Information Retrieval
|
|
|
- Ονησίφορος Τελαμών Παπαντωνίου
- 8 χρόνια πριν
- Προβολές:
Transcript
1 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 6: Θέματα Υλοποίησης. Περίληψη Αποτελεσμάτων. 1
2 Κεφ. 6 Τι είδαμε στο προηγούμενο μάθημα Βαθμολόγηση και κατάταξη εγγράφων Στάθμιση όρων (term weighting) Αναπαράσταση εγγράφων και ερωτημάτων ως διανύσματα 2
3 Κεφ. 6 Boolean ανάκτηση ερωτήματα Boolean. Τα έγγραφα ήταν ταίριαζαν, είτε όχι Κατάλληλη για ειδικούς με σαφή κατανόηση των αναγκών τους και της συλλογής Αλλά, όχι κατάλληλη για την πλειοψηφία των χρηστών Το πρόβλημα με τα πάρα πολλά ή τα πολύ λίγα αποτελέσματα 3
4 Μοντέλα διαβαθμισμένης ανάκτησης Αντί ενός συνόλου εγγράφων που ικανοποιούν το ερώτημα, η διαβαθμισμένη ανάκτηση (ranked retrieval) επιστρέφει μια διάταξη των (κορυφαίων) για την ερώτηση εγγράφων της συλλογής Συνήθως μαζί με ερωτήματα ελεύθερου κειμένου (Free text queries) Πως διατάσουμε-διαβαθμίζουμε τα έγγραφα μιας συλλογής με βάση ένα ερώτημα Αναθέτουμε ένα βαθμό (score) score(d, q) μετρά πόσο καλά το έγγραφο d ταιριάζει (match) με το ερώτημα q 4
5 Κεφ. 6 Διαβαθμισμένη ανάκτηση Όταν το σύστημα παράγει ένα διατεταγμένο σύνολο αποτελεσμάτων, τα μεγάλα σύνολα δεν αποτελούν πρόβλημα Δείχνουμε απλώς τα κορυφαία (top) k ( 10) αποτελέσματα Δεν παραφορτώνουμε το χρήστη Προϋπόθεση: ο αλγόριθμος διάταξης να δουλεύει σωστά 5
6 Κεφ. 6 Βαθμός ταιριάσματος ερωτήματοςεγγράφου Χρειαζόμαστε ένα τρόπο για να αναθέσουμε ένα βαθμό σε κάθε ζεύγος ερωτήματος(q)/εγγράφου(d) score(d, q) 6
7 Κεφ. 6.2 Στάθμιση με log-συχνότητας Η συχνότητα όρου tf t,d του όρου t σε ένα έγγραφο d ορίζεται ως αριθμός των φορών που το t εμφανίζεται στο d. Επειδή η συνάφεια (relevance) δεν αυξάνει αναλογικά με τη συχνότητα όρου, στάθμιση με χρήση του λογάριθμου της συχνότητα (log frequency weight) του όρου t στο d είναι w t,d 1 log10 tft,d, if tft,d 0 0, otherwise 0 0, 1 1, 2 1.3, 10 2, 100->3, , κλπ. 7
8 Κεφ. 6.2 Στάθμιση με log-συχνότητας Ο βαθμός για ένα ζεύγος εγγράφου-ερωτήματος: άθροισμα των βαρών όλων των κοινών όρων: t q d score w t, d Ο βαθμός είναι 0 όταν κανένας από τους όρους του ερωτήματος δεν εμφανίζεται στο έγγραφο 8
9 Κεφ. 6.2 Στάθμιση με log-συχνότητας Ερώτημα q a b Έγγραφα d 1 a.. b d 2 a a d 3 a a b d 4 b.. b b d 5 a a b b d 6 a. b d 7 Διάταξη?? 9
10 Κεφ Συχνότητα εγγράφων (Document frequency) Οι σπάνιοι όροι δίνουν περισσότερη πληροφορία από τους συχνούς όρους Θυμηθείτε τα stop words (διακοπτόμενες λέξεις) Θεωρείστε έναν όρο σε μια ερώτηση που είναι σπάνιος στη συλλογή (π.χ., arachnocentric) Το έγγραφο που περιέχει αυτόν τον όρο είναι πιο πιθανό να είναι πιο σχετικό με το ερώτημα από ένα έγγραφο που περιέχει ένα λιγότερο σπάνιο όρο του ερωτήματος Θέλουμε να δώσουμε μεγαλύτερο βάρος στους σπάνιους όρους αλλά πως; df 10
11 Κεφ Βάρος idf df t είναι η συχνότητα εγγράφων του t: ο αριθμός (πλήθος) των εγγράφων της συλλογής που περιέχουν το t (df t N) df t είναι η αντίστροφη μέτρηση της πληροφορίας που παρέχει ο όρος t Ορίζουμε την αντίστροφη συχνότητα εγγράφων idf (inverse document frequency) του t ως idf log ( N/df ) t 10 t Χρησιμοποιούμε log (N/df t ) αντί για N/df t για να «ομαλοποιήσουμε» την επίδραση του idf. 11
12 Κεφ Παράδειγμα idf, έστω N = 1 εκατομμύριο term df t idf t calpurnia 1 6 animal sunday 1,000 3 fly 10,000 2 under 100,000 1 the 1,000,000 0 idf log ( N/df ) t 10 t Κάθε όρος στη συλλογή έχει μια τιμή idf 12
13 Κεφ Στάθμιση tf-idf Το tf-idf βάρος ενός όρου είναι το γινόμενο του βάρους tf και του βάρους idf. w (1 log(tft, )) log( N / df t, d d t ) Το πιο γνωστό σχήμα διαβάθμισης στην ανάκτηση πληροφορίας -- Εναλλακτικά ονόματα: tf.idf, tf x idf Αυξάνει με τον αριθμό εμφανίσεων του όρου στο έγγραφο Αυξάνει με τη σπανιότητα του όρου στη συλλογή 13
14 Κεφ Στάθμιση tf-idf Score(q,d) t q d tf.idf t,d Υπάρχουν πολλές άλλες παραλλαγές Πως υπολογίζεται το tf (με ή χωρίς log) Αν δίνεται βάρος και στους όρους του ερωτήματος 14
15 Κεφ Στάθμιση tf-idf Ερώτημα q a b Έγγραφα d 1 a.. b d 2 a a d 3 a a b d 4 b.. b b d 5 a a b b a. d 6 Διάταξη?? 15
16 Κεφ. 6.2 Δυαδική μήτρα σύμπτωσης (binary termdocument incidence matrix) Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser Κάθε έγγραφο αναπαρίσταται ως ένα δυαδικό διάνυσμα {0,1} V (την αντίστοιχη στήλη) 16
17 Κεφ. 6.2 Ο πίνακας με μετρητές Κάθε έγγραφο είναι ένα διάνυσμα μετρητών (συχνότητα εμφάνισης του όρου στο έγγραφο) στο N v : μια στήλη παρακάτω Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser

18 Κεφ. 6.3 Ο πίνακας με βάρη Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser Θεωρούμε το tf-idf βάρος του όρου: Κάθε έγγραφο είναι ένα διάνυσμα tf-idf βαρών στο R v 18
19 Κεφ. 6.3 Τα έγγραφα ως διανύσματα Έχουμε ένα V -διάστατο διανυσματικό χώρο Οι όροι είναι οι άξονες αυτού του χώρου Τα έγγραφα είναι σημεία ή διανύσματα σε αυτόν τον χώρο Πολύ μεγάλη διάσταση: δεκάδες εκατομμύρια διαστάσεις στην περίπτωση της αναζήτησης στο web Πολύ αραιά διανύσματα οι περισσότεροι όροι είναι 0 19
20 Κεφ. 6.3 Τα ερωτήματα ως διανύσματα Βασική ιδέα 1: Εφαρμόζουμε το ίδιο και για τα ερωτήματα, δηλαδή, αναπαριστούμε και τα ερωτήματα ως διανύσματα στον ίδιο χώρο Βασική ιδέα 2: Διαβάθμιση των εγγράφων με βάση το πόσο κοντά είναι στην ερώτηση σε αυτό το χώρο Κοντινά = ομοιότητα διανυσμάτων Ομοιότητα αντίθετο της απόστασης 20
21 Κεφ. 6.3 Ομοιότητα διανυσμάτων Πρώτη προσέγγιση: απόσταση μεταξύ δυο διανυσμάτων Ευκλείδεια απόσταση; Δεν είναι καλή ιδέα είναι μεγάλη για διανύσματα διαφορετικού μήκους 21
22 Ομοιότητα συνημιτόνου 22
23 cosine(query, document) V i i V i i V i i i d q q d d d q q d q d q d q ), cos( Dot product Unit vectors q i είναι το tf-idf βάρος του όρου i στην ερώτηση d i είναι το tf-idf βάρος του όρου i στο έγγραφο cos(q, d) είναι η ομοιότητα συνημίτονου των q και d, που ορίζεται ως το συνημίτονο της γωνίας μεταξύ των q και d. Κεφ
24 Κεφ. 6.3 Κανονικοποίηση του μήκους Ένα διάνυσμα μπορεί να κανονικοποιηθεί διαιρώντας τα στοιχεία του με το μήκος του, με χρήση της L 2 νόρμας: Διαιρώντας ένα διάνυσμα με την L 2 νόρμα το κάνει μοναδιαίο Ως αποτέλεσμα, μικρά και μεγάλα έγγραφα έχουν συγκρίσιμα βάρη Για διανύσματα που έχουμε κανονικοποιήσει το μήκος τους (length-normalized vectors) το συνημίτονο είναι απλώς το εσωτερικό γινόμενο (dot or scalar product): x 2 i x 2 i cos(q,d ) q d V q d i 1 i i 24
25 Βαθμολόγηση στο διανυσματικό χώρο 1. Αναπαράσταση του ερωτήματος ως ένα διαβαθμισμένο tf-idf διάνυσμα 2. Αναπαράσταση κάθε εγγράφου ως ένα διαβαθμισμένο tf-idf διάνυσμα 3. Υπολόγισε το συνημίτονο για κάθε ζεύγος ερωτήματος, εγγράφου 4. Διάταξε τα έγγραφα με βάση αυτό το βαθμό 5. Επέστρεψε τα κορυφαία Κ (π.χ., Κ =10) έγγραφα στο χρήστη 25
26 Κεφ. 6.4 Παραλλαγές της tf-idf στάθμισης Augmented: θεωρούμε τη συχνότητα του πιο συχνού όρου στο έγγραφο και κανονικοποιούμε με αυτήν Το 0.5 είναι ένας τελεστές στάθμισης (εξομάλυνσης) smoothing factor (συχνά και 0.4 αντί 0.5) για να αντιμετωπίσουμε το γεγονός ότι μεγάλα έγγραφα μπορεί να έχουν μεγάλα tf τιμές γιατί επαναλαμβάνουν πληροφορία 26
27 Κεφ. 6.4 Στάθμιση ερωτημάτων και εγγράφων Πολλές μηχανές αναζήτησης σταθμίζουν διαφορετικά τις ερωτήσεις από τα έγγραφα Συμβολισμό: ddd.qqq, με χρήση των ακρωνύμων του πίνακα (πρώτα 3 γράμματα έγγραφο- επόμενα 3 ερώτημα) Συχνό σχήμα : lnc.ltc Έγγραφο: logarithmic tf (l), no idf (n), cosine normalization (c) Γιατί; idf: ολικό μέγεθος 27
28 Κεφ. 6.3 Παράδειγμα Ποια είναι οι ομοιότητα μεταξύ των έργων SaS: Sense and Sensibility PaP: Pride and Prejudice, and WH: Wuthering Heights? Συχνότητα όρων (μετρητές) όρος SaS PaP WH affection jealous gossip wuthering
29 Κεφ. 6.3 Παράδειγμα (συνέχεια) Για απλοποίηση δε θα χρησιμοποιήσουμε τα idf βάρη lnc (logarithmic, none, normalized cosine) Log frequency βάρος όρος SaS PaP WH όρος SaS PaP WH affection jealous gossip wuthering affection jealous gossip wuthering Μήκος SAS = Μετά την κανονικοποίηση όρος SaS PaP WH affection jealous gossip wuthering
30 Κεφ. 6.3 Παράδειγμα (συνέχεια) όρος SaS PaP WH affection jealous gossip wuthering όρος SaS PaP WH affection jealous gossip wuthering cos(sas,pap) cos(sas,wh) 0.79 Γιατί cos(sas,pap) > cos(sas,wh)? cos(pap,wh)
31 Κεφ. 6.4 Στάθμιση ερωτημάτων και εγγράφων Συχνό σχήμα : lnc.ltc Έγγραφο: logarithmic tf, no idf, cosine normalization Ερώτημα: logarithmic tf (l), idf (t), cosine normalization (c) 31
32 Κεφ. 6.4 Παράδειγμα Ερώτημα: best car insurance Έγγραφο: car insurance auto insurance Ν = 1000Κ Όρος Ερώτημα (Query) Έγγραφο Prod tf-raw tf-wt df idf wt n lize tf-raw tf-wt wt n lize auto best car insurance Μήκος Ερωτήματος = Μήκος Εγγράφου = lnc.ltc Score = 0+0+(0.52*0.52=)27+(0.78*0.68=)0.53 =
33 Μοντέλο Σάκου Λέξεων (Bag of words model) Η διανυσματική αναπαράσταση δεν εξετάζει τη διάταξη των λέξεων σε ένα έγγραφο John is quicker than Mary και Mary is quicker than John Έχουν τα ίδια διανύσματα Αυτό λέγεται μοντέλου σάκου λέξεων (bag of words model). 33
34 Τι άλλο θα δούμε σήμερα Θέματα υλοποίησης Περίληψη εγγράφων 34
35 Επέκταση καταχωρήσεων Συχνότητες όρων Σε κάθε καταχώρηση, αποθήκευση του tf t,d επιπρόσθετα του docid d Η συχνότητα idf t αποθηκεύεται στο λεξικό μαζί με τον όρο t 35
36 Κεφ. 7 Υπολογισμός ανά έγγραφο (document-at-a-time) (document-at-a-time) Μπορούμε να διατρέχουμε τις λίστες των όρων του ερωτήματος παράλληλα όπως στην περίπτωση της Boolean ανάκτησης (merge sort) Αυτό έχει ως αποτέλεσμα λόγω της ίδιας διάταξης των εγγράφων στις λίστες καταχωρίσεων τον υπολογισμό του βαθμού ανά έγγραφο 36
37 Κεφ. 7 Υπολογισμός βαρών Η σχετική διάταξη των εγγράφων δεν επηρεάζεται από την κανονικοποίηση ή όχι του διανύσματος του q Αν κάθε όρος μόνο μια φορά στο ερώτημα, το w t,q μπορεί να αγνοηθεί, οπότε μπορούμε απλώς να αθροίζουμε τα w t,s 37
38 Κεφ. 7 Παράδειγμα Ερώτημα: [Brutus Caesar]: Διατρέχουμε παράλληλα τις λίστες για το Brutus και Caesar 38
39 Κεφ. 7 Υπολογισμός k-κορυφαίων αποτελεσμάτων Σε πολλές εφαρμογές, δε χρειαζόμαστε την πλήρη διάταξη, αλλά μόνο τα κορυφαία k (top-k), για κάποιο μικρό k, π.χ., k = 100 Απλοϊκός τρόπος: Υπολόγισε τους βαθμούς για όλα τα N έγραφα Sort Επέστεψε τα κορυφαία k Αν δε χρειαζόμαστε όλη τη διάταξη, υπάρχει πιο αποδοτικός τρόπος να υπολογίσουμε μόνο τα κορυφαία k; Έστω J τα έγγραφα με μη μηδενικό συνημίτονο. Μπορούμε να βρούμε τα K καλύτερα χωρίς ταξινόμηση όλων των J εγγράφων; 39
40 Κεφ. 7 Χρήση min-heap Χρήση δυαδικού min heap Ένα δυαδικό min heap είναι ένα δυαδικό δέντρο που η τιμή ενός κόμβου είναι μικρότερη από την τιμή των δύο παιδιών του. 40
41 Κεφ. 7 Αποθήκευση σε πίνακα Η ρίζα είναι στη θέση 1 του πίνακα. Για το i-οστό στοιχείο: Το αριστερό παιδί είναι στη θέση 2*i Το δεξί παιδί είναι στη θέση 2*i+1 Ο γονέας στη θέση i/2 41
42 Κεφ. 7 Εισαγωγή στοιχείου Το νέο στοιχείο εισάγεται ως το τελευταίο στοιχείο (στο τέλος του heap) Η ιδιότητα του heap εξασφαλίζεται με σύγκριση του στοιχείου με τον γονιό του και μετακίνηση του προς τα πάνω (swap with parent) μέχρι να συναντήσει στοιχείο ίσο ή μεγαλύτερο (percolation up). 42
43 Κεφ. 7 Διαγραφή μικρότερου στοιχείου Το μικρότερο στοιχείο βρίσκεται στη ρίζα (το πρώτο στοιχείο του πίνακα) Το σβήνουμε από τη λίστα και το αντικαθιστούμε με το τελευταίο στοιχείο στη λίστα, εξασφαλίζοντας την ιδιότητα του heap συγκρίνοντας με τα παιδιά του (percolating down.) 43
44 Κεφ. 7 Επιλογή των κορυφαίων k σε O(N log k) Στόχος: Διατηρούμε τα καλύτερα k που έχουμε δει μέχρι στιγμής Χρήση δυαδικού min heap Για την επεξεργασία ενός νέου εγγράφου d με score s : Get current minimum h m of heap (O(1)) If s h m skip to next document /* υπάρχουν k καλύτερα */ If s > h m heap-delete-root (O(log k)) /* καλύτερο, σβήσε τη ρίζα heap-add d /s (O(log k)) και βάλτο στο heap */ 44
45 Κεφ. 7.1 Χρήση max heap 2J πράξεις για την κατασκευή του, βρίσκουμε τους K winners σε 2log J βήματα. Για J=1M, K=100, 10% του κόστους της ταξινόμησης
46 Κεφ. 7.1 Πιο αποδοτικός υπολογισμός; Η ταξινόμηση έχει πολυπλοκότητα χρόνου O(N) όπου N ο αριθμός των εγγράφων (ή, ισοδύναμα J). Βελτιστοποίηση κατά ένα σταθερό όρο, αλλά ακόμα θέλουμε O(N), N > (δηλαδή, πρέπει να «δούμε» όλα τα έγγραφα) Υπάρχουν sublinear αλγόριθμοι; Αυτό που ψάχνουμε στην πραγματικότητα αντιστοιχεί στο να λύνουμε το πρόβλημα των k-πλησιέστερων γειτόνων (knearest neighbor (knn) problem) στο διάνυσμα του ερωτήματος (= query point). Δεν υπάρχει γενική λύση σε αυτό το πρόβλημα που να είναι sublinear. (ειδικά για πολλές διαστάσεις) 46
47 Κεφ Γενική προσέγγιση «ψαλιδίσματος» Βρες ένα σύνολο A από υποψήφια έγγραφα (contenders), όπου K < A << N Το A δεν περιέχει απαραίτητα όλα τα top K, αλλά περιέχει αρκετά καλά έγγραφα και πολλά από τα top K Επέστρεψε τα top K έγγραφα του A Το Α είναι ένα ψαλίδισμα (pruning) των μη υποψηφίων Έτσι και αλλιώς το συνημίτονο είναι μόνο μια «εκτίμηση» της συνάφειας Θα δούμε σχετικούς ευριστικούς 47
48 Κεφ Περιορισμός του ευρετηρίου Ο βασικός αλγόριθμος υπολογισμού του συνημίτονου θεωρεί έγγραφα που περιέχουν τουλάχιστον έναν όρο του ερωτήματος Μπορούμε να επεκτείνουμε αυτήν την ιδέα; Εξετάζουμε μόνο τους όρους του ερωτήματος με μεγάλο idf Εξετάζουμε μόνο έγγραφα που περιέχουν πολλούς από τους όρους του ερωτήματος 48
49 Κεφ Μόνο όροι με μεγάλο idf Παράδειγμα: Για το ερώτημα «catcher in the rye» Αθροίζουμε μόνο το βαθμό για τους όρους catcher και rye Γιατί; οι όροι in και the έχουν μικρή συνεισφορά στο βαθμό και άρα δεν αλλάζουν σημαντικά τη διάταξη Όφελος: Οι καταχωρήσεις των όρων με μικρά idf περιέχουν πολλά έγγραφα αυτά τα (πολλά) έγγραφα δε μπαίνουν ως υποψήφια στο σύνολο Α 49
50 Κεφ Έγγραφα με πολλούς όρους του ερωτήματος Κάθε έγγραφο που έχει τουλάχιστον έναν όρο του ερωτήματος είναι υποψήφιο για τη λίστα με τα κορυφαία Κ έγγραφα Για ερωτήματα με πολλούς όρους, υπολογίζουμε τους βαθμούς μόνο των εγγράφων που περιέχουν αρκετούς από τους όρους του ερωτήματος Για παράδειγμα, τουλάχιστον 3 από τους 4 όρους Παρόμοιο με ένα είδος μερικής σύζευξης ( soft conjunction ) στα ερωτήματα των μηχανών αναζήτησης (αρχικά στη Google) Εύκολα να υλοποιηθεί κατά τη διάσχιση των καταχωρήσεων 50
51 Κεφ από τους 4 όρους του ερωτήματος Antony Brutus Caesar Calpurnia Υπολογισμοί βαθμών μόνο για τα έγγραφα 8, 16 και 32 51
52 Κεφ Λίστες πρωταθλητών Προ-υπολογισμός για κάθε όρο t του λεξικού, των r εγγράφων με το μεγαλύτερο βάρος ανάμεσα στις καταχωρήσεις του t -> λίστα πρωταθλητών (champion list, fancy list ή top docs για το t) Αν tf.idf, είναι αυτά με το καλύτερο tf Κατά την ώρα του ερωτήματος, πάρε ως Α την ένωση των λιστών πρωταθλητών για τους όρους του ερωτήματος, υπολόγισε μόνο τους βαθμούς για τα έγγραφα της Α και διάλεξε τα Κ ανάμεσα τους To r πρέπει να επιλεγεί κατά τη διάρκεια της κατασκευής του ευρετηρίου Έτσι, είναι πιθανόν ότι r < K 52
53 Κεφ. 7 Με βάση την «ποιότητα» του εγγράφου (g(d)) Συχνά υπάρχει ένας ανεξάρτητος του ερωτήματος (στατικός) χαρακτηρισμός της καταλληλότητας ( goodness, authority) του εγγράφου έστω g(d) Για παράδειγμα: o Στις μηχανές αναζήτησης (στο Google) το PageRank g(d) μιας σελίδας d μετρά το πόσο «καλή» είναι μια σελίδα με βάση το πόσες «καλές» σελίδες δείχνουν σε αυτήν, ή o wikipedia σελίδες ή o άρθρα σε μια συγκεκριμένη εφημερίδα, κλπ 53
54 Κεφ. 7 Με βάση την «ποιότητα» του εγγράφου (g(d)) Αν υπάρχει μια διάταξη της καταλληλότητας τότε ο συγκεντρωτικός βαθμός (net-score) ενός εγγράφου d είναι ένας συνδυασμός της ποιότητας του εγγράφου (που έστω ότι δίνεται από μια συνάρτηση g στο [0, 1]) και της συνάφειας του με το ερώτημα q (που εκφράζεται π.χ., από το συνημίτονο) π.χ.: net-score(q, d) = g(d) + cos(q, d) Θέλουμε να επιλέξουμε σελίδες που είναι και γενικά σημαντικές (authoritative) και συναφείς ως προς την ερώτηση (το οποίο μας δίνει το συνημίτονο) Πως μπορούμε να επιτύχουμε γρήγορο τερματισμό (early termination); Δηλαδή να μην επεξεργαστούμε όλη τη λίστα καταχωρήσεων για να βρούμε τα καλύτερα k; 54
55 Κεφ. 7 Με βάση την «ποιότητα» του εγγράφου (g(d)) Διατάσουμε τις λίστες καταχωρήσεων με βάση την καταλληλότητα (π.χ., PageRank) των εγγράφων: g(d 1 ) > g(d 2 ) > g(d 3 ) >... Η διάταξη των εγγράφων είναι ίδια για όλες τις λίστες καταχωρήσεων Τα «καλά» έγγραφα στην αρχή της κάθε λίστας, οπότε αν θέλουμε να βρούμε γρήγορα καλά αποτελέσματα μπορούμε να δούμε μόνο την αρχή της λίστας 55
56 Κεφ. 7 Με βάση την «ποιότητα» του εγγράφου (g(d)) Υπενθύμιση net-score(q, d) = g(d) + cos(q, d) και τα έγγραφα σε κάθε λίστα σε διάταξη με βάση το g Επεξεργαζόμαστε ένα έγγραφο τη φορά δηλαδή, για κάθε έγγραφο υπολογίζουμε πλήρως το net-score του (για όλους τους όρους του ερωτήματος) Έστω g [0, 1], το τελευταίο k-κορυφαίο έγγραφο έχει βαθμό 1.2 και για το έγγραφο d που επεξεργαζόμαστε g(d) < 0.1, άρα και για όλα τα υπόλοιπα συνολικός βαθμός < 1.1 (στην καλύτερη περίπτωση έχουν cos ίσο με 1 που δεν αρκεί όμως). => δε χρειάζεται να επεξεργαστούμε το υπόλοιπο των λιστών 56
57 Κεφ. 7 Διάταξη καταχωρήσεων του t με βάση το f t,d Προσέγγιση: δεν επεξεργαζόμαστε τις καταχωρήσεις που θα συνεισφέρουν λίγο στον τελικό βαθμό Διάταξη των εγγράφων με βάση το βάρος (weight) wf t,d Όχι κοινή διάταξη των εγγράφων σε όλες τις λίστες Η απλούστερη περίπτωση, normalized tf-idf weight Τα κορυφαία k έγγραφα είναι πιθανόν να βρίσκονται στην αρχή αυτών των ταξινομημένων λιστών. γρήγορος τερματισμός ενώ επεξεργαζόμαστε τις λίστες καταχωρήσεων μάλλον δε θα αλλάξει τα κορυφαία k έγγραφα 57
58 Κεφ. 7 Διάταξη καταχωρήσεων του t με βάση το f t,d Τα «καλά» έγγραφα για έναν όρο είναι στην αρχή της λίστας Αλλά, δε μπορούμε να υπολογίσουμε ένα συνολικό βαθμό για κάθε έγγραφο με merge sort «συσσωρεύουμε τους βαθμούς για τα έγγραφα ανά όρο 58
59 Υπολογισμός ανά όρο Yπολογισμός ανά-όρο (ένας-όρος-τη-φορά - a-termat-a-time) Η απλούστερη περίπτωση είναι να επεξεργαστούμε όλη τη λίστα καταχωρήσεων για τον πρώτο όρο του ερωτήματος Δημιουργούμε ένα συσσωρευτή των βαθμών για κάθε docid εγγράφου που βρίσκουμε Μετά επεξεργαζόμαστε πλήρως τη λίστα καταχωρήσεων για τον δεύτερο όρο κοκ 59
60 Κεφ. 7 Υπολογισμός ανά όρο (term-at-a-time) Για κάθε όρο t του ερωτήματος q Λέμε τα στοιχεία του πίνακα Scores, συσσωρευτές (accumulators) 60
61 Κεφ. 7 Υπολογισμός ανά όρο Μη φέρεις όλη τη λίστα καταχωρήσεων, μόνο τα πρώτα στοιχεία της 61
62 Κεφ Πρόωρος τερματισμός Κατά τη διάσχιση των καταχωρήσεων ενός όρου t, σταμάτα νωρίς αφού: Δεις ένα προκαθορισμένο αριθμό r από έγγραφα Το wf t,d πέφτει κάτω από κάποιο κατώφλι Πάρε την ένωση του συνόλου των εγγράφων που προκύπτει Ένα σύνολο για κάθε όρο Υπολόγισε τους βαθμούς μόνο αυτών των εγγράφων 62
63 Κεφ idf-διατεταγμένοι όροι Κατά την επεξεργασία των όρων του ερωτήματος Τους εξετάζουμε με φθίνουσα διάταξη ως προς idf Όροι με μεγάλο idf πιθανών να συνεισφέρουν περισσότερο στο βαθμό Καθώς ενημερώνουμε τη συμμετοχή στο βαθμό κάθε όρου Σταματάμε αν ο βαθμός των εγγράφων δεν μεταβάλλεται πολύ 63
64 Κεφ Κλάδεμα συστάδων Προ-επεξεργασία - συσταδοποίηση (clustering) εγγράφων Επέλεξε τυχαία N έγγραφα: τα οποία τα ονομάζουμε ηγέτες (leaders) Για κάθε άλλο έγγραφο, προ-υπολογίζουμε τον κοντινότερο ηγέτη του Αυτά τα έγγραφα καλούντα ακόλουθοι (followers); Ο αναμενόμενος αριθμός είναι: ~ N ακόλουθοι ανά ηγέτη Τελικά N ομάδες με N έγγραφα 64
65 Κεφ Κλάδεμα συστάδων Για κάθε ερώτημα q Βρες τον πιο κοντινό ηγέτη L. Ψάξε για τα K πλησιέστερα έγγραφα ανάμεσα στους ακολούθους του L (δηλαδή, στην ομάδα του L). 65
66 Κεφ Κλάδεμα συστάδων Query Leader Follower 66
67 Κεφ Κλάδεμα συστάδων Γιατί τυχαία δείγματα; Γρήγορη Οι ηγέτες αντανακλούν την πραγματική κατανομή 67
68 Κεφ Κλάδεμα συστάδων Γενικές παραλλαγές (b1-b2) Κάθε ακόλουθος συνδέεται με b1=3 (έστω) πλησιέστερους ηγέτες. Για ένα ερώτημα, βρες b2=4 (έστω) κοντινότερους ηγέτες και τους ακολούθους τους 68
69 Κεφ. 7 Επεξεργασία Ανά-Έγγραφο και Ανά-Όρο Υπολογισμός ανά-όρο (term-at-a-time processing): Υπολογίζουμε για κάθε όρο της ερώτησης, για κάθε έγγραφο που εμφανίζεται στη λίστας καταχώρησης του ένα βαθμό και μετά συνεχίζουμε με τον επόμενο όρο της ερώτησης Υπολογισμός Ανά Έγγραφο (document-at-a-time processing): Τελειώνουμε τον υπολογισμό του βαθμού ομοιότητας ερωτήματος-εγγράφου για το έγγραφο d i πριν αρχίσουμε τον υπολογισμό βαθμού ομοιότητας ερωτήματος-εγγράφου για το έγγραφο d i+1. 69
70 Βαθμιδωτά (διαστρωματωμένα) ευρετήρια (Tiered indexes) Βασική ιδέα: Κατασκευάζουμε διάφορα επίπεδα/βαθμίδες από ευρετήρια, όπου το καθένα αντιστοιχεί στη σημαντικότητα των όρων Κατά τη διάρκεια της επεξεργασίας του ερωτήματος, αρχίζουμε από την υψηλότερη βαθμίδα Αν το ευρετήριο της υψηλότερης βαθμίδας, έχει τουλάχιστον k (π.χ., k = 100) αποτελέσματα: σταμάτα και επέστρεψε αυτά τα αποτελέσματα στο χρήστη Αλλιώς, αν έχουμε βρει < k ταιριάσματα: επανέλαβε την αναζήτηση στην επόμενη βαθμίδα 70
71 Βαθμιδωτά ευρετήρια Παράδειγμα Έστω 2 βαθμίδες Βαθμίδα 1: Ευρετήριο για όλους τους τίτλους (ή με τα έγγραφα με μεγάλο tf.idf) Βαθμίδα 2: Ευρετήριο για τα υπόλοιπο έγγραφο (ή με τα έγγραφα με μικρό tf.idf) Οι σελίδες που περιέχουν του όρους αναζήτησης στον τίτλο είναι καλύτερα ταιριάσματα από τις σελίδες που περιέχουν τους όρους στο σώμα του εγγράφου Ή και κάποιο σταθμισμένος συνδυασμός 71
72 Βαθμιδωτά ευρετήρια 72
73 Βαθμιδωτά ευρετήρια Η χρήση βαθμιδωτών ευρετηρίων θεωρείται ως ένας από τους λόγους που η ποιότητα των αποτελεσμάτων του Google ήταν αρχικά σημαντικά καλύτερη (2000/01) από αυτήν των ανταγωνιστών τους. μαζί με το PageRank, τη χρήση του anchor text και περιορισμών θέσεων (proximity constraints) 73
74 Κεφ. 6.1 Παραμετρική αναζήτηση 74
75 Κεφ. 6.1 Παραμετρική αναζήτηση Βασικό ευρετήριο ζώνης στο λεξικό (διαφορετικές λίστες καταχωρήσεων): Η πληροφορία ζώνης στις λίστες καταχώρησης: 75
76 Συνδυασμός διανυσματικής ανάκτησης Πως συνδυάζουμε την ανάκτηση φράσεων (και γενικά την εγγύτητα όρων proximity queries) με τη διανυσματική ανάκτηση; Window: το μικρότερο παράθυρο που περιέχονται όλοι οι όροι του ερωτήματος μετρημένο ως το πλήθος λέξεων του παραθύρου Χρήση στη διάταξη του μεγέθους του παραθύρου πως? Με κάποιο σταθμισμένο άθροισμα? Πως συνδυάζουμε την Boolean ανάκτηση με τη διανυσματική ανάκτηση; Π.χ., AND ή NOT Πως συνδυάζουμε τα * με τη διανυσματική ανάκτηση; Evidence accumulation 76
77 Επεξεργασία ερωτήματος Αναλυτής ερωτημάτων (query parser) Παράδειγμα rising interest rates 1. Εκτέλεσε την ερώτημα ως ερώτημα φράσης rising interest rates και κατάταξε τα αποτελέσματα χρησιμοποιώντας διανυσματική βαθμολόγηση 2. Αν δεν υπάρχουν αρκετά αποτελέσματα, εκτέλεσε το ερώτημα ως 2 ερωτήματα φράσεις: rising interest και interest rates και κατάταξε τα αποτελέσματα χρησιμοποιώντας διανυσματική βαθμολόγηση 3. Αν δεν υπάρχουν αρκετά αποτελέσματα, εκτέλεσε το ερώτημα ως διάνυσμα και κατάταξε τα αποτελέσματα χρησιμοποιώντας διανυσματική βαθμολόγηση Μπορούμε τώρα για τα έγγραφα που εμφανίζονται σε παραπάνω από ένα από τα παραπάνω βήματα να συνδυάσουμε (αθροίσουμε) τους βαθμούς 77
78 Πλήρες σύστημα αναζήτησης Προ-επεξεργασία Επεξεργασία ερωτήματος Ευρετήρια (παραλλαγές του αντεστραμμένου ευρετηρίου) 78
79 Πλήρες σύστημα αναζήτησης Τι έχουμε ήδη δει: Προ-επεξεργασία των εγγράφων Ευρετήρια θέσεων (Positional indexes) Βαθμιδωτά ευρετήρια (Tiered indexes) Διορθώσεις ορθογραφικές (Spelling correction) Ευρετήρα k-γραμμάτων (για ερωτήματα με * και ορθογραφικές διορθώσεις) Επεξεργασία ερωτημάτων Βαθμολόγηση εγγράφων 79
80 Κεφ. 8 Τι (άλλο) θα δούμε σήμερα; Περιλήψεις αποτελεσμάτων Κάνοντας τα καλά αποτελέσματα χρήσιμα 80
81 Πως παρουσιάζουμε τα αποτελέσματα στο χρήστη; 81

82 Κεφ. 8.7 Περιλήψεις αποτελεσμάτων Αφού έχουμε διατάξει τα έγγραφα που ταιριάζουν με το ερώτημα, θέλουμε να τα παρουσιάσουμε στο χρήστη Πιο συχνά ως μια λίστα από τίτλους εγγράφων, URL, μαζί με μια μικρή περίληψη (result snippet), aka 10 blue links 82
83 Κεφ. 8.7 Περιλήψεις αποτελεσμάτων Η περιγραφή του εγγράφου είναι κρίσιμη γιατί συχνά οι χρήστες βασίζονται σε αυτήν για να αποφασίσουν αν το έγγραφο είναι σχετικό Δε χρειάζεται να διαλέξουν ένα-ένα τα έγγραφα με τη σειρά Ο τίτλος αυτόματα από μεταδεδομένα, αλλά πώς να υπολογίσουμε τις περιλήψεις; 83
84 Κεφ. 8.7 Περιλήψεις αποτελεσμάτων Δύο βασικά είδη περιλήψεων Μια στατική περίληψη (static summary) ενός εγγράφου είναι πάντα η ίδια ανεξάρτητα από το ερώτημα που έθεσε ο χρήστης Μια δυναμική περίληψη (dynamic summary) εξαρτάται από το ερώτημα (query-dependent). Προσπαθεί να εξηγήσει γιατί το έγγραφο ανακτήθηκε για το συγκεκριμένο κάθε φορά ερώτημα 84
85 Κεφ. 8.7 Στατικές Περιλήψεις Σε ένα τυπικό σύστημα η στατική περίληψη είναι ένα υποσύνολο του εγγράφου Απλός ευριστικός: οι πρώτες περίπου 50 λέξεις του εγγράφου cached κατά τη δημιουργία του ευρετηρίου Πιο εξελιγμένες μέθοδοι (text summarization) βρες από κάθε έγγραφο κάποιες σημαντικές προτάσεις Απλή γλωσσολογική επεξεργασία (NLP) με ευριστικά για να βαθμολογηθεί κάθε πρόταση (πληροφορία θέσης: πρώτη και τελευταία παράγραφος, πρώτη και τελευταία πρόταση στην παράγραφο, και περιεχομένου: σημαντικές λέξεις) Η περίληψη αποτελείται από τις προτάσεις με το μεγαλύτερο βαθμό Ή και πιο περίπλοκη γλωσσολογική επεξεργασία για τη σύνθεση/δημιουργία περίληψης 85
86 Κεφ. 8.7 Δυναμικές Περιλήψεις Παρουσίασε ένα ή περισσότερα «παράθυρα» (windows, snippets) μέσα στο έγγραφο που να περιέχουν αρκετούς από τους όρους του ερωτήματος KWIC snippets: αναπαράσταση Keyword-in-Context 86 86
87 Κεφ. 8.7 Δυναμικές Περιλήψεις Για τον υπολογισμό των εγγράφων χρειαζόμαστε τα ίδια τα έγγραφα (δεν αρκεί το ευρετήριο) Cache εγγράφων που πρέπει να ανανεώνεται Συχνά όχι όλο το έγγραφο αν είναι πολύ μεγάλο, αλλά κάποιο πρόθεμα του Βρες μικρά παράθυρα στα έγγραφα που περιέχουν όρους του ερωτήματος Απαιτεί γρήγορη αναζήτηση παράθυρου στην cache των εγγράφων 87
88 Κεφ. 8.7 Δυναμικές Περιλήψεις Βαθμολόγησε κάθε παράθυρο ως προς το ερώτημα Με βάση διάφορα χαρακτηριστικά: το πλάτος του παραθύρου, τη θέση του στο έγγραφο, κλπ Συνδύασε τα χαρακτηριστικά Δύσκολο να εκτιμηθεί η ποιότητα Positional indexes (words vs bytes) Ο χώρος που διατίθεται για τα παράθυρα είναι μικρός 88
89 Κεφ. 8.7 Δυναμικές Περιλήψεις Query: new guinea economic development Snippets (in bold) that were extracted from a document:... In recent years, Papua New Guinea has faced severe economic difficulties and economic growth has slowed, partly as a result of weak governance and civil war, and partly as a result of external factors such as the Bougainville civil war which led to the closure in 1989 of the Panguna mine (at that time the most important foreign exchange earner and contributor to Government finances), the Asian financial crisis, a decline in the prices of gold and copper, and a fall in the production of oil. PNG s economic development record over the past few years is evidence that governance issues underly many of the country s problems. Good governance, which may be defined as the transparent and accountable management of human, natural, economic and financial resources for the purposes of equitable and sustainable development, flows from proper public sector management, efficient fiscal and accounting mechanisms, and a willingness to make service delivery a priority in practice

90 Quicklinks Για navigational query όπως united airlines οι χρήστες πιθανόν να ικανοποιούνται από τη σελίδα Quicklinks παρέχουν navigational cues σε αυτή τη σελίδα 90
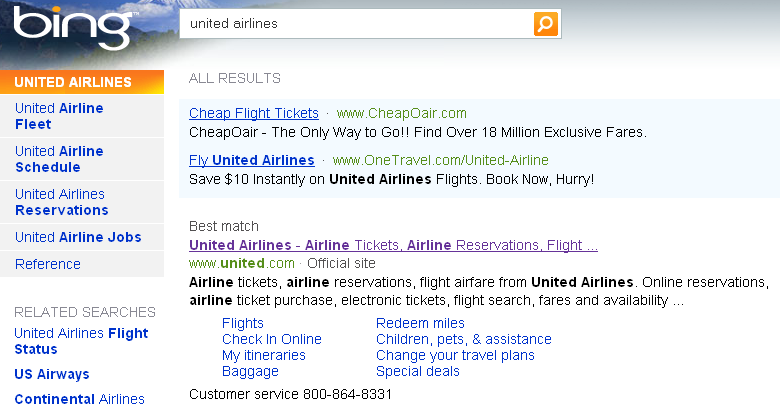
91 91

92 Εναλλακτικές αναπαραστάσεις; 92
93 ΤΕΛΟΣ 6 ου Μαθήματος Ερωτήσεις? Χρησιμοποιήθηκε κάποιο υλικό των: Pandu Nayak and Prabhakar Raghavan, CS276: Information Retrieval and Web Search (Stanford) Hinrich Schütze and Christina Lioma, Stuttgart IIR class 93
Information Retrieval
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι θα δούμε σήμερα; Βαθμολόγηση
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι θα δούμε σήμερα; Βαθμολόγηση
Information Retrieval
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 8: Θέματα Υλοποίησης. Περίληψη Αποτελεσμάτων. 1 Κεφ. 6 Τι είδαμε στο προηγούμενο μάθημα Βαθμολόγηση
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 8: Θέματα Υλοποίησης. Περίληψη Αποτελεσμάτων. 1 Κεφ. 6 Τι είδαμε στο προηγούμενο μάθημα Βαθμολόγηση
Τι (άλλο) θα δούμε σήμερα;
 θα δούμε σήμερα;") Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη6: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι (άλλο) θα δούμε σήμερα;
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη6: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι (άλλο) θα δούμε σήμερα;
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά. Κεφάλαια 6, 7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου.
 ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαια 6, 7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι θα δούμε σήμερα; Βαθμολόγηση και κατάταξη εγγράφων Στάθμιση
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαια 6, 7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι θα δούμε σήμερα; Βαθμολόγηση και κατάταξη εγγράφων Στάθμιση
ΜΥΕ003: Ανάκτηση Πληροφορίας
 ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαια 6, 7, 8.7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. Περιλήψεις. 1 Κεφ. 6 Τι θα δούμε σήμερα; Βαθμολόγηση και κατάταξη
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαια 6, 7, 8.7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. Περιλήψεις. 1 Κεφ. 6 Τι θα δούμε σήμερα; Βαθμολόγηση και κατάταξη
Information Retrieval
 Introduction to Information Retrieval ΜΥΕ003-ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 6-7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι θα δούμε σήμερα;
Introduction to Information Retrieval ΜΥΕ003-ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 6-7: Βαθμολόγηση. Στάθμιση όρων. Το μοντέλο διανυσματικού χώρου. 1 Κεφ. 6 Τι θα δούμε σήμερα;
6. Βαθμολόγηση, Στάθμιση Όρων, και το Μοντέλο Διανυσματικού Χώρου
 Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 6. Βαθμολόγηση, Στάθμιση Όρων, και το Μοντέλο Διανυσματικού Χώρου Ανάκτηση Πληροφοριών Χρήστος ουλκερίδης
Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 6. Βαθμολόγηση, Στάθμιση Όρων, και το Μοντέλο Διανυσματικού Χώρου Ανάκτηση Πληροφοριών Χρήστος ουλκερίδης
Περίληψη διαβάθμισης
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διαλέξεις6-7: Επανάληψη Διάταξης Εγγράφων. Θέματα Υλοποίησης. Περίληψη Αποτελεσμάτων. 1 Κεφ. 6 Περίληψη διαβάθμισης
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διαλέξεις6-7: Επανάληψη Διάταξης Εγγράφων. Θέματα Υλοποίησης. Περίληψη Αποτελεσμάτων. 1 Κεφ. 6 Περίληψη διαβάθμισης
7. Υπολογισμός Βαθμολογιών σε ένα Πλήρες Σύστημα Αναζήτησης
 Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 7. Υπολογισμός Βαθμολογιών σε ένα Πλήρες Σύστημα Αναζήτησης Ανάκτηση Πληροφοριών Χρήστος ουλκερίδης Τμήμα
Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 7. Υπολογισμός Βαθμολογιών σε ένα Πλήρες Σύστημα Αναζήτησης Ανάκτηση Πληροφοριών Χρήστος ουλκερίδης Τμήμα
Information Retrieval
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 5(α): Συμπίεση Ευρετηρίου 1 ΣΤΑΤΙΣΤΙΚΑ ΣΥΛΛΟΓΗΣ 2 Κεφ. 5 Στατιστικά στοιχεία Πόσο μεγάλο είναι το
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 5(α): Συμπίεση Ευρετηρίου 1 ΣΤΑΤΙΣΤΙΚΑ ΣΥΛΛΟΓΗΣ 2 Κεφ. 5 Στατιστικά στοιχεία Πόσο μεγάλο είναι το
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά. Κεφάλαια 8, 11: Περιλήψεις αποτελεσμάτων, Πιθανοτική ανάκτηση πληροφορίας.
 ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαια 8, : Περιλήψεις αποτελεσμάτων, Πιθανοτική ανάκτηση πληροφορίας. Κεφ. 8 Τι θα δούμε σήμερα; Πιθανοτική ανάκτηση Περιλήψεις αποτελεσμάτων
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαια 8, : Περιλήψεις αποτελεσμάτων, Πιθανοτική ανάκτηση πληροφορίας. Κεφ. 8 Τι θα δούμε σήμερα; Πιθανοτική ανάκτηση Περιλήψεις αποτελεσμάτων
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY463 - Συστήματα Ανάκτησης Πληροφοριών Εαρινό Εξάμηνο. Φροντιστήριο 3.
 Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY6 - Συστήματα Ανάκτησης Πληροφοριών 007 008 Εαρινό Εξάμηνο Φροντιστήριο Retrieval Models Άσκηση Θεωρείστε μια συλλογή κειμένων που περιέχει τα ακόλουθα
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY6 - Συστήματα Ανάκτησης Πληροφοριών 007 008 Εαρινό Εξάμηνο Φροντιστήριο Retrieval Models Άσκηση Θεωρείστε μια συλλογή κειμένων που περιέχει τα ακόλουθα
ΜΥΕ003: Ανάκτηση Πληροφορίας. Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο 11: Πιθανοτική ανάκτηση πληροφορίας.
 ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο : Πιθανοτική ανάκτηση πληροφορίας. Κεφ. Πιθανοτική Ανάκτηση Πληροφορίας Βασική ιδέα: Διάταξη εγγράφων με βάση την πιθανότητα να είναι
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο : Πιθανοτική ανάκτηση πληροφορίας. Κεφ. Πιθανοτική Ανάκτηση Πληροφορίας Βασική ιδέα: Διάταξη εγγράφων με βάση την πιθανότητα να είναι
Εύρεση & Διαχείριση Πληροφορίας στον Παγκόσµιο Ιστό. Διδάσκων Δημήτριος Κατσαρός
 Εύρεση & Διαχείριση Πληροφορίας στον Παγκόσµιο Ιστό Διδάσκων Δημήτριος Κατσαρός Διάλεξη 10η: 31/03/2014 1 Problem with Boolean search: feast or famine Ch. 6 Boolean queries often result in either too few
Εύρεση & Διαχείριση Πληροφορίας στον Παγκόσµιο Ιστό Διδάσκων Δημήτριος Κατσαρός Διάλεξη 10η: 31/03/2014 1 Problem with Boolean search: feast or famine Ch. 6 Boolean queries often result in either too few
Εισαγωγή στην Επεξεργασία Ερωτήσεων. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας Τα βασικά βήματα στην επεξεργασία
Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας Τα βασικά βήματα στην επεξεργασία
ΛΥΣΕΙΣ 2 ης ΣΕΙΡΑΣ ΑΣΚΗΣΕΩΝ
 ΛΥΣΕΙΣ 2 ης ΣΕΙΡΑΣ ΑΣΚΗΣΕΩΝ Άσκηση 1 Θεωρείστε μια συλλογή κειμένων που περιέχει τα ακόλουθα 5 έγγραφα: Έγγραφο 1: «Computer Games» Έγγραφο 2: «Computer Games Computer Games» Έγγραφο 3: «Games Theory and
ΛΥΣΕΙΣ 2 ης ΣΕΙΡΑΣ ΑΣΚΗΣΕΩΝ Άσκηση 1 Θεωρείστε μια συλλογή κειμένων που περιέχει τα ακόλουθα 5 έγγραφα: Έγγραφο 1: «Computer Games» Έγγραφο 2: «Computer Games Computer Games» Έγγραφο 3: «Games Theory and
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #04 Εισαγωγή στα Μοντέλα Ανάκτησης Πληροφορίας Boolean Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #04 Εισαγωγή στα Μοντέλα Ανάκτησης Πληροφορίας Boolean Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ. Μάθημα 7 ο : Ανάκτηση πληροφορίας. Γεώργιος Πετάσης. Ακαδημαϊκό Έτος:
 ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 7 ο : Ανάκτηση πληροφορίας Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος βασίζονται
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 7 ο : Ανάκτηση πληροφορίας Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος βασίζονται
Εισαγωγή στην Επεξεργασία Ερωτήσεων. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Εισαγωγή στην Επεξεργασία Ερωτήσεων Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα Βάσεις
Εισαγωγή στην Επεξεργασία Ερωτήσεων Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα Βάσεις
Ανάκτηση Πληροφορίας
 Ανάκτηση Πληροφορίας Το μοντέλο Boolean Το μοντέλο Vector Ταξινόμηση Μοντέλων IR Ανάκτηση Περιήγηση Κλασικά Μοντέλα Boolean Vector Probabilistic Δομικά Μοντέλα Non-Overlapping Lists Proximal Nodes Browsing
Ανάκτηση Πληροφορίας Το μοντέλο Boolean Το μοντέλο Vector Ταξινόμηση Μοντέλων IR Ανάκτηση Περιήγηση Κλασικά Μοντέλα Boolean Vector Probabilistic Δομικά Μοντέλα Non-Overlapping Lists Proximal Nodes Browsing
Ανάκληση Πληποφοπίαρ. Information Retrieval. Διδάζκων Δημήηριος Καηζαρός
 Ανάκληση Πληποφοπίαρ Information Retrieval Διδάζκων Δημήηριος Καηζαρός Διάλεξη 4η: 04/03/2017 1 Phrase queries 2 Ερωτήματα φράσεως Έστω ότι επιθυμούμε ν απαντήσουμε ερωτήματα της μορφής stanford university
Ανάκληση Πληποφοπίαρ Information Retrieval Διδάζκων Δημήηριος Καηζαρός Διάλεξη 4η: 04/03/2017 1 Phrase queries 2 Ερωτήματα φράσεως Έστω ότι επιθυμούμε ν απαντήσουμε ερωτήματα της μορφής stanford university
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #05 Ακρίβεια vs. Ανάκληση Extended Boolean Μοντέλο Fuzzy Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #05 Ακρίβεια vs. Ανάκληση Extended Boolean Μοντέλο Fuzzy Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #06 Πιθανοτικό Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #06 Πιθανοτικό Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Προτεινόμενες Λύσεις 1 ης Σειράς Ασκήσεων (Αξιολόγηση της Αποτελεσματικότητας της Ανάκτησης & Μοντέλα Ανάκτησης)
") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών ΗΥ463 Συστήματα Ανάκτησης Πληροφοριών 28-29 Εαρινό Εξάμηνο Προτεινόμενες Λύσεις 1 ης Σειράς Ασκήσεων (Αξιολόγηση της Αποτελεσματικότητας της Ανάκτησης &
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών ΗΥ463 Συστήματα Ανάκτησης Πληροφοριών 28-29 Εαρινό Εξάμηνο Προτεινόμενες Λύσεις 1 ης Σειράς Ασκήσεων (Αξιολόγηση της Αποτελεσματικότητας της Ανάκτησης &
ΑΣΚΗΣΗ. Δημιουργία Ευρετηρίων Συλλογής Κειμένων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Επεξεργασία Ερωτήσεων
 Εισαγωγή Επεξεργασία Ερωτήσεων Σ Β Βάση εδομένων Η ομή ενός ΣΒ Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 1 Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 2 Εισαγωγή Εισαγωγή ΜΕΡΟΣ 1 (Χρήση Σ Β ) Γενική
Εισαγωγή Επεξεργασία Ερωτήσεων Σ Β Βάση εδομένων Η ομή ενός ΣΒ Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 1 Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 2 Εισαγωγή Εισαγωγή ΜΕΡΟΣ 1 (Χρήση Σ Β ) Γενική
Ανάκτηση Πληροφορίας
 Το Πιθανοκρατικό Μοντέλο Κλασικά Μοντέλα Ανάκτησης Τρία είναι τα, λεγόμενα, κλασικά μοντέλα ανάκτησης: Λογικό (Boolean) που βασίζεται στη Θεωρία Συνόλων Διανυσματικό (Vector) που βασίζεται στη Γραμμική
Το Πιθανοκρατικό Μοντέλο Κλασικά Μοντέλα Ανάκτησης Τρία είναι τα, λεγόμενα, κλασικά μοντέλα ανάκτησης: Λογικό (Boolean) που βασίζεται στη Θεωρία Συνόλων Διανυσματικό (Vector) που βασίζεται στη Γραμμική
Επεξεργασία Ερωτήσεων
 Εισαγωγή Επεξεργασία Ερωτήσεων ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήματος 1. Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασμός) 2. Προγραμματισμός (Σχεσιακή Άλγεβρα, SQL) ημιουργία/κατασκευή Εισαγωγή εδομένων
Εισαγωγή Επεξεργασία Ερωτήσεων ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήματος 1. Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασμός) 2. Προγραμματισμός (Σχεσιακή Άλγεβρα, SQL) ημιουργία/κατασκευή Εισαγωγή εδομένων
Επεξεργασία Ερωτήσεων
 Εισαγωγή Σ Β Σύνολο από προγράμματα για τη διαχείριση της Β Επεξεργασία Ερωτήσεων Αρχεία ευρετηρίου Κατάλογος συστήματος Αρχεία δεδομένων ΒΑΣΗ Ε ΟΜΕΝΩΝ Σύστημα Βάσεων εδομένων (ΣΒ ) Βάσεις Δεδομένων 2007-2008
Εισαγωγή Σ Β Σύνολο από προγράμματα για τη διαχείριση της Β Επεξεργασία Ερωτήσεων Αρχεία ευρετηρίου Κατάλογος συστήματος Αρχεία δεδομένων ΒΑΣΗ Ε ΟΜΕΝΩΝ Σύστημα Βάσεων εδομένων (ΣΒ ) Βάσεις Δεδομένων 2007-2008
Λύση (από: Τσιαλιαμάνης Αναγνωστόπουλος Πέτρος) (α) Το trie του λεξιλογίου είναι
 (α) Το trie του λεξιλογίου είναι") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY463 - Συστήματα Ανάκτησης Πληροφοριών 2006-2007 Εαρινό Εξάμηνο 3 η Σειρά ασκήσεων (Ευρετηρίαση, Αναζήτηση σε Κείμενα και Άλλα Θέματα) (βαθμοί 12: όποιος
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY463 - Συστήματα Ανάκτησης Πληροφοριών 2006-2007 Εαρινό Εξάμηνο 3 η Σειρά ασκήσεων (Ευρετηρίαση, Αναζήτηση σε Κείμενα και Άλλα Θέματα) (βαθμοί 12: όποιος
Information Retrieval
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 3: Δομές για Λεξικά. Ανάκτηση Ανεκτική στα Σφάλματα (υποστήριξη *) 1 Ch. 2 Επανάληψη προηγούμενης
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 3: Δομές για Λεξικά. Ανάκτηση Ανεκτική στα Σφάλματα (υποστήριξη *) 1 Ch. 2 Επανάληψη προηγούμενης
Διαχείριση εγγράφων. Αποθήκες και Εξόρυξη Δεδομένων Διδάσκων: Μ. Χαλκίδη
 Διαχείριση εγγράφων Αποθήκες και Εξόρυξη Δεδομένων Διδάσκων: Μ. Χαλκίδη Απεικόνιση κειμένων για Information Retrieval Δεδομένου ενός κειμένου αναζητούμε μια μεθοδολογία απεικόνισης του γραμματικού χώρου
Διαχείριση εγγράφων Αποθήκες και Εξόρυξη Δεδομένων Διδάσκων: Μ. Χαλκίδη Απεικόνιση κειμένων για Information Retrieval Δεδομένου ενός κειμένου αναζητούμε μια μεθοδολογία απεικόνισης του γραμματικού χώρου
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων
 Απαντήσεις 1 ου Σετ Ασκήσεων") Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Ευρετήρια. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Ευρετήρια Ευαγγελία Πιτουρά 1 τιμή γνωρίσματος Ευρετήρια Ένα ευρετήριο (index) είναι μια βοηθητική δομή αρχείου που κάνει πιο αποδοτική την αναζήτηση μιας εγγραφής σε ένα αρχείο Το ευρετήριο καθορίζεται
Ευρετήρια Ευαγγελία Πιτουρά 1 τιμή γνωρίσματος Ευρετήρια Ένα ευρετήριο (index) είναι μια βοηθητική δομή αρχείου που κάνει πιο αποδοτική την αναζήτηση μιας εγγραφής σε ένα αρχείο Το ευρετήριο καθορίζεται
Δημιουργία Ευρετηρίων Συλλογής Κειμένων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 - Project Σεπτεμβρίου Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος Εξέταση: Προφορική, στο τέλος της εξεταστικής. Θα βγει ανακοίνωση στο forum. Ομάδες
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 - Project Σεπτεμβρίου Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος Εξέταση: Προφορική, στο τέλος της εξεταστικής. Θα βγει ανακοίνωση στο forum. Ομάδες
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ. Δοµές Δεδοµένων
 ΟΝΟΜΑΤΕΠΩΝΥΜΟ: ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ AM: Δοµές Δεδοµένων Εξεταστική Ιανουαρίου 2014 Διδάσκων : Ευάγγελος Μαρκάκης 20.01.2014 ΥΠΟΓΡΑΦΗ ΕΠΟΠΤΗ: Διάρκεια εξέτασης : 2 ώρες και
ΟΝΟΜΑΤΕΠΩΝΥΜΟ: ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ AM: Δοµές Δεδοµένων Εξεταστική Ιανουαρίου 2014 Διδάσκων : Ευάγγελος Μαρκάκης 20.01.2014 ΥΠΟΓΡΑΦΗ ΕΠΟΠΤΗ: Διάρκεια εξέτασης : 2 ώρες και
Ανάκτηση Πληροφορίας
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 4: Μοντελοποίηση: Διανυσματικό μοντέλο Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 4: Μοντελοποίηση: Διανυσματικό μοντέλο Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
1. Financial New Times Year MAXk {FREQij} D D D D
 Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY46 - Συστήματα Ανάκτησης Πληροφοριών 2004-2005 Εαρινό Εξάμηνο 2 η Σειρά ασκήσεων (Μοντέλα Ανάκτησης Πληροφοριών και Ευρετήρια) Ανάθεση: 6 Μαρτίου Παράδοση:
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY46 - Συστήματα Ανάκτησης Πληροφοριών 2004-2005 Εαρινό Εξάμηνο 2 η Σειρά ασκήσεων (Μοντέλα Ανάκτησης Πληροφοριών και Ευρετήρια) Ανάθεση: 6 Μαρτίου Παράδοση:
5. Απλή Ταξινόμηση. ομές εδομένων. Χρήστος ουλκερίδης. Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων
 Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 5. Απλή Ταξινόμηση 2 ομές εδομένων 4 5 Χρήστος ουλκερίδης Τμήμα Ψηφιακών Συστημάτων 11/11/2016 Εισαγωγή Η
Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 5. Απλή Ταξινόμηση 2 ομές εδομένων 4 5 Χρήστος ουλκερίδης Τμήμα Ψηφιακών Συστημάτων 11/11/2016 Εισαγωγή Η
Κεφ.11: Ευρετήρια και Κατακερματισμός
 Κεφ.11: Ευρετήρια και Κατακερματισμός Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Κεφ. 11: Ευρετήρια-Βασική θεωρία Μηχανισμοί ευρετηρίου χρησιμοποιούνται για την επιτάχυνση
Κεφ.11: Ευρετήρια και Κατακερματισμός Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Κεφ. 11: Ευρετήρια-Βασική θεωρία Μηχανισμοί ευρετηρίου χρησιμοποιούνται για την επιτάχυνση
ΑΣΚΗΣΗ. Συγκομιδή και δεικτοδότηση ιστοσελίδων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2010-2011 ΑΣΚΗΣΗ Συγκομιδή και δεικτοδότηση ιστοσελίδων Σκοπός της άσκησης είναι η υλοποίηση ενός ολοκληρωμένου συστήματος συγκομιδής και δεικτοδότησης ιστοσελίδων.
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2010-2011 ΑΣΚΗΣΗ Συγκομιδή και δεικτοδότηση ιστοσελίδων Σκοπός της άσκησης είναι η υλοποίηση ενός ολοκληρωμένου συστήματος συγκομιδής και δεικτοδότησης ιστοσελίδων.
Εισαγωγή στην. Εισαγωγή Σ Β. Αρχεία ευρετηρίου Κατάλογος. συστήματος. Αρχεία δεδομένων
 Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Εισαγωγή Σ Β Σύνολο από προγράμματα για τη διαχείριση της Β Αρχεία ευρετηρίου Κατάλογος ΒΑΣΗ Ε ΟΜΕΝΩΝ Αρχεία δεδομένων συστήματος Σύστημα Βάσεων εδομένων (ΣΒ ) 2 :
Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Εισαγωγή Σ Β Σύνολο από προγράμματα για τη διαχείριση της Β Αρχεία ευρετηρίου Κατάλογος ΒΑΣΗ Ε ΟΜΕΝΩΝ Αρχεία δεδομένων συστήματος Σύστημα Βάσεων εδομένων (ΣΒ ) 2 :
Δεντρικά Ευρετήρια. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δεντρικά Ευρετήρια Ευαγγελία Πιτουρά 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές αναζήτησης και ρ δείκτες
Δεντρικά Ευρετήρια Ευαγγελία Πιτουρά 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές αναζήτησης και ρ δείκτες
Ανάκληση Πληποφοπίαρ. Information Retrieval. Διδάζκων Δημήηριος Καηζαρός
 Ανάκληση Πληποφοπίαρ Information Retrieval Διδάζκων Δημήηριος Καηζαρός Διάλεξη 1η: 20/02/2017 1 Ειζαγωγή ζηο μάθημα & Ειζαγωγή ζηην Ανάκηηζη Πληροθορίας 2 Διδακτικό βοήθημα 1 Καλύπηει ηο ανηικείμενο ηοσ
Ανάκληση Πληποφοπίαρ Information Retrieval Διδάζκων Δημήηριος Καηζαρός Διάλεξη 1η: 20/02/2017 1 Ειζαγωγή ζηο μάθημα & Ειζαγωγή ζηην Ανάκηηζη Πληροθορίας 2 Διδακτικό βοήθημα 1 Καλύπηει ηο ανηικείμενο ηοσ
HY380 Αλγόριθμοι και πολυπλοκότητα Hard Problems
 HY380 Αλγόριθμοι και πολυπλοκότητα Hard Problems Ημερομηνία Παράδοσης: 0/1/017 την ώρα του μαθήματος ή με email: mkarabin@csd.uoc.gr Γενικές Οδηγίες α) Επιτρέπεται η αναζήτηση στο Internet και στην βιβλιοθήκη
HY380 Αλγόριθμοι και πολυπλοκότητα Hard Problems Ημερομηνία Παράδοσης: 0/1/017 την ώρα του μαθήματος ή με email: mkarabin@csd.uoc.gr Γενικές Οδηγίες α) Επιτρέπεται η αναζήτηση στο Internet και στην βιβλιοθήκη
Information Retrieval
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 1: Εισαγωγή. Ανάκτηση Boole Κεφ. 1.1 Τι είναι η «Ανάκτηση Πληροφορίας»; Ανάγκη πληροφόρησης Βάση
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 1: Εισαγωγή. Ανάκτηση Boole Κεφ. 1.1 Τι είναι η «Ανάκτηση Πληροφορίας»; Ανάγκη πληροφόρησης Βάση
Δεντρικά Ευρετήρια. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δεντρικά Ευρετήρια Βάσεις Δεδομένων 2017-2018 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές αναζήτησης και ρ
Δεντρικά Ευρετήρια Βάσεις Δεδομένων 2017-2018 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές αναζήτησης και ρ
Δεντρικά Ευρετήρια. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δεντρικά Ευρετήρια 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές αναζήτησης και ρ δείκτες ως εξής P 1 K 1 P
Δεντρικά Ευρετήρια 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές αναζήτησης και ρ δείκτες ως εξής P 1 K 1 P
Ευρετήρια. Ευρετήρια. Βάσεις Δεδομένων 2009-2010: Ευρετήρια 1
 Ευρετήρια 1 Ευρετήρια Ένα ευρετήριο (index) είναι μια βοηθητική δομή αρχείου που κάνει πιο αποδοτική την αναζήτηση μιας εγγραφής σε ένα αρχείο Το ευρετήριο καθορίζεται (συνήθως) σε ένα γνώρισμα του αρχείου
Ευρετήρια 1 Ευρετήρια Ένα ευρετήριο (index) είναι μια βοηθητική δομή αρχείου που κάνει πιο αποδοτική την αναζήτηση μιας εγγραφής σε ένα αρχείο Το ευρετήριο καθορίζεται (συνήθως) σε ένα γνώρισμα του αρχείου
Δεντρικά Ευρετήρια. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δεντρικά Ευρετήρια Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές
Δεντρικά Ευρετήρια Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Δέντρα Αναζήτησης Ένα δέντρο αναζήτησης (search tree) τάξεως p είναι ένα δέντρο τέτοιο ώστε κάθε κόμβος του περιέχει το πολύ p - 1 τιμές
Ανάκτηση πληροφορίας
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ανάκτηση πληροφορίας Ενότητα 6: Ο Αντεστραμμένος Κατάλογος Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ανάκτηση πληροφορίας Ενότητα 6: Ο Αντεστραμμένος Κατάλογος Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Δομές Δεδομένων και Αλγόριθμοι
 Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 20 Huffman codes 1 / 12 Κωδικοποίηση σταθερού μήκους Αν χρησιμοποιηθεί κωδικοποίηση σταθερού μήκους δηλαδή
Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 20 Huffman codes 1 / 12 Κωδικοποίηση σταθερού μήκους Αν χρησιμοποιηθεί κωδικοποίηση σταθερού μήκους δηλαδή
Σύνοψη Προηγούμενου. Πίνακες (Arrays) Πίνακες (Arrays): Βασικές Λειτουργίες. Πίνακες (Arrays) Ορέστης Τελέλης
 Πίνακες (Arrays): Βασικές Λειτουργίες. Πίνακες (Arrays) Ορέστης Τελέλης") Σύνοψη Προηγούμενου Πίνακες (Arrays Ορέστης Τελέλης telelis@unipi.gr Τμήμα Ψηφιακών Συστημάτων, Πανεπιστήμιο Πειραιώς Διαδικαστικά θέματα. Aντικείμενο Μαθήματος. Aντικείμενα, Κλάσεις, Μέθοδοι, Μεταβλητές.
Σύνοψη Προηγούμενου Πίνακες (Arrays Ορέστης Τελέλης telelis@unipi.gr Τμήμα Ψηφιακών Συστημάτων, Πανεπιστήμιο Πειραιώς Διαδικαστικά θέματα. Aντικείμενο Μαθήματος. Aντικείμενα, Κλάσεις, Μέθοδοι, Μεταβλητές.
ΕΠΛ231 Δομές Δεδομένων και Αλγόριθμοι 4. Παραδείγματα Ανάλυσης Πολυπλοκότητας Ανάλυση Αναδρομικών Αλγόριθμων
 ΕΠΛ31 Δομές Δεδομένων και Αλγόριθμοι 4. Παραδείγματα Ανάλυσης Πολυπλοκότητας Ανάλυση Αναδρομικών Αλγόριθμων Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα
ΕΠΛ31 Δομές Δεδομένων και Αλγόριθμοι 4. Παραδείγματα Ανάλυσης Πολυπλοκότητας Ανάλυση Αναδρομικών Αλγόριθμων Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα
Information Retrieval
 Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 10: Αξιολόγηση στην Ανάκτηση Πληροφοριών II. 1 Κεφ. 8 Αξιολόγηση συστήματος Αποδοτικότητα (Performance)
Introduction to Information Retrieval ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 10: Αξιολόγηση στην Ανάκτηση Πληροφοριών II. 1 Κεφ. 8 Αξιολόγηση συστήματος Αποδοτικότητα (Performance)
Το εσωτερικό ενός Σ Β
 Επεξεργασία Ερωτήσεων 1 Εισαγωγή ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL) ηµιουργία/κατασκευή Εισαγωγή εδοµένων
Επεξεργασία Ερωτήσεων 1 Εισαγωγή ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL) ηµιουργία/κατασκευή Εισαγωγή εδοµένων
Εισαγωγή. Γενική Εικόνα του Μαθήµατος. Το εσωτερικό ενός Σ Β. Εισαγωγή. Εισαγωγή Σ Β Σ Β. Αρχεία ευρετηρίου Κατάλογος συστήµατος Αρχεία δεδοµένων
 Βάσεις εδοµένων 2003-2004 Ευαγγελία Πιτουρά 1 ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Επεξεργασία Ερωτήσεων Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL)
Βάσεις εδοµένων 2003-2004 Ευαγγελία Πιτουρά 1 ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Επεξεργασία Ερωτήσεων Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL)
Επίλυση Προβλημάτων 1
 Επίλυση Προβλημάτων 1 Επίλυση Προβλημάτων Περιγραφή Προβλημάτων Αλγόριθμοι αναζήτησης Αλγόριθμοι τυφλής αναζήτησης Αναζήτηση πρώτα σε βάθος Αναζήτηση πρώτα σε πλάτος (ΒFS) Αλγόριθμοι ευρετικής αναζήτησης
Επίλυση Προβλημάτων 1 Επίλυση Προβλημάτων Περιγραφή Προβλημάτων Αλγόριθμοι αναζήτησης Αλγόριθμοι τυφλής αναζήτησης Αναζήτηση πρώτα σε βάθος Αναζήτηση πρώτα σε πλάτος (ΒFS) Αλγόριθμοι ευρετικής αναζήτησης
Ευρετήρια. Ευρετήρια. Βάσεις Δεδομένων : Ευρετήρια 1
 Ευρετήρια 1 Ευρετήρια Ένα ευρετήριο (index) είναι μια βοηθητική δομή αρχείου που κάνει πιο αποδοτική την αναζήτηση μιας εγγραφής σε ένα αρχείο Το ευρετήριο καθορίζεται (συνήθως) σε ένα γνώρισμα του αρχείου
Ευρετήρια 1 Ευρετήρια Ένα ευρετήριο (index) είναι μια βοηθητική δομή αρχείου που κάνει πιο αποδοτική την αναζήτηση μιας εγγραφής σε ένα αρχείο Το ευρετήριο καθορίζεται (συνήθως) σε ένα γνώρισμα του αρχείου
ΑΣΚΗΣΗ Α. Δεικτοδότηση Συλλογής Κειμένων σε Ανεστραμμένο Ευρετήριο
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2009-2010 ΑΣΚΗΣΗ Α Δεικτοδότηση Συλλογής Κειμένων σε Ανεστραμμένο Ευρετήριο Τα ανεστραμμένα αρχεία αποτελούν μια βασική μορφή ευρετηρίου και μας επιτρέπουν να εντοπίσουμε
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2009-2010 ΑΣΚΗΣΗ Α Δεικτοδότηση Συλλογής Κειμένων σε Ανεστραμμένο Ευρετήριο Τα ανεστραμμένα αρχεία αποτελούν μια βασική μορφή ευρετηρίου και μας επιτρέπουν να εντοπίσουμε
Διάλεξη 16: Σωροί. Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Ουρές Προτεραιότητας - Ο ΑΤΔ Σωρός, Υλοποίηση και πράξεις
 ΕΠΛ231 Δομές Δεδομένων και Αλγόριθμοι 1 Διάλεξη 16: Σωροί Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Ουρές Προτεραιότητας - Ο ΑΤΔ Σωρός, Υλοποίηση και πράξεις Ουρά Προτεραιότητας (Priority
ΕΠΛ231 Δομές Δεδομένων και Αλγόριθμοι 1 Διάλεξη 16: Σωροί Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Ουρές Προτεραιότητας - Ο ΑΤΔ Σωρός, Υλοποίηση και πράξεις Ουρά Προτεραιότητας (Priority
Πιθανοκρατικό μοντέλο
 Πιθανοκρατικό μοντέλο Το μοντέλο MAP Αλέξανδρος Γκιμπερίτης Βασίλης Μπούργος Δημήτρης Σουραβλιάς 1 Εισαγωγικές έννοιες Κάθε έγγραφο d της συλλογής παριστάνεται από το δυαδικό διάνυσμα x = (x 1, x 2,...,
Πιθανοκρατικό μοντέλο Το μοντέλο MAP Αλέξανδρος Γκιμπερίτης Βασίλης Μπούργος Δημήτρης Σουραβλιάς 1 Εισαγωγικές έννοιες Κάθε έγγραφο d της συλλογής παριστάνεται από το δυαδικό διάνυσμα x = (x 1, x 2,...,
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2018-2019 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2018-2019 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Κεφάλαιο 4. Διαίρει και Βασίλευε (Divide and Conquer) Παύλος Εφραιμίδης V1.1,
 Παύλος Εφραιμίδης V1.1,") Κεφάλαιο 4 Διαίρει και Βασίλευε (Divide and Conquer) Παύλος Εφραιμίδης V1.1, 2015-01-19 Χρησιμοποιήθηκε υλικό από τις αγγλικές διαφάνειες του Kevin Wayne. 1 Διαίρει και Βασίλευε (Divide-and-Conquer) Διαίρει-και-βασίλευε
Κεφάλαιο 4 Διαίρει και Βασίλευε (Divide and Conquer) Παύλος Εφραιμίδης V1.1, 2015-01-19 Χρησιμοποιήθηκε υλικό από τις αγγλικές διαφάνειες του Kevin Wayne. 1 Διαίρει και Βασίλευε (Divide-and-Conquer) Διαίρει-και-βασίλευε
EFFICIENT TOP-K QUERYING OVER SOCIAL-TAGGING NETWORKS
 EFFICIENT TOP-K QUERYING OVER SOCIAL-TAGGING NETWORKS Ralf Schenkel, Tom Crecelious, Mouna Kacimi, Sebastian Michel, Thomas Neumann, Josiane Xavier Parreira, Gerhard Weikum ΠΡΟΒΛΗΜΑ Εύρεση ενός αποτελεσματικού
EFFICIENT TOP-K QUERYING OVER SOCIAL-TAGGING NETWORKS Ralf Schenkel, Tom Crecelious, Mouna Kacimi, Sebastian Michel, Thomas Neumann, Josiane Xavier Parreira, Gerhard Weikum ΠΡΟΒΛΗΜΑ Εύρεση ενός αποτελεσματικού
Θέμα : Retrieval Models. Ημερομηνία : 9 Μαρτίου 2006
 ΗΥ-464: Συστήματα Ανάκτησης Πληροφορίας Informaton Retreval Systems Πανεπιστήμιο Κρήτης Άνοιξη 2006 Φροντιστήριο 2 Θέμα : Retreval Models Ημερομηνία : 9 Μαρτίου 2006 Outlne Prevous Semester Exercses Set
ΗΥ-464: Συστήματα Ανάκτησης Πληροφορίας Informaton Retreval Systems Πανεπιστήμιο Κρήτης Άνοιξη 2006 Φροντιστήριο 2 Θέμα : Retreval Models Ημερομηνία : 9 Μαρτίου 2006 Outlne Prevous Semester Exercses Set
Εισαγωγή στην επιστήμη των υπολογιστών. Λογισμικό Υπολογιστών Κεφάλαιο 8ο Αλγόριθμοι
 Εισαγωγή στην επιστήμη των υπολογιστών Λογισμικό Υπολογιστών Κεφάλαιο 8ο Αλγόριθμοι 1 Έννοια Ανεπίσημα, ένας αλγόριθμος είναι μια βήμα προς βήμα μέθοδος για την επίλυση ενός προβλήματος ή την διεκπεραίωση
Εισαγωγή στην επιστήμη των υπολογιστών Λογισμικό Υπολογιστών Κεφάλαιο 8ο Αλγόριθμοι 1 Έννοια Ανεπίσημα, ένας αλγόριθμος είναι μια βήμα προς βήμα μέθοδος για την επίλυση ενός προβλήματος ή την διεκπεραίωση
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή
Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή
Διάλεξη 04: Παραδείγματα Ανάλυσης
 Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Παραδείγματα Ανάλυσης Πολυπλοκότητας : Μέθοδοι, παραδείγματα
Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Παραδείγματα Ανάλυσης Πολυπλοκότητας : Μέθοδοι, παραδείγματα
Τα δεδομένα (περιεχόμενο) μιας βάσης δεδομένων αποθηκεύεται στο δίσκο
 μιας βάσης δεδομένων αποθηκεύεται στο δίσκο") Κατακερματισμός 1 Αποθήκευση εδομένων (σύνοψη) Τα δεδομένα (περιεχόμενο) μιας βάσης δεδομένων αποθηκεύεται στο δίσκο Παραδοσιακά, μία σχέση (πίνακας/στιγμιότυπο) αποθηκεύεται σε ένα αρχείο Αρχείο δεδομένων
Κατακερματισμός 1 Αποθήκευση εδομένων (σύνοψη) Τα δεδομένα (περιεχόμενο) μιας βάσης δεδομένων αποθηκεύεται στο δίσκο Παραδοσιακά, μία σχέση (πίνακας/στιγμιότυπο) αποθηκεύεται σε ένα αρχείο Αρχείο δεδομένων
ΕΡΓΑΣΤΗΡΙΑΚΕΣ ΑΣΚΗΣΕΙΣ C ΣΕΙΡΑ 1 η
 Δημοκρίτειο Πανεπιστήμιο Θράκης Πολυτεχνική Σχολή Τμήμα Μηχανικών Παραγωγής & Διοίκησης Ακαδ. έτος 2015-2016 Τομέας Συστημάτων Παραγωγής Εξάμηνο Β Αναπληρωτής Καθηγητής Στέφανος Δ. Κατσαβούνης ΜΑΘΗΜΑ :
Δημοκρίτειο Πανεπιστήμιο Θράκης Πολυτεχνική Σχολή Τμήμα Μηχανικών Παραγωγής & Διοίκησης Ακαδ. έτος 2015-2016 Τομέας Συστημάτων Παραγωγής Εξάμηνο Β Αναπληρωτής Καθηγητής Στέφανος Δ. Κατσαβούνης ΜΑΘΗΜΑ :
Query-Driven Indexing for Scalable Peer-to-Peer Text Retrieval. Gleb Skobeltsyn, Toan Luu, Ivana Podnar Zarko, Martin Rajman, Karl Aberer
 Query-Driven Indexing for Scalable Peer-to-Peer Text Retrieval Gleb Skobeltsyn, Toan Luu, Ivana Podnar Zarko, Martin Rajman, Karl Aberer Περιγραφή του προβλήματος Ευρετηριοποίηση μεγάλων συλλογών εγγράφων
Query-Driven Indexing for Scalable Peer-to-Peer Text Retrieval Gleb Skobeltsyn, Toan Luu, Ivana Podnar Zarko, Martin Rajman, Karl Aberer Περιγραφή του προβλήματος Ευρετηριοποίηση μεγάλων συλλογών εγγράφων
Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων
 Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Παραδείγματα Ανάλυσης Πολυπλοκότητας : Μέθοδοι, παραδείγματα
Διάλεξη 04: Παραδείγματα Ανάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Παραδείγματα Ανάλυσης Πολυπλοκότητας : Μέθοδοι, παραδείγματα
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #11 Suffix Arrays Φοίβος Μυλωνάς fmylonas@ionio.gr Ανάκτηση Πληροφορίας 1 Άδεια χρήσης Το παρόν
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #11 Suffix Arrays Φοίβος Μυλωνάς fmylonas@ionio.gr Ανάκτηση Πληροφορίας 1 Άδεια χρήσης Το παρόν
Ενότητες 3 & 4: Δένδρα, Σύνολα & Λεξικά Ασκήσεις και Λύσεις
 Ενότητες 3 & 4: Δένδρα, Σύνολα & Λεξικά Ασκήσεις και Λύσεις Άσκηση 1 Γράψτε μία αναδρομική συνάρτηση που θα παίρνει ως παράμετρο ένα δείκτη στη ρίζα ενός δυαδικού δένδρου και θα επιστρέφει το βαθμό του
Ενότητες 3 & 4: Δένδρα, Σύνολα & Λεξικά Ασκήσεις και Λύσεις Άσκηση 1 Γράψτε μία αναδρομική συνάρτηση που θα παίρνει ως παράμετρο ένα δείκτη στη ρίζα ενός δυαδικού δένδρου και θα επιστρέφει το βαθμό του
ΜΥΥ105: Εισαγωγή στον Προγραμματισμό. Αναζήτηση και Ταξινόμηση Χειμερινό Εξάμηνο 2016
 ΜΥΥ105: Εισαγωγή στον Προγραμματισμό Αναζήτηση και Ταξινόμηση Χειμερινό Εξάμηνο 2016 Αναζήτηση και Ταξινόμηση Βασικές λειτουργίες σε προγράμματα Αναζήτηση (searching): Βρες ένα ζητούμενο στοιχείο σε μια
ΜΥΥ105: Εισαγωγή στον Προγραμματισμό Αναζήτηση και Ταξινόμηση Χειμερινό Εξάμηνο 2016 Αναζήτηση και Ταξινόμηση Βασικές λειτουργίες σε προγράμματα Αναζήτηση (searching): Βρες ένα ζητούμενο στοιχείο σε μια
Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα)
 (γράφοι και δένδρα)") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Αφηρημένες
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Αφηρημένες
ΔΥΑΔΙΚΗ ΑΝΑΖΗΤΗΣΗ & ΤΑΞΙΝΟΜΗΣΗ ΜΕ ΣΥΓΧΩΝΕΥΣΗ
 ΔΥΑΔΙΚΗ ΑΝΑΖΗΤΗΣΗ & ΤΑΞΙΝΟΜΗΣΗ ΜΕ ΣΥΓΧΩΝΕΥΣΗ (ΑΛΓΟΡΙΘΜΟΙ, Sanjoy Dasgupta, Christos Papadimitriou, Umesh Vazirani, σελ. 55-62 ΣΧΕΔΙΑΣΜΟΣ ΑΛΓΟΡΙΘΜΩΝ, Jon Kleinberg, Eva Tardos, Κεφάλαιο 5) Δυαδική αναζήτηση
ΔΥΑΔΙΚΗ ΑΝΑΖΗΤΗΣΗ & ΤΑΞΙΝΟΜΗΣΗ ΜΕ ΣΥΓΧΩΝΕΥΣΗ (ΑΛΓΟΡΙΘΜΟΙ, Sanjoy Dasgupta, Christos Papadimitriou, Umesh Vazirani, σελ. 55-62 ΣΧΕΔΙΑΣΜΟΣ ΑΛΓΟΡΙΘΜΩΝ, Jon Kleinberg, Eva Tardos, Κεφάλαιο 5) Δυαδική αναζήτηση
Διάλεξη 17: O Αλγόριθμος Ταξινόμησης HeapSort
 Διάλεξη 17: O Αλγόριθμος Ταξινόμησης HeapSort Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: Η διαδικασία PercolateDown, Δημιουργία Σωρού O Αλγόριθμος Ταξινόμησης HeapSort Υλοποίηση, Παραδείγματα
Διάλεξη 17: O Αλγόριθμος Ταξινόμησης HeapSort Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: Η διαδικασία PercolateDown, Δημιουργία Σωρού O Αλγόριθμος Ταξινόμησης HeapSort Υλοποίηση, Παραδείγματα
ΕΡΓΑΣΤΗΡΙΑΚΕΣ ΑΣΚΗΣΕΙΣ C ΣΕΙΡΑ 1 η
 Δ.Π.Θ. - Πολυτεχνική Σχολή Τμήμα Μηχανικών Παραγωγής & Διοίκησης Ακαδ. έτος 2016-2017 Τομέας Συστημάτων Παραγωγής Εξάμηνο Β Αναπληρωτής Καθηγητής Στέφανος Δ. Κατσαβούνης ΜΑΘΗΜΑ : ΔΟΜΗΜΕΝΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ
Δ.Π.Θ. - Πολυτεχνική Σχολή Τμήμα Μηχανικών Παραγωγής & Διοίκησης Ακαδ. έτος 2016-2017 Τομέας Συστημάτων Παραγωγής Εξάμηνο Β Αναπληρωτής Καθηγητής Στέφανος Δ. Κατσαβούνης ΜΑΘΗΜΑ : ΔΟΜΗΜΕΝΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ
Τι είναι βαθμωτό μέγεθος? Ένα μέγεθος που περιγράφεται μόνο με έναν αριθμό (π.χ. πίεση)
") TETY Εφαρμοσμένα Μαθηματικά Ενότητα ΙΙ: Γραμμική Άλγεβρα Ύλη: Διανυσματικοί χώροι και διανύσματα, μετασχηματισμοί διανυσμάτων, τελεστές και πίνακες, ιδιοδιανύσματα και ιδιοτιμές πινάκων, επίλυση γραμμικών
TETY Εφαρμοσμένα Μαθηματικά Ενότητα ΙΙ: Γραμμική Άλγεβρα Ύλη: Διανυσματικοί χώροι και διανύσματα, μετασχηματισμοί διανυσμάτων, τελεστές και πίνακες, ιδιοδιανύσματα και ιδιοτιμές πινάκων, επίλυση γραμμικών
Δομές Δεδομένων. Δημήτρης Μιχαήλ. Ουρές Προτεραιότητας. Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο
 Δομές Δεδομένων Ουρές Προτεραιότητας Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρά Προτεραιότητας Το πρόβλημα Έχουμε αντικείμενα με κλειδιά και θέλουμε ανά πάσα στιγμή
Δομές Δεδομένων Ουρές Προτεραιότητας Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρά Προτεραιότητας Το πρόβλημα Έχουμε αντικείμενα με κλειδιά και θέλουμε ανά πάσα στιγμή
Σχεδίαση Αλγορίθμων -Τμήμα Πληροφορικής ΑΠΘ - Εξάμηνο 4ο
 Πολλαπλασιασμός μεγάλων ακεραίων (1) Για να πολλαπλασιάσουμε δύο ακεραίους με n 1 και n 2 ψηφία με το χέρι, θα εκτελέσουμε n 1 n 2 πράξεις πολλαπλασιασμού Πρόβλημα ρβημ όταν έχουμε πολλά ψηφία: A = 12345678901357986429
Πολλαπλασιασμός μεγάλων ακεραίων (1) Για να πολλαπλασιάσουμε δύο ακεραίους με n 1 και n 2 ψηφία με το χέρι, θα εκτελέσουμε n 1 n 2 πράξεις πολλαπλασιασμού Πρόβλημα ρβημ όταν έχουμε πολλά ψηφία: A = 12345678901357986429
Πληροφορική 2. Αλγόριθμοι
 Πληροφορική 2 Αλγόριθμοι 1 2 Τι είναι αλγόριθμος; Αλγόριθμος είναι ένα διατεταγμένο σύνολο από σαφή βήματα το οποίο παράγει κάποιο αποτέλεσμα και τερματίζεται σε πεπερασμένο χρόνο. Ο αλγόριθμος δέχεται
Πληροφορική 2 Αλγόριθμοι 1 2 Τι είναι αλγόριθμος; Αλγόριθμος είναι ένα διατεταγμένο σύνολο από σαφή βήματα το οποίο παράγει κάποιο αποτέλεσμα και τερματίζεται σε πεπερασμένο χρόνο. Ο αλγόριθμος δέχεται
Όρια Αλγόριθμων Ταξινόμησης. Εισαγωγή στην Ανάλυση Αλγορίθμων Μάγια Σατρατζέμη
 Όρια Αλγόριθμων Ταξινόμησης Εισαγωγή στην Ανάλυση Αλγορίθμων Μάγια Σατρατζέμη Όρια Αλγόριθμων Ταξινόμησης Μέχρι στιγμής εξετάσθηκαν μέθοδοι ταξινόμησης µε πολυπλοκότητα της τάξης Θ ) ή Θlog ). Τι εκφράζει
Όρια Αλγόριθμων Ταξινόμησης Εισαγωγή στην Ανάλυση Αλγορίθμων Μάγια Σατρατζέμη Όρια Αλγόριθμων Ταξινόμησης Μέχρι στιγμής εξετάσθηκαν μέθοδοι ταξινόμησης µε πολυπλοκότητα της τάξης Θ ) ή Θlog ). Τι εκφράζει
Άσκηση 1 (ανακοινώθηκε στις 20 Μαρτίου 2017, προθεσμία παράδοσης: 24 Απριλίου 2017, 12 τα μεσάνυχτα).
.") Κ08 Δομές Δεδομένων και Τεχνικές Προγραμματισμού Διδάσκων: Μανόλης Κουμπαράκης Εαρινό Εξάμηνο 2016-2017. Άσκηση 1 (ανακοινώθηκε στις 20 Μαρτίου 2017, προθεσμία παράδοσης: 24 Απριλίου 2017, 12 τα μεσάνυχτα).
Κ08 Δομές Δεδομένων και Τεχνικές Προγραμματισμού Διδάσκων: Μανόλης Κουμπαράκης Εαρινό Εξάμηνο 2016-2017. Άσκηση 1 (ανακοινώθηκε στις 20 Μαρτίου 2017, προθεσμία παράδοσης: 24 Απριλίου 2017, 12 τα μεσάνυχτα).
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2017-2018 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2017-2018 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Εργαστήριο 6 ο 7 ο / Ερωτήματα Ι
 Εργαστήριο 6 ο 7 ο / Ερωτήματα Ι Απλά ερωτήματα Επιλογής Ερωτήματα με Ενώσεις πινάκων Ερωτήματα με Παραμετρικά Κριτήρια Ερωτήματα με Υπολογιζόμενα πεδία Απλά ερωτήματα Επιλογής Τα Ερωτήματα μας επιτρέπουν
Εργαστήριο 6 ο 7 ο / Ερωτήματα Ι Απλά ερωτήματα Επιλογής Ερωτήματα με Ενώσεις πινάκων Ερωτήματα με Παραμετρικά Κριτήρια Ερωτήματα με Υπολογιζόμενα πεδία Απλά ερωτήματα Επιλογής Τα Ερωτήματα μας επιτρέπουν
Information Retrieval
 Introduction to Information Retrieval MYE003-ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 1: Εισαγωγή. Ανάκτηση Boole Κεφ. 1.1 Τι είναι η «Ανάκτηση Πληροφορίας»; Ανάγκη πληροφόρησης
Introduction to Information Retrieval MYE003-ΠΛΕ70: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Διάλεξη 1: Εισαγωγή. Ανάκτηση Boole Κεφ. 1.1 Τι είναι η «Ανάκτηση Πληροφορίας»; Ανάγκη πληροφόρησης
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΛΥΣΗ ΣΤΗΝ ΕΥΤΕΡΗ ΑΣΚΗΣΗ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΛΥΣΗ ΣΤΗΝ ΕΥΤΕΡΗ ΑΣΚΗΣΗ ΜΑΘΗΜΑ ΒΑΣΕΙΣ Ε ΟΜΕΝΩΝ ΑΚΑ. ΕΤΟΣ 2012-13 Ι ΑΣΚΟΝΤΕΣ Ιωάννης Βασιλείου Καθηγητής, Τοµέας Τεχνολογίας
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΤΜΗΜΑ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ ΛΥΣΗ ΣΤΗΝ ΕΥΤΕΡΗ ΑΣΚΗΣΗ ΜΑΘΗΜΑ ΒΑΣΕΙΣ Ε ΟΜΕΝΩΝ ΑΚΑ. ΕΤΟΣ 2012-13 Ι ΑΣΚΟΝΤΕΣ Ιωάννης Βασιλείου Καθηγητής, Τοµέας Τεχνολογίας
Διδάσκων: Παναγιώτης Ανδρέου
 Διάλεξη 04: ΠαραδείγματαΑνάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: -Παραδείγματα Ανάλυσης Πολυπλοκότητας : Μέθοδοι, παραδείγματα -Γραμμική
Διάλεξη 04: ΠαραδείγματαΑνάλυσης Πολυπλοκότητας/Ανάλυση Αναδρομικών Αλγόριθμων Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: -Παραδείγματα Ανάλυσης Πολυπλοκότητας : Μέθοδοι, παραδείγματα -Γραμμική
0 The quick brown fox leaped over the lazy lazy dog 1 Quick brown foxes leaped over lazy dogs for fun
 Κ24: Προγραμματισμός Συστήματος - 1η Εργασία, Εαρινό Εξάμηνο 2018 Προθεσμία Υποβολής: Κυριακή 18 Μαρτίου, 23:59 Εισαγωγή Στην εργασία αυτή θα υλοποιήσετε μία μίνι μηχανή αναζήτησης (search engine). Οι
Κ24: Προγραμματισμός Συστήματος - 1η Εργασία, Εαρινό Εξάμηνο 2018 Προθεσμία Υποβολής: Κυριακή 18 Μαρτίου, 23:59 Εισαγωγή Στην εργασία αυτή θα υλοποιήσετε μία μίνι μηχανή αναζήτησης (search engine). Οι
1.4 Αριθμητική υπολογιστών και σφάλματα
 Γ. Γεωργίου, Αριθμητική Ανάλυση 1.4 Αριθμητική υπολογιστών και σφάλματα Στην παράγραφο αυτή καλύπτουμε πρώτα γενικά το θέμα της αριθμητικής υπολογιστών και στην συνέχεια διαπραγματευόμαστε την έννοια του
Γ. Γεωργίου, Αριθμητική Ανάλυση 1.4 Αριθμητική υπολογιστών και σφάλματα Στην παράγραφο αυτή καλύπτουμε πρώτα γενικά το θέμα της αριθμητικής υπολογιστών και στην συνέχεια διαπραγματευόμαστε την έννοια του
Μεταπτυχιακή Διπλωματική Εργασία. «Τεχνικές Δεικτοδότησης Συστημάτων Ανάκτησης Πληροφορίας με τη χρήση Wavelet Trees» Κατσίπη Δήμητρα ΑΜ: 741
 Μεταπτυχιακό Πρόγραμμα: «Επιστήμη και Τεχνολογία Υπολογιστών» Μεταπτυχιακή Διπλωματική Εργασία «Τεχνικές Δεικτοδότησης Συστημάτων Ανάκτησης Πληροφορίας με τη χρήση Wavelet Trees» Κατσίπη Δήμητρα ΑΜ: 741
Μεταπτυχιακό Πρόγραμμα: «Επιστήμη και Τεχνολογία Υπολογιστών» Μεταπτυχιακή Διπλωματική Εργασία «Τεχνικές Δεικτοδότησης Συστημάτων Ανάκτησης Πληροφορίας με τη χρήση Wavelet Trees» Κατσίπη Δήμητρα ΑΜ: 741
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή (ως τρόπος οργάνωσης αρχείου) μέγεθος
Δυναμικός Κατακερματισμός 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή (ως τρόπος οργάνωσης αρχείου) μέγεθος
Ανάκτηση Πληροφορίας
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 5: Μοντελοποίηση: Πιθανοκρατικό Μοντέλο Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Ενότητα 5: Μοντελοποίηση: Πιθανοκρατικό Μοντέλο Απόστολος Παπαδόπουλος Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
MYE003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά. Κεφάλαιο 1: Εισαγωγή. Ανάκτηση Boole
 MYE003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο 1: Εισαγωγή. Ανάκτηση Boole Κεφ. 1.1 Τι είναι η Ανάκτηση Πληροφορίας (Information Retrieval); Ανάγκη πληροφόρησης Συλλογή Εγγράφων Eρώτημα
MYE003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο 1: Εισαγωγή. Ανάκτηση Boole Κεφ. 1.1 Τι είναι η Ανάκτηση Πληροφορίας (Information Retrieval); Ανάγκη πληροφόρησης Συλλογή Εγγράφων Eρώτημα
Γενικά Στοιχεία Ηλεκτρονικού Υπολογιστή
 Γενικά Στοιχεία Ηλεκτρονικού Υπολογιστή 1. Ηλεκτρονικός Υπολογιστής Ο Ηλεκτρονικός Υπολογιστής είναι μια συσκευή, μεγάλη ή μικρή, που επεξεργάζεται δεδομένα και εκτελεί την εργασία του σύμφωνα με τα παρακάτω
Γενικά Στοιχεία Ηλεκτρονικού Υπολογιστή 1. Ηλεκτρονικός Υπολογιστής Ο Ηλεκτρονικός Υπολογιστής είναι μια συσκευή, μεγάλη ή μικρή, που επεξεργάζεται δεδομένα και εκτελεί την εργασία του σύμφωνα με τα παρακάτω
Τα δεδοµένα συνήθως αποθηκεύονται σε αρχεία στο δίσκο Για να επεξεργαστούµε τα δεδοµένα θα πρέπει αυτά να βρίσκονται στη
 Ευρετήρια 1 Αρχεία Τα δεδοµένα συνήθως αποθηκεύονται σε αρχεία στο δίσκο Για να επεξεργαστούµε τα δεδοµένα θα πρέπει αυτά να βρίσκονται στη µνήµη. Η µεταφορά δεδοµένων από το δίσκο στη µνήµη και από τη
Ευρετήρια 1 Αρχεία Τα δεδοµένα συνήθως αποθηκεύονται σε αρχεία στο δίσκο Για να επεξεργαστούµε τα δεδοµένα θα πρέπει αυτά να βρίσκονται στη µνήµη. Η µεταφορά δεδοµένων από το δίσκο στη µνήµη και από τη
Ασκήσεις μελέτης της 4 ης διάλεξης. ), για οποιοδήποτε μονοπάτι n 1
, για οποιοδήποτε μονοπάτι n 1") Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 4 ης διάλεξης 4.1. (α) Αποδείξτε ότι αν η h είναι συνεπής, τότε h(n
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 4 ης διάλεξης 4.1. (α) Αποδείξτε ότι αν η h είναι συνεπής, τότε h(n