Lecture Notes for Chapter 6. Introduction to Data Mining
|
|
|
- Ἄλκανδρος Κορνάρος
- 7 χρόνια πριν
- Προβολές:
Transcript
1 Κανόνες Συσχέτισης: Βασικές αρχές και αλγόριθμοι (Association Analysis: Basic Concepts and Algorithms) Lecture Notes for Chapter 6 Introduction to Data Mining by Tan, Steinbach, Kumar
2 Εξόρυξη κανόνων συσχέτισης (Association Rule Mining) Πρόβλημα Δεδομένου ενός συνόλου συναλλαγών, βρείτε κανόνες που θα προβλέπουν την εμφάνιση ενός στοιχείου (item) με βάση την εμφάνιση άλλων στοιχείων που προέρχονται από το αρχείο με τις συναλλαγές (transactions) TID Items Market-Basket transactions 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke δοσοληψία (transaction) στοιχείο (item) Προώθηση προϊόντων Τοποθέτηση προϊόντων στα ράφια Διαχείριση αποθεμάτων Παραδείγματα κανόνων συχέτισης {Diaper} {Beer}, {Milk, Bread} {Eggs,Coke}, {Beer, Bread} {Milk}, Οι «κανόνες» δηλώνουν από κοινού εμφάνιση (co-occurrence) και όχι αιτιότητα (causality)! Εμφανίζονται μαζί, όχι ότι η εμφάνιση του ενός είναι η αιτία της εμφάνισης του άλλου (co-occurrence, not causality όχι έννοια χρόνου ή διάταξης)
3 Ορισμοί Δυαδική αναπαράσταση Γραμμές: δοσοληψίες Στήλες: Στοιχεία 1 αν το στοιχείο εμφανίζεται στη σχετική δοσοληψία Μη συμμετρική δυαδική μεταβλητή (1 πιο σημαντικό από το 0) Ένας περιορισμός είναι ότι χάνουμε πληροφορία για τις ποσότητες Παράδειγμα TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
4 Ορισμοί Ι = {i 1, i 2,.., i k } ένα σύνολο από διακριτά στοιχεία (items) Παράδειγμα: {Bread, Milk, Diapers, Beer, Eggs, Coke} Στοιχειοσύνολο (Itemset): Ένα υποσύνολο του Ι Παράδειγμα: {Milk, Bread, Diaper} TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke k-στοιχειοσύνολο (k-itemset): ένα στοιχειοσύνολο με k στοιχεία Τ = {t 1, t 2,.., t N } ένα σύνολο από δοσοληψίες, όπου κάθε t i είναι ένα στοιχειοσύνολο Πλάτος (width) δοσοληψίας: αριθμός στοιχείων t i περιέχει ένα στοιχειοσύνολο Χ, αν το Χ είναι υποσύνολο της t i
5 Ορισμοί support count ( ) ενός στοιχειοσυνόλου Η συχνότητα εμφάνισης του στοιχειοσυνόλου Παράδειγμα: ({Milk, Bread, Diaper}) = 2 σ(χ) = { t i X t i, t i T} TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Υποστήριξη (Support (s)) ενός στοιχειοσυνόλου Το ποσοστό των δοσοληψιών που περιέχουν ένα στοιχειοσύνολο Παράδειγμα: s({milk, Bread, Diaper}) = 2/5 Frequent Itemset Συχνό Στοιχειοσύνολο Ένα στοιχειοσύνολο του οποίου η υποστήριξη είναι μεγαλύτερη ή ίση από κάποια τιμή κατωφλίου minsup
6 Συνοπτικά Ορισμοί: Συχνά στοιχειοσύνολα (Frequent Itemset) Στοιχειοσύνολο (Itemset) Ένα σύνολο από ένα ή περισσότερα στοιχεία Παράδειγμα: {Milk, Bread, Diaper} k-στοιχειοσύνολο Ένα στοιχειοσύνολο που περιέχει k στοιχεία Μετρητής υποστήριξης (Support count ( )) Συχνότητα εμφάνισης ενός στοιχειοσυνόλου Π.χ. ({Milk, Bread,Diaper}) = 2 Υποστήριξη (Support ) Ποσοστό των συναλλαγών που περιέχουν ένα στοιχειοσύνολο Π.χ.. s({milk, Bread, Diaper}) = 2/5 Συχνό στοιχειοσύνολο (Frequent Itemset) Ένα στοιχειοσύνολο που η υποστήριξή του είναι μεγαλύτερη ή ίση από ένα κατώφλι minsup TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
7 {Milk, Diaper, Beer} s T Ορισμοί Κανόνας Συσχέτισης (Association Rule) Είναι μια έκφραση της μορφής X Y, όπου X και Y είναι στοιχειοσύνολα Χ Ι, Υ Ι, Χ Υ = Παράδειγμα: {Milk, Diaper} {Beer} TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Υποστήριξη Κανόνα Support (s) Το ποσοστό των δοσοληψιών που περιέχουν και το X και το Y (Χ Υ) σ(χ Υ)/ Τ ( Τ ο αριθμός των δοσοληψιών) Εμπιστοσύνη - Confidence (c) Πόσες από τις δοσοληψίες (ποσοστό) που περιέχουν το Χ περιέχουν και το Υ σ(χ Υ)/σ(Χ) { Milk, Diaper} Beer c {Milk, Diaper, Beer} {Milk, Diaper}
8 Ορισμός: Κανόνας συσχέτισης (Association Rule) Κανόνας συσχέτισης (Association Rule) Μία έκφραση συνεπαγωγής της μορφής X Y, όπου X και Y είναι στοιχειοσύνολα Παράδειγμα: {Milk, Diaper} {Beer} Μέτρα εκτίμησης των κανόνων Υποστήριξη (Support (s)) Ποσοστό των συναλλαγών που περιέχουν και το X και το Y Εμπιστοσύνη (Confidence (c)) Μετράει πόσο συχνά τα στοιχεία του Y εμφανίζονται σε συναλλαγές που περιέχουν το X TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Παράδειγμα: { Milk, Diaper} (Milk, Diaper,Beer) s T (Milk,Diaper,Beer) c (Milk, Diaper) Beer
9 Το έργο της εξόρυξης κανόνων συσχέτισης Δοθέντος ενός συνόλου από συναλλαγές (transactions T), ο στόχος της εξόρυξης κανόνων συσχέτισης είναι να βρει όλους τους κανόνες οι οποίοι έχουν support minsup threshold confidence minconf threshold
10 Εξόρυξη Κανόνων Συσχέτισης s(x Y) = s(x Y) = σ(x Y)/Ν Παρατηρήσεις Ένας κανόνας με μικρή υποστήριξη μπορεί να εμφανίζεται τυχαία Λιγότερη σημασία/χρησιμότητα, γιατί αφορά μικρό αριθμό από συναλλαγές Το κατώφλι minsup εξαιρεί κανόνες που δεν έχουν ενδιαφέρον c(x Y) = σ(x Y)/σ(X) c(x Y) = P(Υ Χ) δεσμευμένη πιθανότητα να εμφανίζεται το Υ όταν εμφανίζεται το Χ Εμπιστοσύνη μετρά την αξιοπιστία, βεβαιότητα της εξάρτησης Όσο μεγαλύτερη εμπιστοσύνη τόσο μεγαλύτερη η πιθανότητα εμφάνισης του Υ σε κανόνες που περιέχουν το Χ
11 Εξόρυξη Κανόνων Συσχέτισης Εύρεση Κανόνων Συσχέτισης Είσοδος: Ένα σύνολο από δοσοληψίες T Έξοδος: Όλοι οι κανόνες με support minsup confidence minconf
12 Εξόρυξη Κανόνων Συσχέτισης Προσέγγισης «ωμής δύναμης» (Brute-force): Δημιουργία λίστας με όλους τους πιθανούς κανόνες συσχέτισης Υπολογισμός της υποστήριξης και της εμπιστοσύνης για κάθε κανόνα Απόρριψη ( Prune) των κανόνων που δεν τηρούν τα κριτήρια για την υποστήριξη και την εμπιστοσύνη minsup και minconf Υπολογιστικά απαγορευτικό!
13 Εξόρυξη κανόνων συσχέτισης TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Παραδείγματα κανόνων: {Milk,Diaper} {Beer} (s=0.4, c=0.67) {Milk,Beer} {Diaper} (s=0.4, c=1.0) {Diaper,Beer} {Milk} (s=0.4, c=0.67) {Beer} {Milk,Diaper} (s=0.4, c=0.67) {Diaper} {Milk,Beer} (s=0.4, c=0.5) {Milk} {Diaper,Beer} (s=0.4, c=0.5) Η υποστήριξη ενός κανόνα X Y εξαρτάται μόνο από την υποστήριξη του Χ Υ Άρα κανόνες που ξεκινούν από τo ίδιο στοιχειοσύνολο έχουν την ίδια υποστήριξη (αλλά πιθανών διαφορετική εμπιστοσύνη) Παρατηρήσεις: Όλοι οι παραπάνω κανόνες προέρχονται από μία δυαδική διαμέριση του ίδιου στοιχειοσυνόλου : {Milk, Diaper, Beer} Κανόνες που προέρχονται από το ίδιο στοιχειοσύνολο έχουν την ίδια τιμή για την υποστήριξη αλλά μπορεί να έχουν διαφορετική τιμή για την εμπιστοσύνη Συνεπώς μπορούμε να διαχωρίσουμε τις απαιτήσεις για την υποστήριξη και την εμπιστοσύνη
14 Εξόρυξη κανόνων συσχέτισης Σε δύο βήματα (υποπροβλήματα): 1. Παραγωγή των συχνών στοιχειοσυνόλων (Frequent Itemset Generation) Εύρεση όλων των στοιχειοσυνόλων με υποστήριξη support minsup 2. Παραγωγή κανόνων (Rule Generation) Παραγωγή κανόνων με υψηλή εμπιστοσύνη από τα συχνά στοιχειοσύνολα, όπου κάθε κανόνας είναι μια δυαδική διαμέριση ενός συχνού στοιχειοσυνόλου Η παραγωγή των συχνών στοιχειοσυνόλων εξακολουθεί να είναι υπολογιστικά ακριβή
15 Εύρεση / Παραγωγή Συχνών Στοιχειοσυνόλων
16 Παραγωγή συχνών στοιχειοσυνόλων null A B C D E Πλέγμα Στοιχειοσυνόλων AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE ABCD ABCE ABDE ACDE BCDE ABCDE Για d στοιχεία υπάρχουν 2 d πιθανά υποψήφια στοιχειοσύνολα (candidate itemsets)
17 Παραγωγή συχνών στοιχειοσυνόλων Προσέγγιση «ωμής δύναμης» (Brute-force) : Κάθε στοιχειοσύνολο στο δικτύωμα (lattice) είναι υποψήφιο (candidate) συχνό στοιχειοσύνολο Υπολογισμός της υποστήριξης του κάθε υποψηφίου διατρέχοντας (scanning) όλη τη βάση δεδομένων Transactions List of Candidates TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke N M 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke w Έλεγχος κάθε συναλλαγής με κάθε υποψήφιο Έχουμε N αριθμός δοσοληψιών, w μέγιστο πλάτος δοσοληψίας Πολυπλοκότητα (Complexity) ~ O(NMw) => «ακριβή» καθώς M = 2 d!!!
18 Υπολογιστική πολυπλοκότητα Για d διαφορετικά (unique) στοιχεία: Ο συνολικός αριθμός των στοιχειοσυνόλων = 2 d Ο συνολικός αριθμός των πιθανών κανόνων συσχέτισης : d d d k k d j j k d k d R Εάν d=6, R = 602 κανόνες
19 Παράδειγμα παραγωγής συχνών στοιχειοσυνόλων
20 Παράδειγμα παραγωγής συχνών στοιχειοσυνόλων
21 Παράδειγμα παραγωγής συχνών στοιχειοσυνόλων
22 Στρατηγικές για την παραγωγή συχνών στοιχειοσυνόλων Διαφορετικές Στρατηγικές Μείωση του αριθμού των υποψηφίων στοιχειοσυνόλων (M) Συνολικό πλήθος : M=2 d Χρησιμοποίηση τεχνικών «κλαδέματος» (pruning) για μείωση του M (Π.χ. apriori) Μείωση του αριθμού των συναλλαγών (N) Μείωση του μεγέθους του N καθώς αυξάνει το μέγεθος των στοιχειοσυνόλων (π.χ αλγόριθμοι βασισμένοι σε κατακερματιμό) Χρησιμοποιείται από «κάθετους» αλγορίθμους εξόρυξης Μείωση του αριθμού των συγκρίσεων (NM) Χρήση αποδοτικών δομών δεδομένων για την αποθήκευση των υποψηφίων ή των συναλλαγών Προσπαθούμε να αποφύγουμε να ταιριάξουμε κάθε υποψήφιο στοιχειοσύνολο με κάθε δοσοληψία. (Δεν απαιτείται να συγκριθεί κάθε υποψήφιος με κάθε συναλλαγή)
23 Μείωση του αριθμού των υποψηφίων Η αρχή Apriori Εάν ένα στοιχειοσύνολο είναι συχνό, τότε όλα τα υποσύνολά του πρέπει να είναι επίσης συχνά Η αρχή Apriori ισχύει λόγω της παρακάτω ιδιότητας της υποστήριξης: X, Y : ( X Y ) s( X ) s( Y ) Η υποστήριξη ενός στοιχειοσυνόλου ποτέ δεν υπερβαίνει την υποστήριξη των υποσυνόλων του (Η υποστήριξη ενός στοιχεισύνολου είναι μικρότερη ή ίση της υποστήριξης οποιουδήποτε υποσυνόλου του) Αυτή είναι γνωστή ως η αντι-μονότονη (antimonotone) ιδιότητα της υποστήριξης
24 ) ( ) ( ) ( :, Y s X s Y X Y X Αρχή apriori Αντι-μονότονη (anti-monotone) ιδιότητα της υποστήριξης s: downwards closed ) ( ) ( ) ( :, Y f X f Y X Y X Mονότονη ιδιότητα ή upwards closed
25 Απεικόνιση της αρχής Apriori Support-based pruning null A B C D E AB AC AD AE BC BD BE CD CE DE Found to be Infrequent ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE Μπορούμε να «ψαλιδίσουμε» όλα τα υπερσύνολα του Pruned supersets ABCD ABCE ABDE ACDE BCDE ABCDE Αντιθετοαντιστροφή: Αν ένα στοιχειοσύνολο δεν είναι συχνό, όλα τα υπερσύνολα του δεν είναι συχνά
26 Απεικόνιση της αρχής Apriori Όλα τα υποσύνολα του συχνά Κλειστό προς τα κάτω Συχνό στοιχειοσύνολο Αν το {c, d, e} είναι συχνό, όλα τα υποσύνολα του είναι συχνά
27 Απεικόνιση της αρχής Apriori Στοιχεία (1-στοιχειοσύνολα) Item Count Bread 4 Coke 2 Milk 4 Beer 3 Diaper 4 Eggs 1 Minimum Support = 3 Εάν είχαμε υπολογίσει όλα τα υποσύνολα, 6 C C C 3 = Με τη χρήση του κλαδέματος με βάση την υποστήριξη: = 13 TID Itemset Count {Bread,Milk} 3 {Bread,Beer} 2 {Bread,Diaper} 3 {Milk,Beer} 2 {Milk,Diaper} 3 {Beer,Diaper} 3 Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Ζεύγη (2-στοιχειοσύνολα) (Δεν χρειάζεται να παραχθούν υποψήφιοι που να εμπλέκουν τα Coke και Eggs) Στοιχεία (1-στοιχειοσύνολα Itemset Count {Bread,Milk,Diaper}
28 Στρατηγική Apriori Γενικός Αλγόριθμος: 1. Έστω k=1 2. Παρήγαγε συχνά στοιχειοσύνολα μήκους 1 3. Επανέλαβε μέχρι να μην ανιχνεύονται νέα συχνά στοιχειοσύνολα 1. Παρήγαγε υποψήφια στοιχειοσύνολα μήκους (k+1) από συχνά στοιχειοσύνολα μήκους k 2. Κλάδεψε υποψήφια στοιχειοσύνολα μήκους k τα οποία δεν είναι συχνά 3. Μέτρησε τη υποστήριξη (support) του κάθε υποψηφίου στοιχειοσυνόλου σαρώνοντας την βάση δεδομένων 4. Εξάλειψε όλα τα υποψήφια που δεν είναι συχνά, διατηρώντας μόνο αυτά που είναι συχνά
29 Στρατηγική apriori Γενικός Αλγόριθμος Διατρέχει το πλέγμα ανά επίπεδο Generate-and-Test στρατηγική Σε κάθε βήμα k: Δημιουργία υποψήφιων k-στοιχειοσυνόλων με βάση τα συχνά k-1 στοιχειοσύνολα Υπολογισμός της υποστήριξής τους και pruning όσων έχουν μικρή υποστήριξη k max περάσματα, όπου k max μέγεθος (αριθμός στοιχείων) του μεγαλύτερου στοιχειοσυνόλου
30 Στρατηγική apriori: Δημιουργία Στοιχειοσυνόλων Σε κάθε βήμα k: Δημιουργία υποψήφιων k-στοιχειοσυνόλων με βάση τα συχνά k-1 στοιχειοσύνολα Όλα τα υποσύνολα του πρέπει να είναι συχνά Δεν πρέπει να δημιουργούμε ένα στοιχειοσύνολο πολλές φορές complete δεν πρέπει να χάνουμε κάποιο συχνό Πως;
31 Στρατηγική apriori: Δημιουργία Στοιχειοσυνόλων Θα δούμε δύο τρόπους: Μέθοδος F k-1 x F 1 Μέθοδος F k-1 x F k-1 Για να αποφύγουμε τη δημιουργία του ίδιου στοιχειοσυνόλου, κρατάμε κάθε στοιχειοσύνολο (λεξικογραφικά) ταξινομημένο Και στις δύο περιπτώσεις, έλεγχος αν τα παραγόμενα στοιχειοσύνολα είναι συχνά με βάση τα υποσύνολά τους.
32 Στρατηγική apriori: Δημιουργία Στοιχειοσυνόλων Μέθοδος F k-1 x F 1 Επέκταση κάθε συχνού (k-1) στοιχειοσυνόλου με άλλα συχνά στοιχεία Itemset Count {Bread,Milk} 3 {Beer,Bread} 2 {Bread,Diaper} 3 {Beer, Milk} 2 {Diaper,Milk} 3 {Beer,Diaper} 3 Item Count Bread 4 Coke 2 Milk 4 Beer 3 Diaper 4 Eggs 1 Κάθε στοιχειοσύνολο (λεξικογραφικά) ταξινομημένο κάθε (k-1) συχνό στοιχεισύνολο επεκτείνεται με συχνά στοιχεία που είναι λεξικογραφικά μεγαλύτερα του Ο( F k-1 x F 1 ) {Beer, Diaper, Milk} Δημιουργεί και κάποια περιττά, πχ το παραπάνω δεν είναι συχνό, γιατί το {Beer, Milk} δεν είναι συχνό
33 Στρατηγική apriori: Δημιουργία Στοιχειοσυνόλων F k-1 x F 1 Επέκταση κάθε συχνού (k-1) στοιχειοσυνόλου με άλλα συχνά στοιχεία Διάφοροι ευριστικοί για να μειωθεί ο αριθμός των στοιχειοσυνόλων που δημιουργούνται και δεν είναι συχνά Πχ έστω το {i 1, i 2, i 3, i 4 } για να είναι συχνό πρέπει όλα τα 3- στοιχειοσύνολα που είναι υποσύνολα του να είναι συχνά, Πχ θα πρέπει να υπάρχουν τουλάχιστον 3 3-στοιχειοσύνολα που περιέχουν πχ το i 4 ({i 1, i 2, i 4 }, {i 1, i 3, i 4 } και {i 2, i 3, i 4 } Γενικά, κάθε στοιχείο ενός k-στοιχειοσυνόλου θα πρέπει να περιέχεται σε τουλάχιστον k-1 από το συχνά (k-1)- στοιχειοσύνολα
34 Στρατηγική apriori: Δημιουργία Στοιχειοσυνόλων F k-1 x F k-1 Συγχώνευση δύο συχνών (k-1) στοιχειοσυνόλου αν τα πρώτα k-2 στοιχεία τους είναι τα ίδια Itemset Count {Bread,Milk} 3 {Beer,Bread} 2 {Bread,Diaper} 3 {Beer, Milk} 2 {Diaper,Milk} 3 {Beer,Diaper} 3 Itemset Count {Bread,Milk} 3 {Beer,Bread} 2 {Bread,Diaper} 3 {Beer, Milk} 2 {Diaper,Milk} 3 {Beer,Diaper} 3 Συγχώνευση δύο συχνών (k-1)-στοιχειοσυνόλων αλλά πρέπει επιπρόσθετα να ελέγξουμε ότι και τα υπόλοιπα k-2 υποσύνολα είναι συχνά
35 Στρατηγική Apriori Γενικός Αλγόριθμος: 1. Έστω k=1 2. Παρήγαγε συχνά στοιχειοσύνολα μήκους 1 3. Επανέλαβε μέχρι να μην ανιχνεύονται νέα συχνά στοιχειοσύνολα 1. Παρήγαγε υποψήφια στοιχειοσύνολα μήκους (k+1) από συχνά στοιχειοσύνολα μήκους k 2. Κλάδεψε υποψήφια στοιχειοσύνολα μήκους k τα οποία δεν είναι συχνά 3. Μέτρησε τη υποστήριξη (support) του κάθε υποψηφίου στοιχειοσυνόλου σαρώνοντας την βάση δεδομένων 4. Εξάλειψε όλα τα υποψήφια που δεν είναι συχνά, διατηρώντας μόνο αυτά που είναι συχνά
36 Στρατηγική apriori: Υπολογισμός Υποστήριξης Υπολογισμός υποστήριξης: για κάθε νέο υποψήφιο συχνό στοιχειοσύνολο, πρέπει να υπολογίσουμε την υποστήριξή του Brute Force: Διαπέρασε τη βάση των δοσοληψιών για τον υπολογισμό της υποστήριξης κάθε υποψήφιου στοιχειοσυνόλου Αν σε ένα βήμα έχουμε m συχνά στοιχειοσύνολα, τότε διαπέραση της βάσης δεδομένων m φορές Συναλλαγές For each item TID Items for i = 1 to N 1 Bread, Milk if t i περιέχει το item 2 Bread, Diaper, Beer, Eggs N 3 Milk, Diaper, Beer, Coke c(item)++ 4 Bread, Milk, Diaper, Beer Πχ έστω 5 Bread, Milk, Diaper, Coke item = {Beer, Bread}
37 Μείωση των αριθμών των συγκρίσεων Μέτρηση των υποψηφίων: Σάρωση της βάσης των συναλλαγών για τον καθορισμό της υποστήριξης κάθε υποψήφιου στοιχειοσυνόλου Για τη μείωση του αριθμού των συγκρίσεων αποθήκευσε τα υποψήφια στοιχειοσύνολα σε μία δομή κατακερματισμού (hash structure) Αντί να συγκριθεί κάθε συναλλαγή με κάθε υποψήφιο, συγκρίνεται με υποψηφίους στην κατακερματισμένη δομή (ταίριαξε κάθε δοσοληψία με τα υποψήφια στοιχειοσύνολα που περιέχονται σε κάδους κατακερματισμού Transactions Hash Structure N TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke k Buckets
38 Στρατηγική apriori: Υπολογισμός Υποστήριξης Απαρίθμηση Στοιχειο-συνόλων Βασική ιδέα του κατακερματισμού 1. Κατά τη διάρκεια του apriori τα συχνά στοιχειοσύνολα που παράγονται κατακερματίζονται σε κάδους και αποθηκεύονται σε ένα δέντρο κατακερματισμού 2. Στη συνέχεια, κάθε δοσοληψία (για την ακρίβεια, κάθε στοιχειοσύνολο που περιέχει) κατακερματίζεται με την ίδια συνάρτηση και τη συγκρίνουμε όχι με όλα τα πιθανά στοιχειοσύνολα, αλλά μόνο με τα στοιχειοσύνολα στους αντίστοιχους κάδους
39 Δημιουργία δένδρου κατακερματισμού (Hash Tree) υποψηφίων στοιχειοσυνόλων Έστω ότι έχουμε 15 υποψήφια στοιχειοσύνολα μήκους 3: {1 4 5}, {1 2 4}, {4 5 7}, {1 2 5}, {4 5 8}, {1 5 9}, {1 3 6}, {2 3 4}, {5 6 7}, {3 4 5}, {3 5 6}, {3 5 7}, {6 8 9}, {3 6 7}, {3 6 8} Χρειάζεται: Μία συνάρτηση κατακερματισμού (ποιο κλαδί θα ακολουθήσουμε σε κάθε επίπεδο) Μέγιστο μέγεθος φύλλου: μέγιστος αριθμός στοιχειοσυνόλων αποθηκευμένων σε ένα κόμβο-φύλλο (εάν ο αριθμός των υποψήφιων στοιχειοσυνόλων υπερβεί το μέγιστο μέγεθος φύλλου, χώρισε (split) τον κόμβο- χρηση κατακερματισμού στο επόμενο στοιχείο) Hash function 3,6,9 1,4,7 2,5,8 m mod Στο δέντρο κατακερματίζουμε τα υποψήφια στοιχειοσύνολα
40 Στρατηγική apriori Εύρεση κανόνων συσχέτισης: Δέντρο κατακερματισμού (Hash tree) για τον υπολογισμό υποστήριξης Συνάρτηση κατακερματισμού (Hash Function) Δένδρο Κατακερματισμού υποψηφίων (Candidate Hash Tree 1,4,7 3,6,9 2,5,8 Hash on 1, 4 or
41 Στρατηγική apriori Εύρεση κανόνων συσχέτισης: Δέντρο κατακερματισμού (Hash tree) για τον υπολογισμό υποστήριξης Συνάρτηση κατακερματισμού (Hash Function) Δένδρο Κατακερματισμού υποψηφίων (Candidate Hash Tree) 1,4,7 3,6,9 2,5,8 Hash on 2, 5 or
42 Στρατηγική apriori Εύρεση κανόνων συσχέτισης: Δέντρο κατακερματισμού (Hash tree) για τον υπολογισμό υποστήριξης Συνάρτηση κατακερματισμού (Hash Function) Δένδρο Κατακερματισμού υποψηφίων (Candidate Hash Tree 1,4,7 3,6,9 2,5,8 Hash on 3, 6 or
43 Στρατηγική apriori: Υπολογισμός Υποστήριξης 2. Απαρίθμηση Υποσυνόλων με χρήση του Δέντρου Κατακερματισμού Έχοντας κατασκευάσει το δέντρο κατακερματισμού (για τα 3-στοιχειοσύνολα), Για κάθε δοσοληψία, κατακερματίζουμε όλα τα 3-στοιχειοσύνολα της δοσοληψίας στο δέντρο και αυξάνουμε τον αντίστοιχο μετρητή
44 Στρατηγική apriori: Υπολογισμός Υποστήριξης Απαρίθμηση Στοιχειο-συνόλων Πχ έστω ότι είμαστε στο 3 βήμα και έχουμε δημιουργήσει όλα τα πιθανά 3-στοιχειο-σύνολα Έστω μια δοσοληψία t με 5 στοιχεία {1, 2, 3, 5, 6} Θα πρέπει να ελέγξουμε για καθένα από αυτά αν το περιέχει η t Αν το περιέχει η t θα πρέπει να αυξήσουμε την υποστήριξη του κατά 1 Ας δούμε πρώτα ένα συστηματικό τρόπο για την απαρίθμηση όλων των 3-στοιχειοσυνόλων της t
45 Στρατηγική apriori: Υπολογισμός Υποστήριξης Απαρίθμηση Στοιχειο-συνόλων Έστω μια δοσοληψία t με 5 στοιχεία {1, 2, 3, 5, 6} - Απαρίθμηση όλων των πιθανών υποσυνόλων της με τρία στοιχεία (3-στοιχειοσύνολα) με λεξικογραφική διάταξη. Ποια είναι τα πιθανά υποσύνολα μεγέθους/μήκους 3? Δοσοληψία t Επίπεδο Επίπεδο Επίπεδο 3 Υποσύνολα 3 στοιχείων
46 Στρατηγική apriori: Υπολογισμός Υποστήριξης Απαρίθμηση Στοιχειο-συνόλων Έστω μια δοσοληψία t με 4 στοιχεία {1, 2, 3, 4} - Απαρίθμηση όλων των πιθανών υποσυνόλων της με τρία στοιχεία (3-στοιχειοσύνολα) με λεξικογραφική διάταξη Δοσοληψία t Επίπεδο Επίπεδο Επίπεδο 3 Υποσύνολα 3 στοιχείων
47 Στρατηγική apriori: Υπολογισμός Υποστήριξης Με βάση το δέντρο απαρίθμησης για την t = {1, 2, 3, 5, 6} όλα τα δυνατά στοχειοσύνολα αρχίζουν από 1, 2 ή 3 => στη ρίζα κατακερματίζουμε χωριστά τα 1, 2 και 3 δηλαδή με βάση τα στοιχεία του πρώτου επιπέδου Δοσοληψία t Συνάρτηση Κατακερματισμού ,4,7 3,6, ,5,
48 Στρατηγική apriori: Υπολογισμός Υποστήριξης στη συνέχεια κατακερματίζουμε με βάση τα αντίστοιχα στοιχεία του δεύτερου επιπέδου: 2, 3, 5 (για το 1) 3, 5 (για το 2) 5 (για το 3) κοκ μέχρι να φτάσουμε σε φύλλα Δοσοληψία Συνάρτηση Κατακερματισμού ,4,7 2,5,8 3,6,
49 Στρατηγική apriori: Υπολογισμός Υποστήριξης transaction Hash Function ,4,7 2,5,8 3,6, Ταίριασμα 11 από τα 15 υποψήφιες (5 από τα 9 φύλλα)
50
51 Στρατηγική apriori Γενικός Αλγόριθμος (ξανά) k = 1 Δημιούργησε όλα τα συχνά στοιχειοσύνολα μήκους 1 Repeat until δεν δημιουργούνται νέα στοιχειοσύνολα Δημιούργησε υποψήφια στοιχειοσύνολα μήκους (k+1) από τα συχνά στοιχειοσύνολα μήκους k (είτε F k- 1 x F 1 είτε F k-1 x F k-1 ) Prune τα υποψήφια στοιχειοσύνολα που περιέχουν υποσύνολα μήκους k που δεν είναι συχνά Υπολόγισε την υποστήριξη (support) κάθε υποψηφίου στοιχειοσύνολου διαβάζοντας από τη βάση δεδομένων (πχ χρησιμοποίησε το δέντρο κατακερματισμού) Σβήσε τα υποψήφια στοιχειοσύνολα που δεν είναι συχνά, αφήνοντας μόνο τα συχνά
52 2 ο Παράδειγμα Apriori (Πηγή: Data Mining: Concepts and Techniques, Han & Kamber) Database D itemset s C 1 {1} 2 L 1 Scan D {2} 3 {3} 3 {4} 1 {5} 3 TID Items t t t t4 2 5 C 2 itemset s C 2 L 2 itemset s {1 2} 1 Scan D {1 3} 2 {1 3} 2 {2 3} 2 {1 5} 1 {2 5} 3 {2 3} 2 {2 5} 3 {3 5} 2 {3 5} 2 itemset s {1} 2 {2} 3 {3} 3 {5} 3 itemset {1 2} {1 3} {1 5} {2 3} {2 5} {3 5} minsup=2 itemset {2 3 5} C 3 L 3 Scan D itemset s {2 3 5} 2
53 Παράγοντες που επηρεάζουν την πολυπλοκότητα Η επιλογή της ελάχιστης τιμής υποστήριξης Μειώνοντας το κατώφλι για την υποστήριξη έχουμε περισσότερα συχνά στοιχειοσύνολα αυτό ίσως να αυξήσει το πλήθος και το μήκος των συχνών στοιχειοσυνόλων Διάσταση (Dimensionality) (πλήθος στοιχείων) του συνόλου δεδομένων Περισσότερος χώρος απαιτείται για την αποθήκευση της μετρητή υποστήριξης για κάθε στοιχείο εάν το πλήθος των συχνών στοιχειοσυνόλων αυξηθεί, τόσο το υπολογιστικό όσο και το I/O κόστος ίσως να αυξηθεί Μέγεθος της βάσης δεδομένων μια και ο Apriori κάνει πολλαπλά περάσματα, ο χρόνο για την εκτέλεση του μπορεί να αυξηθεί με την αύξηση του πλήθους των συναλλαγών Μέσο μήκος των συναλλαγών Το μήκος των συναλλαγών αυξάνει για πυκνά σύνολα δεδομένων Αυτό μπορεί να αυξήσει το μέγιστο μήκος των συχνών στοιχειοσυνόλων και την αναζήτηση στο δέντρο κατακερματισμού (Το πλήθος των υποσυνόλων σε μία συναλλαγή αυξάνει με το μήκος της)
54 Στρατηγική apriori: Πολυπλοκότητα Επιλογή της τιμής του κατωφλιού για την ελάχιστη υποστήριξη Μικρή τιμή => πολλά συχνά στοιχειοσύνολα Αύξηση υποψήφιων στοιχειοσυνόλων (πολυπλοκότητα) και το μέγιστο μήκος των συχνών στοιχειοσυνόλων (περισσότερα περάσματα στα δεδομένα)
55 Στρατηγική apriori: Πολυπλοκότητα Αριθμός διαστάσεων - Dimensionality (αριθμός στοιχείων) του συνόλου δεδομένων Περισσότερος χώρος για την αποθήκευση της υποστήριξης κάθε στοιχείου Αύξηση του αριθμού των συχνών στοιχείων, αύξηση του υπολογιστικού κόστους και του κόστους I/O Μέγεθος της βάσης Επειδή ο Apriori κάνει πολλαπλά περάσματα, ο χρόνος εκτέλεσης μπορεί να αυξηθεί
56 Στρατηγική apriori: Πολυπλοκότητα Μέσο πλάτος δοσοληψίας Το μέγιστο μήκος των συχνών στοιχειοσύνολων τείνει να αυξηθεί με την αύξηση του μέσου πλάτους των δοσοληψιών, άρα και ο αριθμός των υποψηφίων σε κάθε βήμα Επίσης, αύξηση των περασμάτων του δέντρου
57 Στρατηγική apriori: Πολυπλοκότητα 1. Δημιουργία συχνών 1-στοχειοσυνόλων Ο(Νw) 2. Δημιουργία υποψήφιων στοιχειοσυνόλων Έστω F k-1 x F k-1 k-2 συγκρίσεις για κοινό prefix Στη χειρότερη περίπτωση, ταιριάζουν όλα Σ k=2,w F k-1 2 Επίσης κατασκευάζουμε το δέντρο, μέγιστο ύψος k, άρα Σ k=2,w k F k-1 2 Έλεγχος, για τα k-2 υποσύνολα με χρήση του δέντρου 3. Υπολογισμός της Υποστήριξης Κάθε δοσοληψία έχει k από t k-στοιχειοσύνολα
58 Δειγματοληψία Πρόβλημα: Μεγάλες ΒΔ Λύση: Δειγματοληψία στη ΒΔ και εφαρμογή του Apriori στο επιλεγμένο δείγμα. Ενδεχομένως Μεγάλα Itemsets (Potentially Large Itemsets -PL): μεγάλα itemsets από το επιλεγμένο δείγμα Αρνητικό Όριο (Negative Border - BD ): Το ελάχιστο σύνολο των itemsets που δεν ανήκουν στο PL, ενώ όλα τα υποσύνολά τους ανήκουν στο PL.
59 Παραγωγή Κανόνων
60 Παραγωγή Κανόνων (Rule Generation) Δοθέντος ενός συχνού στοιχειοσυνόλου L, βρες όλα τα μη κενά υποσύνολα f L τέτοια ώστε ο κανόνας f L f ικανοποιεί τον περιορισμό της ελάχιστης εμπιστοσύνης Παράδειγμα αν {A,B,C,D} υποψήφιοι κανόνες: ABC D, ABD C, ACD B, BCD A, A BCD, B ACD, C ABD, D ABC AB CD, AC BD, AD BC, BC AD, BD AC, CD AB, Όλοι έχουν την ίδια υποστήριξη, πρέπει να ελέγξουμε την εμπιστοσύνη Αν L = k, τότε υπάρχουν 2 k 2 υποψήφιοι κανόνες συσχέτισης (εξαιρώντας τον L και τον L)
61 Παραγωγή Κανόνων Υπολογισμός Εμπιστοσύνης Παρατήρηση: Δε χρειάζεται να διαπεράσουμε πάλι τα δεδομένα για να υπολογίσουμε την εμπιστοσύνη ενός κανόνα που προκύπτει από ένα συχνό στοιχειοσύνολο: ABC D, ABD C, ACD B, BCD A, A BCD, B ACD, C ABD, D ABC AB CD, AC BD, AD BC, BC AD, BD AC, CD AB Γιατί; Πχ c(cd AB) = σ{a, B, C, D}/σ{C, D} Από την αντι-μονότονη ιδιότητα της υποστήριξης, το {C, D} είναι συχνό στοιχειοσύνολο άρα έχουμε ήδη υπολογίζει την υποστήριξή του
62 Παραγωγή Κανόνων Πως μπορούν να παραχθούν αποδοτικά οι κανόνες από τα συχνά στοιχειοσύνολα; Γενικά, η αντι-μονότονη ιδιότητα δεν ισχύει για την εμπιστοσύνη X, Y : ( X Y ) s( X ) s( Y Δηλαδή, η εμπιστοσύνη του X Y μπορεί να είναι μεγαλύτερη, μικρότερη ή ίση της εμπιστοσύνης ενός κανόνα X Y όπου Χ X και Υ Υ Γενικά έστω {p} {q} με εμπιστοσύνη c 1 Και {p, r} {q} με εμπιστοσύνη c 2 (το αριστερό μέρος LHS - υπερσύνολο) Μπορεί c 2 > c 1, c 2 < c 1 ή c 2 = c 1 Έστω {p} {q, r} με εμπιστοσύνη c 3 (το δεξί μέρος RHS - υπερσύνολο ) c 3 c 1 Επίσης, c 3 c 2 )
63 Παραγωγή Κανόνων Η εμπιστοσύνη για τους κανόνες που παράγονται από το ίδιο στοιχειοσύνολο έχει μια αντι-μονότονη ιδιότητα Για παράδειγμα L = {A,B,C,D}: c(abc D) c(ab CD) c(a BCD) Η εμπιστοσύνη είναι αντι-μονότονη σε σχέση με των αριθμό των στοιχείων στο RHS του κανόνα (ή ισοδύναμα μονότονη στον αριθμό των στοιχείων στο LHS) Pruning Rule: Αν ο κανόνας X Y X δεν ικανοποιεί το κατώφλι εμπιστοσύνης, τότε και ο κανόνας Χ Y X (Χ Χ) δεν τον ικανοποιεί
64 Παραγωγή Κανόνων για τον Αλγόριθμο apriori Έστω κόμβος με μικρή εμπιστοσύνη Πλέγμα Κανόνων Lattice of rules ABCD=>{ } BCD=>A ACD=>B ABD=>C ABC=>D CD=>AB BD=>AC BC=>AD AD=>BC AC=>BD AB=>CD Ψαλιδισμέ νοι κανόνες D=>ABC C=>ABD B=>ACD A=>BCD
65 Παραγωγή Κανόνων για τον Αλγόριθμο apriori Οι κανόνες παράγονται σε επίπεδα με βάση τα στοιχεία στο RHS Αρχικά, θεωρούμε όλους τους κανόνες με ένα στοιχείο στο RHS CD=>AB BD=>AC Στη συνέχεια, οι υποψήφιοι κανόνες παράγονται συγχωνεύοντας το RHS δυο υποψηφίων κανόνων Πχ Συγχώνευση(ACD=>B, ABD=>C) μας δίνει AD=>BC Όπως και στα συχνά στοιχειοσύνολα, στη συνέχεια, με το ίδιο prefix στο RHS Συγχώνευση(CD=>AB, BD=>AC) μας δίνει D => ABC D=>ABC Prune τον κανόνα D=>ABC, αν το υποσύνολο AD=>BC δεν έχει επαρκή εμπιστοσύνη Σε αντίθεση με την περίπτωση των συχνών στοιχειοσυνόλων, δε χρειάζεται να διαβάσουμε τις δοσοληψίες για να υπολογίσουμε την εμπιστοσύνη
66 Παραγωγή Κανόνων για τον Αλγόριθμο apriori Πλέγμα Κανόνων Έστω κόμβος με μικρή εμπιστοσύνη ABCD=>{ } Επίπεδο 1 (ένα στοιχείο στο RHS) BCD=>A ACD=>B ABD=>C ABC=>D Επίπεδο 2 CD=>AB BD=>AC BC=>AD AD=>BC AC=>BD AB=>CD Επίπεδο 3 Ψαλιδισμένοι κανόνες D=>ABC C=>ABD B=>ACD A=>BCD
67 Αρνητικό Όριο: Παράδειγμα PL PL BD - (PL)
68 Παράδειγμα αλγόριθμου apriori
69 Βήματα αλγορίθμου PL 1 ο βήμα: εκτέλεση Apriori σε ένα δείγμα της ΒΔ Όχι απαραίτητα με το ίδιο κατώφλι υποστήριξης Τα συχνά (στο δείγμα) itemsets αποτελούν το σύνολο PL
70 Βήματα αλγορίθμου 2 ο βήμα: Κατασκευή του συνόλου C των υποψηφίων συχνών itemsets με επέκταση του PL με το αρνητικό του όριο BD - (PL), δηλ. C = PL BD - (PL) 1 ο πέρασμα της ΒΔ για μέτρηση της υποστήριξης των itemsets του C Τα συχνά, μεταξύ αυτών που ελέγχθηκαν, itemsets αποτελούν το (αρχικό) σύνολο L C τα σύνολα C και L
71 Βήματα αλγορίθμου 3 ο βήμα: Κατασκευή του συνόλου C των υποψηφίων συχνών itemsets με (επαναληπτική) επέκταση του L με το αρνητικό του όριο 2 ο πέρασμα της ΒΔ για μέτρηση της υποστήριξης των itemsets του C Τα συχνά, μεταξύ αυτών που ελέγχθηκαν, itemsets αποτελούν το (τελικό) σύνολο L C (επαναληπτικά) το σύνολο C
72 ΠΑΡΑΔΕΙΓΜΑ Δίνεται η παρακάτω βάση δεδομένων X με εγγραφές: Χρησιμοποιώντας support = 25% και confidence = 60%, βρείτε: a) Όλα τα μεγάλα (συχνά) σύνολα στοιχείων στη βάση δεδομένων Χ. b) Τους δυνατούς κανόνες συσχέτισης στη βάση δεδομένων Χ TID T01 T02 T03 T04 T05 T06 T07 T08 ITEMS A,B,C,D A,C,D,F C,D,E,G,A A,D,F,B B,C,G D,F,G A,B,G C,D,F,G
73 1-itemsets C1 Count S% A B C D E F G Large 1-itemsets Count S% L1 A B C D E F G
74 2- items C2 2-items count S% Large 2-items L2 coun t S%
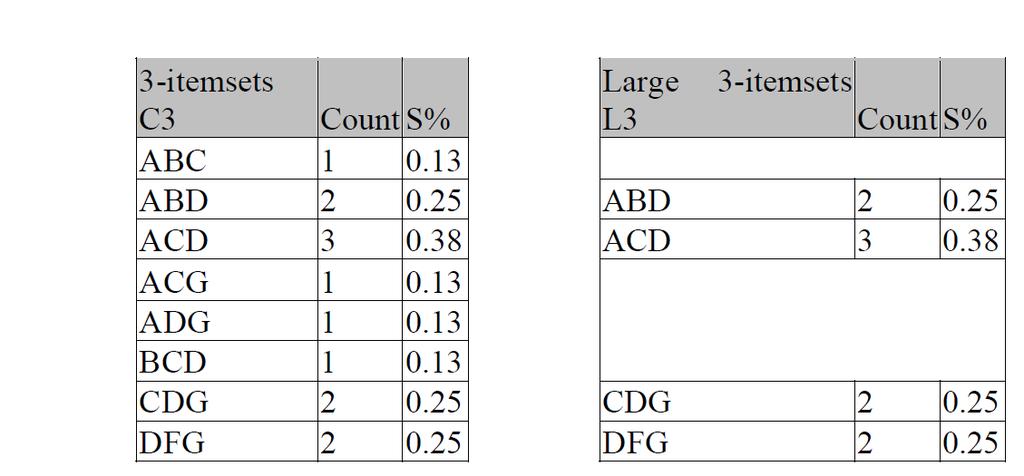
75

76
77
78 Παράδειγμα Δειγματοληψίας
79 Παράδειγμα δειγματοληψίας Θέλουμε να βρούμε τους κανόνες συσχετίσεων, με s = 40% D s = { t 1, t 2 }; smalls = 10% PL = { {Bread}, {Jelly}, {PeanutButter}, {Bread, Jelly}, {Bread, PeanutButter}, {Jelly, PeanutButter}, {Bread, Jelly, PeanutButter} } BD (PL) = { {Beer}, {Milk} } ; C = PL BD (PL) (1 ο πέρασμα στη ΒΔ) Μέτρηση του C απ όπου προκύπτει ότι L = { {Bread}, {PeanutButter}, {Bread, PeanutButter}, {Beer}, {Milk} } ML = BD (PL) L = { {Beer}, {Milk} } C = L; επαναληπτικά: C = C BD (C) // στο παράδειγμα, θα γίνουν 3 επαναλήψεις: για 2-, 3-, 4-itemsets (2 ο πέρασμα στη ΒΔ) Μέτρηση του C απ όπου προκύπτει ότι L = L (που ήδη βρέθηκαν στο βήμα 4) (από το βήμα 7)
80 Αλγόριθμος δειγματοληψίας 1. D s = sample of Database D; 2. PL = Large itemsets in D s (using smalls); 3. C = PL BD (PL); 4. L = Count C in Database (using s); // 1 st pass 5. ML = itemsets in BD (PL) found to be frequent; 6. If ML = then done else C = L; repeat C = C BD (C); until BD (C) = 7. L = Count C in Database (using s); // 2 nd pass
81 Υπέρ και Κατά της Δειγματοληψίας Πλεονεκτήματα: Μειώνει το πλήθος των σαρώσεων της ΒΔ σε 1 (στην καλύτερη περίπτωση) ή 2 (στη χειρότερη περίπτωση). Καλύτερη κλιμάκωση (αποδοτικό σε μικρές αλλά και μεγάλες ΒΔ). Μειονεκτήματα: Ενδεχομένως μεγάλος αριθμός υποψηφίων itemsets στη δεύτερη σάρωση (πολλά υποψήφια λόγω επαναληπτικού υπολογισμού του αρνητικού ορίου)
82 Διαμερισμός
83 Διαμερισμός Διαμερίζουμε τη ΒΔ σε τμήματα (partitions) D 1, D 2,, D p Εφαρμόζουμε τον Apriori σε κάθε τμήμα Κάθε συχνό itemset θα πρέπει να είναι συχνό σε ένα τουλάχιστον από τα τμήματα. Αλγόριθμος: 1. Divide D into partitions D 1,D 2,,D p; 2. For i = 1 to p do 3. L i = Apriori(D i ); // 1 st pass 4. C = L 1 L p ; 5. Count C on D to generate L; // 2 nd pass
84 Παράδειγμα διαμερισμού D 1 L 1 ={ {Bread}, {Jelly}, {PeanutButter}, {Bread,Jelly}, {Bread,PeanutButter}, {Jelly, PeanutButter}, {Bread,Jelly,PeanutButter} } D 2 L 2 ={ {Bread}, {Beer}, {Milk} } s =50% C = L 1 L 2 L = { {Bread}, {PeanutButter}, {Bread,PeanutButter} }
85 Υπέρ και Κατά του Διαμερισμού Πλεονεκτήματα: Προσαρμόζεται στη διαθέσιμη κύρια μνήμη Υλοποιείται εύκολα σε παράλληλη μορφή Μέγιστο πλήθος σαρώσεων της ΒΔ = 2. 1η σάρωση: διαμερισμός σε τμήματα που χωρούν στην κύρια μνήμη (και εκτέλεση Apriori στην κύρια μνήμη) 2η σάρωση: για να εντοπιστούν τα πραγματικά συχνά itemsets από τα υποψήφια που προέκυψαν από την 1η σάρωση Μειονεκτήματα: Μπορεί να έχει πολλά υποψήφια itemsets κατά την διάρκεια της δεύτερης σάρωσης.
86 Αναπαράσταση Κανόνων Συσχέτισης
87 Αναπαράσταση Στοιχειοσυνόλων Τα στοιχειοσύνολα που παράγονται είναι πολλά, κάποια ίσως περιττά Ποια να κρατήσουμε; Αντιπροσωπευτικά συχνά στοιχειοσύνολα Περιττός κανόνας Χ Υ, αν υπάρχει ένας κανόνας Χ Υ, όπου Χ Χ και Υ Υ με την ίδια υποστήριξη και εμπιστοσύνη Πχ., {b} {d, e} περιττός Αν ο {b, c} {d, e}, έχει την ίδια υποστήριξη και εμπιστοσύνη
88 Ένα στοιχειοσύνολο είναι Μέγιστο (maximal) συχνό αν κανένα από τα άμεσα υπερσύνολά του δεν είναι συχνό (δηλ, όλα είναι μη συχνά) Maximal Itemsets Αναπαράσταση Στοιχειοσυνόλων Μέγιστα Συχνά στοιχειοσύνολα προσφέρουν μια συνοπτική αναπαράσταση των συχνών στοιχειοσυνόλων: το μικρότερο σύνολο στοιχειοσυνόλων από το οποίο μπορούμε να πάρουμε όλα τα συχνά στοιχειοσύνολα είναι τα υποσύνολά τους ΟΜΩΣ: Δεν προσφέρουν καμιά πληροφορία για την υποστήριξη των υποσυνόλων τους null A B C D E AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE ABCD ABCE ABDE ACDE BCDE Μη συχνά στοιχειοσυ νολα ABCD E Όριο
89 Αναπαράσταση Στοιχειοσυνόλων Τα μέγιστα (maximal) συχνά στοιχειοσύνολα Προσφέρουν μια συνοπτική αναπαράσταση των συχνών στοιχειοσυνόλων: το μικρότερο σύνολο στοιχειοσυνόλων από το οποίο μπορούμε να πάρουμε όλα τα συχνά στοιχειοσύνολα (είναι όλα τα υποσύνολά τους) Βέβαια, αυτό έχει νόημα μόνο αν έχουμε έναν αποδοτικό αλγόριθμο για τον υπολογισμό τους που δεν παράγει όλα τα δυνατά υποσύνολα τους ΜΕΙΟΝΕΚΤΗΜΑ: Δεν προσφέρουν καμιά πληροφορία για την υποστήριξη των υποσυνόλων τους null A B C D E AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE ABCD ABCE ABDE ACDE BCDE ABCD E Maximal Itemsets: AD ACE BCDE
90 Αναπαράσταση Στοιχειοσυνόλων Κλειστά στοιχειοσύνολα (Closed Itemset) Ένα στοιχειοσύνολο είναι κλειστό εάν κανένα από τα αμέσως επόμενα υπερσύνολα του δεν έχει την ίδια υποστήριξη με το στοιχειοσύνολο Δεν είναι κλειστό αν κάποιο άμεσο υπερσύνολό του έχει την ίδια υποστήριξη! TID Items 1 {A,B} 2 {B,C,D} 3 {A,B,C,D} 4 {A,B,D} 5 {A,B,C,D} Itemset Support {A} 4 {B} 5 {C} 3 {D} 4 {A,B} 4 {A,C} 2 {A,D} 3 {B,C} 3 {B,D} 4 {C,D} 3 Itemset Support {A,B,C} 2 {A,B,D} 3 {A,C,D} 2 {B,C,D} 3 {A,B,C,D} 2
91 Αναπαράσταση Στοιχειοσυνόλων Ένα στοιχειοσύνολο είναι κλειστό συχνό στοιχειοσύνολο αν είναι κλειστό και η υποστήριξη του είναι μικρότερη ή ίση με την τιμή κατωφλίου υποστήριξης: minsup Ο αλγόριθμος υπολογισμού της υποστήριξης βασίζεται στο ότι: Η υποστήριξη ενός μη κλειστού στοιχειοσυνόλου πρέπει να είναι ίση με την μεγαλύτερη υποστήριξη ανάμεσα στα υπερσύνολά του TID Items 1 {A,B} 2 {B,C,D} 3 {A,B,C,D} 4 {A,B,D} 5 {A,B,C,D} Itemset Support {A} 4 {B} 5 {C} 3 {D} 4 {A,B} 4 {A,C} 2 {A,D} 3 {B,C} 3 {B,D} 4 {C,D} 3 Itemset Support {A,B,C} 2 {A,B,D} 3 {A,C,D} 2 {B,C,D} 3 {A,B,C,D} 2
92 TID Items 1 ABC 2 ABCD 3 BCE 4 ACDE 5 DE Αναπαράσταση Στοιχειοσυνόλων Maximal vs Closed Itemsets null Transaction Ids A B C D E AB AC AD AE BC BD BE CD CE DE Minsup=40% ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE 2 4 ABCD ABCE ABDE ACDE BCDE Δεν εμφανίζονται σε καμιά δοσοληψία ABCDE
93 Ελάχιστη υποστήριξη = 2 (40%) Αναπαράσταση Στοιχειοσυνόλων Maximal vs Closed Itemsets null Closed but not maximal A B C D E Closed and maximal AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE 2 4 ABCD ABCE ABDE ACDE BCDE # Closed = 9 # Maximal = 4 ABCDE Για να υπολογίσουμε όλα τα συχνά στοιχειοσύνολα και την υποστήριξη τους, ξεκινάμε από τα μεγαλύτερα κλειστά και προχωράμε
94 Χρήση κλειστών συχνών στοιχειοσυνόλων Το στοιχειοσύνολο {b} δεν είναι κλειστό ενώ το {b, c} είναι κλειστό Επομένως ο κανόνας συσχέτισης : {b} {d, e} περιττός, γιατί έχει την ίδια υποστήριξη και εμπιστοσύνη με τον κανόνα {b, c} {d, e} Τέτοιοι περιττοί κανόνες δεν παράγονται εάν χρησιμοποιούνται κλειστά συχνά στοιχειοσύνολα για την παραγωγή κανόνων. Περιττός κανόνας Χ Υ, αν υπάρχει ένας κανόνας Χ Υ, όπου Χ Χ και Υ Υ με την ίδια υποστήριξη και εμπιστοσύνη
95 Συμπαγής αναπαράσταση συχνών στοιχειοσυνόλων Έστω οι παρακάτω 15 δοσοληψίες με 30 στοιχεία Έστω, υποστήριξη 20% TID A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 B1 B2 B3 B4 B5 B6 B7 B8 B9 B10 C1 C2 C3 C4 C5 C6 C7 C8 C9 C Αριθμός συχνών στοιχειοσυνόλων k 1 k Μερικά στοιχειοσύνολα είναι πλεονάζοντα γιατί έχουν την ίδια τιμή για την υποστήριξη με τα υπερσύνολά τους Πιθανή συνοπτική αναπαράσταση με μόνο τα τρια κλειστά συχνά στοιχειοσύνολα: {Α1, Α2, Α3, Α4, Α5, Α6. Α7, Α8, Α9, Α10}, {Β1, Β2, Β3, Β4, Β5, Β6, Β7, Β8, Β9, Β10}, {C1, C2, C3, C4, C5, C6, C7, C8, C9, C10}
96 Αναπαράσταση Στοιχειοσυνόλων Maximal vs Closed Itemsets Συχνά Στοιχειοσύνολα Κλειστά Συχνά Στοιχειοσύνολα Μέγιστα Συχνά Στοιχειοσύνολα
97 Άλλοι Μέθοδοι Υπολογισμού Συχνών Στοιχειοσυνόλων Ο Apriori από τους παλιότερους αλγορίθμους, αλλά: Συχνά μεγάλο I/O επειδή κάνει πολλαπλά περάσματα στη βάση των δοσοληψιών Κακή απόδοση όταν οι δοσοληψίες έχουν μεγάλο πλάτος Άλλες μέθοδοι: Διαφορετικές διασχίσεις του πλέγματος των στοιχειοσυνόλων Αναπαράσταση Συνόλου Δοσoληψιών
98 Άλλοι Μέθοδοι Υπολογισμού Συχνών Στοιχειοσυνόλων Apriori: Γενικά-προς-Συγκεκριμένα k-1 -> k null Πλέγμα Στοιχειοσυνόλων A B C D E AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE k -> k - 1 ABCD ABCE ABDE ACDE BCDE Συγκεκριμένα-προς- Γενικά Αν αυτό είναι το συχνό, το βρίσκουμε αφού εξετάσουμε όλα τα υποσύνολά του ABCDE Αν τα συχνά είναι προς το κατώτατο σημείο (bottom) τους πλέγματος, ίσως συμφέρει
99 Εναλλακτικές μέθοδοι για την παραγωγή συχνών στοιχειοσυνόλων «Διάσχιση» στο δικτύωμα (Lattice) των στοιχειοσυνόλων Στοιχειοσύνολο μεγέθους k -> k 1 (συγκεκριμένο-προς-γενικό) Πιο χρήσιμη για τον εντοπισμό maximal συχνών στοιχειοσυνόλων σε πυκνές (δηλ, με μεγάλο πλάτος) δοσοληψίες όπου το συχνό στοιχειοσύνολο βρίσκεται κοντά στο κατώτατο σημείο του πλέγματος Αν βρεθεί συχνό στοιχειοσύνολο, δε χρειάζεται να ελέγξουμε κανένα από τα υποσύνολά του Οι σκουρόχρωμοι κόμβοι αναπαραστούν σπάνια στοιχειοσύνολα Frequent itemset border null.... {a 1,a 2,...,a n } (a) General-to-specific null.... {a 1,a 2,...,a n } (b) Specific-to-general Frequent itemset border Frequent itemset border null.... {a 1,a 2,...,a n } (c) Bidirectional
100 Εναλλακτικές μέθοδοι για την παραγωγή συχνών στοιχειοσυνόλων Κλάσεις Ισοδυναμίας (Equivalent Classes) Χωρισμός των στοιχειοσυνόλων του πλέγματος σε ξένες μεταξύ τους ομάδες (κλάσεις ισοδυναμίας) και εξέταση των στοιχειοσυνόλων ανά κλάσεις Apriori: ορίζει τις κλάσεις με βάση το μήκος k των στοιχειοσυνόλων, πρώτα αυτά μήκους 1, μετά μήκους 2 κοκ Prefix (Suffix): Δύο στοιχειοσύνολα ανήκουν στην ίδια κλάση αν έχουν κοινό πρόθεμα (ή επίθεμα-κατάληξη) μήκους k null null Κατηγορίες Ισοδυναμίας με βάση τα προθέματα (prefix) στις ετικέτες στοιχειοσυνόλ ων A B C D AB AC AD BC BD CD ABC ABD ACD BCD ABCD A B C D AB AC BC AD BD CD ABC ABD ACD BCD ABCD Κατηγορίες Ισοδυναμίας με βάση τα επιθέματα (suffix) στις ετικέτες στοιχειοσυνόλ ων (a) Prefix tree (b) Suffix tree
101 Εναλλακτικές μέθοδοι για την παραγωγή συχνών στοιχειοσυνόλων Διάσχιση στο πλέγμα/ δικτύωμα (Lattice) των στοιχειοσυνόλων Πρώτα κατά πλάτος πρώτα κατά βάθος (Breadth-first vs Depth-first) BFS: Breadth-First-Search Διάσχιση κατά Πλάτος DFS: Depth-First-Search Διάσχιση κατά Βάθος (a) Breadth first (b) Depth first DFS Χρήσιμο για την εύρεση maximal συχνών στοιχειοσυνόλων γιατί τα εντοπίζει πιο γρήγορα από το BFS Μόλις εντοπιστεί το maximal, είναι δυνατόν να κλαδευτούν πολλά υποσύνολα του
102 Άλλοι Μέθοδοι Υπολογισμού Συχνών Στοιχειοσυνόλων Διάσχιση του Πλέγματος των Στοιχειοσυνόλων: BFS vs DFS Maximal συχνό στοιχειοσύνολο Prune πχ μόνο τa bc και ac (το υποδέντρa τους μπορεί να έχει maximal) Maximal συχνό στοιχειοσύνολο Μπορούμε να κάνουμε prune όλο το υποδέντρο Επίσης, πχ αν abc ίδια υποστήριξη με ab τότε τα υποδέντρα στο abd και abe pruned δεν έχουν maximal συχνό
103 Εναλλακτικές μέθοδοι για την παραγωγή συχνών στοιχειοσυνόλων Αναπαράσταση της βάσης δεδομένων Αυτό χρησιμοποιεί ο apriori Οριζόντια vs κάθετη διάταξη Horizontal Data Layout TID Items 1 A,B,E 2 B,C,D 3 C,E 4 A,C,D 5 A,B,C,D 6 A,E 7 A,B 8 A,B,C 9 A,C,D 10 B Οριζόντια Διάρθρωση Δεδομένων Εναλλακτικά: Για κάθε στοιχείο σε ποιες δοσοληψίες εμφανίζεται Vertical Data Layout A B C D E Η υποστήριξη υπολογίζεται παίρνοντας τις τομές των TIDλιστών
104 Άλλοι Τρόποι Υπολογισμού Η υποστήριξη υπολογίζεται παίρνοντας τις τομές των TIDλιστών A B Η υποστήριξη ενός k-στοιχειοσυνόλου υπολογίζεται παίρνοντας τις τομές των TIDλιστών δύο από τα (k-1)-ύπο-στοιχειοσύνολα του. AB Πλεονέκτημα: πολύ γρήγορος υπολογισμός της υποστήριξης Πρόβλημα, αν οι TID-λίστες είναι μεγάλες και δε χωρούν στη μνήμη Θα δούμε τον FP-Growth που χρησιμοποιεί μια prefix-based αναπαράσταση των δοσοληψιών
105 Ο Αλγόριθμος FP- Ανάπτυξη (Growth)
106 Αλγόριθμος FP-Ανάπτυξη (Growth) Ο αλγόριθμος χρησιμοποιεί μια συμπιεσμένη αναπαράσταση της βάσης των δοσοληψιών με τη μορφή ενός FP-δέντρου Το δέντρο μοιάζει με προθεματικό δέντρο - prefix tree Ο αλγόριθμος κατασκευής διαβάζει μια δοσοληψία τη φορά, απεικονίζει τη δοσοληψία σε ένα μονοπάτι του FP-δέντρου Μερικά μονοπάτια μπορεί να επικαλύπτονται: όσο περισσότερα μονοπάτια επικαλύπτονται, τόσο καλύτερη συμπίεση Μόλις κατασκευαστεί το FP-δέντρο, ο αλγόριθμος χρησιμοποιεί μια αναδρομική διαίρει-και-βασίλευε (divide-and-conquer) προσέγγιση για την εξόρυξη των συχνών στοιχειοσυνόλων
107 Αλγόριθμος FP-Growth Κατασκευή FP-δέντρου TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} To FP-δέντρο είναι ένα προθεματικό δέντρο Επειδή έχουμε σύνολα, κάπως πρέπει να τα διατάξουμε ώστε να βρίσκουμε προθέματα Δηλαδή δε μπορεί το ένα σύνολο να είναι {Α, Β} και το άλλο {Β, C, A} γιατί χάνουμε το κοινό πρόθεμα ΑΒ (ή ΒΑ) Άρα τα στοιχεία σε κάθε σύνολο πρέπει να ακολουθούν κάποια διάταξη, έστω τη λεξικογραφική (θα δούμε αργότερα αν κάτι άλλο συμφέρει καλύτερα) Αρχικά, το δέντρο κενό null
108 Κατασκευή FP-tree TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} Διάβασμα TID=1: B:1 Διάβασμα TID=2: null A:1 B:1 A:1 null B:1 C:1 Κάθε κόμβος έχει μια ετικέτα: ποιο στοιχείο και τη συχνότητα εμφάνισης (υποστήριξη) πόσες δοσοληψίες φτάνουν σε αυτόν Ετικέτα κόμβου <ΣΤΟΙΧΕΙΟ: ΥΠΟΣΤΗΡΙΞΗ>
109 Αλγόριθμος FP-Growth TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} Κατασκευή FP-δέντρου Διάβασμα TID=1, 2: Πίνακας Δεικτών B:1 A:1 null B:1 C:1 Επίσης, κρατάμε πίνακα δεικτών για να βοηθήσουν στον υπολογισμό των συχνών στοιχειοσυνόλων Item A B C D E Pointer
110 Αλγόριθμος FP-Growth TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} Κατασκευή FP-δέντρου Διάβασμα TID=1, 2: Διάβασμα TID=3 Πίνακας Δεικτών B:1 A:1 null B:1 C:1 Item A B C D E Pointer
111 Αλγόριθμος FP-Growth TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} Κατασκευή FP-δέντρου Διάβασμα TID=1, 2: Διάβασμα TID=3 Πίνακας Δεικτών Item A B C D E Pointer B:1 A:2 null C:1 E:1 B:1 C:1
112 Αλγόριθμος FP-Growth TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} Κατασκευή FP-δέντρου Διάβασμα TID=1, 2: Διάβασμα TID=3 Πίνακας Δεικτών Item A B C D E Pointer B:1 A:2 null C:1 E:1 B:1 C:1
113 Κατασκευή Δένδρου FP- TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} Transaction Database B:5 A:7 C:1 null B:3 C:3 Πίνακας δεικτών Item A B C D E Pointer C:3 E:1 E:1 Οι δείκτες χρησιμοποιούνται για παραχθούν τα συχνά στοιχειοσύνολα E:1
114 Αλγόριθμος FP-Growth Μέγεθος FP-δέντρου Κάθε δοσοληψία αντιστοιχεί σε ένα μονοπάτι από τη ρίζα Το μέγεθος του δέντρου συνήθως μικρότερο των δεδομένων, αν υπάρχουν κοινά προθέματα Αν όλες οι δοσοληψίες μοιράζοντα τα ίδια δεδομένα, μόνο ένα κλαδί Αν όλες οι δοσοληψίες είναι διαφορετικές, ο χώρος μεγαλύτερος (γιατί αποθηκεύεται περισσότερη πληροφορία, όπως δείκτες μεταξύ των κόμβων αλλά και συχνότητες εμφάνισης)
115 Αλγόριθμος FP-Growth Κατασκευή FP-δέντρου Το τελικό δέντρο, εξαρτάται από τη διάταξη: άλλη διάταξη -> άλλα προθέματα TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} (Συνήθως) μικρότερο δέντρο, αν όχι λεξικογραφικά, αλλά με βάση τη συχνότητα εμφάνισης -> Αρχικά, διαβάζουμε όλα τα δεδομένα μια φορά ώστε να υπολογιστεί ο μετρητής υποστήριξης κάθε στοιχείου, και διατάσουμε τα στοιχεία με βάση αυτό Επίσης, αγνοούμε όσα στοιχεία είναι μη συχνά Για τo παράδειγμα, σ(α)=7, σ(β)=8, σ(c)=7, σ(d)=5, σ(ε)=3 Άρα, Β,Α,C,D,E διάταξη TID Items 1 {Β,Α} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {Β,Α,C} 6 {Β,Α,C,D} 7 {B,C} 8 {Β,Α,C} 9 {Β,Α,D} 10 {B,C,E}
116 Αλγόριθμος FP-Growth Αλγόριθμος εύρεσης συχνών στοιχειοσυνόλων Είσοδος: FP-δέντρο Έξοδος: Συχνά στοιχειοσύνολα και η υποστήριξη τους Μέθοδος: Διαίρει-και-Βασίλευε o Χωρίζουμε τα στοιχειοσύνολα σε αυτά που τελειώνουν σε E, D, C, B, A o Μετά αυτά που τελειώνουν σε E σε αυτά σε DE, CE, BE, AE κοκ
117 Αλγόριθμος FP-Growth Αλγόριθμος εύρεσης συχνών στοιχειοσυνόλων Όλα τα στοιχειοσύνολα Ε D C B A DE CE BE AE CD BD AD BC AC AB CDE BDE ADE BCE ACE ABE BCD ACD ABD ABC ACDE BCDE ABDE ABCE ABCD ABCDE Όλα τα δυνατά στοιχειοσύνολα!
118 Αλγόριθμος FP-Growth Αλγόριθμος εύρεσης συχνών στοιχειοσυνόλων Όλα τα στοιχειοσύνολα συχνό; Ε D C B A DE CE BE AE CD BD AD BC AC AB συχνό; CDE BDE ADE BCE ACE ABE BCD ACD ABD ABC συχνό; ACDE BCDE ABDE ABCE ABCD συχνό; ABCDE Όλα τα δυνατά στοιχειοσύνολα!
119 Αλγόριθμος FP-Growth Αλγόριθμος εύρεσης συχνών στοιχειοσυνόλων Όλα τα στοιχειοσύνολα συχνό; Ε D C B A DE CE BE AE CD BD AD BC AC AB συχνό; CDE BDE ADE BCE ACE ABE BCD ACD ABD ABC συχνό; συχνό; ACDE BCDE ABDE ABCE ABCD συχνό; ABCDE Όλα τα δυνατά στοιχειοσύνολα!
120 Αλγόριθμος FP-Growth Αλγόριθμος εύρεσης συχνών στοιχειοσυνόλων Όλα τα στοιχειοσύνολα συχνό; Ε D C B A DE CE BE AE CD BD AD BC AC AB συχνό; CDE BDE ADE BCE ACE ABE BCD ACD ABD ABC συχνό; ACDE BCDE ABDE ABCE ABCD ABCDE Όλα τα δυνατά στοιχειοσύνολα! Στο δέντρο μπορεί να υπάρχουν λιγότερα!
121 TID Items 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 {A,B,C} 9 {A,B,D} 10 {B,C,E} B:5 A:7 Αλγόριθμος FP-Growth Χρήση FP-δέντρου για εύρεση συχνών στοιχειοσυνόλων C:1 null B:3 C:3 Header table Item A B C D E Pointer C:3 E:1 Πως; E:1 E:1 Bottom-up traversal του δέντρου Αυτά που τελειώνουν σε E, μετά αυτά που τελειώνουν σε D, C, B και τέλος Α suffix-based classes (επίθεμα κατάληξη)
122 Αλγόριθμος FP-Growth Υποπρόβλημα: Βρες συχνά στοιχειοσύνολα που τελειώνουν σε E A:7 null B:3 B:5 C:1 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1 Θα δούμε στη συνέχεια πως υπολογίζεται η υποστήριξη για τα πιθανά στοιχειοσύνολα
123 Αλγόριθμος FP-Growth null Για το D A:7 B:3 B:5 C:1 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1
124 Αλγόριθμος FP-Growth null Για το C A:7 B:3 B:5 C:1 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1
125 Αλγόριθμος FP-Growth null Για το B A:7 B:3 B:5 C:1 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1
126 Αλγόριθμος FP-Growth Για το Α null A:7 B:3 B:5 C:1 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1
127 Αλγόριθμος FP-Growth Συνοπτικά Σε κάθε βήμα, για το suffix (επίθεμα) Χ Φάση 1 Κατασκευάζουμε το προθεματικό δέντρο για το Χ και υπολογίζουμε την υποστήριξη χρησιμοποιώντας τον πίνακα Φάση 2 Αν είναι συχνό, κατασκευάζουμε το υπο-συνθήκη δέντρο για το Χ, σε βήματα επανα-υπολογισμός υποστήριξης περικοπή κόμβων με μικρή υποστήριξη περικοπή φύλλων
128 Αλγόριθμος FP-Growth Φάση 1 κατασκευή προθεματικού δέντρου Όλα τα μονοπάτια που περιέχουν το E Προθεματικά Μονοπάτια paths) (prefix B:5 A:7 C:1 null B:3 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1 Προθεματικά μονοπάτια του Ε: {E}, {D,E}, {C,D,E}, {A,D,Ε}, {A,C,D,E}, {C,E}, {B,C,E}
129 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το E Προθεματικά Μονοπάτια paths) (prefix null A:7 B:3 C:1 C:3 E:1 E:1 E:1 Προθεματικά μονοπάτια του Ε: {E}, {D,E}, {C,D,E}, {A,D,Ε}, {A,C,D,E}, {C,E}, {B,C,E}
130 Έστω minsup = 2 Βρες την υποστήριξη του {E} Πως; Ακολούθησε τους συνδέσμους αθροίζοντας 1+1+1=3>2 Οπότε {Ε} συχνό Αλγόριθμος FP-Growth null A:7 B:3 C:1 C:3 E:1 E:1 E:1 {E} συχνό άρα προχωράμε για DE, CE, BE, AE
131 Αλγόριθμος FP-Growth {E} συχνό άρα προχωράμε για DE, CE, BE, AE Φάση 2 Μετατροπή των προθεματικών δέντρων σε FP-δέντρο υπό συνθήκες (conditional FP-tree) Δύο αλλαγές (1) Αλλαγή των μετρητών (2) Περικοπή null A:7 B:3 C:3 C:1 E:1 E:1 E:1
132 Αλγόριθμος FP-Growth Αλλαγή μετρητών Οι μετρητές σε κάποιους κόμβους περιλαμβάνουν δοσοληψίες που δεν έχουν το Ε Πχ στο null->b->c->e μετράμε και την {B, C} null A:7 B:3 C:1 C:3 E:1 E:1 E:1
133 Αλγόριθμος FP-Growth null A:7 B:3 C:1 C:3 E:1 E:1 E:1
134 Αλγόριθμος FP-Growth null A:7 B:3 C:1 C:1 E:1 E:1 E:1
135 Αλγόριθμος FP-Growth null A:7 B:1 C:1 C:1 E:1 E:1 E:1
136 Αλγόριθμος FP-Growth null A:7 B:1 C:1 C:1 E:1 E:1 E:1
137 Αλγόριθμος FP-Growth null A:7 B:1 C:1 C:1 E:1 E:1 E:1
138 Αλγόριθμος FP-Growth null A:2 B:1 C:1 C:1 E:1 E:1 E:1
139 Αλγόριθμος FP-Growth null A:2 B:1 C:1 C:1 E:1 E:1 E:1
140 Αλγόριθμος FP-Growth Περικοπή (truncate) Σβήσε τους κόμβους του Ε null A:2 B:1 C:1 C:1 E:1 E:1 E:1
141 Αλγόριθμος FP-Growth Περικοπή (truncate) Σβήσε τους κόμβους του Ε null A:2 B:1 C:1 C:1 E:1 E:1 E:1
142 Αλγόριθμος FP-Growth Περικοπή (truncate) Σβήσε τους κόμβους του Ε null A:2 B:1 C:1 C:1
143 Αλγόριθμος FP-Growth Πιθανή περαιτέρω περικοπή Κάποια στοιχεία μπορεί να έχουν υποστήριξη μικρότερη της ελάχιστης Πχ το Β -> περικοπή null A:2 B:1 Αυτό σημαίνει ότι το Β εμφανίζεται μαζί με το E λιγότερο από minsup φορές C:1 C:1
144 Αλγόριθμος FP-Growth null A:2 B:1 C:1 C:1
145 Αλγόριθμος FP-Growth null A:2 C:1 C:1
146 Αλγόριθμος FP-Growth Υπο-συνθήκη FP-δέντρο για το Ε Ο αλγόριθμος επαναλαμβάνεται για το {D, E}, {C, E}, {A, E} null A:2 C:1 C:1
147 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το D (DE) Προθεματικά Μονοπάτια paths) (prefix null A:2 C:1 C:1
148 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το D (DE) Προθεματικά Μονοπάτια paths) (prefix A:2 null C:1
149 Αλγόριθμος FP-Growth Βρες την υποστήριξη του {D, E} Πως; Ακολούθησε τους συνδέσμους αθροίζοντας 1+1=2 2 Οπότε {D, Ε} συχνό A:2 C:1 null
150 Αλγόριθμος FP-Growth Φάση 2 Κατασκεύασε το υπο-συνθήκη FP-δέντρο για το {D, E} 1. Αλλαγή υποστήριξης 2. Περικοπές κόμβων A:2 null C:1
151 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:2 C:1
152 Αλγόριθμος FP-Growth 2. Περικοπές κόμβων null A:2 C:1
153 Αλγόριθμος FP-Growth 2. Περικοπές κόμβων null A:2 C:1
154 Αλγόριθμος FP-Growth 2. Περικοπές κόμβων null A:2 C:1 Μικρή υποστήριξη
155 Αλγόριθμος FP-Growth Τελικό υπο-συνθήκη FPδέντρο για το {D, E} null A:2 Υποστήριξη του Α είναι minsup -> {Α, D, E} συχνό Αφού μόνο έναν κόμβο, επιστροφή στο επόμενο υποπρόβλημα
156 Αλγόριθμος FP-Growth null A:2 C:1 Υπο-συνθήκη FP-δέντρο για το Ε Ο αλγόριθμος επαναλαμβάνεται για το {D, E}, {C, E}, {A, E} C:1
157 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το C (CE) null Προθεματικά (prefix paths) Μονοπάτια A:2 C:1 C:1
158 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το C (CE) null Προθεματικά Μονοπάτια paths) (prefix A:2 C:1 C:1
159 Αλγόριθμος FP-Growth Βρες την υποστήριξη του {C, E} Πως; Ακολούθησε τους συνδέσμους αθροίζοντας 1+1=2 2 Οπότε {C, Ε} συχνό null A:2 C:1 C:1
160 Αλγόριθμος FP-Growth Κατασκεύασε το υπο-συνθήκη FP-δέντρο για το {C, E} 1. Αλλαγή υποστήριξης 2. Περικοπές κόμβων null A:2 C:1 C:1
161 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:1 C:1 C:1
162 Αλγόριθμος FP-Growth 2. Περικοπή Κόμβων null A:1 C:1 C:1
163 Αλγόριθμος FP-Growth 2. Περικοπή Κόμβων null A:1
164 Αλγόριθμος FP-Growth 2. Περικοπή Κόμβων null A:1
165 Αλγόριθμος FP-Growth 2. Περικοπή Κόμβων null Άρα, επιστροφή στο επόμενο υποπρόβλημα
166 Αλγόριθμος FP-Growth Υπο-συνθήκη FP-δέντρο για το Ε Ο αλγόριθμος επαναλαμβάνεται για το {D, E}, {C, E}, {A, E} null A:2 C:1 C:1
167 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το Α (AE) null Προθεματικά Μονοπάτια paths) (prefix A:2 C:1 C:1
168 Αλγόριθμος FP-Growth Φάση 1 Όλα τα μονοπάτια που περιέχουν το Α (AE) null Προθεματικά Μονοπάτια paths) (prefix A:2
169 Αλγόριθμος FP-Growth Βρες την υποστήριξη του {Α, E} Οπότε {Α, Ε} συχνό null Δε χρειάζεται να φτιάξουμε υπο-συνθήκη FP-δέντρο για το {Α, Ε} A:2
170 Αλγόριθμος FP-Growth Άρα για το Ε Έχουμε τα εξής συχνά στοιχειοσύνολα {Ε} {D, E} {A, D, E} {C, E} {A, E} Συνεχίζουμε για το D
171 Αλγόριθμος FP-Growth null Για το D A:7 B:3 B:5 C:1 C:3 Header table Item A B C D E Pointer C:3 E:1 E:1 E:1
172 Φάση 1 Όλα τα προθεματικά μονοπάτια που περιέχουν το D Υποστήριξη 5>2 -> άρα συχνό Αλγόριθμος FP-Growth null A:7 B:3 Μετατροπή του προθεματικού δέντρου σε FP-δέντρο B:5 υπό συνθήκη C:1 C:3 C:3
173 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:7 B:3 B:5 C:1 C:3 C:1
174 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:7 B:3 B:2 C:1 C:3 C:1
175 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:3 B:3 B:2 C:1 C:3 C:1
176 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:3 B:3 B:2 C:1 C:1 C:1
177 Αλγόριθμος FP-Growth 1. Αλλαγή υποστήριξης null A:3 B:1 B:2 C:1 C:1 C:1
178 Αλγόριθμος FP-Growth 2. Περικοπή Κόμβων null A:3 B:1 B:2 C:1 C:1 C:1
179 Αλγόριθμος FP-Growth 2. Περικοπή Κόμβων null A:3 B:1 B:2 C:1 C:1 C:1
180 Αλγόριθμος FP-Growth Προθεματικά δέντρα και υποσυνθήκη δέντρα Για τα ΑD, ΒD και CD κοκ A:3 null B:1 B:2 C:1 C:1 C:1
181 Αλγόριθμος FP-Growth Παρατηρήσεις Παράδειγμα τεχνικής διαίρει-και-βασίλευε Σε κάθε αναδρομικό βήμα, λύνεται και ένα υπο-πρόβλημα: Κατασκευάζεται το προθεματικό δέντρο Υπολογίζεται η νέα υποστήριξη για τους κόμβους του Περικόβονται οι κόμβοι με μικρή υποστήριξη Επειδή τα υποπροβλήματα είναι ξένα μεταξύ τους, δεν δημιουργούνται τα ίδια συχνά στοιχειοσύνολα δυο φορές Ο υπολογισμός της υποστήριξης είναι αποδοτικός γίνεται ταυτόχρονα με τη δημιουργία των συχνών στοιχειοσυνόλων
182 Αλγόριθμος FP-Growth Παρατηρήσεις Η απόδοση του FP-Growth εξαρτάται από τον παράγοντα συμπίεσης του συνόλου των δεδομένων (compaction factor) Αν τα τελικά δέντρα είναι «θαμνώδη» (bushy) τότε δε δουλεύει καλά, αυξάνεται ο αριθμός των υποπροβλημάτων (οι αναδρομικές κλήσεις)
183 Αποτίμηση Κανόνων Συσχέτισης
184 Αποτίμηση Κανόνων Συσχέτισης Παράγουν πάρα πολλούς κανόνες που συχνά είναι μη ενδιαφέροντες ή πλεονάζοντες (περιττοί) Πλεονάζοντες αν {A, B, C} {D} και {A,B} {D} έχουν την ίδια υποστήριξη & εμπιστοσύνη Μέτρα ενδιαφέροντος (interestingness) χρησιμοποιούνται για να ελαττώσουν (prune) ή να ιεραρχήσουν (rank) τα παραγόμενα πρότυπα Χρησιμοποιούνται σε διάφορα στάδια της διαδικασίας ανάκτησης γνώσης
 Μέτρηση Ενδιαφέροντος Featur e Prod uct Prod uct")


185 Μέτρα Ενδιαφέροντος Εφαρμογές της μέτρησης του ενδιαφέρον τος(σε διάφορα στάδια) Μέτρηση Ενδιαφέροντος Featur e Prod uct Prod uct Prod uct Prod uct Prod uct Prod uct Prod uct Prod uct Prod uct Prod uct Featur e Featur e Featur e Featur e Featur e Featur e Featur e Featur e Featur e Επιλογή Προ-επεξεργασία Εξόρυξη Μετά-επεξεργασία Δεδομένα Επιλεγμένα Δεδομένα Προ-επεξεργασμένα Δεδομένα Πρότυπα Γνώση
186 Αποτίμηση Κανόνων Συσχέτισης Γενικά: αντικειμενικά (objective) και υποκειμενικά (subjective) μέτρα ενδιαφέροντος Ας δούμε πρώτα μερικά αντικειμενικά κριτήρια: Στην αρχική διατύπωση του προβλήματος της εξόρυξης κανόνων συσχέτισης χρησιμοποιήθηκαν ως μέτρα μόνο η υποστήριξη και η εμπιστοσύνη Γενικά συνήθως βασίζονται σε μετρήσεις της συχνότητας εμφάνισης που δίνονται μέσω ενός πίνακα contingency (συνάφειας)
187 Υπολογισμός του Μέτρου Ενδιαφέροντος (αντικειμενικά μέτρα) Contingency table (πίνακας ενδεχομένων) Μέτρηση συχνότητας εμφάνισης Y Y X f 11 f 10 f 1+ X f 01 f 00 f o+ Μέτρηση Ενδιαφέροντος f +1 f +0 T f 11 : support of X and Y f 10 : support of X and Y f 01 : support of X and Y f 00 : support of X and Y f 11 πόσο συχνά εμφανίζεται το Χ και το Υ (support count) f +1 μετρητής υποστήριξης (support count) του Υ Χρησιμοποιείται για τον ορισμό διαφόρων μέτρων Έστω ένας κανόνας, X Y, η πληροφορία που χρειάζεται για τον υπολογισμό της εμπιστοσύνης και υποστήριξης του κανόνα μπορεί να υπολογιστεί από τον contingency table
188 Μέτρηση Ενδιαφέροντος Μειονεκτήματα της Εμπιστοσύνης Μεγάλες τιμές υποστήριξης μπορεί να «διώξουν» ενδιαφέροντες κανόνες. Τι γίνεται με την εμπιστοσύνη; Coffee Coffee Tea Tea Ποια είναι μια καλή τιμή για την εμπιστοσύνη; Ενδιαφερόμαστε για τη σχέση μεταξύ αυτών που πίνουν καφέ και αυτών που πίνουν τσάι Κανόνας Συσχέτισης: Tea Coffee Εμπιστοσύνη = P(Coffee Tea) = 0.75 Ενώ ο κανόνας έχει υψηλή εμπιστοσύνη, ο κανόνας είναι παραπλανητικός P(Coffee Tea) = P(Coffee) = 0.9 Αγνοεί την υποστήριξη του RHS
189 Μέτρηση Ενδιαφέροντος Εξαιτίας τέτοιων προβλημάτων της υποστήριξης/εμπιστοσύνης, Έχουν προταθεί πολλά αντικειμενικά μέτρα για τη μέτρηση του ενδιαφέροντος των κανόνων, που στηρίζονται κυρίως στην έννοια της στατιστικής ανεξαρτησίας Ας δούμε ένα παράδειγμα
190 Μέτρα βασισμένα στη Στατιστική Στατιστική Ανεξαρτησία Πληθυσμός 1000 σπουδαστών 600 σπουδαστές ξέρουν κολύμπι (S) 700 σπουδαστές ξέρουν ποδήλατο (B) 420 σπουδαστές ξέρουν κολύμπι και ποδήλατο (S, B) P(S B) = 420/1000 = 0.42 P(S) P(B) = = 0.42 P(S B) = P(S) P(B) => Στατιστική ανεξαρτησία P(S B) > P(S) P(B) => Positively correlated (θετική συσχέτιση) P(S B) < P(S) P(B) => Negatively correlated (αρνητική συσχέτιση)
191 )] ( )[1 ( )] ( )[1 ( ) ( ) ( ), ( ) ( ) ( ), ( ) ( ) ( ), ( ) ( ) ( 1 f f f f f f f f Y P Y P X P X P Y P X P Y X P coefficient Y P X P Y X P PS f f f T Y P X P Y X P Interest f f Y P X Y P Lift Μέτρα που λαμβάνουν υπ όψιν τους τη στατιστική εξάρτηση Μέτρα βασισμένα στη Στατιστική Για τη συσχέτιση: Χ Υ
192 Μέτρα βασισμένα στη Στατιστική Παράδειγμα: Lift/Interest Coffee Coffee Tea Tea Κανόνας συσχέτιση: Tea Coffee Εμπιστοσύνη= P(Coffee Tea) = 0.75 αλλά P(Coffee) = 0.9 Interest P( X, Y ) P( X ) P( Y ) T f 1 f f 11 1 Interest = 0.15/(0.9*0.2)= (< 1, άρα αρνητικά συσχετιζόμενα)
193 Μέτρα βασισμένα στη Στατιστική Μειονεκτήματα του Lift & Interest Y Y X X Y Y X X P( X, Y ) T f I 10 Interest I (0.1)(0.1) P( X ) P( Y ) f f (0.9)(0.9) Μεγαλύτερο αν και σπάνια εμφανίζονται μαζί c = 10/100 = 0.1 s = 1 c (confidence εμπιστοσύνη) s (support υποστήριξη) c = 90/100 = 0.9 s = 1
194 Μέτρα βασισμένα στη Στατιστική -Coefficient coefficient P( X, Y) P( X ) P( Y) P( X )[1 P( X )] P( Y)[1 P( Y)] f f 11 1 f f 00 f 1 f 01 0 f f 10 0 Κανονικοποιημένη τιμή μεταξύ του -1 και 1 Δυαδική εκδοχή του Pearson s coefficient 0: στατιστική ανεξαρτησία -1: τέλεια αρνητική συσχέτιση 1: τέλεια θετική συσχέτιση Y Y X f 11 f 10 f 1+ X f 01 f 00 f o+ f +1 f +0 T
195 Μέτρα βασισμένα στη Στατιστική -Coefficient Y Y X X Y Y X X Coefficient ίδιος και για τους δύο πίνακες coefficient P( X, Y) P( X ) P( Y) P( X )[1 P( X )] P( Y)[1 P( Y)] f f 11 1 f f 00 1 f f 01 0 f f 10 0
196 Μέτρα βασισμένα στη Στατιστική -Coefficient coefficient P( X, Y) P( X ) P( Y) P( X )[1 P( X )] P( Y)[1 P( Y)] f f 11 1 f f 00 f 1 f 01 0 f f 10 0 Είναι κατάλληλο για μη συμμετρικές (η απουσία και η παρουσία μετρούν το ίδιο) Λόγω κανονικοποίησης, αγνοεί το μέγεθος του δείγματος
197 IS-measure Μέτρα βασισμένα στη Στατιστική ), ( ), ( ) ( ) ( ), ( ), ( Y x s Y X I f f f Y s X s Y X s Y X IS είναι το συνημίτονο αν θεωρηθούν δυαδικές μεταβλητές γεωμετρικός μέσος της εμπιστοσύνης του Χ Υ και Υ Χ
198 Στη βιβλιογραφία έχουν προταθεί πολλά μέτρα ανάλογα με την εφαρμογή Με ποια κριτήρια θα επιλέξουμε ένα καλό μέτρο; Πως έναν Aprioristyle support based pruning επηρεάζει αυτά τα μέτρα; ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ II 198
199 Αποτίμηση Κανόνων Συσχέτισης Σύγκριση Μέτρων 10 παραδείγματα contingency πινάκων: Ιεράρχηση των πινάκων με βάση τα διάφορα μέτρα (1 ο πιο ενδιαφέρον, 10 ο λιγότερο ενδιαφέρον): Example f 11 f 10 f 01 f 00 E E E E E E E E E E
200 Αποτίμηση Κανόνων Συσχέτισης Ιδιότητες ενός Καλού Μέτρου Piatetsky-Shapiro: 3 γενικές ιδιότητες που πρέπει να ικανοποιεί ένα καλό μέτρο M: M(A, B) = 0 αν τα Α και Β είναι στατιστικά ανεξάρτητα M(A, B) αυξάνει μονότονα με το P(A,B) όταν τα P(A) και P(B) παραμένουν αμετάβλητα M(A, B) μειώνεται μονότονα με το P(A) [ή το P(B)] όταν τα P(A,B) και P(B) [ή P(A)] παραμένουν αμετάβλητα
201 Ιδιότητες Μέτρων Αποτίμησης Αλλαγή Διάταξης Μεταβλητών (variable permutation) B B A p q A r s A A B p r B q s Ισχύει M(A, B) = M(B, A)? Γενικά συμμετρικά μέτρα για στοιχειοσύνολα και μη συμμετρικά για κανόνες Συμμετρικά (symmetric) μέτρα: support (υποστήριξη), lift, collective strength, cosine, Jaccard, κλπ Μη συμμετρικά (asymmetric) μέτρα: confidence (εμπιστοσύνη), conviction, Laplace, J-measure, κλπ
202 Ιδιότητες Μέτρων Αποτίμησης Κλιμάκωση Γραμμής/Στήλης (Row/Column Scaling) Παράδειγμα Βαθμός-Φύλο (Mosteller, 1968): κ 1 κ 2 κ 3 Male κ 4 Female High Low Male Female High Low Mosteller: Η συσχέτιση πρέπει να είναι ανεξάρτητη από το σχετικό αριθμό αγοριών-κοριτσιών στο δείγμα Invariant under the row/column scaling operation αν Μ(Τ) = Μ(Τ ) όπου Τ o πίνακας contingency με μετρητές συχνότητας [f 11, f 10 ; f 01 ; f 00 ] και Τ o πίνακας contingency με μετρητές συχνότητας [κ 1 κ 3 f 11, κ 2 κ 3 f 10 ; κ 1 κ 4 f 01 ; κ 2 κ 4 f 00 ] όπου κ 1, κ 2, κ 3, κ 4 θετικές σταθερές 2x 10x
203 Αντιστροφή (Inversion Operation) A B C D (a) (b) (c) E F Δοσοληψία 1 Δοσοληψία N..... Ιδιότητες Μέτρων Αποτίμησης Invariant under the inversion operation αν η τιμή της παραμένει η ίδια αν ανταλλάξουμε τις τιμές f 11 και f 00 και τις τιμές f 10 και f 01 Χρήσιμο για συμμετρικές μεταβλητές
204 Ιδιότητες Μέτρων Αποτίμησης Null Addition (προσθήκη μη σχετιζόμενων στοιχείων) B B A p q A r s B B A p q A r s + k Δεν επηρεάζονται από την αύξηση του f 00 όταν οι άλλες τιμές παραμένουν αμετάβλητες Invariant measures: support, cosine, Jaccard, κλπ Non-invariant measures: correlation, Gini, mutual information, odds ratio, κλπ
205 Αποτίμηση Κανόνων Συσχέτισης Παράδοξο του Simpson Buy HDTV Yes Buy Exercise Machine No Yes No Students Buy HDTV Yes Buy Exercise Machine No Yes No c({hdtv=yes} {EM=Yes})=1/10=10% c({hdtv=no} {EM=Yes})=4/34=11.8% c({hdtv=yes} {EM=Yes})=99/180=55% c({hdtv=no} {EM=Yes})=54/120=45% Working adults c({htvs=yes} {EM=Yes})=98/170=57.7% c({htvs=no} {EM=Yes})=50/86=58.1% Buy HDTV Yes Buy Exercise Machine No Yes No
206 Αποτίμηση Κανόνων Συσχέτισης Παράδοξο του Simpson Buy HDTV Yes Buy Exercise Machine No Yes 99 a+p b+q No 54 c+r d+s c({hdtv=yes} {EM=Yes})=99/180=55% c({hdtv=no} {EM=Yes})=54/120=45% a/b < c/d p/q < r/s δεν συνεπάγεται ότι (a+p)/(b+q) < (c+r)/(d+s)! Students Buy HDTV Yes No Working adults c({hdtv=yes} {EM=Yes})=1/10=10% c({hdtvs=no} {EM=Yes})=4/34=11.8% Buy HDTV Yes No Yes Buy Exercise Machine No 1 α 9 4 c b 34 d c({hdtv=yes} {EM=Yes})=98/170=57.7% c({hdtv=no} {EM=Yes})=50/86=58.1% Yes Buy Exercise Machine No 98 p r q 86 s Είναι σημαντικό πως θα γίνει διαχωρισμός (stratification) των δεδομένων
207 Υποκειμενικά Μέτρα Ενδιαφέροντος Αντικειμενικά Μέτρα: Ιεραρχούν τα αποτελέσματα με βάση στατιστικά στοιχεία που υπολογίζονται από τα δεδομένα πχ., 21 μετρήσεις συσχέτισης (support, confidence, Laplace, Gini, mutual information, Jaccard, etc). Υποκειμενικά Μέτρα: Ιεράρχηση των προτύπων με βάση την ερμηνεία του χρήστη Ένα πρότυπο είναι υποκειμενικά ενδιαφέρον αν είναι σε αντίθεση με αυτό που αναμένει ο χρήστης (Silberschatz & Tuzhilin) Ένα πρότυπο είναι υποκειμενικά ενδιαφέρον αν μπορεί να χρησιμοποιηθεί (Silberschatz & Tuzhilin)
 Χρειάζεται να συνδυάσουμε το τι αναμένεται από")
208 Υποκειμενικά Μέτρα Ενδιαφέροντος Interestingness (ενδιαφέρον) via Unexpectedness (μη αναμονή) + Pattern expected to be frequent - Pattern expected to be infrequent Pattern found to be frequent Pattern found to be infrequent Expected Patterns Unexpected Patterns Χρειάζεται να μοντελοποιήσουμε τι αναμένει ο χρήστης (domain knowledge) Χρειάζεται να συνδυάσουμε το τι αναμένεται από τους χρήστες με το τι δίνουν τα δεδομένα (δηλαδή τα πρότυπα που παίρνουμε - evidence)
209 Οπτικοποίηση: Απλός Γράφος

210 Οπτικοποίηση: Γράφος Κανόνων

211 Οπτικοποίηση: (SGI/MineSet 3.0)
TID Items. Τ = {t 1, t 2,.., t N } ένα σύνολο από δοσοληψίες, όπου κάθε t i είναι ένα στοιχειοσύνολο
 Εισαγωγή Κανόνες Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 Market-Basket transactions (Το καλάθι της νοικοκυράς!)
Εισαγωγή Κανόνες Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 Market-Basket transactions (Το καλάθι της νοικοκυράς!)
Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006
 Κανόνες Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 Εισαγωγή Market-Basket transactions (Το καλάθι της νοικοκυράς!)
Κανόνες Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 Εισαγωγή Market-Basket transactions (Το καλάθι της νοικοκυράς!)
Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006
 Ανάλυση Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 Εισαγωγή Market Basket transactions (Το καλάθι της νοικοκυράς!)
Ανάλυση Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 Εισαγωγή Market Basket transactions (Το καλάθι της νοικοκυράς!)
Ανάλυση Συσχέτισης IΙ
 Ανάλυση Συσχέτισης IΙ Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 ΟΑλγόριθμοςFP-Growth Εξόρυξη Δεδομένων: Ακ. Έτος 2010-2011 ΚΑΝΟΝΕΣ
Ανάλυση Συσχέτισης IΙ Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 2006 ΟΑλγόριθμοςFP-Growth Εξόρυξη Δεδομένων: Ακ. Έτος 2010-2011 ΚΑΝΟΝΕΣ
Ο Αλγόριθμος FP-Growth
 Ο Αλγόριθμος FP-Growth Με λίγα λόγια: Ο αλγόριθμος χρησιμοποιεί μια συμπιεσμένη αναπαράσταση της βάσης των συναλλαγών με τη μορφή ενός FP-δέντρου Το δέντρο μοιάζει με προθεματικό δέντρο - prefix tree (trie)
Ο Αλγόριθμος FP-Growth Με λίγα λόγια: Ο αλγόριθμος χρησιμοποιεί μια συμπιεσμένη αναπαράσταση της βάσης των συναλλαγών με τη μορφή ενός FP-δέντρου Το δέντρο μοιάζει με προθεματικό δέντρο - prefix tree (trie)
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Κανόνες Συσχέτισης: Μέρος Β http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Κανόνες Συσχέτισης: Μέρος Β http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Κανόνες Συσχέτισης: FP-Growth Ευχαριστίες Xρησιμοποιήθηκε επιπλέον υλικό από τα βιβλία «Εισαγωγή στην Εξόρυξη και τις Αποθήκες Δεδομένων» «Introduction to Data
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Κανόνες Συσχέτισης: FP-Growth Ευχαριστίες Xρησιμοποιήθηκε επιπλέον υλικό από τα βιβλία «Εισαγωγή στην Εξόρυξη και τις Αποθήκες Δεδομένων» «Introduction to Data
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 12: Κανόνες Συσχέτισης Μέρος B Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 12: Κανόνες Συσχέτισης Μέρος B Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 11: Κανόνες Συσχέτισης Μέρος Α Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 11: Κανόνες Συσχέτισης Μέρος Α Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης
Κανόνες Συσχέτισης IΙ
 Κανόνες Συσχέτισης IΙ Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 26 Σύντομη Ανακεφαλαίωση Εξόρυξη Δεδομένων: Ακ. Έτος 28-29 ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ
Κανόνες Συσχέτισης IΙ Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 26 Σύντομη Ανακεφαλαίωση Εξόρυξη Δεδομένων: Ακ. Έτος 28-29 ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ
Κανόνες Συσχέτισης IIΙ
 Κανόνες Συσχέτισης IIΙ Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 26 Σύντομη Ανακεφαλαίωση Εξόρυξη Δεδομένων: Ακ. Έτος 2-2 ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ
Κανόνες Συσχέτισης IIΙ Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to Data Mining», Addison Wesley, 26 Σύντομη Ανακεφαλαίωση Εξόρυξη Δεδομένων: Ακ. Έτος 2-2 ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ
Κανόνες Συσχέτισης Ι. Εισαγωγή. Εισαγωγή. Ορισμοί. Ορισμοί. Ορισμοί. Market-Basket transactions (Το καλάθι της νοικοκυράς!)
") Εισαγωγή Κανόνες Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introdion to Data Mining», Addison Wesley, 26 Market-Basket transactions (Το καλάθι της νοικοκυράς!) TID Items
Εισαγωγή Κανόνες Συσχέτισης Ι Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introdion to Data Mining», Addison Wesley, 26 Market-Basket transactions (Το καλάθι της νοικοκυράς!) TID Items
Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής. Εξόρυξη Γνώσης από εδοµένα (Data Mining) Εξόρυξη Κανόνων Συσχετίσεων. Γιάννης Θεοδωρίδης
 Εξόρυξη Κανόνων Συσχετίσεων. Γιάννης Θεοδωρίδης") Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Εξόρυξη Κανόνων Συσχετίσεων Γιάννης Θεοδωρίδης Οµάδα ιαχείρισης εδοµένων Εργαστήριο Πληροφοριακών Συστηµάτων http://isl.cs.unipi.gr/db
Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Εξόρυξη Κανόνων Συσχετίσεων Γιάννης Θεοδωρίδης Οµάδα ιαχείρισης εδοµένων Εργαστήριο Πληροφοριακών Συστηµάτων http://isl.cs.unipi.gr/db
Κεφάλαιο 7: Εξόρυξη Συχνών Στοιχειοσυνόλων και Κανόνων Συσχέτισης
 Κεφάλαιο 7: Εξόρυξη Συχνών Στοιχειοσυνόλων και Κανόνων Συσχέτισης Σύνοψη Ο βασικός στόχος αυτού του κεφαλαίου είναι η εισαγωγή σε θέματα που αφορούν στην εξόρυξη συχνών στοιχειοσυνόλων και κανόνων συσχέτισης.
Κεφάλαιο 7: Εξόρυξη Συχνών Στοιχειοσυνόλων και Κανόνων Συσχέτισης Σύνοψη Ο βασικός στόχος αυτού του κεφαλαίου είναι η εισαγωγή σε θέματα που αφορούν στην εξόρυξη συχνών στοιχειοσυνόλων και κανόνων συσχέτισης.
Κανόνες Συσχέτισης IΙ Σύντομη Ανακεφαλαίωση
 Κανόνες Συσχέτισης IΙ Σύντομη Ανακεφαλαίωση Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to ata Mining», ddison Wesley, 26 Εξόρυξη Δεδομένων: Ακ. Έτος 27-28 ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ
Κανόνες Συσχέτισης IΙ Σύντομη Ανακεφαλαίωση Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to ata Mining», ddison Wesley, 26 Εξόρυξη Δεδομένων: Ακ. Έτος 27-28 ΚΑΝΟΝΕΣ ΣΥΣΧΕΤΙΣΗΣ
Data mining Εξόρυξη εδοµένων. o Association rules mining o Classification o Clustering o Text Mining o Web Mining
 Data mining Εξόρυξη εδοµένων o Association rules mining o Classification o Clustering o Text Mining o Web Mining ιάγραµµα της παρουσίασης Association rule Frequent itemset mining Γνωστοί Αλγόριθµοι Βελτιώσεις
Data mining Εξόρυξη εδοµένων o Association rules mining o Classification o Clustering o Text Mining o Web Mining ιάγραµµα της παρουσίασης Association rule Frequent itemset mining Γνωστοί Αλγόριθµοι Βελτιώσεις
Αποθήκες και Εξόρυξη Δεδομένων
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΨΗΦΙΑΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Αποθήκες και Εξόρυξη Δεδομένων 4 Ο Εργαστήριο WEKA (Association Rules) Στουγιάννου Ελευθερία estoug@unipi.gr -2- Κανόνες Συσχέτισης (Association Rules) Εύρεση
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΨΗΦΙΑΚΩΝ ΣΥΣΤΗΜΑΤΩΝ Αποθήκες και Εξόρυξη Δεδομένων 4 Ο Εργαστήριο WEKA (Association Rules) Στουγιάννου Ελευθερία estoug@unipi.gr -2- Κανόνες Συσχέτισης (Association Rules) Εύρεση
Κανόνες Συσχέτισης IΙ Σύντομη Ανακεφαλαίωση
 Κανόνες Συσχέτισης IΙ Σύντομη Ανακεφαλαίωση Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to ata Mining», ddison Wesley, 2006 Εξόρυξη Δεδομένων: Ακ. Έτος 2006-2007 ΚΑΝΟΝΕΣ
Κανόνες Συσχέτισης IΙ Σύντομη Ανακεφαλαίωση Οι διαφάνειες στηρίζονται στο P.-N. Tan, M.Steinbach, V. Kumar, «Introduction to ata Mining», ddison Wesley, 2006 Εξόρυξη Δεδομένων: Ακ. Έτος 2006-2007 ΚΑΝΟΝΕΣ
Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα)
 (γράφοι και δένδρα)") Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Αφηρημένες
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Εισαγωγή στην Επιστήμη των Υπολογιστών 2016-17 Αλγόριθμοι και Δομές Δεδομένων (IΙ) (γράφοι και δένδρα) http://mixstef.github.io/courses/csintro/ Μ.Στεφανιδάκης Αφηρημένες
Asocijativna analiza
 Asocijativna analiza Šta je asocijativna analiza? Asocijativna analiza sastoji se u identifikovanju jakih asocijativnih pravila u datom skupu podataka Brojne su varijante osnovnog problema Originalna primjena:
Asocijativna analiza Šta je asocijativna analiza? Asocijativna analiza sastoji se u identifikovanju jakih asocijativnih pravila u datom skupu podataka Brojne su varijante osnovnog problema Originalna primjena:
5.2 ΑΠΛΟΠΟΙΗΣΗ ΜΕ ΤΗΝ ΜΕΘΟΔΟ ΚΑΤΑΤΑΞΗΣ ΣΕ ΠΙΝΑΚΑ
 5.2 ΑΠΛΟΠΟΙΗΣΗ ΜΕ ΤΗΝ ΜΕΘΟΔΟ ΚΑΤΑΤΑΞΗΣ ΣΕ ΠΙΝΑΚΑ 5.2. Εισαγωγή Αν η λογική συνάρτηση που πρόκειται να απλοποιήσουμε έχει περισσότερες από έξι μεταβλητές τότε η μέθοδος απλοποίησης με Χάρτη Καρνώ χρειάζεται
5.2 ΑΠΛΟΠΟΙΗΣΗ ΜΕ ΤΗΝ ΜΕΘΟΔΟ ΚΑΤΑΤΑΞΗΣ ΣΕ ΠΙΝΑΚΑ 5.2. Εισαγωγή Αν η λογική συνάρτηση που πρόκειται να απλοποιήσουμε έχει περισσότερες από έξι μεταβλητές τότε η μέθοδος απλοποίησης με Χάρτη Καρνώ χρειάζεται
Privacy preserving data mining με χρήση δενδρικών δομών εξόρυξης κανόνων συσχέτισης
 -------------------------- Τμήμα Μηχανικών Η/Υ και Πληροφορικής Πολυτεχνική Σχολή Πανεπιστημίου Πατρών Διπλωματική Εργασία για το Μεταπτυχιακό Δίπλωμα Ειδίκευσης στην «Επιστήμη και Τεχνολογία Υπολογιστών»
-------------------------- Τμήμα Μηχανικών Η/Υ και Πληροφορικής Πολυτεχνική Σχολή Πανεπιστημίου Πατρών Διπλωματική Εργασία για το Μεταπτυχιακό Δίπλωμα Ειδίκευσης στην «Επιστήμη και Τεχνολογία Υπολογιστών»
Κεφ.11: Ευρετήρια και Κατακερματισμός
 Κεφ.11: Ευρετήρια και Κατακερματισμός Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Κεφ. 11: Ευρετήρια-Βασική θεωρία Μηχανισμοί ευρετηρίου χρησιμοποιούνται για την επιτάχυνση
Κεφ.11: Ευρετήρια και Κατακερματισμός Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Κεφ. 11: Ευρετήρια-Βασική θεωρία Μηχανισμοί ευρετηρίου χρησιμοποιούνται για την επιτάχυνση
Εισαγωγή στην Επεξεργασία Ερωτήσεων. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας Τα βασικά βήματα στην επεξεργασία
Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας Τα βασικά βήματα στην επεξεργασία
Τα δεδομένα (περιεχόμενο) μιας βάσης δεδομένων αποθηκεύεται στο δίσκο
 μιας βάσης δεδομένων αποθηκεύεται στο δίσκο") Κατακερματισμός 1 Αποθήκευση εδομένων (σύνοψη) Τα δεδομένα (περιεχόμενο) μιας βάσης δεδομένων αποθηκεύεται στο δίσκο Παραδοσιακά, μία σχέση (πίνακας/στιγμιότυπο) αποθηκεύεται σε ένα αρχείο Αρχείο δεδομένων
Κατακερματισμός 1 Αποθήκευση εδομένων (σύνοψη) Τα δεδομένα (περιεχόμενο) μιας βάσης δεδομένων αποθηκεύεται στο δίσκο Παραδοσιακά, μία σχέση (πίνακας/στιγμιότυπο) αποθηκεύεται σε ένα αρχείο Αρχείο δεδομένων
Ερώτημα 1. Μας δίνεται μια συλλογή από k ακολοθίες, k >=2 και αναζητούμε το πρότυπο Ρ, μεγέθους n.
 Πρώτο Σύνολο Ασκήσεων 2014-2015 Κατερίνα Ποντζόλκοβα, 5405 Αθανασία Ζαχαριά, 5295 Ερώτημα 1 Μας δίνεται μια συλλογή από k ακολοθίες, k >=2 και αναζητούμε το πρότυπο Ρ, μεγέθους n. Ο αλγόριθμος εύρεσης
Πρώτο Σύνολο Ασκήσεων 2014-2015 Κατερίνα Ποντζόλκοβα, 5405 Αθανασία Ζαχαριά, 5295 Ερώτημα 1 Μας δίνεται μια συλλογή από k ακολοθίες, k >=2 και αναζητούμε το πρότυπο Ρ, μεγέθους n. Ο αλγόριθμος εύρεσης
Αποθήκες εδομένων και Εξόρυξη εδομένων:
 Αποθήκες εδομένων και Εξόρυξη εδομένων: Κατηγοριοποίηση: Μέρος Α http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες εδομένων και Εξόρυξη εδομένων: Κατηγοριοποίηση: Μέρος Α http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
ΗΥ360 Αρχεία και Βάσεις Δεδομένων
 ΗΥ360 Αρχεία και Βάσεις Δεδομένων Φροντιστήριο Συναρτησιακές Εξαρτήσεις Αξιώματα Armstrong Ελάχιστη Κάλυψη Συναρτησιακές Εξαρτήσεις Τι είναι : Οι Συναρτησιακές εξαρτήσεις είναι περιορισμοί ακεραιότητας
ΗΥ360 Αρχεία και Βάσεις Δεδομένων Φροντιστήριο Συναρτησιακές Εξαρτήσεις Αξιώματα Armstrong Ελάχιστη Κάλυψη Συναρτησιακές Εξαρτήσεις Τι είναι : Οι Συναρτησιακές εξαρτήσεις είναι περιορισμοί ακεραιότητας
auth Αλγόριθμοι - Τμήμα Πληροφορικής ΑΠΘ - Εξάμηνο 4ο
 Σχεδίαση Αλγορίθμων Διαίρει και Βασίλευε http://delab.csd.auth.gr/courses/algorithms/ auth 1 Διαίρει και Βασίλευε Η γνωστότερη ρημέθοδος σχεδιασμού αλγορίθμων: 1. Διαιρούμε το στιγμιότυπο του προβλήματος
Σχεδίαση Αλγορίθμων Διαίρει και Βασίλευε http://delab.csd.auth.gr/courses/algorithms/ auth 1 Διαίρει και Βασίλευε Η γνωστότερη ρημέθοδος σχεδιασμού αλγορίθμων: 1. Διαιρούμε το στιγμιότυπο του προβλήματος
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων
 Απαντήσεις 1 ου Σετ Ασκήσεων") Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Επεξεργασία Ερωτήσεων
 Εισαγωγή Επεξεργασία Ερωτήσεων ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήματος 1. Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασμός) 2. Προγραμματισμός (Σχεσιακή Άλγεβρα, SQL) ημιουργία/κατασκευή Εισαγωγή εδομένων
Εισαγωγή Επεξεργασία Ερωτήσεων ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήματος 1. Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασμός) 2. Προγραμματισμός (Σχεσιακή Άλγεβρα, SQL) ημιουργία/κατασκευή Εισαγωγή εδομένων
Επεξεργασία Ερωτήσεων
 Εισαγωγή Επεξεργασία Ερωτήσεων Σ Β Βάση εδομένων Η ομή ενός ΣΒ Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 1 Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 2 Εισαγωγή Εισαγωγή ΜΕΡΟΣ 1 (Χρήση Σ Β ) Γενική
Εισαγωγή Επεξεργασία Ερωτήσεων Σ Β Βάση εδομένων Η ομή ενός ΣΒ Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 1 Βάσεις Δεδομένων 2006-2007 Ευαγγελία Πιτουρά 2 Εισαγωγή Εισαγωγή ΜΕΡΟΣ 1 (Χρήση Σ Β ) Γενική
Ταξινόμηση κάδου και ταξινόμηση Ρίζας Bucket-Sort και Radix-Sort
 Ταξινόμηση κάδου και ταξινόμηση Ρίζας Bucket-Sort και Radix-Sort 1, c 3, a 3, b 7, d 7, g 7, e B 0 1 3 4 5 6 7 8 9 1 BucketSort (Ταξινόμηση Κάδου) - Αρχικά θεωρείται ένα κριτήριο κατανομής με βάση το οποίο
Ταξινόμηση κάδου και ταξινόμηση Ρίζας Bucket-Sort και Radix-Sort 1, c 3, a 3, b 7, d 7, g 7, e B 0 1 3 4 5 6 7 8 9 1 BucketSort (Ταξινόμηση Κάδου) - Αρχικά θεωρείται ένα κριτήριο κατανομής με βάση το οποίο
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2017-2018 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2017-2018 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Οργάνωση αρχείων: πως είναι τοποθετηµένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο
 Κατακερµατισµός 1 Οργάνωση Αρχείων (σύνοψη) Οργάνωση αρχείων: πως είναι τοποθετηµένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο 1. Αρχεία Σωρού 2. Ταξινοµηµένα Αρχεία Φυσική διάταξη των εγγραφών
Κατακερµατισµός 1 Οργάνωση Αρχείων (σύνοψη) Οργάνωση αρχείων: πως είναι τοποθετηµένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο 1. Αρχεία Σωρού 2. Ταξινοµηµένα Αρχεία Φυσική διάταξη των εγγραφών
Υπερπροσαρμογή (Overfitting) (1)
 (1)") Αλγόριθμος C4.5 Αποφυγή υπερπροσαρμογής (overfitting) Reduced error pruning Rule post-pruning Χειρισμός χαρακτηριστικών συνεχών τιμών Επιλογή κατάλληλης μετρικής για την επιλογή των χαρακτηριστικών διάσπασης
Αλγόριθμος C4.5 Αποφυγή υπερπροσαρμογής (overfitting) Reduced error pruning Rule post-pruning Χειρισμός χαρακτηριστικών συνεχών τιμών Επιλογή κατάλληλης μετρικής για την επιλογή των χαρακτηριστικών διάσπασης
Επεξεργασία Ερωτήσεων
 Εισαγωγή Σ Β Σύνολο από προγράμματα για τη διαχείριση της Β Επεξεργασία Ερωτήσεων Αρχεία ευρετηρίου Κατάλογος συστήματος Αρχεία δεδομένων ΒΑΣΗ Ε ΟΜΕΝΩΝ Σύστημα Βάσεων εδομένων (ΣΒ ) Βάσεις Δεδομένων 2007-2008
Εισαγωγή Σ Β Σύνολο από προγράμματα για τη διαχείριση της Β Επεξεργασία Ερωτήσεων Αρχεία ευρετηρίου Κατάλογος συστήματος Αρχεία δεδομένων ΒΑΣΗ Ε ΟΜΕΝΩΝ Σύστημα Βάσεων εδομένων (ΣΒ ) Βάσεις Δεδομένων 2007-2008
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή
Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2018-2019 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Δυναμικός Κατακερματισμός Βάσεις Δεδομένων 2018-2019 1 Κατακερματισμός Πρόβλημα στατικού κατακερματισμού: Έστω Μ κάδους και r εγγραφές ανά κάδο - το πολύ Μ * r εγγραφές (αλλιώς μεγάλες αλυσίδες υπερχείλισης)
Δυναμικός Κατακερματισμός. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Δυναμικός Κατακερματισμός 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή (ως τρόπος οργάνωσης αρχείου) μέγεθος
Δυναμικός Κατακερματισμός 1 Κατακερματισμός Τι αποθηκεύουμε στους κάδους; Στα παραδείγματα δείχνουμε μόνο την τιμή του πεδίου κατακερματισμού Την ίδια την εγγραφή (ως τρόπος οργάνωσης αρχείου) μέγεθος
Εισαγωγή στην Επεξεργασία Ερωτήσεων. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Εισαγωγή στην Επεξεργασία Ερωτήσεων Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα Βάσεις
Εισαγωγή στην Επεξεργασία Ερωτήσεων Βάσεις Δεδομένων 2013-2014 Ευαγγελία Πιτουρά 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα Βάσεις
2η ΔΙΑΛΕΞΗ Συναρτησιακές εξαρτήσεις
 2η ΔΙΑΛΕΞΗ 1 Συναρτησιακές εξαρτήσεις Συναρτησιακές εξαρτήσεις 2 Θέματα Ανάπτυξης Έννοια και ορισμός των συναρτησιακών εξαρτήσεων Κανόνες του Armstrong Μη αναγώγιμα σύνολα εξαρτήσεων Στόχος και Αποτελέσματα
2η ΔΙΑΛΕΞΗ 1 Συναρτησιακές εξαρτήσεις Συναρτησιακές εξαρτήσεις 2 Θέματα Ανάπτυξης Έννοια και ορισμός των συναρτησιακών εξαρτήσεων Κανόνες του Armstrong Μη αναγώγιμα σύνολα εξαρτήσεων Στόχος και Αποτελέσματα
Τεχνητή Νοημοσύνη (ΥΠ23) 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή
 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή") Τεχνητή Νοημοσύνη (ΥΠ23) 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή raniah@hua.gr 1 Αλγόριθμοι Τυφλής Αναζήτησης Οι αλγόριθμοι τυφλής αναζήτησης εφαρμόζονται σε
Τεχνητή Νοημοσύνη (ΥΠ23) 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή raniah@hua.gr 1 Αλγόριθμοι Τυφλής Αναζήτησης Οι αλγόριθμοι τυφλής αναζήτησης εφαρμόζονται σε
Τεχνητή Νοημοσύνη (ΥΠ23) 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή
 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή") Τεχνητή Νοημοσύνη (ΥΠ23) 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή raniah@hua.gr 1 Αναζήτηση Δοθέντος ενός προβλήματος με περιγραφή είτε στον χώρο καταστάσεων
Τεχνητή Νοημοσύνη (ΥΠ23) 6 ο εξάμηνο Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ουρανία Χατζή raniah@hua.gr 1 Αναζήτηση Δοθέντος ενός προβλήματος με περιγραφή είτε στον χώρο καταστάσεων
Δομές Δεδομένων. Δημήτρης Μιχαήλ. Συμβολοσειρές. Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο
 Δομές Δεδομένων Συμβολοσειρές Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Συμβολοσειρές Συμβολοσειρές και προβλήματα που αφορούν συμβολοσειρές εμφανίζονται τόσο συχνά που
Δομές Δεδομένων Συμβολοσειρές Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Συμβολοσειρές Συμβολοσειρές και προβλήματα που αφορούν συμβολοσειρές εμφανίζονται τόσο συχνά που
Κατανεμημένα Συστήματα Ι
 Κατανεμημένα Συστήματα Ι Παναγιώτα Παναγοπούλου Χριστίνα Σπυροπούλου 8η Διάλεξη 8 Δεκεμβρίου 2016 1 Ασύγχρονη κατασκευή BFS δέντρου Στα σύγχρονα συστήματα ο αλγόριθμος της πλημμύρας είναι ένας απλός αλλά
Κατανεμημένα Συστήματα Ι Παναγιώτα Παναγοπούλου Χριστίνα Σπυροπούλου 8η Διάλεξη 8 Δεκεμβρίου 2016 1 Ασύγχρονη κατασκευή BFS δέντρου Στα σύγχρονα συστήματα ο αλγόριθμος της πλημμύρας είναι ένας απλός αλλά
Δυναμικός Κατακερματισμός
 Δυναμικός Κατακερματισμός Καλό για βάση δεδομένων που μεγαλώνει και συρρικνώνεται σε μέγεθος Επιτρέπει τη δυναμική τροποποίηση της συνάρτησης κατακερματισμού Επεκτάσιμος κατακερματισμός μια μορφή δυναμικού
Δυναμικός Κατακερματισμός Καλό για βάση δεδομένων που μεγαλώνει και συρρικνώνεται σε μέγεθος Επιτρέπει τη δυναμική τροποποίηση της συνάρτησης κατακερματισμού Επεκτάσιμος κατακερματισμός μια μορφή δυναμικού
ΗΥ360 Αρχεία και Βάσεις εδοµένων ιδάσκων:. Πλεξουσάκης
 ΗΥ360 Αρχεία και Βάσεις εδοµένων ιδάσκων:. Πλεξουσάκης Συναρτησιακές Εξαρτήσεις Αξιώµατα Armstrong Ελάχιστη κάλυψη Φροντιστήριο 1 Συναρτησιακές Εξαρτήσεις Οι Συναρτησιακές εξαρτήσεις είναι περιορισµοί
ΗΥ360 Αρχεία και Βάσεις εδοµένων ιδάσκων:. Πλεξουσάκης Συναρτησιακές Εξαρτήσεις Αξιώµατα Armstrong Ελάχιστη κάλυψη Φροντιστήριο 1 Συναρτησιακές Εξαρτήσεις Οι Συναρτησιακές εξαρτήσεις είναι περιορισµοί
Αναζήτηση στους γράφους. - Αναζήτηση η κατά βάθος Συνεκτικές Συνιστώσες - Αλγόριθμος εύρεσης συνεκτικών συνιστωσών
 Αναζήτηση στους γράφους Βασικός αλγόριθμος λό - Αναζήτηση κατά πλάτος - Αναζήτηση η κατά βάθος Συνεκτικές Συνιστώσες - Αλγόριθμος εύρεσης συνεκτικών συνιστωσών Διάσχιση (αναζήτηση ) στους γράφους Φεύγοντας
Αναζήτηση στους γράφους Βασικός αλγόριθμος λό - Αναζήτηση κατά πλάτος - Αναζήτηση η κατά βάθος Συνεκτικές Συνιστώσες - Αλγόριθμος εύρεσης συνεκτικών συνιστωσών Διάσχιση (αναζήτηση ) στους γράφους Φεύγοντας
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος B http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος B http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Εξωτερική Αναζήτηση. Ιεραρχία Μνήμης Υπολογιστή. Εξωτερική Μνήμη. Εσωτερική Μνήμη. Κρυφή Μνήμη (Cache) Καταχωρητές (Registers) μεγαλύτερη ταχύτητα
 Καταχωρητές (Registers) μεγαλύτερη ταχύτητα") Ιεραρχία Μνήμης Υπολογιστή Εξωτερική Μνήμη Εσωτερική Μνήμη Κρυφή Μνήμη (Cache) μεγαλύτερη χωρητικότητα Καταχωρητές (Registers) Κεντρική Μονάδα (CPU) μεγαλύτερη ταχύτητα Πολλές σημαντικές εφαρμογές διαχειρίζονται
Ιεραρχία Μνήμης Υπολογιστή Εξωτερική Μνήμη Εσωτερική Μνήμη Κρυφή Μνήμη (Cache) μεγαλύτερη χωρητικότητα Καταχωρητές (Registers) Κεντρική Μονάδα (CPU) μεγαλύτερη ταχύτητα Πολλές σημαντικές εφαρμογές διαχειρίζονται
Κανόνες συσχέτισης Association rules
 Κανόνες συσχέτισης Association rules Αποθήκες και Εξόρυξη Δεδομένων Διδάσκουσα: Μαρία Χαλκίδη με βάση slides από J. Han and M. Kamber Data Mining: Concepts and Techniques, 2 nd edition Τι είναι η εξόρυξη
Κανόνες συσχέτισης Association rules Αποθήκες και Εξόρυξη Δεδομένων Διδάσκουσα: Μαρία Χαλκίδη με βάση slides από J. Han and M. Kamber Data Mining: Concepts and Techniques, 2 nd edition Τι είναι η εξόρυξη
Περιεχόμενα. Περιεχόμενα
 Περιεχόμενα xv Περιεχόμενα 1 Αρχές της Java... 1 1.1 Προκαταρκτικά: Κλάσεις, Τύποι και Αντικείμενα... 2 1.1.1 Βασικοί Τύποι... 5 1.1.2 Αντικείμενα... 7 1.1.3 Τύποι Enum... 14 1.2 Μέθοδοι... 15 1.3 Εκφράσεις...
Περιεχόμενα xv Περιεχόμενα 1 Αρχές της Java... 1 1.1 Προκαταρκτικά: Κλάσεις, Τύποι και Αντικείμενα... 2 1.1.1 Βασικοί Τύποι... 5 1.1.2 Αντικείμενα... 7 1.1.3 Τύποι Enum... 14 1.2 Μέθοδοι... 15 1.3 Εκφράσεις...
Το εσωτερικό ενός Σ Β
 Επεξεργασία Ερωτήσεων 1 Εισαγωγή ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL) ηµιουργία/κατασκευή Εισαγωγή εδοµένων
Επεξεργασία Ερωτήσεων 1 Εισαγωγή ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL) ηµιουργία/κατασκευή Εισαγωγή εδοµένων
Επίλυση Προβλημάτων 1
 Επίλυση Προβλημάτων 1 Επίλυση Προβλημάτων Περιγραφή Προβλημάτων Αλγόριθμοι αναζήτησης Αλγόριθμοι τυφλής αναζήτησης Αναζήτηση πρώτα σε βάθος Αναζήτηση πρώτα σε πλάτος (ΒFS) Αλγόριθμοι ευρετικής αναζήτησης
Επίλυση Προβλημάτων 1 Επίλυση Προβλημάτων Περιγραφή Προβλημάτων Αλγόριθμοι αναζήτησης Αλγόριθμοι τυφλής αναζήτησης Αναζήτηση πρώτα σε βάθος Αναζήτηση πρώτα σε πλάτος (ΒFS) Αλγόριθμοι ευρετικής αναζήτησης
Χρήστος Ι. Σχοινάς Αν. Καθηγητής ΔΠΘ. Συμπληρωματικές σημειώσεις για το μάθημα: «Επιχειρησιακή Έρευνα ΙΙ»
 Χρήστος Ι. Σχοινάς Αν. Καθηγητής ΔΠΘ Συμπληρωματικές σημειώσεις για το μάθημα: «Επιχειρησιακή Έρευνα ΙΙ» 2 ΔΥΝΑΜΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Προβλήματα ελάχιστης συνεκτικότητας δικτύου Το πρόβλημα της ελάχιστης
Χρήστος Ι. Σχοινάς Αν. Καθηγητής ΔΠΘ Συμπληρωματικές σημειώσεις για το μάθημα: «Επιχειρησιακή Έρευνα ΙΙ» 2 ΔΥΝΑΜΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Προβλήματα ελάχιστης συνεκτικότητας δικτύου Το πρόβλημα της ελάχιστης
Ενότητα 9 Ξένα Σύνολα που υποστηρίζουν τη λειτουργία της Ένωσης (Union-Find)
") Ενότητα 9 Ξένα Σύνολα που υποστηρίζουν τη (Union-Find) ΗΥ240 - Παναγιώτα Φατούρου 1 Ξένα Σύνολα που υποστηρίζουν τη λειτουργία της Ένωσης Έστω ότι S 1,, S k είναι ξένα υποσύνολα ενός συνόλου U, δηλαδή
Ενότητα 9 Ξένα Σύνολα που υποστηρίζουν τη (Union-Find) ΗΥ240 - Παναγιώτα Φατούρου 1 Ξένα Σύνολα που υποστηρίζουν τη λειτουργία της Ένωσης Έστω ότι S 1,, S k είναι ξένα υποσύνολα ενός συνόλου U, δηλαδή
Λυσεις προβλημάτων τελικής φάσης Παγκύπριου Μαθητικού Διαγωνισμού Πληροφορικής 2007
 Λυσεις προβλημάτων τελικής φάσης Παγκύπριου Μαθητικού Διαγωνισμού Πληροφορικής 2007 Πρόβλημα 1 Το πρώτο πρόβλημα λύνεται με τη μέθοδο του Δυναμικού Προγραμματισμού. Για να το λύσουμε με Δυναμικό Προγραμματισμό
Λυσεις προβλημάτων τελικής φάσης Παγκύπριου Μαθητικού Διαγωνισμού Πληροφορικής 2007 Πρόβλημα 1 Το πρώτο πρόβλημα λύνεται με τη μέθοδο του Δυναμικού Προγραμματισμού. Για να το λύσουμε με Δυναμικό Προγραμματισμό
Μελετάμε την περίπτωση όπου αποθηκεύουμε ένα (δυναμικό) σύνολο στοιχειών. Ένα στοιχείο γράφεται ως, όπου κάθε.
 σύνολο στοιχειών. Ένα στοιχείο γράφεται ως, όπου κάθε.") Ψηφιακά Δένδρα Μελετάμε την περίπτωση όπου αποθηκεύουμε ένα (δυναμικό) σύνολο στοιχειών τα οποία είναι ακολουθίες συμβάλλων από ένα πεπερασμένο αλφάβητο Ένα στοιχείο γράφεται ως, όπου κάθε. Μπορούμε να
Ψηφιακά Δένδρα Μελετάμε την περίπτωση όπου αποθηκεύουμε ένα (δυναμικό) σύνολο στοιχειών τα οποία είναι ακολουθίες συμβάλλων από ένα πεπερασμένο αλφάβητο Ένα στοιχείο γράφεται ως, όπου κάθε. Μπορούμε να
Σχεδίαση Αλγορίθμων -Τμήμα Πληροφορικής ΑΠΘ - Εξάμηνο 4ο
 Σχεδίαση Αλγορίθμων Διαίρει και Βασίλευε http://delab.csd.auth.gr/~gounaris/courses/ad auth gounaris/courses/ad 1 Διαίρει και Βασίλευε Η γνωστότερη ρημέθοδος σχεδιασμού αλγορίθμων: 1. Διαιρούμε το στιγμιότυπο
Σχεδίαση Αλγορίθμων Διαίρει και Βασίλευε http://delab.csd.auth.gr/~gounaris/courses/ad auth gounaris/courses/ad 1 Διαίρει και Βασίλευε Η γνωστότερη ρημέθοδος σχεδιασμού αλγορίθμων: 1. Διαιρούμε το στιγμιότυπο
Κεφάλαιο 3. Αλγόριθµοι Τυφλής Αναζήτησης. Τεχνητή Νοηµοσύνη - Β' Έκδοση. Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η.
 Κεφάλαιο 3 Αλγόριθµοι Τυφλής Αναζήτησης Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η. Σακελλαρίου Αλγόριθµοι Τυφλής Αναζήτησης Οι αλγόριθµοι τυφλής αναζήτησης (blind
Κεφάλαιο 3 Αλγόριθµοι Τυφλής Αναζήτησης Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η. Σακελλαρίου Αλγόριθµοι Τυφλής Αναζήτησης Οι αλγόριθµοι τυφλής αναζήτησης (blind
Κατακερµατισµός. Οργάνωση Αρχείων (σύνοψη) Οργάνωση αρχείων: πως είναι τοποθετημένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο
 Οργάνωση αρχείων: πως είναι τοποθετημένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο") Κατακερµατισµός 1 Οργάνωση Αρχείων (σύνοψη) Οργάνωση αρχείων: πως είναι τοποθετημένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο 1. Αρχεία Σωρού 2. Ταξινομημένα Αρχεία Φυσική διάταξη των εγγραφών
Κατακερµατισµός 1 Οργάνωση Αρχείων (σύνοψη) Οργάνωση αρχείων: πως είναι τοποθετημένες οι εγγραφές ενός αρχείου όταν αποθηκεύονται στο δίσκο 1. Αρχεία Σωρού 2. Ταξινομημένα Αρχεία Φυσική διάταξη των εγγραφών
Αλγόριθμοι Τυφλής Αναζήτησης
 Τεχνητή Νοημοσύνη 04 Αλγόριθμοι Τυφλής Αναζήτησης Αλγόριθμοι Τυφλής Αναζήτησης (Blind Search Algorithms) Εφαρμόζονται σε προβλήματα στα οποία δεν υπάρχει πληροφορία που να επιτρέπει αξιολόγηση των καταστάσεων.
Τεχνητή Νοημοσύνη 04 Αλγόριθμοι Τυφλής Αναζήτησης Αλγόριθμοι Τυφλής Αναζήτησης (Blind Search Algorithms) Εφαρμόζονται σε προβλήματα στα οποία δεν υπάρχει πληροφορία που να επιτρέπει αξιολόγηση των καταστάσεων.
Τεχνικές Εξόρυξης Δεδομένων
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Διατμηματικό Μεταπτυχιακό Πρόγραμμα στα Πληροφοριακά Συστήματα ( MIS ) Τεχνικές Εξόρυξης Δεδομένων για την βελτίωση της απόδοσης σε Κατανεμημένα Συστήματα Ζάχος Δημήτριος Επιβλέποντες:
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Διατμηματικό Μεταπτυχιακό Πρόγραμμα στα Πληροφοριακά Συστήματα ( MIS ) Τεχνικές Εξόρυξης Δεδομένων για την βελτίωση της απόδοσης σε Κατανεμημένα Συστήματα Ζάχος Δημήτριος Επιβλέποντες:
Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων ομές εδομένων
 Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 6. Δυαδικά Δέντρα 2 ομές εδομένων 4 5 Χρήστος ουλκερίδης Τμήμα Ψηφιακών Συστημάτων 18/11/2016 Εισαγωγή Τα
Πανεπιστήμιο Πειραιώς Σχολή Τεχνολογιών Πληροφορικής και Επικοινωνιών Τμήμα Ψηφιακών Συστημάτων 6. Δυαδικά Δέντρα 2 ομές εδομένων 4 5 Χρήστος ουλκερίδης Τμήμα Ψηφιακών Συστημάτων 18/11/2016 Εισαγωγή Τα
Κατανεμημένα Συστήματα Ι
 Κατανεμημένα Συστήματα Ι Εκλογή αρχηγού και κατασκευή BFS δένδρου σε σύγχρονο γενικό δίκτυο Παναγιώτα Παναγοπούλου Περίληψη Εκλογή αρχηγού σε γενικά δίκτυα Ορισμός του προβλήματος Ο αλγόριθμος FloodMax
Κατανεμημένα Συστήματα Ι Εκλογή αρχηγού και κατασκευή BFS δένδρου σε σύγχρονο γενικό δίκτυο Παναγιώτα Παναγοπούλου Περίληψη Εκλογή αρχηγού σε γενικά δίκτυα Ορισμός του προβλήματος Ο αλγόριθμος FloodMax
Αναζήτηση σε Γράφους. Μανόλης Κουμπαράκης. ΥΣ02 Τεχνητή Νοημοσύνη 1
 Αναζήτηση σε Γράφους Μανόλης Κουμπαράκης ΥΣ02 Τεχνητή Νοημοσύνη 1 Πρόλογος Μέχρι τώρα έχουμε δει αλγόριθμους αναζήτησης για την περίπτωση που ο χώρος καταστάσεων είναι δένδρο (υπάρχει μία μόνο διαδρομή
Αναζήτηση σε Γράφους Μανόλης Κουμπαράκης ΥΣ02 Τεχνητή Νοημοσύνη 1 Πρόλογος Μέχρι τώρα έχουμε δει αλγόριθμους αναζήτησης για την περίπτωση που ο χώρος καταστάσεων είναι δένδρο (υπάρχει μία μόνο διαδρομή
Θέματα Μεταγλωττιστών
 Γιώργος Δημητρίου Ενότητα 7 η : Περιοχές: Εναλλακτική Μέθοδος Ανάλυσης Ροής Δεδομένων Περιοχές (Regions) Σε κάποιες περιπτώσεις βρόχων η ανάλυση ροής δεδομένων με τον επαναληπτικό αλγόριθμο συγκλίνει αργά
Γιώργος Δημητρίου Ενότητα 7 η : Περιοχές: Εναλλακτική Μέθοδος Ανάλυσης Ροής Δεδομένων Περιοχές (Regions) Σε κάποιες περιπτώσεις βρόχων η ανάλυση ροής δεδομένων με τον επαναληπτικό αλγόριθμο συγκλίνει αργά
Ενότητα 9 Ξένα Σύνολα που υποστηρίζουν τη λειτουργία της Ένωσης (Union-Find)
") Ενότητα 9 (Union-Find) ΗΥ240 - Παναγιώτα Φατούρου 1 Έστω ότι S 1,, S k είναι ξένα υποσύνολα ενός συνόλου U, δηλαδή ισχύει ότι S i S j =, για κάθε i,j µε i j και S 1 S k = U. Λειτουργίες q MakeSet(X): επιστρέφει
Ενότητα 9 (Union-Find) ΗΥ240 - Παναγιώτα Φατούρου 1 Έστω ότι S 1,, S k είναι ξένα υποσύνολα ενός συνόλου U, δηλαδή ισχύει ότι S i S j =, για κάθε i,j µε i j και S 1 S k = U. Λειτουργίες q MakeSet(X): επιστρέφει
Δομές Δεδομένων. Καθηγήτρια Μαρία Σατρατζέμη. Τμήμα Εφαρμοσμένης Πληροφορικής. Δομές Δεδομένων. Τμήμα Εφαρμοσμένης Πληροφορικής
 Ενότητα 8: Γραμμική Αναζήτηση και Δυαδική Αναζήτηση-Εισαγωγή στα Δέντρα και Δυαδικά Δέντρα-Δυαδικά Δέντρα Αναζήτησης & Υλοποίηση ΔΔΑ με δείκτες Καθηγήτρια Μαρία Σατρατζέμη Άδειες Χρήσης Το παρόν εκπαιδευτικό
Ενότητα 8: Γραμμική Αναζήτηση και Δυαδική Αναζήτηση-Εισαγωγή στα Δέντρα και Δυαδικά Δέντρα-Δυαδικά Δέντρα Αναζήτησης & Υλοποίηση ΔΔΑ με δείκτες Καθηγήτρια Μαρία Σατρατζέμη Άδειες Χρήσης Το παρόν εκπαιδευτικό
ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ EPL035: ΔΟΜΕΣ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΑΛΓΟΡΙΘΜΟΙ
 ΠΝΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜ ΠΛΗΡΟΦΟΡΙΚΗΣ EPL035: ΔΟΜΣ ΔΔΟΜΝΩΝ ΚΙ ΛΓΟΡΙΘΜΟΙ ΗΜΡΟΜΗΝΙ: 14/11/2018 ΔΙΓΝΩΣΤΙΚΟ ΠΝΩ Σ ΔΝΔΡΙΚΣ ΔΟΜΣ ΚΙ ΓΡΦΟΥΣ Διάρκεια: 45 λεπτά Ονοματεπώνυμο:. ρ. Ταυτότητας:. ΒΘΜΟΛΟΓΙ ΣΚΗΣΗ ΒΘΜΟΣ
ΠΝΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ ΤΜΗΜ ΠΛΗΡΟΦΟΡΙΚΗΣ EPL035: ΔΟΜΣ ΔΔΟΜΝΩΝ ΚΙ ΛΓΟΡΙΘΜΟΙ ΗΜΡΟΜΗΝΙ: 14/11/2018 ΔΙΓΝΩΣΤΙΚΟ ΠΝΩ Σ ΔΝΔΡΙΚΣ ΔΟΜΣ ΚΙ ΓΡΦΟΥΣ Διάρκεια: 45 λεπτά Ονοματεπώνυμο:. ρ. Ταυτότητας:. ΒΘΜΟΛΟΓΙ ΣΚΗΣΗ ΒΘΜΟΣ
Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό υλικό, όπως εικόνες, που υπόκειται σε άλλου τύ
 Διακριτά Μαθηματικά Ι Ενότητα 4: Θεωρία Μέτρησης Po lya Μέρος 1 Διδάσκων: Χ. Μπούρας (bouras@cti.gr) Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Διακριτά Μαθηματικά Ι Ενότητα 4: Θεωρία Μέτρησης Po lya Μέρος 1 Διδάσκων: Χ. Μπούρας (bouras@cti.gr) Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative Commons. Για εκπαιδευτικό
Ασκήσεις ανακεφαλαίωσης στο μάθημα Τεχνητή Νοημοσύνη
 Ασκήσεις ανακεφαλαίωσης στο μάθημα Τεχνητή Νοημοσύνη Τμήμα Μηχανικών Πληροφορικής ΤΕ (ΤΕΙ Ηπείρου) Τυφλή αναζήτηση Δίνεται το ακόλουθο κατευθυνόμενο γράφημα 1. Ο κόμβος αφετηρία είναι ο Α και ο κόμβος
Ασκήσεις ανακεφαλαίωσης στο μάθημα Τεχνητή Νοημοσύνη Τμήμα Μηχανικών Πληροφορικής ΤΕ (ΤΕΙ Ηπείρου) Τυφλή αναζήτηση Δίνεται το ακόλουθο κατευθυνόμενο γράφημα 1. Ο κόμβος αφετηρία είναι ο Α και ο κόμβος
Πόσες από αυτές τις σκακιέρες είναι αλήθεια διαφορετικές;
 Η ύλη συνοπτικά... Στοιχειώδης συνδυαστική Γεννήτριες συναρτήσεις Σχέσεις αναδρομής Θεωρία Μέτρησης Polyá Αρχή Εγκλεισμού - Αποκλεισμού Πόσες από αυτές τις σκακιέρες είναι αλήθεια διαφορετικές; Αυτές οι
Η ύλη συνοπτικά... Στοιχειώδης συνδυαστική Γεννήτριες συναρτήσεις Σχέσεις αναδρομής Θεωρία Μέτρησης Polyá Αρχή Εγκλεισμού - Αποκλεισμού Πόσες από αυτές τις σκακιέρες είναι αλήθεια διαφορετικές; Αυτές οι
Αλγόριθμοι και Πολυπλοκότητα
 Αλγόριθμοι και Πολυπλοκότητα Διαίρει και Βασίλευε Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Διαίρει και Βασίλευε Divide and Conquer Η τεχνική διαίρει και βασίλευε αναφέρεται
Αλγόριθμοι και Πολυπλοκότητα Διαίρει και Βασίλευε Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Διαίρει και Βασίλευε Divide and Conquer Η τεχνική διαίρει και βασίλευε αναφέρεται
Insert (P) : Προσθέτει ένα νέο πρότυπο P στο λεξικό D. Delete (P) : Διαγράφει το πρότυπο P από το λεξικό D
 : Προσθέτει ένα νέο πρότυπο P στο λεξικό D. Delete (P) : Διαγράφει το πρότυπο P από το λεξικό D") Dynamic dictionary matching problem Έχουμε ένα σύνολο πρότυπων D = { P1, P2,..., Pk } oπου D το λεξικό και ένα αυθαίρετο κειμενο T [1,n] To σύνολο των πρότυπων αλλάζει με το χρόνο (ρεαλιστική συνθήκη).
Dynamic dictionary matching problem Έχουμε ένα σύνολο πρότυπων D = { P1, P2,..., Pk } oπου D το λεξικό και ένα αυθαίρετο κειμενο T [1,n] To σύνολο των πρότυπων αλλάζει με το χρόνο (ρεαλιστική συνθήκη).
Συναρτησιακές Εξαρτήσεις 7ο Φροντιστήριο. Βάρσος Κωνσταντίνος
 ΗΥ-360 Αρχεια και Βασεις εδοµενων, Τµηµα Επιστηµης Υπολογιστων, Πανεπιστηµιο Κρητης Συναρτησιακές Εξαρτήσεις Βάρσος Κωνσταντίνος 24 Νοεµβρίου 2017 Ορισµός 1. Μια συναρτησιακή εξάρτηση µεταξύ X και Y συµβολίζεται
ΗΥ-360 Αρχεια και Βασεις εδοµενων, Τµηµα Επιστηµης Υπολογιστων, Πανεπιστηµιο Κρητης Συναρτησιακές Εξαρτήσεις Βάρσος Κωνσταντίνος 24 Νοεµβρίου 2017 Ορισµός 1. Μια συναρτησιακή εξάρτηση µεταξύ X και Y συµβολίζεται
Αλγόριθμοι Ταξινόμησης Μέρος 4
 Αλγόριθμοι Ταξινόμησης Μέρος 4 Μανόλης Κουμπαράκης Δομές Δεδομένων και Τεχνικές 1 Μέθοδοι Ταξινόμησης Βασισμένοι σε Συγκρίσεις Κλειδιών Οι αλγόριθμοι ταξινόμησης που είδαμε μέχρι τώρα αποφασίζουν πώς να
Αλγόριθμοι Ταξινόμησης Μέρος 4 Μανόλης Κουμπαράκης Δομές Δεδομένων και Τεχνικές 1 Μέθοδοι Ταξινόμησης Βασισμένοι σε Συγκρίσεις Κλειδιών Οι αλγόριθμοι ταξινόμησης που είδαμε μέχρι τώρα αποφασίζουν πώς να
Λύση (από: Τσιαλιαμάνης Αναγνωστόπουλος Πέτρος) (α) Το trie του λεξιλογίου είναι
 (α) Το trie του λεξιλογίου είναι") Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY463 - Συστήματα Ανάκτησης Πληροφοριών 2006-2007 Εαρινό Εξάμηνο 3 η Σειρά ασκήσεων (Ευρετηρίαση, Αναζήτηση σε Κείμενα και Άλλα Θέματα) (βαθμοί 12: όποιος
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY463 - Συστήματα Ανάκτησης Πληροφοριών 2006-2007 Εαρινό Εξάμηνο 3 η Σειρά ασκήσεων (Ευρετηρίαση, Αναζήτηση σε Κείμενα και Άλλα Θέματα) (βαθμοί 12: όποιος
Δομές Δεδομένων. Τι είναι η δομή δεδομένων; Έστω η ακολουθία αριθμών: 8, 10,17,19,22,5,12 Λογικό Επίπεδο. Φυσικό Επίπεδο RAM. Ταξινομημένος.
 Δομές Δεδομένων Τι είναι η δομή δεδομένων; Έστω η ακολουθία αριθμών: 8, 10,17,19,22,5,12 Λογικό Επίπεδο Φυσικό Επίπεδο RAM Πίνακας 8 10 17 19 22 Ταξινομημένος Πίνακας 5 8 10 12 17 Δένδρο 8 5 10 12 19 17
Δομές Δεδομένων Τι είναι η δομή δεδομένων; Έστω η ακολουθία αριθμών: 8, 10,17,19,22,5,12 Λογικό Επίπεδο Φυσικό Επίπεδο RAM Πίνακας 8 10 17 19 22 Ταξινομημένος Πίνακας 5 8 10 12 17 Δένδρο 8 5 10 12 19 17
Επεξεργασία Ερωτήσεων
 Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Εισαγωγή ΣΔΒΔ Σύνολο από προγράµµατα για τη διαχείριση της ΒΔ Αρχεία ευρετηρίου Κατάλογος ΒΑΣΗ ΔΕΔΟΜΕΝΩΝ Αρχεία δεδοµένων συστήµατος Σύστηµα Βάσεων Δεδοµένων (ΣΒΔ)
Εισαγωγή στην Επεξεργασία Ερωτήσεων 1 Εισαγωγή ΣΔΒΔ Σύνολο από προγράµµατα για τη διαχείριση της ΒΔ Αρχεία ευρετηρίου Κατάλογος ΒΑΣΗ ΔΕΔΟΜΕΝΩΝ Αρχεία δεδοµένων συστήµατος Σύστηµα Βάσεων Δεδοµένων (ΣΒΔ)
Δομές Δεδομένων και Αλγόριθμοι
 Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 1 Εισαγωγή 1 / 14 Δομές Δεδομένων και Αλγόριθμοι Δομή Δεδομένων Δομή δεδομένων είναι ένα σύνολο αποθηκευμένων
Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 1 Εισαγωγή 1 / 14 Δομές Δεδομένων και Αλγόριθμοι Δομή Δεδομένων Δομή δεδομένων είναι ένα σύνολο αποθηκευμένων
Δομές Δεδομένων και Αλγόριθμοι
 Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 19 Hashing - Κατακερματισμός 1 / 23 Πίνακες απευθείας πρόσβασης (Direct Access Tables) Οι πίνακες απευθείας
Δομές Δεδομένων και Αλγόριθμοι Χρήστος Γκόγκος ΤΕΙ Ηπείρου Χειμερινό Εξάμηνο 2014-2015 Παρουσίαση 19 Hashing - Κατακερματισμός 1 / 23 Πίνακες απευθείας πρόσβασης (Direct Access Tables) Οι πίνακες απευθείας
Διάλεξη 22: Δυαδικά Δέντρα. Διδάσκων: Παναγιώτης Ανδρέου
 Διάλεξη 22: Δυαδικά Δέντρα Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Δυαδικά Δένδρα - Δυαδικά Δένδρα Αναζήτησης - Πράξεις Εισαγωγής, Εύρεσης Στοιχείου, Διαγραφής Μικρότερου Στοιχείου
Διάλεξη 22: Δυαδικά Δέντρα Στην ενότητα αυτή θα μελετηθούν τα εξής επιμέρους θέματα: - Δυαδικά Δένδρα - Δυαδικά Δένδρα Αναζήτησης - Πράξεις Εισαγωγής, Εύρεσης Στοιχείου, Διαγραφής Μικρότερου Στοιχείου
Δμόξπμε Γεδνκέλσλ. Καλόλεο Σπζρέηηζεο: Βαζηθέο Έλλνηεο θαη Αιγόξηζκνη
 Δμόξπμε Γεδνκέλσλ Καλόλεο Σπζρέηηζεο: Βαζηθέο Έλλνηεο θαη Αιγόξηζκνη (Σημειώσεις μεταυρασμένες από το Κευάλαιο 6 τοσ βιβλίοσ των Tan, Steinbach, Kumar) Καλόλεο Σπζρέηηζεο Δμόξπμε Καλόλσλ Σπζρέηηζεο Γεδνκέλνπ
Δμόξπμε Γεδνκέλσλ Καλόλεο Σπζρέηηζεο: Βαζηθέο Έλλνηεο θαη Αιγόξηζκνη (Σημειώσεις μεταυρασμένες από το Κευάλαιο 6 τοσ βιβλίοσ των Tan, Steinbach, Kumar) Καλόλεο Σπζρέηηζεο Δμόξπμε Καλόλσλ Σπζρέηηζεο Γεδνκέλνπ
2. Η πιθανότητα της αριθμήσιμης ένωσης ξένων μεταξύ τους ενδεχομένων είναι το άθροισμα των πιθανοτήτων των ενδεχομένων.
 Ένα μέτρο πιθανότητας πάνω στο δειγματικός χώρο Ω, είναι μία συνάρτηση P ( ) που αντιστοιχεί σε υποσύνολα του Ω, έναν αριθμό στο [ 0, ], με τις εξής ιδιότητες: P ( Ω ) 2 Η πιθανότητα της αριθμήσιμης ένωσης
Ένα μέτρο πιθανότητας πάνω στο δειγματικός χώρο Ω, είναι μία συνάρτηση P ( ) που αντιστοιχεί σε υποσύνολα του Ω, έναν αριθμό στο [ 0, ], με τις εξής ιδιότητες: P ( Ω ) 2 Η πιθανότητα της αριθμήσιμης ένωσης
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος Α http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος Α http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Σχεδίαση Αλγορίθμων -Τμήμα Πληροφορικής ΑΠΘ - Εξάμηνο 4ο
 Πολλαπλασιασμός μεγάλων ακεραίων (1) Για να πολλαπλασιάσουμε δύο ακεραίους με n 1 και n 2 ψηφία με το χέρι, θα εκτελέσουμε n 1 n 2 πράξεις πολλαπλασιασμού Πρόβλημα ρβημ όταν έχουμε πολλά ψηφία: A = 12345678901357986429
Πολλαπλασιασμός μεγάλων ακεραίων (1) Για να πολλαπλασιάσουμε δύο ακεραίους με n 1 και n 2 ψηφία με το χέρι, θα εκτελέσουμε n 1 n 2 πράξεις πολλαπλασιασμού Πρόβλημα ρβημ όταν έχουμε πολλά ψηφία: A = 12345678901357986429
Δένδρα Αναζήτησης Πολλαπλής Διακλάδωσης
 Δένδρα Αναζήτησης Πολλαπλής Διακλάδωσης Δένδρα στα οποία κάθε κόμβος μπορεί να αποθηκεύει ένα ή περισσότερα κλειδιά. Κόμβος με d διακλαδώσεις : k 1 k 2 k 3 k 4 d-1 διατεταγμένα κλειδιά d διατεταγμένα παιδιά
Δένδρα Αναζήτησης Πολλαπλής Διακλάδωσης Δένδρα στα οποία κάθε κόμβος μπορεί να αποθηκεύει ένα ή περισσότερα κλειδιά. Κόμβος με d διακλαδώσεις : k 1 k 2 k 3 k 4 d-1 διατεταγμένα κλειδιά d διατεταγμένα παιδιά
Ασκήσεις μελέτης της 4 ης διάλεξης. ), για οποιοδήποτε μονοπάτι n 1
, για οποιοδήποτε μονοπάτι n 1") Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 4 ης διάλεξης 4.1. (α) Αποδείξτε ότι αν η h είναι συνεπής, τότε h(n
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 4 ης διάλεξης 4.1. (α) Αποδείξτε ότι αν η h είναι συνεπής, τότε h(n
Η ΔΟΜΗ ΕΠΑΝΑΛΗΨΗΣ Εντολές Επανάληψης REPEAT UNTIL, FOR, WHILE
 ΕΡΓΑΣΤΗΡΙΟ 7 Ο Η ΔΟΜΗ ΕΠΑΝΑΛΗΨΗΣ Εντολές Επανάληψης REPEAT UNTIL, FOR, WHILE Βασικές Έννοιες: Δομή Επανάληψης, Εντολές Επανάληψης (For, While do, Repeat until), Αλγόριθμος, Αθροιστής, Μετρητής, Παράσταση
ΕΡΓΑΣΤΗΡΙΟ 7 Ο Η ΔΟΜΗ ΕΠΑΝΑΛΗΨΗΣ Εντολές Επανάληψης REPEAT UNTIL, FOR, WHILE Βασικές Έννοιες: Δομή Επανάληψης, Εντολές Επανάληψης (For, While do, Repeat until), Αλγόριθμος, Αθροιστής, Μετρητής, Παράσταση
Εισαγωγή. Γενική Εικόνα του Μαθήµατος. Το εσωτερικό ενός Σ Β. Εισαγωγή. Εισαγωγή Σ Β Σ Β. Αρχεία ευρετηρίου Κατάλογος συστήµατος Αρχεία δεδοµένων
 Βάσεις εδοµένων 2003-2004 Ευαγγελία Πιτουρά 1 ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Επεξεργασία Ερωτήσεων Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL)
Βάσεις εδοµένων 2003-2004 Ευαγγελία Πιτουρά 1 ΜΕΡΟΣ 1 Γενική Εικόνα του Μαθήµατος Επεξεργασία Ερωτήσεων Μοντελοποίηση (Μοντέλο Ο/Σ, Σχεσιακό, Λογικός Σχεδιασµός) Προγραµµατισµός (Σχεσιακή Άλγεβρα, SQL)
Εισαγωγή στην Επεξεργασία Ερωτήσεων. Βάσεις Δεδομένων Ευαγγελία Πιτουρά 1
 Εισαγωγή στην Επεξεργασία Ερωτήσεων Βάσεις Δεδομένων 2018-2019 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας
Εισαγωγή στην Επεξεργασία Ερωτήσεων Βάσεις Δεδομένων 2018-2019 1 Επεξεργασία Ερωτήσεων Θα δούμε την «πορεία» μιας SQL ερώτησης (πως εκτελείται) Ερώτηση SQL Ερώτηση ΣΒΔ Αποτέλεσμα 2 Βήματα Επεξεργασίας
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ. Δοµές Δεδοµένων
 ΟΝΟΜΑΤΕΠΩΝΥΜΟ: ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ AM: Δοµές Δεδοµένων Εξεταστική Ιανουαρίου 2014 Διδάσκων : Ευάγγελος Μαρκάκης 20.01.2014 ΥΠΟΓΡΑΦΗ ΕΠΟΠΤΗ: Διάρκεια εξέτασης : 2 ώρες και
ΟΝΟΜΑΤΕΠΩΝΥΜΟ: ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ AM: Δοµές Δεδοµένων Εξεταστική Ιανουαρίου 2014 Διδάσκων : Ευάγγελος Μαρκάκης 20.01.2014 ΥΠΟΓΡΑΦΗ ΕΠΟΠΤΗ: Διάρκεια εξέτασης : 2 ώρες και
Αλγόριθμοι και Πολυπλοκότητα
 Αλγόριθμοι και Πολυπλοκότητα Ανάλυση Αλγορίθμων Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ανάλυση Αλγορίθμων Η ανάλυση αλγορίθμων περιλαμβάνει τη διερεύνηση του τρόπου
Αλγόριθμοι και Πολυπλοκότητα Ανάλυση Αλγορίθμων Δημήτρης Μιχαήλ Τμήμα Πληροφορικής και Τηλεματικής Χαροκόπειο Πανεπιστήμιο Ανάλυση Αλγορίθμων Η ανάλυση αλγορίθμων περιλαμβάνει τη διερεύνηση του τρόπου
Πληροφορική 2. Δομές δεδομένων και αρχείων
 Πληροφορική 2 Δομές δεδομένων και αρχείων 1 2 Δομή Δεδομένων (data structure) Δομή δεδομένων είναι μια συλλογή δεδομένων που έχουν μεταξύ τους μια συγκεκριμένη σχέση Παραδείγματα δομών δεδομένων Πίνακες
Πληροφορική 2 Δομές δεδομένων και αρχείων 1 2 Δομή Δεδομένων (data structure) Δομή δεδομένων είναι μια συλλογή δεδομένων που έχουν μεταξύ τους μια συγκεκριμένη σχέση Παραδείγματα δομών δεδομένων Πίνακες
Κατακερματισμός. 4/3/2009 Μ.Χατζόπουλος 1
 Κατακερματισμός 4/3/2009 Μ.Χατζόπουλος 1 H ιδέα που βρίσκεται πίσω από την τεχνική του κατακερματισμού είναι να δίνεται μια συνάρτησης h, που λέγεται συνάρτηση κατακερματισμού ή παραγωγής τυχαίων τιμών
Κατακερματισμός 4/3/2009 Μ.Χατζόπουλος 1 H ιδέα που βρίσκεται πίσω από την τεχνική του κατακερματισμού είναι να δίνεται μια συνάρτησης h, που λέγεται συνάρτηση κατακερματισμού ή παραγωγής τυχαίων τιμών
Αλγόριθμοι και πολυπλοκότητα Δυναμικός Προγραμματισμός
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Αλγόριθμοι και πολυπλοκότητα Δυναμικός Προγραμματισμός Ιωάννης Τόλλης Τμήμα Επιστήμης Υπολογιστών Δυναμικός Προγραμματισμός Δυναμικός Προγραμματισμός 1 Περίληψη
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ Αλγόριθμοι και πολυπλοκότητα Δυναμικός Προγραμματισμός Ιωάννης Τόλλης Τμήμα Επιστήμης Υπολογιστών Δυναμικός Προγραμματισμός Δυναμικός Προγραμματισμός 1 Περίληψη
Ταχεία Ταξινόμηση Quick-Sort
 Ταχεία Ταξινόμηση Quc-Sort 7 4 9 6 2 2 4 6 7 9 4 2 2 4 7 9 7 9 2 2 9 9 Δομές Δεδομένων και Αλγόριθμοι Εργαστήριο Γνώσης και Ευφυούς Πληροφορικής 1 Outlne Quc-sort Αλγόριθμος Βήμα διαχωρισμού Δένδρο Quc-sort
Ταχεία Ταξινόμηση Quc-Sort 7 4 9 6 2 2 4 6 7 9 4 2 2 4 7 9 7 9 2 2 9 9 Δομές Δεδομένων και Αλγόριθμοι Εργαστήριο Γνώσης και Ευφυούς Πληροφορικής 1 Outlne Quc-sort Αλγόριθμος Βήμα διαχωρισμού Δένδρο Quc-sort
ΔΙΑΣΧΙΣΗ ΓΡΑΦΗΜΑΤΩΝ 1
 ΔΙΑΣΧΙΣΗ ΓΡΑΦΗΜΑΤΩΝ 1 Θέματα μελέτης Πρόβλημα αναζήτησης σε γραφήματα Αναζήτηση κατά βάθος (Depth-first search DFS) Αναζήτηση κατά πλάτος (Breadth-first search BFS) 2 Γράφημα (graph) Αναπαράσταση συνόλου
ΔΙΑΣΧΙΣΗ ΓΡΑΦΗΜΑΤΩΝ 1 Θέματα μελέτης Πρόβλημα αναζήτησης σε γραφήματα Αναζήτηση κατά βάθος (Depth-first search DFS) Αναζήτηση κατά πλάτος (Breadth-first search BFS) 2 Γράφημα (graph) Αναπαράσταση συνόλου