ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ
|
|
|
- Ιδουμα Πόντιος Αθανασιάδης
- 6 χρόνια πριν
- Προβολές:
Transcript

1 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΤΗΣ ΦΟΙΤΗΤΡΙΑΣ ΔΟΥΜΟΥ ΕΛΕΝΗΣ ΑΕΜ:893 ΜΕ ΘΕΜΑ:ΟΠΤΙΚΟΠΟΙΗΣΗ ΤΩΝ ΔΕΔΟΜΕΝΩΝ ΠΟΥ ΠΡΟΕΡΧΟΝΤΑΙ ΑΠΟ ΒΙΟΛΟΓΙΚΑ ΚΕΙΜΕΝΑ ΕΠΙΒΛΕΠΩΝ ΚΑΘΗΓΗΤΗΣ:ΑΓΓΕΛΗΣ ΕΛΕΥΘΕΡΙΟΣ 1
2 ΠΕΡΙΕΧΟΜΕΝΑ ΠΕΡΙΛΗΨΗ ΕΙΣΑΓΩΓΗ..4 2.ΒΙΟΛΟΓΙΚΑ ΚΕΙΜΕΝΑ - ΓΟΝΙΔΙΑΚΕΣ ΟΝΤΟΛΟΓΙΕΣ. 8 3.ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ.28 4.ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΜΕ ΤΟ MATLAB ΠΑΡΑΣΤΑΣΗ ΔΕΔΟΜΕΝΩΝ ΣΤΟ ΒΙΟΛΟΓΙΚΟ ΚΕΙΜΕΝΟ ΜΕ ΕΡΓΑΛΕΙΑ ΕΠΕΞΕΡΓΑΣΙΑΣ ΕΙΚΟΝΑΣ ΣΥΜΠΕΡΑΣΜΑΤΑ ΒΙΒΛΙΟΓΡΑΦΙΑ..99 2
3 ΠΕΡΙΛΗΨΗ Το αντικείμενο της παρούσας διατριβής είναι η οπτικοποίηση δεδομένων τα οποία προέρχονται από κείμενα βιολογικού περιεχομένου. Συγκεκριμένα με τρόπο που θα περιγράψουμε αναλυτικά στο 2 ο κεφάλαιο τα κείμενα ανατέθηκαν σε κατηγορίες(ομάδες) και εμείς κληθήκαμε να αναπαραστήσουμε τις εικόνες αυτών των ομάδων έτσι ώστε να διαπιστώσουμε διαφορές-ομοιότητες μεταξύ των κειμένων μιας ομάδας αλλά και διαφορές-ομοιότητες μεταξύ των διαφόρων ομάδων. Μ αυτόν τον τρόπο, με λίγα λόγια μέσω του οπτικού αποτελέσματος, κρίναμε κατά πόσο η κατηγοριοποίηση των κειμένων που κάναμε ήταν ακριβής. Ταυτόχρονα όμως, όπως προαναφέραμε, συγκρίναμε και τις ομάδες μεταξύ τους αλλά και προχωρήσαμε στην αναπαράσταση των κειμένων όλων των ομάδων μαζί σε μία ενιαία αναπαράσταση για μία πιο πλήρη και ολοκληρωμένη εικόνα. Εκτός όμως των αρχικών γραφικών παραστάσεων των ομάδων προβήκαμε και σε μια περαιτέρω επεξεργασία αυτών προκειμένου να πάρουμε καλύτερα και ευκρινέστερα αποτελέσματα. Πειραματιστήκαμε με κάποιες τεχνικές οπτικοποίησης δεδομένων(π.χ Chernoff faces, Star Plots, Andrew s Curves) οι οποίες όμως δεν μας παρείχαν τα επιθυμητά αποτελέσματα, δηλαδή καλές γραφικές αναπαραστάσεις, αλλά ούτε και την δυνατότητα να επεξεργαστούμε αυτές περαιτέρω. Προκειμένου λοιπόν να πετύχουμε τους προαναφερθέντες στόχους χρησιμοποιήσαμε το πρόγραμμα του Matlab.Το ισχυρό αυτό πρόγραμμα όπως γνωρίζουμε μας παρέχει μια σειρά από εργαλεία(toolboxes), η επιλογή των οποίων εξαρτάται από την εργασία την οποία θέλουμε να διεκπεραιώσουμε. Για παράδειγμα υπάρχει εργαλείο για την επεξεργασία σήματος(signal Processing), για τα νευρωνικά δίκτυα(neural Network),για την σχεδίαση φίλτρων(filter Design) και πολλά άλλα. Πιο συγκεκριμένα για την δική μας εργασία, δηλαδή για την αναπαράσταση και την επεξεργασία εικόνων χρησιμοποιήσαμε το εργαλείο Image Processing Toolbox του Matlab R27a. Το παραπάνω πακέτο επεξεργασίας εικόνας μας παρέχει ένα σύνολο συναρτήσεων που όπως θα διαπιστώσουμε παρακάτω μας δίνουν την δυνατότητα και να απεικονίσουμε εύκολα και απλά τα δεδομένα μας αλλά και να προχωρήσουμε σε περαιτέρω επεξεργασία αυτών των αρχικών γραφικών αναπαραστάσεων. Η πρωτοτυπία λοιπόν της χρησιμοποίησης του Matlab για την οπτικοποίηση των δεδομένων μας οδήγησε ένα βήμα παραπάνω στην μέχρι τώρα έρευνα που είχε γίνει(βλέπε στο κεφάλαιο σχετικές εργασίες) αποφέροντάς μας πολλά οφέλη τα οποία μέχρι τώρα δεν είχαμε. 3
4 1.ΕΙΣΑΓΩΓΗ Η περιγραφή της λειτουργίας των γονιδίων και των γονιδιακών προϊόντων είναι ένα πολύ σημαντικό θέμα στη βιολογία, αφού δίνει πληροφορίες για τις αλληλεπιδράσεις των γονιδίων αλλά και για τα ομόλογά τους σε άλλους οργανισμούς. Η λειτουργία των γονιδίων περιγράφεται κάπου μέσα στη βιβλιογραφία του βιολογικού κειμένου. Η απόδοση στο κάθε γονίδιο ενός GO 1 code (ενός «κωδικού» που περιγράφει τη λειτουργία του) είναι μία επίπονη διαδικασία, αφού απαιτείται η αναζήτηση και η εξέταση αρκετών άρθρων από ειδικούς. Τα τελευταία χρόνια, γίνεται μία προσπάθεια να αυτοματοποιηθεί η διαδικασία αυτή, κάνοντας χρήση των τεχνικών του Natural Language Processing [Raychaudhuri, 22]. Οι μέθοδοι που έχουν χρησιμοποιηθεί για το σκοπό αυτό, προέρχονται από το πεδίο του machine learning και του data mining, όπως οι maximum entropy, naïve Bayes, nearest neighbor(πρόκειται για 3 machine learning αλγόριθμους) και support vector machines(svm). Επίσης έχει εφαρμοστεί και έχει διαπιστωθεί ότι ανταποκρίνεται πολύ καλά η στατιστική μέθοδος multinomial logistic regression ενώ τελευταία, παρουσιάστηκε μία μέθοδος που στηρίζεται στην Linear discriminant analysis [Theodosiou, 26]. Τα τελευταία χρόνια σημειώθηκε τεράστια αύξηση της πληροφορίας στο πεδίο της βιολογίας. Οι εξελίξεις τόσο στις υπολογιστικές, όσο και στις βιολογικές μεθόδους άλλαξαν την κλίμακα στη βιολογική έρευνα. Ολόκληρα γονιδιώματα μπορούν πλέον, να αναλυθούν μέσα σε λίγους μήνες, ακόμα και μέσα σε λίγες βδομάδες, υπολογιστικές μέθοδοι επισπεύδουν την αναγνώριση δεκάδων χιλιάδων γονιδίων σε ένα αποκωδικοποιημένο DNA και αυτοματοποιημένα εργαλεία αναπτύσσονται για να αναλύσουν ιδιότητες γονιδίων και πρωτεϊνών. Καινούριες τεχνικές, όπως οι DNA microarrays, επιτρέπουν ταυτόχρονες μετρήσεις όλων των γονιδίων-πρωτεϊνών που εκφράζονται σε ένα ζωτικό σύστημα. Αυτές οι μεγάλης κλίμακας πειραματικές μέθοδοι παράγουν τεράστιες ποσότητες δεδομένων. Μετά από επεξεργασία, τα δεδομένα μπορούν να παράγουν «πραγματική» πληροφορία σχετικά με την έκφραση των αντιγράφων των γονιδίων, για παράδειγμα, ποια γονίδια εκφράζονται σε διάφορες περιπτώσεις και ποια γονίδια υπερλειτουργούν ή υπολειτουργούν σε μία επίθεση μίας ασθένειας ή κατά τη διάρκεια μίας συγκεκριμένης φάσης της ανάπτυξης του κυττάρου. Ο πρωταρχικός στόχος της πραγματοποίησης τέτοιων πειραμάτων είναι η ερμηνεία της πληροφορίας και η μετατροπή της σε γνώση, με απώτερο σκοπό την κατανόηση της πολύπλοκης βιολογικής διεργασίας που κυβερνά το ανθρώπινο σώμα και η χρήση της γνώσης αυτής στην ιατρική. Σχεδόν όλη η γνωστή πληροφορία που αναφέρεται στα γονίδια, στις πρωτεΐνες και στο ρόλο αυτών στη βιολογική διεργασία, είναι καταγεγραμμένη κάπου στο τεράστιο όγκο της βιβλιογραφίας. Ωστόσο, η εξέλιξη των τεχνικών της αποκωδικοποίησης των γονιδιωμάτων συνεπάγεται και τεράστια αύξηση συγγραμμάτων που αναλύουν τα γονίδια αυτά. Αυτό, σε συνδυασμό με το πλήθος των γονιδίων και της βιβλιογραφίας, προκαλεί μεγάλη σύγχυση στην ερμηνεία και στο σχεδιασμό πειραμάτων. Έτσι, η ικανότητα να ερευνήσει κανείς τη βιβλιογραφία απαιτεί ένα επιπλέον βήμα στη σχεδίαση και ερμηνεία των μεγάλης κλίμακας πειραμάτων. Επίσης, η αυτοματοποιημένη εξόρυξη της βιβλιογραφίας προσφέρει μία 1 Στο επόμενο κεφάλαιο περιγράφεται ο συγκεκριμένος όρος αναλυτικά 4
5 ευκαιρία στην ολοκλήρωση πολλών επιμέρους πληροφοριών που έχουν ανακαλυφθεί από τους ερευνητές από πολλά διαφορετικά πεδία εξειδίκευσης σε μία ολοκληρωμένη εικόνα που φαίνονται οι σχέσεις μεταξύ των γονιδίων, πρωτεϊνών και χημικών αντιδράσεων στα κύτταρα και στους οργανισμούς. Κατά τη διάρκεια των τελευταίων ετών υπήρξε μία τεράστια αύξηση ενδιαφέροντος για τη χρήση και εκμετάλλευση της βιολογικής βιβλιογραφίας, που εκτείνεται από σχετικά απλά θέματα, όπως η εύρεση της θέσης του γονιδίου μέσα στο χρωμόσωμα μέχρι πιο φιλόδοξες προσπάθειες, όπως η κατασκευή υποτιθέμενων δικτύων γονιδίων βασιζόμενα στη συνύπαρξη ονομάτων γονιδίων μέσα σε άρθρα. Αφού η βιβλιογραφία καλύπτει όλους τους τομείς της βιολογίας, της χημείας και της ιατρικής, δεν υπάρχει σχεδόν κανένα όριο στον τύπο της πληροφορίας που ίσως ανακαλυφθεί με προσεκτική και εξαντλητική εξόρυξη. Κάποιες πιθανές εφαρμογές περιέχουν την απόδειξη σχέσεων μεταξύ ασθενειών και γονιδίων, την εύρεση σχέσεων μεταξύ γονιδίων και συγκεκριμένων βιολογικών λειτουργιών και πολλών ακόμα. [Shatkay, Feldman, 23]. Πέρα από τους ξεκάθαρους στόχους, υπάρχουν αρκετά εμπόδια που πρέπει να ξεπεραστούν όταν χρησιμοποιείται η βιβλιογραφία για την εύρεση πληροφορίας. Το πιο προφανές είναι ο τεράστιος αριθμός των διαθέσιμων άρθρων, που συνεχίζει να αυξάνεται. Για παράδειγμα, η πιο διαδεδομένη και ευρέως χρησιμοποιούμενη βάση δεδομένων στο βιολογικό κείμενο η PubMed περιέχει πάνω από 12.. abstract κείμενα. Ένα ερώτημα που αναφέρεται σε γονίδιο ή σε πρωτεΐνη επιστρέφει σχεδόν 3.. άρθρα, που περίπου τα 2/3 εκδόθηκαν μέσα στην περασμένη δεκαετία. Αξίζει να σημειωθεί ότι η βάση αύτη δεν καλύπτει όλες τις εκδόσεις στο πεδίο της βιολογίας, αλλά αυτές που ανταποκρίνονται σε ορισμένα κριτήρια. [Grivell, 22]. Ο αυτοματοποιημένος χειρισμός των κειμένων είναι μία ενεργή περιοχή έρευνας. Ανήκει στο ευρύτερο πεδίο του Data Mining. Η ειδοποιός διαφορά μεταξύ των παραδοσιακών τεχνικών του Data Mining και του Text Mining είναι ότι το text mining εξάγει την πληροφορία από κείμενα γραμμένα σε φυσική γλώσσα, ενώ στο data mining η πληροφορία εξάγεται από δομημένες βάσεις δεδομένων. Το γεγονός ότι επεξεργάζεται δεδομένα χωρίς καμία δομή σημαίνει ότι είναι απαραίτητη μία προεπεξεργασία των δεδομένων. Τεχνικές του NLP χρησιμοποιούνται για το λόγο αυτό. Οι πιο διαδεδομένες τεχνικές που έχουν εφαρμοστεί στο βιολογικό κείμενο είναι το Information retrieval (IR) και το Information Extraction (IE), που συχνά αναφέρονται ως τεχνικές text mining.. Το IR αφορά στην εύρεση και ανάκτηση κειμένων που ικανοποιούν μία συγκεκριμένη ανάγκη πληροφορίας μέσα σε μία μεγάλη βάση δεδομένων με κείμενα, το information extraction επικεντρώνεται στην εύρεση συγκεκριμένων οντοτήτων και γεγονότων σε αδόμητο κείμενο, ενώ πολλοί κάνουν τη διάκριση ορίζοντας ως text mining τη συνδυαστική και αυτοματοποιημένη διαδικασία ανάλυσης κειμένων γραμμένων στη φυσική γλώσσα με σκοπό την ανακάλυψη πληροφορίας και γνώσης που είναι δύσκολο να ανακτηθεί [Hearst, 1999]. Ωστόσο, μιας και οι διαδικασίες που χρησιμοποιούνται στο text mining όπως ορίζεται από τον Hearst, προέρχονται από τα πεδία του IR και του IE στο παρόν κείμενο δε θα γίνει αυτή η διάκριση, αλλά ο όρος text mining θα αναφέρεται στο σύνολο των διαδικασιών εξαγωγής πληροφορίας από κείμενα γραμμένα σε φυσική γλώσσα. Όλες αυτές οι τεχνικές μπορούν να συνδυαστούν με διαδικασίες επεξεργασίας της φυσικής γλώσσας (διαδικασίες Natural Language Processing) και λεξικά ή θησαυρούς για καλύτερα αποτελέσματα. 5
6 Ο σκοπός του information retrieval είναι η ανάκτηση ήδη γνωστής πληροφορίας, από μία μεγάλη συλλογή δεδομένων, σύμφωνα με κάποια κριτήρια που θέτει ο χρήστης συνήθως με τη Μορφή ερωτήματος (query). Στο πεδίο της βιολογίας η πληροφορία βρίσκεται σε μορφή κειμένων και σκοπός είναι η ανάκτησή της και όχι η ανακάλυψη νέας γνώσης. Η αναζήτηση γίνεται είτε με τη μορφή ερωτήματος (query) είτε με αναζήτηση παρόμοιων κειμένων που έχουν θεματική συνάφεια προς ένα δοθέν κείμενο. Στην περίπτωση των query, που είναι και ο πιο συνηθισμένος τρόπος αναζήτησης, ο χρήστης αναζητά κείμενα με βάση μία λέξη ή φράση-κλειδί που συνοψίζει την πληροφορία. Ο τρόπος αυτός είναι οικείος στους χρήστες του web, αφού μηχανές αναζήτησης όπως το google, το yahoo και το altavista, που έχουν ως βάση το query, αποτελούν τα πιο διαδεδομένα εργαλεία αναζήτησης. Η αναζήτηση μέσω κειμένων γίνεται όταν ο χρήστης δίνει ένα κείμενο-πρότυπο, ενώ αναζητά παρεμφερή με αυτό κείμενα. Παράδειγμα τέτοιας αναζήτησης είναι ο σύνδεσμος που υπάρχει στο google δίπλα σε ανακτημένες σελίδες που αναγράφει «παρόμοιες σελίδες». Οι μέθοδοι του information retrieval δεν κάνουν καμία σημασιολογική ή συντακτική ανάλυση, αντιμετωπίζοντας το κείμενο ως σωρό λέξεων. Η μόνη προεργασία που γίνεται αφορά στην εύρεση του λεξιλογίου και στη συνέχεια τη δεικτοδότησή του. Το πεδίο του information extraction αφορά στην εξόρυξη συγκεκριμένης πληροφορίας από δεδομένα γραμμένα σε φυσική γλώσσα. Υπάρχει μία σύγχυση του information extraction με το information retrieval. Πολλοί πιστεύουν ότι οι δύο αυτοί όροι είναι δύο διαφορετικές ονομασίες του ίδιου πεδίου. Η θεώρηση αυτή είναι λανθασμένη. Το information retrieval σχετίζεται με την ανάκτηση κειμένων σύμφωνα με βάση ένα ερώτημα που έχει τεθεί από κάποιο χρήστη, ενώ το information extraction σχετίζεται με την ανακάλυψη συγκεκριμένης πληροφορίας μέσα σε μία συλλογή κειμένων ή ακόμα και μέσα σε ένα κείμενο. Το information extraction είναι από τις πιο υποσχόμενες τεχνικές που εφαρμόζονται στο πεδίο του text mining. Συνδυάζει εργαλεία του Natural Language Processing και πηγές σημασιολογικής ανάλυσης, όπως λεξικά, θησαυρούς, οντολογίες με σκοπό την ανακάλυψη συγκεκριμένης γνώσης ανάμεσα σε κείμενα, που πολλές φορές μπορεί να χρησιμοποιηθούν για ανακαλυφθούν σχέσεις και γεγονότα άγνωστα μέχρι τότε. Ο στόχος της βιολογικής έρευνας είναι η ανακάλυψη της γνώσης, που αφορά στους κανόνες που διέπουν τους ζωντανούς οργανισμούς και η εφαρμογή της στη βελτίωση της ανθρώπινης ζωής. Ωστόσο, η διαχείριση και η οργάνωσή της είναι μία επίπονη και χρονοβόρα διαδικασία. Η χρήση τεχνικών text mining επιτάχυνε τις διαδικασίες και έχει γίνει πλέον αναπόσπαστο κομμάτι της βιολογική έρευνας, δίνοντας τη δυνατότητα στους επιστήμονες να έχουν πρόσβαση και να χειρίζονται γρήγορα και αποτελεσματικά πληροφορίες που βρίσκονται σε κείμενα γραμμένα σε φυσική γλώσσα ή ακόμα και να ανακαλύπτουν γεγονότα, άγνωστα μέχρι τότε. Το text mining έχει εδραιωθεί στη βιολογική έρευνα και έχει κάνει πολλούς επιστήμονες να στρέψουν το ενδιαφέρον τους προς τα εκεί, αναζητώντας αποτελεσματικότερα συστήματα για τη διαχείριση και εκμετάλλευση της πληροφορίας. Το ενδιαφέρον αυτό φαίνεται και από τις προσπάθειες που έχουν γίνει 6
7 για την αξιολόγηση αυτών των συστημάτων και την ενσωμάτωσή τους στην βιολογική έρευνα. Πολλές εργασίες έχουν γίνει και στον τομέα της κατηγοριοποίησης κειμένων. Η κατηγοριοποίηση των κειμένων είναι η διαδικασία ένταξης των κειμένων σε κάποιες προκαθορισμένες κατηγορίες. Ο γενικότερος ορισμός του text categorization είναι ο ακόλουθος: δίνονται ένα σύνολο κειμένων D και ένα σύνολο κατηγοριών C={c1,c2, cn}. Σε κάθε κείμενο δίνεται μία λογική τιμή για κάθε ζευγάρι (di,cj )E C X D. Η τιμή 1 δίνεται αν το κείμενο ανήκει στην κατηγορία, ενώ η τιμή, όταν το κείμενο δεν ανήκει. Το text categorization ανήκει στο πεδίο του information retrieval. Η βιολογική βιβλιογραφία αντιμετωπίζει το πρόβλημα των διφορούμενων λέξεων. Μία βιολογική οντότητα μέσα στο σωρό από τα κείμενα που υπάρχουν αναφέρεται με διάφορα ονόματα και συντομογραφίες. Οι υπάρχουσες βάσεις δεδομένων, τα λεξικά και οι οντολογίες επιβάλλεται να παραμένουν ενημερωμένα με τα νέα συνώνυμα και συντομογραφίες που εμφανίζονται στα κείμενα. Η λύση αυτού του προβλήματος θα βοηθούσε πολύ στην απόδοση άλλων συστημάτων text mining. Έχουν αναπτυχθεί αρκετά συστήματα που χαρτογραφούν όλα τα συνώνυμα και τις συντομογραφίες σε ένα και μοναδικό όρο και αφορούν κυρίως τα ονόματα των γονιδίων. Τα συστήματα αυτά αναφέρονται ως συστήματα εξόρυξης συνωνύμων και συντομογραφιών και ανήκουν στο πεδίο του information extraction. Ένα άλλο πολύ σημαντικό πεδίο είναι η εξόρυξη σχέσεων, που επίσης ανήκει στο πεδίο του information extraction. Ο στόχος της εξόρυξης σχέσεων είναι να ανιχνεύει έναν προκαθορισμένο τύπο σχέσεων μεταξύ ενός ζευγαριού οντοτήτων συγκεκριμένου τύπου. Ο τύπος των οντοτήτων είναι πολύ συγκεκριμένος, για παράδειγμα μία οντότητα μπορεί να είναι γονίδιο, πρωτεΐνη, φάρμακο κτλ. Αντίθετα, ο τύπος της σχέσης μπορεί να είναι πολύ γενικός, όπως αναζήτηση βιοχημικής σχέσης ή πολύ συγκεκριμένος, για παράδειγμα ρυθμιστική σχέση. Οι περισσότεροι ερευνητές έχουν στρέψει το ενδιαφέρον τους στις σχέσεις μεταξύ γονιδίων και πρωτεϊνών. Αυτό έγινε με το σκεπτικό ότι η ομαδοποίηση των γονιδίων σύμφωνα με τη λειτουργία τους θα βοηθήσει στην ανάλυση της γονιδιακής έκφρασης και στις βάσεις δεδομένων. Υπάρχουν αρκετά συστήματα για την εξόρυξη σχέσεων μεταξύ γονιδίων. Ενώ η εξόρυξη σχέσεων που αναφέρθηκε προηγουμένως, ασχολείται με την εύρεση σχέσεων μεταξύ οντοτήτων που βρίσκονται αποκλειστικά σε κείμενα, η δημιουργία υποθέσεων προσπαθεί να ανακαλύψει σχέσεις που δεν υπάρχουν στα κείμενα, αλλά συμπεραίνονται από άλλες σχέσεις που υπάρχουν. Ο στόχος είναι η ανακάλυψη σχέσεων, άγνωστων μέχρι τότε, που να παρουσιάζουν ενδιαφέρον για περαιτέρω μελέτη και έρευνα. Όλη η έρευνα που γίνεται στο πεδίο της δημιουργίας υποθέσεων στηρίζεται σε μία ιδέα του Swanson που διατυπώθηκε τη δεκαετία του 8 και ονομάζεται complementary structures in disjoint literature (CSD). Σε αυτή την εργασία ο Swanson υποστηρίζει ότι είναι δυνατό να πραγματοποιηθούν ανακαλύψεις χρησιμοποιώντας μεγάλες βάσεις επιστημονικής βιβλιογραφίας με απλά λογικά συμπεράσματα. Πρότεινε ένα απλό μοντέλο, το ABC που είναι της μορφής «το Α επηρεάζει το Β, το Β επηρεάζει το C, άρα το A ίσως να επηρεάζει το C». Με το πείραμά του, ο Swanson ανακάλυψε αιτίες που προκαλούν ημικρανίες εξάγοντας γεγονότα από τη βιβλιογραφία της βιολογίας. Πιο συγκεκριμένα εξήγαγε τα παρακάτω στοιχεία: 7
8 1. Το άγχος σχετίζεται με τις ημικρανίες. 2. Το άγχος μπορεί να οδηγήσει στην απώλεια μαγνησίου. 3. Οι υποδοχές δέσμευσης ασβεστίου προλαμβάνουν τις ημικρανίες. 4. Το μαγνήσιο είναι μία φυσική υποδοχή δέσμευσης ασβεστίου. 5. Η εξάπλωση εγκεφαλικής κατάθλιψης (Spreading Cortical Depression, SCD) σχετίζεται σε ορισμένες περιπτώσεις με τις ημικρανίες. 6. Μεγάλες ποσότητες μαγνησίου αναστέλλουν την SCD. 7. Οι ασθενείς που πάσχουν από ημικρανίες έχουν μεγάλο αριθμό αιμοπεταλίων. 8. Το μαγνήσιο μπορεί να αναστείλει την αύξηση των αιμοπεταλίων. Τα στοιχεία αυτά υπήρχαν στη βιβλιογραφία και οδήγησαν τον Swanson στην υπόθεση ότι η έλλειψη μαγνησίου μπορεί να σχετίζεται με την ημικρανία. Η πρόταση αυτή δεν υπήρχε στη βιβλιογραφία. Τέλος, έχουν αρχίσει και αναπτύσσονται συστήματα που ολοκληρώνουν τις παραπάνω μεθόδους και μπορούν να ικανοποιήσουν διαφορετικές ανάγκες των χρηστών. Τα συστήματα αυτά βρίσκονται στη φάση της έρευνας και της ανάπτυξης. Απομένει να φανεί αν θα καταφέρουν να αντεπεξέλθουν στις προσδοκίες των επιστημόνων και αν θα υιοθετηθούν από την επιστημονική κοινότητα ως αναπόσπαστο εργαλείο της βιολογικής έρευνας. 8


9 2.ΒΙΟΛΟΓΙΚΑ ΚΕΙΜΕΝΑ-ΓΟΝΙΔΙΑΚΕΣ ΟΝΤΟΛΟΓΙΕΣ Η ανάγκη μίας καθολικά αποδεκτής ορολογίας και σημειολογίας για την περιγραφή των γονιδιακών λειτουργιών, ώθησε τους επιστήμονες στη δημιουργία λεξικών και οντολογιών. Η ανάγκη αυτή προέκυψε λόγω της τεράστιας βιβλιογραφίας βιολογικού περιεχομένου η οποία δημιουργεί συγχύσεις και δυσκολίες ενώ είναι φυσιολογικό να μην μπορεί εξαιτίας του μεγέθους της να μελετηθεί εξ ολοκλήρου. ΠΑΡΑΔΟΣΙΑΚΗ ΑΝΑΛΥΣΗ Μελετά κάθε γονίδιο ξεχωριστά Απαιτεί ψάξιμο στη βιβλιογραφία Χρονοβόρα διαδικασία Η πληρέστερη οντολογία για το σκοπό αυτό είναι η Γονιδιακή Οντολογία ή όπως αλλιώς είναι γνωστή Gene Ontology (GO). Θα μπορούσαμε να πούμε ότι η Gene Ontology παρέχει έναν τρόπο να «αιχμαλωτίσουμε» και να αναπαραστήσουμε όλη αυτήν την γνώση που περιέχεται στη βιβλιογραφία σε υπολογιστική μορφή. 9


10 Η ΓΟΝΙΔΙΑΚΗ ΟΝΤΟΛΟΓΙΑ ΜΑΣ ΠΑΡΕΧΕΙ ΕΝΑΝ ΤΡΟΠΟ ΩΣΤΕ ΝΑ ΜΕΤΑΦΕΡΟΥΜΕ ΣΤΟΝ ΥΠΟΛΟΓΙΣΤΗ ΟΛΗ ΑΥΤΗΝ ΤΗΝ ΓΝΩΣΗ ΒΙΟΛΟΓΙΚΟΥ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΟΥ ΒΡΙΣΚΕΤΑΙ ΣΤΑ ΒΙΒΛΙΑ. Η Gene Ontology είναι μία ιεραρχία με δομή κατευθυνόμενου άκυκλου γράφου. Η διαφορά από τις συνηθισμένες ιεραρχίες, που συνήθως έχουν δομή δένδρου, είναι το γεγονός ότι ένας κόμβος παιδί μπορεί να έχει περισσότερους του ενός κόμβου γονέα. Δύο κόμβοι συνδέονται μεταξύ τους με δύο είδη σχέσεων: part of και is a, δηλώνοντας ότι ο κόμβος παιδί είναι μέρος του κόμβου γονέα ή είναι ένα είδος του αντίστοιχα. 1
11 Κύτταρο IS A PART OF Κατευθυνόμενος άκυκλος γράφος-ένας κόμβος-παιδί έχει περισσότερους του ενός κόμβου-γονέα. Μεμβράνη Χλωροπλάστης Μιτοχονδριακή Μεμβράνη Χλωροπλαστική Μεμβράνη Στην παραδοσιακή τεχνική για να μελετήσουμε μια λειτουργία πρέπει να εξετάσουμε όλα τα γονίδια για να δούμε ποια από αυτά συμβάλλουν σ αυτήν. (για να καταλάβουμε την δυσκολία αυτού ας αναλογιστούμε ότι ένα γονίδιο μπορεί να επιτελέσει κάποιο ρόλο σε πολλές λειτουργίες και ότι μια λειτουργία για να διεκπεραιωθεί σωστά απαιτεί μεγάλο αριθμό γονιδίων).αντίθετα η Γονιδιακή Οντολογία περιέχει κώδικες(γνωστοί ως GO codes) κάθε ένας από τους οποίους περιγράφει μία λειτουργία στην οποία μπορούν να συμβάλλουν διαφορετικά γονίδια. Δηλαδή ένας όρος Γονιδιακής Οντολογίας περιέχει γονίδια τα οποία συνδέονται μεταξύ τους με τις γονιδιακές συσχετίσεις όπως είναι γνωστές(gene annotations/gene associations) και οι οποίες βρίσκονται στις γονιδιακές βάσεις. Ως εκ τούτου αυτή η κατηγοριοποίηση των γονιδίων σε όρους της Gene Ontology ονομάζεται συσχέτιση(annotation).τα παραπάνω περιγράφονται στα παραδείγματα που ακολουθούν: 11
12 GO ΣΥΣΧΕΤΙΣΜΟΙ GO Βάση Δεδομένων γονίδιο -> GO όρος Συσχετιζόμενα γονίδια Γονιδιακές και πρωτεϊνικές βάσεις 12
13 Παραδοσιακή ανάλυση-μελετά τα χαρακτηριστικά κάθε γονιδίου(σε ποια λειτουργία συμβάλλει κάθε γονίδιο). Γονίδιο 1 Απόπτωση Cell-cell signaling Πρωτεϊνική φωσφορυλάση Μίτωση Γονίδιο 2 Έλεγχος ανάπτυξης Μίτωση Ογκογένεση Πρωτεϊνική φωσφορυλάση Γονίδιο 3 Έλεγχος ανάπτυξης Μίτωση Γονίδιο 4 Ογκογένεση Νευρικό σύστημα Πρωτεϊνική Εγκυμοσύνη φωσφορυλάση Ογκογένεση Μίτωση Γονίδιο 1 Θετικός έλεγχος του πολλαπλασιασμού των κυττάρων Μίτωση Ογκογένεση 13

14 Αλλά χρησιμοποιώντας τις συσχετίσεις της Γονιδιακής Οντολογίας αυτή η δουλειά έχει ήδη γίνει GO:6915 : apoptosis Κώδικας Γονιδιακής Οντολογίας Λειτουρ γία που περιγρά φει 14
15 ΩΣ ΑΠΟΤΕΛΕΣΜΑ. Απόπτωση Γονίδιο 1 Γονίδιο 53 Μίτωση Γονίδιο 2 Γονίδιο 5 Γονίδιο45 Γονίδιο 7 Γονίδιο 35 Μεταφορά Γλυκόζης Γονίδιο 7 Γονίδιο 3 Γονίδιο 6 Θετικός έλεγχος του πολλαπλασιασμού των κυττάρων Γονίδιο 7 Γονίδιο 3 Γονίδιο 12 Ανάπτυξη Γονίδιο 5 Γονίδιο 2 Γονίδιο 6 Σ αυτήν την φάση γεννάται το ερώτημα του πως προκύπτουν οι κώδικες της Gene Ontology. Για την εξαγωγή λοιπόν αυτών ακολουθούνται 3 βήματα τα οποία έχουμε σχηματοποιήσει αμέσως παρακάτω. Θα πρέπει επίσης να αναφέρουμε ότι οι όροι της Gene Ontology διαιρούνται σε 3 τμήματα: Συστατικά κυττάρων Συναρτήσεις μορίων Βιολογικές διαδικασίες 15

16 1 ο Βήμα:Επιλέγω ένα γονίδιο ή μια πρωτεΐνη. P514 Γονίδιο 16

17 2 ο Βήμα:Βρίσκω άρθρα από την PubMed γι αυτό το γονίδιο. P5147 PMID: Κωδικός άρθρου της PubMed 17


18 3 ο Βήμα:Εύρεση του GO όρου(κωδικού)που περιγράφει την λειτουργία στην οποία συμμετέχει το γονίδιο για την συγκεκριμένη περίπτωση. P5147 PMID: GO:47519 GO κωδικός 18
19 Οι όροι της Gene Ontology καλύπτουν τις εξής 3 αναζητήσεις μας σχετικά με τα Οι όροι της Gene Ontology καλύπτουν τις εξής 3 αναζητήσεις μας σχετικά με τα γονίδια: Τι μπορεί να κάνει ένα γονίδιο; Με λίγα λόγια σε ποιες λειτουργίες μπορεί να συμβάλλει; Πότε και που δρα ένα γονίδιο; Γιατί συμμετέχει σ αυτές τις δραστηριότητες; Τελειώνοντας την αναφορά μας για την Γονιδιακή Οντολογία αναφέρουμε την «ανατομία» της δηλαδή τα βασικά μέρη που την απαρτίζουν και αποτελούν αναπόσπαστο τμήμα σε οποιαδήποτε αναφορά της: id: GO:694 name: gluconeogenesis namespace: process def: The formation of glucose from noncarbohydrate precursors, such as pyruvate, amino acids and glycerol. [ exact_synonym: glucose biosynthesis xref_analog: MetaCyc:GLUCONEO-PWY is_a: GO:66 is_a: GO:692 μοναδικός GO κωδικός αντίστοιχη λειτουργία είδος οντολογίας ορισμός λειτουργίας συνώνυμη λειτουργία αναφορά στη Βάση Δεδομένων γονέας γονέας 19
20 Στην ουσία λοιπό αυτό που περιέχει η Gene Ontology είναι κώδικες οι οποίοι περιγράφουν τις λειτουργίες των γονιδίων(για ευκολία ας φανταστούμε ότι οι όροι της Gene Ontology αντιστοιχίζονται με λέξεις /όρους βιολογικού περιεχομένου οι οποίοι με την σειρά τους μπορούν να περιγράψουν τις διάφορες λειτουργίες των γονιδίων). Στην εργασία μας χρησιμοποιήσαμε 12 όρους γονιδιακής οντολογίας οι οποίοι είναι οι εξής: GO code GO:6914 GO:749 GO:8219 GO:8283 GO:7267 GO:6943 GO:7126 GO:8152 GO:748 GO:7165 GO:695 GO:681 Γενικά ισχύει ότι η κατηγοριοποίηση των κειμένων και η απόδοση στο καθένα από αυτά ενός GO code είναι μέρος μίας γενικότερης διαδικασίας, που περιλαμβάνει την ανάκτηση των κατάλληλων κειμένων, την αρχική τους επεξεργασία, την αναπαράστασή τους σε διανυσματική μορφή και την εφαρμογή στα δεδομένα μίας στατιστικής μεθόδου ώστε να είναι όσο το δυνατό ανεξάρτητα μεταξύ τους και να 2
21 μειωθεί ο όγκος τους. Όσον αφορά την δική μας εργασία χωρίσαμε αυτήν την διαδικασία σε 4 φάσεις. ΠΡΩΤΗ ΦΑΣΗ Η πρώτη φάση της εργασίας μας ήταν i) η ανάκτηση κειμένων που σχετίζονται με τους 12 παραπάνω GO codes, ii) η αρχική επεξεργασία τους και iii) η μετατροπή τους σε μία μορφοποίηση που να είναι δυνατό να την επεξεργαστεί ένα υπολογιστικό σύστημα. Μετά το τέλος της φάσης αυτής, είχε δημιουργηθεί το αρχικό σύνολο των δεδομένων πάνω στο οποίο στηρίχτηκε η εφαρμογή. Αρχικά ανακτήθηκαν κατάλληλα για τον σκοπό αυτό abstract κείμενα (τίτλος και άλλες λεπτομέρειες του άρθρου), που είναι δημοσιευμένα στην βάση δεδομένων PubMed. Η PubMed είναι η πιο διαδεδομένη και ευρέως χρησιμοποιούμενη βάση δεδομένων στο βιολογικό κείμενο περιέχοντας πάνω από 12.. abstract κείμενα. Συγκεκριμένα ανακτήθηκαν 99 abstract κείμενα από την PubMed. Για την ανάκτησή τους, χρησιμοποιήθηκαν κάποιες λέξεις κλειδιά με τη μορφή ερωτήματος (query) στην PubMed.Αυτή η λογική της αναζήτησης των κειμένων μέσω των queries, αναζητά κείμενα με βάση μία λέξη ή φράση-κλειδί που συνοψίζει την πληροφορία. Οι λέξεις κλειδιά που χρησιμοποιήθηκαν, είναι όροι της Medical Subject Headings (MeSH)(και αυτή κατά κάποιο τρόπο αποτελεί μια Gene Ontology, ενώ στον πίνακά μας οι όροι της αναφέρονται στην στήλη με όνομα Biological term ) για καλύτερα αποτελέσματα στην αναζήτηση. Αξίζει να σημειωθεί ότι ο στόχος των όρων της MeSH είναι να δεικτοδοτήσει τα άρθρα στην PubMed, ενώ οι όροι της GO έχουν σκοπό να περιγράψουν τις λειτουργίες των γονιδίων ή των γονιδιακών προϊόντων. Ωστόσο, κάποιοι όροι της MeSH μπορούν να αντιστοιχηθούν σε όρους της GO [Theodosiou, 26]. Η αντιστοίχηση των όρων της MeSH που χρησιμοποιήθηκαν με τους όρους της GO φαίνεται στον παρακάτω πίνακα. 21
22 GO code GO:6914 GO:749 GO:8219 GO:8283 GO:7267 GO:6943 GO:7126 GO:8152 GO:748 GO:7165 GO:695 GO:681 Biological term Autophagy Cell cycle Cell death Cell proliferation Cell-cell signalling Chemimechanical Meiosis Metabolism Oncogenesis Signal transduction Stress response Transport Χρησιμοποιήθηκαν λοιπόν, 12 λέξεις κλειδιά από τη MeSH, όπου κάθε μία από αυτές αντιστοιχίζεται με τον αντίστοιχο GO code και μας επιστράφηκαν από την PubMed 99 κείμενα (Για ευκολία ας φανταστούμε την πληκτρολόγηση μίας λέξης κλειδί στην μηχανή αναζήτησης google και την εμφάνιση των αποτελεσμάτων που σχετίζονται με αυτήν την λέξη). Τα κείμενα χωρίστηκαν σε k=12 κατηγορίες σύμφωνα με τη λέξη κλειδί που χρησιμοποιήθηκε για την ανάκτησή τους, όπως φαίνεται και στον παρακάτω συγκεντρωτικό πίνακα. Λόγω ευκολίας, οι κατηγορίες δεικτοδοτήθηκαν με αριθμούς από 1 ως 12, όπου ο αριθμός 1 αναφέρεται στην κατηγορία 1, ο αριθμός 2 στην κατηγορία 2 κ.ο.κ. Αξίζει να σημειωθεί ότι ο αριθμός των κειμένων που ανήκουν σε κάθε κατηγορία δεν είναι ο ίδιος (τα κείμενα δεν είναι ομοιόμορφα κατανεμημένα), ωστόσο αυτό δε δημιουργεί προβλήματα στην κατασκευή του μοντέλου. 22

23 Τα κείμενα που ανακτήθηκαν επεξεργάστηκαν έτσι ώστε να βρεθεί το λεξιλόγιο έτσι ώστε με τον συνδυασμό κειμένων και λεξιλογίου να μπορέσουμε να εξάγουμε τον αρχικό πίνακα των δεδομένων μας. Στα 99 λοιπόν κείμενα εφαρμόστηκαν με την σειρά που αναφέρονται οι εξής διαδικασίες: Tokenization. Απόρριψη των stop words. Stemming. Απόρριψη των όρων που έχουν συχνότητα πάνω από 95% και κάτω από.5% στο σύνολο των κειμένων. Tokenization Τα token είναι οι λέξεις που αποτελούν το κάθε κείμενο, μιας και η αναζήτηση γίνεται μέσω λέξεων-κλειδιά ή φράσεων. Η λειτουργία του tokenization είναι να μας δώσει τις λέξεις των κειμένων συρρικνώνοντας το κείμενο με την αφαίρεση χαρακτήρων ή γραμματοσειρών, που σε πρώτο επίπεδο τουλάχιστον, δεν έχουν σχέση με το περιεχόμενο του κειμένου. Συγκεκριμένα, στα κείμενα περιέχονται στοιχεία, χαρακτηριστικά του κάθε τύπου κειμένου που καθορίζουν τη μορφή αυτού. Αυτά τα στοιχεία πρέπει να αφαιρεθούν, αφού δεν σχετίζονται με το περιεχόμενό του (π.χ σημεία στίξης και αριθμητικά σύμβολα). Σε αυτό το στάδιο μετατρέπονται επίσης, όλα τα γράμματα σε πεζά. Αν δε γίνει αυτό, ενέχει ο κίνδυνος η ίδια λέξη να 23
24 θεωρηθεί διαφορετική, απλά και μόνο επειδή ένα γράμμα της είναι κεφαλαίο. Τέλος, θα πρέπει οι χαρακτήρες να μετατραπούν σε μία πρότυπη αναπαράσταση (π.χ. Unicode) καθώς είναι πολύ πιθανό, στη συλλογή να υπάρχουν κείμενα σε διαφορετικές γλώσσες ή ακόμη και στο ίδιο κείμενο να χρησιμοποιούνται χαρακτήρες από διαφορετικά αλφάβητα. Σε αυτές τις περιπτώσεις είναι επιβεβλημένη η μετατροπή της κωδικοποίησης, έτσι ώστε να είναι δυνατή η αναζήτηση και η ανάκτηση κειμένων μέσω λέξεων γραμμένων σε κάποια άλλη γλώσσα. Stop Words Η ιδέα, στην οποία στηρίζεται αυτή η διαδικασία, είναι ότι υπάρχουν λέξεις σε όλα τα κείμενα που δεν σχετίζονται με το περιεχόμενο του κειμένου ούτε βοηθούν στο διαχωρισμό των κειμένων μεταξύ τους. Τέτοιες λέξεις είναι τα βοηθητικά ρήματα (είμαι, έχω, μπορώ κτλ) σε όλους τους χρόνους και όλα τα πρόσωπα, σύνδεσμοι, προθέσεις, άρθρα, αντωνυμίες κτλ..οι λέξεις αυτές όπως είναι φυσικό δεν περιλαμβάνονται στο λεξιλόγιο. Stemming Σύμφωνα με αυτήν την διαδικασία, οι λέξεις που έχουν κοινή ρίζα κόβουν την κατάληξή τους και ομαδοποιούνται όλες στην ίδια ρίζα. Με αυτόν τον τρόπο βρίσκονται λέξεις σ ένα κείμενο που διαφορετικά δεν θα βρίσκονταν και έτσι το κείμενο τελικά επιστρέφεται στο χρήστη.(π.χ αν θέσω σαν ερώτημα τη λέξη γονίδιο και το κείμενο περιέχει τη λέξη γονιδιακός.με stemming το κείμενο που περιέχει τη λέξη γονιδιακός θα επιστραφεί, αλλιώς όχι). Απόρριψη των όρων που έχουν συχνότητα πάνω από 95% και κάτω από.5% στο σύνολο των κειμένων. Αυτή η τεχνική εύρεσης των λέξεων χρησιμοποιεί την συχνότητα των όρων, δηλαδή το πόσες φορές εμφανίζεται μία λέξη σε κάθε κείμενο. Εμείς θέσαμε το όριο (95%-.5%) δηλαδή απορρίψαμε τους όρους με συχνότητα πάνω από 95%(αυτούς που εμφανίζονταν σε ποσοστό παραπάνω από το 95% του συνολικού αριθμού των άρθρων) καθώς και αυτούς με συχνότητα κάτω από.5%( αυτούς που εμφανίζονταν σε ποσοστό λιγότερο από το.5% του συνολικού αριθμού των άρθρων). Από την εφαρμογή των 4 παραπάνω διαδικασιών προέκυψε το λεξιλόγιο το οποίο μετρά 1621 όρους. Δηλαδή από τα 99 κείμενα πήραμε 1621 λέξεις. Μετά την εύρεση του λεξιλογίου, κάθε όρος αντιπροσωπεύεται με ένα διάνυσμα. Τα διανύσματα είναι κάθετα μεταξύ τους, που στην πράξη σημαίνει, ότι 24
25 κάθε όρος θεωρείται ανεξάρτητος από τους άλλους. Σε αυτόν το διανυσματικό χώρο, που δημιουργείται από τις λέξεις-κλειδιά τα κείμενα αντιπροσωπεύονται επίσης από διανύσματα. Τα διανύσματα των κειμένων δεν δημιουργούνται αυθαίρετα, αλλά από τις συνιστώσες τους, δηλαδή τους όρους. Σε αυτό το σημείο συμπεραίνουμε λοιπόν ότι πρέπει να βρεθούν οι συνιστώσες του κάθε κειμένου για να γίνει δυνατή και η αναπαράστασή του από ένα διάνυσμα. Αν σε ένα κείμενο υπάρχει ένας όρος, τότε το κείμενο αυτό έχει μία συνιστώσα σε αυτόν τον άξονα. Ωστόσο, ο κάθε όρος δεν έχει την ίδια βαρύτητα σε κάθε κείμενο. Έτσι κάθε κείμενο d, αντιπροσωπεύεται από ένα n-διάστατο διάνυσμα(xd 1, xd 2,, xdn), όπου x di είναι το βάρος του όρου ti στο κείμενο d. Για την απόδοση των βαρών στην εργασία αυτή, χρησιμοποιήθηκε το δυαδικό σχήμα,που σύμφωνα με αυτό, το βάρος x di ισούται με 1 όταν ο όρος ti εμφανίζεται μέσα στο κείμενο d, ενώ ισούται με όταν ο όρος t i δεν εμφανίζεται στο κείμενο. Σύμφωνα με τα παραπάνω κάθε κείμενο αναπαριστάται από ένα n-διάστατο διάνυσμα. Κάθε διάσταση αντιπροσωπεύει έναν όρο του λεξιλογίου και ένα διάνυσμα(κείμενο) έχει μία συνιστώσα μοναδιαίου μέτρου στη διάσταση αυτή αν ο όρος βρίσκεται μέσα στο κείμενο, ενώ σε αντίθετη περίπτωση δεν έχει συνιστώσα στην διάσταση αυτή. Το αποτέλεσμα των παραπάνω διαδικασιών(των 3 μερών της πρώτης φάσης) είναι ένας πίνακας , 99 γραμμές, μία για κάθε κείμενο και 1643 στήλες, 1642 στήλες για τους όρους του λεξιλογίου, και μία στήλη που αναφέρει την κατηγορία(αριθμό ομάδας) στην οποία ανήκει κάθε κείμενο. Οι 1642 στήλες για τους όρους του λεξιλογίου συμπληρώνονται με και 1 σύμφωνα με όσα αναφέρθηκαν παραπάνω(αν υπάρχει ο όρος στο κείμενο η αντίστοιχη θέση στον πίνακα συμπληρώνεται με 1, διαφορετικά, αν δεν υπάρχει δηλαδή ο όρος στο κείμενο, η αντίστοιχη θέση συμπληρώνεται με ) ενώ η πρώτη στήλη συμπληρώνεται με έναν φυσικό αριθμό από 1 ως 12 που αναπαριστούν τις 12 κατηγορίες. ΔΕΥΤΕΡΗ ΦΑΣΗ Επειδή το μέγεθος του πίνακα είναι πολύ μεγάλο και δεν μπορούμε να τον επεξεργαστούμε αρχικά προβήκαμε σε διαφόρους μετασχηματισμούς για να μειώσουμε τον αριθμό των στηλών ενώ στη δεύτερη φάση εφαρμόστηκε η Principal Components Analysis (PCA), μία στατιστική μέθοδος που ελαχιστοποίησε τις εξαρτήσεις και έδωσε το τελικό σύνολο των δεδομένων, αρκετά μικρότερο από το αρχικό. Πάνω στο σύνολο αυτό εκπαιδεύτηκε το μοντέλο. Παρατηρούμε λοιπόν ότι μετά την εφαρμογή των μετασχηματισμών, δημιουργήθηκαν 622 μεταβλητές, που αντικατέστησαν τις 1643 αρχικές ανεξάρτητες μεταβλητές, χάνοντας ένα πολύ μικρό(και σχεδόν ασήμαντο θα μπορούσαμε να πούμε) ποσοστό πληροφορίας. Θα πρέπει να αναφέρουμε ότι το ποσοστό της πληροφορίας που χάνεται είναι ασήμαντο επειδή μειώσαμε τις μεταβλητές μετασχηματίζοντάς τις κρατώντας όμως τις πιο σημαντικές. Όπως αναφέραμε παραπάνω αρχικά είχαμε έναν δυαδικό πίνακα μεγέθους 99Χ1643 (πίνακας αποτελούμενος από 1 και εκτός της πρώτης στήλης που έχει ακέραιες τιμές στο διάστημα [1-12]).Εφαρμόζοντας διάφορους μετασχηματισμούς προέκυψε και πάλι ένας δυαδικός πίνακας αυτήν την φορά μεγέθους 99Χ622(δηλαδή από τις 1642 καταφέραμε να κρατήσουμε τις 622 πιο σημαντικές μεταβλητές).εφαρμόζοντας άλλη μία φορά τους ίδιους μετασχηματισμούς 25
26 καταλήξαμε στον δυαδικό πίνακα που χρησιμοποιούμε για να προκύψουν οι δυαδικές εικόνες ο οποίος είναι μεγέθους 99Χ51( δηλαδή από τις 622 καταφέραμε να κρατήσουμε τις 5 πιο σημαντικές μεταβλητές) και τον αποθηκεύουμε ως αρχείο απλού κειμένου με όνομα test.txt. Τέλος εφαρμόσαμε την PCA για να προκύψει πίνακας ακόμη μικρότερης διάστασης και τα καταφέραμε καθώς προέκυψε πίνακας μεγέθους 99Χ2. Θα πρέπει να σημειώσουμε όμως ότι αυτές οι 2 μεταβλητές δεν αντικατοπτρίζουν τώρα πια λέξεις κλειδιά και ούτε έχουν εννοιολογικό περιεχόμενο όπως οι προηγούμενες (1642,622,5 μεταβλητές) καθώς η PCA είναι μία αλγεβρική μέθοδος που μετασχηματίζει τα δεδομένα. Επίσης θα πρέπει να πούμε ότι το ποσοστό της πληροφορίας που χάνεται είναι ασήμαντο επειδή η και σ αυτό το στάδιο η PCA μειώνει τις μεταβλητές μετασχηματίζοντάς της κρατώντας δε τις πιο σημαντικές. Ως αποτέλεσμα τα δεδομένα του τελευταίου πίνακα(αυτού που έχει μέγεθος 99Χ21) δεν είναι τιμές και 1 αλλά τιμές στο διάστημα [,1].Και αυτόν τον πίνακα τον αποθηκεύσαμε ως αρχείο απλού κειμένου με όνομα p2.txt.συνεπώς θα δουλέψουμε με 2 αρχεία. Το αρχείο test θα μας δίνει δυαδικές εικόνες ενώ το αρχείο p2 θα μας δίνει έγχρωμες εικόνες. ΤΡΙΤΗ ΦΑΣΗ Στην τρίτη φάση, δημιουργήθηκε το μοντέλο κατηγοριοποίησης από τη Διακριτή Γραμμική Ανάλυση γνωστή ευρέως ως Linear discriminant analysis (LDA) και εκπαιδεύτηκε πάνω στα δεδομένα που προέκυψαν μετά την εφαρμογή της PCA.Στην ουσία δηλαδή σ αυτήν την φάση εφαρμόστηκε η στατιστική μέθοδος LDA για την κατηγοριοποίηση των 99 κειμένων της PubMed σύμφωνα με τους 12 όρους της Gene Ontology που αναφέραμε στην αρχή. Με λίγα λόγια πρόκειται για την μέθοδο με την οποία τα 99 κείμενα ανατέθηκαν στις 12 κατηγορίες(ομάδες). ΤΕΤΑΡΤΗ ΦΑΣΗ Στην τέταρτη και τελευταία φάση, αξιολογήθηκαν και ερμηνεύτηκαν τα αποτελέσματα του μοντέλου μέσω των μετρικών απόδοσης(precision, Recall, F- score, Accuracy). Το precision αναφέρεται στο ποσοστό της επιστρεφόμενης πληροφορίας που είναι σχετική, σε σχέση με την πληροφορία που επιστράφηκε. Για παράδειγμα, έστω ότι έχουν επιστραφεί δέκα κείμενα μετά την αναζήτηση. Αν τα οχτώ από τα δέκα που επιστράφηκαν είναι σχετικά με το ερώτημα, τότε το precision έχει την τιμή 8%. Η τιμή του recall δείχνει την ποσότητα της σχετική πληροφορίας που ανακτήθηκε, σε σχέση με την ποσότητα σχετικής πληροφορίας που υπάρχει στο σύνολο που γίνεται η αναζήτηση. Αν στο προηγούμενο παράδειγμα, η συλλογή των κειμένων, στην οποία πραγματοποιείται η αναζήτηση, είχε δεκαέξι κείμενα σχετικά με το ερώτημα που τέθηκε και ανακτήθηκαν τα οχτώ, τότε η τιμή του recall είναι 5%. Πολλές φορές υπάρχει μία «δοσοληψία» μεταξύ του precision και του recall. Μία εναλλακτική λύση που συνδυάζει τις δύο αυτές τιμές είναι το F-score Στην πιο απλή μορφή του περιγράφεται από τη σχέση: F=2PR/P+R όπου P το precision και R το recall, όπως ορίστηκαν παραπάνω. Η τιμή του F κυμαίνεται μεταξύ και 1, όπου το 1 σημαίνει ότι το σύστημα αξιολογεί σωστά όλα τα αντικείμενα και χαρακτηρίζει, κατ επέκταση τα όλα τα σχετικά αντικείμενα της συλλογής ως σχετικά και όλα τα μη σχετικά αντικείμενα ως μη σχετικά. Μία άλλη μετρική είναι η accuracy η οποία 26
27 αξιολογεί την ακρίβεια του συστήματος. Ισούται με το λόγο των αντικειμένων που έχουν αξιολογηθεί σωστά είτε ως σχετικά είτε ως μη σχετικά, προς το σύνολο των αντικειμένων. acc=a+c/n Το acc παίρνει τιμές από ως 1 και ισούται με τη μονάδα όταν όλα τα αντικείμένα έχουν αξιολογηθεί σωστά, ενώ ισούται με το όταν κανένα αντικείμενο δεν έχει αξιολογηθεί σωστά. Για τα δικά μας αποτελέσματα προέκυψαν οι εξής τιμές: Precision=77.2%, Recall=74.3%, F-score=75.4% και Accuracy=77.31%.Τ αποτελέσματα αυτά δείχνουν ότι κλασικές μέθοδοι στατιστικής ανάλυσης μπορούν να χρησιμοποιηθούν για την κατασκευή μοντέλων κατηγοριοποίησης δίνοντας μάλιστα πολύ ικανοποιητικά αποτελέσματα(στην δική μας εργασία χρησιμοποιήθηκαν οι μέθοδοι LDA και PCA για την κατηγοριοποίηση 99 κειμένων με βάση 12 όρους της Gene Ontology). 27
28 3.ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Πολλοί ερευνητές έχουν ασχοληθεί με την κατηγοριοποίηση κειμένων στο βιολογικό κείμενο. Ο Donaldson χρησιμοποίησε μία SVM, που την εκπαίδευσε σε λέξεις abstract κειμένων της MEDLINE, με σκοπό να βρει abstract κείμενα που περιείχαν πληροφορίες σχετικά με την αλληλεπίδραση πρωτεϊνών και στη συνέχεια να εισάγει τα κείμενα αυτά στη βάση δεδομένων BIND. Τα κείμενα αντιμετωπίστηκαν ως σωρός από λέξεις και εφαρμόστηκε ένας SVM κατηγοριοποιητής. Σε ένα μικρό σύνολο εκατό κειμένων το σύστημα είχε 96% precision και 84% recall. Υπολογίζεται ότι το σύστημα μειώνει τα κείμενα που πρέπει να διαβάσουν οι χειριστές της βάσης κατά δύο τρίτα. Πολλοί προσπάθησαν να κατηγοριοποιήσουν κείμενα της MEDLINE σύμφωνα με τους όρους από την Gene Ontology, χρησιμοποιώντας κοινούς machinelearning αλγορίθμους τους maximum entropy, naïve Bayes και nearest neighbor. Προτάθηκε από τον Raychauduri και τους συνεργάτες του και η μέθοδός του έδειξε καλά αποτελέσματα. Αναλυτικότερα, οι τρεις αλγόριθμοι εφαρμόστηκαν σε ένα σύνολο abstract άρθρων από την PubMed που ανταποκρινόταν σε 21 GO codes, ένα υποσύνολο της GO για τα γονίδια του Saccharomyces cerecisiae. Η σύγκριση των τριών διαφορετικών μοντέλων έδειξε ότι ο αλγόριθμος maximum entropy έδινε καλύτερα αποτελέσματα με μέση επίδοση (accuracy) 72% σε σχέση με τους αλγορίθμους nearest-neighbor και naïve Bayes που έδωσαν accuracy 61.5% και 59.62% αντίστοιχα [Raychauduri, 22]. Οι Izumitani, Taira, Kazawa και Maeda, εφάρμοσαν Support Vector Machines (SVM) και maximum entropy σε άρθρα που αναφερόταν γονίδια μαγιάς (yeast genes) καταχωρημένα στη βάση Saccharomyces Genome Database (SGD), με σκοπό να αποδώσουν στα κείμενα 12 GO codes. Η κατηγοριοποίηση με SVM έδωσε καλύτερα αποτελέσματα από την κατηγοριοποίησημέσω maximum entropy με Fscore 67% και 49% αντίστοιχα. Τέλος, οι Theodosiou, Angelis, Vakali και Thomopoulos εφάρμοσαν μία στατιστική μέθοδο, τη Linear Discriminant Analysis, για την κατηγοριοποίηση κειμένων της PubMed σύμφωνα με 12 όρους της Gene Ontology. Για την κατασκευή του μοντέλου χρησιμοποιήθηκαν 1,485 άρθρα που είχαν εκδοθεί ως το 1999, ενώ για την αξιολόγηση του μοντέλου χρησιμοποιήθηκε ένα σύνολο 1,76 άρθρων που δημοσιεύτηκαν μεταξύ 2 και 24. Το μοντέλο είχε μέσο F-score 75.4%, ενώ η μέθοδος SVM έδωσε μέσο F-score 68.7% για το ίδιο σύνολο δεδομένων [Θεοδοσίου, 26]. Η προσπάθεια αυτή έδειξε ότι κλασικές μέθοδοι στατικής ανάλυσης μπορούν να χρησιμοποιηθούν για την κατασκευή μοντέλων κατηγοριοποίησης. Παρακάτω περιγράφουμε την επεξεργασία εικόνας με το Matlab ενότητα η οποία αποτελεί το βασικό κομμάτι της παρούσας εργασίας και κατά την οποία επεξεργάστηκαν τα αποτελέσματα που προέκυψαν από την κατηγοριοποίηση των κειμένων. Αξίζει να αναφέρουμε ότι η οπτικοποίηση των δεδομένων με το εργαλείο του Matlab αποτελεί μία ιδέα που δεν έχει υλοποιηθεί στο παρελθόν. 28
. Δηλαδή πως αντιστοιχεί μία τιμή του πίνακα σε ένα pixel.")
29 4.ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΜΕ ΤΟ MATLAB Το πακέτο επεξεργασίας εικόνας του Matlab(Image Processing Toolbox)αναγνωρίζει τέσσερις τύπους εικόνας οι οποίοι συνοψίζονται στον πίνακα που φαίνεται παρακάτω. Αυτοί οι τύποι εικόνας προσδιορίζουν τον τρόπο με τον οποίο το Matlab αντιστοιχεί τα δεδομένα ενός πίνακα σε pixels(σε εικόνα). Δηλαδή πως αντιστοιχεί μία τιμή του πίνακα σε ένα pixel. ΤΥΠΟΣ ΕΙΚΟΝΑΣ ΠΩΣ ΕΡΜΗΝΕΥΕΙ ΚΑΙ ΑΠΟΘΗΚΕΥΕΙ ΤΟ MATLAB ΤΗΝ ΕΙΚΟΝΑ ΩΣ ΠΙΝΑΚΑ Δυαδική εικόνα(binary Ένας πίνακας που αποτελείται από 1 και. Η τιμή 1 image) αντιστοιχεί σε άσπρο pixel, ενώ η τιμή σε μαύρο pixel. Ένας τέτοιος πίνακας ονομάζεται λογικός πίνακας. Δεικτοδοτούμενη Ένας πίνακας που αποτελείται από μη εικόνα(indexed image) προσημασμένους8-bit ακεραίους(uint8) ή από μη προσημασμένους 16-bit ακεραίους (uint16) ή από πραγματικούς αριθμούς απλής(single)ή διπλής ακρίβειας(double), των οποίων τα pixels αποτελούν δείκτες σε έναν colormap. Ο colormap είναι ένας m Χ 3 πίνακας που περιέχει πραγματικούς αριθμούς μεταξύ του και του 1.Κάθε γραμμή του είναι ένα RGB διάνυσμα που προσδιορίζει ένα χρώμα. Η κ-οστή γραμμή του πίνακα colormap προσδιορίζει το κ-οστό χρώμα όπου η εντολή map(k,:) = [r(k) g(k) b(k)]) ορίζει την ένταση του κόκκινου, πράσινου και μπλε χρώματος. Για single ή double αριθμούς οι τιμές των ακεραίων κυμαίνονται στο διάστημα [1,μήκος του colormap].για uint8 ή uint16 αριθμούς οι τιμές κυμαίνονται στο διάστημα[ μήκος του colormap- 1]Συνοψίζοντας μία δεικτοδοτούμενη εικόνα αποτελείται από έναν πίνακα και τον colormap, ενώ μία τιμή ενός pixel δείχνει απευθείας σε μία τιμή του colormap η οποία με την σειρά της αποτελείται από 3 τιμές(τις εντάσεις του κόκκινου, του πράσινου και του μπλε χρώματος). Εικόνα με διαβαθμίσεις του γκρι(grayscale ή intensity image) Ένας πίνακας που αποτελείται από μη προσημασμένους8-bit ακεραίους(uint8) ή από μη προσημασμένους 16-bit ακεραίους (uint16) ή από ακέραιους 16-bit(int16) ή από πραγματικούς αριθμούς απλής(single)ή διπλής ακρίβειας(double), των οποίων οι τιμές των pixels αντιστοιχούν σε τιμές εντάσεων χρώματος(intensity values). Για single ή double αριθμούς οι τιμές κυμαίνονται στο διάστημα [,1]. Για uint8 οι τιμές κυμαίνονται στο διάστημα [,255]. Για uint16 οι τιμές κυμαίνονται στο διάστημα[,65535]. Για int16 οι τιμές κυμαίνονται στο διάστημα [-32768, 29
![Έγχρωμη image) εικόνα(rgb 32767]. Συνοψίζοντας σε μία grayscale εικόνα κάθε τιμή του πίνακα(που αντιπροσωπεύει μία τιμή φωτεινότητας) αντιστοιχεί σε ένα pixel.](/docs-images/64/51223820/images/30-0.jpg "Ένας mxnx3 πίνακας που αποτελείται από μη προσημασμένους8-bit ακεραίους(uint8) ή από μη προσημασμένους 16-bit ακεραίους (uint16) ή από πραγματικούς αριθμούς απλής(single)ή διπλής ακρίβειας(double),")
30 Έγχρωμη image) εικόνα(rgb 32767]. Συνοψίζοντας σε μία grayscale εικόνα κάθε τιμή του πίνακα(που αντιπροσωπεύει μία τιμή φωτεινότητας) αντιστοιχεί σε ένα pixel. Ένας mxnx3 πίνακας που αποτελείται από μη προσημασμένους8-bit ακεραίους(uint8) ή από μη προσημασμένους 16-bit ακεραίους (uint16) ή από πραγματικούς αριθμούς απλής(single)ή διπλής ακρίβειας(double), των οποίων οι τιμές των pixels αντιστοιχούν σε τιμές εντάσεων χρώματος(intensity values). Για single ή double αριθμούς οι τιμές κυμαίνονται στο διάστημα[,1]. Για uint8 οι τιμές κυμαίνονται στο διάστημα [,255]. Για uint16 οι τιμές κυμαίνονται στο διάστημα[,65535]. Συνοψίζοντας στις έγχρωμες εικόνες κάθε pixel προσδιορίζεται από 3 τιμές, μία για την κόκκινη, μία για την πράσινη και μία για την μπλε συνιστώσα. Ένα pixel του οποίου οι 3 συνιστώσες έχουν τιμές(,,)εμφανίζεται μαύρο, ενώ ένα pixel με αντίστοιχες τιμές(1,1,1) απεικονίζεται άσπρο.οι 3 αυτές συνιστώσες για κάθε pixel αποθηκεύονται στην 3 διάσταση του πίνακα(από εδώ προκύπτει και ο αριθμός 3 στην έκφραση mxnx3).για παράδειγμα η κόκκινη, η πράσινη και η μπλε συνιστώσα του pixel που βρίσκεται στην θέση(1,5) αποθηκεύονται στις θέσεις (1,5,1), (1,5,2),(1,5,3).Όπως γίνεται φανερό οι RGB εικόνες δεν χρησιμοποιούν τον colormap καθώς τα pixels αντιστοιχίζονται απευθείας σε τιμές κόκκινου, πράσινου και μπλε χρώματος. Παρακάτω παραθέτουμε από ένα παράδειγμα για κάθε τύπο εικόνας 3


31 Στο παραπάνω παράδειγμα ο πίνακας των δεδομένων βάσει του οποίου αναπαρίσταται η εικόνα είναι πραγματικός(double)γεγονός που σημαίνει ότι θα αποτελείται από ακέραιους αριθμούς από το 1 μέχρι έναν αριθμό που σηματοδοτεί το μήκος του colormap.δηλαδή το m στην έκφραση του colormap mx3.η τιμή 1 δείχνει στην πρώτη γραμμή του colormap,η τιμή 2 στην δεύτερη γραμμή, κ.ο.κ. Οπότε η τιμή 5 θα δείχνει στην πέμπτη γραμμή του αντίστοιχου colormap. Μία grayscale image της οποίας ο αντίστοιχος πίνακας,τον οποίο αποθηκεύει το Matlab ως αντιστοίχιση αυτής, αποτελείται από double αριθμούς. 31
των συναρτήσεων με τις οποίες αναπαρίστανται τα παραπάνω είδη εικόνων ΤΥΠΟΣ ΕΙΚΟΝΑΣ ΣΥΝΑΡΤΗΣΕΙΣ")
32 Μία RGB εικόνα της οποίας ο αντίστοιχος πίνακας,τον οποίο αποθηκεύει το Matlab ως αντιστοίχιση αυτής, αποτελείται από double αριθμούς. Στο σημείο αυτό αξίζει να κάνουμε μια απλή αναφορά(παρακάτω θα τις περιγράψουμε αναλυτικότερα)των συναρτήσεων με τις οποίες αναπαρίστανται τα παραπάνω είδη εικόνων ΤΥΠΟΣ ΕΙΚΟΝΑΣ ΣΥΝΑΡΤΗΣΕΙΣ ΧΡΗΣΙΜΟΠΟΙΟΥΝ COLORMAP; Binary Imagesc(BW) ή imshow(bw) Όχι Indexed image(x); colormap(map) ή Ναι imshow(x) Grayscale imagesc(i,[1]);colormap(gray) Ναι ή imshow(i) RGB image(rgb) ή imshow(rgb) Όχι 32
33 Στο σημείο αυτό παρατηρούμε ότι στις δυαδικές εικόνες αναφερόμαστε με τον συμβολισμό BW, στις δεικτοδοτούμενες με το γράμμα X, στις εικόνες με διαβαθμίσεις του γκρι με το γράμμα I,και στις έγχρωμες εικόνες με τον συμβολισμό RGB. Στη συνέχεια θα δώσουμε μια γενική περιγραφή των συναρτήσεων οι οποίες υπάρχουν στο πακέτο επεξεργασίας εικόνας του Matlab και θα παραθέσουμε κάποια παραδείγματα εφαρμογής τους σε διάφορες εικόνες έτσι ώστε να καταλήξουμε στις πιο αντιπροσωπευτικές που θα χρησιμοποιήσουμε για τα δεδομένα μας. ΣΥΝΑΡΤΗΣΗ ΠΕΡΙΓΡΑΦΗ Imagesc: Η συνάρτηση imagesc κλιμακώνει και αντιστοιχεί τα δεδομένα ενός πίνακα(μιας εικόνας)σε ολόκληρη την περιοχή του τρέχοντος colormap και εμφανίζει την αντίστοιχη γραφική αναπαράσταση αυτών των δεδομένων. Imshow: Η imshow όπως αναφέραμε παραπάνω μπορεί να χρησιμοποιηθεί για να μας δώσει όλους τους τύπους των εικόνων, χρησιμοποιώντας βέβαια το κατάλληλο όρισμα(γράμμα ή συμβολισμό) Bwselect: Επιλέγει αντικείμενα σε μία δυαδική εικόνα. Im2bw: Μετατρέπει μία εικόνα σε δυαδική βασιζόμενη σε κατώφλι. Edge: Η συνάρτηση edge ανιχνεύει διαφορές πυκνότητας (κορυφές) σε μια εικόνα Gray2ind: Μετατρέπει μία δυαδική ή grayscale εικόνα σε εικόνα indexed. Imcomplement: Υπολογίζει το συμπληρωματικό μιας δυαδικής, grayscale ή RGB εικόνας. Εμφανίζει το ιστόγραμμα μιας εικόνας. Imhist: Imnoise: Προσθέτει θόρυβο σε μία εικόνα. Ind2gray: Μετατρέπει μία εικόνα indexed σε grayscale. Dither: Μετατρέπει τις εικόνες αυξάνοντας την ανάλυση των χρωμάτων μέσω dithering. Imfill: Γεμίζει τις «τρύπες» αλλά και διάφορες περιοχές μιας εικόνας. Imadjust: Δημιουργεί μία καινούρια εικόνα έτσι ώστε το 1% των δεδομένων της νέας εικόνας να είναι συγκεντρωμένο στις χαμηλές και στις υψηλές τιμές εντάσεων της αρχικής εικόνας. 33
 Colormap(gray)")
34 Στο παραπάνω παράδειγμα στην αριστερή εικόνα υπάρχει αντιστοιχία μεταξύ όλων των τιμών του πίνακα και του colormap gray χρησιμοποιώντας τον κώδικα: load clown imagesc (X) colormap (gray) Η δεξιά εικόνα έχει τιμές στο διάστημα [1,6] αλλά οι τιμές αυτές εκτείνονται σε όλη την περιοχή τομών του colormap gray χρησιμοποιώντας τον κώδικα: Load clown Clims = [1 6]; Imagesc(X, clims) Colormap(gray) Για να γίνουν πιο κατανοητά τα παραπάνω και να γίνει πιο σαφής η έννοια του όρου clims παραθέτουμε το επόμενο παράδειγμα:στην εικόνα που ακολουθεί clims=[1,6] και το μέγεθος του τρέχοντος colormap είναι 81X3.Τιμες του πίνακα δεδομένων<=1 αντιστοιχίζονται στο πρώτο χρώμα του colormap, δηλαδή στην τιμή του 1 ου στοιχείου του colormap ενώ τιμές του πίνακα δεδομένων>=6 ) αντιστοιχίζονται στο τελευταίο χρώμα του colormap, δηλαδή στην τιμή του 81 ου στοιχείου του colormap. Στην ουσία το διάνυσμα clims παρέχει την αντιστοιχία μεταξύ των τιμών του colormap και των τιμών του πίνακα δεδομένων μας. 34
; Επιστρέφει μία δυαδική εικόνα η οποία περιέχει 4 συν c = [43 185 212]; δεδεμένα αντικείμενα που υπερβαίνουν την τιμή του r = [38 68 181];")
, figure, imshow (BW2) παίρνει είτε την τιμή 4 είτε την τιμή 8.")
35 BW1 = imread ('text.png'); Επιστρέφει μία δυαδική εικόνα η οποία περιέχει 4 συν c = [ ]; δεδεμένα αντικείμενα που υπερβαίνουν την τιμή του r = [ ]; pixel(r, c). Αντικείμενο είναι μια σειρά από on pixel BW2 = bwselect (BW1, c, r, 4); (pixel που έχουν τιμή 1).Το τελευταίο όρισμα Imshow (BW1), figure, imshow (BW2) παίρνει είτε την τιμή 4 είτε την τιμή 8. Load trees BW = im2bw(x, map, ); Pixel που έχουν φωτεινότητα> παίρνουν την τιμή 1 Imshow(X, map), figure, στην νέα εικόνα και απεικονίζονται άσπρα ενώ pixel imshow (BW) που έχουν φωτεινότητα< παίρνουν την τιμή και απεικονίζονται μαύρα. 35
; BW2 = edge (I,'canny'); Imshow (BW1); Figure, imshow (BW2) Όπου")

36 I = imread ('circuit.tif'); Διαβάζει εικόνα από ένα αρχείο γραφικών. BW1 = edge (I,'prewitt'); BW2 = edge (I,'canny'); Imshow (BW1); Figure, imshow (BW2) Όπου Prewitt και Canny είναι 2 διαφορετικές μέθοδοι για την ανίχνευση κορυφών σε μια εικόνα. I = imread ('cameraman.tif'); [X, map] = gray2ind (I, 16);To 16 δείχνει το μέγεθος του colormap. Imshow (X, map); 36
; J = imcomplement (I); Imshow (I), figure, imshow (J) Παρατηρούμε ότι πρόκειται")

37 I = imread ('glass.png'); J = imcomplement (I); Imshow (I), figure, imshow (J) Παρατηρούμε ότι πρόκειται για μια δυαδική εικόνα, όπου υπάρχει άσπρο στην αρχική εικόνα αντικαθίστανται με μαύρο χρώμα στην συμπληρωματική εικόνα και όπου υπάρχει μαύρο στην αρχική αντικαθίστανται με άσπρο στην συμπληρωματική. I = imread ('pout.tif'); Imshow (I); imhist (I) 37
; J = imnoise (I,'salt & pepper',.")
 είναι η πυκνότητα του θορύβου.")
38 Ιστόγραμμα της εικόνας I = imread ('eight.tif'); J = imnoise (I,'salt & pepper',.2); salt &pepper είναι είδος θορύβου ενώ το.2 figure, imshow (I) είναι η πυκνότητα του θορύβου. Ανάλογα με το είδος του figure, imshow(j) θορύβου ποικίλλουν και τα ορίσματα που το συνοδεύουν. 38
; Εφόσον πρόκειται για εικόνα indexed ο πίνακας της εικόνας Imshow")
 I = imread ('cameraman.")
39 Load trees Φορτώνει την εικόνα κ δημιουργεί τον αντίστοιχο πίνακα στοworkspace I = ind2gray(x, map); Εφόσον πρόκειται για εικόνα indexed ο πίνακας της εικόνας Imshow (X, map) πρέπει να συνοδεύεται από τον colormap (εδώ παίρνει την Figure, imshow (I) τιμή map) I = imread ('cameraman.tif'); BW = dither (I); Imshow (I), figure, imshow (BW) 39
); Μετατροπή πρώτα σε δυαδική εικόνα BW5 = imfill (BW4,'holes'); Γεμίζουμε τις")

40 BW4 = im2bw (imread ('coins.png')); Μετατροπή πρώτα σε δυαδική εικόνα BW5 = imfill (BW4,'holes'); Γεμίζουμε τις τρύπες Imshow (BW4), figure, imshow (BW5) Γεμίζουμε τις τρύπες μιας δυαδικής εικόνας. I = imread ('tire.tif'); I2 = imfill (I,'holes'); Figure, imshow (I), figure, imshow (I2) Γεμίζουμε τις τρύπες μιας grayscale εικόνας. 4

41 I = imread ('pout.tif'); J = imadjust (I); Imshow (I), figure, imshow (J) Όπως παρατηρούμε παραπάνω ο όρος colormap αναφέρεται πολύ συχνά. Αν και δώσαμε έναν σύντομο ορισμό του colormap αξίζει ν αναφέρουμε και την συνάρτηση colormap η οποία αν και δεν εντάσσεται στο Image Processing Toolbox,εντάσσεται στην γενική κατηγορία συναρτήσεων του Matlab.Γι αυτό το λόγο την αναφέρουμε ανεξάρτητα από τις υπόλοιπες. Colormap: Δέχεται και θέτει τον τρέχοντα colormap.με λίγα λόγια είναι η συνάρτηση που διαχειρίζεται τον colormap. Το Matlab μας παρέχει μια σειρά από έτοιμους colormap, οι οποίοι περιέχουν διαφορετικές διαβαθμίσεις διαφόρων χρωμάτων. Εμείς στην εργασία μας χρησιμοποιήσαμε τον colormap autumn ο οποίος διαβαθμίζεται αρμονικά μεταξύ του κόκκινου, του πορτοκαλί και του κίτρινου χρώματος. Colormap (autumn) Για να εμφανίσουμε τον colormap είτε γράφουμε την εντολή colorbar είτε πηγαίνουμε στο μενού insert του παραθύρου figure και επιλέγουμε colorbar. 41
42 5.ΠΑΡΑΣΤΑΣΗ ΔΕΔΟΜΕΝΩΝ ΑΠΟ ΒΙΟΛΟΓΙΚΟ ΚΕΙΜΕΝΟ ΜΕ ΕΡΓΑΛΕΙΑ ΕΠΕΞΕΡΓΑΣΙΑΣ ΕΙΚΟΝΑΣ Το αρχείο απλού κειμένου test.txt είναι ένας πίνακας με διαστάσεις 99Χ51. Η πρώτη στήλη του περιέχει τον αριθμό της ομάδας(η στήλη αυτή έχει τιμές από 1-12).Οι υπόλοιπες 5 στήλες αποτελούν 5 μεταβλητές οι οποίες προέκυψαν ύστερα από εφαρμογή της PCA. Οι 99 γραμμές αποτελούν τα 99 κείμενα. Το Matlab για να διαβάσει το αρχείο test.txt χρησιμοποιούμε την εντολή A=textread( test.txt )Ως αποτέλεσμα το Matlab αφενός διαβάζει το αρχείο και αφετέρου δημιουργεί στο workspace έναν πίνακα Α μεγέθους 99Χ51.Για να εξάγουμε τα κείμενα μιας ομάδας γράφουμε το παρακάτω μικρό κομμάτι κώδικα. A1=[]; for i=1:99 if A (i,1)==1 Αλλάζοντας αυτόν τον αριθμό παίρνουμε τα κείμενα κάθε A1= [A1; A (i, 2:51)]; ομάδας. Παίρνει τιμές όπως είναι φυσικό από end end Για να απεικονίσουμε κάθε μία από τις ομάδες ξεχωριστά χρησιμοποιούμε την συνάρτηση imshow καθώς οι πίνακες που προκύπτουν αποτελούνται μόνο από 1 και άρα θα προκύψουν δυαδικές εικόνες. Δηλαδή γράφουμε imshow(a1),imshow(a2)..imshow (A12).Οπότε προκύπτουν οι εξής γραφικές παραστάσεις: 42

43 Ομάδα 1 Ομάδα 2 43
44 Ομάδα 3 Ομάδα 4 44
45 Ομάδα 5 Ομάδα 6 45
46 Ομάδα 7 Ομάδα 8 46
47 Ομάδα 9 Ομάδα 1 47
48 Ομάδα 11 Ομάδα 12 48
49 Το αρχείο απλού κειμένου p2.txt είναι ένας πίνακας με διαστάσεις 99Χ21.Και γι αυτό το αρχείο ισχύει ότι ισχύει και για το αρχείο test.txt, μόνο που αυτό το αρχείο περιέχει τιμές στο διάστημα [,1] αντί για 1 και.χρησιμοποιώντας λοιπόν τον ίδιο κώδικα όπως παραπάνω και την συνάρτηση imshow, προσθέτοντας και τον colormap autumn(ενώ για να φανεί αυτός πήγαμε στο μενού insert του παραθύρου figure και επιλέξαμε colorbar) προέκυψαν οι εξής γραφικές παραστάσεις: 49
50 1 Ομάδα 1 1 Ομάδα 2 5
51 1 Ομάδα 3 1 Ομάδα 4 51
52 1 Ομάδα 5 1 Ομάδα 6 52
53 1 Ομάδα 7 1 Ομάδα 8 53
54 1 Ομάδα 9 1 Ομάδα 1 54
55 1 Ομάδα 11 1 Ομάδα 12 55
.")
56 Από τα παραπάνω προέκυψε ότι η 1 η ομάδα περιέχει 178 κείμενα, η 2 η ομάδα 678, η 3 η ομάδα 316, η 4 η ομάδα 182, η 5 η ομάδα 931, η 6 η ομάδα 842, η 7 η ομάδα 869, η 8 η ομάδα 184, η 9 η ομάδα 973, η 1 η ομάδα 93, η 11 η ομάδα 989 και η 12 η ομάδα 137.(Εννοείται ότι τα παραπάνω αποτελέσματα ισχύουν και για τις ασπρόμαυρες αλλά και για τις έγχρωμες εικόνες). Αν και μπορούμε να εξάγουμε κάποια αρχικά συμπεράσματα όπως για παράδειγμα ότι τα κείμενα της 1 ης παρουσιάζουν ομοιότητα για κάποιες μεταβλητές(όπως επίσης και τα κείμενα,της 3 ης και της 4 ης ομάδας) ωστόσο δεν μπορούμε να προχωρήσουμε περαιτέρω εξαιτίας της αδυναμίας της συνάρτησης imshow να επεξεργαστεί πίνακες μεγάλου μεγέθους. Χαρακτηριστικό είναι ότι μας δίνει ως έχουν τις γραφικές παραστάσεις των 3 ομάδων που αναφέρθηκαν αλλά για τις υπόλοιπες μας εμφανίζει ένα ποσοστό αυτών εξαιτίας αυτής ακριβώς της αδυναμίας της. Αυτό εξάλλου είναι φανερό και από το γεγονός ότι ενώ οι υπόλοιπες ομάδες έχουν περισσότερα κείμενα, εμφανίζονται να έχουν και μικρότερες γραφικές παραστάσεις(από τις ομάδες 1, 3 και 4), πράγμα που είναι εντελώς αντιφατικό και μας οδηγεί να καταλάβουμε ότι το Matlab μας δίνει ένα μέρος αυτών(άλλωστε το Matlab μας εμφανίζει αυτό το πρόβλημα και ως μήνυμα στο Command Window όταν προβαίνει στην εμφάνιση των εικόνων των ομάδων). Γι αυτόν το λόγο χρησιμοποιήσαμε την συνάρτηση imagesc. Συγκεκριμένα για τις δυαδικές εικόνες χρησιμοποιήσαμε τις συναρτήσεις imagesc(a1),imagesc(a2), imagesc(a12) και colormap autumn ενώ για να εμφανίσουμε τον colormap autumn γράψαμε και την συνάρτηση colorbar(αντί να πάμε στο μενού insert). O colormap μας είναι τυπικά «άχρηστος» αφού οι δυαδικές εικόνες δεν τον χρησιμοποιούν. Τον χρησιμοποιήσαμε απλά για να βλέπουμε σε ποιο χρώμα αντιστοιχεί το και σε ποιο το 1.Έτσι προέκυψαν οι εξής γραφικές παραστάσεις: Ομάδα 1 56


57 Ομάδα Ομάδα 3 57

58 Ομάδα 4 Ομάδα 5 58

59 Ομάδα 6 Ομάδα 7 59


60 Ομάδα Ομάδα 9 6


61 Ομάδα Ομάδα 11 61

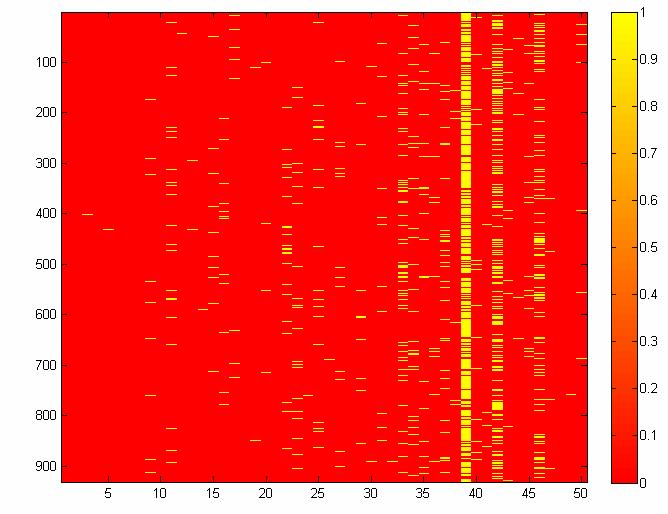
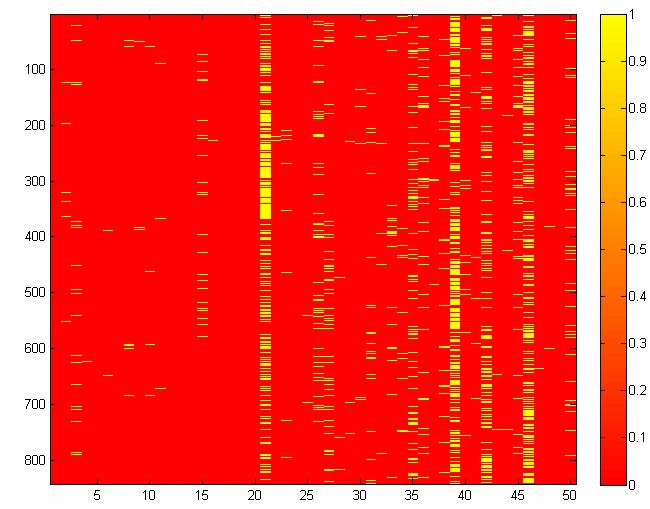
62 Ομάδα 12 Με την βοήθεια της imagesc κάθε σημείο ενός πίνακα αναπαρίσταται ως μία ορθογώνια περιοχή(σαν μία παύλα) και ως εκ τούτου είναι εύκολο να καταλάβουμε τις τιμές που έχουν τα κείμενα των 12 ομάδων για κάθε μία από τις 5 μεταβλητές. Με τις γραφικές παραστάσεις που προκύπτουν λοιπόν με την βοήθεια της imagesc μπορούμε να πούμε ότι έχουμε 4 οφέλη: 1) Μπορούμε να συμπεράνουμε βλέποντας απλά την εικόνα πόσα κείμενα έχει κάθε ομάδα με σχετικά μεγάλη ακρίβεια. 2) Εκεί που υπάρχει κίτρινο χρώμα σημαίνει ότι η τιμή του πίνακα γι αυτήν την θέση είναι 1 που σημαίνει ότι η λέξη αυτή( που είναι η αντίστοιχη στήλη) περιέχεται στο αντίστοιχο κείμενο (που είναι η αντίστοιχη γραμμή) ενώ εκεί που υπάρχει κόκκινο χρώμα σημαίνει ότι η τιμή του πίνακα γι αυτήν την θέση είναι που σημαίνει ότι η λέξη αυτή δεν περιέχεται στο αντίστοιχο κείμενο. 3) Τα κείμενα μιας ομάδας πού παρουσιάζουν ομοιότητα(για ποιες μεταβλητές). 4) Αν υπάρχουν κάποιες ομάδες που μοιάζουν μεταξύ τους. Αναφέρουμε λοιπόν τις παρατηρήσεις μας για κάθε ομάδα. 62
63 Τα κείμενα της πρώτης ομάδας(178 στον αριθμό) έχουν για τις πρώτες 26 μεταβλητές (αλλά και για την 28 η και για την 29 η ) μηδενικές τιμές(πλην 7 εξαιρέσεων που έχουν τιμή 1).Συγκεκριμένα οι στήλες 1-3,6-14,16-23,25-26 έχουν μόνο μηδενικές τιμές. Για την 42 η και την 45 η μεταβλητή σχεδόν όλα τα κείμενα έχουν τιμή 1. Για την 2 η ομάδα(678 στον αριθμό) όλα τα κείμενά της ανεξαιρέτως για την 4 η έως την 8 η μεταβλητή έχουν τιμή.ενώ τα περισσότερα κείμενά της έχουν τιμή 1 για τις στήλες 39,42,46. Για την 3 η ομάδα όλα τα κείμενά της(316 στον αριθμό)πλην μίας εξαίρεσης έχουν μηδενικές τιμές για τις μεταβλητές 6-1, ενώ τα περισσότερα έχουν τιμή 1 για τις στήλες 39,42,45,46. Για την 4 η ομάδα (182 στον αριθμό)όλα τα κείμενά της έχουν μηδενικές τιμές για τις στήλες 1-8 και ενώ τα πιο πολλά έχουν τιμή 1 για τις στήλες 39,42,46. Για την 5 η ομάδα όλα τα κείμενά τη(931 στον αριθμό) έχουν μηδενικές τιμές(πλην 2 εξαιρέσεων) για τις μεταβλητές 1-8 ενώ τα περισσότερα τιμή 1 για τις στήλες 39,42,46. Για την 6 η ομάδα όλα τα κείμενά της (842 στον αριθμό)έχουν μηδενικές τιμές για τις στήλες 16-2(πλην μίας εξαίρεσης)ενώ έχουν τιμή 2 για τις στήλες 21,39,42,46. Για την 7 η ομάδα όλα τα κείμενά της έχουν μηδενική τιμή για την 1 η στήλη. Επίσης σχεδόν όλα πλην ελαχίστων εξαιρέσεων έχουν μηδενική τιμή και για τις στήλες 2-6.Έχουν δε τιμή 1 για τις στήλες 39,42,46. Για την 8 η ομάδα όλα τα κείμενά της (184 στον αριθμό)έχουν μηδενικές τιμές για τις στήλες 6-1(εκτός της στήλης 9 που παρουσιάζονται ελάχιστες τιμές 1).Τα περισσότερα κείμενα παρουσιάζουν τιμή 1 για τις στήλες 4,39,42,46. Για την 9 η ομάδα όλα τα κείμενα της(973) έχουν μηδενικές τιμές για τις στήλες 1-4(πλην 5 εξαιρέσεων)ενώ για τις στήλες 6,8,39,42,46 τα περισσότερα έχουν τιμή 1. Για την 1 η ομάδα(93 στον αριθμό)όλα τα κείμενά της με ελάχιστες εξαιρέσεις έχουν μηδενικές τιμές για τις μεταβλητές 1-9 ενώ τα περισσότερα έχουν τιμή 1 για τις στήλες 39,42. Για την 11 η ομάδα όλα τα κείμενά της(989 στον αριθμό)έχουν τιμή για τις στήλες 3-8 και με ελάχιστες εξαιρέσεις ενώ τα περισσότερα έχουν τιμή 1 για τις στήλες 1,39,42,44,45,46. 63

64 Για την 12 η ομάδα όλα τα κείμενά της τα κείμενά της(137 στον αριθμό)έχουν τιμή για τις μεταβλητές1-9 με ελάχιστες 2 εξαιρέσεις ενώ τα περισσότερα έχουν τιμή 1 για τις στήλες 28,39,42, 46. Συνοψίζοντας συμπεραίνουμε ότι σχεδόν όλα τα κείμενα όλων των ομάδων έχουν μηδενικές τιμές για τις 8 πρώτες στήλες και τιμή 1 για τις στήλες 39,42,46.Επίσης αξιοσημείωτο είναι ότι δεν υπάρχει στήλη που να έχει μόνο τιμές 1 αλλά υπάρχουν πολλές στήλες με μόνο μηδενικές τιμές. Ακόμη παρατηρούμε ότι οι γραφικές παραστάσεις της ομάδας 1 και 4 είναι πιο ευδιάκριτες. Αυτό άλλωστε είναι και αναμενόμενο καθώς έχουν μικρότερο πλήθος κειμένων. Κάτι ακόμη σημαντικό που κερδίζουμε από την συνάρτηση imagesc είναι η απεικόνιση όλων των ομάδων μαζί. Αρκεί να αφαιρέσουμε την πρώτη στήλη(αυτή που δείχνει τον αριθμό της ομάδας)από τον αρχικό πίνακα(αυτόν που δημιουργήθηκε από την συνάρτηση textread, έστω Α αυτός ο πίνακας) γράφοντας C= Α(1:99,2:51) Imagesc(C) Colormap autumn Colorbar. Η γραφική παράσταση όλων των ομάδων φαίνεται παρακάτω: όλες μαζί για δυαδικά δεδομένα Προκύπτουν αυτά που αναφέραμε παραπάνω για τα σημεία όπου παρουσιάζεται η ομοιότητα των ομάδων(1-8 στήλες σχεδόν όλες μηδενικές τιμές,39,42,46 σχεδόν όλες τιμή 1).Προβαίνοντας στις ίδιες ενέργειες και για το αρχείο p2.txt που περιέχει τιμές στο διάστημα [,1] προκύπτουν οι εξής γραφικές παραστάσεις για κάθε ομάδα: 2 Με τον όρο ελάχιστες εννοούμε τιμή<1. 64

65 Ομάδα Ομάδα 2 65


66 Ομάδα Ομάδα 4 66


67 Ομάδα Ομάδα 6 67


68 Ομάδα Ομάδα 8 68


69 Ομάδα Ομάδα 1 69


70 Ομάδα Ομάδα 12 7
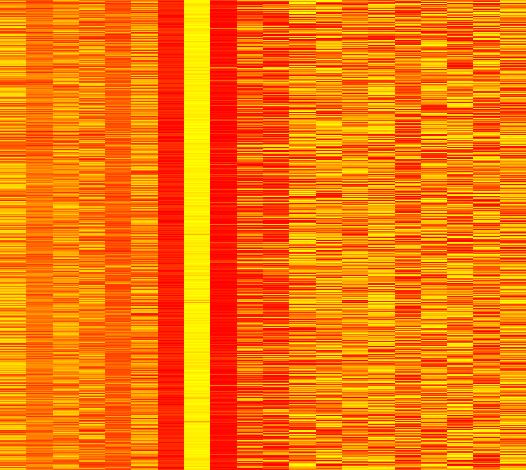
71 Για την 1 η ομάδα όλα τα κείμενα έχουν τιμή 1 3 για τις μεταβλητές 6,8 και 9.Για την μεταβλητή 11 έχουν τιμή, ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 2 η ομάδα όλα τα κείμενα έχουν τιμή για τις μεταβλητές 7 και 9 και τιμή 1 για την μεταβλητή 8,, ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 3 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 7 και τιμή 1 για την στήλη 11 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 4 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 7 και την στήλη 1 και τιμή 1 για την στήλη 9 και για την στήλη 11 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 5 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 7 και την στήλη 8 και τιμή 1 για την στήλη 9 και την στήλη 1 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 6 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 2 και τιμή 1 για την στήλη 1 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 7 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 6 και τιμή 1 για την στήλη 2 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 8 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 1 και τιμή 1 για την στήλη 3 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 9 η ομάδα όλα τα κείμενα έχουν τιμή για τις στήλες 4 και 5 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 1 η ομάδα όλα τα κείμενα έχουν τιμή για την στήλη 9και 1 για την στήλη 6 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 11 η ομάδα όλα τα κείμενα έχουν τιμή για τις στήλες1-4 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Για την 12 η ομάδα όλα τα κείμενα έχουν τιμή για τις στήλες 3 και 5 και τιμή 1 για την στήλη 4 ενώ για τις υπόλοιπες μεταβλητές έχουν τιμή στο διάστημα [,1]. Συνοψίζοντας θα μπορούσαμε να πούμε ότι η περιοχή που σχηματίζουν οι μεταβλητές 12-2 μοιάζει αρκετά για όλες τις ομάδες εκτός τις 1,3,4 περιλαμβάνοντας τιμές σε όλο το διάστημα [,1].Επίσης για τις ομάδες 5,9,11,12 η περιοχή που σχηματίζουν οι μεταβλητές 6-1 μοιάζει πάρα πολύ. Όπως είναι φυσικό οι γραφικές παραστάσεις με 2 μεταβλητές είναι ευκρινέστερες από αυτές με 5(π.χ η στήλη κάθε μεταβλητής διακρίνεται πολύ πιο εύκολα).γι αυτόν τον λόγο άλλωστε ξαναεφαρμόσαμε την PCA.Παρακάτω έχουμε την εικόνα για όλες τις ομάδες μαζί. 3 Για τις ομάδες του αρχείου p2.txt όταν αναφέρεται ότι οι τιμές των μεταβλητών τους είναι 1 ή θα εννοείται ότι είναι πολύ κοντά στο 1 και στο αντίστοιχα. 71
![1 1 2 3 4 5 6 7 8 9 2 4 6 8 1 12 14 16 18 2 όλες μαζί για τιμές στο [,1] Παρατηρούμε ότι και τα 99 κείμενα έχουν τιμές στο διάστημα [,1] για τις μεταβλητές 12-2.](/docs-images/64/51223820/images/72-0.jpg "Επίσης τα κείμενα στις θέσεις 7-8(κείμενα 11 η και 27 κείμενα 12 ης ομάδας) έχουν σχεδόν μηδενικές τιμές για τις μεταβλητές 1-4.")
72 όλες μαζί για τιμές στο [,1] Παρατηρούμε ότι και τα 99 κείμενα έχουν τιμές στο διάστημα [,1] για τις μεταβλητές 12-2.Επίσης τα κείμενα στις θέσεις 7-8(κείμενα 11 η και 27 κείμενα 12 ης ομάδας) έχουν σχεδόν μηδενικές τιμές για τις μεταβλητές 1-4.Ομοίως και τα κείμενα 1-22(κείμενα 1 ης 5 ης ομάδας) για την στήλη 7, αλλά και τα 8-9 κείμενα 12 ης ομάδας) για τις στήλες 3 και 5, ενώ τα τελευταία έχουν τιμή 1 για την στήλη 4. Στο σημείο αυτό αφού πήραμε μια γενική ιδέα των ομάδων θα προχωρήσουμε ένα βήμα παραπάνω έτσι ώστε να μπορέσουμε να δούμε ακριβώς ποιες είναι οι τιμές των κειμένων για τις 2 μεταβλητές. Γι αυτόν λόγο θα χρησιμοποιήσουμε την συνάρτηση im2bw η οποία μετατρέπει μία εικόνα σε δυαδική βασιζόμενη σε κατώφλι σύμφωνα με την σύνταξη im2bw(a,level), όπου Α είναι ο πίνακας(η εικόνα) που θέλουμε να μετατρέψουμε και level το κατώφλι. π.χ αν θέσουμε στο level την τιμή, τότε τιμές του πίνακα Α μεγαλύτερες του θα πάρουν την τιμή 1 και θ απεικονιστούν με κίτρινο χρώμα ενώ τιμές μικρότερες του θα πάρουν την τιμή και θα απεικονιστούν με κόκκινο χρώμα. Ως αποτέλεσμα θα προκύψει ένας πίνακας με τιμές 1 και, δηλαδή ένας δυαδικός πίνακας. Εμείς θέσαμε στο κατώφλι τις τιμές 9 και.1 έτσι ώστε να δούμε ποιες τιμές είναι μηδενικές(ή τόσο κοντά στο μηδέν ώστε να μπορούν να θεωρηθούν )και ποιες τιμές ισούνται με 1(ή τόσο κοντά στο 1 ώστε να μπορούν να θεωρηθούν 1) και πήραμε τις παρακάτω εικόνες. Πρώτα παρουσιάζουμε τις εικόνες με κατώφλι.1 και μετά τις εικόνες με κατώφλι 9.Ενώ στο τέλος έχουμε τις εικόνες για όλες τις ομάδες μαζί και για τα 2 κατώφλια. 72


73 Ομάδα Ομάδα 2 73


74 Ομάδα Ομάδα 4 74


75 Ομάδα Ομάδα 6 75


76 Ομάδα Ομάδα 8 76


77 Ομάδα Ομάδα 1 77


78 Ομάδα Ομάδα 12 78
79 Για την 1 η ομάδα μόνο για την 11 η στήλη υπάρχουν τιμές που ισούνται με ενώ υπάρχουν και 2 τιμές που ισούνται με στη στήλη 12 και μία στην στήλη 13.Όλες οι υπόλοιπες είναι>.1. Για την 2 η ομάδα αρκετές τιμές στις στήλες 7,9 και 11 ισούνται με ενώ για τις στήλες 1-6 όλες οι τιμές είναι >.1.. Για την 3 η ομάδα όλες οι τιμές των κειμένων για τις στήλες 1-12(πλην μίας εξαίρεσης στην στήλη 7 και μίας στην στήλη 12)είναι>.1.Η στήλη 2 περιέχει αρκετές τιμες=. Για την 4 η ομάδα τα περισσότερα κείμενά της έχουν τιμή για την μεταβλητή 1 ενώ για τις υπόλοιπες στήλες έχουν τιμή>.1 πλην 14 εξαιρέσεων. Για την 5 η ομάδα οι στήλες 7 και 8 περιέχουν αρκετές τιμές= ενώ για τις στήλες 1-6,9-11,16-17 όλες οι τιμές των κειμένων είναι>.1. Για την 6 η ομάδα υπάρχουν πολλές μηδενικές τιμές στην στήλη 19 ενώ για τις στήλες 1-7,13,14,18 όλες οι τιμές των κειμένων είναι >.1. Για την 7 η ομάδα η στήλη 6 έχει μηδενικές τιμές για αρκετά κείμενα ενώ οι στήλες 1-5,7-77,2 για όλα τα κείμενα έχουν τιμές>.1. Για την 8 η ομάδα οι στήλες 1 και 17 έχουν αρκετές τιμές= ενώ για τις στήλες 2-1 και 14 όλες οι τιμές είναι>.1. Για την 9 η ομάδα αρχίζει να διαφοροποιείται αυτό που μέχρι τώρα είχαμε παρατηρήσει καθώς αυξάνονται οι μηδενικές τιμές και μάλιστα εξαπλώνονται σχεδόν σε όλες τις μεταβλητές. Πιο συγκεκριμένα για τις στήλες 4,5,12,15 υπάρχουν αρκετές τιμές= ενώ για τις στήλες 1-3 και 6-11 όλες οι τιμές τους είναι>.1. Επίσης και για όλες τις υπόλοιπες στήλες υπάρχει σε κάθε μία το λιγότερο από μία μηδενική τιμή. Για την 1 η ομάδα υπάρχουν γενικά λίγες μηδενικές τιμές σε σχέση με το μέγεθος της ομάδας. Συγκεκριμένα έχουμε λίγες τιμές- για τις στήλες ενώ για τις στήλες 1 11 όλες οι τιμές τους είναι>.1. Για την 11 η ομάδα υπάρχουν πολλές μηδενικές τιμές στις στήλες 2,3 ενώ για τις στήλες 1,4-12(πλην 2 εξαιρέσεων της ομάδας 11)όλες οι τιμές των κειμένων είναι>.1. Για την 12 η ομάδα υπάρχουν πολλές μηδενικές τιμές στην στήλη 14 και λίγες στην στήλη 16 ενώ οι μεταβλητές 1-13 έχουν για όλα τα κείμενα τιμές >.1(πλην από μιας εξαίρεσης για τις ομάδες 3,5 και 3ων της ομάδας 13). Παρακάτω βλέπουμε τις γραφικές παραστάσεις των ομάδων με τιμή κατωφλίου τώρα 9. 79
80 Ομάδα Ομάδα 2 8
81 Ομάδα Ομάδα 4 81
82 Ομάδα Ομάδα 6 82
83 Ομάδα Ομάδα 8 83
84 Ομάδα Ομάδα 1 84

85 Ομάδα Ομάδα 12 85
86 Για την 1 η ομάδα υπάρχουν πολλές τιμές που ισούνται με 1 στην στήλη 9, λίγες στην στήλη 8, 2 στην στήλη 6 και μία στην στήλη 1.όλες οι υπόλοιπες είναι<9. Για την 2 η ομάδα υπάρχουν αρετές τιμές=1 στην στήλη8 ενώ όλες οι τιμές των κειμένων στις στήλες 1-7 και 9-11 είναι,9. Για την 3 η ομάδα υπάρχουν πολλές τιμές=1 στις στήλες 1 και11 ενώ όλες οι τιμές για τα κείμενα 1-9 και 2 είναι<9.επίσης μπορούμε να διακρίνουμε λίγες τιμές =1 στην περιοχή που σχηματίζουν οι μεταβλητές Για την 4 η ομάδα υπάρχει μία τιμή =1 στην στήλη 11, μία στην στήλη 13, μία στην στήλη 19 και μία στην στήλη 2(οι 2 τελευταίες αναφέρονται στο ίδιο κείμενο, καθώς βρίσκονται στην ίδια ευθεία). Για την 5 η ομάδα υπάρχουν ελάχιστες τιμές=1 και αυτό που διακρίνουμε εύκολα σ αυτήν την ομάδα είναι ότι για τις στήλες 1-9 οι τιμές όλων των κειμένων είναι<9. Για την 6 η ομάδα έχουμε πολλές τιμές =1 στις στήλες 1 και 2 ενώ για όλες τις υπόλοιπες στήλες(2-19_όλες οι τιμές πλην 11 εξαιρέσεων είναι<9. Για την 7 η ομάδα υπάρχουν αρκετά κείμενα με τιμές =1 στην στήλη 5 και πολλά στην στήλη 14.Επίσης για τις στήλες 8-13 όλα τα κείμενα έχουν τιμή <.9. Για την 8 η στήλη οι στήλες 3,13 έχουν αρκετέ τιμές=1 ενώ οι στήλες 1,2 και 4-11 έχουν για όλα τα κείμενά τους τιμές<9. Για την 9 η ομάδα διακρίνουμε μία περιοχή με μηδενικές τιμές για τις στήλες 1-11 και μία περιοχή με αρκετές τιμές=1 για τις στήλες Για την 1 η ομάδα οι στήλες 2,6,7 έχουν αρκετές τιμές=1 ενώ οι στήλες 1,3,4,8-13 έχουν τιμές<9. Για την 11 η ομάδα οι στήλες 1-11 σχηματίζουν μία περιοχή όπου οι τιμές είναι<9 ενώ οι στήλες 12-2 σχηματίζουν μία περιοχή με ελάχιστες τιμές =1 Για την 12 η ομάδα η στήλη 4 έχει πολλές τιμές=1 ενώ οι στήλες 1-3 και 8-11 έχουν όλες τις τιμές τους<9. Παρακάτω βλέπουμε την απεικόνιση όλων των ομάδων μαζί. Πρώτα για τιμή κατωφλίου ίση με.1 και έπειτα για κατώφλι 9. 86
![1 1 2 3 4 5 6 7 8 9 2 4 6 8 1 12 14 16 18 2 όλες μαζί για τιμές στο [,1]](/docs-images/64/51223820/images/87-0.jpg "87")
87 όλες μαζί για τιμές στο [,1] όλες μαζί για τιμές στο [,1] 87
ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΜΕ ΘΕΜΑ: «ΕΦΑΡΜΟΓΗ ΣΤΑΤΙΣΤΙΚΩΝ ΜΕΘΟ ΩΝ ΓΙΑ ΤΗΝ ΑΝΑΛΥΣΗ ΒΙΟΛΟΓΙΚΩΝ ΚΕΙΜΕΝΩΝ»
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΜΕ ΘΕΜΑ: «ΕΦΑΡΜΟΓΗ ΣΤΑΤΙΣΤΙΚΩΝ ΜΕΘΟ ΩΝ ΓΙΑ ΤΗΝ ΑΝΑΛΥΣΗ ΒΙΟΛΟΓΙΚΩΝ ΚΕΙΜΕΝΩΝ» ΕΠΙΜΕΛΕΙΑ ΕΡΓΑΣΙΑΣ: ΦΡΑΓΚΟΠΟΥΛΟΥ
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΜΕ ΘΕΜΑ: «ΕΦΑΡΜΟΓΗ ΣΤΑΤΙΣΤΙΚΩΝ ΜΕΘΟ ΩΝ ΓΙΑ ΤΗΝ ΑΝΑΛΥΣΗ ΒΙΟΛΟΓΙΚΩΝ ΚΕΙΜΕΝΩΝ» ΕΠΙΜΕΛΕΙΑ ΕΡΓΑΣΙΑΣ: ΦΡΑΓΚΟΠΟΥΛΟΥ
ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ 1
 ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ 1 ΒΑΣΙΚΟΙ ΧΕΙΡΙΣΜΟΙ ΕΙΚΟΝΑΣ Αντικείμενο: Εισαγωγή στις βασικές αρχές της ψηφιακής επεξεργασίας εικόνας χρησιμοποιώντας το MATLAB και το πακέτο Επεξεργασίας Εικόνας. Περιγραφή και αναπαράσταση
ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ 1 ΒΑΣΙΚΟΙ ΧΕΙΡΙΣΜΟΙ ΕΙΚΟΝΑΣ Αντικείμενο: Εισαγωγή στις βασικές αρχές της ψηφιακής επεξεργασίας εικόνας χρησιμοποιώντας το MATLAB και το πακέτο Επεξεργασίας Εικόνας. Περιγραφή και αναπαράσταση
Εξόρυξη Γνώσης από Βιολογικά εδομένα
 Παρουσίαση Διπλωματικής Εργασίας Εξόρυξη Γνώσης από Βιολογικά εδομένα Καρυπίδης Γεώργιος (Μ27/03) Επιβλέπων Καθηγητής: Ιωάννης Βλαχάβας MIS Πανεπιστήμιο Μακεδονίας Φεβρουάριος 2005 Εξόρυξη Γνώσης από Βιολογικά
Παρουσίαση Διπλωματικής Εργασίας Εξόρυξη Γνώσης από Βιολογικά εδομένα Καρυπίδης Γεώργιος (Μ27/03) Επιβλέπων Καθηγητής: Ιωάννης Βλαχάβας MIS Πανεπιστήμιο Μακεδονίας Φεβρουάριος 2005 Εξόρυξη Γνώσης από Βιολογικά
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Data Mining - Classification
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Data Mining - Classification Data Mining Ανακάλυψη προτύπων σε μεγάλο όγκο δεδομένων. Σαν πεδίο περιλαμβάνει κλάσεις εργασιών: Anomaly Detection:
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Data Mining - Classification Data Mining Ανακάλυψη προτύπων σε μεγάλο όγκο δεδομένων. Σαν πεδίο περιλαμβάνει κλάσεις εργασιών: Anomaly Detection:
ΑΣΚΗΣΗ 2 ΒΑΣΙΚΑ ΚΑΙ ΣΥΝΘΕΤΑ ΣΗΜΑΤΑ ΔΥΟ ΔΙΑΣΤΑΣΕΩΝ - ΕΙΚΟΝΑΣ
 ΑΣΚΗΣΗ 2 ΒΑΣΙΚΑ ΚΑΙ ΣΥΝΘΕΤΑ ΣΗΜΑΤΑ ΔΥΟ ΔΙΑΣΤΑΣΕΩΝ - ΕΙΚΟΝΑΣ Αντικείμενο: Κατανόηση και αναπαράσταση των βασικών σημάτων δύο διαστάσεων και απεικόνισης αυτών σε εικόνα. Δημιουργία και επεξεργασία των διαφόρων
ΑΣΚΗΣΗ 2 ΒΑΣΙΚΑ ΚΑΙ ΣΥΝΘΕΤΑ ΣΗΜΑΤΑ ΔΥΟ ΔΙΑΣΤΑΣΕΩΝ - ΕΙΚΟΝΑΣ Αντικείμενο: Κατανόηση και αναπαράσταση των βασικών σημάτων δύο διαστάσεων και απεικόνισης αυτών σε εικόνα. Δημιουργία και επεξεργασία των διαφόρων
Συνδυαστικά Λογικά Κυκλώματα
 Συνδυαστικά Λογικά Κυκλώματα Ένα συνδυαστικό λογικό κύκλωμα συντίθεται από λογικές πύλες, δέχεται εισόδους και παράγει μία ή περισσότερες εξόδους. Στα συνδυαστικά λογικά κυκλώματα οι έξοδοι σε κάθε χρονική
Συνδυαστικά Λογικά Κυκλώματα Ένα συνδυαστικό λογικό κύκλωμα συντίθεται από λογικές πύλες, δέχεται εισόδους και παράγει μία ή περισσότερες εξόδους. Στα συνδυαστικά λογικά κυκλώματα οι έξοδοι σε κάθε χρονική
Γενικά Στοιχεία Ηλεκτρονικού Υπολογιστή
 Γενικά Στοιχεία Ηλεκτρονικού Υπολογιστή 1. Ηλεκτρονικός Υπολογιστής Ο Ηλεκτρονικός Υπολογιστής είναι μια συσκευή, μεγάλη ή μικρή, που επεξεργάζεται δεδομένα και εκτελεί την εργασία του σύμφωνα με τα παρακάτω
Γενικά Στοιχεία Ηλεκτρονικού Υπολογιστή 1. Ηλεκτρονικός Υπολογιστής Ο Ηλεκτρονικός Υπολογιστής είναι μια συσκευή, μεγάλη ή μικρή, που επεξεργάζεται δεδομένα και εκτελεί την εργασία του σύμφωνα με τα παρακάτω
[2] Υπολογιστικά συστήματα: Στρώματα. Τύποι δεδομένων. Μπιτ. επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό
![[2] Υπολογιστικά συστήματα: Στρώματα. Τύποι δεδομένων. Μπιτ. επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό](/thumbs/24/3678673.jpg "[2] Υπολογιστικά συστήματα: Στρώματα. Τύποι δεδομένων. Μπιτ. επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό") Υπολογιστικά συστήματα: Στρώματα 1 ΕΠΛ 003: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό δεδομένα Αναπαράσταση δεδομένων 2 Τύποι δεδομένων Τα δεδομένα
Υπολογιστικά συστήματα: Στρώματα 1 ΕΠΛ 003: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό δεδομένα Αναπαράσταση δεδομένων 2 Τύποι δεδομένων Τα δεδομένα
ΕΠΛ 003: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ. Αναπαράσταση δεδομένων
 ΕΠΛ 003: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ Αναπαράσταση δεδομένων Υπολογιστικά συστήματα: Στρώματα 1 επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό δεδομένα Τύποι δεδομένων 2 Τα δεδομένα
ΕΠΛ 003: ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ Αναπαράσταση δεδομένων Υπολογιστικά συστήματα: Στρώματα 1 επικοινωνία εφαρμογές λειτουργικό σύστημα προγράμματα υλικό δεδομένα Τύποι δεδομένων 2 Τα δεδομένα
1 Συστήματα Αυτοματισμού Βιβλιοθηκών
 1 Συστήματα Αυτοματισμού Βιβλιοθηκών Τα Συστήματα Αυτοματισμού Βιβλιοθηκών χρησιμοποιούνται για τη διαχείριση καταχωρήσεων βιβλιοθηκών. Τα περιεχόμενα των βιβλιοθηκών αυτών είναι έντυπα έγγραφα, όπως βιβλία
1 Συστήματα Αυτοματισμού Βιβλιοθηκών Τα Συστήματα Αυτοματισμού Βιβλιοθηκών χρησιμοποιούνται για τη διαχείριση καταχωρήσεων βιβλιοθηκών. Τα περιεχόμενα των βιβλιοθηκών αυτών είναι έντυπα έγγραφα, όπως βιβλία
Δύο είναι οι κύριες αιτίες που μπορούμε να πάρουμε από τον υπολογιστή λανθασμένα αποτελέσματα εξαιτίας των σφαλμάτων στρογγυλοποίησης:
 Ορολογία bit (binary digit): δυαδικό ψηφίο. Τα δυαδικά ψηφία είναι το 0 και το 1 1 byte = 8 bits word: η θεμελιώδης μονάδα σύμφωνα με την οποία εκπροσωπούνται οι πληροφορίες στον υπολογιστή. Αποτελείται
Ορολογία bit (binary digit): δυαδικό ψηφίο. Τα δυαδικά ψηφία είναι το 0 και το 1 1 byte = 8 bits word: η θεμελιώδης μονάδα σύμφωνα με την οποία εκπροσωπούνται οι πληροφορίες στον υπολογιστή. Αποτελείται
Εργαλεία Προγραμματισμού Ψηφιακής Επεξεργασίας Εικόνας: Το Matlab Image Processing Toolbox
 ΚΕΣ 03 Αναγνώριση προτύπων και ανάλυση εικόνας Εργαλεία Προγραμματισμού Ψηφιακής Επεξεργασίας Εικόνας: Το Matlab Image Processing Toolbox Τμήμα Επιστήμης και Τεχνολογίας Τηλεπικοινωνιών Πανεπιστήμιο Πελοποννήσου
ΚΕΣ 03 Αναγνώριση προτύπων και ανάλυση εικόνας Εργαλεία Προγραμματισμού Ψηφιακής Επεξεργασίας Εικόνας: Το Matlab Image Processing Toolbox Τμήμα Επιστήμης και Τεχνολογίας Τηλεπικοινωνιών Πανεπιστήμιο Πελοποννήσου
ΑΣΚΗΣΗ. Δημιουργία Ευρετηρίων Συλλογής Κειμένων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Οπτική αντίληψη. Μετά?..
 Οπτική αντίληψη Πρωτογενής ερεθισµός (φυσικό φαινόµενο) Μεταφορά µηνύµατος στον εγκέφαλο (ψυχολογική αντίδραση) Μετατροπή ερεθίσµατος σε έννοια Μετά?.. ΓΙΑ ΝΑ ΚΑΤΑΝΟΗΣΟΥΜΕ ΤΗΝ ΟΡΑΣΗ ΠΡΕΠΕΙ ΝΑ ΑΝΑΛΟΓΙΣΤΟΥΜΕ
Οπτική αντίληψη Πρωτογενής ερεθισµός (φυσικό φαινόµενο) Μεταφορά µηνύµατος στον εγκέφαλο (ψυχολογική αντίδραση) Μετατροπή ερεθίσµατος σε έννοια Μετά?.. ΓΙΑ ΝΑ ΚΑΤΑΝΟΗΣΟΥΜΕ ΤΗΝ ΟΡΑΣΗ ΠΡΕΠΕΙ ΝΑ ΑΝΑΛΟΓΙΣΤΟΥΜΕ
Κ15 Ψηφιακή Λογική Σχεδίαση 2: Δυαδικό Σύστημα / Αναπαραστάσεις
 Κ15 Ψηφιακή Λογική Σχεδίαση 2: Δυαδικό Σύστημα / Αναπαραστάσεις Γιάννης Λιαπέρδος TEI Πελοποννήσου Σχολή Τεχνολογικών Εφαρμογών Τμήμα Μηχανικών Πληροφορικής ΤΕ Δυαδικό Σύστημα Αρίθμησης Περιεχόμενα 1 Δυαδικό
Κ15 Ψηφιακή Λογική Σχεδίαση 2: Δυαδικό Σύστημα / Αναπαραστάσεις Γιάννης Λιαπέρδος TEI Πελοποννήσου Σχολή Τεχνολογικών Εφαρμογών Τμήμα Μηχανικών Πληροφορικής ΤΕ Δυαδικό Σύστημα Αρίθμησης Περιεχόμενα 1 Δυαδικό
Η ΜΕΘΟΔΟΣ PCA (Principle Component Analysis)
") Η ΜΕΘΟΔΟΣ PCA (Principle Component Analysis) Η μέθοδος PCA (Ανάλυση Κύριων Συνιστωσών), αποτελεί μία γραμμική μέθοδο συμπίεσης Δεδομένων η οποία συνίσταται από τον επαναπροσδιορισμό των συντεταγμένων ενός
Η ΜΕΘΟΔΟΣ PCA (Principle Component Analysis) Η μέθοδος PCA (Ανάλυση Κύριων Συνιστωσών), αποτελεί μία γραμμική μέθοδο συμπίεσης Δεδομένων η οποία συνίσταται από τον επαναπροσδιορισμό των συντεταγμένων ενός
Ενδεικτική πολυ-εργασία 1 - εφαρμογή στην υπολογιστική όραση
 Ενδεικτική πολυ-εργασία 1 - εφαρμογή στην υπολογιστική όραση Εντοπισμός ενός σήματος STOP σε μια εικόνα. Περιγράψτε τη διαδικασία με την οποία μπορώ να εντοπίσω απλά σε μια εικόνα την ύπαρξη του παρακάτω
Ενδεικτική πολυ-εργασία 1 - εφαρμογή στην υπολογιστική όραση Εντοπισμός ενός σήματος STOP σε μια εικόνα. Περιγράψτε τη διαδικασία με την οποία μπορώ να εντοπίσω απλά σε μια εικόνα την ύπαρξη του παρακάτω
Τμήμα Λογιστικής. Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές. Μαθήματα 6 και 7 Αναπαράσταση της Πληροφορίας στον Υπολογιστή. 1 Στέργιος Παλαμάς
 ΤΕΙ Ηπείρου Παράρτημα Πρέβεζας Τμήμα Λογιστικής Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές Μαθήματα 6 και 7 Αναπαράσταση της Πληροφορίας στον Υπολογιστή 1 1. Αριθμοί: Το Δυαδικό Σύστημα Οι ηλεκτρονικοί υπολογιστές
ΤΕΙ Ηπείρου Παράρτημα Πρέβεζας Τμήμα Λογιστικής Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές Μαθήματα 6 και 7 Αναπαράσταση της Πληροφορίας στον Υπολογιστή 1 1. Αριθμοί: Το Δυαδικό Σύστημα Οι ηλεκτρονικοί υπολογιστές
ΗΥ562 Προχωρημένα Θέματα Βάσεων Δεδομένων Efficient Query Evaluation over Temporally Correlated Probabilistic Streams
 ΗΥ562 Προχωρημένα Θέματα Βάσεων Δεδομένων Efficient Query Evaluation over Temporally Correlated Probabilistic Streams Αλέκα Σεληνιωτάκη Ηράκλειο, 26/06/12 aseliniotaki@csd.uoc.gr ΑΜ: 703 1. Περίληψη Συνεισφοράς
ΗΥ562 Προχωρημένα Θέματα Βάσεων Δεδομένων Efficient Query Evaluation over Temporally Correlated Probabilistic Streams Αλέκα Σεληνιωτάκη Ηράκλειο, 26/06/12 aseliniotaki@csd.uoc.gr ΑΜ: 703 1. Περίληψη Συνεισφοράς
Εισαγωγή στην Πληροφορική & τον Προγραμματισμό
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα Εισαγωγή στην Πληροφορική & τον Προγραμματισμό Ενότητα 3 η : Κωδικοποίηση & Παράσταση Δεδομένων Ι. Ψαρομήλιγκος Χ. Κυτάγιας Τμήμα
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα Εισαγωγή στην Πληροφορική & τον Προγραμματισμό Ενότητα 3 η : Κωδικοποίηση & Παράσταση Δεδομένων Ι. Ψαρομήλιγκος Χ. Κυτάγιας Τμήμα
Εισαγωγή στην επιστήμη των υπολογιστών. Υπολογιστές και Δεδομένα Κεφάλαιο 2ο Αναπαράσταση Δεδομένων
 Εισαγωγή στην επιστήμη των υπολογιστών Υπολογιστές και Δεδομένα Κεφάλαιο 2ο Αναπαράσταση Δεδομένων 1 2.1 Τύποι Δεδομένων Τα δεδομένα σήμερα συναντώνται σε διάφορες μορφές, στις οποίες περιλαμβάνονται αριθμοί,
Εισαγωγή στην επιστήμη των υπολογιστών Υπολογιστές και Δεδομένα Κεφάλαιο 2ο Αναπαράσταση Δεδομένων 1 2.1 Τύποι Δεδομένων Τα δεδομένα σήμερα συναντώνται σε διάφορες μορφές, στις οποίες περιλαμβάνονται αριθμοί,
ΑΣΚΗΣΗ 3 ΒΕΛΤΙΩΣΗ ΕΙΚΟΝΑΣ ΜΕΛΕΤΗ ΙΣΤΟΓΡΑΜΜΑΤΟΣ. ( ) 1, αν Ι(i,j)=k hk ( ), διαφορετικά
 1, αν Ι(i,j)=k hk ( ), διαφορετικά") ΑΣΚΗΣΗ 3 ΒΕΛΤΙΩΣΗ ΕΙΚΟΝΑΣ ΜΕΛΕΤΗ ΙΣΤΟΓΡΑΜΜΑΤΟΣ Αντικείμενο: Εξαγωγή ιστογράμματος εικόνας, απλοί μετασχηματισμοί με αυτό, ισοστάθμιση ιστογράμματος. Εφαρμογή βασικών παραθύρων με την βοήθεια του ΜΑΤLAB
ΑΣΚΗΣΗ 3 ΒΕΛΤΙΩΣΗ ΕΙΚΟΝΑΣ ΜΕΛΕΤΗ ΙΣΤΟΓΡΑΜΜΑΤΟΣ Αντικείμενο: Εξαγωγή ιστογράμματος εικόνας, απλοί μετασχηματισμοί με αυτό, ισοστάθμιση ιστογράμματος. Εφαρμογή βασικών παραθύρων με την βοήθεια του ΜΑΤLAB
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ. Ενότητα 1: Εισαγωγή στην Ψηφιακή Επεξεργασία Εικόνας
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ Ενότητα 1: Εισαγωγή στην Ψηφιακή Επεξεργασία Εικόνας Ιωάννης Έλληνας Τμήμα Υπολογιστικών Συστημάτων Άδειες
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ Ενότητα 1: Εισαγωγή στην Ψηφιακή Επεξεργασία Εικόνας Ιωάννης Έλληνας Τμήμα Υπολογιστικών Συστημάτων Άδειες
ΕΡΕΥΝΗΤΙΚΑ ΠΡΟΓΡΑΜΜΑΤΑ ΑΡΧΙΜΗΔΗΣ ΕΝΙΣΧΥΣΗ ΕΡΕΥΝΗΤΙΚΩΝ ΟΜΑΔΩΝ ΣΤΟ ΤΕΙ ΣΕΡΡΩΝ. Ενέργεια. 2.2.3.στ ΘΕΜΑ ΕΡΕΥΝΑΣ: ΔΙΑΡΘΡΩΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΕΧΡΩΜΩΝ ΕΓΓΡΑΦΩΝ
 ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ (Τ.Ε.Ι.) ΣΕΡΡΩΝ Τμήμα ΠΛΗΡΟΦΟΡΙΚΗΣ & ΕΠΙΚΟΙΝΩΝΙΩΝ ΕΡΕΥΝΗΤΙΚΑ ΠΡΟΓΡΑΜΜΑΤΑ ΑΡΧΙΜΗΔΗΣ ΕΝΙΣΧΥΣΗ ΕΡΕΥΝΗΤΙΚΩΝ ΟΜΑΔΩΝ ΣΤΟ ΤΕΙ ΣΕΡΡΩΝ Ενέργεια. 2.2.3.στ ΘΕΜΑ ΕΡΕΥΝΑΣ: ΔΙΑΡΘΡΩΣΗ
ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ (Τ.Ε.Ι.) ΣΕΡΡΩΝ Τμήμα ΠΛΗΡΟΦΟΡΙΚΗΣ & ΕΠΙΚΟΙΝΩΝΙΩΝ ΕΡΕΥΝΗΤΙΚΑ ΠΡΟΓΡΑΜΜΑΤΑ ΑΡΧΙΜΗΔΗΣ ΕΝΙΣΧΥΣΗ ΕΡΕΥΝΗΤΙΚΩΝ ΟΜΑΔΩΝ ΣΤΟ ΤΕΙ ΣΕΡΡΩΝ Ενέργεια. 2.2.3.στ ΘΕΜΑ ΕΡΕΥΝΑΣ: ΔΙΑΡΘΡΩΣΗ
DIP_01 Εισαγωγή στην ψηφιακή εικόνα. ΤΕΙ Κρήτης
 DIP_01 Εισαγωγή στην ψηφιακή εικόνα ΤΕΙ Κρήτης Πληροφορίες Μαθήματος ιαλέξεις Πέμπτη 12:15 15:00 Αιθουσα Γ7 ιδάσκων:. Κοσμόπουλος Γραφείο: Κ23-0-15 (ισόγειο( κλειστού γυμναστηρίου) Ωρες γραφείου Τε 16:00
DIP_01 Εισαγωγή στην ψηφιακή εικόνα ΤΕΙ Κρήτης Πληροφορίες Μαθήματος ιαλέξεις Πέμπτη 12:15 15:00 Αιθουσα Γ7 ιδάσκων:. Κοσμόπουλος Γραφείο: Κ23-0-15 (ισόγειο( κλειστού γυμναστηρίου) Ωρες γραφείου Τε 16:00
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #06 Πιθανοτικό Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #06 Πιθανοτικό Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Μεταπτυχιακό Πρόγραμμα «Γεωχωρικές Τεχνολογίες» Ψηφιακή Επεξεργασία Εικόνας. Εισηγητής Αναστάσιος Κεσίδης
 Μεταπτυχιακό Πρόγραμμα «Γεωχωρικές Τεχνολογίες» Ψηφιακή Επεξεργασία Εικόνας Εισηγητής Αναστάσιος Κεσίδης Σημειακή επεξεργασία και μετασχηματισμοί Κατηγορίες μετασχηματισμού εικόνων Σημειακοί μετασχηματισμοί
Μεταπτυχιακό Πρόγραμμα «Γεωχωρικές Τεχνολογίες» Ψηφιακή Επεξεργασία Εικόνας Εισηγητής Αναστάσιος Κεσίδης Σημειακή επεξεργασία και μετασχηματισμοί Κατηγορίες μετασχηματισμού εικόνων Σημειακοί μετασχηματισμοί
Ανάκτηση πολυμεσικού περιεχομένου
 Ανάκτηση πολυμεσικού περιεχομένου Ανίχνευση / αναγνώριση προσώπων Ανίχνευση / ανάγνωση κειμένου Ανίχνευση αντικειμένων Οπτικές λέξεις Δεικτοδότηση Σχέσεις ομοιότητας Κατηγοριοποίηση ειδών μουσικής Διάκριση
Ανάκτηση πολυμεσικού περιεχομένου Ανίχνευση / αναγνώριση προσώπων Ανίχνευση / ανάγνωση κειμένου Ανίχνευση αντικειμένων Οπτικές λέξεις Δεικτοδότηση Σχέσεις ομοιότητας Κατηγοριοποίηση ειδών μουσικής Διάκριση
ΜΗΧΑΝΙΚΗ ΟΡΑΣΗ. 1η ΕΡΓΑΣΙΑ ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΚΡΗΤΗΣ ΣΧΟΛΗ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΦΑΡΜΟΓΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ
 ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΚΡΗΤΗΣ ΣΧΟΛΗ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΦΑΡΜΟΓΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΠΡΟΗΓΜΕΝΑ ΣΥΣΤΗΜΑΤΑ ΠΑΡΑΓΩΓΗΣ ΑΥΤΟΜΑΤΙΣΜΟΥ & ΡΟΜΠΟΤΙΚΗΣ ΜΗΧΑΝΙΚΗ ΟΡΑΣΗ 1η ΕΡΓΑΣΙΑ ΣΠΟΥΔΑΣΤΕΣ:
ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΚΡΗΤΗΣ ΣΧΟΛΗ ΤΕΧΝΟΛΟΓΙΚΩΝ ΕΦΑΡΜΟΓΩΝ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΠΡΟΗΓΜΕΝΑ ΣΥΣΤΗΜΑΤΑ ΠΑΡΑΓΩΓΗΣ ΑΥΤΟΜΑΤΙΣΜΟΥ & ΡΟΜΠΟΤΙΚΗΣ ΜΗΧΑΝΙΚΗ ΟΡΑΣΗ 1η ΕΡΓΑΣΙΑ ΣΠΟΥΔΑΣΤΕΣ:
Κεφάλαιο 2. Συστήματα Αρίθμησης και Αναπαράσταση Πληροφορίας. Περιεχόμενα. 2.1 Αριθμητικά Συστήματα. Εισαγωγή
 Κεφάλαιο. Συστήματα Αρίθμησης και Αναπαράσταση Πληροφορίας Περιεχόμενα. Αριθμητικά συστήματα. Μετατροπή αριθμών από ένα σύστημα σε άλλο.3 Πράξεις στο δυαδικό σύστημα.4 Πράξεις στο δεκαεξαδικό σύστημα.5
Κεφάλαιο. Συστήματα Αρίθμησης και Αναπαράσταση Πληροφορίας Περιεχόμενα. Αριθμητικά συστήματα. Μετατροπή αριθμών από ένα σύστημα σε άλλο.3 Πράξεις στο δυαδικό σύστημα.4 Πράξεις στο δεκαεξαδικό σύστημα.5
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ
 ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΠΑΡΑΔΕΙΓΜΑΤΑ ΜΕ ΧΡΗΣΗ MATLAB ΑΘΑΝΑΣΙΑ ΚΟΛΟΒΟΥ (Ε.Τ.Ε.Π.) 2012 ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ Ο σκοπός αυτού
ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΠΑΡΑΔΕΙΓΜΑΤΑ ΜΕ ΧΡΗΣΗ MATLAB ΑΘΑΝΑΣΙΑ ΚΟΛΟΒΟΥ (Ε.Τ.Ε.Π.) 2012 ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ Ο σκοπός αυτού
Εισαγωγή στην επιστήμη των υπολογιστών
 Εισαγωγή στην επιστήμη των υπολογιστών Υπολογιστές και Δεδομένα Κεφάλαιο 3ο Αναπαράσταση Αριθμών www.di.uoa.gr/~organosi 1 Δεκαδικό και Δυαδικό Δεκαδικό σύστημα 2 3 Δεκαδικό και Δυαδικό Δυαδικό Σύστημα
Εισαγωγή στην επιστήμη των υπολογιστών Υπολογιστές και Δεδομένα Κεφάλαιο 3ο Αναπαράσταση Αριθμών www.di.uoa.gr/~organosi 1 Δεκαδικό και Δυαδικό Δεκαδικό σύστημα 2 3 Δεκαδικό και Δυαδικό Δυαδικό Σύστημα
Πληροφορική 2. Δομές δεδομένων και αρχείων
 Πληροφορική 2 Δομές δεδομένων και αρχείων 1 2 Δομή Δεδομένων (data structure) Δομή δεδομένων είναι μια συλλογή δεδομένων που έχουν μεταξύ τους μια συγκεκριμένη σχέση Παραδείγματα δομών δεδομένων Πίνακες
Πληροφορική 2 Δομές δεδομένων και αρχείων 1 2 Δομή Δεδομένων (data structure) Δομή δεδομένων είναι μια συλλογή δεδομένων που έχουν μεταξύ τους μια συγκεκριμένη σχέση Παραδείγματα δομών δεδομένων Πίνακες
Τετάρτη 5-12/11/2014. ΣΗΜΕΙΩΣΕΙΣ 3 ου και 4 ου ΜΑΘΗΜΑΤΟΣ ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ Η/Υ Α ΕΞΑΜΗΝΟ
 Τετάρτη 5-12/11/2014 ΣΗΜΕΙΩΣΕΙΣ 3 ου και 4 ου ΜΑΘΗΜΑΤΟΣ ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ Η/Υ Α ΕΞΑΜΗΝΟ ΕΚΠΑΙΔΕΥΤΗΣ: ΤΡΟΧΙΔΗΣ ΠΑΝΑΓΙΩΤΗΣ 1. Παράσταση και οργάνωση δεδομένων
Τετάρτη 5-12/11/2014 ΣΗΜΕΙΩΣΕΙΣ 3 ου και 4 ου ΜΑΘΗΜΑΤΟΣ ΕΙΔΙΚΟΤΗΤΑ: ΤΕΧΝΙΚΟΣ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΑΘΗΜΑ: ΑΡΧΙΤΕΚΤΟΝΙΚΗ Η/Υ Α ΕΞΑΜΗΝΟ ΕΚΠΑΙΔΕΥΤΗΣ: ΤΡΟΧΙΔΗΣ ΠΑΝΑΓΙΩΤΗΣ 1. Παράσταση και οργάνωση δεδομένων
Αρχιτεκτονική Μηχανής. Αποθήκευση εδοµένων
 Αρχιτεκτονική Μηχανής Αποθήκευση εδοµένων Οι πράξεις AND, OR, και Αλγεβρας Boole XOR (exclusive or) της Μία απεικόνιση των πυλών AND, OR, XOR, και NOT καθώς και των τιµών εισόδου (inputs) και εξόδου (output)
Αρχιτεκτονική Μηχανής Αποθήκευση εδοµένων Οι πράξεις AND, OR, και Αλγεβρας Boole XOR (exclusive or) της Μία απεικόνιση των πυλών AND, OR, XOR, και NOT καθώς και των τιµών εισόδου (inputs) και εξόδου (output)
Ακαδημαϊκό Έτος , Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS
 Ακαδημαϊκό Έτος 2016-2017, Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS A. Εισαγωγή στις βάσεις δεδομένων - Γνωριμία με την ACCESS B. Δημιουργία Πινάκων 1. Εξήγηση των
Ακαδημαϊκό Έτος 2016-2017, Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS A. Εισαγωγή στις βάσεις δεδομένων - Γνωριμία με την ACCESS B. Δημιουργία Πινάκων 1. Εξήγηση των
ΑΣΚΗΣΗ. Συγκομιδή και δεικτοδότηση ιστοσελίδων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2010-2011 ΑΣΚΗΣΗ Συγκομιδή και δεικτοδότηση ιστοσελίδων Σκοπός της άσκησης είναι η υλοποίηση ενός ολοκληρωμένου συστήματος συγκομιδής και δεικτοδότησης ιστοσελίδων.
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2010-2011 ΑΣΚΗΣΗ Συγκομιδή και δεικτοδότηση ιστοσελίδων Σκοπός της άσκησης είναι η υλοποίηση ενός ολοκληρωμένου συστήματος συγκομιδής και δεικτοδότησης ιστοσελίδων.
Γλωσσικη τεχνολογια. Προεπεξεργασία Κειμένου
 Γλωσσικη τεχνολογια Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε το πληροφοριακό περιεχόμενο Ποσοτικοποιήσουμε
Γλωσσικη τεχνολογια Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε το πληροφοριακό περιεχόμενο Ποσοτικοποιήσουμε
Η παρουσίαση των ευρημάτων στην ερευνητική αναφορά ΠΕΤΡΟΣ ΡΟΥΣΣΟΣ
 Η παρουσίαση των ευρημάτων στην ερευνητική αναφορά ΠΕΤΡΟΣ ΡΟΥΣΣΟΣ 1 Η ενότητα των Αποτελεσμάτων Στην ενότητα Αποτελέσματα του δοκιμίου μιας πτυχιακής εργασίας παρουσιάζονται τα ευρήματα που προέκυψαν από
Η παρουσίαση των ευρημάτων στην ερευνητική αναφορά ΠΕΤΡΟΣ ΡΟΥΣΣΟΣ 1 Η ενότητα των Αποτελεσμάτων Στην ενότητα Αποτελέσματα του δοκιμίου μιας πτυχιακής εργασίας παρουσιάζονται τα ευρήματα που προέκυψαν από
Εξόρυξη γνώμης πολιτών από ελεύθερο κείμενο
 Δίκαρος Νίκος Δ/νση Μηχανογράνωσης κ Η.Ε.Σ. Υπουργείο Εσωτερικών. Τελική εργασία Κ Εκπαιδευτικής Σειράς Ε.Σ.Δ.Δ. Επιβλέπων: Ηρακλής Βαρλάμης Εξόρυξη γνώμης πολιτών από ελεύθερο κείμενο Κεντρική ιδέα Προβληματισμοί
Δίκαρος Νίκος Δ/νση Μηχανογράνωσης κ Η.Ε.Σ. Υπουργείο Εσωτερικών. Τελική εργασία Κ Εκπαιδευτικής Σειράς Ε.Σ.Δ.Δ. Επιβλέπων: Ηρακλής Βαρλάμης Εξόρυξη γνώμης πολιτών από ελεύθερο κείμενο Κεντρική ιδέα Προβληματισμοί
1 Ανάλυση Προβλήματος
 1 Ανάλυση Προβλήματος 1.1 Η Έννοια Πρόβλημα Τι είναι δεδομένο; Δεδομένο είναι οτιδήποτε μπορεί να γίνει αντιληπτό από έναν τουλάχιστον παρατηρητή, με μία από τις πέντε αισθήσεις του. Τι είναι επεξεργασία
1 Ανάλυση Προβλήματος 1.1 Η Έννοια Πρόβλημα Τι είναι δεδομένο; Δεδομένο είναι οτιδήποτε μπορεί να γίνει αντιληπτό από έναν τουλάχιστον παρατηρητή, με μία από τις πέντε αισθήσεις του. Τι είναι επεξεργασία
Οδηγίες σχεδίασης στο περιβάλλον Blender
 Οδηγίες σχεδίασης στο περιβάλλον Blender Στον πραγματικό κόσμο, αντιλαμβανόμαστε τα αντικείμενα σε τρεις κατευθύνσεις ή διαστάσεις. Τυπικά λέμε ότι διαθέτουν ύψος, πλάτος και βάθος. Όταν θέλουμε να αναπαραστήσουμε
Οδηγίες σχεδίασης στο περιβάλλον Blender Στον πραγματικό κόσμο, αντιλαμβανόμαστε τα αντικείμενα σε τρεις κατευθύνσεις ή διαστάσεις. Τυπικά λέμε ότι διαθέτουν ύψος, πλάτος και βάθος. Όταν θέλουμε να αναπαραστήσουμε
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ
 ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ
 ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ Εξετάσεις Προσομοίωσης 06/04/2015 Θέμα Α Α1. Να γράψετε στο τετράδιο σας τον αριθμό κάθε πρότασης και δίπλα τη λέξη ΣΩΣΤΟ, αν είναι σωστή και ΛΑΘΟΣ αν
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ Εξετάσεις Προσομοίωσης 06/04/2015 Θέμα Α Α1. Να γράψετε στο τετράδιο σας τον αριθμό κάθε πρότασης και δίπλα τη λέξη ΣΩΣΤΟ, αν είναι σωστή και ΛΑΘΟΣ αν
Βιοπληροψορική, συσιημική βιολογία και εξατομικευμένη θεραπεία
 Βιοπληροψορική, συσιημική βιολογία και εξατομικευμένη θεραπεία Φραγκίσκος Κολίσης Καθηγητής Βιοτεχνολογίας, Σχολή Χημικών Μηχανικών ΕΜΠ, Διευθυντής Ινστιτούτου Βιολογικών Ερευνών και Βιοτεχνολογίας, EIE
Βιοπληροψορική, συσιημική βιολογία και εξατομικευμένη θεραπεία Φραγκίσκος Κολίσης Καθηγητής Βιοτεχνολογίας, Σχολή Χημικών Μηχανικών ΕΜΠ, Διευθυντής Ινστιτούτου Βιολογικών Ερευνών και Βιοτεχνολογίας, EIE
Ψηφιακή Επεξεργασία και Ανάλυση Εικόνας. Παρουσίαση 12 η. Θεωρία Χρώματος και Επεξεργασία Έγχρωμων Εικόνων
 Ψηφιακή Επεξεργασία και Ανάλυση Εικόνας Παρουσίαση 12 η Θεωρία Χρώματος και Επεξεργασία Έγχρωμων Εικόνων Εισαγωγή (1) Το χρώμα είναι ένας πολύ σημαντικός παράγοντας περιγραφής, που συχνά απλουστεύει κατά
Ψηφιακή Επεξεργασία και Ανάλυση Εικόνας Παρουσίαση 12 η Θεωρία Χρώματος και Επεξεργασία Έγχρωμων Εικόνων Εισαγωγή (1) Το χρώμα είναι ένας πολύ σημαντικός παράγοντας περιγραφής, που συχνά απλουστεύει κατά
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Προεπεξεργασία Κειμένου
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Προεπεξεργασία Κειμένου Στόχος Επεξεργασίας Γραπτό κείμενο: Τρόπος επικοινωνίας Φέρει σημασιολογικό περιεχόμενο Αναζητούμε τρόπο να: Μετρήσουμε
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων
 Απαντήσεις 1 ου Σετ Ασκήσεων") Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Τμήμα Μηχανολόγων Μηχανικών Πανεπιστήμιο Θεσσαλίας ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Η/Υ. Βασικές Έννοιες Προγραμματισμού. Ιωάννης Λυχναρόπουλος Μαθηματικός, MSc, PhD
 Τμήμα Μηχανολόγων Μηχανικών Πανεπιστήμιο Θεσσαλίας ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Η/Υ Βασικές Έννοιες Προγραμματισμού Ιωάννης Λυχναρόπουλος Μαθηματικός, MSc, PhD Αριθμητικά συστήματα Υπάρχουν 10 τύποι ανθρώπων: Αυτοί
Τμήμα Μηχανολόγων Μηχανικών Πανεπιστήμιο Θεσσαλίας ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Η/Υ Βασικές Έννοιες Προγραμματισμού Ιωάννης Λυχναρόπουλος Μαθηματικός, MSc, PhD Αριθμητικά συστήματα Υπάρχουν 10 τύποι ανθρώπων: Αυτοί
Άσκηση 1 (ανακοινώθηκε στις 20 Μαρτίου 2017, προθεσμία παράδοσης: 24 Απριλίου 2017, 12 τα μεσάνυχτα).
.") Κ08 Δομές Δεδομένων και Τεχνικές Προγραμματισμού Διδάσκων: Μανόλης Κουμπαράκης Εαρινό Εξάμηνο 2016-2017. Άσκηση 1 (ανακοινώθηκε στις 20 Μαρτίου 2017, προθεσμία παράδοσης: 24 Απριλίου 2017, 12 τα μεσάνυχτα).
Κ08 Δομές Δεδομένων και Τεχνικές Προγραμματισμού Διδάσκων: Μανόλης Κουμπαράκης Εαρινό Εξάμηνο 2016-2017. Άσκηση 1 (ανακοινώθηκε στις 20 Μαρτίου 2017, προθεσμία παράδοσης: 24 Απριλίου 2017, 12 τα μεσάνυχτα).
Μαθησιακές δραστηριότητες με υπολογιστή
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Μαθησιακές δραστηριότητες με υπολογιστή Κατευθυντήριες γραμμές σχεδίασης μαθησιακών δραστηριοτήτων Διδάσκων: Καθηγητής Αναστάσιος Α. Μικρόπουλος Άδειες
ΠΑΝΕΠΙΣΤΗΜΙΟ ΙΩΑΝΝΙΝΩΝ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Μαθησιακές δραστηριότητες με υπολογιστή Κατευθυντήριες γραμμές σχεδίασης μαθησιακών δραστηριοτήτων Διδάσκων: Καθηγητής Αναστάσιος Α. Μικρόπουλος Άδειες
ΑΕΠΠ Ερωτήσεις θεωρίας
 ΑΕΠΠ Ερωτήσεις θεωρίας Κεφάλαιο 1 1. Τα δεδομένα μπορούν να παρέχουν πληροφορίες όταν υποβάλλονται σε 2. Το πρόβλημα μεγιστοποίησης των κερδών μιας επιχείρησης είναι πρόβλημα 3. Για την επίλυση ενός προβλήματος
ΑΕΠΠ Ερωτήσεις θεωρίας Κεφάλαιο 1 1. Τα δεδομένα μπορούν να παρέχουν πληροφορίες όταν υποβάλλονται σε 2. Το πρόβλημα μεγιστοποίησης των κερδών μιας επιχείρησης είναι πρόβλημα 3. Για την επίλυση ενός προβλήματος
Αναγνώριση Προτύπων Ι
 Αναγνώριση Προτύπων Ι Ενότητα 1: Μέθοδοι Αναγνώρισης Προτύπων Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Αναγνώριση Προτύπων Ι Ενότητα 1: Μέθοδοι Αναγνώρισης Προτύπων Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Διπλωματική Εργασία: «Συγκριτική Μελέτη Μηχανισμών Εκτίμησης Ελλιπούς Πληροφορίας σε Ασύρματα Δίκτυα Αισθητήρων»
 Τμήμα Πληροφορικής και Τηλεπικοινωνιών Πρόγραμμα Μεταπτυχιακών Σπουδών Διπλωματική Εργασία: «Συγκριτική Μελέτη Μηχανισμών Εκτίμησης Ελλιπούς Πληροφορίας σε Ασύρματα Δίκτυα Αισθητήρων» Αργυροπούλου Αιμιλία
Τμήμα Πληροφορικής και Τηλεπικοινωνιών Πρόγραμμα Μεταπτυχιακών Σπουδών Διπλωματική Εργασία: «Συγκριτική Μελέτη Μηχανισμών Εκτίμησης Ελλιπούς Πληροφορίας σε Ασύρματα Δίκτυα Αισθητήρων» Αργυροπούλου Αιμιλία
Ιατρική Πληροφορική. Δρ. Π. ΑΣΒΕΣΤΑΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΒΙΟΪΑΤΡΙΚΗΣ ΤΕΧΝΟΛΟΓΙΑΣ Τ.Ε.
 Ιατρική Πληροφορική Δρ. Π. ΑΣΒΕΣΤΑΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΒΙΟΪΑΤΡΙΚΗΣ ΤΕΧΝΟΛΟΓΙΑΣ Τ.Ε. Οι διάφορες τεχνικές απεικόνισης (imaging modalities) της ανθρώπινης ανατομίας περιγράφονται κατά DICOM ως συντομογραφία
Ιατρική Πληροφορική Δρ. Π. ΑΣΒΕΣΤΑΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΒΙΟΪΑΤΡΙΚΗΣ ΤΕΧΝΟΛΟΓΙΑΣ Τ.Ε. Οι διάφορες τεχνικές απεικόνισης (imaging modalities) της ανθρώπινης ανατομίας περιγράφονται κατά DICOM ως συντομογραφία
Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα)
 (γράφοι και δένδρα)") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Αφηρημένες
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Αφηρημένες
Διακριτά Μαθηματικά ΙΙ Χρήστος Νομικός Τμήμα Μηχανικών Η/Υ και Πληροφορικής Πανεπιστήμιο Ιωαννίνων 2018 Χρήστος Νομικός ( Τμήμα Μηχανικών Η/Υ Διακριτά
 Διακριτά Μαθηματικά ΙΙ Χρήστος Νομικός Τμήμα Μηχανικών Η/Υ και Πληροφορικής Πανεπιστήμιο Ιωαννίνων 2018 Χρήστος Νομικός ( Τμήμα Μηχανικών Η/Υ Διακριτά και Πληροφορικής Μαθηματικά Πανεπιστήμιο ΙΙ Ιωαννίνων
Διακριτά Μαθηματικά ΙΙ Χρήστος Νομικός Τμήμα Μηχανικών Η/Υ και Πληροφορικής Πανεπιστήμιο Ιωαννίνων 2018 Χρήστος Νομικός ( Τμήμα Μηχανικών Η/Υ Διακριτά και Πληροφορικής Μαθηματικά Πανεπιστήμιο ΙΙ Ιωαννίνων
Δομές Δεδομένων και Αλγόριθμοι
 Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 20 Huffman codes 1 / 12 Κωδικοποίηση σταθερού μήκους Αν χρησιμοποιηθεί κωδικοποίηση σταθερού μήκους δηλαδή
Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 20 Huffman codes 1 / 12 Κωδικοποίηση σταθερού μήκους Αν χρησιμοποιηθεί κωδικοποίηση σταθερού μήκους δηλαδή
ΑΚΕΡΑΙΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ & ΣΥΝΔΥΑΣΤΙΚΗ ΒΕΛΤΙΣΤΟΠΟΙΗΣΗ ΚΕΦΑΛΑΙΟ 1
 ΑΚΕΡΑΙΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ & ΣΥΝΔΥΑΣΤΙΚΗ ΒΕΛΤΙΣΤΟΠΟΙΗΣΗ ΚΕΦΑΛΑΙΟ 1 1 Βελτιστοποίηση Στην προσπάθεια αντιμετώπισης και επίλυσης των προβλημάτων που προκύπτουν στην πράξη, αναπτύσσουμε μαθηματικά μοντέλα,
ΑΚΕΡΑΙΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ & ΣΥΝΔΥΑΣΤΙΚΗ ΒΕΛΤΙΣΤΟΠΟΙΗΣΗ ΚΕΦΑΛΑΙΟ 1 1 Βελτιστοποίηση Στην προσπάθεια αντιμετώπισης και επίλυσης των προβλημάτων που προκύπτουν στην πράξη, αναπτύσσουμε μαθηματικά μοντέλα,
Μορφές των χωρικών δεδομένων
 Μορφές των χωρικών δεδομένων Eάν θελήσουμε να αναπαραστήσουμε το περιβάλλον με ακρίβεια, τότε θα χρειαζόταν μιά απείρως μεγάλη και πρακτικά μη πραγματοποιήσιμη βάση δεδομένων. Αυτό οδηγεί στην επιλογή
Μορφές των χωρικών δεδομένων Eάν θελήσουμε να αναπαραστήσουμε το περιβάλλον με ακρίβεια, τότε θα χρειαζόταν μιά απείρως μεγάλη και πρακτικά μη πραγματοποιήσιμη βάση δεδομένων. Αυτό οδηγεί στην επιλογή
ΠΕΙΡΑΜΑΤΙΚΕΣ ΠΡΟΣΟΜΟΙΩΣΕΙΣ ΚΕΦΑΛΑΙΟ 4. είναι η πραγματική απόκριση του j δεδομένου (εκπαίδευσης ή ελέγχου) και y ˆ j
 και y ˆ j") Πειραματικές Προσομοιώσεις ΚΕΦΑΛΑΙΟ 4 Όλες οι προσομοιώσεις έγιναν σε περιβάλλον Matlab. Για την υλοποίηση της μεθόδου ε-svm χρησιμοποιήθηκε το λογισμικό SVM-KM που αναπτύχθηκε στο Ecole d Ingenieur(e)s
Πειραματικές Προσομοιώσεις ΚΕΦΑΛΑΙΟ 4 Όλες οι προσομοιώσεις έγιναν σε περιβάλλον Matlab. Για την υλοποίηση της μεθόδου ε-svm χρησιμοποιήθηκε το λογισμικό SVM-KM που αναπτύχθηκε στο Ecole d Ingenieur(e)s
Εισαγωγή στους Ηλεκτρονικούς Υπολογιστές. 5 ο Μάθημα. Λεωνίδας Αλεξόπουλος Λέκτορας ΕΜΠ. url:
 στους Ηλεκτρονικούς Υπολογιστές 5 ο Μάθημα Λεωνίδας Αλεξόπουλος Λέκτορας ΕΜΠ email: leo@mail.ntua.gr url: http://users.ntua.gr/leo Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative
στους Ηλεκτρονικούς Υπολογιστές 5 ο Μάθημα Λεωνίδας Αλεξόπουλος Λέκτορας ΕΜΠ email: leo@mail.ntua.gr url: http://users.ntua.gr/leo Άδεια Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative
Αριθμητικά Συστήματα
 Αριθμητικά Συστήματα Οργάνωση Δεδομένων (1/2) Bits: Η μικρότερη αριθμητική μονάδα ενός υπολογιστικού συστήματος, η οποία δείχνει δύο καταστάσεις, 0 ή 1 (αληθές η ψευδές). Nibbles: Μονάδα 4 bit που παριστά
Αριθμητικά Συστήματα Οργάνωση Δεδομένων (1/2) Bits: Η μικρότερη αριθμητική μονάδα ενός υπολογιστικού συστήματος, η οποία δείχνει δύο καταστάσεις, 0 ή 1 (αληθές η ψευδές). Nibbles: Μονάδα 4 bit που παριστά
2 ΟΥ και 7 ΟΥ ΚΕΦΑΛΑΙΟΥ
 ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΕΠΙΜΕΛΕΙΑ: ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΘΕΩΡΙΑ 2 ΟΥ και 7 ΟΥ ΚΕΦΑΛΑΙΟΥ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΑΛΓΟΡΙΘΜΩΝ και ΔΟΜΗ ΑΚΟΛΟΥΘΙΑΣ 2.1 Να δοθεί ο ορισμός
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΕΠΙΜΕΛΕΙΑ: ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΘΕΩΡΙΑ 2 ΟΥ και 7 ΟΥ ΚΕΦΑΛΑΙΟΥ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΑΛΓΟΡΙΘΜΩΝ και ΔΟΜΗ ΑΚΟΛΟΥΘΙΑΣ 2.1 Να δοθεί ο ορισμός
3 ο Εργαστήριο Μεταβλητές, Τελεστές
 3 ο Εργαστήριο Μεταβλητές, Τελεστές Μια μεταβλητή έχει ένα όνομα και ουσιαστικά είναι ένας δείκτης σε μια συγκεκριμένη θέση στη μνήμη του υπολογιστή. Στη θέση μνήμης στην οποία δείχνει μια μεταβλητή αποθηκεύονται
3 ο Εργαστήριο Μεταβλητές, Τελεστές Μια μεταβλητή έχει ένα όνομα και ουσιαστικά είναι ένας δείκτης σε μια συγκεκριμένη θέση στη μνήμη του υπολογιστή. Στη θέση μνήμης στην οποία δείχνει μια μεταβλητή αποθηκεύονται
Γ Γυμνασίου: Οδηγίες Γραπτής Εργασίας και Σεμιναρίων. Επιμέλεια Καραβλίδης Αλέξανδρος. Πίνακας περιεχομένων
 Γ Γυμνασίου: Οδηγίες Γραπτής Εργασίας και Σεμιναρίων. Πίνακας περιεχομένων Τίτλος της έρευνας (title)... 2 Περιγραφή του προβλήματος (Statement of the problem)... 2 Περιγραφή του σκοπού της έρευνας (statement
Γ Γυμνασίου: Οδηγίες Γραπτής Εργασίας και Σεμιναρίων. Πίνακας περιεχομένων Τίτλος της έρευνας (title)... 2 Περιγραφή του προβλήματος (Statement of the problem)... 2 Περιγραφή του σκοπού της έρευνας (statement
Υπάρχουν δύο τύποι μνήμης, η μνήμη τυχαίας προσπέλασης (Random Access Memory RAM) και η μνήμη ανάγνωσης-μόνο (Read-Only Memory ROM).
 και η μνήμη ανάγνωσης-μόνο (Read-Only Memory ROM).") Μνήμες Ένα από τα βασικά πλεονεκτήματα των ψηφιακών συστημάτων σε σχέση με τα αναλογικά, είναι η ευκολία αποθήκευσης μεγάλων ποσοτήτων πληροφοριών, είτε προσωρινά είτε μόνιμα Οι πληροφορίες αποθηκεύονται
Μνήμες Ένα από τα βασικά πλεονεκτήματα των ψηφιακών συστημάτων σε σχέση με τα αναλογικά, είναι η ευκολία αποθήκευσης μεγάλων ποσοτήτων πληροφοριών, είτε προσωρινά είτε μόνιμα Οι πληροφορίες αποθηκεύονται
1 η Εργαστηριακή Άσκηση MATLAB Εισαγωγή
 ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΗΠΕΙΡΟΥ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ Τ.Ε. Εργαστήριο Επεξεργασία Εικόνας & Βίντεο 1 η Εργαστηριακή Άσκηση MATLAB Εισαγωγή Νικόλαος Γιαννακέας Άρτα 2018 1 Εισαγωγή Το Matlab
ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΗΠΕΙΡΟΥ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ Τ.Ε. Εργαστήριο Επεξεργασία Εικόνας & Βίντεο 1 η Εργαστηριακή Άσκηση MATLAB Εισαγωγή Νικόλαος Γιαννακέας Άρτα 2018 1 Εισαγωγή Το Matlab
Αναπαράσταση Μη Αριθμητικών Δεδομένων
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2014-15 Αναπαράσταση Μη Αριθμητικών Δεδομένων (κείμενο, ήχος και εικόνα στον υπολογιστή) http://di.ionio.gr/~mistral/tp/csintro/
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2014-15 Αναπαράσταση Μη Αριθμητικών Δεδομένων (κείμενο, ήχος και εικόνα στον υπολογιστή) http://di.ionio.gr/~mistral/tp/csintro/
! Δεδομένα: ανεξάρτητα από τύπο και προέλευση, στον υπολογιστή υπάρχουν σε μία μορφή: 0 και 1
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 5-6 Αναπαράσταση Μη Αριθμητικών Δεδομένων (κείμενο, ήχος και εικόνα στον υπολογιστή) http://di.ionio.gr/~mistral/tp/csintro/
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 5-6 Αναπαράσταση Μη Αριθμητικών Δεδομένων (κείμενο, ήχος και εικόνα στον υπολογιστή) http://di.ionio.gr/~mistral/tp/csintro/
Κεφάλαιο 20. Ανακάλυψη Γνώσης σε Βάσεις δεδοµένων. Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η.
 Κεφάλαιο 20 Ανακάλυψη Γνώσης σε Βάσεις δεδοµένων Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η. Σακελλαρίου Τεχνητή Νοηµοσύνη, B' Έκδοση - 1 - Ανακάλυψη Γνώσης σε
Κεφάλαιο 20 Ανακάλυψη Γνώσης σε Βάσεις δεδοµένων Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η. Σακελλαρίου Τεχνητή Νοηµοσύνη, B' Έκδοση - 1 - Ανακάλυψη Γνώσης σε
Τεχνικές ταξινόµησης αποτελεσµάτων µηχανών αναζήτησης µε βάση την ιστορία του χρήστη
 Τεχνικές ταξινόµησης αποτελεσµάτων µηχανών αναζήτησης µε βάση την ιστορία του χρήστη Όνοµα: Νικολαΐδης Αντώνιος Επιβλέπων: Τ. Σελλής Περίληψη ιπλωµατικής Εργασίας Συνεπιβλέποντες: Θ. αλαµάγκας, Γ. Γιαννόπουλος
Τεχνικές ταξινόµησης αποτελεσµάτων µηχανών αναζήτησης µε βάση την ιστορία του χρήστη Όνοµα: Νικολαΐδης Αντώνιος Επιβλέπων: Τ. Σελλής Περίληψη ιπλωµατικής Εργασίας Συνεπιβλέποντες: Θ. αλαµάγκας, Γ. Γιαννόπουλος
ΚΑΤΑΓΡΑΦΗ ΕΠΙΧΕΙΡΗΣΕΩΝ ΣΤΗΝ ΟΔΟ ΕΡΜΟΥ (ΜΥΤΙΛΗΝΗ, Ν. ΛΕΣΒΟΥ)
") ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΚΑΤΑΓΡΑΦΗ ΕΠΙΧΕΙΡΗΣΕΩΝ ΣΤΗΝ ΟΔΟ ΕΡΜΟΥ (ΜΥΤΙΛΗΝΗ, Ν. ΛΕΣΒΟΥ) ΤΜΗΜΑ ΓΕΩΓΡΑΦΙΑΣ ΝΙΚΟΣ ΣΤΑΣΙΝΟΣ ΜΥΤΙΛΗΝΗ 2016 ΠΕΡΙΕΧΟΜΕΝΑ 1. ΕΙΣΑΓΩΓΗ 1.1 ΣΚΟΠΟΣ ΣΕΛ.2 2. ΜΕΘΟΔΟΛΟΓΙΑ ΣΕΛ.3 3. ΑΠΟΤΕΛΕΣΜΑΤΑ
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΚΑΤΑΓΡΑΦΗ ΕΠΙΧΕΙΡΗΣΕΩΝ ΣΤΗΝ ΟΔΟ ΕΡΜΟΥ (ΜΥΤΙΛΗΝΗ, Ν. ΛΕΣΒΟΥ) ΤΜΗΜΑ ΓΕΩΓΡΑΦΙΑΣ ΝΙΚΟΣ ΣΤΑΣΙΝΟΣ ΜΥΤΙΛΗΝΗ 2016 ΠΕΡΙΕΧΟΜΕΝΑ 1. ΕΙΣΑΓΩΓΗ 1.1 ΣΚΟΠΟΣ ΣΕΛ.2 2. ΜΕΘΟΔΟΛΟΓΙΑ ΣΕΛ.3 3. ΑΠΟΤΕΛΕΣΜΑΤΑ
Περί της Ταξινόμησης των Ειδών
 Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Σχολή Θετικών Επιστημών Τμήμα Φυσικής 541 24 Θεσσαλονίκη Καθηγητής Γεώργιος Θεοδώρου Tel.: +30 2310998051, Ιστοσελίδα: http://users.auth.gr/theodoru Περί της Ταξινόμησης
Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Σχολή Θετικών Επιστημών Τμήμα Φυσικής 541 24 Θεσσαλονίκη Καθηγητής Γεώργιος Θεοδώρου Tel.: +30 2310998051, Ιστοσελίδα: http://users.auth.gr/theodoru Περί της Ταξινόμησης
Τεχνικές Μείωσης Διαστάσεων. Ειδικά θέματα ψηφιακής επεξεργασίας σήματος και εικόνας Σ. Φωτόπουλος- Α. Μακεδόνας
 Τεχνικές Μείωσης Διαστάσεων Ειδικά θέματα ψηφιακής επεξεργασίας σήματος και εικόνας Σ. Φωτόπουλος- Α. Μακεδόνας 1 Εισαγωγή Το μεγαλύτερο μέρος των δεδομένων που καλούμαστε να επεξεργαστούμε είναι πολυδιάστατα.
Τεχνικές Μείωσης Διαστάσεων Ειδικά θέματα ψηφιακής επεξεργασίας σήματος και εικόνας Σ. Φωτόπουλος- Α. Μακεδόνας 1 Εισαγωγή Το μεγαλύτερο μέρος των δεδομένων που καλούμαστε να επεξεργαστούμε είναι πολυδιάστατα.
Αριθμητικά Συστήματα
 Αριθμητικά Συστήματα Σε οποιοδήποτε αριθμητικό σύστημα, με βάση τον αριθμό Β, ένας ακέραιος αριθμός με πλήθος ψηφίων ν, εκφράζεται ως ακολούθως: α ν-1 α ν-2 α 1 α 0 = α ν-1 Β ν-1 + α ν-2 Β ν-2 + + α 1
Αριθμητικά Συστήματα Σε οποιοδήποτε αριθμητικό σύστημα, με βάση τον αριθμό Β, ένας ακέραιος αριθμός με πλήθος ψηφίων ν, εκφράζεται ως ακολούθως: α ν-1 α ν-2 α 1 α 0 = α ν-1 Β ν-1 + α ν-2 Β ν-2 + + α 1
ΚΕΦΑΛΑΙΟ 18. 18 Μηχανική Μάθηση
 ΚΕΦΑΛΑΙΟ 18 18 Μηχανική Μάθηση Ένα φυσικό ή τεχνητό σύστηµα επεξεργασίας πληροφορίας συµπεριλαµβανοµένων εκείνων µε δυνατότητες αντίληψης, µάθησης, συλλογισµού, λήψης απόφασης, επικοινωνίας και δράσης
ΚΕΦΑΛΑΙΟ 18 18 Μηχανική Μάθηση Ένα φυσικό ή τεχνητό σύστηµα επεξεργασίας πληροφορίας συµπεριλαµβανοµένων εκείνων µε δυνατότητες αντίληψης, µάθησης, συλλογισµού, λήψης απόφασης, επικοινωνίας και δράσης
Προγραμματισμός Ι (HY120)
") Προγραμματισμός Ι (HY20) # μνήμη & μεταβλητές πρόγραμμα & εκτέλεση Ψηφιακά δεδομένα, μνήμη, μεταβλητές 2 Δυαδικός κόσμος Οι υπολογιστές είναι δυαδικές μηχανές Όλη η πληροφορία (δεδομένα και κώδικας) κωδικοποιείται
Προγραμματισμός Ι (HY20) # μνήμη & μεταβλητές πρόγραμμα & εκτέλεση Ψηφιακά δεδομένα, μνήμη, μεταβλητές 2 Δυαδικός κόσμος Οι υπολογιστές είναι δυαδικές μηχανές Όλη η πληροφορία (δεδομένα και κώδικας) κωδικοποιείται
ΜΕΓΙΣΤΙΚΟΣ ΤΕΛΕΣΤΗΣ 18 Σεπτεμβρίου 2014
 ΜΕΓΙΣΤΙΚΟΣ ΤΕΛΕΣΤΗΣ 18 Σεπτεμβρίου 2014 Περιεχόμενα 1 Εισαγωγή 2 2 Μεγιστικός τελέστης στην μπάλα 2 2.1 Βασικό θεώρημα........................ 2 2.2 Γενική περίπτωση μπάλας.................. 6 2.2.1 Στο
ΜΕΓΙΣΤΙΚΟΣ ΤΕΛΕΣΤΗΣ 18 Σεπτεμβρίου 2014 Περιεχόμενα 1 Εισαγωγή 2 2 Μεγιστικός τελέστης στην μπάλα 2 2.1 Βασικό θεώρημα........................ 2 2.2 Γενική περίπτωση μπάλας.................. 6 2.2.1 Στο
ΚΑΤΑΣΚΕΥΗ ΠΙΝΑΚΩΝ ΚΑΙ ΣΧΗΜΑΤΩΝ ΣΤΟ ΔΟΚΙΜΙΟ ΕΡΕΥΝΗΤΙΚΗΣ ΕΡΓΑΣΙΑΣ: Μερικές χρήσιμες(;) υποδείξεις. Βασίλης Παυλόπουλος
 υποδείξεις. Βασίλης Παυλόπουλος") ΚΑΤΑΣΚΕΥΗ ΠΙΝΑΚΩΝ ΚΑΙ ΣΧΗΜΑΤΩΝ ΣΤΟ ΔΟΚΙΜΙΟ ΕΡΕΥΝΗΤΙΚΗΣ ΕΡΓΑΣΙΑΣ: Μερικές χρήσιμες(;) υποδείξεις Βασίλης Παυλόπουλος Διάγραμμα της παρουσίασης Πότε (δεν) χρειάζονται πίνακες και σχήματα σε μια ερευνητική
ΚΑΤΑΣΚΕΥΗ ΠΙΝΑΚΩΝ ΚΑΙ ΣΧΗΜΑΤΩΝ ΣΤΟ ΔΟΚΙΜΙΟ ΕΡΕΥΝΗΤΙΚΗΣ ΕΡΓΑΣΙΑΣ: Μερικές χρήσιμες(;) υποδείξεις Βασίλης Παυλόπουλος Διάγραμμα της παρουσίασης Πότε (δεν) χρειάζονται πίνακες και σχήματα σε μια ερευνητική
Εισαγωγή στην επιστήµη των υπολογιστών ΑΡΙΘΜΗΤΙΚΑ ΣΥΣΤΗΜΑΤΑ
 Εισαγωγή στην επιστήµη των υπολογιστών ΑΡΙΘΜΗΤΙΚΑ ΣΥΣΤΗΜΑΤΑ 1 Αριθµητικό Σύστηµα! Ορίζει τον τρόπο αναπαράστασης ενός αριθµού µε διακεκριµένα σύµβολα! Ένας αριθµός αναπαρίσταται διαφορετικά σε κάθε σύστηµα,
Εισαγωγή στην επιστήµη των υπολογιστών ΑΡΙΘΜΗΤΙΚΑ ΣΥΣΤΗΜΑΤΑ 1 Αριθµητικό Σύστηµα! Ορίζει τον τρόπο αναπαράστασης ενός αριθµού µε διακεκριµένα σύµβολα! Ένας αριθµός αναπαρίσταται διαφορετικά σε κάθε σύστηµα,
Εργαστήρια Text Mining & Sentiment Analysis με Rapid Miner
 10. Text Mining Για να μπορέσουμε να χρησιμοποιήσουμε τις δυνατότητες text mining του Rapid Miner πρέπει να εγκαταστήσουμε το Text Mining Extension. Πηγαίνουμε Help Updates and Extensions (Marketplace)
10. Text Mining Για να μπορέσουμε να χρησιμοποιήσουμε τις δυνατότητες text mining του Rapid Miner πρέπει να εγκαταστήσουμε το Text Mining Extension. Πηγαίνουμε Help Updates and Extensions (Marketplace)
1 η Θεµατική Ενότητα : Δυαδικά Συστήµατα
 1 η Θεµατική Ενότητα : Δυαδικά Συστήµατα Δεκαδικοί Αριθµοί Βάση : 10 Ψηφία : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 Αριθµοί: Συντελεστές Χ δυνάµεις του 10 7392.25 = 7x10 3 + 3x10 2 + 9x10 1 + 2x10 0 + 2x10-1 + 5x10-2
1 η Θεµατική Ενότητα : Δυαδικά Συστήµατα Δεκαδικοί Αριθµοί Βάση : 10 Ψηφία : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 Αριθµοί: Συντελεστές Χ δυνάµεις του 10 7392.25 = 7x10 3 + 3x10 2 + 9x10 1 + 2x10 0 + 2x10-1 + 5x10-2
Α. Θα καλεί υποπρόγραμμα INPUT που θα διαβάζει τις τιμές του πίνακα MAP.
 Διαγώνισμα νάπτυξης Εφαρμογών Γ Λυκείου Θέμα Το GIS είναι ένα υπολογιστικό σύστημα το οποίο χρησιμοποιείται για την συλλογή, αποθήκευση και ανάλυση δεδομένων και πληροφοριών με γεωγραφική διάσταση. Ένα
Διαγώνισμα νάπτυξης Εφαρμογών Γ Λυκείου Θέμα Το GIS είναι ένα υπολογιστικό σύστημα το οποίο χρησιμοποιείται για την συλλογή, αποθήκευση και ανάλυση δεδομένων και πληροφοριών με γεωγραφική διάσταση. Ένα
ΟΜΑΔΕΣ. Δημιουργία Ομάδων
 Δημιουργία Ομάδων Μεθοδολογίες ομαδοποίησης δεδομένων: Μέθοδοι για την εύρεση των κατηγοριών και των υποκατηγοριών που σχηματίζουν τα δεδομένα του εκάστοτε προβλήματος. Ομαδοποίηση (clustering): εργαλείο
Δημιουργία Ομάδων Μεθοδολογίες ομαδοποίησης δεδομένων: Μέθοδοι για την εύρεση των κατηγοριών και των υποκατηγοριών που σχηματίζουν τα δεδομένα του εκάστοτε προβλήματος. Ομαδοποίηση (clustering): εργαλείο
Μέρος Β /Στατιστική. Μέρος Β. Στατιστική. Γεωπονικό Πανεπιστήμιο Αθηνών Εργαστήριο Μαθηματικών&Στατιστικής/Γ. Παπαδόπουλος (www.aua.
 Μέρος Β /Στατιστική Μέρος Β Στατιστική Γεωπονικό Πανεπιστήμιο Αθηνών Εργαστήριο Μαθηματικών&Στατιστικής/Γ. Παπαδόπουλος (www.aua.gr/gpapadopoulos) Από τις Πιθανότητες στη Στατιστική Στα προηγούμενα, στο
Μέρος Β /Στατιστική Μέρος Β Στατιστική Γεωπονικό Πανεπιστήμιο Αθηνών Εργαστήριο Μαθηματικών&Στατιστικής/Γ. Παπαδόπουλος (www.aua.gr/gpapadopoulos) Από τις Πιθανότητες στη Στατιστική Στα προηγούμενα, στο
Ασκήσεις Φροντιστηρίου «Υπολογιστική Νοημοσύνη Ι» 5 o Φροντιστήριο
 Πρόβλημα ο Ασκήσεις Φροντιστηρίου 5 o Φροντιστήριο Δίνεται το παρακάτω σύνολο εκπαίδευσης: # Είσοδος Κατηγορία 0 0 0 Α 2 0 0 Α 0 Β 4 0 0 Α 5 0 Β 6 0 0 Α 7 0 Β 8 Β α) Στον παρακάτω κύβο τοποθετείστε τα
Πρόβλημα ο Ασκήσεις Φροντιστηρίου 5 o Φροντιστήριο Δίνεται το παρακάτω σύνολο εκπαίδευσης: # Είσοδος Κατηγορία 0 0 0 Α 2 0 0 Α 0 Β 4 0 0 Α 5 0 Β 6 0 0 Α 7 0 Β 8 Β α) Στον παρακάτω κύβο τοποθετείστε τα
Σχεδιασμός και Διεξαγωγή Πειραμάτων
 Σχεδιασμός και Διεξαγωγή Πειραμάτων Πρώτο στάδιο: λειτουργικοί ορισμοί της ανεξάρτητης και της εξαρτημένης μεταβλητής Επιλογή της ανεξάρτητης μεταβλητής Επιλέγουμε μια ανεξάρτητη μεταβλητή (ΑΜ), την οποία
Σχεδιασμός και Διεξαγωγή Πειραμάτων Πρώτο στάδιο: λειτουργικοί ορισμοί της ανεξάρτητης και της εξαρτημένης μεταβλητής Επιλογή της ανεξάρτητης μεταβλητής Επιλέγουμε μια ανεξάρτητη μεταβλητή (ΑΜ), την οποία
Ψηφιακή Επεξεργασία Εικόνας. Σ. Φωτόπουλος ΨΕΕ
 Ψηφιακή Επεξεργασία Εικόνας ΒΕΛΤΙΩΣΗ ΕΙΚΟΝΑΣ ΜΕ ΙΣΤΟΓΡΑΜΜΑ ΔΠΜΣ ΗΕΠ 1/46 Περιλαμβάνει: Βελτίωση (Enhancement) Ανακατασκευή (Restoration) Κωδικοποίηση (Coding) Ανάλυση, Κατανόηση Τμηματοποίηση (Segmentation)
Ψηφιακή Επεξεργασία Εικόνας ΒΕΛΤΙΩΣΗ ΕΙΚΟΝΑΣ ΜΕ ΙΣΤΟΓΡΑΜΜΑ ΔΠΜΣ ΗΕΠ 1/46 Περιλαμβάνει: Βελτίωση (Enhancement) Ανακατασκευή (Restoration) Κωδικοποίηση (Coding) Ανάλυση, Κατανόηση Τμηματοποίηση (Segmentation)
ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΜΕ ΙΣΤΟΓΡΑΜΜΑ
 Ψηφιακή Επεξεργασία Εικόνας-ΚΕΦ. -- ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΜΕ ΙΣΤΟΓΡΑΜΜΑ ΜΕΤΑΣΧΗΜΑΤΙΣΜΟΙ ΕΝΤΑΣΕΩΣ Η επεξεργασία εικόνας µέσω του ιστογράµµατος ουσιαστικά αποτελεί µία βασική επεξεργασία εικόνας που ανήκει
Ψηφιακή Επεξεργασία Εικόνας-ΚΕΦ. -- ΕΠΕΞΕΡΓΑΣΙΑ ΕΙΚΟΝΑΣ ΜΕ ΙΣΤΟΓΡΑΜΜΑ ΜΕΤΑΣΧΗΜΑΤΙΣΜΟΙ ΕΝΤΑΣΕΩΣ Η επεξεργασία εικόνας µέσω του ιστογράµµατος ουσιαστικά αποτελεί µία βασική επεξεργασία εικόνας που ανήκει
Κατηγοριοποίηση βάσει διανύσματος χαρακτηριστικών
 Κατηγοριοποίηση βάσει διανύσματος χαρακτηριστικών Αναπαράσταση των δεδομένων ως διανύσματα χαρακτηριστικών (feature vectors): Επιλογή ενός
Κατηγοριοποίηση βάσει διανύσματος χαρακτηριστικών Αναπαράσταση των δεδομένων ως διανύσματα χαρακτηριστικών (feature vectors): Επιλογή ενός
Μετάδοση Πολυμεσικών Υπηρεσιών Ψηφιακή Τηλεόραση
 Χειμερινό Εξάμηνο 2013-2014 Μετάδοση Πολυμεσικών Υπηρεσιών Ψηφιακή Τηλεόραση 5 η Παρουσίαση : Ψηφιακή Επεξεργασία Εικόνας Διδάσκων: Γιάννης Ντόκας Σύνθεση Χρωμάτων Αφαιρετική Παραγωγή Χρώματος Χρωματικά
Χειμερινό Εξάμηνο 2013-2014 Μετάδοση Πολυμεσικών Υπηρεσιών Ψηφιακή Τηλεόραση 5 η Παρουσίαση : Ψηφιακή Επεξεργασία Εικόνας Διδάσκων: Γιάννης Ντόκας Σύνθεση Χρωμάτων Αφαιρετική Παραγωγή Χρώματος Χρωματικά
Ψηφιακά Κυκλώματα Ι. Μάθημα 1: Δυαδικά συστήματα - Κώδικες. Λευτέρης Καπετανάκης
 ΤΛ2002 Ψηφιακά Κυκλώματα Ι Μάθημα 1: Δυαδικά συστήματα - Κώδικες Λευτέρης Καπετανάκης ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΚΡΗΤΗΣ ΤΜΗΜΑ ΗΛΕΚΤΡΟΝΙΚΗΣ Άνοιξη 2011 ΤΛ-2002: L1 Slide 1 Ψηφιακά Συστήματα ΤΛ-2002:
ΤΛ2002 Ψηφιακά Κυκλώματα Ι Μάθημα 1: Δυαδικά συστήματα - Κώδικες Λευτέρης Καπετανάκης ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΚΡΗΤΗΣ ΤΜΗΜΑ ΗΛΕΚΤΡΟΝΙΚΗΣ Άνοιξη 2011 ΤΛ-2002: L1 Slide 1 Ψηφιακά Συστήματα ΤΛ-2002:
Επιµέλεια Θοδωρής Πιερράτος
 Η έννοια πρόβληµα Ανάλυση προβλήµατος Με τον όρο πρόβληµα εννοούµε µια κατάσταση η οποία χρήζει αντιµετώπισης, απαιτεί λύση, η δε λύση της δεν είναι γνωστή ούτε προφανής. Μερικά προβλήµατα είναι τα εξής:
Η έννοια πρόβληµα Ανάλυση προβλήµατος Με τον όρο πρόβληµα εννοούµε µια κατάσταση η οποία χρήζει αντιµετώπισης, απαιτεί λύση, η δε λύση της δεν είναι γνωστή ούτε προφανής. Μερικά προβλήµατα είναι τα εξής:
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ
 ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ Κ. Δεμέστιχας Εργαστήριο Πληροφορικής Γεωπονικό Πανεπιστήμιο Αθηνών Επικοινωνία μέσω e-mail: cdemest@aua.gr, cdemest@cn.ntua.gr 1 2. ΑΡΙΘΜΗΤΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΜΕΡΟΣ Α 2 Τεχνολογία
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΠΛΗΡΟΦΟΡΙΚΗ Κ. Δεμέστιχας Εργαστήριο Πληροφορικής Γεωπονικό Πανεπιστήμιο Αθηνών Επικοινωνία μέσω e-mail: cdemest@aua.gr, cdemest@cn.ntua.gr 1 2. ΑΡΙΘΜΗΤΙΚΗ ΥΠΟΛΟΓΙΣΤΩΝ ΜΕΡΟΣ Α 2 Τεχνολογία
Δύο είναι οι κύριες αιτίες που μπορούμε να πάρουμε από τον υπολογιστή λανθασμένα αποτελέσματα εξαιτίας των σφαλμάτων στρογγυλοποίησης:
 Ορολογία bit (binary digit): δυαδικό ψηφίο. Τα δυαδικά ψηφία είναι το 0 και το 1 1 byte = 8 bits word: η θεμελιώδης μονάδα σύμφωνα με την οποία εκπροσωπούνται οι πληροφορίες στον υπολογιστή. Αποτελείται
Ορολογία bit (binary digit): δυαδικό ψηφίο. Τα δυαδικά ψηφία είναι το 0 και το 1 1 byte = 8 bits word: η θεμελιώδης μονάδα σύμφωνα με την οποία εκπροσωπούνται οι πληροφορίες στον υπολογιστή. Αποτελείται
Digital Image Processing
 Digital Image Processing Intensity Transformations Πέτρος Καρβέλης pkarvelis@gmail.com Images taken from: R. Gonzalez and R. Woods. Digital Image Processing, Prentice Hall, 2008. Image Enhancement: είναι
Digital Image Processing Intensity Transformations Πέτρος Καρβέλης pkarvelis@gmail.com Images taken from: R. Gonzalez and R. Woods. Digital Image Processing, Prentice Hall, 2008. Image Enhancement: είναι
Τίτλος Πακέτου Certified Computer Expert-ACTA
 Κωδικός Πακέτου ACTA - CCE - 002 Τίτλος Πακέτου Certified Computer Expert-ACTA Εκπαιδευτικές Ενότητες Επεξεργασία Κειμένου - Word Δημιουργία Εγγράφου Προχωρημένες τεχνικές επεξεργασίας κειμένου & αρχείων
Κωδικός Πακέτου ACTA - CCE - 002 Τίτλος Πακέτου Certified Computer Expert-ACTA Εκπαιδευτικές Ενότητες Επεξεργασία Κειμένου - Word Δημιουργία Εγγράφου Προχωρημένες τεχνικές επεξεργασίας κειμένου & αρχείων
ΜΟΝΤΕΛΟΠΟΙΗΣΗ ΔΙΑΚΡΙΤΩΝ ΕΝΑΛΛΑΚΤΙΚΩΝ ΣΕ ΠΡΟΒΛΗΜΑΤΑ ΣΧΕΔΙΑΣΜΟΥ ΚΑΙ ΣΥΝΘΕΣΗΣ ΔΙΕΡΓΑΣΙΩΝ
 ΜΕΡΟΣ ΙΙ ΜΟΝΤΕΛΟΠΟΙΗΣΗ ΔΙΑΚΡΙΤΩΝ ΕΝΑΛΛΑΚΤΙΚΩΝ ΣΕ ΠΡΟΒΛΗΜΑΤΑ ΣΧΕΔΙΑΣΜΟΥ ΚΑΙ ΣΥΝΘΕΣΗΣ ΔΙΕΡΓΑΣΙΩΝ 36 ΜΟΝΤΕΛΟΠΟΙΗΣΗ ΔΙΑΚΡΙΤΩΝ ΕΝΑΛΛΑΚΤΙΚΩΝ ΣΕ ΠΡΟΒΛΗΜΑΤΑ ΣΧΕΔΙΑΣΜΟΥ ΚΑΙ ΣΥΝΘΕΣΗΣ ΔΙΕΡΓΑΣΙΩΝ Πολλές από τις αποφάσεις
ΜΕΡΟΣ ΙΙ ΜΟΝΤΕΛΟΠΟΙΗΣΗ ΔΙΑΚΡΙΤΩΝ ΕΝΑΛΛΑΚΤΙΚΩΝ ΣΕ ΠΡΟΒΛΗΜΑΤΑ ΣΧΕΔΙΑΣΜΟΥ ΚΑΙ ΣΥΝΘΕΣΗΣ ΔΙΕΡΓΑΣΙΩΝ 36 ΜΟΝΤΕΛΟΠΟΙΗΣΗ ΔΙΑΚΡΙΤΩΝ ΕΝΑΛΛΑΚΤΙΚΩΝ ΣΕ ΠΡΟΒΛΗΜΑΤΑ ΣΧΕΔΙΑΣΜΟΥ ΚΑΙ ΣΥΝΘΕΣΗΣ ΔΙΕΡΓΑΣΙΩΝ Πολλές από τις αποφάσεις
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #02 Ιστορική αναδρομή Σχετικές επιστημονικές περιοχές 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #02 Ιστορική αναδρομή Σχετικές επιστημονικές περιοχές 1 Άδεια χρήσης Το παρόν εκπαιδευτικό