Ομαδοποίηση Εγγράφων (Document Clustering)
|
|
|
- Εὔα Γαλάνης
- 10 χρόνια πριν
- Προβολές:
Transcript
1 Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2008 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Ομαδοποίηση Εγγράφων (Document Clustering) Γιάννης Τζίτζικας ιάλεξη :13 Ημερομηνία : CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 1 Clustering Clustering is the process of grouping similar objects into naturally associated subclasses. This process results in a set of clusters which somehow describe the underlying objects at a more abstract or approximate level. The process of clustering is typically based on a similarity measure which allows the objects to be classified into separate natural groupings. A cluster is then simply a collection of objects that are grouped together because they collectively have a strong internal similarity based on such a measure. A similarity measure (or dissimilarity measure) quantifies the conceptual distance between two objects, that is, how alike or disalike a pair of objects are. Determining exactly what type of similarity measure to use is typically a domain dependent problem. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 2

2 Clustering A clustering of a set N is a partition of N, i.e. a set C 1,, C k of subsets of N, such that: C 1 C k = N and C i C j =, for all i j. According to the above definition, clusters are disjoint (C i C j =, for all i j.) However there are clustering approaches that yield overlapping clusters (it may be C i C j ) Clustering is used in areas such as: medicine, anthropology, economics, data mining software engineering (reverse engineering, program comprehension, software maintenance) information retrieval In general, any field of endeavor that necessitates the analysis and comprehension of large amounts of data may use clustering. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 3 Clustering Example CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 4
 information retrieval In general, any field of endeavor that necessitates the analysis and comprehension of large amounts of data")
3 Παράδειγμα ομαδοποίησης αποτελεσμάτων CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 5 Παράδειγμα ομαδοποίησης αποτελεσμάτων CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 6
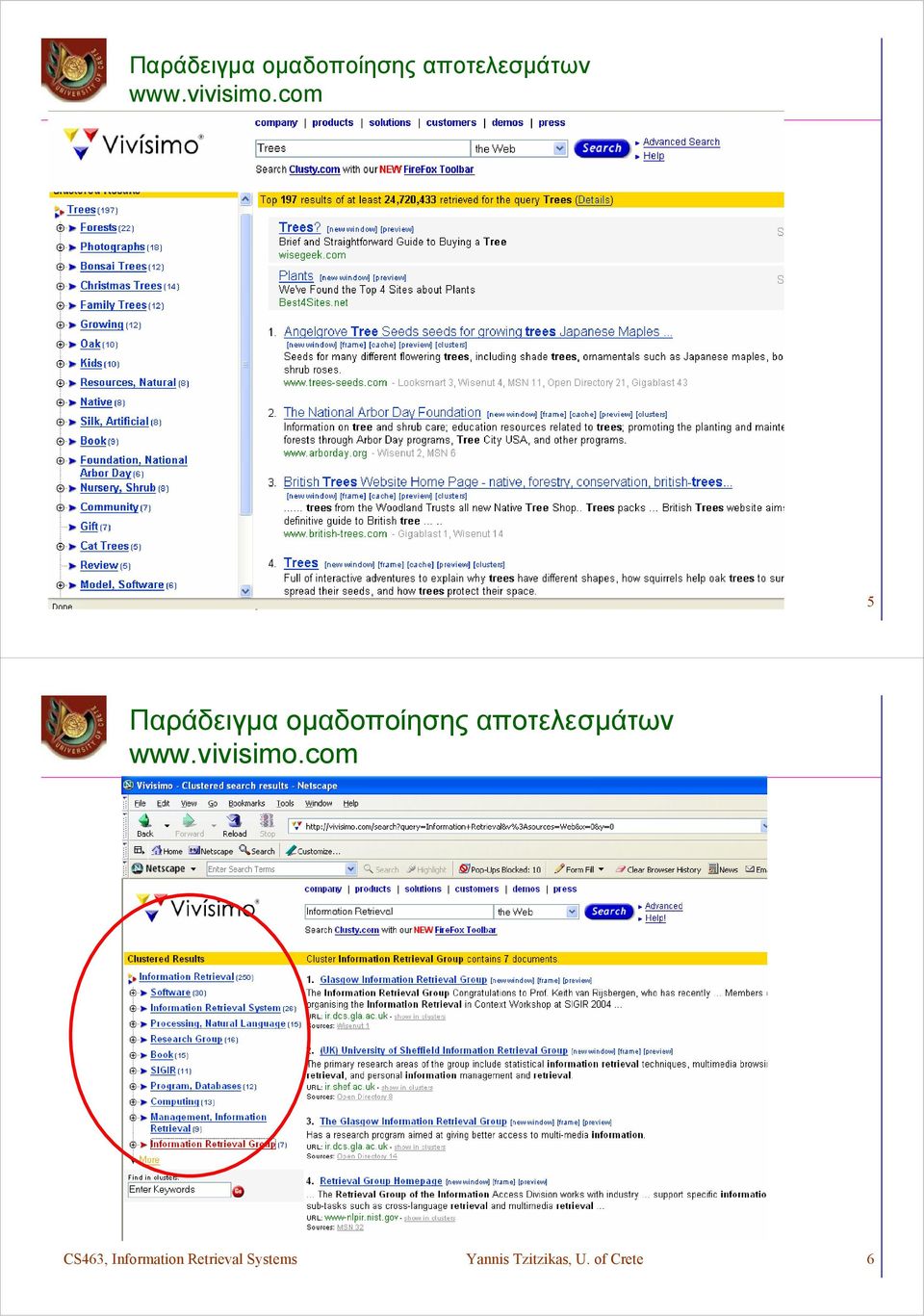
4 Παράδειγμα ομαδοποίησης αποτελεσμάτων CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 7 q=santorini CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 8

5 Τύποι Ομαδοποίησης Ανάλογα με τη σχέση μεταξύ Ιδιοτήτων και Κλάσεων Monothetic clustering Polythetic clustering Ανάλογα με τη σχέση μεταξύ Αντικειμένων και Κλάσεων Αποκλειστική (exclusive) ομαδοποίηση Επικαλυπτόμενη (οverlapping) ομαδοποίηση Ένα αντικείμενο μπορεί να ανήκει σε παραπάνω από μία κλάση Ανάλογα με τη σχέση μεταξύ Κλάσεων Χωρίς διάταξη: οι κλάσεις δεν συνδέονται μεταξύ τους Με διάταξη (ιεραρχική): υπάρχουν σχέσεις μεταξύ των κλάσεων CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 9 Monothetic vs. Polythetic Monothetic Μια κλάση ορίζεται βάσει ενός συνόλου ικανών και αναγκαίων ιδιοτήτων που πρέπει να ικανοποιούν τα μέλη της (Αριστοτελικός ορισμός) Polythetic Μια κλάση ορίζεται βάσει ενός συνόλου ιδιοτήτων Φ =φ1,...,φn, τ.ω. Κάθε μέλος της κλάσης πρέπει να έχει ένα μεγάλο αριθμό των ιδιοτήτων Φ Κάθε φ του Φ χαρακτηρίζει πολλά αντικείμενα Δεν είναι αναγκαίο να υπάρχει μια φ που να ικανοποιείται από όλα τα μέλη της κλάσης Στην ΑΠ, έχει δοθεί έμφαση σε αλγόριθμους για αυτόματη παραγωγή polythetic classifications. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 10
 Polythetic Μια κλάση ορίζεται βάσει ενός")
6 Monothetic vs. Polythetic 8 individuals (1-8) and 8 properties (A-H). The possession of a property is indicated by a plus sign. The individuals 1-4 constitute a polythetic group each individual possessing three out of four of the properties A,B,C,D. The other 4 individuals can be split into two monothetic classes {5,6} and {7,8}. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 11 Μέτρα Συσχέτισης (Association) Μετρικές συναρτήσεις ομοιότητας, συσχέτισης (απόστασης): Pairwise measure Similarity increases as the number or proportion of shared properties increase Typically normalized between 0 and 1 S(X,X)=1, S(X,Y)=S(Y,X) Παραδείγματα μετρικών ομοιότητας Οι περισσότερες είναι κανονικοποιημένες εκδόσεις του Χ Y ή του εσωτερικού γινομένου (εάν έχουμε βεβαρημένους όρους) Dice s coefficient 2 Χ Y / X + Y Jaccard s coefficient Χ Y / X Y Cosine correlation Δεν υπάρχει το «καλύτερο» μέτρο (που να δίνει τα καλύτερα αποτελέσματα σε κάθε περίπτωση) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 12
 Μετρικές συναρτήσεις ομοιότητας, συσχέτισης (απόστασης): Pairwise measure Similarity increases as the number or proportion of shared properties increase")
7 Παραδείγματα Μέτρων για Έγγραφα Dice s coefficient 2 Χ Y / X + Y Jaccard s coefficient Χ Y / X Y Μέτρα για την περίπτωση που τα βάρη δεν είναι δυαδικά: DiceSim (dj, dm) = t 2 t i= 1 w ( ij w 2 ij + i= 1 i= 1 t w im ) w im 2 JaccardSim (dj, dm) = CosSim(dj, dm) = r d r d j j t w r r d d m m ij 2 + i= 1 i= 1 CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 13 = t i= 1 t ( w i = 1 t w im t ij 2 ( w w t ( w i= 1 w ij im ) ij i = 1 i = 1 2 ij w t w im ) im ) w im 2 Ομαδοποίηση ως τρόπος Αναπαράστασης (Clustering as Representation) Η ομαδοποίηση είναι μια μορφή μη επιτηρούμενης μάθησης (unsupervised learning) Για εκμάθηση της υποκείμενης δομής και κλάσεων Η ομαδοποίηση είναι μια μορφή μετασχηματισμού της αναπαράστασης (representation transformation) Τα έγγραφα παριστάνονται όχι μόνο βάσει των όρων αλλά και βάσει των κλάσεων στις οποίες μετέχουν Η ομαδοποίηση μπορεί να θεωρηθεί ως μια τεχνική για μείωση των διαστάσεων (dimensionality reduction) Ειδικά το term clustering Latent Semantic Indexing, Factor Analysis είναι παρόμοιες τεχνικές CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 14
 Για εκμάθηση της υποκείμενης δομής και κλάσεων Η ομαδοποίηση είναι μια μορφή μετασχηματισμού της αναπαράστασης (representation")
8 Ομαδοποίηση για βελτίωση της απόδοσης (Clustering for Efficiency) Ένας τρόπος επιτάχυνσης της αποτίμησης των επερωτήσεων θα μπορούσε να είναι ο εξής Method: 1/ Cluster all documents of the collection We have to do it only once 2/ Represent clusters by mean or average document We have to do it only once 3/ compare each received query to the cluster representatives It is like ranking the cluster representatives (as if they were document vectors) 4/ Return the documents of the most similar(s) cluster(s) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 15 Ομαδοποίηση για βελτίωση της Αποτελεσματικότητας (Clustering for Effectiveness) By transforming representation, clustering may also result in more effective retrieval Retrieval of clusters makes it possible to retrieve documents that may not have many terms in common with the query E.g. LSI CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 16
 By transforming representation, clustering may also result in more effective retrieval Retrieval of")
9 Document Clustering Approaches Graph Theoretic Defines clusters based on a graph where documents are nodes and edges exist if similarity greater than some threshold Require at least O(n^2) computation Naturally hierarchic (agglomerative) Good formal properties Reflect structure of data Based on relationships to cluster representatives or means Define criteria for separability of cluster representatives Typically have some measure of goodness of cluster Require only O(n logn) or even O(n) computations Tend to impose structure (e.g. number of clusters) Can have undesirable properties (e.g. order dependence) Usually produce partitions (no overlapping clusters) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 17 Criteria of Adequacy for Clustering Methods Criteria Stability under growth The method produces a clustering which is unlikely to be altered drastically when further objects are incorporated (stable under growth) Stability The method is stable in the sense that small errors in the description of objects lead to small changes in the clustering Order Independence The method is independent of the initial ordering of the objects CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 18
 Usually produce partitions (no overlapping clusters) CS463, Information Retrieval Systems Yannis Tzitzikas, U.")
10 Graph Theoretic Clustering Algorithms Graph Clustering Graph clustering deals with the problem of clustering a graph the nodes of the graph are the objects to be clustered an edge between two nodes of the graph exist if the similarity of the nodes is greater than some threshold we can view the clustering process as a process that groups similar nodes into a set of subgraphs CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 20

11 Quality criteria for graph clustering methods Graph clustering methods should produce clusters with high cohesion and low coupling high cohesion: there should be many internal edges low cut size : The cut size (else called external cost) of a clustering measures how many edges are external to all sub-graphs, that is, how many edges cross cluster boundaries. Uniformity of cluster size is also often desirable. A uniform graph clustering is where C i is close to C j for all i,j in {1..k} CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 21 Example A 2 B Cut size = C A B Cut size =2 4 C CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 22

12 Quality Measures for Graph Clustering There are several. One well known is the CC measure (Coupling-Cohesion measure) CC E = in E E E in : the internal edges: those that connect nodes of the same cluster E ex : the external edges: those that cross cluster boundaries maximum value of CC: 1 when all edges are internal minimum value of CC: -1 when all edges are external ex CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 23 Example A 2 B Cut size = C CC = = 0. 2 A B C 5 6 Cut size =2 8 2 CC = 10 = CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 24

13 Hierarchical Graph Clustering The clusters of the graph can be clustered themselves to form a higher level clustering, and so on. A hierarchical clustering is a collection of clusters where any two clusters are either disjoint or nested. E A C 9 B A D B C CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 25 Hierarchical Clustered Graph A Hierarchical Clustered Graph (HCG) is a pair (G,T) where G is the underlying graph, and T is a rooted tree such that the leaves of T are the nodes of G. (the tree T represents an inclusion relationship: the leaves of T are nodes of G, the internal nodes of T represent a set of graph nodes, i.e. a cluster) E D E HCG A B 5 6 D A B C 4 C CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 26
 is a pair (G,T) where G is the underlying graph, and T is a rooted tree such that the leaves of T are the nodes of G.")
14 Implied Edges Implied edges: edges between the internal nodes. Two clusters are connected iff the nodes that they contain are related. Multiple implied edges (between the same pair of clusters) can be ignored or summed up to form weighted implied edges. Thresholding can applied in order to filter out some implied edges E D 1 A B C A Hierarchical Compound Graph is a triad (G,T, I) where (G,T) is a hierarchical clustered graph (HCG), and I the set of implied edges set. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 27 Graph Theoretic Clustering Approaches Given a graph of objects connected by links that represent similarities greater than some threshold, the following cluster definitions are straightforward: Connected Component: subgraph such that each node is connected to at least one other node in the subgraph and the set of nodes is maximal with respect to that property Called single link clusters Maximal complete subgraph: subgraph such that each node is connected to every other node in the subgraph (clique) Complete link clusters Others are possible and very common: Average link: each cluster member has a greater average similarity to the remaining members of the cluster than it does to all members of any other cluster CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 28

15 Hierarchical Clustering Build a tree-based hierarchical taxonomy (dendrogram). Recursive application of a standard clustering algorithm can produce a hierarchical clustering. animal vertebrate fish reptile amphib. mammal invertebrate worm insect crustacean Hierarchical Clustering Methods Agglomerative (συσσώρευσης) (bottom-up) methods start with each example in its own cluster and iteratively combine them to form larger and larger clusters. Divisive (διαίρεσης) (partitional, top-down) separate all examples immediately into clusters. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 29 An hierarchical (agglomerative ) clustering algorithm 1/ Βάλε κάθε έγγραφο σε ένα διαφορετικό cluster 2. Υπολόγισε την ομοιότητα μεταξύ όλων των ζευγαριών cluster 3. Βρες το ζεύγος {Cu,Cv} με την υψηλότερη (inter-cluster) ομοιότητα 4. Συγχώνευσε τα clusters Cu, Cv 5. Επανέλαβε (από το βήμα 2) έως ότου να καταλήξουμε να έχουμε 1 μόνο cluster 6. Επέστρεψε την ιεραρχία των clusters (το ιστορικό των συγχωνεύσεων) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 30
 (partitional, top-down) separate all examples immediately into clusters. CS463, Information Retrieval Systems Yannis Tzitzikas, U.")
16 An hierarchical (agglomerative ) clustering algorithm 1/ Βαλε κάθε έγγραφο σε ένα διαφορετικό cluster C:= ; For i=1 to n C:=C [di] 2. Υπολόγισε την ομοιότητα μεταξύ όλων των ζευγαριών cluster Compute SIM(c,c ) for each c, c C 3. Βρες το ζεύγος {Cu,Cv} με την υψηλότερη (inter-cluster) ομοιότητα 4. Συγχώνευσε τα clusters Cu, Cv 5. Επανέλαβε (από το βήμα 2) έως ότου να καταλήξουμε να έχουμε 1 μόνο cluster 6. Επέστρεψε την ιεραρχία των clusters (το ιστορικό των συγχωνεύσεων) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 31 An hierarchical (agglomerative) clustering algorithm 1/ Βαλε κάθε έγγραφο σε ένα διαφορετικό cluster C:= ; For i=1 to n C:=C [di] 2. Υπολόγισε την ομοιότητα μεταξύ όλων των ζευγαριών cluster Compute SIM(c,c ) for each c, c C sim(d,d ) = CosineSim(d,d ) or DiceSim(d,d ) or JaccardSim(d,d ) 3. Βρες το ζεύγος {Cu,Cv} με την υψηλότερη (inter-cluster) ομοιότητα 4. Συγχώνευσε τα clusters Cu, Cv 5. Επανέλαβε (από το βήμα 2) έως ότου να καταλήξουμε να έχουμε 1 μόνο cluster 6. Επέστρεψε την ιεραρχία των clusters (το ιστορικό των συγχωνεύσεων) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 32
 CS463, Information Retrieval Systems Yannis Tzitzikas, U.")
17 An hierarchical (agglomerative ) clustering algorithm 1/ Βαλε κάθε έγγραφο σε ένα διαφορετικό cluster C:= ; For i=1 to n C:=C [di] 2. Υπολόγισε την ομοιότητα μεταξύ όλων των ζευγαριών cluster Compute SIM(c,c ) for each c, c C sim(d,d ) = CosineSim(d,d ) or DiceSim(d,d ) or JaccardSim(d,d ) single link: similarity of two most similar. = max{ sim(d,d ) d c,d c } SIM(c,c )=complete link: similarity of two least similar. = min{ sim(d,d ) d c,d c } average link: average similarity b. = avg{ sim(d,d ) d c,d c } 3. Βρες το ζεύγος {Cu,Cv} με την υψηλότερη (inter-cluster) ομοιότητα 4. Συγχώνευσε τα clusters Cu, Cv 5. Επανέλαβε (από το βήμα 2) έως ότου να καταλήξουμε να έχουμε 1 μόνο cluster 6. Επέστρεψε την ιεραρχία των clusters (το ιστορικό των συγχωνεύσεων) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 33 Dendogram or Cluster Hierarchy CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 34
 ομοιότητα 4. Συγχώνευσε τα clusters Cu, Cv 5. Επανέλαβε (από το βήμα 2) έως ότου να καταλήξουμε να έχουμε 1 μόνο cluster 6.")
18 Single Link Example CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 35 Complete Link Example CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 36

19 Σύγκριση Single-link is provably the only method that satisfies criteria of adequacy however it produces long, straggly (ανάκατα) string that are not good clusters Only a single-link required to connect Complete link produces good clusters (more tight, spherical clusters), but too few of them (many singletons) Average-link For both searching and browsing applications, average-link clustering has been shown to produce the best overall effectiveness CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 37 Ward s method (an alternative to single/complete/average link) Cluster merging: Merge the pair of clusters whose merger minimizes the increase in the total within-group error sum of squares, based on the Euclidean distance between centroids Remarks: this method tends to create symmetric hierarchies CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 38
 Cluster merging: Merge the pair of clusters whose merger minimizes the increase in the total within-group error sum of")
20 Computing the Document Similarity Matrix d 1 d 2 s 21 d 3 : s 31 s 32 : : : : d n s n1 s n2 s n,n-1 d 1 d 2. d n-1 d n Empty because sim(x,y)=sim(y,x) Optimization: Compute sim(di,dj) only if di and dj have at least one term in common (otherwise it is 0) This is done by exploiting the inverted index CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 39 Clustering algorithms based on relationships to cluster representatives or means (Fast Partition Algorithms)

21 Fast Partition Methods Single Pass Assign the document d1 as the representative (centroid,mean) for c1 For each di, calculate the similarity Sim with the representative for each existing cluster If SimMax is greater than threshold value simthres, add the document to the corresponding cluster and recalculate the cluster representative; otherwise use di to initiate a new cluster If a document di remains to be clustered, repeat CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 41 Fast Partition Methods K-means (or reallocation methods) Select K cluster representatives For i = 1 to N, assign di to the most similar centroid For j = 1 to K, recalculate the cluster centroid cj Repeat the above steps until there is little or no change in cluster membership Issues: How should K representatives be chosen? Numerous variations on this basic method cluster splitting and merging strategies criteria for cluster coherence seed selection CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 42
22 K-Means Assumes instances are real-valued vectors. Clusters based on centroids, center of gravity, or mean of points in a cluster, c: For example, the centroid of (1,2,3), (4,5,6) and (7,2,6) is (4,3,5). r μ(c) = 1 c x r c r x Reassignment of instances to clusters is based on distance to the current cluster centroids. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 43 K Means Example (K=2) Pick seeds Reassign clusters Compute centroids Reasssign clusters x x x x Compute centroids Reassign clusters Converged! CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 44
23 Nearest Neighbor Clusters Cluster each document with its k nearest neighbors Produces overlapping clusters Called star clusters by Sparck Jones Can be used to produce hierarchic clusters cf. documents like this in web search CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 45 Complexity Remarks Computing the matrix with document similarities: O(n^2) Simple reallocation clustering method with k clusters O(kn) πιο γρήγορος από τους αλγορίθμους για ιεραρχική ομαδοποίηση Agglomerative or Divisive Hierarchical Clustering: απαιτεί n-1 συγχωνεύσεις/διαιρέσεις η πολυπλοκότητα του είναι τουλάχιστον O(n^2) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 46
24 Cluster Searching Document Retrieval from a Clustered Data Set Top-down searching: start at top of cluster hierarchy,choose one of more of the best matching clusters to expand at the next level tends to get lost Bottom-up searching: create inverted file of lowestlevel clusters and rank them more effective indicates that highest similarity clusters (such as nearest neighbor) are the most useful for searching After clusters are retrieved in order, documents in those clusters are ranked Cluster search produces similar level of effectiveness to document search, finds different relevant documents CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 47 Some notes HAC and K-Means have been applied to text in a straightforward way. Typically use normalized, TF/IDF-weighted vectors and cosine similarity. Optimize computations for sparse vectors. Applications: During retrieval, add other documents in the same cluster as the initial retrieved documents to improve recall. Clustering of results of retrieval to present more organized results to the user (e.g. vivisimo search engine) Automated production of hierarchical taxonomies of documents for browsing purposes (like Yahoo & DMOZ). CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 48
25 Questions: Human Clustering (χειρονακτική ομαδοποίηση) Is there a clustering that people will agree on? Is clustering something that people do consistently? Yahoo suggests there s value in creating categories Fixed hierarchy that people like Human performance on clustering Web pages Macskassy, Banerjee, Davison, and Hirsh (Rutgers) KDD 1998, and extended technical report Αποτελέσματα: Μάλλον δεν υπάρχει μεγάλη συμφωνία γενικά προτίμηση σε μικρά clusters άλλοι χρήστες προτιμούν/δημιουργούν επικαλυπτόμενα, άλλοι αποκλειστικά clusters τα περιεχόμενα των clusters διέφεραν αρκετά γενική ομαδοποίηση (ανεξαρτήτου επερώτησης) δεν φαίνεται να είναι πολύ χρήσιμη CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 49 Παραδείγματα Ομαδοποίησης Αποτελεσμάτων Αναζήτησης (Results Clustering)
26 Vivisimo.com CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 51 Clusty.com CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 52
27 CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 53 On mouse over hotels CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 54
28 CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 55 Grouper It is a Research Web Meta-Search Engine Users can specify the number of documents to be retrieved (10-200) from each of the participating search engines. The system queries 10 search engines, so it will retrieve documents. Clustering is applied on snippets returned by the search engines. Snippet: a fragment of a web page returned by search engines summarizing the context of search keywords Clusters together documents with large common subphrases. It uses the Suffix Tree Clustering (STC) algorithm create overlapping clusters because all suffixes of each phrase are generated CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 56
29 Grouper CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 57 Carrot 2 ( Open-source Web Meta-Search Engine Acquire search results from various sources (YahooAPI, GoogleAPI, MSN Search API, etools Meta Search, Alexa Web Search, PubMed, OpenSearch, Lucene index, SOLR) 5 clustering algorithms are available that are suitable for different kinds of document clustering tasks STC FussyAnts Lingo HAOG-STC Rough k-means Open-source implementation of Grouper Lingo is the default clustering algorithm used in the Carrot2 live demos. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 58
30 Carrot 2 ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 59 Carrot 2 ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 60
31 SNAKET ( Open-source Web Meta-Search Engine Draws about 200 snippets from 16 search engines about Web, Blog, News and Books domain Offers both hierarchical clustering and folder labeling with variable-length sentences drawn on-the-fly from snippets Use gapped sentences as labels, namely sequences of terms occurring notcontiguously into the snippets CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 61 SNAKET ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 62
32 SNAKET ( Personalized ranking User selects the two labels Tutorial and Training and gets its personalized ranked list CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 63 Next-generation meta search engines Display a visual interface Goal: Make easier the visualization of internet & intranet information Help user apprehend huge quantities of information KartOO ( Display search results as two-dimensional, interactive maps Map Sites are represented by more or less important size pages, depending on their relevance On mouse over these pages, the concerned keywords are illuminated and a brief description of the site appears on the left side of the screen Queries can follow specific syntax E.g. TEXT : Search on the text of the page as a priority LINK : Search a word on the hypertext link follow natural language CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 64
33 KartOO ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 65 KartOO ( On mouse over hotel CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 66
34 KartOO ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 67 UJIKO ( New version of KartOO Uses the brand new Yahoo (c) search technology, which indexes more than 5 billion pages. Customizable User is free to decide if the website is relevant whether or not by a button heart and trashcan. Clicking on a site, make it go up automatically in the results list with all the associated sites, which share common topics (wide personalization). Separation into levels Each time user visit a new site, he gains one point of expertise. With every 10 points, user move to the next level. New buttons appear giving you access to advanced features (search video, images, news, encyclopedia, advanced filters, animated skins, web archive, traffic details ) From level 2, in the center of screen are set of themes are displayed Some of these topics are coloured and linked to small bricks with the same color: these indicate which sites are associated with a specific theme. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 68
35 UJIKO ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 69 UJIKO ( Refined query CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 70
36 KartOOvisu ( Display results with a thematic map Functionalities added Cartography of topics to filter results Contextual summary generated when click on a topic An integrated history of previous searches CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 71 KartOOvisu ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 72
37 KartOOvisu ( CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 73 Result Clustering of groogle 2007 Ομαδοποίηση των εγγράφων που εμπεριέχουν τη φράση αναζήτησης με τους αλγορίθμους Kmeans Hierarchical (agglomerative) Ορθή συλλογή (φιλτράρισμα) και ονομασία των πιο πάνω αποτελεσμάτων Kmeans έχει επεκταθεί με ένα επιπλέον βήμα, το οποίο δίνει ένα όνομα σε κάθε cluster και με μεθόδους που δημιουργούν ιεραρχίες πάνω σ αυτά τα ονόματα Bottom-up Intersection (BU-i) Bottom-up Weighted (BU-w) Top-Down (TD) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 74
38 Result Clustering of groogle 2007 Kmeans 1. Δημιουργείται ένα Label για κάθε Cluster στο οποίο δίνετε ως όνομα αντίστοιχο αριθμό καταχώρισης (1,2,3.Κ). 2. Τα Ν έγγραφα, top-l έγγραφα της τρέχουσας απάντησης, τοποθετούνται τυχαία στα παραπάνω clusters, βάζοντας τα πρώτα Ν/Κ στοπρώτο, τα επόμενα τα Ν/Κ στο επόμενο κ.ο. στην περίπτωση που υπάρχει modulo (υπόλοιπο) μοιράζονται αντίστοιχα στα παραπάνω Clusters L : παράμετρος με default τιμή Για κάθε ένα i=1,,k από τα Clusters υπολογίζονται τα Centroids. Μπορεί να είναι: Ο μέσος όρος των βαρών των αντίστοιχων εγγράφων (Centroids). Το έγγραφο με την πλησιέστερη τιμή στον μέσο όρο των βαρών των αντίστοιχων εγγράφων (Memoids). 4. Για κάθε ένα από τα έγγραφα (documents), αναζητάτε το πιο κοντινό (στην τιμή του βάρους) Centroid (δημιουργία του centroid vector του κάθε cluster) 5. Τα βήματα 3,4 επαναλαμβάνονται μέχρι όλα τα labels να είναι διαφορετικά μεταξύ τους σε κάθε γύρο. Ο αριθμός των επαναλήψεων δίνεται σαν παράμετρος Ωστόσο, η διαδικασία του αλγορίθμου σταματάει σε περίπτωση που δεν έχουμε μετακίνηση- αλλαγή του αντίστοιχου label 6. Υπολογίζεται το όνομα και η ιεραρχικότητα (που τυχόν δημιουργείτε ) για τα αποτελέσματα. CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 75 Result Clustering of groogle 2007 Μέθοδοι που χρησιμοποιούνται για τη δημιουργία ιεραρχιών Bottom-up Intersection (BU-i) Bασίζεται στην ομοιότητα των όρων μεταξύ των original clusters Αρχικά, οι κόμβοι με τα ονόματα με τη μεγαλύτερη (σε μέγεθος) τομή ομαδοποιούνται δημιουργώντας ένα νέο κόμβο με παιδιά αυτούς τους κόμβους Το όνομα ενός νέου κόμβου είναι η τομή των ονομάτων των παιδιών του Η διαδικασία συνεχίζεται μέχρι να φτάσουμε σε έναν κόμβο Οι κόμβοι που ήδη έχουν γονείς αγνοούνται Bottom-up Weighted (BU-w) Bασίζεται στα βάρη των centroid vectors Αρχικά, γίνεται ταξινόμηση των λέξεων του ονόματος κάθε cluster με βάση το βάρος τους σε φθίνουσα σειρά Στη συνέχεια, τα ονόματα των clusters ταξινομούνται αλφαβητικά Έτσι, τα clusters που έχουν τους ίδιους πιο βεβαρημένους όρους θα τοποθετηθούν διαδοχικά Γίνεται ομαδοποίηση δύο ή περισσότερων clusters κάτω από τον ίδιο κόμβο εάν τα ονόματα τους έχουν κάποιο κοινό πρόθεμα Top-Down (TD) Τα original K clusters θεωρούνται παιδιά του κόμβου root Εφαρμόζεται ξανά ο K-means στα περιεχόμενα του κάθε cluster Η διαδικασία γίνεται αναδρομικά έως το δέντρο να έχει βάθος maxdepth ή το μέγεθος του cluster να είναι μικρότερο από ένα όριο(sz mn ) CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 76
39 Result Clustering of groogle 2007 Παραμετροποίηση Κ: αριθμός των αρχικών κέντρων κατανομής του αλγορίθμου, αλλά και εν τέλει το ελάχιστο πλήθος ομάδων που μπορεί να προκύψουν Max number of docs: μέγιστο μέγεθος των εγγράφων που μπορεί να γίνει clustered (default 100) Minimum title: ελάχιστο μήκος του ονόματος για ένα cluster. Επίσης μπορεί να αλλάξει αρκετά τις τιμές ονοματοδοσίας, αν χρησιμοποιηθεί στην bottom up (InterSection approach) Max Depth: μέγιστο βάθος που μπορεί να έχει το δέντρο. Στην περίπτωση του top Down Hierarchy η πραγματική τιμή είναι maxdepth +1 μιας και εφαρμόζουμε τουλ. σε ένα πιο κάτω επίπεδο τον συγκεκριμένο αλγόριθμο Name hierarchy: οι μέθοδοι δημιουργίας ιεραρχικότητας των clusters Max number of words: ο αριθμός των πιο βεβαρημένων όρων που χρησιμοποιούνται από κάθε έγγραφο Max Title Length: μέγιστο πλήθος λέξεων που μπορεί να απαρτίζεται ένα cluster Min docs in cluster(sz mn ): ελάχιστος αριθμός από έγγραφα που θα υπάρχουν σε ένα cluster Προβλήματα Στο ευρετήριο του groogle 2007 αποθηκεύονται μόνο οι ρίζες των λέξεων, με αποτέλεσμα τη μείωση της αναγνωσιμότητας των ονομάτων των cluster που δημιουργούνται CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 77 Result Clustering of groogle 2007 BU-w CS463, Information Retrieval Systems Yannis Tzitzikas, U. of Crete 78
Ομαδοποίηση Εγγράφων (Document Clustering)
") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 007 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Ομαδοποίηση Εγγράφων (Document Clustering) Γιάννης Τζίτζικας ιάλεξη
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 007 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Ομαδοποίηση Εγγράφων (Document Clustering) Γιάννης Τζίτζικας ιάλεξη
Ομαδοποίηση Εγγράφων (Document Clustering)
") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 006 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Ομαδοποίηση Εγγράφων (Document Clustering) Γιάννης Τζίτζικας ιάλεξη
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 006 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Ομαδοποίηση Εγγράφων (Document Clustering) Γιάννης Τζίτζικας ιάλεξη
ΚΥΠΡΙΑΚΗ ΕΤΑΙΡΕΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ CYPRUS COMPUTER SOCIETY ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 19/5/2007
 Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Αν κάπου κάνετε κάποιες υποθέσεις να αναφερθούν στη σχετική ερώτηση. Όλα τα αρχεία που αναφέρονται στα προβλήματα βρίσκονται στον ίδιο φάκελο με το εκτελέσιμο
Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Αν κάπου κάνετε κάποιες υποθέσεις να αναφερθούν στη σχετική ερώτηση. Όλα τα αρχεία που αναφέρονται στα προβλήματα βρίσκονται στον ίδιο φάκελο με το εκτελέσιμο
EPL 603 TOPICS IN SOFTWARE ENGINEERING. Lab 5: Component Adaptation Environment (COPE)
") EPL 603 TOPICS IN SOFTWARE ENGINEERING Lab 5: Component Adaptation Environment (COPE) Performing Static Analysis 1 Class Name: The fully qualified name of the specific class Type: The type of the class
EPL 603 TOPICS IN SOFTWARE ENGINEERING Lab 5: Component Adaptation Environment (COPE) Performing Static Analysis 1 Class Name: The fully qualified name of the specific class Type: The type of the class
Other Test Constructions: Likelihood Ratio & Bayes Tests
 Other Test Constructions: Likelihood Ratio & Bayes Tests Side-Note: So far we have seen a few approaches for creating tests such as Neyman-Pearson Lemma ( most powerful tests of H 0 : θ = θ 0 vs H 1 :
Other Test Constructions: Likelihood Ratio & Bayes Tests Side-Note: So far we have seen a few approaches for creating tests such as Neyman-Pearson Lemma ( most powerful tests of H 0 : θ = θ 0 vs H 1 :
ΚΥΠΡΙΑΚΗ ΕΤΑΙΡΕΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ CYPRUS COMPUTER SOCIETY ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 6/5/2006
 Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Ολοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα είναι μικρότεροι το 1000 εκτός αν ορίζεται διαφορετικά στη διατύπωση του προβλήματος. Διάρκεια: 3,5 ώρες Καλή
Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Ολοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα είναι μικρότεροι το 1000 εκτός αν ορίζεται διαφορετικά στη διατύπωση του προβλήματος. Διάρκεια: 3,5 ώρες Καλή
derivation of the Laplacian from rectangular to spherical coordinates
 derivation of the Laplacian from rectangular to spherical coordinates swapnizzle 03-03- :5:43 We begin by recognizing the familiar conversion from rectangular to spherical coordinates (note that φ is used
derivation of the Laplacian from rectangular to spherical coordinates swapnizzle 03-03- :5:43 We begin by recognizing the familiar conversion from rectangular to spherical coordinates (note that φ is used
Πρόβλημα 1: Αναζήτηση Ελάχιστης/Μέγιστης Τιμής
 Πρόβλημα 1: Αναζήτηση Ελάχιστης/Μέγιστης Τιμής Να γραφεί πρόγραμμα το οποίο δέχεται ως είσοδο μια ακολουθία S από n (n 40) ακέραιους αριθμούς και επιστρέφει ως έξοδο δύο ακολουθίες από θετικούς ακέραιους
Πρόβλημα 1: Αναζήτηση Ελάχιστης/Μέγιστης Τιμής Να γραφεί πρόγραμμα το οποίο δέχεται ως είσοδο μια ακολουθία S από n (n 40) ακέραιους αριθμούς και επιστρέφει ως έξοδο δύο ακολουθίες από θετικούς ακέραιους
Main source: "Discrete-time systems and computer control" by Α. ΣΚΟΔΡΑΣ ΨΗΦΙΑΚΟΣ ΕΛΕΓΧΟΣ ΔΙΑΛΕΞΗ 4 ΔΙΑΦΑΝΕΙΑ 1
 Main source: "Discrete-time systems and computer control" by Α. ΣΚΟΔΡΑΣ ΨΗΦΙΑΚΟΣ ΕΛΕΓΧΟΣ ΔΙΑΛΕΞΗ 4 ΔΙΑΦΑΝΕΙΑ 1 A Brief History of Sampling Research 1915 - Edmund Taylor Whittaker (1873-1956) devised a
Main source: "Discrete-time systems and computer control" by Α. ΣΚΟΔΡΑΣ ΨΗΦΙΑΚΟΣ ΕΛΕΓΧΟΣ ΔΙΑΛΕΞΗ 4 ΔΙΑΦΑΝΕΙΑ 1 A Brief History of Sampling Research 1915 - Edmund Taylor Whittaker (1873-1956) devised a
HOMEWORK 4 = G. In order to plot the stress versus the stretch we define a normalized stretch:
 HOMEWORK 4 Problem a For the fast loading case, we want to derive the relationship between P zz and λ z. We know that the nominal stress is expressed as: P zz = ψ λ z where λ z = λ λ z. Therefore, applying
HOMEWORK 4 Problem a For the fast loading case, we want to derive the relationship between P zz and λ z. We know that the nominal stress is expressed as: P zz = ψ λ z where λ z = λ λ z. Therefore, applying
TMA4115 Matematikk 3
 TMA4115 Matematikk 3 Andrew Stacey Norges Teknisk-Naturvitenskapelige Universitet Trondheim Spring 2010 Lecture 12: Mathematics Marvellous Matrices Andrew Stacey Norges Teknisk-Naturvitenskapelige Universitet
TMA4115 Matematikk 3 Andrew Stacey Norges Teknisk-Naturvitenskapelige Universitet Trondheim Spring 2010 Lecture 12: Mathematics Marvellous Matrices Andrew Stacey Norges Teknisk-Naturvitenskapelige Universitet
Physical DB Design. B-Trees Index files can become quite large for large main files Indices on index files are possible.
 B-Trees Index files can become quite large for large main files Indices on index files are possible 3 rd -level index 2 nd -level index 1 st -level index Main file 1 The 1 st -level index consists of pairs
B-Trees Index files can become quite large for large main files Indices on index files are possible 3 rd -level index 2 nd -level index 1 st -level index Main file 1 The 1 st -level index consists of pairs
The challenges of non-stable predicates
 The challenges of non-stable predicates Consider a non-stable predicate Φ encoding, say, a safety property. We want to determine whether Φ holds for our program. The challenges of non-stable predicates
The challenges of non-stable predicates Consider a non-stable predicate Φ encoding, say, a safety property. We want to determine whether Φ holds for our program. The challenges of non-stable predicates
5.4 The Poisson Distribution.
 The worst thing you can do about a situation is nothing. Sr. O Shea Jackson 5.4 The Poisson Distribution. Description of the Poisson Distribution Discrete probability distribution. The random variable
The worst thing you can do about a situation is nothing. Sr. O Shea Jackson 5.4 The Poisson Distribution. Description of the Poisson Distribution Discrete probability distribution. The random variable
CHAPTER 25 SOLVING EQUATIONS BY ITERATIVE METHODS
 CHAPTER 5 SOLVING EQUATIONS BY ITERATIVE METHODS EXERCISE 104 Page 8 1. Find the positive root of the equation x + 3x 5 = 0, correct to 3 significant figures, using the method of bisection. Let f(x) =
CHAPTER 5 SOLVING EQUATIONS BY ITERATIVE METHODS EXERCISE 104 Page 8 1. Find the positive root of the equation x + 3x 5 = 0, correct to 3 significant figures, using the method of bisection. Let f(x) =
Fractional Colorings and Zykov Products of graphs
 Fractional Colorings and Zykov Products of graphs Who? Nichole Schimanski When? July 27, 2011 Graphs A graph, G, consists of a vertex set, V (G), and an edge set, E(G). V (G) is any finite set E(G) is
Fractional Colorings and Zykov Products of graphs Who? Nichole Schimanski When? July 27, 2011 Graphs A graph, G, consists of a vertex set, V (G), and an edge set, E(G). V (G) is any finite set E(G) is
Math 6 SL Probability Distributions Practice Test Mark Scheme
 Math 6 SL Probability Distributions Practice Test Mark Scheme. (a) Note: Award A for vertical line to right of mean, A for shading to right of their vertical line. AA N (b) evidence of recognizing symmetry
Math 6 SL Probability Distributions Practice Test Mark Scheme. (a) Note: Award A for vertical line to right of mean, A for shading to right of their vertical line. AA N (b) evidence of recognizing symmetry
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ. του Γεράσιμου Τουλιάτου ΑΜ: 697
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΣΤΑ ΠΛΑΙΣΙΑ ΤΟΥ ΜΕΤΑΠΤΥΧΙΑΚΟΥ ΔΙΠΛΩΜΑΤΟΣ ΕΙΔΙΚΕΥΣΗΣ ΕΠΙΣΤΗΜΗ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ του Γεράσιμου Τουλιάτου
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΑΤΡΩΝ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ ΣΤΑ ΠΛΑΙΣΙΑ ΤΟΥ ΜΕΤΑΠΤΥΧΙΑΚΟΥ ΔΙΠΛΩΜΑΤΟΣ ΕΙΔΙΚΕΥΣΗΣ ΕΠΙΣΤΗΜΗ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ του Γεράσιμου Τουλιάτου
Instruction Execution Times
 1 C Execution Times InThisAppendix... Introduction DL330 Execution Times DL330P Execution Times DL340 Execution Times C-2 Execution Times Introduction Data Registers This appendix contains several tables
1 C Execution Times InThisAppendix... Introduction DL330 Execution Times DL330P Execution Times DL340 Execution Times C-2 Execution Times Introduction Data Registers This appendix contains several tables
Nowhere-zero flows Let be a digraph, Abelian group. A Γ-circulation in is a mapping : such that, where, and : tail in X, head in
 Nowhere-zero flows Let be a digraph, Abelian group. A Γ-circulation in is a mapping : such that, where, and : tail in X, head in : tail in X, head in A nowhere-zero Γ-flow is a Γ-circulation such that
Nowhere-zero flows Let be a digraph, Abelian group. A Γ-circulation in is a mapping : such that, where, and : tail in X, head in : tail in X, head in A nowhere-zero Γ-flow is a Γ-circulation such that
Ανάκτηση Πληροφορίας
 Ανάκτηση Πληροφορίας Αποτίμηση Αποτελεσματικότητας Μέτρα Απόδοσης Precision = # σχετικών κειμένων που επιστρέφονται # κειμένων που επιστρέφονται Recall = # σχετικών κειμένων που επιστρέφονται # συνολικών
Ανάκτηση Πληροφορίας Αποτίμηση Αποτελεσματικότητας Μέτρα Απόδοσης Precision = # σχετικών κειμένων που επιστρέφονται # κειμένων που επιστρέφονται Recall = # σχετικών κειμένων που επιστρέφονται # συνολικών
Approximation of distance between locations on earth given by latitude and longitude
 Approximation of distance between locations on earth given by latitude and longitude Jan Behrens 2012-12-31 In this paper we shall provide a method to approximate distances between two points on earth
Approximation of distance between locations on earth given by latitude and longitude Jan Behrens 2012-12-31 In this paper we shall provide a method to approximate distances between two points on earth
Phys460.nb Solution for the t-dependent Schrodinger s equation How did we find the solution? (not required)
") Phys460.nb 81 ψ n (t) is still the (same) eigenstate of H But for tdependent H. The answer is NO. 5.5.5. Solution for the tdependent Schrodinger s equation If we assume that at time t 0, the electron starts
Phys460.nb 81 ψ n (t) is still the (same) eigenstate of H But for tdependent H. The answer is NO. 5.5.5. Solution for the tdependent Schrodinger s equation If we assume that at time t 0, the electron starts
ΕΙΣΑΓΩΓΗ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ
 ΕΙΣΑΓΩΓΗ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΕΛΕΝΑ ΦΛΟΚΑ Επίκουρος Καθηγήτρια Τµήµα Φυσικής, Τοµέας Φυσικής Περιβάλλοντος- Μετεωρολογίας ΓΕΝΙΚΟΙ ΟΡΙΣΜΟΙ Πληθυσµός Σύνολο ατόµων ή αντικειµένων στα οποία αναφέρονται
ΕΙΣΑΓΩΓΗ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΕΛΕΝΑ ΦΛΟΚΑ Επίκουρος Καθηγήτρια Τµήµα Φυσικής, Τοµέας Φυσικής Περιβάλλοντος- Μετεωρολογίας ΓΕΝΙΚΟΙ ΟΡΙΣΜΟΙ Πληθυσµός Σύνολο ατόµων ή αντικειµένων στα οποία αναφέρονται
Homework 3 Solutions
 Homework 3 Solutions Igor Yanovsky (Math 151A TA) Problem 1: Compute the absolute error and relative error in approximations of p by p. (Use calculator!) a) p π, p 22/7; b) p π, p 3.141. Solution: For
Homework 3 Solutions Igor Yanovsky (Math 151A TA) Problem 1: Compute the absolute error and relative error in approximations of p by p. (Use calculator!) a) p π, p 22/7; b) p π, p 3.141. Solution: For
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΜΣ «ΠΡΟΗΓΜΕΝΑ ΣΥΣΤΗΜΑΤΑ ΠΛΗΡΟΦΟΡΙΚΗΣ» ΚΑΤΕΥΘΥΝΣΗ «ΕΥΦΥΕΙΣ ΤΕΧΝΟΛΟΓΙΕΣ ΕΠΙΚΟΙΝΩΝΙΑΣ ΑΝΘΡΩΠΟΥ - ΥΠΟΛΟΓΙΣΤΗ»
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΜΣ «ΠΡΟΗΓΜΕΝΑ ΣΥΣΤΗΜΑΤΑ ΠΛΗΡΟΦΟΡΙΚΗΣ» ΚΑΤΕΥΘΥΝΣΗ «ΕΥΦΥΕΙΣ ΤΕΧΝΟΛΟΓΙΕΣ ΕΠΙΚΟΙΝΩΝΙΑΣ ΑΝΘΡΩΠΟΥ - ΥΠΟΛΟΓΙΣΤΗ» ΜΕΤΑΠΤΥΧΙΑΚΗ ΙΑΤΡΙΒΗ ΤΟΥ ΕΥΘΥΜΙΟΥ ΘΕΜΕΛΗ ΤΙΤΛΟΣ Ανάλυση
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΜΣ «ΠΡΟΗΓΜΕΝΑ ΣΥΣΤΗΜΑΤΑ ΠΛΗΡΟΦΟΡΙΚΗΣ» ΚΑΤΕΥΘΥΝΣΗ «ΕΥΦΥΕΙΣ ΤΕΧΝΟΛΟΓΙΕΣ ΕΠΙΚΟΙΝΩΝΙΑΣ ΑΝΘΡΩΠΟΥ - ΥΠΟΛΟΓΙΣΤΗ» ΜΕΤΑΠΤΥΧΙΑΚΗ ΙΑΤΡΙΒΗ ΤΟΥ ΕΥΘΥΜΙΟΥ ΘΕΜΕΛΗ ΤΙΤΛΟΣ Ανάλυση
Lecture 2: Dirac notation and a review of linear algebra Read Sakurai chapter 1, Baym chatper 3
 Lecture 2: Dirac notation and a review of linear algebra Read Sakurai chapter 1, Baym chatper 3 1 State vector space and the dual space Space of wavefunctions The space of wavefunctions is the set of all
Lecture 2: Dirac notation and a review of linear algebra Read Sakurai chapter 1, Baym chatper 3 1 State vector space and the dual space Space of wavefunctions The space of wavefunctions is the set of all
Block Ciphers Modes. Ramki Thurimella
 Block Ciphers Modes Ramki Thurimella Only Encryption I.e. messages could be modified Should not assume that nonsensical messages do no harm Always must be combined with authentication 2 Padding Must be
Block Ciphers Modes Ramki Thurimella Only Encryption I.e. messages could be modified Should not assume that nonsensical messages do no harm Always must be combined with authentication 2 Padding Must be
Congruence Classes of Invertible Matrices of Order 3 over F 2
 International Journal of Algebra, Vol. 8, 24, no. 5, 239-246 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/.2988/ija.24.422 Congruence Classes of Invertible Matrices of Order 3 over F 2 Ligong An and
International Journal of Algebra, Vol. 8, 24, no. 5, 239-246 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/.2988/ija.24.422 Congruence Classes of Invertible Matrices of Order 3 over F 2 Ligong An and
ΚΥΠΡΙΑΚΗ ΕΤΑΙΡΕΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ CYPRUS COMPUTER SOCIETY ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 11/3/2006
 ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 11/3/26 Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Ολοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα μικρότεροι το 1 εκτός αν ορίζεται διαφορετικά στη διατύπωση
ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 11/3/26 Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Ολοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα μικρότεροι το 1 εκτός αν ορίζεται διαφορετικά στη διατύπωση
On a four-dimensional hyperbolic manifold with finite volume
 BULETINUL ACADEMIEI DE ŞTIINŢE A REPUBLICII MOLDOVA. MATEMATICA Numbers 2(72) 3(73), 2013, Pages 80 89 ISSN 1024 7696 On a four-dimensional hyperbolic manifold with finite volume I.S.Gutsul Abstract. In
BULETINUL ACADEMIEI DE ŞTIINŢE A REPUBLICII MOLDOVA. MATEMATICA Numbers 2(72) 3(73), 2013, Pages 80 89 ISSN 1024 7696 On a four-dimensional hyperbolic manifold with finite volume I.S.Gutsul Abstract. In
Συστήματα Διαχείρισης Βάσεων Δεδομένων
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Συστήματα Διαχείρισης Βάσεων Δεδομένων Φροντιστήριο 5: Tutorial on External Sorting Δημήτρης Πλεξουσάκης Τμήμα Επιστήμης Υπολογιστών TUTORIAL ON EXTERNAL SORTING
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Συστήματα Διαχείρισης Βάσεων Δεδομένων Φροντιστήριο 5: Tutorial on External Sorting Δημήτρης Πλεξουσάκης Τμήμα Επιστήμης Υπολογιστών TUTORIAL ON EXTERNAL SORTING
ΑΓΓΛΙΚΑ Ι. Ενότητα 7α: Impact of the Internet on Economic Education. Ζωή Κανταρίδου Τμήμα Εφαρμοσμένης Πληροφορικής
 Ενότητα 7α: Impact of the Internet on Economic Education Τμήμα Εφαρμοσμένης Πληροφορικής Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως
Ενότητα 7α: Impact of the Internet on Economic Education Τμήμα Εφαρμοσμένης Πληροφορικής Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ. Ψηφιακή Οικονομία. Διάλεξη 7η: Consumer Behavior Mαρίνα Μπιτσάκη Τμήμα Επιστήμης Υπολογιστών
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Ψηφιακή Οικονομία Διάλεξη 7η: Consumer Behavior Mαρίνα Μπιτσάκη Τμήμα Επιστήμης Υπολογιστών Τέλος Ενότητας Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Ψηφιακή Οικονομία Διάλεξη 7η: Consumer Behavior Mαρίνα Μπιτσάκη Τμήμα Επιστήμης Υπολογιστών Τέλος Ενότητας Χρηματοδότηση Το παρόν εκπαιδευτικό υλικό έχει αναπτυχθεί
Αλγόριθμοι και πολυπλοκότητα NP-Completeness (2)
") ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Αλγόριθμοι και πολυπλοκότητα NP-Completeness (2) Ιωάννης Τόλλης Τμήμα Επιστήμης Υπολογιστών NP-Completeness (2) x 1 x 1 x 2 x 2 x 3 x 3 x 4 x 4 12 22 32 11 13 21
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Αλγόριθμοι και πολυπλοκότητα NP-Completeness (2) Ιωάννης Τόλλης Τμήμα Επιστήμης Υπολογιστών NP-Completeness (2) x 1 x 1 x 2 x 2 x 3 x 3 x 4 x 4 12 22 32 11 13 21
Assalamu `alaikum wr. wb.
 LUMP SUM Assalamu `alaikum wr. wb. LUMP SUM Wassalamu alaikum wr. wb. Assalamu `alaikum wr. wb. LUMP SUM Wassalamu alaikum wr. wb. LUMP SUM Lump sum lump sum lump sum. lump sum fixed price lump sum lump
LUMP SUM Assalamu `alaikum wr. wb. LUMP SUM Wassalamu alaikum wr. wb. Assalamu `alaikum wr. wb. LUMP SUM Wassalamu alaikum wr. wb. LUMP SUM Lump sum lump sum lump sum. lump sum fixed price lump sum lump
C.S. 430 Assignment 6, Sample Solutions
 C.S. 430 Assignment 6, Sample Solutions Paul Liu November 15, 2007 Note that these are sample solutions only; in many cases there were many acceptable answers. 1 Reynolds Problem 10.1 1.1 Normal-order
C.S. 430 Assignment 6, Sample Solutions Paul Liu November 15, 2007 Note that these are sample solutions only; in many cases there were many acceptable answers. 1 Reynolds Problem 10.1 1.1 Normal-order
[1] P Q. Fig. 3.1
![[1] P Q. Fig. 3.1](/thumbs/79/80362156.jpg "[1] P Q. Fig. 3.1") 1 (a) Define resistance....... [1] (b) The smallest conductor within a computer processing chip can be represented as a rectangular block that is one atom high, four atoms wide and twenty atoms long. One
1 (a) Define resistance....... [1] (b) The smallest conductor within a computer processing chip can be represented as a rectangular block that is one atom high, four atoms wide and twenty atoms long. One
2 Composition. Invertible Mappings
 Arkansas Tech University MATH 4033: Elementary Modern Algebra Dr. Marcel B. Finan Composition. Invertible Mappings In this section we discuss two procedures for creating new mappings from old ones, namely,
Arkansas Tech University MATH 4033: Elementary Modern Algebra Dr. Marcel B. Finan Composition. Invertible Mappings In this section we discuss two procedures for creating new mappings from old ones, namely,
3.4 SUM AND DIFFERENCE FORMULAS. NOTE: cos(α+β) cos α + cos β cos(α-β) cos α -cos β
 cos α + cos β cos(α-β) cos α -cos β") 3.4 SUM AND DIFFERENCE FORMULAS Page Theorem cos(αβ cos α cos β -sin α cos(α-β cos α cos β sin α NOTE: cos(αβ cos α cos β cos(α-β cos α -cos β Proof of cos(α-β cos α cos β sin α Let s use a unit circle
3.4 SUM AND DIFFERENCE FORMULAS Page Theorem cos(αβ cos α cos β -sin α cos(α-β cos α cos β sin α NOTE: cos(αβ cos α cos β cos(α-β cos α -cos β Proof of cos(α-β cos α cos β sin α Let s use a unit circle
Solutions to Exercise Sheet 5
 Solutions to Eercise Sheet 5 jacques@ucsd.edu. Let X and Y be random variables with joint pdf f(, y) = 3y( + y) where and y. Determine each of the following probabilities. Solutions. a. P (X ). b. P (X
Solutions to Eercise Sheet 5 jacques@ucsd.edu. Let X and Y be random variables with joint pdf f(, y) = 3y( + y) where and y. Determine each of the following probabilities. Solutions. a. P (X ). b. P (X
SCHOOL OF MATHEMATICAL SCIENCES G11LMA Linear Mathematics Examination Solutions
 SCHOOL OF MATHEMATICAL SCIENCES GLMA Linear Mathematics 00- Examination Solutions. (a) i. ( + 5i)( i) = (6 + 5) + (5 )i = + i. Real part is, imaginary part is. (b) ii. + 5i i ( + 5i)( + i) = ( i)( + i)
SCHOOL OF MATHEMATICAL SCIENCES GLMA Linear Mathematics 00- Examination Solutions. (a) i. ( + 5i)( i) = (6 + 5) + (5 )i = + i. Real part is, imaginary part is. (b) ii. + 5i i ( + 5i)( + i) = ( i)( + i)
EE512: Error Control Coding
 EE512: Error Control Coding Solution for Assignment on Finite Fields February 16, 2007 1. (a) Addition and Multiplication tables for GF (5) and GF (7) are shown in Tables 1 and 2. + 0 1 2 3 4 0 0 1 2 3
EE512: Error Control Coding Solution for Assignment on Finite Fields February 16, 2007 1. (a) Addition and Multiplication tables for GF (5) and GF (7) are shown in Tables 1 and 2. + 0 1 2 3 4 0 0 1 2 3
ΚΥΠΡΙΑΚΗ ΕΤΑΙΡΕΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ CYPRUS COMPUTER SOCIETY ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ 24/3/2007
 Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Όλοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα μικρότεροι του 10000 εκτός αν ορίζεται διαφορετικά στη διατύπωση του προβλήματος. Αν κάπου κάνετε κάποιες υποθέσεις
Οδηγίες: Να απαντηθούν όλες οι ερωτήσεις. Όλοι οι αριθμοί που αναφέρονται σε όλα τα ερωτήματα μικρότεροι του 10000 εκτός αν ορίζεται διαφορετικά στη διατύπωση του προβλήματος. Αν κάπου κάνετε κάποιες υποθέσεις
The Simply Typed Lambda Calculus
 Type Inference Instead of writing type annotations, can we use an algorithm to infer what the type annotations should be? That depends on the type system. For simple type systems the answer is yes, and
Type Inference Instead of writing type annotations, can we use an algorithm to infer what the type annotations should be? That depends on the type system. For simple type systems the answer is yes, and
About these lecture notes. Simply Typed λ-calculus. Types
 About these lecture notes Simply Typed λ-calculus Akim Demaille akim@lrde.epita.fr EPITA École Pour l Informatique et les Techniques Avancées Many of these slides are largely inspired from Andrew D. Ker
About these lecture notes Simply Typed λ-calculus Akim Demaille akim@lrde.epita.fr EPITA École Pour l Informatique et les Techniques Avancées Many of these slides are largely inspired from Andrew D. Ker
the total number of electrons passing through the lamp.
 1. A 12 V 36 W lamp is lit to normal brightness using a 12 V car battery of negligible internal resistance. The lamp is switched on for one hour (3600 s). For the time of 1 hour, calculate (i) the energy
1. A 12 V 36 W lamp is lit to normal brightness using a 12 V car battery of negligible internal resistance. The lamp is switched on for one hour (3600 s). For the time of 1 hour, calculate (i) the energy
Αλγόριθμοι και πολυπλοκότητα Depth-First Search
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Αλγόριθμοι και πολυπλοκότητα Depth-First Search Ιωάννης Τόλλης Τμήμα Επιστήμης Υπολογιστών Depth-First Search A B D E C Depth-First Search 1 Outline and Reading
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Αλγόριθμοι και πολυπλοκότητα Depth-First Search Ιωάννης Τόλλης Τμήμα Επιστήμης Υπολογιστών Depth-First Search A B D E C Depth-First Search 1 Outline and Reading
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ
 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΨΥΧΟΛΟΓΙΚΕΣ ΕΠΙΠΤΩΣΕΙΣ ΣΕ ΓΥΝΑΙΚΕΣ ΜΕΤΑ ΑΠΟ ΜΑΣΤΕΚΤΟΜΗ ΓΕΩΡΓΙΑ ΤΡΙΣΟΚΚΑ Λευκωσία 2012 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ
ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΝΟΣΗΛΕΥΤΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΨΥΧΟΛΟΓΙΚΕΣ ΕΠΙΠΤΩΣΕΙΣ ΣΕ ΓΥΝΑΙΚΕΣ ΜΕΤΑ ΑΠΟ ΜΑΣΤΕΚΤΟΜΗ ΓΕΩΡΓΙΑ ΤΡΙΣΟΚΚΑ Λευκωσία 2012 ΤΕΧΝΟΛΟΓΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ
6.1. Dirac Equation. Hamiltonian. Dirac Eq.
 6.1. Dirac Equation Ref: M.Kaku, Quantum Field Theory, Oxford Univ Press (1993) η μν = η μν = diag(1, -1, -1, -1) p 0 = p 0 p = p i = -p i p μ p μ = p 0 p 0 + p i p i = E c 2 - p 2 = (m c) 2 H = c p 2
6.1. Dirac Equation Ref: M.Kaku, Quantum Field Theory, Oxford Univ Press (1993) η μν = η μν = diag(1, -1, -1, -1) p 0 = p 0 p = p i = -p i p μ p μ = p 0 p 0 + p i p i = E c 2 - p 2 = (m c) 2 H = c p 2
Démographie spatiale/spatial Demography
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ Démographie spatiale/spatial Demography Session 1: Introduction to spatial demography Basic concepts Michail Agorastakis Department of Planning & Regional Development Άδειες Χρήσης
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ Démographie spatiale/spatial Demography Session 1: Introduction to spatial demography Basic concepts Michail Agorastakis Department of Planning & Regional Development Άδειες Χρήσης
Μηχανική Μάθηση Hypothesis Testing
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Μηχανική Μάθηση Hypothesis Testing Γιώργος Μπορμπουδάκης Τμήμα Επιστήμης Υπολογιστών Procedure 1. Form the null (H 0 ) and alternative (H 1 ) hypothesis 2. Consider
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Μηχανική Μάθηση Hypothesis Testing Γιώργος Μπορμπουδάκης Τμήμα Επιστήμης Υπολογιστών Procedure 1. Form the null (H 0 ) and alternative (H 1 ) hypothesis 2. Consider
ΚΥΠΡΙΑΚΟΣ ΣΥΝΔΕΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ CYPRUS COMPUTER SOCIETY 21 ος ΠΑΓΚΥΠΡΙΟΣ ΜΑΘΗΤΙΚΟΣ ΔΙΑΓΩΝΙΣΜΟΣ ΠΛΗΡΟΦΟΡΙΚΗΣ Δεύτερος Γύρος - 30 Μαρτίου 2011
 Διάρκεια Διαγωνισμού: 3 ώρες Απαντήστε όλες τις ερωτήσεις Μέγιστο Βάρος (20 Μονάδες) Δίνεται ένα σύνολο από N σφαιρίδια τα οποία δεν έχουν όλα το ίδιο βάρος μεταξύ τους και ένα κουτί που αντέχει μέχρι
Διάρκεια Διαγωνισμού: 3 ώρες Απαντήστε όλες τις ερωτήσεις Μέγιστο Βάρος (20 Μονάδες) Δίνεται ένα σύνολο από N σφαιρίδια τα οποία δεν έχουν όλα το ίδιο βάρος μεταξύ τους και ένα κουτί που αντέχει μέχρι
k A = [k, k]( )[a 1, a 2 ] = [ka 1,ka 2 ] 4For the division of two intervals of confidence in R +
[a 1, a 2 ] = [ka 1,ka 2 ] 4For the division of two intervals of confidence in R +](/thumbs/73/69566903.jpg "k A = [k, k]( )[a 1, a 2 ] = [ka 1,ka 2 ] 4For the division of two intervals of confidence in R +") Chapter 3. Fuzzy Arithmetic 3- Fuzzy arithmetic: ~Addition(+) and subtraction (-): Let A = [a and B = [b, b in R If x [a and y [b, b than x+y [a +b +b Symbolically,we write A(+)B = [a (+)[b, b = [a +b
Chapter 3. Fuzzy Arithmetic 3- Fuzzy arithmetic: ~Addition(+) and subtraction (-): Let A = [a and B = [b, b in R If x [a and y [b, b than x+y [a +b +b Symbolically,we write A(+)B = [a (+)[b, b = [a +b
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2009. HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems
 Systems") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2009 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Στατιστικά Κειμένου Text Statistics Γιάννης Τζίτζικας άλ ιάλεξη :
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2009 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Στατιστικά Κειμένου Text Statistics Γιάννης Τζίτζικας άλ ιάλεξη :
Chapter 6: Systems of Linear Differential. be continuous functions on the interval
 Chapter 6: Systems of Linear Differential Equations Let a (t), a 2 (t),..., a nn (t), b (t), b 2 (t),..., b n (t) be continuous functions on the interval I. The system of n first-order differential equations
Chapter 6: Systems of Linear Differential Equations Let a (t), a 2 (t),..., a nn (t), b (t), b 2 (t),..., b n (t) be continuous functions on the interval I. The system of n first-order differential equations
Statistical Inference I Locally most powerful tests
 Statistical Inference I Locally most powerful tests Shirsendu Mukherjee Department of Statistics, Asutosh College, Kolkata, India. shirsendu st@yahoo.co.in So far we have treated the testing of one-sided
Statistical Inference I Locally most powerful tests Shirsendu Mukherjee Department of Statistics, Asutosh College, Kolkata, India. shirsendu st@yahoo.co.in So far we have treated the testing of one-sided
Section 8.3 Trigonometric Equations
 99 Section 8. Trigonometric Equations Objective 1: Solve Equations Involving One Trigonometric Function. In this section and the next, we will exple how to solving equations involving trigonometric functions.
99 Section 8. Trigonometric Equations Objective 1: Solve Equations Involving One Trigonometric Function. In this section and the next, we will exple how to solving equations involving trigonometric functions.
Section 9.2 Polar Equations and Graphs
 180 Section 9. Polar Equations and Graphs In this section, we will be graphing polar equations on a polar grid. In the first few examples, we will write the polar equation in rectangular form to help identify
180 Section 9. Polar Equations and Graphs In this section, we will be graphing polar equations on a polar grid. In the first few examples, we will write the polar equation in rectangular form to help identify
Ανάκτηση Πληροφορίας
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 8: Λανθάνουσα Σημασιολογική Ανάλυση (Latent Semantic Analysis) Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 8: Λανθάνουσα Σημασιολογική Ανάλυση (Latent Semantic Analysis) Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό
Συντακτικές λειτουργίες
 2 Συντακτικές λειτουργίες (Syntactic functions) A. Πτώσεις και συντακτικές λειτουργίες (Cases and syntactic functions) The subject can be identified by asking ποιος (who) or τι (what) the sentence is about.
2 Συντακτικές λειτουργίες (Syntactic functions) A. Πτώσεις και συντακτικές λειτουργίες (Cases and syntactic functions) The subject can be identified by asking ποιος (who) or τι (what) the sentence is about.
Προσομοίωση BP με το Bizagi Modeler
 Προσομοίωση BP με το Bizagi Modeler Α. Τσαλγατίδου - Γ.-Δ. Κάπος Πρόγραμμα Μεταπτυχιακών Σπουδών Τεχνολογία Διοίκησης Επιχειρησιακών Διαδικασιών 2017-2018 BPMN Simulation with Bizagi Modeler: 4 Levels
Προσομοίωση BP με το Bizagi Modeler Α. Τσαλγατίδου - Γ.-Δ. Κάπος Πρόγραμμα Μεταπτυχιακών Σπουδών Τεχνολογία Διοίκησης Επιχειρησιακών Διαδικασιών 2017-2018 BPMN Simulation with Bizagi Modeler: 4 Levels
Abstract Storage Devices
 Abstract Storage Devices Robert König Ueli Maurer Stefano Tessaro SOFSEM 2009 January 27, 2009 Outline 1. Motivation: Storage Devices 2. Abstract Storage Devices (ASD s) 3. Reducibility 4. Factoring ASD
Abstract Storage Devices Robert König Ueli Maurer Stefano Tessaro SOFSEM 2009 January 27, 2009 Outline 1. Motivation: Storage Devices 2. Abstract Storage Devices (ASD s) 3. Reducibility 4. Factoring ASD
ΓΡΑΜΜΙΚΟΣ & ΔΙΚΤΥΑΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ
 ΓΡΑΜΜΙΚΟΣ & ΔΙΚΤΥΑΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Ενότητα 12: Συνοπτική Παρουσίαση Ανάπτυξης Κώδικα με το Matlab Σαμαράς Νικόλαος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons.
ΓΡΑΜΜΙΚΟΣ & ΔΙΚΤΥΑΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Ενότητα 12: Συνοπτική Παρουσίαση Ανάπτυξης Κώδικα με το Matlab Σαμαράς Νικόλαος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons.
Problem Set 3: Solutions
 CMPSCI 69GG Applied Information Theory Fall 006 Problem Set 3: Solutions. [Cover and Thomas 7.] a Define the following notation, C I p xx; Y max X; Y C I p xx; Ỹ max I X; Ỹ We would like to show that C
CMPSCI 69GG Applied Information Theory Fall 006 Problem Set 3: Solutions. [Cover and Thomas 7.] a Define the following notation, C I p xx; Y max X; Y C I p xx; Ỹ max I X; Ỹ We would like to show that C
LECTURE 2 CONTEXT FREE GRAMMARS CONTENTS
 LECTURE 2 CONTEXT FREE GRAMMARS CONTENTS 1. Developing a grammar fragment...1 2. A formalism that is too strong and too weak at the same time...3 3. References...4 1. Developing a grammar fragment The
LECTURE 2 CONTEXT FREE GRAMMARS CONTENTS 1. Developing a grammar fragment...1 2. A formalism that is too strong and too weak at the same time...3 3. References...4 1. Developing a grammar fragment The
Section 7.6 Double and Half Angle Formulas
 09 Section 7. Double and Half Angle Fmulas To derive the double-angles fmulas, we will use the sum of two angles fmulas that we developed in the last section. We will let α θ and β θ: cos(θ) cos(θ + θ)
09 Section 7. Double and Half Angle Fmulas To derive the double-angles fmulas, we will use the sum of two angles fmulas that we developed in the last section. We will let α θ and β θ: cos(θ) cos(θ + θ)
6.3 Forecasting ARMA processes
 122 CHAPTER 6. ARMA MODELS 6.3 Forecasting ARMA processes The purpose of forecasting is to predict future values of a TS based on the data collected to the present. In this section we will discuss a linear
122 CHAPTER 6. ARMA MODELS 6.3 Forecasting ARMA processes The purpose of forecasting is to predict future values of a TS based on the data collected to the present. In this section we will discuss a linear
Mean bond enthalpy Standard enthalpy of formation Bond N H N N N N H O O O
 Q1. (a) Explain the meaning of the terms mean bond enthalpy and standard enthalpy of formation. Mean bond enthalpy... Standard enthalpy of formation... (5) (b) Some mean bond enthalpies are given below.
Q1. (a) Explain the meaning of the terms mean bond enthalpy and standard enthalpy of formation. Mean bond enthalpy... Standard enthalpy of formation... (5) (b) Some mean bond enthalpies are given below.
HISTOGRAMS AND PERCENTILES What is the 25 th percentile of a histogram? What is the 50 th percentile for the cigarette histogram?
 HISTOGRAMS AND PERCENTILES What is the 25 th percentile of a histogram? The point on the horizontal axis such that of the area under the histogram lies to the left of that point (and to the right) What
HISTOGRAMS AND PERCENTILES What is the 25 th percentile of a histogram? The point on the horizontal axis such that of the area under the histogram lies to the left of that point (and to the right) What
PARTIAL NOTES for 6.1 Trigonometric Identities
 PARTIAL NOTES for 6.1 Trigonometric Identities tanθ = sinθ cosθ cotθ = cosθ sinθ BASIC IDENTITIES cscθ = 1 sinθ secθ = 1 cosθ cotθ = 1 tanθ PYTHAGOREAN IDENTITIES sin θ + cos θ =1 tan θ +1= sec θ 1 + cot
PARTIAL NOTES for 6.1 Trigonometric Identities tanθ = sinθ cosθ cotθ = cosθ sinθ BASIC IDENTITIES cscθ = 1 sinθ secθ = 1 cosθ cotθ = 1 tanθ PYTHAGOREAN IDENTITIES sin θ + cos θ =1 tan θ +1= sec θ 1 + cot
Elements of Information Theory
 Elements of Information Theory Model of Digital Communications System A Logarithmic Measure for Information Mutual Information Units of Information Self-Information News... Example Information Measure
Elements of Information Theory Model of Digital Communications System A Logarithmic Measure for Information Mutual Information Units of Information Self-Information News... Example Information Measure
CHAPTER 48 APPLICATIONS OF MATRICES AND DETERMINANTS
 CHAPTER 48 APPLICATIONS OF MATRICES AND DETERMINANTS EXERCISE 01 Page 545 1. Use matrices to solve: 3x + 4y x + 5y + 7 3x + 4y x + 5y 7 Hence, 3 4 x 0 5 y 7 The inverse of 3 4 5 is: 1 5 4 1 5 4 15 8 3
CHAPTER 48 APPLICATIONS OF MATRICES AND DETERMINANTS EXERCISE 01 Page 545 1. Use matrices to solve: 3x + 4y x + 5y + 7 3x + 4y x + 5y 7 Hence, 3 4 x 0 5 y 7 The inverse of 3 4 5 is: 1 5 4 1 5 4 15 8 3
SCITECH Volume 13, Issue 2 RESEARCH ORGANISATION Published online: March 29, 2018
 Journal of rogressive Research in Mathematics(JRM) ISSN: 2395-028 SCITECH Volume 3, Issue 2 RESEARCH ORGANISATION ublished online: March 29, 208 Journal of rogressive Research in Mathematics www.scitecresearch.com/journals
Journal of rogressive Research in Mathematics(JRM) ISSN: 2395-028 SCITECH Volume 3, Issue 2 RESEARCH ORGANISATION ublished online: March 29, 208 Journal of rogressive Research in Mathematics www.scitecresearch.com/journals
Potential Dividers. 46 minutes. 46 marks. Page 1 of 11
 Potential Dividers 46 minutes 46 marks Page 1 of 11 Q1. In the circuit shown in the figure below, the battery, of negligible internal resistance, has an emf of 30 V. The pd across the lamp is 6.0 V and
Potential Dividers 46 minutes 46 marks Page 1 of 11 Q1. In the circuit shown in the figure below, the battery, of negligible internal resistance, has an emf of 30 V. The pd across the lamp is 6.0 V and
TaxiCounter Android App. Περδίκης Ανδρέας ME10069
 TaxiCounter Android App Περδίκης Ανδρέας ME10069 Content Android Operating System Development Tools Taxi Counter Algorithm Design Development Process Android Operating System Android is a Linux-based operating
TaxiCounter Android App Περδίκης Ανδρέας ME10069 Content Android Operating System Development Tools Taxi Counter Algorithm Design Development Process Android Operating System Android is a Linux-based operating
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems
 Systems") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2007 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Στατιστικά Κειμένου Text Statistics Γιάννης Τζίτζικας ιάλεξη : 14a
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2007 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Στατιστικά Κειμένου Text Statistics Γιάννης Τζίτζικας ιάλεξη : 14a
Terabyte Technology Ltd
 Terabyte Technology Ltd is a Web and Graphic design company in Limassol with dedicated staff who will endeavour to deliver the highest quality of work in our field. We offer a range of services such as
Terabyte Technology Ltd is a Web and Graphic design company in Limassol with dedicated staff who will endeavour to deliver the highest quality of work in our field. We offer a range of services such as
Ανάκτηση Πληροφορίας. Διδάσκων: Φοίβος Μυλωνάς. Διάλεξη #03
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #03 Βασικές έννοιες Ανάκτησης Πληροφορίας Δομή ενός συστήματος IR Αναζήτηση με keywords ευφυής
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #03 Βασικές έννοιες Ανάκτησης Πληροφορίας Δομή ενός συστήματος IR Αναζήτηση με keywords ευφυής
Μηχανισμοί πρόβλεψης προσήμων σε προσημασμένα μοντέλα κοινωνικών δικτύων ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΕΠΙΚΟΙΝΩΝΙΩΝ, ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΣΥΣΤΗΜΑΤΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ Μηχανισμοί πρόβλεψης προσήμων σε προσημασμένα μοντέλα κοινωνικών
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΕΠΙΚΟΙΝΩΝΙΩΝ, ΗΛΕΚΤΡΟΝΙΚΗΣ ΚΑΙ ΣΥΣΤΗΜΑΤΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ Μηχανισμοί πρόβλεψης προσήμων σε προσημασμένα μοντέλα κοινωνικών
Dynamic types, Lambda calculus machines Section and Practice Problems Apr 21 22, 2016
 Harvard School of Engineering and Applied Sciences CS 152: Programming Languages Dynamic types, Lambda calculus machines Apr 21 22, 2016 1 Dynamic types and contracts (a) To make sure you understand the
Harvard School of Engineering and Applied Sciences CS 152: Programming Languages Dynamic types, Lambda calculus machines Apr 21 22, 2016 1 Dynamic types and contracts (a) To make sure you understand the
department listing department name αχχουντσ ϕανε βαλικτ δδσϕηασδδη σδηφγ ασκϕηλκ τεχηνιχαλ αλαν ϕουν διξ τεχηνιχαλ ϕοην µαριανι
 She selects the option. Jenny starts with the al listing. This has employees listed within She drills down through the employee. The inferred ER sttricture relates this to the redcords in the databasee
She selects the option. Jenny starts with the al listing. This has employees listed within She drills down through the employee. The inferred ER sttricture relates this to the redcords in the databasee
Numerical Analysis FMN011
 Numerical Analysis FMN011 Carmen Arévalo Lund University carmen@maths.lth.se Lecture 12 Periodic data A function g has period P if g(x + P ) = g(x) Model: Trigonometric polynomial of order M T M (x) =
Numerical Analysis FMN011 Carmen Arévalo Lund University carmen@maths.lth.se Lecture 12 Periodic data A function g has period P if g(x + P ) = g(x) Model: Trigonometric polynomial of order M T M (x) =
ΦΥΛΛΟ ΕΡΓΑΣΙΑΣ Α. Διαβάστε τις ειδήσεις και εν συνεχεία σημειώστε. Οπτική γωνία είδησης 1:.
 ΦΥΛΛΟ ΕΡΓΑΣΙΑΣ Α 2 ειδήσεις από ελληνικές εφημερίδες: 1. Τα Νέα, 13-4-2010, Σε ανθρώπινο λάθος αποδίδουν τη συντριβή του αεροσκάφους, http://www.tanea.gr/default.asp?pid=2&artid=4569526&ct=2 2. Τα Νέα,
ΦΥΛΛΟ ΕΡΓΑΣΙΑΣ Α 2 ειδήσεις από ελληνικές εφημερίδες: 1. Τα Νέα, 13-4-2010, Σε ανθρώπινο λάθος αποδίδουν τη συντριβή του αεροσκάφους, http://www.tanea.gr/default.asp?pid=2&artid=4569526&ct=2 2. Τα Νέα,
Capacitors - Capacitance, Charge and Potential Difference
 Capacitors - Capacitance, Charge and Potential Difference Capacitors store electric charge. This ability to store electric charge is known as capacitance. A simple capacitor consists of 2 parallel metal
Capacitors - Capacitance, Charge and Potential Difference Capacitors store electric charge. This ability to store electric charge is known as capacitance. A simple capacitor consists of 2 parallel metal
( ) 2 and compare to M.
 2 and compare to M.") Problems and Solutions for Section 4.2 4.9 through 4.33) 4.9 Calculate the square root of the matrix 3!0 M!0 8 Hint: Let M / 2 a!b ; calculate M / 2!b c ) 2 and compare to M. Solution: Given: 3!0 M!0 8
Problems and Solutions for Section 4.2 4.9 through 4.33) 4.9 Calculate the square root of the matrix 3!0 M!0 8 Hint: Let M / 2 a!b ; calculate M / 2!b c ) 2 and compare to M. Solution: Given: 3!0 M!0 8
ΣΙΣΛΟ ΓΙΑΣΡΙΒΗ ΔΞΑΓΧΓΗ ΥΑΡΑΚΣΗΡΙΣΙΚΧΝ ΔΙΚΟΝΟΠΛΑΙΙΧΝ ΑΠΟ ΑΚΟΛΟΤΘΙΔ ΒΙΝΣΔΟ ΜΔ ΥΡΗΗ ΟΜΑΓΟΠΟΙΗΗ ΠΟΛΛΑΠΛΧΝ ΟΦΔΧΝ ΜΔΣΑΠΣΤΥΙΑΚΗ ΔΡΓΑΙΑ ΔΞΔΙΓΙΚΔΤΗ
 ΣΙΣΛΟ ΓΙΑΣΡΙΒΗ ΔΞΑΓΧΓΗ ΥΑΡΑΚΣΗΡΙΣΙΚΧΝ ΔΙΚΟΝΟΠΛΑΙΙΧΝ ΑΠΟ ΑΚΟΛΟΤΘΙΔ ΒΙΝΣΔΟ ΜΔ ΥΡΗΗ ΟΜΑΓΟΠΟΙΗΗ ΠΟΛΛΑΠΛΧΝ ΟΦΔΧΝ Η ΜΔΣΑΠΣΤΥΙΑΚΗ ΔΡΓΑΙΑ ΔΞΔΙΓΙΚΔΤΗ Τπνβάιιεηαη ζηελ νξηζζείζα από ηελ Γεληθή πλέιεπζε Δηδηθήο ύλζεζεο
ΣΙΣΛΟ ΓΙΑΣΡΙΒΗ ΔΞΑΓΧΓΗ ΥΑΡΑΚΣΗΡΙΣΙΚΧΝ ΔΙΚΟΝΟΠΛΑΙΙΧΝ ΑΠΟ ΑΚΟΛΟΤΘΙΔ ΒΙΝΣΔΟ ΜΔ ΥΡΗΗ ΟΜΑΓΟΠΟΙΗΗ ΠΟΛΛΑΠΛΧΝ ΟΦΔΧΝ Η ΜΔΣΑΠΣΤΥΙΑΚΗ ΔΡΓΑΙΑ ΔΞΔΙΓΙΚΔΤΗ Τπνβάιιεηαη ζηελ νξηζζείζα από ηελ Γεληθή πλέιεπζε Δηδηθήο ύλζεζεο
Modbus basic setup notes for IO-Link AL1xxx Master Block
 n Modbus has four tables/registers where data is stored along with their associated addresses. We will be using the holding registers from address 40001 to 49999 that are R/W 16 bit/word. Two tables that
n Modbus has four tables/registers where data is stored along with their associated addresses. We will be using the holding registers from address 40001 to 49999 that are R/W 16 bit/word. Two tables that
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ. Ψηφιακή Οικονομία. Διάλεξη 10η: Basics of Game Theory part 2 Mαρίνα Μπιτσάκη Τμήμα Επιστήμης Υπολογιστών
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Ψηφιακή Οικονομία Διάλεξη 0η: Basics of Game Theory part 2 Mαρίνα Μπιτσάκη Τμήμα Επιστήμης Υπολογιστών Best Response Curves Used to solve for equilibria in games
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Ψηφιακή Οικονομία Διάλεξη 0η: Basics of Game Theory part 2 Mαρίνα Μπιτσάκη Τμήμα Επιστήμης Υπολογιστών Best Response Curves Used to solve for equilibria in games
ω ω ω ω ω ω+2 ω ω+2 + ω ω ω ω+2 + ω ω+1 ω ω+2 2 ω ω ω ω ω ω ω ω+1 ω ω2 ω ω2 + ω ω ω2 + ω ω ω ω2 + ω ω+1 ω ω2 + ω ω+1 + ω ω ω ω2 + ω
 0 1 2 3 4 5 6 ω ω + 1 ω + 2 ω + 3 ω + 4 ω2 ω2 + 1 ω2 + 2 ω2 + 3 ω3 ω3 + 1 ω3 + 2 ω4 ω4 + 1 ω5 ω 2 ω 2 + 1 ω 2 + 2 ω 2 + ω ω 2 + ω + 1 ω 2 + ω2 ω 2 2 ω 2 2 + 1 ω 2 2 + ω ω 2 3 ω 3 ω 3 + 1 ω 3 + ω ω 3 +
0 1 2 3 4 5 6 ω ω + 1 ω + 2 ω + 3 ω + 4 ω2 ω2 + 1 ω2 + 2 ω2 + 3 ω3 ω3 + 1 ω3 + 2 ω4 ω4 + 1 ω5 ω 2 ω 2 + 1 ω 2 + 2 ω 2 + ω ω 2 + ω + 1 ω 2 + ω2 ω 2 2 ω 2 2 + 1 ω 2 2 + ω ω 2 3 ω 3 ω 3 + 1 ω 3 + ω ω 3 +
Απόκριση σε Μοναδιαία Ωστική Δύναμη (Unit Impulse) Απόκριση σε Δυνάμεις Αυθαίρετα Μεταβαλλόμενες με το Χρόνο. Απόστολος Σ.
 Απόκριση σε Δυνάμεις Αυθαίρετα Μεταβαλλόμενες με το Χρόνο. Απόστολος Σ.") Απόκριση σε Δυνάμεις Αυθαίρετα Μεταβαλλόμενες με το Χρόνο The time integral of a force is referred to as impulse, is determined by and is obtained from: Newton s 2 nd Law of motion states that the action
Απόκριση σε Δυνάμεις Αυθαίρετα Μεταβαλλόμενες με το Χρόνο The time integral of a force is referred to as impulse, is determined by and is obtained from: Newton s 2 nd Law of motion states that the action
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Σημασιολογική Συσταδοποίηση Αντικειμένων Με Χρήση Οντολογικών Περιγραφών.
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΤΕΧΝΟΛΟΓΙΑΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΥΠΟΛΟΓΙΣΤΩΝ Σημασιολογική Συσταδοποίηση Αντικειμένων Με Χρήση Οντολογικών Περιγραφών.
Code Breaker. TEACHER s NOTES
 TEACHER s NOTES Time: 50 minutes Learning Outcomes: To relate the genetic code to the assembly of proteins To summarize factors that lead to different types of mutations To distinguish among positive,
TEACHER s NOTES Time: 50 minutes Learning Outcomes: To relate the genetic code to the assembly of proteins To summarize factors that lead to different types of mutations To distinguish among positive,
New bounds for spherical two-distance sets and equiangular lines
 New bounds for spherical two-distance sets and equiangular lines Michigan State University Oct 8-31, 016 Anhui University Definition If X = {x 1, x,, x N } S n 1 (unit sphere in R n ) and x i, x j = a
New bounds for spherical two-distance sets and equiangular lines Michigan State University Oct 8-31, 016 Anhui University Definition If X = {x 1, x,, x N } S n 1 (unit sphere in R n ) and x i, x j = a
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΣΥΣΤΗΜΑΤΩΝ ΜΕΤΑΔΟΣΗΣ ΠΛΗΡΟΦΟΡΙΑΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΛΙΚΩΝ Εξαγωγή χαρακτηριστικών μαστογραφικών μαζών και σύγκριση
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΤΟΜΕΑΣ ΣΥΣΤΗΜΑΤΩΝ ΜΕΤΑΔΟΣΗΣ ΠΛΗΡΟΦΟΡΙΑΣ ΚΑΙ ΤΕΧΝΟΛΟΓΙΑΣ ΥΛΙΚΩΝ Εξαγωγή χαρακτηριστικών μαστογραφικών μαζών και σύγκριση
Second Order Partial Differential Equations
 Chapter 7 Second Order Partial Differential Equations 7.1 Introduction A second order linear PDE in two independent variables (x, y Ω can be written as A(x, y u x + B(x, y u xy + C(x, y u u u + D(x, y
Chapter 7 Second Order Partial Differential Equations 7.1 Introduction A second order linear PDE in two independent variables (x, y Ω can be written as A(x, y u x + B(x, y u xy + C(x, y u u u + D(x, y
Concrete Mathematics Exercises from 30 September 2016
 Concrete Mathematics Exercises from 30 September 2016 Silvio Capobianco Exercise 1.7 Let H(n) = J(n + 1) J(n). Equation (1.8) tells us that H(2n) = 2, and H(2n+1) = J(2n+2) J(2n+1) = (2J(n+1) 1) (2J(n)+1)
Concrete Mathematics Exercises from 30 September 2016 Silvio Capobianco Exercise 1.7 Let H(n) = J(n + 1) J(n). Equation (1.8) tells us that H(2n) = 2, and H(2n+1) = J(2n+2) J(2n+1) = (2J(n+1) 1) (2J(n)+1)
Παλεπηζηήκην Πεηξαηώο Τκήκα Πιεξνθνξηθήο Πξόγξακκα Μεηαπηπρηαθώλ Σπνπδώλ «Πξνεγκέλα Σπζηήκαηα Πιεξνθνξηθήο»
 Παλεπηζηήκην Πεηξαηώο Τκήκα Πιεξνθνξηθήο Πξόγξακκα Μεηαπηπρηαθώλ Σπνπδώλ «Πξνεγκέλα Σπζηήκαηα Πιεξνθνξηθήο» Μεηαπηπρηαθή Γηαηξηβή Τίηινο Γηαηξηβήο Ανάπτυξη διαδικτυακού εκπαιδευτικού παιχνιδιού για τη
Παλεπηζηήκην Πεηξαηώο Τκήκα Πιεξνθνξηθήο Πξόγξακκα Μεηαπηπρηαθώλ Σπνπδώλ «Πξνεγκέλα Σπζηήκαηα Πιεξνθνξηθήο» Μεηαπηπρηαθή Γηαηξηβή Τίηινο Γηαηξηβήο Ανάπτυξη διαδικτυακού εκπαιδευτικού παιχνιδιού για τη
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems
 Systems") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2008 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Στατιστικά Κειμένου Text Statistics Γιάννης Τζίτζικας ιάλεξη : 14a
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών Άνοιξη 2008 HΥ463 - Συστήματα Ανάκτησης Πληροφοριών Information Retrieval (IR) Systems Στατιστικά Κειμένου Text Statistics Γιάννης Τζίτζικας ιάλεξη : 14a
ST5224: Advanced Statistical Theory II
 ST5224: Advanced Statistical Theory II 2014/2015: Semester II Tutorial 7 1. Let X be a sample from a population P and consider testing hypotheses H 0 : P = P 0 versus H 1 : P = P 1, where P j is a known
ST5224: Advanced Statistical Theory II 2014/2015: Semester II Tutorial 7 1. Let X be a sample from a population P and consider testing hypotheses H 0 : P = P 0 versus H 1 : P = P 1, where P j is a known