Λογιστική Παλινδρόμηση & Διαχωριστική Ανάλυση
|
|
|
- Πρόχορος Δημητρίου
- 7 χρόνια πριν
- Προβολές:
Transcript
1 ΤΜΗΜΑ ΜΑΘΗΜΑΤΙΚΩΝ ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΠΟΥΔΩΝ «ΜΑΘΗΜΑΤΙΚΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΚΑΙ ΤΩΝ ΑΠΟΦΑΣΕΩΝ» Λογιστική Παλινδρόμηση & Διαχωριστική Ανάλυση ΜΕΤΑΠΤΥΧΙΑΚΗ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ Επιβλέπων : Αλεβίζος Φίλιππος Επίκουρος Καθηγητής Ξενή Μαρία
2 Πίνακας Περιεχομένων ΕΙΣΑΓΩΓΗ 5 ΕΙΣΑΓΩΓΗ ΣΤΗ ΜΗ ΓΡΑΜΜΙΚΗ ΠΑΛΙΝΔΡΟΜΗΣΗ 6. Μη γραμμικό μοντέλο παλινδρόμησης 6. Εκτίμηση παραμέτρων παλινδρόμησης 7. Επαναληπτικές αριθμητικές μέθοδοι 8 3. Συμπεράσματα για τις μη γραμμικές παραμέτρους παλινδρόμησης 0 3. Θεώρημα μεγάλου δείγματος 0 4. Διαστήματα εμπιστοσύνης για τους συντελεστές παλινδρόμησης 4. Διάστημα εμπιστοσύνης για το k 4. Κοινά διαστήματα εμπιστοσύνης-διαδικασία Bonferron 4.3 Έλεγχοι υποθέσεων για το k ΛΟΓΙΣΤΙΚΗ ΠΑΛΙΝΔΡΟΜΗΣΗ 3. Εισαγωγή 3. Ερμηνεία της συνάρτησης απόκρισης όταν η Υ είναι δυαδική 3. Γιατί δεν μπορούμε να χρησιμοποιήσουμε το γραμμικό μοντέλο 4. Απλό Λογιστικό Μοντέλο 6 3. Απλή λογιστική Παλινδρόμηση 8 3. Ερμηνεία για το συντελεστή παλινδρόμησης b 0 3. Επαναλαμβανόμενες παρατηρήσεις 4. Πολλαπλή λογιστική παλινδρόμηση 4. Εκτίμηση παραμέτρων 3 4. Ερμηνεία για τους συντελεστές παλινδρόμησης 4 5. Κατασκευή μοντέλου 4 5. Έλεγχος αν κάποια από τα βκ= Διαγνωστικά Ανεπίσημη μέθοδος καταλληλότητας μοντέλου X έλεγχος καλής προσαρμογής Έλεγχος απόκλισης ως έλεγχος καλής προσαρμογής Απόκλιση καταλοίπων 3
3 7. Συμπεράσματα για τις παραμέτρους 3 7. Διάστημα εμπιστοσύνης για το β κ Διαδικασία Bonferron Έλεγχος για τα β κ Εκτίμηση του αποκρινόμενου μέσου Εκτίμηση σημείου Διαστήματα Εμπιστοσύνης Πρόβλεψη μιας νέας μεταβλητής Έλεγχος αξιοπιστίας της πρόβλεψης 38 ΔΙΑΧΩΡΙΣΤΙΚΗ Η ΔΙΑΚΡΙΤΗ ΑΝΑΛΥΣΗ 39. Εισαγωγή 39. Διαχωρισμός σε δύο ομάδες 40. Κριτήριο μέγιστης πιθανοφάνειας 4. Κριτήριο Bayes 4.3 Κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης 44.4 Ελαχιστοποίηση της συνολικής πιθανότητας λανθασμένης κατάταξης Διαχωρισμός δυο πληθυσμών με τη χρήση της κανονικής κατανομής Κανονικοί πληθυσμοί με 3. Κανονικοί πληθυσμοί με Αξιολόγηση των συναρτήσεων κατάταξης 6 5. Η Διαχωριστική Συνάρτηση του Fsher Γενίκευση της διαχωριστικής ανάλυσης σε g πληθυσμούς Κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης Ελαχιστοποίηση της συνολικής πιθανότητας λανθασμένης κατάταξης Κανόνας Bayes Διαχωρισμός των πληθυσμών όταν αυτοί ακολουθούν την κανονική κατανομή Γενίκευση της μεθόδου του Fsher για k πληθυσμούς Ομοιότητες- διαφορές λογιστικής παλινδρόμησης και διαχωριστικής ανάλυσης 85 ΛΟΓΙΣΤΙΚΗ ΠΑΛΙΝΔΡΟΜΗΣΗ ΚΑΙ ΔΙΑΧΩΡΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΣΤΟ SPSS 87. Παράδειγμα για Λογιστική Παλινδρόμηση (Agrest, 99) 87 3
4 . Παράδειγμα με Διαχωριστική Ανάλυση ( R. Johnson - D.Wchern, 99) 99 ΒΙΒΛΙΟΓΡΑΦΙΑ 7 4
5 Εισαγωγή Σε αυτή την εργασία ασχοληθήκαμε με δύο μεθόδους, που σκοπός τους είναι να κατατάσσουν τις παρατηρήσεις σε γνωστές ομάδες και στη συνέχεια να κάνουν προβλέψεις για καινούριες παρατηρήσεις. Αυτές οι μέθοδοι είναι η λογιστική παλινδρόμηση ( logstc regresson ) και η διαχωριστική ανάλυση ( dscrmnant analyss ). Στο πρώτο κεφάλαιο αναφέραμε περιληπτικά τα μη γραμμικά μοντέλα παλινδρόμησης ( αφού και η λογιστική παλινδρόμηση είναι ένα τέτοιο μοντέλο ). Απλά αναφέρουμε τη μορφή που έχουν αυτά τα μοντέλα, με ποιες μεθόδους μπορούμε να εκτιμήσουμε τις παραμέτρους παλινδρόμησης, ποια είναι τα διαστήματα εμπιστοσύνης για τους συντελεστές παλινδρόμησης και τη μορφή που θα έχουν οι έλεγχοι υποθέσεων. Στο δεύτερο κεφάλαιο περιγράφουμε τη λογιστική παλινδρόμηση. Η λογιστική παλινδρόμηση είναι χρήσιμη σε καταστάσεις στις οποίες επιθυμούμε να προβλέψουμε την ύπαρξη ή την απουσία ενός χαρακτηριστικού ή ενός συμβάντος. Η πρόβλεψη αυτή βασίζεται στην κατασκευή ενός μοντέλου και συγκεκριμένα στον προσδιορισμό των τιμών που παίρνουν οι συντελεστές. Αυτή η μέθοδος είναι μια γενίκευση της απλή γραμμικής παλινδρόμησης για την περίπτωση όπου η εξαρτημένη μεταβλητή είναι δίτιμη ( παίρνει την τιμή 0 όταν το χαρακτηριστικό απουσιάζει και την τιμή όταν υπάρχει το χαρακτηριστικό ). Στο τρίτο κεφάλαιο αναλύουμε τη διαχωριστική ανάλυση, η οποία έχει δύο στόχους: να χωρίσει ένα πληθυσμό σε ευδιάκριτες ομάδες και με τη βοήθεια ενός διαχωριστικού κανόνα να κατατάσσει παρατηρήσεις στις ευδιάκριτες ομάδες. Στο τέλος του κεφαλαίου περιγράφουμε τις ομοιότητες και τις διαφορές της διαχωριστικής ανάλυσης και της λογιστικής παλινδρόμησης. Στο τέταρτο και τελευταίο κεφάλαιο απλά δίνουμε ένα παράδειγμα που το λύνουμε με τη μέθοδο της λογιστικής παλινδρόμησης και ένα παράδειγμα που το λύνουμε με τη μέθοδο της διαχωριστικής ανάλυσης. Αυτό το κάνουμε με τη βοήθεια του στατιστικού πακέτου SPSS. 5
6 Κεφάλαιο ο Εισαγωγή στη μη γραμμική παλινδρόμηση. Μη γραμμικό μοντέλο παλινδρόμησης Τα μη γραμμικά μοντέλα έχουν την πιο κάτω μορφή:, Y f X Εδώ βέβαια παρατηρούμε πως η μορφή αυτή μοιάζει με τη μορφή που έχουμε για τα γραμμικά μοντέλα ( δηλαδή η παρατήρηση συνάρτησης f, X με τα τυχαία σφάλματα Y είναι το άθροισμα της αναμενόμενης ) με τη διαφορά ότι η αναμενόμενη συνάρτηση εδώ είναι μη γραμμική, για να μην υπάρχει παρανόηση θα συμβολίζουμε τις παραμέτρους με. Τα σφάλματα είναι τυχαίες μεταβλητές με τις πιο κάτω υποθέσεις: (a) Η μαθηματική ελπίδα είναι ίση με μηδέν, δηλαδή E 0, (b) Η διασπορά θα είναι σταθερή, (c) Ανά δυο τα σφάλματα είναι ασυσχέτιστα, δηλαδή j E, 0 j, (d) Επίσης πολλές φορές υποθέτουμε ότι είναι κανονικές μεταβλητές. Οπότε από το c και d συμπεραίνουμε ότι είναι και ανεξάρτητες μεταβλητές. Μια σημαντική διαφορά που έχουν τα γραμμικά μοντέλα με τα μη γραμμικά μοντέλα είναι πως το πλήθος των παραμέτρων παλινδρόμησης δεν είναι συνδεδεμένο με το πλήθος των ανεξάρτητων μεταβλητών του μοντέλου. Οπότε θα συμβολίζουμε με q το πλήθος των ανεξάρτητων μεταβλητών X και το πλήθος των παραμέτρων παλινδρόμησης θα συνεχίσουμε να το συμβολίζουμε με p. Αρά για το μη γραμμικό μοντέλο θα έχουμε: 6
7 Y f X, όπου το X X X και q p X q 0. p Παρατήρηση: Εδώ να αναφέρουμε πως πολλά μη γραμμικά μοντέλα μπορούν με τον κατάλληλο μετασχηματισμό να μετατραπούν σε γραμμικά μοντέλα. Τέτοια μοντέλα ονομάζονται ενδογενώς γραμμικά μοντέλα. Μερικές φορές όμως αυτή η μετατροπή μπορεί και να μην αποδίδει καλά.. Εκτίμηση παραμέτρων παλινδρόμησης Η εκτίμηση των παραμέτρων παλινδρόμησης γίνεται, όπως και στα γραμμικά μοντέλα, δηλαδή είτε με τη μέθοδο μέγιστης πιθανοφάνειας είτε με τη μέθοδο ελαχίστων τετραγώνων. Όταν τα σφάλματα ακολουθούν κανονική κατανομή με σταθερή διασπορά τότε αυτές οι δύο μέθοδοι θα μας δίνουν τους ίδιους εκτιμητές. Αυτό γιατί η συνάρτηση αθροίσματος τετραγώνων για το κριτήριο ελαχίστων n ενώ η συνάρτηση πιθανοφάνειας είναι τετραγώνων είναι Q Y f X, 3 L, n Yf X, n e, η οποία είναι γνησίως φθίνουσα ως προς την Q και άρα θα γίνεται μέγιστη όταν η συνάρτηση Q γίνεται ελάχιστη. Για τη μέθοδο των ελαχίστων τετραγώνων θα πρέπει να βρούμε τις κανονικές εξισώσεις ( βρίσκουμε δηλαδή τις μερικές παραγώγους ως προς τις παραμέτρους και τις εξισώνουμε με 0 ) μετά θα πρέπει να βρούμε τις λύσεις από το σύστημα των εξισώσεων που θα προκύψει. Όμως στα μη γραμμικά μοντέλα, ειδικά όταν υπάρχουν πολλοί παράμετροι, η λύση αυτών των κανονικών εξισώσεων μπορεί να είναι υπερβολικά δύσκολο να βρεθεί ή πολλές φορές μπορεί να υπάρχουν άπειρες λύσεις. 7
8 Για την αποφυγή αυτού του προβλήματος θα χρησιμοποιήσουμε επαναληπτικές αριθμητικές μεθόδους.. Επαναληπτικές αριθμητικές μέθοδοι Σε πολλά μη γραμμικά μοντέλα είναι πιο πρακτικό να βρεθούν αμέσως οι εκτιμήσεις των ελαχίστων τετραγώνων με αριθμητικές μεθόδους, από το να βρεθούν πρώτα οι κανονικές εξισώσεις και μετά να χρησιμοποιηθούν οι αριθμητικές μέθοδοι. Εδώ θα συζητήσουμε τρεις μεθόδους:. Μέθοδος γραμμικοποίησης ή Μέθοδος Gauss-Newton Σε αυτή τη μέθοδο χρησιμοποιείται η σειρά Taylor για να προσεγγίσει το μη γραμμικό μοντέλο με γραμμικούς όρους. Στη συνέχεια οι εκτιμώμενοι παράμετροι θα βρεθούν με τη χρήση των ελαχίστων τετραγώνων. Βρίσκουμε πρώτα τις αρχικές τιμές των παραμέτρων και τις συμβολίζουμε με g, g, g,, g p ( οι τιμές αυτές μπορεί να είναι λογικές εικασίες ή μπορεί (0) (0) (0) (0) 0 να βρεθούν από προηγούμενες ή σχετικές μελέτες ) και με τις διαδοχικές επαναλήψεις προσπαθούμε να τις βελτιώσουμε. Θα πρέπει να αναπτύξουμε με σειρά Taylor την f, X γύρω από τις αρχικές τιμές. Οπότε για την περίπτωση θα έχουμε p (0) (0) k k 0 k g 0 f X, f X, f X, g g 4 όπου το (0) g είναι το διάνυσμα των αρχικών τιμών δηλαδή g g g g 0 p. Θα p χρησιμοποιήσουμε κάποιους συμβολισμούς για να απλοποιήσουμε την πιο (0) (0) πάνω παράσταση. Οι συμβολισμοί είναι: f f X, g D 0 f X, k k g 0,. Άρα η (4) θα γίνει, g και 0 0 k k k p k k και k0 f X f D κατά συνέπεια η εξίσωση () θα μπορεί να μετατραπεί σε μια εξίσωση γραμμικής μορφής με τον πιο κάτω τρόπο 8
9 p p p Y f D Y f D Y D k k k k k k k0 k0 k0 Μετά θα βρεθούν οι εκτιμήσεις των παραμέτρων 0 εφαρμόζοντας τη μέθοδο των ελαχίστων τετραγώνων. Στη συνέχεια θα βρούμε τους εκτιμώμενους συντελεστές παλινδρόμησης 0 0 k k k g με τη βοήθεια της σχέσης g g b. Αυτή η επαναληπτική διαδικασία συνεχίζεται μέχρις ότου να συγκλίνει η λύση. Για να γίνει αυτό θα χρησιμοποιήσουμε το κριτήριο ελαχίστων τετραγώνων Q στο οποίο πρώτα θα αντικαθιστούμε τους k εκτιμώμενους συντελεστές ( s) g ( συμβολίζεται με SSE(s) ) και στη συνέχεια τους επαναλαμβανόμενους συντελεστές ( s ) g ( αντίστοιχα ο συμβολισμός θα είναι SSE (s+) ). Η μέθοδος θα συγκλίνει όταν η ποσότητα SSE Αυτή η μέθοδος βέβαια έχει και κάποια μειονεκτήματα: a. Σε κάποιες περιπτώσεις συγκλίνει αργά b. Οι τιμές για τα SSE αυξομειώνονται είναι αμελητέα. SSE ( s) s c. Μπορεί να μη συγκλίνει και καθόλου, δηλαδή να αυξάνεται συνεχώς η τιμή των SSE. Μέθοδος Ταχύτατης Καθόδου (steepest descent) Η μέθοδος αυτή χρησιμοποιεί μια επαναληπτική διαδικασία για να βρεθεί το ελάχιστο της συνάρτησης του αθροίσματος τετραγώνων σχέση (3). Η ιδέα είναι να μετακινηθούμε από το αρχικό σημείο μήκος του διανύσματος με συνιστώσες που είδαμε στη S Q S Q S Q,,, 0 p (0) g κατά οποίου οι τιμές συνεχώς μεταβάλλονται καθώς μετακινούμαστε. Αυτό μπορεί να γίνει και χωρίς να υπολογίσουμε τις παραγώγους της συνάρτησης, αλλά με το να εκτιμήσουμε το διάνυσμα συνιστωσών κλίσης σε διάφορες θέσεις στην επιφάνεια Q προσαρμόζοντας προσεγγιστικές συναρτήσεις. Ενώ αυτή η μέθοδος θα συγκλίνει πάντα, αυτό μπορεί να γίνεται με πολύ αργό ρυθμό. Η μέθοδος αυτή δουλεύει πολύ καλά όταν οι αρχικές τιμές και βρίσκονται πολύ μακριά από τις τελικές τιμές g. του 0 g δεν είναι καλές 9
10 3. Η Μέθοδος του Marquardt Η μέθοδος αυτή συνδυάζει τις δυο πιο πάνω μεθόδους δηλαδή είναι ένας συνδυασμός της μεθόδου γραμμικοποίησης και της μεθόδου ταχύτατης καθόδου. Συνδυάζει τα καλά στοιχεία που έχει η κάθε μέθοδος ενώ αποφεύγει τους περιορισμούς τους. Συγκλίνει σχεδόν πάντα και δεν είναι αργή. Στις περισσότερες περιπτώσεις αυτή η μέθοδος δουλεύει πολύ καλά. 3. Συμπεράσματα για τις μη γραμμικές παραμέτρους παλινδρόμησης Για να μπορέσουμε να καταλήξουμε σε κάποια συμπεράσματα στα μη γραμμικά μοντέλα θα πρέπει να βασιστούμε στη θεωρία μεγάλου δείγματος. Και αυτό γιατί μόνο τότε οι εκτιμητές ελαχίστων τετραγώνων και μέγιστης πιθανοφάνειας θα προσεγγίζουν την κανονική κατανομή, θα είναι σχεδόν αμερόληπτοι και θα έχουν ελάχιστη διασπορά. Εδώ να αναφέρουμε πως δεν υπάρχει κάποιος κανόνας με τον οποίο να αποφασίζουμε αν το μέγεθος του δείγματος μας είναι αρκετά μεγάλο ώστε να ισχύει το θεώρημα. Βέβαια υπάρχουν κάποιες κατευθυντήριες γραμμές από τις οποίες θα μπορούμε να καταλάβουμε αν το μέγεθος του δείγματος είναι ικανοποιητικό. 3. Θεώρημα μεγάλου δείγματος N και Όταν τα σφάλματα είναι ανεξάρτητα, ακολουθούν κανονική κατανομή 0, το δείγμα μας είναι πολύ μεγάλο τότε η δειγματική κατανομή του g, το οποίο είναι το διάνυσμα το τελικών εκτιμώμενων παραμέτρων, θα προσεγγίζει την κανονική κατανομή, οπότε θα έχουμε Eg. Επίσης ο πίνακας διασπορών- συνδιασπορών θα εκτιμάται με s g MSE D D, οπού D ο πίνακας των μερικών παραγώγων υπολογισμένων με τις τελικές εκτιμήσεις των ελαχίστων 0
11 τετραγώνων. Να σημειωθεί ότι το θεώρημα αυτό ισχύει και όταν τα σφάλματα δεν ακολουθούν κανονική κατανομή. Τα συμπεράσματα για τις µη γραμμικές παραμέτρους παλινδρόμησης θα βρίσκονται µε τον ίδιο τρόπο µε αυτά της γραμμικής παλινδρόμησης όταν έχουμε χρησιμοποιήσει το θεώρημα μεγάλου δείγματος, δηλαδή χρησιμοποιούμε τους γνωστούς τύπους για το διάστημα εμπιστοσύνης και για τους ελέγχους υποθέσεων. Βέβαια, τα αποτελέσματα είναι προσεγγιστικά εδώ αλλά η προσέγγιση μπορεί να είναι αρκετά καλή. Όταν δεν μπορούμε να εφαρμόσουμε το θεώρημα ακολουθούμε τα παρακάτω: (α) Να αυξήσουμε το μέγεθος του δείγματος, (β) Να χρησιμοποιήσουμε σαν μέθοδο δειγματοληψίας τη bootstrap για τους εκτιμητές, και (γ) Να μετασχηματίσουμε τις παραμέτρους της συνάρτησης παλινδρόμησης. 4. Διαστήματα εμπιστοσύνης για τους συντελεστές παλινδρόμησης 4. Διάστημα εμπιστοσύνης για το k Όταν το μέγεθος του δείγματος είναι μεγάλο και τα ακολουθούν κανονική κατανομή, N, τότε με βάση το θεώρημα που είδαμε πιο πάνω θα έχουμε gk k s g k t k 0,,, p. Οπότε το διάστημα εμπιστοσύνης με συντελεστή n p εμπιστοσύνης για το k θα είναι: : g t s k k g k., np 4. Κοινά διαστήματα εμπιστοσύνης-διαδικασία Bonferron Αυτή η διαδικασία μας βοηθάει να εξετάσουμε από κοινού τις παραμέτρους του μοντέλου μας, δηλαδή θα μπορούμε να εκτιμήσουμε ταυτόχρονα και το και το 0.
12 Εάν είχαμε ένα μοντέλο με περισσότερες παραμέτρους και έστω ότι θέλουμε να εκτιμήσουμε ταυτόχρονα m παραμέτρους με κοινό συντελεστή εμπιστοσύνης a, θα πρέπει να κατασκευάσω m διαστήματα με συντελεστή εμπιστοσύνης για το καθένα a m. Οπότε τα διαστήματα εμπιστοσύνης θα έχουν την πιο κάτω μορφή: k : gk B s gk οπού B t., a m n p 4.3 Έλεγχοι υποθέσεων για το k Εάν ο έλεγχος που θέλω να πραγματοποιήσω είναι H : έναντι H : 0 k k0 k k0 Για να βρω τη στατιστική συνάρτηση θα πρέπει να έχω πάλι μεγάλο δείγμα, ώστε να μπορεί να χρησιμοποιηθεί το θεώρημα μεγάλου δείγματος, όπου θα είναι: g t s g k. k 0 k Άρα ο κανόνας απόφασης θα γίνει: Εάν Εάν t t αποδέχομαι την H a a, n p t t αποδέχομαι την H, n p 0
13 Κεφάλαιο ο Λογιστική παλινδρόμηση. Εισαγωγή Το λογιστικό μοντέλο είναι ένα μη γραμμικό μοντέλο στο οποίο όμως τα σφάλματα δεν ακολουθούν κανονική κατανομή και η μεταβλητή απόκρισης είναι διακριτή. Η λογιστική παλινδρόμηση χρησιμοποιείται σε περιπτώσεις στις οποίες επιθυμούμε να προβλέψουμε την απουσία ή την παρουσία ενός χαρακτηριστικού, ή ενός συμβάντος. Είναι μια γενίκευση της απλής γραμμικής παλινδρόμησης για την περίπτωση όπου η εξαρτημένη μεταβλητή (Υ) είναι δίτιμη ( δηλαδή παίρνει την τιμή 0 όταν απουσιάζει το χαρακτηριστικό ή την τιμή όταν υπάρχει το χαρακτηριστικό ). Μερικά παραδείγματα στα οποία χρησιμοποιούμε τη λογιστική παλινδρόμηση είναι τα εξής: Μια βιομηχανία βαμβακιού θέλει να εξετάσει εάν κάποιοι από τους εργάτες της πάσχουν από καρκίνο του πνεύμονα ( 0:δεν πάσχει και :πάσχει) με ανεξάρτητες μεταβλητές το φύλο, εάν καπνίζουν και τη διάρκεια εργασία Σε ένα νοσοκομείο εξετάζουν την εμφάνιση στεφανιαίας νόσου σε ένα δείγμα ανδρών σε σχέση με την ηλικία, εάν καπνίζουν, τη συστολική και διαστολική πίεση του αίματος, τα επίπεδα της χοληστερόλης και το βάρος τους ( κωδικοποίησαν με 0 τα άτομα που δεν έχουν πάθει έμφραγμα τα τελευταία 0 χρόνια και με τα άτομα που έχουν υποστεί έμφραγμα ) Σε ένα δείγμα από γυναίκες θέλουμε να δούμε κατά πόσο οι γυναίκες εργάζονται ( 0: δεν εργάζεται, : εργάζεται ) σε σχέση με την ηλικία, το εισόδημα του συζύγου και το αριθμό των παιδιών. Ερμηνεία της συνάρτησης απόκρισης όταν η Υ είναι δυαδική Όπως είπαμε και πιο πάνω η λογιστική παλινδρόμηση είναι η γενίκευση της απλής γραμμικής παλινδρόμησης, οπότε θα ξεκινήσουμε από το απλό γραμμικό μοντέλο: 3
14 Y X, οπού το Y είναι δυαδικό, δηλαδή παίρνει ή την τιμή 0 ή την. 0 Επειδή E 0 έχουμε: 0 = E( X ) E E Y E X 0 X 0 () Επίσης, αφού η Y είναι μια δίτιμη μεταβλητή θα είναι μια μεταβλητή Bernoull, οπότε ορίζουμε τις πιθανότητες ως εξής: Όταν το Όταν το 0 Y έχουμε Y Y έχουμε Y 0 Με τη βοήθεια του ορισμού της αναμενόμενης τιμής βρίσκουμε ότι 0 E Y Εξισώνοντας τις () και () βρίσκουμε: E Y X δηλαδή η αναμενόμενη τιμή είναι η πιθανότητα το 3 0 Y όταν η ανεξάρτητη μεταβλητή είναι X.. Γιατί δεν μπορούμε να χρησιμοποιήσουμε το γραμμικό μοντέλο Εδώ πρέπει να αναφέρουμε ότι έχουμε τρία βασικά προβλήματα όταν η μεταβλητή Υ είναι δυαδική και μας απαγορεύουν να χρησιμοποιήσουμε το γραμμικό μοντέλο:. Τα σφάλματα δεν είναι κανονικά Έχουμε Y X Y X 0 0 Όταν Y 0: X ενώ όταν 0 τα σφάλματα δεν κατανέμονται κανονικά. Y : X οπότε 0 4
15 . Τα σφάλματα έχουν άνισες διασπορές Όταν η αποκρινόμενη μεταβλητή παίρνει τις τιμές 0 ή τα σφάλματα δεν έχουν ίσες διασπορές. Εδώ να πούμε πως Var Y 0 Var Y Var Var Y Var Y Var αφού το είναι μια σταθερά. Άρα θα βρούμε, με βάση τον ορισμό, τη κατά συνέπεια θα έχουμε βρει και τη Var. Οπότε Var Y E Y E Y 0 E Y E Y X X Var Var Y και Από την πιο πάνω σχέση βλέπουμε πως η διασπορά των σφαλμάτων εξαρτάται από τα X, άρα η τιμή της διασποράς θα είναι διαφορετική για κάθε διαφορετικό X. Αυτό μας εμποδίζει να χρησιμοποιήσουμε τη μέθοδο των ελαχίστων τετραγώνων. 3. Περιορισμός στη συνάρτηση απόκρισης Η συνάρτηση απόκρισης επειδή παριστάνει πιθανότητες θα πρέπει να ισχύει ο περιορισμός 0 EY. Εδώ να τονίσουμε ότι τα προβλήματα και είναι σημαντικά αλλά με κάποιες τεχνικές θα μπορούσαμε να τα παραλείψουμε και να χρησιμοποιούσαμε το γραμμικό μοντέλο ( α. Με ένα μεγάλο δείγμα η μέθοδος των ελαχίστων τετραγώνων θα έδινε εκτιμητές που είναι ασυμπωτικά κανονικοί ακόμα και αν τα σφάλματα δεν είναι κανονικά και β. Τις άνισες διασπορές θα μπορούσαμε να τις αντιμετωπίσουμε με τη βοήθεια των σταθμισμένων ελαχίστων τετραγώνων ). Το πρόβλημα 3 δεν μπορούμε να το αντιμετωπίσουμε, για αυτό το λόγο μας απαγορεύεται να χρησιμοποιήσουμε το γραμμικό μοντέλο. Άρα θα πρέπει να βρούμε ένα άλλο μοντέλο που θα εφαρμόζουμε όταν η Y είναι δίτιμη. 5
16 . Απλό Λογιστικό Μοντέλο Το μοντέλο που χρησιμοποιούμε όταν η ορίζεται ως εξής: Y E Y όπου Y : ανεξάρτητη τ.μ. Bernoull και ( X ) e 0 e 0 X E Y Y είναι δίτιμη είναι το λογιστικό, το οποίο 0X e 5 Τώρα θα δούμε με ποια λογική βγήκε αυτή η αναμενόμενη συνάρτηση: Είδαμε πως η αναμενόμενη συνάρτηση πρέπει να παίρνει τιμές στο διάστημα [0,] E Y και είχαμε δει τη σχέση (3), δηλαδή 0 0 X. Οι τιμές όμως της X κυμαίνονται σε όλο το σύνολο των πραγματικών αριθμών. Για να αντιμετωπίσουμε αυτό το πρόβλημα, μια σκέψη θα ήταν να αντικαταστήσουμε την πιθανότητα της επιτυχίας του γεγονότος με τη σχετική πιθανότητα επιτυχίας, δηλαδή με το λόγο της πιθανότητας επιτυχίας του γεγονότος προς την πιθανότητα αποτυχίας του γεγονότος. Ένα μοντέλο της μορφής X 0 όμως και πάλι δε θα ήταν σωστό, γιατί ο λόγος παίρνει τιμές από το 0 μέχρι το +. Αν όμως πάρουμε το φυσικό λογάριθμο αυτού του λόγου θα λύναμε και αυτό το πρόβλημα, οπότε ο μετασχηματισμός είναι ln 6. Οπότε έχουμε: ln X 7 0 e 0 X 0 X e e e ( e ) e X X X X
17 e e X 0 X 0 E Y e e X 0 X 0 E Y e : Επίσης πρέπει να δείξουμε γιατί ισχύει 0 X EY 0X 0 X 0 X e e e 0X e e e e X X X 0 X e Ορισμοί: Ο λόγος ονομάζεται odds ενώ ο μετασχηματισμός (6) ονομάζεται logt μετασχηματισμός της πιθανότητας. Η αναμενόμενη λογιστική συνάρτηση είναι: a) Είτε μονότονα αύξουσα συνάρτηση είτε μονότονα φθίνουσα, b) Είναι σχεδόν γραμμική στην περιοχή [0., 0.8], c) Πλησιάζει το 0 και στις ακραίες τιμές της εμβέλειας του Χ όπως βλέπουμε και στην εικόνα. 7
18 Εικόνα : Παράδειγμα για τη λογιστική αναμενόμενη συνάρτηση, (α) μονότονα αύξουσα και (β) μονότονα φθίνουσα 3. Απλή λογιστική Παλινδρόμηση Πρέπει να εκτιμήσουμε τις παραμέτρους που έχει το λογιστικό μοντέλο και αυτό θα το κάνουμε με τη μέθοδο μέγιστης πιθανοφάνειας, γιατί αυτή η μέθοδος μπορεί να αντιμετωπίσει το πρόβλημα το ότι οι μεταβλητές Y είναι δίτιμες. ΣΥΝΑΡΤΗΣΗ ΠΙΘΑΝΟΦΑΝΕΙΑΣ Αφού τα Y είναι τυχαίες μεταβλητές Bernoull όπου Y Y 0 η συνάρτηση πυκνότητας πιθανότητας είναι: Οι παρατηρήσεις θα είναι: Y Y 0, και,, 8 f Y Y n και Y είναι ανεξάρτητες οπότε η από κοινού συνάρτησης πιθανότητας 8
19 Y Y,, 9 n g Y Y f Y n n Βέβαια είναι πιο εύκολο να δουλέψουμε με το λογάριθμο της από κοινού συνάρτησης και άρα η σχέση (9) θα γίνει: Y Y ln g Y,, ln n n Y n n Y ln ln 0 Όμως λόγω των σχέσεων (5) και (7) μπορούμε να αντικαταστήσουμε το ln και το οπότε θα έχουμε τη λογαριθμική συνάρτηση πιθανοφάνειας των εκτιμώμενων παραμέτρων: n n e ln L, Y X ln X X 0 e n Y X e 0 X 0 e n ln e X X 0 0 n n X 0 ln 0 Y X e n X 0 ln 0 Y X e n Εδώ να πούμε πως δεν μπορούμε να βρούμε τους εκτιμητές όπως θα τους βρίσκαμε στα γραμμικά μοντέλα ( να βρούμε τις τιμές των β 0, β που θα μεγιστοποιούσαν τη λογαριθμική συνάρτηση πιθανοφάνειας ), γιατί πολύ απλά δεν υπάρχουν λύσεις κλειστής μορφής για τις τιμές των β 0, β που θα μεγιστοποιούσαν τη σχέση (). Πρέπει να χρησιμοποιηθούν επαναληπτικές αριθμητικές μέθοδοι οι οποίες θα μας δίνουν τους εκτιμητές b o και b. Αν τους αντικαταστήσουμε στη σχέση (5) θα βρούμε την προσαρμοσμένη αποκρινόμενη συνάρτηση για την παρατήρηση και άρα θα 9
20 έχουμε και την αποκρινόμενη λογιστική συνάρτηση η οποία είναι: b0bx e ˆ b. Χρησιμοποιώντας το μετασχηματισμό logt θα έχουμε 0bX e ˆ ˆ ln ˆ και οπότε θα πάρουμε την προσαρμοσμένη αναμενόμενη λογιστική συνάρτηση ( ftted logt ) ˆ b b X Ερμηνεία για το συντελεστή παλινδρόμησης b Ο εκτιμώμενος συντελεστής δεν έχει την ερμηνεία της κλίση όπως είχαμε δει στα γραμμικά μοντέλα αλλά έχει μια εντελώς διαφορετική ερμηνεία. Η ερμηνεία προέρχεται από την ιδιότητα που έχει ο εκτιμώμενος λόγος πιθανοτήτων (odds) ο οποίος πολλαπλασιάζεται με το b e για κάθε μονάδα που αυξάνεται το X. Αυτό μπορούμε να το δούμε, γιατί γίνεται με βάση τα πιο κάτω βήματα:. Θα βρούμε την τιμή για την προσαρμοσμένη αναμενόμενη λογιστική συνάρτηση (3) όταν 0 ˆ X b b X j j X X : j. Θα το βρούμε και όταν X X j : X b b j 0 X j ˆ 3. Βρίσκουμε τη διαφορά αυτών των δύο: ˆ ˆ b X X b X b X j j j j j 0 0 b X b b X b Όμως πιο πριν είδαμε πως το ˆ X j b είναι ο λογάριθμος των εκτιμώμενων odds αρά ˆ X lnodds και ˆ X lnodds σχέση θα γίνει: j οπότε η πιο πάνω j 0
21 lnodds lnodds ln odds b odds odds b το οποίο ονομάζεται λόγος των εκτιμώμενων πιθανοτήτων και odds e το συμβολίζουμε με OR. OR odds odds e b 4 Αν το b είναι θετικό, ο παράγοντας b e είναι μεγαλύτερος από τη μονάδα, δηλαδή ο εκτιμώμενος λόγος πιθανοτήτων αυξάνεται. Αν το b είναι αρνητικό, ο παράγοντας b e είναι μικρότερος της μονάδας, και άρα ο εκτιμώμενος λόγος πιθανοτήτων μειώνεται. 3. Επαναλαμβανόμενες παρατηρήσεις Σε κάποιες περιπτώσεις, σε διαφορετικά επίπεδα της ανεξάρτητης μεταβλητής X μπορούμε να έχουμε έναν αριθµό επαναλαµβανόµενων παρατηρήσεων. Για παράδειγμα θέλουμε να κάνουμε μια μελέτη στο αν οι πελάτες μιας εταιρίας θα αγόραζαν ένα προϊόν και σε ποια τιμή. Μελετήθηκαν 5 τιµές και 00 άτοµα. Η συνάρτηση απόκρισης εδώ είναι δυαδική ( θα αγοραστεί το προϊόν ή όχι ) οι μεταβλητές πρόβλεψης είναι οι τιµές του προϊόντος και έχει 5 επίπεδα. Όταν έχουµε επαναλαµβανόµενες παρατηρήσεις η συνάρτηση πιθανοφάνειας () μπορεί να απλουστευθεί. Θα δηλώσουμε τα X επίπεδα στα οποία έχουμε επαναλαµβανόµενες παρατηρήσεις ως X X. Ο αριθµός των παρατηρήσεων c στα επίπεδα Y έχουμε σε κάθε γίνει: X j θα ορίζεται από το X j. Οπότε n, j,,, c j R και με R j θα ορίζουμε πόσα j j, άρα η συνάρτηση πιθανοφάνειας () θα n j
22 c n j 0X j ln L, 0 ln R X 0 n ln e j j j j R. j 4. Πολλαπλή λογιστική παλινδρόμηση Πολλές φορές έχουμε περισσότερες από μια ανεξάρτητη μεταβλητή οπότε θα πρέπει να προεκτείνουμε το απλό λογιστικό μοντέλο σε πολλαπλό μοντέλο. Το πολλαπλό λογιστικό μοντέλο είναι: X X X 0 p p e Y 0 X X p X p E Y e 5, για να διευκολυνθούμε με τις πράξεις αλλά και για την απλοποίηση των σχέσεων θα χρησιμοποιήσουμε πίνακες και διανύσματα: 0 X X X X p p p X 6 X p p X, p X X X και X X 0 p p 0 p X, p Με τη βοήθεια των πιο πάνω και με τα. οπότε θα έχουμε Y να είναι ανεξάρτητες μεταβλητές Bernoull μπορούμε να γράψουμε την αναμενόμενη λογιστική ως εξής: X e e 7 EY X Παρατηρήσεις:. Πρέπει να πούμε εδώ ότι όλες οι σχέσεις που είχαμε δει στο απλό λογιστικό μοντέλο μπορούν να επεκταθούν και στο πολλαπλό λογιστικό μοντέλο
23 . Επίσης να πούμε ότι και εδώ η αναμενόμενη λογιστική συνάρτηση είναι μονότονη και η καμπύλη έχει σχήμα s ή ανάποδο s σε σχέση με το είναι σχεδόν γραμμική όταν 0. EY 0.8. X και 3. Οι μεταβλητές X μπορεί να είναι είτε ποσοτικές είτε ποιοτικές. Στην περίπτωση που είναι ποιοτικές αναπαριστώνται με δυαδικές μεταβλητές. Αν οι μεταβλητές είναι όλες ποιοτικές τότε το μοντέλο μπορεί να το ονομάσουμε και λογαριθμικό μοντέλο. 4. Εκτίμηση παραμέτρων Όπως και στο απλό λογιστικό μοντέλο έτσι και εδώ η εκτίμηση παραμέτρων θα γίνει με τη βοήθεια της μεθόδου μέγιστης πιθανοφάνειας. Οπότε η συνάρτηση πιθανοφάνειας εδώ είναι: n X ln L Y X ln e 8 n Και πάλι για να τους βρούμε τους εκτιμητές θα πρέπει να χρησιμοποιήσουμε κάποια αριθμητική μέθοδο η οποία θα μας δίνει τις τιμές των,,,, 0 p που θα μεγιστοποιούν τη σχέση (8 ). Τις τιμές αυτές θα τις συμβολίζουμε με το μοναδιαίο διάνυσμα b0 b b p bp. Οπότε η αναμενόμενη λογιστική συνάρτηση θα γίνει bx e bx ˆ e 9a bx e ή για κάποια τιμή bx e bx ˆ e 9b bx e. Παρατηρήσεις:. Πιο πριν είπαμε πως οι εκτιμητές βρίσκονται με τη βοήθεια κάποιας αριθμητικής μεθόδου, μερικές φορές μπορεί να παρουσιαστεί κάποιο 3
24 πρόβλημα σύγκλισης. Αυτό μπορεί να συμβεί όταν οι μεταβλητές πρόβλεψης είναι πάρα πολλές ή όταν κάποιες έχουν μεγάλη συσχέτιση. Αν συμβεί κάτι τέτοιο πρέπει να μειώσουμε τις μεταβλητές πρόβλεψης. Οι εκτιμητές μέγιστης πιθανοφάνειας μπορούν να βρεθούν και με τη μέθοδο των επαναλαμβανόμενων σταθμισμένων ελαχίστων τετραγώνων 3. Όταν η λογιστική συνάρτηση δεν είναι μονότονη ή δεν έχει τη μορφή s θα πρέπει όλες τις μεταβλητές πρόβλεψης να τις μετατρέψουμε σε κατηγορικές, οπότε θα χρησιμοποιήσουμε το λογαριθμικό μοντέλο. 4. Ερμηνεία για τους συντελεστές παλινδρόμησης Όταν το πολλαπλό μοντέλο παλινδρόμησης είναι ένα πρώτης τάξεως μοντέλο, η ερμηνεία των εκτιμώμενων συντελεστών είναι ίδια με αυτή της απλής λογιστικής συνάρτησης. Ξανά bk e είναι ο εκτιμώμενος λόγος πιθανοτήτων για τη μεταβλητή υπό την προϋπόθεση ότι οι άλλες μεταβλητές πρόβλεψης είναι σταθερές. Όταν το πολλαπλό μοντέλο λογιστικής παλινδρόμησης δεν είναι ένα πρώτης τάξεως αλλά περιέχει τετραγωνικούς ή μεγαλύτερου βαθμού όρους για τις μεταβλητές πρόβλεψης, οι εκτιμώμενοι συντελεστές παλινδρόμησης δεν έχουν πλέον μια απλή ερμηνεία. X, k 5. Κατασκευή μοντέλου 5. Έλεγχος αν κάποια από τα βκ=0 Η κατασκευή του μοντέλου μας εξαρτάται από ποιες μεταβλητές πρόβλεψης θα χρησιμοποιήσουμε. Ο σκοπός μας είναι να βρούμε τις μεταβλητές εκείνες που θα κάνουν το μοντέλο μας πιο βέλτιστο. Αυτό μπορούμε να το κάνουμε με το να ελέγξουμε εάν κάποια από τα είναι ίσα με το μηδέν. k Ο έλεγχος αυτός γίνεται με το τεστ λόγου πιθανοφάνειας ( lkelhood rato test ) και θα πρέπει να έχουμε μεγάλο δείγμα. Η στατιστική συνάρτηση που χρησιμοποιεί ονομάζεται μοντέλο απόκλισης. 4
25 ΜΟΝΤΕΛΟ ΑΠΟΚΛΙΣΗΣ Η απόκλιση στο αναμενόμενο μοντέλο συγκρίνει τη λογαριθμική πιθανοφάνεια του αναμενόμενου μοντέλου με τη λογαριθμική συνάρτηση ενός κορεσμένου ( saturated ) μοντέλου ( δηλαδή με ένα μοντέλο με n παραμέτρους που έχουν οριστεί τέλεια, οπότε το μοντέλο είναι τέλεια προσαρμοσμένο ). Άρα θα πρέπει να βρούμε δύο συναρτήσεις: α) Λογαριθμική συνάρτηση πιθανοφάνειας του προσαρμοσμένου μοντέλου: Είναι η συνάρτηση του πολλαπλού λογιστικού μοντέλου όταν έχουμε τους εκτιμητές μέγιστης πιθανοφάνειας ( γιατί τότε έχουμε τη μέγιστη τιμή της λογαριθμικής συνάρτησης ), δηλαδή n n bx 0 p ln L b, b,, b Y b X ln e 0 β) Λογαριθμική συνάρτηση πιθανοφάνειας του κορεσμένου μοντέλου: Με τη βοήθεια της σχέση (0) θα ορίσουμε τη λογαριθμική συνάρτηση του κορεσμένου μοντέλου. Για να μπορέσουμε να το κάνουμε αυτό θα πρέπει το να μην έχει κανένα περιορισμό και να είναι η πιθανότητα όταν το Y, οπότε θα έχουμε n παραμέτρους και n παρατηρήσεις οι οποίες προσαρμόζονται πλήρως. Επίσης να πούμε πως τη μέγιστη τιμή την παίρνει όταν Y. Ο εκτιμητής για αυτό το μοντέλο θα ορίζεται με συνάρτηση θα είναι: s και έχουμε ότι Y s. Οπότε η λογαριθμική 5
26 0 ln L,, Y ln ln Y s ns n Y Y n n ln L,, Y ln Y Y ln Y ln Y s ns n Y ln Y Y ln Y ln Y n = Y ln Y Y ln Y n s ns ln L,, Y ln Y Y ln Y 0 Η απόκλιση είναι η διαφορά των δύο αυτών λογαριθμικών συναρτήσεων ( εδώ να πούμε πως η τιμή της συνάρτησης για το κορεσμένο μοντέλο είναι μεγαλύτερη, γιατί στο προσαρμοσμένο μοντέλο έχουμε λιγότερες παραμέτρους ). Την απόκλιση θα την ορίζουμε με,,, 0 p n DEV X X X και έχουμε ότι: 0,,, p ln s,, ns ln 0,,, p DEV X X X L L b b b n = 0 Y b X ln () n bx e n n Y ln ln n Y ln Y ln ln n = Y ln Y ln ln n = Y ln Y ln lnln n = Y ln ln Y 6
27 Να αναφέρουμε πως η απόκλιση μπορεί να χρησιμοποιηθεί ως κριτήριο καλής προσαρμογής, γιατί όσο πιο μικρή τιμή έχει τόσο πιο κοντά είναι το προσαρμοσμένο μοντέλο στο κορεσμένο και άρα έχουμε καλύτερη προσαρμογή. ΜΕΡΙΚΗ ΑΠΟΚΛΙΣΗ Ονομάζουμε τη διαφορά των αποκλίσεων δύο προσαρμοσμένων μοντέλων, το πλήρες μοντέλο και το μειωμένο. Με τη μερική απόκλιση ελέγχουμε εάν μπορούμε να παραλείψουμε κάποιες προβλεπόμενες μεταβλητές. Έστω ότι το πλήρες μοντέλο είναι και έστω ότι ο έλεγχος που θέλω να κάνω είναι ο εξής: F e όπου F 0 p H : 0 0 q q p H :έστω κάποιο από τα β όχι μηδέν (3) Οπότε το μειωμένο μοντέλο ( είναι το μοντέλο που περιέχει όλες τις μεταβλητές για τις οποίες δεν κάνω έλεγχο ) θα είναι R e όπου R 0 q. Βρίσκουμε τους εκτιμητές και την απόκλιση που έχει το κάθε μοντέλο. Εάν η απόκλιση που έχει το μειωμένο μοντέλο,,,..., 0 q DEV X X X, δεν έχει μεγάλη διαφορά από την απόκλιση που έχει το πλήρες μοντέλο,,,..., 0 p DEV X X X, τότε θα μπορούμε να πούμε ότι ισχύει η H, γιατί και το μειωμένο μοντέλο μας θα έχει 0 καλή προσαρμογή. Ενώ αν η διαφορά είναι μεγάλη τότε η H απορρίπτεται. 0 Η διαφορά των δύο αποκλίσεων θα ορίζεται ως εξής: DEV X,, X X, X, X q p 0 q 0,, q 0,, p 4 DEV X X X DEV X X X Ο έλεγχος ( 3 ) θα γίνεται με τη βοήθεια του πιο κάτω κανόνα απόφασης: q p 0 q a, pq 0 q p 0 q a, pq Εάν DEV X,, X X, X,, X τότε ισχύει η H Εάν DEV X,, X X, X,, X τότε ισχύει η H 5 7
28 και αυτό γιατί αν ισχύει η H 0 και το n είναι πολύ μεγάλο η ( 4 ) ακολουθεί την κατανομή και οι βαθμοί ελευθερίας είναι η διαφορά των βαθμών ελευθερίας των δύο μοντέλων n q n p p q. Παραδείγματα: Έστω ότι έχουμε το μοντέλο ελέγξουμε τα. e e και θέλουμε να Εάν ο έλεγχος που θέλω να κάνω είναι H0 : 4 0, τότε θα συγκρίνουμε τη μερική απόκλιση που εδώ είναι,,,,,,,,, DEV X X X X X DEV X X X DEV X X X X X με την κατανομή με p-q=5-3= βαθμούς ελευθερίας. Ενώ αν θέλω να κάνω τον έλεγχο H0: 3 0 θα πρέπει να συγκρίνω τη μερική απόκλιση,,, X,,, X,,,, DEV X X X X DEV X X X DEV X X X X X με την κατανομή με p-q=5-4= βαθμούς ελευθερίας. Επιπλέον Εφαρμογή: Εδώ θα πρέπει να αναφέρουμε πως τη μερική απόκλιση και το τεστ που είδαμε παραπάνω μπορούμε να το χρησιμοποιήσουμε για να ελέγξουμε εάν το μοντέλο μας έχει όρους αλληλεπίδρασης. Εμείς θα θέλαμε να μην υπάρχει κανένας τέτοιος όρος ( δηλαδή θα θέλαμε να αποδεχτούμε την H ), γιατί δε θα είχαμε την ερμηνεία που 0 αναφέραμε πιο πάνω για το e e k e Δηλαδή έστω ότι έχουμε το μοντέλο, οπότε θέλουμε να κάνουμε τον έλεγχο H : 0. Η μερική απόκλιση εδώ θα είναι DEV X X, X X, X X X, X, X, X και θα το συγκρίνουμε με την κατανομή με p-q=7-4=3 βαθμούς ελευθερίας. 8
29 ΤΕΣΤ ΤΟΥ ΛΟΓΟΥ ΠΙΘΑΝΟΦΑΝΕΙΑΣ Το τεστ αυτό είναι το ίδιο με το τεστ μερικής απόκλισης. Βασίζεται στο λόγο της συνάρτησης πιθανοφάνειας του πλήρους μοντέλου και της συνάρτησης πιθανοφάνειας του μειωμένου μοντέλου. Για να βρεθεί η συνάρτηση πιθανοφάνειας για το πλήρες μοντέλο ( F e ) θα αντικαταστήσουμε στη σχέση ( 8 ) το διάνυσμα με το διάνυσμα των εκτιμητών b. Τη τιμή αυτή την ορίζουμε με LF Lb, b,..., b 0 p F συνάρτησης πιθανοφάνειας για το μειωμένο μοντέλο (,,..., 0 q. Όμοια και η τιμή της e R ) θα είναι L R L b b b. Τη στατιστική συνάρτηση για το τεστ μέγιστης πιθανοφάνειας θα την ορίζουμε με X και είναι Τώρα θα δούμε γιατί είναι ακριβώς ίδιο με τη μερική απόκλιση. Απόδειξη: X L R ln L F L F ln L R ln ln L R ln L F,,..., ln 0 s,..., q ns DEV X X X L s ns 0 p ln L,..., DEV X, X,..., X,,..., 0,,..., q 0 p DEV X X X DEV X X X DEV X,..., X X, X,..., X q p 0 q X L R ln 6 L F. 9
30 6. Διαγνωστικά Πριν χρησιμοποιήσουμε το λογιστικό μοντέλο θα πρέπει να ελέγχουμε αν είναι αποτελεσματικό. Άρα θα πρέπει να ελέγξουμε αν η αναμενόμενη λογιστική συνάρτηση είναι μονότονη και το σχήμα της είναι σιγμοειδές. Επίσης θα πρέπει να δούμε ποιες είναι οι ακραίες τιμές και ποιες από τις μεταβλητές πρόβλεψης ασκούν μεγαλύτερη επιρροή. 6. Ανεπίσημη μέθοδος καταλληλότητας μοντέλου Σε αυτή τη μέθοδο χωρίζουμε τις παρατηρήσεις μας σε κλάσεις. Τις κλάσεις τις χωρίζουμε με βάση τις προσαρμοσμένες τιμές, ή καλύτερα με τη βοήθεια των προσαρμοσμένων λογαριθμικών τιμών. Θα θέλαμε βέβαια σε κάθε κλάση να είχαμε περίπου τον ίδιο αριθμών περιπτώσεων. Πρέπει να βρούμε τη μεσαία τιμή της κάθε κλάσης και να κατασκευάσουμε ένα διάγραμμα σε σχέση με το p j πόσα έχουν σαν. n j Αν δούμε ότι η γραφική παράσταση είναι μονότονη και έχει σιγμοειδές σχήμα τότε θα καταλάβουμε πως το προσαρμοσμένο μοντέλο μας θα είναι κατάλληλο. 6. X έλεγχος καλής προσαρμογής Για να μπορέσουμε να χρησιμοποιήσουμε αυτή τη μέθοδο θα πρέπει οι Y να είναι ανεξάρτητες μεταβλητές και το μέγεθος του δείγματος να είναι πολύ μεγάλο. Οι εναλλακτικές αυτού του ελέγχου θα είναι: H H 0 : E Y exp 7 : E Y exp Η διαδικασία που ακολουθούμε είναι η εξής: 30
31 . Θα χωρίσουμε τις περιπτώσεις μας σε ομάδες με βάση τις τιμές ( εδώ να αναφέρουμε πως ο διαχωρισμός θα μπορούσε να γίνει και με τις τιμές ). Συνήθως έχουμε 5 έως 0 ομάδες και τον αριθμό των ομάδων τον συμβολίζουμε με c. Σε κάθε ομάδα θέλουμε να έχουμε περίπου τον ίδιο αριθμό παρατηρήσεων, ο οποίος θα συμβολίζεται με c n n ( 8 ). j j n j. Άρα θα έχουμε. Θα ορίσουμε με O τον αριθμό των παρατηρήσεων στην j j κλάση όπου Y. Ενώ με O τον αριθμό των παρατηρήσεων στην j κλάση όπου Y 0 j0. Οπότε έχουμε: Oj Y ( 9a ) και O 0 j Y n O j j ( 9b ). 3. Εάν η αποκρινόμενη λογιστική συνάρτηση είναι κατάλληλη, οι αναμενόμενες τιμές όταν Y και Y 0 θα είναι E j ( 30a ) και E j 0 n j E j ( 30b ). Εδώ να αναφέρουμε πως οι περισσότερες συχνότητες για τα E jk πρέπει να είναι μεγαλύτερες ή ίσες με 5 και καμία να μην είναι μικρότερη από. Η στατιστική συνάρτηση του ελέγχου είναι: X c O E jk jk ( 3 ). E j k0 jk 4. Αν η λογιστική αποκρινόμενη συνάρτηση είναι κατάλληλη τότε η ακολουθεί μια X θα κατανομή με c βαθμούς ελευθερίας. Οπότε ο κανόνας απόφασης για τον έλεγχο ( 7 ) είναι: Εάν X συμπεραίνουμε, c 0 Εάν X συμπεραίνουμε H (3) H, c 6.3 Έλεγχος απόκλισης ως έλεγχος καλής προσαρμογής Αν το λογιστικό μας μοντέλο είναι σωστό και το δείγμα μας είναι μεγάλο, τότε και η απόκλιση ( DEV ) θα ακολουθεί μια κατανομή με n-p βαθμούς. Άρα ο κανόνας απόφασης για τον έλεγχο (7) εδώ είναι: 3
32 0 p a, n p 0 0 p a, n p Εάν DEV X, X,..., X τότε H Εάν DEV X, X,..., X τότε H Απόκλιση καταλοίπων Στη λογιστική παλινδρόμηση τα κατάλοιπα δεν κατανέμονται κανονικά και μάλιστα εάν το μοντέλο μας είναι σωστό δεν μπορούμε να ξέρουμε και ποια κατανομή ακολουθούν, οπότε δεν μπορούμε να χρησιμοποιήσουμε τη γραφική των καταλοίπων, όμως μπορούμε να πάρουμε την απόκλιση καταλοίπων. Τι είναι όμως η απόκλιση καταλοίπων; Είναι η τετραγωνική ρίζα των παραγόντων που βρίσκονται μέσα στο άθροισμα της απόκλισης που είδαμε πιο πάνω και το συμβολίζουμε με, δηλαδή ln ln 34 dev Y Y Η οποία θα παίρνει θετική τιμή όταν Y dev και θα παίρνει αρνητική τιμή όταν Οπότε η γραφική παράσταση που θα έχουμε εδώ θα είναι ένα ndex plot, δηλαδή θα σχεδιάσουμε τα Y dev σε συνάρτηση με κάθε. Με αυτή την απεικόνιση βρίσκουμε τα outlyng κατάλοιπα, για τα οποία όμως δε συνεπάγεται πως είναι και ακραίες παρατηρήσεις. 7. Συμπεράσματα για τις παραμέτρους Όταν καταλήξουμε στο λογιστικό μοντέλο που θα χρησιμοποιήσουμε, πρέπει να δούμε ποια συμπεράσματα βγάζουμε για τους συντελεστές παλινδρόμησης, την εκτίμηση του αποκρινόμενου μέσου και να κάνουμε πρόβλεψη καινούριων παρατηρήσεων. Πρέπει να έχουμε μεγάλο δείγμα για να μπορούμε να καταλήξουμε σε συμπεράσματα. Αυτό γιατί αν το δείγμα μας είναι μεγάλο οι εκτιμητές μέγιστης πιθανοφάνειας προσεγγιστικά θα ακολουθούν κανονική κατανομή, και ο πίνακας διασποράς-συνδιασποράς δημιουργείται από ένα πίνακα Hessan, δηλαδή ένας 3
33 πίνακας με όρους της ης τάξης μερικών παραγώγων της ln L που είδαμε στη σχέση ( 8 ). Τον πίνακα αυτό τον συμβολίζουμε με G. Έχουμε G g 0,,..., p j 0,,..., p p p j ln L( ) ln L( ) ln L( ) ό g, g, g, Οπότε ο πίνακας διασποράς-συνδιασποράς με τη βοήθεια των εκτιμητών θα είναι s b gj b 36 παλινδρόμησης βασίζονται στο ότι ο λόγος κανονική κατανομή.. Τα συμπεράσματα για τους εκτιμητές της λογιστικής b k k s b k θα ακολουθεί μια τυπική b k k s b k z k 0,,..., p Διάστημα εμπιστοσύνης για το β κ Με βάση τη σχέση ( 37 ) και με συντελεστή εμπιστοσύνης το βρίσκουμε ότι το διάστημα εμπιστοσύνης θα είναι k k k. για : b z s b 38 και αντίστοιχα το διάστημα εμπιστοσύνης για το λόγο πιθανοτήτων θα είναι a b z s b k k k. για e : e
34 7. Διαδικασία Bonferron Η διαδικασία αυτή εξετάζει από κοινού τις παραμέτρους του μοντέλου. Δηλαδή θέλω να φτιάξω ένα κοινό διάστημα εμπιστοσύνης για διάφορες παραμέτρους της λογιστικής παλινδρόμησης. Οπότε αν θέλω να βρω αυτά τα διαστήματα με κοινό συντελεστή εμπιστοσύνης -α, θα πρέπει να κατασκευάσω τα g διαστήματα ως εξής: b B sb 40 όπου B z k k. 4 g 7.3 Έλεγχος για τα β κ Ένα τέτοιο έλεγχο ξαναείδαμε πιο πάνω που ασχοληθήκαμε με τη μερική απόκλιση, εδώ όμως θα δούμε και ένα άλλο έλεγχο ο οποίος βασίζεται στη σχέση ( 37 ). Ο έλεγχος μας θα είναι: H 0 k : 0 έναντι H : 0 4 και ο κανόνας απόφασης θα είναι: Εάν k z z τότε θα έχουμε H Εάν z z τότε θα έχουμε H 43 0 Εδώ πρέπει να αναφέρουμε ποιες είναι οι διαφορές μεταξύ των δύο ελέγχων. Εάν τα δείγματα μας είναι μεγάλα, τότε ο έλεγχος που είδαμε μόλις τώρα είναι πιο ευέλικτος από τον έλεγχο που είχαμε δει με τις μερικές παραγώγους. Αυτό γίνεται γιατί ο έλεγχος αυτός μπορεί να χρησιμοποιηθεί και για μονόπλευρους ελέγχους, επίσης και για ελέγχους που εξετάζουν αν τα ισούνται και με άλλους αριθμούς εκτός του k μηδέν. Εάν ελέγχουμε H : 0 0 k δε σημαίνει ότι και οι δυο έλεγχοι θα μας δώσουν τα ίδια αποτελέσματα. 34
35 8. Εκτίμηση του αποκρινόμενου μέσου 8. Εκτίμηση σημείου Συμβολίζουμε με έχουμε εκτιμήσει το, οπότε είναι X ένα διάνυσμα στο οποίο έχουμε τις μεταβλητές X στις οποίες h X h p X X X h h h, p και ο αποκρινόμενος μέσος θα είναι h e X h οπότε για να βρούμε τη σημειακή εκτίμηση θα χρησιμοποιήσουμε τους εκτιμητές των συντελεστών παλινδρόμησης, άρα έχουμε bx h h e. 8. Διαστήματα Εμπιστοσύνης Θέλουμε να βρούμε ένα διάστημα εμπιστοσύνης όταν X X h. Είδαμε πιο πάνω ότι h e X h και αντικαθιστούμε X. Άρα θα έχουμε h h h e h 44, αυτή η σχέση θα μας βοηθήσει να μετατρέψουμε τα διαστήματα εμπιστοσύνης για το σε διαστήματα εμπιστοσύνης για το h. h Τα όρια εμπιστοσύνης για το λογαριθμικό αποκρινόμενο μέσο, μεγάλο θα είναι: L z s h a h h, όταν το n είναι 35
36 h U h z a s 45 s s s X b X s b X. Παρατηρούμε εδώ ότι όπου το bx h h h h h h h bx X b, αυτό συμβαίνει γιατί πολύ απλά το αποτέλεσμα είναι αριθμός. Επειδή όμως η σχέση ( 44 ) είναι μια μονότονη σχέση μεταξύ των h και θα h μπορούμε να βρούμε, με τον κατάλληλο μετασχηματισμό, το πάνω και το κάτω όριο για το h τα οποία θα είναι: L U L e και U e 46. Παρατήρηση: Εάν θέλαμε να βρούμε ταυτόχρονα διαστήματα εμπιστοσύνης αρκετών αποκρινόμενων συναρτήσεων μπορούμε να χρησιμοποιούμε τη διαδικασία Bonferron με κοινό συντελεστή εμπιστοσύνης α. 9. Πρόβλεψη μιας νέας μεταβλητής Πολλές φορές όταν έχουμε μια παλινδρόμηση χρειάζεται να κάνω πρόβλεψη για μια καινούρια μεταβλητή. Αυτό χρειάζεται και στη λογιστική παλινδρόμηση. Το δύσκολο της υπόθεσης εδώ είναι να βρούμε σε ποιο σημείο, δηλαδή σε ποια τιμή του, μπορούμε να αποφασίσουμε εάν το h Y παίρνει την τιμή 0 ή την τιμή. Αυτό το σημείο το ονομάζουμε σημείο αποκοπής. 36
37 ΚΑΝΟΝΕΣ ΠΡΟΒΛΕΨΗΣ. Θα χρησιμοποιήσουμε σαν σημείο αποκοπής το 0,5 οπότε ο κανόνας πρόβλεψης θα είναι : Εάν 0,5 τότε πρόβλεψε h Y, διαφορετικά Y 0. Αυτή τη μέθοδο μπορούμε να τη χρησιμοποιούμε: α) όταν η πιθανότητα για να έχουμε το Y 0 ή το Y είναι ίδια και β) το κόστος λανθασμένης πρόβλεψης να είναι περίπου το ίδιο.. Θέλουμε να βρούμε το καλύτερο σημείο αποκοπής με βάση τα δεδομένα της παλινδρόμησης που έχουμε. Δηλαδή βρίσκουμε διάφορα σημεία αποκοπής και για το κάθε σημείο κάνουμε πρόβλεψη για τις n παρατηρήσεις που έχουμε, και βρίσκουμε την αναλογία των λανθασμένων προβλέψεων. Καλύτερο σημείο αποκοπής θα είναι αυτό με τη μικρότερη αναλογία. Αυτή θα χρησιμοποιείται: α) όταν τα δεδομένα μας είναι ένα τυχαίο δείγμα από τον αντίστοιχο πληθυσμό και β) το κόστος λανθασμένης πρόβλεψης είναι περίπου ίδιο. Στο βέλτιστο σημείο αποκοπής μπορεί η αναλογία των λανθασμένων προβλέψεων να είναι πολύ μικρή αλλά αυτό δε σημαίνει πως το σημείο αποκοπής μπορεί να προβλέψει και σωστά τις καινούριες παρατηρήσεις ( ειδικά αν το δείγμα μας δεν είναι πολύ μεγάλο ). Αυτό συμβαίνει γιατί το σημείο αποκοπής επιλέγεται με βάση το σύνολο δεδομένων από τα οποία προσαρμόσαμε το λογιστικό μοντέλο οπότε είναι το καλύτερο μόνο για αυτά τα δεδομένα. 3. Θα χρησιμοποιήσουμε τις εκ των προτέρων πιθανότητες και το κόστος λανθασμένης πρόβλεψη. Όταν τα δεδομένα μας δεν έχουν επιλεγεί τυχαία από ένα πληθυσμό και όταν οι εκ των προτέρων πιθανότητες για το εάν θα έχουμε Y ή 0 είναι γνωστές, τότε θα μπορούν να χρησιμοποιηθούν για να βρούμε ένα βέλτιστο σημείο αποκοπής. Επίσης αν το κόστος να προβλέψουμε λανθασμένα ότι έχουμε Y διαφέρει σημαντικά από το κόστος να προβλέψουμε λάθος ότι το Y 0, τότε το σημείο αποκοπής θα είναι αυτό που θα έχει το μικρότερο αναμενόμενο κόστος λανθασμένων προβλέψεων. 37
38 9. Έλεγχος αξιοπιστίας της πρόβλεψης Για να δούμε αν είναι αξιόπιστη η πρόβλεψη θα χρησιμοποιήσουμε τη βοήθεια των τιμών των σφαλμάτων. Αυτό γίνεται αν εφαρμόσουμε τον κανόνα πρόβλεψης που επιλέξαμε στο καινούριο σύνολο δεδομένων. Αν τα καινούρια σφάλματα έχουν περίπου τις ίδιες τιμές με τα προηγούμενα σφάλματα, τότε το προσαρμοσμένο μοντέλο με το επιλεγμένο σημείο αποκοπής προβλέπει καλά τις καινούριες παρατηρήσεις, άρα η επιλογή του είναι σωστή. Αν όμως τα καινούρια σφάλματα διαφέρουν σημαντικά, τότε το σημείο αποκοπής στο προσαρμοσμένο μοντέλο δεν προβλέπει καλά τις καινούριες παρατηρήσεις, οπότε θα πρέπει να βρούμε ένα άλλο σημείο αποκοπής. 38
39 Κεφάλαιο 3 ο Διαχωριστική ή Διακριτή Ανάλυση. Εισαγωγή Η διαχωριστική ανάλυση είναι μια στατιστική τεχνική η οποία έχει δύο στόχους: Να χωρίσει ένα πληθυσμό σε ευδιάκριτα σύνολα ( υποομάδες ) παραδείγματος χάρη ένα πλήθος παρατηρήσεων θέλουμε να το χωρίσουμε σε ή περισσότερες υποομάδες και Με τη βοήθεια ενός διαχωριστικού κανόνα προσπαθεί να κατατάξει σωστά όσο το δυνατό πιο πολλές παρατηρήσεις που έχουμε πάρει σε γνωστούς πληθυσμούς, όπου ο κάθε πληθυσμός έχει γνωστή την κατανομή του. Εδώ να αναφέρουμε πως αυτή η μέθοδος εφαρμόζεται σε πάρα πολλές επιστήμες. Να αναφέρουμε μερικές από αυτές: Στην Ιατρική, χρησιμοποιείται για να διαγνώσουμε μια ασθένεια με βάση τα συμπτώματα που θα έχουμε. Κατασκευάζουμε ένα κανόνα ( επειδή ήδη γνωρίζουμε τα συμπτώματα από κάθε ασθένεια ) όπου θα μας κάνει διάγνωση για ένα καινούριο ασθενή. Στη Χωρολογία, θέλουμε να βρούμε το είδος της βλάστησης που υπάρχει σε μια περιοχή με βάση τις εικόνες που παίρνουμε από ένα δορυφόρο. Όμως επειδή αρκετές φορές οι εικόνες δεν είναι άμεσα εκμεταλλεύσιμες χρησιμοποιούμε τη διαχωριστική ανάλυση. Στη Βιολογία, θα μπορούσαμε να καταγράψουμε τα διαφορετικά χαρακτηριστικά που έχουμε για τα ίδια είδη λουλουδιών και στη συνέχεια να γίνει μια διαχωριστική ανάλυση ώστε να βρεθεί το σύνολο των χαρακτηριστικών που θα βοηθήσει να διαχωρίσει τα καινούρια δείγματα λουλουδιών αυτού του είδους. 39
40 Στη χρηματοοικονομική επιστήμη, οι τράπεζες θέλουν να κατασκευάσουν κάποιους κανόνες οι οποίοι θα διαχωρίζουν τους πελάτες σε αυτούς που πληρώνουν τις δόσεις τους κανονικά και σε αυτούς που δεν τις πληρώνουν, έτσι ώστε να δούνε εάν θα εγκριθεί ή όχι ένα δάνειο ή και ακόμα αν θα δοθεί σε ένα πελάτη κάποια πιστωτική κάρτα. Στη βιομηχανία, για παράδειγμα μπορεί ένα εργοστάσιο πακεταρίσματος να θέλει να αυτοματοποιήσει τη διαδικασία ταξινόμησης των εισερχόμενων ψαριών επάνω σε έναν ιμάντα μεταφοράς, ανάλογα με το είδος του ψαριού. Οπότε με βάση τα χαρακτηριστικά που γνωρίζουμε ότι έχει το κάθε είδος ψαριού, κατασκευάζεται ένας κανόνας διαχωρισμού. Στις ασφαλιστικές εταιρείες, οι οποίες θα πρέπει να αποφασίσουν εάν θα ασφαλίσουν ή όχι ένα κίνδυνο ( nsurance rsk management ), δημιουργώντας κανόνες με βάση τα στοιχεία που ήδη υπάρχουν. Στην επιστήμη των υπολογιστών η μέθοδος είναι γνωστή αναγνώριση προτύπων. με την ονομασία. Διαχωρισμός σε δύο ομάδες Θα δούμε πρώτα τι κάνουμε εάν θέλουμε να χωρίσουμε τις παρατηρήσεις μας σε δύο ομάδες ( αυτό συμβαίνει στις περιπτώσεις έγκρισης δανείων από τράπεζες ), και πώς μπορούμε να κατατάξουμε μια καινούρια μεταβλητή σε μια από τις δύο ομάδες. Έστω ότι τις δύο ομάδες τις συμβολίζουμε με και, και οι συναρτήσεις πυκνότητας πιθανότητας αντίστοιχα θα είναι f x και f x. Ο διαχωρισμός των δυο ομάδων γίνεται με τη βοήθεια των τιμών που θα παίρνουν κάποιες μεταβλητές X ( τις οποίες τις καθορίζουμε κάθε φορά με βάση το διαχωρισμό που θέλουμε να κάνουμε ). Έτσι έχουμε το διάνυσμα X p X X X p. 40

41 Θέλουμε να βρούμε ένα κανόνα ταξινόμησης, ο οποίος να μας χωρίζει το δειγματικό μας χώρο σε δύο περιοχές, την R και R. Ότι ανήκει στην R περιοχή πρέπει να τα κατατάξουμε στην πρώτη ομάδα, ενώ ότι βρίσκεται στην R ανήκει στην ομάδα. Εικόνα : Διαχωρισμός σε δυο πληθυσμούς με μεταβλητές X και X Το βασικότερο πρόβλημα που έχουμε σε προβλήματα ταξινόμησης είναι ότι όλοι οι κανόνες διαχωρισμού θα μας δίνουν και κάποια λάθη. Δηλαδή μπορεί μια παρατήρηση να την ταξινομήσουμε στην ομάδα ενώ στην πραγματικότητα ανήκει στην, ή μπορεί να ανήκει στην ομάδα και το κριτήριο μας να την ταξινομήσουμε στην ομάδα. Οπότε το βασικότερο μέλημα μας είναι να βρούμε κανόνες οι οποίοι θα ελαχιστοποιούν την πιθανότητα να κάνουμε λάθος κατάταξη. Οι κανόνες που θα αναλύσουμε είναι τέσσερις: α) το κριτήριο μέγιστης πιθανοφάνειας, β) o κανόνας του Bayes, γ) o κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης, δ) o κανόνας ελαχιστοποίησης της συνολικής πιθανότητας λανθασμένης κατάταξης. 4
42 . Κριτήριο μέγιστης πιθανοφάνειας Είναι ένας απλός τρόπος για να αποφασίσουμε σε ποια ομάδα θα κατατάξουμε μια καινούρια παρατήρηση. Η λογική του κριτηρίου είναι να βρεθεί η τιμή της πιθανοφάνειας που έχει αυτή η παρατήρηση στην καθεμία ομάδα, και όπου έχουμε τη μεγαλύτερη πιθανοφάνεια θα είναι και η πιο πιθανή περιοχή για να κατατάξουμε την παρατήρησή μας. Δηλαδή το κριτήριο λέει ότι μια παρατήρηση x : Θα την κατατάξουμε στη περιοχή R δηλαδή στην ομάδα όταν f x / f x f x fx ενώ f x / f x Θα την κατατάξουμε στην ομάδα όταν f x / f x f x fx. f x / f x. Κριτήριο Bayes Ο πιο πάνω κανόνας δε λαμβάνει υπόψη του εάν οι ομάδες μας έχουν διαφορετικά μεγέθη. Οπότε θέλουμε να βρούμε ένα κανόνα στον οποίο θα χρησιμοποιούμε και την πιθανότητα να πάρουμε μια παρατήρηση από την κάθε ομάδα. Για να γίνει αυτό πρέπει να χρησιμοποιήσουμε τον κανόνα απόφασης του Bayes, οπότε πρέπει να βρούμε τις εκ των υστέρων πιθανότητες οι οποίες για να βρεθούν χρειαζόμαστε τις τιμές της πιθανοφάνειας αλλά και τις εκ των προτέρων πιθανότητες ( δηλαδή P ). Ο τύπος απόφασης του Bayes περιγράφεται με λόγια ως εξής: εκ των υστέρων πιθανότητα πιθανοφάνεια εκ των προτέρων πιθανότητα γεγονός Δηλαδή P x P, x P x /. P P / x, P x /. P 4
43 Οπότε με τη βοήθεια των συμβολισμών που είχαμε δώσει πιο πάνω, και συμβολίζοντας με p την εκ των προτέρων πιθανότητα της ομάδας, δηλαδή p P, και αντίστοιχα με p P πιθανότητες: θα έχουμε τις εξής εκ των υστέρων P / x f x. p f x. p f x. p και P / x f x. p f x. p f x. p. P( / x) Εδώ να αναφέρουμε πως εάν υπάρχει μια παρατήρηση x για την οποία η είναι μεγαλύτερη από την P x στην /. Αντίστοιχα, εάν η P x, υπονοείται πως θα πρέπει να το κατατάξουμε P( / x) / είναι μεγαλύτερη από την, θα πρέπει να επιλέξουμε να τοποθετήσουμε την παρατήρηση στην. Για να καταλήξουμε στον κανόνα απόφασης θα πρέπει να γίνουν και κάποιες απλοποιήσεις, οπότε: Εάν P / x P / x f x. p f x. p f x. p f x. p f x. p f x. p f x p f x. p f x. p τότε κατέταξε την παρατήρηση x f x p στην ομάδα. Εάν f x p τότε κατέταξε την παρατήρηση x στην ομάδα. f x p Παρατηρήσεις:. Για κάθε x, οι τιμές των εκ των προτέρων πιθανοτήτων έχουν άθροισμα τη μονάδα, δηλαδή P P p p.. Εάν οι εκ των προτέρων πιθανότητες είναι ίσες ( p p ), τότε η απόφαση θα εξαρτάται μόνο από τις συναρτήσεις πιθανοφάνειας, άρα είναι ίδιος με τον κανόνα πιθανοφάνειας. 3. Εάν για κάποια τιμή του x οι τιμές των πιθανοφανειών είναι ίσες, τότε η συγκεκριμένη παρατήρηση δεν μας παρέχει κάποια χρήσιμη πληροφορία για 43
44 την ομάδα στην οποία πρέπει να την κατατάξουμε. Οπότε η απόφαση θα εξαρτηθεί από τις εκ των προτέρων πιθανότητες..3 Κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης Όπως αναφέραμε πιο πάνω οι κανόνες διαχωρισμού κάποιες φορές κάνουν λάθος στην κατάταξη. Όμως σε μερικές περιπτώσεις, ενδέχεται η κατάταξη μιας παρατήρησης που θα έπρεπε να είναι στην ομάδα, αλλά τοποθετείται στην ομάδα, να είναι πιο σοβαρό σφάλμα από ότι η παρατήρηση να είναι της ομάδας όμως να τοποθετείται στην ομάδα. Για παράδειγμα έστω ότι υπάρχει ένα εργοστάσιο κονσερβοποίησης ψαριών, η οποία γνωρίζει ότι οι πελάτες θα δέχονται μερικές φορές κομμάτια σολομού στις κονσέρβες με τίτλο «πέρκα», αλλά δυσανασχετούν όταν κομμάτια πέρκας βρεθούν σε κονσέρβα με τίτλο «σολομός». Άρα το κόστος να κατατάξουμε μια πέρκα σαν σολομό είναι μεγαλύτερο από ότι να κατατάξουμε το σολομό σαν πέρκα. Επομένως θα πρέπει να λαμβάνουμε υπόψη και το κόστος που θα έχουμε από την κάθε μια λανθασμένη κατάταξη ώστε να βρεθεί ένας βέλτιστος κανόνας. Για να δημιουργηθεί αυτός ο κανόνας θα πρέπει να ορίσουμε ένα τύπο ο οποίος θα μας δίνει το αναμενόμενο κόστος λανθασμένης κατάταξης, έτσι ώστε να κατατάξουμε την καθεμία παρατήρηση στην ομάδα που θα έχει το μικρότερο αναμενόμενο κόστος. Το αναμενόμενο κόστος λανθασμένης κατάταξης μιας παρατήρησης που προέρχεται από την k ομάδα ( ECM k ) δίνεται ως εξής: k k K m / / ECM p c m k P m k όπου cm / k : το κόστος να κατατάξουμε την παρατήρηση στην m ομάδα, ενώ ανήκει στην k, P m / k : η πιθανότητα να κατατάξουμε την παρατήρηση στην m ομάδα, ενώ 44
45 ανήκει στην k, p k : η εκ των προτέρων πιθανότητα να ανήκει μια παρατήρηση στην k ομάδα Το συνολικό αναμενόμενο κόστος λανθασμένης κατάταξης ( ECM: Expected Cost Of Msclassfcaton ) θα είναι ίσο με το άθροισμα των επιμέρους περίπτωση που έχουμε δύο ομάδες θα έχουμε: ECM k. Τώρα στην / / / / 0 / / / / / ECM p c P c P Και p P c P p c P / / / / ECM p c P c P / / 0 / p c P P / / p c P οπότε το αναμενόμενο κόστος λανθασμένης κατάταξης θα είναι ECM ECM ECM / / / / p c P p c P Παρατηρήσεις:. Το κόστος που προκύπτει όταν μια κατάταξη είναι σωστή θα είναι μηδέν, δηλαδή c/ c / 0 και γενικά cm m. Οι P / και / / 0 m. P είναι δεσμευμένες πιθανότητες οι οποίες ισούνται με: a. P / Px R / f xdx R b. P/ Px R / f xdx 3 R Το ολοκλήρωμα στη σχέση () παριστάνει τον όγκο που σχηματίζεται από τη συνάρτηση πυκνότητας f x πάνω στην περιοχή R, και με την ίδια λογική 45
46 το ολοκλήρωμα στη σχέση (3) παριστάνει τον όγκο που σχηματίζεται από την f x πάνω στην περιοχή R. Αυτό το παρουσιάζουμε για τη μονοδιάστατη περίπτωση ( p ) στην πιο κάτω εικόνα. Εικόνα : Πιθανότητες λανθασμένης κατάταξης όταν p 3. Θέλουμε το ECM να είναι μικρό ή όσο το δυνατό πιο μικρό. Ο κανόνας κατάταξης όπως αναφέραμε και πιο πάνω θα είναι: Εάν ECM ECM κατέταξε την παρατήρηση στην ομάδα, αλλιώς κατέταξε την στην ομάδα. Όμως αν θέλουμε να χρησιμοποιήσουμε στον κανόνα και τις συναρτήσεις πυκνότητας πιθανότητας, θα χρησιμοποιήσουμε την πιο κάτω πρόταση. ΠΡΟΤΑΣΗ : Εάν εάν f x c / p f x c / p f x c / p f x c / p κατέταξε την παρατήρηση μας στην ομάδα αλλιώς τότε κατέταξε την παρατήρηση στην ομάδα. 46
47 ΑΠΟΔΕΙΞΗ: Πιο πάνω είχαμε δει ότι για την περίπτωση που έχουμε δύο ομάδες, το αναμενόμενο κόστος λανθασμένης κατάταξης είναι / / / / ECM p c P p c P, το οποίο με τη βοήθεια των σχέσεων () και (3) θα γίνει: / / ECM p c f x dx p c f x dx 4 R R Επίσης γνωρίζουμε ότι f x dx f x dx f x dx R R R R R, οπότε έχουμε: 5 f x dx f x dx R Από τις σχέσεις (4) και (5) έχουμε: ECM p c / f xdx p c/ f xdx R R / / / p c p c f x dx p c f x dx R R / / / p c p c f x dx p c f x dx R R / / / p c p c f x p c f x dx R Στην πιο πάνω σχέση βλέπουμε ότι τα,, /, / ποσότητες και οι συναρτήσεις πυκνότητας πιθανότητας μοναδικές ποσότητες στο ECM αρνητικές για κάθε τιμή του διανύσματος x. p p c c είναι μη αρνητικές f x και f x είναι οι που εξαρτώνται από το x. Επίσης είναι και μη Συνεπώς, το ECM θα ελαχιστοποιηθεί όταν η περιοχή R πάρει εκείνες τις τιμές του διανύσματος x για τις οποίες το παραπάνω ολοκλήρωμα γίνει μικρότερο ή ίσο του 47
48 μηδενός. Δηλαδή θέλουμε: R p c / f x p c / f x dx 0 p c / f x p c / f x 0 / / p c f x p c f x p c / f x p c / f x p c / f x p c / f x f x c / p f x c / p Οπότε την παρατήρηση θα την κατατάξουμε στην ομάδα f x c / p f x c / p αλλιώς θα την κατατάξουμε στην. αν Παρατηρούμε πως ο κανόνας αυτός περιέχει το λόγο με το κόστος λανθασμένης κατάταξης των δυο περιπτώσεων, το λόγο των εκ των προτέρων πιθανοτήτων και το λόγο των συναρτήσεων πυκνότητας για την καινούρια παρατήρηση x. Αυτό είναι πολύ σημαντικό γιατί σε κάποιες περιπτώσεις είναι πιο εύκολο να γνωρίζουμε τους λόγους παρά την κάθε τιμή ξεχωριστά. ΕΙΔΙΚΕΣ ΠΕΡΙΠΤΩΣΕΙΣ. Εάν έχουμε ίσες τις εκ των προτέρων πιθανότητες, τότε ο λόγος τους θα είναι ίσο με ( δηλαδή p p παρατήρηση στην ομάδα αν ομάδα. ) με αποτέλεσμα ο κανόνας να είναι: κατέταξε την f x c / διαφορετικά κατέταξε στην f x c / 48
49 .. Εάν το κόστος που έχουμε από κάθε μια λανθασμένη κατάταξη είναι ίσα ( δηλαδή c c / / στην ομάδα αν ), τότε ο κανόνας θα γίνει: κατέταξε την παρατήρηση f x p αλλιώς κατέταξε στην ομάδα. f x p Εάν είναι ίσα το κόστος λανθασμένης κατάταξης των δυο περιπτώσεων και οι εκ των προτέρων πιθανότητες ( δηλαδή τότε ο κανόνας είναι: κατέταξε στην ομάδα εάν στην ομάδα. p p c / ή c / f f x x p p c / ) c / αλλιώς κατέταξε Εδώ να αναφέρουμε πως εάν σε κάποια περίπτωση δε γνωρίζουμε τις εκ των προτέρων πιθανότητες τότε θα θεωρούμε πως είναι ίσες μεταξύ τους. Με την ίδια λογική θα λειτουργούμε και αν ο λόγος από το κόστος λανθασμένης κατάταξης των δυο περιπτώσεων είναι άγνωστος ( δηλαδή θα το θεωρήσουμε σαν )..4 Ελαχιστοποίηση της συνολικής πιθανότητας λανθασμένης κατάταξης Είναι ένας κανόνας που χρησιμοποιείται για το διαχωρισμό δύο πληθυσμών, ο οποίος όμως δε χρησιμοποιεί το κόστος. Σκοπός του είναι να ελαχιστοποιήσει τη συνολική πιθανότητα λανθασμένων κατατάξεων ( TPM - total probablty of msclassfcaton ) και ορίζεται ως: TPM λανθασμένης κατάταξης μιας παρατήρησης ή λανθασμένης κατάταξης P μιας παρατήρησης TPM P να ανήκει στην και να κατατάσσεται λάθος P να ανήκει στην και να κατατάσσεται λάθος 49
50 / / TPM P X R P P X R P / / TPM p P p P TPM p f x dx p f x dx 6 R R Παρατηρήσεις:. Ο κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης, αν έχουμε ίσο το κόστος και στις δυο περιπτώσεις και ίσες τις εκ των προτέρων πιθανότητες είναι ίδιος με τον κανόνα μέγιστης πιθανοφάνειας.. Επίσης ο κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης, όταν έχουμε ίσο κόστος λανθασμένης κατάταξης είναι ο κανόνας Bayes. 3. Ο κανόνας ελαχιστοποίησης της συνολικής πιθανότητας λανθασμένης κατάταξης συμπίπτει με τον κανόνα ελαχιστοποίησης του αναμενόμενου κόστους λανθασμένης κατάταξης, όταν το κόστος και στις δυο περιπτώσεις είναι ίσα ( c/ c / ). 4. Ο κανόνας πιθανοφάνειας είναι ο πιο απλός καθώς στηρίζεται μόνο στο τι μοιάζει πιο πιθανό. Στον κανόνα του Bayes λαμβάνουμε υπόψη τις εκ των προτέρων πιθανότητες της κάθε ομάδας, ενώ στον τελευταίο κανόνα λαμβάνουμε υπόψη και το κόστος λανθασμένης κατάταξης. Όλα τα κριτήρια είναι της μορφής x f k f x. 3. Διαχωρισμός δυο πληθυσμών με τη χρήση της κανονικής κατανομής Από τις διάφορες συναρτήσεις πυκνότητας πιθανότητας που έχουν ερευνηθεί, το μεγαλύτερο ενδιαφέρον παρουσιάζεται για την πολυδιάστατη κανονική κατανομή. Και αυτό, γιατί οι διαδικασίες ταξινόμησης, που είναι βασισμένες στους κανονικούς 50
51 πληθυσμούς, υπερισχύουν στην πράξη λόγω της απλότητας και της εύλογα υψηλής αποδοτικότητάς τους. Έστω ότι έχουμε δύο ομάδες ( πληθυσμούς ) οι οποίες προέρχονται από κανονικούς πληθυσμούς. Και έστω ότι το x είναι ένα διάνυσμα στήλης για τον κάθε ένα πληθυσμό, δηλαδή x x, x,, x p. Άρα για τον πληθυσμό έχουμε x, με συνάρτηση πυκνότητας πιθανότητας την f p τον πληθυσμό έχουμε συνάρτηση πυκνότητας πιθανότητας την x,. p x. Ομοίως και για f x και Όπου τα και διανύσματα της μέσης τιμής για τον κάθε ένα πληθυσμό, δηλαδή p E x,. Επίσης οι και είναι οι πίνακες διασποράς για τους και πληθυσμούς και ορίζονται ως εξής:, Cov x. Τη διαδικασία διαχωρισμού θα τη δούμε μέσα από δύο περιπτώσεις οι οποίες έχουν να κάνουν με τους πίνακες διασποράς. 3. Κανονικοί πληθυσμοί με Στην πρώτη περίπτωση οι πίνακες διασποράς που έχουν οι δύο πληθυσμοί ( ομάδες ) θα είναι ίσοι και μάλιστα θα είναι της μορφής:,, p,, p Var x Cov x x Cov x x Cov x x Var x Cov x x Cov x Cov x, xp Cov x, xp Var xp p p Οι συναρτήσεις πυκνότητας πιθανότητας για τους πληθυσμούς και δίνονται από τη σχέση: 5
52 f x exp x x για, 7 p Έστω ότι οι παράμετροι, και είναι γνωστές Βασικά θα ξεκινήσουμε από τον κανόνα που ελαχιστοποιεί το αναμενόμενο κόστος λανθασμένης κατάταξης ( ECM ) που αναλύσαμε πιο πάνω, απλά θα χρησιμοποιήσουμε τις συναρτήσεις πυκνότητας πιθανότητας για κανονικούς πληθυσμούς. Οπότε ο κανόνας είναι: Εάν x x x x c p p e / c / τότε κατέταξε την παρατήρηση στον πληθυσμό. Εάν x x x x c p p e / c / τότε κατέταξε την παρατήρηση x στον πληθυσμό. Αυτός ο κανόνας αποδεικνύεται ως εξής: Για την κατάταξη στον πληθυσμό f x c / p f x c / p x x e p c p x x c / p e p / x x e c / p x x c / e p 5
53 e p p x x x x c/ c / e p p x x x x c/ c / Με την ίδια λογική αποδεικνύεται και η κατάταξη στον πληθυσμό. Βέβαια ο κανόνας αυτός μπορεί να απλοποιηθεί και άλλο και δίνει τον τελικό κανόνα, τον οποίο βλέπουμε στην πιο κάτω πρόταση. ΠΡΟΤΑΣΗ : c / p ln Εάν x 0 c / p τότε κατέταξε την παρατήρηση x 0 στον πληθυσμό. c / p ln Εάν x 0 c / p τότε κατέταξε την παρατήρηση x 0 στον πληθυσμό. ΑΠΟΔΕΙΞΗ: Θα αποδείξουμε το πρώτο κομμάτι της πρότασης, αλλά ακριβώς με τον ίδιο τρόπο αποδεικνύεται και το δεύτερο κομμάτι. Την x 0 παρατήρηση την κατατάσσουμε στον πληθυσμό αν: x x x x c p p e / c / x x x x c p ln e p / ln c / c / p x0 x0 x0 x0 ln c / p 53
54 x x x x x c / p x0 ln c / p x0 x0 x0 x0 c/ p x0 ln c / p c / p ln c / p x0 x 0 x 0 x x 0 0 c / p c / p x x 0 0 c / p c / p c / p x0 c / p Άρα την x0 παρατήρηση θα την κατατάξουμε στον πληθυσμό όταν c / p x 0 c / p 54
55 Έστω ότι οι παράμετροι, και είναι άγνωστες Η υπόθεση που κάναμε πιο πάνω, ότι οι παράμετροι μας είναι γνωστές δεν είναι ρεαλιστική. Στην πράξη τα, και είναι άγνωστες, οπότε θα πρέπει να τα εκτιμήσουμε. Έχουμε ένα δείγμα με n παρατηρήσεις για τον πληθυσμό και ένα δείγμα με n παρατηρήσεις για τον πληθυσμό. Οπότε έχουμε: x x, x,, x n για το, και για το έχουμε pn x x, x,, x n pn με n n p. Οι εκτιμώμενες τιμές για τα,, και θα είναι οι x, x, S και S αντίστοιχα και ορίζονται ως εξής: x n n x j S x j x x j x p n j p p n j x n n x j S x j x x j x ( p) n j p p n j Όμως,, για αυτό οι δειγματικοί πίνακες συνδιασποράς S και S συνδυάζονται ( pooled ), συμβολίζονται με τον S pooled, ο οποίος δίνεται από τον πιο κάτω τύπο: n n S pooled S S n n n n S pooled n S n S n n 8 Αντικαθιστώντας τις πληθυσμιακές ποσότητες από τις δειγματικές τους, η πρόταση θα γίνει: 55
56 c / p ln c / p Εάν x x S pooled x x x S pooled x x τότε κατέταξε την παρατήρηση x στον πληθυσμό. (9) c / p ln c / p Εάν x x S pooled x x x S pooled x x τότε κατέταξε την παρατήρηση x στον πληθυσμό. ΕΙΔΙΚΗ ΠΕΡΙΠΤΩΣΗ Μια ειδική περίπτωση θα είναι όταν το γινόμενο του λόγου με το κόστος λανθασμένης κατάταξης των δυο περιπτώσεων και του λόγου των εκ των προτέρων πιθανοτήτων είναι ίσο με, δηλαδή c / p. Και αυτό γιατί όταν πάρουμε το c / p λογάριθμο αυτής της ποσότητας θα είναι ίσο με μηδέν ( οπότε ο κανόνας που είδαμε πιο πάνω για τον πληθυσμό θα γίνει: x x S pooled x x x S pooled x x 0 x x S pooled x x x S pooled x x x x S x x x S x x x S x pooled pooled pooled l x x S : Θα θέσουμε με pooled c / p c / p ln 0 ), l x l x l x Εδώ θα δημιουργήσουμε μια καινούρια μεταβλητή, η οποία είναι γραμμικός συνδυασμός των παρατηρήσεων από τους πληθυσμούς και. Η καινούρια αυτή μεταβλητή είναι η y l x, και κατά συνέπεια θα έχουμε y l x και y l x. Οπότε ο κανόνας θα είναι: 56
57 y y y y y y ym 0 m Άρα σε αυτή την ειδική περίπτωση ο κανόνας ( εδώ ονομάζεται και γραμμικός κανόνας κατάταξης αφού είναι πρώτου βαθμού γραμμικός συνδυασμός ) θα γίνει: Εάν y m τότε την παρατήρηση x θα την κατατάξουμε στον πληθυσμό. Εάν y m τότε την παρατήρηση x θα την κατατάξουμε στον πληθυσμό. Παρατήρηση: Εδώ να πούμε, πως το l S pooled x x δεν είναι ο μοναδικός συντελεστής που θα μας δίνει κάποιο διαχωρισμό, όλα τα διανύσματα τα οποία είναι πολλαπλάσια του l θα μας δίνουν και αυτά κάποιους διαχωρισμούς ( δηλαδή είναι της μορφής l c l και c είναι μια σταθερά θετική ποσότητα). Όμως για να έχουμε ένα κανόνα διαχωρισμού θα πρέπει να τυποποιήσουμε το l. Αυτό το κάνουμε με δύο τρόπους:. Θέτουμε με. Θέτουμε με l l l l l ll 3. Κανονικοί πληθυσμοί με Αφού οι πίνακες συνδιακύμανσης δεν είναι ίσοι, ο κανόνας κατάταξης θα είναι πιο περίπλοκος από αυτό που είδαμε στην πρόταση, αυτό διότι δεν μπορούν να γίνουν οι απλοποιήσεις που είχαμε κάνει. Στην πιο κάτω πρόταση θα δούμε πως γίνεται σε αυτή την περίπτωση ο κανόνας. 57
58 Έστω ότι οι παράμετροι, και, είναι γνωστές ΠΡΟΤΑΣΗ 3: Εάν x x x k ln c / p κατέταξε την παρατήρηση x στον πληθυσμό. Εάν c / p x x x k ln c / p c / p τότε τότε κατέταξε την παρατήρηση x στον πληθυσμό. Όπου k ln ΑΠΟΔΕΙΞΗ: Από τον κανόνα ελαχιστοποίησης του κόστους λανθασμένης κατάταξης, αποδεικνύουμε ότι για να κατατάξουμε την παρατήρηση x στον πληθυσμό θα πρέπει: f x c / p f x c / p x x e p c p x x c / p e p / x x e c/ p x x c / p. e 58
59 x x c/ p x x c / p e e x x x x c/ p c / p e x x x x c/ p ln e ln c / p c/ p ln ln c p x x x x / x x x x x x c / p x x ln ln c / p x x x x x x c / p x x ln ln c / p x x x x x x c / p ln ln c / p 59
60 x x x c / p ln ln c / p Θα θέσουμε με k ln άρα θα καταλήξουμε c / p x x x k ln 3 c / p Οπότε την παρατήρηση θα την κατατάσσουμε στον πληθυσμό, όταν ισχύει η σχέση (3). Έστω ότι οι παράμετροι, και, είναι άγνωστες Αφού οι πληθυσμιακές παράμετροι είναι άγνωστες, θα πρέπει να τις αντικαταστήσουμε με τις δειγματικές ποσότητες και άρα η πρόταση 3 θα γίνει: c / p x S S x x S x S x k ln c / p Εάν τότε κατέταξε την παρατήρηση x στον πληθυσμό. c / p x S S x x S x S x k ln c / p Εάν τότε κατέταξε την παρατήρηση x στον πληθυσμό. Παρατήρηση: Ο κανόνας που είδαμε όταν, είτε οι παράμετροι είναι γνωστές είτε όχι, ονομάζεται τετραγωνικός κανόνας κατάταξης. Αυτό οφείλεται στον όρο 60
61 x x ( ή στον όρο βαθμού συναρτήσεις. x S S x ) αφού θα μας δίνει ου 4. Αξιολόγηση των συναρτήσεων κατάταξης Πρέπει όμως να κρίνουμε και την απόδοση αυτών των συναρτήσεων ( δηλαδή πόσο καλά διαχωρίζουν τους πληθυσμούς ). Αυτό μπορούμε να το κάνουμε με δύο διαφορετικούς τρόπους: α) να βρούμε το «ρυθμό σφάλματος» ή τις πιθανότητες λανθασμένης κατάταξης και β) να χρησιμοποιήσουμε τη μέθοδο Lachenbruch. α) «Ρυθμός σφάλματος» ή πιθανότητες λανθασμένης κατάταξης. Οι και πληθυσμοί είναι γνωστοί Σε αυτή την περίπτωση θέλουμε να βρούμε το βέλτιστο ρυθμό σφάλματος ( OER- optmum error rate ), δηλαδή πρέπει να βρούμε την ελάχιστη τιμή που μπορεί να πάρει η συνολική πιθανότητα λανθασμένης κατάταξης ( TPM ) που είχαμε δει πιο πάνω. Άρα θα έχουμε: OER mn TPM mn p f x dx p f x dx 4 R R Όσο πιο μικρή τιμή παίρνει ο OER τόσο καλύτερος, είναι ο κανόνας κατάταξης.. Οι και πληθυσμοί είναι άγνωστοι Στις περισσότερες περιπτώσεις πρέπει να εκτιμήσουμε τις παραμέτρους, αφού είναι άγνωστες και οπότε δεν μπορεί να χρησιμοποιηθεί ο OER. Εδώ θα βρούμε το πραγματικό ρυθμό σφάλματος ( AER- actual error rate ), το οποίο ορίζεται ως εξής: AER p f x dx f x dx 5 R R όπου οι περιοχές R και R δίνονται ως εξής: 6
62 . c / p R : x x S pooled x x x S pooled x x ln c / p c / p R : x x S pooled x x x S pooled x x ln c / p Αυτός ο τρόπος δεν είναι και τόσο καλός αφού εξαρτάται από τις άγνωστες συναρτήσεις πυκνοτήτων πιθανοτήτων f x και f x. Πρέπει να βρούμε κάποια μέθοδο που θα βρίσκει το ρυθμό σφάλματος χωρίς να ανακατεύει τις f x και f x. Αυτή η μέθοδος μπορεί να χρησιμοποιηθεί σε οποιαδήποτε περίπτωση και να έχω. Θα πρέπει να βρούμε το φαινομενικό ρυθμό σφάλματος ( APER-apparent error rate ), το οποίο βρίσκεται με τη βοήθεια ενός πίνακα ( confuson matrx ). Πραγματικοί αριθμοί M C Προβλεπόμενοι αριθμοί n n n n n C M C n n n C n n όπου n C : ο αριθμός των παρατηρήσεων που σωστά κατατάσσονται στον πληθυσμό n C : ο αριθμός των παρατηρήσεων που σωστά κατατάσσονται στον πληθυσμό n M : ο αριθμός των παρατηρήσεων που κατατάσσονται λανθασμένα στον πληθυσμό n M : ο αριθμός των παρατηρήσεων που κατατάσσονται λανθασμένα στον Πληθυσμό 6
63 Ο φαινομενικός ρυθμός σφάλματος θα είναι: n APER n n n M M 6 Παρατήρηση: Για να πάρουμε καλά αποτελέσματα θα πρέπει τα δείγματά μας n και n να είναι μεγάλα, διαφορετικά μπορεί να υποτιμήσει το AER. Και αυτό γιατί τα ίδια δεδομένα που χρησιμοποιούνται για να κατασκευάσουμε τον κανόνα κατάταξης, τα ίδια χρησιμοποιούνται και για να τον αξιολογήσουμε. Αυτό βέβαια μπορεί να διορθωθεί αν το δείγμα μας το χωρίσουμε στα δύο, όπου το ένα θα το χρησιμοποιήσουμε για να κατασκευάσουμε τη συνάρτηση κατάταξης ( εκπαιδευόμενο δείγμα ) και το άλλο θα το χρησιμοποιήσουμε για να κάνουμε την αξιολόγηση ( δείγμα αξιολόγησης). Όμως και αυτή η μέθοδος έχει τα μειονεκτήματα της: α) η συνάρτηση για την αξιολόγηση δεν είναι η συνάρτηση που μας ενδιαφέρει, αφού για τον κανόνα διαχωρισμού θα πρέπει να χρησιμοποιήσουμε όλα τα δεδομένα αλλιώς μπορεί να χαθεί πολύτιμη πληροφορία και β) και αυτή θα χρειάζεται μεγάλα δείγματα. β) Μέθοδος Lachenbruch Αυτή η μέθοδος χρησιμοποιεί έναν αλγόριθμο, ο οποίος λέει: Βήμα ο : Από τον πληθυσμό παραλείπουμε μια παρατήρηση και βρίσκουμε μια συνάρτηση διαχωρισμού για τις παρατηρήσεις που έχουν απομείνει, δηλαδή για τις n και n παρατηρήσεις.. Βήμα ο : Την παρατήρηση που παραλείψαμε ( «holdout» παρατήρηση ) θα πρέπει να την κατατάξουμε σε κάποιο από τους δύο πληθυσμούς, με τη βοήθεια του κανόνα που θα βρούμε στο ο βήμα. Βήμα 3 ο : Επανέλαβε το ο και ο βήμα μέχρι όλες οι παρατηρήσεις του πληθυσμού καταταχθούν. Τις παραλειπόμενες παρατηρήσεις που θα καταταχθούν λανθασμένα στον H πληθυσμό τις συμβολίζουμε με n. M 63
64 Βήμα 4 ο : Επανέλαβε το ο, ο και 3 ο βήμα για τις παρατηρήσεις που βρίσκονται στον πληθυσμό. Άρα θα συμβολίζουμε με n τις παραλειπόμενες παρατηρήσεις που θα H M καταταχθούν λανθασμένα στον πληθυσμό. Βήμα 5 ο : Θα εκτιμήσουμε τις δεσμευμένες πιθανότητες λανθασμένης κατάταξης που είδαμε στις σχέσεις () και (3). Οι εκτιμήσεις θα είναι: P P / / H n M (7) n H nm (8) n Με τη βοήθεια τους μπορούμε να βρούμε τον αμερόληπτο εκτιμητή του αναμενόμενου πραγματικού ρυθμού σφάλματος ( E AER ), το οποίο δίνεται από τον τύπο E AER H H n n n n M M ( ) 9 5. Η Διαχωριστική Συνάρτηση του Fsher O Fsher σκέφτηκε να μετασχηματίσει τις πολυμεταβλητές παρατηρήσεις x σε μονομεταβλητές παρατηρήσεις y, τέτοιες ώστε οι μεταβλητές που προέρχονται από τους πληθυσμούς και να είναι όσο το δυνατό πιο καλά χωρισμένες. Για να γίνει αυτό θα πρέπει να φτιάξουμε κάποιες διαχωριστικές συναρτήσεις, οι οποίες είναι γραμμικοί συνδυασμοί των x. Εδώ να αναφέρουμε πως δε γίνεται καμία αναφορά για την κατανομή των πληθυσμών, εντούτοις υποθέτει ότι οι πίνακες συνδιασποράς πληθυσμό είναι ίσοι, αφού χρησιμοποιεί το S pooled. για τον κάθε ένα 64
65 Έστω yl x και y l x οι συναρτήσεις (σκορ) που αντιστοιχούν στους και πληθυσμούς. Ο Fsher πήρε σαν μέτρο απόστασης των δύο ομάδων την ποσότητα y y D seperaton όπου S y S y n n y j y y j y j j n n (0) και σκοπός του είναι να μεγιστοποιήσει την απόσταση D ( ή την απόσταση D ) αφού αυτό σημαίνει ότι τα σκορ των δύο πληθυσμών θα είναι όσο το δυνατό γίνεται διαφορετικά μεταξύ τους. ΠΡΟΤΑΣΗ 4: Η απόσταση D θα μεγιστοποιηθεί όταν D x x S pooled x x. ΑΠΟΔΕΙΞΗ: y y D D S y y y S y Όμως έχουμε ότι y l. x άρα D lx lx l x x D Sy Sy Όμως d x x και S l S l οπότε y pooled l d D ls pooled l Θα χρησιμοποιήσουμε την ανισότητα Cauchy-Schwarz, ώστε να αποδείξουμε πότε μεγιστοποιείται το D. 65
66 Η ανισότητα Cauchy-Schwarz μας λέει ότι ab aa bb b είναι διανύσματα p., όπου α και Θα θέσουμε pooled και b S pooled x x a S l άρα η σχέση () θα γίνει: S l S x x S l S l S x x S x x pooled pooled pooled pooled pooled pooled l S S pooled pooled x x l S S l pooled pooled x x S S x x pooled pooled pooled pooled l x x l S l x x S x x l x x ls l pooled pooled ls l x x S pooled x x ls l pooled pooled l xx ls l x x S pooled x x pooled D x x S x x Επομένως το D μεγιστοποιείται όταν θα πάρει την τιμή x x S pooled x x Ο διαχωριστικός κανόνας του Fsher θα είναι: Κατέταξε την x παρατήρηση στον 0 πληθυσμό εάν y x x S x m όπου 0 pooled 0 y y l x l x m 66
67 pooled l x x x x S x x. Κατέταξε την x παρατήρηση στον 0 πληθυσμό εάν y x x S x m. 0 pooled 0 Εικόνα 3: Βλέπουμε τη λογική που έχει η διαχωριστική συνάρτηση του Fsher για δυο πληθυσμούς με p=. Όλα τα σημεία σχεδιάζονται πάνω σε μια γραμμή με κατεύθυνση l, η οποία μεταβάλλεται μέχρι τα δείγματα να είναι όσο πιο πολύ γίνεται διαχωρισμένα. Παρατηρήσεις:. Ο διαχωριστικός κανόνας του Fsher είναι ίδιος με τον κανόνα ελάχιστης λανθασμένης κατάταξης, στην περίπτωση που το κόστος και στις δύο περιπτώσεις είναι ίσο και ίσες οι εκ των προτέρων πιθανότητες.. Τον κανόνα Fsher τον χρησιμοποιούμε πιο πολύ, γιατί δεν υποθέτει ότι οι δύο πληθυσμοί ακολουθούν κανονική κατανομή. 67
68 6. Γενίκευση της διαχωριστικής ανάλυσης σε g πληθυσμούς Σε αυτή την ενότητα θα δούμε τι θα κάνουμε σε περίπτωση που οι παρατηρήσεις μας προέρχονται από περισσότερους από δύο πληθυσμούς. Θα δούμε τους κανόνες που είδαμε πιο πριν, απλά με κάποιες τροποποιήσεις, ώστε να χρησιμοποιούνται για το διαχωρισμό σε g πληθυσμούς. 6. Κανόνας ελαχιστοποίησης του κόστους λανθασμένης κατάταξης Έχουμε f x : Είναι η πυκνότητα πιθανότητας να παρατηρηθούν οι τιμές του διανύσματος x στον πληθυσμό,,,, g p : Οι εκ των προτέρων πιθανότητες για τους πληθυσμούς,,,, g c k / : Είναι το κόστος να κατατάξουμε την παρατήρηση στον k πληθυσμό ενώ ανήκει στον πληθυσμό,, k :,,, g / P k f x dx R Παρατηρήσεις: k Αν k c : Είναι η πιθανότητα να κατατάξουμε την παρατήρηση στον k πληθυσμό ενώ ανήκει στον πληθυσμό,, k :,,, g. / 0 g / / Αν k P Pk k k 68
69 Το συνολικό αναμενόμενο κόστος, είναι ίσο με το άθροισμα των επιμέρους αναμενόμενων κοστών ταξινόμησης ( ECM p ck / Pk / είναι: ECM ECM ECM ECM g g ), δηλαδή k g g g / / / / / / p c k P k p c k P k p c k g P k g g k k k g g p c k P k k / / Κατατάσσουμε την παρατήρηση στον πληθυσμό με το μικρότερο αναμενόμενο κόστος λανθασμένης κατάταξης, το οποίο είναι ισοδύναμο με την ελαχιστοποίηση του συνολικού κόστους λανθασμένης κατάταξης. ΠΡΟΤΑΣΗ 5: Θα κατατάσσουμε μια παρατήρηση x στον πληθυσμό για τον οποίο το g p fx ck / 3 είναι μικρότερο. Αν έχουμε κάποια ισότητα θα k κατατάσσουμε το x σε οποιοδήποτε από τους ισόπαλους πληθυσμούς. 6. Ελαχιστοποίηση της συνολικής πιθανότητας λανθασμένης κατάταξης Αν το κόστος λανθασμένης κατάταξης για όλες τις περιπτώσεις είναι ίσα, τότε ο κανόνας που είδαμε στην πρόταση 5 θα είναι ίδιος με τον κανόνα της ελάχιστης συνολικής πιθανότητας λανθασμένης κατάταξης ( TPM ). Οπότε ο κανόνας θα λέει, πως μια παρατήρηση x θα την κατατάσσουμε στον πληθυσμό k g για τον οποίο το p f x είναι το μικρότερο. Εδώ να αναφέρουμε πως ο κανόνας μπορεί να k γραφτεί και με δύο ισοδύναμους τρόπους οι οποίοι είναι : 69
70 Εάν p f x p f x k για κάθε τότε κατέταξε την παρατήρηση x στον πληθυσμό k k k. (4) Εάν ln p f x ln p f x τότε κατέταξε την παρατήρηση x στον k k πληθυσμό k για κάθε k. (5) 6.3 Κανόνας Bayes Θα κατατάσσουμε την παρατήρηση, στον πληθυσμό όπου η εκ των υστέρων πιθανότητα είναι η πιο μεγάλη. Η εκ των υστέρων πιθανότητα θα μας δίνεται από τον πιο κάτω τύπο. P k / x εκ των προτέρων πιθανοφάνεια πιθανότητες γεγονός k P / x / P P x k / / g g P x P P x P k pk fk P k / x g x k,,, g p f x Ο κανόνας θα είναι: Κατέταξε την παρατήρηση x στον k πληθυσμό εάν / / P x P x k. (6) k 6.4 Διαχωρισμός των πληθυσμών όταν αυτοί ακολουθούν την κανονική κατανομή Αφού οι πληθυσμοί ακολουθούν την κανονική κατανομή, οι συναρτήσεις πυκνότητας πιθανότητας θα έχουν τη μορφή: 70
71 x x f x e,,, g p Αν το κόστος λανθασμένης κατάταξης για την κάθε περίπτωση είναι ίσα, τότε με τη βοήθεια του κανόνα (5) που είδαμε πιο πάνω θα έχουμε: Κατέταξε την παρατήρηση x στον k πληθυσμό εάν p ln ln ln ln pk fk x pk k x k k x k x max ln p f 7 ΑΠΟΔΕΙΞΗ: pk fk x pk fk x ln ln ln x k k xk ln pk ln e p k p k e ln p ln ln ln k p x x k k k ln p ln ln x k k k k x k p Μια παρατήρηση που μπορεί να γίνει εδώ είναι ότι η ποσότητα ln είναι ίδια για όλους τους πληθυσμούς και οπότε μπορούμε να την παραλείψουμε. Επίσης την ποσότητα που θα απομείνει, την ορίζουμε ως τετραγωνικό διαχωριστικό σκορ για τον πληθυσμό δηλαδή : Q d x x x p g ln ln,,, 8 Επομένως ο κανόνας θα γίνει: 7
72 Q Εάν το τετραγωνικό σκορ,,, Q Q Q g d x είναι το μεγαλύτερο από τα k d x d x d x, τότε θα κατατάσσουμε την παρατήρηση x στον k πληθυσμό. Παρατήρηση: Αν οι πίνακες συνδιασποράς είναι ίδιοι σε κάθε πληθυσμό, δηλαδή,,, g, τότε θα μπορέσουμε να απλοποιήσουμε ελάχιστα το τετραγωνικό διαχωριστικό σκορ. Άρα Q d x ln x x ln p d x ln x x x ln p Q d x ln x x x x ln p Q d x ln x x x x ln p Q Q d x ln x x x ln p Εδώ βλέπουμε πως η ποσότητα πληθυσμό, άρα την αγνοούμε. Οπότε: θα είναι ίδια για οποιοδήποτε ln x x d x x p ln 9 Η σχέση αυτή λέγεται γραμμικό διαχωριστικό σκορ, γιατί είναι άθροισμα μιας σταθεράς και ενός γραμμικού συνδυασμού με τα x. Ο κανόνας θα έχει την ίδια λογική με τον πιο πάνω κανόνα, δηλαδή : 7
73 Εάν το τετραγωνικό σκορ dk x είναι το μεγαλύτερο από τα d x, d x,, dg x, τότε θα κατατάσσουμε την παρατήρηση x στον k πληθυσμό. Όταν οι παράμετροι είναι άγνωστες Όπως είπαμε και στην περίπτωση που είχαμε ομάδες, τα και τα είναι συνήθως άγνωστα, άρα θα πρέπει να τα εκτιμήσουμε. Κατά συνέπεια θα εκτιμηθεί και το τετραγωνικό διαχωριστικό σκορ, το οποίο θα είναι ˆQ d x ln S x x S x x ln p Άρα ο κανόνας θα γίνει: Εάν το τετραγωνικό σκορ ˆQ,,, Q Q Q g d x είναι το μεγαλύτερο από τα k dˆ x dˆ x dˆ x, τότε θα κατατάσσουμε την παρατήρηση x στον k πληθυσμό. Αν είχαμε ίσους τους πίνακες διασποράς, ο κανόνας θα βρεθεί με τη βοήθεια της εκτίμησης του γραμμικού διαχωριστικού σκορ, δηλαδή ˆ d x x S pooled x x S pooled x ln p όπου S pooled g n S n S n S n n n g g g Ο κανόνας θα είναι: Εάν το τετραγωνικό σκορ dˆk x είναι το μεγαλύτερο από τα dˆ ˆ ˆ x, d x,, dg x, τότε θα κατατάσσουμε την παρατήρηση x στον k πληθυσμό. (30) 73
74 Παρατηρήσεις:. Ένας ισοδύναμος κανόνας με τον κανόνα (30), είναι αυτός που βασίζεται στην τετραγωνική απόσταση της παρατήρησης x από το δειγματικό μέσο του κάθε πληθυσμού x, η οποία είναι D x x x S pooled x x κατατάσσουμε την παρατήρηση x στον πληθυσμό όπου η. Θα D x ln p έχει τη μεγαλύτερη της τιμή. Βέβαια κάποιες φορές οι εκ των προτέρων πιθανότητες δεν είναι γνωστές, οπότε θα κατατάσσουμε την παρατήρηση στον πληθυσμό που έχει τη μικρότερη τετραγωνική απόσταση.. Ο γραμμικός διαχωριστικός κανόνας στηρίζεται στην υπόθεση ότι οι πληθυσμοί είναι κανονικοί και έχουν ίσους πίνακες συνδιακύμανσης. Προτού λοιπόν εφαρμόσουμε τον κανόνα, πρέπει να ελέγξουμε αν ισχύουν οι δυο υποθέσεις. Αν μια από τις δυο ή και οι δυο υποθέσεις παραβιάζονται, πρέπει πρώτα να μετασχηματίσουμε τα δεδομένα και μετά να εφαρμόσουμε τον κανόνα. Αντιθέτως, για τους τετραγωνικούς κανόνες θέλουμε μόνο οι πληθυσμοί μας να είναι κανονικοί. ΓΕΩΜΕΤΡΙΚΗ ΕΡΜΗΝΕΙΑ Για να μπορέσουμε να κάνουμε ένα διαχωρισμό για περισσότερες από δύο ομάδες, με τη βοήθεια των γραμμικών διαχωριστικών σκορ θα πρέπει να τα συγκρίνουμε ανά δύο. Δηλαδή μια παρατήρηση θα την κατατάσσουμε στον k πληθυσμό όταν: d x d x d x d x 0 k k k x k k ln pk x ln p 0 k x k k ln pk ln p 0 k x k k ln pk ln p 74
75 p k x k k ln pk p d k x x ln 3 dk pk Από την πιο πάνω σχέση μπορούμε να βρούμε τις περιοχές διαχωρίζονται από υπερεπίπεδα, αφού συνιστωσών του x. dk R, R, g R, οι οποίες x είναι γραμμικός συνδυασμός των Θα δούμε όλη τη λογική στην περίπτωση που έχουμε 3 πληθυσμούς, g 3. Η περιοχή R θα αποτελείται από εκείνα τα x d p ln p που θα ικανοποιούν την ανισότητα, δηλαδή πρέπει να ικανοποιούνται ταυτόχρονα οι ανισότητες p d x x ln p p 3 d3 x 3 x 3 3 ln p Αν υποθέσουμε ότι, και δεν είναι συνευθειακά, τότε οι 3 εξισώσεις d p p x ln τέμνονται. Ο όρος d και 3 3 ln p p x ln p p αν το p είναι μεγαλύτερο από το p. θα ορίζουν δύο υπερεπίπεδα που θα τοποθετεί το επίπεδο πιο κοντά στο από ότι στο, Στην περίπτωση που θα πρέπει να εκτιμήσουμε τα και τα, οι περιοχές κατάταξης θα απεικονίζονται με τον ίδιο τρόπο, με ˆ p dk x xk x S pooled x xk x S pooled xk x ln pk 75
76 Αν τώρα οι εκ των προτέρων πιθανότητες είναι άγνωστες τότε θα έχουμε p p. Οπότε ln 0 g pk pk p p p g έχουμε dk x 0. και κατά συνέπεια θα Εικόνα 4: Οι περιοχές ταξινόμησης για R, R και R 3 Αν έχουμε δυο μόνο μεταβλητές, οι γραμμικές διαχωριστικές συναρτήσεις χωρίζουν το επίπεδο σε 3 περιοχές, κάθε περιοχή αντιστοιχεί και σε μια ομάδα. Έτσι, όταν θέλουμε να κατατάξουμε καινούριες παρατηρήσεις, απλώς κοιτάμε σε ποια περιοχή πέφτουν. 6.5 Γενίκευση της μεθόδου του Fsher για k πληθυσμούς Ο Fsher πρότεινε μια προέκταση της μεθόδου που είδαμε πιο πάνω ώστε να μπορούμε να διαχωρίζουμε τις παρατηρήσεις όταν έχουμε περισσότερους από δύο πληθυσμούς. Όπως είδαμε και στην περίπτωση των δυο ομάδων, έτσι και εδώ δεν είναι αναγκαίο οι πληθυσμοί μας να είναι κανονικοί, αλλά θα πρέπει οι πίνακες συνδιασποράς να είναι ίσοι, δηλαδή g. Εδώ να αναφέρουμε 76
77 πως η γενίκευση του Fsher προτάθηκε για να διαχωρίσουμε τους πληθυσμούς, αλλά μπορεί να χρησιμοποιηθεί και για να κατατάσσουμε καινούριες παρατηρήσεις στους ήδη υπάρχοντες πληθυσμούς. ΔΙΑΧΩΡΙΣΜΟΣ ΤΩΝ ΠΛΗΘΥΣΜΩΝ Έστω ότι οι μεταβλητές Y X X X, δηλαδή Y l. X. X g Y Y Yg είναι γραμμικοί συνδυασμοί των μεταβλητών Θα δούμε τώρα κάποιους ορισμούς και στη συνέχεια θα καταλήξουμε στον κανόνα του Fsher. Η μέση τιμή του Y θα εξαρτάται από ποιο πληθυσμό προέρχεται η παρατήρηση. Εάν προέρχεται από τον πληθυσμό θα είναι Οπότε και η ολική μέση τιμή θα είναι g g g g Y Y l l l l g g g g E Y l E X l. / Y Ενώ η διασπορά θα είναι ίδια για όλους τους πληθυσμούς οπότε Var Y l Cov X l l l Θα σχηματίσουμε ένα λόγο που θα μετράει τη μεταβλητότητα μεταξύ των ομάδων για τις τιμές των Y που σχετίζεται με την κοινή μεταβλητότητα μεταξύ των ομάδων. Ο λόγος αυτός θα είναι: άθροισμα των τετραγωνικών αποστάσεων από την ολική μέση τιμή Διασπορά του g g Y Y l l Y ll 77
78 g l l lb l ll l l 0 3 g όπου B0., Εμείς θέλουμε να βρίσκουμε εκείνο το l που θα μεγιστοποιεί αυτό το λόγο. Όπως έχουμε πει και σε πιο πάνω περιπτώσεις θα πρέπει να εκτιμηθούν τα γιατί είναι άγνωστα. Θα πάρουμε από κάθε πληθυσμό ένα δείγμα μεγέθους και n,,,, g. Άρα για τον πληθυσμό, η δειγματική μέση τιμή είναι x n n j x j και κατά συνέπεια η εκτίμηση για την ολική μέση τιμή είναι: x p g n g x n g j g n n x j. Το 0. g B εκτιμάται ως εξής B0 x xx x Επίσης ο πίνακας διασποράς θα εκτιμάται από τη S poole S pooled, n S n S n S n g g g n j S n n n g n n n g g xj xxj x W n n n g n n n g g W n n n g S g pooled g g g 78
79 Και αφού το W είναι ένα πολλαπλάσιο της S pooled, το ίδιο l που θα μεγιστοποιεί τη l B0 l ls l pooled θα μεγιστοποιεί και τη σχέση l B0 l lw l. Μπορούμε να παρουσιάσουμε το βέλτιστο l ως ιδιοδιανύσματα e του πίνακα W B0. Γραμμικός Διαχωρισμός Του Fsher: όπου s mn g, p Έστω,,, s 0 W B0 είναι οι μη μηδενικές ιδιοτιμές του και e, e, e s είναι τα αντίστοιχα ιδιοδιανύσματα έτσι ώστε e S pooled e. Το διάνυσμα των συντελεστών l που θα μεγιστοποιεί το λόγο g l x x x x l l B0 l g n l W l l xj xxj x l j 33 l e θα είναι. Ο γραμμικός συνδυασμός l x είναι ο πρώτος διαχωριστής ή η διαχωριστική συνάρτηση. Όταν l e θα έχουμε το δεύτερο διαχωριστή ή η διαχωριστική συνάρτηση l δηλαδή x( θα θέλουμε Covl x, l x 0). Συνεχίζοντας, το l k x ek x είναι ο κ-οστός διαχωριστής ή κ διαχωριστική συνάρτηση, με k s και k, 0,. Επίσης έχουμε,,,, Cov l x l x k Var l x s. Εδώ να σημειώσουμε πως για να βρούμε τις ιδιοτιμές θα πρέπει να λύσουμε τη W B0 I 0, και τα ιδιοδιανύσματα θα τα βρούμε με τη βοήθεια της εξίσωσης W 0 B I l 0. 79
80 ΑΠΟΔΕΙΞΗ: Έστω P P, όπου είναι ένας διαγώνιος πίνακας με θετικά στοιχεία. Οπότε θα είναι ένας διαγώνιος πίνακας με στοιχεία. Άρα θα έχουμε P και P P. P Αν l τότε l l l l B l B l l B l Εμείς θέλουμε να μεγιστοποιήσουμε το λόγο B 0. Μπορεί να αποδειχθεί ότι το μέγιστο του λόγου είναι η, η μεγαλύτερη ιδιοτιμή του B 0. Το μέγιστο θα συμβεί όταν a e ιδιοδιάνυσμα που σχετίζεται με το ). ( e είναι το κανονικοποιημένο Αφού e l l e τότε Var l x l l e e e e e e Ακόμα, a e, άρα το μέγιστο του παραπάνω λόγου ισχύει όταν e, που είναι το κανονικοποιημένο ιδιοδιάνυσμα που αντιστοιχεί στην ιδιοτιμή. Όμοια l και e Επίσης Cov l x, l x l l e e e e 0 αφού e e. Var l x l l e e. Συνεχίζουμε με τον ίδιο τρόπο και για τους υπόλοιπους διαχωριστές. ΠΡΟΤΑΣΗ 5: Έχουμε s διαχωριστές με τον περιορισμό s mn g, p, όταν s είναι οι μη μηδενικές ιδιοτιμές του πίνακα B 0 ή του πίνακα. B 0 80
81 ΑΠΟΔΕΙΞΗ: Αφού ο πίνακας B 0 έχει διάσταση p p τότε θα πρέπει s p. Επίσης τα g διανύσματα,,, g (34) θα ικανοποιούν τη σχέση g g g g 0 Έτσι, το πρώτο διάνυσμα μπορεί να γραφτεί ως γραμμικός συνδυασμός των τελευταίων g διανυσμάτων. Οι γραμμικοί συνδυασμοί των g διανυσμάτων qg καθορίζουν ένα υπερεπίπεδο με διάσταση. Αν πάρουμε οποιοδήποτε διάνυσμα e κάθετο σε κάθε, τότε το υπερεπίπεδο θα δίνει g B e e g άρα Επομένως, υπάρχουν p 0 0 B e e q ορθογώνια ιδιοδιανύσματα που αντιστοιχούν στη μηδενική ιδιοτιμή. Αυτό σημαίνει ότι υπάρχουν q ή λιγότερες μη μηδενικές ιδιοτιμές. Επειδή πάντοτε αληθεύει ότι θα πρέπει να ικανοποιεί τη σχέση s mn p, g qg τότε ο αριθμός των μη μηδενικών ιδιοτιμών s. Παρατηρήσεις:. Δεν υπάρχει απώλεια πληροφορίας αν σχεδιάσουμε τους διαχωριστές σε δυο διαστάσεις, εφ όσον οι ακόλουθες συνθήκες ισχύουν. Αριθμός Μεταβλητών Αριθμός Πληθυσμών Μέγιστος Αριθμός Διαχωριστών p g p g 3 p g 8
82 . Η ερμηνεία των παραπάνω διαχωριστικών συναρτήσεων είναι ότι η η διαχωριστική συνάρτηση μεγιστοποιεί τις διαφορές των μέσων σε μια διάσταση. Η η διαχωριστική συνάρτηση μεγιστοποιεί την απόσταση των μέσων σε μια κατεύθυνση ορθογώνια στην η. Η 3 η μας δείχνει την απόσταση σε μια 3 η διάσταση ανεξάρτητη των άλλων, και ως εξής για τις επόμενες διαχωριστικές συναρτήσεις. ΤΑΞΙΝΟΜΗΣΗ ΚΑΙΝΟΥΡΙΩΝ ΠΑΡΑΤΗΣΗΣΕΩΝ Ένας κανόνας με τον οποίο μπορούμε να κατατάξουμε μια νέα παρατήρηση y στον k πληθυσμό, είναι ο κανόνας που χρησιμοποιεί την τετραγωνική απόσταση του y από το. Για να πούμε ποιος είναι αυτός ο κανόνας θα πρέπει να δώσουμε Y κάποιους ορισμούς. Οπότε: Y Y Y Ys συναρτήσεων. Y l x όπου j k δηλαδή είναι το διάνυσμα των διαχωριστικών Y Y l Y l Ys l είναι το διάνυσμα των μέσων τιμών για τον πληθυσμό. I μοναδιαίος πίνακας, είναι ο πίνακας συνδιασποράς για όλους τους πληθυσμούς. y y y από το. Y Y Y j Y j s είναι η τετραγωνική απόσταση του Y y j 8
83 Η λογική του κανόνα είναι να κατατάσσει μια παρατήρηση y στον k πληθυσμό, όταν η τετραγωνική απόσταση του y από το απόσταση του y από το, για κάθε k. Y είναι μικρότερη από την τετραγωνική ky Αν μόνο r από τους s διαχωριστές χρησιμοποιούνται για την κατάταξη, ο κανόνας είναι: Κατέταξε την παρατήρηση x στον k πληθυσμό εάν y ky l 35 j j x k l j x k r r r j j j Θα δούμε τη σχέση που μπορεί να έχει ο κανόνας κατάταξης του Fsher με τον κανόνα γραμμικού διαχωριστικού σκορ που είδαμε στη σχέση (9). ΠΡΟΤΑΣΗ 6: Έστω, j j y l x όπου l j ej με το j e να είναι ένα ιδιοδιάνυσμα του πίνακα. Τότε B 0 p p y j Y l j j x x x j j d x x x p ln, το y 0 Αν s s p p j Y θα είναι σταθερό για j j s όλους τους πληθυσμούς. Άρα μόνο οι πρώτοι s διαχωριστές y ή το y j s j Y j θα συνεισφέρουν στην κατάταξη. ΑΠΟΔΕΙΞΗ: Ξέρουμε ότι d x x ln p 83
84 d x x x x ln p x x d x x x x x ln p d x x x x x ln p x x d x x x ln p Επίσης έχουμε πως x x x x x EE x Όπου E e, e,, e p είναι ένας ορθογώνιος πίνακας. Αφού l x e l l e l θα έχουμε x E x l p x και άρα x E E x l x j j p Στη συνέχεια κάθε l j ej, j s, είναι ένα ιδιοδιάνυσμα του B 0 όπου η ιδιοτιμή του είναι μηδέν. Όπως φαίνεται από τη σχέση (34), το l j είναι κάθετο στο κάθε ένα και έτσι k k για κάθε, k,,, g., συνεπάγεται ότι Από τη συνθήκη l 0 j k ky Y j j y y, j ky j Y j j 84
85 p y j Y είναι σταθερό για όλα τα,,, j άρα το j s g. Επομένως, μόνο οι πρώτοι s διαχωριστές χρειάζονται για να χρησιμοποιηθούν στην ταξινόμηση. Όταν οι παράμετροι είναι άγνωστες Ο κανόνας του Fsher γίνεται αφού εκτιμήσουμε τις άγνωστες παραμέτρους ως εξής: Κατέταξε την παρατήρηση x στον k πληθυσμό εάν y ykj l j x xk l j x x k 36 r r r j j j όπου l j ορίζονται από τη σχέση (33) και r Όταν οι εκ των προτέρων πιθανότητες είναι ίσες, δηλαδή p p p g και g r s, τότε ο κανόνας (36) θα είναι ισοδύναμος με τον κανόνα (30). Αν r s θα p υπάρχει απώλεια της τετραγωνικής απόστασης, ή του σκορ του για κάθε πληθυσμό. s jr l j x x 7. Ομοιότητες- διαφορές λογιστικής παλινδρόμησης και διαχωριστικής ανάλυσης Και οι δύο μέθοδοι χρησιμοποιούνται για να κατατάξουν τις παρατηρήσεις μας, σε γνωστές ομάδες αλλά και για να προβλέψουν σε ποια ομάδα θα τοποθετήσουμε τις καινούριες παρατηρήσεις. Μάλιστα είναι από τις πιο διαδεδομένες μεθόδους κατάταξης, βέβαια έχουν πολλές διαφορές μεταξύ τους. Στη λογιστική παλινδρόμηση δε χρειάζονται οι περίπλοκες υποθέσεις όπως χρειάζονται να γίνουν στη διαχωριστική ανάλυση. Δηλαδή στη λογιστική παλινδρόμηση δε μας ενδιαφέρει αν οι 85
86 ανεξάρτητες μεταβλητές ακολουθούν κανονική κατανομή, αν σχετίζονται γραμμικά ή και αν έχουν ίσες διασπορές για τον κάθε ένα πληθυσμό όπως συμβαίνει στη διαχωριστική ανάλυση. Επίσης η λογιστική παλινδρόμηση δεν κάνει καμία υπόθεση για τις ανεξάρτητες μεταβλητές. Για το λόγο αυτό η λογιστική παλινδρόμηση χρησιμοποιείται πιο συχνά. Εδώ να πούμε πως η λογιστική παλινδρόμηση απαιτεί αρκετά μεγάλα δείγματα, τουλάχιστον 50 περιπτώσεις για κάθε ανεξάρτητη μεταβλητή. Βέβαια η διαχωριστική ανάλυση στηρίζεται σε πιο ρεαλιστικές μεθόδους και υπολογιστικά είναι πιο εύκολη. Αν σε κάποια περίπτωση ισχύουν: α) η υπόθεση της κανονικότητας και β) οι πίνακες συνδιασποράς για κάθε πληθυσμό είναι ίσοι, η διαχωριστική ανάλυση θα δίνει καλύτερα αποτελέσματα σε σχέση με τη λογιστική παλινδρόμηση. 86
87 Κεφάλαιο 4 ο Λογιστική Παλινδρόμηση και Διαχωριστική Ανάλυση στο SPSS Σε αυτό το κεφάλαιο θα δούμε κάποια αριθμητικά παραδείγματα που μπορούν να λυθούν με τις μεθόδους που αναφέραμε στα πιο πάνω κεφάλαια με τη βοήθεια του στατιστικού πακέτου SPSS. Στην αρχή θα δούμε ένα παράδειγμα που μπορεί να λυθεί με τη Λογιστική Παλινδρόμηση, στη συνέχεια ένα άλλο παράδειγμα που θα λυθεί με τη Διαχωριστική Ανάλυση.. Παράδειγμα για Λογιστική Παλινδρόμηση (Agrest, 99) Σε αυτό το παράδειγμα έχουμε ένα δείγμα με 54 ηλικιωμένους οι οποίοι έκαναν μια ψυχιατρική εξέταση, στην οποία εξετάστηκαν για τη νόσο του γήρατος ( senlty symptoms ). Θέλουμε να δούμε κατά πόσο μπορούμε να προβλέψουμε αν κάποιος ηλικιωμένος έχει τη νόσο, χρησιμοποιώντας μόνο την κλίμακα ευφυΐας του Wechsler ( Wechsler adult ntellgence scale, Was ). Βασικά θέλουμε να δούμε για ποια τιμή του Was έχουμε αυξημένο κίνδυνο να εμφανιστεί η νόσος και να ερμηνεύσουμε τη σχέση της νόσου με την κλίμακα Was. Η κλίμακα ευφυΐας Was είναι ένα γενικό τεστ της διανοητικής ικανότητας, ή να το θέσουμε απλά, ένα τεστ IQ. Αποτελείται από υποενότητες οι οποίες χωρίζονται σε δύο μέρη, τα προφορικά ( οι 6 υποενότητες ) και τα γραπτά ( 5 υποενότητες ). Οι προφορικές εξετάσεις είναι: () γενικές γνώσεις, () κατανόηση, (3) αριθμητική, (4) dgt span, (5) ομοιότητες και (6) λεξιλόγιο. Ενώ οι γραπτές εξετάσεις είναι: () διάταξη εικόνας, () ολοκλήρωση εικόνας, (3) σχεδιασμός με κύβους- Block desgn, (4) εύρεση αντικειμένου- object assembly και (5) dgt symbol. 87
88 Σε αυτό το παράδειγμα θα έχουμε δύο μεταβλητές, τη μεταβλητή Was και τη μεταβλητή senlty. Θα πρέπει να εφαρμόσουμε τη λογιστική παλινδρόμηση αφού η μεταβλητή senlty είναι δίτιμη ( παίρνει την τιμή 0 εάν ο ηλικιωμένος δεν πάσχει από τη γεροντική νόσο, και παίρνει την τιμή εάν πάσχει ). Τα δεδομένα μας φαίνονται στον πίνακα. Πίνακας WAIS SENILITY
89
90 Εισάγουμε τα δεδομένα στο φύλλο δεδομένων του SPSS και στη συνέχεια για να εφαρμόσουμε τη λογιστική παλινδρόμηση θα ακολουθήσουμε την εξής διαδρομή: Analyze Regresson Bnary Logstc. Στο πεδίο με την ένδειξη «Dependent» εισάγουμε την εξαρτημένη μεταβλητή, που σε αυτή την περίπτωση είναι η senlty, και στο πεδίο «Covarates» εισάγουμε τις ανεξάρτητες μεταβλητές, οπού εδώ είναι η μεταβλητή Was. Επίσης από το υπομενού «Optons» επιλέγουμε τα : Hosmer- Lemeshow goodness-of-ft και το CI for exp(b). Στο output του SPSS θα πάρουμε τους πιο κάτω πίνακες: Case Processng Summary Unweghted Cases a N Percent Selected Cases Included n Analyss 54 00,0 Mssng Cases 0,0 Total 54 00,0 Unselected Cases 0,0 Total 54 00,0 a. If weght s n effect, see classfcaton table for the total number of cases. Dependent Varable Encodng Orgnal Value Internal Value No 0 Yes 90
91 Στον πίνακα Case Processng Summary απλά βλέπουμε πόσες περιπτώσεις έχουμε στο παράδειγμά μας και αν υπάρχουν περιπτώσεις που δεν έχουν όλα τα δεδομένα. Στο συγκεκριμένο έχουμε 54 πλήρεις περιπτώσεις. Στον πίνακα Dependent Varable Encodng μας δείχνει πως είναι κωδικοποιημένη η εξαρτημένη μεταβλητή. Εδώ μας λέει πως η μεταβλητή senlty κωδικοποιείται με τη τιμή 0 όταν ο ηλικιωμένος δεν έχει τη νόσο και την τιμή όταν έχει τη νόσο. Το Block 0 λαμβάνει υπόψη του μόνο τη σταθερά του μοντέλου μας, οπότε τα αποτελέσματα που μας δίνει, είναι το ποσοστό ένας ηλικιωμένος να έχει τη νόσο ( 40/54 = 74, % δεν έχει τη νόσο και 5,9 % έχει τη νόσο ) χωρίς καμία άλλη πληροφορία. Χρησιμοποιώντας μόνο τη σταθερά η πρόβλεψή μας θα ήταν σωστή 74, %. Block 0: Begnnng Block Classfcaton Table a,b Predcted Observed No Senlty Yes Percentage Correct Step 0 Senlty No ,0 Yes 4 0,0 Overall Percentage 74, a. Constant s ncluded n the model. b. The cut value s,500 Επίσης από τον πίνακα Varables n the Equaton όταν έχουμε μόνο τη σταθερά παίρνουμε ότι ln( odds),050 και οπότε το αναμενόμενο odd θα είναι Exp B,050 ( 0) e 0,350. Δεδομένου ότι 4 ηλικιωμένοι πάσχουν από την ασθένεια 9
92 και 40 δεν πάσχουν, τα παρατηρηθέντα odds θα είναι 4/40 = 0,35. Varables n the Equaton B S.E. Wald Df Sg. Exp(B) Step 0 Constant -,050,3,49,00,350 Τώρα στο Block εισάγεται και η μεταβλητή Was. Block : Method = Enter Varables n the Equaton 95,0% C.I.for EXP(B) B S.E. Wald Df Sg. Exp(B) Lower Upper Step a Was -,34,4 8,057,005,74,579,905 Constant,404,9 4,069,044,068 a. Varable(s) entered on step : Was. Οπότε από τον πίνακα Varables n the Equaton θα πάρουμε την εξίσωση που θα έχει το μοντέλο μας, η οποία είναι: ln( odds) b b,404 0,34 Was 0 Οπότε Odds e,404 0,34Was 9
93 e e,4040,34was,4040,34was Βέβαια από τον πιο πάνω πίνακα και από την εξίσωση παλινδρόμησης μπορούμε να βγάλουμε κάποια βασικά συμπεράσματα: Αν κάποιος ηλικιωμένος δε δώσει καμιά θετική απάντηση στην κλίμακα Was,404 0,34 0,404 ( δηλαδή Was=0 ) τότε Odds e e,068 Exp( b ), τότε η πιθανότητα η νόσος να είναι παρούσα είναι φορές περισσότερη της 0 πιθανότητας η νόσος να είναι απούσα. Επίσης η πιθανότητα να είναι παρούσα η νόσος, σε έναν ηλικιωμένο που δεν έχει δώσει καμία σωστή απάντηση στην κλίμακα Was θα είναι ίση με 9,7% αφού,4040,340,404 e e ( was 0) 0,97,4040,340,404 e e Αν τα δύο άτομα διαφέρουν ως προς το Was κατά μία μονάδα, τότε OR e e b 0,34. Συνεπώς αν έχουμε αύξηση σε σωστές 0,74 απαντήσεις κατά μια στην κλίμακα Was, συνεπάγεται μείωση της σχετικής πιθανότητας η νόσος να είναι παρούσα κατά 7.6% αφού 0, ,6% Επίσης από τον πίνακα μπορούμε να δούμε τα διαστήματα εμπιστοσύνης για την παράμετρο b και για το λόγο πιθανοτήτων OR ( βασικά αυτό το δ.ε. μας δίνεται στον πίνακα, αλλά με μια λογαρίθμηση και στα δύο μέλη, μπορούμε να βρούμε και το διάστημα για το b ). Άρα τα διαστήματα εμπιστοσύνης είναι:. για το b : ln 0.579,ln , για το OR : 0.579,
94 Ακόμα βλέπουμε και τη στατιστική συνάρτηση Wald η οποία ελέγχει τη σημαντικότητα της κάθε μεταβλητής στο μοντέλο. Υπολογίζεται ως εξής: παράμετρος S. E της παραμέτρου S. E του B και συγκρίνεται με μια κατανομή με βαθμό ελευθερίας. Να αναφέρουμε εδώ ότι όσο πιο μεγάλη είναι η τιμή Wald τόσο πιο «σημαντική» είναι η μεταβλητή. Άρα μπορούν να γίνουν και κάποιοι έλεγχοι που αφορούν τις παραμέτρους : Α Έλεγχος H : 0 έναντι H : 0 0 Με αυτό τον έλεγχο μπορούμε να δούμε αν σχετίζεται η κλίμακα ευφυΐας Was με την εμφάνιση της νόσου. Θα πρέπει να βρούμε το p-value και να το συγκρίνουμε με το 0,05 ( αν είναι μικρότερο από 0,05 θα πρέπει να απορρίψουμε την H ). Το p- 0 value αυτού του ελέγχου μπορούμε να το βρούμε αν κοιτάξουμε τον πιο πάνω πίνακα στη στήλη Sg. και στην πρώτη γραμμή. Άρα p value 0,005 0,05 Απορρίπτουμε την H Αυτό ουσιαστικά σημαίνει, ότι για κάθε επιπλέον σωστή απάντηση στην κλίμακα Was, μειώνει σημαντικά τη σχετική πιθανότητα της εμφάνισης της νόσου. Οπότε βλέπουμε πως η νόσος σχετίζεται με την κλίμακα. 0 Β Έλεγχος H : 0 έναντι H : Και σε αυτό τον έλεγχο θα πρέπει να βρούμε το p-value, το οποίο είναι και αυτό στη στήλη Sg. αλλά στη δεύτερη γραμμή. p value 0,044 0,05 Απορρίπτουμε την H Δηλαδή αν κάποιος δε δώσει καμία σωστή απάντηση, τότε θα έχει πιθανότητα εμφάνισης της νόσου σημαντικά διαφορετική του 50%. 0 Ο πίνακας Model Summary δείχνει και κάποιους δείκτες ( όπως είχαμε το R στη γραμμική παλινδρόμηση ). Οι δείκτες αυτοί μας δίνουν μία ένδειξη για το μέγεθος της διακύμανσης του δείγματος, που τελικά ερμηνεύεται από την παλινδρόμηση. Εάν 94
95 αυξηθεί η τιμή των δεικτών «Cox & Snell R Square» ( Nagelkerke R Square» ( D0 / N RN Rcs e cs D D N 0 R e / ) και «, αυτός μπορεί να πάρει μέχρι και την τιμή ) είναι ένδειξη ότι κάθε μεταβλητή που εισάγεται, προσθέτει πληροφορία στην εξίσωση. Βέβαια αυτές οι μετρήσεις είναι πιο χρήσιμες όταν συγκρίνεις πολλά λογιστικά μοντέλα ( δηλαδή όταν έχουμε πολλές μεταβλητές και θέλουμε να δούμε ποιες είναι πιο χρήσιμες για το μοντέλο μας ). Από τους πίνακες Omnbus Test of Model Coeffcents και Model Summary μπορούμε να βρούμε τις αποκλίσεις οι οποίες έχουν ιδιαίτερη σημασία. Και αυτό γιατί η απόκλιση είναι ένα δείκτης της απόστασης των εκτιμώμενων τιμών ( αυτών που προβλέπει το μοντέλο ) από τις παρατηρούμενες τιμές. Επίσης χρησιμοποιούνται και για τους ελέγχους καλής προσαρμογής του μοντέλου. Omnbus Tests of Model Coeffcents Ch-square df Sg. Step Step 0,789,00 Block 0,789,00 Model 0,789,00 Model Summary Step - Log lkelhood Cox & Snell R Square Nagelkerke R Square 5,07 a,8,66 a. Estmaton termnated at teraton number 5 because parameter estmates changed by less than,
96 Από τον πίνακα Omnbus Test of Model Coeffcents η τιμή που έχουμε επισημάνει είναι η διαφορά της απόκλισης από αυτό το βήμα, και της απόκλισης από το προηγούμενο βήμα ( εδώ το προηγούμενο βήμα είναι το σταθερό, άρα είναι η διαφορά από την απόκλιση από το σταθερό μοντέλο ). Δηλαδή D0 D0,78894 (). Ενώ από τον πίνακα Model Summary παίρνουμε την τιμή της απόκλισης για το πλήρες μοντέλο, η οποία είναι D 5,07 (). Η D είναι ίση με ln( lkelhood ), σε ένα βέλτιστο μοντέλο η πιθανοφάνεια θα είναι ίση με, άρα όσο η τιμή του -LL πλησιάζει στο μηδέν τόσο καλύτερο είναι το μοντέλο. Συνεπώς με τη βοήθεια των σχέσεων () και () βρίσκουμε την απόκλιση που έχει το σταθερό μοντέλο η οποία είναι D0 6,8063. Αν η διαφορά των δυο αποκλίσεων συγκριθεί με μια X κατανομή με ένα βαθμό ελευθερίας, τότε προκύπτει το p-value του ελέγχου ( Sg.=0,00) άρα η διαφορά των μοντέλων είναι στατιστικά σημαντική. Οπότε το μοντέλο που λαμβάνει υπόψη την κλίμακα ευφυΐας Was, εφαρμόζει καλύτερα στα δεδομένα παρά το μοντέλο που δεν έχει καμία πληροφορία. Για να κάνουμε τον έλεγχο καλής προσαρμογής αντί να χρησιμοποιήσουμε τον έλεγχο, θα χρησιμοποιούμε ένα εναλλακτικό έλεγχο, το Hosmer and Lemeshow. Αυτός ο έλεγχος είναι πιο ισχυρός από τον παραδοσιακό οι ανεξάρτητες μεταβλητές είναι συνεχείς ή το δείγμα είναι μικρό. X X έλεγχο, ιδιαίτερα όταν Εν συντομία θα χωρίσουμε τις παρατηρήσεις σε ομάδες με βάση τις προβλεπόμενες πιθανότητες ( συνήθως 0 ) και στη συνέχεια υπολογίζουμε τη X O E όπου E E / m g k k k k k k O : παρατηρούμενες τιμές στην k ομάδα με Senlty= k E : οι αναμενόμενες τιμές στην k ομάδα με Senlty= k m : ο συνολικός αριθμός ατόμων στην k ομάδα. k Τέλος θα τη συγκρίνουμε με μια κατανομή με βαθμούς ελευθερίας [(αριθμός ομάδων)-]. Είναι μια παραλλαγή του στο ο κεφάλαιο, στην 6. υποενότητα. X ελέγχου καλής προσαρμογής που είδαμε 96
97 Στον πίνακα Contngency Table for Hosmer and Lemeshow Test βλέπουμε σε πόσες ομάδες έχουμε χωρίσει τις παρατηρήσεις μας, επίσης βλέπουμε τις παρατηρούμενες και τις αναμενόμενες τιμές που έχουμε. Την τιμή του τη βλέπουμε στον πίνακα Hosmer and Lemeshow Test και η οποία είναι ίση με 5,99. Επίσης βλέπουμε και το p-value του ελέγχου που είναι 0,648>0,05, άρα θα αποδεχτούμε τη μηδενική υπόθεση, δηλαδή το μοντέλο είναι καλά προσαρμοσμένο. Contngency Table for Hosmer and Lemeshow Test Senlty = No Senlty = Yes Observed Expected Observed Expected Total Step 4 3,885 0, ,765 0, ,76 0, ,53, ,50, ,9, ,80, ,746,54 6 9,488 4,5 5 0,58 3 3,49 5 Hosmer and Lemeshow Test 97
98 Step Ch-square Df Sg. 5,99 8,648 Και ο τελευταίος πίνακας είναι ο πίνακας από τον οποίο βλέπουμε ποιο είναι το ποσοστό σωστής πρόβλεψης για το μοντέλο μας. Όπως επίσης βλέπουμε και τα επιμέρους ποσοστά. Ο πίνακας αυτός είναι ο Classfcaton Table. Classfcaton Table a Predcted Observed No Senlty Yes Percentage Correct Step Senlty No ,5 Yes ,7 Overall Percentage 77,8 a. The cut value s,500 Εδώ βλέπουμε πως το μοντέλο μας έχει πιθανότητα σωστής πρόβλεψης 77,8% ( Pσωστής κατάταξης 0,7777 ). P Y No / Y No ή P Y Yes / Y Yes 37 5 N 54 Επίσης η πιθανότητα κάποιος να μην πάσχει από τη νόσο και να το έχουμε προβλέψει σωστά είναι 9,5% ( PY Y 37 No / No 0, ), ενώ πιθανότητα κάποιος να πάσχει από τη νόσο και να το έχουμε βρει είναι 35,7% 5 Yes / Yes 0, ( PY Y ). 98
99 . Παράδειγμα με Διαχωριστική Ανάλυση ( R. Johnson - D.Wchern, 99) Σε αυτό το παράδειγμα έχουμε ένα δείγμα από 85 προπτυχιακούς φοιτητές που ενδιαφέρονται για ένα μεταπτυχιακό πρόγραμμα σε μια σχολή διοίκηση επιχειρήσεων. Ο υπεύθυνος για την εισαγωγή στο μεταπτυχιακό πρόγραμμα θα βασιστεί στο βαθμό πτυχίου ( GPA graduate grade pont average ) και στο βαθμό σε ένα τεστ επιδεξιότητας στην διοίκηση ( GMAT- graduate management apttude test ), ώστε να αποφασίσει ποιοι από τους υποψήφιους θα μπούνε στο μεταπτυχιακό πρόγραμμα. Οπότε θέλει να διαχωρίσει τα δεδομένα του σε τρεις ομάδες ( πληθυσμούς ): (α) : Εισαγωγή, (β) : Απόρριψη και (γ) 3 : Στα όρια. Επίσης θέλει να βρει και ένα κανόνα ταξινόμησης, με τον οποίο κάθε νέα παρατήρηση να ταξινομείται στη σωστή ομάδα. Εδώ να αναφέρουμε πως την ομάδα θα την κωδικοποιήσουμε με, την ομάδα την κωδικοποιούμε με και την 3 ομάδα την κωδικοποιούμε με 3. Τα δεδομένα δίνονται στο πίνακα. Πίνακας Ομάδες GPA GMAT, , , 48 3,9 57 3, , , , , ,
100 3, , , , , , , , , ,8 53 3, 530 3, , , , , , , ,80 5 3, ,4 467,54 446,43 45,0 474,36 53,57 54,35 406,5 4,5 458,36 399,36 48,66 40,
101 ,48 533,46 509,63 504,44 336,3 408,4 469,55 538,3 505,4 489,9 4,35 3,60 394,55 58,7 399,85 38, , , , ,8 37 3, , , , , , ,0 47 3, , , , , , 463 0
102 3 3, , , , , , , , , Πριν ξεκινήσουμε με την διαχωριστική ανάλυση, θα πρέπει να δούμε αν ικανοποιούνται κάποιες προϋποθέσεις. Πρώτα θέλουμε να δούμε αν ισχύει η υπόθεση της κανονικότητας των ανεξάρτητων μεταβλητών ( εδώ είναι η GPA και η GMAT ). Στην συνέχεια αν υπάρχει ομοιογένεια στους πίνακες διακυμάνσεωνσυνδιακυμάνσεων, εδώ να αναφέρουμε πως αυτός ο έλεγχος γίνεται μέσα από την διαχωριστική ανάλυση. Αξίζει να αναφέρουμε ότι σε πραγματικά δεδομένα είναι σπάνιο να βρούμε ότι πληρείται η υπόθεση της κανονικότητας και πόσο μάλλον η υπόθεση της ισότητας των πινάκων διακύμανσης-συνδιακύμανσης. Για αυτό το λόγο οι ερευνητές εφαρμόζουν την διαχωριστική ανάλυση ακόμα και όταν δεν ισχύουν οι υποθέσεις. Για να ελέγξουμε αν οι ανεξάρτητες μεταβλητές ακολουθούν την κανονική κατανομή θα πρέπει με την βοήθεια του SPSS να ακολουθήσουμε την πιο κάτω διαδρομή: Analyze Descrptve Statstcs Explore. Στο πεδίο «Dependent Lst» θα εισάγουμε τις συνεχείς μεταβλητές GPA και GMAT. Από το υπομενού «Plots» επιλέγουμε από το Boxplots το None, από το Descrptve το Hstogram και επιλέγουμε και το Normalty plots wth tests. Στο output του SPSS θα πάρουμε τα πιο κάτω αποτελέσματα: 0

103 Tests of Normalty Kolmogorov-Smrnov a Shapro-Wlk Statstc df Sg. Statstc df Sg. GPA,074 85,00 *,974 85,08 GMAT,07 85,00 *,980 85,3 a. Lllefors Sgnfcance Correcton *. Ths s a lower bound of the true sgnfcance. 03
104 Οπότε από το πίνακα Tests of Normalty βλέπουμε πως και οι δύο μεταβλητές ακολουθούν κανονική κατανομή αφού τα p-value τους είναι μεγαλύτερα από το επίπεδο στατιστικής σημαντικότητας 0,05 και με τους δύο ελέγχους που μας δίνονται στο πίνακα. Επίσης αυτό το βλέπουμε και με την βοήθεια του Q-Q plot για κάθε μεταβλητής. Αν τα σημεία είναι κοντά στην ευθεία τότε θα έχουμε κανονική κατανομή, το οποίο το βλέπουμε και στις πιο πάνω εικόνες. Συνεχίζουμε με την διαχωριστική ανάλυση, η οποία βρίσκεται από την διαδρομή Analyze Classfy Dscrmnant. Στο πεδίο «Groupng Varable» θα βάλουμε την μεταβλητή που καθορίζει τις ομάδες, δηλαδή την μεταβλητή Group. Στο «Defne Range» θα ορίσουμε σαν ελάχιστη τιμή το και σαν μέγιστη τιμή το 3. Στο πεδίο «Independents» θα βάλουμε τις μεταβλητές GPA και GMAT ( ανεξάρτητες 04
105 μεταβλητές ). Θα επιλέξουμε το Enter Independents Together αφού έχουμε δύο μεταβλητές ( εάν είχαμε περισσότερες τότε θα ήταν καλύτερα να επιλέγαμε την Use Stepwse Method ). Από το υπομενού «Statstcs» επιλέγουμε τα: Mean, Unvarate ANOVAs, Box s M, Fsher s και το Wthn-groups covarance. Από το υπομενού «Classfy» επιλέγουμε: All groups equal, Summary table, Wthn-groups και όλα τα Plots. Στο Output του SPSS θα πάρουμε τους πιο κάτω πίνακες και τα πιο κάτω γραφήματα: Analyss Case Processng Summary Unweghted Cases N Percent Vald 85 00,0 Excluded Mssng or out-of-range group codes At least one mssng dscrmnatng varable Both mssng or out-of-range group codes and at least one mssng dscrmnatng varable 0,0 0,0 0,0 Total 0,0 Total 85 00,0 Σε αυτό το πίνακα απλά βλέπουμε πόσες περιπτώσεις έχουμε. Στο συγκεκριμένο παράδειγμα έχουμε 85 υποψήφιους για το μεταπτυχιακό πρόγραμμα. 05
106 Στη συνέχεια πρέπει να κοιτάξουμε το Box s Test of Equalty of Covarance, το οποίο αποτελείται από δύο πίνακες, το Log Determnants και το Test Results ώστε να δούμε αν ισχύει η ομοιογένεια στους πίνακες διακυμάνσεων- συνδιακυμάνσεων. Box's Test of Equalty of Covarance Matrces Log Determnants Group Rank Log Determnant Admt 5,304 not admt 4,864 Borderlne 3,65 Pooled wthn-groups 4,850 The ranks and natural logarthms of determnants prnted are those of the group covarance matrces. Test Results Box's M 6,665 F Approx.,679 df 6 df 4673,896 Sg.,03 Tests null hypothess of equal populaton covarance matrces. 06
107 Η μηδενική υπόθεση στο έλεγχο Box s M είναι η ισότητα των πινάκων συνδιασπορών H :. Εμείς θέλουμε να αποδεχόμαστε τη μηδενική υπόθεση, δηλαδή 0 3 όμως εδώ βλέπουμε πως το p-value= 0,03 < 0,05 άρα θα πρέπει να απορρίψω την H 0. Πρέπει όμως να αναφέρουμε πως όταν το δείγμα είναι μεγάλο ( που εδώ είναι ) τότε και μικρές αποκλίσεις από τους πίνακες να θεωρούνται αρκετά σημαντικές, για αυτό το λόγο δίνεται και ο πίνακας Log Determnants. Αν σε αυτό το πίνακα οι τιμές στην στήλη Log Determnant είναι κοντά τότε στην πραγματικότητα οι πίνακες διασποράς- συνδιασποράς είναι στην πραγματικότητα ίσοι. Στο παράδειγμα μας βλέπουμε πως οι τιμές στην στήλη Log Determnant είναι πολύ κοντά, οπότε θα συμπεράνουμε πως 3. Στην περίπτωση που θα υπήρχαν μεγάλες διαφορές στις τιμές του Log Determnant τότε θα έπρεπε να συμπεράνουμε πως οι πίνακες είναι άνισοι, άρα θα έπρεπε να ξαναγίνει η διαχωριστική ανάλυση με την μόνη διαφορά στο υπομενού Classfy θα πρέπει να επιλέξουμε το Separate groups. Group Statstcs Vald N (lstwse) Group Mean Std. Devaton Unweghted Weghted Admt GPA 3,4039, ,000 GMAT 56,58 67, ,000 not admt GPA,485, ,000 GMAT 447,074 6, ,000 Borderlne GPA,997,73 6 6,000 GMAT 446,308 47, ,000 Total GPA,9746, ,000 GMAT 488,447 8, ,000 07
108 Από το πίνακα Group Statstcs βλέπουμε κάποιους περιγραφικούς δείκτες για τις ομάδες μας. Μας δείχνει πόσες παρατηρήσεις υπάρχουν σε κάθε ομάδα, όπως επίσης βλέπουμε οι μέσες τιμές και τις τυπικές αποκλίσεις που έχει η κάθε μεταβλητή στην κάθε μια ομάδα. Από αυτό μπορούμε να δούμε εάν υπάρχουν διαφορές στις μέσες τιμές τις κάθε ομάδας ώστε να δούμε αν μπορεί να γίνει ένας καλός διαχωρισμός. Στην ομάδα βλέπουμε πως υπάρχουν 3 υποψήφιοι, στην ομάδα υπάρχουν 8 υποψήφιοι και στην 3 6 υποψήφιοι. Εδώ βλέπουμε πως οι μέσες τιμές διαφέρουν οπότε μάλλον ο διαχωρισμός μας θα είναι καλός. Tests of Equalty of Group Means Wlks' Lambda F df df Sg. GPA,9 73,305 8,000 GMAT,537 35,350 8,000 Στο πίνακα Tests of Equalty of Group Means βλέπουμε ότι και για τις δύο μεταβλητές οι μέσες τιμές στις τρεις ομάδες διαφοροποιούνται σημαντικά. Αυτό το βλέπουμε από το p-value και για τις δύο ομάδες είναι 0,000 που είναι μικρότερο από το 0,05 οπότε θα πρέπει να απορρίψω την H 0. Εδώ υπάρχει και ο δείκτης Wlks Lambda, ο οποίος κυμαίνεται από το 0 μέχρι το. Όσο πιο μικρή είναι η τιμή του Wlks Lambda τόσο πιο σημαντική είναι η ανεξάρτητη μεταβλητή στην ανάλυση μας. Στο πίνακα Pooled Wthn-Groups Matrces απλά βλέπουμε το είναι ένας πίνακας. S pooled πίνακα. Εδώ 08
109 Pooled Wthn-Groups Matrces a GPA GMAT Covarance GPA,036 -,09 GMAT -, ,90 a. The covarance matrx has 8 degrees of freedom. Από το πίνακα Egenvalues βλέπουμε τις ιδιοτιμές που έχουμε στην ανάλυση. Ο αριθμός των ιδιοτιμών είναι ίσο με το ( αριθμό των ομάδων- ) ή ίσο με το αριθμό των ανεξάρτητων μεταβλητών. Εδώ αφού έχουμε τρεις ομάδες τότε θα έχουμε δύο ιδιοτιμές και κατά συνέπεια δύο συναρτήσεις διαχωρισμούς. Egenvalues Functon Egenvalue % of Varance Cumulatve % Canoncal Correlaton 5,646 a 96,7 96,7,9,9 a 3,3 00,0,400 a. Frst canoncal dscrmnant functons were used n the analyss. Οι ιδιοτιμές είναι χρήσιμες ως δείκτες μέτρησης της διασποράς των κεντροειδών στον αντίστοιχο πολυμεταβλητό χώρο. Οι ιδιοτιμές μας δίνονται με σειρά σημαντικότητας, δηλαδή η πρώτη είναι πιο σημαντική από την δεύτερη και ως εξής. Ο δείκτης κανονικής συσχέτισης ( Canoncal Correlaton ) μας δείχνει πόσο συσχέτιση υπάρχει μεταξύ των ομάδων και των σκορ της διαχωριστικής συνάρτηση. Όταν η τιμή του Canoncal Correlaton είναι μεγάλη ( ιδανική τιμή το ) τόσο πιο ισχυρή συσχέτιση υπάρχει μεταξύ των ομάδων και των σκορ της διαχωριστικής συνάρτηση, άρα θα έχουμε και καλό διαχωρισμό. Εδώ βλέπουμε πως για την πρώτη διαχωριστική 09
110 ανάλυση έχουμε υψηλή συσχέτιση ( R 0,9 ) και για την δεύτερη όχι και τόσο μεγάλη ( R 0,400 ). Στη συνέχεια βλέπουμε το πίνακα Wlks lambda. Wlks' Lambda Test of Functon(s) Wlks' Lambda Ch-square Df Sg. through,6 68,58 4,000,840 4,9,000 Η τιμή του Wlks lambda είναι το ποσοστό της διακύμανσης που δεν εξηγείται από την ανάλυση διακύμανσης και μπορούμε να το υπολογίσουμε ως Canoncal Correlaton. Μπορούμε να χρησιμοποιήσουμε το Wlks lambda για να ελέγξουμε την υπόθεση ότι οι μέσοι όλων των μεταβλητών ανά ομάδα είναι ίσοι. Δηλαδή μπορούμε να δούμε αν οι μεταβλητές μας δεν είναι καλές για το διαχωρισμό των ομάδων ( όταν αποδέχομαι την H 0 ). Ένα μικρό lambda δείχνει ότι οι μέσοι διαφέρουν. Εδώ έχουμε ότι το p-value= 0,000 και στα δύο άρα η ισότητα των μέσων απορρίπτεται και άρα δεν φαίνεται να υπάρχει πρόβλημα με την εφαρμογή της διαχωριστικής ανάλυσης. Από το πίνακα Structure Matrx έχουμε τους δείκτες συσχέτισης κάθε ανεξάρτητης μεταβλητής με τις διαχωριστικές συναρτήσεις. Από αυτούς μπορούμε να αξιολογήσουμε πόσο σημαντική είναι η κάθε μεταβλητή για τη κατασκευή των διαχωριστικών συναρτήσεων. Στο παράδειγμα βλέπουμε πως για την πρώτη διαχωριστική συνάρτηση είναι πιο σημαντική η μεταβλητή GPA ( 0,860 ) ενώ για την δεύτερη διαχωριστική πιο σημαντική είναι η μεταβλητή GMAT ( 0,936 ). 0
111 Structure Matrx Functon GPA,860 * -,50 GMAT,35,936 * Pooled wthn-groups correlatons between dscrmnatng varables and standardzed canoncal dscrmnant functons Varables ordered by absolute sze of correlaton wthn functon. *. Largest absolute correlaton between each varable and any dscrmnant functon Από το πίνακα Functons at Group Centrods παίρνουμε τη μέση τιμή της κάθε κανονικοποιημένης διαχωριστικής συνάρτησης για κάθε ομάδα. Βασικά με βάση τις τιμές αυτές το πρόγραμμα κάνει τη κατάταξη των παρατηρήσεων. Περιπτώσεις που έχουν σκορ κοντά στο centrod κατατάσσονται σε εκείνη την ομάδα. Functons at Group Centrods Functon Group Admt,774,46 not admt -,89,36 Borderlne -,7 -,644 Unstandardzed canoncal dscrmnant functons evaluated at group means
112 Τώρα όσο αφορά τους πίνακες Classfcaton Processng Summary και Pror Probabltes for Groups, απλά βλέπουμε ποίες περιπτώσεις έχουν καταταχθεί με βάση την ανάλυση και βλέπουμε και τις εκ των προτέρων πιθανότητες που έχει η κάθε ομάδα. Εδώ αφού επιλέξαμε να έχουμε ίσες εκ των προτέρων πιθανότητες στην κάθε ομάδα και αφού έχουμε τρεις υποομάδες τότε p p p 0, Classfcaton Processng Summary Processed 85 Excluded Mssng or out-of-range group codes At least one mssng dscrmnatng varable 0 0 Used n Output 85 Pror Probabltes for Groups Cases Used n Analyss Group Pror Unweghted Weghted Admt, ,000 not admt, ,000 borderlne, ,000 Total, ,000 Ο επόμενος πίνακας Classfcaton Functon Coeffcents υπολογίζει τους συντελεστές των γραμμικών διαχωριστικών συναρτήσεων των σκορ με την μέθοδο του Fsher.
113 Classfcaton Functon Coeffcents Group admt not admt Borderlne GPA 06,50 78,086 9,670 GMAT,,65,73 (Constant) -4,470-34,998-78,44 Fsher's lnear dscrmnant functons Τα τρία σκορ ( ένα για την κάθε ομάδα ) είναι: y 06,50 GPA 0, GMAT 4,470 y 78,086 GPA 0,65 GMAT 34,998 y 3 9,670 GPA 0,73 GMAT 78,44 Με την βοήθεια αυτό των σκορ μπορούμε να κατατάξουμε κάποιο καινούργιο υποψήφιο. Θα τον κατατάσσουμε στην ομάδα όπου θα είναι το μεγαλύτερο σκορ. Έστω ότι έχουμε ένα καινούργιο υποψήφιο με GPA=3, και GMAT=497 οπότε για να δούμε σε ποια ομάδα θα το κατατάξουμε θα βρούμε τα σκορ, τα οποία είναι: y 06,50 3, 0, 497 4,470 04,9565 y 78,086 3, 0, ,998 97,66306 y 3 9,670 3, 0, ,44 05,0377 Αφού το σκορ για την τρίτη ομάδα είναι το μεγαλύτερο θα πρέπει να κατατάξουμε το υποψήφιο σε εκείνη την ομάδα, δηλαδή ο υποψήφιος αυτός είναι στα όρια. 3
114 Ο επόμενος πίνακας είναι ο τελευταίος πίνακας που μας δίνει το πρόγραμμα και είναι και από τους πιο βασικούς. Από αυτό το πίνακα βλέπουμε πόσες από τις παρατηρήσεις μας έχουν ταξινομηθεί σωστά. Όπως επίσης βλέπουμε και το ποσοστό σωστού διαχωρισμού. Classfcaton Results a Predcted Group Membershp group admt not admt borderlne Total Orgnal Count admt not admt borderlne % admt 87,,0,9 00,0 not admt,0 9,9 7, 00,0 borderlne 3,8,0 96, 00,0 a. 9,8% of orgnal grouped cases correctly classfed. Μπορούμε να δούμε ότι από την πρώτη ομάδα ( admt ) ταξινομήθηκα σωστά 7 υποψήφιοι και 4 λάθος ( ταξινομήθηκαν στη τρίτη ομάδα ). Από την δεύτερη ομάδα ταξινομήθηκα σωστά οι 6 και οι ταξινομήθηκα λάθος. Από την τρίτη ομάδα ταξινομήθηκα σωστά οι 5 από τους 6 υποψήφιους. Επίσης το ποσοστό σωστού διαχωρισμού είναι 9,8% ( 87,% είναι το ποσοστό για την πρώτη ομάδα, 9,9 για την δεύτερη και 96,% για την τρίτη ομάδα ). Αρά βλέπουμε ότι η διαχωριστική ανάλυση που κάναμε πιο πάνω είναι καλή. Στη συνέχεια έχουμε διάφορα γραφήματα, τα πρώτα τρία δείχνουν την κάθε ομάδα μόνη της και το τελευταίο διάγραμμα δίνει μια συνολική εικόνα της κατανομής 4

115 των σημείων των δύο διαχωριστικών συναρτήσεων για κάθε ομάδα. Separate-Groups Graphs 5
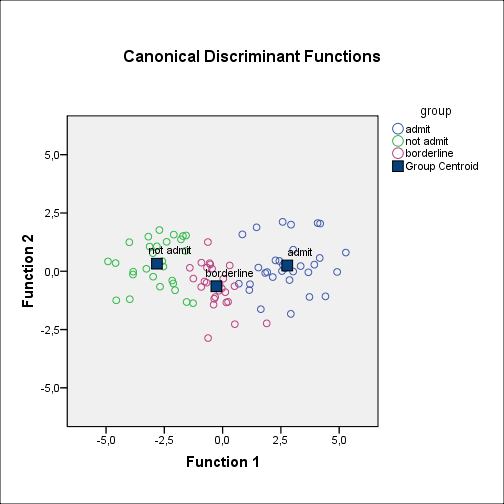
116 6
ΜΗ ΓΡΑΜΜΙΚΗ ΠΑΛΙΝΔΡΟΜΙΣΗ
 ΜΗ ΓΡΑΜΜΙΚΗ ΠΑΛΙΝΔΡΟΜΙΣΗ Τα μη γραμμικά μοντέλα έχουν την πιο κάτω μορφή: η μορφή αυτή μοιάζει με τη μορφή που έχουμε για τα γραμμικά μοντέλα ( δηλαδή η παρατήρηση Y i είναι το άθροισμα της αναμενόμενης
ΜΗ ΓΡΑΜΜΙΚΗ ΠΑΛΙΝΔΡΟΜΙΣΗ Τα μη γραμμικά μοντέλα έχουν την πιο κάτω μορφή: η μορφή αυτή μοιάζει με τη μορφή που έχουμε για τα γραμμικά μοντέλα ( δηλαδή η παρατήρηση Y i είναι το άθροισμα της αναμενόμενης
Απλή Γραμμική Παλινδρόμηση και Συσχέτιση 19/5/2017
 Απλή Γραμμική Παλινδρόμηση και Συσχέτιση 2 Εισαγωγή Η ανάλυση παλινδρόμησης περιλαμβάνει το σύνολο των μεθόδων της στατιστικής που αναφέρονται σε ποσοτικές σχέσεις μεταξύ μεταβλητών Πρότυπα παλινδρόμησης
Απλή Γραμμική Παλινδρόμηση και Συσχέτιση 2 Εισαγωγή Η ανάλυση παλινδρόμησης περιλαμβάνει το σύνολο των μεθόδων της στατιστικής που αναφέρονται σε ποσοτικές σχέσεις μεταξύ μεταβλητών Πρότυπα παλινδρόμησης
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 07-08 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 07-08 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
Υ: Νόσος. Χ: Παράγοντας Κινδύνου 1 (Ασθενής) 2 (Υγιής) Σύνολο. 1 (Παρόν) n 11 n 12 n 1. 2 (Απών) n 21 n 22 n 2. Σύνολο n.1 n.2 n..
 2 (Υγιής) Σύνολο. 1 (Παρόν) n 11 n 12 n 1. 2 (Απών) n 21 n 22 n 2. Σύνολο n.1 n.2 n..") Μέτρα Κινδύνου για Δίτιμα Κατηγορικά Δεδομένα Σε αυτή την ενότητα θα ορίσουμε δείκτες μέτρησης του κινδύνου εμφάνισης μίας νόσου όταν έχουμε δίτιμες κατηγορικές μεταβλητές. Στην πιο απλή περίπτωση μας
Μέτρα Κινδύνου για Δίτιμα Κατηγορικά Δεδομένα Σε αυτή την ενότητα θα ορίσουμε δείκτες μέτρησης του κινδύνου εμφάνισης μίας νόσου όταν έχουμε δίτιμες κατηγορικές μεταβλητές. Στην πιο απλή περίπτωση μας
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 08-09 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 08-09 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutra@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutra@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
Υ: Νόσος. Χ: Παράγοντας Κινδύνου 1 (Ασθενής) 2 (Υγιής) Σύνολο. 1 (Παρόν) n 11 n 12 n 1. 2 (Απών) n 21 n 22 n 2. Σύνολο n.1 n.2 n..
 2 (Υγιής) Σύνολο. 1 (Παρόν) n 11 n 12 n 1. 2 (Απών) n 21 n 22 n 2. Σύνολο n.1 n.2 n..") Μέτρα Κινδύνου για Δίτιμα Κατηγορικά Δεδομένα Σε αυτή την ενότητα θα ορίσουμε δείκτες μέτρησης του κινδύνου εμφάνισης μίας νόσου όταν έχουμε δίτιμες κατηγορικές μεταβλητές. Στην πιο απλή περίπτωση μας
Μέτρα Κινδύνου για Δίτιμα Κατηγορικά Δεδομένα Σε αυτή την ενότητα θα ορίσουμε δείκτες μέτρησης του κινδύνου εμφάνισης μίας νόσου όταν έχουμε δίτιμες κατηγορικές μεταβλητές. Στην πιο απλή περίπτωση μας
Αντικείμενο του κεφαλαίου είναι: Ανάλυση συσχέτισης μεταξύ δύο μεταβλητών. Εξίσωση παλινδρόμησης. Πρόβλεψη εξέλιξης
 Γραμμική Παλινδρόμηση και Συσχέτιση Αντικείμενο του κεφαλαίου είναι: Ανάλυση συσχέτισης μεταξύ δύο μεταβλητών Εξίσωση παλινδρόμησης Πρόβλεψη εξέλιξης Διμεταβλητές συσχετίσεις Πολλές φορές χρειάζεται να
Γραμμική Παλινδρόμηση και Συσχέτιση Αντικείμενο του κεφαλαίου είναι: Ανάλυση συσχέτισης μεταξύ δύο μεταβλητών Εξίσωση παλινδρόμησης Πρόβλεψη εξέλιξης Διμεταβλητές συσχετίσεις Πολλές φορές χρειάζεται να
Συσχέτιση μεταξύ δύο συνόλων δεδομένων
 Διαγράμματα διασποράς (scattergrams) Συσχέτιση μεταξύ δύο συνόλων δεδομένων Η οπτική απεικόνιση δύο συνόλων δεδομένων μπορεί να αποκαλύψει με παραστατικό τρόπο πιθανές τάσεις και μεταξύ τους συσχετίσεις,
Διαγράμματα διασποράς (scattergrams) Συσχέτιση μεταξύ δύο συνόλων δεδομένων Η οπτική απεικόνιση δύο συνόλων δεδομένων μπορεί να αποκαλύψει με παραστατικό τρόπο πιθανές τάσεις και μεταξύ τους συσχετίσεις,
9. Παλινδρόμηση και Συσχέτιση
 9. Παλινδρόμηση και Συσχέτιση Παλινδρόμηση και Συσχέτιση Υπάρχει σχέση ανάμεσα σε δύο ή περισσότερες μεταβλητές; Αν ναι, ποια είναι αυτή η σχέση; Πως μπορεί αυτή η σχέση να χρησιμοποιηθεί για να προβλέψουμε
9. Παλινδρόμηση και Συσχέτιση Παλινδρόμηση και Συσχέτιση Υπάρχει σχέση ανάμεσα σε δύο ή περισσότερες μεταβλητές; Αν ναι, ποια είναι αυτή η σχέση; Πως μπορεί αυτή η σχέση να χρησιμοποιηθεί για να προβλέψουμε
Έλεγχος υποθέσεων και διαστήματα εμπιστοσύνης
 1 Έλεγχος υποθέσεων και διαστήματα εμπιστοσύνης Όπως γνωρίζουμε από προηγούμενα κεφάλαια, στόχος των περισσότερων στατιστικών αναλύσεων, είναι η έγκυρη γενίκευση των συμπερασμάτων, που προέρχονται από
1 Έλεγχος υποθέσεων και διαστήματα εμπιστοσύνης Όπως γνωρίζουμε από προηγούμενα κεφάλαια, στόχος των περισσότερων στατιστικών αναλύσεων, είναι η έγκυρη γενίκευση των συμπερασμάτων, που προέρχονται από
Εφαρμοσμένη Στατιστική Δημήτριος Μπάγκαβος Τμήμα Μαθηματικών και Εφαρμοσμένων Μαθηματικών Πανεπισ τήμιο Κρήτης 14 Μαρτίου /34
 Εφαρμοσμένη Στατιστική Δημήτριος Μπάγκαβος Τμήμα Μαθηματικών και Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης 14 Μαρτίου 018 1/34 Διαστήματα Εμπιστοσύνης. Εχουμε δει εκτενώς μέχρι τώρα τρόπους εκτίμησης
Εφαρμοσμένη Στατιστική Δημήτριος Μπάγκαβος Τμήμα Μαθηματικών και Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης 14 Μαρτίου 018 1/34 Διαστήματα Εμπιστοσύνης. Εχουμε δει εκτενώς μέχρι τώρα τρόπους εκτίμησης
Εφαρμοσμένη Στατιστική Δημήτριος Μπάγκαβος Τμήμα Μαθηματικών και Εφαρμοσμένων Μαθηματικών Πανεπισ τήμιο Κρήτης 2 Μαΐου /23
 Εφαρμοσμένη Στατιστική Δημήτριος Μπάγκαβος Τμήμα Μαθηματικών και Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης 2 Μαΐου 2017 1/23 Ανάλυση Διακύμανσης. Η ανάλυση παλινδρόμησης μελετά τη στατιστική σχέση ανάμεσα
Εφαρμοσμένη Στατιστική Δημήτριος Μπάγκαβος Τμήμα Μαθηματικών και Εφαρμοσμένων Μαθηματικών Πανεπιστήμιο Κρήτης 2 Μαΐου 2017 1/23 Ανάλυση Διακύμανσης. Η ανάλυση παλινδρόμησης μελετά τη στατιστική σχέση ανάμεσα
Εισόδημα Κατανάλωση 1500 500 1600 600 1300 450 1100 400 600 250 700 275 900 300 800 352 850 400 1100 500
 Εισόδημα Κατανάλωση 1500 500 1600 600 1300 450 1100 400 600 250 700 275 900 300 800 352 850 400 1100 500 Πληθυσμός Δείγμα Δείγμα Δείγμα Ο ρόλος της Οικονομετρίας Οικονομική Θεωρία Διατύπωση της
Εισόδημα Κατανάλωση 1500 500 1600 600 1300 450 1100 400 600 250 700 275 900 300 800 352 850 400 1100 500 Πληθυσμός Δείγμα Δείγμα Δείγμα Ο ρόλος της Οικονομετρίας Οικονομική Θεωρία Διατύπωση της
Σ ΤΑΤ Ι Σ Τ Ι Κ Η ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ
 Σ ΤΑΤ Ι Σ Τ Ι Κ Η i ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ Κατανομή Δειγματοληψίας του Δειγματικού Μέσου Ο Δειγματικός Μέσος X είναι μια Τυχαία Μεταβλητή. Καθώς η επιλογή και χρήση διαφορετικών δειγμάτων από έναν
Σ ΤΑΤ Ι Σ Τ Ι Κ Η i ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ Κατανομή Δειγματοληψίας του Δειγματικού Μέσου Ο Δειγματικός Μέσος X είναι μια Τυχαία Μεταβλητή. Καθώς η επιλογή και χρήση διαφορετικών δειγμάτων από έναν
Αναλυτική Στατιστική
 Αναλυτική Στατιστική Συμπερασματολογία Στόχος: εξαγωγή συμπερασμάτων για το σύνολο ενός πληθυσμού, αντλώντας πληροφορίες από ένα μικρό υποσύνολο αυτού Ορισμοί Πληθυσμός: σύνολο όλων των υπό εξέταση μονάδων
Αναλυτική Στατιστική Συμπερασματολογία Στόχος: εξαγωγή συμπερασμάτων για το σύνολο ενός πληθυσμού, αντλώντας πληροφορίες από ένα μικρό υποσύνολο αυτού Ορισμοί Πληθυσμός: σύνολο όλων των υπό εξέταση μονάδων
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 6-7 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 735468 Σε αρκετές εφαρμογές
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 6-7 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 735468 Σε αρκετές εφαρμογές
ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ: ΠΙΘΑΝΟΤΗΤΕΣ 11 ΚΕΦΑΛΑΙΟ 1 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 13
 ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ: ΠΙΘΑΝΟΤΗΤΕΣ 11 ΚΕΦΑΛΑΙΟ 1 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 13 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 20 2.1 Αβεβαιότητα, Τυχαία Διαδικασία, και Συναφείς Έννοιες 20 2.1.1 Αβεβαιότητα
ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ: ΠΙΘΑΝΟΤΗΤΕΣ 11 ΚΕΦΑΛΑΙΟ 1 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 13 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 20 2.1 Αβεβαιότητα, Τυχαία Διαδικασία, και Συναφείς Έννοιες 20 2.1.1 Αβεβαιότητα
Ανάλυση διακύμανσης (Μέρος 1 ο ) 17/3/2017
 17/3/2017") Ανάλυση διακύμανσης (Μέρος 1 ο ) 17/3/2017 2 Γιατί ανάλυση διακύμανσης; (1) Ας θεωρήσουμε k πληθυσμούς με μέσες τιμές μ 1, μ 2,, μ k, αντίστοιχα Πως μπορούμε να συγκρίνουμε τις μέσες τιμές k πληθυσμών
Ανάλυση διακύμανσης (Μέρος 1 ο ) 17/3/2017 2 Γιατί ανάλυση διακύμανσης; (1) Ας θεωρήσουμε k πληθυσμούς με μέσες τιμές μ 1, μ 2,, μ k, αντίστοιχα Πως μπορούμε να συγκρίνουμε τις μέσες τιμές k πληθυσμών
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 7-8 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 735468 Σε αρκετές εφαρμογές
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 7-8 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 735468 Σε αρκετές εφαρμογές
ΕΙΣΑΓΩΓΗ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ
 ΕΙΣΑΓΩΓΗ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ Μ.Ν. Ντυκέν, Πανεπιστήμιο Θεσσαλίας Τ.Μ.Χ.Π.Π.Α. Ε. Αναστασίου, Πανεπιστήμιο Θεσσαλίας Τ.Μ.Χ.Π.Π.Α. ΔΙΑΛΕΞΗ 07 & ΔΙΑΛΕΞΗ 08 ΣΗΜΠΕΡΑΣΜΑΤΙΚΗ ΣΤΑΤΙΣΤΙΚΗ Βόλος, 016-017 ΕΙΣΑΓΩΓΗ ΣΤΗΝ
ΕΙΣΑΓΩΓΗ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ Μ.Ν. Ντυκέν, Πανεπιστήμιο Θεσσαλίας Τ.Μ.Χ.Π.Π.Α. Ε. Αναστασίου, Πανεπιστήμιο Θεσσαλίας Τ.Μ.Χ.Π.Π.Α. ΔΙΑΛΕΞΗ 07 & ΔΙΑΛΕΞΗ 08 ΣΗΜΠΕΡΑΣΜΑΤΙΚΗ ΣΤΑΤΙΣΤΙΚΗ Βόλος, 016-017 ΕΙΣΑΓΩΓΗ ΣΤΗΝ
Σ ΤΑΤ Ι Σ Τ Ι Κ Η. Statisticum collegium iv
 Σ ΤΑΤ Ι Σ Τ Ι Κ Η i Statisticum collegium iv Στατιστική Συμπερασματολογία Ι Σημειακές Εκτιμήσεις Διαστήματα Εμπιστοσύνης Στατιστική Συμπερασματολογία (Statistical Inference) Το πεδίο της Στατιστικής Συμπερασματολογία,
Σ ΤΑΤ Ι Σ Τ Ι Κ Η i Statisticum collegium iv Στατιστική Συμπερασματολογία Ι Σημειακές Εκτιμήσεις Διαστήματα Εμπιστοσύνης Στατιστική Συμπερασματολογία (Statistical Inference) Το πεδίο της Στατιστικής Συμπερασματολογία,
Κεφάλαιο 9. Έλεγχοι υποθέσεων
 Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ. Επικ. Καθ. Στέλιος Ζήμερας. Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά
 ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ. Καθ. Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 05 Πολλαπλές συγκρίσεις Στην ανάλυση διακύμανσης ελέγχουμε την ισότητα
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ. Καθ. Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 05 Πολλαπλές συγκρίσεις Στην ανάλυση διακύμανσης ελέγχουμε την ισότητα
Στατιστική είναι το σύνολο των μεθόδων και θεωριών που εφαρμόζονται σε αριθμητικά δεδομένα προκειμένου να ληφθεί κάποια απόφαση σε συνθήκες
 Ορισμός Στατιστική είναι το σύνολο των μεθόδων και θεωριών που εφαρμόζονται σε αριθμητικά δεδομένα προκειμένου να ληφθεί κάποια απόφαση σε συνθήκες αβεβαιότητας. Βασικές έννοιες Η μελέτη ενός πληθυσμού
Ορισμός Στατιστική είναι το σύνολο των μεθόδων και θεωριών που εφαρμόζονται σε αριθμητικά δεδομένα προκειμένου να ληφθεί κάποια απόφαση σε συνθήκες αβεβαιότητας. Βασικές έννοιες Η μελέτη ενός πληθυσμού
Αναπλ. Καθηγήτρια, Ελένη Κανδηλώρου. Αθήνα Σημειώσεις. Εκτίμηση των Παραμέτρων β 0 & β 1. Απλό γραμμικό υπόδειγμα: (1)
") Σημειώσεις Αναπλ. Καθηγήτρια, Ελένη Κανδηλώρου Αθήνα -3-7 Εκτίμηση των Παραμέτρων β & β Απλό γραμμικό υπόδειγμα: Y X () Η αναμενόμενη τιμή του Υ, δηλαδή, μέση τιμή του Υ, δίνεται παρακάτω: EY ( ) X EY
Σημειώσεις Αναπλ. Καθηγήτρια, Ελένη Κανδηλώρου Αθήνα -3-7 Εκτίμηση των Παραμέτρων β & β Απλό γραμμικό υπόδειγμα: Y X () Η αναμενόμενη τιμή του Υ, δηλαδή, μέση τιμή του Υ, δίνεται παρακάτω: EY ( ) X EY
ΠΑΛΙΝΔΡΟΜΗΣΗ ΤΑΞΗΣ ΜΕΓΕΘΟΥΣ
 . ΠΑΛΙΝΔΡΟΜΗΣΗ ΤΑΞΗΣ ΜΕΓΕΘΟΥΣ (RANK REGRESSION).1 Μονότονη Παλινδρόμηση (Monotonic Regression) Από τη γραφική παράσταση των δεδομένων του προηγουμένου προβλήματος παρατηρούμε ότι τα ζευγάρια (Χ i, i )
. ΠΑΛΙΝΔΡΟΜΗΣΗ ΤΑΞΗΣ ΜΕΓΕΘΟΥΣ (RANK REGRESSION).1 Μονότονη Παλινδρόμηση (Monotonic Regression) Από τη γραφική παράσταση των δεδομένων του προηγουμένου προβλήματος παρατηρούμε ότι τα ζευγάρια (Χ i, i )
Χ. Εμμανουηλίδης, 1
 Εφαρμοσμένη Στατιστική Έρευνα Απλό Γραμμικό Υπόδειγμα AΠΛΟ ΓΡΑΜΜΙΚΟ ΥΠΟ ΕΙΓΜΑ Δρ. Χρήστος Εμμανουηλίδης Αν. Καθηγητής Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Εφαρμοσμένη Στατιστική, Τμήμα Ο.Ε. ΑΠΘ Χ. Εμμανουηλίδης,
Εφαρμοσμένη Στατιστική Έρευνα Απλό Γραμμικό Υπόδειγμα AΠΛΟ ΓΡΑΜΜΙΚΟ ΥΠΟ ΕΙΓΜΑ Δρ. Χρήστος Εμμανουηλίδης Αν. Καθηγητής Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Εφαρμοσμένη Στατιστική, Τμήμα Ο.Ε. ΑΠΘ Χ. Εμμανουηλίδης,
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 5-6 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 735468 Σε αρκετές εφαρμογές
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 5-6 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 735468 Σε αρκετές εφαρμογές
ΧΡΟΝΙΚΕΣ ΣΕΙΡΕΣ. Παπάνα Αγγελική
 ΧΡΟΝΙΚΕΣ ΣΕΙΡΕΣ 7ο μάθημα: Πολυμεταβλητή παλινδρόμηση (ΕΠΑΝΑΛΗΨΗ) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ & ΠΑΜΑΚ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana
ΧΡΟΝΙΚΕΣ ΣΕΙΡΕΣ 7ο μάθημα: Πολυμεταβλητή παλινδρόμηση (ΕΠΑΝΑΛΗΨΗ) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ & ΠΑΜΑΚ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana
ΠΕΡΙΕΧΟΜΕΝΑ ΚΕΦΑΛΑΙΟ 3 ΔΕΣΜΕΥΜΕΝΗ ΠΙΘΑΝΟΤΗΤΑ, ΟΛΙΚΗ ΠΙΘΑΝΟΤΗΤΑ ΘΕΩΡΗΜΑ BAYES, ΑΝΕΞΑΡΤΗΣΙΑ ΚΑΙ ΣΥΝΑΦΕΙΣ ΕΝΝΟΙΕΣ 71
 ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ ΠΙΘΑΝΟΤΗΤΕΣ 11 ΚΕΦΑΛΑΙΟ 1 ΕΙΣΑΓΩΓΗ 13 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 19 2.1 Αβεβαιότητα, Τυχαία Διαδικασία, και Συναφείς Έννοιες 21 2.1.1 Αβεβαιότητα και Τυχαίο Πείραμα
ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ ΠΙΘΑΝΟΤΗΤΕΣ 11 ΚΕΦΑΛΑΙΟ 1 ΕΙΣΑΓΩΓΗ 13 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 19 2.1 Αβεβαιότητα, Τυχαία Διαδικασία, και Συναφείς Έννοιες 21 2.1.1 Αβεβαιότητα και Τυχαίο Πείραμα
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΠΟΥΔΩΝ ΜΑΘΗΜΑΤΙΚΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΚΑΙ ΑΠΟΦΑΣΕΩΝ. Διαχωριστική Ανάλυση Λογιστική Παλινδρόμηση
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΠΟΥΔΩΝ ΜΑΘΗΜΑΤΙΚΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΚΑΙ ΑΠΟΦΑΣΕΩΝ Διαχωριστική Ανάλυση Λογιστική Παλινδρόμηση Χουντής Βασίλειος Επιβλέπων : Αλεβίζος Φίλιππος, Επίκουρος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΠΟΥΔΩΝ ΜΑΘΗΜΑΤΙΚΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΚΑΙ ΑΠΟΦΑΣΕΩΝ Διαχωριστική Ανάλυση Λογιστική Παλινδρόμηση Χουντής Βασίλειος Επιβλέπων : Αλεβίζος Φίλιππος, Επίκουρος
10.7 Λυμένες Ασκήσεις για Διαστήματα Εμπιστοσύνης
 10.7 Λυμένες Ασκήσεις για Διαστήματα Εμπιστοσύνης Διαστήματα εμπιστοσύνης για τον μέσο ενός πληθυσμού (Μικρά δείγματα) Άσκηση 10.7.1: Ο επόμενος πίνακας τιμών δείχνει την αύξηση σε ώρες ύπνου που είχαν
10.7 Λυμένες Ασκήσεις για Διαστήματα Εμπιστοσύνης Διαστήματα εμπιστοσύνης για τον μέσο ενός πληθυσμού (Μικρά δείγματα) Άσκηση 10.7.1: Ο επόμενος πίνακας τιμών δείχνει την αύξηση σε ώρες ύπνου που είχαν
ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Τραπεζικής & Χρηματοοικονομικής
 ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Τραπεζικής & Χρηματοοικονομικής Υποθέσεις του Απλού γραμμικού υποδείγματος της Παλινδρόμησης Η μεταβλητή ε t (διαταρακτικός όρος) είναι τυχαία μεταβλητή με μέσο όρο
ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Τραπεζικής & Χρηματοοικονομικής Υποθέσεις του Απλού γραμμικού υποδείγματος της Παλινδρόμησης Η μεταβλητή ε t (διαταρακτικός όρος) είναι τυχαία μεταβλητή με μέσο όρο
Εφαρμοσμένη Στατιστική: Συντελεστής συσχέτισης. Παλινδρόμηση απλή γραμμική, πολλαπλή γραμμική
 ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΜΕΡΟΣ B Δημήτρης Κουγιουμτζής e-mal: dkugu@auth.gr Ιστοσελίδα αυτού του τμήματος του μαθήματος: http://uer.auth.gr/~dkugu/teach/cvltraport/dex.html Εφαρμοσμένη Στατιστική:
ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΜΕΡΟΣ B Δημήτρης Κουγιουμτζής e-mal: dkugu@auth.gr Ιστοσελίδα αυτού του τμήματος του μαθήματος: http://uer.auth.gr/~dkugu/teach/cvltraport/dex.html Εφαρμοσμένη Στατιστική:
ΧΡΟΝΙΚΕΣ ΣΕΙΡΕΣ. Παπάνα Αγγελική
 ΧΡΟΝΙΚΕΣ ΣΕΙΡΕΣ 7o Μάθημα: Απλή παλινδρόμηση (ΕΠΑΝΑΛΗΨΗ) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ & ΠΑΜΑΚ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana
ΧΡΟΝΙΚΕΣ ΣΕΙΡΕΣ 7o Μάθημα: Απλή παλινδρόμηση (ΕΠΑΝΑΛΗΨΗ) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ & ΠΑΜΑΚ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana
ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ Ι Συμπληρωματικές Σημειώσεις Δημήτριος Παντελής
 ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ Ι Συμπληρωματικές Σημειώσεις Δημήτριος Παντελής ΣΤΑΤΙΣΤΙΚΕΣ ΕΚΤΙΜΗΣΕΙΣ Οι συναρτήσεις πιθανότητας ή πυκνότητας πιθανότητας των διαφόρων τυχαίων μεταβλητών χαρακτηρίζονται από κάποιες
ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ Ι Συμπληρωματικές Σημειώσεις Δημήτριος Παντελής ΣΤΑΤΙΣΤΙΚΕΣ ΕΚΤΙΜΗΣΕΙΣ Οι συναρτήσεις πιθανότητας ή πυκνότητας πιθανότητας των διαφόρων τυχαίων μεταβλητών χαρακτηρίζονται από κάποιες
ΔΙΑΧΩΡΙΣΜΟΣ ΚΑΙ ΤΑΞΙΝΟΜΗΣΗ ΚΡΗΤΙΚΟΥ ΚΑΤΕΡΙΝΑ NΙΚΑΚΗ ΚΑΤΕΡΙΝΑ NΙΚΟΛΑΪΔΟΥ ΧΡΥΣΑ
 ΔΙΑΧΩΡΙΣΜΟΣ ΚΑΙ ΤΑΞΙΝΟΜΗΣΗ ΚΡΗΤΙΚΟΥ ΚΑΤΕΡΙΝΑ NΙΚΑΚΗ ΚΑΤΕΡΙΝΑ NΙΚΟΛΑΪΔΟΥ ΧΡΥΣΑ ΔΙΑΧΩΡΙΣΜΟΣ ΚΑΙ ΤΑΞΙΝΟΜΗΣΗ Είναι τεχνικές που έχουν σκοπό: τον εντοπισμό χαρακτηριστικών των οποίων οι αριθμητικές τιμές επιτυγχάνουν
ΔΙΑΧΩΡΙΣΜΟΣ ΚΑΙ ΤΑΞΙΝΟΜΗΣΗ ΚΡΗΤΙΚΟΥ ΚΑΤΕΡΙΝΑ NΙΚΑΚΗ ΚΑΤΕΡΙΝΑ NΙΚΟΛΑΪΔΟΥ ΧΡΥΣΑ ΔΙΑΧΩΡΙΣΜΟΣ ΚΑΙ ΤΑΞΙΝΟΜΗΣΗ Είναι τεχνικές που έχουν σκοπό: τον εντοπισμό χαρακτηριστικών των οποίων οι αριθμητικές τιμές επιτυγχάνουν
ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ ΠΙΘΑΝΟΤΗΤΕΣ 13 ΚΕΦΑΛΑΙΟ 1 ΕΙΣΑΓΩΓΗ 15 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 19
 ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ ΠΙΘΑΝΟΤΗΤΕΣ 13 ΚΕΦΑΛΑΙΟ 1 ΕΙΣΑΓΩΓΗ 15 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 19 2.1 Αβεβαιότητα, Τυχαία Διαδικασία, και Συναφείς Έννοιες 21 2.1.1 Αβεβαιότητα και Τυχαίο Πείραμα
ΠΕΡΙΕΧΟΜΕΝΑ ΜΕΡΟΣ ΠΡΩΤΟ ΠΙΘΑΝΟΤΗΤΕΣ 13 ΚΕΦΑΛΑΙΟ 1 ΕΙΣΑΓΩΓΗ 15 ΚΕΦΑΛΑΙΟ 2 ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΠΙΘΑΝΟΤΗΤΑΣ 19 2.1 Αβεβαιότητα, Τυχαία Διαδικασία, και Συναφείς Έννοιες 21 2.1.1 Αβεβαιότητα και Τυχαίο Πείραμα
ΣΧΟΛΗ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΤΜΗΜΑ ΟΡΓΑΝΩΣΗΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΔΙΔΑΣΚΩΝ: ΘΑΝΑΣΗΣ ΚΑΖΑΝΑΣ. Οικονομετρία
 ΣΧΟΛΗ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΤΜΗΜΑ ΟΡΓΑΝΩΣΗΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΔΙΔΑΣΚΩΝ: ΘΑΝΑΣΗΣ ΚΑΖΑΝΑΣ Οικονομετρία 4.1 Πολλαπλό Γραμμικό Υπόδειγμα Παλινδρόμησης Γενικεύοντας τη διμεταβλητή (Y, X) συνάρτηση
ΣΧΟΛΗ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΤΜΗΜΑ ΟΡΓΑΝΩΣΗΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΔΙΔΑΣΚΩΝ: ΘΑΝΑΣΗΣ ΚΑΖΑΝΑΣ Οικονομετρία 4.1 Πολλαπλό Γραμμικό Υπόδειγμα Παλινδρόμησης Γενικεύοντας τη διμεταβλητή (Y, X) συνάρτηση
Στατιστικός έλεγχος υποθέσεων (Μέρος 1 ο )
") Στατιστικός έλεγχος υποθέσεων (Μέρος 1 ο ) 2 Η γενική ιδέα της διαδικασίας στατιστικού ελέγχου υποθέσεων Πρόκειται για μια διαδικασία απόφασης μεταξύ δύο υποθέσεων Η μια υπόθεση ονομάζεται μηδενική (Η
Στατιστικός έλεγχος υποθέσεων (Μέρος 1 ο ) 2 Η γενική ιδέα της διαδικασίας στατιστικού ελέγχου υποθέσεων Πρόκειται για μια διαδικασία απόφασης μεταξύ δύο υποθέσεων Η μια υπόθεση ονομάζεται μηδενική (Η
Μέθοδοι πολυδιάστατης ελαχιστοποίησης
 Μέθοδοι πολυδιάστατης ελαχιστοποίησης με παραγώγους Μέθοδοι πολυδιάστατης ελαχιστοποίησης Δ. Γ. Παπαγεωργίου Τμήμα Μηχανικών Επιστήμης Υλικών Πανεπιστήμιο Ιωαννίνων dpapageo@cc.uoi.gr http://pc64.materials.uoi.gr/dpapageo
Μέθοδοι πολυδιάστατης ελαχιστοποίησης με παραγώγους Μέθοδοι πολυδιάστατης ελαχιστοποίησης Δ. Γ. Παπαγεωργίου Τμήμα Μηχανικών Επιστήμης Υλικών Πανεπιστήμιο Ιωαννίνων dpapageo@cc.uoi.gr http://pc64.materials.uoi.gr/dpapageo
Στατιστική Συμπερασματολογία
 4. Εκτιμητική Στατιστική Συμπερασματολογία εκτιμήσεις των αγνώστων παραμέτρων μιας γνωστής από άποψη είδους κατανομής έλεγχο των υποθέσεων που γίνονται σε σχέση με τις παραμέτρους μιας κατανομής και σε
4. Εκτιμητική Στατιστική Συμπερασματολογία εκτιμήσεις των αγνώστων παραμέτρων μιας γνωστής από άποψη είδους κατανομής έλεγχο των υποθέσεων που γίνονται σε σχέση με τις παραμέτρους μιας κατανομής και σε
Κεφάλαιο 10 Εισαγωγή στην Εκτίμηση
 Κεφάλαιο 10 Εισαγωγή στην Εκτίμηση Εκεί που είμαστε Κεφάλαια 7 και 8: Οι διωνυμικές,κανονικές, εκθετικές κατανομές και κατανομές Poisson μας επιτρέπουν να κάνουμε διατυπώσεις πιθανοτήτων γύρω από το Χ
Κεφάλαιο 10 Εισαγωγή στην Εκτίμηση Εκεί που είμαστε Κεφάλαια 7 και 8: Οι διωνυμικές,κανονικές, εκθετικές κατανομές και κατανομές Poisson μας επιτρέπουν να κάνουμε διατυπώσεις πιθανοτήτων γύρω από το Χ
Μέθοδος μέγιστης πιθανοφάνειας
 Μέθοδος μέγιστης πιθανοφάνειας Αν x =,,, παρατηρήσεις των Χ =,,,, τότε έχουμε διαθέσιμο ένα δείγμα Χ={Χ, =,,,} της κατανομής F μεγέθους με από κοινού σ.κ. της Χ f x f x Ορισμός : Θεωρούμε ένα τυχαίο δείγμα
Μέθοδος μέγιστης πιθανοφάνειας Αν x =,,, παρατηρήσεις των Χ =,,,, τότε έχουμε διαθέσιμο ένα δείγμα Χ={Χ, =,,,} της κατανομής F μεγέθους με από κοινού σ.κ. της Χ f x f x Ορισμός : Θεωρούμε ένα τυχαίο δείγμα
ΠΑΝΕΠΙΣΤΗΜΙΑΚΑ ΦΡΟΝΤΙΣΤΗΡΙΑ ΚΟΛΛΙΝΤΖΑ. Ερωτήσεις πολλαπλής επιλογής. Συντάκτης: Δημήτριος Κρέτσης
 ΠΑΝΕΠΙΣΤΗΜΙΑΚΑ ΦΡΟΝΤΙΣΤΗΡΙΑ ΚΟΛΛΙΝΤΖΑ Ερωτήσεις πολλαπλής επιλογής Συντάκτης: Δημήτριος Κρέτσης 1. Ο κλάδος της περιγραφικής Στατιστικής: α. Ασχολείται με την επεξεργασία των δεδομένων και την ανάλυση
ΠΑΝΕΠΙΣΤΗΜΙΑΚΑ ΦΡΟΝΤΙΣΤΗΡΙΑ ΚΟΛΛΙΝΤΖΑ Ερωτήσεις πολλαπλής επιλογής Συντάκτης: Δημήτριος Κρέτσης 1. Ο κλάδος της περιγραφικής Στατιστικής: α. Ασχολείται με την επεξεργασία των δεδομένων και την ανάλυση
3. Κατανομές πιθανότητας
 3. Κατανομές πιθανότητας Τυχαία Μεταβλητή Τυχαία μεταβλητή (τ.μ.) (X) είναι μια συνάρτηση που σε κάθε σημείο (ω) ενός δειγματικού χώρου (Ω) αντιστοιχεί έναν πραγματικό αριθμό. Ω ω X (ω ) R Διακριτή τ.μ.
3. Κατανομές πιθανότητας Τυχαία Μεταβλητή Τυχαία μεταβλητή (τ.μ.) (X) είναι μια συνάρτηση που σε κάθε σημείο (ω) ενός δειγματικού χώρου (Ω) αντιστοιχεί έναν πραγματικό αριθμό. Ω ω X (ω ) R Διακριτή τ.μ.
ΟΙΚΟΝΟΜΕΤΡΙΑ. Β μέρος: Ετεροσκεδαστικότητα. Παπάνα Αγγελική
 ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 10: Οικονομετρικά προβλήματα: Παραβίαση των υποθέσεων Β μέρος: Ετεροσκεδαστικότητα Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr
ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 10: Οικονομετρικά προβλήματα: Παραβίαση των υποθέσεων Β μέρος: Ετεροσκεδαστικότητα Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ. Επικ. Καθ. Στέλιος Ζήμερας. Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά
 ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ. Καθ. Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 2015 Πληθυσμός: Εισαγωγή Ονομάζεται το σύνολο των χαρακτηριστικών που
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ. Καθ. Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 2015 Πληθυσμός: Εισαγωγή Ονομάζεται το σύνολο των χαρακτηριστικών που
ΘΕΩΡΙΑ ΟΙΚΟΝΟΜΕΤΡΙΑΣ ΣΥΝΟΠΤΙΚΕΣ ΣΗΜΕΙΩΣΕΙΣ
 ΘΕΩΡΙΑ ΟΙΚΟΝΟΜΕΤΡΙΑΣ ΣΥΝΟΠΤΙΚΕΣ ΣΗΜΕΙΩΣΕΙΣ ΑΠΛΟ ΓΡΑΜΜΙΚΟ ΥΠΟΔΕΙΓΜΑ Συντελεστής συσχέτισης (εκτιμητής Person: r, Y ( ( Y Y xy ( ( Y Y x y, όπου r, Y (ισχυρή θετική γραμμική συσχέτιση όταν, ισχυρή αρνητική
ΘΕΩΡΙΑ ΟΙΚΟΝΟΜΕΤΡΙΑΣ ΣΥΝΟΠΤΙΚΕΣ ΣΗΜΕΙΩΣΕΙΣ ΑΠΛΟ ΓΡΑΜΜΙΚΟ ΥΠΟΔΕΙΓΜΑ Συντελεστής συσχέτισης (εκτιμητής Person: r, Y ( ( Y Y xy ( ( Y Y x y, όπου r, Y (ισχυρή θετική γραμμική συσχέτιση όταν, ισχυρή αρνητική
Στατιστική Ι. Ενότητα 9: Κατανομή t-έλεγχος Υποθέσεων. Δρ. Γεώργιος Κοντέος Τμήμα Διοίκησης Επιχειρήσεων Γρεβενών
 Στατιστική Ι Ενότητα 9: Κατανομή t-έλεγχος Υποθέσεων Δρ. Γεώργιος Κοντέος Τμήμα Διοίκησης Επιχειρήσεων Γρεβενών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για
Στατιστική Ι Ενότητα 9: Κατανομή t-έλεγχος Υποθέσεων Δρ. Γεώργιος Κοντέος Τμήμα Διοίκησης Επιχειρήσεων Γρεβενών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για
Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Οικονομετρία Διάλεξη 2η: Απλή Γραμμική Παλινδρόμηση. Διδάσκουσα: Κοντογιάννη Αριστούλα
 Μάθημα: Οικονομετρία Διάλεξη 2η: Απλή Γραμμική Παλινδρόμηση. Διδάσκουσα: Κοντογιάννη Αριστούλα") Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Οικονομετρία Διάλεξη 2η: Απλή Γραμμική Παλινδρόμηση Διδάσκουσα: Κοντογιάννη Αριστούλα Πώς συσχετίζονται δυο μεταβλητές; Ένας απλός τρόπος για να αποκτήσουμε
Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Οικονομετρία Διάλεξη 2η: Απλή Γραμμική Παλινδρόμηση Διδάσκουσα: Κοντογιάννη Αριστούλα Πώς συσχετίζονται δυο μεταβλητές; Ένας απλός τρόπος για να αποκτήσουμε
Κεφάλαιο 9. Έλεγχοι υποθέσεων
 Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
Κεφάλαιο 9 Έλεγχοι υποθέσεων 9.1 Εισαγωγή Όταν παίρνουμε ένα ή περισσότερα τυχαία δείγμα από κανονικούς πληθυσμούς έχουμε τη δυνατότητα να υπολογίζουμε στατιστικά, όπως μέσους όρους, δειγματικές διασπορές
ΠΕΡΙΓΡΑΦΗ ΚΑΙ ΑΝΑΛΥΣΗ ΔΕΔΟΜΕΝΩΝ
 ΠΕΡΙΓΡΑΦΗ ΚΑΙ ΑΝΑΛΥΣΗ ΔΕΔΟΜΕΝΩΝ Είδη μεταβλητών Ποσοτικά δεδομένα (π.χ. ηλικία, ύψος, αιμοσφαιρίνη) Ποιοτικά δεδομένα (π.χ. άνδρας/γυναίκα, ναι/όχι) Διατεταγμένα (π.χ. καλό/μέτριο/κακό) 2 Περιγραφή ποσοτικών
ΠΕΡΙΓΡΑΦΗ ΚΑΙ ΑΝΑΛΥΣΗ ΔΕΔΟΜΕΝΩΝ Είδη μεταβλητών Ποσοτικά δεδομένα (π.χ. ηλικία, ύψος, αιμοσφαιρίνη) Ποιοτικά δεδομένα (π.χ. άνδρας/γυναίκα, ναι/όχι) Διατεταγμένα (π.χ. καλό/μέτριο/κακό) 2 Περιγραφή ποσοτικών
5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο
 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο") 5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο Ένα εναλλακτικό μοντέλο της απλής γραμμικής παλινδρόμησης (που χρησιμοποιήθηκε
5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο Ένα εναλλακτικό μοντέλο της απλής γραμμικής παλινδρόμησης (που χρησιμοποιήθηκε
ΟΙΚΟΝΟΜΕΤΡΙΑ. Παπάνα Αγγελική
 ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 13: Επανάληψη Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana 1 Γιατί μελετούμε την Οικονομετρία;
ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 13: Επανάληψη Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana 1 Γιατί μελετούμε την Οικονομετρία;
Μέρος V. Ανάλυση Παλινδρόμηση (Regression Analysis)
") Μέρος V. Ανάλυση Παλινδρόμηση (Regresso Aalss) Βασικές έννοιες Απλή Γραμμική Παλινδρόμηση Πολλαπλή Παλινδρόμηση Εφαρμοσμένη Στατιστική Μέρος 5 ο - Κ. Μπλέκας () Βασικές έννοιες Έστω τ.μ. Χ,Υ όπου υπάρχει
Μέρος V. Ανάλυση Παλινδρόμηση (Regresso Aalss) Βασικές έννοιες Απλή Γραμμική Παλινδρόμηση Πολλαπλή Παλινδρόμηση Εφαρμοσμένη Στατιστική Μέρος 5 ο - Κ. Μπλέκας () Βασικές έννοιες Έστω τ.μ. Χ,Υ όπου υπάρχει
Περιγραφική Στατιστική. Ακαδ. Έτος 2012-2013 1 ο εξάμηνο. Κ. Πολίτης
 Περιγραφική Στατιστική Ακαδ. Έτος 2012-2013 1 ο εξάμηνο Κ. Πολίτης 1 2 Η στατιστική ασχολείται με τη συλλογή, οργάνωση, παρουσίαση και ανάλυση πληροφοριών. Οι πληροφορίες αυτές, πολύ συχνά αριθμητικές,
Περιγραφική Στατιστική Ακαδ. Έτος 2012-2013 1 ο εξάμηνο Κ. Πολίτης 1 2 Η στατιστική ασχολείται με τη συλλογή, οργάνωση, παρουσίαση και ανάλυση πληροφοριών. Οι πληροφορίες αυτές, πολύ συχνά αριθμητικές,
ΠΕΡΙΕΧΟΜΕΝΑ. Πρόλογος... 13
 ΠΕΡΙΕΧΟΜΕΝΑ / 7 ΠΕΡΙΕΧΟΜΕΝΑ Πρόλογος... 13 Κεφάλαιο 1: Περιγραφική Στατιστική... 15 1.1 Περιγραφική και Συμπερασματική Στατιστική... 15 1.2 Μεταβλητές - Τιμές - Παρατηρήσεις... 19 1.3 Είδη μεταβλητών...
ΠΕΡΙΕΧΟΜΕΝΑ / 7 ΠΕΡΙΕΧΟΜΕΝΑ Πρόλογος... 13 Κεφάλαιο 1: Περιγραφική Στατιστική... 15 1.1 Περιγραφική και Συμπερασματική Στατιστική... 15 1.2 Μεταβλητές - Τιμές - Παρατηρήσεις... 19 1.3 Είδη μεταβλητών...
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.outras@e.aegea.gr Τηλ: 7035468 Μέθοδος Υπολογισμού
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.outras@e.aegea.gr Τηλ: 7035468 Μέθοδος Υπολογισμού
Α Ν Ω Τ Α Τ Ο Σ Υ Μ Β Ο Υ Λ Ι Ο Ε Π Ι Λ Ο Γ Η Σ Π Ρ Ο Σ Ω Π Ι Κ Ο Υ Ε Ρ Ω Τ Η Μ Α Τ Ο Λ Ο Γ Ι Ο
 Α Ν Ω Τ Α Τ Ο Σ Υ Μ Β Ο Υ Λ Ι Ο Ε Π Ι Λ Ο Γ Η Σ Π Ρ Ο Σ Ω Π Ι Κ Ο Υ Ε Ρ Ω Τ Η Μ Α Τ Ο Λ Ο Γ Ι Ο «Περιγραφική & Επαγωγική Στατιστική» 1. Πάνω από το 3 ο τεταρτημόριο ενός δείγματος βρίσκεται το: α) 15%
Α Ν Ω Τ Α Τ Ο Σ Υ Μ Β Ο Υ Λ Ι Ο Ε Π Ι Λ Ο Γ Η Σ Π Ρ Ο Σ Ω Π Ι Κ Ο Υ Ε Ρ Ω Τ Η Μ Α Τ Ο Λ Ο Γ Ι Ο «Περιγραφική & Επαγωγική Στατιστική» 1. Πάνω από το 3 ο τεταρτημόριο ενός δείγματος βρίσκεται το: α) 15%
ΟΙΚΟΝΟΜΕΤΡΙΑ. Παπάνα Αγγελική
 ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 5: Ανάλυση γραμμικού υποδείγματος Πολυμεταβλητή παλινδρόμηση (1 ο μέρος) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: ageliki.papaa@gmail.com, agpapaa@auth.gr Webpage: http://users.auth.gr/agpapaa
ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 5: Ανάλυση γραμμικού υποδείγματος Πολυμεταβλητή παλινδρόμηση (1 ο μέρος) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: ageliki.papaa@gmail.com, agpapaa@auth.gr Webpage: http://users.auth.gr/agpapaa
Ελλιπή δεδομένα. Εδώ έχουμε 1275. Στον πίνακα που ακολουθεί δίνεται η κατά ηλικία κατανομή 1275 ατόμων
 Ελλιπή δεδομένα Στον πίνακα που ακολουθεί δίνεται η κατά ηλικία κατανομή 75 ατόμων Εδώ έχουμε δ 75,0 75 5 Ηλικία Συχνότητες f 5-4 70 5-34 50 35-44 30 45-54 465 55-64 335 Δεν δήλωσαν 5 Σύνολο 75 Μπορεί
Ελλιπή δεδομένα Στον πίνακα που ακολουθεί δίνεται η κατά ηλικία κατανομή 75 ατόμων Εδώ έχουμε δ 75,0 75 5 Ηλικία Συχνότητες f 5-4 70 5-34 50 35-44 30 45-54 465 55-64 335 Δεν δήλωσαν 5 Σύνολο 75 Μπορεί
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ. Επικ. Καθ. Στέλιος Ζήμερας. Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά
 ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ Καθ Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 5 Έστω για την σύγκριση δειγμάτων συλλέγουμε παρατηρήσεις Υ =,,, από
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ Καθ Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 5 Έστω για την σύγκριση δειγμάτων συλλέγουμε παρατηρήσεις Υ =,,, από
ΠΑΡΟΥΣΙΑΣΗ ΣΤΑΤΙΣΤΙΚΩΝ ΔΕΔΟΜΕΝΩΝ
 ο Κεφάλαιο: Στατιστική ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΚΑΙ ΟΡΙΣΜΟΙ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ Πληθυσμός: Λέγεται ένα σύνολο στοιχείων που θέλουμε να εξετάσουμε με ένα ή περισσότερα χαρακτηριστικά. Μεταβλητές X: Ονομάζονται
ο Κεφάλαιο: Στατιστική ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΚΑΙ ΟΡΙΣΜΟΙ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ Πληθυσμός: Λέγεται ένα σύνολο στοιχείων που θέλουμε να εξετάσουμε με ένα ή περισσότερα χαρακτηριστικά. Μεταβλητές X: Ονομάζονται
X = = 81 9 = 9
 Πιθανότητες και Αρχές Στατιστικής (11η Διάλεξη) Σωτήρης Νικολετσέας, καθηγητής Τμήμα Μηχανικών Η/Υ & Πληροφορικής, Πανεπιστήμιο Πατρών Ακαδημαϊκό Ετος 2018-2019 Σωτήρης Νικολετσέας, καθηγητής 1 / 35 Σύνοψη
Πιθανότητες και Αρχές Στατιστικής (11η Διάλεξη) Σωτήρης Νικολετσέας, καθηγητής Τμήμα Μηχανικών Η/Υ & Πληροφορικής, Πανεπιστήμιο Πατρών Ακαδημαϊκό Ετος 2018-2019 Σωτήρης Νικολετσέας, καθηγητής 1 / 35 Σύνοψη
ΜΑΘΗΜΑΤΙΚΑ. 1 ο ΔΙΑΓΩΝΙΣΜΑ. ΘΕΜΑ 1 ο Δίνεται η συνάρτηση f x. Ι. Το πεδίο ορισμού της f είναι:., 1 υ -1, B. 1, Γ. -1,., 1.
 Γ ΛΥΚΕΙΟΥ-ΓΕΝΙΚΗ ΠΑΙΔΕΙΑ ΜΑΘΗΜΑΤΙΚΑ ο ΔΙΑΓΩΝΙΣΜΑ ΘΕΜΑ ο Δίνεται η συνάρτηση f Ι. Το πεδίο ορισμού της f είναι:., υ -, B., Γ. -,.,., ΙΙ. Το όριο f lm 0 είναι ίσο με: Α. 0 Β. Γ. Δ. Ε. Τίποτε από τα προηγούμενα
Γ ΛΥΚΕΙΟΥ-ΓΕΝΙΚΗ ΠΑΙΔΕΙΑ ΜΑΘΗΜΑΤΙΚΑ ο ΔΙΑΓΩΝΙΣΜΑ ΘΕΜΑ ο Δίνεται η συνάρτηση f Ι. Το πεδίο ορισμού της f είναι:., υ -, B., Γ. -,.,., ΙΙ. Το όριο f lm 0 είναι ίσο με: Α. 0 Β. Γ. Δ. Ε. Τίποτε από τα προηγούμενα
ΜΑΘΗΜΑΤΙΚΑ ΓΕΝΙΚΗΣ ΠΑΙΔΕΙΑΣ
 ΜΑΘΗΜΑΤΙΚΑ ΓΕΝΙΚΗΣ ΠΑΙΔΕΙΑΣ Γ. ΛΥΚΕΙΟΥ ΘΕΜΑΤΑ ΕΠΑΝΑΛΗΨΗΣ - ΘΕΜΑ Ο Έστω η συνάρτηση f( ) =, 0 ) Να αποδείξετε ότι f ( ). f( ) =. ) Να υπολογίσετε το όριο lm f ( )+ 4. ) Να βρείτε την εξίσωση της εφαπτομένης
ΜΑΘΗΜΑΤΙΚΑ ΓΕΝΙΚΗΣ ΠΑΙΔΕΙΑΣ Γ. ΛΥΚΕΙΟΥ ΘΕΜΑΤΑ ΕΠΑΝΑΛΗΨΗΣ - ΘΕΜΑ Ο Έστω η συνάρτηση f( ) =, 0 ) Να αποδείξετε ότι f ( ). f( ) =. ) Να υπολογίσετε το όριο lm f ( )+ 4. ) Να βρείτε την εξίσωση της εφαπτομένης
ΠΕΡΙΕΧΟΜΕΝΑ ΠΡΟΛΟΓΟΣ 7. ΚΕΦΑΛΑΙΟ 1: Εισαγωγικές Έννοιες 13
 ΠΕΡΙΕΧΟΜΕΝΑ ΠΡΟΛΟΓΟΣ 7 ΚΕΦΑΛΑΙΟ 1: Εισαγωγικές Έννοιες 13 1.1. Εισαγωγή 13 1.2. Μοντέλο ή Υπόδειγμα 13 1.3. Η Ανάλυση Παλινδρόμησης 16 1.4. Το γραμμικό μοντέλο Παλινδρόμησης 17 1.5. Πρακτική χρησιμότητα
ΠΕΡΙΕΧΟΜΕΝΑ ΠΡΟΛΟΓΟΣ 7 ΚΕΦΑΛΑΙΟ 1: Εισαγωγικές Έννοιες 13 1.1. Εισαγωγή 13 1.2. Μοντέλο ή Υπόδειγμα 13 1.3. Η Ανάλυση Παλινδρόμησης 16 1.4. Το γραμμικό μοντέλο Παλινδρόμησης 17 1.5. Πρακτική χρησιμότητα
Η ΙΣΧΥΣ ΕΝΟΣ ΕΛΕΓΧΟΥ. (Power of a Test) ΚΕΦΑΛΑΙΟ 21
 ΚΕΦΑΛΑΙΟ 21") ΚΕΦΑΛΑΙΟ 21 Η ΙΣΧΥΣ ΕΝΟΣ ΕΛΕΓΧΟΥ (Power of a Test) Όπως είδαμε προηγουμένως, στον Στατιστικό Έλεγχο Υποθέσεων, ορίζουμε δύο είδη πιθανών λαθών (κινδύνων) που μπορεί να συμβούν όταν παίρνουμε αποφάσεις
ΚΕΦΑΛΑΙΟ 21 Η ΙΣΧΥΣ ΕΝΟΣ ΕΛΕΓΧΟΥ (Power of a Test) Όπως είδαμε προηγουμένως, στον Στατιστικό Έλεγχο Υποθέσεων, ορίζουμε δύο είδη πιθανών λαθών (κινδύνων) που μπορεί να συμβούν όταν παίρνουμε αποφάσεις
Εφαρμοσμένη Στατιστική
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Εφαρμοσμένη Στατιστική Παλινδρόμηση Διδάσκων: Επίκουρος Καθηγητής Κωνσταντίνος Μπλέκας Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Εφαρμοσμένη Στατιστική Παλινδρόμηση Διδάσκων: Επίκουρος Καθηγητής Κωνσταντίνος Μπλέκας Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Απλή Γραμμική Παλινδρόμηση I
 Απλή Γραμμική Παλινδρόμηση I. Εισαγωγή Έστω ότι θέλουμε να ερευνήσουμε εμπειρικά τη σχέση που υπάρχει ανάμεσα στις δαπάνες κατανάλωσης και στο διαθέσιμο εισόδημα, των οικογενειών. Σύμφωνα με την Κεϋνσιανή
Απλή Γραμμική Παλινδρόμηση I. Εισαγωγή Έστω ότι θέλουμε να ερευνήσουμε εμπειρικά τη σχέση που υπάρχει ανάμεσα στις δαπάνες κατανάλωσης και στο διαθέσιμο εισόδημα, των οικογενειών. Σύμφωνα με την Κεϋνσιανή
ΟΙΚΟΝΟΜΕΤΡΙΑ Κεφάλαιο 2
 013 [Κεφάλαιο ] ΟΙΚΟΝΟΜΕΤΡΙΑ Κεφάλαιο Μάθημα Εαρινού Εξάμηνου 01-013 M.E. OE0300 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Χωροταξίας, Πολεοδομίας και Περιφερειακής Ανάπτυξης [Οικονομετρία 01-013] Μαρί-Νοέλ
013 [Κεφάλαιο ] ΟΙΚΟΝΟΜΕΤΡΙΑ Κεφάλαιο Μάθημα Εαρινού Εξάμηνου 01-013 M.E. OE0300 Πανεπιστήμιο Θεσσαλίας Τμήμα Μηχανικών Χωροταξίας, Πολεοδομίας και Περιφερειακής Ανάπτυξης [Οικονομετρία 01-013] Μαρί-Νοέλ
HMY 795: Αναγνώριση Προτύπων
 HMY 795: Αναγνώριση Προτύπων Διάλεξη 3 Επιλογή μοντέλου Επιλογή μοντέλου Θεωρία αποφάσεων Επιλογή μοντέλου δεδομένα επικύρωσης Η επιλογή του είδους του μοντέλου που θα χρησιμοποιηθεί σε ένα πρόβλημα (π.χ.
HMY 795: Αναγνώριση Προτύπων Διάλεξη 3 Επιλογή μοντέλου Επιλογή μοντέλου Θεωρία αποφάσεων Επιλογή μοντέλου δεδομένα επικύρωσης Η επιλογή του είδους του μοντέλου που θα χρησιμοποιηθεί σε ένα πρόβλημα (π.χ.
ΘΕΩΡΙΑ ΑΠΟΦΑΣΕΩΝ 3 ο ΦΡΟΝΤΙΣΤΗΡΙΟ ΛΥΣΕΙΣ ΤΩΝ ΑΣΚΗΣΕΩΝ
 ΘΕΩΡΙΑ ΑΠΟΦΑΣΕΩΝ 3 ο ΦΡΟΝΤΙΣΤΗΡΙΟ ΛΥΣΕΙΣ ΤΩΝ ΑΣΚΗΣΕΩΝ ΑΣΚΗΣΗ Σύμφωνα με στοιχεία από το Πανεπιστήμιο της Οξφόρδης η πιθανότητα ένας φοιτητής να αποφοιτήσει μέσα σε 5 χρόνια από την ημέρα εγγραφής του στο
ΘΕΩΡΙΑ ΑΠΟΦΑΣΕΩΝ 3 ο ΦΡΟΝΤΙΣΤΗΡΙΟ ΛΥΣΕΙΣ ΤΩΝ ΑΣΚΗΣΕΩΝ ΑΣΚΗΣΗ Σύμφωνα με στοιχεία από το Πανεπιστήμιο της Οξφόρδης η πιθανότητα ένας φοιτητής να αποφοιτήσει μέσα σε 5 χρόνια από την ημέρα εγγραφής του στο
Λίγα λόγια για τους συγγραφείς 16 Πρόλογος 17
 Περιεχόμενα Λίγα λόγια για τους συγγραφείς 16 Πρόλογος 17 1 Εισαγωγή 21 1.1 Γιατί χρησιμοποιούμε τη στατιστική; 21 1.2 Τι είναι η στατιστική; 22 1.3 Περισσότερα για την επαγωγική στατιστική 23 1.4 Τρεις
Περιεχόμενα Λίγα λόγια για τους συγγραφείς 16 Πρόλογος 17 1 Εισαγωγή 21 1.1 Γιατί χρησιμοποιούμε τη στατιστική; 21 1.2 Τι είναι η στατιστική; 22 1.3 Περισσότερα για την επαγωγική στατιστική 23 1.4 Τρεις
ΕΚΤΙΜΙΣΗ ΜΕΓΙΣΤΗΣ ΠΙΘΑΝΟΦΑΝΕΙΑΣ
 3.1 Εισαγωγή ΕΚΤΙΜΙΣΗ ΜΕΓΙΣΤΗΣ ΠΙΘΑΝΟΦΑΝΕΙΑΣ Στο κεφ. 2 είδαμε πώς θα μπορούσαμε να σχεδιάσουμε έναν βέλτιστο ταξινομητή εάν ξέραμε τις προγενέστερες(prior) πιθανότητες ( ) και τις κλάση-υπό όρους πυκνότητες
3.1 Εισαγωγή ΕΚΤΙΜΙΣΗ ΜΕΓΙΣΤΗΣ ΠΙΘΑΝΟΦΑΝΕΙΑΣ Στο κεφ. 2 είδαμε πώς θα μπορούσαμε να σχεδιάσουμε έναν βέλτιστο ταξινομητή εάν ξέραμε τις προγενέστερες(prior) πιθανότητες ( ) και τις κλάση-υπό όρους πυκνότητες
Μάθημα Αστικής Γεωγραφίας
 Μάθημα Αστικής Γεωγραφίας Διδακτικό Έτος 2015-2016 Παραδόσεις Διδακτικής Ενότητας: Πληθυσμιακή πρόβλεψη Δούκισσας Λεωνίδας, Στατιστικός, Υποψ. Διδάκτορας, Τμήμα Γεωγραφίας, Χαροκόπειο Πανεπιστήμιο Σελίδα
Μάθημα Αστικής Γεωγραφίας Διδακτικό Έτος 2015-2016 Παραδόσεις Διδακτικής Ενότητας: Πληθυσμιακή πρόβλεψη Δούκισσας Λεωνίδας, Στατιστικός, Υποψ. Διδάκτορας, Τμήμα Γεωγραφίας, Χαροκόπειο Πανεπιστήμιο Σελίδα
Αναγνώριση Προτύπων Ι
 Αναγνώριση Προτύπων Ι Ενότητα 3: Στοχαστικά Συστήματα Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Αναγνώριση Προτύπων Ι Ενότητα 3: Στοχαστικά Συστήματα Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Χρονικές σειρές 2 Ο μάθημα: Εισαγωγή στις χρονοσειρές
 Χρονικές σειρές 2 Ο μάθημα: Εισαγωγή στις χρονοσειρές Εαρινό εξάμηνο 2018-2019 μήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή, Α.Π.Θ. & Οικονομικό μήμα, Πανεπιστήμιο
Χρονικές σειρές 2 Ο μάθημα: Εισαγωγή στις χρονοσειρές Εαρινό εξάμηνο 2018-2019 μήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή, Α.Π.Θ. & Οικονομικό μήμα, Πανεπιστήμιο
Αριθμητική Ανάλυση και Εφαρμογές
 Αριθμητική Ανάλυση και Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 07-08 Αριθμητική Παραγώγιση Εισαγωγή Ορισμός 7. Αν y f x είναι μια συνάρτηση ορισμένη σε ένα διάστημα
Αριθμητική Ανάλυση και Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 07-08 Αριθμητική Παραγώγιση Εισαγωγή Ορισμός 7. Αν y f x είναι μια συνάρτηση ορισμένη σε ένα διάστημα
Κεφ. Ιο ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΘΕΩΡΙΑΣ ΠΙΘΑΝΟΤΗΤΩΝ
 ΠΕΡΙΕΧΟΜΕΝΑ Πρόλογος 75 Κεφ. Ιο ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΘΕΩΡΙΑΣ ΠΙΘΑΝΟΤΗΤΩΝ 1.1. Τυχαία γεγονότα ή ενδεχόμενα 17 1.2. Πειράματα τύχης - Δειγματικός χώρος 18 1.3. Πράξεις με ενδεχόμενα 20 1.3.1. Ενδεχόμενα ασυμβίβαστα
ΠΕΡΙΕΧΟΜΕΝΑ Πρόλογος 75 Κεφ. Ιο ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΘΕΩΡΙΑΣ ΠΙΘΑΝΟΤΗΤΩΝ 1.1. Τυχαία γεγονότα ή ενδεχόμενα 17 1.2. Πειράματα τύχης - Δειγματικός χώρος 18 1.3. Πράξεις με ενδεχόμενα 20 1.3.1. Ενδεχόμενα ασυμβίβαστα
Γ. Πειραματισμός Βιομετρία
 Γενικά Συσχέτιση και Συμμεταβολή Όταν σε ένα πείραμα παραλλάσουν ταυτόχρονα δύο μεταβλητές, τότε ενδιαφέρει να διερευνηθεί εάν και πως οι αλλαγές στη μία μεταβλητή σχετίζονται με τις αλλαγές στην άλλη.
Γενικά Συσχέτιση και Συμμεταβολή Όταν σε ένα πείραμα παραλλάσουν ταυτόχρονα δύο μεταβλητές, τότε ενδιαφέρει να διερευνηθεί εάν και πως οι αλλαγές στη μία μεταβλητή σχετίζονται με τις αλλαγές στην άλλη.
ΚΕΦΑΛΑΙΟ 0. Απλή Γραμμική Παλινδρόμηση. Ένα Πρόβλημα. Η επιδιωκόμενη ιδιότητα. Ένα χρήσιμο γράφημα. Οι υπολογισμοί. Η μέθοδος ελαχίστων τετραγώνων ...
 ΚΕΦΑΛΑΙΟ 0 Ένα Πρόβλημα Δεδομένα.6 3. 3.8 4. 4.4 5.8 6.0 6.7 7. 7.8 5.6 7.9 8.0 8. 8. 9. 9.5 9.4 9.6 9.9 Απλή Γραμμική Παλινδρόμηση Μωυσιάδης Χρόνης 6 o Εξάμηνο Μαθηματικών Έχει σχέση το με το ; Ειδικότερα
ΚΕΦΑΛΑΙΟ 0 Ένα Πρόβλημα Δεδομένα.6 3. 3.8 4. 4.4 5.8 6.0 6.7 7. 7.8 5.6 7.9 8.0 8. 8. 9. 9.5 9.4 9.6 9.9 Απλή Γραμμική Παλινδρόμηση Μωυσιάδης Χρόνης 6 o Εξάμηνο Μαθηματικών Έχει σχέση το με το ; Ειδικότερα
Σ ΤΑΤ Ι Σ Τ Ι Κ Η. Statisticum collegium Iii
 Σ ΤΑΤ Ι Σ Τ Ι Κ Η i Statisticum collegium Iii Η Κανονική Κατανομή Λέμε ότι μία τυχαία μεταβλητή X, ακολουθεί την Κανονική Κατανομή με παραμέτρους και και συμβολίζουμε X N, αν έχει συνάρτηση πυκνότητας
Σ ΤΑΤ Ι Σ Τ Ι Κ Η i Statisticum collegium Iii Η Κανονική Κατανομή Λέμε ότι μία τυχαία μεταβλητή X, ακολουθεί την Κανονική Κατανομή με παραμέτρους και και συμβολίζουμε X N, αν έχει συνάρτηση πυκνότητας
Μέθοδος μέγιστης πιθανοφάνειας
 Αν x =,,, παρατηρήσεις των Χ =,,,, τότε έχουμε διαθέσιμο ένα δείγμα Χ={Χ, =,,,} της κατανομής F μεγέθους με από κοινού σκ της Χ f x f x Ορισμός : Θεωρούμε ένα τυχαίο δείγμα Χ=(Χ, Χ,, Χ ) από πληθυσμό το
Αν x =,,, παρατηρήσεις των Χ =,,,, τότε έχουμε διαθέσιμο ένα δείγμα Χ={Χ, =,,,} της κατανομής F μεγέθους με από κοινού σκ της Χ f x f x Ορισμός : Θεωρούμε ένα τυχαίο δείγμα Χ=(Χ, Χ,, Χ ) από πληθυσμό το
Πινάκες συνάφειας. Βαρύτητα συμπτωμάτων. Φύλο Χαμηλή Υψηλή. Άνδρες. Γυναίκες
 Πινάκες συνάφειας εξερεύνηση σχέσεων μεταξύ τυχαίων μεταβλητών. Είναι λογικό λοιπόν, στην ανάλυση των κατηγορικών δεδομένων να μας ενδιαφέρει η σχέση μεταξύ δύο ή περισσότερων κατηγορικών μεταβλητών. Έστω
Πινάκες συνάφειας εξερεύνηση σχέσεων μεταξύ τυχαίων μεταβλητών. Είναι λογικό λοιπόν, στην ανάλυση των κατηγορικών δεδομένων να μας ενδιαφέρει η σχέση μεταξύ δύο ή περισσότερων κατηγορικών μεταβλητών. Έστω
Δειγματοληψία. Πρέπει να γνωρίζουμε πως πήραμε το δείγμα Το πλήθος n ij των παρατηρήσεων σε κάθε κελί είναι τ.μ. με μ ij συμβολίζουμε την μέση τιμή:
 Δειγματοληψία Πρέπει να γνωρίζουμε πως πήραμε το δείγμα Το πλήθος των παρατηρήσεων σε κάθε κελί είναι τ.μ. με μ συμβολίζουμε την μέση τιμή: Επομένως στην δειγματοληψία πινάκων συνάφειας αναφερόμαστε στον
Δειγματοληψία Πρέπει να γνωρίζουμε πως πήραμε το δείγμα Το πλήθος των παρατηρήσεων σε κάθε κελί είναι τ.μ. με μ συμβολίζουμε την μέση τιμή: Επομένως στην δειγματοληψία πινάκων συνάφειας αναφερόμαστε στον
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ. Επικ. Καθ. Στέλιος Ζήμερας. Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά
 ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ Καθ Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 05 Έλεγχος διακυμάνσεων Μας ενδιαφέρει να εξετάσουμε 5 δίαιτες που δίνονται
ΑΝΑΛΥΣΗ ΔΙΑΚΥΜΑΝΣΗΣ Επικ Καθ Στέλιος Ζήμερας Τμήμα Μαθηματικών Κατεύθυνση Στατιστικής και Αναλογιστικά Χρηματοοικονομικά Μαθηματικά 05 Έλεγχος διακυμάνσεων Μας ενδιαφέρει να εξετάσουμε 5 δίαιτες που δίνονται
ΣΤΑΤΙΣΤΙΚΗ ΕΠΙΧΕΙΡΗΣΕΩΝ ΕΙΔΙΚΑ ΘΕΜΑΤΑ ΚΕΦΑΛΑΙΟ 9. Κατανομές Δειγματοληψίας
 ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΠΑΤΡΑΣ Εργαστήριο Λήψης Αποφάσεων & Επιχειρησιακού Προγραμματισμού Καθηγητής Ι. Μητρόπουλος ΣΤΑΤΙΣΤΙΚΗ ΕΠΙΧΕΙΡΗΣΕΩΝ ΕΙΔΙΚΑ ΘΕΜΑΤΑ
ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΠΑΤΡΑΣ Εργαστήριο Λήψης Αποφάσεων & Επιχειρησιακού Προγραμματισμού Καθηγητής Ι. Μητρόπουλος ΣΤΑΤΙΣΤΙΚΗ ΕΠΙΧΕΙΡΗΣΕΩΝ ΕΙΔΙΚΑ ΘΕΜΑΤΑ
Περιγραφική Ανάλυση ποσοτικών μεταβλητών
 Περιγραφική Ανάλυση ποσοτικών μεταβλητών Στο data file Worldsales.sav (αρχείο υποθετικών πωλήσεων ανά ήπειρο και προϊόν) Analyze Descriptive Statistics Frequencies Επιλογή μεταβλητής Revenue Πατάμε στο
Περιγραφική Ανάλυση ποσοτικών μεταβλητών Στο data file Worldsales.sav (αρχείο υποθετικών πωλήσεων ανά ήπειρο και προϊόν) Analyze Descriptive Statistics Frequencies Επιλογή μεταβλητής Revenue Πατάμε στο
ΟΙΚΟΝΟΜΕΤΡΙΑ. Παπάνα Αγγελική
 ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 6: Ανάλυση γραμμικού υποδείγματος Πολυμεταβλητή παλινδρόμηση (2 ο μέρος) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage:
ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 6: Ανάλυση γραμμικού υποδείγματος Πολυμεταβλητή παλινδρόμηση (2 ο μέρος) Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage:
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ
 ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
Το μοντέλο Perceptron
 Το μοντέλο Perceptron Αποτελείται από έναν μόνο νευρώνα McCulloch-Pitts w j x x 1, x2,..., w x T 1 1 x 2 w 2 Σ u x n f(u) Άνυσμα Εισόδου s i x j x n w n -θ w w 1, w2,..., w n T Άνυσμα Βαρών 1 Το μοντέλο
Το μοντέλο Perceptron Αποτελείται από έναν μόνο νευρώνα McCulloch-Pitts w j x x 1, x2,..., w x T 1 1 x 2 w 2 Σ u x n f(u) Άνυσμα Εισόδου s i x j x n w n -θ w w 1, w2,..., w n T Άνυσμα Βαρών 1 Το μοντέλο
Τμήμα Τεχνολόγων Γεωπόνων-Κατεύθυνση Αγροτικής Οικονομίας Εφαρμοσμένη Στατιστική Μάθημα 4 ο :Τυχαίες μεταβλητές Διδάσκουσα: Κοντογιάννη Αριστούλα
 Τμήμα Τεχνολόγων Γεωπόνων-Κατεύθυνση Αγροτικής Οικονομίας Εφαρμοσμένη Στατιστική Μάθημα 4 ο :Τυχαίες μεταβλητές Διδάσκουσα: Κοντογιάννη Αριστούλα Ορισμός τυχαίας μεταβλητής Τυχαία μεταβλητή λέγεται η συνάρτηση
Τμήμα Τεχνολόγων Γεωπόνων-Κατεύθυνση Αγροτικής Οικονομίας Εφαρμοσμένη Στατιστική Μάθημα 4 ο :Τυχαίες μεταβλητές Διδάσκουσα: Κοντογιάννη Αριστούλα Ορισμός τυχαίας μεταβλητής Τυχαία μεταβλητή λέγεται η συνάρτηση
Είδη Μεταβλητών Κλίμακα Μέτρησης Οι τεχνικές της Περιγραφικής στατιστικής ανάλογα με την κλίμακα μέτρησης Οι τελεστές Π και Σ
 ΠΕΡΙΕΧΟΜΕΝΑ ΚΕΦΑΛΑΙΟ 1 Εισαγωγικές Έννοιες 19 1.1 1.2 1.3 1.4 1.5 1.6 1.7 Η Μεταβλητότητα Η Στατιστική Ανάλυση Η Στατιστική και οι Εφαρμοσμένες Επιστήμες Στατιστικός Πληθυσμός και Δείγμα Το στατιστικό
ΠΕΡΙΕΧΟΜΕΝΑ ΚΕΦΑΛΑΙΟ 1 Εισαγωγικές Έννοιες 19 1.1 1.2 1.3 1.4 1.5 1.6 1.7 Η Μεταβλητότητα Η Στατιστική Ανάλυση Η Στατιστική και οι Εφαρμοσμένες Επιστήμες Στατιστικός Πληθυσμός και Δείγμα Το στατιστικό
Στατιστική Ι. Ανάλυση Παλινδρόμησης
 Στατιστική Ι Ανάλυση Παλινδρόμησης Ανάλυση παλινδρόμησης Η πρόβλεψη πωλήσεων, εσόδων, κόστους, παραγωγής, κτλ. είναι η βάση του επιχειρηματικού σχεδιασμού. Η ανάλυση παλινδρόμησης και συσχέτισης είναι
Στατιστική Ι Ανάλυση Παλινδρόμησης Ανάλυση παλινδρόμησης Η πρόβλεψη πωλήσεων, εσόδων, κόστους, παραγωγής, κτλ. είναι η βάση του επιχειρηματικού σχεδιασμού. Η ανάλυση παλινδρόμησης και συσχέτισης είναι
Στατιστική Συμπερασματολογία
 Στατιστική Συμπερασματολογία Διαφάνειες 1 ου κεφαλαίου Βιβλίο: Κολυβά Μαχαίρα, Φ. & Χατζόπουλος Στ. Α. (2016). Μαθηματική Στατιστική, Έλεγχοι Υποθέσεων. [ηλεκτρ. βιβλ.] Αθήνα: Σύνδεσμος Ελληνικών Ακαδημαϊκών
Στατιστική Συμπερασματολογία Διαφάνειες 1 ου κεφαλαίου Βιβλίο: Κολυβά Μαχαίρα, Φ. & Χατζόπουλος Στ. Α. (2016). Μαθηματική Στατιστική, Έλεγχοι Υποθέσεων. [ηλεκτρ. βιβλ.] Αθήνα: Σύνδεσμος Ελληνικών Ακαδημαϊκών
ΔΕΟ13 - Επαναληπτικές Εξετάσεις 2010 Λύσεις
 ΔΕΟ - Επαναληπτικές Εξετάσεις Λύσεις ΘΕΜΑ () Το Διάγραμμα Διασποράς εμφανίζεται στο επόμενο σχήμα. Από αυτό προκύπτει καταρχήν μία θετική σχέση μεταξύ των δύο μεταβλητών. Επίσης, από το διάγραμμα φαίνεται
ΔΕΟ - Επαναληπτικές Εξετάσεις Λύσεις ΘΕΜΑ () Το Διάγραμμα Διασποράς εμφανίζεται στο επόμενο σχήμα. Από αυτό προκύπτει καταρχήν μία θετική σχέση μεταξύ των δύο μεταβλητών. Επίσης, από το διάγραμμα φαίνεται