ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ. Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης
|
|
|
- Τίμω Ράγκος
- 10 χρόνια πριν
- Προβολές:
Transcript
1 ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης «Γλωσσικά μοντέλα μορφολογικά περίπλοκων γλωσσών» Δημήτρης Μπαμπανιώτης Επιβλέπων: Ίων Ανδρουτσόπουλος Βοηθός Επιβλέπων: Δημήτρης Μαυροειδής ΑΘΗΝΑ, ΙΟΥΝΙΟΣ 2012

2 Περιεχόμενα 1. Εισαγωγή Θεωρητικό Υπόβαθρο Στατιστικά γλωσσικά μοντέλα Εξομάλυνση Good Turing Εντροπία και διασταυρωμένη εντροπία Εντροπία γλώσσας Διασταυρωμένη εντροπία και περιπλοκή γλωσσικού μοντέλου Πειράματα με Δείκτη Αξιολόγησης την Περιπλοκή Σύνολα δεδομένων Πειράματα με μοντέλα n-γραμμάτων ολόκληρων λέξεων Πειράματα με μοντέλα n-γραμμάτων ψευδο-καταλήξεων Πειράματα με μοντέλα n-γραμμάτων ψευδο-θεμάτων Πειράματα με τον πιθανοτικό ταξινομητή του Lang Πειράματα με μοντέλα n-γραμμάτων ολόκληρων λέξεων και περιορισμένο λεξιλόγιο Πειράματα αξιολόγησης γλωσσικών μοντέλων μέσω ενσωμάτωσής τους σε συστήματα μηχανικής μετάφρασης Πειράματα Πειράματα χωρίς γλωσσικό μοντέλο Πειράματα με μοντέλο n-γραμμάτων ολόκληρων λέξεων Πειράματα με μοντέλο n-γραμμάτων ψευδο-καταλήξεων Πειράματα με μοντέλο n-γραμμάτων ψευδο-θεμάτων Πειράματα με συνδυασμό μοντέλου n-γραμμάτων ψευδο-θεμάτων και μοντέλου n-γραμμάτων ψευδο-καταλήξεων

3 4.1.6 Πειράματα με συνδυασμό μοντέλου n-γραμμάτων ολόκληρων λέξεων και μοντέλου n-γραμμάτων ψευδο-καταλήξεων Πειράματα με συνδυασμό μοντέλου n-γραμμάτων ολόκληρων λέξεων και μοντέλου n-γραμμάτων ψευδο-θεμάτων Πειράματα με συνδυασμό μοντέλου n-γραμμάτων ολόκληρων λέξεων, μοντέλου n-γραμμάτων ψευδο-θεμάτων και μοντέλου n-γραμμάτων ψευδοκαταλήξεων Συμπέρασμα πειραμάτων μέτρησης BLEU Συμπεράσματα και Μελλοντικές Κατευθύνσεις Έρευνας Βιβλιογραφία

4 1. Εισαγωγή Σκοπός της εργασίας ήταν να διερευνήσει τις επιδόσεις υπαρχόντων στατιστικών γλωσσικών μοντέλων, κυρίως μοντέλων n-γραμμάτων, σε γλώσσες με μορφολογικές διαφορές, ιδιαίτερα γλώσσες με περίπλοκη μορφολογία (π.χ. κλίσεις ουσιαστικών, ρημάτων κλπ.) όπως τα ελληνικά. Πιο συγκεκριμένα, αρχικά δημιουργήθηκαν στατιστικά γλωσσικά μοντέλα n- γραμμάτων για τα ελληνικά, αγγλικά, γερμανικά και ισπανικά, χρησιμοποιώντας το ιδιαίτερα διαδεδομένο εργαλείο κατασκευής γλωσσικών μοντέλων SRILM και το σώμα κειμένων Europarl, που περιλαμβάνει κείμενα από τα πρακτικά του Ευρωπαϊκού Κοινοβουλίου σε πολλές γλώσσες 1 Τα γλωσσικά αυτά μοντέλα αξιολογήθηκαν βάσει της περιπλοκής τους (perplexity). Στη συνέχεια, με τον ίδιο τρόπο δημιουργήθηκαν και αξιολογήθηκαν στατιστικά γλωσσικά μοντέλα n- γραμμάτων χρησιμοποιώντας, όμως, τώρα μόνο τις ψευδο-καταλήξεις και τα ψευδοθέματα των λέξεων ονομάζουμε ψευδο-καταλήξεις και ψευδο-θέματα τα τελευταία τρία και τα πρώτα τρία, αντίστοιχα, γράμματα των λέξεων. Επίσης, αξιολογήθηκε στο ίδιο σώμα κειμένων το γλωσσικό μοντέλο του Lang (2011), το οποίο υποστηρίζεται από το SRILM και βασίζεται σε έναν πιθανοτικό ταξινομητή. Κατόπιν ενσωματώθηκαν τα παραπάνω γλωσσικά μοντέλα (και συνδυασμοί τους) στο σύστημα στατιστικής μηχανικής μετάφρασης MOSES. 2 Τα συστήματα μηχανικής μετάφρασης χρησιμοποιούν, μεταξύ άλλων, γλωσσικά μοντέλα (της γλώσσαςστόχου) και ο σκοπός αυτού του σταδίου της εργασίας ήταν να διερευνήσει ποια από τα παραπάνω γλωσσικά μοντέλα (ή συνδυασμοί τους) βοηθούν περισσότερο ένα σύστημα μηχανικής μετάφρασης να παραγάγει καλύτερες μεταφράσης. Η ποιότητα των παραγόμενων μεταφράσεων αξιολογήθηκε με το δείκτη BLEU, που συγκρίνει τις παραγόμενες μεταφράσεις με μεταφράσεις ανθρώπων μεταφραστών. Το υπόλοιπο κείμενο της εργασίας είναι διαρθρωμένο ως εξής: το κεφάλαιο 2 εξηγεί περιληπτικά βασικές έννοιες των στατιστικών γλωσσικών μοντέλων το κεφάλαιο 3 παρουσιάζει τα πειράματα με τα οποία μετρήθηκε η περιπλοκή των διάφορων 1 Βλ. και 2 Βλ. 4

5 γλωσσικών μοντέλων το κεφάλαιο 4 παρουσιάζει τα πειράματα με τα οποία μετρήθηκε ο δείκτης BLEU του MOSES με διαφορετικά γλωσσικά μοντέλα ή συνδυασμούς τους και το κεφάλαιο 5 συνοψίζει τα αποτελέσματα της εργασίας και προτείνει μελλοντικές κατευθύνσεις έρευνας. 5

6 2. Θεωρητικό Υπόβαθρο Το κεφάλαιο αυτό εξηγεί περιληπτικά βασικές έννοιες των στατιστικών γλωσσικών μοντέλων. Περισσότερες πληροφορίες για τα στατιστικά γλωσσικά μοντέλα, αλλά και τα συστήματα στατιστικής μηχανικής μετάφρασης, παρέχει το βιβλίο των Jurafsky και Martin (2009), καθώς και το βιβλίο του (Koehn, 2010) Στατιστικά γλωσσικά μοντέλα Ένα στατιστικό γλωσσικό μοντέλο προσπαθεί να εκτιμήσει την πιθανότητα εμφάνισης μιας δεδομένης ακολουθίας λέξεων (π.χ. μιας προτάσεως). Χρησιμοποιούμε το συμβολισμό ως συντομογραφία του. Η πιθανότητα εμφάνισης μιας ακολουθίας λέξεων είναι: ( ) ( ) ( ) ( ) ( ) ( ) Τα γλωσσικά μοντέλα n-γραμμάτων κάνουν την παραδοχή ότι ( ) ( ). Για παράδειγμα, στην περίπτωση ενός μοντέλου 2-γραμμάτων έχουμε: ( ) ( ) ( ) ( ) ( ) όπου θεωρούμε ότι κάθε ακολουθία λέξεων ξεκινά με την ψευδο-λέξη. Ομοίως, στην περίπτωση μοντέλου 3-γραμμάτων έχουμε: ( ) ( ) ( ) ( ) ( ) όπου θεωρούμε ότι κάθε ακολουθία λέξεων ξεκινά με τις ψευδο-λέξεις και. 2.2 Εξομάλυνση Good Turing Οι παραπάνω πιθανότητες εκτιμώνται από ένα σώμα κειμένων εκπαίδευσης. Προκειμένου να αποφευχθούν μηδενικές εκτιμήσεις πιθανοτήτων για n-γράμματα που δεν εμφανίζονται στο σώμα εκπαίδευσης, χρησιμοποιούνται διάφορες τεχνικές εξομάλυνσης των πιθανοτήτων. 3 Βλ. επίσης τις σχετικές διαφάνειες του Ι. Ανδρουτσόπουλου για το μάθημα «Γλωσσική Τεχνολογία» του ΟΠΑ ( 6
 ( ) ( ) ( ) ( ) ( ) Τα γλωσσικά μοντέλα n-γραμμάτων κάνουν την παραδοχή ότι ( ) ( ).")
7 Μεταξύ των πιο διαδεδομένων στα γλωσσικά μοντέλα είναι η εξομάλυνση Good Turing. Αν δεν έχουμε συναντήσει μια λέξη w στο σώμα εκπαίδευσης, θέτουμε: ( ) όπου N 1 είναι ο αριθμός των (διαφορετικών) λέξεων που έχουμε συναντήσει ακριβώς μία φορά στο σώμα εκπαίδευσης («άπαξ λεγόμενα») και C είναι το σύνολο των εμφανίσεων λέξεων (word occurrences) του σώματος εκπαίδευσης. Με άλλα λόγια, η πιθανότητα να συναντήσουμε μια λέξη που δεν έχουμε ξανασυναντήσει θεωρούμε ότι ισούται με την πιθανότητα να συναντήσουμε μια λέξη που έχουμε συναντήσει μία μόνο φορά. Στην περίπτωση που έχουμε συναντήσει την w ακριβώς c φορές (c > 0) στο σώμα εκπαίδευσης, τότε ο τύπος που χρησιμοποιούμε είναι: ( ) όπου είναι ο αριθμός των (διαφορετικών) λέξεων που έχουμε συναντήσει ακριβώς c + 1 φορές και είναι ο αριθμός των (διαφορετικών) λέξεων που έχουμε συναντήσει ακριβώς c φορές. Ομοίως, αν δεν έχουμε συναντήσει κατά την εκπαίδευση την ακολουθία θεωρούμε ότι:, τότε ( ) ( ) όπου εδώ είναι ο αριθμός των (διαφορετικών) 3-γραμμάτων που έχουμε συναντήσει ακριβώς μία φορά στο σώμα εκπαίδευσης και ( ) είναι ο αριθμός εμφανίσεων του 2- γράμματος στο σώμα εκπαίδευσης. Διαφορετικά, αν έχουμε ξανασυναντήσει κατά την εκπαίδευση την ακολουθία, τότε: ( ) ( ) όπου εδώ το είναι ο αριθμός των 3-γραμμάτων που έχουμε συναντήσει c + 1 φορές. Αντίστοιχα ορίζονται οι πιθανότητες για 4-γράμματα, 5-γράμματα κλπ. 7

8 2.3 Εντροπία και διασταυρωμένη εντροπία Η Εντροπία μιας τυχαίας μεταβλητής C δείχνει πόσο αβέβαιοι είμαστε για την τιμή της C, ισοδύναμα πόση είναι η αναμενόμενη ελάχιστη ποσότητα πληροφορίας (μετρούμενη σε δυφία (bits) και χρησιμοποιώντας τη ιδανική κωδικοποίηση) που πρέπει να μας δοθεί για να γνωρίζουμε με βεβαιότητα την τιμή της C. Ο τύπος της εντροπίας είναι: ( ) ( ) ( ) όπου είναι οι δυνατές τιμές της C και ( ) είναι ο αριθμός των διφύων που απαιτούνται για τη μετάδοση του, όταν χρησιμοποιείται η ιδανική κωδικοποίηση. Αν έχουμε κωδικοποίηση βασισμένη σε μη ακριβείς εκτιμήσεις πιθανοτήτων P m αντί των σωστών P, τότε θα χρειαστεί να μεταδώσουμε περισσότερα δυφία. Ο αναμενόμενος αριθμός δυφίων που θα χρειαστεί να μεταδώσουμε δίδεται από τον παρακάτω τύπο της διασταυρωμένης εντροπίας (cross-entropy): ( ) ( ) ( ) Η διασταυρωμένη εντροπία μιας τυχαίας μεταβλητής είναι πάντα μεγαλύτερη από (ή ίση με) την εντροπία της. Αν έχουμε δύο μοντέλα ( ) ( ), ακριβέστερες εκτιμήσεις των πραγματικών ( ) δίνει το μοντέλο με τη χαμηλότερη διασταυρωμένη εντροπία. 2.4 Εντροπία γλώσσας Στην περίπτωση που αντί για μια τυχαία μεταβλητή C έχουμε τις τυχαίες μεταβλητές που αντιστοιχούν σε ακολουθίες λέξεων μιας γλώσσας L, τότε η εντροπία της ακολουθίας τυχαίων μεταβλητών είναι: ( ) ( ) ( ) ( ) όπου ( ) είναι το λεξιλόγιο της L. Η εντροπία ( ) δείχνει πόσο αβέβαιοι είμαστε για το ποια ακριβώς ακολουθία λέξεων θα προκύψει, αν διαλέξουμε στην τύχη μια ( ) 8

9 ακολουθία λέξεων από ένα μεγάλο σώμα κειμένων της γλώσσας L. Συνήθως η παραπάνω εντροπία κανονικοποιείται ως προς το μήκος της ακολουθίας (per word entropy): ( ) ( ) ( ) ( ) Η εντροπία μιας γλώσσας L ορίζεται ως εξής: 1 n L lim H( W1 L) n n ( ) ( ) ( ) Αποδεικνύεται (για στάσιμες και εργοδικές γλώσσες) ότι: ( ) ( ) ( ) ( ) Αυτό σημαίνει ότι μπορούμε να χρησιμοποιήσουμε μόνο μία, αλλά πολύ μεγάλη, ακολουθία Ν λέξεων της γλώσσας (π.χ. ένα μεγάλο σώμα κειμένων) για να εκτιμήσουμε την εντροπία της γλώσσας. 2.5 Διασταυρωμένη εντροπία και περιπλοκή γλωσσικού μοντέλου Αν έχουμε δύο γλωσσικά μοντέλα ( ) ( ) για μια γλώσσα L, καλύτερο είναι το μοντέλο με τη χαμηλότερη διασταυρωμένη εντροπία. ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 9
 για να εκτιμήσουμε την εντροπία της γλώσσας. 2.")
10 Επειδή οι τιμές της διασταυρωμένης εντροπίας είναι πολύ κοντά στο 0 συνήθως δημοσιεύονται αποτελέσματα περιπλοκής (perplexity). Η περιπλοκή ενός γλωσσικού μοντέλου ( ) ορίζεται ως εξής: ( ) ( ) ( ) ( ) ( ) Οπότε, αν χρησιμοποιούμε, π.χ., μοντέλο 2-γραμμάτων, η περιπλοκή του είναι: ( ) Όσο μικρότερη είναι η περιπλοκή, τόσο καλύτερο είναι το γλωσσικό μοντέλο που εξετάζουμε. Σε ένα μοντέλο n-γραμμάτων, μπορεί επίσης να σκεφτεί κανείς την περιπλοκή (και τη διασταυρωμένη εντροπία) ως ένα μέτρο του κατά πόσον το γλωσσικό μοντέλο προβλέπει με βεβαιότητα την κάθε λέξη, δεδομένων των προηγούμενων n 1. 10
 Όσο μικρότερη είναι η περιπλοκή, τόσο καλύτερο είναι το γλωσσικό μοντέλο που εξετάζουμε.")
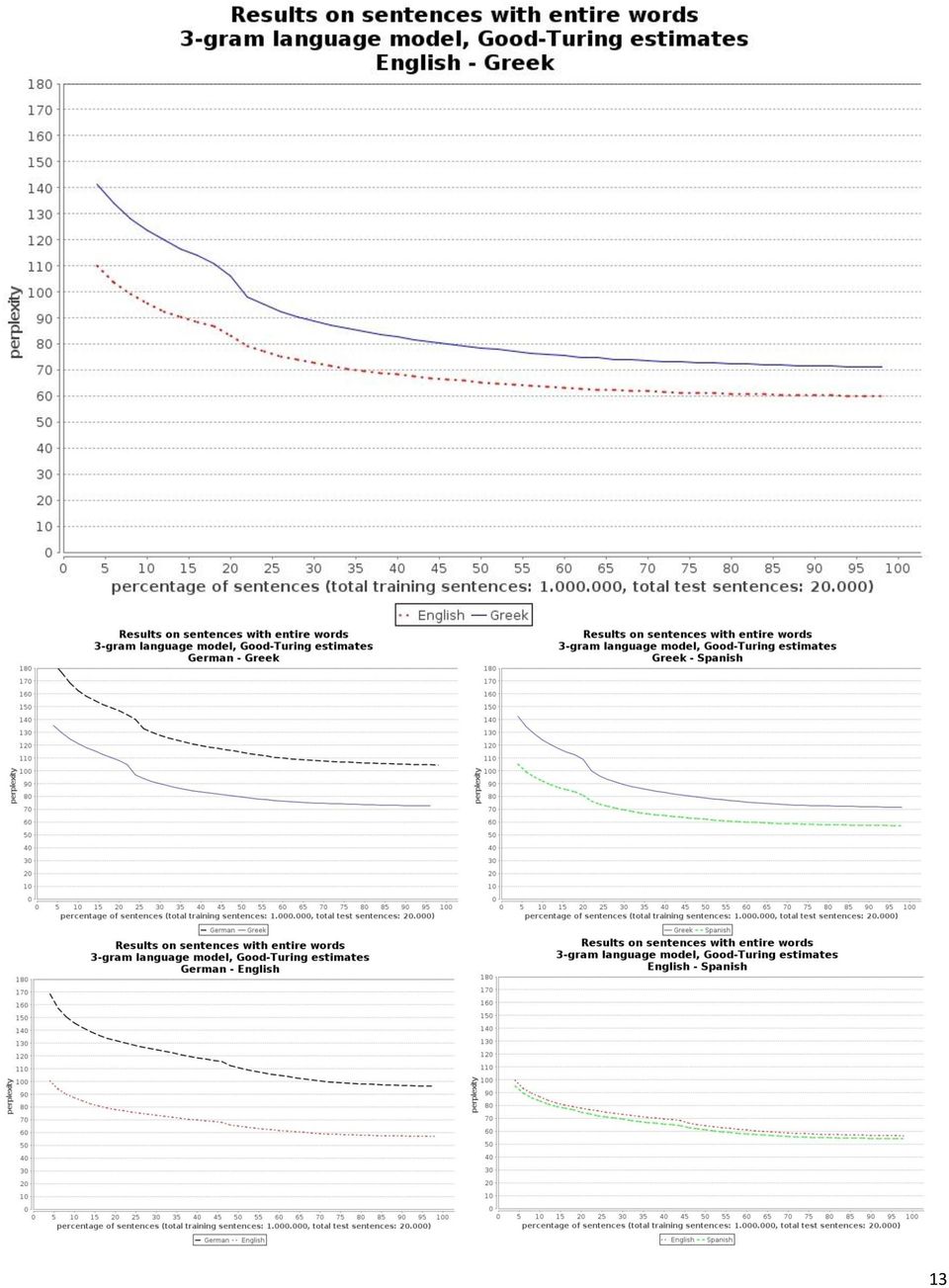
11 3. Πειράματα με Δείκτη Αξιολόγησης την Περιπλοκή Όπως προαναφέρθηκε, στη διάρκεια της εργασίας αξιολογήθηκαν μοντέλα n-γραμμάτων (για n = 3, 4, 5) ολόκληρων λέξεων, ψευδο-καταλήξεων (τρία τελευταία γράμματα των λέξεων), ψευδο-θεμάτων (τρία πρώτα γράμματα), καθώς και το μοντέλο του Lang (2011). Στο κεφάλαιο αυτό παρουσιάζονται πειράματα με τα οποία μετρήθηκε η περιπλοκή των γλωσσικών αυτών μοντέλων, για μεταβλητό μέγεθος σώματος εκπαίδευσης. Χρησιμοποιήθηκαν οι υλοποιήσεις των γλωσσικών μοντέλων που παρέχει το SRILM. 3.1 Σύνολα δεδομένων Τα πειράματα αυτού του κεφαλαίου έγιναν σε κείμενα του Europarl, που περιλαμβάνει πρακτικά των συνεδριάσεων του Ευρωπαϊκού Κοινοβουλίου (Koehn, 2005). Πιο συγκεκριμένα, χρησιμοποιήθηκε ένα υποσύνολο του Europarl σε τέσσερις γλώσσες, τα ελληνικά, αγγλικά, γερμανικά και ισπανικά. Χρησιμοποιώντας τα εργαλεία προ-επεξεργασίας του συστήματος μηχανικής μετάφρασης MOSES (Koehn κ.ά. 2007), τα κείμενα χωρίστηκαν σε προτάσεις, διαχωρίστηκαν οι λεκτικές μονάδες (tokenization) και όλα τα γράμματα μετατράπηκαν σε πεζά. Για την περαιτέρω επεξεργασία των κειμένων (π.χ. την μετατροπή των λέξεων σε ψευδοκαταλήξεις ή ψευδο-θέματα), αναπτύχθηκε πρόσθετο λογισμικό σε Java. Για την πραγματοποίηση των πειραμάτων αυτού του κεφαλαίου, χρησιμοποιήθηκαν 1,000,000 προτάσεις εκπαίδευσης (κάθε φορά της γλώσσας στην οποία εκπαιδευόταν το γλωσσικό μοντέλο) και 20,000 προτάσεις αξιολόγησης (της ίδιας γλώσσας, χωρίς επικάλυψη με τις προτάσεις εκπαίδευσης). Επαναλάβαμε κάθε πείραμα πολλές φορές, χρησιμοποιώντας σε κάθε επανάληψη ένα διαφορετικό ποσοστό των προτάσεων εκπαίδευσης, αλλά το ίδιο πάντα σύνολο προτάσεων αξιολόγησης. Στα παρακάτω διαγράμματα, ο κατακόρυφος άξονας παριστάνει την περιπλοκή που πετυχαίνει το γλωσσικό μοντέλο στα δεδομένα αξιολόγησης, ενώ ο οριζόντιος άξονα παριστάνει το ποσοστό των προτάσεων εκπαίδευσης που έχει χρησιμοποιηθεί για την εκπαίδευση του γλωσσικού μοντέλου. 11

12 3.2 Πειράματα με μοντέλα n-γραμμάτων ολόκληρων λέξεων Αρχικά εξετάστηκε η περιπλοκή γλωσσικών μοντέλων n-γραμμάτων (για n = 3, 4, 5), χρησιμοποιώντας ακέραιες λέξεις (π.χ. χωρίς αποκοπή καταλήξεων), με εξομάλυνση Good- Turing. Υπενθυμίζεται ότι όσο πιο μικρή είναι η περιπλοκή, τόσο καλύτερο είναι το γλωσσικό μοντέλο. Αρχικός στόχος ήταν να επιβεβαιωθεί η υπόθεσή μας ότι ένα μοντέλο n-γραμμάτων θα έχει χειρότερες επιδόσεις σε γλώσσες με πιο περίπλοκη μορφολογία (π.χ. ελληνικά, γερμανικά) και καλύτερες επιδόσεις σε γλώσσες με απλούστερη μορφολογία (π.χ. αγγλικά, ισπανικά), επειδή όσο πιο περίπλοκη μορφολογικά είναι μια γλώσσα (δηλαδή όσο πιο πολλούς τύπους διαθέτει κάθε λήμμα) τόσο πιο δύσκολη θα γίνεται η εκτίμηση των πιθανοτήτων των n- γραμμάτων (π.χ. θα αυξάνονται τα n-γράμματα των προτάσεων αξιολόγησης που δεν θα τα έχουμε συναντήσει κατά την εκπαίδευση). Τα επόμενα διαγράμματα παρουσιάζουν τα αποτελέσματα αυτών των πειραμάτων για μοντέλα 3-γραμμάτων, 4-γραμμάτων και 5-γραμμάτων, αντίστοιχα. Βλέπουμε ότι επιβεβαιώνεται η υπόθεσή μας. Η περιπλοκή των μοντέλων στα ελληνικά είναι πάντα χειρότερη (μεγαλύτερη) της περιπλοκής των ίδιων μοντέλων στα αγγλικά και τα ισπανικά. Ομοίως, η περιπλοκή των μοντέλων στα γερμανικά είναι πάντα χειρότερη της περιπλοκής στα αγγλικά και τα ισπανικά. Μεταξύ αγγλικών και ισπανικών, η διαφορά στην περιπλοκή είναι μικρή, ενώ μεταξύ γερμανικών και ελληνικών, η περιπλοκή είναι μεγαλύτερη στα γερμανικά, ενδεχομένως λόγω των πολύ περισσότερων σύνθετων λέξεων των γερμανικών. Επίσης, όπως θα περίμενε κανείς τα αποτελέσματα που επιτυγχάνουν τα μοντέλα 4-γραμμάτων είναι ελαφρά καλύτερα από τα αποτελέσματα των αντίστοιχων μοντέλων 3-γραμμάτων, αλλά οι διαφορές μεταξύ μοντέλων 4- γραμμάτων και 5-γραμμάτων είναι πολύ μικρές ή ανύπαρκτες. 12
, επειδή όσο πιο περίπλοκη μορφολογικά είναι μια γλώσσα (δηλαδή όσο πιο πολλούς τύπους διαθέτει κάθε λήμμα) τόσο πιο δύσκολη θα γίνεται η εκτίμηση των πιθανοτήτων των n-")
13 13
14 14

15 15

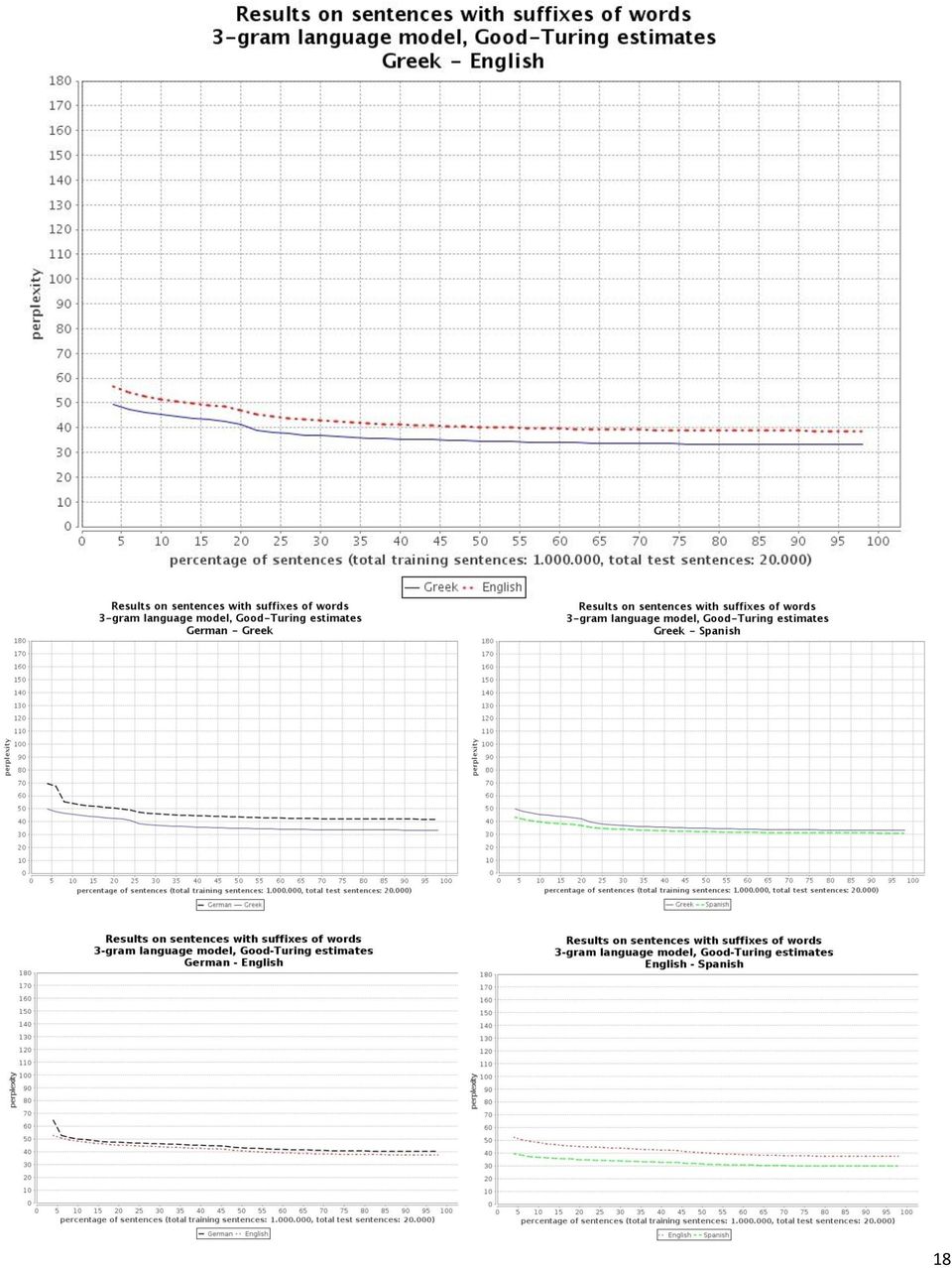
16 3.3 Πειράματα με μοντέλα n-γραμμάτων ψευδο-καταλήξεων Στα παρακάτω πειράματα μετρήθηκε η περιπλοκή των ίδιων μοντέλων n-γραμμάτων που είχαν χρησιμοποιηθεί και στην προηγούμενη ενότητα, αλλά τώρα τα μοντέλα εκπαιδεύονταν και αξιολογούνταν σε κείμενα στα οποία όλες οι λέξεις είχαν αντικατασταθεί από τις ψευδο-καταλήξεις τους (τελευταία τρία γράμματα). Ο σκοπός αυτών των πειραμάτων ήταν να επιβεβαιωθεί η υπόθεσή μας ότι στις μορφολογικά πιο περίπλοκες γλώσσες, οι καταλήξεις μεταφέρουν περισσότερη πληροφορία (π.χ. για το μέρος του λόγου, τον αριθμό, την πτώση κλπ. μιας κλιτής λέξης), με αποτέλεσμα να μπορεί κανείς να προβλέψει ευκολότερα (μικρότερη περιπλοκή) την κατάληξη της επόμενης λέξης από τις καταλήξεις των προηγούμενων λέξεων, σε σχέση με τις προβλέψεις που μπορεί να κάνει κανείς για τις καταλήξεις μορφολογικά πιο απλών γλωσσών. Αν η υπόθεση αυτή είναι σωστή, τότε ενδέχεται τα γλωσσικά μοντέλα καταλήξεων να δίνουν επίσης μια καλή εκτίμηση της φυσικότητας (πιθανότητας εμφάνισης) μιας ακολουθίας λέξεων, παρ όλο που δεν εξετάζουν τα θέματα των λέξεων. Για παράδειγμα, ένα μοντέλο 2-γραμμάτων ψευδο-καταλήξεων (ως τριών τελευταίων γραμμάτων) ενδεχομένως θα έδινε χαμηλή πιθανότητα στην λανθασμένη πρόταση: «Οι αναγνώστης διαβάζουν τα κείμενο» παρ όλο που εξετάζει μόνο τις καταλήξεις των λέξεων, δηλαδή την ακολουθία: «Οι της ουν τα ενο» αν τα ζεύγη διαδοχικών ψευδο-καταλήξεων «οι της», «της ουν», «τα ενο» είναι σπάνια. Κάτι τέτοιο θα ήταν ενδεχομένως χρήσιμο σε ένα σύστημα μηχανικής μετάφρασης που μεταφράζει προς τα ελληνικά, αφού το μοντέλο καταλήξεων θα μπορούσε να απορρίψει (λόγω χαμηλής πιθανότητας) τη λανθασμένη πρόταση, εξετάζοντας μόνο τις ψευδο-καταλήξεις των λέξεών της. Τα επόμενα διαγράμματα παρουσιάζουν τα αποτελέσματα αυτών των πειραμάτων για μοντέλα 3-γραμμάτων, 4-γραμμάτων και 5-γραμμάτων ψευδο-καταλήξεων. Τα αποτελέσματα δείχνουν ότι τα ελληνικά μοντέλα n-γραμμάτων καταλήξεων έχουν 16

17 καλύτερη (χαμηλότερη) περιπλοκή από τα αντίστοιχα των αγγλικών και είναι παρόμοια με των ισπανικών, δηλαδή επιβεβαιώνουν την υπόθεση ότι η πρόβλεψη καταλήξεων είναι ευκολότερη στα ελληνικά, συγκρινόμενη με την πρόβλεψη καταλήξεων στα αγγλικά και εξίσου εύκολη στα ισπανικά, ενώ αντίθετα η περιπλοκή των αντιστοίχων μοντέλων n-γραμμάτων ολόκληρων λέξεων ήταν χειρότερη (υψηλότερη) στα ελληνικά και καλύτερη στα αγγλικά και τα ισπανικά (βλ. διαγράμματα προηγούμενης ενότητας). Τα αποτελέσματα των επόμενων διαγραμμάτων δείχνουν, επίσης, ότι η περιπλοκή των μοντέλων n-γραμμάτων καταλήξεων είναι καλύτερη (χαμηλότερη) στα ελληνικά συγκρινόμενη με τα γερμανικά, κάτι που συνέβαινε και με τα μοντέλα n-γραμμάτων ολόκληρων λέξεων. Αντίθετα από την υπόθεσή μας, όμως, τα αποτελέσματα δείχνουν ότι η πρόβλεψη καταλήξεων στα μορφολογικά περίπλοκα γερμανικά δεν είναι ευκολότερη από την πρόβλεψη καταλήξεων στα μορφολογικά απλούστερα αγγλικά. Είναι επίσης σημαντικό να τονιστεί ότι τα αποτελέσματα περιπλοκής της προηγούμενης ενότητας (ολόκληρες λέξεις) δεν είναι απευθείας συγκρίσιμα με τα αποτελέσματα περιπλοκής αυτής της ενότητας (ψευδο-καταλήξεις), γιατί πρόκειται ουσιαστικά για μοντέλα διαφορετικών γλωσσών (π.χ. της γλώσσας των ελληνικών ψευδο-καταλήξεων, αντί της γλώσσας των ολόκληρων ελληνικών λέξεων). 17
 στα ελληνικά συγκρινόμενη με τα γερμανικά, κάτι που")
18 18
19 19

20 20

21 3.4 Πειράματα με μοντέλα n-γραμμάτων ψευδο-θεμάτων Στα παρακάτω πειράματα μετρήθηκε η περιπλοκή των ίδιων μοντέλων n-γραμμάτων που είχαν χρησιμοποιηθεί και στην προηγούμενη ενότητα, αλλά τώρα τα μοντέλα εκπαιδεύονταν και αξιολογούνταν σε κείμενα στα οποία όλες οι λέξεις είχαν αντικατασταθεί από τα ψευδο-θέματά τους (τα πρώτα τρία γράμματα). Ο σκοπός αυτών των πειραμάτων ήταν να διερευνηθεί αν κρατώντας μόνο τα ψευδο-θέματα των λέξεων (αγνοώντας, δηλαδή, προσεγγιστικά τις καταλήξεις) βελτιώνεται η περιπλοκή στις μορφολογικά περίπλοκες γλώσσες, όπου υπάρχουν πολλοί τύποι κάθε λήμματος, οι οποίοι διαφέρουν συχνά κυρίως στις καταλήξεις τους. Τα επόμενα διαγράμματα παρουσιάζουν τα αποτελέσματα αυτών των πειραμάτων για μοντέλα 3-γραμμάτων, 4-γραμμάτων και 5-γραμμάτων ψευδο-θεμάτων. Τα αποτελέσματα δείχνουν ότι, πράγματι, όταν λαμβάνονται υπόψη μόνο τα ψευδο-θέματα, η περιπλοκή στα ελληνικά είναι καλύτερη (χαμηλότερη) από την περιπλοκή στα (μορφολογικά απλούστερα) αγγλικά και ισπανικά, αντίθετα από ό,τι συνέβαινε στην περίπτωση των μοντέλων που εκπαιδεύονταν σε ολόκληρες λέξεις. Η διαφορά της περιπλοκής μεταξύ γερμανικών και αγγλικών επίσης μειώνεται πολύ, όταν χρησιμοποιούνται ψευδο-θέματα αντί για ολόκληρες λέξεις. Και πάλι, όμως, είναι σημαντικό να τονιστεί ότι τα αποτελέσματα περιπλοκής αυτής και των προηγούμενων δύο ενοτήτων (ολόκληρες λέξεις, ψευδο-καταλήξεις, ψευδο-θέματα) δεν είναι απευθείας συγκρίσιμα, γιατί πρόκειται ουσιαστικά για μοντέλα διαφορετικών γλωσσών (π.χ. της γλώσσας των ελληνικών ψευδο-θεμάτων ή ψευδο-καταλήξεων, αντί της γλώσσας των ολόκληρων ελληνικών λέξεων). 21
22 22
23 23
24 24
25 3.5 Πειράματα με τον πιθανοτικό ταξινομητή του Lang Στα πειράματα αυτής της ενότητας επαναλήφθηκαν τα πειράματα με τις ολόκληρες λέξεις, αλλά αυτή τη φορά χρησιμοποιώντας το μοντέλο του Lang (2011). Το μοντέλο αυτό είναι παρόμοιο με ένα μοντέλο n-γραμμάτων, αλλά χρησιμοποιεί έναν πιθανοτικό ταξινομητή, παρόμοιο με ταξινομητή μεγίστης εντροπίας (maximum entropy), για να υπολογίζει τις πιθανότητες ( ). Ο ταξινομητής εκτιμά κάθε ( ), δηλαδή εκτιμά πόσο πιθανό είναι να εμφανιστεί η λέξη μετά την «ιστορία», βασιζόμενος σε χαρακτηριστικά (features) που εξάγονται από τις λέξεις της ιστορίας αλλά και από τα ευρύτερα συμφραζόμενα της δείτε την εργασία του Lang (2011) για περισσότερες πληροφορίες. Ο Lang (2011) έχει δημοσιεύσει αποτελέσματα που δείχνουν ότι το μοντέλο του επιτυγχάνει καλύτερες επιδόσεις από εκείνες των κλασικών μοντέλων n-γραμμάτων. Θέλαμε να επιβεβαιώσουμε το συμπέρασμα αυτό, αλλά και να διερευνήσουμε τις επιδόσεις του μοντέλου του Lang σε μορφολογικά περίπλοκες γλώσσες. Τα επόμενα διαγράμματα παρουσιάζουν τα αποτελέσματα αυτών των πειραμάτων για μοντέλα 3-γραμμάτων, 4-γραμμάτων και 5-γραμμάτων ολόκληρων λέξεων με το μοντέλο του Lang. Τα αποτελέσματα φαίνεται να επιβεβαιώνουν τους ισχυρισμούς του Lang. Για παράδειγμα, η περιπλοκή των ελληνικών όταν χρησιμοποιούνται 3-γράμματα καταλήγει να είναι περίπου 40 με το μοντέλο του Lang, ενώ η αντίστοιχη τιμή με το κλασικό μοντέλο n-γραμμάτων ολόκληρων λέξεων ήταν περίπου 70. Μάλιστα η περιπλοκή των ελληνικών φαίνεται να είναι καλύτερη (χαμηλότερη) της περιπλοκής των αγγλικών. Σημειώνουμε, όμως, ότι το μοντέλο του Lang χρησιμοποιεί ένα περιορισμένο λεξιλόγιο, το οποίο επιλέγεται κατά την εκπαίδευση, ώστε να περιλαμβάνει μόνο συχνές λέξεις. 4 Όποια λέξη δεν ανήκει στο λεξιλόγιο, αντικαθίσταται από την ψευδο-λέξη UNK (unknown, άγνωστη). Με τον τρόπο αυτό, όμως, κατασκευάζεται ουσιαστικά ένα γλωσσικό μοντέλο για απλοποιημένες γλώσσες, στις οποίες οι πιο σπάνιες λέξεις έχουν 4 Στα πειράματα αυτής της ενότητας, το λεξιλόγιο επελέγη από προτάσεις που δεν είχαν χρησιμοποιηθεί ούτε για εκπαίδευση ούτε για αξιολόγηση. 25
26 αντικατασταθεί με UNK. Σε μορφολογικά περίπλοκες γλώσσες όπως τα ελληνικά, μάλιστα, οι σπάνιες λέξεις είναι περισσότερες, επειδή τα λήμματα έχουν περισσότερους τύπους, με αποτέλεσμα να αντικαθίστανται περισσότερες λέξεις με UNK και η απλοποίηση να γίνεται εντονότερη. Επομένως τα αποτελέσματα περιπλοκής των παρακάτω πειραμάτων δεν είναι άμεσα συγκρίσιμα με τα αποτελέσματα της ενότητας 3.2, στην οποία είχαμε μετρήσει την περιπλοκή των κλασικών μοντέλων n-γραμμάτων ολόκληρων λέξεων. Προκειμένου να είναι πιο άμεσα συγκρίσιμα τα αποτελέσματα της μεθόδου του Lang με τα αντίστοιχα αποτελέσματα των κλασικών μοντέλων n-γραμμάτων, επαναλάβαμε στην επόμενη ενότητα τα πειράματα των κλασικών μοντέλων n-γραμμάτων με ολόκληρες λέξεις, χρησιμοποιώντας το ίδιο λεξιλόγιο με εκείνο της μεθόδου του Lang, δηλαδή αντικαθιστώντας τις (ίδιες) σπάνιες λέξεις με UNK. 26
27 27
28 28
29 29
30 3.6 Πειράματα με μοντέλα n-γραμμάτων ολόκληρων λέξεων και περιορισμένο λεξιλόγιο Στα πειράματα αυτής της ενότητας, επαναλάβαμε τα πειράματα των κλασικών μοντέλων n-γραμμάτων ολόκληρων λέξεων, χρησιμοποιώντας το ίδιο λεξιλόγιο με εκείνο της μεθόδου του Lang (βλ. προηγούμενη ενότητα), δηλαδή αντικαθιστώντας τις (ίδιες) σπάνιες λέξεις με UNK. Τα επόμενα διαγράμματα παρουσιάζουν τα αποτελέσματα αυτών των πειραμάτων για κλασικά μοντέλα 3-γραμμάτων, 4-γραμμάτων και 5-γραμμάτων ολόκληρων λέξεων με περιορισμένο λεξιλόγιο. Παρατηρούμε ότι η χρήση περιορισμένου λεξιλογίου μειώνει σημαντικά την τιμή της περιπλοκής. Για παράδειγμα, στη σύγκριση ελληνικών αγγλικών χρησιμοποιώντας κλασικά γλωσσικά μοντέλα 5-γραμμάτων, η τιμή της περιπλοκής στα ελληνικά χωρίς της χρήση περιορισμένου λεξιλογίου κατέληγε περίπου στο 78, ενώ με τη χρήση περιορισμένου λεξιλογίου περίπου στο 35. Σε σχέση με το μοντέλο του Lang, η περιπλοκή των κλασικών μοντέλων n-γραμμάτων (με περιορισμένο λεξιλόγιο) είναι ελαφρά μόνο χειρότερη, όμως ο χρόνος εκτέλεσης των πειραμάτων με τα κλασικά μοντέλα n-γραμμάτων ήταν 10 φορές μικρότερος σε σχέση με το μοντέλο του Lang, επειδή το τελευταίο απαιτεί περισσότερο χρόνο για την εκπαίδευση και χρήση του πιθανοτικού ταξινομητή. Συμπεραίνουμε ότι οι βελτιώσεις στα αποτελέσματα περιπλοκής που είχε παρατηρήσει ο Lang, όταν συνέκρινε το μοντέλο του με κλασικό μοντέλο n-γραμμάτων, οφείλονται σε πολύ μεγάλο βαθμό στη χρήση περιορισμένου λεξιλογίου πολύ παρόμοιες βελτιώσεις στα αποτελέσματα της περιπλοκής παρατηρούνται και στην περίπτωση κλασικών μοντέλων n-γραμμάτων όταν χρησιμοποιηθεί και σε εκείνα περιορισμένο λεξιλόγιο. 30
31 31
32 32
33 33
34 4. Πειράματα αξιολόγησης γλωσσικών μοντέλων μέσω ενσωμάτωσής τους σε συστήματα μηχανικής μετάφρασης Στο προηγούμενο κεφάλαιο αξιολογήθηκαν γλωσσικά μοντέλα διαφόρων ειδών μετρώντας την περιπλοκή τους. Ένας άλλος τρόπος (έμμεσης) αξιολόγησης των γλωσσικών μοντέλων είναι να εξετάσουμε κατά πόσον βελτιώνουν τις παραγόμενες μεταφράσεις, όταν τα γλωσσικά μοντέλα ενσωματώνονται σε συστήματα μηχανικής μετάφρασης. Ένα ευρέως διαδεδομένο σύστημα στατιστικής μηχανικής μετάφρασης είναι το MOSES (Koehn κ.ά., 2003). Το MOSES απαιτεί παράλληλα σώματα κειμένων εκπαίδευσης, δηλαδή σώματα κειμένων στα οποία τα ίδια κείμενα αποδίδονται σε πολλές γλώσσες επίσης οι προτάσεις της κάθε γλώσσας είναι ευθυγραμμισμένες με τις αντίστοιχες προτάσεις των άλλων γλωσσών, αλλά δεν είναι γνωστή η ευθυγράμμιση μικρότερων φράσεων ή λέξεων. Η χρήση του MOSES χωρίζεται σε τρία στάδια: το στάδιο της εκπαίδευσης, κατά το οποίο ευθυγραμμίζονται λέξεις και φράσεις των παράλληλων κειμένων εκπαίδευσης και το σύστημα εκτιμά τις κατανομές πιθανοτήτων που χρειάζεται το μεταφραστικό μοντέλο, το στάδιο επιλογής βαρών, κατά το οποίο το σύστημα εκτιμά τα βάρη που πρέπει να δώσει στην απόκριση του γλωσσικού μοντέλου, καθώς και σε ιδιότητες του μεταφραστικού μοντέλου και άλλων εμπλεκόμενων μοντέλων, που συνδυάζονται με ένα γραμμικό συνδυασμό των λογαρίθμων τους, και το στάδιο της μετάφρασης, κατά το οποίο το σύστημα καλείται να μεταφράσει νέα κείμενα. 5 Για την αξιολόγηση των μεταφράσεων, χρησιμοποιείται ο δείκτης BLEU (Papineni κ.ά., 2002), ο οποίος συγκρίνει τις μεταφράσεις του αξιολογούμενου συστήματος με τις αντίστοιχες μεταφράσεις ανθρώπων-μεταφραστών, μετρώντας χοντρικά τα κοινά τους 4-γράμματα, 3-γράμματα, 2-γράμματα και 1-γράμματα. 5 Βλ. για περισσότερες πληροφορίες. 34
35 4.1 Πειράματα Το σώμα κειμένων που χρησιμοποιήθηκε στα πειράματα αυτού του κεφαλαίου ήταν το ίδιο με εκείνο του 3 ου Κεφαλαίου, δηλαδή χρησιμοποιήθηκαν κείμενα του Ευρωπαϊκού Κοινοβουλίου. Για την εκπαίδευση του κάθε μεταφραστικού μοντέλου του MOSES χρησιμοποιήθηκαν παράλληλες προτάσεις, το 10% δηλαδή των προτάσεων που είχαν χρησιμοποιηθεί στα πειράματα του 3 ου Κεφαλαίου η μείωση αυτή ήταν απαραίτητη, επειδή ο χρόνος εκπαίδευσης των μεταφραστικών μοντέλων του MOSES ήταν ιδιαίτερα μεγάλος. Παρ όλα αυτά τα γλωσσικά μοντέλα εκπαιδεύτηκαν σε προτάσεις, όπως στο 3 ο Κεφάλαιο. Στο στάδιο της επιλογής βαρών του MOSES χρησιμοποιήθηκαν παράλληλες προτάσεις, οι οποίες δεν χρησιμοποιήθηκαν για κανέναν άλλο σκοπό. Τέλος, για τον υπολογισμό του δείκτη BLEU χρησιμοποιήθηκαν παράλληλες προτάσεις, οι οποίες επίσης δεν είχαν χρησιμοποιηθεί για άλλους σκοπούς. Τα ζεύγη γλωσσών (γλώσσα-πηγή, γλώσσα-στόχος) για τα οποία μετρήθηκε ο δείκτης BLEU ήταν: σε Γερμανικά σε Γερμανικά σε. Τα πειράματα έγιναν ενσωματώνοντας στο MOSES τα παρακάτω γλωσσικά μοντέλα το «+» χρησιμοποιείται σε περιπτώσεις όπου ενσωματώθηκαν στο MOSES περισσότερα του ενός γλωσσικά μοντέλα μαζί και το n είχε τιμές 3, 4 ή 5. μοντέλο n-γραμμάτων ολόκληρων λέξεων μοντέλο n-γραμμάτων ψευδο-καταλήξεων μοντέλο n-γραμμάτων ψευδο-θεμάτων μοντέλο n-γραμμάτων ψευδο-θεμάτων + μοντέλο n-γραμμάτων ψευδοκαταλήξεων μοντέλο n-γραμμάτων ολόκληρων λέξεων + μοντέλο n-γραμμάτων ψευδοκαταλήξεων 35
36 μοντέλο n-γραμμάτων ολόκληρων λέξεων + μοντέλο n-γραμμάτων ψευδοθεμάτων μοντέλο n-γραμμάτων ολόκληρων λέξεων + μοντέλο n-γραμμάτων ψευδοθεμάτων + μοντέλο n-γραμμάτων ψευδο-καταλήξεων. Μετρήθηκε επίσης ο δείκτης BLEU στην περίπτωση όπου το MOSES χρησιμοποιείται χωρίς γλωσσικό μοντέλο Πειράματα χωρίς γλωσσικό μοντέλο Στον παρακάτω πίνακα φαίνονται τα αποτελέσματα BLEU χωρίς της χρήση γλωσσικού μοντέλου. Αποτελέσματα BLEU χωρίς την χρήση γλωσσικού μοντέλου σε Γερμανικά σε Γερμανικά σε Από τη σύγκριση του παραπάνω πίνακα με τους πίνακες των επόμενων ενοτήτων προκύπτει ότι οι μεταφράσεις που παράγει το MOSES χωρίς γλωσσικό μοντέλο δεν είναι καθόλου καλές. Επίσης, τα αποτελέσματα BLEU είναι καλύτερα όταν η γλώσσα-στόχος (για την οποία χρησιμοποιείται συνήθως το γλωσσικό μοντέλο) είναι μορφολογικά απλούστερη. 36
37 4.1.2 Πειράματα με μοντέλο n-γραμμάτων ολόκληρων λέξεων Στα πειράματα αυτά ενσωματώσαμε στο MOSES γλωσσικό μοντέλο n-γραμμάτων ολόκληρων λέξεων (για n = 3, 4, 5). Αυτού του είδους τα μοντέλα είναι τα πιο διαδεδομένα στη μηχανική μετάφραση. Παρακάτω φαίνονται τα αποτελέσματα BLEU που προέκυψαν. Αποτελέσματα BLEU με μοντέλα n-γραμμάτων ολόκληρων λέξεων σε Γερμανικά σε Γερμανικά σε n = 3 n = 4 n = Στο παρακάτω διάγραμμα συγκρίνονται τα αποτελέσματα BLEU του MOSES χωρίς γλωσσικό μοντέλο (baseline) και με γλωσσικό μοντέλο n-γραμμάτων ολόκληρων λέξεων (για n = 5). Όπως θα περίμενε κανείς, η προσθήκη γλωσσικού μοντέλου βελτιώνει αισθητά τα αποτελέσματα. 37
38 Moses results comparison B L E U Baseline LM with entire words 0 en to el de to el es to el de to en es to en Πειράματα με μοντέλο n-γραμμάτων ψευδο-καταλήξεων Στα πειράματα αυτά ενσωματώσαμε στο MOSES γλωσσικό μοντέλο n-γραμμάτων ψευδο-καταλήξεων (για n = 3, 4, 5). Θέλαμε να εξετάσουμε αν η χρησιμοποίηση γλωσσικών μοντέλων ψευδο-καταλήξεων μπορεί να βοηθήσει ή και να αντικαταστήσει τα γλωσσικά μοντέλα ολόκληρων λέξεων. Για την πραγματοποίηση αυτών των πειραμάτων, στο κάθε σώμα κειμένων (σώμα εκπαίδευσης, σώμα επιλογής βαρών, σώμα αξιολόγησης) προστέθηκαν ως παράγοντες (factors) οι ψευδοκαταλήξεις των λέξεων, ώστε το MOSES να επιλέγει τις ψευδο-καταλήξεις όταν θέλει να «συμβουλευτεί» το γλωσσικό μοντέλο ψευδο-καταλήξεων. Παρακάτω φαίνονται τα αποτελέσματα BLEU που προέκυψαν. 38
39 Αποτελέσματα BLEU με μοντέλα n-γραμμάτων ψευδο-καταλήξεων σε Γερμανικά σε Γερμανικά σε n = 3 n = 4 n = Στα παρακάτω διαγράμματα συγκρίνονται τα αποτελέσματα BLEU του MOSES με γλωσσικό μοντέλο n-γραμμάτων ολόκληρων λέξεων και με γλωσσικό μοντέλο n- γραμμάτων ψευδο-καταλήξεων (για n = 5). Παρατηρούμε ότι τα γλωσσικά μοντέλα ολόκληρων λέξεων οδηγούν σε καλύτερα αποτελέσματα BLEU, αλλά η διαφορά από τα αποτελέσματα που επιτυγχάνονται με γλωσσικά μοντέλα ψευδο-καταλήξεων είναι μικρή, κάτι που είναι ενδιαφέρον, δεδομένου ότι τα μοντέλα ψευδο-καταλήξεων εξετάζουν μόνο τα τρία τελευταία γράμματα κάθε λέξης. 39
40 30 MOSES results comparison 25 B L E U LM with entire words LM with suffixes 5 0 σε Γερμανικά σε 35 MOSES results comparison B L E U LM with entire words LM with suffixes 0 Γερμανικά σε 40
41 4.1.4 Πειράματα με μοντέλο n-γραμμάτων ψευδο-θεμάτων Στα πειράματα αυτά ενσωματώσαμε στο MOSES γλωσσικό μοντέλο n-γραμμάτων ψευδο-θεμάτων (για n = 3, 4, 5). Θέλαμε να εξετάσουμε αν η χρησιμοποίηση γλωσσικών μοντέλων ψευδο-θεμάτων μπορεί να βοηθήσει ή και να αντικαταστήσει τα γλωσσικά μοντέλα ολόκληρων λέξεων. Παρακάτω φαίνονται τα αποτελέσματα BLEU που προέκυψαν. Αποτελέσματα BLEU με μοντέλα n-γραμμάτων ψευδο-θεμάτων σε Γερμανικά σε Γερμανικά σε n = 3 n = 4 n = Στα παρακάτω διαγράμματα συγκρίνονται τα αποτελέσματα BLEU του MOSES με γλωσσικό μοντέλο n-γραμμάτων ολόκληρων λέξεων και με γλωσσικό μοντέλο n- γραμμάτων ψευδο-θεμάτων (για n = 5). Παρατηρούμε ότι τα γλωσσικά μοντέλα ολόκληρων λέξεων οδηγούν και πάλι σε καλύτερα αποτελέσματα BLEU, αλλά η διαφορά από τα αποτελέσματα που επιτυγχάνονται με γλωσσικά μοντέλα ψευδοθεμάτων είναι μικρή. 41
Ασκήσεις μελέτης της 16 ης διάλεξης
 Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 16 ης διάλεξης 16.1. (α) Έστω ένα αντικείμενο προς κατάταξη το οποίο
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 16 ης διάλεξης 16.1. (α) Έστω ένα αντικείμενο προς κατάταξη το οποίο
Επικοινωνία Ανθρώπου Υπολογιστή
 Επικοινωνία Ανθρώπου Υπολογιστή Β1. Εισαγωγή στη γλωσσική τεχνολογία, γλωσσικά μοντέλα, διόρθωση και πρόβλεψη κειμένου (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ Οι διαφάνειες αυτές βασίζονται
Επικοινωνία Ανθρώπου Υπολογιστή Β1. Εισαγωγή στη γλωσσική τεχνολογία, γλωσσικά μοντέλα, διόρθωση και πρόβλεψη κειμένου (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ Οι διαφάνειες αυτές βασίζονται
Γλωσσική Τεχνολογία. Εισαγωγή. Ίων Ανδρουτσόπουλος.
 Γλωσσική Τεχνολογία Εισαγωγή 2015 16 Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/in/ Τι θα ακούσετε Εισαγωγή στη γλωσσική τεχνολογία. Ύλη και οργάνωση του μαθήματος. Προαπαιτούμενες γνώσεις και άλλα προτεινόμενα
Γλωσσική Τεχνολογία Εισαγωγή 2015 16 Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/in/ Τι θα ακούσετε Εισαγωγή στη γλωσσική τεχνολογία. Ύλη και οργάνωση του μαθήματος. Προαπαιτούμενες γνώσεις και άλλα προτεινόμενα
Ανάλυση Δεδομένων με χρήση του Στατιστικού Πακέτου R
 Ανάλυση Δεδομένων με χρήση του Στατιστικού Πακέτου R, Επίκουρος Καθηγητής, Τομέας Μαθηματικών, Σχολή Εφαρμοσμένων Μαθηματικών και Φυσικών Επιστημών, Εθνικό Μετσόβιο Πολυτεχνείο. Περιεχόμενα Εισαγωγή στο
Ανάλυση Δεδομένων με χρήση του Στατιστικού Πακέτου R, Επίκουρος Καθηγητής, Τομέας Μαθηματικών, Σχολή Εφαρμοσμένων Μαθηματικών και Φυσικών Επιστημών, Εθνικό Μετσόβιο Πολυτεχνείο. Περιεχόμενα Εισαγωγή στο
Τεχνητή Νοημοσύνη. 18η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 18η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Machine Learning του T. Mitchell, McGraw- Hill, 1997,
Τεχνητή Νοημοσύνη 18η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Machine Learning του T. Mitchell, McGraw- Hill, 1997,
Η εξέλιξη στα συστήματα Μηχανικής Μετάφρασης
 Η εξέλιξη στα συστήματα Μηχανικής Μετάφρασης Σοφιανόπουλος Σωκράτης Ινστιτούτο Επεξεργασίας του Λόγου Δομή παρουσίασης Τι είναι η Μηχανική Μετάφραση (Machine Translation) Ιστορική αναδρομή Είδη συστημάτων
Η εξέλιξη στα συστήματα Μηχανικής Μετάφρασης Σοφιανόπουλος Σωκράτης Ινστιτούτο Επεξεργασίας του Λόγου Δομή παρουσίασης Τι είναι η Μηχανική Μετάφραση (Machine Translation) Ιστορική αναδρομή Είδη συστημάτων
Τεχνητή Νοημοσύνη. 21η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 21η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται στα βιβλία: «Artificial Intelligence A Modern Approach» των. Russel
Τεχνητή Νοημοσύνη 21η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται στα βιβλία: «Artificial Intelligence A Modern Approach» των. Russel
1.1 ΔΕΙΓΜΑΤΙΚΟΙ ΧΩΡΟΙ ΕΝΔΕΧΟΜΕΝΑ
 ΚΕΦΑΛΑΙΟ : ΠΙΘΑΝΟΤΗΤΕΣ. ΔΕΙΓΜΑΤΙΚΟΙ ΧΩΡΟΙ ΕΝΔΕΧΟΜΕΝΑ Αιτιοκρατικό πείραμα ονομάζουμε κάθε πείραμα για το οποίο, όταν ξέρουμε τις συνθήκες κάτω από τις οποίες πραγματοποιείται, μπορούμε να προβλέψουμε με
ΚΕΦΑΛΑΙΟ : ΠΙΘΑΝΟΤΗΤΕΣ. ΔΕΙΓΜΑΤΙΚΟΙ ΧΩΡΟΙ ΕΝΔΕΧΟΜΕΝΑ Αιτιοκρατικό πείραμα ονομάζουμε κάθε πείραμα για το οποίο, όταν ξέρουμε τις συνθήκες κάτω από τις οποίες πραγματοποιείται, μπορούμε να προβλέψουμε με
ΕΙΣΑΓΩΓΗ σ. 2 Α. ΕΡΕΥΝΑ ΚΑΙ ΕΠΕΞΕΡΓΑΣΙΑ Ε ΟΜΕΝΩΝ 2
 1 Π Ε Ρ Ι Ε Χ Ο Μ Ε Ν Α ΕΙΣΑΓΩΓΗ σ. 2 Α. ΕΡΕΥΝΑ ΚΑΙ ΕΠΕΞΕΡΓΑΣΙΑ Ε ΟΜΕΝΩΝ 2 Β. ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΚΑΙ ΕΡΕΥΝΑ 1. Γενικά Έννοιες.. 2 2. Πρακτικός Οδηγός Ανάλυσης εδοµένων.. 4 α. Οδηγός Λύσεων στο πλαίσιο
1 Π Ε Ρ Ι Ε Χ Ο Μ Ε Ν Α ΕΙΣΑΓΩΓΗ σ. 2 Α. ΕΡΕΥΝΑ ΚΑΙ ΕΠΕΞΕΡΓΑΣΙΑ Ε ΟΜΕΝΩΝ 2 Β. ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΚΑΙ ΕΡΕΥΝΑ 1. Γενικά Έννοιες.. 2 2. Πρακτικός Οδηγός Ανάλυσης εδοµένων.. 4 α. Οδηγός Λύσεων στο πλαίσιο
Γλωσσική Τεχνολογία. 8 η Ενότητα: Μηχανική μετάφραση. Ίων Ανδρουτσόπουλος. http://www.aueb.gr/users/ion/
 Γλωσσική Τεχνολογία 8 η Ενότητα: Μηχανική μετάφραση 2014 15 Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/in/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται στην ύλη του βιβλίου «Speech and Language Prcessing»
Γλωσσική Τεχνολογία 8 η Ενότητα: Μηχανική μετάφραση 2014 15 Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/in/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται στην ύλη του βιβλίου «Speech and Language Prcessing»
Τεχνητή Νοημοσύνη. 16η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 16η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται σε ύλη του βιβλίου Artificial Intelligence A Modern Approach των
Τεχνητή Νοημοσύνη 16η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται σε ύλη του βιβλίου Artificial Intelligence A Modern Approach των
3.1 ΔΕΙΓΜΑΤΙΚΟΙ ΧΩΡΟΙ ΕΝΔΕΧΟΜΕΝΑ
 ΚΕΦΑΛΑΙΟ : ΠΙΘΑΝΟΤΗΤΕΣ. ΔΕΙΓΜΑΤΙΚΟΙ ΧΩΡΟΙ ΕΝΔΕΧΟΜΕΝΑ Αιτιοκρατικό πείραμα ονομάζουμε κάθε πείραμα για το οποίο, όταν ξέρουμε τις συνθήκες κάτω από τις οποίες πραγματοποιείται, μπορούμε να προβλέψουμε με
ΚΕΦΑΛΑΙΟ : ΠΙΘΑΝΟΤΗΤΕΣ. ΔΕΙΓΜΑΤΙΚΟΙ ΧΩΡΟΙ ΕΝΔΕΧΟΜΕΝΑ Αιτιοκρατικό πείραμα ονομάζουμε κάθε πείραμα για το οποίο, όταν ξέρουμε τις συνθήκες κάτω από τις οποίες πραγματοποιείται, μπορούμε να προβλέψουμε με
Γ. Πειραματισμός Βιομετρία
 Γενικά Συσχέτιση και Συμμεταβολή Όταν σε ένα πείραμα παραλλάσουν ταυτόχρονα δύο μεταβλητές, τότε ενδιαφέρει να διερευνηθεί εάν και πως οι αλλαγές στη μία μεταβλητή σχετίζονται με τις αλλαγές στην άλλη.
Γενικά Συσχέτιση και Συμμεταβολή Όταν σε ένα πείραμα παραλλάσουν ταυτόχρονα δύο μεταβλητές, τότε ενδιαφέρει να διερευνηθεί εάν και πως οι αλλαγές στη μία μεταβλητή σχετίζονται με τις αλλαγές στην άλλη.
ΑΣΚΗΣΕΙΣ ΠΙΘΑΝΟΤΗΤΩΝ του Παν. Λ. Θεοδωρόπουλου 0
 ΑΣΚΗΣΕΙΣ ΠΙΘΑΝΟΤΗΤΩΝ του Παν. Λ. Θεοδωρόπουλου 0 Η Θεωρία Πιθανοτήτων είναι ένας σχετικά νέος κλάδος των Μαθηματικών, ο οποίος παρουσιάζει πολλά ιδιαίτερα χαρακτηριστικά στοιχεία. Επειδή η ιδιαιτερότητα
ΑΣΚΗΣΕΙΣ ΠΙΘΑΝΟΤΗΤΩΝ του Παν. Λ. Θεοδωρόπουλου 0 Η Θεωρία Πιθανοτήτων είναι ένας σχετικά νέος κλάδος των Μαθηματικών, ο οποίος παρουσιάζει πολλά ιδιαίτερα χαρακτηριστικά στοιχεία. Επειδή η ιδιαιτερότητα
Ασκήσεις μελέτης της 4 ης διάλεξης. ), για οποιοδήποτε μονοπάτι n 1
, για οποιοδήποτε μονοπάτι n 1") Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 4 ης διάλεξης 4.1. (α) Αποδείξτε ότι αν η h είναι συνεπής, τότε h(n
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 4 ης διάλεξης 4.1. (α) Αποδείξτε ότι αν η h είναι συνεπής, τότε h(n
Τυχαία μεταβλητή (τ.μ.)
") Τυχαία μεταβλητή (τ.μ.) Τυχαία μεταβλητή (τ.μ.) είναι μια συνάρτηση X ( ) με πεδίο ορισμού το δειγματικό χώρο Ω του πειράματος και πεδίο τιμών ένα υποσύνολο πραγματικών αριθμών που συμβολίζουμε συνήθως
Τυχαία μεταβλητή (τ.μ.) Τυχαία μεταβλητή (τ.μ.) είναι μια συνάρτηση X ( ) με πεδίο ορισμού το δειγματικό χώρο Ω του πειράματος και πεδίο τιμών ένα υποσύνολο πραγματικών αριθμών που συμβολίζουμε συνήθως
Σχεδιασμός και Διεξαγωγή Πειραμάτων
 Σχεδιασμός και Διεξαγωγή Πειραμάτων Πρώτο στάδιο: λειτουργικοί ορισμοί της ανεξάρτητης και της εξαρτημένης μεταβλητής Επιλογή της ανεξάρτητης μεταβλητής Επιλέγουμε μια ανεξάρτητη μεταβλητή (ΑΜ), την οποία
Σχεδιασμός και Διεξαγωγή Πειραμάτων Πρώτο στάδιο: λειτουργικοί ορισμοί της ανεξάρτητης και της εξαρτημένης μεταβλητής Επιλογή της ανεξάρτητης μεταβλητής Επιλέγουμε μια ανεξάρτητη μεταβλητή (ΑΜ), την οποία
Ανάλυση διακύμανσης (Μέρος 1 ο ) 17/3/2017
 17/3/2017") Ανάλυση διακύμανσης (Μέρος 1 ο ) 17/3/2017 2 Γιατί ανάλυση διακύμανσης; (1) Ας θεωρήσουμε k πληθυσμούς με μέσες τιμές μ 1, μ 2,, μ k, αντίστοιχα Πως μπορούμε να συγκρίνουμε τις μέσες τιμές k πληθυσμών
Ανάλυση διακύμανσης (Μέρος 1 ο ) 17/3/2017 2 Γιατί ανάλυση διακύμανσης; (1) Ας θεωρήσουμε k πληθυσμούς με μέσες τιμές μ 1, μ 2,, μ k, αντίστοιχα Πως μπορούμε να συγκρίνουμε τις μέσες τιμές k πληθυσμών
Θεωρία Πληροφορίας. Διάλεξη 4: Διακριτή πηγή πληροφορίας χωρίς μνήμη. Δρ. Μιχάλης Παρασκευάς Επίκουρος Καθηγητής
 Θεωρία Πληροφορίας Διάλεξη 4: Διακριτή πηγή πληροφορίας χωρίς μνήμη Δρ. Μιχάλης Παρασκευάς Επίκουρος Καθηγητής 1 Ατζέντα Διακριτή πηγή πληροφορίας χωρίς μνήμη Ποσότητα πληροφορίας της πηγής Κωδικοποίηση
Θεωρία Πληροφορίας Διάλεξη 4: Διακριτή πηγή πληροφορίας χωρίς μνήμη Δρ. Μιχάλης Παρασκευάς Επίκουρος Καθηγητής 1 Ατζέντα Διακριτή πηγή πληροφορίας χωρίς μνήμη Ποσότητα πληροφορίας της πηγής Κωδικοποίηση
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #08 Συµπίεση Κειµένων Φοίβος Μυλωνάς fmylonas@ionio.gr Ανάκτηση Πληροφορίας 1 Άδεια χρήσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #08 Συµπίεση Κειµένων Φοίβος Μυλωνάς fmylonas@ionio.gr Ανάκτηση Πληροφορίας 1 Άδεια χρήσης
Τεχνητή Νοημοσύνη. 4η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 4η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται κυρίως στα βιβλία Τεχνητή Νοημοσύνη των Βλαχάβα κ.ά., 3η έκδοση, Β.
Τεχνητή Νοημοσύνη 4η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται κυρίως στα βιβλία Τεχνητή Νοημοσύνη των Βλαχάβα κ.ά., 3η έκδοση, Β.
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ. Λογική. Δημήτρης Πλεξουσάκης
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Λογική Δημήτρης Πλεξουσάκης 2ο μέρος σημειώσεων: Συστήματα Αποδείξεων για τον ΠΛ, Μορφολογική Παραγωγή, Κατασκευή Μοντέλων Τμήμα Επιστήμης Υπολογιστών Άδειες Χρήσης
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Λογική Δημήτρης Πλεξουσάκης 2ο μέρος σημειώσεων: Συστήματα Αποδείξεων για τον ΠΛ, Μορφολογική Παραγωγή, Κατασκευή Μοντέλων Τμήμα Επιστήμης Υπολογιστών Άδειες Χρήσης
 Β Γραφικές παραστάσεις - Πρώτο γράφημα Σχεδιάζοντας το μήκος της σανίδας συναρτήσει των φάσεων της σελήνης μπορείτε να δείτε αν υπάρχει κάποιος συσχετισμός μεταξύ των μεγεθών. Ο συνήθης τρόπος γραφικής
Β Γραφικές παραστάσεις - Πρώτο γράφημα Σχεδιάζοντας το μήκος της σανίδας συναρτήσει των φάσεων της σελήνης μπορείτε να δείτε αν υπάρχει κάποιος συσχετισμός μεταξύ των μεγεθών. Ο συνήθης τρόπος γραφικής
Κεφάλαιο 9. Έλεγχοι υποθέσεων
 Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
ΛΟΓΙΣΜΟΣ ΜΙΑΣ ΜΕΤΑΒΛΗΤΗΣ, ΕΣΠΙ 1
 ΛΟΓΙΣΜΟΣ ΜΙΑΣ ΜΕΤΑΒΛΗΤΗΣ, ΕΣΠΙ 1 ΣΥΝΑΡΤΗΣΕΙΣ Η έννοια της συνάρτησης είναι θεμελιώδης στο λογισμό και διαπερνά όλους τους μαθηματικούς κλάδους. Για το φοιτητή είναι σημαντικό να κατανοήσει πλήρως αυτή
ΛΟΓΙΣΜΟΣ ΜΙΑΣ ΜΕΤΑΒΛΗΤΗΣ, ΕΣΠΙ 1 ΣΥΝΑΡΤΗΣΕΙΣ Η έννοια της συνάρτησης είναι θεμελιώδης στο λογισμό και διαπερνά όλους τους μαθηματικούς κλάδους. Για το φοιτητή είναι σημαντικό να κατανοήσει πλήρως αυτή
5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο
 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο") 5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο Ένα εναλλακτικό μοντέλο της απλής γραμμικής παλινδρόμησης (που χρησιμοποιήθηκε
5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο Ένα εναλλακτικό μοντέλο της απλής γραμμικής παλινδρόμησης (που χρησιμοποιήθηκε
Ανάπτυξη συστήματος ερωταποκρίσεων για αρχεία ελληνικών εφημερίδων
 Ανάπτυξη συστήματος ερωταποκρίσεων για αρχεία ελληνικών εφημερίδων Οικονομικό Πανεπιστήμιο Αθηνών Πρόγραμμα Μεταπτυχιακών Σπουδών «Επιστήμη των Υπολογιστών» Διπλωματική Εργασία Μαρία-Ελένη Κολλιάρου 2
Ανάπτυξη συστήματος ερωταποκρίσεων για αρχεία ελληνικών εφημερίδων Οικονομικό Πανεπιστήμιο Αθηνών Πρόγραμμα Μεταπτυχιακών Σπουδών «Επιστήμη των Υπολογιστών» Διπλωματική Εργασία Μαρία-Ελένη Κολλιάρου 2
Ασκήσεις μελέτης της 19 ης διάλεξης
 Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 19 ης διάλεξης 19.1. Δείξτε ότι το Perceptron με (α) συνάρτηση ενεργοποίησης
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 19 ης διάλεξης 19.1. Δείξτε ότι το Perceptron με (α) συνάρτηση ενεργοποίησης
Μια από τις σημαντικότερες δυσκολίες που συναντά ο φυσικός στη διάρκεια ενός πειράματος, είναι τα σφάλματα.
 Εισαγωγή Μετρήσεις-Σφάλματα Πολλές φορές θα έχει τύχει να ακούσουμε τη λέξη πείραμα, είτε στο μάθημα είτε σε κάποια είδηση που αφορά τη Φυσική, τη Χημεία ή τη Βιολογία. Είναι όμως γενικώς παραδεκτό ότι
Εισαγωγή Μετρήσεις-Σφάλματα Πολλές φορές θα έχει τύχει να ακούσουμε τη λέξη πείραμα, είτε στο μάθημα είτε σε κάποια είδηση που αφορά τη Φυσική, τη Χημεία ή τη Βιολογία. Είναι όμως γενικώς παραδεκτό ότι
Σφάλματα Είδη σφαλμάτων
 Σφάλματα Σφάλματα Κάθε μέτρηση ενός φυσικού μεγέθους χαρακτηρίζεται από μία αβεβαιότητα που ονομάζουμε σφάλμα, το οποίο αναγράφεται με τη μορφή Τιμή ± αβεβαιότητα π.χ έστω ότι σε ένα πείραμα μετράμε την
Σφάλματα Σφάλματα Κάθε μέτρηση ενός φυσικού μεγέθους χαρακτηρίζεται από μία αβεβαιότητα που ονομάζουμε σφάλμα, το οποίο αναγράφεται με τη μορφή Τιμή ± αβεβαιότητα π.χ έστω ότι σε ένα πείραμα μετράμε την
σ = και σ = 4 αντιστοίχως. Τότε θα ισχύει
 Θέματα ομάδας A 1. Σε κάποιο πείραμα τύχης μία τυχαία μεταβλητή λαμβάνει τις τιμές = 10 και = 10. Τότε η μέση τιμή x της θα είναι α. 10 β. 10 γ.,5 10 δ. 19,5 10 1= 10, = 10,. Δυο τυχαίες μεταβλητές, ακολουθούν
Θέματα ομάδας A 1. Σε κάποιο πείραμα τύχης μία τυχαία μεταβλητή λαμβάνει τις τιμές = 10 και = 10. Τότε η μέση τιμή x της θα είναι α. 10 β. 10 γ.,5 10 δ. 19,5 10 1= 10, = 10,. Δυο τυχαίες μεταβλητές, ακολουθούν
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ. Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων. Γεώργιος Πετάσης. Ακαδημαϊκό Έτος:
 ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος
Τηλεπικοινωνιακά Συστήματα ΙΙ
 Τηλεπικοινωνιακά Συστήματα ΙΙ Διάλεξη 11: Κωδικοποίηση Πηγής Δρ. Μιχάλης Παρασκευάς Επίκουρος Καθηγητής 1 Ατζέντα 1. Αλγόριθμοι κωδικοποίησης πηγής Αλγόριθμος Fano Αλγόριθμος Shannon Αλγόριθμος Huffman
Τηλεπικοινωνιακά Συστήματα ΙΙ Διάλεξη 11: Κωδικοποίηση Πηγής Δρ. Μιχάλης Παρασκευάς Επίκουρος Καθηγητής 1 Ατζέντα 1. Αλγόριθμοι κωδικοποίησης πηγής Αλγόριθμος Fano Αλγόριθμος Shannon Αλγόριθμος Huffman
Γιατί πιθανότητες; Γιατί πιθανότητες; Θεωρία πιθανοτήτων. Θεωρία Πιθανοτήτων. ΗΥ118, Διακριτά Μαθηματικά Άνοιξη 2017.
 HY118-Διακριτά Μαθηματικά Τρίτη, 02/05/2017 Θεωρία πιθανοτήτων Αντώνης Α. Αργυρός e-mail: argyros@csd.uoc.gr 04-May-17 1 1 04-May-17 2 2 Γιατί πιθανότητες; Γιατί πιθανότητες; Στον προτασιακό και κατηγορηματικό
HY118-Διακριτά Μαθηματικά Τρίτη, 02/05/2017 Θεωρία πιθανοτήτων Αντώνης Α. Αργυρός e-mail: argyros@csd.uoc.gr 04-May-17 1 1 04-May-17 2 2 Γιατί πιθανότητες; Γιατί πιθανότητες; Στον προτασιακό και κατηγορηματικό
2. ΕΠΙΛΟΓΗ ΜΟΝΤΕΛΟΥ ΜΕ ΤΗ ΜΕΘΟΔΟ ΤΟΥ ΑΠΟΚΛΕΙΣΜΟΥ ΜΕΤΑΒΛΗΤΩΝ (Backward Elimination Procedure) Στην στατιστική βιβλιογραφία υπάρχουν πολλές μέθοδοι για
 Στην στατιστική βιβλιογραφία υπάρχουν πολλές μέθοδοι για") 2. ΕΠΙΛΟΓΗ ΜΟΝΤΕΛΟΥ ΜΕ ΤΗ ΜΕΘΟΔΟ ΤΟΥ ΑΠΟΚΛΕΙΣΜΟΥ ΜΕΤΑΒΛΗΤΩΝ (Backward Elimination Procedure) Στην στατιστική βιβλιογραφία υπάρχουν πολλές μέθοδοι για τον καθορισμό του καλύτερου υποσυνόλου από ένα σύνολο
2. ΕΠΙΛΟΓΗ ΜΟΝΤΕΛΟΥ ΜΕ ΤΗ ΜΕΘΟΔΟ ΤΟΥ ΑΠΟΚΛΕΙΣΜΟΥ ΜΕΤΑΒΛΗΤΩΝ (Backward Elimination Procedure) Στην στατιστική βιβλιογραφία υπάρχουν πολλές μέθοδοι για τον καθορισμό του καλύτερου υποσυνόλου από ένα σύνολο
Άσκηση 3 Υπολογισμός του μέτρου της ταχύτητας και της επιτάχυνσης
 Άσκηση 3 Υπολογισμός του μέτρου της ταχύτητας και της επιτάχυνσης Σύνοψη Σκοπός της συγκεκριμένης άσκησης είναι ο υπολογισμός του μέτρου της στιγμιαίας ταχύτητας και της επιτάχυνσης ενός υλικού σημείου
Άσκηση 3 Υπολογισμός του μέτρου της ταχύτητας και της επιτάχυνσης Σύνοψη Σκοπός της συγκεκριμένης άσκησης είναι ο υπολογισμός του μέτρου της στιγμιαίας ταχύτητας και της επιτάχυνσης ενός υλικού σημείου
Οικονομικό Πανεπιστήμιο Αθηνών. Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης. Άρης Κοσμόπουλος
 Οικονομικό Πανεπιστήμιο Αθηνών Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης Άρης Κοσμόπουλος Πρόβλημα ανεπιθύμητων μηνυμάτων Περισσότερα από το 60% των ηλεκτρονικών μηνυμάτων είναι ανεπιθύμητα
Οικονομικό Πανεπιστήμιο Αθηνών Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης Άρης Κοσμόπουλος Πρόβλημα ανεπιθύμητων μηνυμάτων Περισσότερα από το 60% των ηλεκτρονικών μηνυμάτων είναι ανεπιθύμητα
ΜΕΤΑ-ΑΝΑΛΥΣΗ (Meta-Analysis)
") ΚΕΦΑΛΑΙΟ 23 ΜΕΤΑ-ΑΝΑΛΥΣΗ (Meta-Analysis) ΕΙΣΑΓΩΓΗ Έχοντας παρουσιάσει τις βασικές έννοιες των ελέγχων υποθέσεων, θα ήταν, ίσως, χρήσιμο να αναφερθούμε σε μια άλλη περιοχή στατιστικής συμπερασματολογίας
ΚΕΦΑΛΑΙΟ 23 ΜΕΤΑ-ΑΝΑΛΥΣΗ (Meta-Analysis) ΕΙΣΑΓΩΓΗ Έχοντας παρουσιάσει τις βασικές έννοιες των ελέγχων υποθέσεων, θα ήταν, ίσως, χρήσιμο να αναφερθούμε σε μια άλλη περιοχή στατιστικής συμπερασματολογίας
Τεχνητή Νοημοσύνη. 17η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 17η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Artificia Inteigence A Modern Approach των S. Russe και
Τεχνητή Νοημοσύνη 17η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Artificia Inteigence A Modern Approach των S. Russe και
Κεφάλαιο 9. Έλεγχοι υποθέσεων
 Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
Τεχνολογία Πολυμέσων. Ενότητα # 7: Θεωρία πληροφορίας Διδάσκων: Γεώργιος Ξυλωμένος Τμήμα: Πληροφορικής
 Τεχνολογία Πολυμέσων Ενότητα # 7: Θεωρία πληροφορίας Διδάσκων: Γεώργιος Ξυλωμένος Τμήμα: Πληροφορικής Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί στα πλαίσια του εκπαιδευτικού έργου του διδάσκοντα.
Τεχνολογία Πολυμέσων Ενότητα # 7: Θεωρία πληροφορίας Διδάσκων: Γεώργιος Ξυλωμένος Τμήμα: Πληροφορικής Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί στα πλαίσια του εκπαιδευτικού έργου του διδάσκοντα.
ΑΘΑΝΑΣΟΠΟΥΛΟΣ 30ο ΛΥΚΕΙΟ ΑΘΗΝΩΝ
 1. Τίτλος της έρευνας. Απόδοση των φωτοβολταϊκών σε διαφορετικές συνθήκες φωτισμού. Λέξεις κλειδιά: Φωτοβολταϊκά Φωτεινή ένταση Απόσταση Απόχρωση Απόδοση 2. Παρουσίαση του προβλήματος. Πραγματοποιήθηκε
1. Τίτλος της έρευνας. Απόδοση των φωτοβολταϊκών σε διαφορετικές συνθήκες φωτισμού. Λέξεις κλειδιά: Φωτοβολταϊκά Φωτεινή ένταση Απόσταση Απόχρωση Απόδοση 2. Παρουσίαση του προβλήματος. Πραγματοποιήθηκε
ΕΝΟΤΗΤΑ 2 η -ΟΙ ΚΙΝΗΣΕΙΣ
 ΕΝΟΤΗΤΑ η -ΟΙ ΚΙΝΗΣΕΙΣ.1. ΓΕΝΙΚΑ Σύστημα αναφοράς καλούμε ένα ορθογώνιο σύστημα αξόνων, η αρχή του οποίουσυνήθως συμπίπτει με την αρχική θέση ενός σώματος. Το θεωρούμε ως κάτι στατικό ή κινούμενο με σταθερή
ΕΝΟΤΗΤΑ η -ΟΙ ΚΙΝΗΣΕΙΣ.1. ΓΕΝΙΚΑ Σύστημα αναφοράς καλούμε ένα ορθογώνιο σύστημα αξόνων, η αρχή του οποίουσυνήθως συμπίπτει με την αρχική θέση ενός σώματος. Το θεωρούμε ως κάτι στατικό ή κινούμενο με σταθερή
Λήψη αποφάσεων κατά Bayes
 Λήψη αποφάσεων κατά Bayes Σημειώσεις μαθήματος Thomas Bayes (1701 1761) Στυλιανός Χατζηδάκης ECE 662 Άνοιξη 2014 1. Εισαγωγή Οι σημειώσεις αυτές βασίζονται στο μάθημα ECE662 του Πανεπιστημίου Purdue και
Λήψη αποφάσεων κατά Bayes Σημειώσεις μαθήματος Thomas Bayes (1701 1761) Στυλιανός Χατζηδάκης ECE 662 Άνοιξη 2014 1. Εισαγωγή Οι σημειώσεις αυτές βασίζονται στο μάθημα ECE662 του Πανεπιστημίου Purdue και
4.3.3 Ο Έλεγχος των Shapiro-Wilk για την Κανονική Κατανομή
 4.3.3 Ο Έλεγχος των Shapro-Wlk για την Κανονική Κατανομή Ένας άλλος πολύ γνωστός έλεγχος καλής προσαρμογής για την κανονική κατανομή, ο οποίος μπορεί να χρησιμοποιηθεί στην θέση του ελέγχου Lllefors, είναι
4.3.3 Ο Έλεγχος των Shapro-Wlk για την Κανονική Κατανομή Ένας άλλος πολύ γνωστός έλεγχος καλής προσαρμογής για την κανονική κατανομή, ο οποίος μπορεί να χρησιμοποιηθεί στην θέση του ελέγχου Lllefors, είναι
Διαδικασία Ελέγχου Μηδενικών Υποθέσεων
 Διαδικασία Ελέγχου Μηδενικών Υποθέσεων Πέτρος Ρούσσος, Τμήμα Ψυχολογίας, ΕΚΠΑ Η λογική της διαδικασίας Ο σάκος περιέχει έναν μεγάλο αλλά άγνωστο αριθμό (αρκετές χιλιάδες) λευκών και μαύρων βόλων: 1 Το
Διαδικασία Ελέγχου Μηδενικών Υποθέσεων Πέτρος Ρούσσος, Τμήμα Ψυχολογίας, ΕΚΠΑ Η λογική της διαδικασίας Ο σάκος περιέχει έναν μεγάλο αλλά άγνωστο αριθμό (αρκετές χιλιάδες) λευκών και μαύρων βόλων: 1 Το
Σεραφείµ Καραµπογιάς. Πηγές Πληροφορίας και Κωδικοποίηση Πηγής 6.3-1
 Ο αλγόριθµος Lempel-iv Ο αλγόριθµος Lempel-iv ανήκει στην κατηγορία των καθολικών universal αλγορίθµων κωδικοποίησης πηγής δηλαδή αλγορίθµων που είναι ανεξάρτητοι από τη στατιστική της πηγής. Ο αλγόριθµος
Ο αλγόριθµος Lempel-iv Ο αλγόριθµος Lempel-iv ανήκει στην κατηγορία των καθολικών universal αλγορίθµων κωδικοποίησης πηγής δηλαδή αλγορίθµων που είναι ανεξάρτητοι από τη στατιστική της πηγής. Ο αλγόριθµος
Κάνοντας ακριβέστερες μετρήσεις με την βοήθεια των Μαθηματικών. Ν. Παναγιωτίδης, Υπεύθυνος ΕΚΦΕ Ν. Ιωαννίνων
 Κάνοντας ακριβέστερες μετρήσεις με την βοήθεια των Μαθηματικών Ν. Παναγιωτίδης, Υπεύθυνος ΕΚΦΕ Ν. Ιωαννίνων Αν κάναμε ένα τεστ νοημοσύνης στους μαθητές και θέταμε την ερώτηση: Πως μπορεί να μετρηθεί το
Κάνοντας ακριβέστερες μετρήσεις με την βοήθεια των Μαθηματικών Ν. Παναγιωτίδης, Υπεύθυνος ΕΚΦΕ Ν. Ιωαννίνων Αν κάναμε ένα τεστ νοημοσύνης στους μαθητές και θέταμε την ερώτηση: Πως μπορεί να μετρηθεί το
Εισαγωγή στη Στατιστική
 Εισαγωγή στη Στατιστική Μετεκπαιδευτικό Σεμινάριο στην ΨΥΧΟΚΟΙΝΩΝΙΚΗ ΑΠΟΚΑΤΑΣΤΑΣΗ ΨΥΧΟΚΟΙΝΩΝΙΚΕΣ ΘΕΡΑΠΕΥΤΙΚΕΣ ΠΡΟΣΕΓΓΙΣΕΙΣ Δημήτρης Φουσκάκης, Επίκουρος Καθηγητής, Τομέας Μαθηματικών, Σχολή Εφαρμοσμένων
Εισαγωγή στη Στατιστική Μετεκπαιδευτικό Σεμινάριο στην ΨΥΧΟΚΟΙΝΩΝΙΚΗ ΑΠΟΚΑΤΑΣΤΑΣΗ ΨΥΧΟΚΟΙΝΩΝΙΚΕΣ ΘΕΡΑΠΕΥΤΙΚΕΣ ΠΡΟΣΕΓΓΙΣΕΙΣ Δημήτρης Φουσκάκης, Επίκουρος Καθηγητής, Τομέας Μαθηματικών, Σχολή Εφαρμοσμένων
Παρουσίαση της εργασίας στο μάθημα Νέες Τεχνολογίες στην Επιστημονική Έρευνα: Διαδίκτυο και Εκπαίδευση (Εαρινό 2016) Β Μέρος. Γιώργος Μικρός ΕΚΠΑ
 Β Μέρος. Γιώργος Μικρός ΕΚΠΑ") Παρουσίαση της εργασίας στο μάθημα Νέες Τεχνολογίες στην Επιστημονική Έρευνα: Διαδίκτυο και Εκπαίδευση (Εαρινό 2016) Β Μέρος Γιώργος Μικρός ΕΚΠΑ Γλωσσικά χαρακτηριστικά Θα αναλύσουμε την συχνότητα ορισμένων
Παρουσίαση της εργασίας στο μάθημα Νέες Τεχνολογίες στην Επιστημονική Έρευνα: Διαδίκτυο και Εκπαίδευση (Εαρινό 2016) Β Μέρος Γιώργος Μικρός ΕΚΠΑ Γλωσσικά χαρακτηριστικά Θα αναλύσουμε την συχνότητα ορισμένων
ΘΕΜΑ ΈΡΕΥΝΑΣ: Η ΣΧΕΣΗ ΑΝΑΜΕΣΑ ΣΤΗ
 Μαθήτρια: Αίγλη Θ. Μπορονικόλα Καθηγητής : Ιωάννης Αντ. Παπατσώρης ΜΑΘΗΜΑ: ΈΡΕΥΝΑ & ΤΕΧΝΟΛΟΓΙΑ ΘΕΜΑ ΈΡΕΥΝΑΣ: Η ΣΧΕΣΗ ΑΝΑΜΕΣΑ ΣΤΗ ΓΩΝΙΑ ΚΕΚΛΙΜΕΝΟΥ ΕΠΙΠΕΔΟΥ ΚΑΙ ΤΗ ΔΥΝΑΜΗ ΕΛΞΗΣ ΓΙΑ ΝΑ ΙΣΟΡΡΟΠΗΣΕΙ ΕΝΑ ΣΩΜΑ
Μαθήτρια: Αίγλη Θ. Μπορονικόλα Καθηγητής : Ιωάννης Αντ. Παπατσώρης ΜΑΘΗΜΑ: ΈΡΕΥΝΑ & ΤΕΧΝΟΛΟΓΙΑ ΘΕΜΑ ΈΡΕΥΝΑΣ: Η ΣΧΕΣΗ ΑΝΑΜΕΣΑ ΣΤΗ ΓΩΝΙΑ ΚΕΚΛΙΜΕΝΟΥ ΕΠΙΠΕΔΟΥ ΚΑΙ ΤΗ ΔΥΝΑΜΗ ΕΛΞΗΣ ΓΙΑ ΝΑ ΙΣΟΡΡΟΠΗΣΕΙ ΕΝΑ ΣΩΜΑ
ΜΕ - 9900 ΕΠΕΑΕΚ: ΑΝΑΜΟΡΦΩΣΗ ΤΟΥ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΠΟΥΔΩΝ ΤΟΥ ΤΕΦΑΑ ΠΘ ΑΥΤΕΠΙΣΤΑΣΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΤΜΗΜΑ ΕΠΙΣΤΗΜΗΣ ΦΥΣΙΚΗΣ ΑΓΩΓΗΣ & ΑΘΛΗΤΙΣΜΟΥ
 ΕΠΕΑΕΚ: ΑΝΑΜΟΡΦΩΣΗ ΤΟΥ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΠΟΥΔΩΝ ΤΟΥ ΤΕΦΑΑ ΠΘ ΑΥΤΕΠΙΣΤΑΣΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΤΜΗΜΑ ΕΠΙΣΤΗΜΗΣ ΦΥΣΙΚΗΣ ΑΓΩΓΗΣ & ΑΘΛΗΤΙΣΜΟΥ ΜΕ9900 ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ Έρευνα και Συγγραφή Λέκτορας Διάλεξη
ΕΠΕΑΕΚ: ΑΝΑΜΟΡΦΩΣΗ ΤΟΥ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΠΟΥΔΩΝ ΤΟΥ ΤΕΦΑΑ ΠΘ ΑΥΤΕΠΙΣΤΑΣΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΤΜΗΜΑ ΕΠΙΣΤΗΜΗΣ ΦΥΣΙΚΗΣ ΑΓΩΓΗΣ & ΑΘΛΗΤΙΣΜΟΥ ΜΕ9900 ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ Έρευνα και Συγγραφή Λέκτορας Διάλεξη
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΣΤΑΤΙΣΤΙΚΗ ΤΩΝ ΕΠΙΧΕΙΡΗΣΕΩΝ. Κεφάλαιο 8. Συνεχείς Κατανομές Πιθανοτήτων Η Κανονική Κατανομή
 ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΠΑΤΡΑΣ Εργαστήριο Λήψης Αποφάσεων & Επιχειρησιακού Προγραμματισμού Καθηγητής Ι. Μητρόπουλος ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΣΤΑΤΙΣΤΙΚΗ ΤΩΝ ΕΠΙΧΕΙΡΗΣΕΩΝ
ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΠΑΤΡΑΣ Εργαστήριο Λήψης Αποφάσεων & Επιχειρησιακού Προγραμματισμού Καθηγητής Ι. Μητρόπουλος ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΣΤΑΤΙΣΤΙΚΗ ΤΩΝ ΕΠΙΧΕΙΡΗΣΕΩΝ
ΘΕΩΡΙΑ ΠΛΗΡΟΦΟΡΙΑΣ. Κεφάλαιο 2 : Πληροφορία και Εντροπία Διάλεξη: Κώστας Μαλιάτσος Χρήστος Ξενάκης, Κώστας Μαλιάτσος
 ΘΕΩΡΙΑ ΠΛΗΡΟΦΟΡΙΑΣ Κεφάλαιο 2 : Πληροφορία και Εντροπία Διάλεξη: Κώστας Μαλιάτσος Χρήστος Ξενάκης, Κώστας Μαλιάτσος Πανεπιστήμιο Πειραιώς, Τμήμα Ψηφιακών Συστημάτων Περιεχόμενα Πιθανότητες Πληροφορία Μέτρο
ΘΕΩΡΙΑ ΠΛΗΡΟΦΟΡΙΑΣ Κεφάλαιο 2 : Πληροφορία και Εντροπία Διάλεξη: Κώστας Μαλιάτσος Χρήστος Ξενάκης, Κώστας Μαλιάτσος Πανεπιστήμιο Πειραιώς, Τμήμα Ψηφιακών Συστημάτων Περιεχόμενα Πιθανότητες Πληροφορία Μέτρο
ΔΙΕΡΕΥΝΗΣΗ ΤΟΥ ΠΡΟΒΛΗΜΑΤΟΣ ΤΗΣ ΑΠΟΡΡΟΗΣ ΤΩΝ ΟΜΒΡΙΩΝ ΣΕ ΚΡΙΣΙΜΕΣ ΓΙΑ ΤΗΝ ΑΣΦΑΛΕΙΑ ΠΕΡΙΟΧΕΣ ΤΩΝ ΟΔΙΚΩΝ ΧΑΡΑΞΕΩΝ
 ΔΙΕΡΕΥΝΗΣΗ ΤΟΥ ΠΡΟΒΛΗΜΑΤΟΣ ΤΗΣ ΑΠΟΡΡΟΗΣ ΤΩΝ ΟΜΒΡΙΩΝ ΣΕ ΚΡΙΣΙΜΕΣ ΓΙΑ ΤΗΝ ΑΣΦΑΛΕΙΑ ΠΕΡΙΟΧΕΣ ΤΩΝ ΟΔΙΚΩΝ ΧΑΡΑΞΕΩΝ Ν. Ε. Ηλιού Αναπληρωτής Καθηγητής Τμήματος Πολιτικών Μηχανικών Πανεπιστημίου Θεσσαλίας Γ. Δ.
ΔΙΕΡΕΥΝΗΣΗ ΤΟΥ ΠΡΟΒΛΗΜΑΤΟΣ ΤΗΣ ΑΠΟΡΡΟΗΣ ΤΩΝ ΟΜΒΡΙΩΝ ΣΕ ΚΡΙΣΙΜΕΣ ΓΙΑ ΤΗΝ ΑΣΦΑΛΕΙΑ ΠΕΡΙΟΧΕΣ ΤΩΝ ΟΔΙΚΩΝ ΧΑΡΑΞΕΩΝ Ν. Ε. Ηλιού Αναπληρωτής Καθηγητής Τμήματος Πολιτικών Μηχανικών Πανεπιστημίου Θεσσαλίας Γ. Δ.
Κεφάλαιο 5 Κριτήρια απόρριψης απόμακρων τιμών
 Κεφάλαιο 5 Κριτήρια απόρριψης απόμακρων τιμών Σύνοψη Στο κεφάλαιο αυτό παρουσιάζονται δύο κριτήρια απόρριψης απομακρυσμένων από τη μέση τιμή πειραματικών μετρήσεων ενός φυσικού μεγέθους και συγκεκριμένα
Κεφάλαιο 5 Κριτήρια απόρριψης απόμακρων τιμών Σύνοψη Στο κεφάλαιο αυτό παρουσιάζονται δύο κριτήρια απόρριψης απομακρυσμένων από τη μέση τιμή πειραματικών μετρήσεων ενός φυσικού μεγέθους και συγκεκριμένα
ΠΡΟΔΙΑΓΡΑΦΕΣ - ΟΔΗΓΙΕΣ ΔΙΑΜΟΡΦΩΣΗΣ ΘΕΜΑΤΩΝ ΓΙΑ ΤΟ ΜΑΘΗΜΑ
 ΠΡΟΔΙΑΓΡΑΦΕΣ - ΟΔΗΓΙΕΣ ΔΙΑΜΟΡΦΩΣΗΣ ΘΕΜΑΤΩΝ ΓΙΑ ΤΟ ΜΑΘΗΜΑ Μαθηματικά (Άλγεβρα - Γεωμετρία) Α ΤΑΞΗ ΗΜΕΡΗΣΙΟΥ και Α, Β ΤΑΞΕΙΣ ΕΣΠΕΡΙΝΟΥ ΓΕΝΙΚΟΥ ΛΥΚΕΙΟΥ Α ΤΑΞΗ ΗΜΕΡΗΣΙΟΥ και Α ΤΑΞΗ ΕΣΠΕΡΙΝΟΥ ΕΠΑΛ ΚΕΝΤΡΙΚΗ
ΠΡΟΔΙΑΓΡΑΦΕΣ - ΟΔΗΓΙΕΣ ΔΙΑΜΟΡΦΩΣΗΣ ΘΕΜΑΤΩΝ ΓΙΑ ΤΟ ΜΑΘΗΜΑ Μαθηματικά (Άλγεβρα - Γεωμετρία) Α ΤΑΞΗ ΗΜΕΡΗΣΙΟΥ και Α, Β ΤΑΞΕΙΣ ΕΣΠΕΡΙΝΟΥ ΓΕΝΙΚΟΥ ΛΥΚΕΙΟΥ Α ΤΑΞΗ ΗΜΕΡΗΣΙΟΥ και Α ΤΑΞΗ ΕΣΠΕΡΙΝΟΥ ΕΠΑΛ ΚΕΝΤΡΙΚΗ
Θέματα Συστημάτων Πολυμέσων
 Θέματα Συστημάτων Πολυμέσων Ενότητα # 6: Στοιχεία Θεωρίας Πληροφορίας Διδάσκων: Γεώργιος K. Πολύζος Τμήμα: Μεταπτυχιακό Πρόγραμμα Σπουδών Επιστήμη των Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό
Θέματα Συστημάτων Πολυμέσων Ενότητα # 6: Στοιχεία Θεωρίας Πληροφορίας Διδάσκων: Γεώργιος K. Πολύζος Τμήμα: Μεταπτυχιακό Πρόγραμμα Σπουδών Επιστήμη των Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό
Σχεδιασμός Ψηφιακών Εκπαιδευτικών Εφαρμογών ΙI
 Σχεδιασμός Ψηφιακών Εκπαιδευτικών Εφαρμογών ΙI Εργασία 1 ΣΤΟΙΧΕΙΑ ΦΟΙΤΗΤΡΙΑΣ: Τσελίγκα Αρετή, 1312009161, Στ εξάμηνο, κατεύθυνση: Εκπαιδευτική Τεχνολογία και Διαπολιτισμική Επικοινωνία Το γνωστικό αντικείμενο
Σχεδιασμός Ψηφιακών Εκπαιδευτικών Εφαρμογών ΙI Εργασία 1 ΣΤΟΙΧΕΙΑ ΦΟΙΤΗΤΡΙΑΣ: Τσελίγκα Αρετή, 1312009161, Στ εξάμηνο, κατεύθυνση: Εκπαιδευτική Τεχνολογία και Διαπολιτισμική Επικοινωνία Το γνωστικό αντικείμενο
1. Πείραμα τύχης. 2. Δειγματικός Χώρος ΣΤΟΙΧΕΙΑ ΑΠΟ ΤΗ ΘΕΩΡΙΑ ΠΙΘΑΝΟΤΗΤΩΝ
 1 ΣΤΟΙΧΕΙ ΠΟ ΤΗ ΘΕΩΡΙ ΠΙΘΝΟΤΗΤΩΝ 1. Πείραμα τύχης Πείραμα τύχης (π.τ.) ονομάζουμε κάθε πείραμα που μπορεί να επαναληφθεί όσες φορές επιθυμούμε υπό τις ίδιες συνθήκες και του οποίου το αποτέλεσμα είναι
1 ΣΤΟΙΧΕΙ ΠΟ ΤΗ ΘΕΩΡΙ ΠΙΘΝΟΤΗΤΩΝ 1. Πείραμα τύχης Πείραμα τύχης (π.τ.) ονομάζουμε κάθε πείραμα που μπορεί να επαναληφθεί όσες φορές επιθυμούμε υπό τις ίδιες συνθήκες και του οποίου το αποτέλεσμα είναι
6 ο ΜΑΘΗΜΑ Έλεγχοι Υποθέσεων
 6 ο ΜΑΘΗΜΑ Έλεγχοι Υποθέσεων 6.1 Το Πρόβλημα του Ελέγχου Υποθέσεων Ενός υποθέσουμε ότι μία φαρμακευτική εταιρεία πειραματίζεται πάνω σε ένα νέο φάρμακο για κάποια ασθένεια έχοντας ως στόχο, τα πρώτα θετικά
6 ο ΜΑΘΗΜΑ Έλεγχοι Υποθέσεων 6.1 Το Πρόβλημα του Ελέγχου Υποθέσεων Ενός υποθέσουμε ότι μία φαρμακευτική εταιρεία πειραματίζεται πάνω σε ένα νέο φάρμακο για κάποια ασθένεια έχοντας ως στόχο, τα πρώτα θετικά
ΣΤΑΤΙΣΤΙΚΗ ΠΙΘΑΝΟΤΗΤΕΣ
 9/10/009 ΤΕΙ ΥΤΙΚΗΣ ΜΑΚΕ ΟΝΙΑΣ ΠΑΡΑΡΤΗΜΑ ΚΑΣΤΟΡΙΑΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ & ΤΕΧΝΟΛΟΓΙΑΣ Η/Υ ΣΤΑΤΙΣΤΙΚΗ ΠΙΘΑΝΟΤΗΤΕΣ 3o ΜΑΘΗΜΑ Ι ΑΣΚΩΝ ΒΑΣΙΛΕΙΑ ΗΣ ΓΕΩΡΓΙΟΣ Emal: gasl@math.auth.gr Ιστοσελίδα Μαθήματος: users.auth.gr/gasl
9/10/009 ΤΕΙ ΥΤΙΚΗΣ ΜΑΚΕ ΟΝΙΑΣ ΠΑΡΑΡΤΗΜΑ ΚΑΣΤΟΡΙΑΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ & ΤΕΧΝΟΛΟΓΙΑΣ Η/Υ ΣΤΑΤΙΣΤΙΚΗ ΠΙΘΑΝΟΤΗΤΕΣ 3o ΜΑΘΗΜΑ Ι ΑΣΚΩΝ ΒΑΣΙΛΕΙΑ ΗΣ ΓΕΩΡΓΙΟΣ Emal: gasl@math.auth.gr Ιστοσελίδα Μαθήματος: users.auth.gr/gasl
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ
 ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ Πτυχιακή Εργασία Στατιστική μηχανική μετάφραση από τα Αρχαία Ελληνικά στα Αγγλικά Βασίλειος Καλογηράς Επιβλέπων: Ίων Ανδρουτσόπουλος Βοηθός επιβλέπων:
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ Πτυχιακή Εργασία Στατιστική μηχανική μετάφραση από τα Αρχαία Ελληνικά στα Αγγλικά Βασίλειος Καλογηράς Επιβλέπων: Ίων Ανδρουτσόπουλος Βοηθός επιβλέπων:
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ (Δ.Π.Μ.Σ.)
") ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ (Δ.Π.Μ.Σ.) «Διερμηνεία και Μετάφραση» Tων Τμημάτων: Φιλολογίας, Αγγλικής Γλώσσας και Φιλολογίας, Γαλλικής Γλώσσας και
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ (Δ.Π.Μ.Σ.) «Διερμηνεία και Μετάφραση» Tων Τμημάτων: Φιλολογίας, Αγγλικής Γλώσσας και Φιλολογίας, Γαλλικής Γλώσσας και
Στατιστική Ι. Ενότητα 9: Κατανομή t-έλεγχος Υποθέσεων. Δρ. Γεώργιος Κοντέος Τμήμα Διοίκησης Επιχειρήσεων Γρεβενών
 Στατιστική Ι Ενότητα 9: Κατανομή t-έλεγχος Υποθέσεων Δρ. Γεώργιος Κοντέος Τμήμα Διοίκησης Επιχειρήσεων Γρεβενών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για
Στατιστική Ι Ενότητα 9: Κατανομή t-έλεγχος Υποθέσεων Δρ. Γεώργιος Κοντέος Τμήμα Διοίκησης Επιχειρήσεων Γρεβενών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για
Έλεγχος υποθέσεων και διαστήματα εμπιστοσύνης
 1 Έλεγχος υποθέσεων και διαστήματα εμπιστοσύνης Όπως γνωρίζουμε από προηγούμενα κεφάλαια, στόχος των περισσότερων στατιστικών αναλύσεων, είναι η έγκυρη γενίκευση των συμπερασμάτων, που προέρχονται από
1 Έλεγχος υποθέσεων και διαστήματα εμπιστοσύνης Όπως γνωρίζουμε από προηγούμενα κεφάλαια, στόχος των περισσότερων στατιστικών αναλύσεων, είναι η έγκυρη γενίκευση των συμπερασμάτων, που προέρχονται από
5 Σύγκλιση σε τοπολογικούς χώρους
 121 5 Σύγκλιση σε τοπολογικούς χώρους Στο κεφάλαιο αυτό πρόκειται να μελετήσουμε την έννοια της σύγκλισης σε γενικούς τοπολογικούς χώρους, πέραν των μετρικών χώρων. Όπως έχουμε ήδη διαπιστώσει ( πρβλ.
121 5 Σύγκλιση σε τοπολογικούς χώρους Στο κεφάλαιο αυτό πρόκειται να μελετήσουμε την έννοια της σύγκλισης σε γενικούς τοπολογικούς χώρους, πέραν των μετρικών χώρων. Όπως έχουμε ήδη διαπιστώσει ( πρβλ.
Τεχνητή Νοημοσύνη. 15η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 15η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται σε ύλη του βιβλίου Artificial Intelligence A Modern Approach των
Τεχνητή Νοημοσύνη 15η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται σε ύλη του βιβλίου Artificial Intelligence A Modern Approach των
Αναγνώριση Προτύπων Ι
 Αναγνώριση Προτύπων Ι Ενότητα 1: Μέθοδοι Αναγνώρισης Προτύπων Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Αναγνώριση Προτύπων Ι Ενότητα 1: Μέθοδοι Αναγνώρισης Προτύπων Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
ΕΝΑΣ ΔΙΚΡΙΤΗΡΙΟΣ ΑΛΓΟΡΙΘΜΟΣ SIMPLEX
 ΚΕΦΑΛΑΙΟ 3 ΕΝΑΣ ΔΙΚΡΙΤΗΡΙΟΣ ΑΛΓΟΡΙΘΜΟΣ SIMPLEX 3.1 Εισαγωγή Ο αλγόριθμος Simplex θεωρείται πλέον ως ένας κλασικός αλγόριθμος για την επίλυση γραμμικών προβλημάτων. Η πρακτική αποτελεσματικότητά του έχει
ΚΕΦΑΛΑΙΟ 3 ΕΝΑΣ ΔΙΚΡΙΤΗΡΙΟΣ ΑΛΓΟΡΙΘΜΟΣ SIMPLEX 3.1 Εισαγωγή Ο αλγόριθμος Simplex θεωρείται πλέον ως ένας κλασικός αλγόριθμος για την επίλυση γραμμικών προβλημάτων. Η πρακτική αποτελεσματικότητά του έχει
Σειρά Προβλημάτων 4 Λύσεις
 Άσκηση 1 Σειρά Προβλημάτων 4 Λύσεις (α) Να διατυπώσετε την τυπική περιγραφή μιας μηχανής Turing που να διαγιγνώσκει την ακόλουθη γλώσσα. { a n b n+2 c n 2 n 2 } Λύση: H ζητούμενη μηχανή Turing μπορεί να
Άσκηση 1 Σειρά Προβλημάτων 4 Λύσεις (α) Να διατυπώσετε την τυπική περιγραφή μιας μηχανής Turing που να διαγιγνώσκει την ακόλουθη γλώσσα. { a n b n+2 c n 2 n 2 } Λύση: H ζητούμενη μηχανή Turing μπορεί να
Συνήθεις διαφορικές εξισώσεις προβλήματα οριακών τιμών
 Συνήθεις διαφορικές εξισώσεις προβλήματα οριακών τιμών Οι παρούσες σημειώσεις αποτελούν βοήθημα στο μάθημα Αριθμητικές Μέθοδοι του 5 ου εξαμήνου του ΤΜΜ ημήτρης Βαλουγεώργης Καθηγητής Εργαστήριο Φυσικών
Συνήθεις διαφορικές εξισώσεις προβλήματα οριακών τιμών Οι παρούσες σημειώσεις αποτελούν βοήθημα στο μάθημα Αριθμητικές Μέθοδοι του 5 ου εξαμήνου του ΤΜΜ ημήτρης Βαλουγεώργης Καθηγητής Εργαστήριο Φυσικών
ΚΕΦΑΛΑΙΟ 2 ΔΙΑΤΑΞΕΙΣ, ΜΕΤΑΘΕΣΕΙΣ, ΣΥΝΔΥΑΣΜΟΙ
 ΚΕΦΑΛΑΙΟ ΔΙΑΤΑΞΕΙΣ ΜΕΤΑΘΕΣΕΙΣ ΣΥΝΔΥΑΣΜΟΙ Εισαγωγή. Οι σχηματισμοί που προκύπτουν με την επιλογή ενός συγκεκριμένου αριθμού στοιχείων από το ίδιο σύνολο καλούνται διατάξεις αν μας ενδιαφέρει η σειρά καταγραφή
ΚΕΦΑΛΑΙΟ ΔΙΑΤΑΞΕΙΣ ΜΕΤΑΘΕΣΕΙΣ ΣΥΝΔΥΑΣΜΟΙ Εισαγωγή. Οι σχηματισμοί που προκύπτουν με την επιλογή ενός συγκεκριμένου αριθμού στοιχείων από το ίδιο σύνολο καλούνται διατάξεις αν μας ενδιαφέρει η σειρά καταγραφή
Φύλλο Εργασίας 3 Μετρήσεις Μάζας Τα Διαγράμματα Α. Παρατηρώ, Πληροφορούμαι, Ενδιαφέρομαι
 Φύλλο Εργασίας 3 Μετρήσεις Μάζας Τα Διαγράμματα Α. Παρατηρώ, Πληροφορούμαι, Ενδιαφέρομαι Ο άνθρωπος πάντοτε αισθανόταν εγκλωβισμένος στη γη από μια δύναμη που τον κρατά κοντά της, ακόμη και τώρα που κάποιοι
Φύλλο Εργασίας 3 Μετρήσεις Μάζας Τα Διαγράμματα Α. Παρατηρώ, Πληροφορούμαι, Ενδιαφέρομαι Ο άνθρωπος πάντοτε αισθανόταν εγκλωβισμένος στη γη από μια δύναμη που τον κρατά κοντά της, ακόμη και τώρα που κάποιοι
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. WordNet
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ WordNet Σημασιολογικά Δίκτυα Ένα δίκτυο που αναπαριστά συσχετίσεις μεταξύ εννοιών. Οι κορυφές παριστάνουν έννοιες και οι ακμές σημασιολογικές
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ WordNet Σημασιολογικά Δίκτυα Ένα δίκτυο που αναπαριστά συσχετίσεις μεταξύ εννοιών. Οι κορυφές παριστάνουν έννοιες και οι ακμές σημασιολογικές
Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η : ,
 Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η : ,") Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η :1-0-017, 3-0-017 Διδάσκουσα: Κοντογιάννη Αριστούλα Σκοπός του μαθήματος Η παρουσίαση
Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η :1-0-017, 3-0-017 Διδάσκουσα: Κοντογιάννη Αριστούλα Σκοπός του μαθήματος Η παρουσίαση
ΠΑΡΟΥΣΙΑΣΗ ΣΤΑΤΙΣΤΙΚΩΝ ΔΕΔΟΜΕΝΩΝ
 ο Κεφάλαιο: Στατιστική ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΚΑΙ ΟΡΙΣΜΟΙ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ Πληθυσμός: Λέγεται ένα σύνολο στοιχείων που θέλουμε να εξετάσουμε με ένα ή περισσότερα χαρακτηριστικά. Μεταβλητές X: Ονομάζονται
ο Κεφάλαιο: Στατιστική ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΚΑΙ ΟΡΙΣΜΟΙ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ Πληθυσμός: Λέγεται ένα σύνολο στοιχείων που θέλουμε να εξετάσουμε με ένα ή περισσότερα χαρακτηριστικά. Μεταβλητές X: Ονομάζονται
Στατιστική Συμπερασματολογία
 Στατιστική Συμπερασματολογία Διαφάνειες 2 ου κεφαλαίου Σταύρος Χατζόπουλος 20/02/2017, 06/03/2017, 13/03/2017 1 Κεφάλαιο 2. Έλεγχος Απλών Υποθέσεων Τα προβλήματα ελέγχου υποθέσεων απορρέουν από παρατηρήσεις
Στατιστική Συμπερασματολογία Διαφάνειες 2 ου κεφαλαίου Σταύρος Χατζόπουλος 20/02/2017, 06/03/2017, 13/03/2017 1 Κεφάλαιο 2. Έλεγχος Απλών Υποθέσεων Τα προβλήματα ελέγχου υποθέσεων απορρέουν από παρατηρήσεις
ΜΕΓΙΣΤΙΚΟΣ ΤΕΛΕΣΤΗΣ 18 Σεπτεμβρίου 2014
 ΜΕΓΙΣΤΙΚΟΣ ΤΕΛΕΣΤΗΣ 18 Σεπτεμβρίου 2014 Περιεχόμενα 1 Εισαγωγή 2 2 Μεγιστικός τελέστης στην μπάλα 2 2.1 Βασικό θεώρημα........................ 2 2.2 Γενική περίπτωση μπάλας.................. 6 2.2.1 Στο
ΜΕΓΙΣΤΙΚΟΣ ΤΕΛΕΣΤΗΣ 18 Σεπτεμβρίου 2014 Περιεχόμενα 1 Εισαγωγή 2 2 Μεγιστικός τελέστης στην μπάλα 2 2.1 Βασικό θεώρημα........................ 2 2.2 Γενική περίπτωση μπάλας.................. 6 2.2.1 Στο
Οδηγίες και αρχές Διπλωµατικών Εργασιών (Διατριβών) του Μεταπτυχιακού Προγράµµατος Σπουδών στη Βιοστατιστική
 του Μεταπτυχιακού Προγράµµατος Σπουδών στη Βιοστατιστική") Οδηγίες και αρχές Διπλωµατικών Εργασιών (Διατριβών) του Μεταπτυχιακού Προγράµµατος Σπουδών στη Βιοστατιστική Α. ΕΠΙΛΟΓΗ ΘΕΜΑΤΟΣ Κάθε φοιτητής µετά το τέλος του 3 ου εξαµήνου επιλέγει θέµα Διπλωµατικής
Οδηγίες και αρχές Διπλωµατικών Εργασιών (Διατριβών) του Μεταπτυχιακού Προγράµµατος Σπουδών στη Βιοστατιστική Α. ΕΠΙΛΟΓΗ ΘΕΜΑΤΟΣ Κάθε φοιτητής µετά το τέλος του 3 ου εξαµήνου επιλέγει θέµα Διπλωµατικής
Η γλώσσα των μέσων κοινωνικής δικτύωσης: Υφομετρική ανάλυση με προεκτάσεις στην γλωσσική διδασκαλία
 Η γλώσσα των μέσων κοινωνικής δικτύωσης: Υφομετρική ανάλυση με προεκτάσεις στην γλωσσική διδασκαλία Γιώργος Κ. Μικρός Τμήμα Ιταλικής Γλώσσας και Φιλολογίας - ΕΚΠΑ Περίγραμμα ομιλίας Κοινωνικά Μέσα Δικτύωσης
Η γλώσσα των μέσων κοινωνικής δικτύωσης: Υφομετρική ανάλυση με προεκτάσεις στην γλωσσική διδασκαλία Γιώργος Κ. Μικρός Τμήμα Ιταλικής Γλώσσας και Φιλολογίας - ΕΚΠΑ Περίγραμμα ομιλίας Κοινωνικά Μέσα Δικτύωσης
Η ΙΣΧΥΣ ΕΝΟΣ ΕΛΕΓΧΟΥ. (Power of a Test) ΚΕΦΑΛΑΙΟ 21
 ΚΕΦΑΛΑΙΟ 21") ΚΕΦΑΛΑΙΟ 21 Η ΙΣΧΥΣ ΕΝΟΣ ΕΛΕΓΧΟΥ (Power of a Test) Όπως είδαμε προηγουμένως, στον Στατιστικό Έλεγχο Υποθέσεων, ορίζουμε δύο είδη πιθανών λαθών (κινδύνων) που μπορεί να συμβούν όταν παίρνουμε αποφάσεις
ΚΕΦΑΛΑΙΟ 21 Η ΙΣΧΥΣ ΕΝΟΣ ΕΛΕΓΧΟΥ (Power of a Test) Όπως είδαμε προηγουμένως, στον Στατιστικό Έλεγχο Υποθέσεων, ορίζουμε δύο είδη πιθανών λαθών (κινδύνων) που μπορεί να συμβούν όταν παίρνουμε αποφάσεις
ΕΕ728 Προχωρηµένα Θέµατα Θεωρίας Πληροφορίας 2η διάλεξη (3η έκδοση, 11/3)
") ΕΕ728 Προχωρηµένα Θέµατα Θεωρίας Πληροφορίας 2η διάλεξη (3η έκδοση, 11/3) ηµήτρης-αλέξανδρος Τουµπακάρης Τµήµα ΗΜ&ΤΥ, Πανεπιστήµιο Πατρών 19 Φεβρουαρίου 2013 ηµήτρης-αλέξανδρος Τουµπακάρης Προχωρηµένα
ΕΕ728 Προχωρηµένα Θέµατα Θεωρίας Πληροφορίας 2η διάλεξη (3η έκδοση, 11/3) ηµήτρης-αλέξανδρος Τουµπακάρης Τµήµα ΗΜ&ΤΥ, Πανεπιστήµιο Πατρών 19 Φεβρουαρίου 2013 ηµήτρης-αλέξανδρος Τουµπακάρης Προχωρηµένα
3 ΠΙΘΑΝΟΤΗΤΕΣ. ο δειγματικός χώρος του πειράματος θα είναι το σύνολο: Ω = ω, ω,..., ω }.
 3 ΠΙΘΑΝΟΤΗΤΕΣ 3.1 ΔΕΙΓΜΑΤΙΚΟΣ ΧΡΟΣ - ΕΝΔΕΧΟΜΕΝΑ Πείραμα Τύχης Ένα πείραμα του οποίου δεν μπορούμε εκ των προτέρων να προβλέψουμε το αποτέλεσμα, μολονότι επαναλαμβάνεται φαινομενικά τουλάχιστον κάτω από
3 ΠΙΘΑΝΟΤΗΤΕΣ 3.1 ΔΕΙΓΜΑΤΙΚΟΣ ΧΡΟΣ - ΕΝΔΕΧΟΜΕΝΑ Πείραμα Τύχης Ένα πείραμα του οποίου δεν μπορούμε εκ των προτέρων να προβλέψουμε το αποτέλεσμα, μολονότι επαναλαμβάνεται φαινομενικά τουλάχιστον κάτω από
Ανάλυση Διασποράς Ανάλυση Διασποράς διακύμανση κατά παράγοντες διακύμανση σφάλματος Παράδειγμα 1: Ισομεγέθη δείγματα
 Ανάλυση Διασποράς Έστω ότι μας δίνονται δείγματα που προέρχονται από άγνωστους πληθυσμούς. Πόσο διαφέρουν οι μέσες τιμές τους; Με άλλα λόγια: πόσο πιθανό είναι να προέρχονται από πληθυσμούς με την ίδια
Ανάλυση Διασποράς Έστω ότι μας δίνονται δείγματα που προέρχονται από άγνωστους πληθυσμούς. Πόσο διαφέρουν οι μέσες τιμές τους; Με άλλα λόγια: πόσο πιθανό είναι να προέρχονται από πληθυσμούς με την ίδια
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ
 ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
Μεθοδολογία των Επιστημών του Ανθρώπου: Στατιστική
 Μεθοδολογία των Επιστημών του Ανθρώπου: Στατιστική Ενότητα 2: Βασίλης Γιαλαμάς Σχολή Επιστημών της Αγωγής Τμήμα Εκπαίδευσης και Αγωγής στην Προσχολική Ηλικία Περιεχόμενα ενότητας Παρουσιάζονται οι βασικές
Μεθοδολογία των Επιστημών του Ανθρώπου: Στατιστική Ενότητα 2: Βασίλης Γιαλαμάς Σχολή Επιστημών της Αγωγής Τμήμα Εκπαίδευσης και Αγωγής στην Προσχολική Ηλικία Περιεχόμενα ενότητας Παρουσιάζονται οι βασικές
(Statistical Machine Translation: SMT[1]) [2]
![(Statistical Machine Translation: SMT[1]) [2]](/thumbs/71/65378195.jpg "(Statistical Machine Translation: SMT[1]) [2]") 1,a) Graham Neubig 1,b) Sakriani Sakti 1,c) 1,d) 1,e) 2 1. (Statistical Machine Translation: SMT[1]) [2] [3] [4][5][6] 2 1 (a) 3 approach 1 Nara Institute of Science and Technology a) miura.akiba.lr9@is.naist.jp
1,a) Graham Neubig 1,b) Sakriani Sakti 1,c) 1,d) 1,e) 2 1. (Statistical Machine Translation: SMT[1]) [2] [3] [4][5][6] 2 1 (a) 3 approach 1 Nara Institute of Science and Technology a) miura.akiba.lr9@is.naist.jp
ΤΕΧΝΟΓΛΩΣΣΙΑ VIII ΛΟΓΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ ΔΙΔΑΣΚΟΝΤΕΣ: ΜΑΪΣΤΡΟΣ ΓΙΑΝΗΣ, ΠΑΠΑΚΙΤΣΟΣ ΕΥΑΓΓΕΛΟΣ ΑΣΚΗΣΗ: ΔΙΟΡΘΩΣΗ ΕΚΦΡΑΣΕΩΝ (Β )
") ΤΕΧΝΟΓΛΩΣΣΙΑ VIII ΛΟΓΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ ΔΙΔΑΣΚΟΝΤΕΣ: ΜΑΪΣΤΡΟΣ ΓΙΑΝΗΣ, ΠΑΠΑΚΙΤΣΟΣ ΕΥΑΓΓΕΛΟΣ ΑΣΚΗΣΗ: ΔΙΟΡΘΩΣΗ ΕΚΦΡΑΣΕΩΝ (Β ) ΣΚΟΠΟΣ Σκοπός της άσκησης είναι ο σχεδιασμός και η υλοποίηση συστήματος διόρθωσης
ΤΕΧΝΟΓΛΩΣΣΙΑ VIII ΛΟΓΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ ΔΙΔΑΣΚΟΝΤΕΣ: ΜΑΪΣΤΡΟΣ ΓΙΑΝΗΣ, ΠΑΠΑΚΙΤΣΟΣ ΕΥΑΓΓΕΛΟΣ ΑΣΚΗΣΗ: ΔΙΟΡΘΩΣΗ ΕΚΦΡΑΣΕΩΝ (Β ) ΣΚΟΠΟΣ Σκοπός της άσκησης είναι ο σχεδιασμός και η υλοποίηση συστήματος διόρθωσης
Εκπαιδευτική Έρευνα: Μέθοδοι Συλλογής και Ανάλυσης εδομένων Έλεγχοι Υποθέσεων
 Εκπαιδευτική Έρευνα: Μέθοδοι Συλλογής και Ανάλυσης εδομένων Έλεγχοι Υποθέσεων Ένα Ερευνητικό Παράδειγμα Σκοπός της έρευνας ήταν να διαπιστωθεί εάν ο τρόπος αντίδρασης μιας γυναίκας απέναντι σε φαινόμενα
Εκπαιδευτική Έρευνα: Μέθοδοι Συλλογής και Ανάλυσης εδομένων Έλεγχοι Υποθέσεων Ένα Ερευνητικό Παράδειγμα Σκοπός της έρευνας ήταν να διαπιστωθεί εάν ο τρόπος αντίδρασης μιας γυναίκας απέναντι σε φαινόμενα
Εισαγωγή στο μάθημα Πιθανότητες - Στατιστική. Τμήμα Πολιτικών Μηχανικών Πανεπιστήμιο Θεσσαλίας
 Εισαγωγή στο μάθημα Πιθανότητες - Στατιστική Τμήμα Πολιτικών Μηχανικών Πανεπιστήμιο Θεσσαλίας 1 Πειραματικά Μοντέλα Μοντέλα:» Καθοριστικά» (π.χ. ο νόμος του Ohm)» Στοχαστικά ή πιθανοτικά» (π.χ. ένταση
Εισαγωγή στο μάθημα Πιθανότητες - Στατιστική Τμήμα Πολιτικών Μηχανικών Πανεπιστήμιο Θεσσαλίας 1 Πειραματικά Μοντέλα Μοντέλα:» Καθοριστικά» (π.χ. ο νόμος του Ohm)» Στοχαστικά ή πιθανοτικά» (π.χ. ένταση
Στατιστική Ι (ΨΥΧ-122) Διάλεξη 2
 Διάλεξη 2") (ΨΥΧ-122) Λεωνίδας Α. Ζαμπετάκης Β.Sc., M.Env.Eng., M.Ind.Eng., D.Eng. Εmail: lzabetak@dpem.tuc.gr Διαλέξεις: ftp://ftp.soc.uoc.gr/psycho/zampetakis/ 28210 37323 Διάλεξη 2 ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ ΤΜΗΜΑ ΨΥΧΟΛΟΓΙΑΣ
(ΨΥΧ-122) Λεωνίδας Α. Ζαμπετάκης Β.Sc., M.Env.Eng., M.Ind.Eng., D.Eng. Εmail: lzabetak@dpem.tuc.gr Διαλέξεις: ftp://ftp.soc.uoc.gr/psycho/zampetakis/ 28210 37323 Διάλεξη 2 ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ ΤΜΗΜΑ ΨΥΧΟΛΟΓΙΑΣ
ΑΝΑΛΥΣΗ ΕΥΑΙΣΘΗΣΙΑΣ Εισαγωγή
 1 ΑΝΑΛΥΣΗ ΕΥΑΙΣΘΗΣΙΑΣ Εισαγωγή Η ανάλυση ευαισθησίας μιάς οικονομικής πρότασης είναι η μελέτη της επιρροής των μεταβολών των τιμών των παραμέτρων της πρότασης στη διαμόρφωση της τελικής απόφασης. Η ανάλυση
1 ΑΝΑΛΥΣΗ ΕΥΑΙΣΘΗΣΙΑΣ Εισαγωγή Η ανάλυση ευαισθησίας μιάς οικονομικής πρότασης είναι η μελέτη της επιρροής των μεταβολών των τιμών των παραμέτρων της πρότασης στη διαμόρφωση της τελικής απόφασης. Η ανάλυση
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 07-08 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 07-08 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
Φύλλο Εργασίας 3 Μετρήσεις μάζας Τα διαγράμματα
 Φύλλο Εργασίας 3 Μετρήσεις μάζας Τα διαγράμματα α. Παρατηρώ, Πληροφορούμαι, Ενδιαφέρομαι Τι πρέπει να κάνουμε για να μετρήσουμε οποιοδήποτε μέγεθος; Πρέπει να ορίσουμε: 1. Μια ομοειδή ποσότητα ως μονάδα
Φύλλο Εργασίας 3 Μετρήσεις μάζας Τα διαγράμματα α. Παρατηρώ, Πληροφορούμαι, Ενδιαφέρομαι Τι πρέπει να κάνουμε για να μετρήσουμε οποιοδήποτε μέγεθος; Πρέπει να ορίσουμε: 1. Μια ομοειδή ποσότητα ως μονάδα
Στατιστική Περιγραφή Φυσικού Μεγέθους - Πιθανότητες
 Στατιστική Περιγραφή Φυσικού Μεγέθους - Πιθανότητες Είπαμε ότι γενικά τα συστηματικά σφάλματα που υπεισέρχονται σε μια μέτρηση ενός φυσικού μεγέθους είναι γενικά δύσκολο να επισημανθούν και να διορθωθούν.
Στατιστική Περιγραφή Φυσικού Μεγέθους - Πιθανότητες Είπαμε ότι γενικά τα συστηματικά σφάλματα που υπεισέρχονται σε μια μέτρηση ενός φυσικού μεγέθους είναι γενικά δύσκολο να επισημανθούν και να διορθωθούν.
ΛΥΜΕΝΕΣ ΕΦΑΡΜΟΓΕΣ ΣΤΟ 2 ο ΚΕΦΑΛΑΙΟ
 ΛΥΜΕΝΕΣ ΕΦΑΡΜΟΓΕΣ ΣΤΟ 2 ο ΚΕΦΑΛΑΙΟ 1. Έστω συνάρτηση ζήτησης με τύπο Q = 200 4P. Να βρείτε: α) Την ελαστικότητα ως προς την τιμή όταν η τιμή αυξάνεται από 10 σε 12. 1ος τρόπος Αν P 0 10 τότε Q 0 200 410
ΛΥΜΕΝΕΣ ΕΦΑΡΜΟΓΕΣ ΣΤΟ 2 ο ΚΕΦΑΛΑΙΟ 1. Έστω συνάρτηση ζήτησης με τύπο Q = 200 4P. Να βρείτε: α) Την ελαστικότητα ως προς την τιμή όταν η τιμή αυξάνεται από 10 σε 12. 1ος τρόπος Αν P 0 10 τότε Q 0 200 410
Άσκηση 4 Θεμελιώδης νόμος της Μηχανικής
 Άσκηση 4 Θεμελιώδης νόμος της Μηχανικής Σύνοψη Η άσκηση αυτή διαφέρει από όλες τις άλλες. Σκοπός της είναι η πειραματική επαλήθευση του θεμελιώδους νόμου της Μηχανικής. Αυτό θα γίνει με τη γραφική ανάλυση
Άσκηση 4 Θεμελιώδης νόμος της Μηχανικής Σύνοψη Η άσκηση αυτή διαφέρει από όλες τις άλλες. Σκοπός της είναι η πειραματική επαλήθευση του θεμελιώδους νόμου της Μηχανικής. Αυτό θα γίνει με τη γραφική ανάλυση
Ανάλυση Ηλεκτρικών Κυκλωμάτων
 Ανάλυση Ηλεκτρικών Κυκλωμάτων Κεφάλαιο 3: Συνδυασμός αντιστάσεων και πηγών Οι διαφάνειες ακολουθούν το βιβλίο του Κων/νου Παπαδόπουλου «Ανάλυση Ηλεκτρικών Κυκλωμάτων» ISBN: 978-960-93-7110-0 κωδ. ΕΥΔΟΞΟΣ:
Ανάλυση Ηλεκτρικών Κυκλωμάτων Κεφάλαιο 3: Συνδυασμός αντιστάσεων και πηγών Οι διαφάνειες ακολουθούν το βιβλίο του Κων/νου Παπαδόπουλου «Ανάλυση Ηλεκτρικών Κυκλωμάτων» ISBN: 978-960-93-7110-0 κωδ. ΕΥΔΟΞΟΣ:
Στατιστική Συμπερασματολογία
 Στατιστική Συμπερασματολογία Διαφάνειες 4 ου κεφαλαίου Ελεγχοσυναρτήσεις Γενικευμένου Λόγου Πιθανοφανειών Σταύρος Χατζόπουλος 27/03/2017, 03/04/2017, 24/04/2017 1 Εισαγωγή Έστω το τ.δ. X,,, από την κατανομή
Στατιστική Συμπερασματολογία Διαφάνειες 4 ου κεφαλαίου Ελεγχοσυναρτήσεις Γενικευμένου Λόγου Πιθανοφανειών Σταύρος Χατζόπουλος 27/03/2017, 03/04/2017, 24/04/2017 1 Εισαγωγή Έστω το τ.δ. X,,, από την κατανομή