Οικονοµικό Πανεπιστήµιο Αθηνών. ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ «Ανάπτυξη φίλτρου διήθησης ηλεκτρονικής αλληλογραφίας για το Mozilla Thunderbird» ηµήτρης Μπόχτης
|
|
|
- Μελίτη Φλέσσας
- 9 χρόνια πριν
- Προβολές:
Transcript
1 Οικονοµικό Πανεπιστήµιο Αθηνών ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ «Ανάπτυξη φίλτρου διήθησης ηλεκτρονικής αλληλογραφίας για το Mozlla Thunderbrd» ηµήτρης Μπόχτης Επιβλέπων: Ίων Ανδρουτσόπουλος ΑΘΗΝΑ, ΟΚΤΩΒΡΙΟΣ 2007

2 Περιεχόµενα 1. Εισαγωγή Ευχαριστίες 5 2. Θεωρητική Περιγραφή Συστήµατος Προσέγγιση Nave Bayes Το προϋπάρχον φίλτρο του Thunderbrd Αueb Spam Flter Extenson Πολυµεταβλητή µορφή Bernoull του απλοϊκού ταξινοµητή Nave Bayes Πολυωνυµικός απλοϊκός ταξινοµητής Bayes Λευκές Λίστες Αποδείξεις Ανθρώπινης Αλληλεπίδρασης Πειραµατική Προσέγγιση Συγκρίσεις Περιγραφή πειραµατικής µεθόδου Πειραµατικά αποτελέσµατα Επίλογος Βιβλιογραφία 22 2

3 Περίληψη Στην παρούσα εργασία αναπτύχθηκε ένα φίλτρο ανεπιθύµητης ηλεκτρονικής αλληλογραφίας (spam flter) που ενσωµατώθηκε στο πρόγραµµα ανάγνωσης ηλεκτρονικής αλληλογραφίας Mozlla Thunderbrd. Το φίλτρο χρησιµοποιεί µια βιβλιοθήκη λογισµικού που είχε αναπτυχθεί σε προηγούµενη εργασία, η οποία παρέχει υλοποιήσεις πολλών παραλλαγών του απλοϊκού ταξινοµητή Bayes (Naïve Bayes) και µηχανισµούς εφαρµογής τους σε µηνύµατα ηλεκτρονικού ταχυδροµείου. Το φίλτρο της παρούσας εργασίας υποστηρίζει, επίσης, αποδείξεις ανθρώπινης αλληλεπίδρασης (human nteracton proofs HIPs). ιατίθεται ελεύθερα ως λογισµικό ανοικτού πηγαίου κώδικα, όπως και το ίδιο το Mozlla Thunderbrd. Πειράµατα που διεξήχθησαν στη διάρκεια της εργασίας έδειξαν ότι το φίλτρο που αναπτύχθηκε επιτυγχάνει καλύτερα αποτελέσµατα από το ενσωµατωµένο φίλτρο ανεπιθύµητης αλληλογραφίας που παρέχει ήδη το Mozlla Thunderbrd. 3

4 1. Εισαγωγή Το ηλεκτρονικό ταχυδροµείο αποτελεί µια από τις σηµαντικότερες υπηρεσίες που προσφέρει το διαδίκτυο. Το κυριότερο ίσως πλεονέκτηµα της υπηρεσίας είναι ότι παρέχεται δωρεάν, αν εξαιρέσει κανείς τη χρέωση πρόσβασης στο διαδίκτυο. Η έλλειψη χρέωσης, όµως, είναι και η πηγή του προβλήµατος της ανεπιθύµητης ηλεκτρονικής αλληλογραφίας (spam): καθότι δωρεάν, πολλοί χρησιµοποιούν το ηλεκτρονικό ταχυδροµείο για να αποστέλλουν διαφηµιστικά και συνήθως ανεπιθύµητα µηνύµατα σε χιλιάδες ή εκατοµµύρια χρήστες. Υπολογίζεται ότι τα ανεπιθύµητα αυτά µηνύµατα αποτελούν περίπου το 60% της διακινούµενης ηλεκτρονικής αλληλογραφίας. Τα ανεπιθύµητα µηνύµατα ηλεκτρονικού ταχυδροµείου σπαταλούν τους πόρους του διαδικτύου αλλά και το το χρόνο των χρηστών, αφού τους υποχρεώνουν να τα αφαιρούν χειρωνακτικά από τα εισερχόµενα µηνύµατά τους. Η αντιµετώπιση του προβλήµατος, που πλέον έχει λάβει διαστάσεις επιδηµίας, αποτελεί στόχο πολλών ερευνητών και εταιρειών. Μια από τις πιο επιτυχηµένες µεθόδους που έχουν προταθεί είναι η χρήση προγραµµάτων αυτόµατης ταξινόµησης µηνυµάτων σε κατηγορίες, που χρησιµοποιούν συνήθως αλγορίθµους µηχανικής µάθησης. Στην προκειµένη περίπτωση, τα προγράµµατα αυτά χρησιµοποιούνται ως φίλτρα που ταξινοµούν τα εισερχόµενα µηνύµατα ως επιθυµητά (ham) ή ανεπιθύµητα (spam), αφού εκπαιδευθούν σε παλαιότερα µηνύµατα που έχουν ταξινοµηθεί χειρωνακτικά. Στην παρούσα εργασία κατασκευάσαµε ένα τέτοιο φίλτρο, το οποίο ενσωµατώθηκε στο πρόγραµµα ανάγνωσης ηλεκτρονικής αλληλογραφίας Mozlla Thunderbrd. 1 Το φίλτρο χρησιµοποιεί µια βιβλιοθήκη λογισµικού που είχε αναπτυχθεί σε προηγούµενη εργασία, η οποία παρέχει υλοποιήσεις πολλών παραλλαγών του απλοϊκού ταξινοµητή Bayes (Naïve Bayes) και µηχανισµούς εφαρµογής τους σε µηνύµατα ηλεκτρονικού ταχυδροµείου. Το φίλτρο της παρούσας εργασίας υποστηρίζει, επίσης, αποδείξεις ανθρώπινης αλληλεπίδρασης (human nteracton proofs HIPs), µια προσέγγιση στην οποία οι αποστολείς καλούνται να λύσουν απλούς γρίφους που απαιτούν, όµως, ανθρώπινη νοηµοσύνη, προκειµένου να αποκλειστούν συστήµατα αυτόµατης µαζικής αποστολής ανεπιθύµητων µηνυµάτων [4]. Το φίλτρο της εργασίας, που ονοµάζεται AUEB Spam Flter, διατίθεται ελεύθερα ως λογισµικό ανοικτού πηγαίου κώδικα, όπως και το ίδιο το Mozlla Thunderbrd. 1 Βλ. 4

5 Στο επόµενο, το δεύτερο, κεφάλαιο της εργασίας παρουσιάζεται αρχικά η γενική µορφή των απλοϊκών ταξινοµητών Bayes και ο τρόπος χρήσης τους κατά την κατάταξη µηνυµάτων. Παρέχονται επίσης παραποµπές προς εργασίες που εξηγούν τον τρόπο λειτουργίας του φίλτρου που διαθέτει ήδη το Thunderbrd. 2 Στη συνέχεια παρουσιάζονται αναλυτικότερα οι παραλλαγές των απλοϊκών ταξινοµητών Bayes που υποστηρίζει το φίλτρο της εργασίας, καθώς και ο πρόσθετος µηχανισµός αποδείξεων ανθρώπινης αλληλεπίδρασης που επίσης παρέχει το φίλτρο. Στο τρίτο κεφάλαιο παρουσιάζονται τα πειράµατα που διεξήχθησαν προκειµένου να συγκριθεί το φίλτρο της εργασίας µε το προϋπάρχον φίλτρο του Thunderbrd, καθώς και τα αποτελέσµατά τους. Τέλος, στο τέταρτο κεφάλαιο συνοψίζεται η εργασία και προτείνονται πιθανές µελλοντικές προεκτάσεις της. 1.1 Ευχαριστίες Θα ήθελα να ευχαριστήσω ιδιαίτερα τον επιβλέποντα καθηγητή της εργασίας µου κύριο Ίωνα Ανδρουτσόπουλο, για την εµπιστοσύνη που µου έδειξε αναθέτοντάς µου αυτή την εργασία, για την καθοδήγησή του καθ όλη τη διάρκειά της και κυρίως για την ευκαιρία που µου έδωσε να ασχοληθώ µε ένα ενδιαφέρον αντικείµενο. Επίσης, θα ήθελα να ευχαριστήσω τον Άρη Κοσµόπουλο για την αµέριστη βοήθειά του στα πειράµατα της εργασίας, αλλά και για την παροχή της βιβλιοθήκης της εργασίας του. 2 Βλ

6 2. Θεωρητική Περιγραφή του Συστήµατος Στο παρόν κεφάλαιο θα περιγράψουµε αρχικά τη γενική µορφή των απλοϊκών ταξινοµητών Bayes και τον τρόπο χρήσης τους κατά την κατάταξη µηνυµάτων. Κατόπιν θα περιγράψουµε τον τρόπο λειτουργίας του φίλτρου που διαθέτει ήδη το Thunderbrd. Στη συνέχεια θα παρουσιάσουµε αναλυτικότερα τις παραλλαγές των απλοϊκών ταξινοµητών Bayes που υποστηρίζει το φίλτρο της εργασίας, καθώς και τον πρόσθετο µηχανισµό αποδείξεων ανθρώπινης αλληλεπίδρασης που επίσης παρέχει το φίλτρο. 2.1 Οι απλοϊκοί ταξινοµητές Bayes ως φίλτρα µηνυµάτων Τα φίλτρα που βασίζονται στους απλοϊκούς ταξινοµητές Bayes (Naïve Bayes, r NB) παριστάνουν κάθε µήνυµα ως ένα διάνυσµα x = ( x1, x2, x3,..., x n ), όπου τα χαρακτηριστικά (features) x 1, x n αντιστοιχούν το καθένα σε µια διαφορετική λέξη. Στην απλούστερη περίπτωση, τα χαρακτηριστικά δείχνουν αν είναι οι αντίστοιχες λέξεις εµφανίζονται (τιµή 1) ή όχι (τιµή 0) στο κείµενο του µηνύµατος. Εναλλακτικά, οι τιµές των χαρακτηριστικών µπορεί να είναι οι συχνότητες εµφάνισης των λέξεων στο µήνυµα, πιθανώς κανονικοποιηµένες µε τρόπους που θα εξετάσουµε αργότερα. Η επιλογή των λέξεων για τις οποίες θα υπάρχουν χαρακτηριστικά στα διανύσµατα µπορεί να γίνει µε µεθόδους επιλογής χαρακτηριστικών (feature selecton), όπως για παράδειγµα µε το µέτρο του πληροφοριακού κέρδους (nformaton gan), ή απλούστερα εισάγοντας στα διανύσµατα ένα χαρακτηριστικό για κάθε λέξη που εµφανίζεται τουλάχιστον π.χ. 5 φορές στα µηνύµατα εκπαίδευσης. Χρησιµοποιώντας το θεώρηµα του Bayes [2], η πιθανότητα να ανήκει ένα µήνυµα µε διάνυσµα x r στην κατηγορία c (όπου c η κατηγορία spam ή ham) είναι: PC ( = c X= x) = PC ( = c) PX ( = x C= c) k { ham, spam} PC ( = k) PX ( = x C= c) Οι ταξινοµητές NB κάνουν την απλοϊκή παραδοχή πως οι τιµές των χαρακτηριστικών είναι ανεξάρτητες δεδοµένης της κατηγορίας, οπότε ο παραπάνω τύπος γίνεται: 6

7 PC ( = c X= x) = PC ( = c) PX ( = x C= c) k { ham, spam} n = 1 n PC ( = k) PX ( = x C= c) = 1 Τα P(X C) και P(C) είναι δυνατόν να εκτιµηθούν εύκολα από τα δεδοµένα εκπαίδευσης. Αν και στην πραγµατικότητα η παραδοχή ανεξαρτησίας δεν ισχύει, οι ταξινοµητές NB επιτυγχάνουν πολύ καλά αποτελέσµατα. Όλες οι µορφές των ταξινοµητών NB που χρησιµοποιούνται στην παρούσα εργασία κατατάσσουν τα µηνύµατα υπολογίζοντας τις P( spam x) και P( ham x), όπου x το διάνυσµα του υπό κατάταξη µηνύµατος. Ακριβέστερα, υπολογίζουν το λόγο των δύο παραπάνω πιθανοτήτων. Οι παρανοµαστές των δύο πιθανοτήτων είναι ίδιοι, οπότε αγνοούνται. Χρησιµοποιώντας λογαρίθµους, ο λόγος γίνεται διαφορά: [log( P( spam)) + log( P( x spam))] [log( P( ham)) + log( P( x ham))] και µε την παραδοχή ανεξαρτησίας: n [log( P( spam)) + log( P( x spam))] [log( P( ham)) + log( P( x ham))] = 1 = 1 Αν η παραπάνω διαφορά υπερβαίνει ένα κατώφλι δ, τότε το µήνυµα κατατάσσεται ως ανεπιθύµητο, διαφορετικά ως επιθυµητό. n 2.2 Το προϋπάρχον φίλτρο του Thunderbrd Το προϋπάρχον φίλτρο του Thunderbrd αποτελεί υλοποίηση του συστήµατος SpamBayes [1] στο περιβάλλον ανάπτυξης του Mozlla. 3 Το SpamBayes ακολούθησε αρχικά, όπως και πολλά άλλα φίλτρα, την προσέγγιση του Paul Graham, η οποία είναι παρόµοια µε τους ταξινοµητές NB, αλλά εµπεριέχει αρκετές, αµφισβητήσιµες από µαθηµατικής σκοπιάς, µετατροπές, καθώς και παραµέτρους των οποίων οι τιµές δεν είναι εύκολο να επιλεγούν. 4 Ένα πρόβληµα της προσέγγισης του Paul Graham, αλλά και πολλών από τις παραλλαγές των ταξινοµητών NB, είναι πως οι πιθανότητες που επιστρέφουν παρουσιάζουν πολύ ακραίες τιµές, µε αποτέλεσµα το φίλτρο να 3 Βλ. 4 Βλ. 7

8 εµφανίζεται συνήθως εξαιρετικά βέβαιο για τις αποφάσεις του, ακόµα και όταν παίρνει λάθος αποφάσεις. Προκειµένου να αντιµετωπιστούν τα προβλήµατα αυτά, το SpamBayes βασίστηκε στη συνέχεια στην προσέγγιση του Gary Robnson Το φίλτρο της εργασίας Η ανάπτυξη του φίλτρου της εργασίας έγινε σε C++ και JavaScrpt, σύµφωνα µε τα πρότυπα ανάπτυξης του Mozlla Development Center. To φίλτρο χρησιµοποιεί δύο βασικές µορφές απλοϊκών ταξινοµητών Bayes (ΝΒ) [2]: την πολυµεταβλητή µορφή Bernoull (Multvarate Bernoull NB) και την πολυωνυµική µορφή (Multnomal NB). Η πολυωνυµική µορφή NB υλοποιήθηκε σε τρεις παραλλαγές: (α) µε δυαδικά χαρακτηριστικά, (β) µε χαρακτηριστικά που αντιστοιχούν σε συχνότητες (term frequences, TF) και (γ) µε χαρακτηριστικά που αντιστοιχούν σε µετασχηµατισµένες συχνότητες [3]. Ο µετασχηµατισµός της περίπτωσης (γ) περιγράφεται παρακάτω Πολυµεταβλητή µορφή Bernoull του απλοϊκού ταξινοµητή Bayes Στην πολυµεταβλητή µορφή Bernoull [2], κάθε µήνυµα παριστάνεται από ένα δυαδικό διάνυσµα της µορφής x =< x1, x2,..., x n >, όπου x {0,1}. Κάθε χαρακτηριστικό x αντιστοιχεί σε µια διαφορετική λεκτική µονάδα (token) και δείχνει αν η λεκτική µονάδα εµφανίζεται (τιµή 1) ή όχι (τιµή 0) στο µήνυµα. Υποθέτουµε ότι κάθε µήνυµα κατηγορίας c είναι το αποτέλεσµα n ανεξάρτητων δοκιµών Bernoull, κατά τις οποίες καθορίζεται αν η λεκτική µονάδα t, που αντιστοιχεί στο χαρακτηριστικό x, εµφανίζεται ή όχι στο µήνυµα. Η υπόθεση ανεξαρτησίας δεν ισχύει στην πραγµατικότητα, αλλά παρ όλα αυτά τα αποτελέσµατα του ταξινοµητή είναι συχνά ικανοποιητικά. Με τις παραπάνω υποθέσεις, η πιθανότητα Pxc ( ) (βλ. ενότητα 2.1) γίνεται: n x Pxc ( ) = Pt ( c) (1 Pt ( c)) = 1 1 x 5 Βλ. και 8
 [2]: την πολυµεταβλητή µορφή Bernoull (Multvarate Bernoull NB) και την πολυωνυµική µορφή (Multnomal NB).")
9 Οι πιθανότητες P(t c) εκτιµώνται ως ακολούθως. Οι σταθεροί όροι στον αριθµητή και τον παρανοµαστή προστίθενται για να αποφεύγονται οι µηδενικές εκτιµήσεις. 1+ M P( t c) = 2 + M t, c c όπου: M, : ο αριθµός των µηνυµάτων της κατηγορίας c που εµπεριέχουν την t. t c M c : ο αριθµός των µηνυµάτων της κατηγορίας c Πολυωνυµικός απλοϊκός ταξινοµητής Bayes Μορφή 1 : Με δυαδικές ιδιότητες Σε αυτή τη µορφή, χρησιµοποιούνται πάλι δυαδικά διανύσµατα, όπως ακριβώς στην προηγούµενη µορφή, αλλά οι πιθανότητες p(t c) εκτιµώνται ως εξής: 1 N Pt ( c) = + n + N tc, c όπου N, ο αριθµός εµφανίσεων του token t στα µηνύµατα της κατηγορίας c και t c N c το άθροισµα των n διαφορετικών N,. Άλλη µια διαφορά εντοπίζεται στον τύπο t c υπολογισµού του Pxc ( ): δεν λαµβάνονται τώρα υπόψη οι λεκτικές µονάδες που απουσιάζουν από το µήνυµα, µε αποτέλεσµα ο όρος 1 x ( 1 p( t c)) να απαλείφεται. Το πώς προκύπτουν αυτοί οι τύποι εξηγείται στην εργασία [2]. Μορφή 2: Με χαρακτηριστικά TF Στη µορφή αυτή, οι τιµές x των διανυσµάτων δείχνουν πόσες φορές εµφανίζονται οι αντίστοιχες λεκτικές µονάδες στο µήνυµα. Η πιθανότητα Pxc ( ) υπολογίζεται πάλι ως n = 1 x p( t c ). Οι πιθανότητες P(t c) υπολογίζονται επίσης s όπως στην προηγούµενη µορφή. Και πάλι, το πώς προκύπτουν αυτοί οι τύποι εξηγείται στην εργασία [2]. 9
 = + n + N tc, c όπου N, ο αριθµός εµφανίσεων του token t στα µηνύµατα της κατηγορίας c και t c N c το άθροισµα των n διαφορετικών N,.")
10 Μορφή 3: Με µετασχηµατισµένες ιδιότητες TF Ο υπολογισµός του Pxc ( ) γίνεται όπως ακριβώς στην προηγούµενη µορφή. Οι τιµές x των διανυσµάτων, όµως, δεν δείχνουν τώρα απευθείας πόσες φορές εµφανίζονται οι αντίστοιχες λεκτικές µονάδες στο µήνυµα (term frequences, TF), αλλά υφίστανται τον παρακάτω µετασχηµατισµό [3]. Πρώτα λογαριθµίζεται το άθροισµα της τιµής TF µε την µονάδα. Η µονάδα προστίθεται για να µην προκύπτουν µηδενικά ορίσµατα στο λογάριθµο, ενώ ο λογάριθµος χρησιµοποιείται προκειµένου να αντιµετωπιστεί το πρόβληµα ότι οι κατανοµές των λεκτικών µονάδων στα µηνύµατα δεν ακολουθούν πολυωνυµική κατανοµή (βλ. εργασία [3] για περισσότερες εξηγήσεις). Έπειτα πολλαπλασιάζουµε το αποτέλεσµα µε τον παράγοντα log k 1 k δ k, που εκφράζει την ανάστροφη συχνότητα εγγράφων (nverse document frequency, IDF) της λεκτικής µονάδας στην οποία αντιστοιχεί το χαρακτηριστικό x. Το k είναι δείκτης προς κάθε ένα µήνυµα εκπαίδευσης και το δ k είναι 1 αν η λεκτική µονάδα που αντιστοιχεί στο χαρακτηριστικό x εµφανίζεται στο µήνυµα j ή 0 αν δεν εµφανίζεται. Οι τιµές IDF χρησιµοποιούνται προκειµένου να αυξηθούν τα βάρη των πιο σπάνιων λεκτικών µονάδων [3]. 2 Τέλος διαιρούµε το έως τώρα αποτέλεσµα µε την τιµή ( d ), όπου d οι µετασχηµατισµένες τιµές των χαρακτηριστικών (για το συγκεκριµένο µήνυµα) που έχουν προκύψει µέχρι και το προηγούµενο βήµα Λευκές λίστες Το φίλτρο που αναπτύχθηκε κατά τη διάρκεια της εργασίας υποστηρίζει και λευκές λίστες (whte-lstng). Η λευκή λίστα κάθε χρήστη περιέχει όλες τις διευθύνσεις που περιλαµβάνονται στο βιβλίο διευθύνσεών του (address book). Όταν η χρήση λευκής λίστας είναι ενεργοποιηµένη, τα εισερχόµενα µηνύµατα που προέρχονται από διευθύνσεις τις λίστας κατατάσσονται άµεσα ως επιθυµητά, χωρίς να εφαρµόζεται σε αυτά το φίλτρο του απλοϊκού ταξινοµητή Bayes. 10
![[3]. Πρώτα λογαριθµίζεται το άθροισµα της τιµής TF µε την µονάδα.](/docs-images/47/3379163/images/page_10.jpg "Η µονάδα προστίθεται για να µην προκύπτουν µηδενικά ορίσµατα στο λογάριθµο, ενώ ο λογάριθµος χρησιµοποιείται προκειµένου να αντιµετωπιστεί το πρόβληµα ότι οι κατανοµές των λεκτικών µονάδων στα")
11 2.3.4 Αποδείξεις ανθρώπινης αλληλεπίδρασης Όπως προαναφέρθηκε, το φίλτρο της εργασίας υποστηρίζει επίσης αποδείξεις ανθρώπινης αλληλεπίδρασης (Human Interactve Proofs, HIPs) [4]. Όταν είναι ενεργοποιηµένος ο µηχανισµός HIPs του φίλτρου, όποτε ένα µήνυµα κατατάσσεται ως ανεπιθύµητο, το φίλτρο ζητά από τον αποστολέα να απαντήσει σε µια προκαθορισµένη εύκολη ερώτηση φυσικής γλώσσας που έχει ορίσει ο παραλήπτης (π.χ. «Ποια είναι η πρωτεύσουσα της Ελλάδας;» ο παραλήπτης µπορεί να αλλάζει περιοδικά την ερώτησή του). Αν ο αποστολέας απαντήσει ορθά µέσα σε ένα εύλογο χρονικό διάστηµα, το µήνυµα, που προηγουµένως είχε καταταγεί ως ανεπιθύµητο, κατατάσσεται ως επιθυµητό και η διεύθυνση του αποστολέα προστίθεται στη λευκή λίστα του παραλήπτη. Ο µηχανισµός αυτός βασίζεται στην υπόθεση πως οι αποστολείς ανεπιθύµητων διαφηµιστικών µηνυµάτων δεν µπορούν να απαντήσουν σε διαφορετικούς ανά χρήστη γρίφους που απαιτούν ανθρώπινη νοηµοσύνη, εξαιτίας του όγκου των µηνυµάτων που αποστέλλουν και άρα και του µεγάλου αριθµού γρίφων που θα δέχονται. Τονίζεται ότι ο µηχανισµός αυτός βρίσκεται σε δοκιµαστικό στάδιο και δεν θα πρέπει να χρησιµοποιείται ακόµη στην πράξη. Ένα σηµαντικό πρόβληµά του είναι πως οι αποστολείς ανεπιθύµητων µηνυµάτων ενδέχεται να αρχίσουν να στέλνουν µηνύµατα χρησιµοποιώντας ως διευθύνσεις αποστολέων τις διευθύνσεις υπαρκτών, αθώων χρηστών του διαδικτύου. Αυτό θα έχει ως αποτέλεσµα οι γρίφοι να καταλήγουν σε άσχετους χρήστες, ουσιαστικά επιτείνοντας το πρόβληµα της ανεπιθύµητης αλληλογραφίας. Το πρόβληµα αυτό ενδέχεται να λυθεί στο µέλλον, αν διαδοθεί ευρέως η χρήση µηχανισµών πιστοποίησης αποστολέα (DKIM, SenderID). 6 Ένα άλλο πρόβληµα είναι πως στο φίλτρο της εργασίας η αποστολή των γρίφων και των απαντήσεών τους γίνεται και αυτή µέσω ηλεκτρονικού ταχυδροµείου, µε αποτέλεσµα να είναι δυνατόν ένας γρίφος ή η απάντησή του να θεωρηθεί από άλλο φίλτρο ανεπιθύµητο µήνυµα και να µην παραδοθεί. 6 Βλ. και 11

12 3 Πειραµατική Προσέγγιση Συγκρίσεις Σε αυτό το κεφάλαιο θα παρουσιάσουµε τα αποτελέσµατα των πειραµάτων µε τις διαφορετικές µορφές του απλοϊκού ταξινοµητή Bayes που εκτελέσθηκαν στη διάρκεια της εργασία, καθώς και τα συµπεράσµατα που προκύπτουν από αυτά. 3.1 Περιγραφή Πειραµατικής Μεθόδου Στα πειράµατα της παρούσας εργασίας χρησιµοποιήθηκε το σύνολο µηνυµάτων Enron-Spam [2], που περιέχει επιθυµητά και ανεπιθύµητα µηνύµατα έξι ψευδο-χρηστών. Η συλλογή αυτή χρησιµοποιήθηκε και στην εργασία [5], κάτι που καθιστά εφικτή τη σύγκριση και σύνθεση των αποτελεσµάτων αυτής της εργασίας και των προηγούµενων. Στα µηνύµατα της παραπάνω συλλογής αξιολογούµε µόνο το σώµα κάθε µηνύµατος, αγνοώντας συνηµµένα αρχεία, ετικέτες HTML και κεφαλίδες (πλην του θέµατος, που προστίθεται στο σώµα). Σύµφωνα µε την εργασία [5], τα καλύτερα αποτελέσµατα επιτυγχάνονται όταν χρησιµοποιούνται όλα τα χαρακτηριστικά, για όλες τις λεκτικές µονάδες, ασχέτως του πληροφοριακού κέρδους που αποκοµίζουµε από αυτά.ακολουθούµε, εποµένως, αυτή την προσέγγιση στα πειράµατά µας. Για την αναπαράσταση των αποτελεσµάτων θα χρησιµοποιηθούν οι καµπύλες ROC, στις οποίες ο κατακόρυφος άξονας παριστάνει το ποσοστό ανάκλησης ανεπιθύµητων µηνυµάτων (Spam Recall, SR), ενώ ο οριζόντιος άξονας το ποσοστό ανάκλησης επιθυµητών µηνυµάτων (Ham Recall, HR). Τα SR και HR αντιστοιχούν στους όρους ευαισθησία (senstvty) και σαφήνεια (specfcty), αντίστοιχα, που συνήθως χρησιµοποιούνται στα διαγράµµατα ROC. Ακριβέστερα, στα παρακάτω διαγράµµατα οι τιµές του οριζόντιου άξονα αντιστοιχούν στο 1 HR. Τα SR και HR ορίζονται ως εξής: TP SR = και TP + FN TN HR = TN + FP όπου TP : true postves, δηλαδή πόσα ανεπιθύµητα µηνύµατα κατετάγησαν σωστά 12
![1 Περιγραφή Πειραµατικής Μεθόδου Στα πειράµατα της παρούσας εργασίας χρησιµοποιήθηκε το σύνολο µηνυµάτων Enron-Spam [2], που περιέχει επιθυµητά και ανεπιθύµητα µηνύµατα έξι ψευδο-χρηστών.](/docs-images/47/3379163/images/page_12.jpg "Η συλλογή αυτή χρησιµοποιήθηκε και στην εργασία [5], κάτι που καθιστά εφικτή τη σύγκριση και σύνθεση των αποτελεσµάτων αυτής της εργασίας και των προηγούµενων.")
13 TN: true negatves, δηλαδή πόσα επιθυµητά µηνύµατα κατετάγησαν σωστά FP: false postve, αριθµός ανεπιθύµητων µηνυµάτων που κατετάγησαν λανθασµένα FN: false negatves, αριθµός επιθυµητών µηνυµάτων που κατετάγησαν λανθασµένα Για να δηµιουργήσουµε τα σηµεία (ζεύγη τιµών SR και HR) στις καµπύλες ROC, επαναλαµβάνουµε τις ταξινοµήσεις των µηνυµάτων αξιολόγησης για διάφορες τιµές του κατωφλίου κατάταξης. Οι καµπύλες που βρίσκονται ψηλότερα αντιστοιχούν στα καλύτερα φίλτρα, αφού τα φίλτρα αυτά εντοπίζουν περισσότερα ανεπιθύµητα µηνύµατα (υψηλότερο SR), ενώ ταυτόχρονα επιτρέπουν στον ίδιο αριθµό επιθυµητών µηνυµάτων (ίδιο HR) να περάσουν το φίλτρο. Όπως στις εργασίες [2] και [5], η αξιολόγηση γίνεται κατά δέσµες χρονικά διατεταγµένων µηνυµάτων (οι δέσµες θα µπορούσαν να αντιστοιχούν π.χ. στα εισερχόµενα µηνύµατα µιας ηµέρας ή εβδοµάδας). Σε κάθε δέσµη µηνυµάτων αξιολόγησης, τα φίλτρα έχουν εκπαιδευθεί στα µηνύµατα των προηγούµενων δεσµών, τα οποία έχουν καταταγεί χειρωνακτικά (υποτίθεται ότι οι χρήστες έχουν διορθώσει τα λάθη των φίλτρων). Στα πειράµατά µας, κάθε δέσµη περιλαµβάνει 100 µηνύµατα, όπως στις εργασίες [2] και [5]. 13
 να περάσουν το φίλτρο. Όπως στις εργασίες [2] και [5], η αξιολόγηση γίνεται κατά δέσµες χρονικά διατεταγµένων µηνυµάτων (οι δέσµες θα µπορούσαν να αντιστοιχούν π.χ. στα εισερχόµενα µηνύµατα µιας ηµέρας ή εβδοµάδας).")
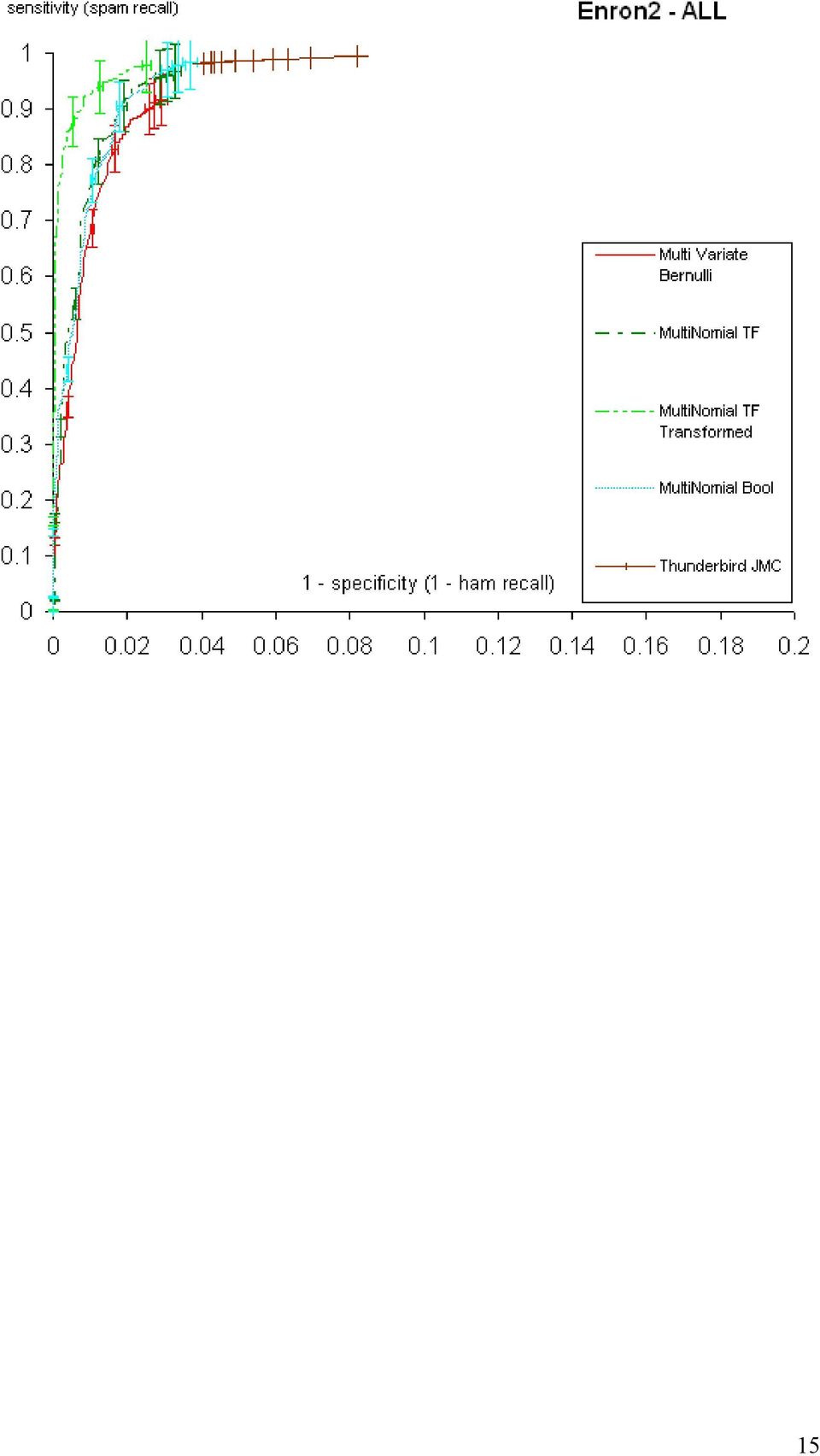
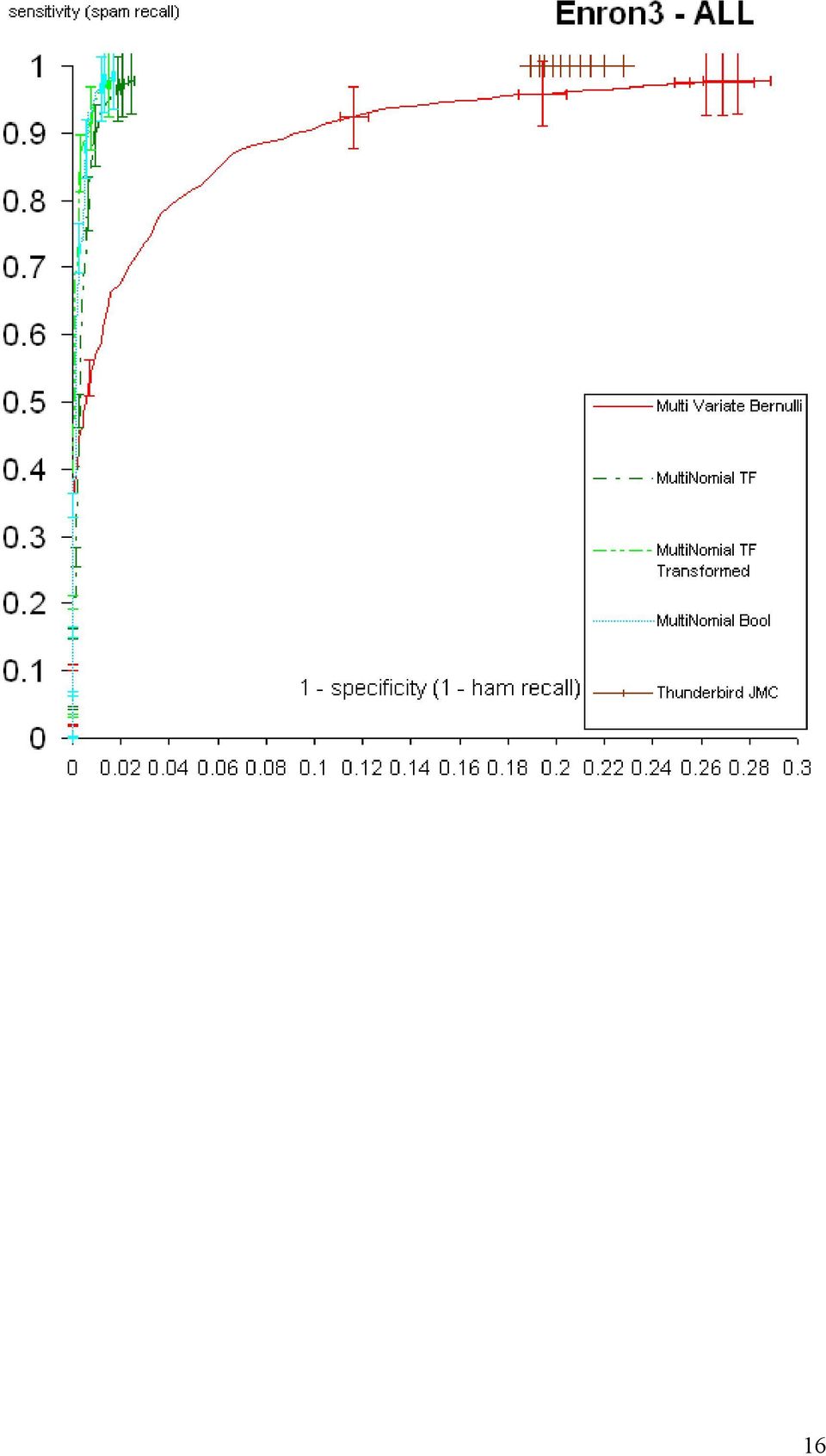
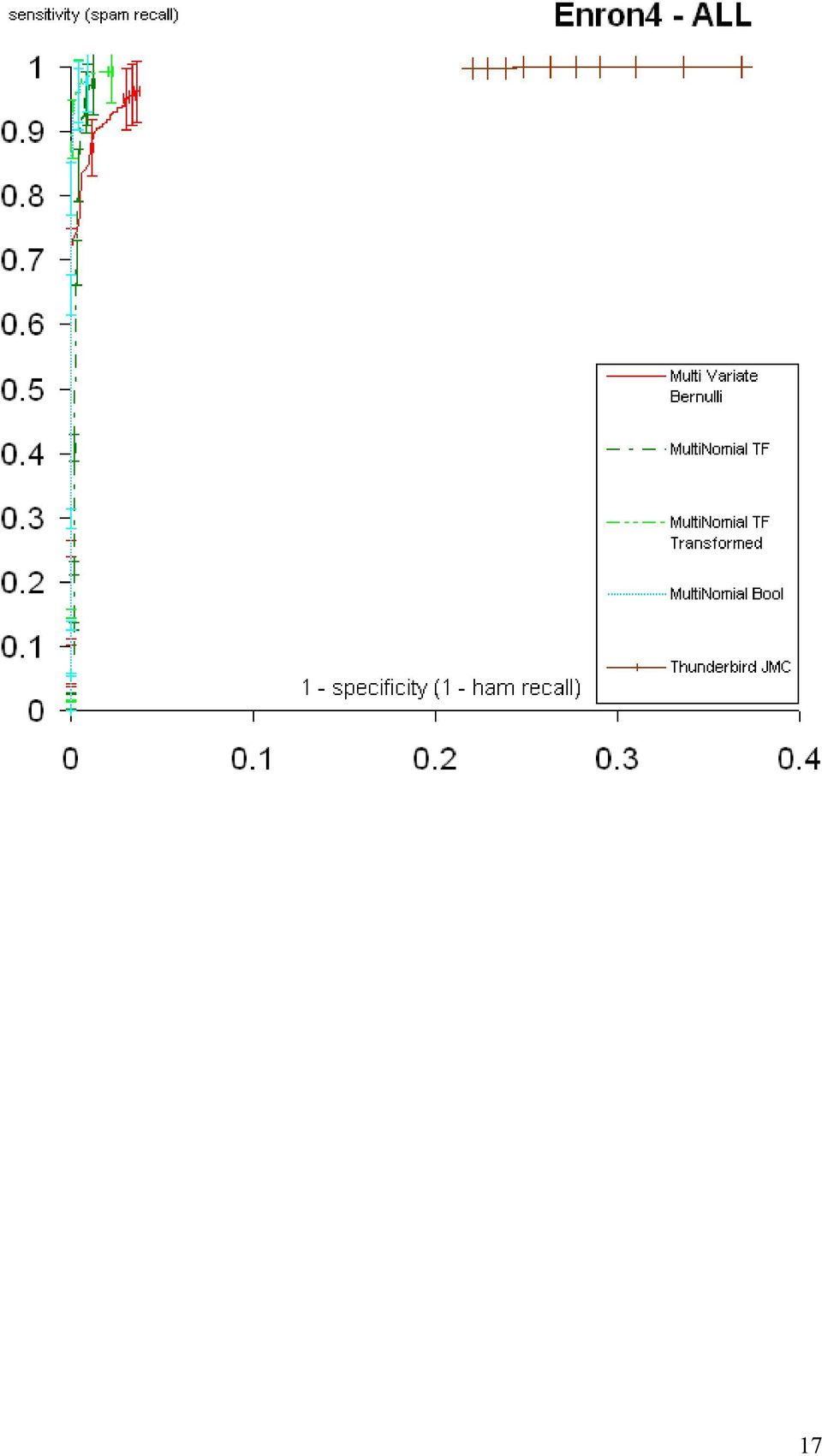
14 3.2 Πειραµατικά αποτελέσµατα ανά χρήστη Στα παρακάτω διαγράµµατα φαίνονται τα πειραµατικά αποτελέσµατα ανά ψευδο-χρήστη του Enron-Spam και συγκεντρωτικά για όλους τους ψευδο-χρήστες µαζί. Οι ράβδοι λάθους αντιστοιχούν σε διαστήµατα εµπιστοσύνης 95%. 14

15 15
16 16
17 17
18 18
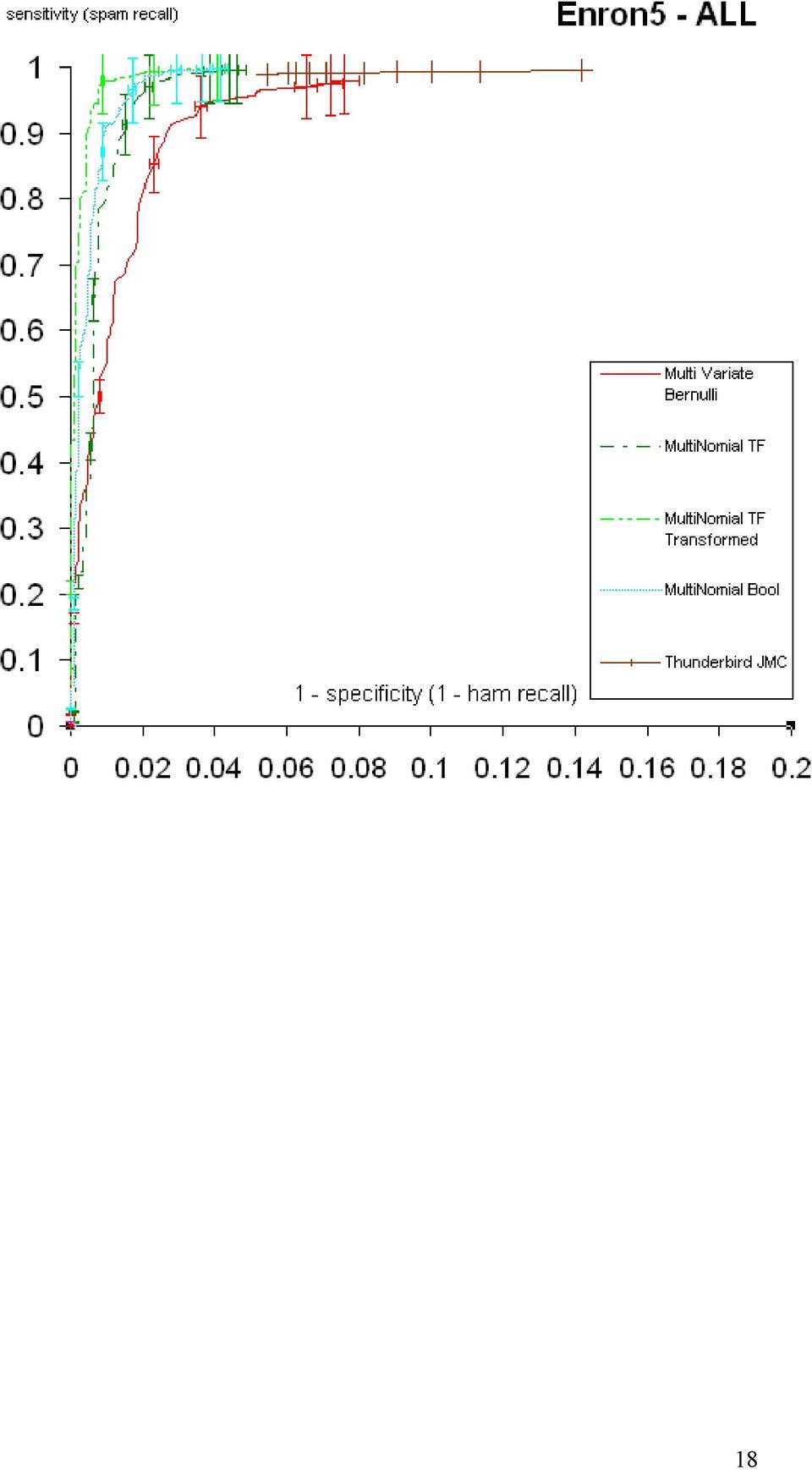
19 Παρατηρούµε ότι σε γενικές γραµµές η πολυωνυµική µορφή µε µετασχηµατισµένα χαρακτηριστικά TF του απλοϊκού ταξινοµητή Bayes υπερτερεί στην περιοχή υψηλού HR (1 HR τείνει στο µηδέν) που κυρίως µας ενδιαφέρει (θέλουµε να µην χάνουµε επιθυµητά µηνύµατα), ιδιαίτερα στους ψευδο-χρήστες Enron1, Enron2 και Enron5. Στους υπόλοιπους τρεις ψευδο-χρήστες, οι διαφορές από τις άλλες δύο µορφές του πολυωνυµικού απλοϊκού ταξινοµητή Bayes είναι δυσδιάκριτες, αλλά και πάλι η πολυωνυµική µορφή µε µετασχηµατισµένα χαρακτηριστικά TF είναι µεταξύ των κορυφαίων. Η πολυµεταβλητή µορφή Bernoull είναι εµφανώς η χειρότερη. Τα αποτελέσµατα αυτά συµφωνούν µε εκείνα των εργασιών [2] και [5]. Το προϋπάρχον φίλτρο του Thunderbrd επιτυγχάνει υψηλές τιµές SR, αλλά δεν καταφέρνει να πλησιάσει τιµές του HR κοντά στο 1, περιοχή που κυρίως µας ενδιαφέρει, για καµιά τιµή του κατωφλίου. 19

20 Στο παρακάτω διάγραµµα φαίνονται τα αποτελέσµατα συγκεντρωτικά, για όλους τους χρήστες µαζί. Είναι και πάλι εµφανής η υπεροχή της πολυωνυµικής µορφής µε µετασχηµατισµένα χαρακτηριστικά TF. 20

21 4 Επίλογος Στην παρούσα εργασία αναπτύχθηκε ένα φίλτρο ανεπιθύµητης ηλεκτρονικής αλληλογραφίας, που ενσωµατώθηκε στο Mozlla Thunderbrd. ιατίθεται ελεύθερα ως λογισµικό ανοικτού πηγαίου κώδικα, όπως και το ίδιο το Mozlla Thunderbrd. Χρησιµοποιεί µια βιβλιοθήκη λογισµικού που είχε αναπτυχθεί σε προηγούµενη εργασία, η οποία παρέχει υλοποιήσεις πολλών παραλλαγών του απλοϊκού ταξινοµητή Bayes. Το φίλτρο της εργασίας χρησιµοποιεί τέσσερις µορφές: την πολυµεταβλητή µορφή Bernoull, την πολυωνυµική µε χαρακτηριστικά TF, την πολυωνυµική µε µετασχηµατισµένα χαρακτηριστικά TF και την πολυωνυµική µε δυαδικά χαρακτηριστικά. Το φίλτρο της παρούσας εργασίας υποστηρίζει, επίσης, αποδείξεις ανθρώπινης αλληλεπίδρασης (HIPs), µηχανισµό που βρίσκεται, όµως, σε δοκιµαστικό στάδιο και δεν αξιολογήθηκε πειραµατικά. Πειράµατα που διεξήχθησαν στη διάρκεια της εργασίας έδειξαν ότι, για τους σκοπούς της διήθησης ανεπιθύµητης αλληλογραφίας, η καλύτερη µορφή του απλοϊκού ταξινοµητή Bayes είναι η πολυωνυµική µε µετασχηµατισµένα χαρακτηριστικά TF. Με αυτή τη µορφή, το φίλτρο που αναπτύχθηκε επιτυγχάνει καλύτερα αποτελέσµατα από το προϋπάρχον φίλτρο του Mozlla Thunderbrd. Μελλοντικά θα ήταν σκόπιµο να αξιολογηθεί πειραµατικά και ο µηχανισµός αποδείξεων ανθρώπινης αλληλεπίδρασης, αφού συνδυασθεί µε µηχανισµούς πιστοποίησης αποστολέα (DKIM ή SenderID) και αντιµετωπισθούν τα προβλήµατα που παρουσιάζει επί του παρόντος. Επίσης, θα ήταν ιδιαίτερα ενδιαφέρον να αξιολογηθεί το φίλτρο της εργασίας στην πράξη, από πραγµατικούς χρήστες. 21
22 5 Βιβλιογραφία [1] T.A Meyer και B Whateley, «SpamBayes: Effectve open-source, Bayesan based, emal classfcaton system». Πρακτικά του 1st Conference on Emal and Ant-Spam (CEAS 2004), Mountan Vew, CA, ΗΠΑ, [2] Β. Μέτσης, Ι. Ανδρουτσόπουλος και Γ. Παλιούρας, «Spam Flterng wth Nave Bayes -- Whch Nave Bayes?». Πρακτικά του 3rd Conference on Emal and Ant- Spam (CEAS 2006), Mountan Vew, CA, ΗΠΑ, [3] J.D.M. Renne, L. Shh, J. Teevan και D.R. Karger, «Tacklng the Poor Assumptons of Nave Bayes Text Classfers». Πρακτικά του 20 th Internatonal Conference on Machne Learnng, Washngton DC, [4].Κ. Βασιλάκης, Ι. Ανδρουτσόπουλος και Ε.Φ. Μαγείρου, «A Game-Theoretc Investgaton of the Effect of Human Interactve Proofs on Spam E-mal». Πρακτικά του 4th Conference on Emal and Ant-Spam (CEAS 2007), Mountan Vew, CA, ΗΠΑ, [5] Α. Κοσµόπουλος, «ιήθηση ανεπιθύµητης ηλεκτρονικής αλληλογραφίας µε διάφορες µορφές του απλοϊκού ταξινοµητή Bayes και διαµοιρασµό φίλτρων µεταξύ χρηστών», µεταπτυχιακή διπλωµατική εργασία, Τµήµα Πληροφορικής, Οικονοµικό Πανεπιστήµιο Αθηνών,
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ
 ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης Θέμα: Διήθηση ανεπιθύμητης ηλεκτρονικής αλληλογραφίας
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΩΝ ΥΠΟΛΟΓΙΣΤΩΝ Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης Θέμα: Διήθηση ανεπιθύμητης ηλεκτρονικής αλληλογραφίας
Οικονομικό Πανεπιστήμιο Αθηνών. Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης. Άρης Κοσμόπουλος
 Οικονομικό Πανεπιστήμιο Αθηνών Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης Άρης Κοσμόπουλος Πρόβλημα ανεπιθύμητων μηνυμάτων Περισσότερα από το 60% των ηλεκτρονικών μηνυμάτων είναι ανεπιθύμητα
Οικονομικό Πανεπιστήμιο Αθηνών Διπλωματική Εργασία Μεταπτυχιακού Διπλώματος Ειδίκευσης Άρης Κοσμόπουλος Πρόβλημα ανεπιθύμητων μηνυμάτων Περισσότερα από το 60% των ηλεκτρονικών μηνυμάτων είναι ανεπιθύμητα
Aueb Spam Filter. A personal spam filter for Thunderbird. Μπόχτης Δημήτρης
 Aueb Spam Filter A personal spam filter for Thunderbird Μπόχτης Δημήτρης Το Πρόβλημα του Spam 2005 30 δισεκατομμύρια ημερησίως. 2006 55 δισεκατομμύρια ημερησίως. 2007 (Φεβ.) 90 δισεκατομμύρια ημερησίως.
Aueb Spam Filter A personal spam filter for Thunderbird Μπόχτης Δημήτρης Το Πρόβλημα του Spam 2005 30 δισεκατομμύρια ημερησίως. 2006 55 δισεκατομμύρια ημερησίως. 2007 (Φεβ.) 90 δισεκατομμύρια ημερησίως.
Τεχνητή Νοημοσύνη. 16η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 16η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται σε ύλη του βιβλίου Artificial Intelligence A Modern Approach των
Τεχνητή Νοημοσύνη 16η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται σε ύλη του βιβλίου Artificial Intelligence A Modern Approach των
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #06 Πιθανοτικό Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #06 Πιθανοτικό Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης
Ασκήσεις μελέτης της 16 ης διάλεξης
 Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 16 ης διάλεξης 16.1. (α) Έστω ένα αντικείμενο προς κατάταξη το οποίο
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 16 ης διάλεξης 16.1. (α) Έστω ένα αντικείμενο προς κατάταξη το οποίο
Ασκήσεις μελέτης της 19 ης διάλεξης
 Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 19 ης διάλεξης 19.1. Δείξτε ότι το Perceptron με (α) συνάρτηση ενεργοποίησης
Οικονομικό Πανεπιστήμιο Αθηνών, Τμήμα Πληροφορικής Μάθημα: Τεχνητή Νοημοσύνη, 2016 17 Διδάσκων: Ι. Ανδρουτσόπουλος Ασκήσεις μελέτης της 19 ης διάλεξης 19.1. Δείξτε ότι το Perceptron με (α) συνάρτηση ενεργοποίησης
Τεχνητή Νοημοσύνη. 18η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 18η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Machine Learning του T. Mitchell, McGraw- Hill, 1997,
Τεχνητή Νοημοσύνη 18η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Machine Learning του T. Mitchell, McGraw- Hill, 1997,
Παρεµβολή και Προσέγγιση Συναρτήσεων
 Κεφάλαιο 4 Παρεµβολή και Προσέγγιση Συναρτήσεων 41 Παρεµβολή µε πολυώνυµο Lagrage Εστω ότι γνωρίζουµε τις τιµές µιας συνάρτησης f (x), f 0, f 1,, f ν σε σηµεία x 0, x 1,, x ν, και Ϲητάµε να υπολογίσουµε
Κεφάλαιο 4 Παρεµβολή και Προσέγγιση Συναρτήσεων 41 Παρεµβολή µε πολυώνυµο Lagrage Εστω ότι γνωρίζουµε τις τιµές µιας συνάρτησης f (x), f 0, f 1,, f ν σε σηµεία x 0, x 1,, x ν, και Ϲητάµε να υπολογίσουµε
Εκπαίδευση ταξινοµητών κειµένου για το χαρακτηρισµό άποψης. Ειρήνη Καλδέλη ιπλωµατική Εργασία. Περίληψη
 Εκπαίδευση ταξινοµητών κειµένου για το χαρακτηρισµό άποψης Ειρήνη Καλδέλη ιπλωµατική Εργασία Περίληψη Εισαγωγή Τα τελευταία χρόνια η αλµατώδης ανάπτυξη της πληροφορικής έχει διευρύνει σε σηµαντικό βαθµό
Εκπαίδευση ταξινοµητών κειµένου για το χαρακτηρισµό άποψης Ειρήνη Καλδέλη ιπλωµατική Εργασία Περίληψη Εισαγωγή Τα τελευταία χρόνια η αλµατώδης ανάπτυξη της πληροφορικής έχει διευρύνει σε σηµαντικό βαθµό
Προγραμματισμός Υπολογιστών με C++
 Προγραμματισμός Υπολογιστών με C++ ( 2012-13 ) 13η διάλεξη Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Τι θα ακούσετε σήμερα Κληρονομικότητα και: δυναμική καταχώριση μνήμης, κατασκευαστές αντιγράφων,
Προγραμματισμός Υπολογιστών με C++ ( 2012-13 ) 13η διάλεξη Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/ion/ 1 Τι θα ακούσετε σήμερα Κληρονομικότητα και: δυναμική καταχώριση μνήμης, κατασκευαστές αντιγράφων,
Β Ρ Υ Ν Ι Ο Σ Π Α Ν Α Γ Ι Ω Τ Η Σ 04/2654 Ε Π Ι Β Λ Ε Π Ω Ν : Η Λ Ι ΟΥΔ Η Σ Χ Ρ Η Σ ΤΟ Σ Θ Ε Σ Σ Α ΛΟ Ν Ι Κ Η, 2014
 «Ανάπτυξη στοιχείων λογισμικού (plug-in) για την ενσωμάτωσή τους σε υπηρεσίες ηλεκτρονικού ταχυδρομείου τύπου Thunderbird και Outlook για το σύστημα «Arachnoid»» Β Ρ Υ Ν Ι Ο Σ Π Α Ν Α Γ Ι Ω Τ Η Σ 04/2654
«Ανάπτυξη στοιχείων λογισμικού (plug-in) για την ενσωμάτωσή τους σε υπηρεσίες ηλεκτρονικού ταχυδρομείου τύπου Thunderbird και Outlook για το σύστημα «Arachnoid»» Β Ρ Υ Ν Ι Ο Σ Π Α Ν Α Γ Ι Ω Τ Η Σ 04/2654
Οδηγίες. για το web περιβάλλον διαχείρισης λογαριασμών. my.teiath.gr
 Οδηγίες για το web περιβάλλον διαχείρισης λογαριασμών my.teiath.gr Περιεχόμενα 1. Γενικά... σελ. 2 2. Είσοδος στο περιβάλλον... σελ. 2 3. Ρυθμίσεις λογαριασμού... σελ. 3 3.1 Αλλαγή κωδικού πρόσβασης...
Οδηγίες για το web περιβάλλον διαχείρισης λογαριασμών my.teiath.gr Περιεχόμενα 1. Γενικά... σελ. 2 2. Είσοδος στο περιβάλλον... σελ. 2 3. Ρυθμίσεις λογαριασμού... σελ. 3 3.1 Αλλαγή κωδικού πρόσβασης...
Αντιµετώπιση των ανεπιθύµητων ηλεκτρονικών µηνυµάτων. Blocking spam mail. ηµήτρης Μπιµπίκας
 Αντιµετώπιση των ανεπιθύµητων ηλεκτρονικών µηνυµάτων Blocking spam mail ηµήτρης Μπιµπίκας 2 ΑΝΤΙΜΕΤΩΠΙΣΗ ΑΝΕΠΙΘΥΜΗΤΩΝ ΗΛΕΚΤΡΟΝΙΚΩΝ ΜΗΝΥΜΑΤΩΝ/ BLOCKING SPAM MAIL Αντιµετώπιση των ανεπιθύµητων ηλεκτρονικών
Αντιµετώπιση των ανεπιθύµητων ηλεκτρονικών µηνυµάτων Blocking spam mail ηµήτρης Μπιµπίκας 2 ΑΝΤΙΜΕΤΩΠΙΣΗ ΑΝΕΠΙΘΥΜΗΤΩΝ ΗΛΕΚΤΡΟΝΙΚΩΝ ΜΗΝΥΜΑΤΩΝ/ BLOCKING SPAM MAIL Αντιµετώπιση των ανεπιθύµητων ηλεκτρονικών
Οδηγίες. για την υπηρεσία. Antispamming. (στα windows XP) Περιεχόµενα
 Περιεχόµενα") Οδηγίες για την υπηρεσία Antispamming (στα windows XP) Περιεχόµενα Ενεργοποίηση της υπηρεσίας (µέσω Internet Explorer)... σελ. 2 ηµιουργία φακέλου για spam στο Outlook Express... σελ. 5 ηµιουργία Κανόνα
Οδηγίες για την υπηρεσία Antispamming (στα windows XP) Περιεχόµενα Ενεργοποίηση της υπηρεσίας (µέσω Internet Explorer)... σελ. 2 ηµιουργία φακέλου για spam στο Outlook Express... σελ. 5 ηµιουργία Κανόνα
Ανάκτηση Πληροφορίας
 Το Πιθανοκρατικό Μοντέλο Κλασικά Μοντέλα Ανάκτησης Τρία είναι τα, λεγόμενα, κλασικά μοντέλα ανάκτησης: Λογικό (Boolean) που βασίζεται στη Θεωρία Συνόλων Διανυσματικό (Vector) που βασίζεται στη Γραμμική
Το Πιθανοκρατικό Μοντέλο Κλασικά Μοντέλα Ανάκτησης Τρία είναι τα, λεγόμενα, κλασικά μοντέλα ανάκτησης: Λογικό (Boolean) που βασίζεται στη Θεωρία Συνόλων Διανυσματικό (Vector) που βασίζεται στη Γραμμική
5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο
 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο") 5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο Ένα εναλλακτικό μοντέλο της απλής γραμμικής παλινδρόμησης (που χρησιμοποιήθηκε
5. ΤΟ ΓΕΝΙΚΟ ΓΡΑΜΜΙΚΟ ΜΟΝΤΕΛΟ (GENERAL LINEAR MODEL) 5.1 Εναλλακτικά μοντέλα του απλού γραμμικού μοντέλου: Το εκθετικό μοντέλο Ένα εναλλακτικό μοντέλο της απλής γραμμικής παλινδρόμησης (που χρησιμοποιήθηκε
Μέθοδοι εκμάθησης ταξινομητών από θετικά παραδείγματα με αριθμητικά χαρακτηριστικά. Νικόλαος Α. Τρογκάνης Διπλωματική Εργασία
 Μέθοδοι εκμάθησης ταξινομητών από θετικά παραδείγματα με αριθμητικά χαρακτηριστικά Νικόλαος Α. Τρογκάνης Διπλωματική Εργασία Αντικείμενο Μελέτη και ανάπτυξη μεθόδων από τον χώρο της μηχανικής μάθησης για
Μέθοδοι εκμάθησης ταξινομητών από θετικά παραδείγματα με αριθμητικά χαρακτηριστικά Νικόλαος Α. Τρογκάνης Διπλωματική Εργασία Αντικείμενο Μελέτη και ανάπτυξη μεθόδων από τον χώρο της μηχανικής μάθησης για
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ
 ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΕΠΙΜΕΛΕΙΑ: ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΘΕΩΡΙΑ 10 ΟΥ ΚΕΦΑΛΑΙΟΥ ΥΠΟΠΡΟΓΡΑΜΜΑΤΑ 1. Πως ορίζεται ο τμηματικός προγραμματισμός; Τμηματικός προγραμματισμός
ΑΝΑΠΤΥΞΗ ΕΦΑΡΜΟΓΩΝ ΣΕ ΠΡΟΓΡΑΜΜΑΤΙΣΤΙΚΟ ΠΕΡΙΒΑΛΛΟΝ ΕΠΙΜΕΛΕΙΑ: ΜΑΡΙΑ Σ. ΖΙΩΓΑ ΚΑΘΗΓΗΤΡΙΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΘΕΩΡΙΑ 10 ΟΥ ΚΕΦΑΛΑΙΟΥ ΥΠΟΠΡΟΓΡΑΜΜΑΤΑ 1. Πως ορίζεται ο τμηματικός προγραμματισμός; Τμηματικός προγραμματισμός
HMY 795: Αναγνώριση Προτύπων
 HMY 795: Αναγνώριση Προτύπων Διάλεξη 3 Επιλογή μοντέλου Επιλογή μοντέλου Θεωρία αποφάσεων Επιλογή μοντέλου δεδομένα επικύρωσης Η επιλογή του είδους του μοντέλου που θα χρησιμοποιηθεί σε ένα πρόβλημα (π.χ.
HMY 795: Αναγνώριση Προτύπων Διάλεξη 3 Επιλογή μοντέλου Επιλογή μοντέλου Θεωρία αποφάσεων Επιλογή μοντέλου δεδομένα επικύρωσης Η επιλογή του είδους του μοντέλου που θα χρησιμοποιηθεί σε ένα πρόβλημα (π.χ.
Ανάκτηση Πληροφορίας
 Ανάκτηση Πληροφορίας Το μοντέλο Boolean Το μοντέλο Vector Ταξινόμηση Μοντέλων IR Ανάκτηση Περιήγηση Κλασικά Μοντέλα Boolean Vector Probabilistic Δομικά Μοντέλα Non-Overlapping Lists Proximal Nodes Browsing
Ανάκτηση Πληροφορίας Το μοντέλο Boolean Το μοντέλο Vector Ταξινόμηση Μοντέλων IR Ανάκτηση Περιήγηση Κλασικά Μοντέλα Boolean Vector Probabilistic Δομικά Μοντέλα Non-Overlapping Lists Proximal Nodes Browsing
ΜΥΕ003: Ανάκτηση Πληροφορίας. Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο 11: Πιθανοτική ανάκτηση πληροφορίας.
 ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο : Πιθανοτική ανάκτηση πληροφορίας. Κεφ. Πιθανοτική Ανάκτηση Πληροφορίας Βασική ιδέα: Διάταξη εγγράφων με βάση την πιθανότητα να είναι
ΜΥΕ003: Ανάκτηση Πληροφορίας Διδάσκουσα: Ευαγγελία Πιτουρά Κεφάλαιο : Πιθανοτική ανάκτηση πληροφορίας. Κεφ. Πιθανοτική Ανάκτηση Πληροφορίας Βασική ιδέα: Διάταξη εγγράφων με βάση την πιθανότητα να είναι
Ανάκτηση Πληροφορίας
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #05 Ακρίβεια vs. Ανάκληση Extended Boolean Μοντέλο Fuzzy Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Ανάκτηση Πληροφορίας Διδάσκων: Φοίβος Μυλωνάς fmylonas@ionio.gr Διάλεξη #05 Ακρίβεια vs. Ανάκληση Extended Boolean Μοντέλο Fuzzy Μοντέλο 1 Άδεια χρήσης Το παρόν εκπαιδευτικό
MEΤΑΣΧΗΜΑΤΙΣΜΟΙ ΤΗΣ ΜΟΡΦΗΣ Y= g( X1, X2,..., Xn)
") MEΤΑΣΧΗΜΑΤΙΣΜΟΙ ΤΗΣ ΜΟΡΦΗΣ g( Έστω τυχαίες µεταβλητές οι οποίες έχουν κάποια από κοινού κατανοµή Ας υποθέσουµε ότι επιθυµούµε να προσδιορίσουµε την κατανοµή της τυχαίας µεταβλητής g( Η θεωρία των ένα-προς-ένα
MEΤΑΣΧΗΜΑΤΙΣΜΟΙ ΤΗΣ ΜΟΡΦΗΣ g( Έστω τυχαίες µεταβλητές οι οποίες έχουν κάποια από κοινού κατανοµή Ας υποθέσουµε ότι επιθυµούµε να προσδιορίσουµε την κατανοµή της τυχαίας µεταβλητής g( Η θεωρία των ένα-προς-ένα
3.4.2 Ο Συντελεστής Συσχέτισης τ Του Kendall
 3..2 Ο Συντελεστής Συσχέτισης τ Του Kendall Ο συντελεστής συχέτισης τ του Kendall μοιάζει με τον συντελεστή ρ του Spearman ως προς το ότι υπολογίζεται με βάση την τάξη μεγέθους των παρατηρήσεων και όχι
3..2 Ο Συντελεστής Συσχέτισης τ Του Kendall Ο συντελεστής συχέτισης τ του Kendall μοιάζει με τον συντελεστή ρ του Spearman ως προς το ότι υπολογίζεται με βάση την τάξη μεγέθους των παρατηρήσεων και όχι
Γενικές Παρατηρήσεις για τις Εργαστηριακές Ασκήσεις Φυσικοχηµείας
 Γενικές Παρατηρήσεις για τις Εργαστηριακές Ασκήσεις Φυσικοχηµείας Σκοπός των ασκήσεων είναι η κατανόηση φυσικών φαινοµένων και µεγεθών και η µέτρησή τους. Η κατανόηση αρχίζει µε την µελέτη των σηµειώσεων,
Γενικές Παρατηρήσεις για τις Εργαστηριακές Ασκήσεις Φυσικοχηµείας Σκοπός των ασκήσεων είναι η κατανόηση φυσικών φαινοµένων και µεγεθών και η µέτρησή τους. Η κατανόηση αρχίζει µε την µελέτη των σηµειώσεων,
Εφαρµογή στην αξιολόγηση επενδύσεων
 Εφαρµογή στην αξιολόγηση επενδύσεων Τα απλούστερα κριτήρια PV IRR Επένδυση: είναι µια χρηµατοροή σε περιοδικά σηµεία του χρόνου t,,,,ν, που εµφανίζονται ποσά Χ,Χ,,Χ Ν, που είναι µη αρνητικά Χ,,, Ν, κατά
Εφαρµογή στην αξιολόγηση επενδύσεων Τα απλούστερα κριτήρια PV IRR Επένδυση: είναι µια χρηµατοροή σε περιοδικά σηµεία του χρόνου t,,,,ν, που εµφανίζονται ποσά Χ,Χ,,Χ Ν, που είναι µη αρνητικά Χ,,, Ν, κατά
4. ΚΕΦΑΛΑΙΟ ΕΦΑΡΜΟΓΕΣ ΤΟΥ ΜΕΤΑΣΧΗΜΑΤΙΣΜΟΥ FOURIER
 4. ΚΕΦΑΛΑΙΟ ΕΦΑΡΜΟΓΕΣ ΤΟΥ ΜΕΤΑΣΧΗΜΑΤΙΣΜΟΥ FOURIER Σκοπός του κεφαλαίου είναι να παρουσιάσει μερικές εφαρμογές του Μετασχηματισμού Fourier (ΜF). Ειδικότερα στο κεφάλαιο αυτό θα περιγραφούν έμμεσοι τρόποι
4. ΚΕΦΑΛΑΙΟ ΕΦΑΡΜΟΓΕΣ ΤΟΥ ΜΕΤΑΣΧΗΜΑΤΙΣΜΟΥ FOURIER Σκοπός του κεφαλαίου είναι να παρουσιάσει μερικές εφαρμογές του Μετασχηματισμού Fourier (ΜF). Ειδικότερα στο κεφάλαιο αυτό θα περιγραφούν έμμεσοι τρόποι
Σέργιος Θεοδωρίδης Κωνσταντίνος Κουτρούμπας. Version 2
 Σέργιος Θεοδωρίδης Κωνσταντίνος Κουτρούμπας Verson 2 1 M = 1 N = N prob k N k { k n ω wrongly classfed} = (1 ) N k 2 Η συνάρτηση πιθανοφάνειας L(p) μεγιστοποιείται όταν =k/n. 3 Αφού τα s είναι άγνωστα,
Σέργιος Θεοδωρίδης Κωνσταντίνος Κουτρούμπας Verson 2 1 M = 1 N = N prob k N k { k n ω wrongly classfed} = (1 ) N k 2 Η συνάρτηση πιθανοφάνειας L(p) μεγιστοποιείται όταν =k/n. 3 Αφού τα s είναι άγνωστα,
Εξαγωγή κανόνων από αριθµητικά δεδοµένα
 Εξαγωγή κανόνων από αριθµητικά δεδοµένα Συχνά το σύστηµα που θέλουµε να µοντελοποιήσουµε η να ελέγξουµε αντιµετωπίζεται ως µαύρο κουτί και η πληροφορία για τη λειτουργία του διατίθεται υπό µορφή ζευγών
Εξαγωγή κανόνων από αριθµητικά δεδοµένα Συχνά το σύστηµα που θέλουµε να µοντελοποιήσουµε η να ελέγξουµε αντιµετωπίζεται ως µαύρο κουτί και η πληροφορία για τη λειτουργία του διατίθεται υπό µορφή ζευγών
"The Project ARXIMIDIS ΙΙ is co-funded by the European Social Fund and National Resources EPEAEK ΙΙ "
 Αρχιµήδης ΙΙ Ενίσχυση Ερευνητικών Οµάδων του ΤΕΙ Κρήτης Τίτλος Υποέργου: Εφαρµογές Τεχνητής Νοηµοσύνης στην Τεχνολογία Λογισµικού και στην Ιατρική Επιστηµονικός Υπεύθυνος: ρ Εµµανουήλ Μαρακάκης ραστηριότητα
Αρχιµήδης ΙΙ Ενίσχυση Ερευνητικών Οµάδων του ΤΕΙ Κρήτης Τίτλος Υποέργου: Εφαρµογές Τεχνητής Νοηµοσύνης στην Τεχνολογία Λογισµικού και στην Ιατρική Επιστηµονικός Υπεύθυνος: ρ Εµµανουήλ Μαρακάκης ραστηριότητα
Κεφάλαιο 10 ο Υποπρογράµµατα
 Κεφάλαιο 10 ο Υποπρογράµµατα Ανάπτυξη Εφαρµογών σε Προγραµµατιστικό Περιβάλλον Η αντιµετώπιση των σύνθετων προβληµάτων και η ανάπτυξη των αντίστοιχων προγραµµάτων µπορεί να γίνει µε την ιεραρχική σχεδίαση,
Κεφάλαιο 10 ο Υποπρογράµµατα Ανάπτυξη Εφαρµογών σε Προγραµµατιστικό Περιβάλλον Η αντιµετώπιση των σύνθετων προβληµάτων και η ανάπτυξη των αντίστοιχων προγραµµάτων µπορεί να γίνει µε την ιεραρχική σχεδίαση,
Ελεγκτικής. ΤΕΙ Ηπείρου (Παράρτηµα Πρέβεζας)
") Πληροφοριακά Συστήµατα ιοίκησης Management Information Systems Εργαστήριο 2 Τµήµα Χρηµατοοικονοµικής και Ελεγκτικής ΤΕΙ Ηπείρου (Παράρτηµα Πρέβεζας) ΑΝΤΙΚΕΙΜΕΝΟ: Προσοµοίωση (Simulation) και τυχαίες µεταβλητές
Πληροφοριακά Συστήµατα ιοίκησης Management Information Systems Εργαστήριο 2 Τµήµα Χρηµατοοικονοµικής και Ελεγκτικής ΤΕΙ Ηπείρου (Παράρτηµα Πρέβεζας) ΑΝΤΙΚΕΙΜΕΝΟ: Προσοµοίωση (Simulation) και τυχαίες µεταβλητές
ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ Τ Μ Η Μ Α Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ Τ Μ Η Μ Α Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ ΕΠΛ 035 - ΔΟΜΕΣ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΑΛΓΟΡΙΘΜΟΙ ΓΙΑ ΗΛΕΚΤΡΟΛΟΓΟΥΣ ΜΗΧΑΝΙΚΟΥΣ ΚΑΙ ΜΗΧΑΝΙΚΟΥΣ ΥΠΟΛΟΓΙΣΤΩΝ Ακαδηµαϊκό έτος 2017-2018 Υπεύθυνος εργαστηρίου: Γεώργιος
ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ Τ Μ Η Μ Α Π Λ Η Ρ Ο Φ Ο Ρ Ι Κ Η Σ ΕΠΛ 035 - ΔΟΜΕΣ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΑΛΓΟΡΙΘΜΟΙ ΓΙΑ ΗΛΕΚΤΡΟΛΟΓΟΥΣ ΜΗΧΑΝΙΚΟΥΣ ΚΑΙ ΜΗΧΑΝΙΚΟΥΣ ΥΠΟΛΟΓΙΣΤΩΝ Ακαδηµαϊκό έτος 2017-2018 Υπεύθυνος εργαστηρίου: Γεώργιος
Τεχνητή Νοημοσύνη. 17η διάλεξη ( ) Ίων Ανδρουτσόπουλος.
 Ίων Ανδρουτσόπουλος.") Τεχνητή Νοημοσύνη 17η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Artificia Inteigence A Modern Approach των S. Russe και
Τεχνητή Νοημοσύνη 17η διάλεξη (2016-17) Ίων Ανδρουτσόπουλος http://.aueb.gr/users/ion/ 1 Οι διαφάνειες αυτής της διάλεξης βασίζονται: στο βιβλίο Artificia Inteigence A Modern Approach των S. Russe και
ΚΕΦΑΛΑΙΟ 18. 18 Μηχανική Μάθηση
 ΚΕΦΑΛΑΙΟ 18 18 Μηχανική Μάθηση Ένα φυσικό ή τεχνητό σύστηµα επεξεργασίας πληροφορίας συµπεριλαµβανοµένων εκείνων µε δυνατότητες αντίληψης, µάθησης, συλλογισµού, λήψης απόφασης, επικοινωνίας και δράσης
ΚΕΦΑΛΑΙΟ 18 18 Μηχανική Μάθηση Ένα φυσικό ή τεχνητό σύστηµα επεξεργασίας πληροφορίας συµπεριλαµβανοµένων εκείνων µε δυνατότητες αντίληψης, µάθησης, συλλογισµού, λήψης απόφασης, επικοινωνίας και δράσης
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕ ΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΙΚΤΥΑ
 ΘΕΜΑ ο 2.5 µονάδες ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕ ΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΙΚΤΥΑ Τελικές εξετάσεις 2 Σεπτεµβρίου 2005 5:00-8:00 Σχεδιάστε έναν αισθητήρα ercetro
ΘΕΜΑ ο 2.5 µονάδες ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕ ΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΙΚΤΥΑ Τελικές εξετάσεις 2 Σεπτεµβρίου 2005 5:00-8:00 Σχεδιάστε έναν αισθητήρα ercetro
Υπολογιστικό Πρόβληµα
 Υπολογιστικό Πρόβληµα Μετασχηµατισµός δεδοµένων εισόδου σε δεδοµένα εξόδου. Δοµή δεδοµένων εισόδου (έγκυρο στιγµιότυπο). Δοµή και ιδιότητες δεδοµένων εξόδου (απάντηση ή λύση). Τυπικά: διµελής σχέση στις
Υπολογιστικό Πρόβληµα Μετασχηµατισµός δεδοµένων εισόδου σε δεδοµένα εξόδου. Δοµή δεδοµένων εισόδου (έγκυρο στιγµιότυπο). Δοµή και ιδιότητες δεδοµένων εξόδου (απάντηση ή λύση). Τυπικά: διµελής σχέση στις
Λύσεις 1 ης Σειράς Ασκήσεων (Αξιολόγηση της Αποτελεσµατικότητας της Ανάκτησης)
") Πανεπιστήµιο Κρήτης, Τµήµα Επιστήµης Υπολογιστών ΗΥ-6 Συστήµατα Ανάκτησης Πληροφοριών 7-8 Εαρινό Εξάµηνο Άσκηση Λύσεις ης Σειράς Ασκήσεων (Αξιολόγηση της Αποτελεσµατικότητας της Ανάκτησης) Θεωρείστε µια
Πανεπιστήµιο Κρήτης, Τµήµα Επιστήµης Υπολογιστών ΗΥ-6 Συστήµατα Ανάκτησης Πληροφοριών 7-8 Εαρινό Εξάµηνο Άσκηση Λύσεις ης Σειράς Ασκήσεων (Αξιολόγηση της Αποτελεσµατικότητας της Ανάκτησης) Θεωρείστε µια
Δοµές Δεδοµένων και Αλγόριθµοι - Εισαγωγή
 Δοµές Δεδοµένων και Αλγόριθµοι - Εισαγωγή Στην ενότητα αυτή θα µελετηθούν τα εξής επιµέρους θέµατα: Εισαγωγή στις έννοιες Αλγόριθµοι και Πολυπλοκότητα, Οργάνωση Δεδοµένων και Δοµές Δεδοµένων Χρήσιµοι µαθηµατικοί
Δοµές Δεδοµένων και Αλγόριθµοι - Εισαγωγή Στην ενότητα αυτή θα µελετηθούν τα εξής επιµέρους θέµατα: Εισαγωγή στις έννοιες Αλγόριθµοι και Πολυπλοκότητα, Οργάνωση Δεδοµένων και Δοµές Δεδοµένων Χρήσιµοι µαθηµατικοί
Οδηγίες. για την υπηρεσία. Antispamming. (στα Windows Vista) Περιεχόµενα
 Περιεχόµενα") Οδηγίες για την υπηρεσία Antispamming (στα Windows Vista) Περιεχόµενα Ενεργοποίηση της υπηρεσίας (µέσω Internet Explorer)... σελ. 2 ηµιουργία Κανόνα Αλληλογραφίας για spam στην Ηλεκτρ. Αλληλ σελ. 5 α.
Οδηγίες για την υπηρεσία Antispamming (στα Windows Vista) Περιεχόµενα Ενεργοποίηση της υπηρεσίας (µέσω Internet Explorer)... σελ. 2 ηµιουργία Κανόνα Αλληλογραφίας για spam στην Ηλεκτρ. Αλληλ σελ. 5 α.
HMY 795: Αναγνώριση Προτύπων
 HMY 795: Αναγνώριση Προτύπων Διάλεξη 5 Κατανομές πιθανότητας και εκτίμηση παραμέτρων δυαδικές τυχαίες μεταβλητές Bayesian decision Minimum misclassificaxon rate decision: διαλέγουμε την κατηγορία Ck για
HMY 795: Αναγνώριση Προτύπων Διάλεξη 5 Κατανομές πιθανότητας και εκτίμηση παραμέτρων δυαδικές τυχαίες μεταβλητές Bayesian decision Minimum misclassificaxon rate decision: διαλέγουμε την κατηγορία Ck για
ΗΛΕΚΤΡΟΝΙΚΗ Ι ΔΙΑΓΡΑΜΜΑΤΑ BODE ΣΥΜΠΛΗΡΩΜΑΤΙΚΟ ΤΕΥΧΟΣ ΣΗΜΕΙΩΣΕΩΝ
 Ε. Μ. Πολυτεχνείο Εργαστήριο Ηλεκτρονικής ΗΛΕΚΤΡΟΝΙΚΗ Ι ΔΙΑΓΡΑΜΜΑΤΑ BODE ΣΥΜΠΛΗΡΩΜΑΤΙΚΟ ΤΕΥΧΟΣ ΣΗΜΕΙΩΣΕΩΝ Γ. ΠΑΠΑΝΑΝΟΣ ΠΑΡΑΡΤΗΜΑ : Συναρτήσεις Δικτύων Βασικοί ορισμοί Ας θεωρήσουμε ένα γραμμικό, χρονικά
Ε. Μ. Πολυτεχνείο Εργαστήριο Ηλεκτρονικής ΗΛΕΚΤΡΟΝΙΚΗ Ι ΔΙΑΓΡΑΜΜΑΤΑ BODE ΣΥΜΠΛΗΡΩΜΑΤΙΚΟ ΤΕΥΧΟΣ ΣΗΜΕΙΩΣΕΩΝ Γ. ΠΑΠΑΝΑΝΟΣ ΠΑΡΑΡΤΗΜΑ : Συναρτήσεις Δικτύων Βασικοί ορισμοί Ας θεωρήσουμε ένα γραμμικό, χρονικά
ΠΕΡΙ ΜΕΤΑΒΑΣΗΣ ΑΠΟ ΤΑ ΙΑΓΡΑΜΜΑΤΑ ΡΟΗΣ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΕ ΙΑΓΡΑΜΜΑΤΑ ΟΜΗΣ Ε ΟΜΕΝΩΝ
 ΠΕΡΙ ΜΕΤΑΒΑΣΗΣ ΑΠΟ ΤΑ ΙΑΓΡΑΜΜΑΤΑ ΡΟΗΣ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΕ ΙΑΓΡΑΜΜΑΤΑ ΟΜΗΣ Ε ΟΜΕΝΩΝ Μερικές παρατηρήσεις και σκέψεις του συγγραφέα του βιβλίου Σχετικά µε τη µετάβαση από Ρ σε ΠΠ υπάρχουν 2 σηµαντικά ερωτήµατα:
ΠΕΡΙ ΜΕΤΑΒΑΣΗΣ ΑΠΟ ΤΑ ΙΑΓΡΑΜΜΑΤΑ ΡΟΗΣ ΠΡΟΓΡΑΜΜΑΤΟΣ ΣΕ ΙΑΓΡΑΜΜΑΤΑ ΟΜΗΣ Ε ΟΜΕΝΩΝ Μερικές παρατηρήσεις και σκέψεις του συγγραφέα του βιβλίου Σχετικά µε τη µετάβαση από Ρ σε ΠΠ υπάρχουν 2 σηµαντικά ερωτήµατα:
Μηχανική ΙI. Λογισµός των µεταβολών. Τµήµα Π. Ιωάννου & Θ. Αποστολάτου 2/2000
 Τµήµα Π Ιωάννου & Θ Αποστολάτου 2/2000 Μηχανική ΙI Λογισµός των µεταβολών Προκειµένου να αντιµετωπίσουµε προβλήµατα µεγιστοποίησης (ελαχιστοποίησης) όπως τα παραπάνω, όπου η ποσότητα που θέλουµε να µεγιστοποιήσουµε
Τµήµα Π Ιωάννου & Θ Αποστολάτου 2/2000 Μηχανική ΙI Λογισµός των µεταβολών Προκειµένου να αντιµετωπίσουµε προβλήµατα µεγιστοποίησης (ελαχιστοποίησης) όπως τα παραπάνω, όπου η ποσότητα που θέλουµε να µεγιστοποιήσουµε
Ακρότατα υπό συνθήκη και οι πολλαπλασιαστές του Lagrange
 64 Ακρότατα υπό συνθήκη και οι πολλαπλασιαστές του Lagrage Ας υποθέσουµε ότι ένας δεδοµένος χώρος θερµαίνεται και η θερµοκρασία στο σηµείο,, Τ, y, z Ας υποθέσουµε ότι ( y z ) αυτού του χώρου δίδεται από
64 Ακρότατα υπό συνθήκη και οι πολλαπλασιαστές του Lagrage Ας υποθέσουµε ότι ένας δεδοµένος χώρος θερµαίνεται και η θερµοκρασία στο σηµείο,, Τ, y, z Ας υποθέσουµε ότι ( y z ) αυτού του χώρου δίδεται από
Σχεδίαση Αλγορίθμων -Τμήμα Πληροφορικής ΑΠΘ - Εξάμηνο 4ο
 Πολλαπλασιασμός μεγάλων ακεραίων (1) Για να πολλαπλασιάσουμε δύο ακεραίους με n 1 και n 2 ψηφία με το χέρι, θα εκτελέσουμε n 1 n 2 πράξεις πολλαπλασιασμού Πρόβλημα ρβημ όταν έχουμε πολλά ψηφία: A = 12345678901357986429
Πολλαπλασιασμός μεγάλων ακεραίων (1) Για να πολλαπλασιάσουμε δύο ακεραίους με n 1 και n 2 ψηφία με το χέρι, θα εκτελέσουμε n 1 n 2 πράξεις πολλαπλασιασμού Πρόβλημα ρβημ όταν έχουμε πολλά ψηφία: A = 12345678901357986429
Διαδικτυακό Περιβάλλον Διαχείρισης Ασκήσεων Προγραμματισμού
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ Διπλωματική Εργασία με θέμα: Διαδικτυακό Περιβάλλον Διαχείρισης Ασκήσεων Προγραμματισμού Καραγιάννης Ιωάννης Α.Μ.
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕΔΟΝΙΑΣ ΔΙΑΤΜΗΜΑΤΙΚΟ ΜΕΤΑΠΤΥΧΙΑΚΟ ΠΡΟΓΡΑΜΜΑ ΣΤΑ ΠΛΗΡΟΦΟΡΙΑΚΑ ΣΥΣΤΗΜΑΤΑ Διπλωματική Εργασία με θέμα: Διαδικτυακό Περιβάλλον Διαχείρισης Ασκήσεων Προγραμματισμού Καραγιάννης Ιωάννης Α.Μ.
HMY 795: Αναγνώριση Προτύπων
 HMY 795: Αναγνώριση Προτύπων Διάλεξη 5 Κατανομές πιθανότητας και εκτίμηση παραμέτρων Κατανομές πιθανότητας και εκτίμηση παραμέτρων δυαδικές τυχαίες μεταβλητές Διαχωριστικές συναρτήσεις Ταξινόμηση κανονικών
HMY 795: Αναγνώριση Προτύπων Διάλεξη 5 Κατανομές πιθανότητας και εκτίμηση παραμέτρων Κατανομές πιθανότητας και εκτίμηση παραμέτρων δυαδικές τυχαίες μεταβλητές Διαχωριστικές συναρτήσεις Ταξινόμηση κανονικών
4.3. Γραµµικοί ταξινοµητές
 Γραµµικοί ταξινοµητές Γραµµικός ταξινοµητής είναι ένα σύστηµα ταξινόµησης που χρησιµοποιεί γραµµικές διακριτικές συναρτήσεις Οι ταξινοµητές αυτοί αναπαρίστανται συχνά µε οµάδες κόµβων εντός των οποίων
Γραµµικοί ταξινοµητές Γραµµικός ταξινοµητής είναι ένα σύστηµα ταξινόµησης που χρησιµοποιεί γραµµικές διακριτικές συναρτήσεις Οι ταξινοµητές αυτοί αναπαρίστανται συχνά µε οµάδες κόµβων εντός των οποίων
Ακαδημαϊκό Έτος , Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS
 Ακαδημαϊκό Έτος 2016-2017, Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS A. Εισαγωγή στις βάσεις δεδομένων - Γνωριμία με την ACCESS B. Δημιουργία Πινάκων 1. Εξήγηση των
Ακαδημαϊκό Έτος 2016-2017, Χειμερινό Εξάμηνο Μάθημα: Εργαστήριο «Πληροφορική Υγείας» ΕΙΣΑΓΩΓΗ ΣΤΗΝ ACCESS A. Εισαγωγή στις βάσεις δεδομένων - Γνωριμία με την ACCESS B. Δημιουργία Πινάκων 1. Εξήγηση των
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ
 ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ «Αναγνώριση και Κατάταξη Ονοµάτων Προσώπων, Οργανισµών και Τοποθεσιών σε Ελληνικά Κείµενα µε Χρήση Μηχανών ιανυσµάτων Υποστήριξης» Ιωάννης
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ «Αναγνώριση και Κατάταξη Ονοµάτων Προσώπων, Οργανισµών και Τοποθεσιών σε Ελληνικά Κείµενα µε Χρήση Μηχανών ιανυσµάτων Υποστήριξης» Ιωάννης
Γραφικά με υπολογιστές. Διδάσκων: Φοίβος Μυλωνάς. Διαλέξεις #11-#12
 Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Χειμερινό εξάμηνο Γραφικά με υπολογιστές Διδάσκων: Φοίβος Μυλωνάς fmlonas@ionio.gr Διαλέξεις #-# Σύνθεση Δ Μετασχηματισμών Ομογενείς Συντεταγμένες Παραδείγματα Μετασχηματισμών
Ιόνιο Πανεπιστήμιο Τμήμα Πληροφορικής Χειμερινό εξάμηνο Γραφικά με υπολογιστές Διδάσκων: Φοίβος Μυλωνάς fmlonas@ionio.gr Διαλέξεις #-# Σύνθεση Δ Μετασχηματισμών Ομογενείς Συντεταγμένες Παραδείγματα Μετασχηματισμών
Εργασία στο µάθηµα Ανάλυση εδοµένων
 Μεταπτυχιακό Υπολογιστικής Φυσικής Εργασία στο µάθηµα Ανάλυση εδοµένων ηµήτρης Κουγιουµτζής E-mail: dkugiu@auth.gr 30 Ιανουαρίου 2018 Οδηγίες : Σχετικά µε την παράδοση της εργασίας ϑα πρέπει : Το κείµενο
Μεταπτυχιακό Υπολογιστικής Φυσικής Εργασία στο µάθηµα Ανάλυση εδοµένων ηµήτρης Κουγιουµτζής E-mail: dkugiu@auth.gr 30 Ιανουαρίου 2018 Οδηγίες : Σχετικά µε την παράδοση της εργασίας ϑα πρέπει : Το κείµενο
Εισαγωγή στην επιστήµη των υπολογιστών. Υπολογιστές και Δεδοµένα Κεφάλαιο 3ο Αναπαράσταση Αριθµών
 Εισαγωγή στην επιστήµη των υπολογιστών Υπολογιστές και Δεδοµένα Κεφάλαιο 3ο Αναπαράσταση Αριθµών 1 Δεκαδικό και Δυαδικό Σύστηµα Δύο κυρίαρχα συστήµατα στο χώρο των υπολογιστών Δεκαδικό: Η βάση του συστήµατος
Εισαγωγή στην επιστήµη των υπολογιστών Υπολογιστές και Δεδοµένα Κεφάλαιο 3ο Αναπαράσταση Αριθµών 1 Δεκαδικό και Δυαδικό Σύστηµα Δύο κυρίαρχα συστήµατα στο χώρο των υπολογιστών Δεκαδικό: Η βάση του συστήµατος
«Αναγνώριση και Κατάταξη Ονομάτων Οντοτήτων σε Ελληνικά Κείμενα με Χρήση Μηχανών ιανυσμάτων Υποστήριξης»
 ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ θέμα: «Αναγνώριση και Κατάταξη Ονομάτων Οντοτήτων σε Ελληνικά Κείμενα με Χρήση Μηχανών ιανυσμάτων Υποστήριξης» Βασιλάκος Ξενοφών Επιβλέπων
ΟΙΚΟΝΟΜΙΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ θέμα: «Αναγνώριση και Κατάταξη Ονομάτων Οντοτήτων σε Ελληνικά Κείμενα με Χρήση Μηχανών ιανυσμάτων Υποστήριξης» Βασιλάκος Ξενοφών Επιβλέπων
ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕ ΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΙΚΤΥΑ
 ΘΕΜΑ ο 2.5 µονάδες ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕ ΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΙΚΤΥΑ Τελικές εξετάσεις 7 Ιανουαρίου 2005 ιάρκεια εξέτασης: 5:00-8:00 Έστω ότι
ΘΕΜΑ ο 2.5 µονάδες ΠΑΝΕΠΙΣΤΗΜΙΟ ΜΑΚΕ ΟΝΙΑΣ ΟΙΚΟΝΟΜΙΚΩΝ ΚΑΙ ΚΟΙΝΩΝΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΕΦΑΡΜΟΣΜΕΝΗΣ ΠΛΗΡΟΦΟΡΙΚΗΣ ΝΕΥΡΩΝΙΚΑ ΙΚΤΥΑ Τελικές εξετάσεις 7 Ιανουαρίου 2005 ιάρκεια εξέτασης: 5:00-8:00 Έστω ότι
Β ΕΙΔΙΚΗ ΦΑΣΗ ΣΠΟΥΔΩΝ
 ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Υπουργείο Εσωτερικών και Διοικητικής Ανασυγκρότησης ΕΘΝΙΚΗ ΣΧΟΛΗ ΔΗΜΟΣΙΑΣ ΔΙΟΙΚΗΣΗΣ ΚΑΙ ΑΥΤΟΔΙΟΙΚΗΣΗΣ Β ΕΙΔΙΚΗ ΦΑΣΗ ΣΠΟΥΔΩΝ Υπεύθυνος Σπουδών & Έρευνας: Δ. Τσιμάρας ΕΚΠΑΙΔΕΥΤΙΚΟ ΥΛΙΚΟ
ΕΛΛΗΝΙΚΗ ΔΗΜΟΚΡΑΤΙΑ Υπουργείο Εσωτερικών και Διοικητικής Ανασυγκρότησης ΕΘΝΙΚΗ ΣΧΟΛΗ ΔΗΜΟΣΙΑΣ ΔΙΟΙΚΗΣΗΣ ΚΑΙ ΑΥΤΟΔΙΟΙΚΗΣΗΣ Β ΕΙΔΙΚΗ ΦΑΣΗ ΣΠΟΥΔΩΝ Υπεύθυνος Σπουδών & Έρευνας: Δ. Τσιμάρας ΕΚΠΑΙΔΕΥΤΙΚΟ ΥΛΙΚΟ
Πίνακες Διασποράς. Χρησιμοποιούμε ένα πίνακα διασποράς T και μια συνάρτηση διασποράς h. Ένα στοιχείο με κλειδί k αποθηκεύεται στη θέση
 Πίνακες Διασποράς Χρησιμοποιούμε ένα πίνακα διασποράς T και μια συνάρτηση διασποράς h Ένα στοιχείο με κλειδί k αποθηκεύεται στη θέση κλειδί k T 0 1 2 3 4 5 6 7 U : χώρος πιθανών κλειδιών Τ : πίνακας μεγέθους
Πίνακες Διασποράς Χρησιμοποιούμε ένα πίνακα διασποράς T και μια συνάρτηση διασποράς h Ένα στοιχείο με κλειδί k αποθηκεύεται στη θέση κλειδί k T 0 1 2 3 4 5 6 7 U : χώρος πιθανών κλειδιών Τ : πίνακας μεγέθους
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΛΟΠΟΝΝΗΣΟΥ
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΛΟΠΟΝΝΗΣΟΥ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΑΣ ΔΙΟΙΚΗΣΗΣ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΜΑΘΗΜΑΤΙΚΑ Ι 11 ΟΚΤΩΒΡΙΟΥ 2016 ΜΗ ΓΡΑΜΜΙΚΕΣ ΣΥΝΑΡΤΗΣΕΙΣ ΕΙΣΑΓΩΓΗ Οικονομικές Συναρτήσεις με μεταβλητούς ρυθμούς
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΛΟΠΟΝΝΗΣΟΥ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΑΣ ΔΙΟΙΚΗΣΗΣ & ΠΛΗΡΟΦΟΡΙΚΗΣ ΤΜΗΜΑ ΟΙΚΟΝΟΜΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΜΑΘΗΜΑΤΙΚΑ Ι 11 ΟΚΤΩΒΡΙΟΥ 2016 ΜΗ ΓΡΑΜΜΙΚΕΣ ΣΥΝΑΡΤΗΣΕΙΣ ΕΙΣΑΓΩΓΗ Οικονομικές Συναρτήσεις με μεταβλητούς ρυθμούς
Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων
 Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων Εισηγητής: ρ Ηλίας Ζαφειρόπουλος Εισαγωγή Ιατρικά δεδοµένα: Συλλογή Οργάνωση Αξιοποίηση Data Mining ιαχείριση εδοµένων Εκπαίδευση
Μέθοδοι Μηχανών Μάθησης για Ευφυή Αναγνώριση και ιάγνωση Ιατρικών εδοµένων Εισηγητής: ρ Ηλίας Ζαφειρόπουλος Εισαγωγή Ιατρικά δεδοµένα: Συλλογή Οργάνωση Αξιοποίηση Data Mining ιαχείριση εδοµένων Εκπαίδευση
Εισαγωγή στην επιστήµη των υπολογιστών. Αναπαράσταση Αριθµών
 Εισαγωγή στην επιστήµη των υπολογιστών Αναπαράσταση Αριθµών 1 Δεκαδικό και Δυαδικό Σύστηµα Δύο κυρίαρχα συστήµατα στο χώρο των υπολογιστών Δεκαδικό: Η βάση του συστήµατος είναι το 10 αναπτύχθηκε τον 8
Εισαγωγή στην επιστήµη των υπολογιστών Αναπαράσταση Αριθµών 1 Δεκαδικό και Δυαδικό Σύστηµα Δύο κυρίαρχα συστήµατα στο χώρο των υπολογιστών Δεκαδικό: Η βάση του συστήµατος είναι το 10 αναπτύχθηκε τον 8
Πιθανοκρατικό μοντέλο
 Πιθανοκρατικό μοντέλο Το μοντέλο MAP Αλέξανδρος Γκιμπερίτης Βασίλης Μπούργος Δημήτρης Σουραβλιάς 1 Εισαγωγικές έννοιες Κάθε έγγραφο d της συλλογής παριστάνεται από το δυαδικό διάνυσμα x = (x 1, x 2,...,
Πιθανοκρατικό μοντέλο Το μοντέλο MAP Αλέξανδρος Γκιμπερίτης Βασίλης Μπούργος Δημήτρης Σουραβλιάς 1 Εισαγωγικές έννοιες Κάθε έγγραφο d της συλλογής παριστάνεται από το δυαδικό διάνυσμα x = (x 1, x 2,...,
Πληροφοριακά Συστήματα Διοίκησης
 Πληροφοριακά Συστήματα Διοίκησης Τρεις αλγόριθμοι μηχανικής μάθησης ΠΜΣ Λογιστική Χρηματοοικονομική και Διοικητική Επιστήμη ΤΕΙ Ηπείρου @ 2018 Μηχανική μάθηση αναγνώριση προτύπων Η αναγνώριση προτύπων
Πληροφοριακά Συστήματα Διοίκησης Τρεις αλγόριθμοι μηχανικής μάθησης ΠΜΣ Λογιστική Χρηματοοικονομική και Διοικητική Επιστήμη ΤΕΙ Ηπείρου @ 2018 Μηχανική μάθηση αναγνώριση προτύπων Η αναγνώριση προτύπων
ΤΕΣΤ ΣΤΑΤΙΣΤΙΚΗΣ ΕΦΑΡΜΟΣΜΕΝΗΣ ΣΤΑΤΙΣΤΙΚΗΣ ΓΕΩΡΓΙΚΟΥ ΠΕΙΡΑΜΑΤΙΣΜΟΥ. Τεστ 1 ο Κατανοµή Συχνοτήτων (50 βαθµοί)
") ΤΕΣΤ ΣΤΑΤΙΣΤΙΚΗΣ ΕΦΑΡΜΟΣΜΕΝΗΣ ΣΤΑΤΙΣΤΙΚΗΣ ΓΕΩΡΓΙΚΟΥ ΠΕΙΡΑΜΑΤΙΣΜΟΥ Τεστ 1 ο Κατανοµή Συχνοτήτων (50 βαθµοί) Α. Ερωτήσεις πολλαπλών επιλογών.(11 βαθµοί) (1:3 βαθµοί, 2-9:8 βαθµοί) 1. ίνεται ο πίνακας: Χ
ΤΕΣΤ ΣΤΑΤΙΣΤΙΚΗΣ ΕΦΑΡΜΟΣΜΕΝΗΣ ΣΤΑΤΙΣΤΙΚΗΣ ΓΕΩΡΓΙΚΟΥ ΠΕΙΡΑΜΑΤΙΣΜΟΥ Τεστ 1 ο Κατανοµή Συχνοτήτων (50 βαθµοί) Α. Ερωτήσεις πολλαπλών επιλογών.(11 βαθµοί) (1:3 βαθµοί, 2-9:8 βαθµοί) 1. ίνεται ο πίνακας: Χ
Τεχνικές ταξινόµησης αποτελεσµάτων µηχανών αναζήτησης µε βάση την ιστορία του χρήστη
 Τεχνικές ταξινόµησης αποτελεσµάτων µηχανών αναζήτησης µε βάση την ιστορία του χρήστη Όνοµα: Νικολαΐδης Αντώνιος Επιβλέπων: Τ. Σελλής Περίληψη ιπλωµατικής Εργασίας Συνεπιβλέποντες: Θ. αλαµάγκας, Γ. Γιαννόπουλος
Τεχνικές ταξινόµησης αποτελεσµάτων µηχανών αναζήτησης µε βάση την ιστορία του χρήστη Όνοµα: Νικολαΐδης Αντώνιος Επιβλέπων: Τ. Σελλής Περίληψη ιπλωµατικής Εργασίας Συνεπιβλέποντες: Θ. αλαµάγκας, Γ. Γιαννόπουλος
ΑΕΝ / ΑΣΠΡΟΠΥΡΓΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΩΝ ΕΡΓΑΣΤΗΡΙΟ ΑΥΤΟΜΑΤΙΣΜΟΥ. Σημειώσεις για τη χρήση του MATLAB στα Συστήματα Αυτομάτου Ελέγχου
 ΑΕΝ / ΑΣΠΡΟΠΥΡΓΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΩΝ ΕΡΓΑΣΤΗΡΙΟ ΑΥΤΟΜΑΤΙΣΜΟΥ Σημειώσεις για τη χρήση του MATLAB στα Συστήματα Αυτομάτου Ελέγχου Κ. ΝΑΣΟΠΟΥΛΟΣ - Α. ΧΡΗΣΤΙ ΟΥ Κ. ΝΑΣΟΠΟΥΛΟΣ - Α. ΧΡΗΣΤΙ ΟΥ Οκτώβριος 011 MATLAB
ΑΕΝ / ΑΣΠΡΟΠΥΡΓΟΥ ΣΧΟΛΗ ΜΗΧΑΝΙΚΩΝ ΕΡΓΑΣΤΗΡΙΟ ΑΥΤΟΜΑΤΙΣΜΟΥ Σημειώσεις για τη χρήση του MATLAB στα Συστήματα Αυτομάτου Ελέγχου Κ. ΝΑΣΟΠΟΥΛΟΣ - Α. ΧΡΗΣΤΙ ΟΥ Κ. ΝΑΣΟΠΟΥΛΟΣ - Α. ΧΡΗΣΤΙ ΟΥ Οκτώβριος 011 MATLAB
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ
 ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
ΤΟΠΟΓΡΑΦΙΚΑ ΔΙΚΤΥΑ ΚΑΙ ΥΠΟΛΟΓΙΣΜΟΙ ΑΝΑΣΚΟΠΗΣΗ ΘΕΩΡΙΑΣ ΣΥΝΟΡΘΩΣΕΩΝ Βασίλης Δ. Ανδριτσάνος Δρ. Αγρονόμος - Τοπογράφος Μηχανικός ΑΠΘ Επίκουρος Καθηγητής ΤΕΙ Αθήνας 3ο εξάμηνο http://eclass.teiath.gr Παρουσιάσεις,
Τα κύρια σηµεία της παρούσας διδακτορικής διατριβής είναι: Η πειραµατική µελέτη της µεταβατικής συµπεριφοράς συστηµάτων γείωσης
 Κεφάλαιο 5 ΣΥΜΠΕΡΑΣΜΑΤΑ Το σηµαντικό στην επιστήµη δεν είναι να βρίσκεις καινούρια στοιχεία, αλλά να ανακαλύπτεις νέους τρόπους σκέψης γι' αυτά. Sir William Henry Bragg 5.1 Ανακεφαλαίωση της διατριβής
Κεφάλαιο 5 ΣΥΜΠΕΡΑΣΜΑΤΑ Το σηµαντικό στην επιστήµη δεν είναι να βρίσκεις καινούρια στοιχεία, αλλά να ανακαλύπτεις νέους τρόπους σκέψης γι' αυτά. Sir William Henry Bragg 5.1 Ανακεφαλαίωση της διατριβής
Εισαγωγή στην Ανάλυση και Προσοµοίωση Δυναµικών Συστηµάτων
 Εισαγωγή στην Ανάλυση και Προσοµοίωση Δυναµικών Συστηµάτων Control Systems Laboratory Περιγραφή Δυναµικών Συστηµάτων Εξίσωση µεταβολής όγκου Η µεταβολή όγκου ισούται µε τη παροχή υγρού Q που σχετίζεται
Εισαγωγή στην Ανάλυση και Προσοµοίωση Δυναµικών Συστηµάτων Control Systems Laboratory Περιγραφή Δυναµικών Συστηµάτων Εξίσωση µεταβολής όγκου Η µεταβολή όγκου ισούται µε τη παροχή υγρού Q που σχετίζεται
Ανάπτυξη συστήματος ερωταποκρίσεων για αρχεία ελληνικών εφημερίδων
 Ανάπτυξη συστήματος ερωταποκρίσεων για αρχεία ελληνικών εφημερίδων Οικονομικό Πανεπιστήμιο Αθηνών Πρόγραμμα Μεταπτυχιακών Σπουδών «Επιστήμη των Υπολογιστών» Διπλωματική Εργασία Μαρία-Ελένη Κολλιάρου 2
Ανάπτυξη συστήματος ερωταποκρίσεων για αρχεία ελληνικών εφημερίδων Οικονομικό Πανεπιστήμιο Αθηνών Πρόγραμμα Μεταπτυχιακών Σπουδών «Επιστήμη των Υπολογιστών» Διπλωματική Εργασία Μαρία-Ελένη Κολλιάρου 2
ΥΣ02 Τεχνητή Νοημοσύνη Χειμερινό Εξάμηνο
 ΥΣ02 Τεχνητή Νοημοσύνη Χειμερινό Εξάμηνο 2014-2015 Πρώτη Σειρά Ασκήσεων (Υποχρεωτική, 25% του συνολικού βαθμού στο μάθημα) Ημερομηνία Ανακοίνωσης: 22/10/2014 Ημερομηνία Παράδοσης: Μέχρι 14/11/2014 23:59
ΥΣ02 Τεχνητή Νοημοσύνη Χειμερινό Εξάμηνο 2014-2015 Πρώτη Σειρά Ασκήσεων (Υποχρεωτική, 25% του συνολικού βαθμού στο μάθημα) Ημερομηνία Ανακοίνωσης: 22/10/2014 Ημερομηνία Παράδοσης: Μέχρι 14/11/2014 23:59
5.1 Θεωρητική εισαγωγή
 ΨΗΦΙΑΚΑ ΚΥΚΛΩΜΑΤΑ - ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ 5 ΚΩ ΙΚΟΠΟΙΗΣΗ BCD Σκοπός: Η κατανόηση της µετατροπής ενός τύπου δυαδικής πληροφορίας σε άλλον (κωδικοποίηση/αποκωδικοποίηση) µε τη µελέτη της κωδικοποίησης BCD
ΨΗΦΙΑΚΑ ΚΥΚΛΩΜΑΤΑ - ΕΡΓΑΣΤΗΡΙΑΚΗ ΑΣΚΗΣΗ 5 ΚΩ ΙΚΟΠΟΙΗΣΗ BCD Σκοπός: Η κατανόηση της µετατροπής ενός τύπου δυαδικής πληροφορίας σε άλλον (κωδικοποίηση/αποκωδικοποίηση) µε τη µελέτη της κωδικοποίησης BCD
ΑΕΠΠ Ερωτήσεις θεωρίας
 ΑΕΠΠ Ερωτήσεις θεωρίας Κεφάλαιο 1 1. Τα δεδομένα μπορούν να παρέχουν πληροφορίες όταν υποβάλλονται σε 2. Το πρόβλημα μεγιστοποίησης των κερδών μιας επιχείρησης είναι πρόβλημα 3. Για την επίλυση ενός προβλήματος
ΑΕΠΠ Ερωτήσεις θεωρίας Κεφάλαιο 1 1. Τα δεδομένα μπορούν να παρέχουν πληροφορίες όταν υποβάλλονται σε 2. Το πρόβλημα μεγιστοποίησης των κερδών μιας επιχείρησης είναι πρόβλημα 3. Για την επίλυση ενός προβλήματος
Αριθµητική Ανάλυση 1 εκεµβρίου / 43
 Αριθµητική Ανάλυση 1 εκεµβρίου 2014 Αριθµητική Ανάλυση 1 εκεµβρίου 2014 1 / 43 Κεφ.5. Αριθµητικός Υπολογισµός Ιδιοτιµών και Ιδιοδιανυσµάτων ίνεται ένας πίνακας A C n n και Ϲητούνται να προσδιορισθούν οι
Αριθµητική Ανάλυση 1 εκεµβρίου 2014 Αριθµητική Ανάλυση 1 εκεµβρίου 2014 1 / 43 Κεφ.5. Αριθµητικός Υπολογισµός Ιδιοτιµών και Ιδιοδιανυσµάτων ίνεται ένας πίνακας A C n n και Ϲητούνται να προσδιορισθούν οι
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ. Data Mining - Classification
 ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Data Mining - Classification Data Mining Ανακάλυψη προτύπων σε μεγάλο όγκο δεδομένων. Σαν πεδίο περιλαμβάνει κλάσεις εργασιών: Anomaly Detection:
ΔΙΑΧΕΙΡΙΣΗ ΠΕΡΙΕΧΟΜΕΝΟΥ ΠΑΓΚΟΣΜΙΟΥ ΙΣΤΟΥ ΚΑΙ ΓΛΩΣΣΙΚΑ ΕΡΓΑΛΕΙΑ Data Mining - Classification Data Mining Ανακάλυψη προτύπων σε μεγάλο όγκο δεδομένων. Σαν πεδίο περιλαμβάνει κλάσεις εργασιών: Anomaly Detection:
4. Ο αισθητήρας (perceptron)
") 4. Ο αισθητήρας (perceptron) Σκοπός: Προσδοκώµενα αποτελέσµατα: Λέξεις Κλειδιά: To µοντέλο του αισθητήρα (perceptron) είναι από τα πρώτα µοντέλα νευρωνικών δικτύων που αναπτύχθηκαν, και έδωσαν µεγάλη ώθηση
4. Ο αισθητήρας (perceptron) Σκοπός: Προσδοκώµενα αποτελέσµατα: Λέξεις Κλειδιά: To µοντέλο του αισθητήρα (perceptron) είναι από τα πρώτα µοντέλα νευρωνικών δικτύων που αναπτύχθηκαν, και έδωσαν µεγάλη ώθηση
Γλωσσική Τεχνολογία. Εισαγωγή. Ίων Ανδρουτσόπουλος.
 Γλωσσική Τεχνολογία Εισαγωγή 2015 16 Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/in/ Τι θα ακούσετε Εισαγωγή στη γλωσσική τεχνολογία. Ύλη και οργάνωση του μαθήματος. Προαπαιτούμενες γνώσεις και άλλα προτεινόμενα
Γλωσσική Τεχνολογία Εισαγωγή 2015 16 Ίων Ανδρουτσόπουλος http://www.aueb.gr/users/in/ Τι θα ακούσετε Εισαγωγή στη γλωσσική τεχνολογία. Ύλη και οργάνωση του μαθήματος. Προαπαιτούμενες γνώσεις και άλλα προτεινόμενα
x=l ηλαδή η ενέργεια είναι µία συνάρτηση της συνάρτησης . Στα µαθηµατικά, η συνάρτηση µίας συνάρτησης ονοµάζεται συναρτησιακό (functional).
.") 3. ΕΙΣΑΓΩΓΗ ΣΤΙΣ ΑΡΙΘΜΗΤΙΚΕΣ ΜΕΘΟ ΟΥΣ Η Μέθοδος των Πεπερασµένων Στοιχείων Σηµειώσεις 3. Ενεργειακή θεώρηση σε συνεχή συστήµατα Έστω η δοκός του σχήµατος, µε τις αντίστοιχες φορτίσεις. + = p() EA = Q Σχήµα
3. ΕΙΣΑΓΩΓΗ ΣΤΙΣ ΑΡΙΘΜΗΤΙΚΕΣ ΜΕΘΟ ΟΥΣ Η Μέθοδος των Πεπερασµένων Στοιχείων Σηµειώσεις 3. Ενεργειακή θεώρηση σε συνεχή συστήµατα Έστω η δοκός του σχήµατος, µε τις αντίστοιχες φορτίσεις. + = p() EA = Q Σχήµα
Εισαγωγή στην Ανάλυση και Προσοµοίωση Δυναµικών Συστηµάτων
 Εισαγωγή στην Ανάλυση και Προσοµοίωση Δυναµικών Συστηµάτων Control Systems Laboratory Περιγραφή Δυναµικών Συστηµάτων Εξίσωση µεταβολής όγκου Η µεταβολή όγκου ισούται µε τη παροχή υγρού Q που σχετίζεται
Εισαγωγή στην Ανάλυση και Προσοµοίωση Δυναµικών Συστηµάτων Control Systems Laboratory Περιγραφή Δυναµικών Συστηµάτων Εξίσωση µεταβολής όγκου Η µεταβολή όγκου ισούται µε τη παροχή υγρού Q που σχετίζεται
Αριθμητική Ανάλυση και Εφαρμογές
 Αριθμητική Ανάλυση και Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 07-08 Πεπερασμένες και Διαιρεμένες Διαφορές Εισαγωγή Θα εισάγουμε την έννοια των διαφορών με ένα
Αριθμητική Ανάλυση και Εφαρμογές Διδάσκων: Δημήτριος Ι. Φωτιάδης Τμήμα Μηχανικών Επιστήμης Υλικών Ιωάννινα 07-08 Πεπερασμένες και Διαιρεμένες Διαφορές Εισαγωγή Θα εισάγουμε την έννοια των διαφορών με ένα
LOGO. Εξόρυξη Δεδομένων. Δειγματοληψία. Πίνακες συνάφειας. Καμπύλες ROC και AUC. Σύγκριση Μεθόδων Εξόρυξης
 Εξόρυξη Δεδομένων Δειγματοληψία Πίνακες συνάφειας Καμπύλες ROC και AUC Σύγκριση Μεθόδων Εξόρυξης Πασχάλης Θρήσκος PhD Λάρισα 2016-2017 pthriskos@mnec.gr LOGO Συμπερισματολογία - Τι σημαίνει ; Πληθυσμός
Εξόρυξη Δεδομένων Δειγματοληψία Πίνακες συνάφειας Καμπύλες ROC και AUC Σύγκριση Μεθόδων Εξόρυξης Πασχάλης Θρήσκος PhD Λάρισα 2016-2017 pthriskos@mnec.gr LOGO Συμπερισματολογία - Τι σημαίνει ; Πληθυσμός
ΤΑΞΙΝΟΜΙΚΗ ΑΝΑΛΥΣΗ ΓΙΑ ΕΞΑ ΙΑΣΤΑΤΗ ΙΩΝΥΜΙΚΗ ΕΦΑΡΜΟΓΗ ΣΤΗΝ ΑΚΤΙΝΟ ΙΑΓΝΩΣΤΙΚΗ ΤΗΣ ΠΝΕΥΜΟΝΟΚΟΝΙΑΣΗΣ
 Ελληνικό Στατιστικό Ινστιτούτο Πρακτικά 7 ου Πανελληνίου Συνεδρίου Στατιστικής (004), σελ. 03-08 ΤΑΞΙΝΟΜΙΚΗ ΑΝΑΛΥΣΗ ΓΙΑ ΕΞΑ ΙΑΣΤΑΤΗ ΙΩΝΥΜΙΚΗ ΕΦΑΡΜΟΓΗ ΣΤΗΝ ΑΚΤΙΝΟ ΙΑΓΝΩΣΤΙΚΗ ΤΗΣ ΠΝΕΥΜΟΝΟΚΟΝΙΑΣΗΣ Θεόφιλος
Ελληνικό Στατιστικό Ινστιτούτο Πρακτικά 7 ου Πανελληνίου Συνεδρίου Στατιστικής (004), σελ. 03-08 ΤΑΞΙΝΟΜΙΚΗ ΑΝΑΛΥΣΗ ΓΙΑ ΕΞΑ ΙΑΣΤΑΤΗ ΙΩΝΥΜΙΚΗ ΕΦΑΡΜΟΓΗ ΣΤΗΝ ΑΚΤΙΝΟ ΙΑΓΝΩΣΤΙΚΗ ΤΗΣ ΠΝΕΥΜΟΝΟΚΟΝΙΑΣΗΣ Θεόφιλος
Στο στάδιο ανάλυσης των αποτελεσµάτων: ανάλυση ευαισθησίας της λύσης, προσδιορισµός της σύγκρουσης των κριτηρίων.
 ΠΕΡΙΛΗΨΗ Η τεχνική αυτή έκθεση περιλαµβάνει αναλυτική περιγραφή των εναλλακτικών µεθόδων πολυκριτηριακής ανάλυσης που εξετάσθηκαν µε στόχο να επιλεγεί η µέθοδος εκείνη η οποία είναι η πιο κατάλληλη για
ΠΕΡΙΛΗΨΗ Η τεχνική αυτή έκθεση περιλαµβάνει αναλυτική περιγραφή των εναλλακτικών µεθόδων πολυκριτηριακής ανάλυσης που εξετάσθηκαν µε στόχο να επιλεγεί η µέθοδος εκείνη η οποία είναι η πιο κατάλληλη για
Ανάλυση των δραστηριοτήτων κατά γνωστική απαίτηση
 Ανάλυση των δραστηριοτήτων κατά γνωστική απαίτηση Πέρα όµως από την Γνωσιακή/Εννοιολογική ανάλυση της δοµής και του περιεχοµένου των σχολικών εγχειριδίων των Μαθηµατικών του Δηµοτικού ως προς τις έννοιες
Ανάλυση των δραστηριοτήτων κατά γνωστική απαίτηση Πέρα όµως από την Γνωσιακή/Εννοιολογική ανάλυση της δοµής και του περιεχοµένου των σχολικών εγχειριδίων των Μαθηµατικών του Δηµοτικού ως προς τις έννοιες
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ. Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων. Γεώργιος Πετάσης. Ακαδημαϊκό Έτος:
 ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος
ΓΛΩΣΣΙΚΗ ΤΕΧΝΟΛΟΓΙΑ Μάθημα 10 ο : Αποσαφήνιση εννοιών λέξεων Γεώργιος Πετάσης Ακαδημαϊκό Έτος: 2012 2013 ΤMHMA MHXANIKΩΝ Η/Υ & ΠΛΗΡΟΦΟΡΙΚΗΣ, Πανεπιστήμιο Πατρών, 2012 2013 Οι διαφάνειες αυτού του μαθήματος
Ακαδημαϊκό Έτος , Χειμερινό Εξάμηνο Διδάσκων Καθ.: Νίκος Τσαπατσούλης
 ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΛΟΠΟΝΝΗΣΟΥ, ΤΜΗΜΑ ΤΕΧΝΟΛΟΓΙΑΣ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΚΕΣ 3: ΑΝΑΓΝΩΡΙΣΗ ΠΡΟΤΥΠΩΝ ΚΑΙ ΑΝΑΛΥΣΗ ΕΙΚΟΝΑΣ Ακαδημαϊκό Έτος 7 8, Χειμερινό Εξάμηνο Καθ.: Νίκος Τσαπατσούλης ΕΡΩΤΗΣΕΙΣ ΕΠΑΝΑΛΗΨΗΣ Το παρόν
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΛΟΠΟΝΝΗΣΟΥ, ΤΜΗΜΑ ΤΕΧΝΟΛΟΓΙΑΣ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΚΕΣ 3: ΑΝΑΓΝΩΡΙΣΗ ΠΡΟΤΥΠΩΝ ΚΑΙ ΑΝΑΛΥΣΗ ΕΙΚΟΝΑΣ Ακαδημαϊκό Έτος 7 8, Χειμερινό Εξάμηνο Καθ.: Νίκος Τσαπατσούλης ΕΡΩΤΗΣΕΙΣ ΕΠΑΝΑΛΗΨΗΣ Το παρόν
Αριθμητική εύρεση ριζών μη γραμμικών εξισώσεων
 Αριθμητική εύρεση ριζών μη γραμμικών εξισώσεων Με τον όρο μη γραμμικές εξισώσεις εννοούμε εξισώσεις της μορφής: f( ) 0 που προέρχονται από συναρτήσεις f () που είναι μη γραμμικές ως προς. Περιέχουν δηλαδή
Αριθμητική εύρεση ριζών μη γραμμικών εξισώσεων Με τον όρο μη γραμμικές εξισώσεις εννοούμε εξισώσεις της μορφής: f( ) 0 που προέρχονται από συναρτήσεις f () που είναι μη γραμμικές ως προς. Περιέχουν δηλαδή
Διαστήματα εμπιστοσύνης, εκτίμηση ακρίβειας μέσης τιμής
 Ενότητα 2 Διαστήματα εμπιστοσύνης, εκτίμηση ακρίβειας μέσης τιμής Ένας από τους βασικούς σκοπούς της Στατιστικής είναι η εκτίμηση των χαρακτηριστικών ενός πληθυσμού βάσει της πληροφορίας από ένα δείγμα.
Ενότητα 2 Διαστήματα εμπιστοσύνης, εκτίμηση ακρίβειας μέσης τιμής Ένας από τους βασικούς σκοπούς της Στατιστικής είναι η εκτίμηση των χαρακτηριστικών ενός πληθυσμού βάσει της πληροφορίας από ένα δείγμα.
Γνωστό: P (M) = 2 M = τρόποι επιλογής υποσυνόλου του M. Π.χ. M = {A, B, C} π. 1. Π.χ.
 = 2 M = τρόποι επιλογής υποσυνόλου του M. Π.χ. M = {A, B, C} π. 1. Π.χ.") Παραδείγματα Απαρίθμησης Γνωστό: P (M 2 M τρόποι επιλογής υποσυνόλου του M Τεχνικές Απαρίθμησης Πχ M {A, B, C} P (M 2 3 8 #(Υποσυνόλων με 2 στοιχεία ( 3 2 3 #(Διατεταγμένων υποσυνόλων με 2 στοιχεία 3 2
Παραδείγματα Απαρίθμησης Γνωστό: P (M 2 M τρόποι επιλογής υποσυνόλου του M Τεχνικές Απαρίθμησης Πχ M {A, B, C} P (M 2 3 8 #(Υποσυνόλων με 2 στοιχεία ( 3 2 3 #(Διατεταγμένων υποσυνόλων με 2 στοιχεία 3 2
Δομές Δεδομένων. Ενότητα 7: Άλλες παραλλαγές Συνδεδεμένων Λιστών-Παράσταση Αραιού Πολυωνύμου με Συνδεδεμένη Λίστα. Καθηγήτρια Μαρία Σατρατζέμη
 Ενότητα 7: Άλλες παραλλαγές Συνδεδεμένων Λιστών-Παράσταση Αραιού Πολυωνύμου με Συνδεδεμένη Λίστα Καθηγήτρια Μαρία Σατρατζέμη Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative
Ενότητα 7: Άλλες παραλλαγές Συνδεδεμένων Λιστών-Παράσταση Αραιού Πολυωνύμου με Συνδεδεμένη Λίστα Καθηγήτρια Μαρία Σατρατζέμη Άδειες Χρήσης Το παρόν εκπαιδευτικό υλικό υπόκειται σε άδειες χρήσης Creative
1. ** α) Αν η f είναι δυο φορές παραγωγίσιµη συνάρτηση, να αποδείξετε ότι. β α. = [f (x) ηµx] - [f (x) συνx] β α. ( )
![1. ** α) Αν η f είναι δυο φορές παραγωγίσιµη συνάρτηση, να αποδείξετε ότι. β α. = [f (x) ηµx] - [f (x) συνx] β α. ( )](/thumbs/52/29634211.jpg "1. ** α) Αν η f είναι δυο φορές παραγωγίσιµη συνάρτηση, να αποδείξετε ότι. β α. = [f (x) ηµx] - [f (x) συνx] β α. ( )") Ερωτήσεις ανάπτυξης. ** α) Αν η f είναι δυο φορές παραγωγίσιµη συνάρτηση, να αποδείξετε ότι β ( f () f () ) + α ηµ d β α = [f () ηµ] - [f () συν] β α. ( ) β) Αν f () = ηµ, να αποδείξετε ότι f () + f ()
Ερωτήσεις ανάπτυξης. ** α) Αν η f είναι δυο φορές παραγωγίσιµη συνάρτηση, να αποδείξετε ότι β ( f () f () ) + α ηµ d β α = [f () ηµ] - [f () συν] β α. ( ) β) Αν f () = ηµ, να αποδείξετε ότι f () + f ()
Αλγόριθµοι δροµολόγησης µε µέσα µαζικής µεταφοράς στο µεταφορικό δίκτυο των Αθηνών
 1 Αλγόριθµοι δροµολόγησης µε µέσα µαζικής µεταφοράς στο µεταφορικό δίκτυο των Αθηνών ΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ της Κωτσογιάννη Μαριάννας Περίληψη 1. Αντικείµενο- Σκοπός Αντικείµενο της διπλωµατικής αυτής εργασίας
1 Αλγόριθµοι δροµολόγησης µε µέσα µαζικής µεταφοράς στο µεταφορικό δίκτυο των Αθηνών ΙΠΛΩΜΑΤΙΚΗ ΕΡΓΑΣΙΑ της Κωτσογιάννη Μαριάννας Περίληψη 1. Αντικείµενο- Σκοπός Αντικείµενο της διπλωµατικής αυτής εργασίας
Κεφάλαιο 5. Το Συμπτωτικό Πολυώνυμο
 Κεφάλαιο 5. Το Συμπτωτικό Πολυώνυμο Σύνοψη Στο κεφάλαιο αυτό παρουσιάζεται η ιδέα του συμπτωτικού πολυωνύμου, του πολυωνύμου, δηλαδή, που είναι του μικρότερου δυνατού βαθμού και που, για συγκεκριμένες,
Κεφάλαιο 5. Το Συμπτωτικό Πολυώνυμο Σύνοψη Στο κεφάλαιο αυτό παρουσιάζεται η ιδέα του συμπτωτικού πολυωνύμου, του πολυωνύμου, δηλαδή, που είναι του μικρότερου δυνατού βαθμού και που, για συγκεκριμένες,
Πληροφορική ΙΙ Ενότητα 1
 Ανοικτά Ακαδημαϊκά Μαθήματα στο ΤΕΙ Ιονίων Νήσων Πληροφορική ΙΙ Ενότητα 1: Εισαγωγή Θεματική Ενότητα: Εισαγωγή στον Προγραμματισμό Το περιεχόμενο του μαθήματος διατίθεται με άδεια Creative Commons εκτός
Ανοικτά Ακαδημαϊκά Μαθήματα στο ΤΕΙ Ιονίων Νήσων Πληροφορική ΙΙ Ενότητα 1: Εισαγωγή Θεματική Ενότητα: Εισαγωγή στον Προγραμματισμό Το περιεχόμενο του μαθήματος διατίθεται με άδεια Creative Commons εκτός
Εντοπισμός τερματισμού. Κατανεμημένα Συστήματα 1
 Εντοπισμός τερματισμού Κατανεμημένα Συστήματα 1 lalis@inf.uth.gr Μοντέλο συστήματος Μια ομάδα διεργασιών εκτελεί έναν υπολογισμό Κατάσταση διεργασίας: ενεργητική ή παθητική (ανάλογα με το αν εκτελεί μέρος
Εντοπισμός τερματισμού Κατανεμημένα Συστήματα 1 lalis@inf.uth.gr Μοντέλο συστήματος Μια ομάδα διεργασιών εκτελεί έναν υπολογισμό Κατάσταση διεργασίας: ενεργητική ή παθητική (ανάλογα με το αν εκτελεί μέρος
ΑΣΚΗΣΗ. Δημιουργία Ευρετηρίων Συλλογής Κειμένων
 Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Γλωσσική Τεχνολογία Ακαδημαϊκό Έτος 2011-2012 Ημερομηνία Παράδοσης: Στην εξέταση του μαθήματος ΑΣΚΗΣΗ Δημιουργία Ευρετηρίων Συλλογής Κειμένων Σκοπός της άσκησης είναι η υλοποίηση ενός συστήματος επεξεργασίας
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY463 - Συστήματα Ανάκτησης Πληροφοριών Εαρινό Εξάμηνο. Φροντιστήριο 3.
 Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY6 - Συστήματα Ανάκτησης Πληροφοριών 007 008 Εαρινό Εξάμηνο Φροντιστήριο Retrieval Models Άσκηση Θεωρείστε μια συλλογή κειμένων που περιέχει τα ακόλουθα
Πανεπιστήμιο Κρήτης, Τμήμα Επιστήμης Υπολογιστών HY6 - Συστήματα Ανάκτησης Πληροφοριών 007 008 Εαρινό Εξάμηνο Φροντιστήριο Retrieval Models Άσκηση Θεωρείστε μια συλλογή κειμένων που περιέχει τα ακόλουθα
Εισαγωγή στον Προγραµµατισµό. Ανάλυση (ή Επιστηµονικοί8 Υπολογισµοί)
") Εισαγωγή στον Προγραµµατισµό Αριθµητική Ανάλυση (ή Επιστηµονικοί Υπολογισµοί) ιδάσκοντες: Καθηγητής Ν. Μισυρλής, Επίκ. Καθηγητής Φ.Τζαφέρης ΕΚΠΑ 8 εκεµβρίου 2014 Ανάλυση (ή Επιστηµονικοί8 Υπολογισµοί)
Εισαγωγή στον Προγραµµατισµό Αριθµητική Ανάλυση (ή Επιστηµονικοί Υπολογισµοί) ιδάσκοντες: Καθηγητής Ν. Μισυρλής, Επίκ. Καθηγητής Φ.Τζαφέρης ΕΚΠΑ 8 εκεµβρίου 2014 Ανάλυση (ή Επιστηµονικοί8 Υπολογισµοί)
Δειγματοληψία. Πρέπει να γνωρίζουμε πως πήραμε το δείγμα Το πλήθος n ij των παρατηρήσεων σε κάθε κελί είναι τ.μ. με μ ij συμβολίζουμε την μέση τιμή:
 Δειγματοληψία Πρέπει να γνωρίζουμε πως πήραμε το δείγμα Το πλήθος των παρατηρήσεων σε κάθε κελί είναι τ.μ. με μ συμβολίζουμε την μέση τιμή: Επομένως στην δειγματοληψία πινάκων συνάφειας αναφερόμαστε στον
Δειγματοληψία Πρέπει να γνωρίζουμε πως πήραμε το δείγμα Το πλήθος των παρατηρήσεων σε κάθε κελί είναι τ.μ. με μ συμβολίζουμε την μέση τιμή: Επομένως στην δειγματοληψία πινάκων συνάφειας αναφερόμαστε στον