές και να είναι ικανοποιημένες οι εξαρτήσεις μνήμης), και αποστέλλονται στην κατάλληλη λειτουργική μονάδα. Ο αριθμός των εντολών αυτών εξαρτάται από τον αριθμό των εντολών σε ετοιμότητα, το πλάτος του σταδίου issue, και τη διαθεσιμότητα των λειτουργικών μονάδων και memory ports. 4. Execution Stage: σε αυτό το στάδιο γίνεται η εκτέλεση των εντολών και κρατάει απασχολημένη κάθε λειτουργική μονάδα κατά τη διάρκεια της καθυστέρησης λειτουργίας. Από τις εντολές μνήμης, μόνο οι εντολές φόρτωσης (load) εκτελούνται σε αυτό το στάδιο. 5. Commit Stage: οι εντολές αποθήκευσης (store) εκτελούνται σε αυτό το στάδιο. Οι εντολές μνήμης και διακλάδωσης είναι υψηλής προτεραιότητας. Το αποτέλεσμα των εκτελεσμένων εντολών αποστέλλονται στη RUU για να απελευθερώσει άλλες εντολές που είναι σε αναμονή. Σε αυτό το στάδιο γίνεται η επαλήθευση της ruu-q και η απόσυρση των εντολών που έχουν ολοκληρωθεί. Όταν μια εντολή πρόσθεσης για μια διεύθυνση μνήμης αποσύρεται στο τέλος του ruu-q, η τελευταία εγγραφή από την ls-q που πρέπει να είναι το δεύτερο μέρος της εντολής, αποσύρεται και αυτή. Όταν έχουμε εντολή διακλάδωσης, επικυρώνεται και η πρόβλεψη. Αν η πρόβλεψη είναι ψευδής, τότε όλες οι εγγραφές στις ruu-q & ls-q καταστρέφονται και η εντολή fetch ανακατευθύνεται στον σωστό στόχο. Σε κάθε κύκλο εξομοίωσης, εκτελούνται όλα τα στάδια της ομοχειρίας και συλλέγονται τα στατιστικά. Ο Sim-outorder είναι πλήρως παραμετροποιήσιμος, και επιτρέπει τον ορισμό των L1 και L2 caches, TLB, branch predictor και άλλες εσωτερικές παραμέτρους της αρχιτεκτονικής. 45
46 4.2 SMT Simplescalar Για την εκπόνηση αυτής της διπλωματικής εργασίας, λόγω του ότι αντικείμενο της μελέτης είναι τα συστήματα πολυπύρηνων επεξεργαστών, χρησιμοποιήσαμε τον SMT SimpleScalar[7]. Υλοποιήθηκε στα πλαίσια μιας διδακτορικής διατριβής, χρησιμοποιώντας ως βάση τον sim-outorder. Στον εξομοιωτή αυτόν, όλες οι συναρτήσεις προσαρμόστηκαν για να δέχονται ένα επιπλέον όρισμα που αντιστοιχεί στο αναγνωριστικό του επεξεργαστή (slot's index). Καθένα από αυτά στην εκτέλεση είναι αφοσιωμένο σε μία μόνο εφαρμογή. Σε κάθε κύκλο, όλοι οι επεξεργαστές εκτελούν εντολές από την εφαρμογή τους παράλληλα. Τα μεμονωμένα αποτελέσματα κάθε εφαρμογής είναι αυτά που εξάγονται από τον αρχικό sim-outorder. Στην εικόνα 4.3, παρουσιάζεται ο βασικός κώδικας για πολυπύρηνους επεξεργαστές. Εικόνα 4.3: Ο απλοποιημένος κώδικα για τον εξομοιωτή πολυεπεξεργαστών Μετά την υλοποίηση του εξομοιωτή για πολυπύρηνους επεξεργαστές, όλα τα στάδια της ομοχειρίας ενοποιούνται και πολλοί πόροι του συστήματος διαμοιράζονται για να γίνει ο εξομοιωτής SMT, όπως φαίνεται στην εικόνα 4.4. Σε αυτή την απεικόνιση, κάθε thread αντιστοιχεί σε μία ανεξάρτητη εφαρμογή. Το σύνολο πόρων που περιέχει το αρχείο καταχωρητών, πίνακες και ουρές, που αποθηκευεται το περιεχόμενο ενός thread αποκαλείται και σε αυτή την περίπτωση slot. 46
47 Εικόνα 4.4: Γενική εικόνα της αρχιτεκτονικής SMT Στο νέο στάδιο fetch φορτώνεται ένα μπλοκ εντολών ανά κύκλο που αποτελείται από εντολές ενός μόνο thread (προγραμματισμένων με round robin). Ενώ τα υπόλοιπα στάδια προγραμματίζουν ένα μπλοκ από μικτές εντολές ανά κύκλο, που αποτελούνται από εντολές από διαφορετικά slot σε round robin, μέχρι να γεμίσει το αντίστοιχο πλάτος διαύλου. Για κάθε slot υπαρχει μια i-queue για να διασφαλίσει ότι οι εντολές από κάθε thread γίνονται fetch και για τη διευκόλυνση της μίξης των εντολών στο pipeline. Στο στάδιο αυτό φέρνει τις εντολές από την il1-cache, με προτεραιότητα στο thread που έχει τις λιγότερες εντολές. Πολλές εντολές αποκωδικοποιούνται και αποστέλλονται στους σταθμούς δέσμευσης (ruu-q & ls-q). Από τους σταθμούς αυτούς οι εντολές κατευθύνονται σε ένα σύνολο διαμοιραζόμενων λειτουργικών μονάδων. Σχετικά με τους καταχωρητές, κάθε slot έχει ένα ξεχωριστό πλαίσιο για να αποθηκεύει διαφορετικό περιεχόμενο. 47
48 4.3 Τροποποιήσεις στον SMT SimpleScalar - Παραμετροποίηση Για να εξομοιώσουμε τη συμπεριφορά ενός CMP στον SMT SimpleScalar, το πρώτο που ορίζουμε ότι τα ruu lsq θα είναι ξεχωριστά (distributed) και έτσι δημιουργεί ξεχωριστούς ReOrder Buffers (ROBs) για κάθε επεξεργαστή, αυτό είναι εφικτό με την παράμετρο -ruulsq:type distributed στο configuration. Επιπροσθέτως, με την παράμετρο -fetch:speed # και το αρχικό τμήμα της εντολής./ss_smt <x1> <x2> δίνουμε την οδηγία στον εξομοιωτή να τρέξει όσα μετροπρογράμματα είναι ανάμεσα στις γραμμές <x1> <x2> και με την ανάλογη -fetch:speed # να φορτώνονται όλα τα cores με εντολε. Για να εξομοιώσουμε ένα CMP με 4 cores, μπορούμε να τρέξουμε το εξής: sim: command line:./ss_smt 1 4 -config conf_1proc -max:cycles fetch:speed 4 -decode:width 8 -issue:width 8 -commit:width 8 -ruu:size 32 -lsq:size 16 -ruulsq:type distributed -il1banks:num 4 -dl1banks:num 4 -ul2banks:num 4 -cache:il1 il1:4:8:32:4:l -cache:dl1 dl1:4:8:32:4:l -cache:dl2 ul2:4:64:32:8:l -cache:il2 dl2 -mem:lat res:ialu 8 -res:imult 4 -res:fpalu 8 -res:fpmult 4 -res:divmult 4 -res:memport 8 -redir:prog /dev/null -redir:sim out_test.txt traces Παρακάτω παρατίθενται κάποια από τα στατιστικά που εξάγονται για τα παρακάτω μετροπρογράμματα Starting sim_load_prog... sim: program 0: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.ammp.eio.gz sim: loading EIO file: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.ammp.eio.gz sim: program 1: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.bzip2.program.eio.gz sim: loading EIO file: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.bzip2.program.eio.gz sim: program 2: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.mcf.eio.gz sim: loading EIO file: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.mcf.eio.gz sim: program 3: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.mesa.eio.gz sim: loading EIO file: /home/gogulina/dipl/lina_ss_smt_mypc/fwd_1b.spec2000.mesa.eio.gz sim: ** simulation statistics ** sim_elapsed_time 219 # total simulation time in seconds sim_num_insn_ # total number of instructions committed sim_num_insn_ # total number of instructions committed sim_num_insn_ # total number of instructions committed sim_num_insn_ # total number of instructions committed sim_num_refs_ # total number of loads and stores committed sim_num_refs_ # total number of loads and stores committed sim_num_refs_ # total number of loads and stores committed sim_num_refs_ # total number of loads and stores committed sim_num_loads_ # total number of loads committed sim_num_loads_ # total number of loads committed sim_num_loads_ # total number of loads committed sim_num_loads_ # total number of loads committed 48
49 sim_num_stores_ # total number of stores committed sim_num_stores_ # total number of stores committed sim_num_stores_ # total number of stores committed sim_num_stores_ # total number of stores committed sim_num_branches_ # total number of branches committed sim_num_branches_ # total number of branches committed sim_num_branches_ # total number of branches committed sim_num_branches_ # total number of branches committed sim_num_good_pred_ # total number of branches committed and predicted correctly sim_num_good_pred_ # total number of branches committed and predicted correctly sim_num_good_pred_ # total number of branches committed and predicted correctly sim_num_good_pred_ # total number of branches committed and predicted correctly sim_inst_rate_ # simulation speed (in insts/sec) sim_inst_rate_ # simulation speed (in insts/sec) sim_inst_rate_ # simulation speed (in insts/sec) sim_inst_rate_ # simulation speed (in insts/sec) sim_total_insn_ # total number of instructions executed sim_total_insn_ # total number of instructions executed sim_total_insn_ # total number of instructions executed sim_total_insn_ # total number of instructions executed sim_total_refs_ # total number of loads and stores executed sim_total_refs_ # total number of loads and stores executed sim_total_refs_ # total number of loads and stores executed sim_total_refs_ # total number of loads and stores executed sim_total_loads_ # total number of loads executed sim_total_loads_ # total number of loads executed sim_total_loads_ # total number of loads executed sim_total_loads_ # total number of loads executed sim_total_stores_ # total number of stores executed sim_total_stores_ # total number of stores executed sim_total_stores_ # total number of stores executed sim_total_stores_ # total number of stores executed sim_total_branches_ # total number of branches executed sim_total_branches_ # total number of branches executed sim_total_branches_ # total number of branches executed sim_total_branches_ # total number of branches executed sim_cycle # total simulation time in cycles sim_ipc_ # instructions per cycle sim_ipc_ # instructions per cycle sim_ipc_ # instructions per cycle sim_ipc_ # instructions per cycle total_ipc # Total IPC sim_cpi_ # cycles per instruction sim_cpi_ # cycles per instruction sim_cpi_ # cycles per instruction sim_cpi_ # cycles per instruction il1_m00_b00.accesses # total number of accesses il1_m00_b00.hits # total number of hits 49
50 il1_m00_b00.misses # total number of misses il1_m00_b00.replacements # total number of replacements il1_m00_b00.writebacks 0 # total number of writebacks il1_m00_b00.invalidations 0 # total number of invalidations il1_m00_b00.miss_rate # miss rate (i.e., misses/ref) il1_m00_b00.repl_rate # replacement rate (i.e., repls/ref) il1_m00_b00.wb_rate # writeback rate (i.e., wrbks/ref) il1_m00_b00.inv_rate # invalidation rate (i.e., invs/ref) il1_m00_b01.accesses # total number of accesses il1_m00_b01.hits # total number of hits il1_m00_b01.misses 121 # total number of misses il1_m00_b01.replacements 0 # total number of replacements il1_m00_b01.writebacks 0 # total number of writebacks il1_m00_b01.invalidations 0 # total number of invalidations il1_m00_b01.miss_rate # miss rate (i.e., misses/ref) il1_m00_b01.repl_rate # replacement rate (i.e., repls/ref) il1_m00_b01.wb_rate # writeback rate (i.e., wrbks/ref) il1_m00_b01.inv_rate # invalidation rate (i.e., invs/ref) il1_m00_b02.accesses # total number of accesses il1_m00_b02.hits # total number of hits il1_m00_b02.misses 138 # total number of misses il1_m00_b02.replacements 0 # total number of replacements il1_m00_b02.writebacks 0 # total number of writebacks il1_m00_b02.invalidations 0 # total number of invalidations il1_m00_b02.miss_rate # miss rate (i.e., misses/ref) il1_m00_b02.repl_rate # replacement rate (i.e., repls/ref) il1_m00_b02.wb_rate # writeback rate (i.e., wrbks/ref) il1_m00_b02.inv_rate # invalidation rate (i.e., invs/ref) il1_m00_b03.accesses # total number of accesses il1_m00_b03.hits # total number of hits il1_m00_b03.misses # total number of misses il1_m00_b03.replacements # total number of replacements il1_m00_b03.writebacks 0 # total number of writebacks il1_m00_b03.invalidations 0 # total number of invalidations il1_m00_b03.miss_rate # miss rate (i.e., misses/ref) il1_m00_b03.repl_rate # replacement rate (i.e., repls/ref) il1_m00_b03.wb_rate # writeback rate (i.e., wrbks/ref) il1_m00_b03.inv_rate # invalidation rate (i.e., invs/ref) ul2_00.accesses # total number of accesses ul2_00.hits # total number of hits ul2_00.misses # total number of misses ul2_00.replacements # total number of replacements ul2_00.writebacks 57 # total number of writebacks ul2_00.invalidations 0 # total number of invalidations ul2_00.miss_rate # miss rate (i.e., misses/ref) ul2_00.repl_rate # replacement rate (i.e., repls/ref) ul2_00.wb_rate # writeback rate (i.e., wrbks/ref) ul2_00.inv_rate # invalidation rate (i.e., invs/ref) ul2_01.accesses # total number of accesses 50
51 ul2_01.hits # total number of hits ul2_01.misses # total number of misses ul2_01.replacements # total number of replacements ul2_01.writebacks # total number of writebacks ul2_01.invalidations 0 # total number of invalidations ul2_01.miss_rate # miss rate (i.e., misses/ref) ul2_01.repl_rate # replacement rate (i.e., repls/ref) ul2_01.wb_rate # writeback rate (i.e., wrbks/ref) ul2_01.inv_rate # invalidation rate (i.e., invs/ref) ul2_02.accesses # total number of accesses ul2_02.hits # total number of hits ul2_02.misses # total number of misses ul2_02.replacements # total number of replacements ul2_02.writebacks # total number of writebacks ul2_02.invalidations 0 # total number of invalidations ul2_02.miss_rate # miss rate (i.e., misses/ref) ul2_02.repl_rate # replacement rate (i.e., repls/ref) ul2_02.wb_rate # writeback rate (i.e., wrbks/ref) ul2_02.inv_rate # invalidation rate (i.e., invs/ref) ul2_03.accesses # total number of accesses ul2_03.hits # total number of hits ul2_03.misses # total number of misses ul2_03.replacements # total number of replacements ul2_03.writebacks # total number of writebacks ul2_03.invalidations 0 # total number of invalidations ul2_03.miss_rate # miss rate (i.e., misses/ref) ul2_03.repl_rate # replacement rate (i.e., repls/ref) ul2_03.wb_rate # writeback rate (i.e., wrbks/ref) ul2_03.inv_rate # invalidation rate (i.e., invs/ref) dl1_00.accesses # total number of accesses dl1_00.hits # total number of hits dl1_00.misses # total number of misses dl1_00.replacements # total number of replacements dl1_00.writebacks 270 # total number of writebacks dl1_00.invalidations 0 # total number of invalidations dl1_00.miss_rate # miss rate (i.e., misses/ref) dl1_00.repl_rate # replacement rate (i.e., repls/ref) dl1_00.wb_rate # writeback rate (i.e., wrbks/ref) dl1_00.inv_rate # invalidation rate (i.e., invs/ref) dl1_01.accesses # total number of accesses dl1_01.hits # total number of hits dl1_01.misses # total number of misses dl1_01.replacements # total number of replacements dl1_01.writebacks # total number of writebacks dl1_01.invalidations 0 # total number of invalidations dl1_01.miss_rate # miss rate (i.e., misses/ref) dl1_01.repl_rate # replacement rate (i.e., repls/ref) dl1_01.wb_rate # writeback rate (i.e., wrbks/ref) dl1_01.inv_rate # invalidation rate (i.e., invs/ref) 51
52 dl1_02.accesses # total number of accesses dl1_02.hits # total number of hits dl1_02.misses # total number of misses dl1_02.replacements # total number of replacements dl1_02.writebacks # total number of writebacks dl1_02.invalidations 0 # total number of invalidations dl1_02.miss_rate # miss rate (i.e., misses/ref) dl1_02.repl_rate # replacement rate (i.e., repls/ref) dl1_02.wb_rate # writeback rate (i.e., wrbks/ref) dl1_02.inv_rate # invalidation rate (i.e., invs/ref) dl1_03.accesses # total number of accesses dl1_03.hits # total number of hits dl1_03.misses # total number of misses dl1_03.replacements # total number of replacements dl1_03.writebacks # total number of writebacks dl1_03.invalidations 0 # total number of invalidations dl1_03.miss_rate # miss rate (i.e., misses/ref) dl1_03.repl_rate # replacement rate (i.e., repls/ref) dl1_03.wb_rate # writeback rate (i.e., wrbks/ref) dl1_03.inv_rate # invalidation rate (i.e., invs/ref) Παρατηρούμε πως ο SMT SimpleScalar εξάγει πληθώρα χρήσιμων στατιστικών για τη συμπεριφορά της μνήμης cache (hits, misses, writebacks, IPC) για κάθε πυρήνα. Για τη μελέτη του αλγόριθμου για DCP, χρειάστηκε να κάνουμε τροποποιήσεις στον εξομοιωτή, ώστε να είναι δυνατή η απεικόνιση της παραπάνω συμπεριφοράς σε σχέση με το χρόνο. Για να γίνει δυνατή η τροποποίηση του τρόπου εξαγωγής των στατιστικών της μνήμης cache, έπρεπε να μελετηθεί η σύνταξη του εξομοιωτή, κυρίως του αλγόριθμου του ss_smt.c και κατ' επέκταση τα αρχεία cache.c και cache.h. Η συνάρτηση sim_main() στο αρχείο ss_smt.c:6145, είναι η βασική συνάρτηση του εξομοιωτή, που υλοποιεί τον βασικό κώδικα που παραθέσαμε στην Εικόνα 4.3. Επιπλέον, στο ss_smt.c:2441 υλοποιείται η συνάρτηση sim_reg_stats(struct stat_sdb_t *sdb) που μέσω αυτής επιλέγουμε τα στατιστικά που θέλουμε να κρατήσουμε. Στη γραμμή 1991, μέσα στη συνάρτηση αυτή γίνεται η κλήση της stat_reg_counter(sdb,"sim_cycle", "total simulation time in cycles", &sim_cycle, /* initial value */0, /* format */NULL,0); η οποία εξάγει το χρόνο εκτέλεσης σε κύκλους, και σε συνδιασμό με την εντολή sim_cycle++; /* computes this cycle */ στη γραμμή 6306, στο βασικό βρόχο for(;;) της sim_main(), μας είναι χρήσιμη για την τροποποίηση και εξαγωγή στατιστικών ανά αριθμό κύκλων που αφορούν τη μνήμη cache. Στη l:2166 για την εξαγωγή των στατιστικών της cache χρησιμοποιούνται μια σειρά από εντολές τύπου if. 52
53 /* register cache stats */ if (cache_il1[0]) for (bank=0;bank<il1_banks_total;bank++) cache_single_reg_stats(cache_il1[bank], sdb); if (cache_il2[0]) for (bank=0;bank<l2_banks_num;bank++) cache_single_reg_stats(cache_il2[bank], sdb); if (cache_dl1[0]) for (bank=0;bank<dl1_banks_num;bank++) cache_single_reg_stats(cache_dl1[bank], sdb); if ( (cache_dl2[0]) && (!cache_dl1[0]) ) for (bank=0;bank<l2_banks_num;bank++) cache_single_reg_stats(cache_dl2[bank], sdb); if (itlb[0]) cache_reg_stats(itlb, sdb); if (dtlb[0]) cache_reg_stats(dtlb, sdb); Από την παραπάνω παρατηρούμε πως η βασική συνάρτηση για τον έλεγχο των στατιστικών της μνήμης cache είναι η cache_single_reg_stats(struct cache_t *cp, struct stat_sdb_t *sdb), που βρίσκεται στο cache.c:489. Με βάση την ανάλυση που προηγήθηκε κάναμε τις απαραίτητες τροποποιήσεις στον SMT SimpleScalar για την υλοποίηση των αλγορίθμων υπό μελέτη και τους εξετάζουμε στο επόμενο κεφάλαιο. 53
54 54
55 Κεφάλαιο 5: Μετρήσεις Αποτελέσματα- Συμπεράσματα 5.1 Επιλογή χαρακτηριστικών συστήματος Για τους σκοπούς της διπλωματικής εργασίας, πραγματοποιήσαμε μετρήσεις σε συστήματα πολυεπεξεργαστών ενός ολοκληρωμένου (CMPs) αποτελούμενα από 2 και 4 cores με εκτέλεση εκτός σειράς, με ξεχωριστές για κάθε πυρήνα il1 και dl1, και ενοποιημένη ul2. Για να εξετάσουμε την επίδραση στην απόδοση, πραγματοποιήθηκε ένα σετ μετρήσεων χωρίς διαχείριση μνήμης (no_memma), ένα δεύτερο σετ με δυναμική κατάτμηση ανάλογα με τον αριθμό των misses ανά interval (βασισμένο στη μέθοδο MinMisses, missi_resize), και ένα τρίτο με δυναμική κατάτμηση που έχει επίγνωση του παραλληλισμού επιπέδου μνήμης, βασιζόμενη στη μέθοδο που καλύψαμε στην ενότητα 3.4 (mlp_resize). Συνοπτικά, διεξάγαμε τρία σετ μετρήσεων (no_memma, misso_resize, mlp_resize) με τα εξής configuration (2C-1, 2C-2, 4C- 1, 4C-2). Επιλογή χαρακτηριστικών μνημών cache: il1, dl1 : μεγέθους 16Κ, 16 δρόμων ul2: μεγέθους 1Μ, 16 δρομων και μεγέθους 2Μ, 32 δρόμων Επιλογή χαρακτηριστικών επεξεργαστή: fetch width: 4 issue width: 8 commit width: 8 RUU: 256 LSQ: 128 Memory latency: 300 Η σουίτα μετροπρογραμμάτων SPEC CPU2000: Για την αποτίμηση των αρχιτεκτονικών αυτών έγινε μια σειρά εξομοιώσεων λειτουργίας με χρήση των μετροπρογραμμάτων της σουίτας SPEC2000. Σκοπός της χρήσης μετροπρογραμμάτων είναι να προσομοιώσουν πραγματικά φορτία που μπορεί να δεχτεί ένα υπολογιστικό σύστημα με τρόπο ώστε να είναι συγκρίσιμη η απόδοση μεταξύ συστημάτων. Είναι κοινά 55
56 αποδεκτή από την επιστημονική κοινότητα και κατάλληλη για να παρέχει μετρικές απόδοσης για τις δυνατότητες του ίδιου του επεξεργαστή καθώς και του υποσυστήματος της μνήμης. Αυτή η συλλογή μετροπρογραμμάτων αποτελείται από δύο διαφορετικά σύνολα. Το ένα σύνολο περιέχει 12 μετροπρογράμματα ακεραίων αριθμών, δηλαδή εφαρμογές, οι οποίες συγκρίνουν την υπολογιστική απόδοση εκτελώντας πράξεις ακεραίων αριθμών. Το άλλο σύνολο αποτελείται από 14 μετροπρογράμματα αριθμών κινητής υποδιαστολής, τα οποία είναι κατάλληλα για να συγκρίνουν την υπολογιστική απόδοση συστημάτων, σε πράξεις δεκαδικών αριθμών. Παρακάτω παρατίθενται τα δύο σύνολα των μετροπρογραμμάτων. CINT gzip C Compression 175.vpr C FPGA Circuit Placement and Routing 176.gcc C C Programming Language Compiler 181.mcf C Combinatorial Optimization 186.crafty C Game Playing: Chess 197.parser C Word Processing 252.eon C++ Computer Visualization 253.perlbmk C PERL Programming Language 254.gap C Group Theory, Interpreter 255.vortex C Object-oriented Database 256.bzip2 C Compression 300.twolf C Place and Route Simulator CFP wupwise Fortran 77 Physics / Quantum Chromodynamics 171.swim Fortran 77 Shallow Water Modeling 172.mgrid Fortran 77 Multi-grid Solver: 3D Potential Field 173.applu Fortran 77 Parabolic / Elliptic Partial Differential Equations 177.mesa C 3-D Graphics Library 178.galgel Fortran 90 Computational Fluid Dynamics 179.art C Image Recognition / Neural Networks 183.equake C Seismic Wave Propagation Simulation 187.facerec Fortran 90 Image Processing: Face Recognition 188.ammp C Computational Chemistry 189.lucas Fortran 90 Number Theory / Primality Testing 191.fma3d Fortran 90 Finite-element Crash Simulation 200.sixtrack Fortran 77 High Energy Nuclear Physics Accelerator Design 301.apsi Fortran 77 Meteorology: Pollutant Distribution 56
57 Για την πειραματική υλοποίηση της διπλωματικής εργασίας, επιλέξαμε το παρακάτω workload και μελετήσαμε τη συμπεριφορα τους στα configuration που αναφέρθηκαν προηγουμένως, σε συνδιασμούς. ammp.eio.gz bzip2.program.eio.gz mesa.eio.gz parser.eio.gz perlbmk.diffmail.eio.gz perlbmk.makerand.eio.gz perlbmk.perfect.eio.gz splitmail.1.eio.gz vpr.place.eio.gz art.1.eio.gz cc1.166.eio.gz cc1.200.eio.gz cc1.expr.eio.gz cc1.integrate.eio.gz cc1.scilab.eio.gz mcf.eio.gz twolf.eio.gz vortex.1.eio.gz vpr.route.eio.gz 5.2 Πειραματική υλοποίηση Υλοποίηση αλγορίθμου δυναμικής κατάτμησης μνήμης με βάση τον αριθμό των misses (missi_resize) Σε πρώτο στάδιο, στην εξομοίωση χωρίς διαχείριση μνήμης, μετρήσαμε τον αριθμό των misses ανά interval, με σκοπό την αναγνώριση τους και για να έχουμε μια σχηματική απεικόνιση τους. Kάναμε μετρήσεις με μέγεθος interval & κύκλους.επιλέγουμε γιατί μπορούμε να κάνουμε πιο ασφαλή εκτίμηση. Προχωρήσαμε στη δημιουργία ένος πολύ απλού αλγόριθμου διαχείρισης της μνήμής με βάση τον αριθμό των misses ανά interval. Κάνοντας χρήση τψν μετρήσεων (no_memma) καθορίσαμε ένα άνω και ένα κάτω όριο για τον αριθμό των misses και ανάλογα κάνουμε αλλαγή μεγέθους είτε αυξάνοντας είτε μειώνοντας τον αριθμό των ways. Η αλλαγή μεγέθος πραγματοποιείται 57
58 χρησιμοποιώντας μια συνάρτηση που υλοποιήσαμε τη repart_ways() η οποία μεταβάλλει το μέγεθος της cache υπό χρήση, με αλλαγή του αριθμού των ways Υλοποίηση αλγορίθμου δυναμικής κατάτμησης μνήμης με βάση το mlp_cost των misses (mlp_resize) Στη sim_main() υπάρχει ένα for loop, [for(;;)] που είναι ο βασικός κορμός του εξομοιωτή. Μέσα σε αυτόν δημιουργούμε μια δομή ελέγχου if( (sim_cycle>0) && (sim_cycle % INTERVAL == 0) ) {} για να χωρίσουμε το χρόνο σε intervals, όπως και στον προηγούμενο αλγόριθμο, αφού πρώτα κάλέσουμε την mshr_update για ενημέρωση των miss status holding registers. Σε κάθε interval εξάγουμε την τρέχουσα συσχετιστικότητα και το interval_mlp_cost για κάθε core. Και στη συνέχεια κάνουμε αλλαγή μεγέθους στην ul2 cache με βάση το mlp_cost που αναθέτουμε στα ul2 misses. Χρησιμοποιήθηκε η ίδια συνάρτηση με την προηγούμενη περίπτωση με την απαραίτητη μεταβολή στον έλεγχο για να περιλαμβάνει το mlp_cost. Πρωταρχικά, είναι απαραίτητο να δημιουργήσουμε μια συνδεδεμένη λίστα για τον mshr, ώστε να αποθηκεύουμε ένα στιγμιότυπο του μέσα στην cache_t struct mshr_t { struct mshr_entry_t *entries[mshr_max]; int head, tail; int size; counter_t misses_served; counter_t interval_misses_served; double interval_mlp_cost; double total_mlp_cost; }; καθώς επίσης και μια δομή που να αποθηκεύει τις απαραίτητες πληροφορίες για κάθε εγγραφή (entry), στιγμιότυπο της οποίας υπάρχει μέσα στον mshr. struct mshr_entry_t { md_addr_t addr; int lat; tick_t ready; double mlp_cost; }; Σε κάθε κύκλο ενημερώνουμε τη συνδεδεμένη λίστα με μια συνάρτηση που υπολογίζει και το total_mlp_cost, την mshr_update(). Υλοποιήσαμε επίσης μια συνάρτηση που διαχειρίζεται τη λίστα και την δομή που αναπαριστά την καθε entry, ώστε να εισάγει ένα νέο miss στον MSHR. 58
 () void mshr_update(struct cache_t *cp, tick_t now) () και έγιναν οι απαραίτητες προσθήκες στους cache miss handlers. 5.")
59 Οι συναρτήσεις που υλοποιήσαμε για τη διαχείρηση, είναι οι παρακάτω void repart_ways(struct cache_t *cp, int sn) () int mshr_new_miss(md_addr_t addr, md_addr_t lsq_addr, int lat, tick_t ready, struct cache_t *cp, tick_t now, int sn) () void mshr_update(struct cache_t *cp, tick_t now) () και έγιναν οι απαραίτητες προσθήκες στους cache miss handlers. 5.3 Μετρήσεις και σύγκριση των τριων περιπτώσεων διαχείρησης Σε αυτή την ενότητα, θα παραθέσουμε τα αποτελέσματα που προέκυψαν από τις εξομοιώσεις τον παραπάνω αλγορίθμων για τα 4 configuration που περιγράψαμε. Από τα traces που συλλέχθηκαν με τη χρήση shell scripts, τα παρακάτω είναι καθοριστικά για την απόδοση του επεξεργαστή και του υποσυστήματος μνήμης. Στο τελευταίο μέρος της παρούσας ενότητας θα κάνουμε μια εκτίμηση των αποτελεσμάτων που εξάγαμε Γραφήματα για το IPC Σαν πρώτο μέτρο σύγκρισης της απόδοσης των τεχνικών που χρησιμοποιήσαμε, είναι το IPC, instructions per cycle. Η αναπαράσταση δίνεται ανά μετροπρόγραμμα. Το συνολικό IPC ανά σενάριο εκτέλεσης, καθώς προκύπτει από το άθροισμα των IPC ανά slot ή μετροπρογράμμα, μας οδηγεί στο ίδιο συμπέρασμα. 59
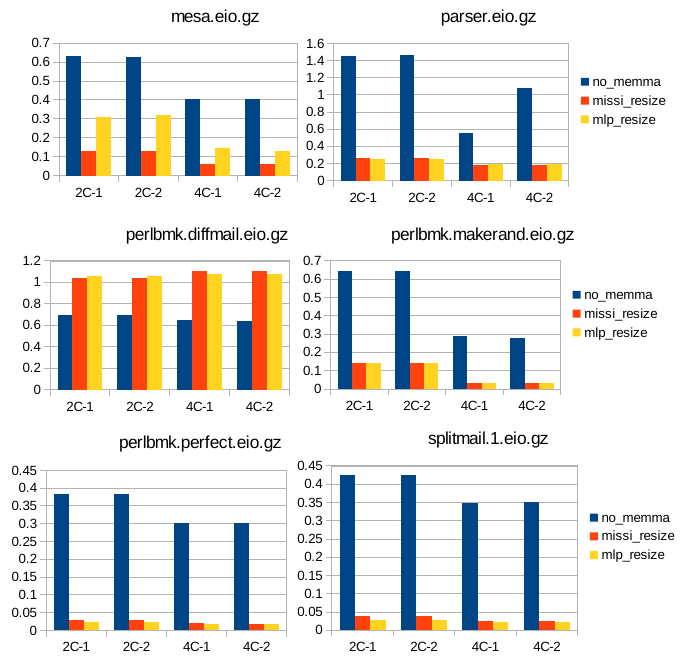
60 60

61 5.3.2 Γραφήματα για τον αριθμό των misses της ul2 cache και το miss rate Η αναγνώριση των ul2 misses, καθώς και ο αριθμός τους παίζουν καθοριστικό ρόλο στην απόδοση. Στην περίπτωση των πολυεπεξεργαστών, όπως αναλύσαμε στα προηγούμενα κεφάλαια της παρούσας διπλωματικής εργασίας, σχετικά με το αντίκτυπο που έχουν τα misses στην απόδοση, εκτός από τον αριθμό και το ρυθμό αστοχίας είναι απαραίτητο να συλλέξουμε και άλλα στοιχεία για να έχουμε μία πληρέστερη εκτίμηση της απόδοσης. 61
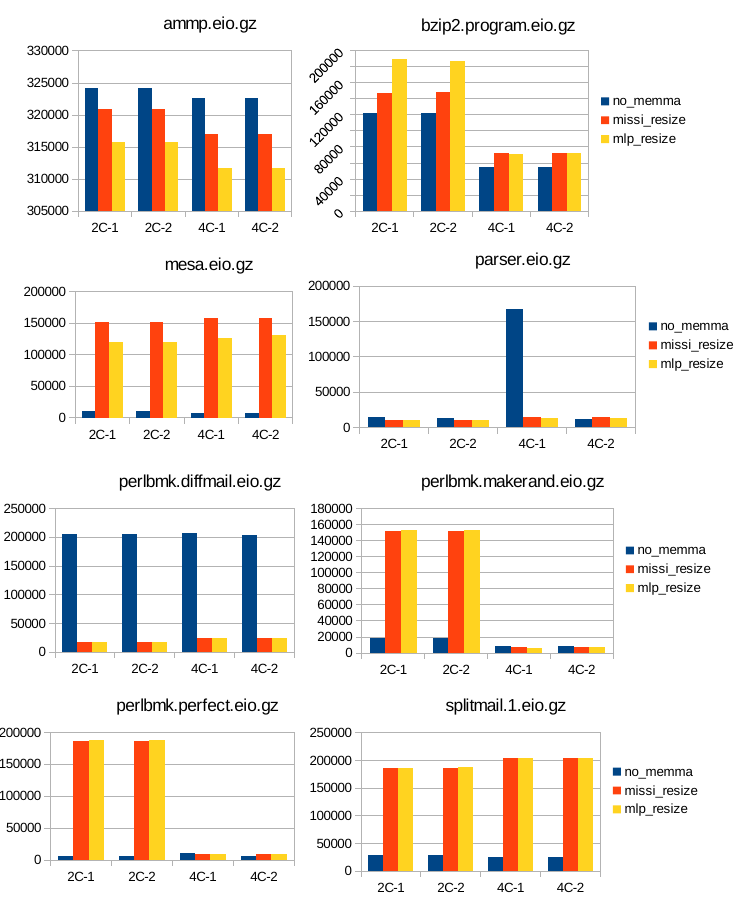
62 α. ul2_misses 62
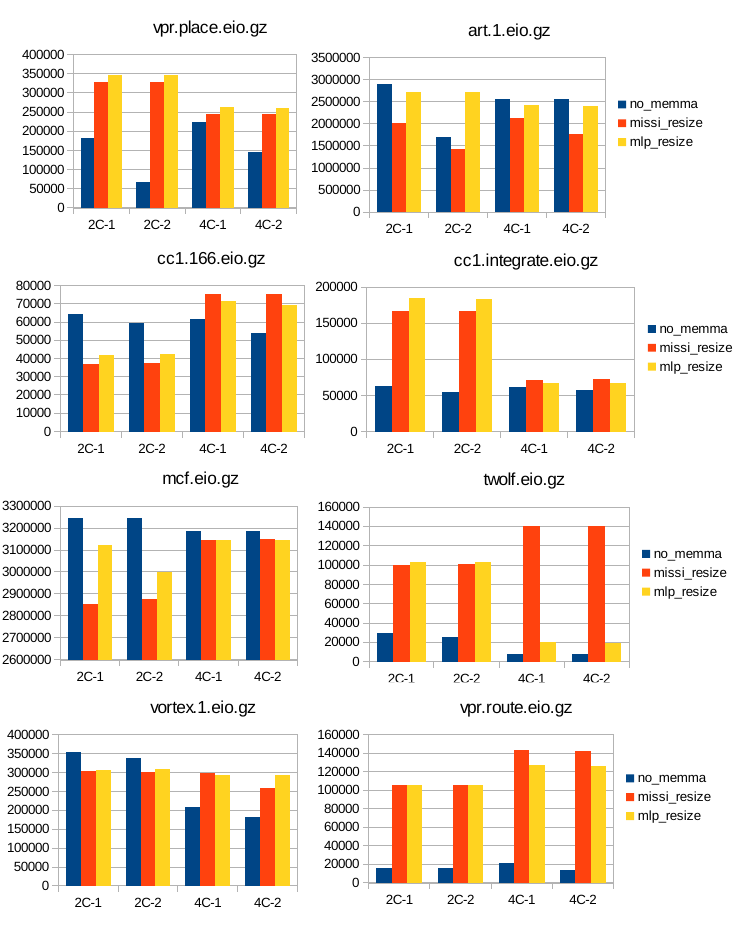
63 63
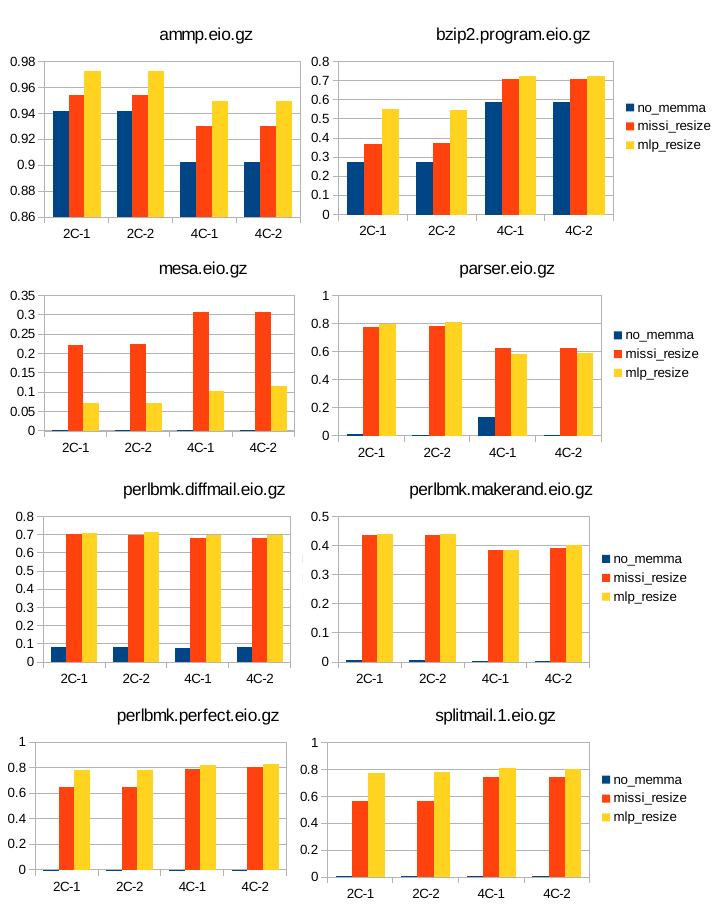
64 β. ul2_miss_rate 64
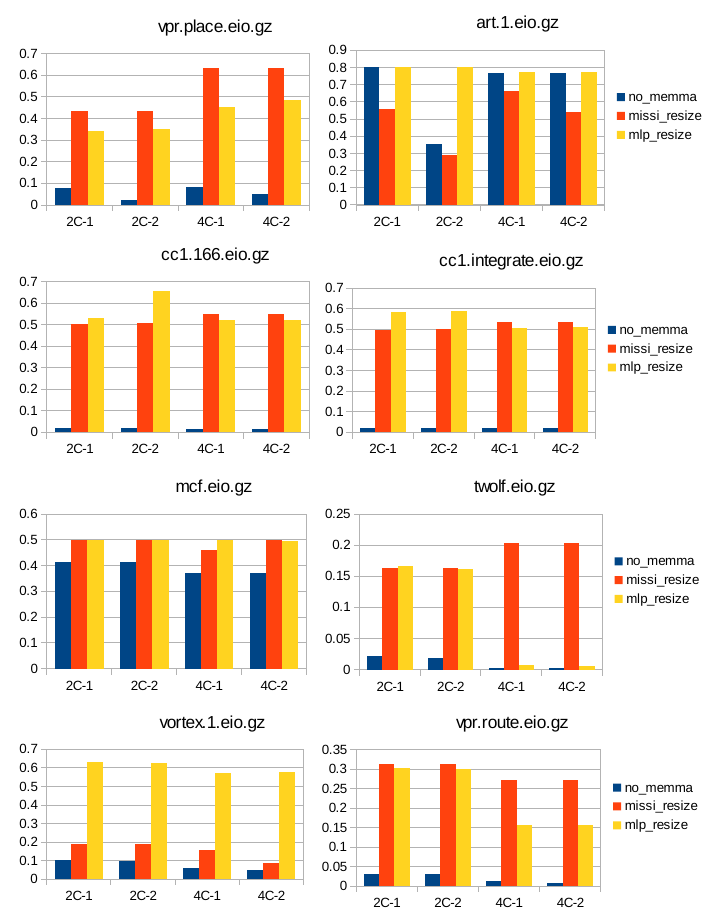
65 65

66 5.3.3 Γραφήματα για την ταχύτητα της εξομοίωσης Μια ακόμη σημαντική παράμετρος που έχει σημαίνοντα ρόλο στη μέτρηση της απόδοσης, είναι ο χρόνος ή η ταχύτητα εκτέλεσης. Παρακάτω παρατίθενται τα στατιστικά του ρυθμού εκτέλεσης ανά μετροπρόγραμμα. 66
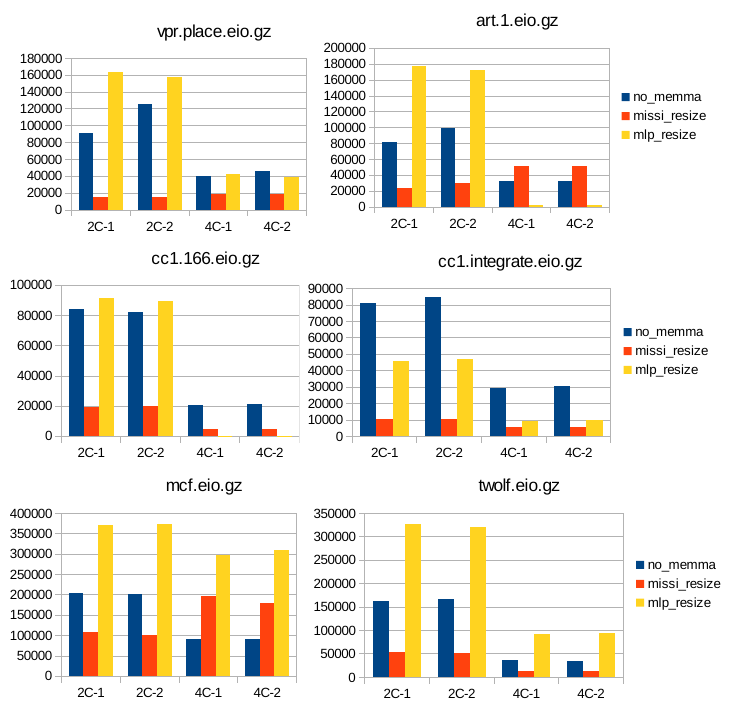
67 67

68 5.3.4 Υπολογισμός του συνολικού mlp_cost Για το δεύτερο αλγόριθμο (mlp_resize) που υλοποιήθηκε στη συγκεκριμένη διπλωματική εργασία, καθοριστικό μέγεθος αποτελεί το mlp_cost που ανατίθεται στα misses, ανάλογα με τη συμπεριφορά τους, αν είναι μεμονωμένα ή αν συμβαίνουν παράλληλα. Το συνολικό mlp_cost για κάθε μετροπρόγραμμα είναι μια αναπαράσταση της αναλογίας των αστοχιών που είναι μεμονωμένα, και έχουν μεγαλύτερο κόστος, και των αστοχιών που έχουν τη δυνατότητα να εξυπηρετηθούν παράλληλα, οι οποίες έχουν χαμηλότερο κοστος. Οπότε όσο μεγαλύτερη η τιμή του mlp_cost ανά μετροπρόγραμμα, τόσο περισσότερα misses είναι μεμονωμένα και έχουν μεγαλύτερη επίδραση στην απόδοση. Κατά τη διάρκεια της εκτέλεσης κάθε σεναρίου εξομοίωσης εξάγαμε σε ξεχωριστό αρχείο το interval_mlp_cost για κάθε μέρος της cache που χρησιμοποιεί κάθε μετροπρόγραμμα - πυρήνας ξεχωριστά σε συνδιασμό με την τρέχουσα συσχετιστικότητα, ώστε να έχουμε τη δυνατότητα να παρακολουθήσουμε την εξέλιξη της δυναμικής κατάτμησης και να επιβεβαιώσουμε πως ο αλγόριθμος λειτουργεί για το σκοπό που σχεδιάστηκε. 68
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Κρυφές Μνήμες. (οργάνωση, λειτουργία και απόδοση)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Ιεραρχία συχνά και το
Ιεραρχία Μνήμης. Ιεραρχία μνήμης και τοπικότητα. Σκοπός της Ιεραρχίας Μνήμης. Κρυφές Μνήμες
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Για βελτίωση της απόδοσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κρυφές Μνήμες (οργάνωση, λειτουργία και απόδοση) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Για βελτίωση της απόδοσης
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 7ο μάθημα: Κρυφές μνήμες (cache) - εισαγωγή Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Σύστημα μνήμης! Η μνήμη είναι σημαντικό
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 7ο μάθημα: Κρυφές μνήμες (cache) - εισαγωγή Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Σύστημα μνήμης! Η μνήμη είναι σημαντικό
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΑΡΧΙΤΕΚΤΟΝΙΚΗ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΑΡΧΙΤΕΚΤΟΝΙΚΗ
ΠΛΕ- 027 Μικροεπεξεργαστές 9ο μάθημα: Αρχιτεκτονική συστήματος μνήμης: Κρυφές μνήμες εισαγωγή
 ΠΛΕ- 027 Μικροεπεξεργαστές 9ο μάθημα: Αρχιτεκτονική συστήματος μνήμης: Κρυφές μνήμες εισαγωγή Αρης Ευθυμίου Σύστημα μνήμης Η μνήμη είναι σημαντικό κομμάτι ενός υπολογιστή Επηρεάζει κόστος, ταχύτητα, κατανάλωση
ΠΛΕ- 027 Μικροεπεξεργαστές 9ο μάθημα: Αρχιτεκτονική συστήματος μνήμης: Κρυφές μνήμες εισαγωγή Αρης Ευθυμίου Σύστημα μνήμης Η μνήμη είναι σημαντικό κομμάτι ενός υπολογιστή Επηρεάζει κόστος, ταχύτητα, κατανάλωση
Διάλεξη 15 Απόδοση της Ιεραρχίας Μνήμης Βελτιστοποίηση της απόδοσης
 ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 5 Απόδοση της Ιεραρχίας Μνήμης Βελτιστοποίηση της απόδοσης Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Πόσο μεγάλη είναι μια μνήμη cache;
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 5 Απόδοση της Ιεραρχίας Μνήμης Βελτιστοποίηση της απόδοσης Νίκος Μπέλλας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Πόσο μεγάλη είναι μια μνήμη cache;
Επιπλέον διδακτικό υλικό κρυφών μνημών: set-associative caches, πολιτικές αντικατάστασης, χειρισμός εγγραφών
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Οργάνωση Υπολογιστών Επιπλέον διδακτικό υλικό κρυφών μνημών: set-associative caches, πολιτικές αντικατάστασης, χειρισμός εγγραφών Μανόλης Γ.Η. Κατεβαίνης Τμήμα Επιστήμης
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Οργάνωση Υπολογιστών Επιπλέον διδακτικό υλικό κρυφών μνημών: set-associative caches, πολιτικές αντικατάστασης, χειρισμός εγγραφών Μανόλης Γ.Η. Κατεβαίνης Τμήμα Επιστήμης
Κεφάλαιο 7 Ιεραρχία Μνήμης (Memory Hierarchy)
") Κεφάλαιο 7 Ιεραρχία Μνήμης (Memory Hierarchy) 1 Συστήματα Μνήμης Η οργάνωση του συστήματος μνήμης επηρεάζει τη λειτουργία και απόδοση ενός μικροεπεξεργαστή: Διαχείριση μνήμης και περιφερειακών (Ι/Ο) απότολειτουργικόσύστημα
Κεφάλαιο 7 Ιεραρχία Μνήμης (Memory Hierarchy) 1 Συστήματα Μνήμης Η οργάνωση του συστήματος μνήμης επηρεάζει τη λειτουργία και απόδοση ενός μικροεπεξεργαστή: Διαχείριση μνήμης και περιφερειακών (Ι/Ο) απότολειτουργικόσύστημα
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική
 ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική") Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Κεφάλαιο 5. ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ -. Σερπάνος 2. Σημείωση
 Κεφάλαιο 5 ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ -. Σερπάνος 1 Σημείωση Οι παρούσες διαφάνειες παρέχονται ως συμπλήρωμα διδασκαλίας για το μάθημα «Αρχιτεκτονική Υπολογιστών» του Τμήματος Ηλεκτρολόγων Μηχανικών & Τεχνολογίας
Κεφάλαιο 5 ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ -. Σερπάνος 1 Σημείωση Οι παρούσες διαφάνειες παρέχονται ως συμπλήρωμα διδασκαλίας για το μάθημα «Αρχιτεκτονική Υπολογιστών» του Τμήματος Ηλεκτρολόγων Μηχανικών & Τεχνολογίας
Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών H/Y Department of Electrical and Computer Engineering. Εργαστήριο 8. Χειμερινό Εξάμηνο
 Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών H/Y Department of Electrical and Computer Engineering Οργάνωση και Σχεδίαση Η/Y (HY232) Εργαστήριο 8 Χειμερινό Εξάμηνο 2016-2017 1. Προσομοίωση λειτουργίας ιεραρχίας
Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών H/Y Department of Electrical and Computer Engineering Οργάνωση και Σχεδίαση Η/Y (HY232) Εργαστήριο 8 Χειμερινό Εξάμηνο 2016-2017 1. Προσομοίωση λειτουργίας ιεραρχίας
Αρχιτεκτονική υπολογιστών
 1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
1 Ελληνική Δημοκρατία Τεχνολογικό Εκπαιδευτικό Ίδρυμα Ηπείρου Αρχιτεκτονική υπολογιστών Ενότητα 4 : Κρυφή Μνήμη Καρβούνης Ευάγγελος Δευτέρα, 30/11/2015 Χαρακτηριστικά Θέση Χωρητικότητα Μονάδα Μεταφοράς
Ασκήσεις Caches
 Ασκήσεις Caches 1 Άσκηση 1η Θεωρήστε ένα σύστημα μνήμης με μία cache: 4-way set associative μεγέθους 256ΚΒ, με cache line 8 λέξεων. Χαρακτηριστικά συστήματος μνήμης: μέγεθος της λέξης είναι 32 bits. 1
Ασκήσεις Caches 1 Άσκηση 1η Θεωρήστε ένα σύστημα μνήμης με μία cache: 4-way set associative μεγέθους 256ΚΒ, με cache line 8 λέξεων. Χαρακτηριστικά συστήματος μνήμης: μέγεθος της λέξης είναι 32 bits. 1
Άσκηση 1η. Θεωρήστε ένα σύστημα μνήμης με μία cache: 4 way set associative μεγέθους 256ΚΒ,
 Ασκήσεις Caches Άσκηση 1η Θεωρήστε ένα σύστημα μνήμης με μία cache: 4 way set associative μεγέθους 256ΚΒ, με cache line 8 λέξεων. Χαρακτηριστικά συστήματος μνήμης: μέγεθος της λέξης είναι 32 bits. 1 byte
Ασκήσεις Caches Άσκηση 1η Θεωρήστε ένα σύστημα μνήμης με μία cache: 4 way set associative μεγέθους 256ΚΒ, με cache line 8 λέξεων. Χαρακτηριστικά συστήματος μνήμης: μέγεθος της λέξης είναι 32 bits. 1 byte
Ασκήσεις Caches
 Ασκήσεις Caches 1 Άσκηση 1η Θεωρήστε ένα σύστημα μνήμης με μία cache: 4-way set associative μεγέθους 256ΚΒ, με cache line 8 λέξεων. Χαρακτηριστικά συστήματος μνήμης: μέγεθος της λέξης είναι 32 bits. 1
Ασκήσεις Caches 1 Άσκηση 1η Θεωρήστε ένα σύστημα μνήμης με μία cache: 4-way set associative μεγέθους 256ΚΒ, με cache line 8 λέξεων. Χαρακτηριστικά συστήματος μνήμης: μέγεθος της λέξης είναι 32 bits. 1
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΤΕΛΙΚΟ ΔΙΑΓΩΝΙΣΜΑ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Τετάρτη, 21 Δεκεμβρίου 2016 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΩΡΕΣ Για πλήρη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΤΕΛΙΚΟ ΔΙΑΓΩΝΙΣΜΑ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Τετάρτη, 21 Δεκεμβρίου 2016 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΩΡΕΣ Για πλήρη
Ασκήσεις Caches. Αρχιτεκτονική Υπολογιστών. 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: Νεκ. Κοζύρης
 Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Ασκήσεις Caches http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Αρχιτεκτονική Υπολογιστών 5ο εξάμηνο ΣΗΜΜΥ ακ. έτος: 2014-2015 Νεκ. Κοζύρης nkoziris@cslab.ece.ntua.gr Ασκήσεις Caches http://www.cslab.ece.ntua.gr/courses/comparch/ Άδεια Χρήσης Το παρόν εκπαιδευτικό
Η ιεραρχία της μνήμης
 Η ιεραρχία της μνήμης Οι περιορισμοί στο σχεδιασμό της μνήμης συνοψίζονται σε τρεις ερωτήσεις : 1) Πόση 2) Πόσο γρήγορη 3) Πόσο ακριβή Ερωτήματα-Απαντήσεις Ερώτημα πόση μνήμη. Είναι ανοικτό. Αν υπάρχει
Η ιεραρχία της μνήμης Οι περιορισμοί στο σχεδιασμό της μνήμης συνοψίζονται σε τρεις ερωτήσεις : 1) Πόση 2) Πόσο γρήγορη 3) Πόσο ακριβή Ερωτήματα-Απαντήσεις Ερώτημα πόση μνήμη. Είναι ανοικτό. Αν υπάρχει
Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC
 Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC Πλεονεκτήματα MPSoC Είναι ευκολότερο να σχεδιαστούν πολλαπλοί πυρήνες επεξεργαστών από τον σχεδιασμό ενός ισχυρότερου και πολύ πιο σύνθετου μονού επεξεργαστή.
Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC Πλεονεκτήματα MPSoC Είναι ευκολότερο να σχεδιαστούν πολλαπλοί πυρήνες επεξεργαστών από τον σχεδιασμό ενός ισχυρότερου και πολύ πιο σύνθετου μονού επεξεργαστή.
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπόβαθρο: Κρυφές μνήμες
 Υ- 01 Αρχιτεκτονική Υπολογιστών Υπόβαθρο: Κρυφές μνήμες Αρης Ευθυμίου Το σημερινό μάθημα Κρυφές μνήμες (cache memory) Βασική οργάνωση, παράμετροι: γραμμές, συσχετιστικότητα, συνολική χωρητικότητα Επίδοση:
Υ- 01 Αρχιτεκτονική Υπολογιστών Υπόβαθρο: Κρυφές μνήμες Αρης Ευθυμίου Το σημερινό μάθημα Κρυφές μνήμες (cache memory) Βασική οργάνωση, παράμετροι: γραμμές, συσχετιστικότητα, συνολική χωρητικότητα Επίδοση:
ΔΙΑΧΕΙΡΙΣΗ ΜΝΗΜΗΣ. Λειτουργικά Συστήματα Ι. Διδάσκων: Καθ. Κ. Λαμπρινουδάκης ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Ι
 ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Ι Μάθημα: Λειτουργικά Συστήματα Ι ΔΙΑΧΕΙΡΙΣΗ ΜΝΗΜΗΣ Διδάσκων: Καθ. Κ. Λαμπρινουδάκης clam@unipi.gr 1 ΕΙΣΑΓΩΓΗ Μνήμη : Πόρος ζωτικής σημασίας του οποίου η διαχείριση απαιτεί ιδιαίτερη
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Ι Μάθημα: Λειτουργικά Συστήματα Ι ΔΙΑΧΕΙΡΙΣΗ ΜΝΗΜΗΣ Διδάσκων: Καθ. Κ. Λαμπρινουδάκης clam@unipi.gr 1 ΕΙΣΑΓΩΓΗ Μνήμη : Πόρος ζωτικής σημασίας του οποίου η διαχείριση απαιτεί ιδιαίτερη
i Στα σύγχρονα συστήματα η κύρια μνήμη δεν συνδέεται απευθείας με τον επεξεργαστή
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης i Στα σύγχρονα
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης i Στα σύγχρονα
ΟΡΓΑΝΩΣΗ ΚΑΙ ΣΧΕΔΙΑΣΗ Η/Υ
 ΟΡΓΑΝΩΣΗ ΚΑΙ ΣΧΕΔΙΑΣΗ Η/Υ Γιώργος Δημητρίου Μάθημα 8 ο ΠΜΣ Εφαρμοσμένη Πληροφορική ΜΟΝΑΔΑ ΜΝΗΜΗΣ Επαρκής χωρητικότητα αποθήκευσης Αποδεκτό μέσο επίπεδο απόδοσης Χαμηλό μέσο κόστος ανά ψηφίο Ιεραρχία μνήμης
ΟΡΓΑΝΩΣΗ ΚΑΙ ΣΧΕΔΙΑΣΗ Η/Υ Γιώργος Δημητρίου Μάθημα 8 ο ΠΜΣ Εφαρμοσμένη Πληροφορική ΜΟΝΑΔΑ ΜΝΗΜΗΣ Επαρκής χωρητικότητα αποθήκευσης Αποδεκτό μέσο επίπεδο απόδοσης Χαμηλό μέσο κόστος ανά ψηφίο Ιεραρχία μνήμης
Διπλωματική Εργασία του φοιτητή του Τμήματος Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών της Πολυτεχνικής Σχολής του Πανεπιστημίου Πατρών
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ: ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ: ΗΛΕΚΤΡΟΝΙΚΩΝ ΕΦΑΡΜΟΓΩΝ Διπλωματική Εργασία του φοιτητή του Τμήματος Ηλεκτρολόγων
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ: ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ: ΗΛΕΚΤΡΟΝΙΚΩΝ ΕΦΑΡΜΟΓΩΝ Διπλωματική Εργασία του φοιτητή του Τμήματος Ηλεκτρολόγων
Τεχνολογίες Κύριας Μνήμης
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κύρια Μνήμη
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κύρια Μνήμη
Πολυπύρηνοι επεξεργαστές Multicore processors
 Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Οργάνωση Υπολογιστών
 Οργάνωση Υπολογιστών Επιμέλεια: Γεώργιος Θεοδωρίδης, Επίκουρος Καθηγητής Ανδρέας Εμερετλής, Υποψήφιος Διδάκτορας Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών 1 Άδειες Χρήσης Το παρόν υλικό
Οργάνωση Υπολογιστών Επιμέλεια: Γεώργιος Θεοδωρίδης, Επίκουρος Καθηγητής Ανδρέας Εμερετλής, Υποψήφιος Διδάκτορας Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών 1 Άδειες Χρήσης Το παρόν υλικό
SMPcache. Ένα εργαλείο για προσομοίωση-οπτικοποίηση κρυφής μνήμης (Cache)
") SMPcache Ένα εργαλείο για προσομοίωση-οπτικοποίηση κρυφής μνήμης (Cache) 1. Βασικές ρυθμίσεις του συστήματος: δημιουργία μια δικής μας σύνθεσης συστήματος. Το SMPcache είναι ένα εργαλείο με το οποίο μπορούμε
SMPcache Ένα εργαλείο για προσομοίωση-οπτικοποίηση κρυφής μνήμης (Cache) 1. Βασικές ρυθμίσεις του συστήματος: δημιουργία μια δικής μας σύνθεσης συστήματος. Το SMPcache είναι ένα εργαλείο με το οποίο μπορούμε
ΕΠΛ 605: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΧΕΙΜΕΡΙΝΟ ΕΞΑΜΗΝΟ 2018 ΕΡΓΑΣΙΑ 3 (13/10/2018) Ηµεροµηνία Παράδοσης δεύτερου µέρους: 18/10/2018
 Ηµεροµηνία Παράδοσης δεύτερου µέρους: 18/10/2018") ΕΠΛ 605: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΧΕΙΜΕΡΙΝΟ ΕΞΑΜΗΝΟ 2018 ΕΡΓΑΣΙΑ 3 (13/10/2018) Ηµεροµηνία Παράδοσης δεύτερου µέρους: 18/10/2018 Ηµεροµηνία Παράδοσης πρώτου µέρους: 25/10/2018 Θα πρέπει να παραδώσετε
ΕΠΛ 605: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΧΕΙΜΕΡΙΝΟ ΕΞΑΜΗΝΟ 2018 ΕΡΓΑΣΙΑ 3 (13/10/2018) Ηµεροµηνία Παράδοσης δεύτερου µέρους: 18/10/2018 Ηµεροµηνία Παράδοσης πρώτου µέρους: 25/10/2018 Θα πρέπει να παραδώσετε
Λειτουργικά Συστήματα (Λ/Σ)
") Λειτουργικά Συστήματα (Λ/Σ) Διαχείριση Μνήμης Βασίλης Σακκάς 6/12/2013 1 Διαχείριση Μνήμης 1 Το τμήμα του Λ/Σ που διαχειρίζεται τη μνήμη λέγεται Διαχειριστής Μνήμης (Memory manager). Καθήκον του είναι
Λειτουργικά Συστήματα (Λ/Σ) Διαχείριση Μνήμης Βασίλης Σακκάς 6/12/2013 1 Διαχείριση Μνήμης 1 Το τμήμα του Λ/Σ που διαχειρίζεται τη μνήμη λέγεται Διαχειριστής Μνήμης (Memory manager). Καθήκον του είναι
Το ολοκληρωμένο κύκλωμα μιας ΚΜΕ. «Φέτα» ημιαγωγών (wafer) από τη διαδικασία παραγωγής ΚΜΕ
 από τη διαδικασία παραγωγής ΚΜΕ") Το ολοκληρωμένο κύκλωμα μιας ΚΜΕ Η Κεντρική Μονάδα Επεξεργασίας (Central Processing Unit -CPU) ή απλούστερα επεξεργαστής αποτελεί το μέρος του υλικού που εκτελεί τις εντολές ενός προγράμματος υπολογιστή
Το ολοκληρωμένο κύκλωμα μιας ΚΜΕ Η Κεντρική Μονάδα Επεξεργασίας (Central Processing Unit -CPU) ή απλούστερα επεξεργαστής αποτελεί το μέρος του υλικού που εκτελεί τις εντολές ενός προγράμματος υπολογιστή
Κεφάλαιο 3. Διδακτικοί Στόχοι
 Κεφάλαιο 3 Σε ένα υπολογιστικό σύστημα η Κεντρική Μονάδα Επεξεργασίας (ΚΜΕ) εκτελεί τις εντολές που βρίσκονται στην κύρια μνήμη του. Οι εντολές αυτές ανήκουν σε προγράμματα τα οποία, όταν εκτελούνται,
Κεφάλαιο 3 Σε ένα υπολογιστικό σύστημα η Κεντρική Μονάδα Επεξεργασίας (ΚΜΕ) εκτελεί τις εντολές που βρίσκονται στην κύρια μνήμη του. Οι εντολές αυτές ανήκουν σε προγράμματα τα οποία, όταν εκτελούνται,
Αρχιτεκτονική Υπολογιστών
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Υποσύστημα μνήμης Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Υποσύστημα μνήμης Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Ι. Λειτουργικά Συστήματα Ι ΔΙΑΧΕΙΡΙΣΗ ΜΝΗΜΗΣ. Επ. Καθ. Κ. Λαμπρινουδάκης
 ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Ι Μάθημα: Λειτουργικά Συστήματα Ι ΔΙΑΧΕΙΡΙΣΗ ΜΝΗΜΗΣ Διδάσκων: Επ. Καθ. Κ. Λαμπρινουδάκης clam@unipi.gr 1 ΕΙΣΑΓΩΓΗ Μνήμη : Πόρος ζωτικής σημασίας του οποίου η διαχείριση απαιτεί ιδιαίτερη
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Ι Μάθημα: Λειτουργικά Συστήματα Ι ΔΙΑΧΕΙΡΙΣΗ ΜΝΗΜΗΣ Διδάσκων: Επ. Καθ. Κ. Λαμπρινουδάκης clam@unipi.gr 1 ΕΙΣΑΓΩΓΗ Μνήμη : Πόρος ζωτικής σημασίας του οποίου η διαχείριση απαιτεί ιδιαίτερη
Υ- 07 Παράλληλα Συστήματα Αρχιτεκτονική σύγχρονων πυρήνων επεξεργαστών
 Υ- 07 Παράλληλα Συστήματα Αρχιτεκτονική σύγχρονων πυρήνων επεξεργαστών Αρης Ευθυμίου Διαδικαστικά Ιστοσελίδα μαθήματος: h:p://www.cs.uoi.gr/~plmy07/ Διαφάνειες μαθημάτων, κτλ 2 Γρήγορη εκτέλεση σειριακού
Υ- 07 Παράλληλα Συστήματα Αρχιτεκτονική σύγχρονων πυρήνων επεξεργαστών Αρης Ευθυμίου Διαδικαστικά Ιστοσελίδα μαθήματος: h:p://www.cs.uoi.gr/~plmy07/ Διαφάνειες μαθημάτων, κτλ 2 Γρήγορη εκτέλεση σειριακού
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Τμήμα Πληροφορικής
 Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Τμήμα Πληροφορικής Άσκηση : Λυμένες Ασκήσεις Έστω ένα σύστημα μνήμης, στο οποίο έχουμε προσθέσει μια κρυφή μνήμη θυμάτων 6 θέσεων
Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Τμήμα Πληροφορικής Άσκηση : Λυμένες Ασκήσεις Έστω ένα σύστημα μνήμης, στο οποίο έχουμε προσθέσει μια κρυφή μνήμη θυμάτων 6 θέσεων
Λειτουργικά Συστήματα Η/Υ
 Λειτουργικά Συστήματα Η/Υ Κεφάλαιο 8 «Ιδεατή Μνήμη» Διδάσκων: Δ. Λιαροκαπης Διαφάνειες: Π. Χατζηδούκας Ιδεατή Μνήμη Οργάνωση. Εισαγωγή. Ιδεατές και πραγματικές διευθύνσεις. Λογική οργάνωση. Τμηματοποίηση
Λειτουργικά Συστήματα Η/Υ Κεφάλαιο 8 «Ιδεατή Μνήμη» Διδάσκων: Δ. Λιαροκαπης Διαφάνειες: Π. Χατζηδούκας Ιδεατή Μνήμη Οργάνωση. Εισαγωγή. Ιδεατές και πραγματικές διευθύνσεις. Λογική οργάνωση. Τμηματοποίηση
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων
 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Οργάνωση Η/Υ Ενότητα 1η: Εισαγωγή στην Οργάνωση Η/Υ Άσκηση 1: Αναλύστε τη διαδοχική εκτέλεση των παρακάτω εντολών MIPS με βάση τις
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Οργάνωση Η/Υ Ενότητα 1η: Εισαγωγή στην Οργάνωση Η/Υ Άσκηση 1: Αναλύστε τη διαδοχική εκτέλεση των παρακάτω εντολών MIPS με βάση τις
Κεντρική Μονάδα Επεξεργασίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Μονάδα Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης
Στοιχεία αρχιτεκτονικής μικροεπεξεργαστή
 Στοιχεία αρχιτεκτονικής μικροεπεξεργαστή Αριθμός bit δίαυλου δεδομένων (Data Bus) Αριθμός bit δίαυλου διευθύνσεων (Address Bus) Μέγιστη συχνότητα λειτουργίας (Clock Frequency) Τύποι εντολών Αριθμητική
Στοιχεία αρχιτεκτονικής μικροεπεξεργαστή Αριθμός bit δίαυλου δεδομένων (Data Bus) Αριθμός bit δίαυλου διευθύνσεων (Address Bus) Μέγιστη συχνότητα λειτουργίας (Clock Frequency) Τύποι εντολών Αριθμητική
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
ΕΘΝΙKΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ. Ονοματεπώνυμο: ΑΜ:
 ΕΘΝΙKΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ονοματεπώνυμο: ΑΜ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ (τμήμα Μ - Ω) Κανονική εξεταστική Φεβρουαρίου
ΕΘΝΙKΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ονοματεπώνυμο: ΑΜ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ (τμήμα Μ - Ω) Κανονική εξεταστική Φεβρουαρίου
Αρχιτεκτονική Υπολογιστών
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Υποσύστημα μνήμης Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αρχιτεκτονική Υπολογιστών Υποσύστημα μνήμης Διδάσκων: Επίκουρος Καθηγητής Αριστείδης Ευθυμίου Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Εικονική Μνήμη (Virtual Memory)
") Εικονική Μνήμη (Virtual Memory) Για τη δημιουργία των διαφανειών έχει χρησιμοποιηθεί υλικό από τις διαφάνειες παραδόσεων που βασίζονται στο βιβλίο, Silberschatz, Galvin and Gagne, Operating Systems Concepts,
Εικονική Μνήμη (Virtual Memory) Για τη δημιουργία των διαφανειών έχει χρησιμοποιηθεί υλικό από τις διαφάνειες παραδόσεων που βασίζονται στο βιβλίο, Silberschatz, Galvin and Gagne, Operating Systems Concepts,
Ιεραρχία Μνήμης. Εικονική μνήμη (virtual memory) Επεκτείνοντας την Ιεραρχία Μνήμης. Εικονική Μνήμη. Μ.Στεφανιδάκης
 Επεκτείνοντας την Ιεραρχία Μνήμης. Εικονική Μνήμη. Μ.Στεφανιδάκης") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής ρχιτεκτονική Υπολογιστών 2016-17 Εικονική Μνήμη (και ο ρόλος της στην ιεραρχία μνήμης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Δευτερεύουσα μνήμη
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής ρχιτεκτονική Υπολογιστών 2016-17 Εικονική Μνήμη (και ο ρόλος της στην ιεραρχία μνήμης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Δευτερεύουσα μνήμη
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I
 ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
ΤΕΧΝΙΚΕΣ ΑΥΞΗΣΗΣ ΤΗΣ ΑΠΟΔΟΣΗΣ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ I MIPS Η MIPS (Microprocessor without Interlocked Pipeline Stages) είναι μία αρχιτεκτονική συνόλου εντολών (ISA) γλώσσας μηχανής που αναπτύχθηκε από την εταιρεία
Ενότητα 2: Η κρυφή µνήµη και η λειτουργία της
 Ενότητα 2: Η κρυφή µνήµη και η λειτουργία της Στην ενότητα αυτή θα αναφερθούµε εκτενέστερα στη λειτουργία και την οργάνωση της κρυφής µνήµης. Θα προσδιορίσουµε τις βασικές λειτουργίες που σχετίζονται µε
Ενότητα 2: Η κρυφή µνήµη και η λειτουργία της Στην ενότητα αυτή θα αναφερθούµε εκτενέστερα στη λειτουργία και την οργάνωση της κρυφής µνήµης. Θα προσδιορίσουµε τις βασικές λειτουργίες που σχετίζονται µε
Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών
 Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών ακ. έτος 2006-2007 Νεκτάριος Κοζύρης Νίκος Αναστόπουλος {nkoziris,anastop}@cslab.ece.ntua.gr Άσκηση 1: pipelining Εξετάζουμε την εκτέλεση του παρακάτω
Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών ακ. έτος 2006-2007 Νεκτάριος Κοζύρης Νίκος Αναστόπουλος {nkoziris,anastop}@cslab.ece.ntua.gr Άσκηση 1: pipelining Εξετάζουμε την εκτέλεση του παρακάτω
Processor-Memory (DRAM) ιαφορά επίδοσης
 ιαφορά επίδοσης") Processor-Memory (DRAM) ιαφορά επίδοσης µproc 6%/yr 98 98 982 983 984 985 986 987 988 989 99 99 992 993 994 995 996 997 998 999 2 2 22 23 24 25 Performance Processor-Memory Performance Gap: (grows 5% /
Processor-Memory (DRAM) ιαφορά επίδοσης µproc 6%/yr 98 98 982 983 984 985 986 987 988 989 99 99 992 993 994 995 996 997 998 999 2 2 22 23 24 25 Performance Processor-Memory Performance Gap: (grows 5% /
Ασκήσεις Αρχιτεκτονικής Υπολογιστών
 Ασκήσεις Αρχιτεκτονικής Υπολογιστών ακαδ. έτος 2008-2009 Άσκηση 1: caches Θεωρούμε το ακόλουθο κομμάτι κώδικα #define N 4 #define M 8 double c[n], a[n][m], b[m]; int i,j; for(i = 0; i < N; i++) for(j =
Ασκήσεις Αρχιτεκτονικής Υπολογιστών ακαδ. έτος 2008-2009 Άσκηση 1: caches Θεωρούμε το ακόλουθο κομμάτι κώδικα #define N 4 #define M 8 double c[n], a[n][m], b[m]; int i,j; for(i = 0; i < N; i++) for(j =
Αρχιτεκτονική Υπολογιστών II 16-2-2012. Ενδεικτικές απαντήσεις στα θέματα των εξετάσεων
 Αρχιτεκτονική Υπολογιστών II 6 --0 Ενδεικτικές απαντήσεις στα θέματα των εξετάσεων Θέμα. Τι γνωρίζετε για την τοπικότητα των αναφορών και ποιών μονάδων του υπολογιστή ή τεχνικών η απόδοση εξαρτάται από
Αρχιτεκτονική Υπολογιστών II 6 --0 Ενδεικτικές απαντήσεις στα θέματα των εξετάσεων Θέμα. Τι γνωρίζετε για την τοπικότητα των αναφορών και ποιών μονάδων του υπολογιστή ή τεχνικών η απόδοση εξαρτάται από
Υ- 01 Αρχιτεκτονική Υπολογιστών Ιεραρχία μνήμης: προχωρημένα θέματα
 Υ- 01 Αρχιτεκτονική Υπολογιστών Ιεραρχία μνήμης: προχωρημένα θέματα Αρης Ευθυμίου Το σημερινό μάθημα Εικονική μνήμη και κρυφές μνήμες Physical/Virtual indexing Σκοπός: μείωση hit Ome Τεχνικές σχετικές
Υ- 01 Αρχιτεκτονική Υπολογιστών Ιεραρχία μνήμης: προχωρημένα θέματα Αρης Ευθυμίου Το σημερινό μάθημα Εικονική μνήμη και κρυφές μνήμες Physical/Virtual indexing Σκοπός: μείωση hit Ome Τεχνικές σχετικές
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Εικονική Μνήμη. (και ο ρόλος της στην ιεραρχία μνήμης)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2011-12 Εικονική (και ο ρόλος της στην ιεραρχία μνήμης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης Ιεραρχία η νέα τάση: [2011]
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2011-12 Εικονική (και ο ρόλος της στην ιεραρχία μνήμης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης Ιεραρχία η νέα τάση: [2011]
Λειτουργικά Συστήματα Η/Υ
 Λειτουργικά Συστήματα Η/Υ Κεφάλαιο 7 «Διαχείριση Μνήμης» Διδάσκων: Δ. Λιαροκάπης Διαφάνειες: Π. Χατζηδούκας 1 Κύρια Μνήμη 1. Εισαγωγή 2. Βασική διαχείριση μνήμης 3. Μνήμη και πολυπρογραμματισμός 4. Τμηματοποίηση
Λειτουργικά Συστήματα Η/Υ Κεφάλαιο 7 «Διαχείριση Μνήμης» Διδάσκων: Δ. Λιαροκάπης Διαφάνειες: Π. Χατζηδούκας 1 Κύρια Μνήμη 1. Εισαγωγή 2. Βασική διαχείριση μνήμης 3. Μνήμη και πολυπρογραμματισμός 4. Τμηματοποίηση
Μηχανοτρονική. Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο,
 Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Οργάνωση και Σχεδίαση Υπολογιστών Η ιασύνδεση Υλικού και Λογισµικού, 4 η έκδοση. Κεφάλαιο 5. Μεγάλη και γρήγορη: Αξιοποίηση της ιεραρχίας της µνήµης
 Οργάνωση και Σχεδίαση Υπολογιστών Η ιασύνδεση Υλικού και Λογισµικού, 4 η έκδοση Κεφάλαιο 5 Μεγάλη και γρήγορη: Αξιοποίηση της ιεραρχίας της µνήµης Ασκήσεις Η αρίθµηση των ασκήσεων είναι από την 4 η έκδοση
Οργάνωση και Σχεδίαση Υπολογιστών Η ιασύνδεση Υλικού και Λογισµικού, 4 η έκδοση Κεφάλαιο 5 Μεγάλη και γρήγορη: Αξιοποίηση της ιεραρχίας της µνήµης Ασκήσεις Η αρίθµηση των ασκήσεων είναι από την 4 η έκδοση
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Οργάνωση Υπολογιστών Εργαστήριο 11: Κρυφές Μνήμες και η Επίδοσή τους Μανόλης Γ.Η. Κατεβαίνης Τμήμα Επιστήμης Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Οργάνωση Υπολογιστών Εργαστήριο 11: Κρυφές Μνήμες και η Επίδοσή τους Μανόλης Γ.Η. Κατεβαίνης Τμήμα Επιστήμης Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό
3 η ΑΣΚΗΣΗ ΑΡΧΙΤΕΚΤΟΝΙΚΗΣ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ntua.gr 3 η ΑΣΚΗΣΗ ΑΡΧΙΤΕΚΤΟΝΙΚΗΣ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ntua.gr 3 η ΑΣΚΗΣΗ ΑΡΧΙΤΕΚΤΟΝΙΚΗΣ
Α. Δίνονται οι. (i) στη. πρέπει να. πιο. (ii) $a0. $s0 θα πρέπει να. αποθήκευση. αυξάνει τον. f: sub sll add sub jr. h: addi sw sw.
 στη. πρέπει να. πιο. (ii) $a0. $s0 θα πρέπει να. αποθήκευση. αυξάνει τον. f: sub sll add sub jr. h: addi sw sw.") ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΡ ΙΟ ΥΠΟΛΟΟ ΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua. gr ΑΡΧΙΤΕΚΤΟΝΙΚΗ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΡ ΙΟ ΥΠΟΛΟΟ ΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua. gr ΑΡΧΙΤΕΚΤΟΝΙΚΗ
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 431 Αρχιτεκτονική Παραλλήλων Συστημάτων Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
Οργάνωση Υπολογιστών (ΙI)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Οργάνωση Υπολογιστών (ΙI) (κύρια και κρυφή μνήμη) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Ένα τυπικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Οργάνωση Υπολογιστών (ΙI) (κύρια και κρυφή μνήμη) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Ένα τυπικό
Είναι το «μυαλό» του υπολογιστή μας. Αυτός κάνει όλους τους υπολογισμούς και τις πράξεις. Έχει δική του ενσωματωμένη μνήμη, τη λεγόμενη κρυφή
 1 Είναι το «μυαλό» του υπολογιστή μας. Αυτός κάνει όλους τους υπολογισμούς και τις πράξεις. Έχει δική του ενσωματωμένη μνήμη, τη λεγόμενη κρυφή μνήμη(cache). Η cache είναι πολύ σημαντική, πολύ γρήγορη,
1 Είναι το «μυαλό» του υπολογιστή μας. Αυτός κάνει όλους τους υπολογισμούς και τις πράξεις. Έχει δική του ενσωματωμένη μνήμη, τη λεγόμενη κρυφή μνήμη(cache). Η cache είναι πολύ σημαντική, πολύ γρήγορη,
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 11: Κρυφή Μνήμη Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 11: Κρυφή Μνήμη Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Ε Ρ Γ ΑΣ Τ ΗΡ ΙΟ Υ ΠΟΛΟΓΙΣ Τ ΙΚΩΝ Σ Υ Σ Τ ΗΜΑΤΩΝ w w w. c s l ab.ece.ntua.gr
ΠΑΡΑΛΛΗΛΗ ΕΠΕΞΕΡΓΑΣΙΑ
 ΠΑΡΑΛΛΗΛΗ ΕΠΕΞΕΡΓΑΣΙΑ ΜΝΗΜΗ Πρωτόκολλα Συνέπειας Μνήµης σε Πολυεπεξεργαστικά Υπολογιστικά Συστήµατα ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΗΛΕΚΤΡΟΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΕΡΓΑΣΤΗΡΙΟ ΠΛΗΡΟΦΟΡΙΑΚΩΝ ΣΥΣΤΗΜΑΤΩΝ ΥΨΗΛΩΝ ΕΠΙ
ΠΑΡΑΛΛΗΛΗ ΕΠΕΞΕΡΓΑΣΙΑ ΜΝΗΜΗ Πρωτόκολλα Συνέπειας Μνήµης σε Πολυεπεξεργαστικά Υπολογιστικά Συστήµατα ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΗΛΕΚΤΡΟΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΕΡΓΑΣΤΗΡΙΟ ΠΛΗΡΟΦΟΡΙΑΚΩΝ ΣΥΣΤΗΜΑΤΩΝ ΥΨΗΛΩΝ ΕΠΙ
ΥΠΟΥΡΓΕΙΟ ΠΑΙΔΕΙΑΣ ΚΑΙ ΠΟΛΙΤΙΣΜΟΥ ΔΙΕΥΘΥΝΣΗ ΑΝΩΤΕΡΗΣ ΚΑΙ ΑΝΩΤΑΤΗΣ ΕΚΠΑΙΔΕΥΣΗΣ ΥΠΗΡΕΣΙΑ ΕΞΕΤΑΣΕΩΝ ΠΑΓΚΥΠΡΙΕΣ ΕΞΕΤΑΣΕΙΣ 2015
 ΥΠΟΥΡΓΕΙΟ ΠΑΙΔΕΙΑΣ ΚΑΙ ΠΟΛΙΤΙΣΜΟΥ ΔΙΕΥΘΥΝΣΗ ΑΝΩΤΕΡΗΣ ΚΑΙ ΑΝΩΤΑΤΗΣ ΕΚΠΑΙΔΕΥΣΗΣ ΥΠΗΡΕΣΙΑ ΕΞΕΤΑΣΕΩΝ ΠΑΓΚΥΠΡΙΕΣ ΕΞΕΤΑΣΕΙΣ 2015 ΤΕΧΝΟΛΟΓΙΑ (Ι) ΤΕΧΝΙΚΩΝ ΣΧΟΛΩΝ ΘΕΩΡΗΤΙΚΗΣ ΚΑΤΕΥΘΥΝΣΗΣ Μάθημα : Μικροϋπολογιστές
ΥΠΟΥΡΓΕΙΟ ΠΑΙΔΕΙΑΣ ΚΑΙ ΠΟΛΙΤΙΣΜΟΥ ΔΙΕΥΘΥΝΣΗ ΑΝΩΤΕΡΗΣ ΚΑΙ ΑΝΩΤΑΤΗΣ ΕΚΠΑΙΔΕΥΣΗΣ ΥΠΗΡΕΣΙΑ ΕΞΕΤΑΣΕΩΝ ΠΑΓΚΥΠΡΙΕΣ ΕΞΕΤΑΣΕΙΣ 2015 ΤΕΧΝΟΛΟΓΙΑ (Ι) ΤΕΧΝΙΚΩΝ ΣΧΟΛΩΝ ΘΕΩΡΗΤΙΚΗΣ ΚΑΤΕΥΘΥΝΣΗΣ Μάθημα : Μικροϋπολογιστές
i Όλες οι σύγχρονες ΚΜΕ είναι πολυπλοκότερες!
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Η υπολογιστική
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Κεντρική Επεξεργασίας (Σχεδιασμός και λειτουργία μιας απλής ΚΜΕ) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Η υπολογιστική
Συστήματα σε Ολοκληρωμένα Κυκλώματα
 Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
Συστήματα σε Ολοκληρωμένα Κυκλώματα Κεφάλαιο 4: Αρχιτεκτονική των Embedded Μικροεπεξεργαστών Διδάσκων: Καθηγητής Οδυσσέας Κουφοπαύλου Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών ΕΙΣΑΓΩΓΗ Παρουσιάζεται
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ
 ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ (Τμήματα Υπολογιστή) ΕΚΠΑΙΔΕΥΤΗΣ:ΠΟΖΟΥΚΙΔΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣ ΤΜΗΜΑΤΑ ΗΛΕΚΤΡΟΝΙΚΟΥ ΥΠΟΛΟΓΙΣΤΗ Κάθε ηλεκτρονικός υπολογιστής αποτελείται
ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ (Τμήματα Υπολογιστή) ΕΚΠΑΙΔΕΥΤΗΣ:ΠΟΖΟΥΚΙΔΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣ ΤΜΗΜΑΤΑ ΗΛΕΚΤΡΟΝΙΚΟΥ ΥΠΟΛΟΓΙΣΤΗ Κάθε ηλεκτρονικός υπολογιστής αποτελείται
Λειτουργικά Συστήματα (διαχείριση επεξεργαστή, μνήμης και Ε/Ε)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2015-16 Λειτουργικά Συστήματα (διαχείριση επεξεργαστή, και Ε/Ε) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Τι είναι
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2015-16 Λειτουργικά Συστήματα (διαχείριση επεξεργαστή, και Ε/Ε) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Τι είναι
Τι είναι ένα λειτουργικό σύστημα (ΛΣ); Μια άλλη απεικόνιση. Το Λειτουργικό Σύστημα ως μέρος του υπολογιστή
; Μια άλλη απεικόνιση. Το Λειτουργικό Σύστημα ως μέρος του υπολογιστή") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2014-15 Λειτουργικά Συστήματα (διαχείριση επεξεργαστή, και Ε/Ε) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Τι είναι
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2014-15 Λειτουργικά Συστήματα (διαχείριση επεξεργαστή, και Ε/Ε) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Τι είναι
Μάθημα 3: Αρχιτεκτονική Υπολογιστών
 Μάθημα 3: Αρχιτεκτονική Υπολογιστών 3.1 Περιφερειακές μονάδες και τμήμα επεξεργασίας Στην καθημερινή μας ζωή ερχόμαστε συνέχεια σε επαφή με υπολογιστές. Ο υπολογιστής είναι μια συσκευή που επεξεργάζεται
Μάθημα 3: Αρχιτεκτονική Υπολογιστών 3.1 Περιφερειακές μονάδες και τμήμα επεξεργασίας Στην καθημερινή μας ζωή ερχόμαστε συνέχεια σε επαφή με υπολογιστές. Ο υπολογιστής είναι μια συσκευή που επεξεργάζεται
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
1. Οργάνωση της CPU 2. Εκτέλεση εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο επίπεδο των επεξεργαστών
 ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΟΡΓΑΝΩΣΗ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ι Γ. Τσιατούχας 2 ο Κεφάλαιο ιάρθρωση 1. Οργάνωση της 2. εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο
ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΟΡΓΑΝΩΣΗ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Ι Γ. Τσιατούχας 2 ο Κεφάλαιο ιάρθρωση 1. Οργάνωση της 2. εντολών 3. Παραλληλία στο επίπεδο των εντολών 4. Γραμμές διοχέτευσης 5. Παραλληλία στο
ΠΛΕ- 027 Μικροεπεξεργαστές
 ΠΛΕ- 027 Μικροεπεξεργαστές 10ο μάθημα: Αρχιτεκτονική συστήματος μνήμης: Εικονική μνήμη, σχεδίαση αποδοτικής κρυφής μνήμης, προγραμματισμός για κρυφή μνήμη Αρης Ευθυμίου Εικονική μνήμη ως cache Η κύρια
ΠΛΕ- 027 Μικροεπεξεργαστές 10ο μάθημα: Αρχιτεκτονική συστήματος μνήμης: Εικονική μνήμη, σχεδίαση αποδοτικής κρυφής μνήμης, προγραμματισμός για κρυφή μνήμη Αρης Ευθυμίου Εικονική μνήμη ως cache Η κύρια
Processor-Memory (DRAM) ιαφορά επίδοσης
 ιαφορά επίδοσης") Processor-Memory (DRAM) ιαφορά επίδοσης µproc 6%/yr 98 98 982 983 984 985 986 987 988 989 99 99 992 993 994 995 996 997 998 999 2 2 22 23 24 25 Performance Processor-Memory Performance Gap: (grows 5% /
Processor-Memory (DRAM) ιαφορά επίδοσης µproc 6%/yr 98 98 982 983 984 985 986 987 988 989 99 99 992 993 994 995 996 997 998 999 2 2 22 23 24 25 Performance Processor-Memory Performance Gap: (grows 5% /
Γενική οργάνωση υπολογιστή «ΑΒΑΚΑ»
 Περιεχόμενα Γενική οργάνωση υπολογιστή «ΑΒΑΚΑ»... 2 Καταχωρητές... 3 Αριθμητική-λογική μονάδα... 3 Μονάδα μνήμης... 4 Μονάδα Εισόδου - Εξόδου... 5 Μονάδα ελέγχου... 5 Ρεπερτόριο Εντολών «ΑΒΑΚΑ»... 6 Φάση
Περιεχόμενα Γενική οργάνωση υπολογιστή «ΑΒΑΚΑ»... 2 Καταχωρητές... 3 Αριθμητική-λογική μονάδα... 3 Μονάδα μνήμης... 4 Μονάδα Εισόδου - Εξόδου... 5 Μονάδα ελέγχου... 5 Ρεπερτόριο Εντολών «ΑΒΑΚΑ»... 6 Φάση
Κύρια μνήμη. Μοντέλο λειτουργίας μνήμης. Ένα τυπικό υπολογιστικό σύστημα σήμερα. Οργάνωση Υπολογιστών (ΙI)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 015-16 Οργάνωση Υπολογιστών (ΙI) (κύρια και ) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα τυπικό υπολογιστικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 015-16 Οργάνωση Υπολογιστών (ΙI) (κύρια και ) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα τυπικό υπολογιστικό
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr ΠΡΟΗΓΜΕΝΑ ΘΕΜΑΤΑ
Τμήμα Λογιστικής. Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές. Μάθημα 8. 1 Στέργιος Παλαμάς
 ΤΕΙ Ηπείρου Παράρτημα Πρέβεζας Τμήμα Λογιστικής Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές Μάθημα 8 Κεντρική Μονάδα Επεξεργασίας και Μνήμη 1 Αρχιτεκτονική του Ηλεκτρονικού Υπολογιστή Μονάδες Εισόδου Κεντρική
ΤΕΙ Ηπείρου Παράρτημα Πρέβεζας Τμήμα Λογιστικής Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές Μάθημα 8 Κεντρική Μονάδα Επεξεργασίας και Μνήμη 1 Αρχιτεκτονική του Ηλεκτρονικού Υπολογιστή Μονάδες Εισόδου Κεντρική
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ. ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ, 5 ο εξάµηνο
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ και ΥΠΟΛΟΓΙΣΤΩΝ ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ, 5 ο εξάµηνο ΦΕΒΡΟΥΑΡΙΟΣ 2006 ΘΕΜΑΤΑ ΚΑΙ ΛΥΣΕΙΣ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ και ΥΠΟΛΟΓΙΣΤΩΝ ΑΡΧΙΤΕΚΤΟΝΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ, 5 ο εξάµηνο ΦΕΒΡΟΥΑΡΙΟΣ 2006 ΘΕΜΑΤΑ ΚΑΙ ΛΥΣΕΙΣ
ΚΕΦΑΛΑΙΟ 5. Κύκλος Ζωής Εφαρμογών ΕΝΟΤΗΤΑ 2. Εφαρμογές Πληροφορικής. Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών
 44 Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών Διδακτικοί στόχοι Σκοπός του κεφαλαίου είναι οι μαθητές να κατανοήσουν τα βήματα που ακολουθούνται κατά την ανάπτυξη μιας εφαρμογής.
44 Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών Διδακτικοί στόχοι Σκοπός του κεφαλαίου είναι οι μαθητές να κατανοήσουν τα βήματα που ακολουθούνται κατά την ανάπτυξη μιας εφαρμογής.
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Απόδοση ΚΜΕ. (Μέτρηση και τεχνικές βελτίωσης απόδοσης)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Μάθημα 8: Διαχείριση Μνήμης
 Μάθημα 8: Διαχείριση Μνήμης 8.1 Κύρια και δευτερεύουσα μνήμη Κάθε μονάδα ενός υπολογιστή που χρησιμεύει για τη μόνιμη ή προσωρινή αποθήκευση δεδομένων ανήκει στην μνήμη (memory) του υπολογιστή. Οι μνήμες
Μάθημα 8: Διαχείριση Μνήμης 8.1 Κύρια και δευτερεύουσα μνήμη Κάθε μονάδα ενός υπολογιστή που χρησιμεύει για τη μόνιμη ή προσωρινή αποθήκευση δεδομένων ανήκει στην μνήμη (memory) του υπολογιστή. Οι μνήμες
Κεφάλαιο 5. Κεφ. 5 Λειτουργικά Συστήματα 1
 Λειτουργικά Συστήματα Κεφάλαιο 5 Κεφ. 5 Λειτουργικά Συστήματα 1 Διαχείριση Κεντρικής Μνήμης Στην Κεντρική (κύρια) Μνήμη του Η/Υ αποθηκεύονται ανα πάσα στιγμή όλα τα προγράμματα που εκτελούνται στην ΚΜΕ
Λειτουργικά Συστήματα Κεφάλαιο 5 Κεφ. 5 Λειτουργικά Συστήματα 1 Διαχείριση Κεντρικής Μνήμης Στην Κεντρική (κύρια) Μνήμη του Η/Υ αποθηκεύονται ανα πάσα στιγμή όλα τα προγράμματα που εκτελούνται στην ΚΜΕ
Κεφάλαιο 3 Αρχιτεκτονική Ηλεκτρονικού Τμήματος (hardware) των Υπολογιστικών Συστημάτων ΕΡΩΤΗΣΕΙΣ ΑΣΚΗΣΕΙΣ
 των Υπολογιστικών Συστημάτων ΕΡΩΤΗΣΕΙΣ ΑΣΚΗΣΕΙΣ") Κεφάλαιο 3 Αρχιτεκτονική Ηλεκτρονικού Τμήματος (hardware) των Υπολογιστικών Συστημάτων ΕΡΩΤΗΣΕΙΣ ΑΣΚΗΣΕΙΣ 1. Τι εννοούμε με τον όρο υπολογιστικό σύστημα και τι με τον όρο μικροϋπολογιστικό σύστημα; Υπολογιστικό
Κεφάλαιο 3 Αρχιτεκτονική Ηλεκτρονικού Τμήματος (hardware) των Υπολογιστικών Συστημάτων ΕΡΩΤΗΣΕΙΣ ΑΣΚΗΣΕΙΣ 1. Τι εννοούμε με τον όρο υπολογιστικό σύστημα και τι με τον όρο μικροϋπολογιστικό σύστημα; Υπολογιστικό
Εικονική Μνήµη. Κεφάλαιο 8. Dr. Garmpis Aristogiannis - EPDO TEI Messolonghi
 Εικονική Μνήµη Κεφάλαιο 8 Υλικό και δοµές ελέγχου Οι αναφορές στην µνήµη υπολογίζονται δυναµικά κατά την εκτέλεση Ηδιεργασίαχωρίζεταισετµήµατα τα οποία δεν απαιτείται να καταλαµβάνουν συνεχόµενες θέσεις
Εικονική Μνήµη Κεφάλαιο 8 Υλικό και δοµές ελέγχου Οι αναφορές στην µνήµη υπολογίζονται δυναµικά κατά την εκτέλεση Ηδιεργασίαχωρίζεταισετµήµατα τα οποία δεν απαιτείται να καταλαµβάνουν συνεχόµενες θέσεις
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ. Διαχείριση μνήμης Εργαστηριακές Ασκήσεις
 ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Διαχείριση μνήμης Εργαστηριακές Ασκήσεις Υλικό από: Modern Operating Systems Laboratory Exercises, Shrivakan Mishra Σύνθεση Κ.Γ. Μαργαρίτης, Τμήμα Εφαρμοσμένης Πληροφορικής, Πανεπιστήμιο
ΛΕΙΤΟΥΡΓΙΚΑ ΣΥΣΤΗΜΑΤΑ Διαχείριση μνήμης Εργαστηριακές Ασκήσεις Υλικό από: Modern Operating Systems Laboratory Exercises, Shrivakan Mishra Σύνθεση Κ.Γ. Μαργαρίτης, Τμήμα Εφαρμοσμένης Πληροφορικής, Πανεπιστήμιο
Εικονική Μνήμη (Virtual Μemory)
") ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
ΗΥ 232 Οργάνωση και Σχεδίαση Υπολογιστών Διάλεξη 16 Εικονική Μνήμη (Virtual Μemory) Νίκος Μπέλλας Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Η/Υ Απλό πείραμα int *data = malloc((1
i Throughput: Ο ρυθμός ολοκλήρωσης έργου σε συγκεκριμένο χρόνο
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Μάθημα 3.2: Κεντρική Μονάδα Επεξεργασίας
 Κεφάλαιο 3 ο Αρχιτεκτονική Υπολογιστών Μάθημα 3.: Κεντρική Μονάδα Επεξεργασίας Όταν ολοκληρώσεις το κεφάλαιο θα μπορείς: Να σχεδιάζεις την εσωτερική δομή της ΚΜΕ και να εξηγείς τη λειτουργία των επιμέρους
Κεφάλαιο 3 ο Αρχιτεκτονική Υπολογιστών Μάθημα 3.: Κεντρική Μονάδα Επεξεργασίας Όταν ολοκληρώσεις το κεφάλαιο θα μπορείς: Να σχεδιάζεις την εσωτερική δομή της ΚΜΕ και να εξηγείς τη λειτουργία των επιμέρους
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 11: Κρυφή Μνήμη Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 11: Κρυφή Μνήμη Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων και Αρχιτεκτονικής Υπολογιστών http://arch.icte.uowm.gr/mdasyg
Πανεπιστήμιο Πατρών. Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών
 Πανεπιστήμιο Πατρών Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Εργαστήριο Σχεδίασης Ολοκληρωμένων Κυκλωμάτων Σχεδιασμός Ολοκληρωμένων Συστημάτων με τεχνικές VLSI Χειμερινό Εξάμηνο 2015 FSM
Πανεπιστήμιο Πατρών Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Εργαστήριο Σχεδίασης Ολοκληρωμένων Κυκλωμάτων Σχεδιασμός Ολοκληρωμένων Συστημάτων με τεχνικές VLSI Χειμερινό Εξάμηνο 2015 FSM
Παραλληλισμός σε επίπεδο εντολών
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Παραλληλισμός σε επίπεδο εντολών (Pipelining και άλλες τεχνικές αύξησης απόδοσης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης
Οι βασικές λειτουργίες (ή πράξεις) που γίνονται σε μια δομή δεδομένων είναι:
 που γίνονται σε μια δομή δεδομένων είναι:") ΔΟΜΕΣ ΔΕΔΟΜΕΝΩΝ Μια δομή δεδομένων στην πληροφορική, συχνά αναπαριστά οντότητες του φυσικού κόσμου στον υπολογιστή. Για την αναπαράσταση αυτή, δημιουργούμε πρώτα ένα αφηρημένο μοντέλο στο οποίο προσδιορίζονται
ΔΟΜΕΣ ΔΕΔΟΜΕΝΩΝ Μια δομή δεδομένων στην πληροφορική, συχνά αναπαριστά οντότητες του φυσικού κόσμου στον υπολογιστή. Για την αναπαράσταση αυτή, δημιουργούμε πρώτα ένα αφηρημένο μοντέλο στο οποίο προσδιορίζονται
ΑΡΧΙΤΕΚΤΟΝΙΚΗ HARDWARE ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ
 ΨΗΦΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΚΕΦΑΛΑΙΟ 7ο ΑΡΧΙΤΕΚΤΟΝΙΚΗ HARDWARE ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Γενικό διάγραμμα υπολογιστικού συστήματος Γενικό διάγραμμα υπολογιστικού συστήματος - Κεντρική Μονάδα Επεξεργασίας ονομάζουμε
ΨΗΦΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΚΕΦΑΛΑΙΟ 7ο ΑΡΧΙΤΕΚΤΟΝΙΚΗ HARDWARE ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Γενικό διάγραμμα υπολογιστικού συστήματος Γενικό διάγραμμα υπολογιστικού συστήματος - Κεντρική Μονάδα Επεξεργασίας ονομάζουμε
Εικονική Μνήμη (virtual memory)
") Εικονική Μνήμη (virtual memory) Πολλά προγράμματα εκτελούνται ταυτόχρονα σε ένα υπολογιστή Η συνολική μνήμη που απαιτείται είναι μεγαλύτερη από το μέγεθος της RAM Αρχή τοπικότητας (η μνήμη χρησιμοποιείται
Εικονική Μνήμη (virtual memory) Πολλά προγράμματα εκτελούνται ταυτόχρονα σε ένα υπολογιστή Η συνολική μνήμη που απαιτείται είναι μεγαλύτερη από το μέγεθος της RAM Αρχή τοπικότητας (η μνήμη χρησιμοποιείται