Gërmimi i dataset-ave masivë. përmbledhje informative
|
|
|
- Λυσιμάχη Ρέντης
- 6 χρόνια πριν
- Προβολές:
Transcript

1 Gërmimi i dataset-ave masivë përmbledhje informative zgjodhi dhe përktheu Ridvan Bunjaku Mars 2017
2 Përmbajtja Parathënie Data mining MapReduce Gjetja e elementeve të ngjashme Gërmimi i stream-ave të shënimeve Analiza e linqeve Itemset-at e shpeshtë Clustering Reklamimi në Web Sistemet e rekomandimit Gërmimi i grafeve të rrjeteve sociale Reduktimi i dimensionalitetit Machine learning në shkallë të gjerë Bibliografia Online Licencimi Ky publikim lëshohet nën licencën Attribution-NonCommercial-ShareAlike: që nënkupton se mund të ripërzihet, rregullohet, dhe të ndërtohet mbi të jo-komercialisht, përderisa përmendet burimi i saktë dhe krijimet e reja licensohen nën terma identikë. Për më shumë detale: 2 / 65
3 Parathënie Ky publikim flet për gërmimin e shënimeve, mirëpo fokusohet në gërmimin e shënimeve të sasive shumë të mëdha, domethënë kaq të mëdha sa që nuk i zë memorja kryesore. Për shkak të theksit në madhësi, shumë nga shembujt janë për Web-in apo shënimet e nxjerra nga Web-i. Për më tepër, libri bazë (Mining Massive Datasets) ka pikëpamje algoritmike: gërmimi i shpënimeve ka të bëjë me aplikimin e algoritmeve në shënime, në vend se të përdoren shënimet për ta trajnuar ndonjë lloj motori të mësimit të makinës. Tekstet janë nga përmbledhjet e kapitujve, ndërsa slajdet janë nga kursi online i autorëve të njëjtë. Ju lutem shihni bibliografinë për më shumë informacion. 3 / 65
 e veçorive më ekstreme të shënimeve.")
4 1. Data mining Data mining (gërmimi i shënimeve): Ky term i referohet procesit të ekstraktimit (nxjerrjes) së modeleve të dobishme të shënimeve. Ndonjëherë, model mund të jetë një përmbledhje e shënimeve, apo mund të jetë grupi (bashkësia) e veçorive më ekstreme të shënimeve. Principi i Bonferroni-t (Bonferroni s Principle): Nëse duam ta shikojmë si veçori interesante të shënimeve diçka që shumë instanca të saj mund të pritet të ekzistojnë në shënime të rastësishme, atëherë nuk mund të mbështetemi në veçori të tilla si të rëndësishme. Ky observim e kufizon aftësinë tonë të gërmojmë në shënime për veçori që nuk janë mjaftueshëm të rralla në praktikë. TF.IDF: Masa e quajtur TF.IDF na lejon t i identifikojmë fjalët në një koleksion të dokumenteve që janë të dobishme për ta përcaktuar temën e secilit dokument. Një fjalë ka pikë TF.IDF të larta në një dokument nëse ajo shfaqet në relativisht pak dokumente, por shfaqet në këtë, dhe kur shfaqet në një dokument priret të shfaqet shumë herë. Funksionet Hash: Një funksion hash ( grirës ) i mapon çelësat-hash të një tipi të shënimeve me numra të plotë të bucket-ave (kovave). Një funksion i mirë hash i shpërndan vlerat e mundura hash-çelës afërsisht baraz ndërmjet bucket-ave. Cilido tip i shënimeve mund të jetë domeni i një funksioni hash. Indeksat: Indeksi është strukturë e shënimeve që na lejon t i ruajmë dhe t i lexojmë recordat (regjistrimet) e shënimeve në mënyrë efikase, kur është dhënë vlera në një apo më shumë fusha të record-it. Hash-imi është një mënyrë për të ndërtuar indeks. Ruajtja në Disk: Kur duhet të ruhen shënimet në disk (memorje sekondare), merr shumë më shumë kohë t i qasemi shënimit të dëshiruar se sa kur të njëjtat shënime do të ruheshin në memorjen kryesore. Kur shënimet janë të mëdha, është me rëndësi që algoritmet të përpiqen t i mbajnë shënimet e nevojshme në memorjen kryesore. Ligjet e fuqisë: Shumë fenomene i binden një ligji që mund të shprehet si y = cx a për ndonjë fuqi a, shpesh rreth 2. Fenomenet e tilla përfshijnë shitjet e librit të x-të më të famshëm, apo numrin e linqeve hyrëse te faqja e x-të më e famshme. 4 / 65
5 5 / 65
. Node-at llogaritës janë të montuar në rack-a (rafte), dhe node-at në një rack janë të lidhur, zakonisht me Ethernetgigabit.")
: Kohëve të fundit është zhvilluar një arkitekturë për sisteme të fajllave me shkallë shumë të madhe.")
6 2. MapReduce Cluster computing (llogaritja në grup/tufë): Një arkitekturë e përgjithshme për aplikacione me shkallë shumë të madhe është një cluster i node-ave (nyjeve) llogaritës (çipi i procesorit, memorja kryesore, dhe disku). Node-at llogaritës janë të montuar në rack-a (rafte), dhe node-at në një rack janë të lidhur, zakonisht me Ethernetgigabit. Rack-at po ashtu janë të lidhur me një rrjet apo switch me shpejtësi të lartë. Distributed file systems (sistemet e shpërndara të fajllave): Kohëve të fundit është zhvilluar një arkitekturë për sisteme të fajllave me shkallë shumë të madhe. Fajllat përbëhen nga pjesë prej rreth 64 megabajtë, dhe secila pjesë replikohet disa herë, në node-a apo rack-a të ndryshëm të llogaritjes. 6 / 65
 menaxhohen nga një proces Master (Zotërues). Task-at në një node të dështuar rinisen nga Master-i.")
7 MapReduce: Ky sistem i programimit e lejon personin ta shfrytëzojë paralelizmin brenda llogaritjes në cluster, dhe i menaxhon dështimet harduerike që mund të ndodhin gjatë një llogaritjeje të gjatë në shumë node-a. Shumë task-a Map dhe shumë task-a Reduce (Zvogëlo) menaxhohen nga një proces Master (Zotërues). Task-at në një node të dështuar rinisen nga Master-i. Funksioni Map: Ky funksion shkruhet nga përdoruesi. Ai e merr një koleksion të objekteve hyrëse dhe e kthen secilin në zero apo më shumë çifte key-value (çelës-vlerë). Key-t nuk janë patjetër unikë. Funksioni Reduce: Një sistem i programimit MapReduce i radhit të gjitha çiftet key-value të prodhuara nga të gjithë task-at Map, i formon të gjitha vlerat e asociuara me një key të dhënë në një listë dhe i shpërndan çiftet key-list (çelës-listë) te task-at Reduce. Secili task Reduce i kombinon elementet në secilën listë, duke e aplikuar funksionin e shkruar nga përdoruesi. Rezultatet e prodhuara nga të gjithë task-at Reduce e formojnë rezultatin dalës të procesit MapReduce. 7 / 65


8 Reducers (Zvogëluesit): Shpesh është e përshtatshme t i referohemi aplikimit të funksionit Reduce në një key të vetëm dhe listës së tij të asociuar të vlerave si reducer. 8 / 65

9 Hadoop: Ky sistem i programimit është implementim open-source (me kod të hapur) i një sistemi të shpërndarë të fajllave (HDFS, the Hadoop Distributed File System) dhe i MapReduce (vetë Hadoop). Ai është në dispozicion përmes Apache Foundation. Menaxhimi i dështimeve të Node-ave llogaritëse: Sistemet MapReduce e përkrahin rinisjen e task-ave që dështojnë për shkak se dështon node-i i vet llogaritës, apo rack-u që e përmban atë node. Për shkak se task-at Map dhe Reduce e japin rezultatin e vet vetëm pasi të kryhen, është e mundur të riniset një task i dështuar pa u shqetësuar për përsëritjen e mundshme të efekteve të atij task-u. Është e nevojshme të riniset i tërë job-i (puna) vetëm nëse dështon node-i në të cilin ekzekutohet Master-i. Aplikimet e MapReduce: Megjithëse jo të gjitha algoritmet paralele janë të përshtatshme për implementim në framework-un (kornizën) MapReduce, ka implementime të thjeshta të shumëzimit matricë-vektor dhe matricë-matricë. Po ashtu, operatorët kryesorë të algjebrës relacionale implementohen lehtë në MapReduce. Sistemet Workflow (Rrjedha e punës): MapReduce është përgjithësuar në sistmet që e përkrahin çfarëdo koleksioni aciklik të funksioneve, ku secili mund të instancinohet me çfarëdo numri të task-ave, secili përgjegjës për ekzekutimin e atij funksioni në një pjesë të shënimeve. Workflow-at rekursivë: Kur implementohet një koleksion rekursiv i funksioneve, nuk është gjithmonë e mundur të ruhet aftësia për rinisje të çfarëdo task-u të dështuar, sepse task-at rekursivë mund të kenë prodhuar rezultate dalëse që janë konsumuar nga një task tjetër para dështimit. Janë propozuar një numër i skemave për checkpoint-im (kontroll në pika të caktuara) të pjesëve të llogaritjes për ta lejuar ristartimin e task-ave individuale, apo për t i ristartuar të gjithë task-at nga një pikë e kohës së fundit. 9 / 65
10 Kosto e Komunikimit: Shumë aplikacione të MapReduce apo të sistemeve të ngjashme bëjnë gjëra shumë të thjeshta për secilin task. Pastaj, kostoja dominante është zakonisht kostoja e transportit të shënimeve nga aty ku janë krijuar te vendi ku përdoren. Në këto raste, efikasiteti i algoritmit MapReduce mund të vlerësohet duke e llogaritur shumën e madhësive të hyrjeve të të gjithë task-ave. Multiway Joins (Bashkimet shumëdrejtimëshe): Nganjëherë është më efikase të replikohen n-shet e relacioneve të përfshira në një join (bashkim) dhe të vendoset që join-i i tri apo më shumë relacioneve të llogaritet si një job i vetëm MapReduce. Teknika e koeficientëve (shumëzuesve) të Lagranzhit (Lagrangean multipliers) mund të përdoret për ta optimizuar shkallën e replikimit për secilin nga relacionet pjesëmarrëse. Star Joins (Bashkimet yll): Query-t (kërkesat, pyetësorët) analitikë shpesh e përfshijnë një tabelë shumë të madhe të fakteve joined (të bashkuar) me tabela më të vogla dimensionale. Këto join-a mund të bëhen gjihmonë në mënyrë efikase përmes teknikës multiway-join. Një alternativë është të shpërndahet tabela e fakteve dhe të replikohen në mënyrë të përhershme tabelat dimensionale, duke e përdorur strategjinë e njëjtë siç do të përdorej po ta merrnim multiway join-in e tabelës së fakteve dhe secilën tabelë dimensionale. Shkalla e replikimit dhe Madhësia e Reducer-it (Zvogëluesit): Shpesh është e përshtatshme të matet komunikimi sipas shkallës së replikimit, që është komunikimi për hyrje. Po ashtu, madhësia e reducer-it është numri maksimal i hyrjeve të asociuara me cilindo reducer. Për shumë probleme, është e mundur të nxirret një kufi më i poshtëm për shkallën e replikimit si funksion i madhësisë së reducer-it. Paraqitja e problemeve si grafe: Shumë probleme që janë të përshtatshme për llogaritjen MapReduce është e mundur të paraqiten me një graf në të cilin node-at (nyjet) i paraqesin hyrjet dhe daljet. Një dalje lidhet me të gjitha hyrjet që nevojiten për ta llogaritur atë dalje. Mapping Schemas (Skemat Mapuese): Kur është dhënë grafi i një problemi, dhe madhësia e një reducer-i, një mapping schema është caktim i hyrjeve të një apo më shumë reducer-ave ashtu që asnjë reducer-i nuk i caktohen më shumë hyrje se që lejon madhësia e reducer-it, dhe prapë për secilën dalje është ndonjë reducer që i merr të gjitha hyrjet që nevojiten për ta llogaritur atë dalje. Kërkesa që të ketë mapping schema për çfarëdo algoritmi MapReduce është shprehje e mirë e asaj se çka i dallon algoritmet MapReduce nga llogaritjet e përgjithshme paralele. Shumëzimi i Matricave me MapReduce: Është një familje e algorimeve one-pass (me një kalim) që e kryejnë shumëzimin e matricave n n me shkallë minimale të mundshme të replikimit r = 2n 2 /q, ku q është madhësia e reducer-it. Në anën tjetër, një algoritëm MapReduce me dy kalime për problemin e njëjtë me madhësi të njëjtë të reducer-it mund të përdorë më pak komunikim deri në një faktor të n. 10 / 65

11 3. Gjetja e elementeve të ngjashme Jaccard Similarity(Ngjashmëria e Jaccard-it): Ngjashmëria e Jaccard-it e bashkësive është raporti i madhësisë së prerjes së bashkësive ndaj madhësisë së unionit. Kjo masë e ngjashmërisë është e përshtatshme për shumë aplikacione, përfshirë ngjashmërinë tekstuale të dokumenteve dhe ngjashmërinë e shprehive të blerjes të klientëve. Shingling ( tjegullimi ): Një k-shingle ( tjegull-k ) janë cilëtdo k karakterë që shfaqen njëpas-një në një dokument. Nëse e paraqesim dokumentin përmes grupit të tij të k-shingleave, atëherë ngjashmëria e Jaccard-it e grupeve të shingle-ave e mat ngjashmërinë tekstuale të dokumenteve. Nganjëherë, është e dobishme të hash-ohen shingle-at në stringje të bitave të një gjatësie më të shkurtër, dhe të përdoren grupet e vlerave hash për t i përfaqësuar dokumentet. 11 / 65


12 Minhashing: Një funksion minhash nëpër bashkësi bazohet në një permutim të bashkësisë universale. Për një permutim të dhënë të tillë, vlera minhash për një bashkësi është ai element i bashkësisë që shfaqet i pari në radhitjen e permutuar. Minhash signatures (Nënshkrimet Minhash): Mund t i përfaqësojmë bashkësitë duke e zgjedhur ndonjë listë të permutacioneve dhe duke e llogaritur për secilën bashkësi nënshkrimin e saj minhash, që është sekuenca e vlerave minhash e fituar duke ia aplikuar secilin permutacion në listë asaj bashkësie. Për dy bashkësi të dhëna, pjesa e pritur e 12 / 65
: Meqë realisht nuk është e mundur të gjenerohen permutacione të rastësishme, është normale të simulohet një permutacion duke e zgjedhur një funksion hash të")
: Kjo teknikë na lejon t i shmangemi llogaritjes së ngjashmërisë së secilit çift të bashkësive apo të")
13 permutacioneve që do ta japë vlerën e njëjtë minhash është saktësisht ngjashmëria e Jaccard-it e bashkësive. Efficient Minhashing (Minhash-imi efikas): Meqë realisht nuk është e mundur të gjenerohen permutacione të rastësishme, është normale të simulohet një permutacion duke e zgjedhur një funksion hash të rastësishëm dhe duke e marrë që vlera minhash për një bashkësi të jetë vlera më e vogël hash e cilitdo nga anëtarët e bashkësisë. Locality-Sensitive Hashing for Signatures (Hash-imi me ndjeshmëri të afërsisë për nënshkrime): Kjo teknikë na lejon t i shmangemi llogaritjes së ngjashmërisë së secilit çift të bashkësive apo të nënshkrimeve të tyre minhash. Nëse na janë dhënë nënshkrimet për bashkësitë, mund t i ndajmë ato në band-a (grupe), dhe ta masim ngjashmërinë e një çifti të bashkësive vetëm nëse janë identike në të paktën një band. Duke zgjedhur në mënyrë të përshtatshme, mund t i eliminojmë nga konsiderimi shumicën e çifteve që nuk e plotësojnë pragun tonë të ngjashmërisë. Matjet e distancës: Matje e distancës është një funksion në çifte të pikave në një hapësirë që plotëson aksioma të caktuara. Distanca ndërmjet dy pikave është 0 nëse pikat janë të njëjta, por më e madhe se 0 nëse pikat janë të ndryshme. Distanca është simetrike; nuk ka rëndësi në çfarë radhe i konsiderojmë dy pikat. Një matje e distancës duhet ta plotësojë jobarazimin e trekëndëshit: distanca ndëmjet dy pikave nuk është kurrë më e madhe se shuma e distancave ndërmjet atyre dy pikave dhe një pike të tretë. 13 / 65
14 Distanca Euklidiane: Nocioni më i shpeshtë i distancës është Distanca Euklidiane në një hapësirë n-dimensionale. Kjo distancë, nganjëherë e quajtur norma L 2, është rrënja katrore e shumës së katrorëve të ndryshimeve ndërmjet pikave në secilin dimension. Një distancë tjetër e përshtatshme për Hapësirat Euklidiane, e quajtur Distanca Manhattan apo norma L 1 është shuma e madhësive (vlerave absolute) të ndryshimeve ndërmjet pikave në secilin dimension. Distanca e Jaccard-it: Një minus ngjashmëria e Jaccard-it është matje e distancës, e quajtur Distanca e Jaccard-it. Distanca Kosinus (Cosine): Këndi ndërmjet vektorëve në një hapësirë vektoriale është matja e distancës kosinus. Mund ta llogarisim kosinusin e atij këndi duke e marrë dot product-in (produktin skalar) të vektorëve dhe duke pjesëtuar me gjatësitë e vektorëve. Distanca e Editimit (Edit Distance): Kjo matje e distancës aplikohet në hapësirë të stringjeve, dhe është numri i insertimeve dhe/apo fshirjeve që nevojiten për ta konvertuar një string në një tjetër. Distanca e editimit mund të llogaritet edhe si shuma e gjatësive të stringjeve minus dyfishi i gjatësisë së nënsekuencës më të gjatë të përbashkët të stringjeve. Distanca e Hamming-ut (Hamming Distance): Kjo matje e distancës aplikohet në hapësirë të vektorëve. Distanca e Hamming-ut ndërmjet dy vektorëve është numri i pozitave në të cilat dallojnë vektorët. Generalized Locality-Sensitive Hashing (Hashimi i përgjithësuar me ndjeshmëri të afërsisë): Mund të fillojmë me çfarëdo koleksioni të funksioneve, siç janë funksionet minhash, që mund ta japin një vendim se a duhet apo jo një çift i elementeve të jenë kandidatë për kontrollim të ngjashmërisë. Kufizimi i vetëm për këto funksione është që ata ta ofrojnë një kufi të poshtëm për gjasën të thonë po nëse distanca (sipas ndonjë matjeje të distancës) është nën një kufi të dhënë, dhe një kufi të sipërm të gjasës të thonë po nëse distanca është mbi një kufi tjetër të dhënë. Pastaj mund ta rrisim gjasën për të thënë po për elementet e largëta në masë sa të duam të madhe, duke e aplikuar një konstrukt DHE (AND) dhe një konstrukt OSE (OR). Hiperplanet (hiper-rrafshet, hyperplanes) e rastësishme dhe LSH për Distancën Kosinus: Mund ta marrim një grup të funksioneve bazë për ta nisur një LSH të përgjithësuar për matjen e distancës kosinus duke e identifikuar secilin funksion me një listë të vektorëve të zgjedhur rastësisht. E aplikojmë një funksion në një vektor të dhënë v duke e marrë dot product (produktin skalar) të v me secilin vektor në listë. Rezulati është një skemë që përbëhet nga shenjat (+1 ose 1) të produkteve skalare. Pjesa e pozitave në të cilat skemat e dy vektorëve përputhen, e shumëzuar me 180, është një llogaritje e këndit ndërmjet dy vektorëve. LHS për Distancën Euklidiane: Një grup i funksioneve bazë për ta nisur LSH për Distancën Euklidiane mund të merret duke zgjedhur drejtëza të rastësishme dhe duke i projektuar pikat në ato drejtëza. Secila drejtëz ndahet në intervale me gjatësi fikse, dhe funksioni i përgjigjet me po një çifti të pikave që bien në intervalin e njëjtë. Detektimi i ngjashmërisë së madhe me krahasim të Stringjeve: Një qasje alternative për të gjetur elemente të ngjashme, kur pragu i ngjashmërisë së Jaccard-it është afër vlerës 1, e shmang përdorjen e minhashing-ut dhe LSH-së. Në vend të kësaj, radhitet bashkësia universale, dhe bashkësitë përfaqësohen nga stringjet, që përbëhen nga elementet e veta të 14 / 65
15 radhitura. Mënyra më e thjeshtë për ta shmangur krahasimin e të gjitha çifteve të bashkësive apo stringjeve të tyre është të vërejmë se bashkësitë me ngjashmëri të madhe do të kenë stringje të gjatësisë afërsisht të njëjtë. Nëse i radhisim stringjet, mund ta krahasojmë secilin string me vetëm një numër të vogël të stringjeve që e pasojnë menjëherë atë. Indekset e karakterëve: Nëse i përfaqësojmë bashkësitë me stringje, dhe pragu i ngjashmërisë është afër vlerës 1, mund t i indeksojmë të gjitha stringjet sipas disa karakterëvetë parë të tyre. Prefiksi (parashtesa), karakteret e të cilit duhet të indeksohen, është afërsisht gjatësia e stringut herë distanca maksimale e Jaccard-it (1 minus ngjashmëria minimale e Jaccard-it). Indekset e pozitës: Mund t i indeksojmë stringjet jo vetëm në karakterët në prefikset e veta, por edhe në pozitën e atij karakteri brenda prefiksit. E zvogëlojmë numrin e çifteve që duhet të krahasohen, sepse nëse dy stringje e kanë një karakter të njëjtë që nuk është në pozitën e parë në të dy stringjet, atëherë e dimë se ose ka disa karakterë paraprijës që janë në union por jo në prerje, ose është një simbol i mëhershëm që shfaqet në të dy stringjet. Indekset e sufiksit (prapashtesës): Mund t i indeksojmë stringjet edhe bazuar jo vetëm në karakterët në prefikset e tyre dhe pozitat e atyre karakterëve, por edhe në gjatësinë e sufiksit të karakterit numrit të pozitave që e pasojnë atë në string. Kjo strukturë e zvogëlon tutje numrin e çifteve që duhet të krahasohen, sepse një simbol i përbashkët me gjatësi të ndryshme të sufiksit nënkupton karakterë shtesë që duhet të jenë në union por jo në prerje. 15 / 65

16 4. Gërmimi i stream-ave të shënimeve The Stream Data Model (Modeli i Shënimeve Rrjedhëse): Ky model supozon se shënimet arrijnë në një engine (motor) procesues në një sasi që e bën të pamundur të ruhet gjithçka në një memorje aktive. Një strategji e trajtimit të stream-ave (rrjedhave) është të mirëmbahen përmbledhjet e stream-ave, të mjaftueshme për t iu përgjigjur query-ve të pritura për shënimet. Një qasje e dytë është të mirëmbahet një dritare rrëshqitëse e shënimeve të fundit të arritura. 16 / 65

17 Sampling of Streams (Mostrimi i Rrjedhave): Për ta krijuar një mostër të një stream-i që është e përdorshme për një klasë të query-ve, e identifikojmë një grup të atributeve key (çelës) për stream-in. Duke e hashuar key-n e cilitdo element të rrjedhës që arrin, mund ta përdorim vlerën hash për të vendosur në mënyrë konsistente se a do të bëhen pjesë e mostrës të gjithë apo asnjëri nga elementet me atë key. Filterët Bloom: Kjo teknikë na lejon t i filtrojmë stream-at ashtu që elementet që i takojnë një bashkësie të caktuar lejohen të kalojnë, ndërsa shumica e joanëtarëve fshihen. E përdorim një varg të madh të biteve, dhe disa funksione hash. Anëtarët e bashkësisë së zgjedhur hashohen në bucket-a (kova), që janë bite në varg, dhe ato bite bëhen 1. Për ta testuar një element të stream-it për anëtarësi, e hash-ojmë elementin në një grup të biteve duke e përdorur secilin nga funksionet hash, dhe e pranojmë elementin vetëm nëse të gjitha këto bite janë 1. Numërimi i Elementeve të Ndryshme: Për ta vlerësuar numrin e elementeve të ndryshme që shfaqen në një stream, mund t i hash-ojmë elementet në numra të plotë, të interpretuar si numra binarë. 2 i ngritur në fuqinë që është sekuenca më e gjatë e 0-ve të para në vlerën hash të cilitdo element të stream-it është një vlerësim i numrit të elementeve të ndryshme. Duke përdorur shumë funksione hash dhe duke i kombinuar këto vlerësime, së pari duke i marrë mesataret brenda grupeve, dhe pastaj duke e marrë medianën e mesatareve, e marrim një vlerësim të besueshëm. Momentet e Stream-ave: Momenti i k-të i një stream-i është shuma e fuqive të k-ta të numërimeve (herave) të secilit element që shfaqet të paktën një herë në stream. Momenti i 0-t është numri i elementeve të ndryshme, dhe momenti i 1-rë është gjatësia e stream-it. Vlerësimi i Momenteve të Dyta: Një vlerësim i mirë i momentit të dytë, apo i surprise number (numrit befasi), merret duke e zgjedhur një pozitë të rastësishme në stream, duke e marrë dyfishin e numrit të herave që shfaqet ky element në stream nga ajo pozitë e tutje, duke zbritur 1, dhe duke e shumëzuar me gjatësinë e stream-it. Shumë ndryshore të rastësishme të këtij tipi mund të kombinohen si vlerësimet për numërimin e numrit të elementeve të ndryshme, për ta prodhuar një vlerësim të besueshëm të momentit të dytë. Vlerësimi i Momenteve më të Larta: Teknika për momentet e dyta funksionon edhe për momentet e k-ta, përderisa e ndërrojmë formulën 2x 1 (ku x është numri i herave që elementi shfaqet te apo pas pozitës së zgjedhur) me x k (x 1) k. Vlerësimi i Numrit të 1-sheve në Dritare: Mund ta vlerësojmë numrin e 1-sheve në një dritare të 0-ve dhe 1-sheve duke i grupuar 1-shet nëpër bucket-a. Secili bucket e ka një numër të 1- sheve që është fuqi e 2-shit; janë një apo dy bucket-a të secilës madhësi, dhe madhësitë nuk 17 / 65

18 zvogëlohen kurrë ndërsa shkojmë prapa në kohë. Nëse e regjistrojmë vetëm pozitën dhe madhësinë e bucket-ave, mund ta paraqesim përmbajtjen e një dritareje të madhësisë N me hapësirë O(log 2 N). Përgjigjja në query-t për numrat e 1-sheve: Nëse duam t i dimë numrat e përafërt të 1-sheve në k elementet më të fundit të një stream-i binar, e gjejmë bucket-in më të hershëm B që është të paktën pjesërisht brenda k pozitave të fundit të dritares dhe e vlerësojmë numrin e 1-sheve të jetë shuma e madhësive të secilit nga bucket-at më të fundit plus gjysma e madhësisë së B. Ky vlerësim nuk mund të jetë kurrë më larg se 50% e numrit të vërtetë të 1- sheve. Përafrime më të mira për numrin e 1-sheve: Duke e ndryshuar rregullin për atë se sa bucketa të një madhësie të dhënë mund të ekzistojnë në paraqitjen e një dritareje binare, ashtu që mund të ekzistojnë ose r ose r-1 të një madhësie të dhënë, mund të sigurohemi që përafrimi për numrin e vërtetë të 1-sheve nuk është kurrë më larg se 1/r. Dritaret që dobësohen eksponencialisht: Në vend se ta fiksojmë madhësinë e dritares, mund të imagjinojmë se dritarja përbëhet nga të gjitha elementet që kanë arritur ndonjëherë në stream, por elementi që ka arritur t njësi kohore më herët peshohet me e -ct për ndonjë konstante kohore c. Ky veprim na lejon të mirëmbajmë lehtë përmbledhje të caktuara të një dritareje që dobësohet eksponencialisht. Për shembull, shuma e peshuar e elementeve mund të rillogaritet, kur arrin një element i ri, duke e shumëzuar shumën e vjetër me 1 c dhe pastaj duke e shtuar elementin e ri. Mirëmbajtja e elementeve të shpeshta në një dritare që dobësohet eksponencialisht: Mund të imagjinojmë se secili element përfaqësohet nga një stream binar, ku 0 domethënë se elementi nuk ishte ai që ka arritur në një kohë të dhënë, dhe 1 domethënë se ishte. Mund t i gjejmë elementet shuma e stream-ave binarë të të cilëve është të paktën 1/2. Kur arrin një element i ri, shumëzoji të gjitha shumat e regjistruara me 1 minus konstanta kohore, shtoja 18 / 65

19 1 sasisë së elementit që sapo arriti, dhe fshije nga regjistri çdo element shuma e të cilit ka rënë nën 1/2. 19 / 65

20 5. Analiza e linqeve Term Spam (Spam-i i termeve): Motorët e hershëm të kërkimit nuk ishin në gjendje të japin rezultate relevante sepse ishin të prekshëm ndaj term spam futja në Web-faqe e fjalëve që e paraqesin ndryshe se me çka ka të bëjë faqja. 20 / 65


: Linqet në Web i paraqesim me një matricë ku rreshti i i-të dhe shtylla e i-të e paraqesin faqen e i-të të Web-it.")
21 Zgjidhja e Google për Term Spam: Google ia doli t i kundërvihet term spam-it me dy teknika. E para ishte algoritmi PageRank (Rangu i Faqes) për përcaktimin e rëndësisë relative të faqeve në Web. E dyta ishte një strategji e të besuarit se çka kanë thënë faqet tjera për një faqe të dhënë, në linqet e tyre për te ajo faqe apo afër atyre linqeve, në vend se ta besonin vetëm atë që e thoshte faqja për veten. PageRank: PageRank është një algoritëm që ia cakton një numër real secilës faqe në Web, të quajtur PageRank-u i saj. PageRank-u i një faqeje është një matje se sa është e rëndësishme faqja, apo sa ka gjasë të jetë përgjigje e mirë për një query të kërkimit. Në formën e vet më të thjeshtë, PageRank-u është zgjidhje për ekuacionin rekursiv një faqe është e rëndësishme nëse në të link-ojnë (lidhen) faqe të rëndësishme. Transition Matrix of the Web (Matrica e Transicionit e Web-it): Linqet në Web i paraqesim me një matricë ku rreshti i i-të dhe shtylla e i-të e paraqesin faqen e i-të të Web-it. Nëse ka një apo më shumë linqe nga faqja j në faqen i, atëherë elementi në rreshtin i dhe shtyllën j është 1/k, ku k është numri i faqeve në të cilat linkon (lidhet) faqja j. Elementet tjera të matricës së transicionit janë / 65
 (principal eigenvector) i matricës transicionale.")
22 Llogaritja e PageRank-ut në Web-grafe të Lidhura Fort: Për Web-grafet e lidhura fort (ato ku secili node (nyje) mund ta arrijë cilindo node tjetër), PageRank-u është vektori vetjak kryesor (më i madhi) (principal eigenvector) i matricës transicionale. PageRank-un mund ta llogarisim duke filluar me çfarëdo vektori jozero dhe duke e shumëzuar në mënyrë të përsëritur vektorin aktual me matricën transicionale, për të marrë vlerësim më të mirë. Pas rreth 50 iterimeve, vlerësimi do të jetë shumë afër limitit, që është PageRank-u i vërtetë. The Random Surfer Model (Modeli i Surfuesit të Rastësishëm): Llogaritja e PageRank-ut mund të mendohet si simulimi i sjelljes së shumë surfuesve të rastësishëm, ku secili fillon në një faqe të rastësishme dhe në cilindo hap lëviz, me rastësi, në njërën nga faqet ku linkon faqja e tyre aktuale. Gjasa limit e një surfuesi të jetë në një faqe të dhënë është PageRank-u i asaj faqeje. Intuita është që njerëzit priren të krijojnë linqe në faqet që iu duken të dobishme, prandaj surfuesit e rastësishëm do të priren të jenë në një faqe të dobishme. Dead Ends (Rrugët e mbyllura): Një rrugë e mbyllur (dead end, qorrsokak) është një Web faqe pa linqe dalëse. Prezenca e rrugëve të mbyllura do të shkaktojë që PageRank-u i disa apo të gjitha faqeve të shkojë në 0 gjatë llogaritjes iterative, duke i përfshirë edhe faqet që nuk janë rrugë të mbyllura. Mund t i eliminojmë të gjitha rrugët e mbyllura para se ta ndërmarrim llogaritjen e PageRank-ut duke i hequr rekursivisht node-at që nuk kanë harqe dalëse. Vëreni se heqja e një node-i mund të shkaktojë që një tjetër, që link-onte vetëm në të, të bëhet rrugë e mbyllur, prandaj procesi duhet të jetë rekursiv. Spider traps (Kurthet e merimangës): Kurth i merimangës është një grup i node-ave që, ndërsa mund të link-ojnë te njëri-tjetri, nuk kanë linqe jashtë në node-a tjerë. Në një llogaritje iterative të PageRank-ut, prezenca e kurtheve të merimangës shkakton që tërë PageRank-u të zihet brenda atij grupi të node-ave. 22 / 65


23 Taxation Schemes(Skemat e Tatimit): Për t iu kundërvënë efektit të kurtheve të merimangës (dhe të rrugëve të mbyllura, nëse nuk i eliminojmë ato), PageRank-u normalisht llogaritet në një mënyrë që e ndryshon shumëzimin e thjeshtë iterativ me matricën e transicionit. Zgjedhet një parametër β, zakonisht rreth Për një vlerësim të dhënë të PageRank-ut, vlerësimi tjetër llogaritet duke e shumëzuar vlerësimin me β herë matrica e transicionit, dhe pastaj duke ia shtuar (1 β)/n vlerësimit për secilën faqe, ku n është numri total i faqeve. Tatimimi dhe Surfuesit e Rastësishëm: Llogaritja e PageRank-ut duke e përdorur parametrin e tatimimit β mund të mendohet si dhënie e secilit surfues të rastësishëm një gjasë 1 β të largimit nga Web-i, dhe futjes së një numri ekuivalent të surfuesve rastësisht nëpër Web. Paraqitja efikase e matricave të transicionit: Meqë një matricë e transicionit është shumë e rrallë (sparse) (pothuajse të gjitha elementet janë 0), kursehet edhe kohë edhe hapësirë ta paraqesim duke i listuar elementet e saj jozero. Mirëpo, pos që është e rrallë, elementet jozero e kanë një veti të veçantë: të gjitha janë të njëjta në cilëndo shtyllë të dhënë; vlera e secilit element jozero është inversi i numrit të elementeve jozero në atë shtyllë. Prandaj, paraqitja e preferuar është shtyllë-për-shtyllë, ku paraqitja e një shtylle është numri i elementeve jozero, i pasuar nga një listë e rreshtave ku ndodhen ato elemente. Shumëzimi Matricë-Vektor në shkallë shumë të madhe: Për grafet me madhësi të Web-it, mund të mos jetë e mundur të ruhet tërë vektori i vlerësimit të PageRank-ut në memorien kryesore të një makine. Prandaj, mund ta ndajmë vektorin në k segmente dhe ta ndajmë 23 / 65

24 matricën e transicionit në k 2 katrorë, të quajtur blloqe, duke ia caktuar secilin katror një makine. Të gjithë segmentet e vektorit dërgohen në k makina, prandaj është një kosto e vogël shtesë në replikimin e vektorit. Paraqitja e Blloqeve të Matricës së Transicionit: Kur e ndajmë një matricë të transicionit në blloqe katrore, shtyllat ndahen në k segmente. Për ta paraqitur një segment të një shtylle, nuk nevojitet asgjë nëse nuk ka elemente jozero në atë segment. Mirëpo, nëse ka një apo më shumë elemente jozero, atëherë na duhet ta paraqesim segmentin e shtyllës me numrin total të elementeve jozero në shtyllë (ashtu që të mund ta dimë se çfarë vlere kanë elementet jozero) të pasuar nga një listë e rreshtave me elemente jozero. Topic-Sensitive PageRank(PageRank-u i ndjeshëm ndaj temës): Nëse e dimë se përpiluesi i query-t është i interesuar në një temë të caktuar, atëherë ka kuptim të ndikohet PageRank-u në favor të faqeve në atë temë. Për ta llogaritur këtë formë të PageRank-ut, e identifikojmë një grup të faqeve që dihet se janë në atë temë, dhe e përdorim atë si grup të teleportimit. Llogaritja e PageRank-ut ndryshohet ashtu që vetëm faqeve në grupin e teleportimit iu jepet një pjesë e tatimit, në vend se të shpërndahet tatimi ndërmjet të gjitha faqeve në Web. Krijimi i Grupeve të Teleportimit: Që të punojë Topic Sensitive PageRank, duhet t i identifikojmë faqet që kanë gjasë të madhe të jenë në një temë të dhënë. Një qasje është të fillojmë me faqet të cilat Open Directory (DMOZ) i identifikon me atë temë. Një qasje tjetër është të identifikohen fjalët që dihet se janë të asociuara me temën, dhe të zgjedhen për grup të teleportimit ato faqe që kanë numër jashtëzakonisht të lartë të paraqitjeve të fjalëve të tilla. Link Spam (Spam-i i Linqeve): Për ta mashtruar algoritmin PageRank, akterë të pandershëm kanë krijuar spam farms (ferma të spam-it). Këto janë koleksione të faqeve qëllimi i të cilave është të koncentrojnë PageRank të lartë në një faqe të caktuar. Struktura e një Spam Farm: Zakonisht, një spam farm përbëhet nga një faqe target (cak) dhe tepër shumë faqe përkrahëse. Faqja target link-on në të gjitha faqet përkrahëse, dhe faqet përkrahëse link-ojnë vetëm në faqen target. Pos kësaj, është esenciale që të krijohen disa 24 / 65
: Një mënyrë për ta zbutur efektin e link spam është të llogaritet një Topic-sensitive PageRank i quajtur TrustRank, ku grupi i teleportimit është një koleksion i faqeve të")
25 linqe nga jashtë fermës së spam-it. Për shembull, spameri mund të fusë linqe në faqen e vet target duke shkruar komente në blogjet e njerëzve tjerë apo në grupe të diskutimit. TrustRank (Rangu i Besimit): Një mënyrë për ta zbutur efektin e link spam është të llogaritet një Topic-sensitive PageRank i quajtur TrustRank, ku grupi i teleportimit është një koleksion i faqeve të besuara. Kjo teknikë e shmang ndarjen e tatimit në llogaritjen e PageRank-ut me numrin e madh të faqeve përkrahëse në fermat e spam-it dhe kështu me preferencë e zvogëlon PageRank-un e tyre. Spam Mass (Masa e Spam-it): Për t i identifikuar fermat e spam-it, mund ta llogarisim edhe PageRank-un tradicional edhe TrustRank-un për të gjitha faqet. Ato faqe që kanë TrustRank shumë më të vogël se sa PageRank-u me gjasë janë pjesë e një ferme të spam-it. Hubs and Authorities (Hub-at dhe Autoritetet): Ndërsa PageRank-u e jep një pamje njëdimensionale të rëndësisë së faqeve, një algoritëm i quajturhits (Hyperlink-Induced Topic Search, Kërkimi i Temave i Nxjerrë nga Hiperlinqet) provon t i masë dy aspekte të ndryshme të rëndësisë. Autoritete janë ato faqe që përmbajnë informacion të çmueshëm. Hub-at (qendrat, boshtet) janë faqet që, ndërsa vetë nuk e përmbajnë informacionin, link-ojnë në vendet ku mund të gjendet informacioni. Formulimi Rekursiv i Algoritmit HITS: Llogaritja e pikëve të hub-ave dhe autoriteteve për faqet varet nga zgjidhja e ekuacioneve rekursive: një hub linkon në shumë autoritete, dhe një autoritet është i linkuar nga shumë hub-a. Zgjidhja e këtyre ekuacioneve është në esencë një shumëzim i iteruar matricë-vektor, sikur i PageRank-ut. Mirëpo, ekzistenca e rrugëve të mbyllura apo grackave të merimangës nuk e dëmton zgjidhjen e ekuacioneve të HITS në mënyrën që e bëjnë për PageRank, prandaj nuk nevojitet skemë e tatimit. 25 / 65
 dhe basket-at (shportat). Ka relacion shumë-meshumë ndërmjet item-ave dhe basket-ave.")
: Suporti (përkrahja, mbështetja) për një grup të item-ave është numri i basket-ave që i përmbajnë të gjithë ata item-a.")
26 6. Itemset-at e shpeshtë (Grupet e shpeshta të elementeve/artikujve) Market-Basket Data (Shënimet e Shportës së Tregut): Ky model i shënimeve supozon se janë dy lloje të entiteteve: item-at (artikujt) dhe basket-at (shportat). Ka relacion shumë-meshumë ndërmjet item-ave dhe basket-ave. Zakonisht, basket-at ndërlidhen me grupe të vogla të item-ave, ndërsa item-at mund të ndërlidhen me shumë basket-a. Frequent Itemsets (Itemset-at e shpeshtë): Suporti (përkrahja, mbështetja) për një grup të item-ave është numri i basket-ave që i përmbajnë të gjithë ata item-a. Itemset-at (grupet e item-ave) me suport që është të paktën sa ndonjë prag quhen itemset-a të shpeshtë. Association Rules (Rregullat e Asociacionit): Këto janë implikimet që nëse një basket e përmban një grup të caktuar të item-ave I, atëherë me gjasë do ta përmbajë edhe një item tjetër të caktuar j. Gjasa që edhe j është në basket-in që e përmban I-në quhet konfidenca (siguria) e rregullit. Interesi i rregullit është sasia për të cilën konfidenca devijon (shmanget) nga pjesa e të gjithë basket-ave që përmbajnë j. 26 / 65
 të një madhësie të caktuar.")
27 The Pair-Counting Bottleneck (Ngushtimi i numërimit të çifteve): Për t i gjetur itemset-at e shpeshtë, na duhet t i ekzaminojmë (kontrollojmë) të gjithë basket-at dhe ta numërojmë sasinë e paraqitjeve të set-eve (grupeve, bashkësive) të një madhësie të caktuar. Për shënime tipike, me qëllimin e prodhimit të një numri të vogël të itemset-ave që janë më të shpeshtit nga të gjithë, pjesa që shpesh e merr shumicën e memorjes kryesore është numërimi i çifteve të item-ave. Prandaj, metodat për gjetjen e itemset-ave të shpeshtë zakonisht koncentrohen në atë se si të minimizohet memorja kryesore që nevojitet për t i numëruar çiftet. Triangular Matrices (Matricat Trekëndëshe): Ndërsa mund të përdoret varg dy-dimensional për t i numëruar çiftet, kjo e harxhon gjysmën e hapësirës, sepse nuk ka nevojë të numërohet çifti {i, j} në të dy elementet i-j dhe j-i të vargut. Duke i renditur çiftet (i, j) për të cilat i<j në renditje leksikografike, mund t i ruajmë vetëm numërimet e nevojshme në një varg një-dimensional pa hapësirë të shpenzuar kot, dhe prapë të mund t i qasemi në mënyrë efikase sasisë për cilindo çift. Ruajtja e Sasive të Çifteve si Triplete: Nëse në basket-a shfaqen më pak se 1/3 e çifteve të mundshme, atëherë është më efikase për hapësirë të ruhen sasitë e çifteve si triplete (i, j, c), ku c është sasia e çiftit {i, j}, dhe i<j. Një strukturë e indeksit si tabela hash na lejon ta gjejmë në mënyrë efikase tripletin për (i, j). Monotonia e Itemset-ave të Shpeshtë: Një veti e rëndësishme e itemset-ave është se nëse një grup i item-ave është i shpeshtë, atëherë të tilla janë të gjitha nëngrupet e tij. E shfrytëzojmë këtë veti për ta eliminuar nevojën t i numërojmë itemset-at e caktuar duke e përdorur kontrapozicionin e saj: nëse një itemset nuk është i shpeshtë, atëherë as mbigrupet e tij nuk janë. The A-Priori Algorithm for Pairs (Algoritmi A-Priori për Çifte): Mund t i gjejmë të gjitha çiftet e shpeshta duke i bërë dy kalime nëpër basket-a. Në kalimin e parë, i numërojmë vetë item-at, dhe pastaj e përcaktojmë se cilët item-a janë të shpeshtë. Në kalimin e dytë, i numërojmë vetëm çiftet e item-ave ku të dytë janë gjetur të shpeshtë në kalimin e parë. Monotonia e justifikon injorimin tonë të çifteve tjera. Gjetja e Itemset-eve të shpeshtë më të mëdhenj: A-Priori dhe shumë algoritme tjera na lejojnë t i gjejmë itemset-at e shpeshtë më të mëdhenj se çiftet, nëse e bëjmë një kalim nëpër basket-a për secilën madhësi të itemset-t, deri në ndonjë kufi. Për t i gjetur itemset-at e madhësisë k, monotonia na lejon ta filtrojmë vëmendjen tonë në vetëm ato itemset-e të tilla që nëngrupet e tyre të madhësisë k 1 tashmë janë gjetur si të shpeshta. 27 / 65

: Mund të fusim kalime shtesë ndërmjet kalimit të parë dhe të dytë të Algoritmit PCY për t i hash-uar çiftet në tabela hash të tjera,")
28 Algoritmi PCY (Park-Chen-Yu): Ky algoritëm e përmirëson A-Priori-n duke e krijuar një tabelë hash në kalimin e parë, duke e përdorur tërë hapësirën e memorjes kryesore që nuk nevojitet për t i numëruar item-at. Çiftet e item-ave hash-ohen, dhe bucket-at e tabelës hash përdoren si sasi të numrit të herave që një çift është hash-uar në atë bucket. Pastaj, në kalimin e dytë, duhet t i numërojmë vetëm çiftet e item-ave të shpeshtë që në kalimin e parë janë hash-uar në një bucket të shpeshtë (që e ka sasinë të paktën sa pragu i suportit). The Multistage Algorithm (Algoritmi me shumë faza, shumëshkallësh): Mund të fusim kalime shtesë ndërmjet kalimit të parë dhe të dytë të Algoritmit PCY për t i hash-uar çiftet në tabela hash të tjera, të pavarura. Në secilin kalim të ndërmjetëm, duhet t i hash-ojmë vetëm çiftet e item-ave të shpeshtë që janë hash-uar në bucket-at e shpeshtë në të gjitha kalimet e mëparshme. The Multihash Algorithm (Algoritmi Multihash): Mund ta ndryshojmë kalimin e parë të Algoritmit PCY për ta ndarë memorjen kryesore të disponueshme në disa tabela hash. Në kalimin e dytë, duhet ta numërojmë një çift të item-ave të shpeshtë vetëm nëse ata janë hash-uar në bucket-a të shpeshtë në të gjitha tabelat hash. 28 / 65

29 Randomized Algorithms (Algoritmet e Rastësuara): Në vend se të bëhen kalime nëpër të gjitha shënimet, mund ta zgjedhim një mostër të rastësishme të basket-ave, mjaft të vogël që të jetë e mundur të ruhen edhe mostra edhe numërimet e nevojshme të itemset-ave në memorjen kryesore. Pragu i suportit duhet të ulet proporcionalisht. Pastaj mund t i gjejmë itemset-at e shpeshtë për mostrën, dhe të shpresojmë se ajo është përfaqësim i mirë i shënimeve si tërësi. Ndërsa kjo metodë e përdor të shumtën një kalim nëpër tërë dataset-in (grupin e shënimeve), ajo është subjekt i false positives (pozitiveve të rrejshme) (itemset-ave që janë të shpeshtëte mostra por jo te tërësia) dhe false negatives (negativeve të rrejshme) (itemset-ave që janë të shpeshtëte tërësia por jo te mostra). Algoritmi SON (Savasere, Omiecinski, and Navathe): Një përmirësim i algoritmit të thjeshtë të rastësuar është të ndahet tërë fajli i basket-ave në segmente mjaft të vogla që të gjithë itemset-at e shpeshtë për segmentin të mund të mund të gjenden në memorjen kryesore. Itemset-at kandidatë janë ata që gjenden të shpeshtë për të paktën një segment. Një kalim i dytë na lejon t i numërojmë të gjithë kandidatët dhe ta gjejmë koleksionin e saktë të itemset-ave të shpeshtë. Ky algoritëm është veçanërisht i përshtatshëm në ambient MapReduce. Algoritmi i Toivonen-it: Ky algoritëm fillon duke i gjetur itemset-et e shpeshtë në një mostër, por me pragun të ulur ashtu që të ketë pak gjasë të huqet ndonjë itemset që është i shpeshtë te tërësia. Pastaj, e ekzaminojmë tërë fajlin e basket-ave, duke i numëruar jo vetëm itemset-at që janë të shpeshtë në mostër, por edhe kufirin negativ itemset-at që nuk janë gjetur të shpeshtë, por tërë nëngrupet e tyre të para janë. Nëse asnjë anëtar i kufirit negativ nuk gjendet i shpeshtë te tërësia, atëherë përgjigjja është e saktë. Por nëse një anëtar i kufirit negativ gjendet i shpeshtë, atëherë i tërë procesi duhet të përsëritet me një mostër tjetër. Itemset-at e shpeshtë në Stream-a: Nëse e përdorim një dritare që dobësohet me konstantë c, atëherë mund të fillojmë ta numërojmë një item sa herë që e shohim në një basket. Fillojmë ta numërojmë një itemset nëse e shohim të përmbajtur brenda basket-it aktual, dhe tërë nëngrupet e tij të para përkatëse tashmë janë duke u numëruar. Ndërsa dritarja dobësohet, i shumëzojmë të gjitha sasitë me 1 c dhe i eliminojmë ato që janë më pak se 1/2. 29 / 65


30 7. Clustering Clustering (Tufëzimi): Cluster-at (tufat, grupet) janë shpesh një përmbledhje e dobishme e shënimeve që është në formë të pikave në ndonjë hapësirë. Për t i cluster-uar pikat, na nevojitet një matje e distancës në atë hapësirë. Idealisht, pikat në cluster-in e njëjtë kanë distanca të vogla ndërmjet tyre, ndërsa pikat në cluster-at e ndryshëm kanë distanca të mëdha ndërmjet tyre. 30 / 65
 fillojnë me të gjitha pikat në një cluster më vete, dhe cluster-at e afërt bashkohen në mënyrë iterative.")
: Pikat në hapësira Euklidiane me dimension të lartë, si dhe pikat në hapësirat jo-euklidiane shpesh sillen në mënyrë jointuitive.")
. Centroid-ët dhe Clustroid-ët: Në një hapësirë Euklidiane, anëtarëve të një cluster-i mund t i nxirret mesatarja, dhe kjo mesatare quhet centroidi.")
31 Algoritmet e cluster-imit: Algoritmet e cluster-imit përgjithësisht e kanë njërën nga dy forma. Algoritmet e cluster-imit hierarkik (Hierarchical clustering) fillojnë me të gjitha pikat në një cluster më vete, dhe cluster-at e afërt bashkohen në mënyrë iterative. Algoritmet e clusterimit me caktim të pikave (Point-assignment clustering) i konsiderojnë pikat me radhë dhe i caktojnë (vendosin) ato në cluster-in në të cilin përshtaten më së miri. The Curse of Dimensionality (Mallkimi i Dimensionalitetit): Pikat në hapësira Euklidiane me dimension të lartë, si dhe pikat në hapësirat jo-euklidiane shpesh sillen në mënyrë jointuitive. Dy veti të papritura të këtyre hapësirave janë se pikat e rastësishme janë pothuajse gjithmonë në distancë pothuajse të njëjtë, dhe vektorët e rastësishëm janë pothuajse gjithmonë ortogonalë ( kënddrejtë ). Centroid-ët dhe Clustroid-ët: Në një hapësirë Euklidiane, anëtarëve të një cluster-i mund t i nxirret mesatarja, dhe kjo mesatare quhet centroidi. Në hapësira jo-euklidiane, nuk ka garancë që pikat kanë mesatare, prandaj detyrohemi ta përdorim njërin nga anëtarët e cluster-it si përfaqësues apo element tipik të cluster-it. Ai përfaqësues quhet clustroid. Zgjedhja e Clustroid-it: Ka shumë mënyra si mund ta përcaktojmë një pikë tipike të një cluster-i në një hapësirë jo-euklidiane. Për shembull, mund ta zgjedhim pikën me shumë më të vogël të distancave me pikat tjera, me shumë më të vogël të katrorëve të atyre distancave, apo atë me distancën më të vogël maksimale me cilëndo pikë në cluster. Rrezja dhe diametri: Qoftë hapësira Euklidiane apo jo, mund ta definojmë rrezen e cluster-it si distanca maksimale nga centroid-i apo clustroid-i te cilado pikë në atë cluster. Mund ta definojmë diametrin e cluster-it si distancën maksimale ndëmjet cilavedo dy pika në cluster. Janë të njohura edhe definicione alternative, sidomos të rrezes, për shembull, distanca mesatare nga centroidi te pikat tjera. Hierarchical Clustering (Cluster-imi hierarkik): Kjo familje e algoritmeve ka shumë variacione, që dallojnë kryesisht në dy fusha. Së pari, mund të zgjedhim në mënyra të ndryshme se cilët dy cluster-a t i bashkojmë herën tjetër. Së dyti, mund të vendosim në mënyra të ndryshme se kur ta ndalim procesin e bashkimit. 31 / 65

32 Zgjedhja e cluster-ëve për bashkim: Një strategji për të vendosur për çiftin më të mirë të cluster-ëve për bashkim në cluster-imin hierarkik është të zgjedhen cluster-ët me centroidët apo clustroid-ët më të afërt. Një qasje tjetër është të zgjedhet çifti i cluster-ëve me pikat më të afërta, nga një nga secili cluster. Një qasje e tretë është të përdoret distanca mesatare ndërmjet pikave nga dy cluster-ët. Ndalja e Procesit të Bashkimit: Një cluster-im hierarkik mund të vazhdojë deri kur të mbeten një numër i fiksuar i cluster-ëve. Alternativisht, do të mund të bashkonim deri kur është e pamundur të gjendet një çift i cluster-ëve bashkimi i të cilëve është mjaftueshëm kompakt, p.sh. cluster-i i bashkuar ka rreze apo diametër nën ndonjë prag. Një qasje tjetër e përfshin bashkimin përderisa cluster-i rezultues ka dendësi mjaftueshëm të lartë, që mund të definohet në mënyra të ndryshme, por është numri i pikave i pjesëtuar me ndonjë matje të madhësisë së cluster-it, p.sh. rrezja. K-Means Algorithms (Algoritmet me k-mesatare): Kjo familje e algoritmeve është e tipit caktim i pikave dhe supozon hapësirë Euklidiane. Supozohet se janë saktësisht k cluster-a për ndonjë k të njohur. Pasi të zgjedhen k centroid-e të clusterëve fillestarë, pikat shqyrtohen një nga një dhe i caktohen centroid-it më të afërt. Centroidi i një cluster-i mund të migrojë (shpërngulet, lëvizë) gjatë caktimit të pikave, dhe një hap opsional i fundit është të ricaktohen të gjitha pikat, ndërsa centroid-et mbahen të fiksuar në vlerat e tyre të fundit të fituara gjatë kalimit të parë. 32 / 65

, duke provuar")
33 Inicializimi i Algoritmeve K-Means: Një mënyrë për t i gjetur k centroidet fillestare është të zgjedhet një pikë e rastësishme, dhe pastaj të zgjedhen k 1 pika shtesë, secila sa më larg që është e mundur nga pikat e zgjedhura paraprakisht. Një alternativë është të nisim me një sample (mostër) të vogël të pikave dhe të përdorim një cluster-im hierarkik për t i bashkuar ato në k cluster-a. Zgjedhja e K-së në një Algoritëm K-Means: Nëse numri i cluster-ëve është i panjohur, mund ta përdorim një teknikë binary-search (të kërkimit binar), duke provuar cluster-im k-means me vlera të ndryshme të k. E kërkojmë vlerën më të madhe të k për të cilën një ulje nën k 33 / 65
 më të")


34 cluster-ë rezulton në diametër radikalisht (rrënjësisht) më të lartë të cluster-ëve. Ky kërkim mund të kryhet në një numër të veprimeve të cluster-imit që është logaritmik në vlerën e vërtetë të k. 34 / 65



35 Algoritmi BFR (Bradley, Fayyad, dhe Reina): Ky algoritëm është version i k-means i dizajnuar që t i trajtojë shënimet që janë tepër të mëdha për t i zënë në memorjen kryesore. Ai supozon se cluster-ët kanë shpërndarje normale përreth boshteve. Përfaqësimii Cluster-ëve në BFR: Pikat lexohen nga disku pjesë-pjesë. Cluster-ët përfaqësohen në memorjen kryesore sipas sasisë së numrit të pikave, shumës vektoriale të të gjitha pikave, dhe vektorit të formuar duke i mbledhur katrorët e komponentave të pikave në secilin dimension. Koleksionet tjera të pikave, që janë tepër larg nga një centroid i clusterit që të përfshihen në një cluster, përfaqësohen si minicluster-ë në mënyrën e njëjtë si k cluster-ët, ndërsa pika të tjera, që nuk janë afër ndonjë pike tjetër do të përfaqësohen si vetja dhe quhen retained points (pika të mbajtura mend ). 35 / 65

36 Procesimi i pikave në BFR: Shumica e pikave në një ngarkim të memorjes kryesore do të caktohen te një cluster i afërt dhe parametrat për atë cluster do të rregullohen për t i llogaritur pikat e reja. Pikat që nuk janë të caktuara askund mund të formohen në minicluster-ë të rinj, dhe ata minicluster-ë mund të bashkohen me minicluster-ë apo pika të mbajtura mend. Pas ngarkimit të fundit të memorjes, minicluster-ët dhe pikat e mbajtura mend mund të bashkohen me cluster-ët e tyre më të afërt apo të mbahen si outlier-a (të veçuar). Algoritmi CURE (Clustering Using REpresentatives Cluster-imi duke i përdorur Përfaqësuesit): Ky algoritëm është i tipit caktim-i-pikave. Është i dizajnuar për hapësirë Euklidiane, por cluster-ët mund të kenë çfarëdo forme. Ai i trajton shënimet që janë tepër të mëdha për t i zënë në memorien kryesore. Përfaqësimi i Cluster-ëve në CURE: Algoritmi nis duke e cluster-uar një sample të vogël të pikave. Pastaj i zgjedh pikat përfaqësuese për secilin cluster, duke i zgjedhur pikat në cluster që janë sa më larg nga njëra-tjetra që është e mundur. Qëllimi është të gjenden pikat përfaqësuese në skajet e jashtme të cluster-it. Mirëpo, pikat përfaqësuese pastaj lëvizen pak në rrugën kah centroidi i cluster-it, ashtu që të gjenden disi në brendësi të cluster-it. Procesimi i pikave në CURE: Pas krijimit të pikave përfaqësuese për secilin cluster, i tërë grupi i pikave mund të lexohet nga disku dhe t i caktohet një cluster-i. Një pikë të dhënë ia caktojmë cluster-it të pikës përfaqësuese që është më e afërta me pikën e dhënë. Algoritmi GRGPF (V. Ganti, R. Ramakrishnan, J. Gehrke, A. Powell, dhej. French): Ky algoritëm është i tipit caktim-i-pikave. Ai i trajton shënimet që janë tepër të mëdha për t i zënë në memorjen kryesore, dhe nuk supozon hapësirë Euklidiane. Përfaqësimi i cluster-ëve në GRGPF: Një cluster përfaqësohet nga numri i pikave në cluster, clustroid-i, një grup i pikave më të afërta me clustroid-in dhe një grup i pikave më të largëta 36 / 65
37 nga clustroid-i. Pikat e afërta na lejojnë ta ndryshojmë clustroid-in nëse cluster-i evoluon, dhe pikat e largëta na lejojnë t i bashkojmë cluster-ët në mënyrë efikase në rrethana të përshtatshme. Për secilën nga këto pika, e regjistrojmë edhe rowsum-in (shumën rreshtore), domethënë rrënjën katrore të shumës së katrorëve të distancave nga ajo pikë te të gjitha pikat tjera të cluster-it. Organizimi i Pemës së Cluster-ëve në GRGPF: Përfaqësimet e cluster-ëve organizohen në strukturë pemë si B-tree, ku node-at e pemës janë zakonisht blloqe të diskut dhe përmbajnë informacion për shumë cluster-ë. Leave-at (gjethet) e mbajnë përfaqësimin e sa më shumë cluster-ave që është e mundur, ndërsa node-at e brendshëm e mbajnë një sample (mostër) të clustroid-ëve të cluster-ëve në leave-at e tyre pasardhës. E organizojmë pemën ashtu që cluster-ët përfaqësuesit e të cilëve janë në nënpemë të jenë sa më afër që është e mundur. Procesimi i pikavenë GRGPF: Pas inicializimit të cluster-ëve nga një sample e pikave, e fusim secilën pikë në cluster-in me clustroid-in më të afërt. Për shkak të strukturës pemë, mund të fillojmë te rrënja dhe të zgjedhim ta vizitojmë fëmijën me clustroid-in e mostrës që është më i afërti me pikën e dhënë. Duke e ndjekur këtë rregull nëpër një rrugë në pemë na çon te një leave (gjethe), ku e fusim pikën në cluster-in me clustroid-in më të afërt në atë leave. Clustering Streams (Stream-at cluster-ues): Një përgjithësim i Algoritmit DGIM (Datar-Gionis- Indyk-Motwani) (për t i numëruar 1-shet në dritaren rrëshqitëse të një stream-i) mund të përdoret për t i cluster-uar pikat që janë pjesë e një stream-i që evoluon ngadalë. Algoritmi BDMO (B. Babcock, M. Datar, R. Motwani, dhe L. O Callaghan) i përdor bucket-at e ngjashëm me ata të DGIM, me madhësitë e lejueshme të bucket-ave që e formojnë një varg ku secila madhësi është sa dyfishi i madhësisë paraprake. Përfaqësimi i Bucket-ave në BDMO: Madhësia e një bucket-i është numri i pikave që i përfaqëson ai. Vetë bucket-i e mban vetëm një përfaqësim të cluster-ëve të këtyre pikave, jo vetë pikat. Një përfaqësim i cluster-it e përfshin një sasi të numrit të pikave, centroid-in apo clustroid-in, dhe informacion tjetër që nevojitet për t i bashkuar cluster-ët sipas ndonjë strategjie të zgjedhur. Bashkimi i bucket-ave në BDMO: Kur duhet të bashkohen bucket-at, e gjejmë përputhjen më të mirë të cluster-ëve, nga një nga secili bucket, dhe i bashkojmë ata në çifte. Nëse stream-i evoluon ngadalë, atëherë presim që bucket-ët e njëpasnjëshëm të kenë numër thuajse të njëjtë të centroid-ëve, prandaj ky çiftim ka kuptim. Përgjigja në Query-t në BDMO: Një query është një gjatësi e një sufiksi (prapashtese) të dritares rrëshqitëse. I marrim të gjithë cluster-ët në të gjithë bucket-at që janë të paktën pjesërisht brenda atij sufiksi dhe i bashkojmë duke e përdorur ndonjë strategji. Cluster-ët rezultues janë përgjigjja në query. Cluster-imi duke përdorur MapReduce: Mund t i ndajmë shënimet në pjesë dhe ta clusterojmë secilën pjesë paralelisht, duke e përdorur një task (punë) Map. Cluster-ët nga secili task Map mund të cluster-ohen tutje në një task të vetëm Reduce. 37 / 65


: Mund ta masim cilësinë e një algoritmi on-line duke e minimuzar, nëpër tërë input-at e mundshëm, vlerën e rezultatit të algoritmit online, në krahasim me vlerën e")
38 8. Reklamimi në Web Targeted Advertising (Reklamimi i target-uar): Përparësia e madhe që e ka reklamimi i bazuar në Web ndaj reklamimit në mediat tradicionale (konvencionale) si gazetat është se reklamimi në Web mund të zgjedhet sipas interesave të secilit përdorues individual. Kjo përparësi ua ka mundësuar shumë shërbimeve në Web që të mbahen plotësisht nga të ardhurat e reklamimit. Algoritmet On-line dhe Off-line: Algoritmet tradicionale të cilave iu lejohet t i shohin të gjitha shënimet e veta para se ta prodhojnë një përgjigje quhen off-line. Një algoritëm on-line kërkohet ta bëjë një përgjigje ndaj secilit element në një stream menjëherë, me njohuri vetëm të elementeve të kaluara, e jo të ardhshme në stream. Algoritmet Greedy (dorështrënguar): Shumë algoritme on-line janë greedy, në sensin që e zgjedhin veprimin e tyre në secilin hap duke e minimizuar një funksion objektiv. Competitive Ratio (Raporti Garues): Mund ta masim cilësinë e një algoritmi on-line duke e minimuzar, nëpër tërë input-at e mundshëm, vlerën e rezultatit të algoritmit online, në krahasim me vlerën e rezultatit të algoritmit off-line më të mirë të mundshëm. Bipartite Matching (Përputhja, Çiftimi Bipartit):Ky problem i përfshin dy bashkësi të nodeave (nyjeve, kulmeve) dhe një grupi të edge-ave (brinjëve, skajeve, teheve) ndërmjet anëtarëve të dy bashkësive. Qëllimi është të gjendet çiftimi maksimal një bashkësi sa më të madhe të mundshme të edge-ave që nuk e përfshin asnjë node më shumë se një herë. Zgjidhja On-line për Problemin e Match-imit: Një algoritëm greedy për gjetjen e një përputhjeje në graf bipartit (apo çfarëdo grafi, sa i përket kësaj) është të radhiten edge-at në njëfarë mënyre, dhe për secilin edge në radhë, shtoja match-it nëse asnjëri nga skajet e tij nuk janë ende pjesë e një edge-i të të zgjedhur paraprakisht për përputhje. Algoritmi mund 38 / 65
: Një motor i kërkimit pranon bid-a (oferta) nga reklamuesit në query të caktuara të kërkimit.")

39 të vërtetohet se ka competitive ratio prej 1/2; domethënë, kurrë nuk dështon t i përputhë të paktën sa gjysma e node-ave që i përputh algoritmi më i mirë off-line. Search Ad Management (Menaxhimi i Reklamave gjatë kërkimit): Një motor i kërkimit pranon bid-a (oferta) nga reklamuesit në query të caktuara të kërkimit. Disa reklama shfaqen me secilën query të kërkimit, dhe motori i kërkimit paguhet me sasinë e bid-it vetëm nëse përdoruesi klikon në reklamë. Secili reklamues mund ta japë një buxhet, sasinë totale që janë të gatshëm ta paguajnë për klika në një muaj. The Adwords Problem (Problemi i Fjalëve reklamuese): Shënimet për problemin e adwordeve janë një grup i bid-ave nga reklamuesit në query të caktuara të kërkimit, bashkë me një buxhet total për secilin reklamues dhe informacionin për shkallën historike të click-through (klikimit në reklamë) për secilën reklamë për secilën query. Një pjesë e shënimeve është stream-i i query-ve të kërkimit të pranuara nga motori i kërkimit. Qëllimi është të zgjedhet on-line një grup me madhësi fikse i reklamave si përgjigje ndaj secilës query i cili do t i maksimizojë të ardhurat për motorin e kërkimit. Simplified Adwords Problem (Problemi i thjeshtësuar i Adword-eve): Për t i parë disa nga nuancat e zgjedhjes së reklamës, e shqyrtojmë një version të thjeshtësuar në të cilin të gjithë bid-at janë ose 0 ose 1, vetëm një reklamë tregohet me secilën query, dhe të gjithë reklamuesit kanë buxhet të njëjtë. Nën këtë model mund të tregohet se algoritmi i qartë 39 / 65


40 greedy - i dhënies së reklamës cilitdo që ka bid në query dhe ka ende buxhet - ka competitive ratio prej 1/2. The Balance Algorithm: Ky algoritëm e përmirëson algoritmin e thjeshtë greedy. Reklama e një query i jepet reklamuesit që ka bid në query dhe e ka buxhetin më të madh të mbetur. Barazimet mund të zgjidhen arbitrarisht. Competitive ratio e Algoritmit Balance: Për modelin e thjeshtësuar të adword-eve, competitive ratio e Algoritmit Balance është 3/4 për rastin e dy reklamuesve dhe 1 1/e, apo rreth 63% për çfarëdo numri të reklamuesve. Algoritmi Balance për Problemin e Përgjithësuar të Adword-eve: Kur ofertuesit (bidder-ët) mund të bëjnë bid-e të ndryshme, kanë buxhete të ndryshme, dhe kanë norma të ndryshme të click-through për query të ndryshme, Algoritmi Balnace e shpërblen me reklamë reklamuesin me vlerën më të lartë të funksionit Ψ = x(1 e f ). Këtu, x është prodhimi i bid-it dhe normës së click-through për atë reklamues dhe query, dhe f është pjesa e buxhetit të reklamuesit që mbetet e pashpenzuar. Implementimi i një Algoritmi Adwords: Versioni më i thjeshtë i implementimit shërben në situatat ku bid-at janë për saktësisht grupin e fjalëve në query-n e kërkimit. Mund ta përfaqësojmë një query me listën e fjalëve të veta, në radhë të sortuar (renditur). Bid-et 40 / 65
41 ruhen në një tabelë hash apo strukturë të ngjashme, me çelës hash të barabartë me listën e sortuar të fjalëve. Një query e kërkimit pastaj mund të krahasohet me bid-et me një lookup (shikim) të drejtpërdrejtë në tabelë. Match-imi (përputhja) e grupeve të fjalëve me dokumente: Një version më i vështirë i problemit të implementimit të adwords lejon bid-e, që janë prapë grupe të vogla të fjalëve si në query të kërkimit, të përputhen me dokumente më të mëdha siç janë -at apo tweetat. Një grup i bid-ave përputhet me dokumentin nëse të gjitha fjalët shfaqen në dokument, në çfarëdo radhe dhe jo patjetër afër njëra-tjetrës. Ruajtja hash e grupeve të fjalëve: Një strukturë e dobishme e shënimeve i ruan fjalët në secilin grup të bid-ave në radhën së-pari-më-e-rralla. Dokumentet i kanë fjalët e veta të radhitura në radhën e njëjtë. Grupet e fjalëve ruhen në një tabelë hash me fjalën e parë, në radhën së-pari-më-e-rralla, si key (çelës). Procesimi i dokumenteve për match-e të bid-ave: I procesojmë fjalët e dokumentit së-parimë-të-rrallat. Grupet e fjalëve ku fjala e parë është fjala aktuale kopjohen në një tabelë të përkohshme hash, me fjalën e dytë si çelës. Grupet që tashmë janë në tabelën e përkohshme hash shqyrohen të shihet nëse fjala që është çelësi i tyre përputhet me fjalën aktuale, dhe nëse po, ato rihash-ohen duke e përdorur fjalën e tyre të radhës. Grupet ku përputhet fjala e fundit kopjohen në output (dalje). 41 / 65

42 9. Sistemet e rekomandimit 42 / 65


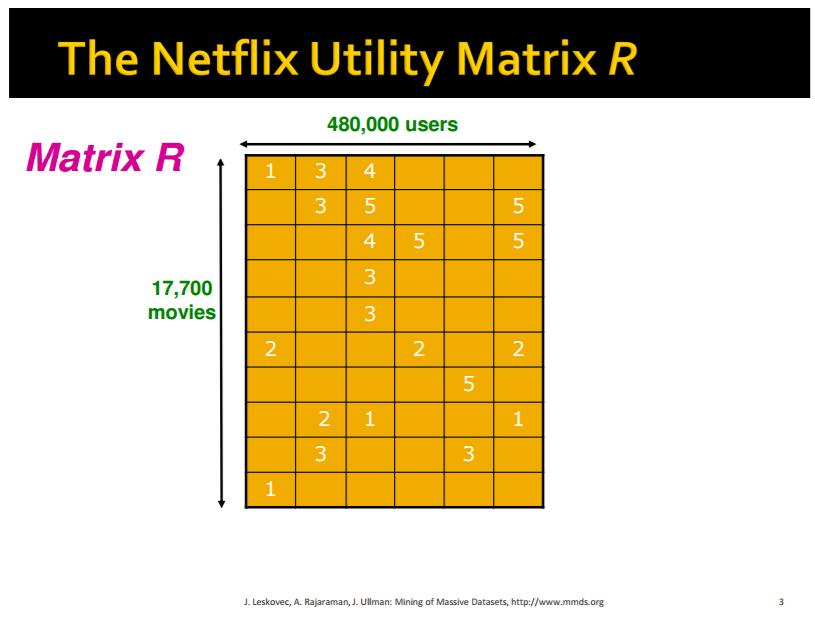
43 Matricat Utility: Sistemet rekomanduese mirren me përdorues dhe item-a (artikuj). Një matricë utility ofron informacion të njohur për shkallën në të cilën një përdorues e pëlqen një artikull. Normalisht, shumica e elementeve janë të panjohura, dhe problemi esencial i rekomandimit të artikujve për përdoruesit është parashikimi i vlerave të elementeve të panjohura në bazë të vlerave të elementeve të njohura. 43 / 65
; ajo e mat ngjashmërinë duke kërkuar veçori të përbashkëta të artikujve.")

44 Dy klasët e Sistemeve të Rekomandimit: Këto sisteme përpiqen ta parashikojnë reagimin e një përdoruesi ndaj një artikulli duke zbuluar artikuj të ngjashëm dhe reagimin e përdoruesit ndaj tyre. Një klasë e sistemeve të rekomandimit është content-based (e bazuar në përmbajtje); ajo e mat ngjashmërinë duke kërkuar veçori të përbashkëta të artikujve. Një klasë e dytë e sistemeve të rekomandimit e përdor collaborative filtering (filtrimin bashkëpunues); këta e masin ngjashmërinë e përdoruesve sipas preferencave të tyre për artikuj dhe/ose e masin ngjashmërinë e artikujve sipas përdoruesve që i pëlqejnë ata. Profilet e artikujve: Këta përbëhen nga veçori të artikujve. Llojet e ndryshme të artikujve kanë veçori të ndryshme në të cilat mund të bazohet ngjashmëria e bazuar në përmbajtje. Veçoritë e dokumenteve janë zakonisht fjalët e rëndësishme apo të pazakonshme. Produktet kanë atribute si madhësia e ekranit për një televizor. Mediat si filmat kanë zhanër dhe detale si aktori apo performuesi. Tagjet mund të përdoren po ashtu si veçori nëse mund të mirren nga përdoruesit e interesuar. 44 / 65

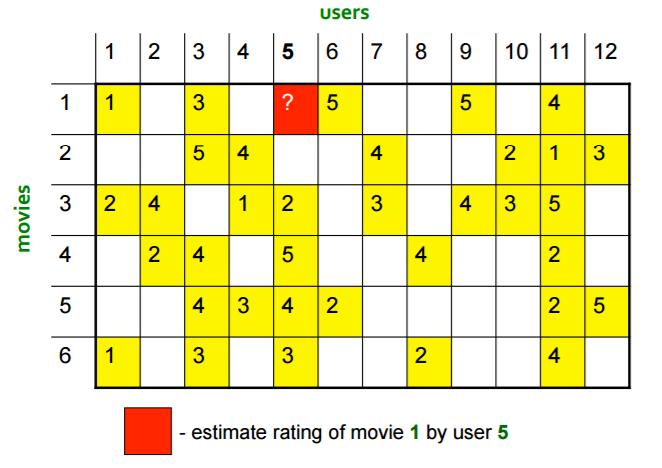
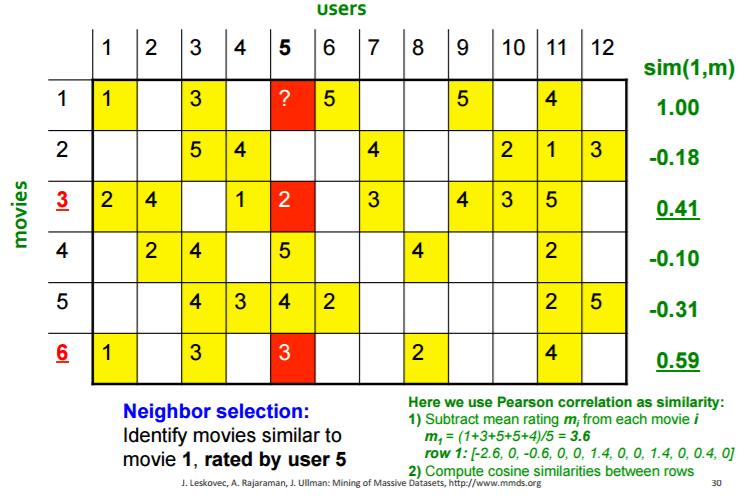
45 Profilet e përdoruesve: Një sistem i collaborative-filtering i bazuar në përmbajtje mund të konstruktojë profile për përdoruesit duke e matur frekuencën me të cilën shfaqen veçoritë në artikujt që i pëlqen përdoruesi. Pastaj mund ta masim shkallën në të cilën një përdorues do ta pëlqejë një artikull sipas afërsisë së profilit të artikullit me profilin e përdoruesit. Klasifikimi i artikujve: Një alternativë për konstruktimin e një profili të përdoruesit është të ndërtohet një klasifikues për secilin përdorues, p.sh. një decision tree (pemë e vendimeve). Rreshti i matricës utility për atë përdorues konsiderohet si shënime trajnuese, dhe klasifikuesi duhet ta parashikojë reagimin e përdoruesit për të gjithë artikujt, pat apo s pat rreshti shënim për atë artikull. Ngjashmëria e Rreshtave dhe Shtyllave të Matricës Utility: Algoritmet e filtrimit bashkëpunues duhet ta masin ngjashmërinë e rreshtave dhe/apo shtyllave të matricës utility. Distanca Jaccard është e përshtatshme kur matrica përbëhet vetëm nga 1-she dhe boshe (për të pavlerësuarat ). Distanca kosinus funksionon për vlera më të përgjithshme në matricën utility. Shpesh është e dobishme të normalizohet matrica utility duke e zbritur vlerën mesatare (ose sipas rreshtit, ose sipas shtyllës, ose sipas të dyjave) para se të matet distanca kosinus. 45 / 65
46 46 / 65


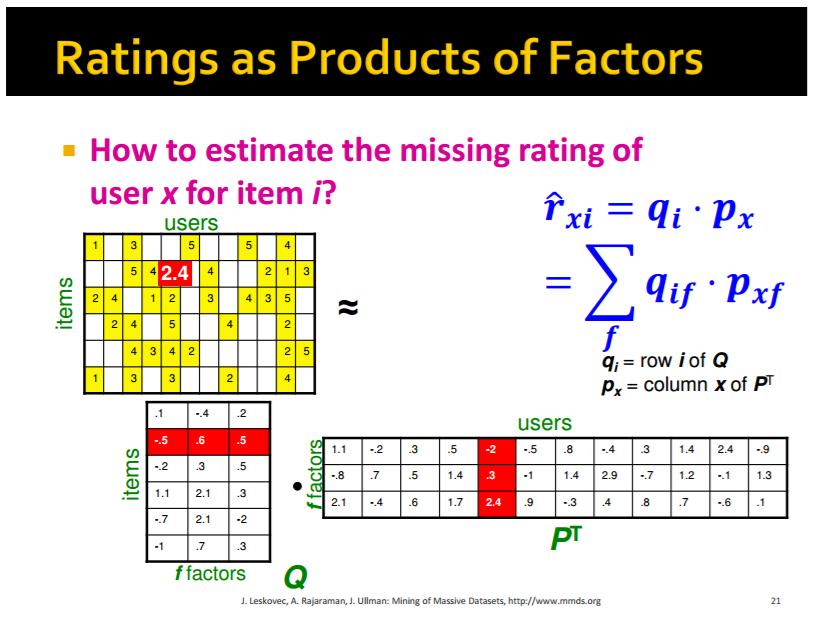
47 Cluster-imi (tufëzimi, grupimi) i përdoruesve dhe artikujve: Meqë matrica utility priret të ketë kryesisht elemente boshe, matjet e distancës si Jaccard apo kosinus shpesh kanë tepër pak shënime me të cilat t i krahasojnë dy rreshta apo dy shtylla. Një apo disa hapa paraprakë, në të cilat përdoret ngjashmëria për t i cluster-uar përdoruesit dhe/apo artikujt në grupe të vogla me ngjashmëri të fuqishme, mund të ndihmojë të ofrohen më shumë komponenta të përbashkta me të cilat mund të krahasohen rreshtat apo shtyllat. Dekompozimi (zbërthimi) UV: Një mënyrë e parashikimit të vlerave boshe në matricë utility është të gjenden dy matrica të gjata, të holla U dhe V, produkti i të cilave është përafrim i matricës së dhënë utility. Meqë produkti matricor UV i jep vlerat për të gjitha çiftet përdorues-artikull, ajo vlerë mund të përdoret për ta parashikuar vlerën e një elementi bosh në matricën utility. Arsyeja intuitive se pse ka kuptim kjo metodë është se shpesh është një 47 / 65
: Një matje e mirë se sa afër është produkti UV me matricën e dhënë utility është RMSE (root-mean-square-error).")

48 numër relativisht i vogël i çështjeve (ai numër është dimensioni i hollë i U dhe V) që e përcaktojnë se a e pëlqen një përdorues një artikull apo jo. Root-Mean-Square-Error (Gabimi-Rrënja-e-katrorëve-të-mesatareve): Një matje e mirë se sa afër është produkti UV me matricën e dhënë utility është RMSE (root-mean-square-error). RMSE llogaritet duke e nxjerrë mesataren e diferencave ndërmjet UV dhe matricës utility, në ato elemente ku matrica utility është joboshe. Rrënja katrore e kësaj mesatareje është RMSE-ja. Llogaritja e U dhe V: Një mënyrë për ta gjetur një zgjedhje të mirë për U dhe V në një zbërthim UV është të fillohet me matrica arbitrare U dhe V. Në mënyrë të përsëritur rregulloje njërin nga elementet e U apo V për ta minimizuar RMSE-në ndërmjet produktit UV dhe matricës utility të dhënë. Procesi konvergjon në një optimum lokal, edhe për të pasur shans të mirë të fitojmë optimum global na duhet ose ta përsërisim procesin për shumë matrica fillestare, ose të kërkojmë nga pika fillestare në shumë mënyra të ndryshme. Sfida NetFlix: Një nxitës i rëndësishëm i kërkimit në sisteme të rekomandimit ishte sfida NetFlix. U pat ofruar një çmim prej 1,000,000$ për garuesin që do të mund ta prodhonte një algoritëm që ishte 10% më i mirë se sa algoritmi i vetë NetFlix-it për parashikimin e rejtingjeve (vlerësimeve) të filmave nga përdoruesit. Shpërblimi u dha në Shtator / 65

49 49 / 65
50 50 / 65
 (komunitetet) kanë densitet (dendësi) shumë më të lartë të edge-ave (brinjëve) se sa densiteti mesatar.")
 normalisht i përkasin disa komuniteteve, dhe matjet e zakonshme të distancave dështojnë ta paraqesin afërsinë ndërmjet kulmeve të një komuniteti.")
51 10. Gërmimi i grafeve të rrjeteve sociale Grafet e rrjeteve sociale: Grafet që i paraqesin lidhjet në një rrjet social janë jo vetëm të mëdha, por e shfaqin edhe një formë të afërsisë (lokalitetit), ku nëngrupe të vogla të nodeave (kulmeve) (komunitetet) kanë densitet (dendësi) shumë më të lartë të edge-ave (brinjëve) se sa densiteti mesatar. Komunitetet dhe cluster-at: Ndërsa komunitetet iu ngjajnë cluster-ave (tufave) në disa mënyra, ka edhe dallime të rëndësishme. Individët (kulmet) normalisht i përkasin disa komuniteteve, dhe matjet e zakonshme të distancave dështojnë ta paraqesin afërsinë ndërmjet kulmeve të një komuniteti. Si rezultat, algoritmet standarde për gjetjen e clusterave në shënime nuk punojnëmirë për gjetje të komuniteteve. Ndërmjetësia (Betweenness): Një mënyrë për t i ndarë kulmet në komunitete është të matet ndërmjetësia e kulmeve, që është shuma e të gjitha çifteve të kulmeve të pjesës së rrugëve më të shkurta ndërmjet atyre kulmeve që kalojnë nëpër brinjën e dhënë. Komunitetet formohen duke i fshirë brinjët që e kanë ndërmjetësinë mbi një prag të dhënë. 51 / 65
 nga secili kulm, dhe një varg i hapave etiketues e llogarit hisen e rrugëve nga rrënja te secili kulm tjetër që kalojnë nëpër secilin nga brinjët.")
52 Algoritmi Girvan-Newman: Algoritmi Girvan-Newman është teknikë efikase për llogaritjen e ndërmjetësisë së brinjëve. Kryhet një kërkim breadthfirst (së pari gjerësia) nga secili kulm, dhe një varg i hapave etiketues e llogarit hisen e rrugëve nga rrënja te secili kulm tjetër që kalojnë nëpër secilin nga brinjët. Hiset e një brinje që janë llogaritur për secilën rrënjë mblidhen për ta nxjerrë ndërmjetësinë. Komunitetet dhe Grafet e plota bipartite: Një graf i plotë bipartit i ka dy grupe të kulmeve, të gjitha brinjët e mundshme ndërmjet çifteve të kulmeve të zgjedhura nga secili grup, dhe asnjë brinjë ndërmjet kulmeve të grupit të njëjtë. Secili komunitet mjaft i dendur (një grup i kulmeve me shumë brinjë ndërmjet vete) do ta ketë një graf të madh të plotë bipartit. Gjetja e Grafeve të plota bipartite: Mund t i gjejmë grafet e plota bipartite me teknikën e njëjtë që e kemi përdorur për t i gjetur itemset-at e shpeshtë. Kulmet e grafit mund të mendohen edhe si item-a (artikuj) edhe si basket-a (shporta). Basket-i që i korrespondon një kulmi është grupi i kulmeve të afërta, i menduar si artikuj. Një graf i plotë bipartit me grupe të kulmeve të madhësisë t dhe s mund të mendohet si gjetja e itemset-ave të shpeshtë të madhësisë t me support (mbështetje, përkrahje) s. Copëtimi (Particionimi) i Grafit: Një mënyrë për t i gjetur komunitetet është të copëtohet një graf në mënyrë të përsëritur në pjesë të madhësive afërsisht të ngjashme. Një prerje është një copëtim i kulmeve të grafit në dy grupe, dhe madhësia e saj është numri i kulmeve që e kanë nga një skaj në secilin grup. Vëllimi i një grupi të kulmeve është numri i brinjëve me të paktën një skaj në atë grup. 52 / 65

: Këto matrica e përshkruajnë një graf.")
: Matrica e shkallës për një graf ka d në elementin e i- të diagonal nëse d është shkalla e")
53 Prerjet e normalizuara: Mund ta normalizojmë madhësinë e një prerjeje duke e marrë raportin e madhësisë së prerjes dhe vëllimin e secilit nga dy grupet e formuara nga prerja. Pastaj i mbledhim këto dy raporte për ta marrë vlerën e normalizuar të prerjes. Prerjet e normalizuara me shumë të ulët janë të mira, në kuptimin që priren t i ndajnë kulmet në dy pjesë afërisht të barabarta, dhe kanë madhësi relativisht të vogël. Matricat e afërsisë (Adjacency Matrices): Këto matrica e përshkruajnë një graf. Elementi në rreshtin i dhe shtyllën j është1 nëse ka brinjë ndërmjet kulmeve i dhe j, përndryshe 0. Matricat e Shkallës (Degree Matrices): Matrica e shkallës për një graf ka d në elementin e i- të diagonal nëse d është shkalla e kulmit të i-të. Jashtë diagonales, të gjitha elementet janë / 65

54 Matricat Laplaciane(Laplacian Matrices): Matrica Laplacianepër një graf është matrica e tij e shkallës minus matrica e tij e afërsisë. Domethënë, elementi në rreshtin i dhe shtyllën i në Matricën Laplaciane është shkalla e kumit të i-të të grafit, dhe elementi në rreshtin i dhe shtyllën j, për i j, është 1 nëse ka brinjë ndërmjet kulmeve i dhe j, përndryshe 0. Metoda Spektrale për Copëtimin e Grafeve: Vlera më e vogël vetjake për çfarëdo Matrice Laplacianeështë 0, dhe vektori i saj vetjak korrespondues përbëhet nga të gjithë 1-sha. Vektorët vetjakë që i korrespondojnë vlerave të vogla vetjake mund të përdoren për ta drejtuar një copëtim të grafit në dy pjesë të madhësisë së ngjashme me vlerë të vogël të prerjes. Si një shembull, vënia e kulmeve me komponentën pozitive në vektorin vetjak me vlerën vetjake të dytë më të vogël në një grup, dhe ato me komponentë negative në grupin tjetër zakonisht funksionon mirë. Komunitetet e mbivendosura: Zakonisht, individët janë anëtarë të disa komuniteteve. Në grafe që i përshkruajnë rrjetet sociale, është normale që gjasa që dy individë të jenë miq të rritet ndërsa rritet numri i komuniteteve ku ata dy janë anëtarë. Modeli i Grafit Affiliation (të Shoqërimit): Një model i përshtatshëm për anëtarësinë në komunitete është të supozohet se për secilin komunitet ka një gjasë që për shkak të këtij komuniteti dy anëtarë të bëhen miq (ta kenë një brinjë në grafin e rrjetit social). Kështu, gjasa që dy kulme të kenë brinjë është 1 minus produkti i gjasave që asnjëri nga komunitetet në të cilat të dy janë anëtarë shkaktojnë që të ketë brinjë ndërmjet tyre. Pastaj e gjejmë caktimin e kulmeve në komunitete dhe vlerat e atyre gjasave që e përshkruajnë më së miri grafin e observuar social. Vlerësimi i gjasës maksimale (Maximum-Likelihood Estimation, MLE): Një teknikë e rëndësishme e modelimit, e dobishme për t i modeluar komunitetet si dhe shumë gjëra tjera, është të llogaritet, si funksion i të gjitha zgjedhjeve të vlerave parametrike që i lejon modeli, gjasa që shënimet e observuara do të gjenerohen. Vlerat që e japin gjasën më të madhe supozohen të jenë korrekte, dhe quhen vlerësimi i gjasës maksimale (MLE). Përdorja e Gradient Descent (Rënies së Gradientit): Nëse e dimë anëtarësinë në komunitete, mund ta gjejmë MLE-në përmes rënies së gradientit apo metoda tjera. Mirëpo, nuk mund ta gjejmë anëtarësinë më të mirë në komunitete përmes rënies së gradientit, sepse anëtarësia është diskrete, e jo e vazhdueshme. Modelimi i Përmirësuar i Komunitetit përmes Fuqisë së Anëtarësisë: Mund ta formulojmë problemin e gjetjes së MLE të komuniteteve në një graf social duke supozuar se individët e 54 / 65
55 kanë një fuqi të anëtarësisë në secilin komunitet, dhe ndoshta 0 nëse nuk janë anëtarë. Nëse e definojmë gjasën e një brinje ndërmjet dy kulmeve të jetë funksion i fuqive të anëtarësive të tyre në komunitetet e tyre më të shpeshta, mund ta kthejmë problemin e gjetjes së MLE në problem të vazhdueshëm dhe ta zgjidhim përmes rënies së gradientit. Simrank-u: Një mënyrë për ta matur ngjashmërinë e kulmeve në një graf me disa lloje të kulmeve është të niset një shëtitës i rastësishëm (random walker) në një kulm dhe të lejohet të bredhë, me gjasë të fiksuar të rifillimit në kulmin e njëjtë. Shpërndarja se ku mund të pritet shëtitësi është matje e mirë e ngjashmërisë së kulmeve me kulmin fillestar. Ky proces duhet të përsëritet me secilin kulm si kulm fillestar nëse duam ta gjejmë ngjashmërinë e të gjitha çifteve. Trekëndëshat në Rrjete Sociale: Numri i trekëndëshave për kulm është matje e rëndësishme e afërsisë së një komuniteti dhe shpesh e reflekton pjekurinë e tij. Mund t i listojmë apo ta llogarisim sasinë e trekëndëshave në një graf me m kulme në kohë O(m 3/2 ), por nuk ekziston ndonjë algoritëm më efikas në përgjithësi. Gjetja e trekëndëshave me MapReduce:Mund t i gjejmë trekëndëshat në një xhiro të vetme të MapReduce duke e trajtuar atë si three-way join (bashkim të trefishtë). Secili kulm duhet t i dërgohet një numri të reducer-ëve që është proporcional me rrënjën kubike të numrit total të reducer-ëve, dhe koha totale e llogaritjes e kaluar në të gjithë reducer-ët është proporcionale me kohën e algoritmit serik për gjetjen e trekëndëshave. Lagjet (Neighborhoods): Lagjja e rrezes d për një kulm v në graf të drejtuar apo të padrejtuar është grupi i kulmeve të arritshme nga v përgjatë rrugëve të gjatësisë të shumtën d. Profili i lagjes për një kulm është vargu i madhësive të lagjeve për të gjitha distancat nga 1 e tutje. Diametri i një grafi të lidhur është d-jamë e vogël për të cilën lagjja e rrezes d për çfarëdo kulmi fillestar e përfshin tërë grafin. Mbyllja kalimtare (Transitive Closure): Një kulm v mund ta arrijë kulmin u nëse u është në lagje të v për ndonjë rreze. Mbyllja kalimtare e një grafi është grupi i çifteve të kulmeve (v, u) të tilla që v mund ta arrijë u-në. Llogaritja e mbylljes kalimtare: Meqë mbyllja kalimare mund ta ketë numrin e fakteve të barabartë me katrorin e numrit të kulmeve të një grafi, është jopraktike të llogaritet direkt mbyllja kalimtare për grafe të mëdha. Një qasje është të gjenden komponentat e lidhura fuqishëm të grafit dhe ato të palosen secila në një kulm të vetëm para se të llogaritet mbyllja kalimtare. Mbyllja kalimtare dhe MapReduce: Mund ta shohim llogaritjen e mbylljes kalimtare si bashkim iterativ të një relacioni të rrugës (çiftet e kulmeve v dhe u të tilla që u dihet se është e arritshme nga v) dhe relacioni harkor i grafit. Një qasje e tillë e kërkon një numër të xhirove MapReduce të barabartë me diametrin e grafit. Mbyllja kalimtare me dyfishim rekursiv: Një qasje që përdor më pak xhiro MapReduce është të bashkohet relacioni i rrugës me veten në secilën xhiro. Në secilën xhiro, e dyfishojmë gjatësinë e rrugëve që janë të afta të kontribuojnë në mbylljen kalimtare. Kështu, numri i xhirove të nevojshme është vetëm logaritmi me bazë 2 i diametrit të grafit. Mbyllja e mençur kalimtare: Ndërsa dyfishimi rekursiv mund të shkaktojë që e njëjta rrugë të konsiderohet disa herë, dhe kështu e rrit kohën totale të llogaritjes (krahasuar me bashkimin 55 / 65
56 iterativ të rrugëve me harqe të njëfishta), një variant i quajtur mbyllja e mençur kalimtare e shmang zbulimin e rrugës së njëjtë më shumë se një herë. Truku është të kërkohet që kur bashkohen dy rrugë, e para të ketë gjatësi që është fuqi e 2-shit. Përafrimi i Madhësive të Lagjeve: Duke e përdorur teknikën Flajolet-Martin për përafrimin e numrit të elementeve të ndryshme në një stream, mund t i gjejmë afërsisht madhësitë e lagjeve me rreze të ndryshme. E mbajmë një grup të gjatësive të tail-ave (bishtave) për secilin kulm. Për ta rritur rrezen për 1, e shqyrtojmë secilën brinjë (u, v) dhe për secilën gjatësi të tail-it për u e caktojmë të barabartë me gjatësinë korresponduese të tail-it për v nëse kjo e fundit është më e madhe se e para. 56 / 65

57 11. Reduktimi i dimensionalitetit Reduktimi (zvogëlimi) i dimensionalitetit:qëllimi i reduktimit të dimensionalitetit është të zëvendësohet një matricë e madhe me dy apo më shumë matrica tjera madhësitë e të cilave janë shumë më të vogla se sa origjinali, por nga nga të cilat mund të rikonstruktohet origjinali, zakonisht duke e marrë produktin e tyre. Vlerat vetjake dhe vektorët vetjakë: Një matricë mund t i ketë disa vektorë vetjakë të tillë që kur matrica e shumëzon vektorin vetjak, rezultati është shumëfish konstant i vektorit vetjak. Ajo konstantë është vlera vetjake e asociuar me këtë vektor vetjak. Bashkë vektori vetjak dhe vlera e tij vetjake quhen çift vetjak. Gjetja e çifteve vetjake përmes iterimit me fuqi: Mund ta gjejmë vektorin vetjak kryesor (vektorin vetjak me vlerën më të madhe vetjake) duke filluar me çfarëdo vektori dhe duke e shumëzuar në mënyrë të përsëritur vektorin aktual me matricën për ta fituar një vektor të ri. Kur ndërrimet në vektor bëhen të vogla, mund ta trajtojmë rezultatin si përafrim të afërt me vektorin vetjak kryesor. Duke e ndryshuar matricën, mund ta përdorim pastaj të njëjtin iterim për ta fituar çiftin vetjak të dytë (atë me me vlerën vetjake të dytë më të madhe), dhe ngjashëm ta nxjerrim secilin nga çiftet vetjake me radhë, në renditje zvogëluese të vlerave vetjake. Analiza e Komponentës Kryesore (Principal-Component Analysis, PCA): Kjo teknikë për reduktimin e dimensionalitetit i sheh shënimet që përbëhen nga një koleksion i pikave në një hapësirë shumëdimensionale si matricë, me rreshtat që iu korrespondojnë pikave dhe shtyllat dimensioneve. Produkti i kësaj matrice dhe të transponuarës së saj ka çifte vetjake, dhe vektori kryesor vetjak mund të shihet sidrejtimi në hapësirë përgjatë të cilit pikat rreshtohen më së miri. Vektori i dytë vetjak e paraqet drejtimin në të cilin shmangiet nga vektori kryesor vetjak janë më të mëdhatë, e kështu me radhë. 57 / 65
 për numrin e dhënë të shtyllave në matricën përfaqësuese.")

58 Reduktimi i dimensionalitetit përmes PCA: Duke e paraqitur matricën e pikave me një numër të vogël të vektorëve vetjakë, mund t i përafrojmë shënimet në një mënyrë që e minimizon gabimin root-mean-square-error (RMSE, gabimi rrënja katrore e mesatareve) për numrin e dhënë të shtyllave në matricën përfaqësuese. Zbërthimi me Vlera Singulare (Singular Value Decomposition, SVD): Zbërthimi me vlera singulare i një matrice përbëhet nga tri matrica, U, Σ, dhe V. Matricat U dhe V janë ortonormale sipas shtyllave, që domethënë se si vektorë, shtyllat janë ortogonale dhe gjatësitë e tyre janë 1. Matrica Σ është matricë diagonale, dhe vlerat përgjatë diagonales së saj quhen vlera singulare. Produkti i U, Σ, dhe të transponuarës së V është baraz me matricën origjinale. Konceptet: SVD është i dobishëm kur ka numër të vogël të koncepteve që i lidhin rreshtat dhe shtyllat e matricës origjinale. Për shembull, nëse matrica origjinale i paraqet rejtingjet e dhëna nga shikuesit e filmave (rreshtat) për filmat (shtyllat), konceptet mund të jenë zhanret e filmave. Matrica U i lidh rreshtat me konceptet, Σ i paraqet fuqitë e koncepteve, dhe V i lidh konceptet me shtyllat. 58 / 65


59 Query-t duke e përdorur Zbërthimin me Vlera Singulare: Mund ta përdorim zbërthimin për t i ndërlidhur rreshta te rinj apo hipotetikë të matricës origjinale me konceptet e paraqitura nga zbërthimi. Shumëzoje një rresht me matricën V të zbërthimit për ta fituar një vektor që e tregon masën në të cilën ai rresht përputhet me secilin nga konceptet. Përdorja e SVD për Reduktim të Dimensionalitetit: Në një SVD të plotë për një matricë, U dhe V janë zakonisht po aq të mëdha sa origjinalja. Për të përdorur më pak shtylla për U dhe V, fshiji shtyllat që i korrespondojnë vlerave më të vogla singulare, U, V, dhe Σ. Kjo zgjedhje e minimizon gabimin në rikonstruktimin e matricës origjinale nga U, Σ, dhe V të ndryshuara. 59 / 65
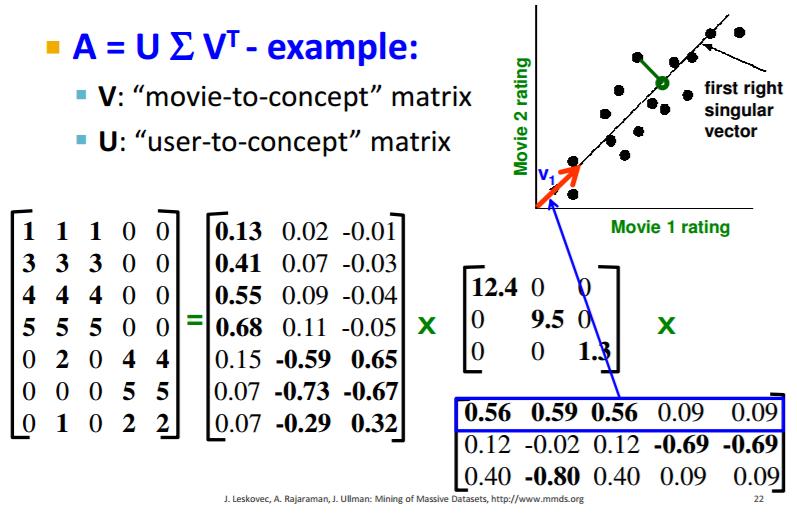


60 60 / 65

61 Zbërthimi i Matricave të Rralla: Edhe në rastin e zakonshëm kur matrica e dhënë është e rrallë, matricat e konstruktuara nga SVD janë të dendura. Zbërthimi CUR kërkon ta zbërthejë një matricë të rrallë në matrica të rralla, më të vogla, produkti i të cilave e përafron matricën origjinale. Zbërthimi CUR: Kjo metodë e zgjedh nga një matricë e dhënë e rrallë një grup të shtyllave C dhe një grup të rreshtave R, që e luajnë rolin e U dhe V T në SVD; përdoruesi mund ta zgjedhë çfarëdo numri të rreshtave dhe shtyllave. Zgjedhja e rreshtave dhe shtyllave bëhet rastësisht me një shpërndarje që varet nga norma Frobenius, rrënja katrore e shumës së katrorëve të elementeve. Ndërmjet C dhe R është një matricë katrore e quajtur U që konstruktohet nga një pseudo-invers i prerjes së rreshtave dhe shtyllave të zgjedhura. 61 / 65
 që e tregon klasën të cilës i takon objekti i përfaqësuar nga veçoria. Veçoritë mund të jenë kategorike që i takojnë një liste të numëruar të vlerave apo numerike.")
62 12. Machine learning në shkallë të gjerë Training Sets (Setet, grupet e trajnimit): Një set i trajnimit përbëhet nga një vektor i veçorive (features), secila komponentë e të cilit është një veçori, dhe një label (etiketë) që e tregon klasën të cilës i takon objekti i përfaqësuar nga veçoria. Veçoritë mund të jenë kategorike që i takojnë një liste të numëruar të vlerave apo numerike. Setet e testit dhe overfitting (mbipërputhja): Gjatë trajnimit të ndonjë classifier-i (klasifikuesi) në një set të trajnimit, është e dobishme të hiqet një pjesë e setit të trajnimit dhe që shënimet e hequra të përdoren si set i testit. Pas prodhimit të një modeli apo klasifikuesi pa e përdorur setin e testit, mund ta ekzekutojmë klasifikuesin në setin e testit për të parë se sa mirë punon. Nëse klasifikuesi nuk punon po aq mirë në setin e testit sa në setin e përdorur 62 / 65
: Në mësimin batch, seti i trajnimit është në dispozicion në çdo kohë dhe mund të përdoret në kalime të përsëritura.")

63 të trajnimit, e kemi mbipërputhur (overfit) setin e trajnimit duke iu përshtatur veçantive të shënimeve të setit të trajnimit që nuk janë të pranishme në shënimet si tërësi. Batch Versus On-Line Learning (Mësimi Bllok Versus On-Line): Në mësimin batch, seti i trajnimit është në dispozicion në çdo kohë dhe mund të përdoret në kalime të përsëritura. Mësimi on-line e përdor një stream të shembujve trajnues, ku secili mund të përdoret vetëm një herë. Perceptron-ët: Kjo metodë e machine-learning supozon se seti i trajnimit i ka vetëm dy labela të klasave, pozitive dhe negative. Perceptronët punojnë kur është një hiperplan (hiperrrafsh) që i ndan vektorët feature (veçorizues) të shembujve pozitivë nga ata të shembujve negativë. E konvergjojmë atë hiperplan duke e rregulluar vlerësimin tonë të hiperplanit për një pjesëz rate-i i mësimit të drejtimit që është mesatarja e pikave të keqklasifikuara aktualisht. Algoritmi Winnow: Ky algoritëm është variant i algoritmit perceptron që kërkon që komponentat e vektorëve feature të jenë 0 ose 1. Shembujt trajnues shqyrtohen sipas mënyrës round-robin, dhe nëse klasifikimi aktual i një shembulli të trajnimit është jokorrekt, komponentat e separatorit (ndarësit) të vlerësuar ku vektori feature ka 1 korrigjohen te-lart apo te-poshtë, në drejtimin që do ta rrisin gjasën që ky shembull i trajnimit klasifikohet në mënyrë korrekte në xhiron tjetër. 63 / 65

64 Separatorët jolinearë: Kur pikat trajnuese nuk kanë funksion linear që i ndan dy klasat, prapë mund të jetë e mundur të përdoret një perceptron për t i klasifikuar ato. Duhet ta gjejmë një funksion që mund ta përdorim t i transformojmë pikat ashtu që në hapësirën e transformuar, separatori është hiperplan. Support-Vector Machines (Makinat e Vektorëve Support): SVM avancohet mbi perceptronët duke e gjetur një hiperplan ndarës që jo vetëm i ndan pikat pozitive dhe negative, por këtë e bën në një mënyrë që e maksimizon margjinën distancën perpendikulare (pingule) në hiperplan nga pikat më të afërta. Pikat që qëndrojnë pikërisht në këtë distancë minimale janë vektorët e suportit. Alternativisht, SVM mund të dizajnohet që të lejojë pika që janë tepër afër hiperplanit, apo madje edhe në anën e gabuar të hiperplanit, por ta minimizojë gabimin për shkak të pikave të tilla të keqvendosura. Zgjidhja e ekuacioneve SVM: Mund ta ndërtojmë një funksion të vektorit që është normal me hiperplanin, gjatësinë e vektorit (që e përcakton margjinën), dhe penalltinë (gjobën) për pikat në anën e gabuar të margjinave. Parametri rregullues e përcakton rëndësinë relative të një margjine të gjerë dhe një penalltie të vogël. Ekuacionet mund të zgjidhen me disa metoda, duke e përfshirë gradient descent (rënien e gradientit) dhe programimin kuadratik. Nearest-Neighbor Learning (Mësimi nga Fqiu më i Afërt): Në këtë qasje në machine learning, i tërë seti i trajnimit përdoret si model. Për secilën pikë ( query ) që do të klasifikohet, i kërkojmë k fqinjtë e tij më të afërt në setin e trajnimit. Klasifikimi i pikës query është ndonjë funksion i label-ave të këtyre k fqinjve. Rasti më i thjeshtë është kur k = 1, në të cilin rast mund ta marrim label-ën e pikës query të jetë label-a e fqiut më të afërt. Regresioni: Një rast i shpeshtë i nearest-neighbor learning, i quajtur regresion, shfaqet kur është vetëm një vektor feature, dhe ai, si edhe label-a, janë numra realë; dmth. shënimet e definojnë një funksion me vlera reale të një ndryshoreje. Për ta vlerësuar label-ën, dmth. vlerën e funksionit, për një pikë shënimi të palabel-uar, mund t i bëjmë disa llogaritje që i përfshijnë k fqinjtë më të afërt. Shembujt përfshijnë nxjerrjen e mesatares së fqinjve apo marrjen e mesatares së peshuar, ku pesha e një fqiu është ndonjë funksion zbritës i distancës së tij nga pika të cilës po provojmë t ia përcaktojmë label-ën. 64 / 65
Algoritmet dhe struktura e të dhënave
 Universiteti i Prishtinës Fakulteti i Inxhinierisë Elektrike dhe Kompjuterike Algoritmet dhe struktura e të dhënave Vehbi Neziri FIEK, Prishtinë 2015/2016 Java 5 vehbineziri.com 2 Algoritmet Hyrje Klasifikimi
Universiteti i Prishtinës Fakulteti i Inxhinierisë Elektrike dhe Kompjuterike Algoritmet dhe struktura e të dhënave Vehbi Neziri FIEK, Prishtinë 2015/2016 Java 5 vehbineziri.com 2 Algoritmet Hyrje Klasifikimi
paraqesin relacion binar të bashkësisë A në bashkësinë B? Prandaj, meqë X A B dhe Y A B,
 Përkufizimi. Le të jenë A, B dy bashkësi të çfarëdoshme. Çdo nënbashkësi e bashkësisë A B është relacion binar i bashkësisë A në bashkësinë B. Simbolikisht relacionin do ta shënojmë me. Shembulli. Le të
Përkufizimi. Le të jenë A, B dy bashkësi të çfarëdoshme. Çdo nënbashkësi e bashkësisë A B është relacion binar i bashkësisë A në bashkësinë B. Simbolikisht relacionin do ta shënojmë me. Shembulli. Le të
Ligji I Ohmit Gjatë rrjedhës së rrymës nëpër përcjellës paraqitet. rezistenca. Georg Simon Ohm ka konstatuar
 Rezistenca elektrike Ligji I Ohmit Gjatë rrjedhës së rrymës nëpër përcjellës paraqitet rezistenca. Georg Simon Ohm ka konstatuar varësinë e ndryshimit të potencialit U në skajët e përcjellësit metalik
Rezistenca elektrike Ligji I Ohmit Gjatë rrjedhës së rrymës nëpër përcjellës paraqitet rezistenca. Georg Simon Ohm ka konstatuar varësinë e ndryshimit të potencialit U në skajët e përcjellësit metalik
PASQYRIMET (FUNKSIONET)
") PASQYRIMET (FUNKSIONET) 1. Përkufizimi i pasqyrimit (funksionit) Përkufizimi 1.1. Le të jenë S, T bashkësi të dhëna. Funksion ose pasqyrim nga S në T quhet rregulla sipas së cilës çdo elementi s S i shoqëronhet
PASQYRIMET (FUNKSIONET) 1. Përkufizimi i pasqyrimit (funksionit) Përkufizimi 1.1. Le të jenë S, T bashkësi të dhëna. Funksion ose pasqyrim nga S në T quhet rregulla sipas së cilës çdo elementi s S i shoqëronhet
Fluksi i vektorit të intenzitetit të fushës elektrike v. intenzitetin të barabartë me sipërfaqen të cilën e mberthejnë faktorët
 Ligji I Gauss-it Fluksi i ektorit të intenzitetit të fushës elektrike Prodhimi ektorial është një ektor i cili e ka: drejtimin normal mbi dy faktorët e prodhimit, dhe intenzitetin të barabartë me sipërfaqen
Ligji I Gauss-it Fluksi i ektorit të intenzitetit të fushës elektrike Prodhimi ektorial është një ektor i cili e ka: drejtimin normal mbi dy faktorët e prodhimit, dhe intenzitetin të barabartë me sipërfaqen
Analiza e regresionit të thjeshtë linear
 Analiza e regresionit të thjeshtë linear 11-1 Kapitulli 11 Analiza e regresionit të thjeshtë linear 11- Regresioni i thjeshtë linear 11-3 11.1 Modeli i regresionit të thjeshtë linear 11. Vlerësimet pikësore
Analiza e regresionit të thjeshtë linear 11-1 Kapitulli 11 Analiza e regresionit të thjeshtë linear 11- Regresioni i thjeshtë linear 11-3 11.1 Modeli i regresionit të thjeshtë linear 11. Vlerësimet pikësore
Distanca gjer te yjet, dritësia dhe madhësia absolute e tyre
 Distanca gjer te yjet, dritësia dhe madhësia absolute e tyre Mr. Sahudin M. Hysenaj 24 shkurt 2009 Përmbledhje Madhësia e dukshme e yjeve (m) karakterizon ndriçimin që vjen nga yjet mbi sipërfaqen e Tokës.
Distanca gjer te yjet, dritësia dhe madhësia absolute e tyre Mr. Sahudin M. Hysenaj 24 shkurt 2009 Përmbledhje Madhësia e dukshme e yjeve (m) karakterizon ndriçimin që vjen nga yjet mbi sipërfaqen e Tokës.
BAZAT E INFRASTRUKTURES NË KOMUNIKACION
 MANUALI NË LËNDEN: BAZAT E INFRASTRUKTURES NË KOMUNIKACION Prishtinë,0 DETYRA : Shtrirja e trasesë së rrugës. Llogaritja e shkallës, tangjentës, dhe sekondit: 6 0 0 0.67 6 6. 0 0 0. 067 60 600 60 600 60
MANUALI NË LËNDEN: BAZAT E INFRASTRUKTURES NË KOMUNIKACION Prishtinë,0 DETYRA : Shtrirja e trasesë së rrugës. Llogaritja e shkallës, tangjentës, dhe sekondit: 6 0 0 0.67 6 6. 0 0 0. 067 60 600 60 600 60
Universiteti i Prishtinës Fakulteti i Inxhinierisë Elektrike dhe Kompjuterike. Agni H. Dika
 Universiteti i Prishtinës Fakulteti i Inxhinierisë Elektrike dhe Kompjuterike Agni H. Dika Prishtinë 007 Libri të cilin e keni në dorë së pari u dedikohet studentëve të Fakultetit të Inxhinierisë Elektrike
Universiteti i Prishtinës Fakulteti i Inxhinierisë Elektrike dhe Kompjuterike Agni H. Dika Prishtinë 007 Libri të cilin e keni në dorë së pari u dedikohet studentëve të Fakultetit të Inxhinierisë Elektrike
Tregu i tët. mirave dhe kurba IS. Kurba ose grafiku IS paraqet kombinimet e normave tët interesit dhe nivelet e produktit tët.
 Modeli IS LM Të ardhurat Kështu që, modeli IS LM paraqet raportin në mes pjesës reale dhe monetare të ekonomisë. Tregjet e aktiveve Tregu i mallrave Tregu monetar Tregu i obligacioneve Kërkesa agregate
Modeli IS LM Të ardhurat Kështu që, modeli IS LM paraqet raportin në mes pjesës reale dhe monetare të ekonomisë. Tregjet e aktiveve Tregu i mallrave Tregu monetar Tregu i obligacioneve Kërkesa agregate
REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA QENDRORE E VLERËSIMIT TË ARRITJEVE TË NXËNËSVE PROVIMI I MATURËS SHTETËRORE 2008
 KUJDES! MOS DËMTO BARKODIN Matematikë Sesioni I BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA QENDRORE E VLERËSIMIT TË ARRITJEVE TË NXËNËSVE PROVIMI I MATURËS SHTETËRORE 008
KUJDES! MOS DËMTO BARKODIN Matematikë Sesioni I BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA QENDRORE E VLERËSIMIT TË ARRITJEVE TË NXËNËSVE PROVIMI I MATURËS SHTETËRORE 008
Q k. E = 4 πε a. Q s = C. = 4 πε a. j s. E + Qk + + k 4 πε a KAPACITETI ELEKTRIK. Kapaciteti i trupit të vetmuar j =
 UNIVERSIEI I PRISHINËS KAPACIEI ELEKRIK Kapaciteti i trupit të vetmuar Kapaciteti i sferës së vetmuar + + + + Q k s 2 E = 4 πε a v 0 fusha në sipërfaqe të sferës E + Qk + + + + j = Q + s + 0 + k 4 πε a
UNIVERSIEI I PRISHINËS KAPACIEI ELEKRIK Kapaciteti i trupit të vetmuar Kapaciteti i sferës së vetmuar + + + + Q k s 2 E = 4 πε a v 0 fusha në sipërfaqe të sferës E + Qk + + + + j = Q + s + 0 + k 4 πε a
KSF 2018 Cadet, Klasa 7 8 (A) 18 (B) 19 (C) 20 (D) 34 (E) 36
 18 (B) 19 (C) 20 (D) 34 (E) 36") Problema me 3 pië # 1. Sa është vlera e shprehjes (20 + 18) : (20 18)? (A) 18 (B) 19 (C) 20 (D) 34 (E) 36 # 2. Në qoftë se shkronjat e fjalës MAMA i shkruajmë verikalisht njëra mbi tjetrën fjala ka një
Problema me 3 pië # 1. Sa është vlera e shprehjes (20 + 18) : (20 18)? (A) 18 (B) 19 (C) 20 (D) 34 (E) 36 # 2. Në qoftë se shkronjat e fjalës MAMA i shkruajmë verikalisht njëra mbi tjetrën fjala ka një
Nyjet, Deget, Konturet
 Nyjet, Deget, Konturet Meqenese elementet ne nje qark elektrik mund te nderlidhen ne menyra te ndryshme, nevojitet te kuptojme disa koncepte baze te topologjise se rrjetit. Per te diferencuar nje qark
Nyjet, Deget, Konturet Meqenese elementet ne nje qark elektrik mund te nderlidhen ne menyra te ndryshme, nevojitet te kuptojme disa koncepte baze te topologjise se rrjetit. Per te diferencuar nje qark
Kapitulli. Programimi linear i plote
 Kapitulli Programimi linear i plote 1-Hyrje Për të gjetur një zgjidhje optimale brenda një bashkesie zgjidhjesh të mundshme, një algoritëm duhet të përmbajë një strategji kërkimi të zgjidhjeve dhe një
Kapitulli Programimi linear i plote 1-Hyrje Për të gjetur një zgjidhje optimale brenda një bashkesie zgjidhjesh të mundshme, një algoritëm duhet të përmbajë një strategji kërkimi të zgjidhjeve dhe një
ELEKTROSTATIKA. Fusha elektrostatike eshte rast i vecante i fushes elektromagnetike.
 ELEKTROSTATIKA Fusha elektrostatike eshte rast i vecante i fushes elektromagnetike. Ajo vihet ne dukje ne hapesiren rrethuese te nje trupi ose te nje sistemi trupash te ngarkuar elektrikisht, te palevizshem
ELEKTROSTATIKA Fusha elektrostatike eshte rast i vecante i fushes elektromagnetike. Ajo vihet ne dukje ne hapesiren rrethuese te nje trupi ose te nje sistemi trupash te ngarkuar elektrikisht, te palevizshem
Shtrohet pyetja. A ekziston formula e përgjithshme për të caktuar numrin e n-të të thjeshtë?
 KAPITULLI II. NUMRAT E THJESHTË Më parë pamë se p.sh. numri 7 plotpjesëtohet me 3 dhe me 9 (uptohet se çdo numër plotpjesëtohet me dhe me vetvetën). Shtrohet pyetja: me cilët numra plotpjesëtohet numri
KAPITULLI II. NUMRAT E THJESHTË Më parë pamë se p.sh. numri 7 plotpjesëtohet me 3 dhe me 9 (uptohet se çdo numër plotpjesëtohet me dhe me vetvetën). Shtrohet pyetja: me cilët numra plotpjesëtohet numri
Kapitulli 1 Hyrje në Analizën Matematike 1
 Përmbajtja Parathënie iii Kapitulli 1 Hyrje në Analizën Matematike 1 1.1. Përsëritje të njohurive nga shkolla e mesme për bashkësitë, numrat reale dhe funksionet 1 1.1.1 Bashkësitë 1 1.1.2 Simbole të logjikës
Përmbajtja Parathënie iii Kapitulli 1 Hyrje në Analizën Matematike 1 1.1. Përsëritje të njohurive nga shkolla e mesme për bashkësitë, numrat reale dhe funksionet 1 1.1.1 Bashkësitë 1 1.1.2 Simbole të logjikës
Algoritmika dhe Programimi i Avancuar KAPITULLI I HYRJE Algoritmat nje problem renditjeje Hyrja: a1, a2,, an> Dalja: <a 1, a 2,, a n> a 1 a 2 a n.
 KAPITULLI I HYRJE Algoritmat Ne menyre informale do te perkufizonim nje algoritem si nje procedure perllogaritese cfaredo qe merr disa vlera ose nje bashkesi vlerash ne hyrje dhe prodhon disa vlera ose
KAPITULLI I HYRJE Algoritmat Ne menyre informale do te perkufizonim nje algoritem si nje procedure perllogaritese cfaredo qe merr disa vlera ose nje bashkesi vlerash ne hyrje dhe prodhon disa vlera ose
DELEGATET DHE ZBATIMI I TYRE NE KOMPONETE
 DELEGATET DHE ZBATIMI I TYRE NE KOMPONETE KAPITULLI 5 Prof. Ass. Dr. Isak Shabani 1 Delegatët Delegati është tip me referencë i cili përdorë metoda si të dhëna. Përdorimi i zakonshëm i delegatëve është
DELEGATET DHE ZBATIMI I TYRE NE KOMPONETE KAPITULLI 5 Prof. Ass. Dr. Isak Shabani 1 Delegatët Delegati është tip me referencë i cili përdorë metoda si të dhëna. Përdorimi i zakonshëm i delegatëve është
REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2011
 KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2011 S E S I O N I II LËNDA: KIMI VARIANTI
KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2011 S E S I O N I II LËNDA: KIMI VARIANTI
REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2011
 KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2011 S E S I O N I II LËNDA: KIMI VARIANTI
KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2011 S E S I O N I II LËNDA: KIMI VARIANTI
INSTITUTI I ZHVILLIMIT TË ARSIMIT. PROGRAM ORIENTUES PËR MATURËN SHTETËRORE (Provim me zgjedhje) LËNDA: MATEMATIKA E THELLUAR
 LËNDA: MATEMATIKA E THELLUAR") INSTITUTI I ZHVILLIMIT TË ARSIMIT PROGRAM ORIENTUES PËR MATURËN SHTETËRORE (Provim me zgjedhje) LËNDA: MATEMATIKA E THELLUAR Koordinatore: Dorina Rapti Viti shkollor 2017-2018 1. UDHËZIME TË PËRGJITHSHME
INSTITUTI I ZHVILLIMIT TË ARSIMIT PROGRAM ORIENTUES PËR MATURËN SHTETËRORE (Provim me zgjedhje) LËNDA: MATEMATIKA E THELLUAR Koordinatore: Dorina Rapti Viti shkollor 2017-2018 1. UDHËZIME TË PËRGJITHSHME
Α ί τ η σ η Δ ή λ ω σ η σ υ μ μ ε τ ο χ ή ς
 ΟΡΘΟΔΟΞΟΣ ΑΥΤΟΚΕΦΑΛΟΣ ΕΚΚΛΗΣΙΑ ΑΛΒΑΝΙΑΣ ΙΕΡΑ ΜΗΤΡΟΠΟΛΙΣ ΑΡΓΥΡΟΚΑΣΤΡΟΥ ΚΑΤΑΣΚΗΝΩΣΗ «Μ Ε Τ Α Μ Ο Ρ Φ Ω Σ Η» Γ Λ Υ Κ Ο Μ Ι Λ Ι Δ Ρ Ο Π Ο Λ Η Σ Α ί τ η σ η Δ ή λ ω σ η σ υ μ μ ε τ ο χ ή ς Πόλη ή Χωριό Σας
ΟΡΘΟΔΟΞΟΣ ΑΥΤΟΚΕΦΑΛΟΣ ΕΚΚΛΗΣΙΑ ΑΛΒΑΝΙΑΣ ΙΕΡΑ ΜΗΤΡΟΠΟΛΙΣ ΑΡΓΥΡΟΚΑΣΤΡΟΥ ΚΑΤΑΣΚΗΝΩΣΗ «Μ Ε Τ Α Μ Ο Ρ Φ Ω Σ Η» Γ Λ Υ Κ Ο Μ Ι Λ Ι Δ Ρ Ο Π Ο Λ Η Σ Α ί τ η σ η Δ ή λ ω σ η σ υ μ μ ε τ ο χ ή ς Πόλη ή Χωριό Σας
R = Qarqet magnetike. INS F = Fm. m = m 0 l. l =
 E T F UNIVERSIETI I PRISHTINËS F I E K QARQET ELEKTRIKE Qarqet magnetike Qarku magnetik I thjeshtë INS F = Fm m = m m r l Permeabililiteti i materialit N fluksi magnetik në berthamë të berthamës l = m
E T F UNIVERSIETI I PRISHTINËS F I E K QARQET ELEKTRIKE Qarqet magnetike Qarku magnetik I thjeshtë INS F = Fm m = m m r l Permeabililiteti i materialit N fluksi magnetik në berthamë të berthamës l = m
ALGJEBËR II Q. R. GASHI
 ALGJEBËR II Q. R. GASHI Shënim: Këto ligjërata janë të paredaktuara, të palekturuara dhe vetëm një verzion fillestar i (ndoshta) një teksti të mëvonshëm. Ato nuk e reflektojnë detyrimisht materien që e
ALGJEBËR II Q. R. GASHI Shënim: Këto ligjërata janë të paredaktuara, të palekturuara dhe vetëm një verzion fillestar i (ndoshta) një teksti të mëvonshëm. Ato nuk e reflektojnë detyrimisht materien që e
PËRMBLEDHJE DETYRASH PËR PËRGATITJE PËR OLIMPIADA TË MATEMATIKËS
 SHOQATA E MATEMATIKANËVE TË KOSOVËS PËRMBLEDHJE DETYRASH PËR PËRGATITJE PËR OLIMPIADA TË MATEMATIKËS Kls 9 Armend Sh Shbni Prishtinë, 009 Bshkësitë numerike Të vërtetohet se numri 004 005 006 007 + është
SHOQATA E MATEMATIKANËVE TË KOSOVËS PËRMBLEDHJE DETYRASH PËR PËRGATITJE PËR OLIMPIADA TË MATEMATIKËS Kls 9 Armend Sh Shbni Prishtinë, 009 Bshkësitë numerike Të vërtetohet se numri 004 005 006 007 + është
UNIVERSITETI SHTETËROR I TETOVËS FAKULTETI I SHKENCAVE HUMANE DHE ARTEVE DEPARTAMENTI I GJEOGRAFISË. DETYRË Nr.1 nga lënda H A R T O G R A F I
 UNIVERSITETI SHTETËROR I TETOVËS FAKULTETI I SHKENCAVE HUMANE DHE ARTEVE DEPARTAMENTI I GJEOGRAFISË DETYRË Nr. nga lënda H A R T O G R A F I Punoi: Emri MBIEMRI Mentor: Asist.Mr.sc. Bashkim IDRIZI Tetovë,
UNIVERSITETI SHTETËROR I TETOVËS FAKULTETI I SHKENCAVE HUMANE DHE ARTEVE DEPARTAMENTI I GJEOGRAFISË DETYRË Nr. nga lënda H A R T O G R A F I Punoi: Emri MBIEMRI Mentor: Asist.Mr.sc. Bashkim IDRIZI Tetovë,
Metodat e Analizes se Qarqeve
 Metodat e Analizes se Qarqeve Der tani kemi shqyrtuar metoda për analizën e qarqeve të thjeshta, të cilat mund të përshkruhen tërësisht me anën e një ekuacioni të vetëm. Analiza e qarqeve më të përgjithshëm
Metodat e Analizes se Qarqeve Der tani kemi shqyrtuar metoda për analizën e qarqeve të thjeshta, të cilat mund të përshkruhen tërësisht me anën e një ekuacioni të vetëm. Analiza e qarqeve më të përgjithshëm
Lënda: Mikroekonomia I. Kostoja. Msc. Besart Hajrizi
 Lënda: Mikroekonomia I Kostoja Msc. Besart Hajrizi 1 Nga funksioni i prodhimit në kurbat e kostove Shpenzimet monetare të cilat i bën firma për inputet fikse (makineritë, paisjet, ndërtesat, depot, toka
Lënda: Mikroekonomia I Kostoja Msc. Besart Hajrizi 1 Nga funksioni i prodhimit në kurbat e kostove Shpenzimet monetare të cilat i bën firma për inputet fikse (makineritë, paisjet, ndërtesat, depot, toka
Metodologji praktike për Deep Learning. kapitull i plotë
 kapitull i plotë zgjodhi dhe përktheu Ridvan Bunjaku maj 2017 Përmbajtja Për publikimin... 3 Bibliografia... 3 Falënderim... 3 Licencimi... 3 Online... 3 Metodologjia praktike... 4 11.1 Metrikat e performansës...
kapitull i plotë zgjodhi dhe përktheu Ridvan Bunjaku maj 2017 Përmbajtja Për publikimin... 3 Bibliografia... 3 Falënderim... 3 Licencimi... 3 Online... 3 Metodologjia praktike... 4 11.1 Metrikat e performansës...
KSF 2018 Student, Klasa 11 12
 Problema me 3 pikë # 1. Figura e e mëposhtme paraqet kalendarin e një muaji të vitit. Për fat të keq, mbi të ka rënë bojë dhe shumica e datave të tij nuk mund të shihen. Cila ditë e javës është data 27
Problema me 3 pikë # 1. Figura e e mëposhtme paraqet kalendarin e një muaji të vitit. Për fat të keq, mbi të ka rënë bojë dhe shumica e datave të tij nuk mund të shihen. Cila ditë e javës është data 27
AISHE HAJREDINI (KARAJ), KRISTAQ LULA. Kimia Inorganike. TESTE TË ZGJIDHURA Të maturës shtetërore
, KRISTAQ LULA. Kimia Inorganike. TESTE TË ZGJIDHURA Të maturës shtetërore") AISHE HAJREDINI (KARAJ), KRISTAQ LULA Kimia Inorganike TESTE TË ZGJIDHURA Të maturës shtetërore AISHE HAJREDINI (KARAJ), KRISTAQ LULA TESTE TË MATURËS SHTETËRORE Kimia inorganike S H T Ë P I A B O T U
AISHE HAJREDINI (KARAJ), KRISTAQ LULA Kimia Inorganike TESTE TË ZGJIDHURA Të maturës shtetërore AISHE HAJREDINI (KARAJ), KRISTAQ LULA TESTE TË MATURËS SHTETËRORE Kimia inorganike S H T Ë P I A B O T U
NDËRTIMI DHE PËRMBAJTJA E PUNIMIT
 NDËRTIMI DHE PËRMBAJTJA E PUNIMIT Punimi monografik Vështrim morfo sintaksor i parafjalëve të gjuhës së re greke në krahasim me parafjalët e gjuhës shqipe është konceptuar në shtatë kapituj, të paraprirë
NDËRTIMI DHE PËRMBAJTJA E PUNIMIT Punimi monografik Vështrim morfo sintaksor i parafjalëve të gjuhës së re greke në krahasim me parafjalët e gjuhës shqipe është konceptuar në shtatë kapituj, të paraprirë
Rikardo dhe modeli standard i tregtisë ndërkombëtare. Fakulteti Ekonomik, Universiteti i Prishtinës
 Rikardo dhe modeli standard i tregtisë ndërkombëtare Fakulteti Ekonomik, Universiteti i Prishtinës Hyrje Teoritë e tregtisë ndërkombëtare; Modeli i Rikardos; Modeli standard i tregtisë ndërkombëtare. Teoritë
Rikardo dhe modeli standard i tregtisë ndërkombëtare Fakulteti Ekonomik, Universiteti i Prishtinës Hyrje Teoritë e tregtisë ndërkombëtare; Modeli i Rikardos; Modeli standard i tregtisë ndërkombëtare. Teoritë
Qëllimet: Në fund të orës së mësimit ju duhet të jeni në gjendje që të:
 Analiza statistikore Metodat e zgjedhjes së mostrës 1 Metodat e zgjedhjes së mostrës Qëllimet: Në fund të orës së mësimit ju duhet të jeni në gjendje që të: Kuptoni pse në shumicën e rasteve vrojtimi me
Analiza statistikore Metodat e zgjedhjes së mostrës 1 Metodat e zgjedhjes së mostrës Qëllimet: Në fund të orës së mësimit ju duhet të jeni në gjendje që të: Kuptoni pse në shumicën e rasteve vrojtimi me
Kërkesat teknike për Listën e Materialeve dhe Pajisjeve të Pranueshme LEME lista - Sektori Banesor dhe i Ndërtesave
 Kërkesat teknike për Listën e Materialeve dhe Pajisjeve të Pranueshme LEME lista - Sektori Banesor dhe i Ndërtesave Kriteret e pranushmërisë së Materialeve dhe Pajisjeve Materiali/Pajisja /Mjeti Dritare
Kërkesat teknike për Listën e Materialeve dhe Pajisjeve të Pranueshme LEME lista - Sektori Banesor dhe i Ndërtesave Kriteret e pranushmërisë së Materialeve dhe Pajisjeve Materiali/Pajisja /Mjeti Dritare
Propozim për strukturën e re tarifore
 Propozim për strukturën e re tarifore (Tarifat e energjisë elektrike me pakicë) DEKLARATË Ky dokument është përgatitur nga ZRRE me qëllim të informimit të palëve të interesuara. Propozimet në këtë raport
Propozim për strukturën e re tarifore (Tarifat e energjisë elektrike me pakicë) DEKLARATË Ky dokument është përgatitur nga ZRRE me qëllim të informimit të palëve të interesuara. Propozimet në këtë raport
MATEMATIKË KONTROLLIMI EKSTERN I DIJES SË NXËNËSVE NË FUND TË CIKLIT TË TRETË TË SHKOLLËS FILLORE VITIT MËSIMOR 2012/2013 UDHËZIM
 MATEMATIKË KONTROLLIMI EKSTERN I DIJES SË NXËNËSVE NË FUND TË CIKLIT TË TRETË TË SHKOLLËS FILLORE VITIT MËSIMOR 2012/2013 UDHËZIM Mjetet e punës: lapsi grafit dhe goma, lapsi kimik, veglat gjeometrike.
MATEMATIKË KONTROLLIMI EKSTERN I DIJES SË NXËNËSVE NË FUND TË CIKLIT TË TRETË TË SHKOLLËS FILLORE VITIT MËSIMOR 2012/2013 UDHËZIM Mjetet e punës: lapsi grafit dhe goma, lapsi kimik, veglat gjeometrike.
MATEMATIKË KONTROLLIMI EKSTERN I DIJES SË NXËNËSVE NË FUND TË CIKLIT TË TRETË TË SHKOLLËS FILLORE
 MATEMATIKË KONTROLLIMI EKSTERN I DIJES SË NXËNËSVE NË FUND TË CIKLIT TË TRETË TË SHKOLLËS FILLORE QERSHOR, VITIT MËSIMOR 2015/2016 UDHËZIM KOHA PËR ZGJIDHJEN E TESTIT: 70 MINUTA Mjetet e punës: lapsi grafit
MATEMATIKË KONTROLLIMI EKSTERN I DIJES SË NXËNËSVE NË FUND TË CIKLIT TË TRETË TË SHKOLLËS FILLORE QERSHOR, VITIT MËSIMOR 2015/2016 UDHËZIM KOHA PËR ZGJIDHJEN E TESTIT: 70 MINUTA Mjetet e punës: lapsi grafit
Kolegji - Universiteti për Biznes dhe Teknologji Fakultetit i Shkencave Kompjuterike dhe Inxhinierisë. Lënda: Bazat Teknike të informatikës - BTI
 Kolegji - Universiteti për Biznes dhe Teknologji Fakultetit i Shkencave Kompjuterike dhe Inxhinierisë Lënda: Bazat Teknike të informatikës - BTI Dispensë Ligjërues: Selman Haxhijaha Luan Gashi Viti Akademik
Kolegji - Universiteti për Biznes dhe Teknologji Fakultetit i Shkencave Kompjuterike dhe Inxhinierisë Lënda: Bazat Teknike të informatikës - BTI Dispensë Ligjërues: Selman Haxhijaha Luan Gashi Viti Akademik
Teste EDLIRA ÇUPI SERVETE CENALLA
 Teste EDLIRA ÇUPI SERVETE CENALLA Matematika gjithmonë me ju 1 Botimet shkollore Albas 1 Test përmbledhës për kapitullin I 1. Lidh me vijë fi gurën me ngjyrën. Ngjyros. (6 pikë) E VERDHË E KUQE E KALTËR
Teste EDLIRA ÇUPI SERVETE CENALLA Matematika gjithmonë me ju 1 Botimet shkollore Albas 1 Test përmbledhës për kapitullin I 1. Lidh me vijë fi gurën me ngjyrën. Ngjyros. (6 pikë) E VERDHË E KUQE E KALTËR
Teste matematike 6. Teste matematike. Botimet shkollore Albas
 Teste matematike 6 Botimet shkollore Albas 1 2 Teste matematike 6 Hyrje Në materiali e paraqitur janë dhënë dy lloj testesh për lëndën e Matematikës për klasën VI: 1. teste me alternativa, 2. teste të
Teste matematike 6 Botimet shkollore Albas 1 2 Teste matematike 6 Hyrje Në materiali e paraqitur janë dhënë dy lloj testesh për lëndën e Matematikës për klasën VI: 1. teste me alternativa, 2. teste të
Indukcioni elektromagnetik
 Shufra pingul mbi ijat e fushës magnetike Indukcioni elektromagnetik Indukcioni elektromagnetik në shufrën përçuese e cila lëizë në fushën magnetike ijat e fushës magnetike homogjene Bazat e elektroteknikës
Shufra pingul mbi ijat e fushës magnetike Indukcioni elektromagnetik Indukcioni elektromagnetik në shufrën përçuese e cila lëizë në fushën magnetike ijat e fushës magnetike homogjene Bazat e elektroteknikës
Testimi i hipotezave/kontrollimi i hipotezave Mostra e madhe
 Testimi i hipotezave/kontrollimi i hipotezave Mostra e madhe Ligjërata e tetë 1 Testimi i hipotezave/mostra e madhe Qëllimet Pas orës së mësimit ju duhet ë jeni në gjendje që të: Definoni termet: hipotezë
Testimi i hipotezave/kontrollimi i hipotezave Mostra e madhe Ligjërata e tetë 1 Testimi i hipotezave/mostra e madhe Qëllimet Pas orës së mësimit ju duhet ë jeni në gjendje që të: Definoni termet: hipotezë
 Përpjesa e kundërt e përpjesës a :b është: Mesi gjeometrik x i segmenteve m dhe n është: Për dy figura gjeometrike që kanë krejtësisht formë të njejtë, e madhësi të ndryshme ose të njëjta themi se janë
Përpjesa e kundërt e përpjesës a :b është: Mesi gjeometrik x i segmenteve m dhe n është: Për dy figura gjeometrike që kanë krejtësisht formë të njejtë, e madhësi të ndryshme ose të njëjta themi se janë
Definimi dhe testimi i hipotezave
 (Master) Ligjerata 2 Metodologjia hulumtuese Definimi dhe testimi i hipotezave Prof.asc. Avdullah Hoti 1 1 Përmbajtja dhe literatura Përmbajtja 1. Definimi i hipotezave 2. Testimi i hipotezave përmes shembujve
(Master) Ligjerata 2 Metodologjia hulumtuese Definimi dhe testimi i hipotezave Prof.asc. Avdullah Hoti 1 1 Përmbajtja dhe literatura Përmbajtja 1. Definimi i hipotezave 2. Testimi i hipotezave përmes shembujve
Cilat nga bashkësitë = {(1, ), (1, ), (2, )},
, (1, ), (2, )},") RELACIONET. RELACIONI BINAR Përkufizimi. Le të jenë A, B dy bashkësi të çfarëdoshme. Çdo nënbashkësi e bashkësisë A B është relacion binar i bashkësisë A në bashkësinë B. Simbolikisht relacionin do ta
RELACIONET. RELACIONI BINAR Përkufizimi. Le të jenë A, B dy bashkësi të çfarëdoshme. Çdo nënbashkësi e bashkësisë A B është relacion binar i bashkësisë A në bashkësinë B. Simbolikisht relacionin do ta
Teori Grafesh. E zëmë se na është dhënë një bashkësi segmentesh mbi drejtëzën reale që po e shënojmë:
 Teori Grafesh Teori grafesh bitbit.uni.cc 1.1 Koncepti i grafit dhe disa nocione shoqeruese Shpeshherë për të lehtësuar veten ne shtrimin dhe analizën e mjaft problemeve që dalin në veprimtarinë tonë,
Teori Grafesh Teori grafesh bitbit.uni.cc 1.1 Koncepti i grafit dhe disa nocione shoqeruese Shpeshherë për të lehtësuar veten ne shtrimin dhe analizën e mjaft problemeve që dalin në veprimtarinë tonë,
Bazat e Programimit në C++
 Universiteti i Europës Juglindore Fakulteti i Shkencave dhe i Teknologjive të Komunikimit Agni Dika Bazat e Programimit në C++ 2005 U lejua për botim nga Komisioni për Botime pranë Universitetit të Europës
Universiteti i Europës Juglindore Fakulteti i Shkencave dhe i Teknologjive të Komunikimit Agni Dika Bazat e Programimit në C++ 2005 U lejua për botim nga Komisioni për Botime pranë Universitetit të Europës
SOFTWARE-T APLIKATIVE LËNDË ZGJEDHORE: FAKULTETI I INXHINIERISË MEKANIKE VITI I PARË, SEMESTRI I PARË
 Dr. sc. Ahmet SHALA SOFTWARE-T APLIKATIVE LËNDË ZGJEDHORE: FAKULTETI I INXHINIERISË MEKANIKE VITI I PARË, SEMESTRI I PARË PRISHTINË, 2004-2010 Dr. sc. Ahmet SHALA PARATHËNIE Programe që mund të i shfrytëzojmë
Dr. sc. Ahmet SHALA SOFTWARE-T APLIKATIVE LËNDË ZGJEDHORE: FAKULTETI I INXHINIERISË MEKANIKE VITI I PARË, SEMESTRI I PARË PRISHTINË, 2004-2010 Dr. sc. Ahmet SHALA PARATHËNIE Programe që mund të i shfrytëzojmë
MATEMATIKA. Manuali për arsimtarët. Podgoricë, Enti i Teksteve dhe i Mjeteve Mësimore PODGORICË
 Izedin Kërniq Marko Jokiq Mirjana Boshkoviq MATEMATIKA Manuali për arsimtarët Enti i Teksteve dhe i Mjeteve Mësimore PODGORICË Podgoricë, 009. Izedin Kërniq Marko Jokiq Mirjana Boshkoviq MATEMATIKA Manuali
Izedin Kërniq Marko Jokiq Mirjana Boshkoviq MATEMATIKA Manuali për arsimtarët Enti i Teksteve dhe i Mjeteve Mësimore PODGORICË Podgoricë, 009. Izedin Kërniq Marko Jokiq Mirjana Boshkoviq MATEMATIKA Manuali
REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI I MATURËS SHTETËRORE 2012 I DETYRUAR
 KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI I MATURËS SHTETËRORE 01 I DETYRUAR VARIANTI A E shtunë, 16 qershor 01
KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI I MATURËS SHTETËRORE 01 I DETYRUAR VARIANTI A E shtunë, 16 qershor 01
Teoria e kërkesës për punë
 L07 (Master) Teoria e kërkesës për punë Prof.as. Avdullah Hoti 1 Literatura: Literatura 1. George Borjas (2002): Labor Economics, 2nd Ed., McGraw-Hill, 2002, Chapter 4 2. Stefan Qirici (2005): Ekonomiksi
L07 (Master) Teoria e kërkesës për punë Prof.as. Avdullah Hoti 1 Literatura: Literatura 1. George Borjas (2002): Labor Economics, 2nd Ed., McGraw-Hill, 2002, Chapter 4 2. Stefan Qirici (2005): Ekonomiksi
Shpërndarjet e mostrave dhe intervalet e besueshmërisë për mesatare aritmetike dhe përpjesën. Ligjërata e shtatë
 Shërdarjet e mostrave dhe itervalet e besueshmërisë ër mesatare aritmetike dhe ërjesë Ligjërata e shtatë Shërdarja e mostrave dhe itervalet e besueshmërisë ër mesatare aritmetike dhe roorcio/ërqidje Qëllimet
Shërdarjet e mostrave dhe itervalet e besueshmërisë ër mesatare aritmetike dhe ërjesë Ligjërata e shtatë Shërdarja e mostrave dhe itervalet e besueshmërisë ër mesatare aritmetike dhe roorcio/ërqidje Qëllimet
Treguesit e dispersionit/shpërndarjes/variacionit
 Treguesit e dispersionit/shpërndarjes/variacionit Qëllimet: Në fund të orës së mësimit, ju duhet të jeni në gjendje që të : Dini rëndësinë e treguesve të dispersionit dhe pse përdoren ata. Llogaritni dhe
Treguesit e dispersionit/shpërndarjes/variacionit Qëllimet: Në fund të orës së mësimit, ju duhet të jeni në gjendje që të : Dini rëndësinë e treguesve të dispersionit dhe pse përdoren ata. Llogaritni dhe
Republika e Serbisë MINISTRIA E ARSIMIT, SHKENCËS DHE E ZHVILLIMIT TEKNOLOGJIK ENTI PËR VLERËSIMIN E CILËSISË SË ARSIMIT DHE TË EDUKIMIT
 Republika e Serbisë MINISTRIA E ARSIMIT, SHKENCËS DHE E ZHVILLIMIT TEKNOLOGJIK ENTI PËR VLERËSIMIN E CILËSISË SË ARSIMIT DHE TË EDUKIMIT PROVIMI PËRFUNDIMTAR PROVUES Viti shkollor 2016/2017 TESTI MATEMATIKË
Republika e Serbisë MINISTRIA E ARSIMIT, SHKENCËS DHE E ZHVILLIMIT TEKNOLOGJIK ENTI PËR VLERËSIMIN E CILËSISË SË ARSIMIT DHE TË EDUKIMIT PROVIMI PËRFUNDIMTAR PROVUES Viti shkollor 2016/2017 TESTI MATEMATIKË
UNIVERSITETI I GJAKOVËS FEHMI AGANI FAKULTETI I EDUKIMIT PROGRAMI PARASHKOLLOR PUNIM DIPLOME
 UNIVERSITETI I GJAKOVËS FEHMI AGANI FAKULTETI I EDUKIMIT PROGRAMI PARASHKOLLOR PUNIM DIPLOME ZHVILLIMI DHE FORMIMI I NJOHURIVE FILLESTARE TEK FËMIJËT E MOSHËS PARASHKOLLORE MBI BASHKËSITË Mentori: Prof.
UNIVERSITETI I GJAKOVËS FEHMI AGANI FAKULTETI I EDUKIMIT PROGRAMI PARASHKOLLOR PUNIM DIPLOME ZHVILLIMI DHE FORMIMI I NJOHURIVE FILLESTARE TEK FËMIJËT E MOSHËS PARASHKOLLORE MBI BASHKËSITË Mentori: Prof.
Materialet në fushën magnetike
 Materialet në fushën magnetike Llojet e materialeve magnetike Elektronet gjatë sjelljes të tyre rreth bërthamës krijojnë taq. momentin magnetik orbital. Vet elektronet kanë momentin magnetik vetiak - spin.
Materialet në fushën magnetike Llojet e materialeve magnetike Elektronet gjatë sjelljes të tyre rreth bërthamës krijojnë taq. momentin magnetik orbital. Vet elektronet kanë momentin magnetik vetiak - spin.
Analiza e qarqeve duke përdorur ligjet Kirchhoff ka avantazhin e madh se ne mund të analizojme një qark pa ngacmuar konfigurimin e tij origjinal.
 Analiza e qarqeve duke përdorur ligjet Kirchhoff ka avantazhin e madh se ne mund të analizojme një qark pa ngacmuar konfigurimin e tij origjinal. Disavantazh i kësaj metode është se llogaritja është e
Analiza e qarqeve duke përdorur ligjet Kirchhoff ka avantazhin e madh se ne mund të analizojme një qark pa ngacmuar konfigurimin e tij origjinal. Disavantazh i kësaj metode është se llogaritja është e
9 KARAKTERISTIKAT E MOTORIT ME DJEGIE TË BRENDSHME DEFINICIONET THEMELORE Për përdorim të rregullt të motorit me djegie të brendshme duhet të dihen
 9 KARAKTERISTIKAT E MOTORIT ME DJEGIE TË BRENDSHME DEFINICIONET THEMELORE Për përdorim të rregullt të motorit me djegie të brendshme duhet të dihen ndryshimet e treguesve të tij themelor - fuqisë efektive
9 KARAKTERISTIKAT E MOTORIT ME DJEGIE TË BRENDSHME DEFINICIONET THEMELORE Për përdorim të rregullt të motorit me djegie të brendshme duhet të dihen ndryshimet e treguesve të tij themelor - fuqisë efektive
Teste matematike. Teste matematike. Miranda Mete. Botime shkollore Albas
 Teste matematike Miranda Mete 9 Botime shkollore Albas Test përmbledhës Kapitulli I - Kuptimi i numrit Mësimet: - 8 Grupi A. Shkruaj si thyesa numrat dhjetorë të mëposhtëm. ( + + pikë) a) 0,5 = ---------
Teste matematike Miranda Mete 9 Botime shkollore Albas Test përmbledhës Kapitulli I - Kuptimi i numrit Mësimet: - 8 Grupi A. Shkruaj si thyesa numrat dhjetorë të mëposhtëm. ( + + pikë) a) 0,5 = ---------
Matematika. Libër për mësuesin. Tony Cotton. Caroline Clissold Linda Glithro Cherri Moseley Janet Rees. Konsulentë gjuhësorë: John McMahon Liz McMahon
 Matematika Libër për mësuesin Tony Cotton Caroline Clissold Linda Glithro Cherri Moseley Janet Rees Konsulentë gjuhësorë: John McMahon Liz McMahon Përmbajtje iv vii Dhjetëshe dhe njëshe A Numërojmë me
Matematika Libër për mësuesin Tony Cotton Caroline Clissold Linda Glithro Cherri Moseley Janet Rees Konsulentë gjuhësorë: John McMahon Liz McMahon Përmbajtje iv vii Dhjetëshe dhe njëshe A Numërojmë me
Definimi i funksionit . Thirrja e funksionit
 Definimi i funksionit Funksioni ngërthen ne vete një grup te urdhrave te cilat i ekzekuton me rastin e thirrjes se tij nga një pjese e caktuar e programit. Forma e përgjithshme e funksionit është: tipi
Definimi i funksionit Funksioni ngërthen ne vete një grup te urdhrave te cilat i ekzekuton me rastin e thirrjes se tij nga një pjese e caktuar e programit. Forma e përgjithshme e funksionit është: tipi
Libër mësuesi Matematika
 Libër mësuesi Nikolla Perdhiku Libër mësuesi Matematika 7 Për klasën e 7 -të të shkollës 9-vjeçare Botime shkollore Albas 1 Libër mësuesi për tekstin Matematika 7 Botues: Latif AJRULLAI Rita PETRO Redaktore
Libër mësuesi Nikolla Perdhiku Libër mësuesi Matematika 7 Për klasën e 7 -të të shkollës 9-vjeçare Botime shkollore Albas 1 Libër mësuesi për tekstin Matematika 7 Botues: Latif AJRULLAI Rita PETRO Redaktore
II. MEKANIKA. FIZIKA I Rrahim MUSLIU ing.dipl.mek. 1
 II.1. Lëvizja mekanike Mekanika është pjesë e fizikës e cila i studion format më të thjeshta të lëvizjes së materies, të cilat bazohen në zhvendosjen e thjeshtë ose kalimin e trupave fizikë prej një pozite
II.1. Lëvizja mekanike Mekanika është pjesë e fizikës e cila i studion format më të thjeshta të lëvizjes së materies, të cilat bazohen në zhvendosjen e thjeshtë ose kalimin e trupave fizikë prej një pozite
Njësitë e matjes së fushës magnetike T mund të rrjedhin për shembull nga shprehjen e forcës së Lorencit: m. C m
 PYETJE n.. - PËRGJIGJE B Duke qenë burimi isotrop, për ruajtjen e energjisë, energjia është e shpërndarë në mënyrë uniforme në një sipërfaqe sferike me qendër në burim. Intensiteti i dritës që arrin në
PYETJE n.. - PËRGJIGJE B Duke qenë burimi isotrop, për ruajtjen e energjisë, energjia është e shpërndarë në mënyrë uniforme në një sipërfaqe sferike me qendër në burim. Intensiteti i dritës që arrin në
Dielektriku në fushën elektrostatike
 Dielektriku në fushën elektrostatike Polarizimi I dielektrikut Njera nga vetit themelore të dielektrikut është lidhja e fortë e gazit elektronik me molekulat e dielektrikut. Në fushën elektrostatike gazi
Dielektriku në fushën elektrostatike Polarizimi I dielektrikut Njera nga vetit themelore të dielektrikut është lidhja e fortë e gazit elektronik me molekulat e dielektrikut. Në fushën elektrostatike gazi
REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2013
 KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2013 LËNDA: FIZIKË BËRTHAMË VARIANTI
KUJDES! MOS DËMTO BARKODIN BARKODI REPUBLIKA E SHQIPËRISË MINISTRIA E ARSIMIT DHE E SHKENCËS AGJENCIA KOMBËTARE E PROVIMEVE PROVIMI ME ZGJEDHJE I MATURËS SHTETËRORE 2013 LËNDA: FIZIKË BËRTHAMË VARIANTI
QARQET ME DIODA 3.1 DREJTUESI I GJYSMËVALËS. 64 Myzafere Limani, Qamil Kabashi ELEKTRONIKA
 64 Myzafere Limani, Qamil Kabashi ELEKTRONKA QARQET ME DODA 3.1 DREJTUES GJYSMËVALËS Analiza e diodës tani do të zgjerohet me funksione të ndryshueshme kohore siç janë forma valore sinusoidale dhe vala
64 Myzafere Limani, Qamil Kabashi ELEKTRONKA QARQET ME DODA 3.1 DREJTUES GJYSMËVALËS Analiza e diodës tani do të zgjerohet me funksione të ndryshueshme kohore siç janë forma valore sinusoidale dhe vala
2.1 Kontrolli i vazhdueshëm (Kv)
") Aneks Nr 2 e rregullores 1 Vlerësimi i cilësisë së dijeve te studentët dhe standardet përkatëse 1 Sistemi i diferencuar i vlerësimit të cilësisë së dijeve të studentëve 1.1. Për kontrollin dhe vlerësimin
Aneks Nr 2 e rregullores 1 Vlerësimi i cilësisë së dijeve te studentët dhe standardet përkatëse 1 Sistemi i diferencuar i vlerësimit të cilësisë së dijeve të studentëve 1.1. Për kontrollin dhe vlerësimin
Ministria e Arsimit, Shkencës dhe Teknologjisë Ministarstvo Obrazovanja, Nauke i Tehnologije Ministry of Education, Science and Technology
 Ministria e Arsimit, Shkencës dhe Teknologjisë Ministarstvo Obrazovanja, Nauke i Tehnologije Ministry of Education, Science and Technology Autor: Dr.sc. Qamil Haxhibeqiri, Mr.sc. Melinda Mula, Mr.sc. Ramadan
Ministria e Arsimit, Shkencës dhe Teknologjisë Ministarstvo Obrazovanja, Nauke i Tehnologije Ministry of Education, Science and Technology Autor: Dr.sc. Qamil Haxhibeqiri, Mr.sc. Melinda Mula, Mr.sc. Ramadan
Skripta e Kursit: Algjebra Elementare, Kalkulusi dhe Matematika Financiare, dhe Statistika Përshkruese Vëll. 1: Algjebra Elementare Edicioni i 3 të
 Skripta e Kursit: Algjebra Elementare, Kalkulusi dhe Matematika Financiare, dhe Statistika Përshkruese Vëll. : Algjebra Elementare Edicioni i të nga Prof. Dr. Dietrich Ohse përkthyer nga. Mas. sc. Armend
Skripta e Kursit: Algjebra Elementare, Kalkulusi dhe Matematika Financiare, dhe Statistika Përshkruese Vëll. : Algjebra Elementare Edicioni i të nga Prof. Dr. Dietrich Ohse përkthyer nga. Mas. sc. Armend
Udhëzues për mësuesin për tekstin shkollor. Matematika 12. Botime shkollore Albas
 Udhëzues për mësuesin për tekstin shkollor Matematika Botime shkollore Albas Shënim. K Udhëzues do të plotësohet me modele mësimi për çdo temë mësimore; për projekte dhe veprimtari praktike. Këtë material
Udhëzues për mësuesin për tekstin shkollor Matematika Botime shkollore Albas Shënim. K Udhëzues do të plotësohet me modele mësimi për çdo temë mësimore; për projekte dhe veprimtari praktike. Këtë material
Qark Elektrik. Ne inxhinierine elektrike, shpesh jemi te interesuar te transferojme energji nga nje pike ne nje tjeter.
 Qark Elektrik Ne inxhinierine elektrike, shpesh jemi te interesuar te transferojme energji nga nje pike ne nje tjeter. Per te bere kete kerkohet nje bashkekomunikim ( nderlidhje) ndermjet pajisjeve elektrike.
Qark Elektrik Ne inxhinierine elektrike, shpesh jemi te interesuar te transferojme energji nga nje pike ne nje tjeter. Per te bere kete kerkohet nje bashkekomunikim ( nderlidhje) ndermjet pajisjeve elektrike.
Analiza e Regresionit dhe Korrelacionit
 1-1 Analiza e Regresionit dhe Korrelacionit Qëllimet: Në fund të orës së mësimit, ju duhet të jeni në gjendje që të : Kuptoni rolin dhe rëndësinë e analizës së regresionit dhe korrelacionit si dhe dallimet
1-1 Analiza e Regresionit dhe Korrelacionit Qëllimet: Në fund të orës së mësimit, ju duhet të jeni në gjendje që të : Kuptoni rolin dhe rëndësinë e analizës së regresionit dhe korrelacionit si dhe dallimet
Qarqet/ rrjetet elektrike
 Qarqet/ rrjetet elektrike Qarku elektrik I thjeshtë lementet themelore të qarkut elektrik Lidhjet e linjave Linja lidhëse Pika lidhëse Kryqëzimi I linjave lidhëse pa lidhje eletrike galvanike 1 1 lementet
Qarqet/ rrjetet elektrike Qarku elektrik I thjeshtë lementet themelore të qarkut elektrik Lidhjet e linjave Linja lidhëse Pika lidhëse Kryqëzimi I linjave lidhëse pa lidhje eletrike galvanike 1 1 lementet
( ) 4πε. ku ρ eshte ngarkesa specifike (ngarkesa per njesine e vellimit ρ ) dhe j eshte densiteti i rrymes
 4πε. ku ρ eshte ngarkesa specifike (ngarkesa per njesine e vellimit ρ ) dhe j eshte densiteti i rrymes") EKUACIONET E MAKSUELLIT Ne kete pjese do te studiojme elektrodinamiken klasike. Fjala klasike perdoret ne fizike, nuk ka rendesi e vjeter ose para shekullit te XX ose jo realiste (mendojne disa studente).
EKUACIONET E MAKSUELLIT Ne kete pjese do te studiojme elektrodinamiken klasike. Fjala klasike perdoret ne fizike, nuk ka rendesi e vjeter ose para shekullit te XX ose jo realiste (mendojne disa studente).
VENDIM Nr.803, date PER MIRATIMIN E NORMAVE TE CILESISE SE AJRIT
 VENDIM Nr.803, date 4.12.2003 PER MIRATIMIN E NORMAVE TE CILESISE SE AJRIT Ne mbështetje te nenit 100 te Kushtetutës dhe te nenit 5 te ligjit nr.8897, date 16.5.2002 "Për mbrojtjen e ajrit nga ndotja",
VENDIM Nr.803, date 4.12.2003 PER MIRATIMIN E NORMAVE TE CILESISE SE AJRIT Ne mbështetje te nenit 100 te Kushtetutës dhe te nenit 5 te ligjit nr.8897, date 16.5.2002 "Për mbrojtjen e ajrit nga ndotja",
MATEMATIKË HYRJE. (5 orë në javë, 185 orë në vit)
") MATEMATIKË (5 orë në javë, 185 orë në vit) HYRJE Në shekullin XXI matematika gjithnjë e më tepër po zë vend qendror, jo vetëm në studimin e fenomeneve natyrore dhe teknike, por me ndërtimin e saj të argumentuar
MATEMATIKË (5 orë në javë, 185 orë në vit) HYRJE Në shekullin XXI matematika gjithnjë e më tepër po zë vend qendror, jo vetëm në studimin e fenomeneve natyrore dhe teknike, por me ndërtimin e saj të argumentuar
Teste matematike 7. Teste matematike. Botimet shkollore Albas
 Teste matematike 7 otimet shkollore Albas 1 Kreu I Kuptimi i numrit TEST 1 (pas orës së 8) Grupi A Rretho përgjigjen e saktë. 1. Te numri 3,435 shifra 4 tregon se: a) numri ka 4 të dhjeta; b) numri ka
Teste matematike 7 otimet shkollore Albas 1 Kreu I Kuptimi i numrit TEST 1 (pas orës së 8) Grupi A Rretho përgjigjen e saktë. 1. Te numri 3,435 shifra 4 tregon se: a) numri ka 4 të dhjeta; b) numri ka
III. FUSHA MAGNETIKE. FIZIKA II Rrahim MUSLIU ing.dipl.mek. 1
 III.1. Fusha magnetike e magnetit të përhershëm Nëse në afërsi të magnetit vendosim një trup prej metali, çeliku, kobalti ose nikeli, magneti do ta tërheq trupin dhe ato do të ngjiten njëra me tjetrën.
III.1. Fusha magnetike e magnetit të përhershëm Nëse në afërsi të magnetit vendosim një trup prej metali, çeliku, kobalti ose nikeli, magneti do ta tërheq trupin dhe ato do të ngjiten njëra me tjetrën.
8 BILANCI TERMIK I MOTORIT ME DJEGIE TË BRENDSHME
 8 BILANCI TERMIK I MOTORIT ME DJEGIE TË BRENDSHME Me termin bilanci termik te motorët nënktohet shërndarja e nxehtësisë të djegies së lëndës djegëse të ftr në motor. Siç është e njohr, vetëm një jesë e
8 BILANCI TERMIK I MOTORIT ME DJEGIE TË BRENDSHME Me termin bilanci termik te motorët nënktohet shërndarja e nxehtësisë të djegies së lëndës djegëse të ftr në motor. Siç është e njohr, vetëm një jesë e
Klasa 2 dhe 3 KENGUR 2014
 Gara ndërkombëtare Kengur viti 014 Klasa dhe 3 KENGUR 014 Çdo detyrë me numër rendor nga 1 deri në 10 vlerësohet me 10 pikë Koha në disponim për zgjidhje është 1h e 15 min Për përgjigje të gabuar të një
Gara ndërkombëtare Kengur viti 014 Klasa dhe 3 KENGUR 014 Çdo detyrë me numër rendor nga 1 deri në 10 vlerësohet me 10 pikë Koha në disponim për zgjidhje është 1h e 15 min Për përgjigje të gabuar të një
Detyra për ushtrime PJESA 4
 0 Detyr për ushtrime të pvrur g lëd ANALIZA MATEMATIKE I VARGJET NUMERIKE Detyr për ushtrime PJESA 4 3 Të jehsohet lim 4 3 ( ) Të tregohet se vrgu + + uk kovergjo 3 Le të jeë,,, k umr relë joegtivë Të
0 Detyr për ushtrime të pvrur g lëd ANALIZA MATEMATIKE I VARGJET NUMERIKE Detyr për ushtrime PJESA 4 3 Të jehsohet lim 4 3 ( ) Të tregohet se vrgu + + uk kovergjo 3 Le të jeë,,, k umr relë joegtivë Të
TEORIA E INFORMACIONIT
 TEORIA E INFORMACIONIT Literature 1. ESSENTIALS OF ERROR-CONTROL CODING, Jorge Castiñeira Moreira, Patrick Guy Farrell, 2006 John Wiley & Sons Ltd. 2. Telecommunications Demystified, Carl Nassar, by LLH
TEORIA E INFORMACIONIT Literature 1. ESSENTIALS OF ERROR-CONTROL CODING, Jorge Castiñeira Moreira, Patrick Guy Farrell, 2006 John Wiley & Sons Ltd. 2. Telecommunications Demystified, Carl Nassar, by LLH
Yjet e ndryshueshëm dhe jo stacionar
 Yjet e ndryshueshëm dhe jo stacionar Sahudin M. HYSENAJ Pjesa më e madhe e yjeve ndriçojnë pa e ndryshuar shkëlqimin e tyre. Por ka yje të cilat edhe e ndryshojnë këtë. Në një pjesë të rasteve ndryshimi
Yjet e ndryshueshëm dhe jo stacionar Sahudin M. HYSENAJ Pjesa më e madhe e yjeve ndriçojnë pa e ndryshuar shkëlqimin e tyre. Por ka yje të cilat edhe e ndryshojnë këtë. Në një pjesë të rasteve ndryshimi
Emërtimi i lëndës Teoria e Avancuar e Grupeve MAT 651. Kredite (ECTS) Auditor (orë) Studim (orë) Leksione Ushtrime Gjithsej
 Auditor (orë) Studim (orë) Leksione Ushtrime Gjithsej") Emërtimi i lëndës Teoria e Avancuar e Grupeve MAT 651 Disiplina të formimit të përgjithshëm Trajtimi i njohurive bazë të algjebrës abstrakte. Njohuri mbi bashkësitë dhe klasat. Pohimi logjik dhe Predikati.
Emërtimi i lëndës Teoria e Avancuar e Grupeve MAT 651 Disiplina të formimit të përgjithshëm Trajtimi i njohurive bazë të algjebrës abstrakte. Njohuri mbi bashkësitë dhe klasat. Pohimi logjik dhe Predikati.
UNIVERSITETI AAB Fakulteti i Shkencave Kompjuterike. LËNDA: Bazat e elektroteknikës Astrit Hulaj
 UNIVERSITETI AAB Fakulteti i Shkencave Kompjuterike LËNDA: Bazat e elektroteknikës Prishtinë, Ligjëruesi: 2014 Astrit Hulaj 1 KAPITULLI I 1. Hyrje në Bazat e Elektroteknikës 1.1. Principet bazë të inxhinierisë
UNIVERSITETI AAB Fakulteti i Shkencave Kompjuterike LËNDA: Bazat e elektroteknikës Prishtinë, Ligjëruesi: 2014 Astrit Hulaj 1 KAPITULLI I 1. Hyrje në Bazat e Elektroteknikës 1.1. Principet bazë të inxhinierisë
SI TË BËHENI NËNSHTETAS GREK? (Udhëzime të thjeshtuara rreth marrjes së nënshtetësisë greke)*
*") SI TË BËHENI NËNSHTETAS GREK? (Udhëzime të thjeshtuara rreth marrjes së nënshtetësisë e)* KUSH NUK MUND TË Për shtetasit e vendeve jashtë BEsë Ata që nuk kanë leje qëndrimi ose kanë vetëm leje të përkohshme
SI TË BËHENI NËNSHTETAS GREK? (Udhëzime të thjeshtuara rreth marrjes së nënshtetësisë e)* KUSH NUK MUND TË Për shtetasit e vendeve jashtë BEsë Ata që nuk kanë leje qëndrimi ose kanë vetëm leje të përkohshme
REPUBLIKA E KOSOVËS REPUBLIKA KOSOVO REPUBLIC OF KOSOVA QEVERIA E KOSOVËS - VLADA KOSOVA - GOVERNMENT OF KOSOVA
 REPUBLIK E KOSOVËS REPUBLIK KOSOVO REPUBLIC OF KOSOV QEVERI E KOSOVËS - VLD KOSOV - GOVERNMENT OF KOSOV MINISTRI E RSIMIT E MINISTRSTVO OBRZOVNJ MINISTRY OF EDUCTION SHKENCËS DHE E TEKNOLOGJISË NUKE I
REPUBLIK E KOSOVËS REPUBLIK KOSOVO REPUBLIC OF KOSOV QEVERI E KOSOVËS - VLD KOSOV - GOVERNMENT OF KOSOV MINISTRI E RSIMIT E MINISTRSTVO OBRZOVNJ MINISTRY OF EDUCTION SHKENCËS DHE E TEKNOLOGJISË NUKE I
KALKULIMI TERMIK I MOTORIT DIESEL. 1. Sasia teorike e nevojshme për djegien e 1 kg lëndës djegëse: kmol ajër / kg LD.
 A KALKULII TERIK I OTORIT DIESEL. Sasa terke e nevjshme ër djegen e kg lëndës djegëse: 8 L C 8H O 0.3 3 C H O 0. 4 3 kml ajër / kg LD kg ajër / kg LD. Sasja e vërtetë e ajrt ër djegen e kg lëndë djegëse:
A KALKULII TERIK I OTORIT DIESEL. Sasa terke e nevjshme ër djegen e kg lëndës djegëse: 8 L C 8H O 0.3 3 C H O 0. 4 3 kml ajër / kg LD kg ajër / kg LD. Sasja e vërtetë e ajrt ër djegen e kg lëndë djegëse:
INDUTIVITETI DHE MESINDUKTIVITETI. shtjellur linearisht 1. m I 2 Për dredhën e mbyllur të njëfisht
 INDUTIVITETI DHE MESINDUKTIVITETI Autoinduksioni + E Ndryshimi I fluksit të mbërthyer indukon tensionin - el = - d Ψ Fluksi I mbërthyer autoinduksionit F është N herë më i madhë për shkak të eksitimit
INDUTIVITETI DHE MESINDUKTIVITETI Autoinduksioni + E Ndryshimi I fluksit të mbërthyer indukon tensionin - el = - d Ψ Fluksi I mbërthyer autoinduksionit F është N herë më i madhë për shkak të eksitimit
10 Probabilitet Orë të lira 20 Shuma 140
 HYRJE Libri që keni në dorë është botim i Shtëpisë botuese UEGEN për t i ardhur në ndihmë mësuesve që japin lëndën e matematikës në klasat e teta. Këtu do të gjeni planin mësimor të matematikës së klasës
HYRJE Libri që keni në dorë është botim i Shtëpisë botuese UEGEN për t i ardhur në ndihmë mësuesve që japin lëndën e matematikës në klasat e teta. Këtu do të gjeni planin mësimor të matematikës së klasës
Studim i Sistemeve të Thjeshta me Fërkim në Kuadrin e Mekanikës Kuantike
 Studim i Sistemeve të Thjeshta me Fërkim në Kuadrin e Mekanikës Kuantike Puna e Diplomës paraqitur në Departamentin e Fizikës Teorike Universiteti i Tiranës nga Dorian Kçira udhëheqës Prof. H. D. Dahmen
Studim i Sistemeve të Thjeshta me Fërkim në Kuadrin e Mekanikës Kuantike Puna e Diplomës paraqitur në Departamentin e Fizikës Teorike Universiteti i Tiranës nga Dorian Kçira udhëheqës Prof. H. D. Dahmen
Erduan RASHICA Shkelzen BAJRAMI ELEKTROTEKNIKA. Mitrovicë, 2016.
 Erduan RASHICA Shkelzen BAJRAMI ELEKTROTEKNIKA Mitrovicë, 2016. PARATHËNIE E L E K T R O T E K N I K A Elektroteknika është një lami e gjerë, në këtë material është përfshi Elektroteknika për fillestar
Erduan RASHICA Shkelzen BAJRAMI ELEKTROTEKNIKA Mitrovicë, 2016. PARATHËNIE E L E K T R O T E K N I K A Elektroteknika është një lami e gjerë, në këtë material është përfshi Elektroteknika për fillestar
Menaxhment Financiar (zgjidhjet)
") Shoqata e Kontabilistëve të Çertifikuar dhe Auditorëve të Kosovës Society of Certified Accountants and Auditors of Kosovo Menaxhment Financiar (zgjidhjet) P7 Nr. FLETË PROVIMI Exam Paper Data: 02.07.2016
Shoqata e Kontabilistëve të Çertifikuar dhe Auditorëve të Kosovës Society of Certified Accountants and Auditors of Kosovo Menaxhment Financiar (zgjidhjet) P7 Nr. FLETË PROVIMI Exam Paper Data: 02.07.2016
I. FUSHA ELEKTRIKE. FIZIKA II Rrahim MUSLIU ing.dipl.mek. 1
 I.1. Ligji mbi ruajtjen e ngarkesës elektrike Më herët është përmendur se trupat e fërkuar tërheqin trupa tjerë, dhe mund të themi se me fërkimin e trupave ato elektrizohen. Ekzistojnë dy lloje të ngarkesave
I.1. Ligji mbi ruajtjen e ngarkesës elektrike Më herët është përmendur se trupat e fërkuar tërheqin trupa tjerë, dhe mund të themi se me fërkimin e trupave ato elektrizohen. Ekzistojnë dy lloje të ngarkesave
Vlerësimi i varfërisë në Kosovë
 Vlerësimi i varfërisë në Kosovë Vëllimi II. Vlerësimi i trendeve nga të dhënat që nuk mund të krahasohen 3 tetor 2007 Banka Botërore Rajoni i Evropës dhe Azisë Qendrore Njësia për reduktimin e varfërisë
Vlerësimi i varfërisë në Kosovë Vëllimi II. Vlerësimi i trendeve nga të dhënat që nuk mund të krahasohen 3 tetor 2007 Banka Botërore Rajoni i Evropës dhe Azisë Qendrore Njësia për reduktimin e varfërisë
Manual i punëve të laboratorit 2009
 Contents PUNË LABORATORI Nr. 1... 3 1. KONTROLLI I AMPERMETRAVE, VOLTMETRAVE DHE VATMETRAVE NJË FAZORË ME METODËN E KRAHASIMIT... 3 1.1. Programi i punës... 3 1.2. Njohuri të përgjithshme... 3 1.2.1. Kontrolli
Contents PUNË LABORATORI Nr. 1... 3 1. KONTROLLI I AMPERMETRAVE, VOLTMETRAVE DHE VATMETRAVE NJË FAZORË ME METODËN E KRAHASIMIT... 3 1.1. Programi i punës... 3 1.2. Njohuri të përgjithshme... 3 1.2.1. Kontrolli