Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
|
|
|
- Ἀκελδαμά Αλεξάνδρου
- 8 χρόνια πριν
- Προβολές:
Transcript


1 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
2 Σύνοψη παρουσίασης Παράλληλες υπολογιστικές πλατφόρμες PRAM: Η ιδανική παράλληλη πλατφόρμα Η ταξινόμηση του Flynn Συστήματα κοινής μνήμης Συστήματα κατανεμημένης μνήμης Ανάλυση παράλληλων προγραμμάτων Μετρικές αξιολόγησης επίδοσης Ο νόμος του Amdahl Μοντελοποίηση παράλληλων προγραμμάτων Σχεδίαση παράλληλων προγραμμάτων Κατανομή υπολογισμών και δεδομένων Σχεδιασμός αλληλεπίδρασης ανάμεσα στα tasks Απεικόνιση των tasks σε διεργασίες (ή threads) Ενορχήστρωση της επικοινωνίας ή/και του συγχρονισμού 2
3 Σύνοψη παρουσίασης Παράλληλα προγραμματιστικά μοντέλα Κοινού χώρου διευθύνσεων Ανταλλαγής μηνυμάτων Παράλληλες προγραμματιστικές δομές SPMD fork / join task graphs parallel for Γλώσσες και εργαλεία POSIX threads, MPI, OpenMP, Cilk, Cuda, Γλώσσες PGAS Αλληλεπίδραση με το υλικό Συστήματα κοινής μνήμης Συστήματα κατανεμημένης μνήμης και υβριδικά 3
4 PRAM: Η ιδανική παράλληλη μηχανή Η θεωρητική ανάλυση και αξιολόγηση σειριακών αλγορίθμων βασίζεται στη χρήση ενός υπολογιστικού μοντέλου: Random Access Machine (RAM) Turing machine Γιατί να μην κάνουμε το ίδιο και για τους παράλληλους αλγόριθμους; Ας ορίσουμε μια παράλληλη υπολογιστική μηχανή που θα μας βοηθάει να αναλύουμε και να συγκρίνουμε παράλληλους αλγορίθμους: PRAM: Parallel Random Access Machine n υπολογιστικές μονάδες (n όσο μεγάλο απαιτεί το προς επίλυση πρόβλημα) Κοινή μνήμη απεριόριστου μεγέθους Ομοιόμορφη πρόσβαση στη μνήμη από όλους τους επεξεργαστές 4
5 PRAM: Ταυτόχρονη πρόσβαση σε δεδομένα Τι συμβαίνει όταν δύο επεξεργαστές αποπειρώνται να προσπελάσουν την ίδια θέση μνήμης ταυτόχρονα; 4 διαφορετικές προσεγγίσεις (διαφορετικά μοντέλα): Exclusive Read Exclusive Write (EREW): Κάθε θέση μνήμης μπορείς να αναγνωστεί/εγγραφεί από μόνο έναν επεξεργαστή (σε μια δεδομένη χρονική στιγμή) Αν συμβεί ταυτόχρονη πρόσβαση το πρόγραμμα τερματίζει Πρόκειται για πολύ περιοριστικό μοντέλο Concurrent Read Exclusive Write (CREW): Επιτρέπεται ταυτόχρονη ανάγνωση αλλά όχι εγγραφή Exclusive Read Concurrent Write (ERCW): Δεν παρουσιάζει θεωρητικό ή πρακτικό ενδιαφέρον Concurrent Read Concurrent Write (CRCW) Ισχυρή μηχανή που επιτρέπει ταυτόχρονες αναγνώσεις / εγγραφές Ταυτόχρονες εγγραφές: (common, arbitrary, priority, reduction) 5
6 PRAM: Προβλήματα Η πλατφόρμα PRAM κάνει κάποιες σοβαρές υπεραπλουστεύσεις που την απομακρύνουν από τις πραγματικές μηχανές: Απεριόριστος αριθμός επεξεργαστών (όσους έχει ανάγκη το πρόγραμμα) Απεριόριστο μέγεθος μνήμης Ομοιόμορφος χρόνος πρόσβασης στη μνήμη Για να συνδυαστούν τα παραπάνω απαιτείται ένα τεράστιας πολυπλοκότητας και κόστους δίκτυο διασύνδεσης με διακόπτες Τέτοια δίκτυα διασύνδεσης με την παρούσα τεχνολογία είναι ρεαλιστικά για λίγες δεκάδες επεξεργαστές Η θεωρητική ανάλυση σε ένα μοντέλο PRAM δεν μας δίνει ασφαλή συμπεράσματα για την εκτέλεση σε ένα πραγματικό παράλληλο σύστημα (π.χ. κοινής μνήμης) Το μοντέλο PRAM έχει θεωρητικό ενδιαφέρον και δεν χρησιμοποιείται στην πράξη 6
7 Flynn s taxonomy SISD Single Instruction Single Data SIMD Single Instruction Multiple Data MISD Multiple Instruction Single Data MIMD Multiple Instruction Multiple Data 7

8 Flynn s taxonomy 8
9 Κοινής μνήμης (shared memory) Παράλληλες αρχιτεκτονικές: Οργάνωση μνήμης UMA (Uniform memory access): Χρόνος προσπέλασης ανεξάρτητος του επεξεργαστή και της θέσης μνήμης NUMA (Non-uniform memory access): Χρόνος προσπέλασης εξαρτάται από τον επεξεργαστή και τη θέση μνήμης cc-numa (cache-coherent NUMA): NUMA με συνάφεια κρυφής μνήμης Κατανεμημένης μνήμης (distributed memory) Υβριδική 9
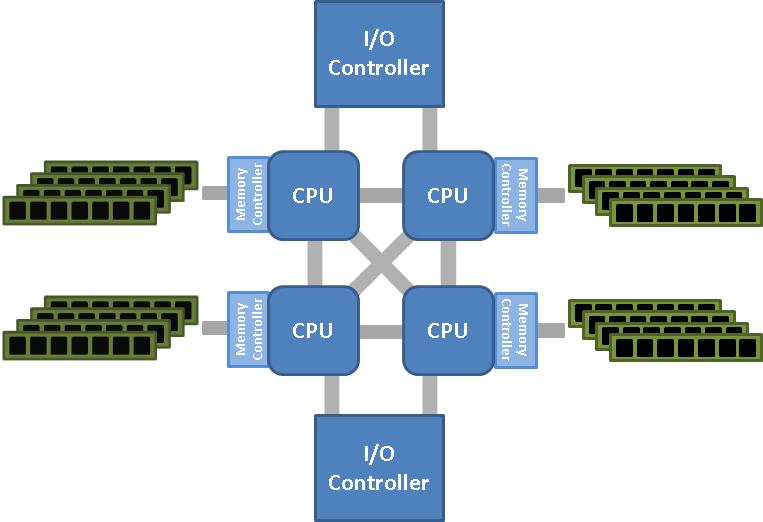
10 Αρχιτεκτονική κοινής μνήμης Οι επεξεργαστές έχουν κοινή μνήμη Κάθε επεξεργαστής διαθέτει τοπική ιεραρχία κρυφών μνημών Συνήθως η διασύνδεση γίνεται μέσω διαδρόμου μνήμης (memory bus) Αλλά και πιο εξελιγμένα δίκτυα διασύνδεσης Ομοιόμορφη ή μη-ομοιόμορφη προσπέλαση στη μνήμη (Uniform Memory Access UMA, Non-uniform Memory Access NUMA) Η κοινή μνήμη διευκολύνει τον παράλληλο προγραμματισμό Δύσκολα κλιμακώσιμη αρχιτεκτονική τυπικά μέχρι λίγες δεκάδες κόμβους (δεν κλιμακώνει το δίκτυο διασύνδεσης) $ CPU $ CPU... $ CPU Διάδρομος Μνήμης (memory bus) M 10
 Non-Uniform Memory Access (NUMA)")
11 SMP vs NUMA Symmetric Multiprocessing (SMP) Uniform Memory Access (UMA) Non-Uniform Memory Access (NUMA) Images taken from: 11
12 Αρχιτεκτονική κατανεμημένης μνήμης Κάθε επεξεργαστής έχει τη δική του τοπική μνήμη και ιεραρχία τοπικών μνημών Διασυνδέεται με τους υπόλοιπους επεξεργαστές μέσω δικτύου διασύνδεσης Η κατανεμημένη μνήμη δυσκολεύει τον προγραμματισμό Η αρχιτεκτονική κλιμακώνει σε χιλιάδες υπολογιστικούς κόμβους Κόμβος 1 Κόμβος 2 Κόμβος Ν $ $ $ CPU CPU... CPU M M M Δίκτυο Διασύνδεσης (π.χ. Ethernet, Myrinet, SCI) 12
13 Υβριδική αρχιτεκτονική Συνδυάζει τις δύο παραπάνω αρχιτεκτονικές: κόμβοι με αρχιτεκτονική κοινής μνήμης διασυνδέονται με ένα δίκτυο διασύνδεσης σε αρχιτεκτονική κατανεμημένης μνήμης Τυπική αρχιτεκτονική των σύγχρονων συστοιχιών-υπερυπολογιστών, data centers και υποδομών cloud SMP κόμβος 1 SMP κόμβος 2 SMP κόμβος Ν $ CPU 0 $ $... CPU Κ CPU 0 $ CPU Κ CPU 0 $... $ CPU Κ M M M Δίκτυο Διασύνδεσης (π.χ. Ethernet, Myrinet, SCI) 13
14 Χρόνος καλύτερου σειριακού αλγορίθμου: T s Χρόνος παράλληλου αλγορίθμου: T p Μετρικές αξιολόγησης επίδοσης: Επιτάχυνση (Speedup) Επιτάχυνση (speedup) S = T s / T p Δείχνει πόσες φορές πιο γρήγορο είναι το παράλληλο πρόγραμμα από το σειριακό linear (perfect) speedup σε p επεξεργαστές: p Τυπικά: S p Αν S > p superlinear speedup (πρέπει να το ερμηνεύσουμε προσεκτικά αν προκύψει στις μετρήσεις μας) 14
15 Αποδοτικότητα (efficiency) E = S / p Αποδοτικότητα (efficiency) και κλιμακωσιμότητα (scalability) Δείχνει πόσο επιτυχημένη είναι η παραλληλοποίηση τι ποσοστό του χρόνου κάθε επεξεργαστής κάνει χρήσιμη δουλειά Τυπικά Ε 1 H κλιμακωσιμότητα (scalability) εκφράζει ποιοτικά την ικανότητα ενός προγράμματος (συστήματος) να βελτιώνει την επίδοσή του με την προσθήκη επιπλέον επεξεργαστών (πόρων) Strong scaling: Κρατάμε το συνολικό μέγεθος του προβλήματος σταθερό Weak scaling: Κρατάμε το μέγεθος ανά επεξεργαστή σταθερό 15
16 Ο (αμείλικτος) νόμος του Amdahl Χρόνος καλύτερου σειριακού αλγορίθμου: T s f το κλάσμα του χρόνου ενός σειριακού προγράμματος που δεν παραλληλοποιείται Νόμος του Amdahl: T p S = = ft T T s p s = + f ( 1- f ) + 1 p T s ( 1- f ) p Έστω ότι ένα πρόγραμμα μπορεί να μοιραστεί σε 5 παράλληλες εργασίες εκ των οποίων η μία απαιτεί διπλάσιο χρόνο από τις υπόλοιπες 4 f = 1/6 Αν p = 5 (αναθέτουμε κάθε μία από τις παράλληλες εργασίες σε έναν επεξεργαστή) S = 3, E=0,6 Συνέπειες του νόμου του Amdahl: Παραλληλοποιούμε (και γενικά βελτιστοποιούμε) τμήματα του κώδικα που καταλαμβάνουν το μεγαλύτερο ποσοστό του χρόνου εκτέλεσης Αναζητούμε παραλληλία παντού! (π.χ. 1% σειριακός κώδικας μέγιστο speedup 100!) 16
17 Γιατί δεν κλιμακώνει το πρόγραμμά μου; 1. Δεν έχει παραλληλοποιήθεί το κατάλληλο τμήμα κώδικα (υπάρχει μεγάλο σειριακό κομμάτι, βλ. Νόμος του Amdahl) 2. Υπάρχει ανισοκατανομή φορτίου (load imbalance) 3. Κόστος συγχρονισμού / επικοινωνίας Μπορεί να οδηγήσει ακόμα και σε αύξηση του χρόνου εκτέλεσης 4. Συμφόρηση στο διάδρομο μνήμης (για αρχιτεκτονικές κοινής μνήμης) 17
18 1 st and 2 nd rule in code optimization Γενικοί κανόνες βελτιστοποίησης κώδικα 18
19 1 st and 2 nd rule in code optimization Γενικοί κανόνες βελτιστοποίησης κώδικα DON T DO IT! Because premature optimization is the root of all evil D. Knuth 19
20 Μοντελοποίηση επίδοσης Η μοντελοποίηση της επίδοσης είναι ιδιαίτερα δύσκολη σε ένα πολύπλοκο σύστημα όπως είναι η εκτέλεση μιας εφαρμογής σε μία παράλληλη πλατφόρμα Θέλουμε το μοντέλο να είναι απλό και ακριβές Συνήθως καθοδηγεί σχεδιαστικές επιλογές (π.χ. συγκρίνει διαφορετικές στρατηγικές) Συχνά αρκεί να έχουμε άνω και κάτω όρια στην επίδοση Ο παράλληλος χρόνος εκτέλεσης καταναλώνεται σε: Χρόνο υπολογισμού (T comp ) Χρόνο επικοινωνίας (T comm ) Άεργο χρόνο (Τ idle ) Παράλληλος χρόνος εκτέλεσης: Τ = T comp + T comm + T idle 20
21 Χρόνος υπολογισμών Κλασικό μοντέλο πρόβλεψης: Τ comp = ops * CPU speed (sec / op) Θεωρεί ότι η CPU μπορεί να τροφοδοτείται με δεδομένα από το υποσύστημα μνήμης Μοντέλο roofline Λαμβάνει υπόψη το bandwidth (bw σε byte/sec) του υποσυστήματος μνήμης Operational intensity (OI σε ops/byte) Τ comp = ops * max (CPU speed, 1/(ΟΙ * bw)) Συσχετίζει την εφαρμογή με την αρχιτεκτονική 21
22 Μοντέλο roofline Image taken from 22
23 Χρόνος υπολογισμών Παράδειγμα: LU decomposition for(k = 0; k < N-1; k++) for(i = k+1; i < N; i++){ L[i] = A[i][k] / A[k][k]; for(j = k+1; j < N; j++) A[i][j] = A[i][j] - L[i]*A[j][i]; } Operations = N 3 / 3 πολλαπλασιασμοί, Ν 3 /3 προσθέσεις Μπορούμε να αγνοήσουμε τις προσθέσεις Operational intensity (ops/byte): Μας αφορούν δεδομένα που έρχονται από την κύρια μνήμη (όχι από την cache) Μπορούμε να αγνοήσουμε το διάνυσμα L Μέγεθος Α = 8*Ν 2 (θεωρούμε διπλή ακρίβεια, 8 bytes για κάθε στοιχείο του Α) Αν ο A χωράει στην cache: ΟΙ = (N 3 / 3) / (8*Ν 2 ) = Ν/24 muls/byte Αν ο Α >> cache size: Ας θεωρήσουμε ότι σε κάθε βήμα k ο Α φορτώνεται από τη μνήμη (γιατί δεν είναι τυπικά σωστό αυτό?). ΟΙ = 1/24 muls/byte 23
24 Χρόνος υπολογισμών Παράδειγμα: LU decomposition Έστω επεξεργαστής με: CPU speed 5*10 8 muls/sec ή 2*10-9 sec/mul (500MFlops) Bandwidth διαδρόμου μνήμης: 4GB/sec = 4*10 9 bytes /sec 4MB L2 cache N = 100 (ο Α χωράει στην cache, OI = 4,16 muls/byte) Παραδοσιακό μοντέλο: Τ comp = ops * CPU speed = 0.33*10 6 muls * 2*10-9 sec/mul = 0.66msec Μοντέλο roofline: T comp = ops * min (CPU speed, 1/(ΟΙ * memory bandwidth)) = 0.33*10 6 muls * max (2*10-9 sec/mul, (4,16 muls/byte * 4*10 9 bytes/sec) -1 )= 0.33*10 6 muls * max (2*10-9 sec/mul, 6*10-11 sec/mul) = 0.66msec N = 2000 (ο Α δεν χωράει στην cache, OI = 0,042 muls/byte) Παραδοσιακό μοντέλο: Τ comp = ops * CPU speed = 2.66*10 9 muls * 2 *10-9 sec/mul = 5.33sec Μοντέλο roofline: T comp = ops * max (CPU speed, 1/(ΟΙ * memory bandwidth)) = 2.66*10 9 muls * max (2 *10-9 sec/mul, (0,042 muls/byte* 4 *10 9 bytes /sec) -1 ) = 2.66*10 9 muls * max (2 *10-9 sec/mul, 5,95*10-9 ) = 15.9sec 24
25 Χρόνος επικοινωνίας Χρόνος επικοινωνίας (point to point): Startup time (t s ) Per-hop time (t h ) Per word transfer time (t w ) T comm = t s + lt h + mt w (l = number of hops, m = message size) Το lt h είναι συνήθως μικρό και μπορεί να ενσωματωθεί στο t s, άρα: T comm = t s + mt w Χρόνος επικοινωνίας (broadcast σε P κόμβους) P διαφορετικά μηνύματα T comm = P(t s + mt w ) Δενδρική υλοποίηση: T comm = log 2 P(t s + mt w ) 25
26 Παράδειγμα: Nearest-neighbor communication 2 διάστατο υπολογιστικό χωρίο L 1 * L 2 Κάθε επεξεργαστής επικοινωνεί με τους γειτονικούς του και ανταλλάζει τις οριακές επιφάνειες Ποια τοπολογία επεξεργαστών ελαχιστοποιεί το κόστος επικοινωνίας; 1D 2D 26
27 Παράδειγμα: Nearest-neighbor communication Αριθμός επεξεργαστών: P = 100 1D = 100*1 2D = 10*10 διπλή ακρίβεια (8 bytes) L 1 =10 4, L 2 = 10 3 t s = 6*10-6 sec bandwidth = 500MB/sec t w =1.9*10-9 sec/byte 1D 2D 2 γείτονες, 1 μήνυμα ανά γείτονα, 2 μηνύματα ανά διεργασία Μέγεθος μηνύματος: m=8l 2 = 8*10 3 bytes T comm = t s + mt w = 2 (6*10-6 sec + 8*10 3 bytes * 1.9*10-9 sec/byte) = 42.4usec 4 μηνύματα ανά διεργασία m 1 =8L 1 /10= 8*10 3 bytes, m 2 =8L 2 /10= 8*10 2 bytes T comm = t s + mt w = 4 (6*10-6 sec) + 2(8*10 3 bytes * 1.9*10-9 sec/byte) + 2(8*10 2 bytes * 1.9*10-9 sec/byte) = 24us + 30,4us + 3,04us = 57,4us 27
28 Χρόνος επικοινωνίας (στον πραγματικό κόσμο) Συστήματα μεγάλης κλίμακας με χιλιάδες κόμβους, δεκάδες πυρήνες ανά κόμβο Παράμετροι που επηρεάζουν την επικοινωνία: Μέγεθος μηνύματος Διαφορετικό bandwidth για μικρά/μεσαία/μεγάλα μηνύματα λόγω χρήσης διαφορετικού πρωτοκόλλου δικτύου Τοπικός ανταγωνισμός στο εσωτερικό του κόμβου για πρόσβαση στο δίκτυο Ανταγωνισμός στο δίκτυο κορμού Μπορεί να οφείλεται και σε άλλες εφαρμογές! Απόσταση μεταξύ των κόμβων που επικοινωνούν Εξαρτάται από τη διάθεση κόμβων από τον scheduler του συστήματος Αριθμός μηνυμάτων 28
29 Άεργος χρόνος Ο άεργος χρόνος μπορεί να μοντελοποιηθεί δύσκολα Προκύπτει συνήθως από ανισοκατανομή του φόρτου εργασίας (load imbalance) Μπορεί να οφείλεται σε αναμονή για δεδομένα Σε αυτή την περίπτωση μπορεί να μοντελοποιηθεί σας μέρος του t s στο χρόνο επικοινωνίας Συχνά δεν είναι απλό να διαχωριστεί από το χρόνο επικοινωνίας Π.χ. στην παρακάτω περίπτωση 2 διεργασιών που επικοινωνούν, δεν είναι ξεκάθαρο ποιο κομμάτι του χρόνου θα πρέπει να χαρακτηριστεί ως άεργος χρόνος και ποιο ως χρόνος επικοινωνίας 29
30 Σχεδιασμός παράλληλων προγραμμάτων Στόχος: Η μετατροπή ενός σειριακού αλγορίθμου σε παράλληλο Κατανομή υπολογισμών σε υπολογιστικές εργασίες (tasks) Διαμοιρασμός των δεδομένων Ορισμός ορθής σειράς εκτέλεσης (χρονοδρομολόγηση) Οργάνωση πρόσβασης στα δεδομένα (συγχρονισμός / επικοινωνία) Ανάθεση εργασιών (απεικόνιση) σε οντότητες εκτέλεσης (processes, threads) Δεν υπάρχει αυστηρά ορισμένη μεθοδολογία για το σχεδιασμό και την υλοποίηση παράλληλων προγραμμάτων It s more art than science Ιδανικά θα θέλαμε ο σχεδιασμός και η υλοποίηση να λαμβάνουν χώρα ανεξάρτητα. Στην πράξη υπάρχει αλληλεπίδραση, π.χ. τον σχεδιασμό επηρεάζουν: Η αρχιτεκτονική της πλατφόρμας εκτέλεσης Τα υποστηριζόμενα προγραμματιστικά μοντέλα Οι δυνατότητες του περιβάλλοντος υλοποίησης 30
31 Σχεδιασμός παράλληλων προγραμμάτων Μετρικές αξιολόγησης: Επίδοση του παραγόμενου κώδικα Επιτάχυνση Αποδοτικότητα Κλιμακωσιμότητα Παραγωγικότητα (code productivity) Χαμηλός χρόνος υλοποίησης Μεταφερσιμότητα (portability) Ευκολία στη συντήρηση (maintainability) Κατανάλωση ενέργειας / ισχύος 31
32 Στάδια σχεδιασμού Στάδιο 1: Κατανομή υπολογισμών και διαμοιρασμός δεδομένων Στάδιο 2: Ορισμός ορθής σειράς εκτέλεσης Στάδιο 3: Οργάνωση πρόσβασης στα δεδομένα Στάδιο 4: Ανάθεση εργασιών σε οντότητες εκτέλεσης 32
33 Στάδιο 1: Κατανομή υπολογισμών και διαμοιρασμός δεδομένων Στόχος: κατανομή και διαμοιρασμός σε υπολογιστικές εργασίες (tasks) Σε τι να εστιάσω πρώτα; Στους υπολογισμούς ή τα δεδομένα; 2 βασικές προσεγγίσεις: task centric: πρώτα μοιράζονται οι υπολογισμοί και στη συνέχεια τα δεδομένα data centric: πρώτα μοιράζονται τα δεδομένα και στη συνέχεια οι υπολογισμοί Και στις 2 περιπτώσεις θα προκύψουν εργασίες (tasks) και διαμοιρασμένα δεδομένα Παράδειγμα: Πολλαπλασιασμός πίνακα με διάνυσμα ( y = A * x ) task centric: π.χ. 1 task = υπολογισμός της τιμής του y i : Ποια δεδομένα χρειάζεται αυτό το task; data centric: π.χ. 1 task = 1 γραμμή του πίνακα Α Ποιοι υπολογισμοί εμπλέκουν τη συγκεκριμένη γραμμή; Ποια άλλα δεδομένα χρειάζεται το συγκεκριμένο task; Ειδική περίπτωση της task centric προσέγγισης είναι η function centric Η κατανομή γίνεται με βάση τις συναρτήσεις (διαφορετικές λειτουργίες/στάδια) Είναι κατάλληλη για εφαρμογές που αποτελούνται από διαδοχικά στάδια υπολογισμών που εφαρμόζονται σε ροές δεδομένων 33
34 Επιλογή στρατηγικής ανάλογα με τον αλγόριθμο Η task centric προσέγγιση είναι η πιο γενική Στάδιο 1: Κατανομή υπολογισμών και διαμοιρασμός δεδομένων Οι task centric και data centric μπορεί να οδηγήσουν σε ακριβώς την ίδια κατανομή Απαιτήσεις: Επίδοση Μεγιστοποίηση παραλληλίας Ελαχιστοποίηση επιβαρύνσεων λόγω διαχείρισης tasks, συγχρονισμού, επικοινωνίας Ισοκατανομή φορτίου Απλότητα Μικρός χρόνος υλοποίησης Ευκολία στην επέκταση και τη συντήρηση Ευελιξία (ανεξαρτησία από απαιτήσεις υλοποίησης) 34
35 Αναλογία: παρασκευή πίτσας Μάγειρας Processing element Υλικά (ζύμη, σάλτσα, τυρί, ) data Στόχος: παραλληλοποίηση της παρασκευής Ν ταψιών πίτσας Υπόθεση: Συνεργάζονται >1 μάγειρες task centric προσέγγιση: «μοιράζω τη δουλειά» 1 task = παρασκευή 1 ταψιού πίτσας data centric προσέγγιση: «μοιράζω τα δεδομένα (υλικά)» η κατανομή της δουλειάς προκύπτει σαν φυσικό επακόλουθο του διαμοιρασμού των δεδομένων μοιράζω τα υλικά σε τμήματα (π.χ. σε Κ μέρη, ή ανά μάγειρα, ή ανά πίτσα) function centric προσέγγιση: διαχωρίζω τις διαφορετικές δουλειές παρασκευή ζύμης, παρασκευή σάλτσας, προετοιμασία λοιπών υλικών, άπλωμα ζύμης, τοποθέτηση σάλτσας, 35
 ευνοούν τη data")
 Επίλυση γραμμικών συστημάτων Stencil computations Όταν")

36 Rule of thumb Αλγόριθμοι σε κανονικές δομές δεδομένων (π.χ. regular computational grids, αλγεβρικοί πίνακες) ευνοούν τη data centric κατανομή: Πολλαπλασιασμός πινάκων (γενικά βασικές αλγεβρικές ρουτίνες) Επίλυση γραμμικών συστημάτων Stencil computations Όταν μπορεί να εφαρμοστεί, η data centric προσέγγιση οδηγεί σε κομψές λύσεις Δοκιμάζουμε πρώτα την data centric και αν δεν πετύχει, καταφεύγουμε στην task centric 36
37 Διαμοιρασμός κανονικών δομών 1-dimensional 2-dimensional + Απλή στην υλοποίηση - Περιοριστική (το task που προκύπτει εξαρτάται από το Ν του πίνακα) - Δυσκολότερη στην υλοποίηση + Πιο ευέλικτη (ο προγραμματιστής ελέγχει το μέγεθος του task) 37
 Αλγόριθμοι σε λίστες, δέντρα, γράφους, κλπ Αναδρομικοί αλγόριθμοι Event-based εφαρμογές")
38 Rule of thumb H task centric προσέγγιση αποτελεί λύση για πιο δυναμικούς αλγορίθμους σε ακανόνιστες δομές δεδομένων (irregular data structures) Αλγόριθμοι σε λίστες, δέντρα, γράφους, κλπ Αναδρομικοί αλγόριθμοι Event-based εφαρμογές 38
39 Rule of thumb H function centric προσέγγιση μπορεί να υιοθετηθεί όταν υπάρχουν διακριτές φάσεις και «ροή δεδομένων» Υπάρχει κάποιου είδους υποστήριξη στο υλικό για κάθε φάση Η παραλληλοποίηση σε κάθε φάση με την data centric προσέγγιση δεν οδηγεί σε ικανοποιητική αξιοποίηση των πόρων (π.χ. δεν κλιμακώνει στο διαθέσιμο αριθμό πυρήνων λόγω συμφόρησης στο διάδρομο μνήμης) 39
40 Rule of thumb H function centric προσέγγιση μπορεί να υιοθετηθεί όταν υπάρχουν διακριτές φάσεις και «ροή δεδομένων» Υπάρχει κάποιου είδους υποστήριξη στο υλικό για κάθε φάση Η παραλληλοποίηση σε κάθε φάση με την data centric προσέγγιση δεν οδηγεί σε ικανοποιητική αξιοποίηση των πόρων (π.χ. δεν κλιμακώνει στο διαθέσιμο αριθμό πυρήνων λόγω συμφόρησης στο διάδρομο μνήμης) data centric: π.χ. 32 threads ανά φάση load image scale image filter image display image 40
41 Rule of thumb H function centric προσέγγιση μπορεί να υιοθετηθεί όταν υπάρχουν διακριτές φάσεις και «ροή δεδομένων» Υπάρχει κάποιου είδους υποστήριξη στο υλικό για κάθε φάση Η παραλληλοποίηση σε κάθε φάση με την data centric προσέγγιση δεν οδηγεί σε ικανοποιητική αξιοποίηση των πόρων (π.χ. δεν κλιμακώνει στο διαθέσιμο αριθμό πυρήνων λόγω συμφόρησης στο διάδρομο μνήμης) data centric: π.χ. 32 threads ανά φάση load image scale image filter image Αν κάθε φάση κλιμακώνει μέχρι τα 8 threads, έχουμε προφανή σπατάλη πόρων display image 41
42 Rule of thumb H function centric προσέγγιση μπορεί να υιοθετηθεί όταν υπάρχουν διακριτές φάσεις και «ροή δεδομένων» Υπάρχει κάποιου είδους υποστήριξη στο υλικό για κάθε φάση Η παραλληλοποίηση σε κάθε φάση με την data centric προσέγγιση δεν οδηγεί σε ικανοποιητική αξιοποίηση των πόρων (π.χ. δεν κλιμακώνει στο διαθέσιμο αριθμό πυρήνων λόγω συμφόρησης στο διάδρομο μνήμης) load image (#4) 8 threads scale image (#3) 8 threads filter image (#2) 8 threads display image (#1) 8 threads 42
43 Παράδειγμα: Εξίσωση θερμότητας Αλγόριθμος του Jacobi (2-διάστατο πλέγμα Χ * Υ) A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) Data centric Μοιράζουμε τα δεδομένα ανά σημείο / γραμμή / στήλη / μπλοκ Κάθε task αναλαμβάνει να υπολογίσει την τιμή σε κάθε διαμοιρασμένο δεδομένο Task centric 1 task = υπολογισμός θερμότητας για κάθε σημείο του χωρίου 1 task = υπολογισμός θερμότητας για κάθε χρονικό βήμα 1 task = υπολογισμός θερμότητας για μία γραμμή / στήλη / block του δισδιάστατου πλέγματος για όλες τις χρονικές στιγμές 1 task = υπολογισμός θερμότητας για μία γραμμή / στήλη / block του δισδιάστατου πλέγματος για μία χρονική στιγμή Κατανομή δεδομένων: Κάθε task κατέχει (owns) τα δεδομένα που γράφει 43
44 Χαρακτηρισμός δεδομένων Τα δεδομένα του προβλήματος μπορούν να ανατεθούν ως: Μοιραζόμενα δεδομένα (shared data): Μπορεί να υποστηριχθεί μόνο από προγραμματιστικά μοντέλα κοινού χώρου διευθύνσεων Αποτελεί ένα πολύ βολικό τρόπο «κατανομής» Χρειάζεται ιδιαίτερη προσοχή για τον εντοπισμό race conditions Κατανεμημένα δεδομένα (distributed data): Τα δεδομένα κατανέμονται ανάμεσα στα tasks Αποτελεί τη βασική προσέγγιση στα προγραμματιστικά μοντέλα ανταλλαγής μηνυμάτων Επιβάλλει επιπλέον προγραμματιστικό κόστος Αντιγραμμένα δεδομένα (replicated data): Για αντιγραφή μικρών read-only δομών δεδομένων Για αντιγραφή υπολογισμών 44
45 Στάδιο 2: Ορισμός ορθής σειράς εκτέλεσης Οι εργασίες που δημιουργήθηκαν στο προηγούμενο στάδιο πρέπει να μπουν στη σωστή σειρά ώστε να εξασφαλίζεται η ίδια σημασιολογία με το σειριακό πρόγραμμα Το στάδιο αυτό συχνά αναφέρεται και ως χρονοδρομολόγηση = ανάθεση εργασιών σε χρονικές στιγμές Απαιτείται εντοπισμός των εξαρτήσεων ανάμεσα στις εργασίες και κατάστρωση του γράφου των εξαρτήσεων (task dependence graph) 45
46 Εξαρτήσεις Εξαρτήσεις δεδομένων υπάρχουν ήδη από το σειριακό πρόγραμμα Εξάρτηση υπάρχει όταν 2 εντολές αναφέρονται στα ίδια δεδομένα (θέση μνήμης) 4 είδη εξαρτήσεων Read-After-Write (RAW) ή true dependence Write-After-Read (WAR) ή anti dependence Write-After-Write (WAW) ή output dependence Read-After-Read (not really a dependence) Η παράλληλη εκτέλεση πρέπει να σεβαστεί τις εξαρτήσεις του προβλήματος Η κατανομή των δεδομένων στα tasks δημιουργεί κατά κανόνα εξαρτήσεις ανάμεσα στα tasks (π.χ. το task1 πρέπει να διαβάσει δεδομένα που παράγει το task2) Διατήρηση των εξαρτήσεων: σειριοποίηση μεταξύ tasks 46
47 Γράφος εξαρτήσεων (task dependence graph) Ή απλά task graph Κορυφές: tasks Label κορυφής: κόστος υπολογισμού του task Ακμές: εξαρτήσεις ανάμεσα στα tasks Βάρος ακμής: όγκος δεδομένων που πρέπει να μεταφερθούν (στην περίπτωση της επικοινωνίας) 47
48 Task graphs: βασικές ιδιότητες Τ 1 : Συνολική εργασία (work), ο χρόνος που απαιτείται για την εκτέλεση σε 1 επεξεργαστή T p : Χρόνος εκτέλεσης σε p επεξεργαστές Κρίσιμο μονοπάτι (critical path): Το μέγιστο μονοπάτι ανάμεσα στην πηγή και τον προορισμό του γράφου T : Χρόνος εκτέλεσης σε επεξεργαστές (span) και χρόνος εκτέλεσης του κρίσιμου μονοπατιού Ισχύει: T p T 1 / p T p T Μέγιστο speedup T 1 / T 48

49 Εξαρτήσεις στην εξίσωση θερμότητας 1 task = υπολογισμός θερμότητας για κάθε σημείο του χωρίου A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) 49

50 Εξαρτήσεις στην εξίσωση θερμότητας 1 task = υπολογισμός θερμότητας για κάθε χρονικό βήμα Δεν υπάρχουν ταυτόχρονα tasks! A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) 50
51 Εξαρτήσεις στην εξίσωση θερμότητας 1 task = υπολογισμός θερμότητας για μία γραμμή του δισδιάστατου πλέγματος για όλες τις χρονικές στιγμές Δεν υπάρχει έγκυρη παράλληλη εκτέλεση! A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) 51

52 Εξαρτήσεις στην εξίσωση θερμότητας 1 task = υπολογισμός θερμότητας για μία γραμμή του δισδιάστατου πλέγματος για μία χρονική στιγμή A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) 52
53 Στάδιο 3: Οργάνωση πρόσβασης στα δεδομένα Η κατανομή των υπολογισμών και των δεδομένων καθώς και ο χαρακτηρισμός τους δημιουργεί ανάγκες για επικοινωνία και συγχρονισμό Επικοινωνία: Κατανεμημένα δεδομένα 1 task χρειάζεται να διαβάσει δεδομένα που κατέχει ένα άλλο task Είτε εξαιτίας του γράφου εξαρτήσεων (παράχθηκαν κατά την εκτέλεση σε άλλο task) Είτε επειδή βρίσκονται αποθηκευμένα σε άλλο task (π.χ. από την αρχική κατανομή) Σημείο-προς-σημείο και συλλογική Καθορισμός ποια δεδομένα πρέπει να αποσταλούν, σε ποιες εργασίες και πότε 53
54 Στάδιο 3: Οργάνωση πρόσβασης στα δεδομένα Η κατανομή των υπολογισμών και των δεδομένων καθώς και ο χαρακτηρισμός τους δημιουργεί ανάγκες για επικοινωνία και συγχρονισμό Συγχρονισμός: Απαιτείται είτε λόγω του γράφου εξαρτήσεων (σειριοποίηση) είτε λόγω καταστάσεων συναγωνισμού (race conditions) Σειριοποίηση: Barriers, condition variables, semaphores Εντοπισμός καταστάσεων συναγωνισμού και εισαγωγή κατάλληλου σχήματος ελέγχου ταυτόχρονης πρόσβασης (concurrency control) Αμοιβαίος αποκλεισμός: Critical section, Locks, readers-writers Lock-free προσεγγίσεις Transactional memory 54
55 Στάδιο 4: Ανάθεση εργασιών σε οντότητες εκτέλεσης Το στάδιο αυτό αναλαμβάνει να αναθέσει εργασίες (tasks) σε οντότητες εκτέλεσης (process, tasks, κλπ) O τρόπος με τον οποίο ανατίθενται τα tasks σε οντότητες εκτέλεσης μπορεί να επηρεάσει σημαντικά την εκτέλεση: Παραλληλισμός και ισοκατανομή φορτίου Τοπικότητα δεδομένων Κόστος συγχρονισμού και επικοινωνίας 55

56 56 Στάδιο 4: Ανάθεση εργασιών σε οντότητες εκτέλεσης

57 Στάδιο 4: Ανάθεση εργασιών σε οντότητες εκτέλεσης Επικοινωνία / συγχρονισμός που είχε προβλεφθεί στο προηγούμενο βήμα μπορεί να απαλειφτεί 57
58 Στατική vs. Δυναμική ανάθεση εργασιών Στατική απεικόνιση: Διαμοιρασμός των tasks σε threads πριν την έναρξη της εκτέλεσης Καλή πρακτική: Αν η εφαρμογή το επιτρέπει, συνηθίζουμε να έχουμε 1 task / thread (προσαρμόζοντας κατάλληλα το σχεδιασμό μας και στο Στάδιο 1) Κατάλληλη στρατηγική για εφαρμογές με: ομοιόμορφη και γνωστή εξαρχής κατανομή φορτίου (π.χ. regular task graph) ανομοιόμορφη αλλά προβλέψιμη κατανομή φορτίου Πλεονεκτήματα : Απλή στην υλοποίηση Καλή επίδοση για «κανονικές εφαρμογές» Μηδενικό overhead Μειονεκτήματα: Κακή επίδοση για δυναμικές και ακανόνιστες εφαρμογές 58
59 Στατική vs. Δυναμική απεικόνιση tasks Δυναμική απεικόνιση: Διαμοιρασμός των tasks σε threads κατά την εκτέλεση Κατάλληλη στρατηγική για εφαρμογές με: Ακανόνιστο γράφο εργασιών μη προβλέψιμο φορτίο δυναμικά δημιουργούμενα tasks Πλεονεκτήματα: Εξισορρόπηση φορτίου σε δυναμικές και ακανόνιστες εφαρμογές Μειονεκτήματα: Δύσκολη στην υλοποίηση (συνήθως το αναλαμβάνει το run-time σύστημα) Μπορεί να δημιουργήσει bottleneck σε περίπτωση υλοποίησης με ένα κεντρικό scheduling thread (απαιτούνται κατανεμημένοι αλγόριθμοι) 59
60 Σχετικά ζητήματα απεικόνισης (δρομολόγησης) Δρομολόγηση εργασιών σε ένα υπερυπολογιστικό σύστημα N κόμβοι, c πυρήνες ανά κόμβο Κ jobs, κάθε job i ζητάει Ν i κόμβους και c i πύρήνες Στατικές προσεγγίσεις Δρομολόγηση παράλληλων εφαρμογών σε επίπεδο λειτουργικού Πολυπύρηνο σύστημα Κ εφαρμογές με διαφορετικός αριθμό από threads η κάθε μία Οι τρέχουσες προσεγγίσεις δεν είναι ικανοποιητικές Δρομολόγηση των tasks μίας παράλληλης εφαρμογής σε ένα πολυπύρηνο σύστημα Επαναλήψεις ενός παράλληλου loop Tasks μίας παράλληλης εφαρμογής 60



61 data centric, στατική απεικόνιση 1-dim 2-dim (block) sequential cyclic sequential cyclic 61
62 Παράδειγμα: Επιλογή απεικόνισης για LU και stencil //LU decomposition kernel for(k=0; k<n-1; k++) for(i=k+1; i<n; i++){ L[i] = A[i][k] / A[k][k]; for(j=k+1; j<n; j++) A[i][j]=A[i][j]-L[i]*A[j][i]; } //stencil for (t=1; t<t; t++){ for (i=1; i<x; i++) for (j=1; j<y; j++) A[t][i][j] = 0.2*(A[t-1][i][j] + A[t-1][i-1][j] + A[t-1][i+1][j] + A[t-1][i][j-1] + A[t-1][i][j]); } 62
63 Σύνοψη σχεδιασμού παράλληλων προγραμμάτων Δεν υπάρχει ξεκάθαρη μεθοδολογία παραλληλοποίησης προγραμμάτων Δύο σημαντικά βήματα (συχνά όχι σειριακά): Σχεδιασμός (σκέψη) Στάδιο 1: Κατανομή υπολογισμών και διαμοιρασμός δεδομένων Στάδιο 2: Ορισμός ορθής σειράς εκτέλεσης Στάδιο 3: Οργάνωση πρόσβασης στα δεδομένα Στάδιο 4: Ανάθεση εργασιών σε οντότητες εκτέλεσης Στη συνέχεια: Υλοποίηση (ομιλία) Έκφραση παραλληλίας Επιλογή προγραμματιστικού μοντέλου και εργαλείων 63
64 «Μιλώντας» παράλληλα Πρώτο βήμα: σχεδιασμός παράλληλων προγραμμάτων = σκέψη Δεύτερο βήμα: υλοποίηση παράλληλων προγραμμάτων = ομιλία Όπως και στις φυσικές γλώσσες, η σκέψη και η ομιλία είναι δύο στενά συνδεδεμένες λειτουργίες Ερώτημα 1: Τι προγραμματιστικές δομές χρειάζομαι για να μιλήσω παράλληλα; Πώς δημιουργώ και τερματίζω εργασίες (tasks) και οντότητες εκτέλεσης (processes, threads); Τι προγραμματιστικές δομές υπάρχουν για το συγχρονισμό και την επικοινωνία ανάμεσα στις εργασίες/οντότητες εκτέλεσης; Ερώτημα 2: Τι υποστήριξη χρειάζεται (από την αρχιτεκτονική, το λειτουργικό, τη γλώσσα προγραμματισμού, τη βιβλιοθήκη χρόνου εκτέλεσης της γλώσσας) για να υλοποιηθούν οι παραπάνω δομές με αποδοτικό τρόπο; 2 κρίσιμα ζητήματα απόδοσης Υψηλή επίδοση του παραγόμενου κώδικα (performance) Γρήγορη και εύκολη υλοποίηση (productivity) 64
65 Προγραμματιστικά μοντέλα Κοινού χώρου διευθύνσεων Υποστηρίζει κοινά δεδομένα ανάμεσα στα νήματα Επιταχύνει τον προγραμματισμό Μπορεί να οδηγήσει σε δύσκολα ανιχνεύσιμα race conditions Δεν μπορεί να υλοποιηθεί αποδοτικά σε πλατφόρμες που δεν παρέχουν πρόσβαση σε κοινή μνήμη στο υλικό Κατάλληλο για συστήματα κοινής μνήμης Περιορισμένος συνολικός αριθμός νημάτων Ανταλλαγής μηνυμάτων Κάθε διεργασία (νήμα) βλέπει μόνο τα δικά της δεδομένα Τα δεδομένα μπορεί να είναι μόνο distributed ή replicated Οδηγεί σε χρονοβόρο προγραμματισμό ακόμα και για απλά προγράμματα (fragmented κώδικας) Μπορεί να υποστηριχθεί από πολύ μεγάλης κλίμακας συστήματα Υβριδικό: συνδυασμός των παραπάνω 2 65
66 Παράλληλες προγραμματιστικές δομές Με αύξουσα ανάγκη σε υποστήριξη από το run-time σύστημα της γλώσσας SPMD parallel for fork / join task graphs 66
67 SPMD SPMD = Single program multiple data Όλες οι διεργασίες εκτελούν το ίδιο τμήμα κώδικα Κάθε διεργασία έχει το δικό της σύνολο δεδομένων Το αναγνωριστικό της διεργασίας χρησιμοποιείται για να διαφοροποιήσει την εκτέλεσή της Αποτελεί ευρύτατα διαδεδομένη προγραμματιστική τεχνική για παράλληλα προγράμματα Έχει υιοθετηθεί από το MPI 67
68 SPMD Ταιριάζει σε εφαρμογές όπου εκτελούνται όμοιες λειτουργίες σε διαφορετικά δεδομένα (data parallelism) Απαιτεί σχήματα συγχρονισμού και ανταλλαγής δεδομένων μεταξύ των διεργασιών Σε πρωτόγονο επίπεδο τα παραπάνω παρέχονται από το λογισμικό συστήματος Το μοντέλο SPMD μπορεί να υλοποιηθεί χωρίς επιπρόσθετη υποστήριξη Παρόλα αυτά το MPI διευκολύνει τον προγραμματισμό παρέχοντας μη πρωτόγονες ρουτίνες και ανεξαρτησία από την πλατφόρμα εκτέλεσης Θεωρείται κοπιαστική προσέγγιση (non-productive) καθώς τα αφήνει (σχεδόν) όλα στον προγραμματιστή Μπορεί να οδηγήσει σε υψηλή επίδοση καθώς ο προγραμματιστής έχει τον (σχεδόν) πλήρη έλεγχο της υλοποίησης 68
69 Βήματα υλοποίησης στο σχήμα SPMD Αρχικοποίηση Λήψη αναγνωριστικού Εκτέλεση του ίδιου κώδικα σε όλους τους κόμβους και διαφοροποίηση ανάλογα με το αναγνωριστικό Εναλλακτικές ροές ελέγχου Ανάληψη διαφορετικών επαναλήψεων σε βρόχο Κατανομή δεδομένων Τερματισμός 69
70 Παράδειγμα: εξίσωση θερμότητας for (steps=0; steps < T; steps++) for (i=1; i<x-1; i++) for (j=1; j<y-1, j++) A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) myid = get_my_id_from_system(); chunk = X / NUM_PRCS; // υποθέτει X % NUM_PRCS == 0 mystart = myid*chunk + 1; myend = myend = mystart + chunk; for (steps=0; steps < T; steps++){ for (i=mystart; i<myend; i++) for (j=1; j<y-1, j++) A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) } synchronize_or_communicate( ); 70
71 parallel for Η παραλληλοποίηση των for-loops αποτελεί σημαντικότατη προσέγγιση στο σχεδιασμό ενός παράλληλου προγράμματος Όπως είδαμε, μπορεί να επιτευχθεί στο μοντέλο SPMD αλλά για προγραμματιστική ευκολία έχει ενσωματωθεί σε γλώσσες και εργαλεία: OpenMP Cilk ΤΒΒs PGAS Χρειάζεται υποστήριξη από το σύστημα Αυτόματη μετάφραση του parallel for σε κώδικα Διαχείριση των δεδομένων Δρομολόγηση των νημάτων/εργασιών Είναι ευθύνη του προγραμματιστή να αποφασίσει αν ένα loop είναι παράλληλο 71
72 automatic parallelization Η εύρεση των παράλληλων for αποτελεί τον κυριότερο στόχο της αυτόματης παραλληλοποίησης Ειδικά περάσματα optimizing compilers αναζητούν: Αν ένα loop είναι παράλληλο Αν αξίζει να παραλληλοποιηθεί Η απόδειξη της παραλληλίας ενός loop είναι πολύ δύσκολη και βασίζεται στα λεγόμενα dependence tests 72
73 dependence analysis Πότε ένα loop είναι παράλληλο; Όταν δεν υπάρχουν εξαρτήσεις ανάμεσα στις επαναλήψεις του Τέλεια φωλιασμένοι βρόχοι: for i 1 = 1 to U 1 for i 2 = 1 to U 2 for i n = 1 to U n Διανύσματα εξαρτήσεων d εκφράζουν τις εξαρτήσεις σε κάθε επίπεδο του φωλιάσματος Πίνακας εξαρτήσεων D, περιέχει κατά στήλες τα διανύσματα εξάρτησης Διανύσματα απόστασης (distance vectors) Στοιχεία του πίνακα D d ij είναι σταθεροί ακέραιοι αριθμοί Διανύσματα κατεύθυνσης (direction vectors): > (υπάρχει εξάρτηση από προσβάσεις στη μνήμη προηγούμενων επαναλήψεων) < (υπάρχει εξάρτηση από προσβάσεις στη μνήμη επόμενων επαναλήψεων) * (υπάρχει εξάρτηση από προσβάσεις στη μνήμη προηγούμενων ή επόμενων επαναλήψεων) 73
74 Παράδειγμα: εξίσωση θερμότητας for (steps=0; steps < T; steps++) for (i=1; i<x-1; i++) for (j=1; j<y-1, j++) A[step+1][i][j] = 1/5 (A[step][i][j] + A[step][i-1][j] + A[step][i+1][j] + A[step][i][j-1] + A[step][i][j+1]) D =
75 Παράδειγμα: Floyd-Warshall for (k=0; k<n; k++) for (i=0; i<n; i++) for (j=0; j<n, j++) A[(k+1)%2][i][j] = min(a[k%2][i][j], A[k%2][i][k] + A[k%2][k][j]) D = * 1 * 0 75
76 Κανόνες παραλληλίας loop Ένας βρόχος στο επίπεδο i ενός φωλιασμένου βρόχου είναι παράλληλος αρκεί να ισχύει οτιδήποτε από τα παρακάτω: 1. το i-οστό στοιχείο ΟΛΩΝ των διανυσμάτων εξάρτησης είναι 0 2. ΟΛΑ τα υποδιανύσματα από 0 εως i-1 να είναι λεξικογραφικά ΘΕΤΙΚΑ (= το πρώτο μη μηδενικό στοιχείο είναι θετικό) Επισήμανση: Για τον εξωτερικότερο βρόχο (i=0) μπορεί να εφαρμοστεί μόνο ο πρώτος κανόνας (δεν υπάρχουν υποδιανύσματα από 0 εως -1) Άσκηση: Ποια loops παραλληλοποιούνται στην εξίσωση θερμότητας και στον αλγόριθμο FW? 76
77 fork / join Αφορά εφαρμογές με δυναμική ανάγκη για δημιουργία / τερματισμό tasks Τα tasks δημιουργούνται (fork) και τερματίζονται (join) δυναμικά Π.χ. αλγόριθμος σχεδιασμένος με την Divide and Conquer στρατηγική OpenMP tasks #pragma omp task #pragma omp taskwait Cilk spawn sync 77
78 Παράδειγμα fork - join A B C D E F G #pragma omp parallel { #pragma omp single { #pragma omp task A(); #pragma omp task if (0) { #pragma omp task B(); #pragma omp task if (0) { #pragma omp task C(); D(); #pragma omp taskwait E(); } #pragma omp taskwait F(); } #pragma omp taskwait G(); } } 78
79 Task graphs Η fork-join δομή δεν μπορεί να περιγράψει όλα τα task graphs Όταν ένα task graph είναι γνωστό στατικά, τότε μπορούμε να το περιγράψουμε άμεσα 79
80 graph g; source_node s; //source node //each node executes a different function body node a( g, body_a() ); node b( g, body_b() ); node c( g, body_c() ); node d( g, body_d() ); node e( g, body_e() ); node f( g, body_f() ); node h( g, body_h() ); node i( g, body_i() ); node j( g, body_j() ); Παράδειγμα task graph //create edges make_edge( s, a ); make_edge( s, b ); make_edge( s, c ); make_edge( a, d ); make_edge( b, e ); make_edge( c, f ); make_edge( d, h ); make_edge( e, h ); make_edge( f, i ); make_edge( h, j ); make_edge( i, j ); s.start(); // start parallel execution of task graph g.wait_for_all(); //wait for all to complete 80
81 POSIX threads Αποτελούν πρωτόγονο τρόπο πολυνηματικού προγραμματισμού για systems programming Συνδυαζόμενα με TCP/IP sockets αποτελούν την πιο βασική πλατφόρμα εργαλείων για παράλληλο προγραμματισμό SPMD ή Master / Slave + : ο χρήστης έχει απόλυτο έλεγχο της εκτέλεσης - : ιδιαίτερα κοπιαστικός και επιρρεπής σε σφάλματα τρόπος προγραμματισμού 81
82 MPI Μοντέλο ανταλλαγής μηνυμάτων για συστήματα κατανεμημένης μνήμης Αποτελεί τον de facto τρόπο προγραμματισμού σε υπερυπολογιστικά συστήματα SPMD (και Master / Slave) Απλοποιεί την υλοποίηση της επικοινωνίας σε σχέση με τη βιβλιοθήκη των sockets καθώς υποστηρίζει μεγάλο αριθμό από χρήσιμες ρουτίνες Βελτιστοποιεί την επικοινωνία (κυρίως σε collective επικοινωνία) Ο χρήστης αναλαμβάνει το διαμοιρασμό των δεδομένων και την επικοινωνία μέσω μηνυμάτων fragmented τρόπος προγραμματισμού 82
83 OpenMP Προγραμματιστικό εργαλείο που βασίζεται σε οδηγίες (directives) προς το μεταγλωττιστή Αφορά κατά κύριο λόγο αρχιτεκτονικές κοινής μνήμης Μπορεί να αξιοποιηθεί για την εύκολη παραλληλοποίηση ήδη υπάρχοντος σειριακού κώδικα Παρέχει ευελιξία στο προγραμματιστικό στυλ: SPMD Master / Workers parallel for Fork / Join (ενσωμάτωση των tasks, 2008) 83
 Σχεδιασμός προγραμμάτων με χρήση αναδρομής Σχήμα Fork / Join Υποστήριξη parallel for Βασικές λέξεις κλειδιά: cilk, spawn, sync C void vadd (real *A, real *B, int n){ int i; for (i=0;")
84 Πολυνηματικός προγραμματισμός για αρχιτεκτονικές κοινής μνήμης Επεκτείνει τη C με λίγες επιπλέον λέξεις κλειδιά Κάθε πρόγραμμα γραμμένο σε Cilk έχει ορθή σειριακή σημασιολογία (μπορεί να εκτελεστεί σωστά σειριακά) Σχεδιασμός προγραμμάτων με χρήση αναδρομής Σχήμα Fork / Join Υποστήριξη parallel for Βασικές λέξεις κλειδιά: cilk, spawn, sync C void vadd (real *A, real *B, int n){ int i; for (i=0; i<n; i++) A[i]+=B[i]; } Cilk C ilk 84 cilk void vadd (real *A, real *B, int n){ if (n<=base) { int i; for (i=0; i<n; i++) A[i]+=B[i]; } else { spawn vadd (A, B, n/2; spawn vadd (A+n/2, B+n/2, n-n/2; } sync; }

85 CUDA Compute Unified Device Architecture Παράλληλη αρχιτεκτονική που προτάθηκε από την NVIDIA Βασίζεται σε GPUs (GP-GPUs = General Purpose-Graphical processing Units) Προγραμματισμός: C extensions για αρχιτεκτονικές CUDA Ανάθεση υπολογιστικά απαιτητικών τμημάτων του κώδικα στην κάρτα γραφικών GPU = accelerator massively data parallel Manycore system 85
86 SIMT = Single Instruction Multiple Threads Προγραμματισμός σε περιβάλλον CUDA Τα threads δρομολογούνται σε ομάδες που λέγονται warps Το κόστος δρομολόγησης των threads είναι μηδενικό Σε κάθε κύκλο όλα τα threads εκτελούν την ίδια εντολή Εκτελούνται όλα τα control paths Τα μη έγκυρα control paths ματαιώνονται (aborted) στο τέλος Οι αλγόριθμοι πρέπει να σχεδιάζονται με data parallel λογική Τα branches και ο συγχρονισμός κοστίζουν Η χωρική τοπικότητα αξιοποιείται κατά μήκος των threads και όχι εντός μιας CPU όπως γίνεται στους συμβατικούς επεξεργαστές Αρκετά «σκιώδη» ζητήματα επηρεάζουν την επίδοση και χρήζουν ιδιαίτερης προσοχής Παραλληλισμός Πρόσβαση στα δεδομένα Συγχρονισμός 86
87 Γλώσσες PGAS Partitioned Global Address Space Προσπαθεί να έχει τα θετικά και από τους δύο κόσμους: Προγραμματιστική ευκολία όπως το μοντέλο του κοινού χώρου διευθύνσεων Επίδοση και κλιμακωσιμότητα όπως το μοντέλο της ανταλλαγής μηνυμάτων Υποθέτει καθολικό χώρο διευθύνσεων (global address space) που κατανέμεται (partitioned) στις τοπικές μνήμες των επεξεργαστών ενός συστήματος κατανεμημένης μνήμης Απαιτεί πολύ ισχυρό run-time σύστημα Για προσβάσεις σε δεδομένα που βρίσκονται σε απομακρυσμένη μνήμη χρησιμοποιεί 1-sided communication Υλοποιήσεις: UPC Fortress Co-array Fortrean X10 Chapel 87
88 Languages and tools SPMD Task graph parallel for fork / join MPI OpenMP Cilk (Cilk++) TBB CUDA 88
Παράλληλος προγραμματισμός: παράλληλες λ υπολογιστικές πλατφόρμες και ανάλυση προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: παράλληλες λ υπολογιστικές πλατφόρμες και ανάλυση προγραμμάτων
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: παράλληλες λ υπολογιστικές πλατφόρμες και ανάλυση προγραμμάτων
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σύνοψη παρουσίασης
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σύνοψη παρουσίασης
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σχεδιασμός παράλληλων
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σχεδιασμός παράλληλων
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σύνοψη παρουσίασης
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σύνοψη παρουσίασης
Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σύνοψη παρουσίασης
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση παράλληλων προγραμμάτων 9 ο Εξάμηνο Σύνοψη παρουσίασης
Σύνοψη παρουσίασης. Παράλληλες υπολογιστικές πλατφόρμες. Ανάλυση παράλληλων προγραμμάτων. Σχεδίαση παράλληλων προγραμμάτων
 Σύνοψη παρουσίασης Παράλληλες υπολογιστικές πλατφόρμες PRAM: Η ιδανική παράλληλη πλατφόρμα Η ταξινόμηση του Flynn Συστήματα κοινής μνήμης Συστήματα κατανεμημένης μνήμης Ανάλυση παράλληλων προγραμμάτων
Σύνοψη παρουσίασης Παράλληλες υπολογιστικές πλατφόρμες PRAM: Η ιδανική παράλληλη πλατφόρμα Η ταξινόμηση του Flynn Συστήματα κοινής μνήμης Συστήματα κατανεμημένης μνήμης Ανάλυση παράλληλων προγραμμάτων
Συστήµατα Παράλληλης Επεξεργασίας. Παράλληλοςπρογραµµατισµός: Υλοποίηση παράλληλων προγραµµάτων
 Παράλληλοςπρογραµµατισµός: Υλοποίηση παράλληλων προγραµµάτων Σύνοψη παρουσίασης «Μιλώντας»παράλληλα SPMD Master / Worker parallel for Fork / Join Υποστηρικτικές δοµές δεδοµένων Μοιραζόµενα δεδοµένα Μοιραζόµενες
Παράλληλοςπρογραµµατισµός: Υλοποίηση παράλληλων προγραµµάτων Σύνοψη παρουσίασης «Μιλώντας»παράλληλα SPMD Master / Worker parallel for Fork / Join Υποστηρικτικές δοµές δεδοµένων Μοιραζόµενα δεδοµένα Μοιραζόµενες
Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παράλληλος προγραμματισμός: Σχεδίαση και υλοποίηση παράλληλων προγραμμάτων 9 ο Εξάμηνο
Συστήµατα Παράλληλης Επεξεργασίας. Παράλληλος προγραµµατισµός: Σχεδιασµός παράλληλων προγραµµάτων
 Παράλληλος προγραµµατισµός: Σχεδιασµός παράλληλων προγραµµάτων Αρχιτεκτονικές Αξιολόγηση επίδοσης Σχεδιασµός παράλληλων προγραµµάτων task centric data centric function centric Σύνοψη παρουσίασης ιαµοιρασµός
Παράλληλος προγραµµατισµός: Σχεδιασµός παράλληλων προγραµµάτων Αρχιτεκτονικές Αξιολόγηση επίδοσης Σχεδιασµός παράλληλων προγραµµάτων task centric data centric function centric Σύνοψη παρουσίασης ιαµοιρασµός
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
2. Στοιχεία Αρχιτεκτονικής Παράλληλων Υπολογιστών... 45
 ΠΕΡΙΕΧΟΜΕΝΑ Πρόλογος... 9 1. Εισαγωγή... 13 1.1 Οι Μεγάλες Σύγχρονες Επιστημονικές Προκλήσεις... 13 1.2 Εξέλιξη της Παράλληλης Επεξεργασίας Δεδομένων... 14 1.3 Οι Έννοιες της Σωλήνωσης, του Παραλληλισμού
ΠΕΡΙΕΧΟΜΕΝΑ Πρόλογος... 9 1. Εισαγωγή... 13 1.1 Οι Μεγάλες Σύγχρονες Επιστημονικές Προκλήσεις... 13 1.2 Εξέλιξη της Παράλληλης Επεξεργασίας Δεδομένων... 14 1.3 Οι Έννοιες της Σωλήνωσης, του Παραλληλισμού
Παρουσίαση 2 ης Άσκησης:
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 2 ης Άσκησης: Ανάπτυξη παράλληλου κώδικα και μελέτη επίδοσης του αλγόριθμου
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 2 ης Άσκησης: Ανάπτυξη παράλληλου κώδικα και μελέτη επίδοσης του αλγόριθμου
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Παρουσίαση 1 ης Άσκησης:
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 1 ης Άσκησης: Ανάπτυξη παράλληλου κώδικα σε πολυπύρηνες αρχιτεκτονικές κοινής
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 1 ης Άσκησης: Ανάπτυξη παράλληλου κώδικα σε πολυπύρηνες αρχιτεκτονικές κοινής
13.2 Παράλληλος Προγραµµατισµός Γλωσσάρι, Σελ. 1
 13.2 Παράλληλος Προγραµµατισµός Γλωσσάρι, Σελ. 1 ΓΛΩΣΣΑΡΙ Αµοιβαίος αποκλεισµός (mutual exclusion) Στο µοντέλο κοινού χώρου διευθύνσεων, ο αµοιβαίος αποκλεισµός είναι ο περιορισµός του αριθµού των διεργασιών
13.2 Παράλληλος Προγραµµατισµός Γλωσσάρι, Σελ. 1 ΓΛΩΣΣΑΡΙ Αµοιβαίος αποκλεισµός (mutual exclusion) Στο µοντέλο κοινού χώρου διευθύνσεων, ο αµοιβαίος αποκλεισµός είναι ο περιορισµός του αριθµού των διεργασιών
EM 361: Παράλληλοι Υπολογισμοί
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #2: Αρχιτεκτονική Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #2: Αρχιτεκτονική Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
Αρχιτεκτονική Υπολογιστών
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Αρχιτεκτονική Υπολογιστών Ενότητα 13: (Μέρος Γ ) Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών
Παράλληλη Επεξεργασία
 Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στο OpenMP Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed Systems Group Τι είναι το OpenMP Πρότυπο Επέκταση στη C/C++ και τη Fortran
Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στο OpenMP Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed Systems Group Τι είναι το OpenMP Πρότυπο Επέκταση στη C/C++ και τη Fortran
Παράλληλα Συστήματα. Γιώργος Δημητρίου. Ενότητα 4 η : Παράλληλος Προγραμματισμός. Πανεπιστήμιο Θεσσαλίας - Τμήμα Πληροφορικής
 Γιώργος Δημητρίου Ενότητα 4 η : Παράλληλος Προγραμματισμός Παράλληλος Προγραμματισμός Ο παράλληλος προγραμματισμός με βάση την αφαιρετικότητα: Ελάχιστη έως καμία γνώση της αρχιτεκτονικής Επεκτάσεις παράλληλου
Γιώργος Δημητρίου Ενότητα 4 η : Παράλληλος Προγραμματισμός Παράλληλος Προγραμματισμός Ο παράλληλος προγραμματισμός με βάση την αφαιρετικότητα: Ελάχιστη έως καμία γνώση της αρχιτεκτονικής Επεκτάσεις παράλληλου
Η πολυνηματική γλώσσα προγραμματισμού Cilk
 Η πολυνηματική γλώσσα προγραμματισμού Cilk Β Καρακάσης Ερευνητικά Θέματα Υλοποίησης Γλωσσών Προγραμματισμού Μεταπτυχιακό Μάθημα (688), ΣΗΜΜΥ Νοέμβριος 2009 Β Καρακάσης (CSLab, NTUA) ΣΗΜΜΥ, Μετ/κό 688 9/2009
Η πολυνηματική γλώσσα προγραμματισμού Cilk Β Καρακάσης Ερευνητικά Θέματα Υλοποίησης Γλωσσών Προγραμματισμού Μεταπτυχιακό Μάθημα (688), ΣΗΜΜΥ Νοέμβριος 2009 Β Καρακάσης (CSLab, NTUA) ΣΗΜΜΥ, Μετ/κό 688 9/2009
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί
 Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 3: Θεωρία Παράλληλου Προγραμματισμού
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 3: Θεωρία Παράλληλου Προγραμματισμού
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί
 Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 4: Παράλληλοι Αλγόριθμοι Ταξινόμηση
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 4: Παράλληλοι Αλγόριθμοι Ταξινόμηση
Αρχιτεκτονική Υπολογιστών
 Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Αρχιτεκτονική Υπολογιστών Παραλληλισμός Βασικές Πηγές: Αρχιτεκτονική Υπολογιστών: μια Δομημένη Προσέγγιση, Α. Tanenbaum, Vrije Universiteit, Amsterdam. Computer Architecture and Engineering, K. Asanovic,
Μετρικές & Επιδόσεις. Κεφάλαιο V
 Μετρικές & Επιδόσεις Κεφάλαιο V Χρόνος εκτέλεσης & επιτάχυνση Σειριακός χρόνος εκτέλεσης: Τ (για τον καλύτερο σειριακό αλγόριθμο) Παράλληλος χρόνος εκτέλεσης: (με επεξεργαστές) Επιτάχυνση (speedup): S
Μετρικές & Επιδόσεις Κεφάλαιο V Χρόνος εκτέλεσης & επιτάχυνση Σειριακός χρόνος εκτέλεσης: Τ (για τον καλύτερο σειριακό αλγόριθμο) Παράλληλος χρόνος εκτέλεσης: (με επεξεργαστές) Επιτάχυνση (speedup): S
Αρχιτεκτονική Υπολογιστών
 Γιώργος Δημητρίου Ενότητα 11 η : Εισαγωγή σε Παράλληλες Αρχιτεκτονικές Παράλληλη Επεξεργασία Επίπεδο Παραλληλισμού Από εντολές έως ανεξάρτητες διεργασίες Οργανώσεις Παράλληλων Αρχιτεκτονικών Συμμετρικοί,
Γιώργος Δημητρίου Ενότητα 11 η : Εισαγωγή σε Παράλληλες Αρχιτεκτονικές Παράλληλη Επεξεργασία Επίπεδο Παραλληλισμού Από εντολές έως ανεξάρτητες διεργασίες Οργανώσεις Παράλληλων Αρχιτεκτονικών Συμμετρικοί,
Εφαρµογές µε ανάγκες για υψηλές επιδόσεις Αξιολόγηση επίδοσης Παραλληλοποίηση εφαρµογών
 Parallelizing applications for the GRID Γιώργος Γκούµας goumas@cslab.ece.ntua.gr Σύνοψη Παρουσίασηςασης Εφαρµογές µε ανάγκες για υψηλές επιδόσεις Αξιολόγηση επίδοσης Παραλληλοποίηση εφαρµογών Γενικές αρχές
Parallelizing applications for the GRID Γιώργος Γκούµας goumas@cslab.ece.ntua.gr Σύνοψη Παρουσίασηςασης Εφαρµογές µε ανάγκες για υψηλές επιδόσεις Αξιολόγηση επίδοσης Παραλληλοποίηση εφαρµογών Γενικές αρχές
Παρουσίαση 2 ης Άσκησης:
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 2 ης Άσκησης: Ανάπτυξη παράλληλου κώδικα και μελέτη της επίδοσης του αλγορίθμου
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 2 ης Άσκησης: Ανάπτυξη παράλληλου κώδικα και μελέτη της επίδοσης του αλγορίθμου
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική
 ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική") Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Οργάνωση επεξεργαστή (2 ο μέρος) ΜΥΥ-106 Εισαγωγή στους Η/Υ και στην Πληροφορική Ταχύτητα εκτέλεσης Χρόνος εκτέλεσης = (αριθμός εντολών που εκτελούνται) Τί έχει σημασία: Χ (χρόνος εκτέλεσης εντολής) Αριθμός
Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC
 Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC Πλεονεκτήματα MPSoC Είναι ευκολότερο να σχεδιαστούν πολλαπλοί πυρήνες επεξεργαστών από τον σχεδιασμό ενός ισχυρότερου και πολύ πιο σύνθετου μονού επεξεργαστή.
Συστήματα μνήμης και υποστήριξη μεταφραστή για MPSoC Πλεονεκτήματα MPSoC Είναι ευκολότερο να σχεδιαστούν πολλαπλοί πυρήνες επεξεργαστών από τον σχεδιασμό ενός ισχυρότερου και πολύ πιο σύνθετου μονού επεξεργαστή.
Πολυπύρηνοι επεξεργαστές Multicore processors
 Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
Πολυπύρηνοι επεξεργαστές Multicore processors 1 Μετάβαση στους πολυπύρηνους(1) Απόδοση των µονοεπεξεργαστών 25% ετήσια βελτίωση της απόδοσης από το 1978 έως το 1986 Κυρίως από την εξέλιξη της τεχνολογίας
EM 361: Παράλληλοι Υπολογισμοί
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #4: Παράλληλοι Αλγόριθμοι Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ EM 361: Παράλληλοι Υπολογισμοί Ενότητα #4: Παράλληλοι Αλγόριθμοι Διδάσκων: Χαρμανδάρης Ευάγγελος ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΠΙΣΤΗΜΩΝ
Διεργασίες και Νήματα (2/2)
") Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Διεργασίες και Νήματα (2/2) Λειτουργικά Συστήματα Υπολογιστών 7ο Εξάμηνο, 2016-2017 Νήματα
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Διεργασίες και Νήματα (2/2) Λειτουργικά Συστήματα Υπολογιστών 7ο Εξάμηνο, 2016-2017 Νήματα
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ. Μελέτη Αλγορίθμων Εκτέλεσης και Χρονοδρομολόγησης Παράλληλων Εργασιών ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Μελέτη Αλγορίθμων Εκτέλεσης και Χρονοδρομολόγησης Παράλληλων Εργασιών
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Μελέτη Αλγορίθμων Εκτέλεσης και Χρονοδρομολόγησης Παράλληλων Εργασιών
Διαφορές single-processor αρχιτεκτονικών και SoCs
 13.1 Τα συστήματα και η επικοινωνία μεταξύ τους γίνονται όλο και περισσότερο πολύπλοκα. Δεν μπορούν να περιγραφούνε επαρκώς στο επίπεδο RTL καθώς αυτή η διαδικασία γίνεται πλέον αρκετά χρονοβόρα. Για αυτό
13.1 Τα συστήματα και η επικοινωνία μεταξύ τους γίνονται όλο και περισσότερο πολύπλοκα. Δεν μπορούν να περιγραφούνε επαρκώς στο επίπεδο RTL καθώς αυτή η διαδικασία γίνεται πλέον αρκετά χρονοβόρα. Για αυτό
Θέματα Μεταγλωττιστών
 Γιώργος Δημητρίου Ενότητα 10 η : Βελτιστοποιήσεις Τοπικότητας και Παραλληλισμού: Εξαρτήσεις και Μετασχηματισμοί Βρόχων Επεξεργασία Πινάκων Παραλληλισμός επιπέδου βρόχου Λόγω παραλληλισμού δεδομένων Επιτυγχάνεται
Γιώργος Δημητρίου Ενότητα 10 η : Βελτιστοποιήσεις Τοπικότητας και Παραλληλισμού: Εξαρτήσεις και Μετασχηματισμοί Βρόχων Επεξεργασία Πινάκων Παραλληλισμός επιπέδου βρόχου Λόγω παραλληλισμού δεδομένων Επιτυγχάνεται
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 10ο μάθημα: Ορια παραλληλίας επιπέδου εντολής και πολυνηματικοί επεξεργαστές Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Ορια
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα 2: Αρχιτεκτονικές Von Neuman, Harvard. Κατηγοριοποίηση κατά Flynn. Υπολογισμός απόδοσης Συστημάτων
ΣΥΣΤΗΜΑΤΑ ΠΑΡΑΛΛΗΛΗΣ ΕΠΕΞΕΡΓΑΣΙΑΣ 9o εξάμηνο ΗΜΜΥ, ακαδημαϊκό έτος
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΞΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr ΣΥΣΤΗΜΑΤΑ
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΞΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr ΣΥΣΤΗΜΑΤΑ
ΕΙΣΑΓΩΓΗ ΣΤΟΝ ΠΑΡΑΛΛΗΛΟ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟ ΜΕ OpenMP (2 ο Μέρος)
") ΕΡΓΑΛΕΙΑ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΥ ΕΙΣΑΓΩΓΗ ΣΤΟΝ ΠΑΡΑΛΛΗΛΟ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟ ΜΕ OpenMP (2 ο Μέρος) Νίκος Τρυφωνίδης Εφαρμογή 7: Ανισορροπία Το πρόγραμμα imbalance.c περιέχει ένα loop το οποίο έχει μεγαλύτερη εργασία
ΕΡΓΑΛΕΙΑ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΥ ΕΙΣΑΓΩΓΗ ΣΤΟΝ ΠΑΡΑΛΛΗΛΟ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟ ΜΕ OpenMP (2 ο Μέρος) Νίκος Τρυφωνίδης Εφαρμογή 7: Ανισορροπία Το πρόγραμμα imbalance.c περιέχει ένα loop το οποίο έχει μεγαλύτερη εργασία
Συστήματα Παράλληλης και Κατανεμημένης Επεξεργασίας
 Συστήματα Παράλληλης και Κατανεμημένης Επεξεργασίας Ενότητα: ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ No:20 OpenMP Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Τμήμα Μηχανικών Πληροφορικής και Τηλεπικοινωνιών Εργαστήριο Ψηφιακών Συστημάτων
Συστήματα Παράλληλης και Κατανεμημένης Επεξεργασίας Ενότητα: ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ No:20 OpenMP Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Τμήμα Μηχανικών Πληροφορικής και Τηλεπικοινωνιών Εργαστήριο Ψηφιακών Συστημάτων
i Throughput: Ο ρυθμός ολοκλήρωσης έργου σε συγκεκριμένο χρόνο
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 6-7 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Παράλληλη Επεξεργασία Κεφάλαιο 1 Γιατί Παράλληλος Προγραμματισμός;
 Παράλληλη Επεξεργασία Κεφάλαιο 1 Γιατί Παράλληλος Προγραμματισμός; Κωνσταντίνος Μαργαρίτης Καθηγητής Τμήμα Εφαρμοσμένης Πληροφορικής Πανεπιστήμιο Μακεδονίας kmarg@uom.gr http://eos.uom.gr/~kmarg Αρετή
Παράλληλη Επεξεργασία Κεφάλαιο 1 Γιατί Παράλληλος Προγραμματισμός; Κωνσταντίνος Μαργαρίτης Καθηγητής Τμήμα Εφαρμοσμένης Πληροφορικής Πανεπιστήμιο Μακεδονίας kmarg@uom.gr http://eos.uom.gr/~kmarg Αρετή
9. Συστολικές Συστοιχίες Επεξεργαστών
 Κεφάλαιο 9: Συστολικές συστοιχίες επεξεργαστών 208 9. Συστολικές Συστοιχίες Επεξεργαστών Οι συστολικές συστοιχίες επεξεργαστών είναι επεξεργαστές ειδικού σκοπού οι οποίοι είναι συνήθως προσκολλημένοι σε
Κεφάλαιο 9: Συστολικές συστοιχίες επεξεργαστών 208 9. Συστολικές Συστοιχίες Επεξεργαστών Οι συστολικές συστοιχίες επεξεργαστών είναι επεξεργαστές ειδικού σκοπού οι οποίοι είναι συνήθως προσκολλημένοι σε
Μηχανοτρονική. Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο,
 Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Τμήμα Μηχανικών Παραγωγής και Διοίκησης 7 ο Εξάμηνο, 2016-2017 ΜΙΚΡΟΕΠΕΞΕΡΓΑΣΤΕΣ Μικροϋπολογιστής Υπολογιστής που χρησιμοποιείται για την είσοδο, επεξεργασία και έξοδο πληροφοριών. Είδη μικροϋπολογιστών:
Παράλληλα Συστήματα. Γιώργος Δημητρίου. Ενότητα 3 η : Παράλληλη Επεξεργασία. Πανεπιστήμιο Θεσσαλίας - Τμήμα Πληροφορικής
 Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Γιώργος Δημητρίου Ενότητα 3 η : Παράλληλη Επεξεργασία Παράλληλες Αρχιτεκτονικές Παράλληλο σύστημα είναι ένα σύνολο από επεξεργαστικά στοιχεία (processing elements) τα οποία: συνεργάζονται για γρήγορη επίλυση
Παρουσίαση 5 ης Άσκησης:
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 5 ης Άσκησης: Θέματα Συγχρονισμού σε Σύγχρονα Πολυπύρηνα Συστήματα Ακ. Έτος
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 5 ης Άσκησης: Θέματα Συγχρονισμού σε Σύγχρονα Πολυπύρηνα Συστήματα Ακ. Έτος
Παράλληλη Επεξεργασία
 Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στα Πολυεπεξεργαστικά Συστήματα Διερασίες και Νήματα σε Πολυεπεξεργαστικά Συστήματα Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed
Παράλληλη Επεξεργασία Φροντιστήριο: Εισαγωγή στα Πολυεπεξεργαστικά Συστήματα Διερασίες και Νήματα σε Πολυεπεξεργαστικά Συστήματα Εργαστήριο Πληροφοριακών Συστημάτων Υψηλής Επίδοσης Parallel and Distributed
Network Algorithms and Complexity Παραλληλοποίηση του αλγορίθμου του Prim. Αικατερίνη Κούκιου
 Network Algorithms and Complexity Παραλληλοποίηση του αλγορίθμου του Prim Αικατερίνη Κούκιου Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό,
Network Algorithms and Complexity Παραλληλοποίηση του αλγορίθμου του Prim Αικατερίνη Κούκιου Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό,
Προγραμματισμός Ι (HY120)
") Προγραμματισμός Ι (HY20) # μνήμη & μεταβλητές πρόγραμμα & εκτέλεση Ψηφιακά δεδομένα, μνήμη, μεταβλητές 2 Δυαδικός κόσμος Οι υπολογιστές είναι δυαδικές μηχανές Όλη η πληροφορία (δεδομένα και κώδικας) κωδικοποιείται
Προγραμματισμός Ι (HY20) # μνήμη & μεταβλητές πρόγραμμα & εκτέλεση Ψηφιακά δεδομένα, μνήμη, μεταβλητές 2 Δυαδικός κόσμος Οι υπολογιστές είναι δυαδικές μηχανές Όλη η πληροφορία (δεδομένα και κώδικας) κωδικοποιείται
Διπλωματική Εργασία του φοιτητή του Τμήματος Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών της Πολυτεχνικής Σχολής του Πανεπιστημίου Πατρών
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ: ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΣΥΣΤΗΜΑΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Διπλωματική Εργασία του φοιτητή του Τμήματος Ηλεκτρολόγων
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ: ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΣΥΣΤΗΜΑΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Διπλωματική Εργασία του φοιτητή του Τμήματος Ηλεκτρολόγων
Minimum Spanning Tree: Prim's Algorithm
 Minimum Spanning Tree: Prim's Algorithm 1. Initialize a tree with a single vertex, chosen arbitrarily from the graph. 2. Grow the tree by one edge: of the edges that connect the tree to vertices not yet
Minimum Spanning Tree: Prim's Algorithm 1. Initialize a tree with a single vertex, chosen arbitrarily from the graph. 2. Grow the tree by one edge: of the edges that connect the tree to vertices not yet
Οργάνωση Υπολογιστών (ΙI)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Οργάνωση Υπολογιστών (ΙI) (κύρια και κρυφή μνήμη) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Ένα τυπικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Οργάνωση Υπολογιστών (ΙI) (κύρια και κρυφή μνήμη) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Ένα τυπικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών Απόδοση ΚΜΕ. (Μέτρηση και τεχνικές βελτίωσης απόδοσης)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Απόδοση ΚΜΕ (Μέτρηση και τεχνικές βελτίωσης απόδοσης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κεντρική Μονάδα Επεξεργασίας
Παρουσίαση 5 ης Άσκησης:
 Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 5 ης Άσκησης: Θέματα Συγχρονισμού σε Σύγχρονα Πολυπύρηνα Συστήματα Ακ. Έτος
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Παρουσίαση 5 ης Άσκησης: Θέματα Συγχρονισμού σε Σύγχρονα Πολυπύρηνα Συστήματα Ακ. Έτος
Κύρια μνήμη. Μοντέλο λειτουργίας μνήμης. Ένα τυπικό υπολογιστικό σύστημα σήμερα. Οργάνωση Υπολογιστών (ΙI)
") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 015-16 Οργάνωση Υπολογιστών (ΙI) (κύρια και ) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα τυπικό υπολογιστικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 015-16 Οργάνωση Υπολογιστών (ΙI) (κύρια και ) http://di.ionio.gr/~mistral/tp/csintro/ Μ.Στεφανιδάκης Ένα τυπικό υπολογιστικό
Σχεδίαση και Υλοποίηση Μηχανισμού Μεταφοράς Δεδομένων από Συσκευές Αποθήκευσης σε Δίκτυο Myrinet, Χωρίς τη Μεσολάβηση της Ιεραρχίας Μνήμης
 Σχεδίαση και Υλοποίηση Μηχανισμού Μεταφοράς Δεδομένων από Συσκευές Αποθήκευσης σε Δίκτυο Myrinet, Χωρίς τη Μεσολάβηση της Ιεραρχίας Μνήμης Αναστάσιος Α. Νάνος ananos@cslab.ntua.gr Επιβλέπων: Νεκτάριος
Σχεδίαση και Υλοποίηση Μηχανισμού Μεταφοράς Δεδομένων από Συσκευές Αποθήκευσης σε Δίκτυο Myrinet, Χωρίς τη Μεσολάβηση της Ιεραρχίας Μνήμης Αναστάσιος Α. Νάνος ananos@cslab.ntua.gr Επιβλέπων: Νεκτάριος
FORTRAN και Αντικειμενοστραφής Προγραμματισμός
 FORTRAN και Αντικειμενοστραφής Προγραμματισμός Παραδόσεις Μαθήματος 2016 Δρ Γ Παπαλάμπρου Επίκουρος Καθηγητής ΕΜΠ georgepapalambrou@lmentuagr Εργαστήριο Ναυτικής Μηχανολογίας (Κτίριο Λ) Σχολή Ναυπηγών
FORTRAN και Αντικειμενοστραφής Προγραμματισμός Παραδόσεις Μαθήματος 2016 Δρ Γ Παπαλάμπρου Επίκουρος Καθηγητής ΕΜΠ georgepapalambrou@lmentuagr Εργαστήριο Ναυτικής Μηχανολογίας (Κτίριο Λ) Σχολή Ναυπηγών
Κατανεμημένος και Παράλληλος Προγραμματισμός
 Κατανεμημένος και Παράλληλος Προγραμματισμός Ηλίας Κ. Σάββας Καθηγητής Τμήμα Μηχανικών Πληροφορικής ΤΕ, ΤΕΙ Θεσσαλίας Email: savvas@teilar.gr Παράλληλος προγραμματισμός OpenMP (3) Critical vs. Single Η
Κατανεμημένος και Παράλληλος Προγραμματισμός Ηλίας Κ. Σάββας Καθηγητής Τμήμα Μηχανικών Πληροφορικής ΤΕ, ΤΕΙ Θεσσαλίας Email: savvas@teilar.gr Παράλληλος προγραμματισμός OpenMP (3) Critical vs. Single Η
Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών
 Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών ακ. έτος 2006-2007 Νεκτάριος Κοζύρης Νίκος Αναστόπουλος {nkoziris,anastop}@cslab.ece.ntua.gr Άσκηση 1: pipelining Εξετάζουμε την εκτέλεση του παρακάτω
Ασκήσεις στα Προηγμένα Θέματα Αρχιτεκτονικής Υπολογιστών ακ. έτος 2006-2007 Νεκτάριος Κοζύρης Νίκος Αναστόπουλος {nkoziris,anastop}@cslab.ece.ntua.gr Άσκηση 1: pipelining Εξετάζουμε την εκτέλεση του παρακάτω
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Διπλωματικές
All Pairs Shortest Path
 All Pairs Shortest Path χρησιμοποιώντας Κυπριώτη Αικατερίνη 6960 Μόσχογλου Στυλιανός 6978 20 Ιανουαρίου 2012 Περιεχόμενα 1 Πρόλογος 3 2 Ο σειριακός APSP 3 3 Η παραλληλοποίηση με 5 3.1 Το προγραμματιστικό
All Pairs Shortest Path χρησιμοποιώντας Κυπριώτη Αικατερίνη 6960 Μόσχογλου Στυλιανός 6978 20 Ιανουαρίου 2012 Περιεχόμενα 1 Πρόλογος 3 2 Ο σειριακός APSP 3 3 Η παραλληλοποίηση με 5 3.1 Το προγραμματιστικό
Επιτεύγµατα των Λ.Σ.
 Επιτεύγµατα των Λ.Σ. ιεργασίες ιαχείριση Μνήµης Ασφάλεια και προστασία δεδοµένων Χρονοπρογραµµατισµός & ιαχείρηση Πόρων οµή Συστήµατος ιεργασίες Ένα πρόγραµµα σε εκτέλεση Ένα στιγµιότυπο ενός προγράµµατος
Επιτεύγµατα των Λ.Σ. ιεργασίες ιαχείριση Μνήµης Ασφάλεια και προστασία δεδοµένων Χρονοπρογραµµατισµός & ιαχείρηση Πόρων οµή Συστήµατος ιεργασίες Ένα πρόγραµµα σε εκτέλεση Ένα στιγµιότυπο ενός προγράµµατος
Chapter 4 ( ή 1 στο βιβλίο σας)
") Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy Chapter 4 ( ή 1 στο βιβλίο σας) Αξιολόγηση και κατανόηση της απόδοσης Δέκατη (10 η ) δίωρη διάλεξη. Διαφάνειες διδασκαλίας από
Η διασύνδεση Υλικού και λογισμικού David A. Patterson και John L. Hennessy Chapter 4 ( ή 1 στο βιβλίο σας) Αξιολόγηση και κατανόηση της απόδοσης Δέκατη (10 η ) δίωρη διάλεξη. Διαφάνειες διδασκαλίας από
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 Πολυπύρηνοι επεξεργαστές, μέρος 2 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Cache coherence & scalability! Τα πρωτόκολλα
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 Πολυπύρηνοι επεξεργαστές, μέρος 2 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Cache coherence & scalability! Τα πρωτόκολλα
Προγραμματισμός συστημάτων UNIX/POSIX. Θέμα επιλεγμένο από τους φοιτητές: Προγραμματιστικές τεχνικές που στοχεύουν σε επιδόσεις
 Προγραμματισμός συστημάτων UNIX/POSIX Θέμα επιλεγμένο από τους φοιτητές: Προγραμματιστικές τεχνικές που στοχεύουν σε επιδόσεις Βελτιστοποιήσεις με στόχο τις επιδόσεις Σε αρκετές περιπτώσεις δεν αρκεί να
Προγραμματισμός συστημάτων UNIX/POSIX Θέμα επιλεγμένο από τους φοιτητές: Προγραμματιστικές τεχνικές που στοχεύουν σε επιδόσεις Βελτιστοποιήσεις με στόχο τις επιδόσεις Σε αρκετές περιπτώσεις δεν αρκεί να
Λειτουργικά Συστήματα Πραγματικού Χρόνου
 Λειτουργικά Συστήματα Πραγματικού Χρόνου 2006-07 Λειτουργικά Συστήματα Πραγματικού Χρόνου Η χρήση του χρόνου Μ.Στεφανιδάκης Συστήματα πραγματικού χρόνου: ελεγκτής και ελεγχόμενο σύστημα real-time system
Λειτουργικά Συστήματα Πραγματικού Χρόνου 2006-07 Λειτουργικά Συστήματα Πραγματικού Χρόνου Η χρήση του χρόνου Μ.Στεφανιδάκης Συστήματα πραγματικού χρόνου: ελεγκτής και ελεγχόμενο σύστημα real-time system
Τεχνικές για διαμοιρασμό φορτίου και μακροεντολές Broadcast - Scatter για αποδοτικές πολύ-επεξεργαστικές εφαρμογές
 Τεχνικές για διαμοιρασμό φορτίου και μακροεντολές Broadcast - Scatter για αποδοτικές πολύ-επεξεργαστικές εφαρμογές Μίλτος Δ. Γραμματικάκης, Αντώνης Παπαγρηγορίου, Πολύδωρος Πετράκης, Γεώργιος Κορνάρος,
Τεχνικές για διαμοιρασμό φορτίου και μακροεντολές Broadcast - Scatter για αποδοτικές πολύ-επεξεργαστικές εφαρμογές Μίλτος Δ. Γραμματικάκης, Αντώνης Παπαγρηγορίου, Πολύδωρος Πετράκης, Γεώργιος Κορνάρος,
Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών
 Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Αρχιτεκτονική Υπολογιστών Άσκηση 6: Ασκήσεις Εξαμήνου Μέρος Β Νοέμβριος 2016 Στην άσκηση αυτή θα μελετήσουμε την εκτέλεση ενός
Πανεπιστήμιο Θεσσαλίας Τμήμα Ηλεκτρολόγων Μηχανικών & Μηχανικών Υπολογιστών Αρχιτεκτονική Υπολογιστών Άσκηση 6: Ασκήσεις Εξαμήνου Μέρος Β Νοέμβριος 2016 Στην άσκηση αυτή θα μελετήσουμε την εκτέλεση ενός
Κεφάλαιο 3. Διδακτικοί Στόχοι
 Κεφάλαιο 3 Σε ένα υπολογιστικό σύστημα η Κεντρική Μονάδα Επεξεργασίας (ΚΜΕ) εκτελεί τις εντολές που βρίσκονται στην κύρια μνήμη του. Οι εντολές αυτές ανήκουν σε προγράμματα τα οποία, όταν εκτελούνται,
Κεφάλαιο 3 Σε ένα υπολογιστικό σύστημα η Κεντρική Μονάδα Επεξεργασίας (ΚΜΕ) εκτελεί τις εντολές που βρίσκονται στην κύρια μνήμη του. Οι εντολές αυτές ανήκουν σε προγράμματα τα οποία, όταν εκτελούνται,
Τεχνολογίες Κύριας Μνήμης
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κύρια Μνήμη
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2016-17 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://mixstef.github.io/courses/comparch/ Μ.Στεφανιδάκης Κύρια Μνήμη
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί
 Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 5: (A) Λογισμικό, Βασικές Εφαρμογές
Επιστημονικοί Υπολογισμοί - Μέρος ΙΙΙ: Παράλληλοι Υπολογισμοί Χαρμανδάρης Βαγγέλης, Τμήμα Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης, Εαρινό Εξάμηνο 2013/14 Κεφάλαιο 5: (A) Λογισμικό, Βασικές Εφαρμογές
Εικονική Μνήμη (1/2)
") Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Εικονική Μνήμη (1/2) Λειτουργικά Συστήματα Υπολογιστών 7ο Εξάμηνο, 2016-2017 Εικονική Μνήμη
Εθνικό Μετσόβιο Πολυτεχνείο Σχολή Ηλεκτρολόγων Μηχ. και Μηχανικών Υπολογιστών Εργαστήριο Υπολογιστικών Συστημάτων Εικονική Μνήμη (1/2) Λειτουργικά Συστήματα Υπολογιστών 7ο Εξάμηνο, 2016-2017 Εικονική Μνήμη
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Συστήματα Παράλληλης
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ www.cslab.ece.ntua.gr Συστήματα Παράλληλης
Chapter 4 (1) Αξιολόγηση και κατανόηση της απόδοσης
 Αξιολόγηση και κατανόηση της απόδοσης") Chapter 4 (1) Αξιολόγηση και κατανόηση της απόδοσης Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση: Καθ. Εφαρμογών Νικόλαος Πετράκης, Τμήματος Ηλεκτρονικών Μηχανικών του
Chapter 4 (1) Αξιολόγηση και κατανόηση της απόδοσης Διαφάνειες διδασκαλίας από το πρωτότυπο αγγλικό βιβλίο (4 η έκδοση), μετάφραση: Καθ. Εφαρμογών Νικόλαος Πετράκης, Τμήματος Ηλεκτρονικών Μηχανικών του
Ελαχιστοποίηση της Καταναλισκόμενης Ενέργειας σε Φορητές Συσκευές
 Ελαχιστοποίηση της Καταναλισκόμενης Ενέργειας σε Φορητές Συσκευές Βασίλης Βλάχος vbill@aueb.gr Υποψήφιος Διδάκτορας Τμήματος Διοικητικής Επιστήμης και Τεχνολογίας 1 Σχεδιασμός ενσωματωμένων συστημάτων
Ελαχιστοποίηση της Καταναλισκόμενης Ενέργειας σε Φορητές Συσκευές Βασίλης Βλάχος vbill@aueb.gr Υποψήφιος Διδάκτορας Τμήματος Διοικητικής Επιστήμης και Τεχνολογίας 1 Σχεδιασμός ενσωματωμένων συστημάτων
QuakeTM: Parallelizing a Complex Sequential Application Using Transactional Memory (Gajinov et al., 2009)
") Quake I QuakeTM: Parallelizing a Complex Sequential Application Using Transactional Memory (Gajinov et al., 2009) Είναι όντως χρήσιμη η transactional memory σε μεγάλες εφαρμογές; Παράλληλη υλοποίηση μιας
Quake I QuakeTM: Parallelizing a Complex Sequential Application Using Transactional Memory (Gajinov et al., 2009) Είναι όντως χρήσιμη η transactional memory σε μεγάλες εφαρμογές; Παράλληλη υλοποίηση μιας
Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας
 Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα: Intel Parallel Studio XE 2013 Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων
Τμήμα Μηχανικών Πληροφορικής & Τηλεπικοινωνιών Συστήματα Παράλληλης & Κατανεμημένης Επεξεργασίας Ενότητα: Intel Parallel Studio XE 2013 Δρ. Μηνάς Δασυγένης mdasyg@ieee.org Εργαστήριο Ψηφιακών Συστημάτων
i Στα σύγχρονα συστήματα η κύρια μνήμη δεν συνδέεται απευθείας με τον επεξεργαστή
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης i Στα σύγχρονα
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Αρχιτεκτονική Υπολογιστών 2015-16 Τεχνολογίες Κύριας (και η ανάγκη για χρήση ιεραρχιών μνήμης) http://di.ionio.gr/~mistral/tp/comparch/ Μ.Στεφανιδάκης i Στα σύγχρονα
Εισαγωγικά & Βασικές Έννοιες
 Εισαγωγικά & Βασικές Έννοιες ΙΙΙ 1 lalis@inf.uth.gr Γιατί πολλές διεργασίες/νήματα; Επίπεδο εφαρμογής Καλύτερη δόμηση κώδικα Αποφυγή μπλοκαρίσματος / περιοδικών ελέγχων Φυσική έκφραση παραλληλισμού Επίπεδο
Εισαγωγικά & Βασικές Έννοιες ΙΙΙ 1 lalis@inf.uth.gr Γιατί πολλές διεργασίες/νήματα; Επίπεδο εφαρμογής Καλύτερη δόμηση κώδικα Αποφυγή μπλοκαρίσματος / περιοδικών ελέγχων Φυσική έκφραση παραλληλισμού Επίπεδο
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232)
") ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Δευτέρα, 3 Νοεμβρίου 25 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΛΕΠΤΑ Για πλήρη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ Η/Υ ΔΕΥΤΕΡΗ ΠΡΟΟΔΟΣ ΣΤΗΝ ΟΡΓΑΝΩΣΗ ΣΤΟΥΣ Η/Y (ΗΥ232) Δευτέρα, 3 Νοεμβρίου 25 ΔΙΑΡΚΕΙΑ ΔΙΑΓΩΝΙΣΜΑΤΟΣ 3 ΛΕΠΤΑ Για πλήρη
Λειτουργικά Συστήματα 7ο εξάμηνο, Ακαδημαϊκή περίοδος
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ KΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr Λειτουργικά
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ KΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ ΕΡΓΑΣΤΗΡΙΟ ΥΠΟΛΟΓΙΣΤΙΚΩΝ ΣΥΣΤΗΜΑΤΩΝ http://www.cslab.ece.ntua.gr Λειτουργικά
Λειτουργικά Συστήματα Η/Υ
 Λειτουργικά Συστήματα Η/Υ Κεφάλαιο 4 «Αρχιτεκτονικές ΛΣ» Διδάσκων: Δ Λιαροκάπης Διαφάνειες: Π. Χατζηδούκας 1 1. Μονολιθικά συστήματα Αρχιτεκτονικές ΛΣ 2. Στρωματοποιημένη αρχιτεκτονική 3. Αρχιτεκτονική
Λειτουργικά Συστήματα Η/Υ Κεφάλαιο 4 «Αρχιτεκτονικές ΛΣ» Διδάσκων: Δ Λιαροκάπης Διαφάνειες: Π. Χατζηδούκας 1 1. Μονολιθικά συστήματα Αρχιτεκτονικές ΛΣ 2. Στρωματοποιημένη αρχιτεκτονική 3. Αρχιτεκτονική
Για τις λύσεις των προβλημάτων υπάρχει τρόπος εκτίμησης της επίδοσης (performance) και της αποδοτικότητας (efficiency). Ερωτήματα για την επίδοση
 και της αποδοτικότητας (efficiency). Ερωτήματα για την επίδοση") Επίδοση Αλγορίθμων Για τις λύσεις των προβλημάτων υπάρχει τρόπος εκτίμησης της επίδοσης (performance) και της αποδοτικότητας (efficiency). Ερωτήματα για την επίδοση πώς υπολογίζεται ο χρόνος εκτέλεσης
Επίδοση Αλγορίθμων Για τις λύσεις των προβλημάτων υπάρχει τρόπος εκτίμησης της επίδοσης (performance) και της αποδοτικότητας (efficiency). Ερωτήματα για την επίδοση πώς υπολογίζεται ο χρόνος εκτέλεσης
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων
 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Προσομοίωση μεγάλης κλίμακας γραμμικών κυκλωμάτων σε παράλληλες πλατφόρμες Ειδικό Θέμα Ιωαννίδης Κ. Σταύρος Αριθμός Ειδικού Μητρώου:
Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Η/Υ, Τηλεπικοινωνιών και Δικτύων Προσομοίωση μεγάλης κλίμακας γραμμικών κυκλωμάτων σε παράλληλες πλατφόρμες Ειδικό Θέμα Ιωαννίδης Κ. Σταύρος Αριθμός Ειδικού Μητρώου:
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2
 ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 11ο μάθημα: πολυπύρηνοι επεξεργαστές, μέρος 1 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Παράλληλη επεξεργασία Στο προηγούμενο
ΠΛΕ- 074 Αρχιτεκτονική Υπολογιστών 2 11ο μάθημα: πολυπύρηνοι επεξεργαστές, μέρος 1 Αρης Ευθυμίου Πηγές διαφανειών: συνοδευτικές διαφάνειες αγγλικης εκδοσης του βιβλιου Παράλληλη επεξεργασία Στο προηγούμενο
Επεξεργασία Ερωτήσεων
 Εισαγωγή Επεξεργασία Ερωτήσεων Σ Β Βάση εδομένων Η ομή ενός ΣΒ Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 1 Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 2 Εισαγωγή Εισαγωγή ΜΕΡΟΣ 1 (Χρήση Σ Β ) Γενική
Εισαγωγή Επεξεργασία Ερωτήσεων Σ Β Βάση εδομένων Η ομή ενός ΣΒ Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 1 Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 2 Εισαγωγή Εισαγωγή ΜΕΡΟΣ 1 (Χρήση Σ Β ) Γενική
Ένα αφαιρετικό πραγματικού χρόνου μοντέλο λειτουργικού συστήματος για MPSoC
 Ένα αφαιρετικό πραγματικού χρόνου μοντέλο λειτουργικού συστήματος για MPSoC Αρχιτεκτονική Πλατφόρμας Μπορεί να μοντελοποιηθεί σαν ένα σύνολο από διασυνδεδεμένα κομμάτια: 1. Στοιχεία επεξεργασίας (processing
Ένα αφαιρετικό πραγματικού χρόνου μοντέλο λειτουργικού συστήματος για MPSoC Αρχιτεκτονική Πλατφόρμας Μπορεί να μοντελοποιηθεί σαν ένα σύνολο από διασυνδεδεμένα κομμάτια: 1. Στοιχεία επεξεργασίας (processing
Εισαγωγή στους Αλγόριθµους. Αλγόριθµοι. Ιστορικά Στοιχεία. Ο πρώτος Αλγόριθµος. Παραδείγµατα Αλγορίθµων. Τι είναι Αλγόριθµος
 Εισαγωγή στους Αλγόριθµους Αλγόριθµοι Τι είναι αλγόριθµος; Τι µπορεί να υπολογίσει ένας αλγόριθµος; Πως αξιολογείται ένας αλγόριθµος; Παύλος Εφραιµίδης pefraimi@ee.duth.gr Αλγόριθµοι Εισαγωγικές Έννοιες
Εισαγωγή στους Αλγόριθµους Αλγόριθµοι Τι είναι αλγόριθµος; Τι µπορεί να υπολογίσει ένας αλγόριθµος; Πως αξιολογείται ένας αλγόριθµος; Παύλος Εφραιµίδης pefraimi@ee.duth.gr Αλγόριθµοι Εισαγωγικές Έννοιες
Κεφάλαιο 7 Ιεραρχία Μνήμης (Memory Hierarchy)
") Κεφάλαιο 7 Ιεραρχία Μνήμης (Memory Hierarchy) 1 Συστήματα Μνήμης Η οργάνωση του συστήματος μνήμης επηρεάζει τη λειτουργία και απόδοση ενός μικροεπεξεργαστή: Διαχείριση μνήμης και περιφερειακών (Ι/Ο) απότολειτουργικόσύστημα
Κεφάλαιο 7 Ιεραρχία Μνήμης (Memory Hierarchy) 1 Συστήματα Μνήμης Η οργάνωση του συστήματος μνήμης επηρεάζει τη λειτουργία και απόδοση ενός μικροεπεξεργαστή: Διαχείριση μνήμης και περιφερειακών (Ι/Ο) απότολειτουργικόσύστημα
ΠΕΡΙΕΧΟΜΕΝΑ. 1.1. Υλικό και Λογισμικό.. 1 1.2 Αρχιτεκτονική Υπολογιστών.. 3 1.3 Δομή, Οργάνωση και Λειτουργία Υπολογιστών 6
 ΠΕΡΙΕΧΟΜΕΝΑ 1. Εισαγωγή στην Δομή, Οργάνωση, Λειτουργία και Αξιολόγηση Υπολογιστών 1.1. Υλικό και Λογισμικό.. 1 1.2 Αρχιτεκτονική Υπολογιστών.. 3 1.3 Δομή, Οργάνωση και Λειτουργία Υπολογιστών 6 1.3.1 Δομή
ΠΕΡΙΕΧΟΜΕΝΑ 1. Εισαγωγή στην Δομή, Οργάνωση, Λειτουργία και Αξιολόγηση Υπολογιστών 1.1. Υλικό και Λογισμικό.. 1 1.2 Αρχιτεκτονική Υπολογιστών.. 3 1.3 Δομή, Οργάνωση και Λειτουργία Υπολογιστών 6 1.3.1 Δομή
Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1
 Προγραμματισμός II 1") Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1 lalis@inf.uth.gr Ο κώδικας δεν εκτελείται «μόνος του» Ο εκτελέσιμος κώδικας αποθηκεύεται σε ένα αρχείο Το αρχείο είναι μια «παθητική» οντότητα
Διεργασίες (μοντέλο μνήμης & εκτέλεσης) Προγραμματισμός II 1 lalis@inf.uth.gr Ο κώδικας δεν εκτελείται «μόνος του» Ο εκτελέσιμος κώδικας αποθηκεύεται σε ένα αρχείο Το αρχείο είναι μια «παθητική» οντότητα
Εισαγωγή Θέματα H/W. Χάρης Μανιφάβας Τμήμα Εφ. Πληροφορικής & Πολυμέσων ΤΕΙ Κρήτης. Κατανεμημένα Συστήματα (Ε) Εισαγωγή: Θέματα H/W 1
 Εισαγωγή: Θέματα H/W 1") Εισαγωγή Θέματα H/W Χάρης Μανιφάβας Τμήμα Εφ. Πληροφορικής & Πολυμέσων ΤΕΙ Κρήτης Εισαγωγή: Θέματα H/W 1 Θέματα Hardware Τα ΚΣ αποτελούνται από πολλαπλά CPUs ιαφορετικοί τρόποι σύνδεσης και επικοινωνίας
Εισαγωγή Θέματα H/W Χάρης Μανιφάβας Τμήμα Εφ. Πληροφορικής & Πολυμέσων ΤΕΙ Κρήτης Εισαγωγή: Θέματα H/W 1 Θέματα Hardware Τα ΚΣ αποτελούνται από πολλαπλά CPUs ιαφορετικοί τρόποι σύνδεσης και επικοινωνίας