Fig. 1.4 Pentru a realiza functia treapta, Matlab are functia hardlim. b)- Functia de transfer liniara (purelin) este in fig. 1.5.
|
|
|
- Ἰουλία Διαμαντόπουλος
- 8 χρόνια πριν
- Προβολές:
Transcript
1 1.- RETELE NEURONALE ARTIFICIALE (RNA) RNA sunt sisteme de procesare a informatiei, compuse din unitati simple de procesare, interconectate intre ele si care actioneaza in paralel. Aceste elemente sunt inspirate din sistemele nervoase biologice. La fel ca in natura, functia retelei e determinata de legaturile dintre elemente. Ponderile legaturilor dintre unitati sunt cele care memoreaza informatia invatata de retea. Reteaua se instruieste prin ajustarea acestor ponderi, conform unui algoritm. Caracteristicile RNA : - reprezentarea distribuita a informatiei : informatia din retea este stocata in mod distribuit ( in structura de ponderi ), ceea ce face ca efectul unei anumite intrari asupra iesirii sa depinda de toate ponderile din retea. - capacitatea de generalizare in cazul unor situatii necontinute in datele de instruire. Aceasta caracteristica depinde de numarul de ponderi, adica de dimensiunea retelei. Se constata ca cresterea dimensiunii retelei duce la o buna memorare a datelor de instruire, dar scad performantele asupra datelor de testare, ceea ce inseamna ca RNA a pierdut capacitatea de generalizare. Stabilirea numarului optim de neuroni din stratul ascuns, care este o etapa cheie in proiectarea unei RNA, se poate face alegand valoarea de la care incepe sa descreasca performanta RNA pe setul de testare. - toleranta la zgomot : RNA pot fi instruite, chiar daca datele sunt afectate de zgomot, diminuandu-se - evident - performanta ei. - rezistenta la distrugerea partiala : datorita reprezentarii distribuite a informatiei, RNA poate opera si in cazul distrugerii unei mici parti a ei. - rapiditate in calcul : RNA consuma mult timp pentru instruire, dar odata antrenate vor calcula rapid iesirea retelei pentru o anumita intrare. Putem antrena o RNA sa realizeze o anumita functie, prin ajustarea valorilor conexiunilor (ponderilor) dintre elemente. De regula RNA sunt ajustate (antrenate), astfel încât un anumit semnal la intrare sa implice o anume iesire (tinta). O asemenea situatie este prezentata in fig Reteaua este ajustata pe baza compararii raspunsului cu tinta, pâna ce iesirea retelei se potriveste tintei. Pentru a antrena o retea, in aceasta instruire supervizata, se utilizeaza mai multe perechi intrare/tinta. Fig NEURONUL CU VECTOR DE INTRARE Un neuron cu un vector de intrare avand R elemente este prezentat in fig Intrarile individuale p 1, p 2,..., p R sunt înmultite cu ponderile w 1,1, w 1,2,..., w 1,R si valorile ponderate se insumeaza. Suma se poate nota Wp, adica produsul scalar al matricei W (cu o linie) si vectorul p. Neuronul are deplasarea b, care se aduna cu intrarile ponderate, rezultand argumentul n al functiei de transfer f : w 1,1 p 1 + w 2,1 p w 1,R p R +b = n. (1.1) Aceasta expresie poate fi scrisa în codul MATLAB: n = W*p + b ; a = f ( n ). (1.2) O notatie abreviata pentru neuronul din fig. 1.2 se prezinta in fig. 1.3, in care:
2 Fig R este numarul elementelor din vectorul de intrare; - vectorul de intrare p este reprezentat de bara groasa verticala din stânga, dimensiunile lui p sunt indicate sub simbolul p (R 1); - o constanta 1 intra în neuron si multiplica deplasarea b; Fig intrarea n în functia de transfer f este data de (1.2); - a este iesirea neuronului. Fig. 1.2 defineste un strat (nivel) al unei retele. Un strat cuprinde combinarea ponderilor, operatiile de inmultire si insumare (realizate aici ca produsul scalar Wp), deplasarea b si functia de transfer f. Blocul intrarilor (vectorul p) nu este inclus în asa numitul strat FUNCTII DE TRANSFER Neuronul biologic se activeaza (da un semnal la iesire) numai daca semnalul de intrare depaseste un anumit prag. In RNA acest efect este simulat aplicand sumei ponderate a intrarilor (n) o functie de transfer (activare) f, pt. a obtine semnalul a la iesire. Patru dintre cele mai utilizate functii de transfer se prezinta mai jos. a)- Functia treapta (fig. 1.4) Fig. 1.4 Pentru a realiza functia treapta, Matlab are functia hardlim. b)- Functia de transfer liniara (purelin) este in fig. 1.5.
3 Fig. 1.5 c)- Functia log-sigmoid: F x 1 = + kx 1 e, k > 0, se prezinta in fig. 1.6.a. Intrarea poate avea orice valoare între plus si minus infinit, iar raspunsul este în domeniul de la 0 la 1. Fig. 1.6.a O alta varianta este functia tan-sigmoid (fig. 1.6.b): F x ( )= e e x x : R [ -1, 1 ]. Fig. 1.6.b In patratul din dreapta fiecarui grafic se prezinta simbolul asociat functiei de transfer. Aceste simboluri vor înlocui simbolul general f în schemele RNA pentru a arata functia particulara de transfer care este folosita. Comportarea unui neuron la diferite functii de transfer se poate vedea in programul demonstrativ: >>nnd2n2 En ARHITECTURA RNA Doi sau mai multi neuroni se pot combina într-un strat, iar o RNA poate contine unul sau mai multe straturi de acest fel UN STRAT DE NEURONI In fig. 1.7 se arata o RNA avand un singur strat, R intrari si S neuroni. În aceasta retea, fiecare element din vectorul intrarilor p, este conectat la intrarea fiecarui neuron, prin matricea ponderilor W:

 reteaua din fig. 1.7. Fig. 1.8 1.3.")
4 Se observa ca primul indice al unui element din matricea W indica carui neuron ii este atribuita ponderea, iar al doilea indice elementul din vectorul intrarilor caruia i se aplica acea pondere. Fig. 1.7 Astfel, indicii lui w 1, 2 arata sensul semnalului: de la al doilea element al vectorului de intrare, catre primul neuron. Neuronul i are un sumator Σ care aduna intrarile sale ponderate si deplasarea, rezultand iesirea scalara n(i). Toate marimile n(i) formeaza un vector n, cu S elemente. Iesirile din stratul de neuroni formeaza un vector a, a carui expresie se da în partea de jos a figurii. In fig. 1.8 se prezinta (in notatie abreviata) reteaua din fig Fig INTRARI SI STRATURI De regula, o RNA are mai multe straturi. Ca urmare, trebuie sa facem diferenta între matricea ponderilor legaturilor la intrari si matricele cu ponderile conexiunilor între straturi. Vom numi matricea ponderilor legaturilor la intrari matricea ponderilor intrarii (notata IW), iar matricele cu ponderile conexiunilor la iesirile unui strat matricea ponderilor stratului (notata LW). Mai departe, vom folosi indici la exponent (superscript) pentru a identifica sursa (indicele
 si destinatia 1 (indice prim).")
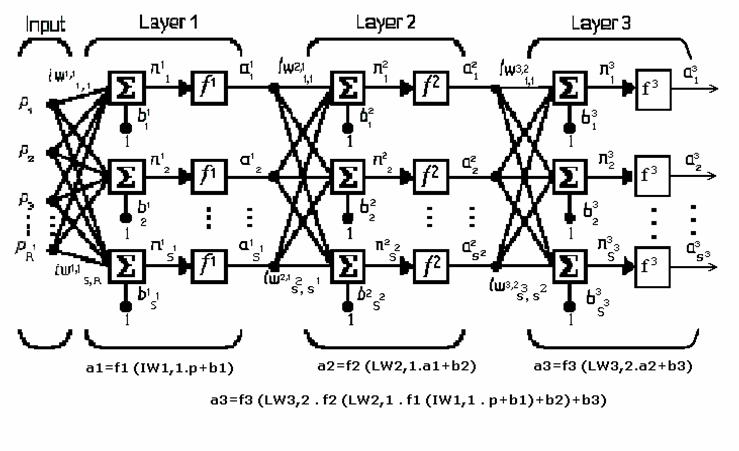
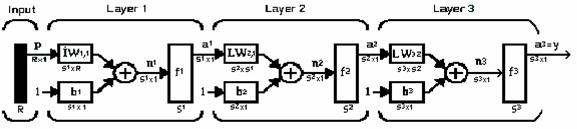
5 secund) si destinatia (indicele prim) pentru ponderile si alte elemente ale retelei. Pentru a ilustra acest lucru, am refacut fig. 1.8 in forma din fig Fig. 1.9 Se vede ca am notat cu IW 1,1 matricea ponderilor intrarilor, având ca sursa 1 (indicele secund) si destinatia 1 (indice prim). De asemenea, elemente ale stratului 1 au superscriptul 1, pentru a arata ca sunt asociate primului strat. Notatia in codul MATLAB pentru o RNA numita net este: Ca urmare, intrarea in functia de transfer se scrie: În urmatorul capitol vom folosi si matricea ponderilor stratului LW STRATURI MULTIPLE DE NEURONI O RNA poate avea mai multe straturi, fiecare strat avand o matrice a ponderilor W, un vector al deplasarilor b si un vector de iesire a. Pentru a distinge matricile ponderilor, vectorii de iesire, etc., pentru fiecare strat din RNA, notam numarul stratului ca superscript la variabila respectiva, cum se vede la reteaua cu trei straturi din figura 1.10 si în ecuatiile din partea de jos. RNA-ua din fig are R 1 intrari, S 1 neuroni în primul strat, S 2 neuroni în al doilea strat, etc. O intrare constanta 1 este atasata la deplasarea fiecarui neuron. Se observa ca iesirile din fiecare strat intermediar reprezinta intrarile pt. stratul urmator. Astfel, stratul 2 poate fi considerat ca o retea cu un singur strat, cu S 1 intrari, S 2 neuroni si o matrice W 2 a ponderilor (cu dimensiunile S 2 S 1 ). Intrarea in stratul 2 este a 1, iar iesirea este a 2. Aceasta abordare se poate aplica oricarui strat din retea. Straturile au roluri diferite: - stratul care produce iesirea retelei este numit strat de iesire. - celelalte straturi se numesc straturi ascunse. Reteaua din fig are un strat de iesire (stratul 3) si doua straturi ascunse (straturile 1 si 2). Reteaua din figura 1.10 se prezinta - in notatie abreviata in fig Iesirea din al treilea strat (a 3 ) este iesirea retelei, notata cu y. Vom folosi aceasta notatie pentru a preciza raspunsul retelelor cu mai multe straturi. Retelele multi-strat sunt foarte eficiente. Retelele cu transmitere inainte au de obicei unul sau mai multe straturi ascunse cu neuroni sigmoidali, urmate de un strat cu neuroni liniari. Mai multe straturi de neuroni, cu functii de transfer neliniare, permit retelei sa invete relatii liniare si neliniare intre vectorii de intrare si de iesire. Stratul liniar de iesire permite retelei sa produca valori in afara domeniului de la -1 la +1. Pe de alta parte, daca se doreste restrictionarea iesirilor unei retele (de ex., intre 0 si 1), atunci stratul de iesire trebuie sa utilizeze o functie de transfer sigmoidala (cum ar fi logsig). De exemplu, o retea cu doua straturi, unde primul strat este sigmoid si al doilea strat este liniar, poate fi antrenat sa aproximeze orice functie (cu un numar finit de discontinuitati).
6 Fig. 1.10
7 Fig. 1.11
8 1.4- CREAREA UNEI RETELE (newff) Prima etapa in antrenarea unei retele cu transmitere inainte este crearea obiectului retea. Functia newff creeaza o astfel de retea. function net = newff(pr,s,tf,btf,blf,pf) NEWFF creaza o retea cu transmitere inainte si retro-propagare. Syntaxa: net = newff(pr,[s1 S2...SNl],{TF1 TF2...TFNl},BTF,BLF,PF) Descriere: NEWFF(PR,[S1 S2...SNl],{TF1 TF2...TFNl},BTF,BLF,PF) in care: PR - matrice Rx2 cu valorile min. si max. ale celor R elemente de la intrare; Si dimensiunea stratului i, pentru cele Nl straturi; TFi functia de transfer a stratului i, implicita = 'tansig'; BTF functia de antrenare a retelei, implicita = 'trainlm'; BLF - functia de instruire backprop a ponderilor/deplasarilor retelei, implicita = 'learngdm'; PF functia de performanta, implicita = 'mse' si returneaza o retea cu transmitere inainte si retro-propagare, avand N straturi. Functiile de transfer TFi pot fi orice functie de transfer diferentiabila, precum TANSIG, LOGSIG, sau PURELIN. Functia de antrenare BTF poate fi oricare dintre functiile de antrenare backprop, precum TRAINLM, TRAINBFG, TRAINRP, TRAINGD, etc. Algoritmul: Retele cu transmitere inainte consista din Nl straturi in care se utilizeaza DOTPROD (produsul scalar) al functiilor pondere, functia de intrare neta NETSUM si functiile de transfer specificate. Primul strat are ponderile legate de intrare. La fiecare strat urmator, ponderile provin din stratul anterior. Toate straturile au deplasari. Ultimul strat reprezinta iesirea din retea. Ponderile si deplasarile se initializeaza cu INITNW. Adaptarea se face cu ADAPTWB, care actualizeaza ponderile cu functia de instruire specificata. Antrenarea se face cu functia de antrenare specificata. Performanta se masoara cu functia de performanta specificata. Deci aceasta functie necesita patru intrari si returneaza obiectul retea. Prima intrare PR este o matrice (R x 2) cu valorile minime si maxime pentru fiecare dintre cele R elemente ale vectorului de intrare. A doua intrare este un sir (matrice) care contine dimensiunile fiecarui strat, adica numarul de neuroni. A treia intrare este formata dintr-o serie de celule care contin numele functiilor de transfer ce vor fi folosite in fiecare strat. Ultima intrare contine numele functiei de antrenare folosita. De exemplu, urmatoarea comanda creeaza o retea cu doua straturi, avand un vector de intrare cu doua elemente. Valorile pentru primul element al vectorului de intrare variaza intre -1 si 2, valorile pentru al doilea element al vectorului de intrare variaza intre 0 si 5. Sunt trei neuroni in primul strat si un neuron in al doilea strat (de iesire). Functia de transfer din primul strat este tansigmoidala, iar functia de transfer din stratul de iesire este liniara. Functia de antrenarea este traingd (care este descrisa intr-un capitol ulterior). Aceasta comanda creeaza obiectul retea si - in plus - initializeaza ponderile si deplasarile retelei; acum reteaua este pregatita pentru a fi antrenata INITIALIZAREA PONDERILOR (init) Inaintea antrenarii unei RNA, trebuiesc initializate ponderile si deplasarile. Comanda newff initializeaza automat ponderile, dar s-ar putea sa vrem sa le reinitializam. Aceasta se poate face cu comanda init. Aceasta functie considera obiectul retea ca intrare si returneaza acelasi obiect, dar cu toate ponderile si deplasarile initializate. Iata cum este initializata (sau reinitializata) o retea: net = init(net); 1.5- SIMULAREA (sim) Functia sim simuleaza o retea. Sim ia vectorul de intrare in retea p si obiectul retea net si returneaza iesirea retelei a.
9 SIM simuleaza o retea neuronala. Syntaxa: [Y,Pf,Af] = sim(net,p,pi,ai) Descriere: [Y,Pf,Af] = SIM(net,P,Pi,Ai) in care: NET Reteaua; P Intrarile in retea; Pi Decalajele initiale ale intrarii, implicit = zero; Ai - Decalajele initiale ale stratului, implicit = zero; si returneaza: Y Iesirile din retea; Pf - Decalajele finale ale intrarii; Af - Decalajele finale ale stratului. Observatie: Argumentele Pi, Ai, Pf si Af sunt optionale si se vor folosi numai pentru retele care au intrarea sau vre-un strat decalat. Iata cum putem folosi sim pentru a simula reteaua pe care am creat-o mai sus pentru un singur vector de intrare: Iesirea ar putea fi diferita, in functie de starea generatorului de numere aleatoare cand reteaua a fost initializata. Mai jos, sim este apelata pentru a calcula iesirile pentru un set concurential cu trei vectori de intrare. Aceasta este modul grupat de simulare, in care toti vectorii de intrare sunt plasati intr-o matrice. Acest lucru este mult mai eficient, decat prezentarea vectorilor pe rand ANTRENAREA Dupa ce ponderile retelei si deplasarile au fost initializate, reteaua este pregatita pentru a fi antrenata. Procesul de antrenare necesita un set de valori privind comportarea retelei: intrarea in retea p si tinta (iesirea) t. In timpul antrenarii, ponderile retelei si deplasarile sunt ajustate iterativ pentru a minimiza functia de performanta a retelei net.performfcn. Functia implicita de performanta pentru retelele cu transmitere inainte este eroarea medie patratica mse dintre iesirea retelei a si tinta t. Consideram eroarea patratica dintre iesirea retelei si tinta impusa (fig. 1.10): E = s 3 j= 1 [ a3( j ) t( 2 j )] unde s 3 este numarul neuronilor din stratul de iesire. E = f (a 3 1, a 3 2,..., a 3 s3) se numeste suprafata de eroare, prin analogie cu E = f(x, y); dar a = f (w, b), deci E= f (w, b) The network weights resulted from the learning are those for which the error is minimum. The weights and shifts adjusting is made by using the gradient with descent step method : k k 1 E wi j = wi j α( k ) ; wi j (1.3) k k 1 E bi = bi α( k ) k bi where α ( k ) represent the learning rate. The learning algorithm for one only step has got 2 stages : 1 o )- Forward - It is determined the error E, in which a 1 = f 1 (IW1,1. p + b1) a 2 = f 2 (LW2,1. a1 + b2) a 3 = f 3 (LW3,2. a2 + b3), p and t being the input, respectively output vectors from the learning set. 2 o )- Backward - With the relations like (1.3) there are adjusted the weights and the shifts în order (fig. 3.11): LW3,2 ; b3, LW2,1 ; b2, IW1,1 ; b 1.,
10 Urmeaza descrierea unor algoritmi de antrenare pentru retelele cu transmitere inainte. Toti acesti algoritmi utilizeaza gradientul functiei de performanta E pentru a determina modul de ajustare a ponderilor cu scopul de a minimiza performanta. Gradientul se determina folosind o tehnica numita propagare inversa, care inseamna efectuarea calculelor in sens invers prin retea. Algoritmul de antrenare prin propagare inversa, in care ponderile variaza in directia gradientului negativ, este descris mai jos ALGORITMUL PROPAGARII INVERSE Cea mai simpla implementare a instruirii prin propagare inversa, actualizeaza ponderile retelei si deplasarile in directia in care functia de performanta scade cel mai rapid, adica in directia gradientului negativ. O iteratie a acestui algoritm poate fi scrisa astfel: unde x k este un vector cu ponderile si deplasarile curente, g k este gradientul curent, iar α k este rata de instruire. Reamintim metoda gradientului negativ: Pentru functia F(x) = F(x 1,, x n ), gradientul este F F G = grad F = F = [,..., ], acest vector indicand directia celei mai mari cresteri. x1 x n Dupa fecare punct nou determinat se ia directia de cautare in sens contrar gradientului, adica in sensul dat de - F, deci pe directia celei mai rapide descresteri. Avansul pe aceasta directie se va face atata timp cat valoarea functiei scade, dupa care se va avansa pe noua orientare a gradientului, s.a.m.d., pana la atingerea minimului. O imagine a modului in care actioneaza aceasta metoda pentru o functie de doua variabile se arata in figura Fig Exista doua modalitati in care poate fi implementat algoritmul gradientului descendent: modul incremental si modul grupat. In modul incremental, gradientul este calculat si ponderile sunt actualizate dupa ce fiecare intrare este aplicata retelei. In modul grupat, toate intrarile sunt aplicate retelei inainte ca ponderile sa fie actualizate. A)- ANTRENAREA GRUPATA (train). In modul grupat, ponderile si deplasarile sunt actualizate numai dupa ce intregul set de antrenare a fost aplicat retelei. Gradientii calculati la fiecare pas de antrenare sunt cumulati pentru a determina variatiile ponderilor si deplasarilor. A1)- ANTRENAREA GRUPATA CU GRADIENT DESCENDENT (traingd) Functia pentru aceasta antrenare este traingd. Daca se doreste antrenarea retelei folosind aceasta
11 modalitate, mai intai trebuie setata functia trainfcn a retelei la traingd si apoi apelata functia train. Exista numai o singura functie de antrenare asociata unei retele date. Exista 7 parametri de antrenare asociati cu traingd: epochs, show, goal, time, min_grad, max_fail, si lr. Rata de instruire lr (notata cu α in relatia (1.3)) se inmulteste cu negativul gradientului pentru a determina modificarile ponderilor si deplasarilor. Cresterea ratei de instruire duce la marirea pasului. Daca rata de instruire este prea mare algoritmul devine instabil. Daca rata de instruire este prea mica, algoritmul necesita mult timp pentru a deveni convergent. Stadiul antrenarii apare pe ecran pt. fiecare iteratie show a algoritmului. Daca show este setat pe NaN, atunci stadiul antrenarii nu este vizibil. Antrenarea se opreste daca numarul iteratiilor depaseste epochs, sau daca functia de performanta (mse) scade sub goal, sau daca marimea gradientului este mai mica decat mingrad sau daca timpul de antrenare este mai mare decat time secunde. Secventa urmatoare creaza un set de antrenare cu intrarile p si tintele t. In cazul antrenarii grupate, toti vectorii de intrare sunt pusi intr-o singura matrice. Acum creem reteaua: Folosim functia minmax pt. a determina domeniul de variatie al intrarilor: pr = minmax (p), in care daca p = (R x Q) matrix, atunci pr = (R x 2) matrix of min. and max. values for each row of p. In aceasta etapa avem posibilitatea sa modificam unii dintre parametrii impliciti de antrenare: Daca vrem sa folosim parametrii impliciti de antrenare, comenzile de mai sus nu sunt necesare. Acum reteaua pate fi antrenata. Inregistrarea antrenarii tr contine informatii despre etapa in care se afla antrenarea. Acum reteaua antrenata poate fi simulata, pentru a se obtine raspunsul ei la intrarile din setul de antrenare. Acest algoritm este ilustrat in programul demo: >>nnd12sd1 En. A2)- ANTRENAREA GRUPATA CU GRADIENT DESCENDENT SI MOMENTUM (traingdm) In afara de traingd, mai exista un algoritm prin grupare pentru retelele cu transmitere inainte,
12 care duce deseori la o convergenta mai rapida traingdm (descrestere abrupta cu momentum). Momentum permite retelei sa raspunda nu numai la gradientul local, dar si evolutiilor recente in suprafata de eroare. Actionand ca un filtru trece-jos, momentum permite retelei sa ignore abaterile minore din suprafata de eroare. Fara momentum, o retea se poate bloca intr-un minim local. Avand momentum, reteaua poate ocoli asemenea minime. Momentum inseamna sa luam variatiile ponderilor egale cu suma unei parti a ultimei variatii a ponderii, cu noua variatie furnizata de regula propagarii inverse. Marimea ultimei modificari a ponderii este mediata de o constanta momentum mc, care poate fi orice numar intre 0 si 1. Atunci cand constanta momentum este 0, variatia ponderii provine numai din gradient. Daca constanta este egala cu 1, noua modificare a ponderii se ia egala cu ultima variatie, gradientul fiind ignorat. Gradientul este calculat prin adunarea gradientilor inregistrati la fiecare pereche de antrenare, iar ponderile si deplasarile sunt doar reactualizate dupa ce toate perechile de antrenare au fost prezentate. Daca noua valoare a functiei de performanta, la o iteratie data, depaseste functia de performanta la iteratia precedenta, cu mai mult decat un raport predefinit max_perf_inc (de regula = 1.04, adica MSE nou / MSE vechi >1.04), noile ponderi si deplasari sunt ignorate, iar coeficientul momentum mc este setat la zero. Antrenarea grupata cu gradient descendent cu momentum este apelata folosind functia de antrenare traingdm. Functia traingdm este utilizata folosind aceleasi etape ca si la functia traingd, cu exceptia faptului ca parametrii de instruire mc, lr si max_perf_inc pot fi alesi. In urmatoarea secventa, vom recrea reteaua precedenta si o vom reantrena folosind gradientul descendent cu momentum. Parametrii de antrenare pentru traingdm sunt aceeasi ca pentru traingd, dar se adauga factorul momentum mc si cresterea maxima a performantei max_perf_inc. Facem observatia ca daca se reinitializeaza ponderile si deplasarile inainte de antrenare (apeland newff, ca mai sus) vom obtine o eroare medie patratica diferita, in comparatie cu cea obtinuta folosind traingd. Daca am reinitializa si reantrena din nou folosind traingdm, vom obtine iar o alta eroare medie patratica. Alegerea aleatorie a ponderilor si a deplasarilor initiale va afecta performanta algoritmului. Daca dorim sa comparam performanta unor algoritmi diferiti, fiecare trebuie testat folosind mai multe seturi diferite de ponderi si deplasari initiale. Este indicat sa se utilizeze net = init (net) pt. a reinitializa ponderile, decat sa se recreeze intreaga retea cu newff. Acest algoritm este ilustrat in programul demo: >>nnd12mo En.
13 1.7- ANTRENAREA MAI RAPIDA Algoritmii de mai sus sunt deseori prea lenti pt. problemele practice. In acest capitol vom discuta cativa algoritmi de inalta performanta care pot converge de la zece pana la o suta de ori mai rapid decat algoritmii prezentati anterior. Toti algoritmii din acest capitol opereaza in modul grupat si sunt apelati cu comanda train. Acesti algoritmi rapizi se impart in doua categorii. Prima categorie foloseste tehnici euristice, care au fost elaborate pe baza analizei performantei algoritmului standard de gradient descendent. O modificare euristica este tehnica momentum, din capitolul anterior. In aceasta categorie se prezinta doua tehnici mai euristice: propagarea inversa cu rata de instruire variabila (traingda) si propagarea inversa flexibila (trainrp). A doua categorie de algoritmi rapizi foloseste tehnici standard de optimizare numerica: gradientul conjugat (traincgf, traincgp, traincgb, trainscg), quasi-newton (trainbfg, trainoss), si Levenberg-Marquardt (trainlm) RATA VARIABILA DE INSTRUIRE (traingda, traingdx) In antrenarea standard cu descrestere rapida, rata de instruire (α, lr) este constanta. Performanta algoritmului este foarte senzitiva la aceasta rata. Daca rata este prea mare, algoritmul poate oscila si devine instabil. Daca rata este prea mica, algoritmului ii v-a lua prea mult timp pentru a converge. Stabilirea valorii optime a ratei de instruire, inainte de antrenare, nu este un lucru practic, pt. ca - de fapt - rata de instruire optima variaza in timpul antrenarii. Performanta algoritmului cu descrestere rapida poate fi imbunatatita daca permitem ca rata de instruire sa se modifice in timpul antrenarii. O rata de instruire adaptiva va incerca sa mentina marimea pasului de instruire cat de mare posibila, in timp ce mentine si instruirea stabila. Adaptarea ratei de instruire necesita unele modificari in procedura de antrenare folosita de traingd. Mai intai se calculeaza iesirea initiala a retelei si eroarea. La fiecare epoca se calculeaza noile ponderi si deplasari folosind rata de instruire curenta. Apoi sunt calculate noile iesiri si erori. Ca si la momentum, daca noua eroare depaseste eroarea precedenta cu mai mult de un raport prestabilit max_perf_inc (de obicei = 1.04), se v-a renunta la noile ponderi si deplasari si rata de instruire este diminuata (prin inmultirea cu lr_dec = 0.7). In caz contrar, se pastreaza noile ponderi, etc. Daca noua eroare este mai mica decat eroarea precedenta, rata de instruire se mareste (inmultind-o cu lr_inc = 1.05). Acest procedeu mareste rata de instruire, dar numai in masura in care reteau poate fi instruita fara cresterea erorii. Astfel, se obtine o rata de instruire cuasi-optima pentru conditiile locale. Atunci cand o rata de instruire mai mare se poate folosi intr-o instruire stabila, rata de instruire este marita. Cand rata de instruire e prea mare pentru a garanta micsorarea erorii, ea va fi redusa, pana se reia instruirea stabila. Antrenarea prin propagare inversa cu rata de instruire adaptiva se face cu functia traingda, care se apeleaza ca si traingd, exceptie facand parametrii aditionali max_perf_inc, lr_dec si lr_inc. Iata cum se antreneaza reteaua cu doua nivele, pe care am descris-o mai sus.
14 Functia traingdx combina rata de instruire adaptiva si antrenarea cu momentum. Se apeleaza ca si traingda, cu exceptia faptului ca are coeficientul momentum mc ca un parametru in plus. Acest algoritm este ilustrat in programul demo: >>nnd12vl En PROPAGAREA INVERSA FLEXIBILA Retelele multi-strat folosesc de obicei - in straturile ascunse - functii de transfer sigmoidale. Aceste functii sunt numite si functii de comprimare, pentru ca ele comprima un domeniu infinit de la intrare intr-un domeniu finit la iesire. Functiile sigmoidale sunt caracterizate de faptul ca panta lor trebuie sa fie zero, cand intrarea este mare. Aceasta duce la aparitia unei probleme, cand se foloseste coborarea cea mai rapida la antrenarea unei retele multi-strat cu functii sigmoidale, anume ca gradientul fiind foarte mic, provoaca mici modificari ale valorilor ponderilor si deplasarilor, chiar cand acestea sunt departe de valorile lor optimale. Scopul algoritmului de antrenare prin propagare inversa flexibila (Rprop) este acela de a elimina aceste efectele nedorite cauzate de derivatele partiale. Se foloseste numai semnul derivatei pentru a afla directia actualizarii ponderii; marimea derivatei nu are nici un efect asupra actualizarii ponderii. Marimea variatiei ponderii se determina cu o valoare de actualizare separata. Valoarea actualizarii pentru fiecare pondere si deplasare se amplifica cu un factor delt-inc daca derivata functiei de performanta in raport cu acea pondere are acelasi semn in doua iteratii successive. Valoarea actualizata se micsoreaza cu factorul delt-dec cand derivata in raport cu acea pondere isi schimba semnul fata de iteratia anterioara. Daca derivata are valoarea zero, atunci valoarea actualizata ramane aceeasi. Cand ponderile oscileaza, variatia ponderii va fi redusa. Daca ponderea continua sa se modifice in aceeasi directie pe parcursul mai multor iteratii, atunci marimea variatiei ponderii se va amplifica. In urmatoarea secventa vom recrea reteaua anterioara si o vom antrena folosind algoritmul Rprop. Parametrii de antrenare pentru trainrp sunt epochs, show, goal, time, min-grad, maxfail, delt-inc, delt-dec, delta0, deltamax. Am discutat in sectiunea anterioara primii opt parametrii; ultimii doi reprezinta marimea pasului initial si respectiv, marimea pasului maxim. Performanta lui Rprop nu este influentata mult de setarile parametrilor de antrenare. In exemplul de mai jos, am lasat majoritatea parametrilor la valorile lor implicite. Am redus parametrul show fata de valoarea anterioara, pentru ca in general Rprop converge mult mai rapid decat algoritmii anteriori. Rprop este in general mult mai rapid decat algoritmul standard cu gradient descendent si cere doar o mica marire a necesarului de memorie. Este nevoie sa stocam valorile actualizate pentru fiecare pondere si deplasare, ceea ce este echivalent cu stocarea gradientului.
15 ALGORITMII CU GRADIENT CONJUGAT Algoritmul de baza al propagarii inverse ajusteaza ponderile in directia celei mai abrupte descresteri (care este gradientul negativ). Aceasta este directia in care functia de performanta descreste cel mai rapid. Facem observatia ca, desi functia descreste cel mai rapid in lungul gradientului negativ, aceasta nu duce neaparat la cea mai rapida convergenta. Algoritmii cu gradient conjugat realizeaza o cautare in lungul directiilor conjugate, care duce in general - la o convergenta mai rapida decat directiile celor mai abrupte descresteri. In aceasta sectiune, vom prezenta patru variante diferite ale algoritmilor cu gradient conjugat. In majoritatea algoritmilor discutati pana acum se foloseste o rata de instruire pentru a determina marimea actualizarii ponderii (dimensiunea pasului). La majoritatea algoritmilor cu gradient conjugat, marimea pasului este ajustata la fiecare iteratie. Se face o cautare in lungul directiei gradientului conjugat, pentru a determina marimea pasului care minimizeaza functia de performanta in lungul acelei linii. Exista cinci functii de cautare incluse in toolbox. Oricare dintre aceste functii poate fi folosita cu functiile de antrenare care sunt descrise in restul capitolului. Anumite functii de cautare sunt cele mai potrivite anumitor functii de antrenare, desi gasirea optimului poate varia in functie de aplicatia specifica. O functie de cautare implicita potrivita este repartizata fiecarei functii de antrenare, dar acest lucru poate fi modificat de catre utilizator. A)- ACTUALIZAREA FLETCHER-REEVES (traincgf) Toti algoritmii cu gradient conjugat pornesc prin a cauta in directia celei mai abrupte descresteri (gradientul negativ), la prima iteratie: p o = -g o. Apoi se realizeaza o linie de cautare, pentru a determina distanta optima de miscare de-a lungul directiei curente de cautare:. Apoi se determina urmatoarea directie de cautare, astfel incat ea este conjugate directiilor de cautare anterioare. Procedura tipica de determinare a noii directii de cautare este de a combina noua directie a celei mai abrupte descresteri cu directia de cautare anterioara:. Versiunile diferite ale gradientului conjugat se disting prin modul in care este calculata constanta β k. Pentru actualizarea Fletcher-Reeves, procedura este urmatoarea:. Acesta este raportul intre patratul normei gradientului curent si patratul normei gradientului precedent. In urmatorul program vom reinitializa reteaua de mai sus si o vom reantrena folosind versiunea Fletcher-Reeves a algoritmului gradientului conjugat. Parametrii lui traincgf sunt epochs, show, goal, time, min-grad, max-fail, srchfcn, scal-tol, alpha, beta, delta, gama, low-lim, up-lim, maxstep, minstep, bmax. Primii sase parametrii sunt ca mai sus. Parametrul srchfcn este denumirea functiei de cautare pe linie; ea poate fi oricare dintre functiile care vor fi descrise in continuare (sau o functie introdusa de utilizator). Restul parametrilor sunt asociati cu rutinele specifice de cautare pe linie si vor fi descrise mai tarziu. In acest exemplu va fi folosita rutina implicita de cautare pe linie srchcha. Traincgf converge in general in mai putine iteratii decat trainrp (desi sunt necesare mai multe calcule pentru fiecare iteratie).
16 De obicei algoritmii cu gradient conjugat sunt mult mai rapizi decat propagarea inversa cu o rata variabila de instruire si sunt uneori mai rapizi decat trainrp, cu toate ca rezultatele vor varia de le o problema la alta. Algoritmii cu gradient conjugat necesita putin mai multa memorie decat algoritmii mai simpli, deci sunt deseori o alegere mai buna pentru retelele cu un numar mare de ponderi. Acest algoritm este ilustrat in programul demo: >>nnd12eg En. B)- ACTUALIZAREA POLAK-RIBIÉRE (traincgp) Polak si Ribiere au propus o alta varianta a algoritmului cu gradient conjugat. Ca si in cazul Fletcher-Reeves, directia de cautare la fiecare iteratie se determina cu: Pentru actualizarea Polak-Ribiere, constanta β k se calculeaza cu: Acesta este produsul scalar al variatiilor anterioare in gradient cu gradientul current, divizat cu patratul normei gradientului precedent. In urmatorul program vom recreea reteaua anterioara si o vom antrena folosind varianta Polak- Ribiere a algoritmului cu gradient conjugat. Parametrii lui traincgp sunt aceeasi ca si pentru traincgf. Rutina implicita de cautare pe linie srchcha v-a fi folosita si in acest exemplu. Parametrii show si epochs sunt stabiliti la aceeasi valoare pe care le-au avut pentru traincgf.
17 Rutina traincgp are o performanta similara cu traincgf. Este dificil de prevazut care algoritm va avea cea mai buna performanta intr-o problema. Memoria necesara pentru Polak-Ribiere (patru vectori) este putin mai mare decat pentru Fletcher-Reeves (trei vectori). C)- RESTARTUL POWELL-BEALE (traincgb) Pentru toti algoritmii cu gradient conjugat, directia de cautare va fi periodic resetata la negativul gradientului. Punctul standard de resetare apare cand numarul de iteratii este egal cu numarul de parametrii din retea (ponderi si deplasari), dar exista si alte metode de resetare care pot imbunatati eficienta antrenarii. O astfel de metoda de resetare a fost propusa de Powell si Beale. Aceasta tehnica se aplica daca exista o foarte mica ortogonalitate intre gradientul curent si cel precedent. Acest fapt este testat in urmatoarea inegalitate: Daca aceasta conditie e satisfacuta, directia de cautare se reseteaza la negativul gradientului. In urmatorul program, vom recrea reteaua precedenta si o vom antrena folosind versiunea Powell-Beale a algoritmului cu gradient conjugat. Parametrii lui traincgb sunt aceeasi ca cei pentru traincgf. Rutina implicita de cautare pe linie srchcha v-a fi folosita si pentru acest exemplu. Parametrii show si epoch au aceleasi valori pe care le-au avut pentru traincgf. Rutina traincgb are calitatea de a fi ceva mai buna decat traincgp in cazul unor probleme, desi performanta in cazul unei probleme date este dificil de prevazut. Necesitatile de memorie pentru algoritmul Powell-Beale (sase vectori) sunt ceva mai mari decat cele pentru Polak-Ribiere (patru
18 vectori) ALGORITMII QUASI-NEWTON A)- ALGORITMUL BFGS (trainbgf) Metoda lui Newton este o alternativa la metodele cu gradient conjugat pentru optimizare rapida. Relatia de baza in metoda lui Newton este: unde A k este matricea Hessiana (cu derivatele secunde ale functiei de performanta in raport cu valorile curente ale ponderilor si deplasarilor). Metoda lui Newton converge deseori mai rapid decat metodele cu gradient conjugat. Din pacate, este complicat si costisitor sa se calculeze matricea Hessiana pentru RNA cu transmitere inainte. Exista o categorie de algoritmi bazati pe metoda lui Newton, dar care nu necesita calcularea derivatelor secundare. Aceste sunt numite metode quasi-newton. Aceste metode actualizeaza la fiecare iteratie o matrice Hessiana aproximativa. Actualizarea este calculata ca o functie de gradient. Metoda quasi-newton care a avut cel mai mare succes a fost descoperita de Broyden, Fletcher, Goldfarb si Shanno (BFGS), algoritmul fiind implementat in rutina trainbfg. In urmatorul program vom recreea reteaua anterioara si o vom reantrena folosind algoritmul quasi-newton BFGS. Parametrii pentru trainbfg sunt aceeasi ca si pentru traincgf. Rutina implicita a cautarii pe linie srchbac v-a fi folosita in acest exemplu. Parametrii show si epochs sunt stabiliti la 5, respectiv 300: Algoritmul BFGS necesita mai multe calcule in fiecare iteratie si mai multa memorie decat metodele cu gradient conjugat, desi in general converge in mai putine iteratii. Hessianul aproximativ trebuie stocat, iar dimensiunile sale sunt n n, unde n este egal cu numarul ponderilor si deplasarilor din retea. In cazul retelelor foarte mari se recomanda utilizarea Rprop sau al unui algoritm cu gradient conjugat. Totusi, pentru retelele mai mici, trainbfg poate fi o functie de antrenare eficienta. B)- LEVENBERG-MARQUARDT (trainlm) La fel ca la metodele quasi-newton, algoritmul Levenberg-Marquardt a fost proiectat pentru atinge o viteza de antrenare de ordinul doi, fara a fi necesara calcularea matricei Hessiene. Cand functia de performanta are forma unei sume de patrate (caracteristic pt. retelele cu transmitere inainte), atunci matricea Hessiana poate fi aproximata astfel: H = J T J, iar gradientul poate fi calculat astfel: g = J T e, unde J este matricea Jacobiana care contine primele derivate ale erorilor retelei (adica a functiei
19 de performanta) in raport cu ponderile si deplasarile, iar e este vectorul erorilor retelei. Matricea Jacobiana poate fi calculata printr-o tehnica standard de propagare inversa (care este mult mai putin complicata decat calcularea matricii Hessiene). Algoritmul Levenberg-Marquardt foloseste aceasta aproximare pt. matricea Hessiana, intr-o recurenta asemanatoare cu metoda Newton: Cand scalarul μ este zero, aceasta este chiar metoda Newton, folosind matricea Hessiana aproximativa. Cand μ este mare, aceasta devine gradientul descendent, cu un pas mic. Metoda Newton este mai rapida si mai precisa in privinta minimului erorii, astfel ca ideea este de a ne deplasa catre metoda lui Newton, cat mai repede posibil. Ca atare, μ este micsorat dupa fiecare pas realizat cu succes (care face o reducere in functia de performanta) si este marit doar, cand in urma pasului, creste functia de performanta. In acest fel, functia de performanta va fi intotdeauna redusa la fiecare iteratie a algoritmului. In urmatorul program reinitializam reteaua anterioara si o reantrenam folosind algoritmul Levenberg-Marquardt. Parametrii pentru trainlm sunt epochs, show, goal, time, min_grad, max_fail, mu, mu_dec, mu_inc, mu_max, mem_reduc. Mai inainte am discutat primii sase parametrii. Parametrul mu este valoarea initiala pentru μ. Aceasta valoare este inmultita cu mu_dec de cate ori functia de performanta se reduce dupa un pas, sau este inmultita cu mu_inc de cate ori un pas va face sa creasca functia de performanta. Daca mu devine mai mare decat mu_max, algoritmul este oprit. Parametrul mem_reduc, care controleaza marimea memoriei utilizata de algoritm, va fi prezentat in sectiunea urmatoare. Parametrii show si epoch sunt fixati la 5 si respectiv 300. Acest algoritm pare a fi metoda cea mai rapida de antrenare a retelelor neuronale cu transmitere inainte, ce au o marime moderata (pana la cateva sute de ponderi). Acest algoritm este ilustrat in programul demo: >>nnd12m En. RECOMANDARI In general, la problemele de aproximare a unei functii, pentru retelele care contin pana la cateva sute de ponderi, algoritmul LM va avea convergenta cea mai rapida. Acest avantaj este observabil in special daca se cere o mare precizie a antrenarii. In multe cazuri, trainlm poate obtine o eroare medie patratica mai mica decat oricare alt algoritm. Totusi, pe masura ce numarul ponderilor din retea creste, avantajul lui trainlm scade. In plus, performanta lui trainlm este relativ slaba in problemele de recunoastere a formelor. Cererile de memorie pt. trainlm sunt mai mari decat pt. alti algoritmi. Prin ajustarea parametrului mem_reduc, discutat mai sus, cererile de memorie se pot reduce, dar cu riscul cresterii timpului de executie. Functia trainrp este cel mai rapid algoritm in problemele de recunoastere a formelor, eficienta ei scazand in problemele de aproximare a unei functii. Performanta ei scade, de asemenea, pe
20 masura ce se reduce eroarea impusa. Cererile de memorie pentru acest algoritm sunt relativ mici in comparatie cu ceilalti algoritmi. Algoritmii cu gradient conjugat, in particular trainscg, functioneaza bine intr-o varietate larga de probleme, in special pentru retelele cu un numar mare de ponderi. Algoritmul SCG este aproape la fel de rapid ca algoritmul LM in problemele de aproximare a unei functii (mai rapid pentru retelele mari) si este aproape la fel de rapid ca trainrp in problemele de recunoastere a formelor. Performanta lui nu scade la fel de repede ca la trainrp cand se reduce eroarea. Algoritmii cu gradient conjugat au cereri relativ mici de memorie. Performanta lui trainbfg este similara cu cea a lui trainlm; nu cere la fel de multa memorie ca trainlm, dar efortul de calcul creste geometric cu marimea retelei, pt. ca echivalentul unei matrici inverse trebuie calculata la fiecare iteratie. Algoritmul cu rata de instruire variabila traingdx este de obicei mult mai lent decat celelalte metode si are aproximativ aceleasi cereri de memorie ca si trainrp, dar poate fi util pentru unele probleme. LIMITARII SI PRECAUTII Algoritmul cu gradient coborator este in general foarte lent, intrucat pentru o instruire stabila cere rate de instruire mici. Varianta momentum este uzual mai rapida decat gradientul coborator simplu, ea permitand rate de instruire mai mari, cu asigurarea mentinerea stabilitatii, dar ramane prea lenta pentru multe aplicatii practice. Pentru retele de dimensiuni mici si medii, usual se utilizeaza antrenarea Levenberg-Marquardt, daca se dispune de memorie suficienta. Daca memoria este o problema, atunci exista o varietate de alti algoritmi rapizi. Pentru retele mari se va folosi trainscg sau trainrp. Retelele multistrat sunt capabile de a realiza corect orice calcul liniar sau neliniar si pot aproxima oricat de bine orice functie. Totusi, desi o retea antrenata este teoretic capabila de realizari corecte, este posibil ca retro-propagarea si variatiile ei sa nu gaseasca intotdeauna solutia. Alegerea ratei de instruire pentru o retea neliniara constituie o provocare. O rate de instruire prea mare duce la o instruire instabila. Reciproc, o rata de instruire prea mica duce la un timp de antrenare foarte lung. Alegerea unei bune rate de instruire pentru o retea multistrat neliniara nu este deloc usoara. In cazul algoritmilor de antrenare rapida, este indicat de ales valorile implicite ale parametrilor. Suprafata de eroare a unei retele neliniare este complexa. Problema este ca functiile de transfer nenliniare ale retelelor multistrat introduc multe minime locale in suprafata de eroare. Cum gradientul coborator se realizeaza pe suprafata de eroare, este posibil ca solutia sa cada intr-unul din aceste minime locale. Aceasta se poate intampla in functie de conditiile initiale de plecare. Caderea intr-un minim local poate fi buna sau rea, depinzand de cat de aproape este minimul local de cel global si cat de mica eroare se cere. In orice caz, trebuie ratinut ca desi o retea multistrat cu retro-propagare si cu suficienti neuroni poate implementa aproape orice functie, retro-propagarea nu va gasi intotdeauna ponderile corecte pentru solutia optima. Reteaua va trebui reinitializata si reantrenata de cateva ori pentru a avea garantia obtinerii celei mai bune solutii APLICATII CATEVA RNA SIMPLE Mai intai ne antrenam cu cateva RNA simple, in MATLAB 6.5. Mai jos intrarea P si tinta T defineste o functie simpla, ce se poate plota (fig. 1.13): figure(1); p=[ ]; t=[ ]; subplot(211);plot(p,t,'o');grid In continuare utilizam functia NEWFF pentru a crea o retea cu doua straturi si cu transmitere inainte. Reteaua are o intrare (in domeniul dela 0 la 8), urmata de un prim strat cu 10 neuroni TANSIG, urmat de un strat cu 1 neuron PURELIN. Folosim TRAINLM si retro-propagarea.
21 Facem simularea retelei, adica se introduce intrarea si se scoate iesirea. Se observa (fig ) ca iesirea nu este cea dorita (pentru ca RNA nu este antrenata, adica nu i s-au ajustat ponderile). Fig net=newff([0 8],[10 1],{'tansig','purelin'},'trainlm'); y1=sim(net,p); subplot(212);plot(p,t,'o',p,y1,'x') Fig Acum antrenam reteaua pana la 50 de epoci, cu o eroare impusa de 0.03, apoi o resimulam (fig. 1.15). figure(2); net.trainparam.epochs=50; net.trainparam.goal=0.03; net=train(net,p,t); y2=sim(net,p) plot(p,t,'o',p,y1,'x',p,y2,'*');grid Fig RNA PENTRU RECUNOASTEREA FORMELOR Acest program realizeaza recunoasterea formelor (clasificarea a doua multimi). In fereastra Command Window : OPEN WORK\RNA\ demo_rna.m En - Run. Apare
22 Figure 1, in care cu mausul se fac 7 clicuri in coltul din stanga sus (apar 7 * ) En si 9 clicuri in coltul din dreapta jos (apar 9 o ) En; Figure 1 se prezinta in figura Fig Dupa rularea programului, in Training apar doua grafice (fig. 1.17): tinta (o functie treapta cele 7 * sunt considerate zerouri, iar cele 9 o sunt considerate unu ) si RNA-ua realizata (care aproximeaza tinta). Fig % DEMO_RNA.M lx=[0 30] ; ly=[0 30]; ch1='*' ; ch2='o'; n1=7 ; n2=9; cl1=formlot(lx,ly,ch1,n1) ; pause; cl2=formlot(lx,ly,ch2,n2); hold off; pause; p=[cl1 cl2]; pr=[lx;ly]; t=[zeros(1,n1) ones(1,n2)]; % DEFINIRE RETEA s1=9 ; s2=15 ; s3=1; tf1='tansig' ; tf2='tansig' ; tf3='logsig'; plot(cl1(1,:),cl1(2,:),'*') hold on; plot(cl2(1,:),cl2(2,:),'o') hold off ; pause; net=newff(pr,[s1 s2 s3],{tf1 tf2 tf3}); % INSTRUIRE RETEA; net.trainparam.epochs=50; net.trainparam.goal=0.02; net=train(net,p,t); yr=sim(net,p); plot([t' yr']) % t-tinta impusa; yr- iesirea retelei pt cazul cand la intrare s-a aplicat vectorul p, dupa instruire. % FORMLOT.M function cl=formlot(lx,ly,ch,n); % Returneaza coordonatele punctelor marcate cu mausul % cl=formlot(lx,ly,ch,n); % cl reprezinta multimea formelor rezultate in urma apelarii functiei formlot. % Dimensiunea matricei cl este (2 x n). % lx=[lx(1) lx(2)] si ly=[ly(1) ly(2)] delimiteaza spatiul formelor, care
23 % in acest caz este un dreptunghi ce are urmatoarele coordonate ale varfurilor: % [lx(1) ly(1)], [lx(1) ly(2)], [lx(2) ly(1)], [lx(2) ly(2)] % ch reprezinta caracterul ( +,., *, o, x ) cu care se marcheaza forma care apartine clasei % n = nr de forme care apartin clasei % ATENTIE! dupa lansarea programului ecranul ramane in 'on' (noua figura se suprapune % peste cea veche) plot(lx,ly,'.'); hold on; x1=[];y1=[]; for i=1:n; [cx,cy]=ginput(1); plot(cx,cy,ch); x1=[x1,cx]; y1=[y1,cy]; end cl=[x1;y1];
Metode iterative pentru probleme neliniare - contractii
 Metode iterative pentru probleme neliniare - contractii Problemele neliniare sunt in general rezolvate prin metode iterative si analiza convergentei acestor metode este o problema importanta. 1 Contractii
Metode iterative pentru probleme neliniare - contractii Problemele neliniare sunt in general rezolvate prin metode iterative si analiza convergentei acestor metode este o problema importanta. 1 Contractii
(a) se numeşte derivata parţială a funcţiei f în raport cu variabila x i în punctul a.
 se numeşte derivata parţială a funcţiei f în raport cu variabila x i în punctul a.") Definiţie Spunem că: i) funcţia f are derivată parţială în punctul a în raport cu variabila i dacă funcţia de o variabilă ( ) are derivată în punctul a în sens obişnuit (ca funcţie reală de o variabilă
Definiţie Spunem că: i) funcţia f are derivată parţială în punctul a în raport cu variabila i dacă funcţia de o variabilă ( ) are derivată în punctul a în sens obişnuit (ca funcţie reală de o variabilă
Curs 14 Funcţii implicite. Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi"
 Curs 14 Funcţii implicite Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Fie F : D R 2 R o funcţie de două variabile şi fie ecuaţia F (x, y) = 0. (1) Problemă În ce condiţii ecuaţia
Curs 14 Funcţii implicite Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Fie F : D R 2 R o funcţie de două variabile şi fie ecuaţia F (x, y) = 0. (1) Problemă În ce condiţii ecuaţia
Curs 10 Funcţii reale de mai multe variabile reale. Limite şi continuitate.
 Curs 10 Funcţii reale de mai multe variabile reale. Limite şi continuitate. Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Fie p, q N. Fie funcţia f : D R p R q. Avem următoarele
Curs 10 Funcţii reale de mai multe variabile reale. Limite şi continuitate. Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Fie p, q N. Fie funcţia f : D R p R q. Avem următoarele
5. FUNCŢII IMPLICITE. EXTREME CONDIŢIONATE.
 5 Eerciţii reolvate 5 UNCŢII IMPLICITE EXTREME CONDIŢIONATE Eerciţiul 5 Să se determine şi dacă () este o funcţie definită implicit de ecuaţia ( + ) ( + ) + Soluţie ie ( ) ( + ) ( + ) + ( )R Evident este
5 Eerciţii reolvate 5 UNCŢII IMPLICITE EXTREME CONDIŢIONATE Eerciţiul 5 Să se determine şi dacă () este o funcţie definită implicit de ecuaţia ( + ) ( + ) + Soluţie ie ( ) ( + ) ( + ) + ( )R Evident este
V.7. Condiţii necesare de optimalitate cazul funcţiilor diferenţiabile
 Metode de Optimizare Curs V.7. Condiţii necesare de optimalitate cazul funcţiilor diferenţiabile Propoziţie 7. (Fritz-John). Fie X o submulţime deschisă a lui R n, f:x R o funcţie de clasă C şi ϕ = (ϕ,ϕ
Metode de Optimizare Curs V.7. Condiţii necesare de optimalitate cazul funcţiilor diferenţiabile Propoziţie 7. (Fritz-John). Fie X o submulţime deschisă a lui R n, f:x R o funcţie de clasă C şi ϕ = (ϕ,ϕ
SEMINAR 14. Funcţii de mai multe variabile (continuare) ( = 1 z(x,y) x = 0. x = f. x + f. y = f. = x. = 1 y. y = x ( y = = 0
 ( = 1 z(x,y) x = 0. x = f. x + f. y = f. = x. = 1 y. y = x ( y = = 0") Facultatea de Hidrotehnică, Geodezie şi Ingineria Mediului Matematici Superioare, Semestrul I, Lector dr. Lucian MATICIUC SEMINAR 4 Funcţii de mai multe variabile continuare). Să se arate că funcţia z,
Facultatea de Hidrotehnică, Geodezie şi Ingineria Mediului Matematici Superioare, Semestrul I, Lector dr. Lucian MATICIUC SEMINAR 4 Funcţii de mai multe variabile continuare). Să se arate că funcţia z,
Metode de interpolare bazate pe diferenţe divizate
 Metode de interpolare bazate pe diferenţe divizate Radu Trîmbiţaş 4 octombrie 2005 1 Forma Newton a polinomului de interpolare Lagrange Algoritmul nostru se bazează pe forma Newton a polinomului de interpolare
Metode de interpolare bazate pe diferenţe divizate Radu Trîmbiţaş 4 octombrie 2005 1 Forma Newton a polinomului de interpolare Lagrange Algoritmul nostru se bazează pe forma Newton a polinomului de interpolare
Esalonul Redus pe Linii (ERL). Subspatii.
. Subspatii.") Seminarul 1 Esalonul Redus pe Linii (ERL). Subspatii. 1.1 Breviar teoretic 1.1.1 Esalonul Redus pe Linii (ERL) Definitia 1. O matrice A L R mxn este in forma de Esalon Redus pe Linii (ERL), daca indeplineste
Seminarul 1 Esalonul Redus pe Linii (ERL). Subspatii. 1.1 Breviar teoretic 1.1.1 Esalonul Redus pe Linii (ERL) Definitia 1. O matrice A L R mxn este in forma de Esalon Redus pe Linii (ERL), daca indeplineste
5.4. MULTIPLEXOARE A 0 A 1 A 2
 5.4. MULTIPLEXOARE Multiplexoarele (MUX) sunt circuite logice combinaţionale cu m intrări şi o singură ieşire, care permit transferul datelor de la una din intrări spre ieşirea unică. Selecţia intrării
5.4. MULTIPLEXOARE Multiplexoarele (MUX) sunt circuite logice combinaţionale cu m intrări şi o singură ieşire, care permit transferul datelor de la una din intrări spre ieşirea unică. Selecţia intrării
III. Serii absolut convergente. Serii semiconvergente. ii) semiconvergentă dacă este convergentă iar seria modulelor divergentă.
 semiconvergentă dacă este convergentă iar seria modulelor divergentă.") III. Serii absolut convergente. Serii semiconvergente. Definiţie. O serie a n se numeşte: i) absolut convergentă dacă seria modulelor a n este convergentă; ii) semiconvergentă dacă este convergentă iar
III. Serii absolut convergente. Serii semiconvergente. Definiţie. O serie a n se numeşte: i) absolut convergentă dacă seria modulelor a n este convergentă; ii) semiconvergentă dacă este convergentă iar
Functii definitie, proprietati, grafic, functii elementare A. Definitii, proprietatile functiilor X) functia f 1
 functia f 1") Functii definitie proprietati grafic functii elementare A. Definitii proprietatile functiilor. Fiind date doua multimi X si Y spunem ca am definit o functie (aplicatie) pe X cu valori in Y daca fiecarui
Functii definitie proprietati grafic functii elementare A. Definitii proprietatile functiilor. Fiind date doua multimi X si Y spunem ca am definit o functie (aplicatie) pe X cu valori in Y daca fiecarui
Curs 4 Serii de numere reale
 Curs 4 Serii de numere reale Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Criteriul rădăcinii sau Criteriul lui Cauchy Teoremă (Criteriul rădăcinii) Fie x n o serie cu termeni
Curs 4 Serii de numere reale Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Criteriul rădăcinii sau Criteriul lui Cauchy Teoremă (Criteriul rădăcinii) Fie x n o serie cu termeni
DISTANŢA DINTRE DOUĂ DREPTE NECOPLANARE
 DISTANŢA DINTRE DOUĂ DREPTE NECOPLANARE ABSTRACT. Materialul prezintă o modalitate de a afla distanţa dintre două drepte necoplanare folosind volumul tetraedrului. Lecţia se adresează clasei a VIII-a Data:
DISTANŢA DINTRE DOUĂ DREPTE NECOPLANARE ABSTRACT. Materialul prezintă o modalitate de a afla distanţa dintre două drepte necoplanare folosind volumul tetraedrului. Lecţia se adresează clasei a VIII-a Data:
 10. STABILIZATOAE DE TENSIUNE 10.1 STABILIZATOAE DE TENSIUNE CU TANZISTOAE BIPOLAE Stabilizatorul de tensiune cu tranzistor compară în permanenţă valoare tensiunii de ieşire (stabilizate) cu tensiunea
10. STABILIZATOAE DE TENSIUNE 10.1 STABILIZATOAE DE TENSIUNE CU TANZISTOAE BIPOLAE Stabilizatorul de tensiune cu tranzistor compară în permanenţă valoare tensiunii de ieşire (stabilizate) cu tensiunea
Planul determinat de normală şi un punct Ecuaţia generală Plane paralele Unghi diedru Planul determinat de 3 puncte necoliniare
 1 Planul în spaţiu Ecuaţia generală Plane paralele Unghi diedru 2 Ecuaţia generală Plane paralele Unghi diedru Fie reperul R(O, i, j, k ) în spaţiu. Numim normala a unui plan, un vector perpendicular pe
1 Planul în spaţiu Ecuaţia generală Plane paralele Unghi diedru 2 Ecuaţia generală Plane paralele Unghi diedru Fie reperul R(O, i, j, k ) în spaţiu. Numim normala a unui plan, un vector perpendicular pe
Functii definitie, proprietati, grafic, functii elementare A. Definitii, proprietatile functiilor
 Functii definitie, proprietati, grafic, functii elementare A. Definitii, proprietatile functiilor. Fiind date doua multimi si spunem ca am definit o functie (aplicatie) pe cu valori in daca fiecarui element
Functii definitie, proprietati, grafic, functii elementare A. Definitii, proprietatile functiilor. Fiind date doua multimi si spunem ca am definit o functie (aplicatie) pe cu valori in daca fiecarui element
Curs 1 Şiruri de numere reale
 Bibliografie G. Chiorescu, Analiză matematică. Teorie şi probleme. Calcul diferenţial, Editura PIM, Iaşi, 2006. R. Luca-Tudorache, Analiză matematică, Editura Tehnopress, Iaşi, 2005. M. Nicolescu, N. Roşculeţ,
Bibliografie G. Chiorescu, Analiză matematică. Teorie şi probleme. Calcul diferenţial, Editura PIM, Iaşi, 2006. R. Luca-Tudorache, Analiză matematică, Editura Tehnopress, Iaşi, 2005. M. Nicolescu, N. Roşculeţ,
SERII NUMERICE. Definiţia 3.1. Fie (a n ) n n0 (n 0 IN) un şir de numere reale şi (s n ) n n0
 n n0 (n 0 IN) un şir de numere reale şi (s n ) n n0") SERII NUMERICE Definiţia 3.1. Fie ( ) n n0 (n 0 IN) un şir de numere reale şi (s n ) n n0 şirul definit prin: s n0 = 0, s n0 +1 = 0 + 0 +1, s n0 +2 = 0 + 0 +1 + 0 +2,.......................................
SERII NUMERICE Definiţia 3.1. Fie ( ) n n0 (n 0 IN) un şir de numere reale şi (s n ) n n0 şirul definit prin: s n0 = 0, s n0 +1 = 0 + 0 +1, s n0 +2 = 0 + 0 +1 + 0 +2,.......................................
MARCAREA REZISTOARELOR
 1.2. MARCAREA REZISTOARELOR 1.2.1 MARCARE DIRECTĂ PRIN COD ALFANUMERIC. Acest cod este format din una sau mai multe cifre şi o literă. Litera poate fi plasată după grupul de cifre (situaţie în care valoarea
1.2. MARCAREA REZISTOARELOR 1.2.1 MARCARE DIRECTĂ PRIN COD ALFANUMERIC. Acest cod este format din una sau mai multe cifre şi o literă. Litera poate fi plasată după grupul de cifre (situaţie în care valoarea
Seminar 5 Analiza stabilității sistemelor liniare
 Seminar 5 Analiza stabilității sistemelor liniare Noțiuni teoretice Criteriul Hurwitz de analiză a stabilității sistemelor liniare În cazul sistemelor liniare, stabilitatea este o condiție de localizare
Seminar 5 Analiza stabilității sistemelor liniare Noțiuni teoretice Criteriul Hurwitz de analiză a stabilității sistemelor liniare În cazul sistemelor liniare, stabilitatea este o condiție de localizare
Integrala nedefinită (primitive)
") nedefinita nedefinită (primitive) nedefinita 2 nedefinita februarie 20 nedefinita.tabelul primitivelor Definiţia Fie f : J R, J R un interval. Funcţia F : J R se numeşte primitivă sau antiderivată a funcţiei
nedefinita nedefinită (primitive) nedefinita 2 nedefinita februarie 20 nedefinita.tabelul primitivelor Definiţia Fie f : J R, J R un interval. Funcţia F : J R se numeşte primitivă sau antiderivată a funcţiei
a n (ζ z 0 ) n. n=1 se numeste partea principala iar seria a n (z z 0 ) n se numeste partea
 n. n=1 se numeste partea principala iar seria a n (z z 0 ) n se numeste partea") Serii Laurent Definitie. Se numeste serie Laurent o serie de forma Seria n= (z z 0 ) n regulata (tayloriana) = (z z n= 0 ) + n se numeste partea principala iar seria se numeste partea Sa presupunem ca,
Serii Laurent Definitie. Se numeste serie Laurent o serie de forma Seria n= (z z 0 ) n regulata (tayloriana) = (z z n= 0 ) + n se numeste partea principala iar seria se numeste partea Sa presupunem ca,
Asupra unei inegalităţi date la barajul OBMJ 2006
 Asupra unei inegalităţi date la barajul OBMJ 006 Mircea Lascu şi Cezar Lupu La cel de-al cincilea baraj de Juniori din data de 0 mai 006 a fost dată următoarea inegalitate: Fie x, y, z trei numere reale
Asupra unei inegalităţi date la barajul OBMJ 006 Mircea Lascu şi Cezar Lupu La cel de-al cincilea baraj de Juniori din data de 0 mai 006 a fost dată următoarea inegalitate: Fie x, y, z trei numere reale
Sisteme diferenţiale liniare de ordinul 1
 1 Metoda eliminării 2 Cazul valorilor proprii reale Cazul valorilor proprii nereale 3 Catedra de Matematică 2011 Forma generală a unui sistem liniar Considerăm sistemul y 1 (x) = a 11y 1 (x) + a 12 y 2
1 Metoda eliminării 2 Cazul valorilor proprii reale Cazul valorilor proprii nereale 3 Catedra de Matematică 2011 Forma generală a unui sistem liniar Considerăm sistemul y 1 (x) = a 11y 1 (x) + a 12 y 2
5.5. REZOLVAREA CIRCUITELOR CU TRANZISTOARE BIPOLARE
 5.5. A CIRCUITELOR CU TRANZISTOARE BIPOLARE PROBLEMA 1. În circuitul din figura 5.54 se cunosc valorile: μa a. Valoarea intensității curentului de colector I C. b. Valoarea tensiunii bază-emitor U BE.
5.5. A CIRCUITELOR CU TRANZISTOARE BIPOLARE PROBLEMA 1. În circuitul din figura 5.54 se cunosc valorile: μa a. Valoarea intensității curentului de colector I C. b. Valoarea tensiunii bază-emitor U BE.
Seminariile Capitolul X. Integrale Curbilinii: Serii Laurent şi Teorema Reziduurilor
 Facultatea de Matematică Calcul Integral şi Elemente de Analiă Complexă, Semestrul I Lector dr. Lucian MATICIUC Seminariile 9 20 Capitolul X. Integrale Curbilinii: Serii Laurent şi Teorema Reiduurilor.
Facultatea de Matematică Calcul Integral şi Elemente de Analiă Complexă, Semestrul I Lector dr. Lucian MATICIUC Seminariile 9 20 Capitolul X. Integrale Curbilinii: Serii Laurent şi Teorema Reiduurilor.
 4. CIRCUITE LOGICE ELEMENTRE 4.. CIRCUITE LOGICE CU COMPONENTE DISCRETE 4.. PORŢI LOGICE ELEMENTRE CU COMPONENTE PSIVE Componente electronice pasive sunt componente care nu au capacitatea de a amplifica
4. CIRCUITE LOGICE ELEMENTRE 4.. CIRCUITE LOGICE CU COMPONENTE DISCRETE 4.. PORŢI LOGICE ELEMENTRE CU COMPONENTE PSIVE Componente electronice pasive sunt componente care nu au capacitatea de a amplifica
Metode Runge-Kutta. 18 ianuarie Probleme scalare, pas constant. Dorim să aproximăm soluţia problemei Cauchy
 Metode Runge-Kutta Radu T. Trîmbiţaş 8 ianuarie 7 Probleme scalare, pas constant Dorim să aproximăm soluţia problemei Cauchy y (t) = f(t, y), a t b, y(a) = α. pe o grilă uniformă de (N + )-puncte din [a,
Metode Runge-Kutta Radu T. Trîmbiţaş 8 ianuarie 7 Probleme scalare, pas constant Dorim să aproximăm soluţia problemei Cauchy y (t) = f(t, y), a t b, y(a) = α. pe o grilă uniformă de (N + )-puncte din [a,
Lectia VI Structura de spatiu an E 3. Dreapta si planul ca subspatii ane
 Subspatii ane Lectia VI Structura de spatiu an E 3. Dreapta si planul ca subspatii ane Oana Constantinescu Oana Constantinescu Lectia VI Subspatii ane Table of Contents 1 Structura de spatiu an E 3 2 Subspatii
Subspatii ane Lectia VI Structura de spatiu an E 3. Dreapta si planul ca subspatii ane Oana Constantinescu Oana Constantinescu Lectia VI Subspatii ane Table of Contents 1 Structura de spatiu an E 3 2 Subspatii
Analiza în curent continuu a schemelor electronice Eugenie Posdărăscu - DCE SEM 1 electronica.geniu.ro
 Analiza în curent continuu a schemelor electronice Eugenie Posdărăscu - DCE SEM Seminar S ANALA ÎN CUENT CONTNUU A SCHEMELO ELECTONCE S. ntroducere Pentru a analiza în curent continuu o schemă electronică,
Analiza în curent continuu a schemelor electronice Eugenie Posdărăscu - DCE SEM Seminar S ANALA ÎN CUENT CONTNUU A SCHEMELO ELECTONCE S. ntroducere Pentru a analiza în curent continuu o schemă electronică,
R R, f ( x) = x 7x+ 6. Determinați distanța dintre punctele de. B=, unde x și y sunt numere reale.
 = x 7x+ 6. Determinați distanța dintre punctele de. B=, unde x și y sunt numere reale.") 5p Determinați primul termen al progresiei geometrice ( b n ) n, știind că b 5 = 48 și b 8 = 84 5p Se consideră funcția f : intersecție a graficului funcției f cu aa O R R, f ( ) = 7+ 6 Determinați distanța
5p Determinați primul termen al progresiei geometrice ( b n ) n, știind că b 5 = 48 și b 8 = 84 5p Se consideră funcția f : intersecție a graficului funcției f cu aa O R R, f ( ) = 7+ 6 Determinați distanța
Laborator 1: INTRODUCERE ÎN ALGORITMI. Întocmit de: Claudia Pârloagă. Îndrumător: Asist. Drd. Gabriel Danciu
 INTRODUCERE Laborator 1: ÎN ALGORITMI Întocmit de: Claudia Pârloagă Îndrumător: Asist. Drd. Gabriel Danciu I. NOŢIUNI TEORETICE A. Sortarea prin selecţie Date de intrare: un şir A, de date Date de ieşire:
INTRODUCERE Laborator 1: ÎN ALGORITMI Întocmit de: Claudia Pârloagă Îndrumător: Asist. Drd. Gabriel Danciu I. NOŢIUNI TEORETICE A. Sortarea prin selecţie Date de intrare: un şir A, de date Date de ieşire:
Teme de implementare in Matlab pentru Laboratorul de Metode Numerice
 Teme de implementare in Matlab pentru Laboratorul de Metode Numerice As. Ruxandra Barbulescu Septembrie 2017 Orice nelamurire asupra enunturilor/implementarilor se rezolva in cadrul laboratorului de MN,
Teme de implementare in Matlab pentru Laboratorul de Metode Numerice As. Ruxandra Barbulescu Septembrie 2017 Orice nelamurire asupra enunturilor/implementarilor se rezolva in cadrul laboratorului de MN,
CURS XI XII SINTEZĂ. 1 Algebra vectorială a vectorilor liberi
 Lect. dr. Facultatea de Electronică, Telecomunicaţii şi Tehnologia Informaţiei Algebră, Semestrul I, Lector dr. Lucian MATICIUC http://math.etti.tuiasi.ro/maticiuc/ CURS XI XII SINTEZĂ 1 Algebra vectorială
Lect. dr. Facultatea de Electronică, Telecomunicaţii şi Tehnologia Informaţiei Algebră, Semestrul I, Lector dr. Lucian MATICIUC http://math.etti.tuiasi.ro/maticiuc/ CURS XI XII SINTEZĂ 1 Algebra vectorială
Subiecte Clasa a VIII-a
 Subiecte lasa a VIII-a (40 de intrebari) Puteti folosi spatiile goale ca ciorna. Nu este de ajuns sa alegeti raspunsul corect pe brosura de subiecte, ele trebuie completate pe foaia de raspuns in dreptul
Subiecte lasa a VIII-a (40 de intrebari) Puteti folosi spatiile goale ca ciorna. Nu este de ajuns sa alegeti raspunsul corect pe brosura de subiecte, ele trebuie completate pe foaia de raspuns in dreptul
Definiţia generală Cazul 1. Elipsa şi hiperbola Cercul Cazul 2. Parabola Reprezentari parametrice ale conicelor Tangente la conice
 1 Conice pe ecuaţii reduse 2 Conice pe ecuaţii reduse Definiţie Numim conica locul geometric al punctelor din plan pentru care raportul distantelor la un punct fix F şi la o dreaptă fixă (D) este o constantă
1 Conice pe ecuaţii reduse 2 Conice pe ecuaţii reduse Definiţie Numim conica locul geometric al punctelor din plan pentru care raportul distantelor la un punct fix F şi la o dreaptă fixă (D) este o constantă
Problema a II - a (10 puncte) Diferite circuite electrice
 Diferite circuite electrice") Olimpiada de Fizică - Etapa pe judeţ 15 ianuarie 211 XI Problema a II - a (1 puncte) Diferite circuite electrice A. Un elev utilizează o sursă de tensiune (1), o cutie cu rezistenţe (2), un întrerupător
Olimpiada de Fizică - Etapa pe judeţ 15 ianuarie 211 XI Problema a II - a (1 puncte) Diferite circuite electrice A. Un elev utilizează o sursă de tensiune (1), o cutie cu rezistenţe (2), un întrerupător
1.7. AMPLIFICATOARE DE PUTERE ÎN CLASA A ŞI AB
 1.7. AMLFCATOARE DE UTERE ÎN CLASA A Ş AB 1.7.1 Amplificatoare în clasa A La amplificatoarele din clasa A, forma de undă a tensiunii de ieşire este aceeaşi ca a tensiunii de intrare, deci întreg semnalul
1.7. AMLFCATOARE DE UTERE ÎN CLASA A Ş AB 1.7.1 Amplificatoare în clasa A La amplificatoarele din clasa A, forma de undă a tensiunii de ieşire este aceeaşi ca a tensiunii de intrare, deci întreg semnalul
V O. = v I v stabilizator
 Stabilizatoare de tensiune continuă Un stabilizator de tensiune este un circuit electronic care păstrează (aproape) constantă tensiunea de ieșire la variaţia între anumite limite a tensiunii de intrare,
Stabilizatoare de tensiune continuă Un stabilizator de tensiune este un circuit electronic care păstrează (aproape) constantă tensiunea de ieșire la variaţia între anumite limite a tensiunii de intrare,
Aplicaţii ale principiului I al termodinamicii la gazul ideal
 Aplicaţii ale principiului I al termodinamicii la gazul ideal Principiul I al termodinamicii exprimă legea conservării şi energiei dintr-o formă în alta şi se exprimă prin relaţia: ΔUQ-L, unde: ΔU-variaţia
Aplicaţii ale principiului I al termodinamicii la gazul ideal Principiul I al termodinamicii exprimă legea conservării şi energiei dintr-o formă în alta şi se exprimă prin relaţia: ΔUQ-L, unde: ΔU-variaţia
Curs 2 DIODE. CIRCUITE DR
 Curs 2 OE. CRCUTE R E CUPRN tructură. imbol Relația curent-tensiune Regimuri de funcționare Punct static de funcționare Parametrii diodei Modelul cu cădere de tensiune constantă Analiza circuitelor cu
Curs 2 OE. CRCUTE R E CUPRN tructură. imbol Relația curent-tensiune Regimuri de funcționare Punct static de funcționare Parametrii diodei Modelul cu cădere de tensiune constantă Analiza circuitelor cu
prin egalizarea histogramei
 Lucrarea 4 Îmbunătăţirea imaginilor prin egalizarea histogramei BREVIAR TEORETIC Tehnicile de îmbunătăţire a imaginilor bazate pe calculul histogramei modifică histograma astfel încât aceasta să aibă o
Lucrarea 4 Îmbunătăţirea imaginilor prin egalizarea histogramei BREVIAR TEORETIC Tehnicile de îmbunătăţire a imaginilor bazate pe calculul histogramei modifică histograma astfel încât aceasta să aibă o
Ovidiu Gabriel Avădănei, Florin Mihai Tufescu,
 vidiu Gabriel Avădănei, Florin Mihai Tufescu, Capitolul 6 Amplificatoare operaţionale 58. Să se calculeze coeficientul de amplificare în tensiune pentru amplficatorul inversor din fig.58, pentru care se
vidiu Gabriel Avădănei, Florin Mihai Tufescu, Capitolul 6 Amplificatoare operaţionale 58. Să se calculeze coeficientul de amplificare în tensiune pentru amplficatorul inversor din fig.58, pentru care se
Examen AG. Student:... Grupa: ianuarie 2016
 16-17 ianuarie 2016 Problema 1. Se consideră graful G = pk n (p, n N, p 2, n 3). Unul din vârfurile lui G se uneşte cu câte un vârf din fiecare graf complet care nu-l conţine, obţinându-se un graf conex
16-17 ianuarie 2016 Problema 1. Se consideră graful G = pk n (p, n N, p 2, n 3). Unul din vârfurile lui G se uneşte cu câte un vârf din fiecare graf complet care nu-l conţine, obţinându-se un graf conex
FLUXURI MAXIME ÎN REŢELE DE TRANSPORT. x 4
 FLUXURI MAXIME ÎN REŢELE DE TRANSPORT Se numeşte reţea de transport un graf în care fiecărui arc îi este asociat capacitatea arcului şi în care eistă un singur punct de intrare şi un singur punct de ieşire.
FLUXURI MAXIME ÎN REŢELE DE TRANSPORT Se numeşte reţea de transport un graf în care fiecărui arc îi este asociat capacitatea arcului şi în care eistă un singur punct de intrare şi un singur punct de ieşire.
2. Circuite logice 2.4. Decodoare. Multiplexoare. Copyright Paul GASNER
 2. Circuite logice 2.4. Decodoare. Multiplexoare Copyright Paul GASNER Definiţii Un decodor pe n bits are n intrări şi 2 n ieşiri; cele n intrări reprezintă un număr binar care determină în mod unic care
2. Circuite logice 2.4. Decodoare. Multiplexoare Copyright Paul GASNER Definiţii Un decodor pe n bits are n intrări şi 2 n ieşiri; cele n intrări reprezintă un număr binar care determină în mod unic care
a. Caracteristicile mecanice a motorului de c.c. cu excitaţie independentă (sau derivaţie)
") Caracteristica mecanică defineşte dependenţa n=f(m) în condiţiile I e =ct., U=ct. Pentru determinarea ei vom defini, mai întâi caracteristicile: 1. de sarcină, numită şi caracteristica externă a motorului
Caracteristica mecanică defineşte dependenţa n=f(m) în condiţiile I e =ct., U=ct. Pentru determinarea ei vom defini, mai întâi caracteristicile: 1. de sarcină, numită şi caracteristica externă a motorului
Laborator 6. Integrarea ecuaţiilor diferenţiale
 Laborator 6 Integrarea ecuaţiilor diferenţiale Responsabili: 1. Surdu Cristina(anacristinasurdu@gmail.com) 2. Ştirbăţ Bogdan(bogdanstirbat@yahoo.com) Obiective În urma parcurgerii acestui laborator elevul
Laborator 6 Integrarea ecuaţiilor diferenţiale Responsabili: 1. Surdu Cristina(anacristinasurdu@gmail.com) 2. Ştirbăţ Bogdan(bogdanstirbat@yahoo.com) Obiective În urma parcurgerii acestui laborator elevul
Sisteme liniare - metode directe
 Sisteme liniare - metode directe Radu T. Trîmbiţaş 27 martie 2016 1 Eliminare gaussiană Să considerăm sistemul liniar cu n ecuaţii şi n necunoscute Ax = b, (1) unde A K n n, b K n 1 sunt date, iar x K
Sisteme liniare - metode directe Radu T. Trîmbiţaş 27 martie 2016 1 Eliminare gaussiană Să considerăm sistemul liniar cu n ecuaţii şi n necunoscute Ax = b, (1) unde A K n n, b K n 1 sunt date, iar x K
Noţiuni introductive
 Metode Numerice Noţiuni introductive Erori. Condiţionare numerică. Stabilitatea algoritmilor. Complexitatea algoritmilor. Metodele numerice reprezintă tehnici prin care problemele matematice sunt reformulate
Metode Numerice Noţiuni introductive Erori. Condiţionare numerică. Stabilitatea algoritmilor. Complexitatea algoritmilor. Metodele numerice reprezintă tehnici prin care problemele matematice sunt reformulate
COLEGIUL NATIONAL CONSTANTIN CARABELLA TARGOVISTE. CONCURSUL JUDETEAN DE MATEMATICA CEZAR IVANESCU Editia a VI-a 26 februarie 2005.
 SUBIECTUL Editia a VI-a 6 februarie 005 CLASA a V-a Fie A = x N 005 x 007 si B = y N y 003 005 3 3 a) Specificati cel mai mic element al multimii A si cel mai mare element al multimii B. b)stabiliti care
SUBIECTUL Editia a VI-a 6 februarie 005 CLASA a V-a Fie A = x N 005 x 007 si B = y N y 003 005 3 3 a) Specificati cel mai mic element al multimii A si cel mai mare element al multimii B. b)stabiliti care
Stabilizator cu diodă Zener
 LABAT 3 Stabilizator cu diodă Zener Se studiază stabilizatorul parametric cu diodă Zener si apoi cel cu diodă Zener şi tranzistor. Se determină întâi tensiunea Zener a diodei şi se calculează apoi un stabilizator
LABAT 3 Stabilizator cu diodă Zener Se studiază stabilizatorul parametric cu diodă Zener si apoi cel cu diodă Zener şi tranzistor. Se determină întâi tensiunea Zener a diodei şi se calculează apoi un stabilizator
Subiecte Clasa a VII-a
 lasa a VII Lumina Math Intrebari Subiecte lasa a VII-a (40 de intrebari) Puteti folosi spatiile goale ca ciorna. Nu este de ajuns sa alegeti raspunsul corect pe brosura de subiecte, ele trebuie completate
lasa a VII Lumina Math Intrebari Subiecte lasa a VII-a (40 de intrebari) Puteti folosi spatiile goale ca ciorna. Nu este de ajuns sa alegeti raspunsul corect pe brosura de subiecte, ele trebuie completate
riptografie şi Securitate
 riptografie şi Securitate - Prelegerea 12 - Scheme de criptare CCA sigure Adela Georgescu, Ruxandra F. Olimid Facultatea de Matematică şi Informatică Universitatea din Bucureşti Cuprins 1. Schemă de criptare
riptografie şi Securitate - Prelegerea 12 - Scheme de criptare CCA sigure Adela Georgescu, Ruxandra F. Olimid Facultatea de Matematică şi Informatică Universitatea din Bucureşti Cuprins 1. Schemă de criptare
Conice. Lect. dr. Constantin-Cosmin Todea. U.T. Cluj-Napoca
 Conice Lect. dr. Constantin-Cosmin Todea U.T. Cluj-Napoca Definiţie: Se numeşte curbă algebrică plană mulţimea punctelor din plan de ecuaţie implicită de forma (C) : F (x, y) = 0 în care funcţia F este
Conice Lect. dr. Constantin-Cosmin Todea U.T. Cluj-Napoca Definiţie: Se numeşte curbă algebrică plană mulţimea punctelor din plan de ecuaţie implicită de forma (C) : F (x, y) = 0 în care funcţia F este
Functii Breviar teoretic 8 ianuarie ianuarie 2011
 Functii Breviar teoretic 8 ianuarie 011 15 ianuarie 011 I Fie I, interval si f : I 1) a) functia f este (strict) crescatoare pe I daca x, y I, x< y ( f( x) < f( y)), f( x) f( y) b) functia f este (strict)
Functii Breviar teoretic 8 ianuarie 011 15 ianuarie 011 I Fie I, interval si f : I 1) a) functia f este (strict) crescatoare pe I daca x, y I, x< y ( f( x) < f( y)), f( x) f( y) b) functia f este (strict)
III. Reprezentarea informaţiei în sistemele de calcul
 Metode Numerice Curs 3 III. Reprezentarea informaţiei în sistemele de calcul III.1. Reprezentarea internă a numerelor întregi III. 1.1. Reprezentarea internă a numerelor întregi fără semn (pozitive) Reprezentarea
Metode Numerice Curs 3 III. Reprezentarea informaţiei în sistemele de calcul III.1. Reprezentarea internă a numerelor întregi III. 1.1. Reprezentarea internă a numerelor întregi fără semn (pozitive) Reprezentarea
I. Noţiuni introductive
 Metode Numerice Curs 1 I. Noţiuni introductive Metodele numerice reprezintă tehnici prin care problemele matematice sunt reformulate astfel încât să fie rezolvate numai prin operaţii aritmetice. Prin trecerea
Metode Numerice Curs 1 I. Noţiuni introductive Metodele numerice reprezintă tehnici prin care problemele matematice sunt reformulate astfel încât să fie rezolvate numai prin operaţii aritmetice. Prin trecerea
2. Sisteme de forţe concurente...1 Cuprins...1 Introducere Aspecte teoretice Aplicaţii rezolvate...3
 SEMINAR 2 SISTEME DE FRŢE CNCURENTE CUPRINS 2. Sisteme de forţe concurente...1 Cuprins...1 Introducere...1 2.1. Aspecte teoretice...2 2.2. Aplicaţii rezolvate...3 2. Sisteme de forţe concurente În acest
SEMINAR 2 SISTEME DE FRŢE CNCURENTE CUPRINS 2. Sisteme de forţe concurente...1 Cuprins...1 Introducere...1 2.1. Aspecte teoretice...2 2.2. Aplicaţii rezolvate...3 2. Sisteme de forţe concurente În acest
1.3 Baza a unui spaţiu vectorial. Dimensiune
 .3 Baza a unui spaţiu vectorial. Dimensiune Definiţia.3. Se numeşte bază a spaţiului vectorial V o familie de vectori B care îndeplineşte condiţiile de mai jos: a) B este liniar independentă; b) B este
.3 Baza a unui spaţiu vectorial. Dimensiune Definiţia.3. Se numeşte bază a spaţiului vectorial V o familie de vectori B care îndeplineşte condiţiile de mai jos: a) B este liniar independentă; b) B este
Laborator 11. Mulţimi Julia. Temă
 Laborator 11 Mulţimi Julia. Temă 1. Clasa JuliaGreen. Să considerăm clasa JuliaGreen dată de exemplu la curs pentru metoda locului final şi să schimbăm numărul de iteraţii nriter = 100 în nriter = 101.
Laborator 11 Mulţimi Julia. Temă 1. Clasa JuliaGreen. Să considerăm clasa JuliaGreen dată de exemplu la curs pentru metoda locului final şi să schimbăm numărul de iteraţii nriter = 100 în nriter = 101.
Algebra si Geometrie Seminar 9
 Algebra si Geometrie Seminar 9 Decembrie 017 ii Equations are just the boring part of mathematics. I attempt to see things in terms of geometry. Stephen Hawking 9 Dreapta si planul in spatiu 1 Notiuni
Algebra si Geometrie Seminar 9 Decembrie 017 ii Equations are just the boring part of mathematics. I attempt to see things in terms of geometry. Stephen Hawking 9 Dreapta si planul in spatiu 1 Notiuni
Fig Impedanţa condensatoarelor electrolitice SMD cu Al cu electrolit semiuscat în funcţie de frecvenţă [36].
![Fig Impedanţa condensatoarelor electrolitice SMD cu Al cu electrolit semiuscat în funcţie de frecvenţă [36].](/thumbs/72/67648751.jpg "Fig Impedanţa condensatoarelor electrolitice SMD cu Al cu electrolit semiuscat în funcţie de frecvenţă [36].") Componente şi circuite pasive Fig.3.85. Impedanţa condensatoarelor electrolitice SMD cu Al cu electrolit semiuscat în funcţie de frecvenţă [36]. Fig.3.86. Rezistenţa serie echivalentă pierderilor în funcţie
Componente şi circuite pasive Fig.3.85. Impedanţa condensatoarelor electrolitice SMD cu Al cu electrolit semiuscat în funcţie de frecvenţă [36]. Fig.3.86. Rezistenţa serie echivalentă pierderilor în funcţie
Capitolul 4. Integrale improprii Integrale cu limite de integrare infinite
 Capitolul 4 Integrale improprii 7-8 În cadrul studiului integrabilităţii iemann a unei funcţii s-au evidenţiat douăcondiţii esenţiale:. funcţia :[ ] este definită peintervalînchis şi mărginit (interval
Capitolul 4 Integrale improprii 7-8 În cadrul studiului integrabilităţii iemann a unei funcţii s-au evidenţiat douăcondiţii esenţiale:. funcţia :[ ] este definită peintervalînchis şi mărginit (interval
Concurs MATE-INFO UBB, 1 aprilie 2017 Proba scrisă la MATEMATICĂ
 UNIVERSITATEA BABEŞ-BOLYAI CLUJ-NAPOCA FACULTATEA DE MATEMATICĂ ŞI INFORMATICĂ Concurs MATE-INFO UBB, aprilie 7 Proba scrisă la MATEMATICĂ SUBIECTUL I (3 puncte) ) (5 puncte) Fie matricele A = 3 4 9 8
UNIVERSITATEA BABEŞ-BOLYAI CLUJ-NAPOCA FACULTATEA DE MATEMATICĂ ŞI INFORMATICĂ Concurs MATE-INFO UBB, aprilie 7 Proba scrisă la MATEMATICĂ SUBIECTUL I (3 puncte) ) (5 puncte) Fie matricele A = 3 4 9 8
Criptosisteme cu cheie publică III
 Criptosisteme cu cheie publică III Anul II Aprilie 2017 Problema rucsacului ( knapsack problem ) Considerăm un număr natural V > 0 şi o mulţime finită de numere naturale pozitive {v 0, v 1,..., v k 1 }.
Criptosisteme cu cheie publică III Anul II Aprilie 2017 Problema rucsacului ( knapsack problem ) Considerăm un număr natural V > 0 şi o mulţime finită de numere naturale pozitive {v 0, v 1,..., v k 1 }.
Proiectarea filtrelor prin metoda pierderilor de inserţie
 FITRE DE MIROUNDE Proiectarea filtrelor prin metoda pierderilor de inserţie P R Puterea disponibila de la sursa Puterea livrata sarcinii P inc P Γ ( ) Γ I lo P R ( ) ( ) M ( ) ( ) M N P R M N ( ) ( ) Tipuri
FITRE DE MIROUNDE Proiectarea filtrelor prin metoda pierderilor de inserţie P R Puterea disponibila de la sursa Puterea livrata sarcinii P inc P Γ ( ) Γ I lo P R ( ) ( ) M ( ) ( ) M N P R M N ( ) ( ) Tipuri
Vectori liberi Produs scalar Produs vectorial Produsul mixt. 1 Vectori liberi. 2 Produs scalar. 3 Produs vectorial. 4 Produsul mixt.
 liberi 1 liberi 2 3 4 Segment orientat liberi Fie S spaţiul geometric tridimensional cu axiomele lui Euclid. Orice pereche de puncte din S, notată (A, B) se numeşte segment orientat. Dacă A B, atunci direcţia
liberi 1 liberi 2 3 4 Segment orientat liberi Fie S spaţiul geometric tridimensional cu axiomele lui Euclid. Orice pereche de puncte din S, notată (A, B) se numeşte segment orientat. Dacă A B, atunci direcţia
Componente şi Circuite Electronice Pasive. Laborator 4. Măsurarea parametrilor mărimilor electrice
 Laborator 4 Măsurarea parametrilor mărimilor electrice Obiective: o Semnalul sinusoidal, o Semnalul dreptunghiular, o Semnalul triunghiular, o Generarea diferitelor semnale folosind placa multifuncţională
Laborator 4 Măsurarea parametrilor mărimilor electrice Obiective: o Semnalul sinusoidal, o Semnalul dreptunghiular, o Semnalul triunghiular, o Generarea diferitelor semnale folosind placa multifuncţională
CURS 11: ALGEBRĂ Spaţii liniare euclidiene. Produs scalar real. Spaţiu euclidian. Produs scalar complex. Spaţiu unitar. Noţiunea de normă.
 Sala: 2103 Decembrie 2014 Conf. univ. dr.: Dragoş-Pătru Covei CURS 11: ALGEBRĂ Specializarea: C.E., I.E., S.P.E. Nota: Acest curs nu a fost supus unui proces riguros de recenzare pentru a fi oficial publicat.
Sala: 2103 Decembrie 2014 Conf. univ. dr.: Dragoş-Pătru Covei CURS 11: ALGEBRĂ Specializarea: C.E., I.E., S.P.E. Nota: Acest curs nu a fost supus unui proces riguros de recenzare pentru a fi oficial publicat.
Curs 6 Rețele Neuronale Artificiale
 SISTEME INTELIGENTE DE SUPORT DECIZIONAL Ș.l.dr.ing. Laura-Nicoleta IVANCIU Curs 6 Rețele Neuronale Artificiale Cuprins Principii Bazele biologice Arhitectura RNA Instruire Tipuri de probleme rezolvabile
SISTEME INTELIGENTE DE SUPORT DECIZIONAL Ș.l.dr.ing. Laura-Nicoleta IVANCIU Curs 6 Rețele Neuronale Artificiale Cuprins Principii Bazele biologice Arhitectura RNA Instruire Tipuri de probleme rezolvabile
4. Măsurarea tensiunilor şi a curenţilor electrici. Voltmetre electronice analogice
 4. Măsurarea tensiunilor şi a curenţilor electrici oltmetre electronice analogice oltmetre de curent continuu Ampl.c.c. x FTJ Protectie Atenuator calibrat Atenuatorul calibrat divizor rezistiv R in const.
4. Măsurarea tensiunilor şi a curenţilor electrici oltmetre electronice analogice oltmetre de curent continuu Ampl.c.c. x FTJ Protectie Atenuator calibrat Atenuatorul calibrat divizor rezistiv R in const.
8 Intervale de încredere
 8 Intervale de încredere În cursul anterior am determinat diverse estimări ˆ ale parametrului necunoscut al densităţii unei populaţii, folosind o selecţie 1 a acestei populaţii. În practică, valoarea calculată
8 Intervale de încredere În cursul anterior am determinat diverse estimări ˆ ale parametrului necunoscut al densităţii unei populaţii, folosind o selecţie 1 a acestei populaţii. În practică, valoarea calculată
 11.3 CIRCUITE PENTRU GENERAREA IMPULSURILOR CIRCUITE BASCULANTE Circuitele basculante sunt circuite electronice prevăzute cu o buclă de reacţie pozitivă, folosite la generarea impulsurilor. Aceste circuite
11.3 CIRCUITE PENTRU GENERAREA IMPULSURILOR CIRCUITE BASCULANTE Circuitele basculante sunt circuite electronice prevăzute cu o buclă de reacţie pozitivă, folosite la generarea impulsurilor. Aceste circuite
Examen AG. Student:... Grupa:... ianuarie 2011
 Problema 1. Pentru ce valori ale lui n,m N (n,m 1) graful K n,m este eulerian? Problema 2. Să se construiască o funcţie care să recunoască un graf P 3 -free. La intrare aceasta va primi un graf G = ({1,...,n},E)
Problema 1. Pentru ce valori ale lui n,m N (n,m 1) graful K n,m este eulerian? Problema 2. Să se construiască o funcţie care să recunoască un graf P 3 -free. La intrare aceasta va primi un graf G = ({1,...,n},E)
Spatii liniare. Exemple Subspaţiu liniar Acoperire (înfăşurătoare) liniară. Mulţime infinită liniar independentă
 liniară. Mulţime infinită liniar independentă") Noţiunea de spaţiu liniar 1 Noţiunea de spaţiu liniar Exemple Subspaţiu liniar Acoperire (înfăşurătoare) liniară 2 Mulţime infinită liniar independentă 3 Schimbarea coordonatelor unui vector la o schimbare
Noţiunea de spaţiu liniar 1 Noţiunea de spaţiu liniar Exemple Subspaţiu liniar Acoperire (înfăşurătoare) liniară 2 Mulţime infinită liniar independentă 3 Schimbarea coordonatelor unui vector la o schimbare
Curs 2 Şiruri de numere reale
 Curs 2 Şiruri de numere reale Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Convergenţă şi mărginire Teoremă Orice şir convergent este mărginit. Demonstraţie Fie (x n ) n 0 un
Curs 2 Şiruri de numere reale Facultatea de Hidrotehnică Universitatea Tehnică "Gh. Asachi" Iaşi 2014 Convergenţă şi mărginire Teoremă Orice şir convergent este mărginit. Demonstraţie Fie (x n ) n 0 un
Ecuatii trigonometrice
 Ecuatii trigonometrice Ecuatiile ce contin necunoscute sub semnul functiilor trigonometrice se numesc ecuatii trigonometrice. Cele mai simple ecuatii trigonometrice sunt ecuatiile de tipul sin x = a, cos
Ecuatii trigonometrice Ecuatiile ce contin necunoscute sub semnul functiilor trigonometrice se numesc ecuatii trigonometrice. Cele mai simple ecuatii trigonometrice sunt ecuatiile de tipul sin x = a, cos
* K. toate K. circuitului. portile. Considerând această sumă pentru toate rezistoarele 2. = sl I K I K. toate rez. Pentru o bobină: U * toate I K K 1
 FNCȚ DE ENERGE Fie un n-port care conține numai elemente paive de circuit: rezitoare dipolare, condenatoare dipolare și bobine cuplate. Conform teoremei lui Tellegen n * = * toate toate laturile portile
FNCȚ DE ENERGE Fie un n-port care conține numai elemente paive de circuit: rezitoare dipolare, condenatoare dipolare și bobine cuplate. Conform teoremei lui Tellegen n * = * toate toate laturile portile
2 Transformări liniare între spaţii finit dimensionale
 Transformări 1 Noţiunea de transformare liniară Proprietăţi. Operaţii Nucleul şi imagine Rangul şi defectul unei transformări 2 Matricea unei transformări Relaţia dintre rang şi defect Schimbarea matricei
Transformări 1 Noţiunea de transformare liniară Proprietăţi. Operaţii Nucleul şi imagine Rangul şi defectul unei transformări 2 Matricea unei transformări Relaţia dintre rang şi defect Schimbarea matricei
2. Circuite logice 2.5. Sumatoare şi multiplicatoare. Copyright Paul GASNER
 2. Circuite logice 2.5. Sumatoare şi multiplicatoare Copyright Paul GASNER Adunarea în sistemul binar Adunarea se poate efectua în mod identic ca la adunarea obişnuită cu cifre arabe în sistemul zecimal
2. Circuite logice 2.5. Sumatoare şi multiplicatoare Copyright Paul GASNER Adunarea în sistemul binar Adunarea se poate efectua în mod identic ca la adunarea obişnuită cu cifre arabe în sistemul zecimal
Cursul Măsuri reale. D.Rusu, Teoria măsurii şi integrala Lebesgue 15
 MĂSURI RELE Cursul 13 15 Măsuri reale Fie (,, µ) un spaţiu cu măsură completă şi f : R o funcţie -măsurabilă. Cum am văzut în Teorema 11.29, dacă f are integrală pe, atunci funcţia de mulţime ν : R, ν()
MĂSURI RELE Cursul 13 15 Măsuri reale Fie (,, µ) un spaţiu cu măsură completă şi f : R o funcţie -măsurabilă. Cum am văzut în Teorema 11.29, dacă f are integrală pe, atunci funcţia de mulţime ν : R, ν()
Analiza funcționării și proiectarea unui stabilizator de tensiune continuă realizat cu o diodă Zener
 Analiza funcționării și proiectarea unui stabilizator de tensiune continuă realizat cu o diodă Zener 1 Caracteristica statică a unei diode Zener În cadranul, dioda Zener (DZ) se comportă ca o diodă redresoare
Analiza funcționării și proiectarea unui stabilizator de tensiune continuă realizat cu o diodă Zener 1 Caracteristica statică a unei diode Zener În cadranul, dioda Zener (DZ) se comportă ca o diodă redresoare
a. 11 % b. 12 % c. 13 % d. 14 %
 1. Un motor termic funcţionează după ciclul termodinamic reprezentat în sistemul de coordonate V-T în figura alăturată. Motorul termic utilizează ca substanţă de lucru un mol de gaz ideal având exponentul
1. Un motor termic funcţionează după ciclul termodinamic reprezentat în sistemul de coordonate V-T în figura alăturată. Motorul termic utilizează ca substanţă de lucru un mol de gaz ideal având exponentul
2.1 Sfera. (EGS) ecuaţie care poartă denumirea de ecuaţia generală asferei. (EGS) reprezintă osferă cu centrul în punctul. 2 + p 2
 ecuaţie care poartă denumirea de ecuaţia generală asferei. (EGS) reprezintă osferă cu centrul în punctul. 2 + p 2") .1 Sfera Definitia 1.1 Se numeşte sferă mulţimea tuturor punctelor din spaţiu pentru care distanţa la u punct fi numit centrul sferei este egalăcuunnumăr numit raza sferei. Fie centrul sferei C (a, b,
.1 Sfera Definitia 1.1 Se numeşte sferă mulţimea tuturor punctelor din spaţiu pentru care distanţa la u punct fi numit centrul sferei este egalăcuunnumăr numit raza sferei. Fie centrul sferei C (a, b,
Modelare fuzzy. Problematica modelarii Sisteme fuzzy in modelare Procedura de modelare ANFIS Clasificare substractiva. Modelare fuzzy. G.
 Modelare fuzzy Problematica modelarii Sisteme fuzzy in modelare Procedura de modelare ANFIS Clasificare substractiva 1 /13 Problematica modelarii Estimarea unei funcţii necunoscute pe baza unor eşantioane
Modelare fuzzy Problematica modelarii Sisteme fuzzy in modelare Procedura de modelare ANFIS Clasificare substractiva 1 /13 Problematica modelarii Estimarea unei funcţii necunoscute pe baza unor eşantioane
Subiecte Clasa a V-a
 (40 de intrebari) Puteti folosi spatiile goale ca ciorna. Nu este de ajuns sa alegeti raspunsul corect pe brosura de subiecte, ele trebuie completate pe foaia de raspuns in dreptul numarului intrebarii
(40 de intrebari) Puteti folosi spatiile goale ca ciorna. Nu este de ajuns sa alegeti raspunsul corect pe brosura de subiecte, ele trebuie completate pe foaia de raspuns in dreptul numarului intrebarii
Erori si incertitudini de măsurare. Modele matematice Instrument: proiectare, fabricaţie, Interacţiune măsurand instrument:
 Erori i incertitudini de măurare Sure: Modele matematice Intrument: proiectare, fabricaţie, Interacţiune măurandintrument: (tranfer informaţie tranfer energie) Influente externe: temperatura, preiune,
Erori i incertitudini de măurare Sure: Modele matematice Intrument: proiectare, fabricaţie, Interacţiune măurandintrument: (tranfer informaţie tranfer energie) Influente externe: temperatura, preiune,
Aparate de măsurat. Măsurări electronice Rezumatul cursului 2. MEE - prof. dr. ing. Ioan D. Oltean 1
 Aparate de măsurat Măsurări electronice Rezumatul cursului 2 MEE - prof. dr. ing. Ioan D. Oltean 1 1. Aparate cu instrument magnetoelectric 2. Ampermetre şi voltmetre 3. Ohmetre cu instrument magnetoelectric
Aparate de măsurat Măsurări electronice Rezumatul cursului 2 MEE - prof. dr. ing. Ioan D. Oltean 1 1. Aparate cu instrument magnetoelectric 2. Ampermetre şi voltmetre 3. Ohmetre cu instrument magnetoelectric
z a + c 0 + c 1 (z a)
") 1 Serii Laurent (continuare) Teorema 1.1 Fie D C un domeniu, a D şi f : D \ {a} C o funcţie olomorfă. Punctul a este pol multiplu de ordin p al lui f dacă şi numai dacă dezvoltarea în serie Laurent a funcţiei
1 Serii Laurent (continuare) Teorema 1.1 Fie D C un domeniu, a D şi f : D \ {a} C o funcţie olomorfă. Punctul a este pol multiplu de ordin p al lui f dacă şi numai dacă dezvoltarea în serie Laurent a funcţiei
Proiectarea Algoritmilor 2. Scheme de algoritmi Divide & Impera
 Platformă de e-learning și curriculă e-content pentru învățământul superior tehnic Proiectarea Algoritmilor 2. Scheme de algoritmi Divide & Impera Cuprins Scheme de algoritmi Divide et impera Exemplificare
Platformă de e-learning și curriculă e-content pentru învățământul superior tehnic Proiectarea Algoritmilor 2. Scheme de algoritmi Divide & Impera Cuprins Scheme de algoritmi Divide et impera Exemplificare
Seminar Algebra. det(a λi 3 ) = 0
 = 0") Rezolvari ale unor probleme propuse "Matematica const în a dovedi ceea ce este evident în cel mai puµin evident mod." George Polya P/Seminar Valori si vectori proprii : Solutie: ( ) a) A = Valorile proprii:
Rezolvari ale unor probleme propuse "Matematica const în a dovedi ceea ce este evident în cel mai puµin evident mod." George Polya P/Seminar Valori si vectori proprii : Solutie: ( ) a) A = Valorile proprii:
LUCRAREA NR. 1 STUDIUL SURSELOR DE CURENT
 LUCAEA N STUDUL SUSELO DE CUENT Scopul lucrării În această lucrare se studiază prin simulare o serie de surse de curent utilizate în cadrul circuitelor integrate analogice: sursa de curent standard, sursa
LUCAEA N STUDUL SUSELO DE CUENT Scopul lucrării În această lucrare se studiază prin simulare o serie de surse de curent utilizate în cadrul circuitelor integrate analogice: sursa de curent standard, sursa
TEMA 9: FUNCȚII DE MAI MULTE VARIABILE. Obiective:
 TEMA 9: FUNCȚII DE MAI MULTE VARIABILE 77 TEMA 9: FUNCȚII DE MAI MULTE VARIABILE Obiective: Deiirea pricipalelor proprietăţi matematice ale ucţiilor de mai multe variabile Aalia ucţiilor de utilitate şi
TEMA 9: FUNCȚII DE MAI MULTE VARIABILE 77 TEMA 9: FUNCȚII DE MAI MULTE VARIABILE Obiective: Deiirea pricipalelor proprietăţi matematice ale ucţiilor de mai multe variabile Aalia ucţiilor de utilitate şi
Valori limită privind SO2, NOx şi emisiile de praf rezultate din operarea LPC în funcţie de diferite tipuri de combustibili
 Anexa 2.6.2-1 SO2, NOx şi de praf rezultate din operarea LPC în funcţie de diferite tipuri de combustibili de bioxid de sulf combustibil solid (mg/nm 3 ), conţinut de O 2 de 6% în gazele de ardere, pentru
Anexa 2.6.2-1 SO2, NOx şi de praf rezultate din operarea LPC în funcţie de diferite tipuri de combustibili de bioxid de sulf combustibil solid (mg/nm 3 ), conţinut de O 2 de 6% în gazele de ardere, pentru
CONCURSUL DE MATEMATICĂ APLICATĂ ADOLF HAIMOVICI, 2017 ETAPA LOCALĂ, HUNEDOARA Clasa a IX-a profil științe ale naturii, tehnologic, servicii
 Clasa a IX-a 1 x 1 a) Demonstrați inegalitatea 1, x (0, 1) x x b) Demonstrați că, dacă a 1, a,, a n (0, 1) astfel încât a 1 +a + +a n = 1, atunci: a +a 3 + +a n a1 +a 3 + +a n a1 +a + +a n 1 + + + < 1
Clasa a IX-a 1 x 1 a) Demonstrați inegalitatea 1, x (0, 1) x x b) Demonstrați că, dacă a 1, a,, a n (0, 1) astfel încât a 1 +a + +a n = 1, atunci: a +a 3 + +a n a1 +a 3 + +a n a1 +a + +a n 1 + + + < 1
Exemple de probleme rezolvate pentru cursurile DEEA Tranzistoare bipolare cu joncţiuni
 Problema 1. Se dă circuitul de mai jos pentru care se cunosc: VCC10[V], 470[kΩ], RC2,7[kΩ]. Tranzistorul bipolar cu joncţiuni (TBJ) este de tipul BC170 şi are parametrii β100 şi VBE0,6[V]. 1. să se determine
Problema 1. Se dă circuitul de mai jos pentru care se cunosc: VCC10[V], 470[kΩ], RC2,7[kΩ]. Tranzistorul bipolar cu joncţiuni (TBJ) este de tipul BC170 şi are parametrii β100 şi VBE0,6[V]. 1. să se determine
EDITURA PARALELA 45 MATEMATICĂ DE EXCELENŢĂ. Clasa a X-a Ediţia a II-a, revizuită. pentru concursuri, olimpiade şi centre de excelenţă
 Coordonatori DANA HEUBERGER NICOLAE MUŞUROIA Nicolae Muşuroia Gheorghe Boroica Vasile Pop Dana Heuberger Florin Bojor MATEMATICĂ DE EXCELENŢĂ pentru concursuri, olimpiade şi centre de excelenţă Clasa a
Coordonatori DANA HEUBERGER NICOLAE MUŞUROIA Nicolae Muşuroia Gheorghe Boroica Vasile Pop Dana Heuberger Florin Bojor MATEMATICĂ DE EXCELENŢĂ pentru concursuri, olimpiade şi centre de excelenţă Clasa a
CURS 8: METODE DE OPTIMIZARE PARAMETRICĂ
 CURS 8: METODE DE OPTIMIZARE PARAMETRICĂ Problemele de optimizare vizează extremizarea (maximizarea sau minimizarea) unui criteriu de performanţă. Acesta din urmă poate fi o funcţie caz în care este vorba
CURS 8: METODE DE OPTIMIZARE PARAMETRICĂ Problemele de optimizare vizează extremizarea (maximizarea sau minimizarea) unui criteriu de performanţă. Acesta din urmă poate fi o funcţie caz în care este vorba