Ανάλυση των Χρηματιστηριακών Δεδομένων με χρήση των Αλγορίθμων Εξόρυξης
|
|
|
- Τρυφωσα Χατζηιωάννου
- 7 χρόνια πριν
- Προβολές:
Transcript

1 1 Πανεπιστήμιο Πατρών Τμήμα Μαθηματικών & Τμήμα Μηχανικών Η/Υ και Πληροφορικής ΔΠΜΣ «Μαθηματικά των Υπολογιστών και των Αποφάσεων» Μεταπτυχιακή Διπλωματική Εργασία Ανάλυση των Χρηματιστηριακών Δεδομένων με χρήση των Αλγορίθμων Εξόρυξης Τζαχίντα Μπεγκόμ Επιβλέπων: Βασίλειος Μεγαλοοικονόμου Τριμελής επιτροπή : Ευφροσύνη Μακρή, Νικόλαος Τσάντας Πάτρα Σεπτέμβριος 13
2
3 3
4 4 ΠΕΡΙΕΧΟΜΕΝΑ Ευρετήριο Εικόνων...7 Ευρετήριο Πινάκων... 1 Περίληψη ΜΕΡΟΣ Α - ΕΙΣΑΓΩΓΗ ΜΕΡΟΣ Β- ΘΕΩΡΗΤΙΚΟ ΥΠΟΒΑΘΡΟ Β.1. Η ΕΞΟΡΥΞΗ ΤΩΝ ΔΕΔΟΜΕΝΩΝ Η εξόρυξη ως στάδιο ανακάλυψης γνώσης σε βάσεις δεδομένων Προεπεξεργασία των Δεδομένων Μέτρα αξιολόγησης της εξόρυξης γνώσης από δεδομένα... Β. ΑΝΑΛΥΣΗ ΚΑΙ ΕΞΟΡΥΞΗ ΧΡΟΝΟΛΟΓΙΚΩΝ ΣΕΙΡΩΝ Ανάλυση των χρονολογικών σειρών.... Μοντελοποίηση των χρονολογικών σειρών Εξόρυξη των χρονοσειρών... 5 Μετασχηματισμός... 6 Ομοιότητα των Χρονοσειρών... 7 Μέτρα ομοιοτητας... 7 Κριτήρια Σύνδεσης (Ιεραρχικής Συσταδοποίησης) ΣΥΣΤΑΔΟΠΟΙΗΣΗ ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ ΠΡΟΒΛΕΨΗ Πρόβλεψη με Στατιστικά Μοντέλα Χρονοσειρών Ο Λευκός Θόρυβος White Noise Αυτοπαλινδρόμηση (Autoregressions AR) Κινούμενοι Μέσοι όροι ( Moving averages MA) ARMA (Autoregressive Moving Average) ARIMA (Autoregressive Integrated Moving Average) Εκθετική Εξομάλυνση (Exponential Smoothing) Απλή Εκθετική εξομάλυνση- Single Exponential Smoothing Διπλή Εκθετική Εξομάλυνση Double Exponential Smoothing... 5 Τριπλή εκθετική εξομάλυνση Triple Exponential Smoothing Μηχανές Διανυσματικής Υποστήριξης (Support Vector Machines)... 56
5 5 SVM για Κατηγοριοποίηση Περίπτωση του Γραμμικού Διαχωρισμού Περίπτωση του Μη Γραμμικού Διαχωρισμού Επίλυση του Προβλήματος Βελτιστοποίησης... 6 SVM για Παλινδρόμηση (Support Vector Regression) ΜΕΡΟΣ Γ - ΜΕΘΟΔΟΛΟΓΙΑ Γ. Οι μεθοδολογίες Γ.1 Συσταδοποιηση Γ.1.1. Η Ιεραρχικη Συσταδοποιηση Γ.1.. Συσταδοποίηση - k-means Αξιολόγηση συσταδοποίησης - Εύρεση του βέλτιστου κ... 8 Inter-Intra cluster distance Γ. Κατηγοριοποίηση - κ-πλησιέστεροι Γείτονες Γ.3 Πρόβλεψη - SMOreg Επέκταση του SVR SMO (Sequential Minimal Optimization) Επέκταση του SMO... 9 Μέτρα αξιολόγησης της πρόβλεψης ΜΕΡΟΣ Δ - ΠΕΙΡΑΜΑΤΑ - ΑΠΟΤΕΛΕΣΜΑΤΑ Δεδομένα του πειράματος Προεπεξεργασία των δεδομένων Συσταδοποίηση Κατηγοριοποίηση Πρόβλεψη ΜΕΡΟΣ Ε - ΣΥΜΠΕΡΑΣΜΑΤΑ... 1 ΜΕΡΟΣ ΣΤ - ΠΑΡΑΡΤΗΜΑ Βιβλιογραφία
6 6 Ευρετήριο Εικόνων Εικόνα Β.1: Σχηματική αναπαράσταση της διαδικασίας KDD [1]...19 Εικόνα Β.: Η απεικόνιση μίας χρονοσειράς...1 Εικόνα Β.3: Η αποσύνθεση μίας χρονοσειράς ως προς την εποχικότητα, τάση, κατάλοιπα...3 Εικόνα Β.4: Απεικονίσεις δύο όμοιων χρονοσειρών...7 Εικόνα Β.5: (α) Οι χρονοσειρές Q και C, (β) Δυναμική στρέβλωση -μη γραμμική ευθυγράμμιση, (γ) Το μονοπάτι στρέβλωσης [9]...3 Εικόνα Β.6: (α) Ένα προς ένα αντιστοιχία των Q και C στην περίπτωση της Ευκλείδειας απόστασης, (β) Μη γραμμική αντιστόιχιση των Q και C στην περίπτωση της μετρικής DTW [9]...33 Εικόνα Β.7: Απόσταση απλού συνδέσμου δύο συστάδων [46]...34 Εικόνα Β.8: Απόσταση πλήρους συνδέσμου δύο συστάδων [46]...34 Εικόνα Β.9: Απόσταση μέσου συνδέσμου δύο συστάδων [46]...35 Εικόνα Β.1: Απόσταση κέντρων βάρους δύο συστάδων [46]...35 Εικόνα Β.11: Γραμμικός και μη γραμμικός ταξινομητής. Τα σημεία πάνω στα H 1 και H αποτελούν τα διανύσματα υποστήριξης (support vectors)...59 Εικόνα Γ.1 : (α) Δημιουργία των συστάδων με το κόψιμο του δέντρου στο κατάλληλο ύψος, (β) Η απόσταση cophenetic distance και η σύνδεση μεταξύ δύο υποδέντρων-συστάδων [9]...75 Εικόνα Γ.: Δενδρόγραμματα που απεικονίζουν την ασυνέπεια των συνδέσμων [9]...77 Εικόνα Γ.3: Καθορισμός του σωλήνα «ε-insensitive»με ακτίνα ε μέσω του Support vector Regression [15]...85 Εικόνα Γ.4: Η αρχιτεκτονική της μηχανής παλινδρόμησης SVR [1]...88 Εικόνα Γ.5: Προσέγγιση της συνάρτησης sincx με ακρίβεια (α) ε=.1, (β) ε=., (γ) ε=.5 [1]...88 Εικόνα Γ.6: Μοντέλο παλινδρόμησης της συνάρτησης sincx (συμπαγής γραμμή), δεδομένα εκπαίδευσης (μικρές τελείες), διανύσματα υποστήριξης (μεγάλες τελείες). Προσέγγιση με ακρίβεια (α) ε=.1, (β) ε=., (γ) ε=.5 [1] 89 Εικόνα Δ.1: Τα αρχικά δεδομένα με όλες τις πληροφορίες για τις μετοχές...97 Εικόνα Δ.: dataset 1 μετά την πρώτη προεπεξεργασία (αριστερά) και μετά τον μετασχηματισμό (δεξιά)...98 Εικόνα Δ.3: dataset μετά την πρώτη προεπεξεργασία (αριστερά) και μετά τον μετασχηματισμό (δεξιά)...99 Εικόνα Δ.4: dataset 3 μετά την πρώτη προεπεξεργασία (αριστερά) και μετά τον μετασχηματισμό (δεξιά)...99 Εικόνα Δ.5: : Αρχική συσταδοποίηση με σύνδεση Single για κ= Εικόνα Δ.6: Στιγμιότυπο της 5 ης επανάληψης της μεθοδολογίας...13 Εικόνα Δ.7: Αρχικός διαχωρισμός των 446 μετοχών χωρίς την εφαρμογή της μεθοδολογίας...14
7 7 Εικόνα Δ.8: Στιγμιότυπο της 8 ης επανάληψης της συσταδοποίησης με σύνδεση average για κ=3, n1= Εικόνα Δ.9: Συστάδες που προέκυψαν από την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ= Εικόνα Δ.1: Οι τιμές silhouettes...15 Εικόνα Δ.11: Η αναλυτική εικόνα των 1 πρώτων μετοχών της συστάδας...16 Εικόνα Δ.1: Οι μετοχές που αφαιρέθηκαν πριν την υλοποίηση οποιουδήποτε αλγορίθμου συσταδοποίησης...17 Εικόνα Δ.13: Συσταδοποίηση μετά την αφαίρεση των outliers. Ιεραρχική συσταδοποίηση με απόσταση DTW και σύνδεση ward για κ= Εικόνα Δ.14: : validity 1, validity, validity 3 αντίστοιχα για το dataset 3 για την Ιεραρχική συσταδοποίηση (με απόσταση Ευκλείδεια και DTW και σύνδεση ward) και για τη συσταδοποίηση με k-means για κ από 3 έως Εικόνα Δ.15: Η μέση τιμή των silhouettes εκφράζει τη συμπαγότητα των συστάδων Εικόνα Δ.16: Αναπαράσταση της δειγματοληπτικής μεθόδου k-fold crossvalidation...11 Εικόνα Δ.17: Το σύνολο εκπαίδευσης (αριστερά) και σύνολο ελέγχου (δεξιά) στη 1 η επανάληψης του crossvalidation Εικόνα Δ.18: Κατηγοριοποίηση των 8 μετοχών μετά τη συσταδοποίηση με την Ιεραρχική μέθοδο με Ευκλείδεια απόσταση Εικόνα Δ.19: Πρόβλεψη των 16 τυχαίων μετοχών της συστάδας 4 από την ιεραρχική συσταδοποίηση με DTW για κ=1, η μέση τιμή του MAPE όλων των μετοχών είναι.6% Εικόνα Δ.: Πρόβλεψη με τη μέθοδο SMOreg των 6 πρώτων μετοχών της συστάδας από την ιεραρχική συσταδοποίηση με DTW για κ=. Με μπλέ χρώμα απεικονίζονται οι πραγματικές τιμές και με κόκκινο οι προβλεπόμενες. Η μέση τιμή του MAPE όλων των μετοχών για 5 ημέρες είναι 5.68% Εικόνα Δ.1: Πρόβλεψη με τη μέθοδο Exponential Smoothing με σφάλμα 4.3 %...11 Εικόνα Δ.: Πρόβλεψη με τη μέθοδο ARIMA με σφάλμα 4.9 %...1 Εικόνα Δ.3: Πρόβλεψη με τη μέθοδο Linear Regression με σφάλμα %...1 Εικόνα Δ.4: Πρόβλεψη με τη συνδυασμένη μέθοδο με σφάλμα 4.57%...11
8 8 Ευρετήριο Πινάκων Πίνακας Β.1: Βασικές εργασίες εξόρυξης γνώσης απο δεδομένα [1]...17 Πίνακας Γ.1: Σφάλματα και οι αντίστοιχες συναρτήσεις πυκνότητας [1]...87 Πίνακας Δ.1: Τα δεδομένα του πειράματος...98 Πίνακας Δ.: Σφάλματα κατηγοριοποίησης για κάθε fold. Ο μέσος όρος των σφαλμάτων είναι Πίνακας Δ.3: Πίνακας απολύτων σχετικών σφαλμάτων % για κάθε μετοχή της εικόνας Πίνακας Δ.4: Μέση τιμή των σφαλμάτων όλων των μεθόδων με σειρά κατάταξης Πίνακας Δ.5: Σφάλματα για τη συστάδα...11
9 9
10 1
11 11 Περίληψη Λόγω της έξαρσης της τεχνολογικής ανάπτυξης ο όγκος των πληροφοριών σήμερα είναι τεράστιος και έχει δημιουργήσει την ανάγκη για ανάλυση και επεξεργασία των δεδομένων ώστε, μετά την επεξεργασία, να μπορούν να μετατραπούν σε χρήσιμες πληροφορίες και να μας βοηθήσουν στη λήψη αποφάσεων. Οι τεχνικές εξόρυξης δεδομένων σε συνδυασμό με τις στατιστικές μεθόδους αποτελούν σπουδαίο εργαλείο για την ανάκτηση αυτών των πληροφοριών. Η χρήση αυτών των πληροφοριών βοηθά στη μελέτη και κατ επέκταση στην εξαγωγή των συμπερασμάτων για το χαρακτηριστικό που εξετάζεται. Ένας τομέας που παρουσιάζει μεγάλο ερευνητικό ενδιαφέρον, λόγω του όγκου των πληροφοριών που συσσωρεύει καθημερινά, είναι το χρηματιστήριο. Η εξόρυξη γνώσης από τα δεδομένα με σκοπό την όσο το δυνατόν «σωστή» πρόβλεψη μπορεί να αποφέρει πολύ μεγάλο κέρδος και αυτός είναι ένας λόγος για τον οποίο πολλές επιχειρήσεις έχουν επενδύσει στην τεχνολογία των πληροφοριών. Μέχρι στιγμής έχουν γίνει πολλές τεχνικές αναλύσεις στα χρηματιστηριακά δεδομένα, η εργασία αυτή όμως εστιάζεται στην ανάλυσή τους με τις τεχνικές εξόρυξης. Για τις ανάγκες της εργασίας έχουν ληφθεί ιστορικά δεδομένα, από τον ημερήσιο δείκτη S&P5 (Standard and Poor s 5), στα οποία εξετάζεται μόνο η τιμή κλεισίματος των μετοχών. Η εργασία αυτή χωρίζεται σε πέντε μέρη, εισαγωγή, θεωρητικό υπόβαθρο, μεθοδολογία, πειράματααποτελέσματα και συμπεράσματα. Στο μέρος Α, που είναι το εισαγωγικό κομμάτι, αναφέρεται το αντικείμενο και το κίνητρο της εργασίας. Στο μέρος Β γίνεται η βιβλιογραφική ανασκόπηση και παρουσιάζεται αναλυτικά όλο το θεωρητικό υπόβαθρο των μεθόδων που χρησιμοποιήθηκαν. Στο μέρος Γ παρουσιάζονται οι μεθοδολογίες (μεθόδοι εξόρυξης για συσταδοποίηση, κατηγοριοποίηση και πρόβλεψη) που χρησιμοποιήθηκαν για τη μελέτη, ενώ στο επόμενο μέρος παρουσιάζονται εκτενέστατα τα πειραματικά αποτελέσματα των μεθοδολογιών αυτών. Και τέλος, στο μέρος Ε παρουσιάζονται τα συμπεράσματα.
12 1
13 ΜΕΡΟΣ Α - ΕΙΣΑΓΩΓΗ 13
14 14
15 15 ΕΙΣΑΓΩΓΗ Αντικείμενο-Κίνητρο-Εφαρμογές Το χρηματιστήριο είναι ένα περιβάλλον δυναμικό και απρόβλεπτο. Η εύρεση ενός αποτελεσματικού τρόπου ανάλυσης και οπτικοποίησης των χρηματιστηριακών δεδομένων έχει προσελκύσει πολλούς ερευνητές καθώς ο όγκος των δεδομένων που υπάρχει στη διάθεσή μας για επεξεργασία αυξάνεται συνεχως και η εξαγωγή των χρήσιμων πληροφοριών από αυτά τα δεδομένα θα μπορούσαν να δείξουν πώς κινείται η αγορά και να βοηθήσουν στη λήψη αποφάσεων. Πολλές επιχειρήσεις που διαχειρίζονται κεφάλαια έχουν επενδύσει σε μεγάλο βαθμό στην τεχνολογία των πληροφοριών ώστε να τους βοηθήσει στη διαχείριση του χαρτοφυλακίου. Οι τεχνικές αναλύσεις προσφέρουν κάποια εργαλεία στους επενδυτές για τη διαχείριση των μετοχών τους, ωστόσο δεν μπορούν να ανακαλύψουν όλες τις δυνατές σχέσεις μεταξύ των μετοχών και συνεπώς υπάρχει η ανάγκη μίας προσέγγισης που θα προσφέρει βαθύτερη ανάλυση. Η εξόρυξη δεδομένων είναι η επιστήμη που σχεδιάστηκε για να βοηθήσει τους επενδυτές να ανακαλύψουν πρότυπα που κρύβονται στα ιστορικά δεδομένα ώστε να τους βοηθήσουν στην απόφασή τους ως προς την επένδυση. Πέρα όμως από την επένδυση χρησιμοποιείται ευρέως και στη λήψη αποφάσεων σε άλλους τομείς (Ιατρική, αστρονομία, μάρκετινγκ κ.ο.κ). Η εξόρυξη δεδομένων βασισμένη σε ιστορικά δεδομένα μπορεί να ανακαλύψει πρότυπα και σχέσεις μεταξύ των δεδομένων, να ομαδοποιήσει και να ταξινομήσει δεδομένα, να μοντελοποιήσει και προπάντων να προβλέψει, τα αποτελέσματα των οποίων φυσικά βοηθούν στη λήψη αποφάσεων. Με άλλα λόγια η εξόρυξη δεδομένων μπορεί να χαρακτηριστεί ως «καλύτερη χρήση των δεδομένων» [43]. Το αντικείμενο της παρούσας διπλωματικής εργασίας είναι η ανάλυση των χρηματιστηριακών δεδομένων (χρονοσειρών) με τεχνικές εξόρυξης που μπορούν να βοηθήσουν στη ληψη αποφάσεων. Συγκεκριμένα, η ομαδοποίηση των παρόμοιων μετοχών, η εύρεση της κατηγορίας των μετοχών στην οποία μπορεί να ανήκει μία νέα μετοχή και η πρόβλεψη των μελλοντικών τιμών αποτελούν στόχoυς της εργασίας. Οι μελέτες αυτές εκτός απο το χρηματιστήριο, μπορούν να εφαρμοστούν επίσης για την αναγνώριση των προτύπων, τη διαχείριση του χαρτοφυλακίου και τις χρηματοπιστωτικές αγορές.
16 16 Δομή της εργασίας Στο πρώτο σκέλος της εργασίας εξετάζεται το πρόβλημα της συσταδοποίησης με σκοπό την εύρεση των «όμοιων» μετοχών και για την υλοποίησή της χρησιμοποιείται ο αλγόριθμος K-means, Hierarchical clustering, με διάφορες μετρικές αποστάσεων εκ των οποίων επιλέγεται η Ευκλείδεια και η DTW και κριτήριο σύνδεσης ward για την ιεραρχική συσταδοποίηση. Στη συνέχεια με τη χρήση των inter και intra cluster distance γίνονται δοκιμές για την εύρεση του καλύτερου πλήθους των συστάδων με σκοπό τον καλύτερο διαχωρισμό των δεδομένων. Ως μέτρο αξιολόγησης των συστάδων αποτελούν επίσης οι τιμές των Silhouettes. Στο δέυτερο σκέλος εφαρμόζεται ο αλγόριθμος της κατηγοριοποίησης (classification) ώστε για κάθε καινούρια μετοχή που μπαίνει στο χρηματιστήριο να υπάρχει δυνατότητα ταξινόμησης σε μία από τις προκαθορισμένες ομάδες που έχουν ληφθεί μέσω της συσταδοποίησης. Στο τρίτο σκέλος της εργασίας γίνεται μία προσπάθεια πρόβλεψης της τιμής του κλεισίματος των μετοχών. Η προσέγγιση γίνεται με τη μέθοδο SMOreg (Sequential Minimal Optimization for Support Vector Regression) η οποία εφαρμόζει τις μηχανές διανυσματικής υποστήριξης για παλινδρόμηση (SVR) σε συνδυασμό με τον βελτιωμένο αλγόριθμο, του Sequential Minimal Optimization (SMO), RegSMOImproved. Οι τιμές αυτές συγκρίνονται με τα αποτελέσματα των προβλέψεων των στατιστικών μοντέλων (ARIMA, Exponential Smoothing ή Holt Winters, Linear Regression) μέσω των σφαλμάτων πρόβλεψης. Επίσης χρησιμοποιήθηκε και ένας συνδυασμός των προβλέψεων αυτών, ο οποίος έδωσε μικρότερο σφάλμα σε σύγκριση με τη μέθοδο SMOreg.
17 ΜΕΡΟΣ Β- ΘΕΩΡΗΤΙΚΟ ΥΠΟΒΑΘΡΟ 17
18 18
19 19 ΘΕΩΡΗΤΙΚΟ ΥΠΟΒΑΘΡΟ Β.1. Η ΕΞΟΡΥΞΗ ΤΩΝ ΔΕΔΟΜΕΝΩΝ Με τον όρο «εξόρυξη γνώσης από δεδομένα» (data mining) εννοούμε την εύρεση των κρυμμένων πληροφοριών που περιέχονται σε μία βάση δεδομένων ή την εξερευνητική ανάλυση των δεδομένων. Πολλές φορές όμως έχει την έννοια της ανακάλυψης καθοδηγούμενη από δεδομένα ή την έννοια της συμπερασματικής μάθησης [1]. Η περιοχή της εξόρυξης γνώσης αναπτύχθηκε τα τελευταία χρόνια για να αντιμετωπίσει το πρόβλημα του μεγάλου όγκου των δεδομένων. Αποτελεί μία σημαντική ερευνητική περιοχή με αρκετό αντίκτυπο στον πραγματικό κόσμο. Η σημαντικότητά της οφείλεται στο γεγονός ότι πολλές επιχειρήσεις χρησιμοποιώντας την εξόρυξη γνώσης εξοικονομούν πολλά χρήματα με τη μείωση του κόστους που επιτυγχάνουν στις λειτουργίες της επιχείρησης ή αυξάνουν το κεφάλαιό τους μέσω των επενδύσεων προβλέποντας τη μελλοντική πορεία [1]. Η εξόρυξη των δεδομένων περιλαμβάνει ένα σύνολο μεθόδων που αυτοματοποιούν τη διαδικασία της επιστημονικής ανακάλυψης. Η μοναδικότητά της εντοπίζεται στην επίλυση των προβλημάτων με μεγάλο όγκο δεδομένων που περιέχουν πολύπλοκες και κρυμμένες σχέσεις. Υπάρχουν πολλοί αλγόριθμοι που χρησιμοποιούνται για την εξόρυξη γνώσης από δεδομενα οι οποίοι διαφέρουν αναλόγως του είδους των εργασιών που καλούνται να διεκπεραιώσουν. Οι αλγόριθμοι αυτοί, συνήθως, έχουν ως στόχο την προσαρμογή ενός μοντέλου στα δεδομένα πλησιέστερο στα χαρακτηριστικά που εξετάζονται. Τα μέρη ενός αλγορίθμου εξόρυξης είναι τρία (μοντέλο, προτίμηση και αναζήτηση). Στο πρώτο μέρος, ο σκοπός του αλγορίθμου είναι η προσαρμογή του μοντέλου στα δεδομένα. Στο δεύτερο μέρος πρέπει να περιλαμβάνει κάποια κριτήρια σύμφωνα με τα οποία το
20 μοντέλο αυτό να προτιμάται συγκριτικά με ένα άλλο (ή άλλα). Στο τρίτο μέρος, ο αλγόριθμος πρέπει να απαιτεί μία τεχνική αναζήτησης των δεδομένων [1]. Ένα μοντέλο που δημιουργείται χαρακτηρίζεται ως περιγραφικό (descriptive) ή προβλεπτικό (predictive). Το περιγραφικό μοντέλο αναγνωρίζει πρότυπα ή συσχετίσεις στα δεδομένα, λειτουργεί ως μέσο διερεύνησης των ιδιοτήτων των δεδομένων υπό εξέταση και δεν προβλέπει νέες ιδιότητες. Ενώ το προβλεπτικό μοντέλο με τη κάνει μία πρόβλεψη για τις τιμές των δεδομένων με τη χρήση των ιστορικών δεδομένων και των γνωστών αποτελεσμάτων από άλλα δεδομένα [1]. Εξόρυξη γνώσης από δεδομένα Προβλεπτικά Μοντέλα Περιγραφικά Μοντέλα Πρόβλεψη Κατηγοριοποίηση Παλινδρόμηση Ανάλυση των Χρονοσειρών Συσταδοποίηση Κανόνες Συσχετίσεων Παρουσίαση Συνόψεων Ανακάλυψη Ακολουθιών Πίνακας Β.1: Βασικές εργασίες εξόρυξης γνώσης απο δεδομένα Όπως φαίνεται στον πίνακα 1, οι τεχνικές εξόρυξης των δεδομένων διαφέρουν ανάλογα με το μοντέλο στο οποίο υλοποιούνται. Στα περιγραφικά μοντέλα, λόγω της αναγνώρισης των προτύπων, κατατάσσονται οι τεχνικές της συσταδοποίησης, της παρουσίασης συνόψεων, της ανακάλυψης ακολουθιών και των κανόνων συσχετίσεων. Ενώ στα προβλεπτικά μοντέλα, λόγω του ότι προβλέπουν μία τιμή ή κάποιες τιμές, καταχωρούνται οι τεχνικές της κατηγοριοποίησης, της παλινδρόμησης, της ανάλυσης των χρονολογικών σειρών και της πρόβλεψης [1]. Τα μοντέλα, επίσης, διακρίνονται σε παραμετρικά και μη παραμετρικά. Τα παραμετρικά μοντέλα προσδιορίζουν τη συσχέτιση που υπάρχει ανάμεσα στην είσοδο και στην έξοδο, μέσω των
21 1 αλγεβρικών εξισώσεων. Στις εξισώσεις αυτές υπάρχουν παράμετροι, που είναι απροσδιόριστες, και εκτιμώνται μέσω των παραδειγμάτων (σύνολο εκπαίδευσης) που δίνονται στην είσοδο. Σε αυτήν την περίπτωση ένα συγκεκριμένο μοντέλο θεωρείται δεδομένο εκ των προτέρων για αυτό και απαιτούν περισσότερη γνώση από τα δεδομένα πριν ξεκινήσει η διαδικασία της μοντελοποίησης. Εν αντιθέσει με αυτά, τα μη παραμετρικά μοντέλα όπως περιγράφει και η λέξη δεν περιέχουν παραμέτρους αλλά καθοδηγούνται από τα δεδομένα. Δηλαδή, δεν υπάρχουν εξισώσεις για το μοντέλο αλλά προσαρμόζεται το μοντέλο μέσω των δεδομένων. Με άλλα λόγια, οι μη παραμετρικές τεχνικές δημιουργούν ένα μοντέλο που βασίζεται στην είσοδο για αυτό και είναι περισσότερο κατάλληλες για τις εφαρμογές της εξόρυξης γνώσης. Οι μη παραμετρικές μέθοδοι περιέχουν τεχνικές μηχανικής μάθησης που έχουν τη δυνατότητα δυναμικής εκμάθησης με την πρόσθεση νέων δεδομένων στην είσοδο. Με αυτόν τον τρόπο, όσο περισσότερα δεδομένα προστίθενται τόσο καλύτερο είναι το μοντέλο που δημιουργείται. Αυτή η διαδικασία της μάθησης επιτρέπει στο μοντέλο να διευρύνεται συνεχώς καθώς εισάγονται νέα δεδομένα. Τα νευρωνικά δίκτυα, τα δένδρα αποφάσεων και οι γενετικοί αλγόριθμοι αποτελούν μερικά από τα παραδείγματα των μη παραμετρικών τεχνικών [1]. Η εξόρυξη ως στάδιο ανακάλυψης γνώσης σε βάσεις δεδομένων Σύμφωνα με την Dunham, η ανακάλυψη της γνώσης από τις βάσεις δεδομένων (Knowledge Discovery in Databases) αποκτά διαφορετική έννοια από την εξόρυξη γνώσης των δεδομένων (data mining), σε σχέση με άλλες βιβλιογραφίες που χρησιμοποιούν τους όρους αυτούς για την ίδια ερμηνεία. ΟΡΙΣΜΟΣ 1: Η ανακάλυψη γνώσης σε βάσεις δεδομένων (Knowledge Discovery in Databases - KDD) είναι η διαδικασία εύρεσης χρήσιμων πληροφοριών και προτύπων στα δεδομένα. ΟΡΙΣΜΟΣ : Η εξόρυξη γνώσης από δεδομένα είναι η χρήση αλγορίθμων για την εξαγωγή των πληροφοριών και προτύπων που παράγονται με τη διαδικασία KDD. Η KDD (Εικόνα Β.1) δηλαδή είναι μία διαδικασία που αποτελείται από πολλά διαφορετικά στάδια. Στη διαδικασία αυτή, αρχικά επιλέγονται δεδομένα απο διάφορες βάσεις δεδομένων. Έπειτα τα δεδομένα αυτά περνούν από μία προεπεξεργασία για την διόρθωση των τυχών ελλείψεων, ανωμαλιών, λαθών

22 κτλ. Στη συνέχεια, μετασχηματίζονται τα δεδομένα ώστε να έχουν κοινό σχήμα σύγκρισης, εφόσον προήλθαν από ετερογενείς πηγές. Μερικές φορές, μετά τον μετασχηματισμό, χρειάζεται επιπλέον η κωδικοποίησή τους για τη μετατροπή τους σε χρήσιμα σχήματα. Με βάση το είδος της εξόρυξης που επιθυμεί ο χρήστης, εφαρμόζονται οι αλγόριθμοι εξόρυξης στα μετασχηματισμένα δεδομένα. Στο τελικό στάδιο απαιτείται η ερμηνεία των αποτελεσμάτων και η αξιολόγησή τους. Τα αρχικά δεδομένα αποτελούν την είσοδο ενώ οι χρήσιμες πληροφορίες (ή γνώσεις) που λαμβάνουμε ερμηνεύοντας το μοντέλο αποτελούν την έξοδο. Αρχικά Δεδομένα επιλογή Στοχευμένα Δεδομένα προεπεξεργασία Προεπεξεργασμένα Δεδομένα Μετασχηματισμός Μετασχηματισμένα Δεδομένα Εξόρυξη Γνώσης Μοντέλο Εικόνα Β.1: Σχηματική αναπαράσταση της διαδικασίας KDD Προεπεξεργασία των Δεδομένων Η προεπεξεργασία των δεδομένων αποτελεί ένα πολύ σημαντικό στάδιο για την εξόρυξη των δεδομένων και υλοποιείται για να βελτιώσει την ποιότητα της εξόρυξης [6]. Τα δεδομένα που
23 3 λαμβάνουμε συνήθως είναι ελλιπή (λείπουν κάποια χαρακτηριστικά ή λείπουν κάποιες τιμές των χαρακτηριστικών), δεν είναι συνεπείς (έχουν διαφορετική κωδικοποίηση ή διαφορετική ονομασία ή και τιμές έξω από το διάστημα που έχουμε καθορίσει) και περιέχουν σφάλματα (θορύβους) [1]. Τα προβλήματα αυτά μπορεί να οφείλονται στον μεγάλο όγκο των δεδομένων και στις διάφορες ετερογενείς πηγές. Η χαμηλή ποιότητα των δεδομένων μπορεί να έχει ως αποτέλεσμα την χαμηλή ποιότητα της εξόρυξης και κατ επέκταση των αποτελεσμάτων της. Οι λόγοι αυτοί καθιστούν την προεπεξεργασία απαραίτητη. Η προεπεξεργασία των δεδομένων μπορεί να γίνει με πολλούς τρόπους, μερικοί από αυτούς αναφέρονται παρακάτω [6]. Καθαρισμός των δεδομένων: εκτελείται για την αφαίρεση των δεδομένων και τη διόρθωση της ασυνέπειας στα δεδομένα. Ενσωμάτωση των δεδομένων: πραγματοποιείται η ένωση των δεδομένων που λαμβάνονται από διάφορες πηγές και η αποθήκευσή τους στην αποθήκη των δεδομένων (data ware house). Μείωση των δεδομένων: για τη μείωση της διάστασης των δεδομένων αφαιρούνται τα πλεονάζουσα χαρακτηριστικά. Μετασχηματισμός των δεδομένων: οι τιμές των δεδομένων μετασχηματίζονται σε ένα μικρότερο εύρος π.χ. από εως 1. Ο μετασχηματισμός μπορεί να βελτιώσει την ακρίβεια και την αποδοτικότητα των αλγορίθμων καθώς και των μέτρων απόστασης. Μέτρα αξιολόγησης της εξόρυξης γνώσης από δεδομένα Το μέτρο αξιολόγησης των τεχνικών εξόρυξης είναι μία δύσκολη υπόθεση διότι υπάρχουν διαφορετικά μέτρα αξιολόγησης για διαφορετικές τεχνικές και επιλέγεται ανάλογα με το επίπεδο ενδιαφέροντος. Για παράδειγμα, για την συνολική αξιολόγηση μίας επιχείρησης ή της χρησιμότητας της τεχνικής που εφαρμόζεται, χρησιμοποιείται συνήθως ως μέτρο αξιολόγησης η απόδοση της επένδυσης (Return On Investment - ROI). Το μέτρο ROI εξετάζει τη διαφορά ανάμεσα στο κόστος εφαρμογής της τεχνικής από τη μία και στην εξοικονόμηση ή στα κέρδη από την άλλη που προκύπτουν από τη χρήση αυτής της τεχνικής [1].
24 value 4 Β. ΑΝΑΛΥΣΗ ΚΑΙ ΕΞΟΡΥΞΗ ΧΡΟΝΟΛΟΓΙΚΩΝ ΣΕΙΡΩΝ Χρονολογικές σειρές Χρονοσειρά είναι μια πεπερασμένη ή άπειρη ακολουθία από παρατηρήσεις που λαμβάνονται σε ορισμένες χρονικές στιγμές ή περιόδους που ισαπέχουν μεταξύ τους. Οι τιμές αυτές μπορεί να είναι ημερήσιες, εβδομαδιαίες, ωριαίες κ.ο.κ. Οι χρονοσειρές συνήθως οπτικοποιούνται μέσω ένος διαγράμματος. Τα βασικά χαρακτηριστικά των χρονοσειρών που μελετώνται συνήθως είναι η στασιμότητα, η τάση, η περιοδικότητα, η εποχικότητα και η αυτοσυσχέτιση. ΟΡΙΣΜΟΣ: Δοθείσης μιας ιδιότητας, Χ, μια χρονολογική σειρά είναι ένα σύνολο από p τιμές: {<t 1,x 1 >, <t,x >,,<t n,x p >}. Σε καθεμιά από p χρονικές τιμές αντιστοιχεί μία τιμή της Α. Συχνά οι τιμές προσδιορίζονται για κάποιες συγκεκριμένες και καλά ορισμένες χρονικές στιγμές, στην περίπτωση αυτή οι τιμές μπορούν να παρασταθούν σαν ένα διάνυσμα <x 1, x,,x p > [1]. 1.5 time series time (days) Εικόνα Β.: Η απεικόνιση μίας χρονοσειράς Η εύρεση των αποτελεσματικών μεθόδων για την ανάλυση των χρονοσειρών έχει απασχολήσει πολλούς τομείς λόγω των εφαρμογών τους. Οι χρονοσειρές βρίσκουν εφαρμογές στη στατιστική, στη διαχείριση σημάτων, στην αναγνώριση προτύπων, στην οικονομετρία, στα οικονομικά μαθηματικά,
25 5 στην πρόγνωση καιρού, στην πρόβλεψη του σεισμού, στα ηλεκτροεγκεφαλογραφήματα, στον μηχανικό έλεγχο, στη μηχανική επικοινωνιών κ.ο.κ. 1. Ανάλυση των χρονολογικών σειρών Με την ανάλυση των χρονοσειρών μελετάται η συμπεριφορά ενός χαρακτηριστικού με την πάροδο του χρόνου. Η ανάλυση αυτή έχει ως στόχο την εύρεση των προτύπων στα δεδομένα και την πρόβλεψη των μελλοντικών τιμών. Για την ακρίβεια, μελετάται η εύρεση της ομοιότητας μεταξύ των χρονοσειρών, εξετάζεται η δομή των χρονοσειρών και κατηγοριοποιείται η συμπεριφορά τους, χρησιμοποιούνται κάποια διαγράμματα των χρονοσειρών για την πρόβλεψη των μελλοντικών τιμών. Δηλαδή, η ανάλυση των χρονοσειρών μπορεί να υλοποιηθεί μέσω της περιγραφής των δεδομένων που λαμβάνονται στην πάροδο του χρόνου, της επεξήγησης των δεδομένων αυτών, και προπάντων μέσω της πρόβλεψης των εξαρτημένων δεδομένων. Η περιγραφή μπορεί να πραγματοποιηθεί μέσω διαφόρων γραφημάτων, ενώ για την επεξήγησή τους χρησιμοποιούνται κάποια μοντέλα που εξετάζουν τους μηχανισμούς δημιουργίας της χρονοσειράς, και τέλος η πρόβλεψη μπορεί να επιτευχθεί μέσω κάποιων μοντέλων [17]. Για αυτό και οι μέθοδοι ανάλυσης των χρονοσειρών λαμβάνουν υπόψιν την πιθανή εσωτερική δομή που μπορεί να υπάρχει στα δεδομένα [4]. Για την κατανόηση της εσωτερικής δομής (Εικόνα Β.) μίας χρονοσειράς εξετάζονται τα εξής χαρακτηριστικά: Τάσεις (Trend ): Εάν υπάρχουν μεγάλες αυξομειώσεις στον μέσο όρο Κύκλοι (Cycle ): Εάν υπάρχουν κυκλικές διακυμάνσεις Εποχιακά (Seasonal Effects ): Εάν υπάρχουν κυκλικές διακυμάνσεις που σχετίζονται με την εποχή Κατάλοιπα (Residuals ): Εάν οι διακυμάνσεις είναι τυχαίες ή συστηματικές
26 6 Εικόνα Β.3: Η αποσύνθεση μίας χρονοσειράς ως προς την εποχικότητα, τάση, κατάλοιπα Ένα μοντέλο σχηματίζεται με βάση τα τέσσερα χαρακτηριστικά ως εξής: Προσθετικό μοντέλο: Πολλαπλασιαστικό μοντέλο: Όπου ή είναι η τιμή μιας χρονοσειράς τη χρονική στιγμή t. Οι χρονοσειρές διακρίνονται σε στάσιμες και μη στάσιμες. Οι περισσότερες τεχνικές πρόβλεψης απαιτούν τη στασιμότητα των χρονοσειρών εκτός από αυτές που χρησιμοποιούν πολύπλοκες τεχνικές και υποθέτουν ότι είναι μη στάσιμες. Μία χρονοσειρά λεγεται στάσιμη όταν οι διακυμάνσεις των τιμών της δεν αλλάζουν με την πάροδο του χρόνου. Επομένως μία χρονοσειρά που δεν είναι στάσιμη μπορεί να έχει τάση (ανοδική, καθοδική ή και τα δύο), να εμφανίζει περιοδικότητα (δηλαδή να επαναλαμβάνεται), να παρουσιάζει εποχικότητα (δηλαδή να έχει κάποιες διακυμάνσεις σε συγκεκριμένες εποχές).
27 7 Μία χρονοσειρά ονομάζεται στάσιμη πρώτης τάξης όταν η μέση τιμή της X(t) παραμένει στάσιμη για όλα τα t. Δηλαδή, στις στάσιμες χρονοσειρές οι τιμές προέρχονται από ένα μοντέλο με σταθερό μέσο όρο. Με τη στασιμότητα δεύτερης τάξης χαρακτηρίζεται μία χρονοσειρά, εάν είναι πρώτης τάξης στάσιμη και η συνδιασπορά μεταξύ των X(t) και X(s) είναι μία συνάρτηση μόνο μήκους (t-s). Η σταθεροποίηση των χρονοσειρών, που δεν είναι στάσιμες πρώτης τάξης, γίνεται λαμβάνοντας τις διαφορές των τιμών τους. Ενώ στη δεύτερη περίπτωση η σταθεροποίηση επιτυγχάνεται εφαρμόζοντας κάποιους μετασχηματισμούς (π.χ. η τετραγωνική ρίζα) [45]. Επιπλέον, σε μία στάσιμη χρονοσειρά η γραμμική αυτοσυσχέτιση ή αλλιώς αυτοσυσχέτιση ρ τ (autocorrelation) για κάποια υστέρηση τ ονομάζεται ο συντελεστής συσχέτισης δύο στοιχείων της χρονοσειράς που απέχουν, χρονικά, τ βήματα και υπολογίζεται ως όπου με x t συμβολίζουμε τη χρονοσειρά. Στις μη στάσιμες χρονοσειρές η αυτοσυσχέτιση και η αυτοδιασπορά μπορούν να οριστούν μονο για κάθε χρονική στιγμή t και όχι ως συνάρτηση της υστέρησης [1].. Μοντελοποίηση των χρονολογικών σειρών Υπάρχουν πολλές τεχνικές μοντελοποίησης χρονοσειρών εκ των οποίων τα μοντέλα Markov (MM), κρυφά μοντέλα Markov (HMM) και τα επανατροφοδοτήσιμα νευρωνικά δίκτυα (RNN) είναι τα πιο γνωστά. Τα μοντέλα Markov μπορούν να χρησιμοποιηθούν για την αναγνώριση των προτύπων. Ένα γνωστό παράδειγμα στο οποίο εφαρμόζεται το μοντέλο Markov είναι η αναγνώριση της συμβολοσειράς που είναι μία χρονική σειρά από γεγονότα [1]. ΜΟΝΤΕΛΟ MARKOV: Ένα μοντέλο Markov (Markov Model) είναι ένας κατευθυνόμενος γράφος όπου οι κορυφές αναπαραστούν καταστάσεις και τα τόξα,, δείχνουν μεταβάσεις μεταξύ των καταστάσεων. Κάθε τόξο χαρακτηρίζεται από μία πιθανότητα της
28 8 μετάβασης από τη στη. Σε κάθε χρονική στιγμή t, η πιθανότητα για κάθε μελλοντική μετάβαση εξαρτάται μόνο από τη και όχι από οποιαδήποτε προηγούμενη κατάσταση. [1] ΚΡΥΦΟ ΜΟΝΤΕΛΟ MARKOV: Ένα κρυφό μοντέλο Markov (Hidden Markov Model) είναι ένας κατευθυνόμενος γράφος όπου οι κορυφές αναπαραστούν καταστάσεις και τα τόξα, δείχνουν μεταβάσεις μεταξύ των καταστάσεων. Κάθε HMM έχει τα παρακάτω επιπλέον χαρακτηριστικά: 1. Μια κατανομή αρχικής κατάστασης,, χρησιμοποιείται για να προσδιορίσει την αρχική κατάσταση τη χρονική στιγμή.. Κάθε τόξο χαρακτηρίζεται από μία πιθανότητα της μετάβασης από τη στη. Η τιμή αυτή είναι προκαθορισμένη. 3. Δοθέντος ενός συνόλου από πιθανές παρατηρήσεις,, κάθε κατάσταση,, περιέχει ένα σύνολο από πιθανότητες για κάθε παρατήρηση { } [1]. 3. Εξόρυξη των χρονοσειρών Εφόσον η εξόρυξη των δεδομένων έχει τη δυνατότητα της αποκάλυψης των κρυμμένων προτύπων, οι τεχνικές εξόρυξης των χρονοσειρών βελτιώνουν περαιτέρω την ανάλυση των δεδομένων (χρονοσειρών για την ακρίβεια, μιας και αποτελούν το επίκεντρο της εργασίας). Οι έρευνες για την εξορυξη των χρονοσειρών επικεντρώνονται στις ακόλουθες διεργασίες [1,44]: 1. Συσταδοποίηση (Clustering): ομαδοποίηση των χρονοσειρών, που βρίσκονται στη βάση δεδομένων, με βάση κάποιων μέτρων ομοιότητας ή ανομοιότητας. Κατηγοριοποίηση (Classification): ανάθεση μίας χρονοσειράς Q σε μία από τις προκαθορισμένες κατηγορίες. 3. Πρόβλεψη (Forecasting): πρόβλεψη της n+1 οστής τιμής μίας χρονοσειράς δοθέντος όλων των προηγούμενων σημείων της.
29 9 4. Τμηματοποίηση (Segmentation): κατασκευή ενός μοντέλου που διαμερίζεται σε κ τμήματα (με κ<<n) για την προσέγγιση μίας χρονοσειράς. Ευρετηριοποίηση (Indexing Query by content): δοθέντος μίας χρονοσειράς (που αποτελεί query) και κάποιων μέτρων ομοιότητας ή ανομοιότητας ζητείται η εύρεση της κοντινότερης χρονοσειράς που ταιριάζει στη βάση των δεδομένων. 5. Σύνοψη (Summerization): Δοθέντος μίας χρονοσειράς πολύ μεγάλων διαστάσεων ζητείται να σχηματιστεί μία προσέγγισή της (γραφική ενδεχομένως) με την διατήρηση των αρχικών χαρακτηριστικών και την προσαρμογή της σε μία σελίδα. 6. Ανίχνευση των Ανωμαλιών (Anomaly Detection): Δοθέντος μίας κανονικοποιημένης χρονοσειράς Q, και μίας άλλης χρονοσειράς R χωρίς κάποια ένδειξη, ζητείται η εύρεση όλων των τμημάτων της R που περιέχουν ανωμαλίες. Μετασχηματισμός Ο μετασχηματισμός είναι μία διαδικασία πολύ σημαντική για την ανάλυση των χρονοσειρών και στην εξόρυξή τους. Υλοποιείται πριν εκτελεστούν οι αλγόριθμοι της εξόρυξης και μπορεί να βοηθήσει στην ανακάλυψη των προτύπων και να αντιμετωπίσει το πρόβλημα των πολλών διαστάσεων (dimensionality curse). Η εξόρυξη γνώσης από χρονοσειρές με πολλές μεταβλητές είναι δύσκολη και ακριβή. Ο μετασχηματισμός ή η εξαγωγή των χαρακτηριστικών αποτελούν λύσεις στο πρόβλημα της έλλειψης των αποτελεσματικών δομών για την αποθήκευση πολυδιάστατων δεδομένων, διότι έχουν τη δυνατότητα να μειώσουν αριθμό των διαστάσεων. Επίσης αξίζει να αναφερθεί ότι ο λογαριθμικός είναι ο πιο απλός μετασχηματισμός που σταθεροποιεί τη διακύμανση και κάνει τις εποχιακές τάσεις σταθερές στο χρόνο [1]. Η κανονικοποίηση είναι και αυτή ένα είδος μετασχηματισμού, πραγματοποιείται με στόχο τη σύγκριση των χρονοσειρών που έχουν διαφορετικές μετατοπίσεις (offsets) και διαφορετικά πλάτη (amplitudes). Μέσω του η μέση τιμή γίνεται και η τυπική απόκλιση 1. Με αυτόν τον τρόπο είναι δυνατή η σύγκριση των χρονοσειρών [13].
30 3 Ομοιότητα των Χρονοσειρών Η αναζήτηση της ομοιότητας των χρονοσειρών θεωρείται σημαντική για την εξόρυξη των χρονοσειρών. Υπάρχουν δύο τρόποι αναζήτησης της ομοιότητας: 1. Με βάση το σχήμα (shape based similarity). Με βάση τη δομή (structure or model based similarity) Ο πρώτος τρόπος προσδιορίζει την ομοιότητα μέσω της τοπική σύγκρισης (local comparison) των προτύπων, ενώ ο δεύτερος με την καθολική σύγκριση (global comparison) των δομών. Για δύο χρονοσειρές μεγάλων διαστάσεων χρησιμοποιείται ο δεύτερος τρόπος, διότι εξάγει καθολικά χαρακτηριστικά (τάση, αυτοσυσχέτιση, κυρτότητα, παραμέτρους μοντέλων από τα δεδομένα). Όμως από τις δύο αυτές μεθόδους, μελετάται η πρώτη στην εν λόγω μελέτη [13]. Για την αναζήτηση που βασίζεται στο σχήμα χρησιμοποιούνται κάποια μέτρα ομοιότητας ή ανομοιότητας τα οποία αναφέρονται στη συνέχεια [13]. ΜΕΤΡΑ ΟΜΟΙΟΤΗΤΑΣ Στα προβλήματα ομαδοποίησης, η επιλογή του τρόπου υπολογισμού της ομοιότητας μεταξύ δύο αντικειμένων αποτελεί ένα αξιοσημείωτο θέμα, εφόσον οι περισσότεροι αλγόριθμοι ομαδοποίησης χρησιμοποιούν μετρικούς χώρους και μετρικές για τον προσδιορισμό της ομοιότητας. Ζητείται λοιπόν, ένας ορισμός για την απεικόνιση της ομοιότητας έτσι ώστε τα αντικείμενα να μοιάζουν μεταξύ τους περισσότερο [1]. ΟΡΙΣΜΟΣ: Η ομοιότητα ανάμεσα σε δύο πλειάδες και σε μία βάση δεδομένων, είναι μία απεικόνιση από DxD στο διάτημα [,1]. [1] Εικόνα Β.4: Απεικονίσεις δύο όμοιων χρονοσειρών
31 31 Τα επιθυμητά χαρακτηριστικά ενός καλού μέτρου ομοιότητας είναι [1]:, εάν το μοιάζει περισσότερο με το παρά με. ΟΡΙΣΜΟΣ: Μετρική καλείται μία συνάρτηση , για την οποία ισχύουν Σε έναν χώρο εφοδιασμένο με μία μετρική, ορίζεται η έννοια της απόστασης δύο σημείων. Οι αποστάσεις Minkowski χρησιμοιποιούνται στα περισσότερα προβλήματα. Ο γενικός τύπος της απόστασης Minkowski είναι: Η απόσταση αυτή ευνοεί τις συντεταγμένες με μεγάλες τιμές και μεγάλες διακυμάνσεις []. Η συνάρτηση ομοιότητας και η συνάρτηση ανομοιότητας μεταξύ δύο πλειάδων μπορούν να οριστούν ως εξής: ΟΡΙΣΜΟΣ: Μία συνάρηση Εάν επιπλέον ισχύει: 4. καλείται συνάρτηση ομοιότητας αν
32 3 5. Τότε η S καλείται μετρική ομοιότητας []. ΟΡΙΣΜΟΣ : Μία συνάρηση καλείται συνάρτηση ομοιότητας αν 1. Είναι συμμετρική. Είναι θετικά ορισμένη 3. Εάν επιπλέον ισχύει: Τότε η συνάρτηση διαφορετικότητας είναι μετρική []. Η μεγαλύτερη ομοιότητα μεταξύ δύο αντικειμένων επιτυγχάνεται με τη μεγαλύτερη τιμή της συνάρτησης ομοιότητας ή με τη μικρότερη τιμή της συνάρτησης διαφορετικότητας. Οι περισσότεροι αλγόριθμοι επιλέγουν ως μέτρο ομοιότητας τη συνάρτηση διαφορετικότητας. Ένα μέτρο διαφορετικότητας μπορεί έυκολα να μετασχηματιστεί και να χρησιμοποιηθεί ως μέτρο ομοιότητας και συνεπώς κάθε μετρική μπορεί να μετασχηματιστεί σε μέτρο ομοιότητας []. Μερικά από τα πιο συνηθισμένα μέτρα ομοιότητας (similarity measures)είναι: o Ομοιότητα Dice: o Ομοιότητα Jaccard: o Ομοιότητα Συνημιτόνου: Επειδή η ομοιότητα συνημιτόνου επηρεάζεται μόνο από γραμμικούς μετασχηματισμούς και όχι από το μήκος ενός δανύσματος ή από την περιστροφή των αξόνων, με την κανονικοποίηση των δεδομένων λαμβάνουμε:.
33 33 o Απόσταση Mahalanobis: o Συσχέτιση Pearson:, όπου o Απόσταση Συμμετρίας Σημείου:, όπου z ένα σημείο αναφοράς. Μερικά από τα ευρέως χρησιμοποιούμενα μέτρα ανομοιότητας ή απόστασης (dissimilarity measures) ή αλλιώς μέτρα απόστασης (distance measures): Eυκλείδεια (p=) Manhatttan (p=1) Chebyshev (p ) DTW
34 34 Οι τρείς πρώτες αποστάσεις, Eυκλείδεια, Manhattan και Chebyshev, βρίσκονται με τη χρήση του γενικού τύπου της απόστασης Minkowski, για διάφορες τιμές του p []. Η Eυκλείδεια απόσταση, παρόλο που λειτουργεί καλά, δεν παράγει πάντα ακριβά αποτελέσματα όταν οι ακολουθίες μετατοπίζονται, ως προς τον άξονα του χρόνου. Σε αυτήν την περίπτωση χρησιμοποιείται μία άλλη μετρική, πιο αποδοτική, που ονομάζεται Dynamic Time Warping (δυναμική στρέβλωση ως προς το χρόνο) και αναλύεται διεξοδικότερα παρακάτω [13]. Η μετρική Dynamic Time Warping Η μετρική Dynamic Time Warping (DTW) υπολογίζει την ομοιότητα μεταξύ δύο χρονοσειρών που μπορεί να διαφέρουν ως προς τον χρόνο ή και την ταχύτητα. Ο σκοπός της είναι να βρει το βέλτιστο ταίριασμα μεταξύ των δύο χρονοσειρών με κάποιους περιορισμούς [6]. Για παράδειγμα, δοθέντος των χρονοσειρών και διάστασης και αντίστοιχα, για τον υπολογισμό της απόστασης DTW πρέπει πρώτα να οριστεί το μονοπάτι στρέβλωσης (warping path). Το μονοπάτι αυτό αποτελείται από ένα σύνολο, συνεχόμενων στοιχείων του πίνακα, που ορίζει μία αντιστοίχιση (μη γραμμική) μεταξύ των και. Δηλαδή και το κ-οστό στοιχείο του W. Το μονοπάτι αυτό μπορεί να βρεθεί δυναμικά μέσω της παρακάτω επανάληπτικής σχέσης. Όπου Για την ευθυγράμμιση των χρονοσειρών με τη DTW σχηματίζεται ένας πίνακας διάστασης όπου το στοιχείο περιέχει την απόσταση μεταξύ των δύο σημείων και (όπου ). Το κάθε στοιχείο του μητρώου αντιστοιχεί στην ευθυγράμμιση μεταξύ των δύο σημείων και. Το μήκος της στρέβλωσης είναι μία παράμετρος που υπολογίζει τη βέλτιστη απόσταση προσδιορίζοντας την επιτρεπτή στρέβλωση.
35 35 Εικόνα Β.5: (α) Οι χρονοσειρές Q και C, (β) Δυναμική στρέβλωση -μη γραμμική ευθυγράμμιση, (γ) το μονοπάτι στρέβλωσης Υπάρχουν οι εξής περιορισμοί για το μονοπάτι στρέβλωσης : Συνοριακές συνθήκες (Boundary): και, σύμφωνα με αυτή τη συνθήκη το μονοπάτι στρέβλωσης πρέπει να αρχίζει απο το κελί που βρίσκεται διαγώνια της μήτρας και να τελειώνει στο κελί που βρίσκεται επίσης διαγώνια αλλά στην απέναντι πλευρά της μήτρας. Συνθήκη συνέχειας (Continuity): έστω ότι και με και. Αυτή η συνθήκη μειώνει τα επιτρεπτά βήματα του μονοπατιού σε γειτονικά κελιά (συμπεριλαμβανομένων των διαγωνίων κελιών). Συνθήκη Μονοτονίας (Monotonicity): έστω ότι και με και. Η συνθήκη αυτή αναγκάζει τα σημεία του W να απέχουν μονοτονικά στο χρόνο. Πολλά μονοπάτια στρέβλωσης ικανοποιούν τις συνθήκες αυτές, όμως προτιμάται εκείνο το μονοπάτι που ελαχιστοποιεί το κόστος της στρέβλωσης:
36 36 Όπου το είναι το κ-οστό σημείο από το μονοπάτι στρέβλωσης W και το K χρησιμοποιείται για αντιμετωπίσει το πρόβλημα του διαφορετικού μήκους των μονοπατιών στρέβλωσης [9,1]. Σύγκριση της μετρικής DTW με την Ευκλείδεια Η Eυκλείδεια απόσταση είναι ειδική περίπτωση της DTW, όπου οι ακολουθίες ευθυγραμμίζονται σημείο προς σημείο (δηλαδή το i-οστό σημείο της χρονοσειράς C ταιριάζει με το i-οστό σημείο της χρονοσειράς Q). Μερικά χαρακτηριστικά της Ευκλείδειας απόστασης είναι τα ακόλουθα: το κ-οστό στοιχείο του W περιορίζεται στο ό δεν επιτρέπεται καμία στρέβλωση οι δύο χρονοσειρές πρέπει να έχουν το ίδιο μήκος Εικόνα Β.6: (α) Ένα προς ένα αντιστοιχία των Q και C στην περίπτωση της Ευκλείδειας απόστασης, (β) Μη γραμμική αντιστόιχιση των Q και C στην περίπτωση της μετρικής DTW Η DTW αντιστοιχίζει τις ακολουθίες καλύτερα από την Ευκλείδεια μετρική, χρησιμοποιώντας την επαναληπτική σχέση (1). Και μάλιστα, στην Eυκλείδεια απόσταση τα τοπικά ελάχιστα (dips) και τα τοπικά μέγιστα (peaks) των χρονοσειρών αντιστοιχίζονται λανθασμένα με αποτέλεσμα να μην ταιριάζουν, ενώ στην DTW τα ακρότατα αυτά ευθυγραμμίζονται με τα αντίστοιχα ακρότατα. Εύλογα μπορούμε να συμπεράνουμε ότι η DTW υπερτερεί της Ευκλείδειας απόστασης ως προς την ευθυγράμμιση αλλά είναι υπολογιστικά ασύμφορη με πολυπλοκότητα αντιμετώπισης αυτού του προβλήματος είναι η ευρετηριοποίηση της DTW [13,1].. Ένας τρόπος
37 37 Κριτήρια Σύνδεσης (Ιεραρχικής Συσταδοποίησης) Στην ιεραρχική συσταδοποίηση η ενοποίηση ή ο διαχωρισμός των συστάδων εκτελείται σύμφωνα με κάποια κριτήρια σύνδεσης τα οποία εξετάζονται παρακάτω [1,4,8]. 1. Aπόσταση απλού συνδέσμου (Single-link clustering): θεωρεί ότι η απόσταση μεταξύ δύο συστάδων ισούται με την ελάχιστη απόσταση μεταξύ δύο πλειάδων που ανήκουν στις δύο συστάδες. Όπου : το i-οστό μέλος της συστάδας r Εικόνα Β.7: Απόσταση απλού συνδέσμου δύο συστάδων : το j-οστό μέλος της συστάδας s. Aπόσταση πλήρους συνδέσμου (Complete-link clustering): θεωρεί ότι η απόσταση μεταξύ δύο συστάδων είναι ίση με τη μέγιστη απόσταση μεταξύ δύο πλειάδων που ανήκουν στις δύο συστάδες. Όπου : το i-οστό μέλος της συστάδας r Εικόνα Β.8: Απόσταση πλήρους συνδέσμου δύο συστάδων : το j-οστό μέλος της συστάδας s
38 38 3. Απόσταση μέσου συνδέσμου (Average-link clustering): θεωρεί ότι η απόσταση μεταξύ δύο συστάδων είναι ίση με τη μέση απόσταση από οποιοδήποτε μέλος μίας συστάδας προς οποιοδήποτε μέλος της άλλης συστάδας. Όπου : το i-οστό μέλος της συστάδας r : το j-οστό μέλος της συστάδας s : το πλήθος των πλειάδων της της συστάδας r Εικόνα Β.9: Απόσταση μέσου συνδέσμου δύο συστάδων : το πλήθος των πλειάδων της της συστάδας s 4. Απόσταση κέντρων βάρους (Centroid-link clustering): Χρησιμοποιεί την Ευκλείδεια απόσταση μεταξύ των centroids των δύο συστάδων. Όπου Το κέντρο βάρους της συστάδας r Το κέντρο βάρους της συστάδας s Εικόνα Β.1: Απόσταση κέντρων βάρους δύο συστάδων
39 39 5. Απόσταση των διαμέσων (Median-link clustering): Χρησιμοποιεί την Ευκλείδεια απόσταση μεταξύ των σταθμισμέων centroids των δύο συστάδων όπου είναι σταθμισμένα κεντροειδή (centroids) των συστάδων r και s. Εάν η συστάδα r δημιουργείται με τον συνδυασμό των p και q, τότε το κεντροειδές ορίζεται αναδρομικά ως 6. Απόσταση με τη μέθοδο του Ward (Ward-link clustering): Η μέθοδος αυτή αποτελεί το ιεραρχικό ανάλογο του k-means. Χρησιμοποιεί το κριτήριο της ελάχιστης διασποράς μέσω ενός επαναληπτικού αλγορίθμου. Σε κάθε βήμα βρίσκει το ζεύγος των συστάδων που οδηγεί στην ελάχιστη αύξηση της συνολικής διασποράς μέσα στη συστάδα μετά τη συγχώνευση. Για αυτό και λέγεται ότι το κριτήριο σύνδεσης Ward χρησιμοποιεί το κλιμακωτό άθροισμα των τετραγώνων. Το άθροισμα των τετραγώνων των within-cluster σημαίνει το άθροισμα των τετραγώνων των αποστάσεων μεταξύ όλων των αντικειμένων και του κεντροειδούς της συστάδας. Ο επαναληπτικός αλγόριθμος έχει τον παρακάτω τύπο όταν πρόκειται να συγχωνευτούν οι συστάδες και το αποτέλεσμά της συγχώνευσής τους είναι η συστάδα : Όπου : συστάδα i : κεντροειδές της συστάδας i Οι αποστάσεις των αρχικών συστάδων (που περιέχουν ένα αντικείμενο) υπολογίζεται από την τετραγωνική Ευκλείδεια απόσταση μεταξύ των σημείων.
40 4 7. Σταθμισμένη μέση απόσταση (Weighted-link clustering): Ορίζει μία επαναληπτική σχέση για την απόσταση μεταξύ δύο συστάδων. Εάν μία συστάδα r δημιουργείται με τον συνδυασμό των συστάδων p και q, η απόσταση μεταξύ r και άλλης συστάδας s ορίζεται ως η μέση απόσταση μεταξύ των αποστάσεων d( p, s) και d(q,s): Σημείωση: συμβολίζει την Eυκλείδεια απόσταση και και είναι τα κεντροειδή των συστάδων r και s αντίστοιχα είναι το πλήθος των συστάδων r και s αντίστοιχα
41 ΣΥΣΤΑΔΟΠΟΙΗΣΗ Το πρόβλημα της συσταδοποίησης έχει ως στόχο τον διαχωρισμό των δεδομένων σε ομάδες ώστε κάθε μέλος της συστάδας να βρίσκεται όσο το δυνατόν κοντά στα μέλη της συστάδας στην οποία ανήκει και συγχρόνως να απέχει όσο το δυνατόν περισσότερο από τα μέλη άλλων συστάδων. Μερικές από της εφαρμογές της συσταδοποίησης είναι Η ομαδοποίηση των γονιδίων και των πρωτεϊνών που έχουν την ίδια λειτουργία Η ομαδοποίηση των ασθενειών με βάση τα χαρακτηριστικά Η ομαδοποίηση των μετοχών με παρόμοια διακύμανση τιμών Η ομαδοποίηση του weblog για την εύρεση των παρόμοιων προτύπων προσπέλασης Η ομαδοποίηση των σχετιζόμενων αρχείων για browsing, ομαδοποίηση κειμένων Η ομαδοποίηση πελατών με παρόμοια συμπεριφορά Ο εναλλακτικός ορισμός της συσταδοποίησης, σύμφωνα με την Dunham, είναι ό εξής: ΟΡΙΣΜΟΣ: Δοθείσης μιας βάσης δεδομένων που αποτελείται από πλειάδες και μιας ακέραιας τιμής κ, το πρόβλημα της συσταδοποίησης είναι να οριστεί μια αντιστοίχιση όπου κάθε ανατίθεται σε μία πλειάδα. Μία συστάδα,, περιέχει ακριβώς εκείνες τις πλειάδες που της ανατέθηκαν δηλαδή,. Η διαδικασία της συσταδοποίησης ακολουθεί τέσσερα βασικά στάδια [31]: Επιλογή των χαρακτηριστικών γνωρισμάτων: Αποτελεί μέρος της προεπεξεργασίας των δεδομένων και θεωρείται απαραίτητη για την επίτευξη της βέλτιστης ομοιογένειας των συστάδων. Επιλογή του αλγορίθμου συσταδοποίησης: Ο κατάλληλος αλγόριθμος μπορεί να δώσει ένα καλύτερο σχήμα συσταδοποίησης. Η επιλογή του αλγορίθμου προσδιορίζεται από το μέτρο γειτνίασης και το κριτήριο συσταδοποίησης.
42 4 Επικύρωση των αποτελεσμάτων: Αποτελεί βασικό στάδιο για την αξιολόγηση των συστάδων εφόσον προσδιορίζει την ποιότητά τους. Αυτή επιτυγχάνεται μέσω της σύγκρισης των αποτελεσμάτων αυτών με τα αποτελέσματα που γνωρίζουμε εκ των προτέρων. Ερμηνεία των αποτελεσμάτων: Ερμηνεύονται τα αποτελέσματα από ειδικούς. Τα αποτελέσματα αυτά σε συνδυασμό με άλλα στοιχεία βοηθούν στην εξαγωγή της γνώσης. Αλγόριθμοι συσταδοποίησης: Οι αλγόριθμοι της συσταδοποίησης αναζητούν ομάδες που περιέχουν παρόμοιες εγγραφές και η διαδικασία αυτή επιτυγχάνεται βρίσκοντας ομοιότητες μεταξύ των δεδομένων βάσει των χαρακτηριστικών. Με άλλα λόγια, ο βαθμός συσχέτισης μεταξύ των μελών μίας συστάδας να είναι ισχυρός και με τα μέλη άλλων συστάδων να είναι λιγότερο ισχυρός. Μέθοδοι συσταδοποίησης: Υπάρχει μία πληθώρα τεχνικών για τη συσταδοποίηση από τις οποίες επιλέγεται κάθε φορά η μέθοδος ανάλογα με το πρόβλημα που θέλουμε να λύσουμε. Οι αλγόριθμοι συσταδοποίησης χωρίζονται σε ιεραρχικούς (Hierarchical), διαμεριστικούς (Partitioning), αλγορίθμους που βασίζονται στην πυκνότητα (density based), γενετικούς αλγορίθμους και σε αλγορίθμους για μεγάλες βάσεις δεδομένων. Από όλες αυτές τις τεχνικές θα αναλυθούν μόνο οι δύο πρώτες οι οποίες χρησιμοποιήθηκαν για τους σκοπούς αυτής της εργασίας. Ιεραρχική Συσταδοποίηση Στην ιεραρχική συσταδοποίηση δημιουργείται ένα σύνολο από εμφωλευμένες συστάδες που οργανώνονται σε ένα ιεραρχικό δέντρο το οποίο καλείται και δενδρόγραμμα. Σε κάθε επίπεδο της ιεραρχίας υπάρχει ένα ξεχωριστό σύνολο συστάδων ενώ στο κατώτατο επίπεδο κάθε αντικείμενο αποτελεί μία συστάδα. Οι ιεραρχικοί αλγόριθμοι, επομένως, διαφέρουν ως προς το πώς δημιουργούνται τα σύνολα των συστάδων. Ένα πλεονέκτημα τους είναι ότι δεν απαιτείται η εισαγωγή του πλήθους των συστάδων, μπορεί όμως να επιτευχθεί το επιθυμητό πλήθος με το «κόψιμο» του δενδρογράμματος στο κατάλληλο επίπεδο.
43 43 Οι ιεραρχικοί αλγόριθμοι διακρίνονται σε συσσωρευτικούς (Agglomerative) και διαιρετικούς (Divisive). Οι συσσωρευτικοί αλγόριθμοι ξεκινούν με τα σημεία ως ξεχωριστές ομάδες και προχωρούν συγχωνεύοντας σε κάθε βήμα τα πιο κοντινά ζεύγη συστάδων. Η διαδικασία της συγχώνευσης επαναλαμβάνεται έως ότου μείνουν κ συστάδες (ή μία συστάδα).οι συσσωρευτικοί αλγόριθμοι εκτελούνται απο κάτω προς τα πάνω (bottom-up). Ενώ οι διαιρετικοί αλγόριθμοι ακολουθούν την αντίθετη πορεία, δηλαδή εκτελούνται από πάνω προς τα κάτω (top-down), ξεκινούν με μία συστάδα που περιέχει όλα τα σημεία και εξελίσσονται προοδευτικά διαιρώντας τις μεγάλες συστάδες σε μικρότερες μέχρι να φτάσει στο επιθυμητό πλήθος συστάδων [1]. Το πλεονέκτημα των ιεραρχικών μεθόδων είναι ότι δεν παράγουν ένα διαχωρισμό, αλλά περιέχουν πολλά εμφωλευμένα τμήματα, που επιτρέπουν σε διαφορετικούς χρήστες να επιλέγουν διαφορετικούς διαχωρισμούς, σύμφωνα με το επιθυμητό επίπεδο ομοιότητας. Τα κύρια μειονεκτήματα τους είναι: β) Οι ιεραρχικές μέθοδοι δεν μπορούν ποτέ να αναιρέσουν τα πεπραγμένα. Δηλαδή δεν έχει την ικανότητα της οπισθοδρόμησης. γ) Στον απλό σύνδεσμο λίγα αντικείμενα που σχηματίζουν τη γέφυρα ανάμεσα σε δύο συστάδες, προκαλούν την ένωση των δύο αυτών συστάδων (chaining effect). δ) Στον μέσο σύνδεσμο, μπορεί να προκαλέσει επιμήκυνση των συστάδων για τον διαχωρισμό και για ενοποίηση τμήματα επιμήκων γειτονικών συστάδων ε) Η μέθοδος απόσταση πλήρους συνδέσμου δημιουργεί πιο συμπαγείς συστάδες και πιο χρήσιμες ιεραρχίες από ότι η μέθοδος απλού συνδέσμου, επίσης η μέθοδος απλού συνδέσμου είναι πιο ευέλικτη. Διαμεριστική συσταδοποίηση Συγκριτικά με την ιεραρχική μέθοδο, η διαμεριστική δε σχηματίζει κάποια ιεραρχική δομή. Αντιθέτως η ανάθεση των αντικειμένων σε συστάδες πραγματοποιείται σε ένα βήμα και ως αποτέλεσμα λαμβάνεται μόνο ένα σύνολο συστάδων, παρά το γεγονός ότι εσωτερικά μπορεί να δημιουργηθούν αρκετά διαφορετικά σύνολα συστάδων. Για την εύρεση της βέλτιστης λύσης χρησιομοποιείται μία συνάρτηση κριτηρίου με τη βοήθεια μίας μετρικής που χρησιμοποιείται συχνά. Για την ακρίβεια,
44 44 ζητείται η ελαχιστοποίηση του αθροίσματος του τετραγωνικού σφάλματος (Least Squared Error). Και ως τελική λύση επιλέγεται εκείνη που έχει την καλύτερη τιμή της συναρτήρσης κριτήριου. Το γεγονός ότι για την εύρεση της βέλτιστης λύσης ο υπολογισμός όλων των πιθανών διαμερίσεων (πιθανών συνδυασμών των n-στοιχείων σε κ-συστάδες) είναι εξαντλητικός και αυξάνει την πολυπλοκότητά του, η αναζήτηση περιορίζεται σε ένα μικρό υποσύνολο των πιθανών λύσεων. Με τη χρήση των ευρετικών τεχνικών λαμβάνονται οι προσεγγιστικά βέλτιστες λύσεις. Ένα άλλο μειονέκτημα αυτής της μεθόδου είναι ότι απαιτείται η εισαγωγή του επιθυμητού πλήθους των συστάδων προκειμένου να υλοποιηθεί ο αλγόριθμος [3,1]. Μερικοί διμεριστικοί αλγόριθμοι που χρησιμοποιούνται ευρέως, είναι το δέντρο ελάχιστης ζεύξης (minimal spanning tree), ο αλγόριθμος συσταδοποίησης του τετραγωνικού σφάλματος (squared error cluster algorithms), K-means, αλγόριθμος του πλησιέστερου γείτονα, PAM, CLARA, CLARANS, αλγόριθμοι ενέργειας δεσμού, συσταδοποίηση με γενετικούς αλγορίθμους, συσταδοποίηση με Νευρωνικά δίκτυα, BIRCH, DBSCAN, CURE, ROCK. Αξίζει να σημειωθεί ότι δεν υπάρχει μία μόνο σωστή λύση σε ένα πρόβλημα συσταδοποίησης. Ένα άλλο πρόβλημα της συσταδοποίησης, που είναι κρίσιμο, είναι η επιλογή του πλήθους των συστάδων. Δηλαδή, δεν είναι τόσο εύκολο να προσδιοριστεί το ακριβές πλήθος των συστάδων που απαιτείται. Με την αλλαγή του κ μπορεί να προκύψουν διαφορετικές συστάδες. Μία καλή αρχικοποίηση των κεντροειδών των συστάδων μπορεί να είναι και κρίσιμη. Επίσης, υπάρχει πιθανότητα μερικές συστάδες να είναι άδειες (να μην περιέχουν κανένα αντικείμενο) εάν τα κεντροειδή του βρίσκονται αρχικά μακριά από τα δεδομένων [1]. Τα αποτελέσματα της συσταδοποίησης μπορούν να συνεισφέρουν στον ορισμό της κατηγοριοποίησης (όπως η ταξινόμηση των μετοχών που σχετίζονται με κάποια ομάδα) ή να βοηθήσουν στην κατασκευή των στατιστικών μοντέλων με τα οποία είναι εφικτό να γίνει η περιγραφή του πληθυσμού. Η συστδοποίηση δημιουργεί κανόνες για ανάθεση νέων εγγραφών σε κλάσεις και χρησιμεύει για αναγνώριση και διάγνωση.
45 45 Εγκυρότητα Οι τεχνικές που χρησιμοποιούνται συνήθως για την αξιολόγηση των αποτελεσμάτων (cluster validation techniques) διακρίνονται σε εσωτερικές και εξωτερικές. Ως εσωτερικά κριτήρια χρησιμοποιούνται οι δείκτες Davis Bouldin και Dunn ενώ για την εξωτερική αξιολόγηση χρησιμοποιούνται οι Jaccard index, Fowlkes-Mallows index, Rund measure, F measure, Confusion matrix, Mutual information [31]. 3. ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ Η κατηγοριοποίηση είναι μία τεχνική εξόρυξης που χρησιμοποιείται κατα κόρον. Εφαρμόζεται στην αναγνώριση των προτύπων και εικόνας, στην ιατρική διάγνωση, στην ανίχνευση λαθών σε βιομηχανικές εφαρμογές, στην κατηγοριοποίηση των τάσεων στην οικονομία [1]. Η κατηγοριοποίηση, που συχνά αναφέρεται ως εποπτευόμενη μάθηση, απεικονίζει τα εισερχόμενα δεδομένα σε μία από τις προκαθορισμένες ομάδες. Οι ομάδες αυτές ορίζονται από πριν, κατα τη διαδικασία της μάθησης της αναγνώρισης των προτύπων, με τη χρήση ενός συνόλου δεδομένων που ονομάζεται training set. Η αναγνώριση των προτύπων, θεωρείται και αυτή ένα είδος της κατηγοριοποίησης, εφόσον, ο στόχος της είναι να ταξινομήσει δεδομένα με βάση την ομοιότητα. Η μέθοδος του κοντινότερου γείτονα (k Nearest Neighbor) και τα δέντρα αποφάσεων (Decision Trees) είναι από τις γνωστές μεθόδους που χρησιμοποιούνται για την κατηγοριοποίηση. Ο αλγόριθμος του κοντινότερου γείτονα χρησιμοποιεί μέτρα ομοιότητας, για τον βέλτιστο καθορισμό της ομάδας στην οποία ανήκει, βασισμένος σε ήδη υπάρχοντα ομαδοποιημένα δεδομένα. Με τη χρήση του training set εξάγονται κάποιοι κανόνες για τα δέντρα αποφάσεων, οι οποίοι χρησιμοποιούνται αργότερα, για την κατηγοριοποίηση νέων δεδομένων. Παρόλο που τα δέντρα αποφάσεων ορίζονται για τα πραγματικά δεδομένα, η εφαρμογή τους ωστόσο σε ακατέργαστες χρονοσειρές (raw time series) μπορεί να αποτελέσει μία λανθασμένη επιλογή, γεγονός που οφείλεται στην υψηλή διαστατικότητα και στον θόρυβο και μπορεί να έχει ως αποτέλεσμα ένα βαθύ και θαμνώδες δέντρο. Η αναπαράσταση των χρονοσειρών ως δέντρα παλινδρόμησης έχει προταθεί για να χρησιμοποιηθούν στην εκμάθηση του
46 46 δέντρου απόφασης. Η απόδοση των αλγορίθμων κατηγοριοποίησης αξιολογείται συνήθως με τον υπολογισμό της ακρίβειας (accuracy) της κατηγοριοποίησης, με τον καθορισμό του ποσοστού των αντικειμένων που έχουν καταχωρηθεί σωστά [44]. ΟΡΙΣΜΟΣ: Δεδομένης μίας βάσης δεδομένων πλειάδων (στοιχείων) και ένα σύνολο από κατηγορίες, το πρόβλημα της κατηγοριοποίησης είναι να ορίσουμε μία απεικόνιση όπου κάθε εκχωρείται σε μία κατηγορία. Μία κατηγορία ή κλάση,, περιέχει ακριβώς αυτές τις πλειάδες όπου έχουν απεικονιστεί σε αυτή, δηλαδή. [1] Η κατηγοριοποίηση έχει ως στόχο τη γενίκευση των γνωστών δομών για να εφαρμοστεί σε νέα δεδομένα. Συγκεκριμένα, έχοντας μία βάση δεδομένων και κάποιες προκαθορισμένες κατηγορίες, προσπαθεί να δημιουργήσει ένα μοντέλο το οποίο να μπορεί να καταχωρεί επιτυχώς κάθε αντικείμενο της βάσης σε μία μόνο από τις κατηγορίες αυτές. Επίσης, οι κατηγορίες είναι προκαθορισμένες, δεν είναι επικαλυπτόμενες και διαμερίζουν ολόκληρη τη βάση δεδομένων. Συγκριτικά με τη συσταδοποιήση, παρατηρούμε ότι η κατηγοριοποίηση προϋποθέτει κάποια γνώση των δεδομένων [1]. Αλγόριθμοι κατηγοριοποίησης Πολλές τεχνικές έχουν αναπτυχθεί για την επίλυση τέτοιου είδους προβλημάτων, εκ των οποίων οι πιο γνώστες είναι οι αλγόριθμοι που βασίζονται στη στατιστική, στην απόσταση, στα δέντρα αποφάσεων, στα νευρωνικά δίκτυα και στους κανόνες. Μπορουν επίσης να συνδυαστούν οι παραπάνω τεχνικές [1]. Μέτρα αξιολόγησης Ο καθορισμός του καλύτερου εργαλείου για την κατηγοριοποίηση εξαρτάται από την ερμηνεία που δίνουν στο πρόβλημα οι χρήστες. Η ακρίβεια της κατηγοριοποίησης συνήθως, υπολογίζεται με τον
47 47 καθορισμό του ποσοστού των πλειάδων που τοποθετούνται στη σωστή κατηγορία, ενώ αγνοούμε το γεγονός ότι υπάρχει επίσης κάποιο κόστος το οποίο συνδέεται με μη σωστή εκχώρηση σε λανθασμένη κατηγορία. Ένας πίνακας σύγχησης (Confusion matrix) επιδεικνύει την ακρίβεια της λύσης σε ένα πρόβλημα κατηγοριοποίησης. Με δεδομένες m κατηγορίες, μία μήτρα σύγχυσης είναι μία μήτρα διάστασης όπου κάθε καταχώρηση δείχνει τον αριθμό των πλειάδων από το D οι οποίες εκχωρήθηκαν στην κατηγορία αλλά των οποίων η πραγματική κατηγορία είναι η. Οι καλύτερες λύσεις θα έχουν μηδενικά έξω από τη διαγώνιο. Για την αξιοπιστία της κατηγοριοποίησης χρησιμοποιείται συνήθως το Confusion matrix και χρησιμοποιείται επίσης η τεχνική crossvalidation στο σύνολο των δεδομένων [1]. 3.3 ΠΡΟΒΛΕΨΗ Η πρόβλεψη των χρηματοοικονομικών δεδομένων αποτελεί το σημαντικότερο ζήτημα στον χώρο του χρηματιστηρίου αλλά και σε σε πολλά προβλήματα (επεξεργασία σημάτων, μετοχές, αναγνώριση προτύπων, ιατρικές διαγνώσεις, ρομποτική-μηχανική μάθηση, σεισμολογία). Για τον λόγο αυτό έχει μελετηθεί εκτενέστερα από πολλούς ερευνητές. Γεγονός που παραπέμπει και την συγκεκριμένη εργασία, τη μελέτη τους και κατ επέκταση την πρόβλεψη των μελλοντικών τους τιμών. Οι μέθοδοι ανάλυσης των χρονοσειρών, που χρησιμοποιούνται συνήθως για την πρόβλεψη, είναι οι autoregression (AR), moving average (MA), ARMA, ARIMA, ARMAX και Exponential Smoothing. Ενώ τελευταία έχουν κάνει δυναμικά την εμφάνισή τους οι τεχνικές εξόρυξης, όπως για παράδειγμα, τα νευρωνικά δίκτυα και οι Support Vector Machines (SVMs). Στην προσπάθεια πρόβλεψης στην εν λόγω μελέτη, υλοποιήθηκε η μέθοδος Support Vector Regression (SMOreg) του weka (περιβάλλον για την εξόρυξη των δεδομένων) και οι κλασικές μέθοδοι Exponential Smoothing και ARIMA για συγκριτικά αποτελέσματα. Η μέθοδος SMOreg είναι μία επέκταση της μεθόδου των SVMs, η οποία θα αναλυθεί διεξοδικά παρακάτω. Για αυτό τον λόγο γίνεται αρχικά μία εισαγωγή για τα SVMs. Για την πρόβλεψη των χρονοσειρών έχουν προταθεί διάφορα στατιστικά μοντέλα όπως linear regression, autoregression (AR), moving average (MA), ARMA, ARIMA, ARMAX και NARMAX. Πέραν όμως των κλασικών αυτών μεθόδων, τελευταία έχουν κάνει την εμφάνιση τους οι μέθοδοι
48 48 πρόβλεψης των χρονοσειρών με τεχνικές εξόρυξης όπως για παράδειγμα, τα νευρωνικά δίκτυα και οι Support Vector Machines. Το πρόβλημα της πρόβλεψης ορίζεται ως εξής: Δοθείσης μίας διακριτής χρονολογικής σειράς με ισαπέχοντα χρονικά διαστήματα, να προβλεφθεί τη χρονική στιγμή t η τιμή, για ένα προβλεπόμενο χρόνο υποθέτοντας ότι οι προηγούμενες τιμές της σειράς είναι γνωστές [1]. Η πρόβλεψη αυτή διαφέρει από το είδος της πρόβλεψης που γίνεται στην κατηγοριοποίηση. Δηλαδή, στην πρόβλεψη εκτιμώνται οι μελλοντικές τιμές μιας χρονοσειράς σε συγκεκριμένες χρονικές στιγμές, ενώ στην κατηγοριοποίηση «προβλέπονται» σε ποιά κλάση ανήκουν τα νέα εισερχόμενα δεδομένα. 1. Πρόβλεψη με Στατιστικά Μοντέλα Χρονοσειρών Η ανάπτυξη των μαθηματικών μοντέλων αποτελεί το κυριότερο ζήτημα της ανάλυσης των χρονοσειρών διότι παρέχουν κάποιες περιγραφές για το δείγμα των δεδομένων (μία εσωτερική δομή όπως η αυτοσυσχέτιση, η τάση ή οι εποχιακές διαφοροποιήσεις), και κάνουν πρόβλεψη των μελλοντικών τιμών με βάση τα χαρακτηριστικά αυτά. Παρακάτω δίνονται μερικά βασικά προβλεπτικά μοντέλα [14]. Συνήθως οι τιμές των χρονοσειρών εξαρτώνται μεταξύ τους αλλά μπορεί να θεωρηθεί ότι έχουν προκύψει από μία σειρά ανεξάρτητων τιμών που λέγονται shocks. Τα shocks επιλέγονται τυχαία από μία κανονική κατανομή με μηδενικό μέσο. Μία ακολουθία τέτοιων τυχαίων τιμών θεωρείται ότι παριστάνει μία διαδικασία λευκού θορύβου (white noise). Με τη χρήση ενός γραμμικού φίλτρου η διαδικασία λευκού θορύβου μετασχηματίζεται σε μία χρονολογική σειρά. Το γραμμικό φίλτρο μπορεί να θεωρηθεί σαν ένα απλό άθροισμα με βάρη προηγούμενων shocks [1].
49 49.Ο Λευκός Θόρυβος White Noise Η συλλογή των ασυσχέτιστων τυχαίων μεταβλητών με μέση τιμή και διασπορά είναι πιο απλή μορφή σειράς και χρησιμοποιείται συνήθως για τον θόρυβο. Η χρονοσειρά αυτή καλείται λευκός θόρυβος (white noise). Ένας ιδιαίτερα χρήσιμος λευκός θόρυβος είναι ο Γκαουσιανός, όπου οι μεταβλητές είναι ανεξάρτητες με μέση τιμή και διασπορά ή ακριβέστερα,. Οι κλασικές στατιστικές μεθοδοι δεν επαρκούν για την ανάλυση των χρονοσειρών διότι η στοχαστική συμπεριφορά τους δεν μπορεί να επεξηγηθεί μέσω των όρων του μοντέλου του λευκού θορύβου. Στα μοντέλα των χρονοσειρών η εισαγωγή της σειριακής αυτοσυσχέτισης και περισσότερης ομαλότητας γίνεται μέσω του κινητού μέσου όρου (moving average) και της αυτοσυσχέτισης (autoregression). Ο κινητός μέσος όρος αντικαθιστά τη σειρά του λευκού θορύβου για να εξομαλύνει τη σειρά αυτή. 3.Αυτοπαλινδρόμηση (Autoregressions AR) Οι συναρτήσεις autocorrelation και cross-correlation αποτελούν τα μέτρα υπολογισμού της εξάρτησης των χρονοσειρών. Παρακάτω δίνονται κάποιοι ορισμοί που είναι σημαντικοί για την ανάλυση των χρονοσειρών. ΟΡΙΣΜΟΣ: Η συνάρτηση αυτοδιακύμανσης (autocovariance) ορίζεται ως: Όπου : η χρονοσειρά τη χρονική στιγμή s. : η χρονοσειρά τη χρονική στιγμή t. Η συνάρτηση αυτοδιακύμανσης χρησιμοποιείται για την περιγραφή της σειριακής εξάρτησης μιας χρονοσειράς που είναι στάσιμη και μη- περιοδική [17].
50 5 ΟΡΙΣΜΟΣ: Η συνάρτηση αυτοσυσχέτισης (autocorrelation - ACF) Οι τιμές της κυμαίνονται από το -1 έως 1, δηλαδή ισχύει η σχέση. Επειδή, αυτοσυσχέτιση αποτελεί δύσκολο μέτρο ικανότητας της πρόβλεψης της χρονοσειράς τη χρονική στιγμή t από την τιμή που βρίσκεται τη χρονική στιγμή s, συχνά προτιμάται η πρόβλεψη μιας άλλης χρονοσειράς μέσω της χρονοσειράς. ΟΡΙΣΜΟΣ: Η συνάρτηση cross-covariance CCF μεταξύ των χρονοσειρών και, δοθέντος ότι έχουν πεπερασμένες διασπορές, ορίζεται ως: ή εναλλακτικά Η συνάρτηση αυτοσυσχέτισης ACF, που είναι η κανονικοποιημένη μορφή της συνάρτησης αυτοδιακύμανσης, μετρά τη συσχέτιση μεταξύ δύο μεταβλητών, που συνθέτουν τη στοχαστική διαδικασία, που βρίσκονται σε απόσταση κ χρονικών υστερήσεων. Επιπλέον, υπολογίζει την γραμμική προβλεψιμότητα της σειράς, τη χρονική στιγμή t, με τη χρήση μόνο της τιμής [17]. Σε σύγκριση με την ACF, η PACF συνάρτηση μερικής αυτοσυσχέτισης μετρά τη μερική συσχέτιση μεταξύ δύο μεταβλητών που συνθέτουν τη στοχαστική διαδικασία, που βρίσκονται σε απόσταση κ χρονικών υστερήσεων [18].
51 51 Οι γραφικές παραστάσεις της αυτοδιακύμανσης ή της αυτοσυσχέτισης χρησιμοποιούνται, συναρτήσει της υστέρησης κ, για τη διερεύνηση των τυχών μηχανισμών δημιουργίας των δεδομένων αλλά και για την υπόδειξη των κατάλληλων μοντέλων [17]. Τα μοντέλα αυτοπαλινδρόμισης (autoregression - AR), βαθμού p, συνήθως έχουν την παρακάτω μορφή: Όπου είναι το σφάλμα ή ο λευκός θόρυβος είναι παράμετροι αυτοπαλινδρόμησης είναι ένας σταθερός όρος : τάξη του μοντέλου AR Τα μοντέλα αυτά προβλέπουν τη μελλοντική τιμή μίας χρονοσειράς, δοθένοτος των προηγούμενων τιμών της από τις οποίες εξαρτάται. Αποτελούν, επίσης, ειδική μορφή γραμμικού φίλτρου [1]. 4.Κινούμενοι Μέσοι όροι ( Moving averages MA) Μια άλλη εξάρτηση που μπορεί να υπάρχει μεταξύ των τιμών σε μία χρονοσειρά είναι αυτή του κινητού μέσου όρου(μα). Υπάρχουν πολλά διαφορετικά μοντέλα κινούμενου μέσου όρου. Οποιοδήποτε από αυτά μπορεί να χρησιμοποιηθεί. Η πρόβλεψη μελλοντικών τιμών τέτοιου μοντέλου μπορεί να βρεθεί από την παρακάτω σχέση [1]: Όπου : είναι παράμετροι : είναι το σφάλμα : τάξη του μοντέλου ΜΑ
52 5 5.ARMA (Autoregressive Moving Average) Ο συνδυασμός των μοντέλων αυτοπαλινδρόμησης(ar) και κινούμενου μέσου όρου (ΜΑ) συνθέτουν το μοντέλο ARMA το οποίο είναι μία κλάση των στοχαστικών διαδικασιών που εκφράζονται ως (Box- Jenkins 197) [18]: όπου : η τάξη της αυτοπαλινδρόμησης AR : η τάξη του κινητού μέσου όρου MA : παράμετροι Εάν Β τελεστής τέτοιο ώστε γραφτεί ως:, τότε η γενική μορφή του μοντέλου ARMA μπορεί να Τα κριτήρια που πρέπει να ικανοποιηθούν για την εκτίμηση αυτών των μοντέλων, είναι: Η χρονοσειρά να είναι στάσιμη Η αυτοσυσχέτιση (ACF) και η μερική αυτοσυσχέτιση (PACF) πρέπει να είναι χρονικά ανεξάρτητες.
53 53 6.ARIMA (Autoregressive Integrated Moving Average) Στην περίπτωση που το μοντέλο δεν είναι στάσιμο, χρησιμοποιείται η μέθοδος ARIMA. Η μέθοδος Box-Jenkins ή Autoregressive Integrated Moving Average (ARIMA) είναι επέκταση του μοντέλου ARMA και αποσκοπεί στην εύρεση των λύσεων της εξίσωσης των διαφορών [18]: Όπου : είναι ο μη-εποχικός (non seasonal) τελεστης αυτοπαλινδρόμησης μοντέλου τάξης p : είναι ο εποχικός (seasonal) τελεστής αυτοπαλινδρόμησης μοντέλου τάξης p : είναι η χρονοσειρά : είναι ο μη-εποχικός (non seasonal) τελεστής κινητού μέσου μοντέλου τάξης q : είναι ο εποχικός (seasonal) τελεστής κινητού μέσου μοντέλου τάξης Q : είναι μία ακολουθία τυχαίων ανεξάρτητων τιμών που λέγονται shocks : είναι μία σταθερά Οι τάξεις των τελεστών επιλέγονται, ενώ οι παράμετροι υπολογίζονται από τα δεδομένα των χρονοσειρών με τη χρήση των μεθόδων βελτιστοποίησης όπως η μέθοδος της μέγιστης πιθανοφάνειας και η μέθοδος των ελάχιστων τετραγώνων. Η μέθοδος ARIMA περιορίζεται στις απαιτήσεις της στασιμότητας και της αντιστρεψιμότητας των χρονοσειρών. Το σύστημα που παράγει τη χρονοσειρά, πρέπει να είναι χρονικά αμετάβλητο και σταθερό. Επιπλέον, τα κατάλοιπα, πρέπει να είναι ανεξάρτητα και να ακολουθούν την κανονική κατανομή.
54 54 7.Εκθετική Εξομάλυνση (Exponential Smoothing) Η εκθετική εξομάλυνση (exponential smoothing) είναι μία τεχνική που εφαρμοζεται στις χρονοσειρές για την εξομάλυνση των δεδομένων ή για την πρόβλεψη. Ενώ με τη μέθοδο moving average οι προηγούμενες παρατηρήσεις έχουν ίσα βάρη (weights), στην εκθετική εξομάλυνση οι τιμές που ανατίθενται στα βάρη μειώνονται εκθετικά. Απλή Εκθετική εξομάλυνση- Single Exponential Smoothing Υποθέτονας ότι το μέσο επίπεδο μιας σειράς ολισθαίνει αργά με την πάροδο του χρόνου. οι προηγούμενες τιμές μίας σειράς παίζουν ρόλο στην πρόβλεψη δεδομένου ότι οι πιο πρόσφατες τιμές έχουν το μεγαλύτερο βάρος. η εξίσωση της πρόβλεψης ενός βήματος μπορεί να σχηματιστεί ως εξής: όπου ω είναι τα βάρη που κυμαίνονται στο διάστημα και επιλέγονται με τέτοιον τρόπο ώστε να μειώνονται εκθετικά, και είναι η πρόβλεψη ενός βήματος. Η σχέση (1) γράφεται καθώς με Η θεωρείται απλή εκθετική εξομάλυνση (simple exponential smoothing), η οποία βοηθάει στον υπολογισμό της, που είναι η πρόβλεψη ενός βήματος. Εάν, τότε η μπορεί να γραφτεί ως και η πρόβλεψη ως:
55 55 Δηλαδή η πρόβλεψη ενός βήματος τη χρονική στιγμή t ισούται με την πρόβλεψη ενός βήματος τη χρονική στιγμή t-1, αυξημένο κατά α φορές το σφάλμα πρόβλεψης στο χρόνο t-1. Η αρχική τιμή του S,, μπορεί να επιλεγεί ως ο μέσος όρος κάποιων αρχικών σημείων, ενώ η τιμή του α επιλέγεται με κριτήριο ώστε να ελαχιστοποιηθεί το μέσο σφάλμα της πρόβλεψης (η τιμή αυτή συνήθως κυμαίνεται από.5 έως.5). Διπλή Εκθετική Εξομάλυνση Double Exponential Smoothing Όταν υπάρχει τάση στα δεδομένα, τότε εφαρμόζεται η μέθοδος της διπλής εκθετικής εξομάλυνσης. Η εκθετική εξομάλυνση με τάση λειτουγεί περισσότερο σαν την απλή με τη διαφορά ότι, σε κάθε περίοδο (level and trend) πρέπει να ενημερώνονται δύο συνιστώσες. Το επίπεδο (level) είναι μία εξομαλυσμένη εκτίμηση της τιμής των δεδομένων στο τέλος της κάθε περιόδου. Η τάση (trend) είναι η εξομαλυσμένη εκτίμηση της μέσης αύξησης στο τέλος της κάθε περιόδου [45]. Ο τύπος της δίνεται από: Οι αρχικές τιμές των και μπορούν να επιλεγούν με πολλούς τρόπους. Γενικά θέτουμε, ενώ για το προτείνονται μία από τις παρακάτω τιμές:
56 56 Τριπλή εκθετική εξομάλυνση Triple Exponential Smoothing Αυτή η μέθοδος χρησιμοποιείται όταν τα δεδομένα, εκτός από την τάση (trend), δείχνουν και την εποχικότητα (seasonality). Για να προστεθεί και η εποχικότητα στους τύπους της εκθετικής εξομάλυνσης μπαίνει και μία τρίτη παράμετρος, γ. Το σύνολο των εξισώσεων καλείται μέθοδος Holt- Winters (HW). Υπάρχουν δύο κυριότερα μοντέλα HW που εξαρτώνται από το είδος της εποχικότητας. Πολλαπλασιαστικό Μοντέλο (Multiplicative Seasonal Model) Προσθετικό Μοντέλο (Additive Seasonal Model) Συχνά, οι χρονοσειρές παρουσιάζουν εποχική συμπεριφορά. Η εποχικότητα ορίζεται ως η τάση των χρονοσειρών να επιδείξουν συμπεριφορά που επαναλαμβάνεται σε κάθε περίοδο L. Ο όρος season χρησιμοποιείται για την αναπαράσταση της χρονικής περιόδου πριν την έναρξη της επανάληψης της συμπεριφοράς. Με L συμβολίζεται το μήκος της περιόδου. Υπάρχουν δύο τύποι εποχικότητας, τα οποία μέσω κάποιων χαρακτηριστικών που εμφανίζουν στα γραφήματα. Στην περίπτωση του προσθετικού μοντέλου, η σειρά εμφανίζει σταθερή εποχική διακύμανση ανεξάρτητα από το συνολικό επίπεδο της σειράς. Ενώ στην περίπτωση του πολλαπλαστικού μοντέλου το μέγεθος της εποχικής διακύμανσης ποικίλει, ανάλογα με το συνολικό επίπεδο της σειράς [45]. Πολλαπλασιαστικό Μοντέλο (Multiplicative Seasonal Model) Η χρονοσειρά αντιπροσωπεύεται από το μοντέλο: όπου είναι η βασική παράμετρος είναι η συνιστώσα που εκφράζει τη γραμμική τάση, η οποία μπορεί να διαγραφεί γιατί θεωρείται ασήμαντη είναι ο εποχικός πολλαπλασιαστικός παράγοντας το τυχαίο σφάλμα
57 57 Οι εποχικοί παράγοντες ορίζονται έτσι ώστε το άθροισμά τους να δίνει το L (το μήκος της εποχής), δηλαδή Η διαδικασία ενημέρωσης (update) για την εκτίμηση των παραμέτρων του μοντέλου εκτελείται στα εξής στάδια: Εκτίμηση για το επίπεδο αφαίρεσης της εποχικότητας (deseasonalized level): Εκτίμηση για την τάση: Εκτίμηση για την εποχική συνιστώσα: όπου είναι ο παράγοντας εξομάλυνσης των δεδομένων είναι ο παράγοντας εξομάλυνσης της τάσης είναι ο παράγοντας εξομάλυνσης της αλλαγής της εποχικότητας Ενώ οι τιμές για την πρόβλεψη υπολογίζονται από τις παρακάτω σχέσεις: Πρόβλεψη για την επόμενη περίοδο (one step-ahead) : Πρόβλεψη για τις επόμενες Τ περιόδους (Multiple step-ahead): Αρχικοποιήσεις:
58 58 Προσθετικό Μοντέλο (Additive Seasonal Model) Έστω είναι το μοντέλο που αντιπροσωπεύει τη χρονοσειρά. Οι εποχικοί παράγοντες ορίζονται έτσι ώστε το άθροισμά τους να δίνει, δηλαδή Η διαδικασία ενημέρωσης (update) για την εκτίμηση των παραμέτρων αλλάζει ως εξής: Εκτίμηση για το επίπεδο αφαίρεσης της εποχικότητας (deseasonalized level): Εκτίμηση για την τάση: Εκτίμηση για την εποχική συνιστώσα: H πρόβλεψη για την επόμενη περίοδο υπολογίζεται από τον τύπο. [45]
59 59 8. Μηχανές Διανυσματικής Υποστήριξης (Support Vector Machines) Οι μηχανές διανυσματικής υποστήριξης (Support Vector Machines ή SVMs) είναι μοντέλα επιβλεπόμενης μάθησης (supervised learning models) που εφαρμόζονται συχνά στην κατηγοριοποίηση (classification) και στην παλινδρόμηση (Regression) και κατάταξη συναρτήσεων (ranking functions). Είναι από τους βέλτιστους αλγορίθμους μηχανικής μάθησης με επίβλεψη που βασίζονται στη θεωρία της στατιστικής μάθησης και στη διάσταση Vapnik-Chervonenkis (VC) η οποία εισήχθηκε από τους Vladimir Vapnik και Alexey Chervonenkis. Αρχικά, τα μοντέλα αυτά, είχαν οριστεί για την κατηγοριοποίηση και αργότερα επεκτάθηκαν για την παλινδρόμηση [33,34]. Οι SVMs μπορούν να χρησιμοποιηθούν για την αναγνώριση των προτύπων (χειρόγραφων ψηφίων, εγγραφών, φωνής), την κατηγοριοποίηση των κειμένων και την ανίχνευση του προσώπου στις εικόνες [19]. Εκτός από την αναγνώριση των προτύπων, αποτελούν υποσχόμενες μέθοδοι για την πρόβλεψη των χρηματοοικονομικών χρονοσειρών διότι χρησιμοποιούν τη συνάρτηση κινδύνου που περιέχει τo εμπειρικό σφάλμα και έναν γενικευμένο ρίσκο που προέρχεται από την αρχή της ελαχιστοποίησης του κινδύνου [8]. SVM για Κατηγοριοποίηση Οι μηχανές διανυσματικής υποστήριξης, στην περίπτωση της κατηγοριοποίησης, λειτουργούν ως δυαδικοί ταξινομητές που ως στόχο έχουν την κατηγοριοποίηση των εισερχόμενων δεδομένων σε μία από τις δύο κλάσεις με βάση την έξοδο που σχηματίζουν [34]. Οι SVMs μπορούν να γενικευτούν και για περισσότερες κλάσεις [38]. Οι έννοιες που είναι απαραίτητες για την κατανόηση των SVMs [38]: Υπερεπίπεδο (hyperplane): είναι ένας ταξινομητής, μία γραμμή στις δύο διαστάσεις (επιφάνεια στις τρεις). Περιθώριο (margin): είναι το άθροισμα των αποστάσεων των δύο κοντινότερων σημείων των δύο κλάσεων από το υπερεπίπεδο. Πυρήνες (kernels): δίνουν έναν αποτελεσματικό τρόπο εφαρμογής των μηχανών SVMs στις υψηλές διαστάσεις.
60 6 Στόχος: Η εύρεση ενός βέλτιστου υπερεπίπεδου που διαχωρίζει τις δύο κλάσεις μεγιστοποιώντας το περιθώριο [39]. Γενικά τα ζητούμενα για τον αλγόριθμο SVM είναι: 1. Η γενίκευση με τη μεγιστοποίηση του margin για την αποφυγή της υπερπροσαρμογής.. Η αποτελεσματική εκμάθηση των μη γραμμικων συναρτήσεων μέσω των kernels.[37] Περίπτωση του Γραμμικού Διαχωρισμού Διαχωρίσιμη Περίπτωση Έχουμε την περίπτωση του Hard margin όταν τα δεδομένα εκαπαίδευσης δεν περιέχουν θόρυβο και μπορούν να ταξινομηθούν σωστά μέσω μίας γραμμικής συνάρτησης, δηλαδή όταν τα δεδομένα είναι γραμμικώς διαχωρίσιμα. Δοθέντος ενός συνόλου εκπαίδευσης, όπου ο χώρος των δεδομένων εισόδου, το υπερεπίπεδο (όριο απόφασης) έχει τη μορφή της γραμμικής συνάρτησης με. Όπου : διάνυσμα που περιέχει βάρη : η μεροληψία : η έξοδος που περιέχει την τιμή της κλάσης (1 ή -1) : τα βάρη που καθορίζονται μέσω των αλγορίθμων μάθησης που προσδιορίζουν το υπερεπίπεδο : οι τιμές (εισόδου) των χαρακτηριστικών
61 61 Τα w και b υπολογίζονται μέσω των SVM κατά τη διαδικασία της μάθησης χρησιμοποιώντας το σύνολο εκπαίδευσης. Η απόφαση, για το σε ποιά κατηγορία ανήκει, λαμβάνεται ως εξής: Εάν υπάρχει μία γραμμική συνάρτηση που κατηγοριοποιεί σωστά όλα τα σημεία ή αλλιώς ικανοποιεί την τελευταία σχέση, τότε έχουμε την γραμμικά διαχωρίσιμη περίπτωση. Το περιθώριο (margin) ισούται με, εφόσον η απόσταση ενός διανύσματος από το υπερεπίπεδο γράφεται. Επομένως, για τη μεγιστοποίηση του περιθωρίου απαιτείται η ελαχιστοποίηση του. Άρα, η εκπαίδευση των SVM μετατρέπεται σε ένα πρόβλημα βελτιστοποίησης, το οποίο ονομάζεται πρωτεύον (Primal Problem), με περιορισμούς ως εξής: Σημείωση: το ½ εισήχθηκε για μαθηματική διευκόλυνση. Στην παρακάτω εικόνα φαίνονται δύο κατηγοριοποιητές (γραμμικός αριστερά, μη γραμμικός δεξιά) που διαχωρίζουν τα δεδομένα σε δύο κλάσεις. Τα σημεία από το training set που βρίσκονται κοντά στο υπερεπίπεδο καλούνται διανύσματα υποστήριξης (support vectors) [8].
62 6 Εικόνα Β.11: Γραμμικός και μη γραμμικός ταξινομητής. Τα σημεία πάνω στα H 1 και H αποτελούν τα διανύσματα υποστήριξης (support vectors). Μη Διαχωρίσιμη Περίπτωση: Εάν τα δεδομένα είναι μη διαχωρίσιμα, τότε έχουμε την περίπτωση του soft margin. Σε αυτή την περίπτωση, εισάγονται οι μεταβλητές χαλάρωσης που μετρούν τον βαθμό της λανθασμένης ταξινόμησης. Και το πρόβλημα της βελτιστοποίησης διαφοροποιείται ως εξής: Εφόσον η αναζήτηση του υπερεπίπεδου με το μέγιστο περιθώριο ανάγεται στο πρόβλημα της βελτιστοποίησης, είναι ανάγκη να δούμε πώς επιλύονται τα προβλήματα βελτιστοποίησης [37]. Περίπτωση του Μη Γραμμικού Διαχωρισμού Για τα μη γραμμικώς διαχωρίσιμα δεδομένα χρησιμοποιούμε την επέκταση του προβλήματος βελτιστοποίησης γραμμικού διαχωρισμού. Για την εύρεση του υπερεπίπεδου με τη χρήση των μη γραμμικών SVMs, πρώτα γίνεται ο μετασχηματισμός των δεδομένων εισόδου σε διανύσματα χαρακτηριστικών υψηλής διάστασης και έπειτα χρησιμοποιούνται οι SVMs. Το υπερεπίπεδο αυτό πλέον βρίσκεται στον νέο χώρο των χαρακτηριστικών και επεκτείνεται ως: με.
63 63 Το είναι ένα διάνυσμα διάστασης n. Με συμβολίζουμε τη συνάρτηση μη γραμμικής απεικόνισης (nonlinear mapping function) από τον χώρο των εισόδων στον χώρο των χαρακτηριστικών υψηλής διάστασης. Στον νέο χώρο τα δεδομένα εκπαίδευσης μπορούν να διαχωριστούν γραμμικά. Το είναι το διάνυσμα των βαρών μέσω του οποίου τα δεδομένα, που βρίσκονται στον χώρο των χαρακτηριστικών, μπορούν να απεικονιστούν στον χώρο των εξόδων [37]. Επίλυση του Προβλήματος Βελτιστοποίησης Το πρωτεύον πρόβλημα βελτιστοποίησης, μπορεί να λυθεί με τη μέθοδο των πολλαπλασιαστών Lagrange εφόσον η αντικειμενική της συνάρτηση είναι κυρτή συνάρτηση των είναι γραμμικοί στο. και οι περιορισμοί της Για Την Περίπτωση Hard Margin Κατασκευή της συνάρτησης Lagrange: : πολλαπλασιαστές Lagrange, μη μηδενικοί Η λύση καθορίζεται από το σημείο ισορροπίας (saddle point) της συνάρτησης Langrange, η οποία πρέπει να ελαχιστοποιηθεί ως προς και ενώ ταυτόχρονα πρέπει να μεγιστοποιηθεί ως προς. Οι συνθήκες βελτιστοποίησης για τη συνάρτηση Lagrange είναι και. Επιλύοντας τις συνθήκες λαμβάνουμε και αντίστοιχα. Αντικαθιστώντας τις σχέσεις αυτές η συνάρτηση Lagrange παίρνει τη μορφή
64 64 Το πρωτεύον πρόβλημα ασχολείται με μία κυρτή συνάρτηση κόστους και γραμμικούς περιορισμούς. Δοθέντος ενός τέτοιου προβλήματος, είναι δυνατόν η κατασκευή ενός άλλου που ονομάζεται δυϊκό πρόβλημα (Dual Problem). Το δυϊκό πρόβλημα έχει την ίδια βέλτιστη τιμή όπως το πρωτεύον αλλά οι πολλαπλασιαστές Lagrange παρέχουν την βέλτιστη λύση. Το δυϊκό πρόβλημα Από την επίλυση του δυϊκού προβλήματος λαμβάνουμε τους βέλτιστους πολλαπλασιαστές Lagrange. Αντίστοιχα επηρεάζονται και οι υπόλοιπες βέλτιστες λύσεις Συνθήκες Karush-Kunh-Tucker:
65 65 Οι συνθήκες Karush-Kunh-Tucker (ΚΚΤ) παίζουν σημαντικό ρόλο στους περιορισμούς της βελτιστοποίησης καθώς οι πολλαπλασιαστές να ικανοποιήσουν τη συνθήκη, εκτός από τους υπόλοιπους περιορισμούς, πρέπει. Σύμφωνα με τη συνθήκη αυτή, ένας από τους δύο όρους πρέπει να είναι μηδέν. Εφόσον για τα support vectors, τα είναι μη μηδενικά σε εκείνα τα σημεία. Δηλαδή, τα σημεία για τα οποία (όχι support vectors) δεν επηρεάζουν το βέλτιστο. Σχόλιο: Παρατηρούμε ότι το σύνολο εκπαίδευσης πρόβλημα. γράφεται ως ένας συνδυασμός όρων που περιέχουν δεδομένα από το, για αυτό και οι όροι των δεδομένων εμφανίζονται και στο δυϊκό Για Την Περίπτωση Soft Margin Το δυϊκό πρόβλημα
66 66 Για τη μη Διαχωρίσιμη Περίπτωση: Το δυϊκό πρόβλημα όπου είναι ο πυρήνας που εκφράζει το εσωτερικό γινόμενο είναι τα βάρη είναι το όριο απόφασης. Σύμφωνα με το θεώρημα του Mercer, μία συνάρτηση του πυρήνα Κ είναι έγκυρη όταν και μόνο όταν ικανοποιούνται όπου για οποιαδήποτε συνάρτηση.
67 67 SVM για Παλινδρόμηση (Support Vector Regression) Έστω ότι έχουμε ένα σύνολο εκπαίδευσης { }, όπου ο χώρος των δεδομένων εισόδου, και τη γραμμική συνάρτηση με. Στόχος: Εύρεση της συνάρτησης f(x) που έχει απόκλιση το πολύ ε, από τις πραγματικές τιμές (targets) για όλο το σύνολο εκπαίδευσης, ενώ συγχρόνως η συνάρτηση αυτή να είναι όσο το δυνατόν επίπεδη (να έχει ελάχιστο w). Η επιπεδότητα επιτυγχάνεται με την ελαχιστοποίηση της νόρμας. Για την επιπεδότητα, η αναζήτηση της ελάχιστης ποσότητας του w μπορεί να γραφτεί ως κυρτό πρόβλημα της βελτιστοποίησης. Περίπτωση της Γραμμικής Συνάρτησης: Κυρτό Πρόβλημα Βελτιστοποίησης (Convex optimization problem): Το πρόβλημα αυτό καλείται πρωτεύον. Soft margin: Στην περίπτωση που θέλουμε τα σφάλματα να μην έχουν ακρίβεια ε, εισάγονται οι μεταβλητές χαλάρωσης το πρόβλημα αλλάζει ως εξής,
68 68 Όπου είναι οι μεταβλητές χαλάρωσης C: θετική σταθερά Η σταθερά C προσδιορίζει την ανταλλαγή μεταξύ της επιπεδότητας της συνάρτησης f και της ποσότητας όπου/πάνω στην οποία οι αποκλίσεις πάνω από το ε είναι επιτρεπτές. Αυτό αντιμετωπίζεται με τη συνάρτηση απώλειας που καλείται «ε-insensitive loss function», η οποία ορίζεται ως εξής: Στη συνάρτηση κόστους συνεισφέρουν τα σημεία που βρίσκονται έξω από το margin. Το Δυϊκό Πρόβλημα και ο Τετραγωνικός Προγραμματισμός Το δυϊκό πρόβλημα βασίζεται στην κατασκευή της συνάρτησης Lagrange, από την αντικειμενική συνάρτηση του πρωτεύον προβλήματος και τους αντίστοιχους περιορισμούς, με την εισαγωγή ενός συνόλου των δυϊκών μεταβλητών. Η συνάρτηση αυτή έχει ένα σημείο ισορροπίας (saddle point) σε σχέση με τις μεταβλητές στη λύση του πρωτεύοντος και του δυϊκού. Η συνάρτηση Lagrange δίνεται από τη σχέση:
69 69 Όπου είναι οι πολλαπλασιαστές Lagrange που πρέπει να είναι μη αρνητικοί. Από το σημείο ισορροπίας λαμβάνουμε Σημειώνεται ότι αναφέρεται σε όλα τα και. Μετά τις αντικαταστάσεις το δυϊκό πρόβλημα, το οποίο καλείται και επέκταση του support vector, μετατρέπεται ως εξής: Με και
70 7 Το μπορεί να θεωρηθεί ο γραμμικός συνδυασμός του συνόλου εκπαίδευσης. Περίπτωση της Μη-Γραμμικής Συνάρτησης: Σε αυτή την περίπτωση, το δυϊκό πρόβλημα με τη χρήση των πυρήνων (kernels) γράφεται ως: όπου είναι ο πυρήνας και. Υπολογισμός του b: Για τον υπολογισμό του b χρησιμοποιούνται οι συνθήκες Karush-Kuhn-Tucker (KKT) οι οποίες δηλώνουν ότι, στο σημείο που εμφανίζεται η λύση, το γινόμενο μεταξύ των δυϊκών μεταβλητών και των περιορισμών πρέπει να εξαλειφθεί. Συνθήκες ΚΚΤ:
71 71 Κάποια συμπεράσματα που βγαίνουν από τις συνθήκες αυτές είναι: Μόνο δείγματα με αντίστοιχα βρίσκονται έξω από τον σωλήνα «εinsensitive», δηλαδή δεν μπορεί να υπάρχει σύνολο δυϊκών μεταβλητών που να είναι και οι δύο ταυτόχρονα μηδέν. Για έχουμε, επομένως Aραιότητα για την επέκταση των SV: Μόνο για οι πολλαπλασιαστές Lagrange μπορεί να είναι μη μηδενικοί, δηλαδή για τα δείγματα που βρίσκονται μέσα στον σωλήνα ε εξαλείφονται τα. Για να ικανοποιηθούν οι συνθήκες ΚΚΤ πρέπει να είναι μηδέν. όταν Τα δείγματα που έχουν μη μηδενικούς συντελεστές καλούνται διανύσματα υποστήριξης (Support Vectors).
72 7 Συνάρτηση κόστους: Εφόσον ο στόχος μας είναι η εύρεση μίας συνάρτησης f που ελαχιστοποιεί τον αναμενόμενο κίνδυνο, μπορούμε να ορίσουμε τον κίνδυνο ως Όπου για το σφάλμα εκτίμησης. συμβολίζει τη συνάρτηση κόστους που καθορίζει πώς να επιβάλλουμε κυρώσεις Μία εμπειρική προσέγγιση του κινδύνου είναι η συνάρτηση Και η γενίκευσή του Όπου λ> σταθερά γενίκευσης Επιτυγχάνεται η ικανότητα ελέγχου μεσω του όρου. [1]
73 ΜΕΡΟΣ Γ - ΜΕΘΟΔΟΛΟΓΙΑ 73
74 74
75 75 ΜΕΘΟΔΟΛΟΓΙΑ Ο σκοπός της παρούσας διπλωματικής εργασίας είναι η εφαρμογή των μεθόδων εξόρυξης για την ανάλυση των χρηματιστηριακών δεδομένων. Εφόσον τα δεδομένα μας περιέχουν χρονοσειρές, μελετήθηκαν οι τεχνικές εξόρυξης των χρονοσειρών. Από τις προαναφερθείσες τεχνικές εξόρυξης υλοποιήθηκαν οι τρεις (συσταδοποίηση, κατηγοριοποίηση και πρόβλεψη). Για την υλοποίηση αυτών των αλγορίθμων πρώτα πραγματοποιήθηκε η προεπεξεργασία των δεδομένων η σημαντικότητα της οποίας γίνεται αισθητή μέσω των αποτελεσμάτων (ελάχιστα σε μορφή εικόνων και επί το πλείστων από τον υπολογισμό των σφαλμάτων) πριν και μετά την προεπεξεργασία. Αρχικά, διερευνήθηκαν οι τεχνικές εύρεσης ομοιότητας των χρονοσειρών σε ένα σύνολο δεδομένων με σκοπό την εύρεση των παρόμοιων μετοχών. Τα αποτελέσματα που λαμβάνουμε από τις εφαρμογές αυτές μπορούν να βοηθήσουν περαιτέρω και σε άλλες μορφές εξόρυξης δεδομένων. Όπως για παράδειγμα, μπορούν να αποκαλύψουν συσχετίσεις και δομές στα δεδομένα, να χρησιμποιηθούν για την κατηγοριοποίηση, για την πρόβλεψη ή και για τη μοντελοποίηση. Οι τεχνικές αυτές εκτός από τα αναμενόμενα επιστημονικά πεδία όπως η στατιστική, η βιολογία, η κοινωνιολογία, η ιατρική, βρίσκουν εφαρμογή και στον τομέα της πληροφορικής στην αναγνώριση των προτύπων, στην ανάκτηση των δεδομένων, στην τεχνητή νοημοσύνη και στη μηχανική μάθηση. Οι άπειρες εφαρμογές της σε όλες τις επιστήμες την καθιστά σημαντική και αντικείμενο μελέτης σε όλους αυτούς τους προαναφερόμενους τομείς. Για την εύρεση της ομοιότητας εφαρμόστηκε ο αλγόριθμος της ιεραρχικής συσταδοποίησης Hierarchical Agglomerative και ο αλγόριθμος της διαμεριστικής συσταδοποίησης k-means, στο περιβάλλον της MATLAB, με τα μέτρα απόστασης (Eυκλείδεια απόσταση, Dynamic Time Warping (DTW) ), με διαφορετικούς τρόπους σύνδεσης (single,
76 76 complete, average, ward), για διαφορετικό κ (πλήθος των συστάδων). Έπειτα μελετήθηκε η ποιότητα των συστάδων μέσω των μέτρων αξιολόγησης inter-intra cluster distance και τις τιμές Silhouette. Στη συνέχεια, έχοντας τα αποτελέσματα της συσταδοποίησης εκτελέστηκε ο αλγόριθμος των κ πλησιέστερων γειτόνων, για την κατηγοριοποίηση νέων μετοχών που εισήχθησαν. Ο αλγόριθμος εφαρμόστηκε κ φορές λόγω του διαχωρισμού των δεδομένων με τη μέθοδο k-fold crossvalidation. Η μέθοδος αυτή έχει πολύ μεγάλη απόδοση εφόσον έδωσε σφάλμα κατηγοριοποίησης περίπου 9% κατα μέσο όρο.μ Τέλος μελετήθηκε η πρόβλεψη της τιμής κλεισίματος των μετοχών, που είναι και το φλέγον θέμα όλων των χρηματιστηρίων. Για την πρόβλεψη υλοποιήθηκε η μέθοδος SMOreg (Sequential Minimal Optimization for Support Vector Regression) που αποτελεί μία προσέγγιση της εξόρυξης των δεδομέων και της μηχανικής μάθησης. Ο αλγόριθμος αυτός βασίζεται στη χρήση των μηχανών διανυσματικής υποστήριξης (SVR) σε συνδυασμό με τον πυρήνα polykernel και τον αλγόριθμο βελτιστοποίησης SMO (Sequential Minimal Optimization), και μάλιστα τον βελτιωμένο αλγόριθμο RegSmoImproved [,1,,41,4]. Η μέθοδος αυτή, μελετήθηκε συγκριτικά με τα στατιστικά μοντέλα όπως η Linear Regression, Exponential Smoothing, ARIMA. Ως μέτρο αξιολόγησης χρησιμοποιήθηκαν διάφορα σφάλματα πρόβλεψης. Στο τέλος, προτείνεται ένας συνδυασμός των προαναφερόμενων μεθόδων πρόβλεψης αντιστοιχίζοντας την κάθε μέθοδο με κάποιο βάρος, τέτοιο ώστε το άθροισμά των να ισούται με τη μονάδα. Ο συνδυασμός αυτός δίνει καλύτερα αποτελέσματα από την SMOreg, υστερεί όμως σε σύγκριση με τις υπόλοιπες. Οι μέθοδοι που χρησιμοποιήθηκαν αναλύονται παρακάτω ενώ τα αποτελέσματα από την υλοποίησή τους παρουσιάζονται στο μέρος Δ (Πειράματα-Αποτελέσματα).
77 77 Γ.1 Συσταδοποίηση Γ.1.1. Ο Ιεραρχικός Συσσωρευτικός Αλγόριθμος Ο ιεραρχικός αλγόριθμος της συσταδοποίησης εκτελεί τα παρακάτω βήματα: ΒΗΜΑ 1: Υπολογίζει τις ομοιότητες μεταξύ όλων των χρονοσειρών με τη χρήση των μέτρων ανομοιότητας ή απόστασης. Ως αποτέλεσμα αυτής της διαδικασίας προκύπτει ένας πίνακας που περιέχει τις αποστάσεις όλων των χρονοσειρών. ΒΗΜΑ : Ομαδοποιεί τις χρονοσειρές αυτές σε ένα δυαδικό ιεραρχικό δέντρο το οποίο ενώνει τις συστάδες με βάση το κριτήριο σύνδεσης (linkage). ΒΗΜΑ 3: Προσδιορίζει πού πρέπει να κοπεί το δέντρο με βάση το επιθυμητό πλήθος των συστάδων και αναθέτει τις χρονοσειρές, που βρίσκονται κάτω από την κάθε περικοπή, σε συστάδες. Στο πρώτο βήμα επιλέγει ο χρήστης το μέτρο ομοιότητας που επιθυμεί (Ευκλείδεια, DTW, Cityblock, Spearman Correlation). Ενώ στο δεύτερο βήμα εκτελείται η ενοποίηση ή ο διαχωρισμός των συστάδων με βάση των κριτηρίων σύνδεσης (single, average, complete, weighted, centroid, median, ward). Τα μέτρα αυτά έχουν αναφερθεί στο θεωρητικό υπόβαθρο. Παρακάτω δίνεται έμφαση στο τρίτο βήμα και στα αποτελέσματά του. Το Δενδρογραμμα Ένας τρόπος οπτικοποίησης των αποτελεσμάτων της ιεραρχικής συσταδοποίησης επιτυγχάνεται μέσω του δενδρογράμματος. Το δενδρόγραμμα είναι ένα δυαδικό δεντρο των συστάδων που δημιουργείται με βάση το κριτήριο σύνδεσης (μία αντιπροσωπευτική εικόνα του φαίνεται στο παρακάτω σχήμα). Το δέντρο αυτό δείχνει με ποιόν τρόπο συνδέονται τα αντικείμενα σε συστάδες. Στον οριζόντιο άξονα του δέντρου οι αριθμοί αντιπροσωπεύουν το αντίστοιχα αντικείμενο από το σύνολο των δεδομένων,
78 78 ενώ ο κάθετος άξονας που συμβολίζει το ύψος δείχνει την απόσταση μεταξύ των αντικειμένων. Έχοντας στη διάθεση το δενδρόγραμμα, για τη δημιουργία των συστάδων, ο χρήστης ορίζει που πρέπει να κοπεί το δέντρο. Και με το κόψιμο του δέντρου στο κατάλληλο επίπεδο δημιουργούνται οι συστάδες. Για παράδειγμα, στην παρακάτω εικόνα (αριστερά) η μαύρη γραμμή δημιουργεί 3 συστάδες ενώ η πράσινη δημιουργεί 6 συστάδες. Εικόνα Γ.1 : (α) δημιουργία των συστάδων με το κόψιμο του δέντρου στο κατάλληλο ύψος, (β) με κόκκινο χρώμα φαίνεται η απόσταση «cophenetic distance» και με πράσινο η σύνδεση (link) μεταξύ των δύο υποδέντρων-συστάδων Επαληθευση του Δενδρογραμματος (Verify The Cluster Tree) Για την επικύρωση του δενδρογράμματος υπάρχουν δύο συναρτήσεις στη Matlab, οι οποίες είναι, ο συντελεστής συσχέτισης cophenetic correlation coefficient και inconsistent. Ο συντελεστής cophenetic correlation coefficient δείχνει πόσο καλά συνδέονται τα αντικείμενα στο ιεραρχικό δέντρο με βάση το κριτήριο σύνδεσης που έχουμε επιλέξει. Το cophenetic correlation για ένα δέντρο μίας συστάδας ορίζεται ως συντελεστές της γραμμικής συσχέτισης μεταξύ των cophenetic αποστάσεων του δέντρου, και των πραγματικών αποστάσεων (ή ανομοιοτήτων) που σχηματίζουν το δέντρο. Είναι μέτρο του πόσο πιστά αντιπροσωπεύει το δέντρο τις ανομοιότητες των αντικειμένων.
79 79 Η cophenetic απόσταση μεταξύ δύο αντικειμένων αντιπροσωπεύεται σε ένα δενδρόγραμμα μέσω του ύψους της σύνδεσης στο οποίο συνδέονται τα δύο αντικείμενα για πρώτη φορά. Το ύψος είναι η απόσταση μεταξύ δύο υποσυστάδων που ενώνονται μέσω του κριτηρίου σύνδεσης. Α) Η επαλήθευση της ανομοιότητας (verify dissimilarity): Το ύψος ενός ιεραρχικού δέντρου, στο οποίο ενώνονται δύο αντικείμενα, συμβολίζει την απόσταση μεταξύ των δύο αυτών αντικειμένων ή και συστάδων. Η απόσταση αυτή ονομάζεται «cophenetic distance». Εάν θέλουμε να επαληθεύσουμε κατά πόσο οι αποστάσεις του δέντρου αντιπροσωπεύουν με ακρίβεια τις πραγματικές αποστάσεις μεταξύ δύο αντικειμένων, τότε υπολογίζουμε τον συντελεστή συσχέτισης cophenetic correlation coefficient [9]. Ο τύπος του συντελεστή συσχέτισης cophenetic είναι Όπου είναι η Ευκλείδεια απόσταση μεταξύ των αντικειμένων i,j. απόσταση μεταξύ των αντικειμένων και του δέντρου. Ο συντελεστής αυτός αντιπαραβάλλει τα δύο σύνολα τιμών και υπολογίζει τον βαθμό συσχέτισής τους. Στην περίπτωση που η συσχέτιση είναι ισχυρή, δηλαδή η τιμή της c πλησιάζει όσο το δυνατόν περισσότερο τη μονάδα, η συστάδα τότε είναι έγκυρη. Δηλαδή με τόση ακρίβεια τα αποτελέσματα της συσταδοποίησης αντιπροσωπεύουν τα αρχικά δεδομένα [35].

80 8 Β) Η επαλήθευση της συνέπειας (verify consistency): Ένας τρόπος για τον προσδιορισμό του διαχωρισμού των συστάδων με φυσικό τρόπο είναι η σύγκριση του ύψους της κάθε σύνδεσης σε ένα δέντρο των συστάδων με τα ύψη των γειτονικών συνδέσμων που βρίσκονται κάτω από το δέντρο. Μία σύνδεση που είναι προσεγγιστικά στο ίδιο ύψος με τις άλλες συνδέσεις κάτω από αυτήν, δείχνει ότι δεν υπάρχει διαχωρισμός μεταξύ των αντικειμένων σε αυτό το επίπεδο της ιεραρχίας. Οι συνδέσεις αυτές δείχνουν μία συνοχή υψηλού επιπέδου, διότι η απόσταση μεταξύ των αντικειμένων που ενώνονται είναι ίδια με τις αποστάσεις μεταξύ των αντικειμένων που περιέχουν. Από την άλλη πλευρά ένας σύνδεσμος, ο οποίος έχει ύψος που διαφέρει αισθητά από το ύψος των συνδέσμων που βρίσκονται κάτω από αυτόν, δείχνει ότι τα αντικείμενα που ενώθηκαν σε αυτό το επίπεδο του δέντρου είναι πιο μακριά ο ένας από τον άλλον σε σχέση με τις συνιστώστες τους αν ενώνονταν. Ο σύνδεσμος αυτός θεωρείται ασυνεπής με τους συνδέσμους που βρίσκονται κάτω από αυτόν. Επομένως, στην ανάλυση των συστάδων, οι ασυνεπείς σύνδεσμοι μπορεί να δείχνουν το σύνορο του φυσικού διαχωρισμού των δεδομένων. Εικόνα Γ.: δενδρόγραμματα που απεικονίζουν την ασυνέπεια των συνδέσμων Στις εικόνες παρατηρούμε ότι, η σύνδεση που βρίσκεται στο ανώτατο επίπεδο της ιεραρχίας του δέντρου χωρίζει τα αντικείμενα σε δύο ομάδες ή αλλιώς συστάδες. Η ένωση των δύο αυτών συστάδων είναι ασυνεπής σε σύγκριση με την ένωση στο κατώτατο επίπεδο της ιεραρχίας.
81 81 Ως μέτρο ασυνέπειας, χρησιμοποιείται ο συντελεστής ασυνέπειας (inconsistency coefficient) από τη Matlab, ο οποίος συγκρίνει το ύψος ενός συνδέσμου που βρίσκεται σε μία ιεραρχία της συστάδας με το μέσο ύψος των συνδέσμων που βρίσκονται στο ίδιο επίπεδο της ιεραρχίας. Συγκεκριμένα, συγκρίνει κάθε σύνδεσμο της ιεραρχίας του δέντρου με τους γειτονικούς συνδέσμους που βρίσκονται, λιγότερο από δύο επίπεδα, κάτω από αυτόν. Αυτό ονομάζεται σύγκριση κατα βάθος. Η μεγάλη τιμή του συντελεστής ασυνέπειας υποδηλώνει την ένωση των διαφορετικών ή απομακρυσμένων συστάδων. Επομένως, Όσο υψηλότερη είναι η τιμή του συντελεστή, τόσο λιγότερο όμοια αντικείμενα συνδέονται.
82 8 Γ.1.. Ο Αλγόριθμος k-means Ο k-means είναι ένας από τους ευρετικούς αλγορίθμους που χρησιμοποιείται συχνά λόγω της απλότητας και της ευκολίας στη χρήση. Ο αλγόριθμος αυτός βρίσκει την ελάχιστη τιμή του αθροίσματος του τετραγωνικού σφάλματος που υπολογίζεται από τη σχέση Όπου : είναι το αντικείμενο που ανήκει στη συστάδα-κ : είναι ο δείκτης του κεντροειδούς που βρίσκεται κοντά στο : είναι το κεντροειδές Συγκεκριμένα, αρχίζει με μία αυθαίρετη συσταδοποίηση και υπολογίζει τα αρχικά κεντροειδή (centroids), και κατόπιν αναθέτει κάθε αντικείμενο στη συστάδα του πλησιέστερου κεντροειδούς και υπολογίζει εκ νέου τα κεντροειδή. Επαναλαμβάνει τα δύο τελευταία βήματα μέχρι να μην υπάρχουν άλλες αλλαγές στις συστάδες [3]. Ο επαναληπτικός αλγόριθμος k-means αποτελείται από τα παρακάτω βήματα [5]: ΒΗΜΑ 1: επιλογή κ αρχικών κέντρων των συστάδων. ΒΗΜΑ : στην κ-οστή επανάληψη γίνεται ο διαχωρισμός του δείγματος σε κ συστάδες χρησιμοποιώντας το κριτήριο Όπου συμβολίζει το σύνολο του δείγματος και. ΒΗΜΑ 3: υπολογισμός του κέντρου της νέας συστάδας των τετραγώνων των αποστάσεων από όλα τα σημεία του έτσι ώστε το άθροισμα στο νέο κέντρο της συστάδας να
83 83 είναι το ελάχιστο. Ο δειγματικός μέσος του αποτελεί το μέτρο ελαχιστοποίησης. Το κέντρο της καινούριας συστάδας υπολογίζεται ως Όπου είναι το μέγεθος του δείγματος στο. ΒΗΜΑ 4: εάν τότε ο αλγόριθμος συγκλίνει και η διαδικασία τερματίζεται, διαφορετικά εκτελείται το βήμα. Ο k-means έχει καλύτερη απόδοση σε σφαιρικές και συμπαγείς συστάδες (αποδοτικός και για πολύ μεγάλου μεγέθους σύνολων δεδομένων). Υπάρχουν όμως δύο μειονεκτήματα σε αυτόν τον αλγόριθμο. Πρώτον, είναι ευαίσθητος στην αρχική επιλογή των κεντροειδών, το οποίο αντιμετωπιζεται με την πολλαπλή εκτέλεσή του και διαφορετικές αρχικοποιήσεις κάθε φορά και με αυτόν τον τρόπο επιτυγχάνεται, ως επί το πλείστον, η αποφυγή της σύγκλισης της συνάρτησης κριτηρίου σε κάποιο τοπικό βέλτιστο. Δεύτερον, είναι ευαίσθητος στους θορύβους και στις ακραίες τιμές (outliers). Οι ακραίες τιμές αντιμετωπίζονται με τη μέθοδο k-medians, που είναι μία παραλλαγή του k-means, στην οποία τα γνωρίσματα των κεντροειδών υπολογίζονται από τις ενδιάμεσες τιμές των γνωρισμάτων των υπόλοιπων εγγραφών και όχι από τις μέσες τιμές. Η πολυπλοκότητά του είναι O(mkd) όπου m είναι το πλήθος των εγγραφών, κ το πλήθος των συστάδων και d το πλήθος των χαρακτηριστικών γνωρισμάτων οι οποίες συνήθως δεν ξεπερνούν το m. Παρόλη τη μεγάλη πολυπλοκότητα του, ο k-means παρουσιάζει μεγάλη βελτίωση και επιτάχυνση λόγω των τεχνικών που έχουν αναπτυχθεί τα τελευταία χρόνια [3]. Αξιολόγηση συσταδοποίησης - Εύρεση του βέλτιστου κ Ένα πρόβλημα με τις μεθόδους συσταδοποίησης είναι η δυσκολία ως προς την ερμηνεία των συστάδων. Οι περισσότεροι αλγόριθμοι συσταδοποίησης προτιμούν συγκεκριμένα σχήματα συστάδων, και οι αλγόριθμοι θα αναθέτουν πάντα τα δεδομένα σε συστάδες τέτοιων σχημάτων ακόμα και αν δεν υπάρχουν οι συστάδες. Ο σκοπός δεν είναι η συμπίεση των δεδομένων αλλά η
84 84 εξαγωγή συμπερασμάτων ως προς τη δομή, είναι απαραίτητο να αναλύσει κάποιος εάν το σύνολο των δεδομένων παρουσιάζει μία τάση συσταδοποίησης [5]. Επειδή το τελικό αποτέλεσμα της συσταδοποίησης εξαρτάται από την αρχική επιλογή των κέντρων των συστάδων και από το πλήθος των συστάδων κ, αυτό αποτελεί το μεγαλύτερο μειονέκτημα του k- means εφόσον το πλήθος των συστάδων κ πρέπει να προσδιοριστεί πριν την υλοποίηση του αλγορίθμου. Υπάρχουν πολλά μέτρα αξιολόγησης για την εύρεση του πλήθους των συστάδων, εκ των οποίων χρησιμοποιήθηκε η αξιοπιστία που βασίζεται στο Inter-Intra cluster distance. Ο στόχος για τον προσδιορισμό της αξιοπιστίας είναι η εύρεση των συμπαγών και καλά διαχωρισμένων συστάδων. Δηλαδή, ζητείται η ελαχιστοποίηση της διασποράς μέσα στη συστάδα και παράλληλα η μεγιστοποίηση του διαχωρισμού μεταξύ των συστάδων. Inter-Intra cluster distance Η συμπαγότητα των συστάδων μπορεί να προσδιοριστεί μέσω του Intra-cluster distance, το οποίο εκφράζει τις αποστάσεις των σημείων από τα κέντρα των αντίστοιχων συστάδων : κάθε χρονοσειρά της συστάδας i, : το κεντροειδές της συστάδας i, : το συνολικό πλήθος όλων των χρονοσειρών : συστάδα i, Η αραιότητα μεταξύ των συστάδων μπορεί να προσδιοριστεί μέσω του Inter-cluster distance το οποίο εκφράζει την απόσταση μεταξύ των κέντρων δύο συστάδων
85 85 Για τον προσδιορισμό του κ, υπολογίζεται η αξιοπιστία των συστάδων μέσω της αναλογίας [5]: Σύμφωνα με την αναλογία αυτή ζητάμε την ελάχιστη τιμή του validity εφόσον ο στόχος μας είναι να μεγιστοποιήσουμε, όσο το δυνατόν, την απόσταση μεταξύ των συστάδων και να ελαχιστοποιήσουμε τη διασπορά μέσα σε κάθε συστάδα. Μία παραλλαγή του Inter-Intra cluster distance είναι ότι αντί να υπολογίσουμε τη μέση διασπορά όλων των συστάδων, παίρνουμε τη μέγιστη διασπορά απο όλες τις συστάδες. Σε αυτήν την περίπτωση η αξιοπιστία ορίζεται ως εξής: Μπορούν επίσης να υπάρχουν και άλλες παραλλαγές σε αυτόν τον τύπο αφού μπορούμε να ορίσουμε διαφορετικά το inter cluster και το intra cluster distance κάνοντας διάφορες εναλλαγές. Silhouette value Είναι μία γραφική μέθοδος οπτικοποίησης και αξιολόγησης των συστάδων. Κάθε συστάδα αντιπροσωπεύεται από ένα silhouette, που βασίζεται στη σύγκριση της ως προς τη συμπαγότητα (tightness) και τη διαχωρισιμότητα (separation). Η τιμή silhouette για κάθε μετρά πόσο όμοιο είναι ένα αντικείμενο με τα υπόλοιπα αντικείμενα που ανήκουν στην ίδια συστάδα. Δείχνει δηλαδή, ποιά αντικείμενα βρίσκονται σωστά μέσα στη συστάδα τους. Το αποτέλεσμα της συσταδοποίησης παρουσιάζεται σε ένα γράφημα συνδυάζοντας τα silhouettes. Το μέσο πλάτος τους παρέχει μία εκτίμηση της αξιολόγησης των συσταδοποιήσεων, και μπορεί να χρησιμοποιηθεί για την επιλογή ενός «κατάλληλου» πλήθους συστάδων [3].
86 86 όπου : μέση απόσταση του σημείου i από όλα τα υπόλοιπα σημεία που ανήκουν στην ίδια συστάδα. Υπολογίζει πόσο ανόμοιο είναι το αντικείμενο i με την ίδια του τη συστάδα ( δηλαδή μετρά πόσο καλά ταιριάζει το αντικείμενο i στη συστάδα που έχει ανατεθεί. Όσο μικρότερη είναι η τιμή, τόσο καλύτερα ταιριάζει. : η ελάχιστη μέση απόσταση του σημείου i από τα σημεία που βρίσκονται σε μία διαφορετική συστάδα. Η ελαχιστοποίηση γίνεται μέσα στις συστάδες. Η ελάχιστη μέση ανομοιότητα με το αντικείμενο i από οποιαδήποτε συστάδα (η μεγαλύτερη τιμή δείχνει πόσο «άσχημα» ταιριάζει το i με τα γειτονικά του αντικείμενα). s(i): τιμή silhouette για το αντικείμενο i. Kοντά στο -1 είναι ένδειξη το αντικείμενο i θα ήταν προτιμότερο να ανατεθεί στη γειτονική συστάδα ενώ κοντά στο είναι ένδειξη ότι το αντικείμενο βρίσκεται στο φυσικό όριο των δύο συστάδων. Απαιτούμε a(i)<<b(i) για να επιτύχουμε s(i) κοντά στο 1. Η μέση τιμή των s(i) δείχνει τη συμπαγότητα.
87 87 Γ. Κατηγοριοποίηση - κ-πλησιέστεροι Γείτονες Η μέθοδος των κ πλησιέστερων γειτόνων (κ-νearest Νeighbors) έχει ως στόχο την κατηγοριοποίηση των δεδομένων με βάση το πλησιέστερο training set στον χώρο των χαρακτηριστικών. Για την υλοποίηση της μεθόδου, πρέπει πρώτα να έχουν καθοριστεί οι επιθυμητές κατηγορίες μέσω του συνόλου εκπαίδευσης (training set). Το σύνολο εκπαίδευσης με άλλα λόγια κασκευάζει το μοντέλο. Και στη συνέχεια, με βάση το μοντέλο αυτό μπορεί να εκτελεστεί ο αλγόριθμος της κατηγοριοποίησης, εφόσον το σύνολο εκπαίδευσης έχει δημιουργήσει την επιθυμητή κατηγοριοποίηση [1]. Ο αλγόριθμος των κ πλησιέστερων γειτόνων παίρνει ως είσοδο το σύνολο εκπαίδευσης, το πλήθος των γειτόνων και το νέο αντικείμενο που πρέπει να κατηγοριοποιηθεί. Έπειτα χρησιμοποιεί μέτρα ομοιότητας που βασίζονται στην απόσταση, για να καταχωρήσει τα νέα αντικείμενα στις προκαθορισμένες κλάσεις. Κάθε νέο στοιχείο εκχωρείται στην κατηγορία με τα περισσότερα στοιχεία από το σύνολο των κοντινότερων στοιχείων. Και με αυτόν τον τρόπο λαμβάνουμε ως έξοδο την κλάση στην οποία έχει ταξινομηθεί το νέο αντικείμενο [1]. Έστω, : το σύνολο εκπαίδευσης : το πλήθος των γειτόνων-κλάσεων : νέο αντικείμενο που πρέπει να κατηγοριοποιηθεί : η κλάση στην οποία έχει ταξινομηθεί το νέο αντικείμενο Αλγόριθμος // βρίσκει το σύνολο των γειτόνων, Ν, για το Για κάθε εάν, τότε ; Αλλιώς εάν τέτοιο ώστε, τότε αρχή ; ; τέλος c=κλάση στην οποία έχουν ταξινομηθεί τα περισσότερα
88 88 Γ.3. Πρόβλεψη - SMOreg Ο αλγόριθμος SMOreg είναι ένας ταξινομητής του περιβάλλοντος εξόρυξης δεδομένων WEKA και χρησιμοποιείται για την πρόβλεψη των χρονοσειρών. Συγκεκριμένα, ο αλγόριθμος αυτός κατασκευάζει ένα μοντέλο παλινδρόμησης SVR έχοντας κάποια δεδομένα εκαπαίδευσης (training set) και στη συνέχεια εκπαιδεύει τον παλινδρομητή (εκμάθηση των παραμέτρων) μέσω του αλγορίθμου βελτιστοποίησης RegSMOImproved. Ο αλγόριθμος RegSMOImproved προσφέρει κάποιες βελτιώσεις στον αλγόριθμο SMO που πρότειναν οι Alex J.Smola και Bernhard Schölkopf []. Εν ολίγοις, ο αλγόριθμος SMOreg συνδυάζει την επέκταση του SVR (Alex J.Smola and Bernhard Schölkopf) και την επέκταση του SMO (Shevade και Keerthi) και τον πυρήνα polykernel [,1,,5]. Σημείωση: Η εφαρμογή αυτή αντικαθιστά όλες τις ελλειπείς τιμές και μετατρέπει τα ονομαστικά (nominal) χαρακτηριστικά σε δυαδικές τιμές. Επίσης, κανονικοποιεί όλα τα χαρακτηριστικά πριν υλοποιηθεί η μέθοδος, γι αυτό και τα αποτελέσματα που λαμβάνουμε, οφείλονται σε κανονικοποιημένα δεδομένα και όχι στα αρχικά [5]. Επέκταση του SVR Ο βασικός στόχος του προβλήματος παλινδρόμησης είναι ο σχηματισμός ενός μοντέλου (υπερεπίπεδου), μέσω των δεδομένων εκπαίδευσης. Το μοντέλο αυτό θα πρέπει να ικανοποιεί δύο κριτήρια. Κριτήριο 1: Να έχει όσο το δυνατόν μικρότερο σφάλμα- ελαχιστοποίση της ζώνης του σφάλματος (εinsensitive tube) Κριτήριο : Να είναι όσο το δυνατόν επίπεδο (flatness) Εικόνα Γ.3: Support vector machines regression καθορίζουν έναν σωλήνα «ε-insensitive»με ακτίνα ε
89 89 Η επέκταση του SVR των Smola και Schölkopf έχει την εξής μορφή: Κυρτό πρόβλημα Βελτιστοποίησης (Smola και Schölkopf 1998) Πρωτεύον Δυϊκό
90 9 Σημείωηση: Για λόγους απλότητας υποθέτουμε ότι το c είναι συμμετρικό και έχει (το πολύ) δύο ασυνέχειες στο με στην πρώτη παράγωγο και μηδέν στο διάστημα [-ε,ε]. Όλες οι συναρτήσεις κόστους του πίνακα ανήκουν σε αυτή την κλάση. ε-insensitive Λαπλασιανή Γκαουσιανή Συνάρτηση απώλειας Συνάρτηση Πυκνότητας Ισχυρή απώλεια του Huber Πολυωνυμική Τμηματικά Πολυωνυμική Πίνακας Γ.1: Σφάλματα και οι αντίστοιχες συναρτήσεις πυκνότητας Μία γενική εικόνα Τα δεδομένα εισόδου, για τα οποία πρόκειται να γίνει η πρόβλεψη, απεικονίζονται μέσω της Φ στον χώρο των χαρακτηριστικών. Έπειτα υπολογίζονται οι πυρήνες (kernels), που είναι το εσωτερικό γινόμενο των δεδομένων εισόδου με τις αντίστοιχες εικόνες τους που δημιουργήθηκαν μέσω της Φ. Τελικά, αθροίζονται αυτά τα εσωτερικά γινόμενα (kernels) συνδυάζοντας τα με τα βάρη και παράλληλα προστίθεται και ο σταθερός όρος b. Η διαδικασία αυτή μοιάζει πολύ με την παλινδρόμηση σε ένα νευρωνικό δίκτυο, με τη διαφορά ότι στην περίπτωση των Support Vector τα βάρη αποτελούν ένα υποσύνολο των δεδομένων εισόδου. Στην παρακάτω εικόνα παρουσιάζεται η σχηματική αναπαράσταση της λειτουργίας του παλινδρομητή SVR.
91 91 Εικόνα Γ.4: Η αρχιτεκτονική της μηχανής παλινδρόμησης SVR Εικόνα Γ.5: Προσέγγιση της συνάρτησης sincx με ακρίβεια (α) ε=.1, (β) ε=., (γ) ε=.5. Οι δύο συναρτήσεις που βρίσκονται πάνω και κάτω αποτελούν το φράγμα για το σφάλμα, ενώ η ενδιάμεση συνάρτηση αποτελεί η προσέγγιση της sincx. Οι παραπάνω εικόνες απεικονίζουν τον τρόπο με τον οποίο ο αλγόριθμος SVR επιλέγει την επίπεδη συνάρτηση μεταξύ των προσεγγίσεων με μία δεδομένη ακρίβεια. Αν και απαιτώντας επιπεδότητα μόνο στο χώρο των χαρακτηριστικών, μπορεί να παρατηρήσει κανείς ότι οι συναρτήσεις είναι επίσης πολύ επίπεδες στον χώρο των εισόδων. Αυτό οφείλεται στο γεγονός ότι οι πυρήνες μπορούν να σχετιστούν με την επιπεδότητα μέσω των τελεστών γενίκευσης (regularization operators).
92 9 Εικόνα Γ.6: Μοντέλο παλινδρόμησης της συνάρτησης sincx (συμπαγής γραμμή), δεδομένα εκπαίδευσης (μικρές τελείες), διανύσματα υποστήριξης (μεγάλες τελείες). Προσέγγιση με ακρίβεια (α) ε=.1, (β) ε=., (γ) ε=.5. Οι εικόνες δείχνουν τη σχέση που υπάρχει μεταξύ της ποιότητας της προσέγγισης και της αραιότητας της αναπαράστασης στην υπόθεση SV. Όσο λιγότερη ακρίβεια απαιτείται για την προσέγγιση των δεδομένων, τόσο λιγότερα support vectors χρειάζονται. Επίσης, τα σημεία που δεν αποτελούν διανύσματα υποστήριξης είναι περιττά []. SMO (Sequential Minimal Optimization) Για την επίλυση του δυϊκού προβλήματος διάφοροι αλγόριθμοι έχουν προταθεί. Ο Smola και ο Schölkopf έχουν δώσει μία αναλυτική εικόνα αυτών των αλγορίθμων και των εφαρμογών τους στο [1]. Οι κλασικοί αλγόριθμοι του τετραγωνικού προγραμματισμού (QP), όπως ο αλγόριθμος του εσωτερκού σημείου (interior point algorithm), δεν είναι κατάλληλες για μεγάλα προβλήματα διότι Απαιτούν τον υπολογισμό των πινάκων των πυρήνων (kernel matrix) και την αποθήκευσή τους στη μνήμη (που πρέπει να είναι εξαιρετικά μεγάλη) Αυτές οι μέθοδοι περιλαμβάνουν ακριβές πράξεις μητρώων, όπως η Cholesky decomposition μεγάλου υποπίνακα του kernel matrix Η κωδικοποίηση αυτού του αλγορίθμου είναι δύσκολη υπόθεση Έχουν γίνει προσπάθειες για την επίλυση αυτών των προβλημάτων. Μία μέθοδος αντιμετώπισης είναι η κατάτμηση (chunking). Η μέθοδος αυτή βασίζεται στη διαχείριση ενός υποσυνόλου σταθερού μεγέθους κάθε φορά. Αυτό το υποσύνολο καλείται «working set» και το υποπρόβλημα
93 93 βελτιστοποίησης λύνεται σε σχέση με τις μεταβλητές αντίστοιχα με τα παραδείγματα στο working set και ένα σύνολο των διανυσμάτων υποστήριξης που έχουν βρεθεί για το πρόσφατο working set. Αυτό το νέο σύνολο είναι το χειρότερο σύνολο των δεδομένων που παραβιάζουν τις συνθήκες βελτιστοποίησης για τον πιο πρόσφατο εκτιμητή. Το νέο υποπρόβλημα βελτιστοποίησης λύνεται και αυτή η διαδικασία επαναλαμβάνεται μέχρι να ικανοποιηθούν οι συνθήκες βελτιστοποίησης για όλα τα παραδείγματα (σύνολο εκπαίδευσης) []. Ο Platt πρότεινε έναν αλγόριθμο που καλείται SMO (Sequential Minimal Optimization) για τη γρήγορη εκπαίδευση των SVM. Ο αλγόριθμος αυτός έχει το πλεονέκτημα της διαχείρισης των μεγάλων συνόλων εκπαίδευσης. Για την εκπαίδευση τους απαιτείται η επίλυση ενός μεγάλου προβλήματος βελτιστοποίσης του τετραγωνικού προγραμματισμού (QP). Ο αλγόριθμος SMO σπάει το μεγάλο πρόβλημα σε μικρότερα δυνατά υποπροβλήματα επιλέγοντας επαναληπτικά το working set μεγέθους δύο και βελτιστοποιώντας τη συνάρτηση στόχου (συνάρτηση παλινδρόμησης). Με τη χρήση working set τα προβλήματα αυτά μπορούν να λυθούν αναλυτικά, με εσωτερικό βρόγχο, αγνοώντας τη χρήση των χρονοβόρων αριθμητικών προβλημάτων βελτιστοποίησης του QP. Η διαδιασία κατάτμησης επαναλαμβάνεται έως ότου όλα τα παραδείγματα εκπαίδευσης ικανοποιήσουν τις συνθήκες βελτιστοποίησης [4,]. Για τον αλγόριθμο SMO, επιλέγεται το ζεύγος των δεικτών που βελτιστοποιεί την αντικειμενική συνάρτηση του δυϊκού προβλήματος μεταβάλλοντας τους συντελεστές Lagrange σε σχέση με τους δείκτες []. Για να μην παραβιάσουμε τον περιορισμό επιλέγουμε το ζεύγος, και κρατάμε τους υπόλοιπους πολλαπλασιαστές Lagrange σταθερούς. Ο λόγος για τον οποίο ο SMO είναι αποτελεσματικός είναι διότι η ενημέρωση για τα και μπορεί να γίνει αποτελεσματικά.
94 94 Ο αλγόριθμος SMO υλοποιείται ως εξής: Επανέλαβε τα παρακάτω βήματα μέχρι τη σύγκλιση { 1. Επέλεξε κάποιο ζεύγος και για την επόμενη ενημέρωση (update) (με τη χρήση μίας ευρετικής που θα μας επιτρέψει να κάνουμε τη μεγαλύτερη πρόοδο προς το ολικό μέγιστο, εφόσον το ζητούμενο είναι η μεγιστοποίηση της αντικειμενικής συνάρτησης του δυϊκού προβλήματος).. Βελτιστοποίησε ξανά την αντικειμενική συνάρτηση σε σχέση με το και, κρατώντας όλα τα } υπόλοιπα ) που έχουμε κρατήσει σταθερές. Βασική δομή του αλγορίθμου working set Αρχικοποίησε Επέλεξε τυχαία το working set Επανέλαβε Υπολόγισε τα ζεύγη για Λύσε το μειωμένο πρόβλημα βελτιστοποίησης Επέλεξε νέα από τις μεταβλητές που δεν ικανοποιούν τις συνθήκες ΚΚΤ Μέχρις ότου το working set
95 95 Επέκταση του SMO Οι Smola και Schölkopf επέκτειναν την ιδέα για την επίλυση του προβλήματος SVR (SMO for regression ή SMOreg) []. Ο Αλγόριθμος του εσωτερικού σημείου (Interior Point algorithm) υπολογίζει το δυϊκό πρόβλημα (για το συγκεκριμένο πρόβλημα το δυϊκό του ) και λύνει ταυτόχρονα το δυϊκό και το πρωτεύον πρόβλημα. Αυτό επιτυγχάνεται μόνο επιβάλλοντας σταδιακά τις συνθήκες ΚΚΤ για να βρει επαναληπτικά μία εφικτή λύση και να χρησιμοποιήσει το περιθώριο του δυïκού μεταξύ της αντικειμενικής συνάρτησης του πρωτεύοντος και του δυϊκού προβλήματος για τον καθορισμό της ποιότητας του πιο πρόσφατου συνόλου των μεταβλητών [1]. Τροποποίηση του αλγορίθμου SMO for regression Οι Shevade et al. επέκτειναν τον αλγόριθμο SMO, που πρότειναν οι Smola και Schölkopf, για την επίλυση του προβλήματος παλινδρόμησης [3]. Πρότειναν δύο παραλλαγές για τον αλγόριθμο SMO for regression, οι οποίες αντιμετωπίζουν τα προβλήματα που εμφανίζει ο αλγόριθμος των Smola και Schölkopf. Οι τροποποιήσεις αυτές βελτιώνουν την αποτελεσματικότητα και επιπλέον είναι καλύτερες και από τον αρχικό SMO. Σύμφωνα με τις παραλλαγές αυτές, προτείνεται η χρήση δύο κατωφλιών b up και b low αντί για ένα κατώφλι β για τον έλεγχο των συνθηκών βελτιστοποίησης. Συνθήκες βελτιστοποίησης:
96 96 Για τον έλεγχο της βελτιστοποίησης χρησιμοποιούνται μία από τις δύο παρακάτω σχέσεις: (1) ή (.α) Οι παραλλαγές αυτές είναι κάποιες βελτιώσεις στον αλγόριθμο των Smola και Schölkopf οι οποίες αναφέρονται εκτενέστερα στο []. (.β) Μέτρα αξιολόγησης της πρόβλεψης Τέλος αξιολογήθηκαν οι εκτιμήσεις τους με το απόλυτο σφάλμα πρόβλεψης (η απόλυτη τιμή της διαφοράς των πραγματικών τιμών με τις αντίστοιχες εκτιμώμενες τιμές), το απόλυτο σχετικό σφάλμα πρόβλεψης επί τοις εκατό και το μέσο απόλυτο σχετικό σφάλμα πρόβλεψης επί τοις εκατό. Απόλυτο σφάλμα (Absolute Error): Απόλυτο ποσοστιαίο σφάλμα (Absolute Percentage Error): Μέσο απόλυτο σφάλμα (Mean Absolute Error): Μέσο απόλυτο ποσοστιαίο σφάλμα (Mean Absolute Percentage Error): Όπου : η πραγματική τιμή μίας μετοχής τη χρονική στιγμή t : η εκτιμώμενη τιμή μίας μετοχής τη χρονική στιγμή t κ : πλήθος ημερών πρόβλεψης
97 ΜΕΡΟΣ Δ - ΠΕΙΡΑΜΑΤΑ - ΑΠΟΤΕΛΕΣΜΑΤΑ 97
98 98
99 99 ΠΕΙΡΑΜΑΤΑ - ΑΠΟΤΕΛΕΣΜΑΤΑ Στο κεφάλαιο αυτό παρουσιάζονται τα πειραματικά αποτελέσματα που προέκυψαν από την εφαρμογή των μεθόδων εξόρυξης. Τα αποτελέσματα των πειραμάτων εμφανίζονται με την ακόλουθη σειρά. Αρχικά γίνεται μία αναφορά σχετικά με τα δεδομένα, την προεπεξεργασία των δεδομένων και τα αποτελέσματα της προεπεξεργασίας. Έπειτα παρουσιάζονται τα αποτελέσματα της εφαρμογής των αλγορίθμων συσταδοποίησης με τον ιεραρχικό αλγόριθμο και τον k-means, στη συνέχεια τα αποτελέσματα της κατηγοριοποίησης με τη μέθοδο των κ-πλησιέστερων γειτόνων και τέλος τα αποτελέσματα της πρόβλεψης με τη μέθοδο SMOreg. Τα πειράματα υλοποιήθηκαν κυρίως στο περιβάλλον της Matlab (environment for numerical computation, visualization, and programming), για τους σκοπούς της πρόβλεψης χρησιμοποιήθηκαν επιπλέον το περιβάλλον του Weka (data minining software) και του R (software environment for statistical computing and graphics). 1. Δεδομένα του πειράματος Ο δείκτης Standard and Poor s 5 είναι ο συγκεντρωτικός δείκτης για τις μετοχές 5 επιλεγμένων σημαντικότερων επιχειρήσεων των ΗΠΑ και θεωρείται από τους σημαντικότερους δείκτες της αγοράς μετοχών. Τα δεδομένα που χρησιμοποιήθηκαν στα πειράματα, είναι ιστορικά και αντλήθηκαν από αυτόν τον δείκτη [4] και συγκεκριμένα από δύο χρονολογίες που φαίνονται στον Πίνακα Δ.1. Τα δεδομένα αυτά περιέχουν πληροφορίες για τις μετοχές όπως το όνομα της μετοχής, η τιμή ανοίγματος, η υψηλότερη τιμή της ημέρας, η χαμηλότερη τιμή της ημέρας, η τιμή κλεισίματος, ο όγκος και η αντίστοιχη ημερομηνία. Από τις πληροφορίες αυτές απομονώθηκαν οι τιμές κλεισίματος που μας ενδιαφέρουν για αυτή τη μελέτη. Επειδή η τιμή ενός χρηματιστηριακού δείκτη που δίνεται με κάποιο χρόνο δειγματοληψίας αποτελεί μία χρονοσειρά (με χρόνο δειγματοληψίας μια ημέρα) θα μας απασχολήσουν οι μέθοδοι εξόρυξης των χρονοσειρών για τη μελέτη του χαρακτηριστικού.
100 1 Εικόνα Δ.1: Τα αρχικά δεδομένα με όλες τις πληροφορίες για τις μετοχές. Προεπεξεργασία των δεδομένων Πρώτη προεπεξεργασία των Δεδομένων: Για την πρώτη προεπεξεργασία των δεδομένων: Διαγράφηκαν οι μετοχές που είχαν τιμές για πολύ λίγες ημέρες Οι μετοχές που τους έλειπαν τιμές λιγότερες από 1 ημέρες δεν διαγράφηκαν. Οι μηδενικές εκείνες τιμές αντικαταστάθηκαν με το ημιάθροισμα των γειτονικών στοιχείων. Δεύτερη προεπεξεργασία των δεδομένων- Μετασχηματισμός: Για να είναι δυνατή η σύγκριση των μετοχών πρέπει όλες οι μετοχές να έχουν το ίδιο πλάτος. Επομένως, κανονικοποιήθηκαν τα δεδομένα για να μη διαφέρουν πολύ οι τιμές των μετοχών και να έχουν ένα κοινό πλάτος σύγκρισης.
101 11 Τα δεδομένα αυτά, μετά την προεπεξεργασία, χρησιμοποιήθηκαν με διάφορες παραλλαγές (για κάθε χρόνο, εξάμηνο και τρίμηνο). Στον πίνακα που ακολουθεί υπάρχουν οι πληροφορίες για τα δεδομένα αυτά. Ονομασία Χρονολογία Διάσταση Περιγραφή Δεδομένων Dataset1 6/5/8-5/5/9 446 x 5 Δεδομένα από τον 1 ο χρόνο Dataset 1/8/9 - /8/1 476 x 45 Δεδομένα από τον ο χρόνο Dataset3 Ένωση των δύο χρονολογιών 84 x 44 Ένωση των δεδομένων των κοινών μετοχών από τους δύο χρόνους. Dataset1 και Dataset διάστασης (4 κοινές μετοχές x 44 ημέρες) το έκαστο Πίνακας Δ.1: Τα δεδομένα του πειράματος Σχόλιο: Οι κοινές μετοχές που υπάρχουν στο dataset 3 είναι 4. Οι ίδιες μετοχές χρησιμοποιούνται τον πρώτο και τον δεύτερο χρόνο. Για λόγους διευκόλυνσης όμως θα αναφέρονται ως ξεχωριστές μετοχές. Στις παρακάτω εικόνες οπτικοποιούνται οι τιμές κλεισίματος των μετοχών όλων των datasets ως προς τον χρόνο. Στον άξονα των x εμφανίζεται ο χρόνος σε μέρες, στον άξονα των y εμφανίζονται οι τιμές των μετοχών και το κάθε γράφημα αποτελεί μία μετοχή (χρονοσειρά). Μετά την προεπεξεργασία τα δεδομένα έχουν το ίδιο πλάτος, και το εύρος των τιμών του άξονα y μειώνεται από (,7) σε (-7,4) περίπου.
102 1 dataset 1 of size 446 x 5 - preprocessed data dataset 1 of size 446 x 5 - raw data closing value closing value days days Εικόνα Δ.: dataset 1 μετά την πρώτη προεπεξεργασία (αριστερά) και μετά τον μετασχηματισμό (δεξιά) dataset of size 476 x 45 - preprocessed data dataset of size 476 x 45 - raw data closing value closing value days 15 days Εικόνα Δ.3: dataset μετά την πρώτη προεπεξεργασία (αριστερά) και μετά τον μετασχηματισμό (δεξιά) dataset 3 of size 84 x 44 - raw data dataset 3 of size 84 x 44 - preprocessed data closing value closing value days days Εικόνα Δ.4: dataset 3 μετά την πρώτη προεπεξεργασία (αριστερά) και μετά τον μετασχηματισμό (δεξιά)
103 13 3. Συσταδοποίηση Μετά από την προεπεξεργασία των δεδομένων υλοποιήθηκαν οι αλγόριθμοι της συσταδοποίησης. Χρειάστηκαν όμως να προσδιοριστούν εξ αρχής κάποιες παράμετροι όπως το μέτρο ομοιότητας, το πλήθος των συστάδων και η σύνδεση μεταξύ των συστάδων στην περίπτωση της ιεραρχικής συσταδοποίησης. Στον ιεραρχικό αλγόριθμο χρησιμοποιήθηκαν οι αποστάσεις Ευκλείδεια και DTW ως μετρικές ομοιότητας. Για τον σχηματισμό του δενδρογράμματος χρησιμοποιήθηκαν οι συνδέσεις single, average, complete, weighted, median, centroid και ward. Ο αλγόριθμος αυτός υλοποιήθηκε με όλους τους δυνατούς συνδυασμούς των αποστάσεων, της σύνδεσης και του πλήθους των συστάδων κ. Ο αλγόριθμος k-means υλοποιήθηκε με την Ευκλείδεια απόσταση, με πλήθος επαναλήψεων 5 και για διάφορα κ. Ως αρχική επιλογή των θέσεων των κεντροειδών (σπόρος) επιλέχθηκαν κ τυχαίες παρατηρήσεις από τα δεδομένα. 3.1 Γενική Αξιολόγηση των αποτελεσμάτων της συσταδοποίησης Εκτελώντας τους αλγορίθμους αυτούς δημιουργούνται τα εξής ερωτήματα: Ποιά μετρική είναι καλύτερη; Ποιό κριτήριο σύνδεσης (ιεραρχικής συσταδοποίησης) είναι καλύτερο; Ποιό είναι το «κατάλληλο» πλήθος των συστάδων; Επιλογή της κατάλληλης μετρικής Γενικά η επιλογή των κατάλληλων παραμέτρων δεν είναι πάντοτε σαφής με αποτέλεσμα να μην υπάρχει ένα ξεκάθαρο όριο απόφασης καθώς η εκτίμηση της ποιότητας των συστάδων είναι
104 14 υποκειμενική. Οι αποφάσεις αλλάζουν κάθε φορά ανάλογα με το πρόβλημα που αντιμετωπίζουμε. Παρ όλα αυτά γίνεται μία εμπειρική εκτίμηση για την επίλυση αυτών των ζητημάτων. Η απόσταση DTW έδωσε καλύτερα αποτελέσματα από την Ευκλείδεια απόσταση, το οποίο είναι αναμενόμενο, εφόσον η DTW λαμβάνει υπόψιν τη στρέβλωση ως προς το χρόνο και η Ευκλείδεια απόσταση είναι μία ειδική περίπτωσή της Επιλογή του κατάλληλου κριτηρίου σύνδεσης Όσον αφορά τη σύνδεση των συστάδων στην περίπτωση της ιεραρχικής συσταδοποίησης, η μέθοδος Ward υπερέχει έναντι όλων των υπόλοιπων συνδέσμων. Για τα υπόλοιπα linkages, γενικά, υπήρχαν κάποιες συστάδες που περιείχαν ανόμοιες μετοχές ή όμοιες αλλά πολύ λίγες. Για την αντιμετώπιση αυτού του φαινόμενου κατασκευάστηκε μία μεθοδολογία που αντιμετωπίζει τις χρονοσειρές αυτές ως outliers και τις εξάγει επαναληπτικά μέχρι να βρεθεί το επιθυμητό πλήθος των μετοχών στις συστάδες Μεθοδολογία αντιμετώπισης των outliers για διάφορα linkages Η μεθοδολογία αυτή ξεκινά με κ συστάδες. Εάν εντοπίσει συστάδες που περιέχουν κάτω από n1 μετοχές, εκλαμβάνει τις μετοχές αυτές ως ακραίες τιμές (outliers) και τις βγάζει από τα δεδομένα. Έπειτα επαναλαμβάνεται η συσταδοποίηση για τις υπόλοιπες μετοχές μειώνοντας το κ (πλήθος των συστάδων), κατά ένα, σε κάθε επανάληψη. Η διαδικασία αυτή συνεχίζεται έως ότου δεν εντοπιστούν άλλα outliers. Με τη διαδικασία αυτή αλλάζουν τα δεδομένα συνεχώς, επομένως και τα αποτελέσματα της συσταδοποίησης καθώς επιπλέον μειώνεται το κ.
105 15 Αλγόριθμος της μεθοδολογίας 1 Data:=Old_data //Αρχικές Μετοχές κ: πλήθος συστάδων n1: όριο για το πλήθος των εξαγόμενων μετοχών Β1) Χώρισε τα δεδομένα σε κ συστάδες Β) Για κάθε συστάδα: εάν το πλήθος των μετοχών της συστάδας n1, θέσε New_data=Data-μετοχές outliers,κ=κ-1,data=new_data και πήγαινε στο βήμα 1 διαφορετικά πήγαινε στο επόμενο βήμα Β3) Τύπωσε τις νέες συστάδες Ο αλγόριθμος αυτός επιδέχεται τις εξής παραλλαγές: Το κ αντί να μειωθεί κατα ένα σε κάθε επανάληψη, μπορεί να μειωθεί κατά το πλήθος των συστάδων που αφαιρούνται. Το κ μπορεί να παραμείνει σταθερό εάν η συσταδοποίηση υλοποιείται για μικρό κ (π.χ 1-4). Αποτελέσματα των πειραμάτων: Η σύνδεση single δεν δίνει καθόλου καλά αποτελέσματα καθώς η συσταδοποίηση πραγματοποιήθηκε για κ (το πλήθος των συστάδων) από 3 έως 1. Τα αποτελέσματα έδειξαν ότι οι κ-1 συστάδες περιέχουν από μία μετοχή η έκαστη, και όλες οι υπόλοιπες μετοχές συγκεντρώνονται σε μία συστάδα. Υλοποιώντας τη μεθοδολογία εξαγωγής των ακραίων μετοχών, κρατώντας σταθερά τρεις συστάδες μετά από πολλές επαναλήψεις, λαμβάνουμε τα ίδια αποτελέσματα (κ-1 συστάδες περιέχουν από μία μετοχή η έκαστη, και όλες οι υπόλοιπες μετοχές συγκεντρώνονται σε μία συστάδα). Για τις συνδέσεις average, centroid και median λειτουργεί μόνο η μεθοδολογία με το σταθερό κ.

106 16 Τα πειράματα έχουν πραγματοποιηθεί με όλες τις παραλλαγές στο dataset 1 και dataset και παρατίθενται τα αποτελέσματα από το dataset 1. Σύνδεση single: Εικόνα Δ.5: Αρχική συσταδοποίηση με σύνδεση Single για κ=3 Στιγμιότυπο της 5 ης επανάληψης της μεθοδολογίας και η μη σύγκλιση της μεθόδου για τη σύνδεση single μετά το πέρας πολλών επαναλήψεων: Εικόνα Δ.6: Στιγμιότυπο της 5 ης επανάληψης της μεθοδολογίας. Παρακάτω εμφανίζονται τα στιγμιότυπα των επαναλήψεων όπου ικανοποιείται το κριτήριο εξαγωγής των μετοχών. Επίσης, η μέθοδος εξαγωγής των μετοχών για τις συνδέσεις αυτές υλοποιείται μόνο κρατώντας σταθερό το κ.
 στην 8 η επανάληψη, ενώ για κ=4 στην 1 η επανάληψη και για κ=6 στην 33 η επανάληψη. 3.1.. Η Σύνδεση Ward Για τη σύνδεση Ward δεν απαιτείται να εφαρμοστεί αυτή η μεθοδολογία.")
107 17 Σύνδεση Average: Εικόνα Δ.7: Αρχικός διαχωρισμός των 446 μετοχών χωρίς την εφαρμογή της μεθοδολογίας Εικόνα Δ.8: Στιγμιότυπο της 8 ης επανάληψης της συσταδοποίησης με σύνδεση average για κ=3, n1=1. Για κ=3 συστάδες ικανοποιείται το κριτήριο (πλήθος των μετοχών κάθε συστάδας 1) στην 8 η επανάληψη, ενώ για κ=4 στην 1 η επανάληψη και για κ=6 στην 33 η επανάληψη Η Σύνδεση Ward Για τη σύνδεση Ward δεν απαιτείται να εφαρμοστεί αυτή η μεθοδολογία. Όμως, υλοποιώντας την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση για κ=3 (Εικόνα Δ.9) παρατηρούμε ότι ενώ τα δεδομένα δημιουργούν τρία διαφορετικά σχήματα (3 συστάδες), υπάρχουν ωστόσο μετοχές που διαφέρουν μέσα στην ίδια συστάδα. Η αναλυτική εικόνα μίας συστάδας μπορεί να βοηθήσει στην κατανόηση του θέματος (Εικόνα Δ.11). Το αντίστοιχο γράφημα silhouette δείχνει ότι σχεδόν τα μισά δεδομένα της συστάδας δύο θα έπρεπε να βρίσκονται σε κάποια άλλη συστάδα (Εικόνα Δ.1). Το πρόβλημα δεν λύνεται αυξάνοντας το πλήθος των συστάδων.

108 Cluster 18 Εικόνα Δ.9: Συστάδες που προέκυψαν από την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ=3 Στην εικόνα Δ.9 το κάθε subplot αντιπροσωπεύει μία συστάδα, περιέχει πληροφορίες για το πλήθος των μετοχών που έχουν καταχωρηθεί στις συστάδες και το intra cluster distance των συστάδων αυτών που εκφράζουν διασπορά τους. Οι συστάδες με τις ελάχιστες τιμές του intra cluster distance δείχνουν πόσο κοντά στο κεντροειδές βρίσκονται τα αντικείμενα της συστάδας αυτής. Επίσης, για κάθε διαχωρισμό των δεδομένων παρουσιάζονται και τα αντίστοιχα γραφήματα των silhouettes τα οποία δείχνουν πόσο σωστά έχουν καταχωρηθεί τα αντικείμενα στις συστάδες. Όσο κοντά στο +1 είναι η τιμή ενός αντικειμένου μίας συστάδας, τόσο σωστά έχει εκχωρηθεί στη συστάδα αυτή. Παρατηρούμε ότι το cluster με το μικρότερο intra cluster distance έχει και μεγαλύτερη τιμή silhouette. Με άλλα λόγια οι τιμές των silhouettes υποστηρίζουν τις τιμές του intra cluster distance. Hierarchical with Euclidean Ward - 3 clusters 1 3 Ο άξονας των y περιέχει τον αριθμό των συστάδων και ο άξονας x τις τιμές των silhouettes όλων των μετοχών διαχωρισμένες ανά συστάδες Silhouette Value Εικόνα Δ.1: Οι τιμές silhouettes
109 19 Εικόνα Δ.11: Η αναλυτική εικόνα των 1 πρώτων μετοχών της συστάδας Outliers για τη σύνδεση Ward Τα πειράματα εκτελέστηκαν αρχικά για το dataset1. Επειδή τα αποτελέσματα δεν ήταν ικανοποιητικά (δηλαδή υπήρχαν μετοχές μέσα στις συστάδες που διέφεραν από τις υπόλοιπες ενώ οι συστάδες μεταξύ τους δεν διέφεραν και πολύ και επιπλέον η ένδειξη για το πλήθος των συστάδων ήταν πολύ μικρή), πραγματοποιήθηκε η ένωση των datasets 1 και η οποία μας έδωσε το dataset3. Με τη χρήση του dataset3 αντιμετωπίστηκαν τα προβλήματα αυτά κατα ένα μεγάλο βαθμό, διευρύνθηκε επίσης και το πλήθος των συστάδων εφόσον έδωσε μεγαλύτερο έυρος των σχημάτων συγκριτικά με το dataset 1. Το γεγονός ότι στο dataset 3 εξακολουθούσαν να υπάρχουν μετοχές που δεν έμοιαζαν με τις υπόλοιπες της ίδιας συστάδας, δυσκόλευαν στη λήψη απόφασης για το πότε έπρεπε να σταματήσουμε ώστε να έχουμε τα επιθυμητά αποτελέσματα. Υπήρχαν δηλαδή outliers που έπρεπε να αφαιρεθούν. Ως outliers για τα δεδομένα του προβλήματος θεωρούμε μετοχές που έχουν
110 11 καταχωρηθεί σε μία συστάδα παρόλο που δεν ταιριάζουν με τις υπόλοιπες μετοχές της συστάδας αυτής. Η σύνδεση average από μόνη της θεωρεί ότι κατα μέσο όρο όλες οι μετοχές μοιάζουν (το οποίο φαίνεται και στις εικόνες των δεδομένων). Για αυτό το λόγο τοποθετεί όλες τις μετοχές σε μία συστάδα. Επιβάλλοντας όμως κ συστάδες εξ αρχής, η σύνδεση αυτή αρχίζει και εξάγει μία μία τις μετοχές που ανήκουν λιγότερο σε αυτή τη συστάδα και τις τοποθετεί σε ξεχωριστές συστάδες. Έτσι εξηγείται και το γεγονός ότι οι υπόλοιπες συστάδες περιέχουν μία μετοχή ή κάποιες μετοχές (πολύ λίγες όμως). Εκμεταλλεύοντας αυτόν τον τρόπο για την εξαγωγή των outliers τα αποτελέσματα για το dataset 3 βελτιώθηκαν. Για την ακρίβεια, αφαιρέθηκαν από τα δεδομένα μετοχές εφαρμόζοντας την ιεραρχική συσταδοποίηση με DTW και σύνδεση average για κ=. Στην παρακάτω εικόνα φαίνονται οι μετοχές που αφαιρέθηκαν πριν την υλοποίηση οποιουδήποτε αλγορίθμου συσταδοποίησης. 49 outliers of dataset Εικόνα Δ.1: Οι μετοχές που αφαιρέθηκαν πριν την υλοποίηση οποιουδήποτε αλγορίθμου συσταδοποίησης.
111 closing value closing value closing value closing value closing value closing value 111 Επομένως, η συσταδοποίηση πραγματοποιήθηκε σε δύο βήματα. Στο πρώτο βήμα αφαιρέθηκαν οι ακραίες μετοχές (outliers) υλοποιώντας μία φορά την ιεραρχική μέθοδο με απόσταση DTW και σύνδεση average για κ=. Στο δεύτερο βήμα υλοποιήθηκε ο αλγόριθμος της συσταδοποίησης με σύνδεση Ward για οποιοδήποτε μέτρο απόστασης. Hierarchical clustering of 79 stocks - DTW distance- ward linkage clust1: 67 stocks, intra:55.94 clust: 63 stocks, intra: days clust3: 64 stocks, intra: days clust4: 81 stocks, intra: days clust5: 34 stocks, intra: days clust6: 177 stocks, intra: days days Εικόνα Δ.13: Συσταδοποίηση μετά την αφαίρεση των outliers. Ιεραρχική συσταδοποίηση με απόσταση DTW και σύνδεση ward για κ=6 Σχόλιο: Τα αποτελέσματα των πειράματων που παρουσιάζονται στο παράρτημα, προέρχονται από το dataset 3 μετά τη συγκεκριμένη προεπεξεργασία.
112 Εύρεση του βέλτιστου κ με Inter-Intra Cluster Distance Το σημαντικότερο πρόβλημα που υπάρχει στη συσταδοποίηση, και φάνηκε και στα συγκεκριμένα πειράματα, είναι ότι το πλήθος των συστάδων που πρέπει να πάρουμε δεν είναι ξεκάθαρο. Παρ όλα αυτά, έγινε μία προσπάθεια για την εύρεση του βέλτιστου πλήθους των συστάδων υπολογίζοντας την αξιοπιστία που βασίζεται στο inter-intra cluster distance. Υπολογίστηκαν επίσης οι τιμές silhouette για την αξιολόγηση της συμπαγότητας των συστάδων. Για τον καλύτερο διαχωρισμό των συστάδων, πρέπει τα αντικείμενα μίας συστάδας να βρίσκονται όσο το δυνατόν κοντά μεταξύ τους και όσο το δυνατόν μακριά από τα μέλη των άλλων συστάδων. Δηλαδή η κάθε συστάδα να είναι συμπαγής και οι συστάδες μεταξύ τους να είναι αραιές. Αυτό στη χρονοσειρά εκφράζεται ως, οι χρονοσειρές μίας συστάδας να είναι όμοιες μεταξύ τους και να διαφέρουν από εκείνες που αποτελούν μέλη άλλων συστάδων. Η συμπαγότητα επιτυγχάνεται με την ελαχιστοποίηση της διασποράς και η αραιότητα επιτυγχάνεται με τη μεγιστοποίηση των αποστάσεων μεταξύ των κεντροειδών των συστάδων για το οποίο παίρνουμε τον λόγο τους. Επομένως, μέσω της αναλογίας () αναζητούμε τα ελάχιστα σημεία. Συνήθως λαμβάνονται διάφορες παραλλαγές αυτής της αναλογίας. Στην παρούσα εργασία εκτιμήθηκαν οι εξής:
113 113 Εικόνα Δ.14: validity 1, validity, validity 3 αντίστοιχα για το dataset 3 για την Ιεραρχική συσταδοποίηση (με απόσταση Ευκλείδεια και DTW και σύνδεση ward) και για τη συσταδοποίηση με k-means για κ από 3 έως 5 Από τα δύο πρώτα γραφήματα κάνοντας αναζήτηση για ελάχιστα σημεία, συμπεραίνουμε ότι, το inter-intra cluster distance δίνει καλά αποτελέσματα για τη συσταδοποίηση με μικρό πλήθος των συστάδων. Η τιμή του inter-intra cluster distance validity αυξάνεται καθώς αυξάνεται και η τιμή του κ. Ενώ το τρίτο γράφημα δείχνει προς το μεγαλύτερο κ. Παρατηρήθηκε ότι το validity 1 δίνει περίπου τα ίδια αποτελέσματα με το validity. Τα αποτελέσματα που λάβαμε για τα validities όλων των datasets συγκλίνουν προς το ίδιο συμπέρασμα. Επομένως, η απόφαση με βάση αυτά τα δύο γραφήματα είναι ίδια. Εμπειρικά παρατηρήθηκε ότι, όσο το κ είναι μικρό τόσο πιο γενικά είναι τα σχήματα σε μία συστάδα ενώ με την αύξηση του πλήθους των συστάδων (μέχρι κάποιο επιτρεπτό όριο που εξαρτάται από το σύνολο των δεδομένων) αυξάνεται η
114 mean(silhouette) 114 ακρίβεια ως προς την ομοιότητα των μετοχών. Επομένως, επιλέγουμε το κ ανάλογα με το σκοπό που θέλουμε να εξυπηρετήσουμε. Η μέση μέση τιμή των silhouettes:.7.6 Mean of Silhouettes hier Eucl Hier DTW kmeans Eucl number of clusters Εικόνα Δ.15: Η μέση τιμή των silhouettes εκφράζει τη συμπαγότητα των συστάδων Η μέση τιμή των silhouettes για το dataset 3, για κ από 3 έως 15 δείχνει ότι όσο αυξάνεται το πλήθος των συστάδων μειώνεται η συμπαγότητά τους.
115 Κατηγοριοποίηση Για την κατηγοριοποίηση υλοποιήθηκε η μέθοδος των κ κοντινότερων γειτόνων (k-nearest Neighbor). Η πορεία που ακολουθήθηκε για την κατηγοριοποίηση είναι η εξής: Β1) Πραγματοποιήθηκε αρχικά μία συσταδοποίηση για όλες τις μετοχές για τον καθορισμό των κατηγοριών. Β) Στη συνέχεια, με τη χρήση της δειγματοληπτικής μεθόδου k-fold crossvalidation λήφθηκε το σύνολο ελέγχου και το σύνολο εκπαίδευσης (Εικόνα Δ.17). Β3) Έπειτα υλοποιήθηκε η μέθοδος του κοντινότερου γείτονα προκειμένου να καταχωρηθούν οι μετοχές προς κατηγοριοποίηση (σύνολο ελέγχου) σε κάποιες από τις προκαθορισμένες κλάσεις του βήματος 1. Η κατηγοριοποίηση εκτελέστηκε κ φορές (k-fold) λαμβάνοντας κάθε φορά ως σύνολο ελέγχου το 1/κ των μετοχών και (κ-1)/κ των μετοχών ως σύνολο εκπαίδευσης. Εικόνα Δ.16: Αναπαράσταση της δειγματοληπτικής μεθόδου k-fold crossvalidation
116 116 Παράδειγμα Για τις νέες εισερχόμενες μετοχές όταν ζητείται να προσδιοριστούν σε ποιές κατηγορίες των μετοχών ανήκουν (με άλλα λόγια με ποιές μοιάζουν) μπορεί να εφαρμοστεί η συγκεκριμένη μέθοδος. Στην προκειμένη περίπτωση, από τις 79 μετοχές του dataset 3 αφαιρέθηκαν οι 8 που αποτελούν το σύνολο ελέγχου για να αναπαραστήσουν τις νέες μετοχές. Για τον καθορισμό των κατηγοριών υλοποιήθηκε ο αλγόριθμος της ιεραρχικής συσταδοποίησης (με Ευκλείδεια απόσταση) για 8 συστάδες που εδώ αποτελούν τις κατηγορίες των μετοχών. Εκτελώντας πρώτα την 1- fold crossvalidation και έπειτα τον αλγόριθμο k-nearest Neighbor classification προσδιορίστηκαν οι κατηγορίες στις οποίες ανήκουν οι νέες μετοχές με σφάλμα περίπου 9%. fold 1 Correct Rate Error Rate Πίνακας Δ.: Σφάλματα κατηγοριοποίησης για κάθε fold. Ο μέσος όρος των σφαλμάτων είναι test set training set closing value closing value days days η Εικόνα Δ.17: Το σύνολο εκπαίδευσης (αριστερά) και σύνολο ελέγχου (δεξιά) στη 1 επανάληψης του crossvalidation
117 117 Παρακάτω φαίνονται οι 8 κατηγορίες των μετοχών που προέκυψαν μέσω της συσταδοποίησης και με έντονο μαύρο χρώμα σημειώνονται οι μετοχές που κατηγοριοποιήθηκαν στις συστάδες αυτές. k Nearest Neighbor classification Εικόνα Δ.18: Κατηγοριοποίηση των 8 μετοχών μετά τη συσταδοποίηση με την Ιεραρχική μέθοδο με Ευκλείδεια απόσταση.
118 Πρόβλεψη Για την πρόβλεψη της τιμής κλεισίματος των μετοχών, αφαιρέθηκαν οι τιμές των τελευταίων κ ημερών για όλες τις μετοχές. Στη συνέχεια, οι τιμές αυτές προσεγγίστηκαν με τη μέθοδο SMOreg (Sequential Minimal Optimization for Regression). Οι εκτιμήσεις αυτές αξιολογήθηκαν με το σφάλμα πρόβλεψης MAPE. Στο τέλος η μέθοδος αυτή συγκρίθηκε με τις γνωστές μεθόδους μοντελοποίησης των χρονοσειρών, Linear Regression, Exponential Smoothing, ARIMA και έναν συνδυασμό των μεθόδων αυτών (με κάποια βάρη). 5.1 Η μέθοδος SMOreg Τα πειράματα πραγματοποιήθηκαν αναζητώντας τις απαντήσεις των ακόλουθων ερωτημάτων (α) Η προεπεξεργασία βοηθάει την πρόβλεψη; (β) Η συσταδοποίηση βελτιώνει τα αποτελέσματα της πρόβλεψης; (γ) Η SMOreg είναι καλύτερη από άλλες μεθόδους πρόβλεψης; (δ) Ο συνδυασμός όλων των μεθόδων δίνει καλύτερες εκτιμήσεις; Πρόβλεψη μετά την προεπεξεργασία Για την εξέταση του ενδεχομένου, εάν η προεπεξεργασία των δεδομένων βοηθάει την πρόβλεψη, έγιναν πολλές συγκρίσεις των αποτελεσμάτων της πρόβλεψης που έχουμε λάβει πριν και μετά την προεπεξεργασία των δεδομένων. Όσον αφορά την εκτίμηση του σφάλματος, το γεγονός ότι οι τιμές κυμαίνονται σε διαφορετικό πεδίο τιμών του άξονα y, χρησιμοποιήθηκε το απόλυτο σχετικό σφάλμα επί τοις εκατό διότι καθορίζει καλύτερα την ακρίβεια της ορθότητας του πειράματος. Τα αποτελέσματα έδειξαν ότι η προεπεξεργασία δεν βοηθάει την πρόβλεψη εφόσον το απόλυτο σχετικό σφάλμα επί τοις εκατό (MAPE) διαφέρει κατά πολύ.
119 Πρόβλεψη μετά τη συσταδοποίηση Για την αναζήτηση του ερωτήματος «η πρόβλεψη μετά τη συσταδοποίηση δίνει καλύτερες προσεγγίσεις;» υλοποιήθηκε αρχικά ο αλγόριθμος της συσταδοποίησης και έπειτα εφαρμόστηκε η μέθοδος πρόβλεψης SMOreg σε κάποιες συστάδες που επιλέχτηκαν τυχαία. Καταλήξαμε στο συμπέρασμα ότι τελικά η συσταδοποίηση βελτιώνει τα αποτελέσματα της πρόβλεψης. Το γεγονός αυτό δικαιολογεί την επιλογή των δεδομένων από συστάδες για την υλοποίηση αυτής της μεθόδου στο υπόλοιπο μέρος της εργασίας. real and predicted values real SMOreg Εικόνα Δ.19: Πρόβλεψη των 16 τυχαίων μετοχών της συστάδας 4 από την ιεραρχική συσταδοποίηση με DTW για κ=1, η μέση τιμή του MAPE όλων των μετοχών είναι.6% Μετοχές MAPE Πίνακας Δ.3: Πίνακας απολύτων σχετικών σφαλμάτων % για κάθε μετοχή της εικόνας
120 1 5. Σύγκριση των μεθόδων Για την απάντηση στο ερώτημα εάν η SMOreg είναι καλύτερη από άλλες μεθόδους πρόβλεψης υλοποιήθηκαν οι μέθοδοι ARIMA, Exponential Smoothing και Linear Regression. Επίσης επιλέχτηκε ένας συνδυασμός των αποτελεσμάτων αυτών με καποια βάρη ως εξής: με 5.3 Αποτελέσματα των πειραμάτων Το κεφάλαιο αυτό κλείνει παρουσιάζοντας κάποια αποτελέσματα των μεθόδων πρόβλεψης (για το Dataset 3). Για την αξιολόγησή τους υπολογίστηκαν τα αντίστοιχα σφάλματα πρόβλεψης. Υπολογίζοντας τα σφάλματα των αποτελεσμάτων καταλήγουμε στο συμπέρασμα ότι η μέθοδος SMOreg βρίσκεται στην 4 η σειρά κατάταξης συγκριτικά με τις υπόλοιπες μεθόδους, ενώ ο συνδυασμός των μεθόδων που επιλέχτηκε βρίσκεται στην 3 η σειρά κατάταξης. Στον παρακάτω πίνακα αναφέρονται κατα μέσο όρο τα σφάλματα όλων των μεθόδων για τις συστάδες που δοκιμάστηκαν στα πειράματα. Exp. Sm.5 ARIMA(1,,1) MyPred(.5,.35,.35,.5) SMOreg LinearReg ΜΑPΕ 3.39% 3.47% 3.6% 6.4% 9.19% Πίνακας Δ.4 : Μέση τιμή των σφαλμάτων όλων των μεθόδων με σειρά κατάταξης Παρατηρήθηκε ότι χρησιμοποιώντας την Exponential Smoothing με συχνότητα 6 και την ARIMA τάξης (4,3,4), για το dataset 1, η απόφαση παραμένει ίδια.
121 11 Παρ όλο που τα σφάλματα δείχνουν ότι η μέθοδος SMOreg έχει μεγαλύτερο σφάλμα συγκριτικά με την Exponential Smoothing και την ARIMA, η πορεία που ακολουθεί ωστόσο είναι καλύτερη από αυτές διότι παρατηρείται μία προσπάθεια μάθησης των προτύπων Πρόβλεψη με τη μέθοδο SMOreg και η σύγκριση με άλλες μεθόδους Η πρόβλεψη πραγματοποιήθηκε για τις μετοχές που περιέχονται στη συστάδα της ιεραρχικής συσταδοποίησης με DTW για κ=. Σε κάθε subplot φαίνονται οι πραγματικές και οι προσεγγιστικές τιμές των μετοχών. Οι προβλέψεις έχουν γίνει για 1 ημέρες ενώ τα σφάλματα υπολογίστηκαν για 5 ημέρες. Αυτό διότι αφενός μεν έχουμε μία καλύτερη εικόνα της μεθόδου αφετέρου δε το σφάλμα για λιγότερες ημέρες είναι μικρότερο. real and predicted values real SMOreg Εικόνα Δ.: Πρόβλεψη με τη μέθοδο SMOreg των 6 πρώτων μετοχών της συστάδας από την ιεραρχική συσταδοποίηση με DTW για κ=. Με μπλέ χρώμα απεικονίζονται οι πραγματικές τιμές και με κόκκινο οι προβλεπόμενες. Η μέση τιμή του MAPE όλων των μετοχών για 5 ημέρες είναι 5.68%
122 1 Για τη σύγκριση όλων των μεθόδων παρουσιάζονται τα γραφήματα για την κάθε μέθοδο ξεχωριστά διότι σε ένα γράφημα δεν διακρίνονται καλά όλες οι προσεγγίσεις. Για τον υπολογισμό της συνδυασμένης μεθόδου χρησιμποιήθηκαν τα βάρη (.5,.35,.35,.5) τα οποία σχηματίζουν τη σχέση που έπεται. Εικόνα Δ.1: Πρόβλεψη με τη μέθοδο Exponential Smoothing με σφάλμα 4.3 %

123 13 Εικόνα Δ.: Πρόβλεψη με τη μέθοδο ARIMA με σφάλμα 4.9 % Εικόνα Δ.3: Πρόβλεψη με τη μέθοδο Linear Regression με σφάλμα %
 SMOreg LinearReg ΜΑPΕ 4.9 % 4.3 % 4.57 % 5.68 % 16.74 % Πίνακας Δ.")
124 14 Εικόνα Δ.4: Πρόβλεψη με τη συνδυασμένη μέθοδο με σφάλμα 4.57% ARIMA(1,,1) Exp. Sm.5 MyPred(.5,.35,.35,.5) SMOreg LinearReg ΜΑPΕ 4.9 % 4.3 % 4.57 % 5.68 % % Πίνακας Δ.5: Σφάλματα για τη συστάδα
125 ΜΕΡΟΣ Ε - ΣΥΜΠΕΡΑΣΜΑΤΑ 15
126 16 Ε. ΣΥΜΠΕΡΑΣΜΑΤΑ Τελειώνοντας τα πειράματα καταλήγουμε στα ακόλουθα συμπεράσματα. - Επιβεβαιώνεται το γεγονός ότι η συσταδοποίηση μπορεί να αποκαλύψει συσχετίσεις και δομές οι οποίες μπορούν να βοηθήσουν σε άλλου είδους εξόρυξης δεδομένων. Στα συγκεκριμένα πειράματα, χρησιμοποιήθηκε αρχικά για να καθορίσει κάποιες κλάσεις προκειμένου να υλοποιηθεί ο αλγόριθμος της κατηγοριοποίησης ενώ αργότερα για την πρόβλεψη των μελλοντικών τιμών κάποιων μετοχών που ανήκουν στην ίδια κατηγορία με σκοπό την βελτίωση των αποτελεσμάτων. - Η συσταδοποίηση, μετά την προεπεξεργασία των δεδομένων, δίνει πολύ καλά αποτελέσματα. - Η συσταδοποίηση με συνεχώς αυξανόμενο κ (μέχρι ένα επιτρεπτό όριο) βελτιώνει την ομοιότητα των σχημάτων των μετοχών που βρίσκονται σε μία συστάδα. - Η εφαρμογή για την απομάκρυνση των outliers βελτίωσε αρκετά τα αποτελέσματα. Βέβαια οι ακραίες μετοχές δεν αντιμετωπίστηκαν πλήρως. Υπάρχουν κάποια σφάλματα στη συσταδοποίηση λόγω της λανθασμένης καταχώρησης στις συστάδες. - Η πρόβλεψη μετά την προεπεξεργασία των δεδομέων δίνει πολύ μεγάλα σφάλματα, γι αυτό και προτιμώνται οι εκτιμήσεις χωρίς προεπεξεργασία. - Οι διαφορετικές επιλογές των μετοχών δίνουν διαφορετικά αποτελέσματα στην πρόβλεψη με τη μέθοδο SMOreg. Δηλαδή ο διαφορετικός συνδυασμός των μετοχών δίνει διαφορετικές τιμές πρόβλεψης. Και μάλιστα, η επιλογή των μετοχών που ανήκουν σε μία συστάδα έδωσε μικρότερο σφάλμα πρόβλεψης.
127 17 - Επίσης, οι εκτιμήσεις με τη μέθοδο SMOreg είναι πολύ καλές μόνο για τις δύο πρώτες ημέρες κατα μέσο όρο, ενώ με την πάροδο του χρόνου αποκλίνουν από τις πραγματικές τιμές. - Ο συνδυασμός όλων των μεθόδων πρόβλεψης έδωσε καλύτερα αποτελέσματα απο την SMOreg. Ίσως μία πιο κατάλληλη επιλογή για τα βάρη θα μπορούσε να δώσει καλές προσεγγίσεις (πρόβλημα βελτιστοποίησης). - Για το dataset 1 η Exponential Smoothing δίνει καλές εκιμήσεις με συχνότητα επανάληψης 6 ημέρες. - Στην ARIMA διαφέρουν οι προβλέψεις ανάλογα με τις τάξεις p,d,q επομένως ζητείται μία καλύτερη επιλογή τους. - Η SMOreg βρίσκεται στην 4 η σειρά κατάταξης συγκριτικά με τις υπόλοιπες μεθόδους (Exponential Smoothing, ARIMA, Mypred, Linear Regression). Ως κριτήριο σύγκρισης χρησιμοποιήθηκε το μέσο απόλυτο ποσοστιαίο σφάλμα (MAPE).
128 18
129 ΜΕΡΟΣ ΣΤ - ΠΑΡΑΡΤΗΜΑ 19
130 13 1. Συσταδοποίηση Συσταδοποίηση μετά την αφαίρεση των outliers για τη σύνδεση Ward Εδώ παρουσιάζονται μερικά ενδεικτικά αποτελέσματα των συσταδοποιήσεων για το dataset 3 που υλοποιήθηκαν για κ από 6 έως 16. Σε όλες τις εικόνες, το κάθε subplot αντιπροσωπεύει μία συστάδα, περιέχει πληροφορίες για το πλήθος των μετοχών που έχουν καταχωρηθεί στις συστάδες και το intra cluster distance των συστάδων αυτών που εκφράζουν διασπορά τους. Οι συστάδες με τις ελάχιστες τιμές του intra cluster distance δείχνουν πόσο κοντά στο κεντροειδές βρίσκονται τα αντικείμενα της συστάδας αυτής. Επίσης, για κάθε διαχωρισμό των δεδομένων παρουσιάζονται και τα αντίστοιχα γραφήματα των silhouettes τα οποία δείχνουν πόσο σωστά έχουν καταχωρηθεί τα αντικείμενα στις συστάδες. Όσο κοντά στο +1 είναι η τιμή ενός αντικειμένου μίας συστάδας, τόσο σωστά έχει εκχωρηθεί στη συστάδα αυτή. Κάποια αποτελέσματα που λήφθηκαν από την εκτέλεση των αλγορίθμων συσταδοποίησης για το dataset 3 απεικονίζονται παρακάτω.
131 131 (α) Συσταδοποίηση με Ευκλείδεια απόσταση Hierarchical clustering of 79 stocks - Euclidean distance-ward linkage clust1: 39 stocks, intra:87.51 clust: 71 stocks, intra: clust3: 78 stocks, intra: clust4: 85 stocks, intra: clust5: 173 stocks, intra: clust6: 346 stocks, intra: Εικόνα ΣΤ.1: Ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ=6 Hierarchical with Euclidean Ward - 6 clusters 1 3 Cluster Silhouette Value Εικόνα ΣΤ.: Οι τιμές silhouettes για την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ=6

132 Cluster 13 Εικόνα ΣΤ.3: Ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και κ=9 1 Hierarchical with Euclidean Ward - 9 clusters Silhouette Value Εικόνα ΣΤ.4: Οι τιμές silhouettes για την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ=9
133 Cluster 133 Hierarchical clustering of 79 stocks - Euclidean distance-ward linkage clust1: 38 stocks, intra:53.7 clust: 47 stocks, intra:8.44 clust3: 13 stocks, intra: clust4: 5 stocks, intra: clust5: 69 stocks, intra: clust6: 73 stocks, intra: clust7: 4 stocks, intra: clust8: 47 stocks, intra: clust9: 193 stocks, intra: clust1: 31 stocks, intra: clust11: 39 stocks, intra: clust1: 78 stocks, intra: Εικόνα ΣΤ.5: Ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και κ= Hierarchical with Euclidean Ward - 1 clusters Silhouette Value Εικόνα ΣΤ.6: Οι τιμές silhouettes για την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ=9
134 Cluster 134 Hierarchical clustering of 79 stocks - Euclidean distance-ward linkage clust1: 7 stocks, intra:4.1 clust: 46 stocks, intra:37.5 clust3: 33 stocks, intra:46.47 clust4: 45 stocks, intra: clust5: 18 stocks, intra: clust6: 9 stocks, intra: clust7: 14 stocks, intra: clust8: 51 stocks, intra: clust9: 38 stocks, intra: clust13: 69 stocks, intra: clust1: 47 stocks, intra: clust14: 4 stocks, intra: clust11: 13 stocks, intra: clust15: 31 stocks, intra: clust1: 5 stocks, intra: clust16: 39 stocks, intra: Εικόνα ΣΤ.7: Ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και κ= Hierarchical with Euclidean Ward - 16 clusters Silhouette Value Εικόνα ΣΤ.8: Οι τιμές silhouettes για την ιεραρχική συσταδοποίηση με την Ευκλείδεια απόσταση και σύνδεση Ward, για κ=16

135 Cluster 135 Εικόνα ΣΤ.9: Συσταδοποίηση k-means με την Ευκλείδεια απόσταση για κ=6 kmeans - 6 clusters Silhouette Value Εικόνα ΣΤ.1: Οι τιμές silhouettes συσταδοποίησης k-means με την Ευκλείδεια απόσταση για κ=6

136 Cluster 136 Εικόνα ΣΤ.11: Συσταδοποίηση με k-means με την Ευκλείδεια απόσταση για κ=8 kmeans - 8 clusters Silhouette Value Εικόνα ΣΤ.1: Οι τιμές silhouettes συσταδοποίησης k-means με την Ευκλείδεια απόσταση για κ=8
137 137 (β) Συσταδοποίηση με απόσταση DTW DTW 4 clusters Hierarchical clustering of 79 stocks - DTW distance- ward linkage clust1: 34 stocks, intra:36.3 clust: 13 stocks, intra: clust3: 177 stocks, intra: clust4: 145 stocks, intra:

138 Αναλυτικές εικόνες των συστάδων: 138
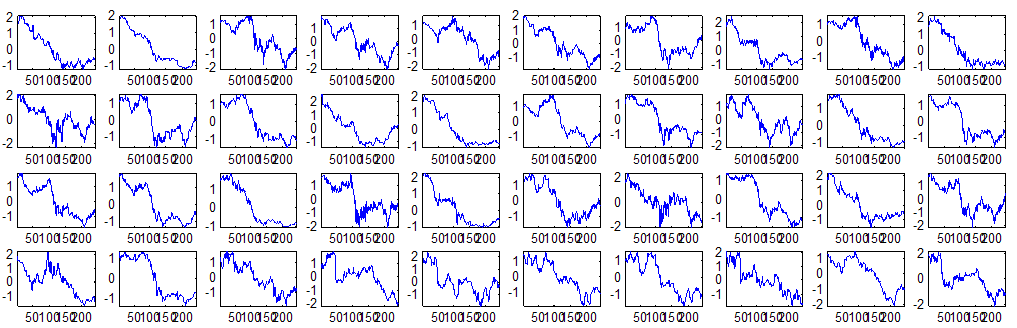
139 139
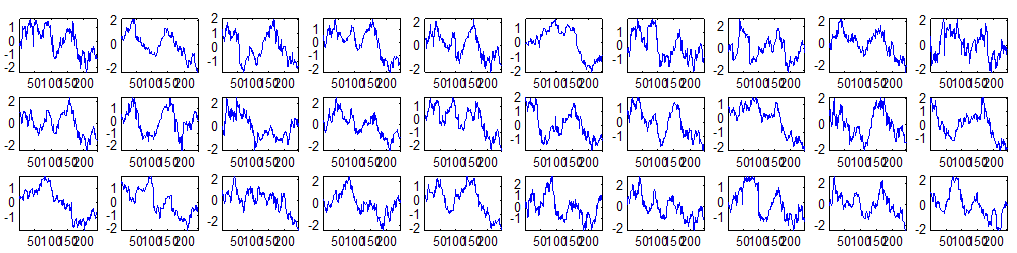
140 14
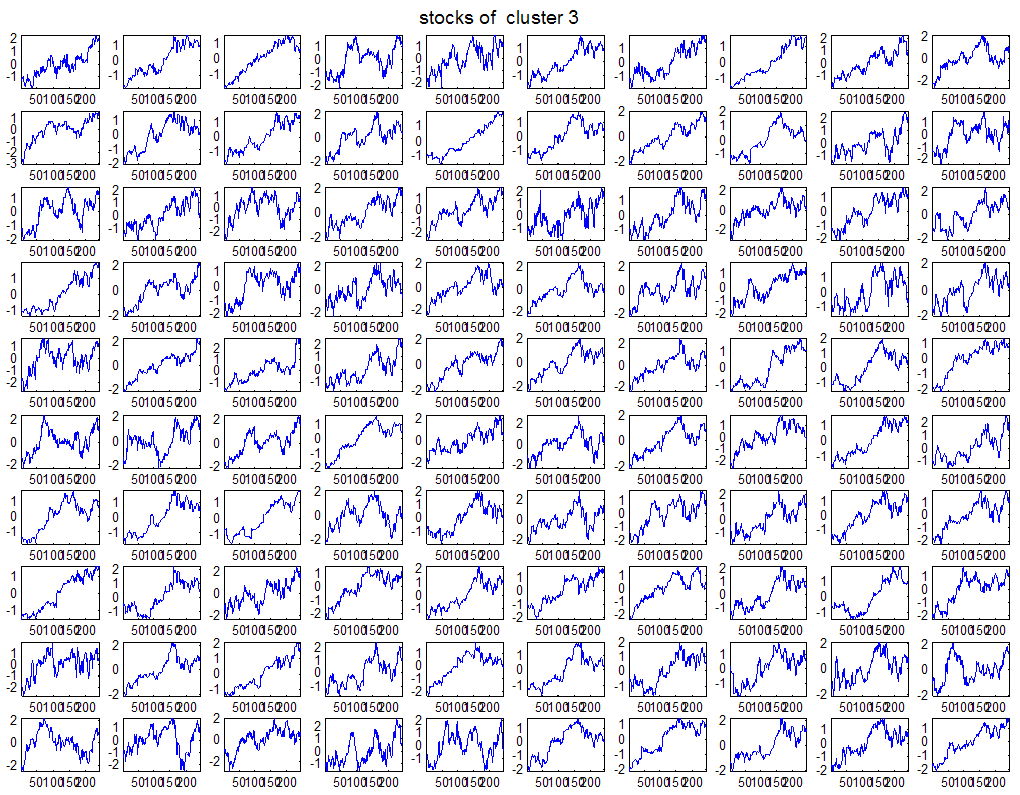
141 141
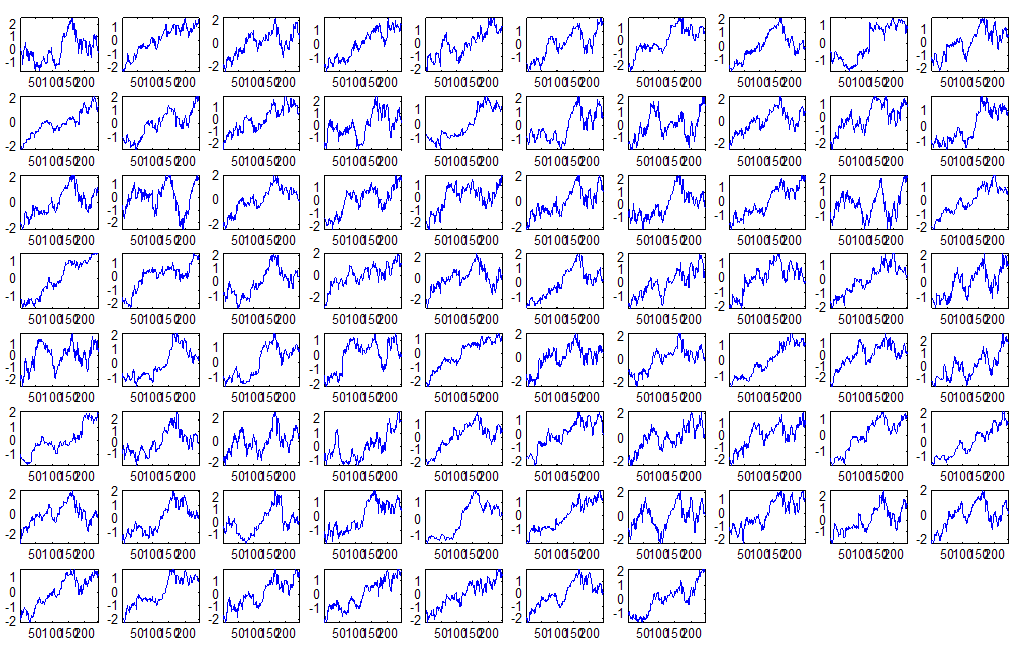
142 14
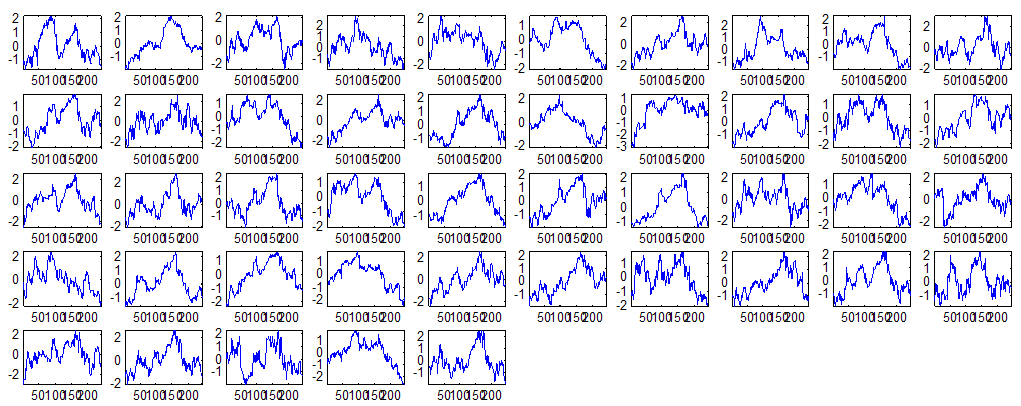
143 143

144 144 DTW k=6 1 Hierarchical clustering of 79 stocks - DTW distance- ward linkage clust1: 67 stocks, intra:55.94 clust: 63 stocks, intra:13.77 clust3: 64 stocks, intra: clust4: 81 stocks, intra:19.5 clust5: 34 stocks, intra:36.3 clust6: 177 stocks, intra:
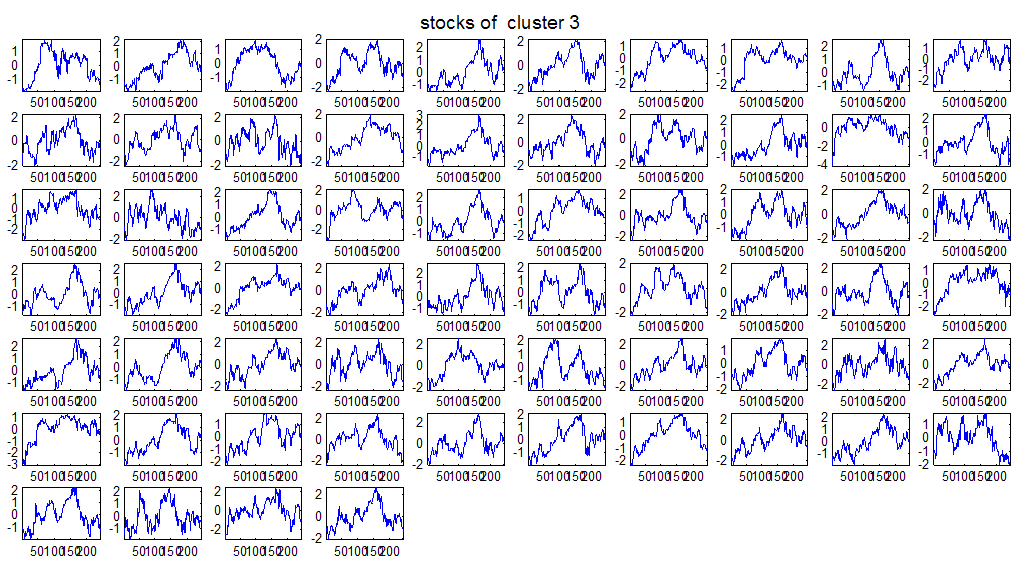
145 145
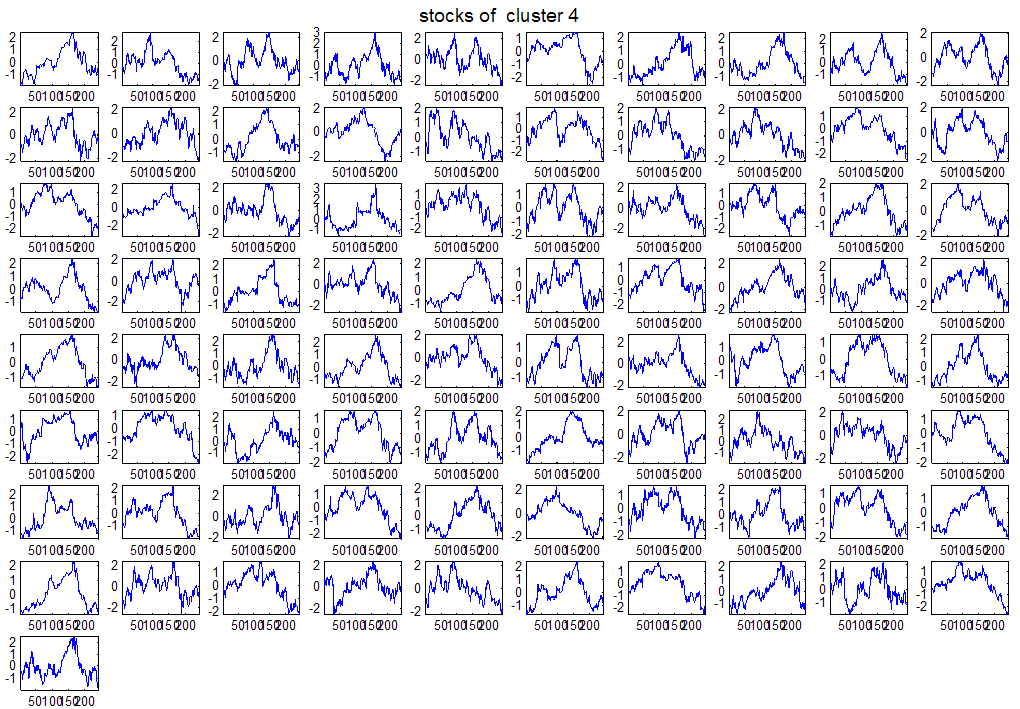
146 146
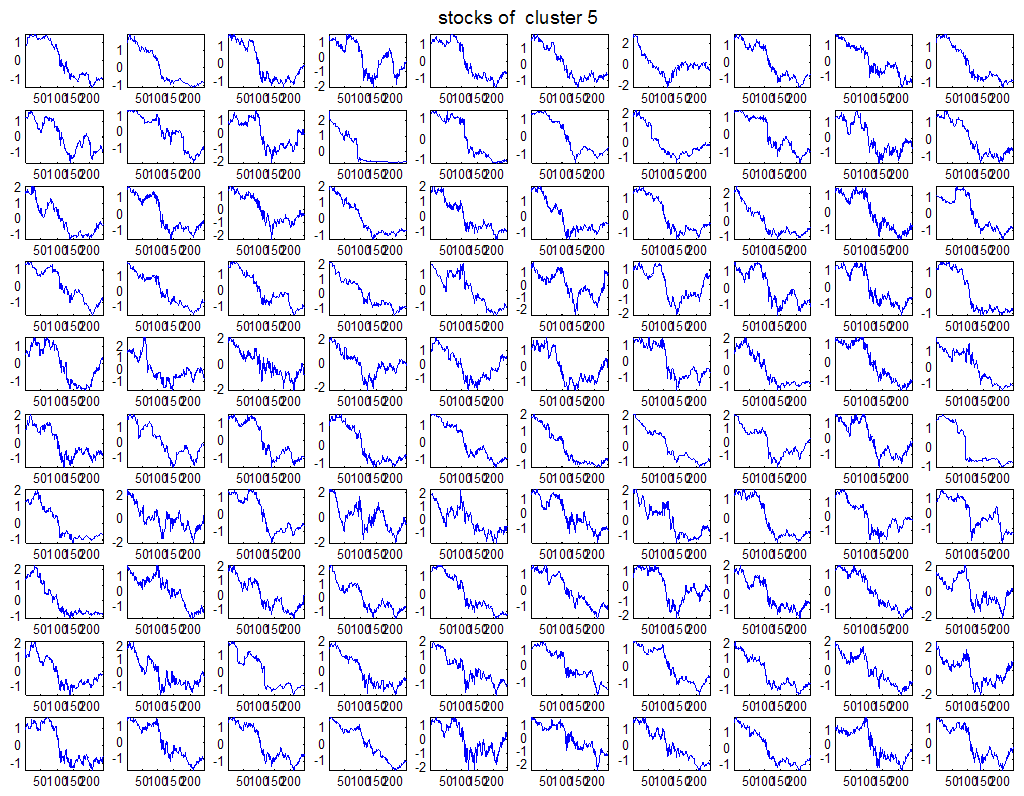
147 147
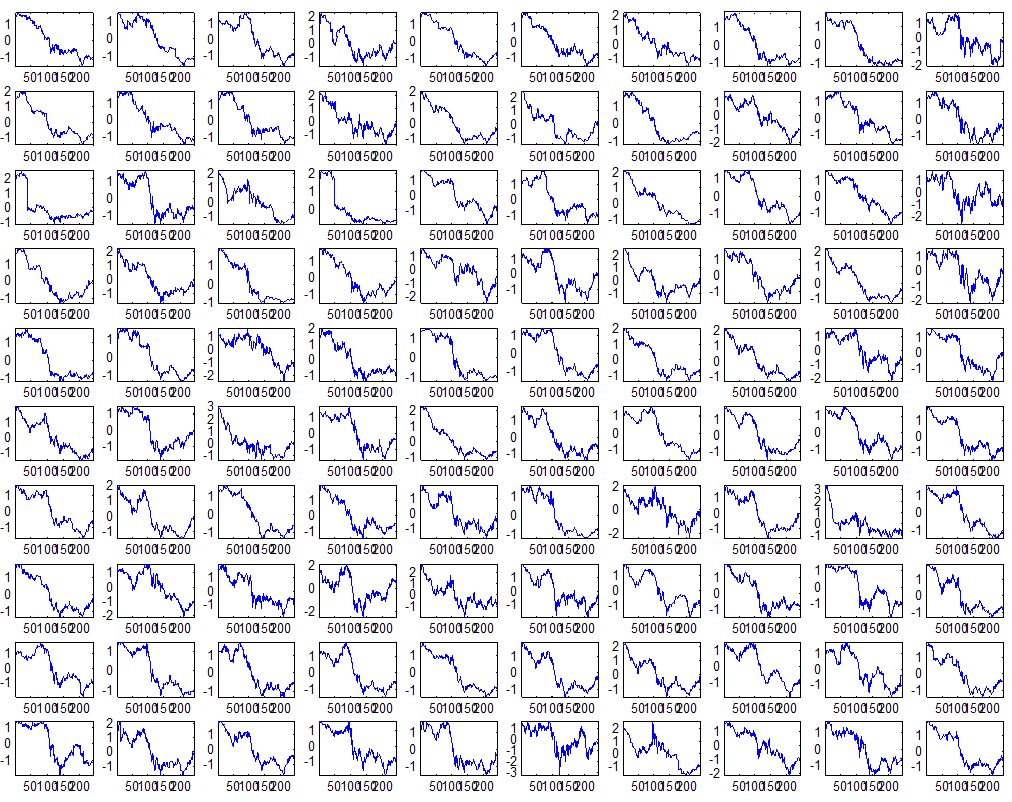
148 148
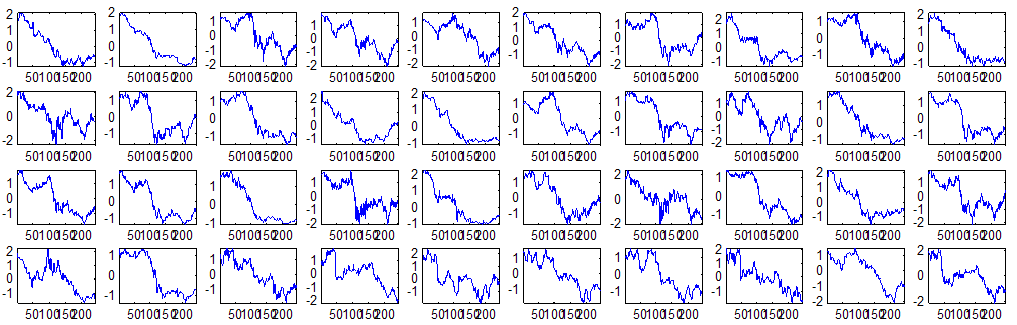
149 149
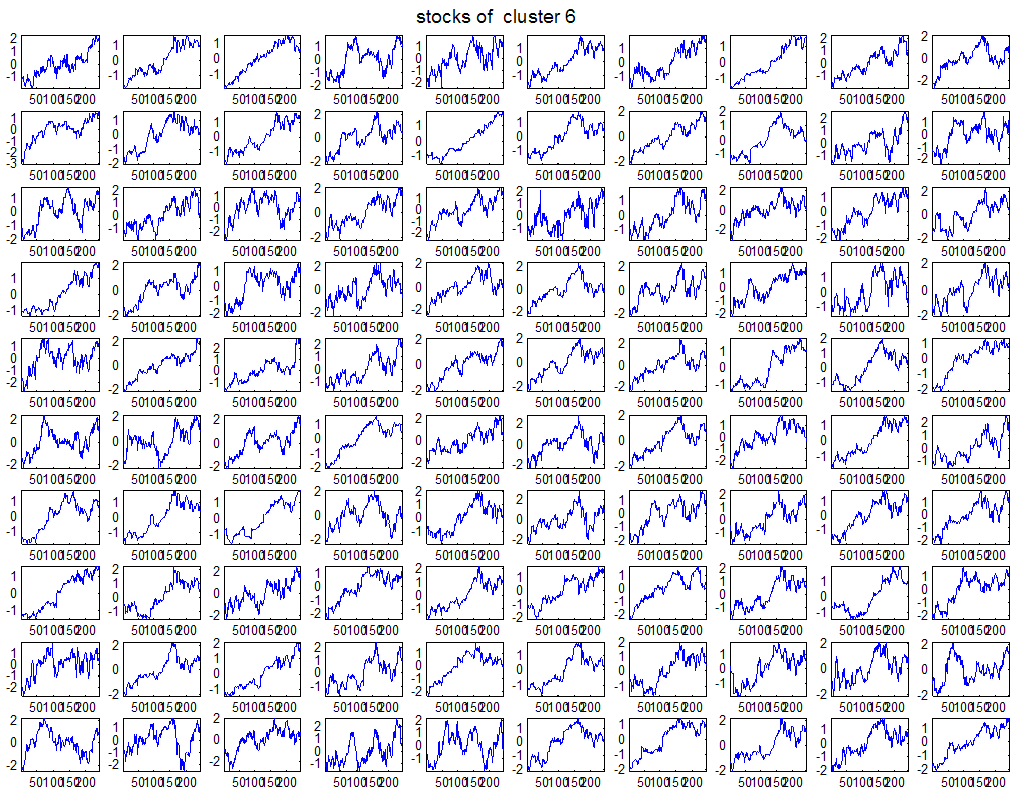
150 15
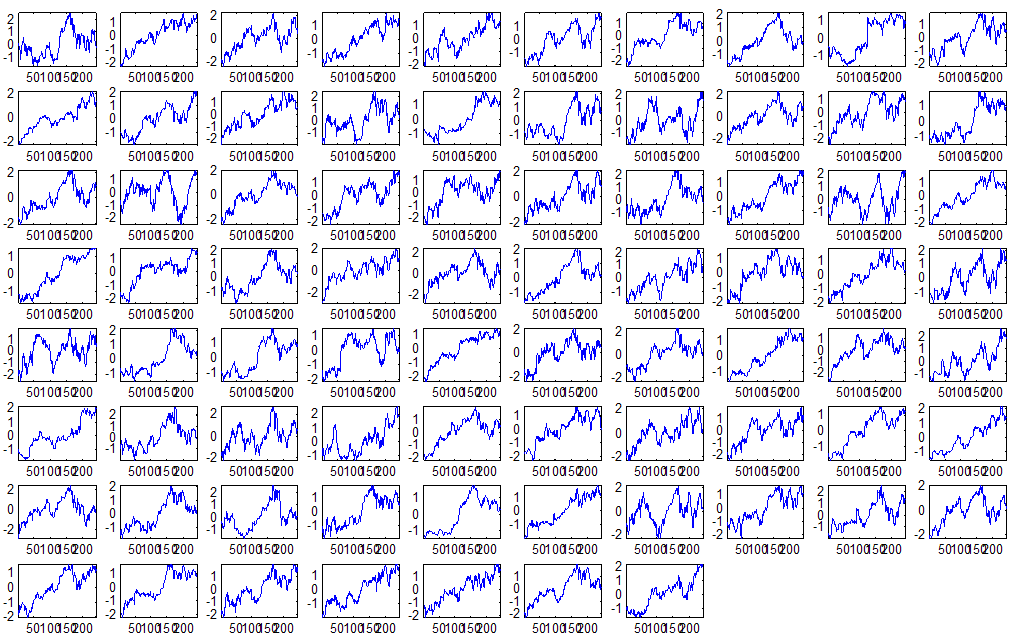
151 151
152 15 DTW k=8 Hierarchical clustering of 79 stocks - DTW distance- ward linkage clust1: 83 stocks, intra:7.4 clust: 57 stocks, intra: clust3: 63 stocks, intra: clust4: 114 stocks, intra: clust5: 67 stocks, intra: clust6: 63 stocks, intra: clust7: 64 stocks, intra: clust8: 81 stocks, intra:
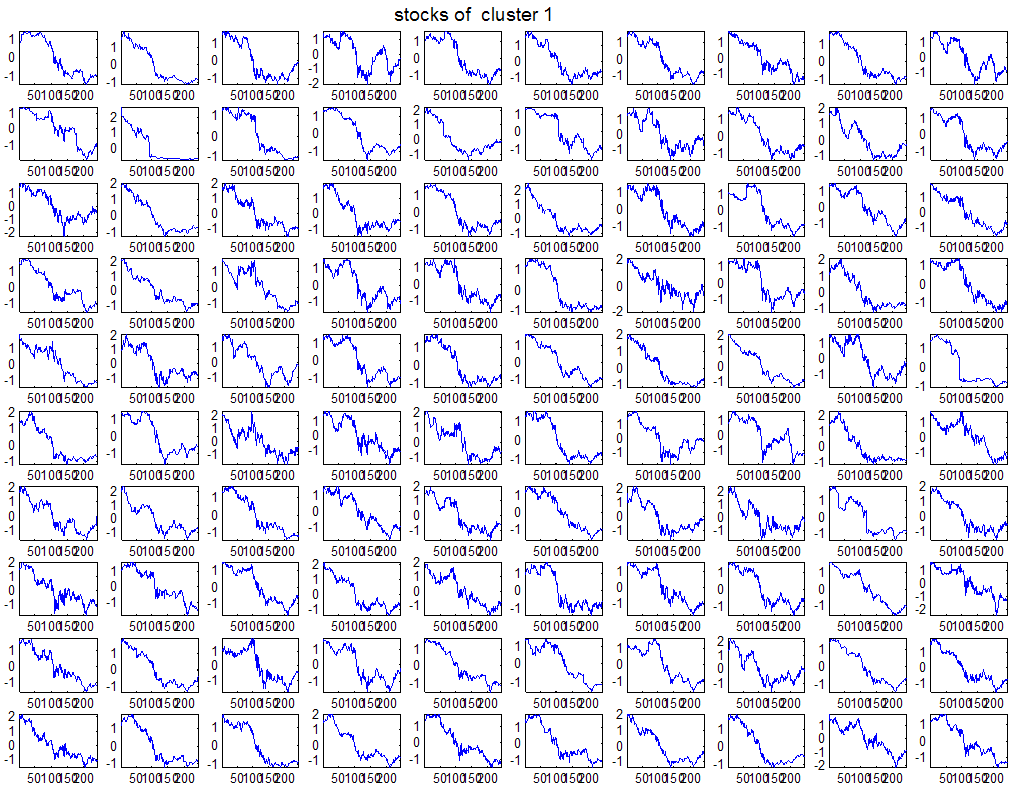
153 153
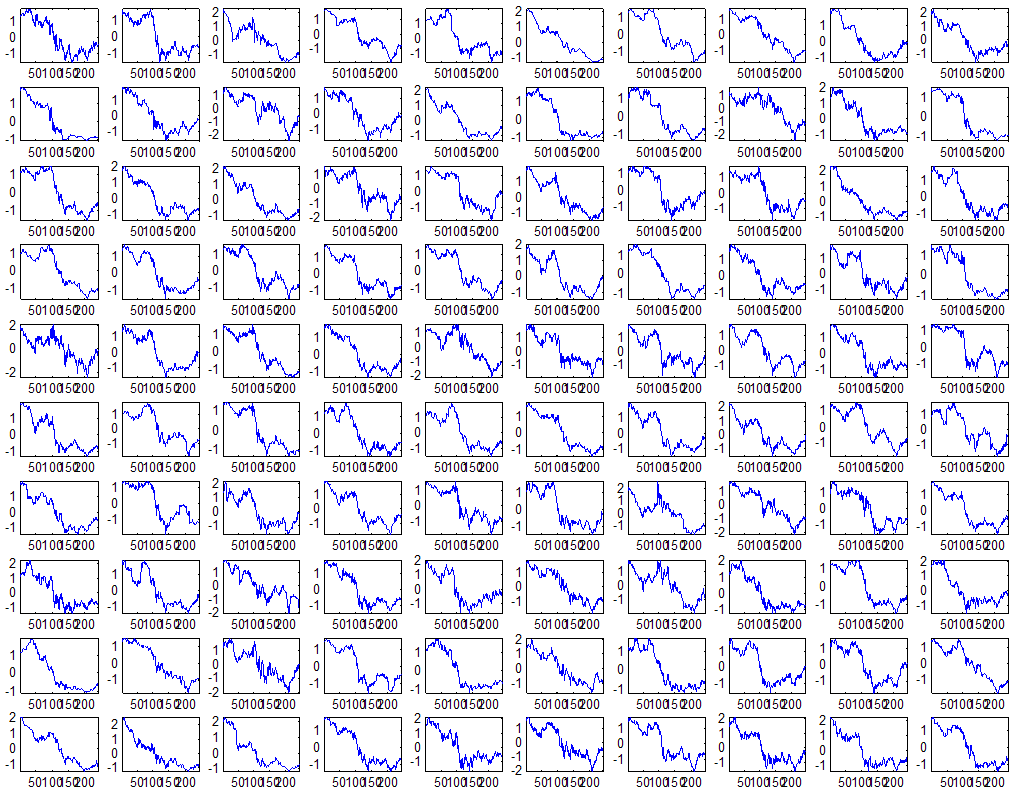
154 154
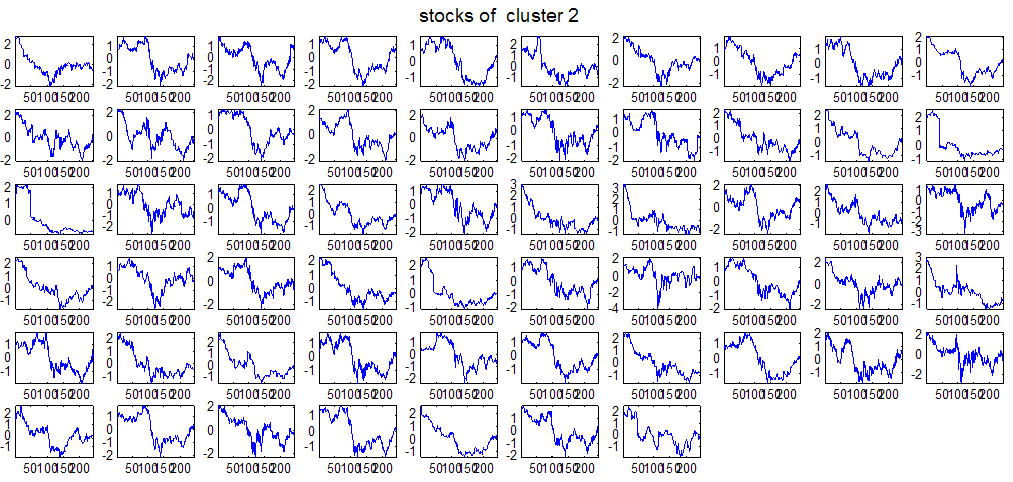
155 155
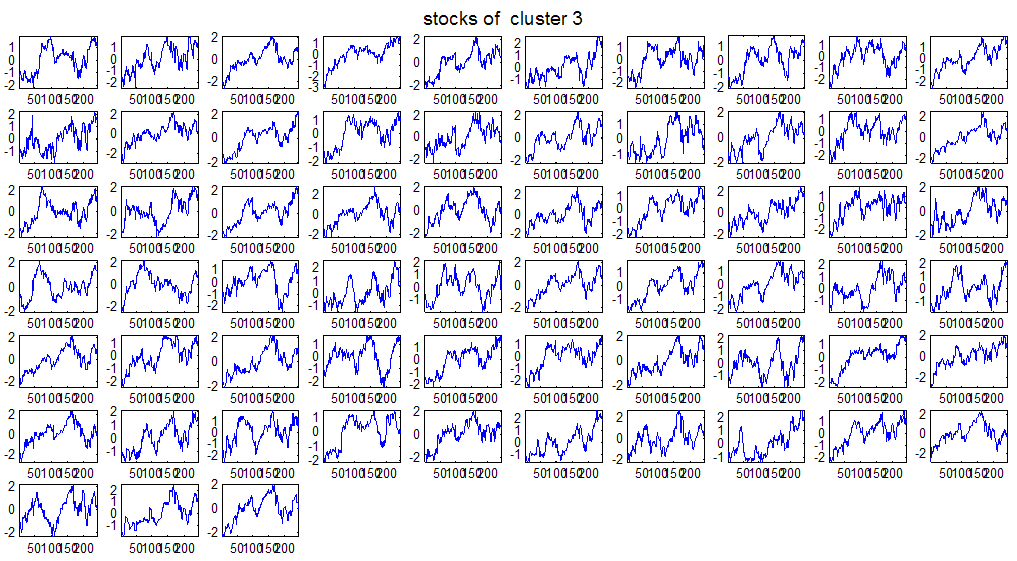
156 156

157 157
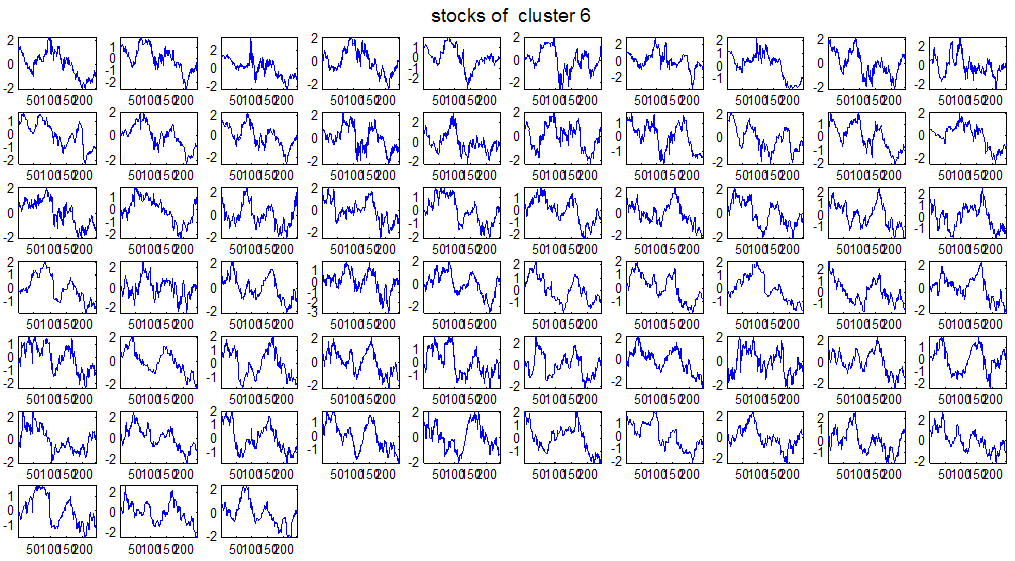
158 158
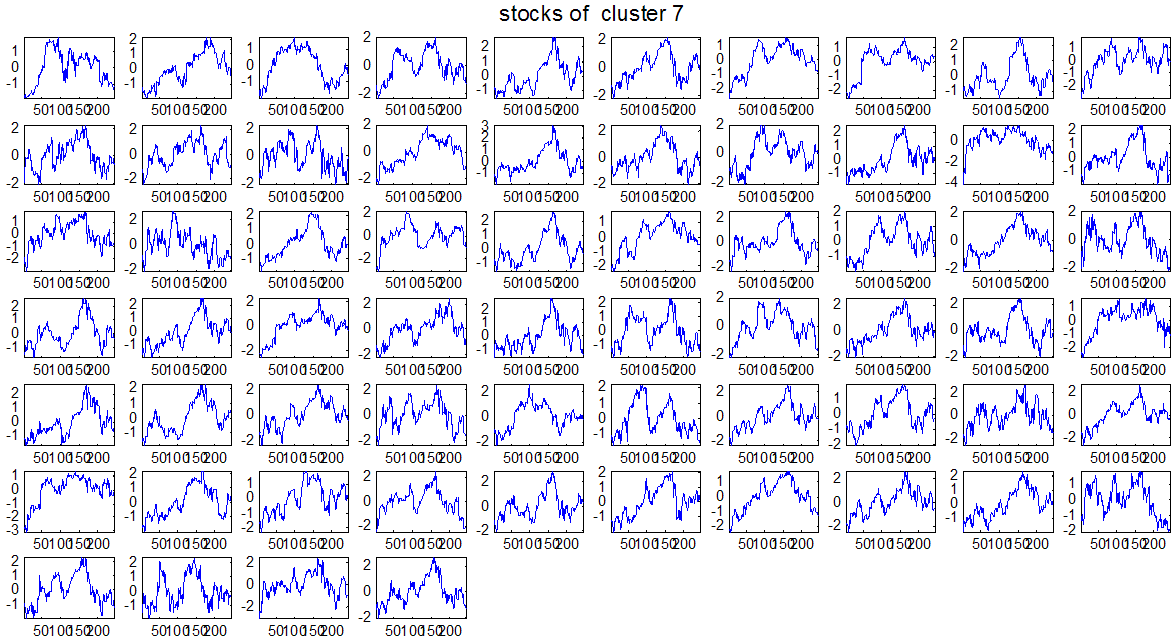
159 159
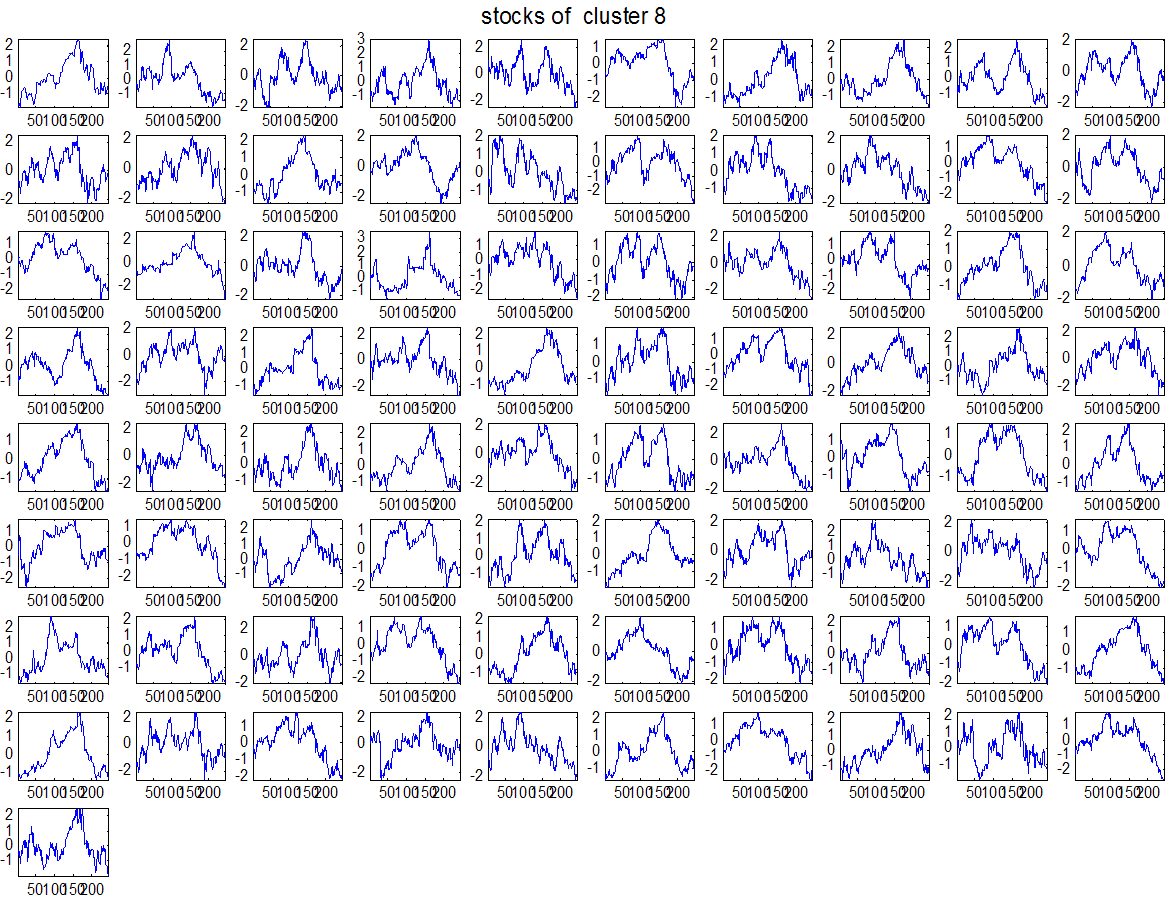
160 16

161 161 Dtw k=1 Hierarchical clustering of 79 stocks - DTW distance- ward linkage clust1: 19 stocks, intra:14. clust: 44 stocks, intra: clust3: 6 stocks, intra: clust4: 31 stocks, intra: clust5: 83 stocks, intra: clust6: 63 stocks, intra: clust7: 114 stocks, intra: clust8: 67 stocks, intra: clust9: 64 stocks, intra: clust1: 81 stocks, intra:
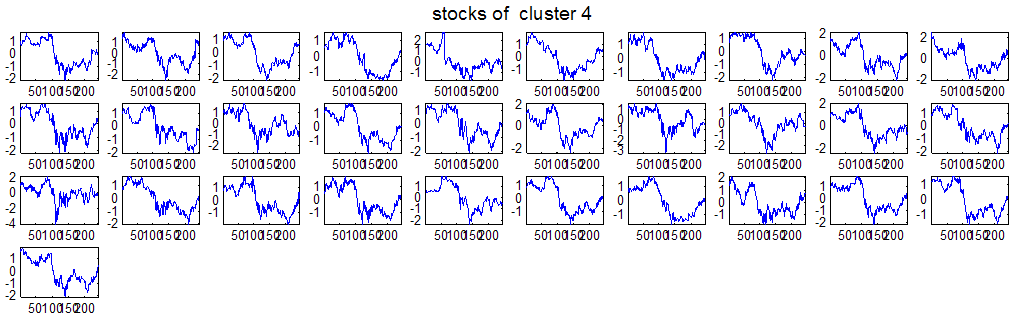
162 16
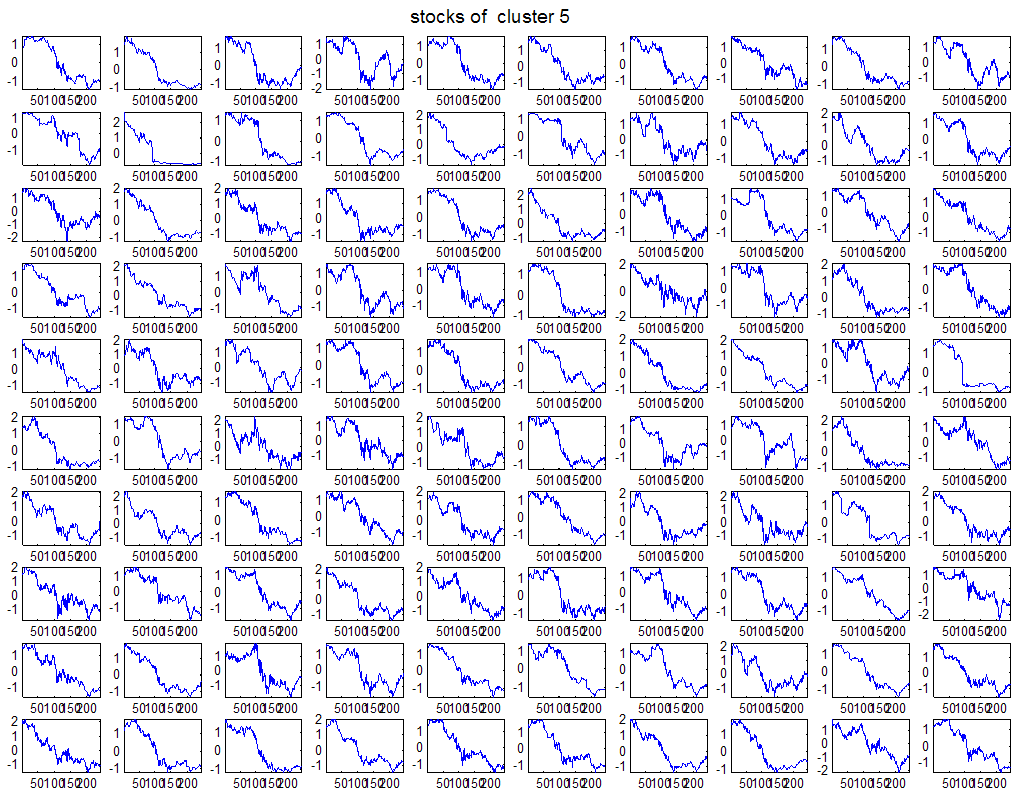
163 163
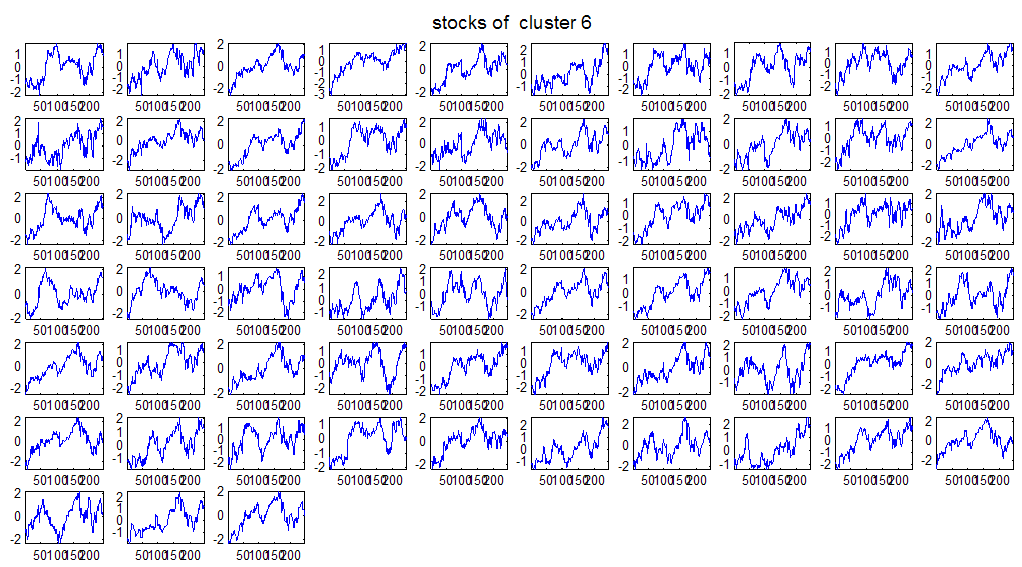
164 164
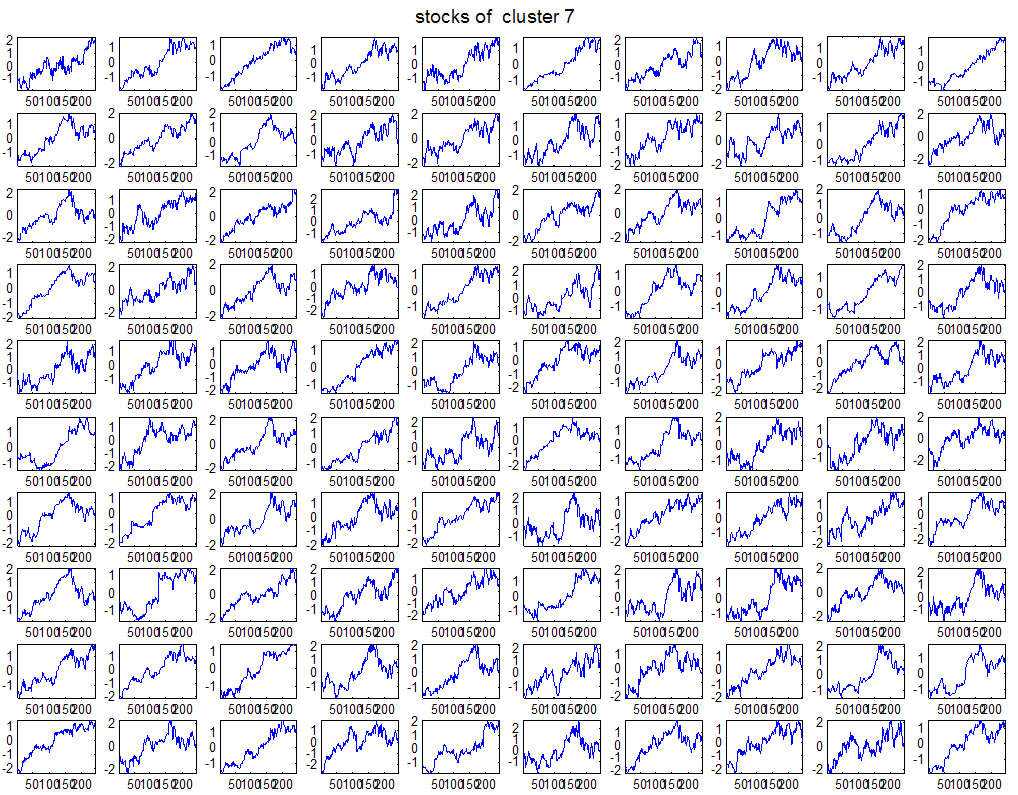
165 165
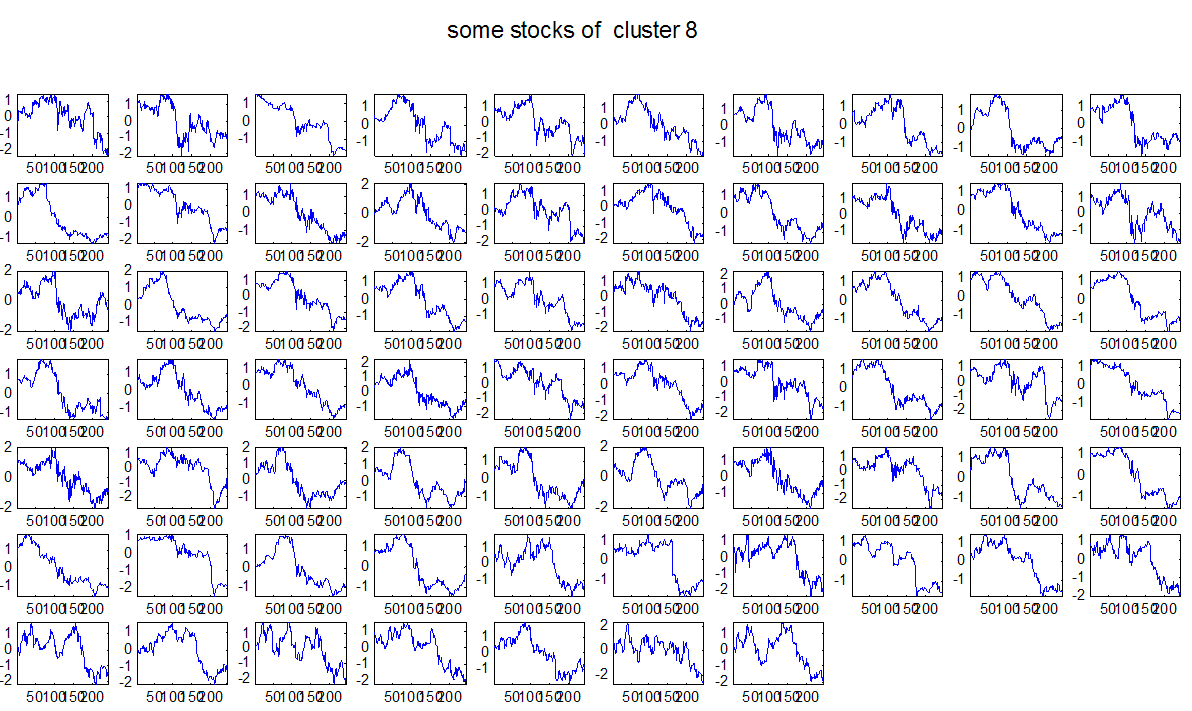
166 166
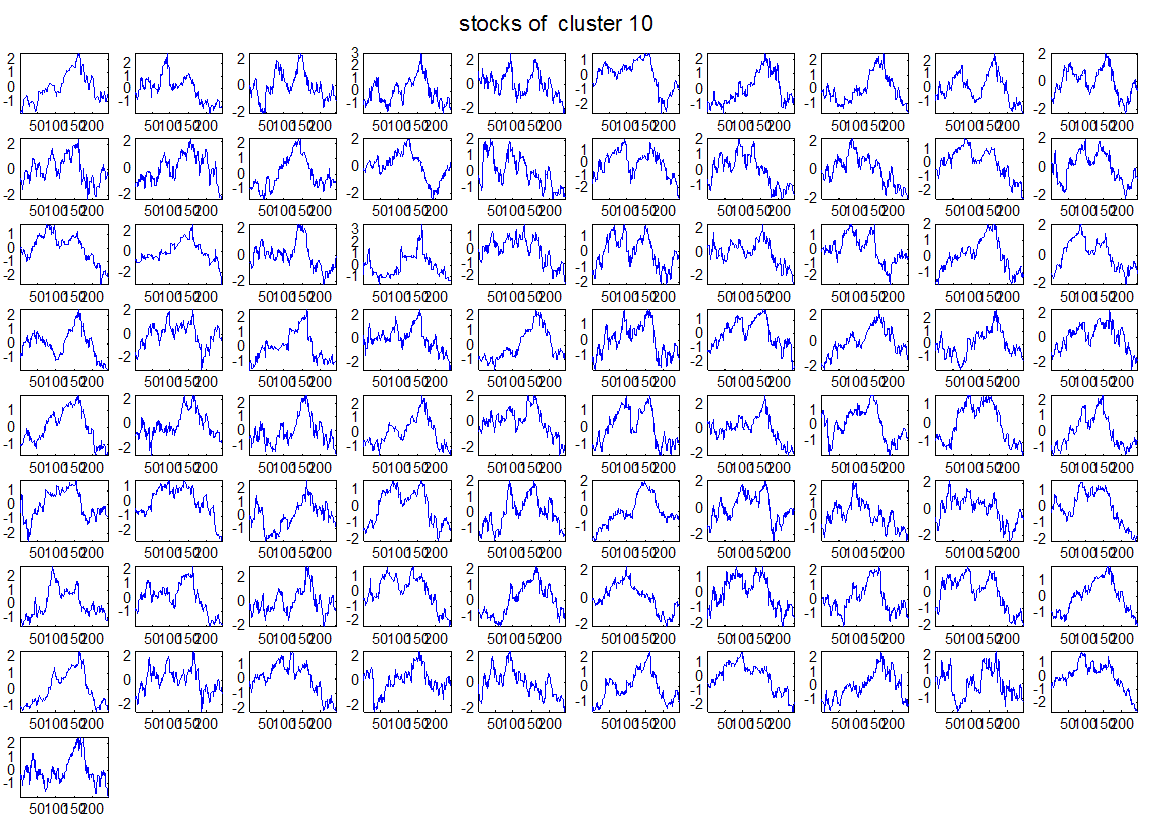
167 167
168 168 DTW k= Hierarchical clustering of 79 stocks - DTW distance- ward linkage clust1: 18 stocks, intra:71.59 clust: 6 stocks, intra:97.76 clust3: 31 stocks, intra:77.7 clust4: 3 stocks, intra: clust5: 6 stocks, intra: clust6: 13 stocks, intra: clust7: 35 stocks, intra: clust8: stocks, intra: clust9: 19 stocks, intra: clust13: 17 stocks, intra: clust1: 48 stocks, intra: clust14: 7 stocks, intra: clust11: 3 stocks, intra: clust15: 37 stocks, intra: clust1: 3 stocks, intra: clust16: 98 stocks, intra: clust17: 59 stocks, intra: clust18: 19 stocks, intra: clust19: 6 stocks, intra: clust: 31 stocks, intra:
169 169
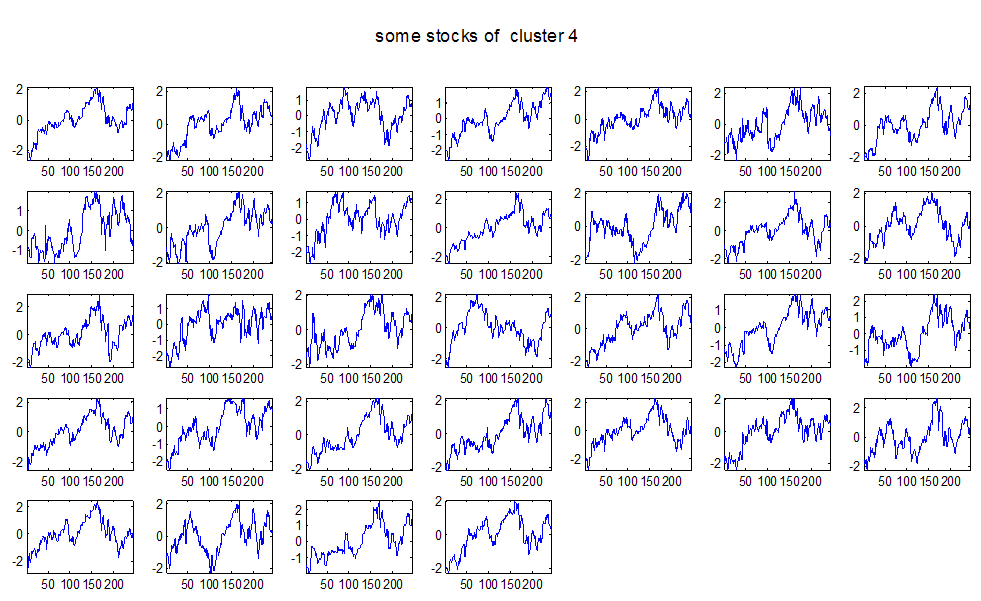
170 17
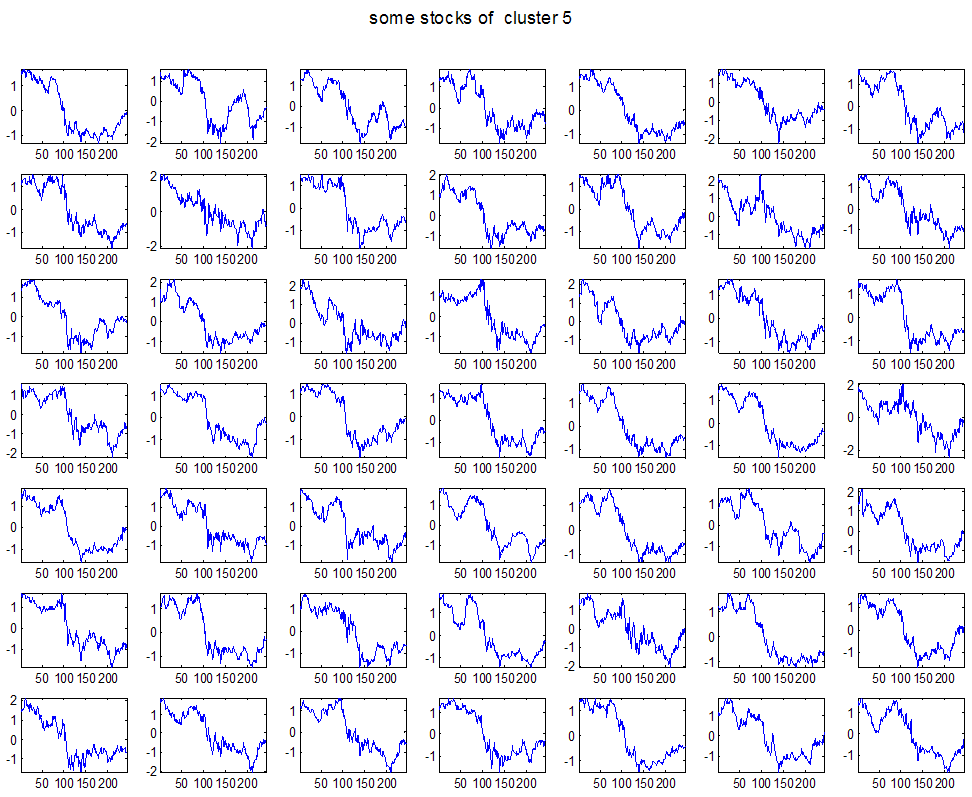
171 171
172 17
173 173
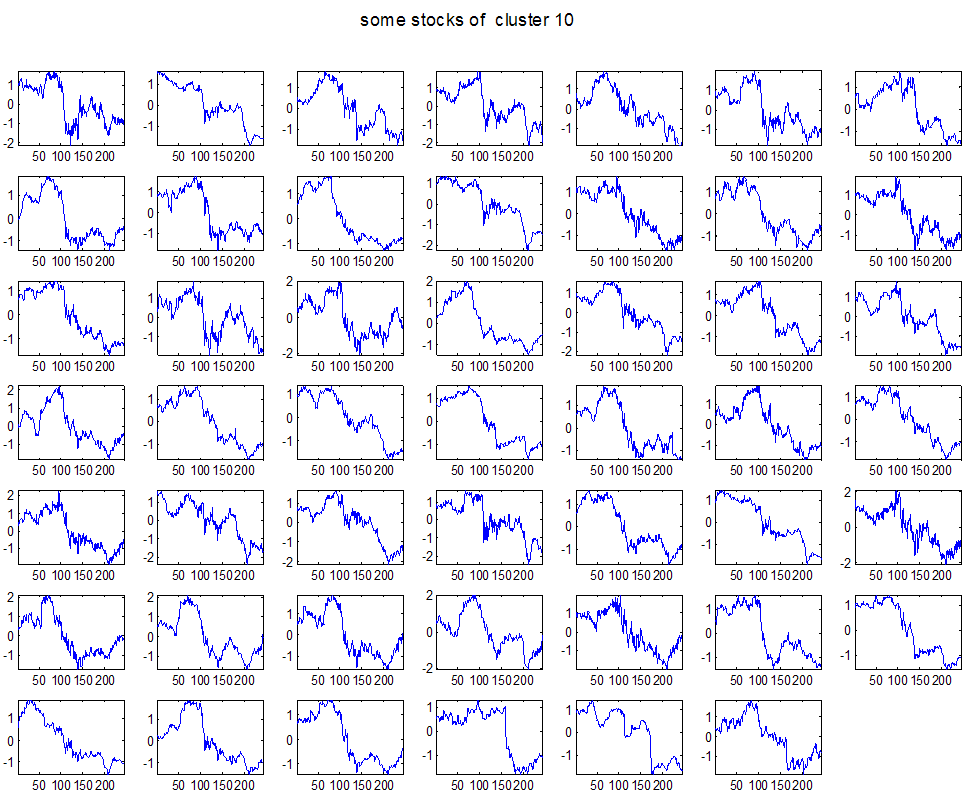
174 174
175 175
176 176
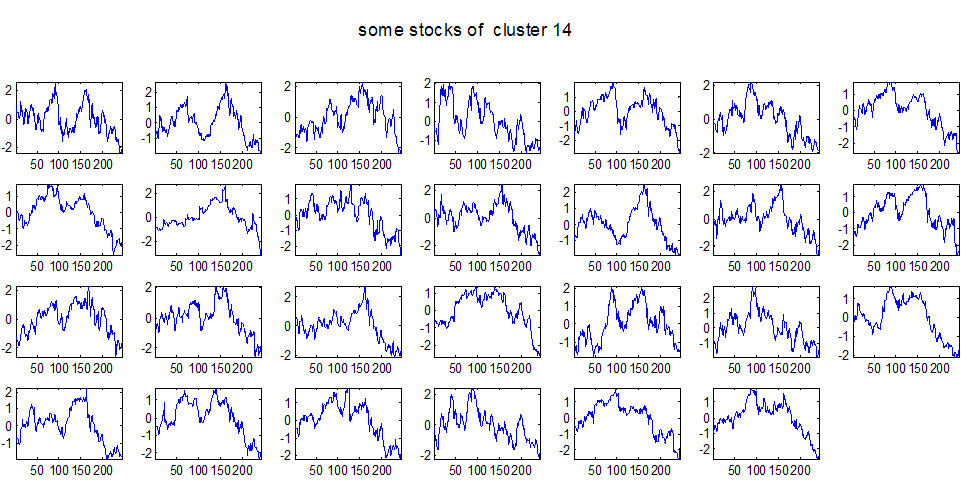
177 177
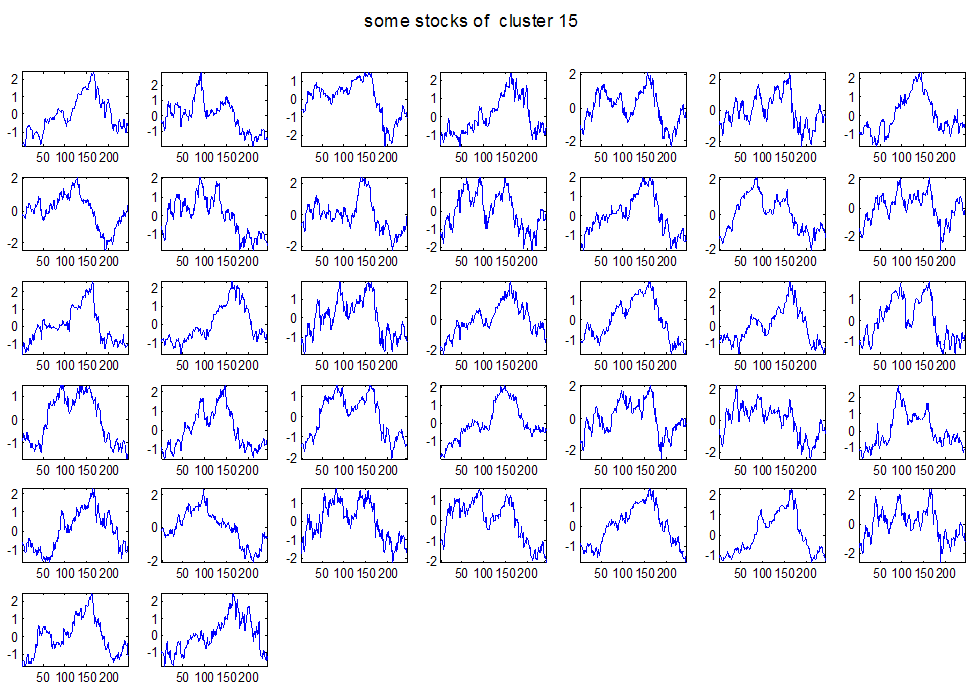
178 178
179 179
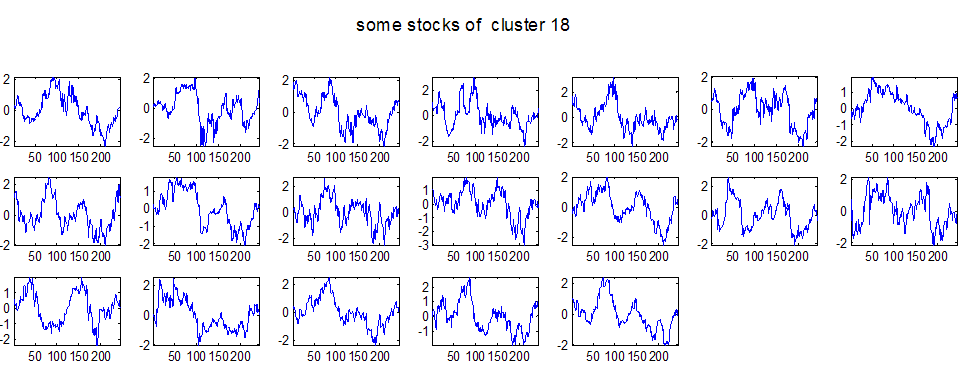
180 18
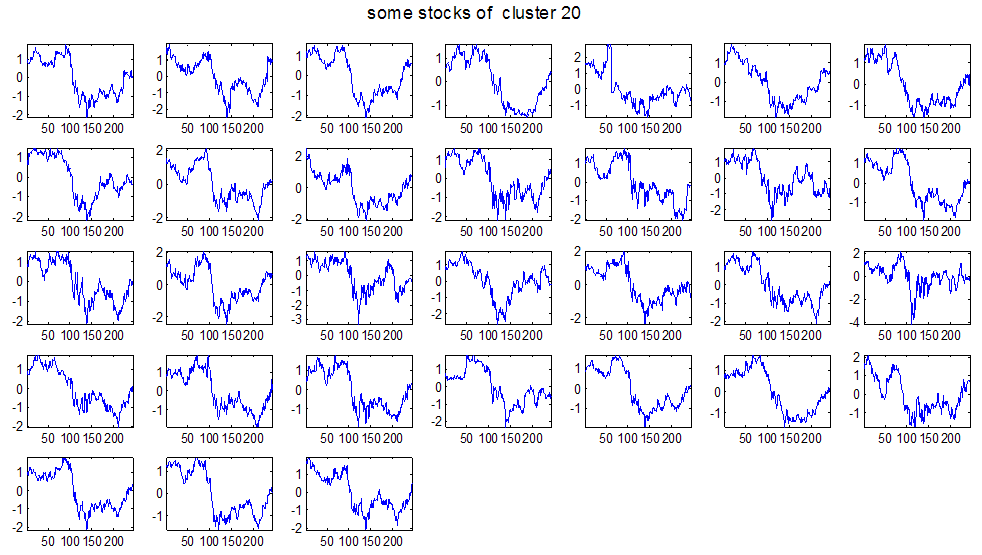
181 181

182 18. Συσταδοποίηση με χρήση της μεθοδολογίας επαναληπτικής εξαγωγής των outliers για τις υπόλοιπες συνδέσεις Σύνδεση Centroid : Αρχικός διαχωρισμός χωρίς την εφαρμογή της μεθοδολογίας: Εικόνα : αρχική συσταδοποίηση με σύνδεση centroid για κ=3 Μετά την εφαρμογή της μεθόδου: Εικόνα : Στιγμιότυπο της 34 ης επανάληψης της συσταδοποίησης με σύνδεση centroid για κ=3, n1=1 Σύνδεση median: Αρχικά δεδομένα Μετά την εφαρμογή της μεθόδου: Εικόνα : Συσταδοποίηση με σύνδεση median για κ=3, n1=
183 Πρόβλεψη (α) Πρόβλεψη με τη μέθοδο SMOreg real and predicted values real SMOreg Εικόνα: πρόβλεψη των 16 πρώτων μετοχών της συστάδας 3 από την ιεραρχική συσταδοποίηση με DTW, η μέση τιμή του MAPE όλων των μετοχών είναι 3.68%
184 184 real and predicted values real SMOreg Εικόνα: Πρόβλεψη των πρώτων μετοχών της συστάδας Ευκλείδεια απόσταση για κ=5, με μέση τιμή του MAPE όλων των μετοχών 4.63% 1 από την ιεραρχική συσταδοποίηση με την Εικόνα: Πρόβλεψη των 6 πρώτων μετοχών της συστάδας 1 από την ιεραρχική συσταδοποίηση με DTW για κ=, η μέση τιμή του MAPE όλων των μετοχών για 5 ημέρες είναι 6.16%
185 185 real and predicted values real SMOreg Εικόνα: Πρόβλεψη για 1 μέρες των 5 πρώτων μετοχών της συστάδας 1 που προέκυψε εκτελωντας τον k- means με κ=15. Ο μέσος όρος του σφάλματος πρόβλεψης για 5 μέρες είναι 5.%

186 186 (β) Σύγκριση των μεθόδων πρόβλεψης Για τη σύγκριση των μεθόδων, παρουσιάζονται μερικά ενδεικτικά αποτελέσματα των προβλέψεων υπό τη μορφή γραφημάτων και ενός πίνακα σφάλματος για όλες τις μεθόδους. Οι προβλέψεις έχουν γίνει για τις μετοχές που περιέχονται Στις συστάδες 1 και της ιεραρχικής συσταδοποίησης με DTW για κ Στις συστάδες 1 και 11 της ιεραρχικής συσταδοποίησης με DTW για κ 5 Iεραρχική συσταδοποίηση με DTW για κ=: Συστάδα 1-18 μετοχές Εικόνα: Πρόβλεψη με τη μέθοδο SMOreg με σφάλμα 4.95 %

187 187 Εικόνα: Πρόβλεψη με τη μέθοδο Exponential Smoothing με σφάλμα 3.13 % Εικόνα: Πρόβλεψη με τη μέθοδο ARIMA με σφάλμα 3.6 %
 Exp. m.5 ARIMA(1,,1) SMOreg LinearReg ΜΑPΕ 3.1 % 3.13 % 3.6 % 4.95 % 6.")
188 188 Εικόνα: Πρόβλεψη με τη μέθοδο Linear Regression με σφάλμα 6.51 % Εικόνα: Πρόβλεψη με τη συνδυασμένη μέθοδο με σφάλμα 3.1 % MyPred(.5,.35,.35,.5) Exp. m.5 ARIMA(1,,1) SMOreg LinearReg ΜΑPΕ 3.1 % 3.13 % 3.6 % 4.95 % 6.51 % Πίνακας: Σφάλματα για τη συστάδα 1

189 189 Συσταδοποίηση με την ιεραρχική DTW για k=5: Συστάδα 1-1 μετοχές Εικόνα: Πρόβλεψη με τη μέθοδο SMOreg με σφάλμα 7.38 % Εικόνα: Πρόβλεψη με τη μέθοδο Linear Regression με σφάλμα 5.1 %
190 19 Εικόνα: Πρόβλεψη με τη μέθοδο ARIMA με σφάλμα.63 % Εικόνα: Πρόβλεψη με τη μέθοδο Exponential Smoothing με σφάλμα.61 %
 LinearReg SMOreg ΜΑPΕ.61 %.63 % 4.57 % 5.11 % 7.")
191 191 Εικόνα: Πρόβλεψη με τη συνδυασμένη μέθοδο με σφάλμα 3.33 % Exp. Sm.5 ARIMA(1,,1) MyPred(.5,.35,.35,.5) LinearReg SMOreg ΜΑPΕ.61 %.63 % 4.57 % 5.11 % 7.38 % Πίνακας: Σφάλματα για τη συστάδα 1

192 19 Συστάδα μετοχές: Εικόνα: Πρόβλεψη με τη μέθοδο SMOreg με σφάλμα 6.16 % Εικόνα: Πρόβλεψη με τη μέθοδο ARIMA με σφάλμα 3.71 %

193 193 Εικόνα: Πρόβλεψη με τη μέθοδο Linear Regression με σφάλμα 8.41 % Εικόνα: Πρόβλεψη με τη μέθοδο Exponential Smoothing με σφάλμα 3.53%
 SMOreg LinearReg ΜΑPΕ 3.48 % 3.53 % 3.71 % 6.16 % 8.")
194 194 Εικόνα: Πρόβλεψη με τη συνδυασμένη μέθοδο με σφάλμα 3.48% MyPred(.5,.35,.35,.5) Exp. Sm.5 ARIMA(1,,1) SMOreg LinearReg ΜΑPΕ 3.48 % 3.53 % 3.71 % 6.16 % 8.41 % Πίνακας: Σφάλματα για τη συστάδα 11
ΟΜΑΔΕΣ. Δημιουργία Ομάδων
 Δημιουργία Ομάδων Μεθοδολογίες ομαδοποίησης δεδομένων: Μέθοδοι για την εύρεση των κατηγοριών και των υποκατηγοριών που σχηματίζουν τα δεδομένα του εκάστοτε προβλήματος. Ομαδοποίηση (clustering): εργαλείο
Δημιουργία Ομάδων Μεθοδολογίες ομαδοποίησης δεδομένων: Μέθοδοι για την εύρεση των κατηγοριών και των υποκατηγοριών που σχηματίζουν τα δεδομένα του εκάστοτε προβλήματος. Ομαδοποίηση (clustering): εργαλείο
Ποσοτικές Μέθοδοι στη Διοίκηση Επιχειρήσεων ΙΙ Σύνολο- Περιεχόμενο Μαθήματος
 Ποσοτικές Μέθοδοι στη Διοίκηση Επιχειρήσεων ΙΙ Σύνολο- Περιεχόμενο Μαθήματος Χιωτίδης Γεώργιος Τμήμα Λογιστικής και Χρηματοοικονομικής Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Ποσοτικές Μέθοδοι στη Διοίκηση Επιχειρήσεων ΙΙ Σύνολο- Περιεχόμενο Μαθήματος Χιωτίδης Γεώργιος Τμήμα Λογιστικής και Χρηματοοικονομικής Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής. Εξόρυξη Γνώσης από εδοµένα (Data Mining) Συσταδοποίηση. Γιάννης Θεοδωρίδης
 Συσταδοποίηση. Γιάννης Θεοδωρίδης") Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Συσταδοποίηση Γιάννης Θεοδωρίδης Οµάδα ιαχείρισης εδοµένων Εργαστήριο Πληροφοριακών Συστηµάτων http://isl.cs.unipi.gr/db
Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Συσταδοποίηση Γιάννης Θεοδωρίδης Οµάδα ιαχείρισης εδοµένων Εργαστήριο Πληροφοριακών Συστηµάτων http://isl.cs.unipi.gr/db
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος B http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος B http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 8: Ομαδοποίηση Μέρος B Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 8: Ομαδοποίηση Μέρος B Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΤΜΗΜΑ ΙΑΤΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ. Χατζηλιάδη Παναγιώτα Ευανθία
 ΜΠΣ «ΜΕΘΟΔΟΛΟΓΙΑ ΒΪΟΙΑΤΡΙΚΗΣ ΕΡΕΥΝΑΣ, ΒΙΟΣΤΑΤΙΣΤΙΚΗ ΚΑΙ ΚΛΙΝΙΚΗ ΒΙΟΠΛΗΡΟΦΟΡΙΚΗ» ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΤΜΗΜΑ ΙΑΤΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ «Ανάπτυξη λογισμικού σε γλώσσα προγραματισμού python για ομαδοποίηση
ΜΠΣ «ΜΕΘΟΔΟΛΟΓΙΑ ΒΪΟΙΑΤΡΙΚΗΣ ΕΡΕΥΝΑΣ, ΒΙΟΣΤΑΤΙΣΤΙΚΗ ΚΑΙ ΚΛΙΝΙΚΗ ΒΙΟΠΛΗΡΟΦΟΡΙΚΗ» ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΙΑΣ ΤΜΗΜΑ ΙΑΤΡΙΚΗΣ ΔΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ «Ανάπτυξη λογισμικού σε γλώσσα προγραματισμού python για ομαδοποίηση
Τεχνικές Μείωσης Διαστάσεων. Ειδικά θέματα ψηφιακής επεξεργασίας σήματος και εικόνας Σ. Φωτόπουλος- Α. Μακεδόνας
 Τεχνικές Μείωσης Διαστάσεων Ειδικά θέματα ψηφιακής επεξεργασίας σήματος και εικόνας Σ. Φωτόπουλος- Α. Μακεδόνας 1 Εισαγωγή Το μεγαλύτερο μέρος των δεδομένων που καλούμαστε να επεξεργαστούμε είναι πολυδιάστατα.
Τεχνικές Μείωσης Διαστάσεων Ειδικά θέματα ψηφιακής επεξεργασίας σήματος και εικόνας Σ. Φωτόπουλος- Α. Μακεδόνας 1 Εισαγωγή Το μεγαλύτερο μέρος των δεδομένων που καλούμαστε να επεξεργαστούμε είναι πολυδιάστατα.
ΠΕΡΙΕΧΟΜΕΝΑ. 1. Εισαγωγή Συνεχής ποσοτική εξαρτημένη μεταβλητή...66 Ενδεικτική εφαρμογή...68 ΛΙΓΑ ΛΟΓΙΑ ΓΙΑ ΤΟΥΣ ΣΥΓΓΡΑΦΕΙΣ...
 ΠΕΡΙΕΧΟΜΕΝΑ ΛΙΓΑ ΛΟΓΙΑ ΓΙΑ ΤΟΥΣ ΣΥΓΓΡΑΦΕΙΣ...................................... 11 ΠΡΟΛΟΓΟΣ..........................................................15 1. ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΧΕΙΡΗΣΙΑΚΗ ΑΝΑΛΥΤΙΚΗ, ΣΤΑ ΠΟΣΟΤΙΚΑ
ΠΕΡΙΕΧΟΜΕΝΑ ΛΙΓΑ ΛΟΓΙΑ ΓΙΑ ΤΟΥΣ ΣΥΓΓΡΑΦΕΙΣ...................................... 11 ΠΡΟΛΟΓΟΣ..........................................................15 1. ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΕΠΙΧΕΙΡΗΣΙΑΚΗ ΑΝΑΛΥΤΙΚΗ, ΣΤΑ ΠΟΣΟΤΙΚΑ
Διπλωματική Εργασία: «Συγκριτική Μελέτη Μηχανισμών Εκτίμησης Ελλιπούς Πληροφορίας σε Ασύρματα Δίκτυα Αισθητήρων»
 Τμήμα Πληροφορικής και Τηλεπικοινωνιών Πρόγραμμα Μεταπτυχιακών Σπουδών Διπλωματική Εργασία: «Συγκριτική Μελέτη Μηχανισμών Εκτίμησης Ελλιπούς Πληροφορίας σε Ασύρματα Δίκτυα Αισθητήρων» Αργυροπούλου Αιμιλία
Τμήμα Πληροφορικής και Τηλεπικοινωνιών Πρόγραμμα Μεταπτυχιακών Σπουδών Διπλωματική Εργασία: «Συγκριτική Μελέτη Μηχανισμών Εκτίμησης Ελλιπούς Πληροφορίας σε Ασύρματα Δίκτυα Αισθητήρων» Αργυροπούλου Αιμιλία
HMY 795: Αναγνώριση Προτύπων
 HMY 795: Αναγνώριση Προτύπων Διάλεξη 3 Επιλογή μοντέλου Επιλογή μοντέλου Θεωρία αποφάσεων Επιλογή μοντέλου δεδομένα επικύρωσης Η επιλογή του είδους του μοντέλου που θα χρησιμοποιηθεί σε ένα πρόβλημα (π.χ.
HMY 795: Αναγνώριση Προτύπων Διάλεξη 3 Επιλογή μοντέλου Επιλογή μοντέλου Θεωρία αποφάσεων Επιλογή μοντέλου δεδομένα επικύρωσης Η επιλογή του είδους του μοντέλου που θα χρησιμοποιηθεί σε ένα πρόβλημα (π.χ.
E[ (x- ) ]= trace[(x-x)(x- ) ]
![E[ (x- ) ]= trace[(x-x)(x- ) ]](/thumbs/55/36021260.jpg "E[ (x- ) ]= trace[(x-x)(x- ) ]") 1 ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ Σε αυτό το μέρος της πτυχιακής θα ασχοληθούμε λεπτομερώς με το φίλτρο kalman και θα δούμε μια καινούρια έκδοση του φίλτρου πάνω στην εφαρμογή της γραμμικής εκτίμησης διακριτού
1 ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ Σε αυτό το μέρος της πτυχιακής θα ασχοληθούμε λεπτομερώς με το φίλτρο kalman και θα δούμε μια καινούρια έκδοση του φίλτρου πάνω στην εφαρμογή της γραμμικής εκτίμησης διακριτού
ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ
 1 ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ Σε αυτό το μέρος της πτυχιακής θα ασχοληθούμε λεπτομερώς με το φίλτρο kalman και θα δούμε μια καινούρια έκδοση του φίλτρου πάνω στην εφαρμογή της γραμμικής εκτίμησης διακριτού
1 ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ Σε αυτό το μέρος της πτυχιακής θα ασχοληθούμε λεπτομερώς με το φίλτρο kalman και θα δούμε μια καινούρια έκδοση του φίλτρου πάνω στην εφαρμογή της γραμμικής εκτίμησης διακριτού
Αναγνώριση Προτύπων Ι
 Αναγνώριση Προτύπων Ι Ενότητα 1: Μέθοδοι Αναγνώρισης Προτύπων Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Αναγνώριση Προτύπων Ι Ενότητα 1: Μέθοδοι Αναγνώρισης Προτύπων Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται
Ομαδοποίηση ΙΙ (Clustering)
") Ομαδοποίηση ΙΙ (Clustering) Πασχάλης Θρήσκος PhD Λάρισα 2016-2017 pthriskos@mnec.gr Αλγόριθμοι ομαδοποίησης Επίπεδοι αλγόριθμοι Αρχίζουμε με μια τυχαία ομαδοποίηση Βελτιώνουμε επαναληπτικά KMeans Ομαδοποίηση
Ομαδοποίηση ΙΙ (Clustering) Πασχάλης Θρήσκος PhD Λάρισα 2016-2017 pthriskos@mnec.gr Αλγόριθμοι ομαδοποίησης Επίπεδοι αλγόριθμοι Αρχίζουμε με μια τυχαία ομαδοποίηση Βελτιώνουμε επαναληπτικά KMeans Ομαδοποίηση
E [ -x ^2 z] = E[x z]
![E [ -x ^2 z] = E[x z]](/thumbs/69/60621176.jpg "E [ -x ^2 z] = E[x z]") 1 1.ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ Σε αυτήν την διάλεξη θα πάμε στο φίλτρο με περισσότερες λεπτομέρειες, και θα παράσχουμε μια νέα παραγωγή για το φίλτρο Kalman, αυτή τη φορά βασισμένο στην ιδέα της γραμμικής
1 1.ΦΙΛΤΡΟ KALMAN ΔΙΑΚΡΙΤΟΥ ΧΡΟΝΟΥ Σε αυτήν την διάλεξη θα πάμε στο φίλτρο με περισσότερες λεπτομέρειες, και θα παράσχουμε μια νέα παραγωγή για το φίλτρο Kalman, αυτή τη φορά βασισμένο στην ιδέα της γραμμικής
MBR Ελάχιστο Περιβάλλον Ορθογώνιο (Minimum Bounding Rectangle) Το µικρότερο ορθογώνιο που περιβάλλει πλήρως το αντικείµενο 7 Παραδείγµατα MBR 8 6.
 Το µικρότερο ορθογώνιο που περιβάλλει πλήρως το αντικείµενο 7 Παραδείγµατα MBR 8 6.") Πανεπιστήµιο Πειραιώς - Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Εξόρυξη Γνώσης από χωρικά δεδοµένα (κεφ. 8) Γιάννης Θεοδωρίδης Νίκος Πελέκης http://isl.cs.unipi.gr/db/courses/dwdm Περιεχόµενα
Πανεπιστήµιο Πειραιώς - Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Εξόρυξη Γνώσης από χωρικά δεδοµένα (κεφ. 8) Γιάννης Θεοδωρίδης Νίκος Πελέκης http://isl.cs.unipi.gr/db/courses/dwdm Περιεχόµενα
Χρονολογικές Σειρές (Time Series) Lecture notes Φ.Κουντούρη 2008
 Lecture notes Φ.Κουντούρη 2008") Χρονολογικές Σειρές (Time Series) Lecture notes Φ.Κουντούρη 2008 1 Τύποι Οικονομικών Δεδομένων Τα οικονομικά δεδομένα που χρησιμοποιούνται για την εξέταση οικονομικών φαινομένων μπορεί να έχουν τις ακόλουθες
Χρονολογικές Σειρές (Time Series) Lecture notes Φ.Κουντούρη 2008 1 Τύποι Οικονομικών Δεδομένων Τα οικονομικά δεδομένα που χρησιμοποιούνται για την εξέταση οικονομικών φαινομένων μπορεί να έχουν τις ακόλουθες
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος Δ http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος Δ http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Χρονικές σειρές 2 Ο μάθημα: Εισαγωγή στις χρονοσειρές
 Χρονικές σειρές 2 Ο μάθημα: Εισαγωγή στις χρονοσειρές Εαρινό εξάμηνο 2018-2019 μήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή, Α.Π.Θ. & Οικονομικό μήμα, Πανεπιστήμιο
Χρονικές σειρές 2 Ο μάθημα: Εισαγωγή στις χρονοσειρές Εαρινό εξάμηνο 2018-2019 μήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή, Α.Π.Θ. & Οικονομικό μήμα, Πανεπιστήμιο
Εξόρυξη Δεδομένων. Συσταδοποίηση: Βασικές Έννοιες και Μέθοδοι
 Εξόρυξη Δεδομένων Συσταδοποίηση: Βασικές Έννοιες και Μέθοδοι 1 2 Συσταδοποίηση: Βασικές Έννοιες και Μέθοδοι Εισαγωγή στη Συσταδοποίηση Μέθοδοι Διαχωρισμού Ιεραρχικές Μέθοδοι Μέθοδοι Πυκνότητας Αξιολόγηση
Εξόρυξη Δεδομένων Συσταδοποίηση: Βασικές Έννοιες και Μέθοδοι 1 2 Συσταδοποίηση: Βασικές Έννοιες και Μέθοδοι Εισαγωγή στη Συσταδοποίηση Μέθοδοι Διαχωρισμού Ιεραρχικές Μέθοδοι Μέθοδοι Πυκνότητας Αξιολόγηση
Χρήστος Ι. Σχοινάς Αν. Καθηγητής ΔΠΘ. Συμπληρωματικές σημειώσεις για το μάθημα: «Επιχειρησιακή Έρευνα ΙΙ»
 Χρήστος Ι. Σχοινάς Αν. Καθηγητής ΔΠΘ Συμπληρωματικές σημειώσεις για το μάθημα: «Επιχειρησιακή Έρευνα ΙΙ» 2 ΔΥΝΑΜΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Προβλήματα ελάχιστης συνεκτικότητας δικτύου Το πρόβλημα της ελάχιστης
Χρήστος Ι. Σχοινάς Αν. Καθηγητής ΔΠΘ Συμπληρωματικές σημειώσεις για το μάθημα: «Επιχειρησιακή Έρευνα ΙΙ» 2 ΔΥΝΑΜΙΚΟΣ ΠΡΟΓΡΑΜΜΑΤΙΣΜΟΣ Προβλήματα ελάχιστης συνεκτικότητας δικτύου Το πρόβλημα της ελάχιστης
Εφαρμοσμένη Στατιστική: Συντελεστής συσχέτισης. Παλινδρόμηση απλή γραμμική, πολλαπλή γραμμική
 ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΜΕΡΟΣ B Δημήτρης Κουγιουμτζής e-mal: dkugu@auth.gr Ιστοσελίδα αυτού του τμήματος του μαθήματος: http://uer.auth.gr/~dkugu/teach/cvltraport/dex.html Εφαρμοσμένη Στατιστική:
ΕΦΑΡΜΟΣΜΕΝΗ ΣΤΑΤΙΣΤΙΚΗ ΑΝΑΛΥΣΗ ΜΕΡΟΣ B Δημήτρης Κουγιουμτζής e-mal: dkugu@auth.gr Ιστοσελίδα αυτού του τμήματος του μαθήματος: http://uer.auth.gr/~dkugu/teach/cvltraport/dex.html Εφαρμοσμένη Στατιστική:
Συνολοκλήρωση και μηχανισμός διόρθωσης σφάλματος
 ΜΑΘΗΜΑ 10 ο Συνολοκλήρωση και μηχανισμός διόρθωσης σφάλματος Η μέθοδος της συνολοκλήρωσης είναι ένας τρόπος με τον οποίο μπορούμε να εκτιμήσουμε τη μακροχρόνια σχέση ισορροπίας που υπάρχει μεταξύ δύο ή
ΜΑΘΗΜΑ 10 ο Συνολοκλήρωση και μηχανισμός διόρθωσης σφάλματος Η μέθοδος της συνολοκλήρωσης είναι ένας τρόπος με τον οποίο μπορούμε να εκτιμήσουμε τη μακροχρόνια σχέση ισορροπίας που υπάρχει μεταξύ δύο ή
Εισόδημα Κατανάλωση 1500 500 1600 600 1300 450 1100 400 600 250 700 275 900 300 800 352 850 400 1100 500
 Εισόδημα Κατανάλωση 1500 500 1600 600 1300 450 1100 400 600 250 700 275 900 300 800 352 850 400 1100 500 Πληθυσμός Δείγμα Δείγμα Δείγμα Ο ρόλος της Οικονομετρίας Οικονομική Θεωρία Διατύπωση της
Εισόδημα Κατανάλωση 1500 500 1600 600 1300 450 1100 400 600 250 700 275 900 300 800 352 850 400 1100 500 Πληθυσμός Δείγμα Δείγμα Δείγμα Ο ρόλος της Οικονομετρίας Οικονομική Θεωρία Διατύπωση της
Εξόρυξη Γνώσης από Βιολογικά εδομένα
 Παρουσίαση Διπλωματικής Εργασίας Εξόρυξη Γνώσης από Βιολογικά εδομένα Καρυπίδης Γεώργιος (Μ27/03) Επιβλέπων Καθηγητής: Ιωάννης Βλαχάβας MIS Πανεπιστήμιο Μακεδονίας Φεβρουάριος 2005 Εξόρυξη Γνώσης από Βιολογικά
Παρουσίαση Διπλωματικής Εργασίας Εξόρυξη Γνώσης από Βιολογικά εδομένα Καρυπίδης Γεώργιος (Μ27/03) Επιβλέπων Καθηγητής: Ιωάννης Βλαχάβας MIS Πανεπιστήμιο Μακεδονίας Φεβρουάριος 2005 Εξόρυξη Γνώσης από Βιολογικά
10. Μη-κατευθυνόμενη ταξινόμηση ΚΥΡΊΩΣ ΜΈΡΗ ΔΕΥ
 ΚΥΡΊΩΣ ΜΈΡΗ ΔΕΥ 1 2 3 1 ΚΑΤΗΓΟΡΊΕΣ ΤΑΞΙΝΌΜΗΣΗΣ Κατευθυνόμενη ταξινόμηση (supervised classification) Μη-κατευθυνόμενη ταξινόμηση (unsupervised classification) Γραμμική: Μη-Γραμμική: Ιεραρχική: Επιμεριστική:
ΚΥΡΊΩΣ ΜΈΡΗ ΔΕΥ 1 2 3 1 ΚΑΤΗΓΟΡΊΕΣ ΤΑΞΙΝΌΜΗΣΗΣ Κατευθυνόμενη ταξινόμηση (supervised classification) Μη-κατευθυνόμενη ταξινόμηση (unsupervised classification) Γραμμική: Μη-Γραμμική: Ιεραρχική: Επιμεριστική:
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 07-08 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 07-08 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
Χρονοσειρές, Μέρος Β 1 Πρόβλεψη Χρονικών Σειρών
 Χρονοσειρές, Μέρος Β Πρόβλεψη Χρονικών Σειρών Ο βασικός σκοπός της μελέτης των μοντέλων για χρονικές σειρές (όπως AR, MA, ARMA, ARIMA, SARIMA) είναι η πρόβλεψη (predicio, forecasig) Η πρόβλεψη των μελλοντικών
Χρονοσειρές, Μέρος Β Πρόβλεψη Χρονικών Σειρών Ο βασικός σκοπός της μελέτης των μοντέλων για χρονικές σειρές (όπως AR, MA, ARMA, ARIMA, SARIMA) είναι η πρόβλεψη (predicio, forecasig) Η πρόβλεψη των μελλοντικών
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΔΙΚΤΥΑ
 ΘΕΜΑ 1 ο (2,5 μονάδες) ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΔΙΚΤΥΑ Τελικές εξετάσεις Πέμπτη 21 Ιουνίου 2012 16:30-19:30 Υποθέστε ότι θέλουμε
ΘΕΜΑ 1 ο (2,5 μονάδες) ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΔΙΚΤΥΑ Τελικές εξετάσεις Πέμπτη 21 Ιουνίου 2012 16:30-19:30 Υποθέστε ότι θέλουμε
Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων
 Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων Εισηγητής: ρ Ηλίας Ζαφειρόπουλος Εισαγωγή Ιατρικά δεδοµένα: Συλλογή Οργάνωση Αξιοποίηση Data Mining ιαχείριση εδοµένων Εκπαίδευση
Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων Εισηγητής: ρ Ηλίας Ζαφειρόπουλος Εισαγωγή Ιατρικά δεδοµένα: Συλλογή Οργάνωση Αξιοποίηση Data Mining ιαχείριση εδοµένων Εκπαίδευση
Αποθήκες εδοµένων και Εξόρυξη Γνώσης (Data Warehousing & Data Mining)
") Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Αποθήκες εδοµένων και Εξόρυξη Γνώσης (Data Warehousing & Data Mining) Εξόρυξη Γνώσης από Χωρικά εδοµένα (spatial data mining) Γιάννης Θεοδωρίδης, Νίκος Πελέκης
Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Αποθήκες εδοµένων και Εξόρυξη Γνώσης (Data Warehousing & Data Mining) Εξόρυξη Γνώσης από Χωρικά εδοµένα (spatial data mining) Γιάννης Θεοδωρίδης, Νίκος Πελέκης
ανάλυση δεδομένων χρονικών σειρών»
 ΤΕΧΝΟΛΟΓΙΚΟΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΣΧΟΛΗ ΔΙΟΙΚΗΣΗΣ ΚΑΙ ΟΙΚΟΝΟΜΙΑΣ (ΠΡΩΗΝ )ΤΜΗΜΑ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΣΤΗΝ ΔΙΟΙΚΗΣΗ ΚΑΙ ΣΤΗΝ ΟΙΚΟΝΟΜΙΑ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗ ΕΠΙΧΕΙΡΗΣΕΩΝ «Εφαρμογή τεχνικών Εξόρυξης
ΤΕΧΝΟΛΟΓΙΚΟΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΣΧΟΛΗ ΔΙΟΙΚΗΣΗΣ ΚΑΙ ΟΙΚΟΝΟΜΙΑΣ (ΠΡΩΗΝ )ΤΜΗΜΑ ΕΦΑΡΜΟΓΩΝ ΠΛΗΡΟΦΟΡΙΚΗΣ ΣΤΗΝ ΔΙΟΙΚΗΣΗ ΚΑΙ ΣΤΗΝ ΟΙΚΟΝΟΜΙΑ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗ ΕΠΙΧΕΙΡΗΣΕΩΝ «Εφαρμογή τεχνικών Εξόρυξης
Σέργιος Θεοδωρίδης Κωνσταντίνος Κουτρούμπας. Version 2
 Σέργιος Θεοδωρίδης Κωνσταντίνος Κουτρούμπας Verson ΧΑΡΤΟΓΡΑΦΗΣΗ ΤΟΥ ΧΩΡΟΥ ΤΩΝ ΤΑΞΙΝΟΜΗΤΩΝ Ταξινομητές Ταξινομητές συναρτ. διάκρισης Ταξινομητές επιφανειών απόφ. Παραμετρικοί ταξινομητές Μη παραμετρικοί
Σέργιος Θεοδωρίδης Κωνσταντίνος Κουτρούμπας Verson ΧΑΡΤΟΓΡΑΦΗΣΗ ΤΟΥ ΧΩΡΟΥ ΤΩΝ ΤΑΞΙΝΟΜΗΤΩΝ Ταξινομητές Ταξινομητές συναρτ. διάκρισης Ταξινομητές επιφανειών απόφ. Παραμετρικοί ταξινομητές Μη παραμετρικοί
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 7: Ομαδοποίηση Μέρος Α Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 7: Ομαδοποίηση Μέρος Α Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
Αναγνώριση Προτύπων Ι
 Αναγνώριση Προτύπων Ι Ενότητα 2: Δομικά Συστήματα Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Αναγνώριση Προτύπων Ι Ενότητα 2: Δομικά Συστήματα Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Βασίλειος Μαχαιράς Πολιτικός Μηχανικός Ph.D.
 Βασίλειος Μαχαιράς Πολιτικός Μηχανικός Ph.D. Μη γραμμικός προγραμματισμός: μέθοδοι μονοδιάστατης ελαχιστοποίησης Πανεπιστήμιο Θεσσαλίας Σχολή Θετικών Επιστημών ΤμήμαΠληροφορικής Διάλεξη 6 η /2017 Τι παρουσιάστηκε
Βασίλειος Μαχαιράς Πολιτικός Μηχανικός Ph.D. Μη γραμμικός προγραμματισμός: μέθοδοι μονοδιάστατης ελαχιστοποίησης Πανεπιστήμιο Θεσσαλίας Σχολή Θετικών Επιστημών ΤμήμαΠληροφορικής Διάλεξη 6 η /2017 Τι παρουσιάστηκε
ΤΜΗΜΑΕΠΙΧΕΙΡΗΜΑΤΙΚΟΥΣΧΕΔΙΑΣΜΟΥ & ΠΛΗΡΟΦΟΡΙΑΚΩΝΣΥΣΤΗΜΑΤΩΝ
 ΤΜΗΜΑΕΠΙΧΕΙΡΗΜΑΤΙΚΟΥΣΧΕΔΙΑΣΜΟΥ & ΠΛΗΡΟΦΟΡΙΑΚΩΝΣΥΣΤΗΜΑΤΩΝ ΤΕΧΝΙΚΕΣ ΠΡΟΒΛΕΨΕΩΝ& ΕΛΕΓΧΟΥ ΜΑΘΗΜΑ ΘΕΩΡΙΑΣ-ΣΤΑΣΙΜΕΣ ΔΙΑΔΙΚΑΣΙΕΣ-ΥΠΟΔΕΙΓΜΑΤΑ SARIMA (sp,sd,qs) ARIMA (p,d,q) ΕΠΙΧ - Τεχνικές Προβλέψεων & Ελέγχου
ΤΜΗΜΑΕΠΙΧΕΙΡΗΜΑΤΙΚΟΥΣΧΕΔΙΑΣΜΟΥ & ΠΛΗΡΟΦΟΡΙΑΚΩΝΣΥΣΤΗΜΑΤΩΝ ΤΕΧΝΙΚΕΣ ΠΡΟΒΛΕΨΕΩΝ& ΕΛΕΓΧΟΥ ΜΑΘΗΜΑ ΘΕΩΡΙΑΣ-ΣΤΑΣΙΜΕΣ ΔΙΑΔΙΚΑΣΙΕΣ-ΥΠΟΔΕΙΓΜΑΤΑ SARIMA (sp,sd,qs) ARIMA (p,d,q) ΕΠΙΧ - Τεχνικές Προβλέψεων & Ελέγχου
Πανεπιστήμιο Κύπρου Πολυτεχνική Σχολή
 Πανεπιστήμιο Κύπρου Πολυτεχνική Σχολή Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών ΗΜΜΥ 795: ΑΝΑΓΝΩΡΙΣΗ ΠΡΟΤΥΠΩΝ Ακαδημαϊκό έτος 2010-11 Χειμερινό Εξάμηνο Practice final exam 1. Έστω ότι για
Πανεπιστήμιο Κύπρου Πολυτεχνική Σχολή Τμήμα Ηλεκτρολόγων Μηχανικών και Μηχανικών Υπολογιστών ΗΜΜΥ 795: ΑΝΑΓΝΩΡΙΣΗ ΠΡΟΤΥΠΩΝ Ακαδημαϊκό έτος 2010-11 Χειμερινό Εξάμηνο Practice final exam 1. Έστω ότι για
Τεχνικές Προβλέψεων Αυτοπαλινδρομικά Μοντέλα Κινητού Μέσου Όρου (ARIMA)
") ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Μονάδα Προβλέψεων & Στρατηγικής Forecasting & Strategy Unit Τεχνικές Προβλέψεων Αυτοπαλινδρομικά Μοντέλα Κινητού Μέσου
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ ΜΗΧΑΝΙΚΩΝ ΚΑΙ ΜΗΧΑΝΙΚΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Μονάδα Προβλέψεων & Στρατηγικής Forecasting & Strategy Unit Τεχνικές Προβλέψεων Αυτοπαλινδρομικά Μοντέλα Κινητού Μέσου
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 10: Ομαδοποίηση Μέρος Δ Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 10: Ομαδοποίηση Μέρος Δ Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΕΠΕΞΕΡΓΑΣΙΑ & ΑΝΑΛΥΣΗ ΙΑΤΡΙΚΩΝ ΣΗΜΑΤΩΝ
 BIOMIG Medical Image Processing, Algorithms and Applications http://biomig.ntua.gr ΕΠΕΞΕΡΓΑΣΙΑ & ΑΝΑΛΥΣΗ ΙΑΤΡΙΚΩΝ ΣΗΜΑΤΩΝ Εισαγωγή στην MRI και στην fmri ΔΡ. Γ. ΜΑΤΣΟΠΟΥΛΟΣ ΑΝ. ΚΑΘΗΓΗΤΗΣ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ
BIOMIG Medical Image Processing, Algorithms and Applications http://biomig.ntua.gr ΕΠΕΞΕΡΓΑΣΙΑ & ΑΝΑΛΥΣΗ ΙΑΤΡΙΚΩΝ ΣΗΜΑΤΩΝ Εισαγωγή στην MRI και στην fmri ΔΡ. Γ. ΜΑΤΣΟΠΟΥΛΟΣ ΑΝ. ΚΑΘΗΓΗΤΗΣ ΣΧΟΛΗ ΗΛΕΚΤΡΟΛΟΓΩΝ
ΑΠΟ ΤΟ ΔΕΙΓΜΑ ΣΤΟΝ ΠΛΗΘΥΣΜΟ
 ΑΠΟ ΤΟ ΔΕΙΓΜΑ ΣΤΟΝ ΠΛΗΘΥΣΜΟ Το ενδιαφέρον επικεντρώνεται πάντα στον πληθυσμό Το δείγμα χρησιμεύει για εξαγωγή συμπερασμάτων για τον πληθυσμό π.χ. το ετήσιο εισόδημα των κατοίκων μιας περιοχής Τα στατιστικά
ΑΠΟ ΤΟ ΔΕΙΓΜΑ ΣΤΟΝ ΠΛΗΘΥΣΜΟ Το ενδιαφέρον επικεντρώνεται πάντα στον πληθυσμό Το δείγμα χρησιμεύει για εξαγωγή συμπερασμάτων για τον πληθυσμό π.χ. το ετήσιο εισόδημα των κατοίκων μιας περιοχής Τα στατιστικά
ΔΙΑΧΩΡΙΣΤΙΚΗ ΟΜΑΔΟΠΟΙΗΣΗ
 ΔΙΑΧΩΡΙΣΤΙΚΗ ΟΜΑΔΟΠΟΙΗΣΗ Εισαγωγή Τεχνικές διαχωριστικής ομαδοποίησης: Ν πρότυπα k ομάδες Ν>>k Συνήθως k καθορίζεται από χρήστη Διαχωριστικές τεχνικές: επιτρέπουν πρότυπα να μετακινούνται από ομάδα σε
ΔΙΑΧΩΡΙΣΤΙΚΗ ΟΜΑΔΟΠΟΙΗΣΗ Εισαγωγή Τεχνικές διαχωριστικής ομαδοποίησης: Ν πρότυπα k ομάδες Ν>>k Συνήθως k καθορίζεται από χρήστη Διαχωριστικές τεχνικές: επιτρέπουν πρότυπα να μετακινούνται από ομάδα σε
Παραβίασητωνβασικώνυποθέσεωντηςπαλινδρόμησης (Violation of the assumptions of the classical linear regression model)
") ΜΑΘΗΜΑ 4 ο 1 Παραβίασητωνβασικώνυποθέσεωντηςπαλινδρόμησης (Violation of the assumptions of the classical linear regression model) Αυτοσυσχέτιση (Serial Correlation) Lagrange multiplier test of residual
ΜΑΘΗΜΑ 4 ο 1 Παραβίασητωνβασικώνυποθέσεωντηςπαλινδρόμησης (Violation of the assumptions of the classical linear regression model) Αυτοσυσχέτιση (Serial Correlation) Lagrange multiplier test of residual
ΚΕΦΑΛΑΙΟ 5. Κύκλος Ζωής Εφαρμογών ΕΝΟΤΗΤΑ 2. Εφαρμογές Πληροφορικής. Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών
 44 Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών Διδακτικοί στόχοι Σκοπός του κεφαλαίου είναι οι μαθητές να κατανοήσουν τα βήματα που ακολουθούνται κατά την ανάπτυξη μιας εφαρμογής.
44 Διδακτικές ενότητες 5.1 Πρόβλημα και υπολογιστής 5.2 Ανάπτυξη εφαρμογών Διδακτικοί στόχοι Σκοπός του κεφαλαίου είναι οι μαθητές να κατανοήσουν τα βήματα που ακολουθούνται κατά την ανάπτυξη μιας εφαρμογής.
ΠΑΡΟΥΣΙΑΣΗ ΣΤΑΤΙΣΤΙΚΩΝ ΔΕΔΟΜΕΝΩΝ
 ο Κεφάλαιο: Στατιστική ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΚΑΙ ΟΡΙΣΜΟΙ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ Πληθυσμός: Λέγεται ένα σύνολο στοιχείων που θέλουμε να εξετάσουμε με ένα ή περισσότερα χαρακτηριστικά. Μεταβλητές X: Ονομάζονται
ο Κεφάλαιο: Στατιστική ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΚΑΙ ΟΡΙΣΜΟΙ ΣΤΗ ΣΤΑΤΙΣΤΙΚΗ ΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ Πληθυσμός: Λέγεται ένα σύνολο στοιχείων που θέλουμε να εξετάσουμε με ένα ή περισσότερα χαρακτηριστικά. Μεταβλητές X: Ονομάζονται
ΟΙΚΟΝΟΜΕΤΡΙΑ. Παπάνα Αγγελική
 ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 2: Ανασκόπηση βασικών εννοιών Στατιστικής και Πιθανοτήτων Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana
ΟΙΚΟΝΟΜΕΤΡΙΑ Ενότητα 2: Ανασκόπηση βασικών εννοιών Στατιστικής και Πιθανοτήτων Παπάνα Αγγελική Μεταδιδακτορική ερευνήτρια, ΑΠΘ E-mail: angeliki.papana@gmail.com, agpapana@auth.gr Webpage: http://users.auth.gr/agpapana
Ομαδοποίηση Ι (Clustering)
") Ομαδοποίηση Ι (Clustering) Πασχάλης Θρήσκος PhD Λάρισα 2016-2017 pthriskos@mnec.gr Αλγόριθμοι ομαδοποίησης Επίπεδοι αλγόριθμοι Αρχίζουμε με μια τυχαία ομαδοποίηση Βελτιώνουμε επαναληπτικά KMeans Ομαδοποίηση
Ομαδοποίηση Ι (Clustering) Πασχάλης Θρήσκος PhD Λάρισα 2016-2017 pthriskos@mnec.gr Αλγόριθμοι ομαδοποίησης Επίπεδοι αλγόριθμοι Αρχίζουμε με μια τυχαία ομαδοποίηση Βελτιώνουμε επαναληπτικά KMeans Ομαδοποίηση
ΕΛΕΓΧΟΣ ΠΑΡΑΓΩΓΙΚΩΝ ΔΙΕΡΓΑΣΙΩΝ
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα ΕΛΕΓΧΟΣ ΠΑΡΑΓΩΓΙΚΩΝ ΔΙΕΡΓΑΣΙΩΝ Ενότητα: Αναγνώριση Διεργασίας - Προσαρμοστικός Έλεγχος (Process Identification) Αλαφοδήμος Κωνσταντίνος
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Ανώτατο Εκπαιδευτικό Ίδρυμα Πειραιά Τεχνολογικού Τομέα ΕΛΕΓΧΟΣ ΠΑΡΑΓΩΓΙΚΩΝ ΔΙΕΡΓΑΣΙΩΝ Ενότητα: Αναγνώριση Διεργασίας - Προσαρμοστικός Έλεγχος (Process Identification) Αλαφοδήμος Κωνσταντίνος
Εξόρυξη Γνώσης από εδοµένα (Data Mining) Συσταδοποίηση
 Συσταδοποίηση") Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Συσταδοποίηση (clustering) Γιάννης Θεοδωρίδης, Νίκος Πελέκης Οµάδα ιαχείρισης εδοµένων Εργαστήριο Πληροφοριακών Συστηµάτων
Πανεπιστήµιο Πειραιώς Τµήµα Πληροφορικής Εξόρυξη Γνώσης από εδοµένα (Data Mining) Συσταδοποίηση (clustering) Γιάννης Θεοδωρίδης, Νίκος Πελέκης Οµάδα ιαχείρισης εδοµένων Εργαστήριο Πληροφοριακών Συστηµάτων
ΚΕΦΑΛΑΙΟ 18. 18 Μηχανική Μάθηση
 ΚΕΦΑΛΑΙΟ 18 18 Μηχανική Μάθηση Ένα φυσικό ή τεχνητό σύστηµα επεξεργασίας πληροφορίας συµπεριλαµβανοµένων εκείνων µε δυνατότητες αντίληψης, µάθησης, συλλογισµού, λήψης απόφασης, επικοινωνίας και δράσης
ΚΕΦΑΛΑΙΟ 18 18 Μηχανική Μάθηση Ένα φυσικό ή τεχνητό σύστηµα επεξεργασίας πληροφορίας συµπεριλαµβανοµένων εκείνων µε δυνατότητες αντίληψης, µάθησης, συλλογισµού, λήψης απόφασης, επικοινωνίας και δράσης
Στασιμότητα χρονοσειρών Νόθα αποτελέσματα-spurious regression Ο έλεγχος στασιμότητας είναι απαραίτητος ώστε η στοχαστική ανάλυση να οδηγεί σε ασφαλή
 Χρονικές σειρές 12 Ο μάθημα: Έλεγχοι στασιμότητας ΑΝΑΚΕΦΑΛΑΙΩΣΗ: Εκτίμηση παραμέτρων γραμμικών μοντέλων Συνάρτηση μερικής αυτοσυσχέτισης Εαρινό εξάμηνο 2018-2019 Τμήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική
Χρονικές σειρές 12 Ο μάθημα: Έλεγχοι στασιμότητας ΑΝΑΚΕΦΑΛΑΙΩΣΗ: Εκτίμηση παραμέτρων γραμμικών μοντέλων Συνάρτηση μερικής αυτοσυσχέτισης Εαρινό εξάμηνο 2018-2019 Τμήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutra@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutra@fme.aegea.gr Τηλ: 7035468 Θα μελετήσουμε
ΣΗΜΑΤΑ ΚΑΙ ΣΥΣΤΗΜΑΤΑ Ι
 ΣΗΜΑΤΑ ΚΑΙ ΣΥΣΤΗΜΑΤΑ Ι Προσέγγιση και Ομοιότητα Σημάτων Επιμέλεια: Πέτρος Π. Γρουμπός Καθηγητής Γεώργιος Α. Βασκαντήρας Υπ. Διδάκτορας Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Άδειες Χρήσης
ΣΗΜΑΤΑ ΚΑΙ ΣΥΣΤΗΜΑΤΑ Ι Προσέγγιση και Ομοιότητα Σημάτων Επιμέλεια: Πέτρος Π. Γρουμπός Καθηγητής Γεώργιος Α. Βασκαντήρας Υπ. Διδάκτορας Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Άδειες Χρήσης
Γραμμικός Προγραμματισμός Μέθοδος Simplex
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ Επιχειρησιακή Έρευνα Γραμμικός Προγραμματισμός Μέθοδος Simplex Η παρουσίαση προετοιμάστηκε από τον Ν.Α. Παναγιώτου Περιεχόμενα Παρουσίασης 1. Πρότυπη Μορφή ΓΠ 2. Πινακοποίηση
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ Επιχειρησιακή Έρευνα Γραμμικός Προγραμματισμός Μέθοδος Simplex Η παρουσίαση προετοιμάστηκε από τον Ν.Α. Παναγιώτου Περιεχόμενα Παρουσίασης 1. Πρότυπη Μορφή ΓΠ 2. Πινακοποίηση
Στατιστική Ι (ΨΥΧ-1202) ιάλεξη 3
 ιάλεξη 3") (ΨΥΧ-1202) Λεωνίδας Α. Ζαμπετάκης Β.Sc., M.Env.Eng., M.Ind.Eng., D.Eng. Εmail: statisticsuoc@gmail.com ιαλέξεις: ftp://ftp.soc.uoc.gr/psycho/zampetakis/ ιάλεξη 3 ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ ΤΜΗΜΑ ΨΥΧΟΛΟΓΙΑΣ Ρέθυμνο,
(ΨΥΧ-1202) Λεωνίδας Α. Ζαμπετάκης Β.Sc., M.Env.Eng., M.Ind.Eng., D.Eng. Εmail: statisticsuoc@gmail.com ιαλέξεις: ftp://ftp.soc.uoc.gr/psycho/zampetakis/ ιάλεξη 3 ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΡΗΤΗΣ ΤΜΗΜΑ ΨΥΧΟΛΟΓΙΑΣ Ρέθυμνο,
Μάθηση και Γενίκευση. "Τεχνητά Νευρωνικά Δίκτυα" (Διαφάνειες), Α. Λύκας, Παν. Ιωαννίνων
, Α. Λύκας, Παν. Ιωαννίνων") Μάθηση και Γενίκευση Το Πολυεπίπεδο Perceptron (MultiLayer Perceptron (MLP)) Έστω σύνολο εκπαίδευσης D={(x n,t n )}, n=1,,n. x n =(x n1,, x nd ) T, t n =(t n1,, t np ) T Θα πρέπει το MLP να έχει d νευρώνες
Μάθηση και Γενίκευση Το Πολυεπίπεδο Perceptron (MultiLayer Perceptron (MLP)) Έστω σύνολο εκπαίδευσης D={(x n,t n )}, n=1,,n. x n =(x n1,, x nd ) T, t n =(t n1,, t np ) T Θα πρέπει το MLP να έχει d νευρώνες
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων:
 Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος Α http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων: Oμαδοποίηση: Μέρος Α http://delab.csd.auth.gr/~gounaris/courses/dwdm/ gounaris/courses/dwdm/ Ευχαριστίες Οι διαφάνειες του μαθήματος σε γενικές γραμμές ακολουθούν
Χρονικές σειρές 11 Ο μάθημα: Προβλέψεις
 Χρονικές σειρές 11 Ο μάθημα: Προβλέψεις Εαρινό εξάμηνο 2018-2019 Τμήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή, Α.Π.Θ. & Οικονομικό Τμήμα, Πανεπιστήμιο
Χρονικές σειρές 11 Ο μάθημα: Προβλέψεις Εαρινό εξάμηνο 2018-2019 Τμήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή, Α.Π.Θ. & Οικονομικό Τμήμα, Πανεπιστήμιο
 Β Γραφικές παραστάσεις - Πρώτο γράφημα Σχεδιάζοντας το μήκος της σανίδας συναρτήσει των φάσεων της σελήνης μπορείτε να δείτε αν υπάρχει κάποιος συσχετισμός μεταξύ των μεγεθών. Ο συνήθης τρόπος γραφικής
Β Γραφικές παραστάσεις - Πρώτο γράφημα Σχεδιάζοντας το μήκος της σανίδας συναρτήσει των φάσεων της σελήνης μπορείτε να δείτε αν υπάρχει κάποιος συσχετισμός μεταξύ των μεγεθών. Ο συνήθης τρόπος γραφικής
Χρονικές σειρές 5 Ο μάθημα: Γραμμικά στοχαστικά μοντέλα (1) Αυτοπαλίνδρομα μοντέλα Εαρινό εξάμηνο Τμήμα Μαθηματικών ΑΠΘ
 Αυτοπαλίνδρομα μοντέλα Εαρινό εξάμηνο Τμήμα Μαθηματικών ΑΠΘ") Χρονικές σειρές 5 Ο μάθημα: Γραμμικά στοχαστικά μοντέλα (1) Αυτοπαλίνδρομα μοντέλα Εαρινό εξάμηνο 2018-2019 Τμήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή,
Χρονικές σειρές 5 Ο μάθημα: Γραμμικά στοχαστικά μοντέλα (1) Αυτοπαλίνδρομα μοντέλα Εαρινό εξάμηνο 2018-2019 Τμήμα Μαθηματικών ΑΠΘ Διδάσκουσα: Αγγελική Παπάνα Μεταδιδακτορική Ερευνήτρια Πολυτεχνική σχολή,
Υπερπροσαρμογή (Overfitting) (1)
 (1)") Αλγόριθμος C4.5 Αποφυγή υπερπροσαρμογής (overfitting) Reduced error pruning Rule post-pruning Χειρισμός χαρακτηριστικών συνεχών τιμών Επιλογή κατάλληλης μετρικής για την επιλογή των χαρακτηριστικών διάσπασης
Αλγόριθμος C4.5 Αποφυγή υπερπροσαρμογής (overfitting) Reduced error pruning Rule post-pruning Χειρισμός χαρακτηριστικών συνεχών τιμών Επιλογή κατάλληλης μετρικής για την επιλογή των χαρακτηριστικών διάσπασης
Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων
 ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 9: Ομαδοποίηση Μέρος Γ Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΑΡΙΣΤΟΤΕΛΕΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΘΕΣΣΑΛΟΝΙΚΗΣ ΑΝΟΙΚΤΑ ΑΚΑΔΗΜΑΪΚΑ ΜΑΘΗΜΑΤΑ Αποθήκες Δεδομένων και Εξόρυξη Δεδομένων Ενότητα 9: Ομαδοποίηση Μέρος Γ Αναστάσιος Γούναρης, Επίκουρος Καθηγητής Άδειες Χρήσης Το παρόν
ΣΥΣΤΗΜΑ ΠΑΡΑΚΟΛΟΥΘΗΣΗΣ ΑΕΡΟΣΩΜΑΤΙ ΙΑΚΗΣ ΡΥΠΑΝΣΗΣ ΣΕ ΣΧΕ ΟΝ ΠΡΑΓΜΑΤΙΚΟ ΧΡΟΝΟ
 ΣΥΣΤΗΜΑ ΠΑΡΑΚΟΛΟΥΘΗΣΗΣ ΑΕΡΟΣΩΜΑΤΙ ΙΑΚΗΣ ΡΥΠΑΝΣΗΣ ΣΕ ΣΧΕ ΟΝ ΠΡΑΓΜΑΤΙΚΟ ΧΡΟΝΟ ΠΑΡΑ ΟΤΕΟ 9 ΠΛΑΤΦΟΡΜΑ ΥΠΟΛΟΓΙΣΜΟΥ ΑΕΡΟΣΩΜΑΤΙ ΙΑΚΗΣ ΡΥΠΑΝΣΗΣ Συγγραφείς: ημήτρης Παρώνης, Αδριανός Ρετάλης, Φίλιππος Τύμβιος,
ΣΥΣΤΗΜΑ ΠΑΡΑΚΟΛΟΥΘΗΣΗΣ ΑΕΡΟΣΩΜΑΤΙ ΙΑΚΗΣ ΡΥΠΑΝΣΗΣ ΣΕ ΣΧΕ ΟΝ ΠΡΑΓΜΑΤΙΚΟ ΧΡΟΝΟ ΠΑΡΑ ΟΤΕΟ 9 ΠΛΑΤΦΟΡΜΑ ΥΠΟΛΟΓΙΣΜΟΥ ΑΕΡΟΣΩΜΑΤΙ ΙΑΚΗΣ ΡΥΠΑΝΣΗΣ Συγγραφείς: ημήτρης Παρώνης, Αδριανός Ρετάλης, Φίλιππος Τύμβιος,
ΑΝΑΛΥΤΙΚΟ ΠΡΟΓΡΑΜΜΑ B ΤΑΞΗΣ. χρησιμοποιήσουμε καθημερινά φαινόμενα όπως το θερμόμετρο, Θετικοί-Αρνητικοί αριθμοί.
 ΑΝΑΛΥΤΙΚΟ ΠΡΟΓΡΑΜΜΑ B ΤΑΞΗΣ ΑΛΓΕΒΡΑ (50 Δ. ώρες) Περιεχόμενα Στόχοι Οδηγίες - ενδεικτικές δραστηριότητες Οι μαθητές να είναι ικανοί: Μπορούμε να ΟΙ ΑΚΕΡΑΙΟΙ ΑΡΙΘΜΟΙ χρησιμοποιήσουμε καθημερινά φαινόμενα
ΑΝΑΛΥΤΙΚΟ ΠΡΟΓΡΑΜΜΑ B ΤΑΞΗΣ ΑΛΓΕΒΡΑ (50 Δ. ώρες) Περιεχόμενα Στόχοι Οδηγίες - ενδεικτικές δραστηριότητες Οι μαθητές να είναι ικανοί: Μπορούμε να ΟΙ ΑΚΕΡΑΙΟΙ ΑΡΙΘΜΟΙ χρησιμοποιήσουμε καθημερινά φαινόμενα
Περιεχόμενα. Περιεχόμενα
 Περιεχόμενα xv Περιεχόμενα 1 Αρχές της Java... 1 1.1 Προκαταρκτικά: Κλάσεις, Τύποι και Αντικείμενα... 2 1.1.1 Βασικοί Τύποι... 5 1.1.2 Αντικείμενα... 7 1.1.3 Τύποι Enum... 14 1.2 Μέθοδοι... 15 1.3 Εκφράσεις...
Περιεχόμενα xv Περιεχόμενα 1 Αρχές της Java... 1 1.1 Προκαταρκτικά: Κλάσεις, Τύποι και Αντικείμενα... 2 1.1.1 Βασικοί Τύποι... 5 1.1.2 Αντικείμενα... 7 1.1.3 Τύποι Enum... 14 1.2 Μέθοδοι... 15 1.3 Εκφράσεις...
Κεφάλαιο 20. Ανακάλυψη Γνώσης σε Βάσεις δεδοµένων. Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η.
 Κεφάλαιο 20 Ανακάλυψη Γνώσης σε Βάσεις δεδοµένων Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η. Σακελλαρίου Τεχνητή Νοηµοσύνη, B' Έκδοση - 1 - Ανακάλυψη Γνώσης σε
Κεφάλαιο 20 Ανακάλυψη Γνώσης σε Βάσεις δεδοµένων Τεχνητή Νοηµοσύνη - Β' Έκδοση Ι. Βλαχάβας, Π. Κεφαλάς, Ν. Βασιλειάδης, Φ. Κόκκορας, Η. Σακελλαρίου Τεχνητή Νοηµοσύνη, B' Έκδοση - 1 - Ανακάλυψη Γνώσης σε
ΜΑΘΗΜΑ 3ο. Βασικές έννοιες
 ΜΑΘΗΜΑ 3ο Βασικές έννοιες Εισαγωγή Βασικές έννοιες Ένας από τους βασικότερους σκοπούς της ανάλυσης των χρονικών σειρών είναι η διενέργεια των προβλέψεων. Στα υποδείγματα αυτά η τρέχουσα τιμή μιας οικονομικής
ΜΑΘΗΜΑ 3ο Βασικές έννοιες Εισαγωγή Βασικές έννοιες Ένας από τους βασικότερους σκοπούς της ανάλυσης των χρονικών σειρών είναι η διενέργεια των προβλέψεων. Στα υποδείγματα αυτά η τρέχουσα τιμή μιας οικονομικής
Αναγνώριση Προτύπων Ι
 Αναγνώριση Προτύπων Ι Ενότητα 3: Στοχαστικά Συστήματα Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Αναγνώριση Προτύπων Ι Ενότητα 3: Στοχαστικά Συστήματα Αν. Καθηγητής Δερματάς Ευάγγελος Τμήμα Ηλεκτρολόγων Μηχανικών και Τεχνολογίας Υπολογιστών Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες
Ανάλυση Δεδομένων με χρήση του Στατιστικού Πακέτου R
 Ανάλυση Δεδομένων με χρήση του Στατιστικού Πακέτου R, Επίκουρος Καθηγητής, Τομέας Μαθηματικών, Σχολή Εφαρμοσμένων Μαθηματικών και Φυσικών Επιστημών, Εθνικό Μετσόβιο Πολυτεχνείο. Περιεχόμενα Εισαγωγή στο
Ανάλυση Δεδομένων με χρήση του Στατιστικού Πακέτου R, Επίκουρος Καθηγητής, Τομέας Μαθηματικών, Σχολή Εφαρμοσμένων Μαθηματικών και Φυσικών Επιστημών, Εθνικό Μετσόβιο Πολυτεχνείο. Περιεχόμενα Εισαγωγή στο
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΣΧΟΛΗ ΕΠΙΣΤΗΜΩΝ ΤΗΣ ΔΙΟΙΚΗΣΗΣ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 06-07 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Λέκτορας v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
Τεχνολογικό Εκπαιδευτικό Ίδρυμα Δυτικής Μακεδονίας Western Macedonia University of Applied Sciences Κοίλα Κοζάνης Kozani GR 50100
 Ποσοτικές Μέθοδοι Τεχνολογικό Εκπαιδευτικό Ίδρυμα Δυτικής Μακεδονίας Western Macedonia University of Applied Sciences Κοίλα Κοζάνης 50100 Kozani GR 50100 Απλή Παλινδρόμηση Η διερεύνηση του τρόπου συμπεριφοράς
Ποσοτικές Μέθοδοι Τεχνολογικό Εκπαιδευτικό Ίδρυμα Δυτικής Μακεδονίας Western Macedonia University of Applied Sciences Κοίλα Κοζάνης 50100 Kozani GR 50100 Απλή Παλινδρόμηση Η διερεύνηση του τρόπου συμπεριφοράς
ΙΑ ΟΧΙΚΕΣ ΒΕΛΤΙΩΣΕΙΣ
 Tel.: +30 2310998051, Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Σχολή Θετικών Επιστημών Τμήμα Φυσικής 541 24 Θεσσαλονίκη Καθηγητής Γεώργιος Θεοδώρου Ιστοσελίδα: http://users.auth.gr/theodoru ΙΑ ΟΧΙΚΕΣ ΒΕΛΤΙΩΣΕΙΣ
Tel.: +30 2310998051, Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Σχολή Θετικών Επιστημών Τμήμα Φυσικής 541 24 Θεσσαλονίκη Καθηγητής Γεώργιος Θεοδώρου Ιστοσελίδα: http://users.auth.gr/theodoru ΙΑ ΟΧΙΚΕΣ ΒΕΛΤΙΩΣΕΙΣ
Αριθμητική Ανάλυση και Εφαρμογές
 Αριθμητική Ανάλυση και Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 07-08 Αριθμητική Ολοκλήρωση Εισαγωγή Έστω ότι η f είναι μία φραγμένη συνάρτηση στο πεπερασμένο
Αριθμητική Ανάλυση και Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 07-08 Αριθμητική Ολοκλήρωση Εισαγωγή Έστω ότι η f είναι μία φραγμένη συνάρτηση στο πεπερασμένο
Ενδεικτικές Ερωτήσεις Θεωρίας
 Ενδεικτικές Ερωτήσεις Θεωρίας Κεφάλαιο 2 1. Τι καλούμε αλγόριθμο; 2. Ποια κριτήρια πρέπει οπωσδήποτε να ικανοποιεί ένας αλγόριθμος; 3. Πώς ονομάζεται μια διαδικασία που δεν περατώνεται μετά από συγκεκριμένο
Ενδεικτικές Ερωτήσεις Θεωρίας Κεφάλαιο 2 1. Τι καλούμε αλγόριθμο; 2. Ποια κριτήρια πρέπει οπωσδήποτε να ικανοποιεί ένας αλγόριθμος; 3. Πώς ονομάζεται μια διαδικασία που δεν περατώνεται μετά από συγκεκριμένο
ΠΑΝΕΠΙΣΤΗΜΙΑΚΑ ΦΡΟΝΤΙΣΤΗΡΙΑ ΚΟΛΛΙΝΤΖΑ. Ερωτήσεις πολλαπλής επιλογής. Συντάκτης: Δημήτριος Κρέτσης
 ΠΑΝΕΠΙΣΤΗΜΙΑΚΑ ΦΡΟΝΤΙΣΤΗΡΙΑ ΚΟΛΛΙΝΤΖΑ Ερωτήσεις πολλαπλής επιλογής Συντάκτης: Δημήτριος Κρέτσης 1. Ο κλάδος της περιγραφικής Στατιστικής: α. Ασχολείται με την επεξεργασία των δεδομένων και την ανάλυση
ΠΑΝΕΠΙΣΤΗΜΙΑΚΑ ΦΡΟΝΤΙΣΤΗΡΙΑ ΚΟΛΛΙΝΤΖΑ Ερωτήσεις πολλαπλής επιλογής Συντάκτης: Δημήτριος Κρέτσης 1. Ο κλάδος της περιγραφικής Στατιστικής: α. Ασχολείται με την επεξεργασία των δεδομένων και την ανάλυση
ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΑΝΑΠΤΥΞΗ ΓΡΑΦΙΚΟΥ ΠΕΡΙΒΑΛΛΟΝΤΟΣ ΣΕ MATLAB ΓΙΑ ΣΥΣΤΑΔΟΠΟΙΗΣΗ ΜΕΣΩ ΤΟΥ ΑΛΓΟΡΙΘΜΟΥ ISODATA
 ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΕΠΙΚΟΙΝΩΝΙΩΝ ΑΝΑΠΤΥΞΗ ΓΡΑΦΙΚΟΥ ΠΕΡΙΒΑΛΛΟΝΤΟΣ ΣΕ MATLAB ΓΙΑ ΣΥΣΤΑΔΟΠΟΙΗΣΗ ΜΕΣΩ ΤΟΥ ΑΛΓΟΡΙΘΜΟΥ ISODATA Μαρκαντωνάτου Μαρία Α.Μ.: 379 ΕΠΙΒΛΕΠΩΝ ΚΑΘΗΓΗΤΗΣ: Δρ. Τσιμπίρης
ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΕΠΙΚΟΙΝΩΝΙΩΝ ΑΝΑΠΤΥΞΗ ΓΡΑΦΙΚΟΥ ΠΕΡΙΒΑΛΛΟΝΤΟΣ ΣΕ MATLAB ΓΙΑ ΣΥΣΤΑΔΟΠΟΙΗΣΗ ΜΕΣΩ ΤΟΥ ΑΛΓΟΡΙΘΜΟΥ ISODATA Μαρκαντωνάτου Μαρία Α.Μ.: 379 ΕΠΙΒΛΕΠΩΝ ΚΑΘΗΓΗΤΗΣ: Δρ. Τσιμπίρης
Αριθμητική Ανάλυση & Εφαρμογές
 Αριθμητική Ανάλυση & Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 2017-2018 Υπολογισμοί και Σφάλματα Παράσταση Πραγματικών Αριθμών Συστήματα Αριθμών Παράσταση Ακέραιου
Αριθμητική Ανάλυση & Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 2017-2018 Υπολογισμοί και Σφάλματα Παράσταση Πραγματικών Αριθμών Συστήματα Αριθμών Παράσταση Ακέραιου
ΕΞΟΡΥΞΗ ΔΕΔΟΜΕΝΩΝ. Εξόρυξη Δεδομένων. Ανάλυση Δεδομένων. Η διαδικασία εύρεσης κρυφών (ήκαλύτεραμηεμφανών) ιδιοτήτων από αποθηκευμένα δεδομένα,
 ιδιοτήτων από αποθηκευμένα δεδομένα,") ΕΞΟΡΥΞΗ ΔΕΔΟΜΕΝΩΝ Ηλίας Κ. Σάββας Εξόρυξη Δεδομένων Η διαδικασία εύρεσης κρυφών (ήκαλύτεραμηεμφανών) ιδιοτήτων από αποθηκευμένα δεδομένα, Μετατροπή δεδομένων σε ΠΛΗΡΟΦΟΡΙΑ, Πολλά δεδομένα αποθηκευμένα
ΕΞΟΡΥΞΗ ΔΕΔΟΜΕΝΩΝ Ηλίας Κ. Σάββας Εξόρυξη Δεδομένων Η διαδικασία εύρεσης κρυφών (ήκαλύτεραμηεμφανών) ιδιοτήτων από αποθηκευμένα δεδομένα, Μετατροπή δεδομένων σε ΠΛΗΡΟΦΟΡΙΑ, Πολλά δεδομένα αποθηκευμένα
«Αναζήτηση Γνώσης σε Νοσοκομειακά Δεδομένα»
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Πρόγραμμα Σπουδών M.I.S. «Αναζήτηση Γνώσης σε Νοσοκομειακά Δεδομένα» Μεταπτυχιακός Φοιτητής: Επιβλέπων Καθηγητής: Εξεταστής Καθηγητής: Τορτοπίδης Γεώργιος Μηχανικός
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Πρόγραμμα Σπουδών M.I.S. «Αναζήτηση Γνώσης σε Νοσοκομειακά Δεδομένα» Μεταπτυχιακός Φοιτητής: Επιβλέπων Καθηγητής: Εξεταστής Καθηγητής: Τορτοπίδης Γεώργιος Μηχανικός
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 08-09 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΙΓΑΙΟΥ ΠΟΛΥΤΕΧΝΙΚΗ ΣΧΟΛΗ ΤΜΗΜΑ ΜΗΧΑΝΙΚΩΝ ΟΙΚΟΝΟΜΙΑΣ ΚΑΙ ΔΙΟΙΚΗΣΗΣ ΣΤΑΤΙΣΤΙΚΗ Ακαδ. Έτος 08-09 Διδάσκων: Βασίλης ΚΟΥΤΡΑΣ Επικ. Καθηγητής v.koutras@fme.aegea.gr Τηλ: 7035468 Εκτίμηση Διαστήματος
ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Τραπεζικής & Χρηματοοικονομικής
 ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Τραπεζικής & Χρηματοοικονομικής Υποθέσεις του Απλού γραμμικού υποδείγματος της Παλινδρόμησης Η μεταβλητή ε t (διαταρακτικός όρος) είναι τυχαία μεταβλητή με μέσο όρο
ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ Μεταπτυχιακό Τραπεζικής & Χρηματοοικονομικής Υποθέσεις του Απλού γραμμικού υποδείγματος της Παλινδρόμησης Η μεταβλητή ε t (διαταρακτικός όρος) είναι τυχαία μεταβλητή με μέσο όρο
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΠΑΡΟΥΣΙΑΣΗ ΔΙΠΛΩΜΑΤΙΚΗΣ ΕΡΓΑΣΙΑΣ ΔΟΥΒΛΕΤΗΣ ΧΑΡΑΛΑΜΠΟΣ ΕΠΙΒΛΕΠΟΝΤΕΣ ΚΑΘΗΓΗΤΕΣ Μαργαρίτης Κωνσταντίνος Βακάλη
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ ΠΑΡΟΥΣΙΑΣΗ ΔΙΠΛΩΜΑΤΙΚΗΣ ΕΡΓΑΣΙΑΣ ΔΟΥΒΛΕΤΗΣ ΧΑΡΑΛΑΜΠΟΣ ΕΠΙΒΛΕΠΟΝΤΕΣ ΚΑΘΗΓΗΤΕΣ Μαργαρίτης Κωνσταντίνος Βακάλη
Εξόρυξη γνώμης πολιτών από ελεύθερο κείμενο
 Δίκαρος Νίκος Δ/νση Μηχανογράνωσης κ Η.Ε.Σ. Υπουργείο Εσωτερικών. Τελική εργασία Κ Εκπαιδευτικής Σειράς Ε.Σ.Δ.Δ. Επιβλέπων: Ηρακλής Βαρλάμης Εξόρυξη γνώμης πολιτών από ελεύθερο κείμενο Κεντρική ιδέα Προβληματισμοί
Δίκαρος Νίκος Δ/νση Μηχανογράνωσης κ Η.Ε.Σ. Υπουργείο Εσωτερικών. Τελική εργασία Κ Εκπαιδευτικής Σειράς Ε.Σ.Δ.Δ. Επιβλέπων: Ηρακλής Βαρλάμης Εξόρυξη γνώμης πολιτών από ελεύθερο κείμενο Κεντρική ιδέα Προβληματισμοί
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων
 Απαντήσεις 1 ου Σετ Ασκήσεων") Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Ειδικά θέματα Αλγορίθμων και Δομών Δεδομένων (ΠΛΕ073) Απαντήσεις 1 ου Σετ Ασκήσεων Άσκηση 1 α) Η δομή σταθμισμένης ένωσης με συμπίεση διαδρομής μπορεί να τροποποιηθεί πολύ εύκολα ώστε να υποστηρίζει τις
Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η : ,
 Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η : ,") Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η :1-0-017, 3-0-017 Διδάσκουσα: Κοντογιάννη Αριστούλα Σκοπός του μαθήματος Η παρουσίαση
Τμήμα Διοίκησης Επιχειρήσεων (Γρεβενά) Μάθημα: Στατιστική II Διάλεξη 1 η : Εισαγωγή-Επανάληψη βασικών εννοιών Εβδομάδα 1 η :1-0-017, 3-0-017 Διδάσκουσα: Κοντογιάννη Αριστούλα Σκοπός του μαθήματος Η παρουσίαση
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΚΑΙ ΦΥΣΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΠΛΗΡΟΦΟΡΙΑΣ ΠΑΡΟΥΣΙΑΣΗ ΤΕΛΙΚΗΣ ΕΡΓΑΣΙΑΣ ΛΙΝΑ ΜΑΣΣΟΥ
 ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΚΑΙ ΦΥΣΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΑΛΓΟΡΙΘΜΟΙ ΕΞΟΡΥΞΗΣ ΠΛΗΡΟΦΟΡΙΑΣ ΠΑΡΟΥΣΙΑΣΗ ΤΕΛΙΚΗΣ ΕΡΓΑΣΙΑΣ ΛΙΝΑ ΜΑΣΣΟΥ Δ.Π.Μ.Σ: «Εφαρμοσμένες Μαθηματικές Επιστήμες» 2008
ΕΘΝΙΚΟ ΜΕΤΣΟΒΙΟ ΠΟΛΥΤΕΧΝΕΙΟ ΣΧΟΛΗ ΕΦΑΡΜΟΣΜΕΝΩΝ ΜΑΘΗΜΑΤΙΚΩΝ ΚΑΙ ΦΥΣΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΑΛΓΟΡΙΘΜΟΙ ΕΞΟΡΥΞΗΣ ΠΛΗΡΟΦΟΡΙΑΣ ΠΑΡΟΥΣΙΑΣΗ ΤΕΛΙΚΗΣ ΕΡΓΑΣΙΑΣ ΛΙΝΑ ΜΑΣΣΟΥ Δ.Π.Μ.Σ: «Εφαρμοσμένες Μαθηματικές Επιστήμες» 2008
Κύρια σημεία. Η έννοια του μοντέλου. Έρευνα στην εφαρμοσμένη Στατιστική. ΈρευναστηΜαθηματικήΣτατιστική. Αντικείμενο της Μαθηματικής Στατιστικής
 Κύρια σημεία Ερευνητική Μεθοδολογία και Μαθηματική Στατιστική Απόστολος Μπουρνέτας Τμήμα Μαθηματικών ΕΚΠΑ Αναζήτηση ερευνητικού θέματος Εισαγωγή στην έρευνα Ολοκλήρωση ερευνητικής εργασίας Ο ρόλος των
Κύρια σημεία Ερευνητική Μεθοδολογία και Μαθηματική Στατιστική Απόστολος Μπουρνέτας Τμήμα Μαθηματικών ΕΚΠΑ Αναζήτηση ερευνητικού θέματος Εισαγωγή στην έρευνα Ολοκλήρωση ερευνητικής εργασίας Ο ρόλος των
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ
 ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
Περιεχόμενα. Πρόλογος... 15
 Περιεχόμενα Πρόλογος... 15 Κεφάλαιο 1 ΘΕΩΡΗΤΙΚΑ ΚΑΙ ΦΙΛΟΣΟΦΙΚΑ ΟΝΤΟΛΟΓΙΚΑ ΚΑΙ ΕΠΙΣΤΗΜΟΛΟΓΙΚΑ ΖΗΤΗΜΑΤΑ ΤΗΣ ΜΕΘΟΔΟΛΟΓΙΑΣ ΕΡΕΥΝΑΣ ΤΟΥ ΠΡΑΓΜΑΤΙΚΟΥ ΚΟΣΜΟΥ... 17 Το θεμελιώδες πρόβλημα των κοινωνικών επιστημών...
Περιεχόμενα Πρόλογος... 15 Κεφάλαιο 1 ΘΕΩΡΗΤΙΚΑ ΚΑΙ ΦΙΛΟΣΟΦΙΚΑ ΟΝΤΟΛΟΓΙΚΑ ΚΑΙ ΕΠΙΣΤΗΜΟΛΟΓΙΚΑ ΖΗΤΗΜΑΤΑ ΤΗΣ ΜΕΘΟΔΟΛΟΓΙΑΣ ΕΡΕΥΝΑΣ ΤΟΥ ΠΡΑΓΜΑΤΙΚΟΥ ΚΟΣΜΟΥ... 17 Το θεμελιώδες πρόβλημα των κοινωνικών επιστημών...
ΠΕΙΡΑΜΑΤΙΚΕΣ ΠΡΟΣΟΜΟΙΩΣΕΙΣ ΚΕΦΑΛΑΙΟ 4. είναι η πραγματική απόκριση του j δεδομένου (εκπαίδευσης ή ελέγχου) και y ˆ j
 και y ˆ j") Πειραματικές Προσομοιώσεις ΚΕΦΑΛΑΙΟ 4 Όλες οι προσομοιώσεις έγιναν σε περιβάλλον Matlab. Για την υλοποίηση της μεθόδου ε-svm χρησιμοποιήθηκε το λογισμικό SVM-KM που αναπτύχθηκε στο Ecole d Ingenieur(e)s
Πειραματικές Προσομοιώσεις ΚΕΦΑΛΑΙΟ 4 Όλες οι προσομοιώσεις έγιναν σε περιβάλλον Matlab. Για την υλοποίηση της μεθόδου ε-svm χρησιμοποιήθηκε το λογισμικό SVM-KM που αναπτύχθηκε στο Ecole d Ingenieur(e)s
Δρ. Βασίλειος Γ. Καμπουρλάζος Δρ. Ανέστης Γ. Χατζημιχαηλίδης
 Μάθημα 4 ο Δρ. Ανέστης Γ. Χατζημιχαηλίδης Τμήμα Μηχανικών Πληροφορικής Τ.Ε. ΤΕΙ Ανατολικής Μακεδονίας και Θράκης 2016-2017 Διευρυμένη Υπολογιστική Νοημοσύνη (ΥΝ) Επεκτάσεις της Κλασικής ΥΝ. Μεθοδολογίες
Μάθημα 4 ο Δρ. Ανέστης Γ. Χατζημιχαηλίδης Τμήμα Μηχανικών Πληροφορικής Τ.Ε. ΤΕΙ Ανατολικής Μακεδονίας και Θράκης 2016-2017 Διευρυμένη Υπολογιστική Νοημοσύνη (ΥΝ) Επεκτάσεις της Κλασικής ΥΝ. Μεθοδολογίες
Ανασκόπηση θεωρίας ελαχίστων τετραγώνων και βέλτιστης εκτίμησης παραμέτρων
 Τοπογραφικά Δίκτυα και Υπολογισμοί 5 ο εξάμηνο, Ακαδημαϊκό Έτος 2017-2018 Ανασκόπηση θεωρίας ελαχίστων τετραγώνων και βέλτιστης εκτίμησης παραμέτρων Χριστόφορος Κωτσάκης Τμήμα Αγρονόμων και Τοπογράφων
Τοπογραφικά Δίκτυα και Υπολογισμοί 5 ο εξάμηνο, Ακαδημαϊκό Έτος 2017-2018 Ανασκόπηση θεωρίας ελαχίστων τετραγώνων και βέλτιστης εκτίμησης παραμέτρων Χριστόφορος Κωτσάκης Τμήμα Αγρονόμων και Τοπογράφων
Clustering. Αλγόριθµοι Οµαδοποίησης Αντικειµένων
 Clustering Αλγόριθµοι Οµαδοποίησης Αντικειµένων Εισαγωγή Οµαδοποίηση (clustering): οργάνωση µιας συλλογής από αντικείµενα-στοιχεία (objects) σε οµάδες (clusters) µε βάση κάποιο µέτρο οµοιότητας. Στοιχεία
Clustering Αλγόριθµοι Οµαδοποίησης Αντικειµένων Εισαγωγή Οµαδοποίηση (clustering): οργάνωση µιας συλλογής από αντικείµενα-στοιχεία (objects) σε οµάδες (clusters) µε βάση κάποιο µέτρο οµοιότητας. Στοιχεία
Μεταπτυχιακό Πρόγραμμα «Γεωχωρικές Τεχνολογίες» Ψηφιακή Επεξεργασία Εικόνας. Εισηγητής Αναστάσιος Κεσίδης
 Μεταπτυχιακό Πρόγραμμα «Γεωχωρικές Τεχνολογίες» Ψηφιακή Επεξεργασία Εικόνας Εισηγητής Αναστάσιος Κεσίδης Τμηματοποίηση εικόνας Τμηματοποίηση εικόνας Γενικά Διαμερισμός μιας εικόνας σε διακριτές περιοχές
Μεταπτυχιακό Πρόγραμμα «Γεωχωρικές Τεχνολογίες» Ψηφιακή Επεξεργασία Εικόνας Εισηγητής Αναστάσιος Κεσίδης Τμηματοποίηση εικόνας Τμηματοποίηση εικόνας Γενικά Διαμερισμός μιας εικόνας σε διακριτές περιοχές
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ
 ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΥΠΟΥΡΓΕΙΟ ΕΘΝΙΚΗΣ ΠΑΙΔΕΙΑΣ ΚΑΙ ΘΡΗΣΚΕΥΜΑΤΩΝ ΠΑΙΔΑΓΩΓΙΚΟ ΙΝΣΤΙΤΟΥΤΟ ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ Π ΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ Π ΕΡΙΒΑΛΛΟΝ Κ Υ Κ Λ Ο Υ Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ Κ Α Ι Υ Π Η Ρ Ε Σ Ι Ω Ν Τ Ε Χ Ν Ο Λ Ο Γ Ι Κ Η
ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ MSc Τραπεζικής & Χρηματοοικονομικής
 ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ MSc Τραπεζικής & Χρηματοοικονομικής ΑΥΤΟΣΥΣΧΕΤΙΣΗ Στις βασικές υποθέσεις των γραμμικών υποδειγμάτων (απλών και πολλαπλών), υποθέτουμε ότι δεν υπάρχει αυτοσυσχέτιση (autocorrelation
ΤΕΙ ΔΥΤΙΚΗΣ ΜΑΚΕΔΟΝΙΑΣ MSc Τραπεζικής & Χρηματοοικονομικής ΑΥΤΟΣΥΣΧΕΤΙΣΗ Στις βασικές υποθέσεις των γραμμικών υποδειγμάτων (απλών και πολλαπλών), υποθέτουμε ότι δεν υπάρχει αυτοσυσχέτιση (autocorrelation
Φίλτρα Kalman. Αναλυτικές μέθοδοι στη Γεωπληροφορική. ιατύπωση του βασικού προβλήματος. προβλήματος. μοντέλο. Πρωτεύων μοντέλο
 Φίλτρα Kalman Εξαγωγή των εξισώσεων τους με βάση το κριτήριο ελαχιστοποίησης της Μεθόδου των Ελαχίστων Τετραγώνων. Αναλυτικές Μέθοδοι στη Γεωπληροφορική Μεταπτυχιακό Πρόγραμμα ΓΕΩΠΛΗΡΟΦΟΡΙΚΗ ιατύπωση του
Φίλτρα Kalman Εξαγωγή των εξισώσεων τους με βάση το κριτήριο ελαχιστοποίησης της Μεθόδου των Ελαχίστων Τετραγώνων. Αναλυτικές Μέθοδοι στη Γεωπληροφορική Μεταπτυχιακό Πρόγραμμα ΓΕΩΠΛΗΡΟΦΟΡΙΚΗ ιατύπωση του
ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΣΤΑΤΙΣΤΙΚΗ ΤΩΝ ΕΠΙΧΕΙΡΗΣΕΩΝ. Κεφάλαιο 8. Συνεχείς Κατανομές Πιθανοτήτων Η Κανονική Κατανομή
 ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΠΑΤΡΑΣ Εργαστήριο Λήψης Αποφάσεων & Επιχειρησιακού Προγραμματισμού Καθηγητής Ι. Μητρόπουλος ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΣΤΑΤΙΣΤΙΚΗ ΤΩΝ ΕΠΙΧΕΙΡΗΣΕΩΝ
ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑ ΔΥΤΙΚΗΣ ΕΛΛΑΔΑΣ ΤΜΗΜΑ ΔΙΟΙΚΗΣΗΣ ΕΠΙΧΕΙΡΗΣΕΩΝ ΠΑΤΡΑΣ Εργαστήριο Λήψης Αποφάσεων & Επιχειρησιακού Προγραμματισμού Καθηγητής Ι. Μητρόπουλος ΕΙΣΑΓΩΓΗ ΣΤΗΝ ΣΤΑΤΙΣΤΙΚΗ ΤΩΝ ΕΠΙΧΕΙΡΗΣΕΩΝ
Συνήθεις διαφορικές εξισώσεις προβλήματα οριακών τιμών
 Συνήθεις διαφορικές εξισώσεις προβλήματα οριακών τιμών Οι παρούσες σημειώσεις αποτελούν βοήθημα στο μάθημα Αριθμητικές Μέθοδοι του 5 ου εξαμήνου του ΤΜΜ ημήτρης Βαλουγεώργης Καθηγητής Εργαστήριο Φυσικών
Συνήθεις διαφορικές εξισώσεις προβλήματα οριακών τιμών Οι παρούσες σημειώσεις αποτελούν βοήθημα στο μάθημα Αριθμητικές Μέθοδοι του 5 ου εξαμήνου του ΤΜΜ ημήτρης Βαλουγεώργης Καθηγητής Εργαστήριο Φυσικών